1. Introduction
Synthetic aperture radar (SAR) can generate radar images with both high range-resolution and Doppler-resolution by synthesizing a series of small aperture antennas into an equivalent large aperture antenna. SAR can work in various extreme conditions, e.g., mist, rain, clouds, etc., thus it is widely applied in electronic reconnaissance, topographic mapping, and vehicle surveillance [
1,
2]. Although numerous SAR images have been generated, the interpretation of SAR images develops far behind imaging them. In SAR image interpretation, target recognition is usually regarded as one of the most challenging tasks [
1,
3]. Generally, target recognition can be compartmentalized into two steps: First, some pre-processing techniques will be performed on raw SAR images, such as filtering, edge detection, region of interest (ROI) extraction, and feature extraction. Second, a classifier is used to categorize them to their corresponding class according to the divergence among extracted features [
4,
5]. However, such complex individual procedures usually bring a huge computation burden, causing difficulty in realizing real-time application and device miniaturization.
To alleviate these limitations of traditional methods, numerous deep learning based target recognition algorithms were proposed in recent decades, particularly combined with convolutional neural network (CNN). CNN is an end-to-end structure which requires no pre-processing implementation [
6]. The input data are abstracted as discriminative features by different convolutional units (kernel, filter, channel) in deep layers for classification. Convolutional units cannot only reduce the number of trainable parameters but also preserve local characteristics in neighbor regions in images. In SAR image processing, much related work has been studied and achieved amazing performance. Wu et al. adopted CNN as a classifier in target recognition and achieved higher recognition rate than an SVM in [
7]. Zhang et al. proposed a fast training method for SAR large scale samples based on CNN for targets recognition in [
3], which can effectively reduce over-fitting. Zhou et al. proposed a large-margin softmax batch-normalization CNN (LM-BN-CNN) for SAR target recognition in [
8], which simultaneously obtained the superior accuracy and convergence speed compared with other general CNN structures. Zhang et al. proposed a feature fusion framework (FEC) based on scattering center features and deep CNN features which achieves superior effectiveness and robustness under both standard operating conditions and extended operating conditions [
9]. Oh et al. proposed a CNN-based SAR target recognition network with pose angle marginalization learning which outperforms the other state-of-the-art SAR-ATR algorithms, yielding the correct target recognition rate with an average of 99.6% [
10].
Although the recognition accuracy is increasingly higher in aforementioned deep learning methods, CNN is usually used as a “black box” since the inner recognition mechanism of CNN is still opaque. Specifically, the semantic information of features extracted by the deep convolutional layers is often difficult for humans to understand [
11,
12]. In this case, the reliability of recognition results is less convincing compared with traditional methods. On the other hand, unexplainability of CNN also makes it difficult to analyze the causes of wrong results. To provide a reasonable explanation of “black box”, many scholars obtained some meaningful achievements. Some of them explain neural network from perspective of structure. Setzu et al. proposed GLocalX to generalize local explanations expressed in form of local decision rules to global explanations iteratively by aggregating them hierarchically [
13]. Xiong et al. proposed a totally interpretable CNN, SPB-Net, by deep unfolding to suppress speckles in SAR images [
14]. In comparison, another group of researchers attempt to visualize what CNN learns from input data [
15,
16,
17,
18,
19], mainly divided into three categories: perturbation methods, activation methods and propagation methods. The former two methods highlight the regions of the input image that are responsible for CNN’s correct classification, while the latter can further detect the regions that are negative for CNN’s judgment in addition. Perturbation methods usually occlude the input image with a sliding patch to check whether the occluded region can cause a dramatic drop of recognition accuracy. Perturbation methods are intuitive and easy to implement; however, they have two obvious limitations: (1).The computation burden is huge for this traversal search. (2). Different data may require specifically designed occlusion rules, leading to huge cost of algorithm design. Perturbation methods are seldom directly adopted to generate heatmaps; instead, they are usually used to verify the performance of other visualization methods. Activation methods visualize CNN decisions by artfully combining the feature maps in deep convolution layers. These kinds of methods integrate input image, features in deep layers and final output of CNN, which obtained remarkable and amazing achievements [
16,
17,
18,
19]. However, in some scenarios, it is not enough to know which parts of the input images are responsible for CNN’s recognition. We also need to know, more specifically, which parts contribute positively to recognition and which parts contribute negatively. Propagation methods can solve this problem well [
20]. They are a kind of pixel rearrangement methods which propagates CNN’s output backward to input space layer for layer. Amin et al. combined layer-wise relevance propagation (LRP) and sparse auto-encoder to obtain an understanding of CNN’s performance on radar-based human motion recognition [
21]. However, the auto-encoder only contains fully-connected layers. For SAR images, such a simple structure is not powerful enough to extract the features which can achieve high recognition accuracy. Therefore, we propose a novel LRP method particularly designed for CNN’s performance in SAR image target recognition. In our proposed method, we provide a concise form of the correlation between the output of convolutional layer and weights of convolutional units.
The contributions of this paper can be summarized as: (1) To the best of our knowledge, this is the first time LRP and CNN are combined in SAR image interpretation; (2) In comparison to [
21], the proposed method can provide the positive and negative contributions under much higher recognition accuracy.
The remainder of this paper is organized as follows. For a comprehensive understanding of propagation methods,
Section 2 reviews basic LRP.
Section 3 introduces the the proposed method in detail.
Section 4 provides numerous experimental results from various perspectives to compare the performance of the proposed method with basic LRP.
Section 5 discusses the experimental results and clarifies some confusion.
3. Our Method
Different from fully-connected networks, CNN involves in weight sharing in convolutional layer and downsampling in pooling operation. Therefore, Equation (
2) of common LRP can not be applied to CNN directly. Here we denote
as the relationship of weight
between
lth layer and those of next layer
th layer.
is in size of
, where
N and
C are the number of convolutional kernels and channels of each kernel in the
lth layer, respectively.
M denotes the width and height of convolutional kernels in
lth layer.
is the output of the
lth layer in size of
. The specific relationship between contribution
z and
and
is described as follows:
where
refers to the corresponding element of
z,
,
,
,
, and
. In this case, the relevance
can be calculated by Equations (
4) and (
5). It should be noted that the relevance map of the next layer needs to be upsampled to the output size of the upper convolutional layer due to pooling operation, which can be described as:
where
means upsampling relevance maps to the size of the output of the upper convolutional layer (
Q,
Q).
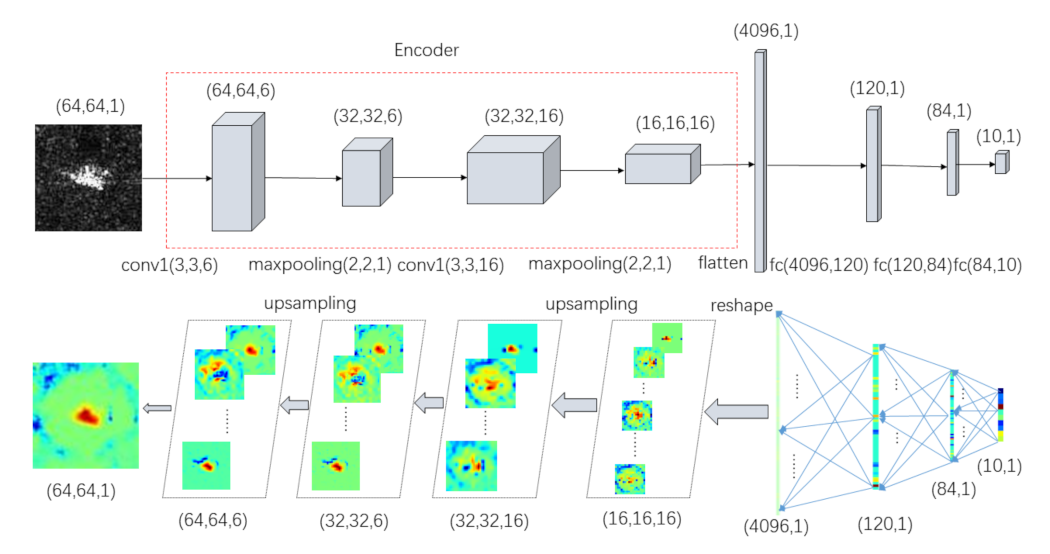
The details and flowchart of LRP method for CNN are described in Algorithm 1 and
Figure 4.
| Algorithm 1 CNN-LRP |
Input: the original SAR image in size of - 1:
model - 2:
parameters: , - 3:
forl in [ ,...,1] do: - 4:
if l in classification layers then: - 5:
as in Equation ( 2) - 6:
as in Equation ( 5) - 7:
- 8:
else l in convolution layers : - 9:
as in Equation ( 6) - 10:
as in Equation ( 5) - 11:
- 12:
end if - 13:
if l in maxpooling layers then: - 14:
- 15:
end if - 16:
end for - 17:
=
Output: the heatmap in size of |
4. Experimental Results
In this section, we compare the performance of common LRP with sparse auto-encoder and the proposed method with CNN. Next, we analyze the results of our proposed method from several perspectives. The experimental dataset adopted in this paper is the real measured SAR images of ground stationary targets of 10 classes of vehicles, namely 2S1 (self-propelled artillery), BRDM_2 (armored reconnaissance vehicle), BTR60 (armored transport vehicle), D7 (bulldozer), T62 (tank), ZIL131 (cargo truck), ZSU234 (self-propelled anti-aircraft gun), and T72 (tank). High-resolution focused synthetic aperture radars with a resolution of 0.3 m × 0.3 m are used in this program, which work in the X-band, and the polarization mode is HH. For simplicity, we utilize a lightweight auto-encoder with only convolutional layers. Adaptive moment estimation (Adam) was adopted as the optimizer,
= 1 ×
,
=
,
= 1 ×
, weight-decay = 0), as shown in
Figure 4. Note that the gist of this paper is not to manipulate a CNN structure or obtain a set of parameters with high recognition accuracy, but to provide a visual understanding of CNN’s performance on SAR images. Some other state-of-the-art CNN models can probably achieve higher recognition accuracy, whereas such complex structures may be obstacles for understanding of CNN.
4.1. Comparison of the Proposed Method and Common LRP
In this experiment, we apply our proposed method and common LRP in MSTAR dataset to obtain heatmaps.
Figure 5 shows a SAR image from each class and their corresponding heatmaps generated by common LRP and our proposed method, respectively. In general, our proposed method can provide better interpretability of CNN than common LRP. Evidently, both positive and negative contributions in the heatmaps of common LRP are numerous scattered speckles, which is difficult to understand why CNN focuses on these elements. In contrast, our proposed method can provide more interpretable positive contributions which coincide with most parts of the target. Next, we will discuss the understanding of CNN’s classification by our method on several different cases.
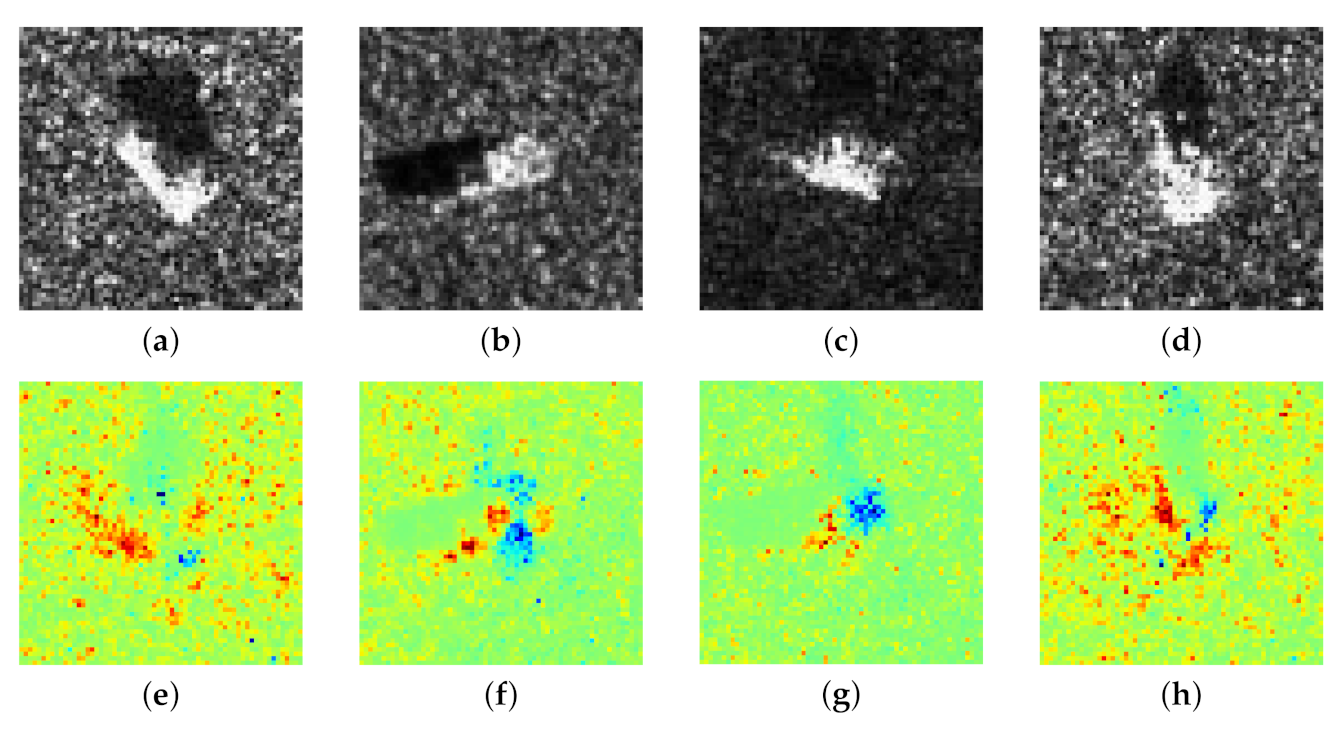
4.2. Proposed Method versus Other Activation-Based Methods
For CNN models, there have existed some activation-based methods, like various CAM methods. In CAM methods, the saliency heatmap
is composed of linear weighted summation of feature maps in the last convolutional layer, defined as follows:
where
is the
k-th feature map in a convolutional layer,
denotes the weight of
for the target class
c. Saurabh Desai and Harish G. Ramaswamy proposed a Ablation CAM which uses the impact of each feature on CNN’s classification accuracy to formulate weights defined as:
where
refers to the prediction score of class
c when all the feature maps are sent to the classifier, and
refers to the prediction score when a specific feature map
is removed. Wang et al. proposed a Score CAM that takes the similarity between input image and each feature map as weights defined as:
where
refers to the
k-th feature map upsampled to the same size of the input image
X, and
is a baseline image which is usually set to 0. Here we also conduct these two CAM methods as comparison to our method. Nonetheless, it should be noted that LRP methods attempt to detect both positive and negative pixels influenced CNN’s classification, while CAM methods aim at providing a highlighted region which matches the target precisely, thus there are neither positive nor negative contribution in CAM heatmaps. To avoid confusion, we adopt different colormaps to exhibit LRP heatmaps and CAM heatmaps in
Figure 6. Note that the value of elements in CAM heatmaps is normalized to
, while the value is normalized to
in LRP heatmaps. We can clearly observe that these two kinds of heatmaps reflect different information. CAM methods can highlight a region precisely matching the target’s shape but they can detect these pixels are positive or negative for CNN’s classification. In contrast, our method can vividly reflect both positive and negative pixels in input image for CNN’s classification.
4.3. Understanding of CNN from Different Perspectives
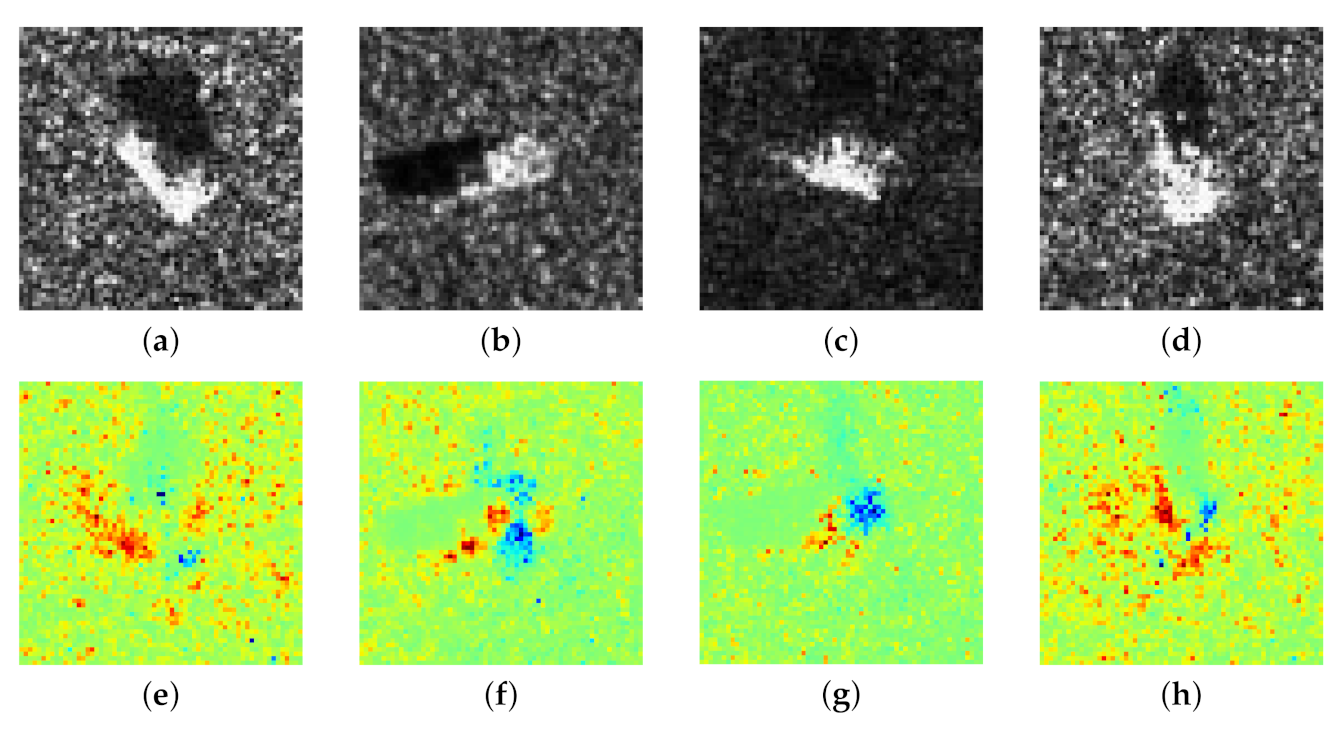
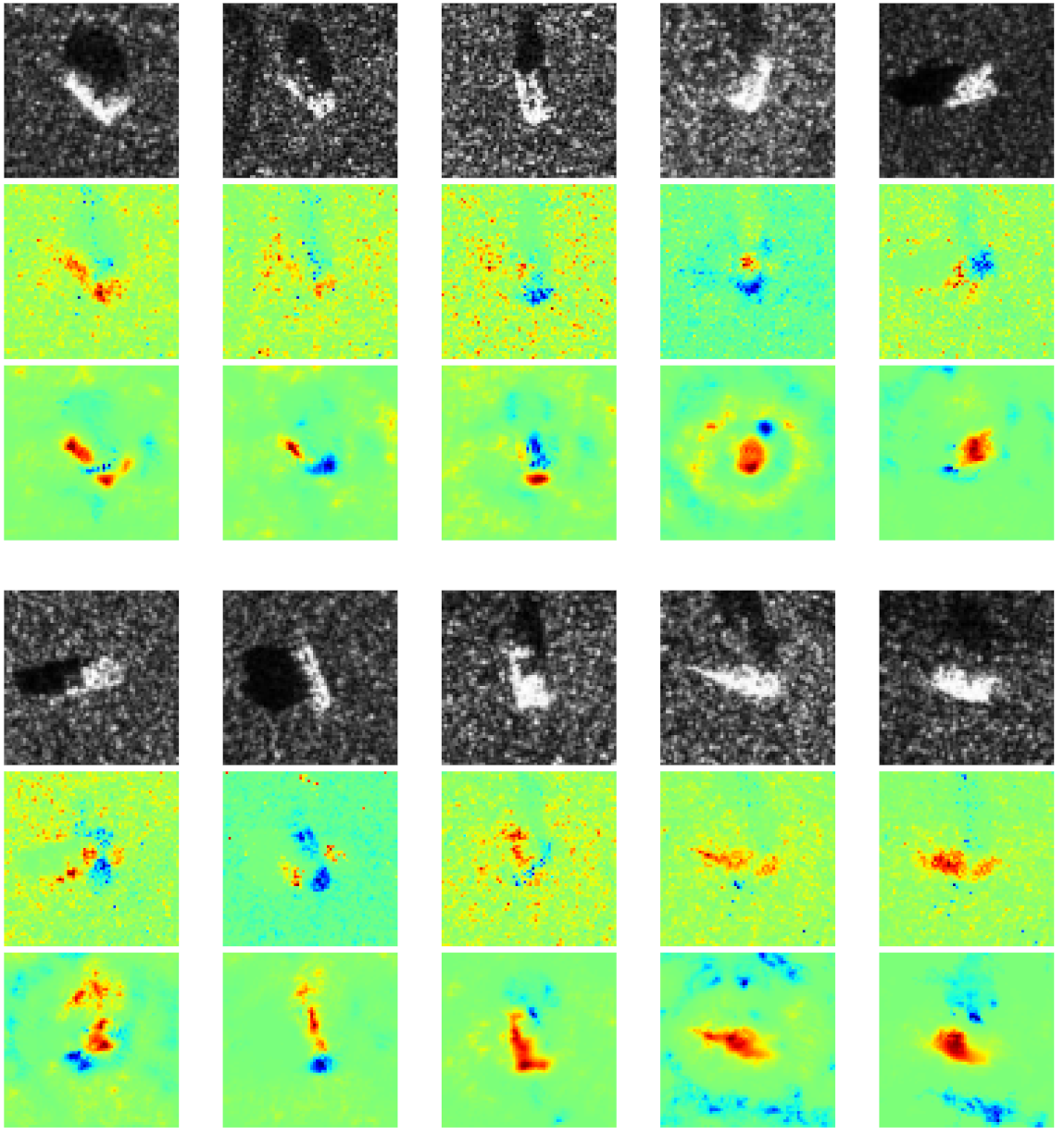
To understand CNN’s classification mechanism of SAR images, we categorized the heatmaps into three parts according to the distribution of positive and negative contributions. Specifically, the three categories are (1) positive and negative contributions are the targets, (2) positive contributions are targets while negative contributions are scattered speckles, and (3) negative contributions are targets while positive contributions are speckles.
We found that some heatmaps show both positive and negative contributions coincide with most parts of the target, as shown in
Figure 7. Specifically, some parts of the target are conducive to CNN’s classification, while the rest are disturbing CNN’s classification. It is probably due to some discriminative components (positive contribution) of the target, like the barrel of self-propelled gun, and some confusing components (negative contribution) that all the vehicles own, like wheels. Besides, it can be observed the intra-class divergence of speckles is quite slight in a certain class, while the extra-class divergence is obviously tremendous. It indicates that for a specific class, the imaging conditions are the same, such as scattering angle, emission power, medium, etc., while for different classes, they are different. Therefore, the speckles make no contribution to classification, which matches human’s cognition.
In contrast to the prior case, some other heatmaps show only positive contribution that coincides with the target, while negative contribution is located in some irregular areas, as shown in
Figure 8. It is probably because imaging conditions of different classes are the same, thus similar interference speckles disturb the CNN’s classification. Conversely, some heatmaps exhibit native contribution which coincides with targets while positive contribution is located near speckles, as shown in
Figure 9. It is probably because in these images, the targets are quite similar, whereas the speckles are the most discriminative features due to different imaging conditions.
5. Discussion
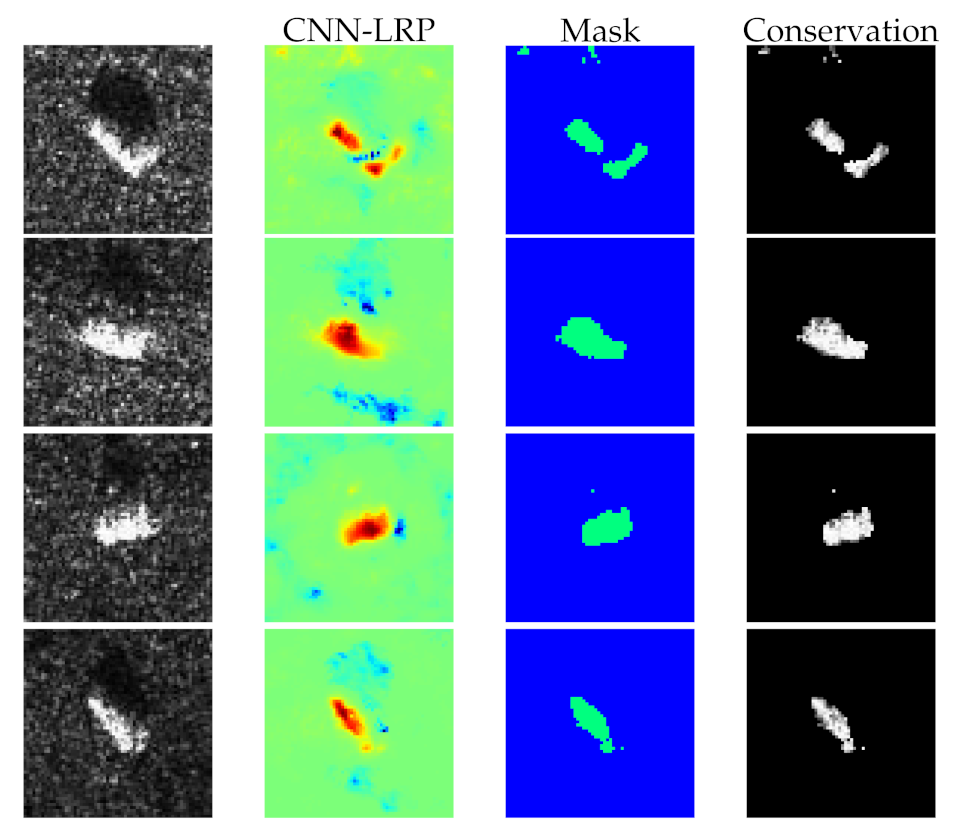
In this section, we will measure the qualitative performance of our method from classification accuracy. To further demonstrate the effectiveness of heatmaps, we binarize the heatmaps to obtain a set of masks by a threshold (in this experiment, we only preserve top 70% positive elements in heatmaps), thus a masked dataset can be generated by performing Hadmard product of masks and original data. This process can be viewed as filtering which only passes the positive or negative contribution pixels in the original SAR images. In this case, it means the preserved pixels really make positive contribution for CNN’s classification if the classification accuracy changes not obviously. We utilize the proposed method and common LRP to generate masked data, respectively.
Figure 10 shows several classes of images, their corresponding heatmaps, masks, and masked images. Then original data and two kinds of masked data are used to train three CNNs with the same structure and parameters.
Table 1 shows the top 5 recognition accuracy of three conditions when only positive contributions are preserved. Here we only select the top five recognition accuracy because a large number of misclassified samples in the other classes probably lead to inaccurate heatmaps which are negative for CNN’s understanding. It is apparent from
Table 1 that CNN and the proposed method outperform the sparse auto-encoder and common LRP, respectively. Note that although the recognition accuracy of masked data generated by our method declines slightly than original data, the accuracy of our method (93.15%) is still higher than that of common LRP (83.99%) dramatically.
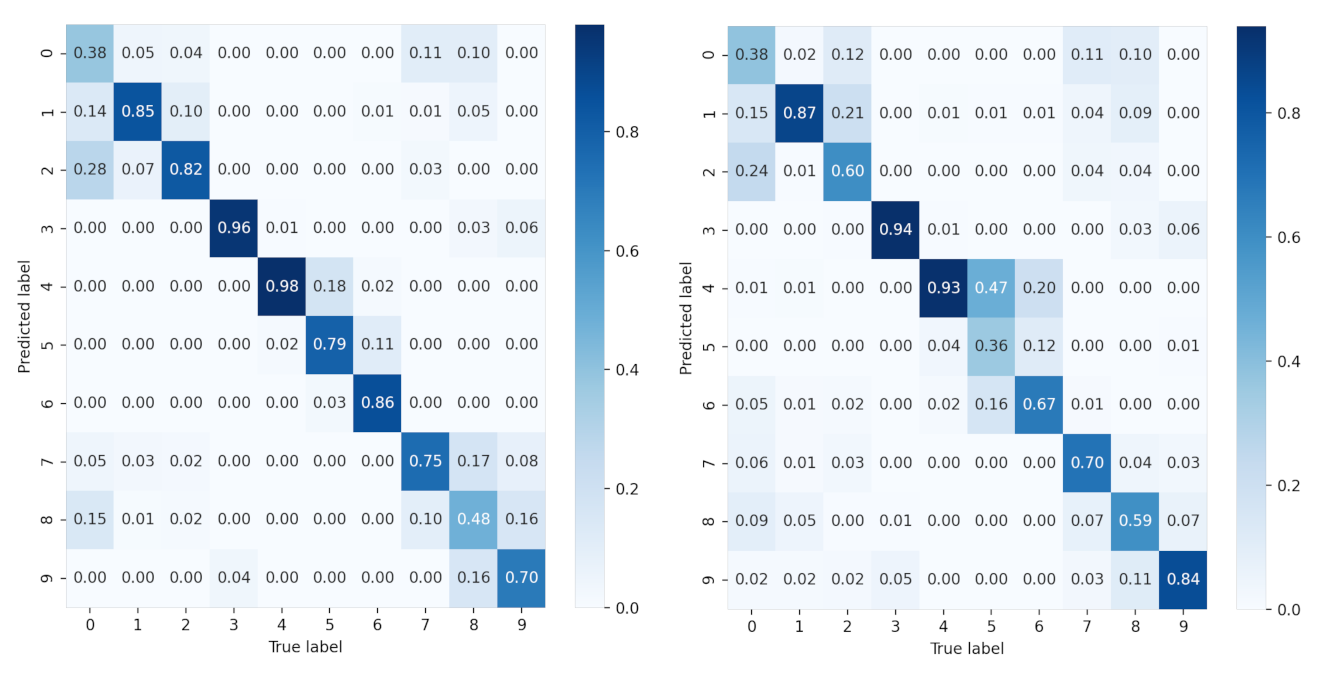
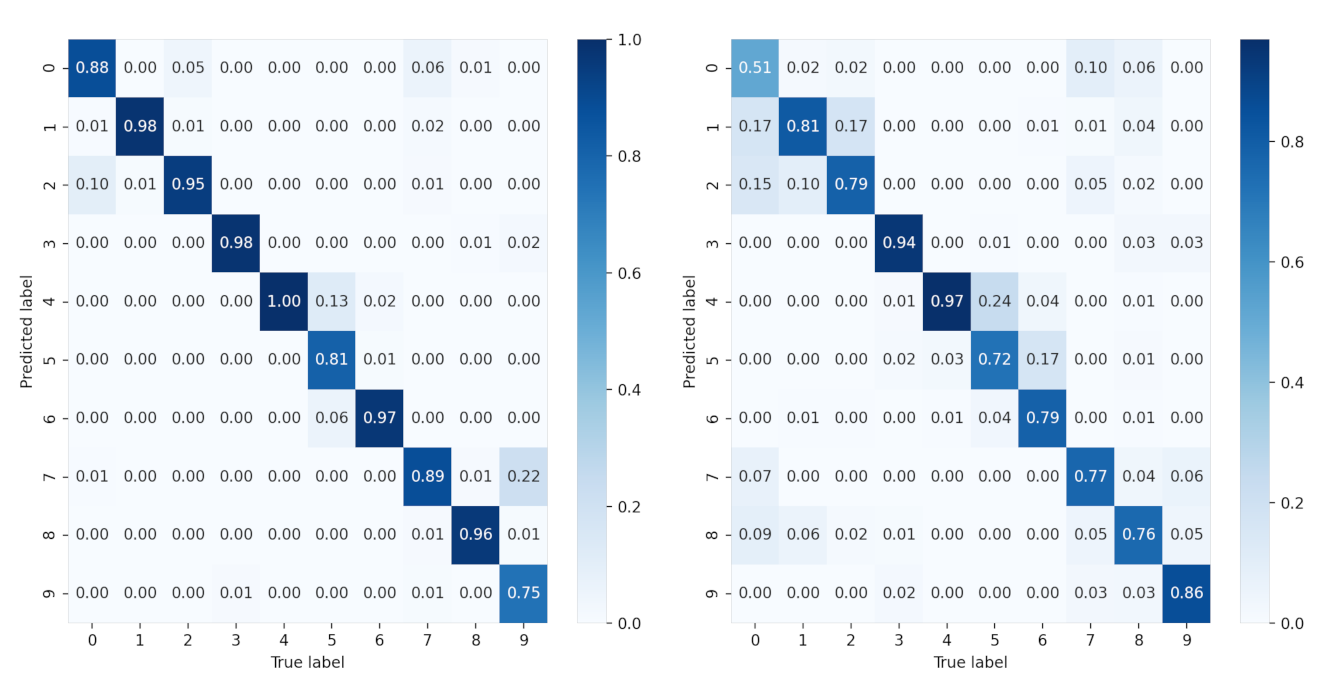
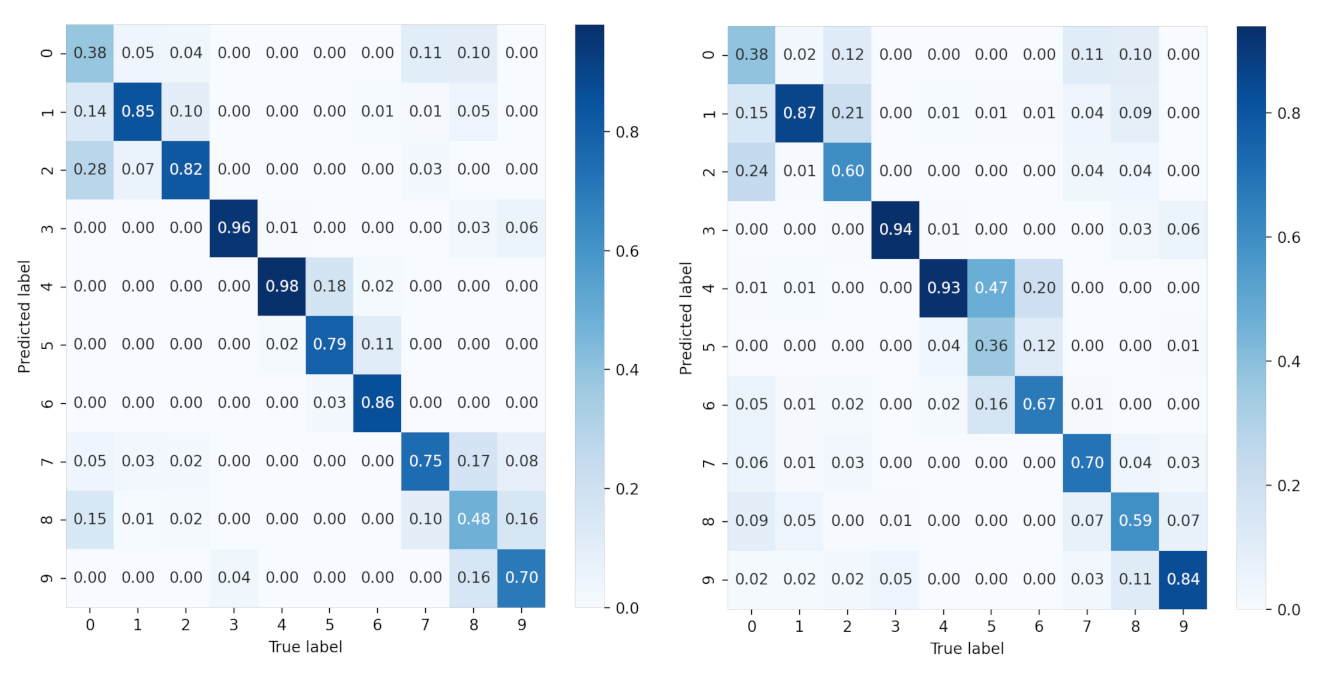
To further study the recognition accuracy of each class, we provide the confusion matrix of all SAR images of 10 classes under each condition in
Figure 11 and
Figure 12. It is clear that for sparse auto-encoder, misclassification occurs frequently among class 0, 1, 2, but seldom emerges when CNN and our proposed method are adopted.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}