
F-Classify: Fuzzy Rule Based Classification Method for Privacy Preservation of Multiple Sensitive Attributes

 , , , and
, , , and
Abstract
:1. Introduction
Motivation
- The article presents a fuzzy logic classifier (F-Classify) based on artificial intelligence (AI). The suggested methodology classifies QIs and SAa using a single methodology, namely fuzzy classification, rather than utilizing two distinct approaches for QIs and SAa. Instead of fixed classes/buckets, variable numbers of classes/buckets (k is variable) are formed in the proposed methodology.
- The proposed algorithm is verified for correctness using higher-level Petri nets (HLPN).
- The proposed F-classify approach is implemented in Python, and the results are compared to those obtained through (p-k) angelization. The results indicate that fuzzy classification (multi-dimensional partitioning) of correlated attributes increases data utility while permutation of multiple tables improves privacy. When compared to techniques that propose two different methods for QIs and SAs privacy, F-classify uses fuzzy logic for both QAs and SAs, resulting in minimal overhead.
2. Literature Review
3. Preliminaries
3.1. Notation
3.2. (p, k) Angelization Revisited
3.3. Fuzzification
3.4. HLPN
4. Proposed Approach: F-Classify
4.1. Linguistic Variables and Fuzzy Sets
- For numerical attributes sort the data in any order, then divide it into two/three/four (depending on mfs) equal lists.
- For categorical attributes, select unique attribute values from the list. Then, for each distinct attribute, assign a random number between 0 and 1. After assigning a random number, divide the unique list into two/three/four equal lists using the same technique.
4.2. Fuzzy Inference Rule-Based
4.3. Defuzzification
4.4. Permutation
5. Formal Modeling and Analysis
5.1. F-Classify Algorithm
| Algorithm 1 F-Classify algorithm: Fuzzification. |
|
| Algorithm 2 F-Classify algorithm: Permutation. |
for to n do
|
5.2. Formal Modeling and Analysis
6. Results and Discussion
6.1. Experimental Setup
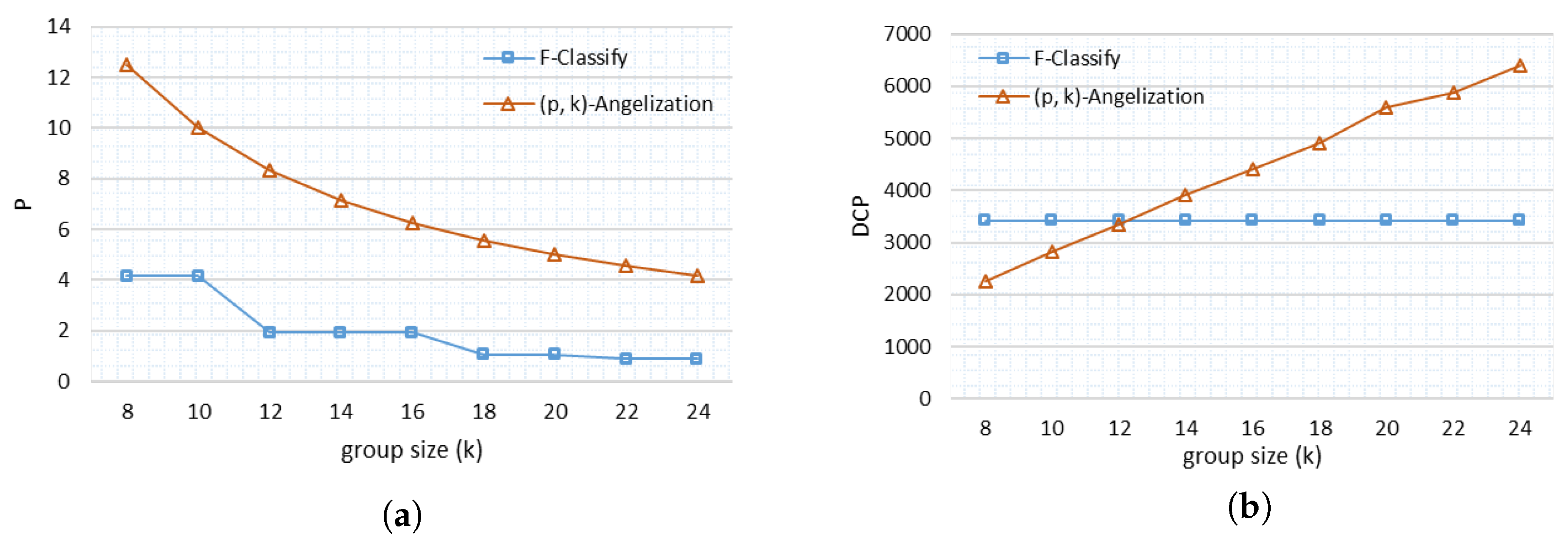
6.2. Measurement of Privacy
6.3. Discernibility Penalty
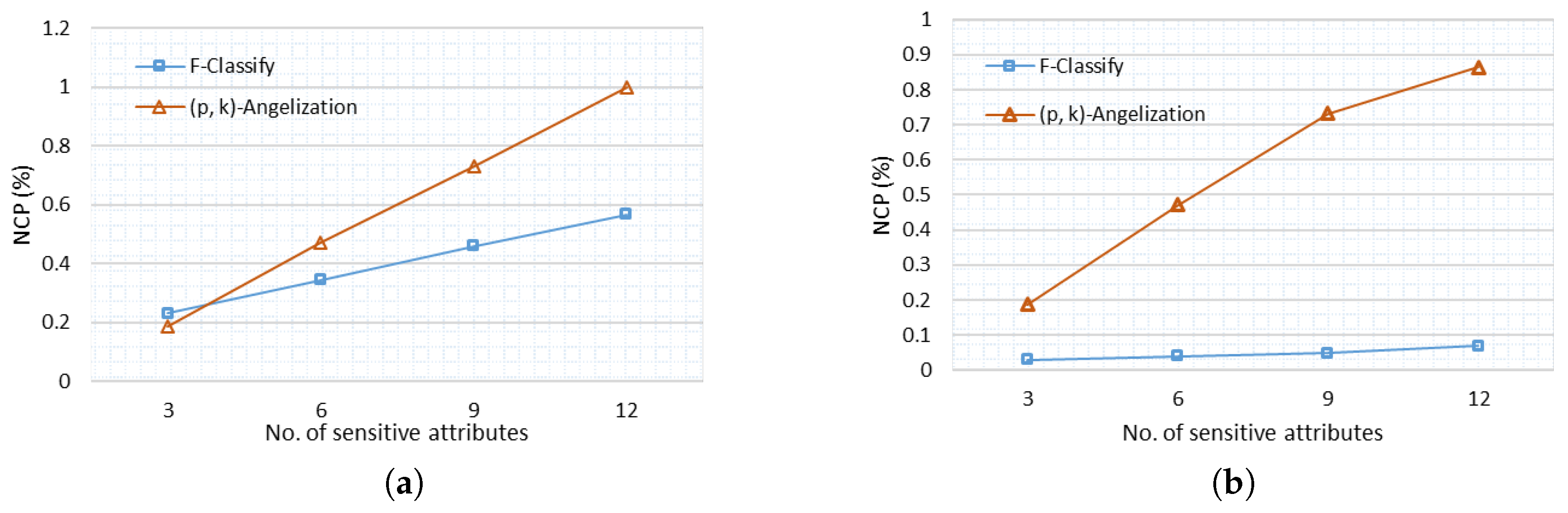
6.4. Normalized Certainty Penalty (NCP)
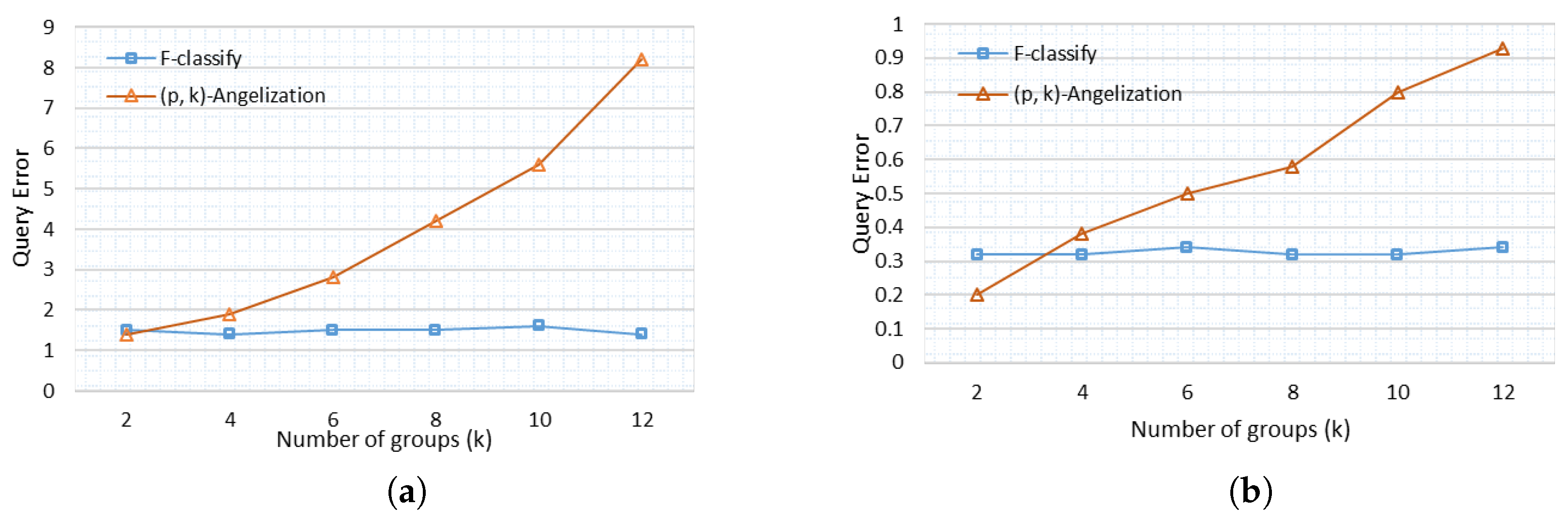
6.5. Query Error
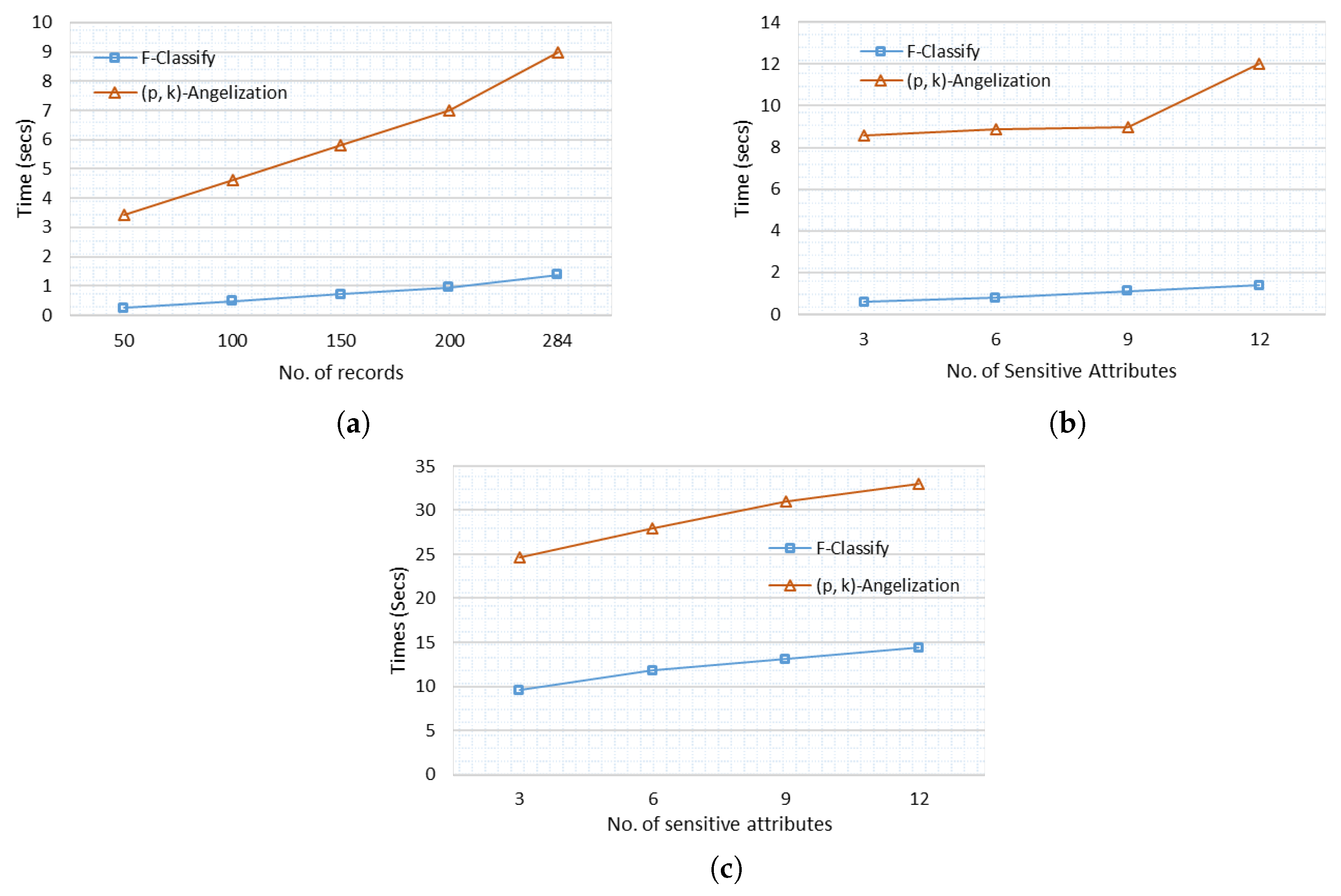
6.6. Execution Time Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 5. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data TKDD 2007, 1, 1. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar]
- LeFevre, K.; DeWitt, D.J.; Incognito, R.R. Efficient full-domain k-anonymity. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 49–60. [Google Scholar]
- Xu, J.; Wang, W.; Pei, J.; Wang, X.; Shi, B.; Fu, A.W.C. Utility-based anonymization using local re-coding. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 785–790. [Google Scholar]
- Sweeney, L. Achieving k-anonymity privacy protection using generalization and suppression. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 571–588. [Google Scholar] [CrossRef]
- Susan, V.S.; Christopher, T. Anatomization with Slicing: A New Privacy Preservation Technique for Multiple Sensitive Attributes; 1–21: SpringerPlus 5.1; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Anjum, A.; Ahmad, N.; Malik, S.U.; Zubair, S.; Shahzad, B. An efficient approach for publishing microdata for multiple sensitive attributes. J. Supercomput. 2018, 74, 5127–5155. [Google Scholar] [CrossRef]
- Han, J.; Luo, F.; Lu, J.; Peng, H. SLOMS: A Privacy-Preserving Data Publishing Method for Multiple Sensitive Attributes Microdata. J. Softw. 2013, 8, 3096–3104. [Google Scholar] [CrossRef] [Green Version]
- Tao, Y.; Chen, H.; Xiao, X.; Zhou, S.; Zhang, D. Angel: Enhancing the utility of generalization for privacy preserving publication. IEEE Trans. Knowl. Data Eng. 2009, 21, 1073–1087. [Google Scholar]
- Klir, G.; Yuan, B. Fuzzy Sets, and Fuzzy Logic; Prentice Hall: Hoboken, NJ, USA, 1995; Volume 4. [Google Scholar]
- Kumari, V.V.; Rao, S.S.; Raju, K.V.S.V.N.; Ramana, K.V.; Avadhani, B.V.S. Fuzzy based approach for privacy preserving publication of data. Int. J. Comput. Sci. Netw. Secur. 2008, 8, 115–121. [Google Scholar]
- Kumar, P.; Varma, K.I.; Sureka, A. Fuzzy based clustering algorithm for privacy preserving data mining. Int. J. Bus. Inf. Syst. 2011, 7, 27. [Google Scholar] [CrossRef] [Green Version]
- Mathworks; M.U.T.: Natick, MA, USA, 1992.
- Iyengar, V.S. Transforming data to satisfy privacy constraints. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 279–288. [Google Scholar]
- Zhang, X.; Liu, C.; Nepal, S.; Chen, J. An efficient quasi-identifier index based approach for privacy preservation over incremental data sets on cloud. J. Comput. Syst. Sci. 2013, 79, 542–555. [Google Scholar] [CrossRef]
- LeFevre, K.; DeWitt, D.J.; Ramakrishnan, R. Mondrian multidimensional k-anonymity. In Proceedings of the Data Engineering. Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006. [Google Scholar]
- Zhang, Q.; Koudas, N.; Srivastava, D.; Yu, T. Aggregate query answering on anonymized tables. In Proceedings of the IEEE 23rd International Conference In Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 116–125. [Google Scholar]
- Hore, B.; Mehrotra, S.; Tsudik, G.A. privacy-preserving index for range queries. In Proceedings of the Thirtieth International Conference on Very Large Databases, VLDB Endowment, Toronto, ON, Canada, 31 August–3 September 2004; Volume 30, pp. 720–731. [Google Scholar]
- Rcw, W.; Li, J.; Awc, F.; Wang, K. (a, k)-anonymity: An enhanced k-anonymity model for privacy-preserving data publishing. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 754–759. [Google Scholar]
- Martin, D.J.; Kifer, D.; Machanavajjhala, A.; Gehrke, J.; Halpern, J.Y. Worst-case background knowledge for privacy-preserving data publishing. In Proceedings of the Data Engineering IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 126–135. [Google Scholar]
- Li, T.; Li, N.; Zhang, J.; Molloy, I. Slicing: A new approach for privacy preserving data publishing. IEEE Trans. Knowl. Data Eng. 2012, 24, 561–574. [Google Scholar] [CrossRef] [Green Version]
- Kiruthika, S.; Raseen, M.M. Enhanced slicing models for preserving privacy in data publication. In Proceedings of the 2013 International Conference on Current Trends in Engineering and Technology (ICCTET), Coimbatore, India, 3 July 2013; pp. 406–409. [Google Scholar]
- Liu, Q.; Shen, H.; Sang, Y. Privacy-preserving data publishing for multiple numerical sensitive attributes. Tsinghua Sci. Technol. 2015, 20, 246–254. [Google Scholar]
- Min, G.U.O.; Zhen, L.I.U.; Huai-Bin, W.A.N.G. Personalized Privacy Preserving Approaches for Multiple Sensitive Attributes in Data Publishing; DEStech Transactions on Engineering and Technology Research Same-Ist; DEStech Publications: Lancaster, PA, USA, 2016. [Google Scholar]
- Yi, T.; Shi, M. Privacy protection method for multiple sensitive attributes based on strong rule. Math. Probl. Eng. 2015, 2015, 464731. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Ye, X. Privacy protection on multiple sensitive attributes. In Proceedings of the International Conference on Information and Communications Security, Zhengzhou, China, 12–15 December 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 141–152. [Google Scholar]
- Liu, J.; Luo, J.; Huang, J.Z. Rating: Privacy preservation for multiple attributes with different sensitivity requirements. In Proceedings of the Data Mining Workshops (ICDMW) 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011. [Google Scholar]
- Yang, E.A. Decomposition: Privacy preservation for multiple sensitive attributes. In International Conference on Database Systems for Advanced Applicationsg; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Das, D.; Bhattacharyya, D.K. Decomposition+: Improving l-Diversity for Multiple Sensitive Attributes. In International Conference on Computer Science and Information Technology; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Luo, F.; Han, J.; Lu, J.; Peng, H. ANGELMS: A privacy-preserving data publishing framework for microdata with multiple sensitive attributes. In Proceedings of the International Conference on Information Science and Technology (ICIST), Yangzhou, China, 23–25 March 2013. [Google Scholar]
- Zhu, H.; Tian, S.; Xie, M.; Yang, M. Preserving privacy for sensitive values of individuals in data publishing based on a new additive noise technique. In Proceedings of the 23rd International Conference on Computer Communication and Networks (ICCCN), Shanghai, China, 4–7 August 2014. [Google Scholar]
- Khan, R.; Tao, X.; Anjum, A.; Sajjad, H.; Khan, A.; Amiri, F. Privacy Preserving for Multiple Sensitive Attributes against Fingerprint Correlation Attack Satisfying c-Diversity. Wirel. Commun. Mob. Comput. 2020, 2020, 8416823. [Google Scholar] [CrossRef] [Green Version]
- Raju, N.L.; Seetaramanath, M.; Rao, P.S. A novel dynamic KCi-slice publishing prototype for retaining privacy and utility of multiple sensitive attributes. Int. J. Inf. Technol. Comput. Sci. 2019, 11, 18–32. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, H. Privacy Preserving Data Publishing for Multiple Sensitive Attributes Based on Security Level. Information 2020, 11, 166. [Google Scholar] [CrossRef] [Green Version]
- Kanwal, T.; Shaukat, S.A.A.; Anjum, A.; Choo, K.K.R.; Khan, A.; Ahmad, N.; Ahmad, M.; Khan, S.U. Privacy-preserving model and generalization correlation attacks for 1:M data with multiple sensitive attributes. Inf. Sci. 2019, 488, 238–256. [Google Scholar] [CrossRef]
- Kanwal, T.; Anjum, A.; Malik, S.U.; Sajjad, H.; Khan, A.; Manzoor, U.; Asheralieva, A. A robust privacy preserving approach for electronic health records using multiple dataset with multiple sensitive attributes. Comput. Secur. 2021, 105, 102224. [Google Scholar] [CrossRef]
- Dhumal, M.T.S.; Patil, M.Y.S. Implementation of slicing for multiple column multiple attributes: Privacy preserving data publishing. Int. J. Recent Innov. Trends Comput. Commun. 2015, 3, 4261–4266. [Google Scholar]
- Xiao, X.; Tao, Y. Anatomy: Simple and effective privacy preservation. In Proceedings of the 32nd International Conference on Very Large Data Bases, VLDB Endowment, Seoul, Korea, 12–15 September 2006; pp. 139–150. [Google Scholar]
- Sowmyarani, C.N.; Srinivasan, G.N. A robust privacy preserving model for data publishing. In Proceedings of the International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 8–10 January 2015. [Google Scholar]
- Majeed, A.; Ullah, F.; Lee, S. Vulnerability-and diversity-aware anonymization of personally identifiable information for improving user privacy and utility of publishing data. Sensors 2017, 17, 5. [Google Scholar] [CrossRef] [Green Version]
- Fuzzy Set Theory and Its Applications; Springer: Berlin/Heidelberg, Germany, 1996.
- Ali, M.; Malik, S.U.; Khan, S.U. DaSCE: Data security for cloud environment with semi-trusted third party. IEEE Trans. Cloud Comput. 2015, 5, 642–655. [Google Scholar] [CrossRef]
- Lin, Y.; Malik, S.U.R.; Bilal, K.; Yang, Q.; Wang, Y.; Khan, S.U. Designing and modeling of covert channels in operating systems. IEEE Trans. Comput. 2016, 65, 1706–1719. [Google Scholar] [CrossRef]
- Xiao, X.; Tao, Y. Dynamic anonymization: Accurate statistical analysis with privacy preservation. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 107–120. [Google Scholar]
- Wong, R.C.W.; Liu, Y.; Yin, J.; Huang, Z.; Fu, A.W.C.; Pei, J. (α, k)-anonymity Based Privacy Preservation by Lossy Join. In Advances in Data and Web Management; Springer: Berlin/Heidelberg, Germany, 2007; pp. 733–744. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Gender | Age | Zipcode | Disease | Treatment | Physician | Symptom | Diagnostic Method |
|---|---|---|---|---|---|---|---|---|
| John | M | 27 | 14248 | HIV | Antiretroviral therapy (ART) | John | Infection | Blood Test |
| Ana | F | 28 | 14207 | HIV | ART | John | Weight loss | ELISA Test |
| Richard | M | 26 | 14206 | Cancer | Radiation | Alice | Weight loss | MRI Scan |
| Dave | M | 25 | 14249 | Cancer | Chemotherapy | Bob | Abdominal Pain | Chest X-ray |
| Kate | F | 41 | 13053 | Hepatitis | Drugs | Sarah | Fever | Blood test |
| William | M | 48 | 13074 | Phthisis | Antibiotic | David | Fever | Molecular diagnostic methods |
| Robert | M | 45 | 13064 | Asthma | Medication | Suzan | Shortness of breath | Methacholine challenge tests |
| Olivia | F | 42 | 13062 | Obesity | Nutrition control | Steven | Eating disorders | Body mass index (BMI) |
| Emily | F | 33 | 14248 | Flu | Medication | Suzan | Fever | RITD tests |
| Alec | M | 37 | 14204 | Flu | Medication | Eve | Fever | RITD tests |
| Oliver | M | 36 | 14205 | Flu | Medication | Anas | Fever | RITD tests |
| James | M | 35 | 14248 | Indigestion | Medication | Jem | Heartburn | Chest X-ray |
| Jessica | F | 28 | 14249 | Cancer | Chemotherapy | Bob | Abdominal pain | Chest X-ray |
| P_ID | Age | Zipcode | Group Id | Disease | Treatment | Physician | Symptom | Diagnostic Method |
|---|---|---|---|---|---|---|---|---|
| P1 | 25–28 | 14206-14249 | 1 | HIV | Antiretroviral therapy (ART) | John | Infection | Blood Test |
| P2 | 28–41 | 13053-14248 | 2 | HIV | ART | John | Weight loss | ELISA Test |
| P3 | 25–28 | 14206-14249 | 1 | Cancer | Radiation | Alice | Weight loss | MRI Scan |
| P4 | 25–28 | 14206-14249 | 1 | Cancer | Chemotherapy | Bob | Abdominal Pain | Chest X-ray |
| P5 | 28–41 | 13053-14248 | 2 | Hepatitis | Drugs | Sarah | Fever | Blood test |
| P6 | 33–48 | 13062-14248 | 3 | Phthisis | Antibiotic | David | Fever | Molecular diagnostic methods |
| P7 | 33–48 | 13062-14248 | 3 | Asthma | Medication | Suzan | Shortness of breath | Methacholine challenge tests |
| P8 | 33–48 | 13062-14248 | 3 | Obesity | Nutrition control | Steven | Eating disorders | Body mass index (BMI) |
| P9 | 33–48 | 13062-14248 | 3 | Flu | Medication | Suzan | Fever | RITD tests |
| P10 | 28–41 | 13053-14248 | 2 | Flu | Medication | Eve | Fever | RITD tests |
| P12 | 28–41 | 13053-14248 | 2 | Indigestion | Medication | Jem | Heartburn | Chest X-ray |
| P13 | 25–28 | 14206-14249 | 1 | Cancer | Chemotherapy | Bob | Abdominal pain | Chest X-ray |
| (a) Classification of QIs (Age-Zipcode) | ||||
|---|---|---|---|---|
| P-ID | Age | Zip | Class | |
| P10 | [25–33] | [13053-14205] | q-C1 | |
| P5 | ||||
| P6 | ||||
| P7 | [35–48] | [13053-14205] | q-C2 | |
| P8 | ||||
| P11 | ||||
| P1 | ||||
| P2 | ||||
| P3 | [25–33] | [14206-14249] | q-C3 | |
| P4 | ||||
| P9 | ||||
| P13 | ||||
| P12 | [35–48] | [14206-14249] | q-C4 | |
| (b) Classification of Sensitive Attributes (Symptom-Diagnostic Method) | ||||
| P-ID | Symptom | Diagnostic Method | Class | |
| P1 P2 P5 | Infection Weight loss Fever | Blood Test Elisa test Blood test | C1 | |
| P3 P4 P6 P9 P10 P11 P13 | Weight loss Abdominal pain Fever Fever Fever Fever Abdominal Pain | MRI Scan Chest X-ray Molecular diagnostic Methods RITD tests RITD tests Chest X-ray | C2 | |
| P7 P8 P12 | Shortness of breath Eating disorders Heartburn | Methacholine challenge tests Body mass index (BMI) Chest X-ray | C3 | |
| (c) Classification of Sensitive Attributes (Disease-Treatment-Physician) | ||||
| P-ID | Disease | Treatment | Physician | Class |
| P1 P2 P3 | HIV HIV Cancer | ART ART Radiation | John John Alice | C1 |
| P4 P5 P13 | Cancer Hepatitis Cancer | Chemotherapy Drugs Chemotherapy | Bob Sarah Bob | C2 |
| P6 P7 P9 | Phthisis Asthma Flu | Antibiotic Medication Medication | David Suzan Suzan | C3 |
| P8 P10 P11 P12 | Obesity Flu Flu Indigestion | Nutritional Control Medication Medication Medication | Steven Eve Anas Jem | C4 |
| (a) Anonymized Table (QT) | |||||
|---|---|---|---|---|---|
| P-ID | Age | Zip | Age-Zip Class | Physician-Disease-Treatment | Symptom-Diagnostic Method |
| P10 | [25–33] | [13053-14205] | q-C1 | C4 | C2 |
| P5 P6 P7 P8 P11 | [35–48] | [13053-14205] | q-C2 | C2 C3 C4 | C1 C2 C3 |
| P1 P2 P3 P4 P9 P13 | [25–33] | [14206-14249] | q-C3 | C1 C2 C3 | C1 C2 |
| P12 | [35–48] | [14206-14249] | q-C4 | C4 | C3 |
| (b) Anonymized Table (Multiple Sensitive Attribute (MST (1))) | |||||
| Disease | Treatment | Physician | Class | ||
| HIV HIV Cancer | ART ART Radiation | John John Alice | C1 | ||
| Cancer Hepatitis Cancer | Chemotherapy, Drugs Chemotherapy | Bob Sarah Bob | C2 | ||
| Phthisis Asthma Flu | Antibiotic Medication Medication | David Suzan Suzan | C3 | ||
| Obesity Flu Flu Indigestion | Nutritional Control Medication Medication Medication | Steven Eve Anas Jem | C4 | ||
| (c) Anonymized Table (Multiple Sensitive Attribute (MST (2))) | |||||
| Symptom | Diagnostic Method | Class | |||
| Infection Weight loss Fever | Blood Test Elisa test Blood test | C1 | |||
| Weight loss Abdominal pain Fever Fever Fever Fever Abdominal Pain | MRI Scan Chest X-ray Molecular diagnostic Methods RITD tests RITD tests Chest X-ray | C2 | |||
| Shortness of breath Eating disorders Heartburn | Methacholine challenge tests Body mass index (BMI) Chest X-ray | C3 | |||
| Privacy Models | Evaluation | Attacks | Utility | |
|---|---|---|---|---|
| [22] | Slicing | It was intended for high dimensional data, but it has failed and has given original tuples when multiple tuples have identical SAs and QIDs. | Skewness, sensitivity, and similarity attacks | Loss of information |
| [7] | Slicing and anatomization | The proposed approach has a very complex solution. It publishes multiple tables, and also has greater execution time. | Demographic knowledge attack | Loss of information |
| [38] | Multiple column multiple attributes slicing | The proposed approach is for the MSAs anonymization, and QIs are overlooked. In case of 1:M occurrence of record, it shows incorrect results. | Skewness attacks, similarity attacks, and sensitivity attacks | Loss of information |
| [9] | SLOMS | Proposed approach released several tables with information loss. The correlation among MSA was also removed in this approach. | Demographic knowledge attack | Loss of information |
| [24] | Multi-sensitive bucketization with clustering | The approach only worked with numerical data if the consequence suppression rate is low. | - | Information loss is less |
| [25] | MSA(,l) | The approach used generalization with suppression and anatomy. It caused the utility to decrease. | - | High information loss |
| [27,39] | (,l), Anatomy, generalization, and suppression | Decrease in utility due to suppression of SA values. | - | Loss of information |
| [28] | Rating | SAs are generalized. | Association privacy attack | Loss of information |
| [29] | Decomposition | The proposed approach preserves privacy by assuring diversity in MSAs, as a consequence it activated information loss. | Similarity and skewness privacy attacks | Loss of information is high |
| [30] | Decomposition plus | Noise is added in proposed method, resulting in loss of utility. Attribute and identity disclosure are also not prevented in this approach. | Similarity and skewness privacy attacks | Loss of information is high |
| [31] | ANGELMS | There is a zero correlation between MSAs and QIDs in this approach, results in high information loss. | Sensitivity, similarity, and skewness privacy attacks | Loss of information is high. |
| [32] | P+ sensitive t-closeness | It assigns sensitivity level to each SA in such a way that each group contains at least p-distinct sensitivity levels. It also generalizes the QIs. | - | Loss of information |
| [40] | P-cover k-anonymity | It generalizes QI values to ensure privacy, it also ensures the MSA P-diversity constraint between MSA. It avoids membership, identity and attribute disclosures. | Sensitivity, skewness, and similarity privacy attacks | Loss of information. |
| [8] | (p, k)-angelization | The proposed approach preserves the privacy of MSAs using weight calculations. Weight calculation takes additional execution time and hence resulted into higher execution time. | - | Loss of information. |
| Symbol | Description |
|---|---|
| DT | Data Table |
| ST | Subset of quasi attributes and sensitive attributes in ST |
| QA | Quasi identifier |
| SA | Sensitive attribute |
| MSAs | Multiple sensitive attributes |
| Class | Classes of quasi attributes and sensitive attributes |
| q-C | Quasi identifier class |
| sa-C | Sensitive attribute class |
| m | Number of data attributes |
| n | Number of tuples |
| (lv) | Linguistic variables |
| Membership function for linguistic variables | |
| Rules | Fuzzy |
| Number of member ship functions for l | |
| Number of fuzzy rules | |
| Number of attributes in one subset | |
| Qc T | Quasi attributes class based tables |
| Sc T | Sensitive attributes class based tables |
| Anonymize T | Anonymize table of quasi and sensitive attributes |
| QT | Quasi identifier table |
| MST | Multiple sensitive attribute tables |
| Types | Description |
|---|---|
| Tp | m tuples in Data Table |
| Dq | Subset of quasi-identifier |
| Ds | Multiple Subsets of sensitive attribute values |
| Qc | Class for quasi-identifiers |
| Sci | Multiple classes for sensitive attributes |
| LV | Linguistic variables for m attributes |
| R | mu number of fuzzy rules |
| PID | Patient identifier in Data Table |
| Q | Group of quasi identifiers |
| C | Quasi identifier classes |
| C | Sensitive attribute classes |
| SA | Multiple number of sensitive attribute Tables |
| Types | Description |
|---|---|
| (PID × Tp) | |
| (Dq × Ds) | |
| (Qc × Sc) | |
| (L V) | |
| (mf) | |
| (R) | |
| (PID × Q x C) | |
| (PID × SA × C ) | |
| ((PID × Q × C x C) | |
| ((Q × C) | |
| ((SA × C) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Attaullah, H.; Anjum, A.; Kanwal, T.; Malik, S.U.R.; Asheralieva, A.; Malik, H.; Zoha, A.; Arshad, K.; Imran, M.A. F-Classify: Fuzzy Rule Based Classification Method for Privacy Preservation of Multiple Sensitive Attributes. Sensors 2021, 21, 4933. https://0-doi-org.brum.beds.ac.uk/10.3390/s21144933
Attaullah H, Anjum A, Kanwal T, Malik SUR, Asheralieva A, Malik H, Zoha A, Arshad K, Imran MA. F-Classify: Fuzzy Rule Based Classification Method for Privacy Preservation of Multiple Sensitive Attributes. Sensors. 2021; 21(14):4933. https://0-doi-org.brum.beds.ac.uk/10.3390/s21144933
Chicago/Turabian StyleAttaullah, Hasina, Adeel Anjum, Tehsin Kanwal, Saif Ur Rehman Malik, Alia Asheralieva, Hassan Malik, Ahmed Zoha, Kamran Arshad, and Muhammad Ali Imran. 2021. "F-Classify: Fuzzy Rule Based Classification Method for Privacy Preservation of Multiple Sensitive Attributes" Sensors 21, no. 14: 4933. https://0-doi-org.brum.beds.ac.uk/10.3390/s21144933