
Enhanced Soft 3D Reconstruction Method with an Iterative Matching Cost Update Using Object Surface Consensus



Abstract
:1. Introduction
- (1)
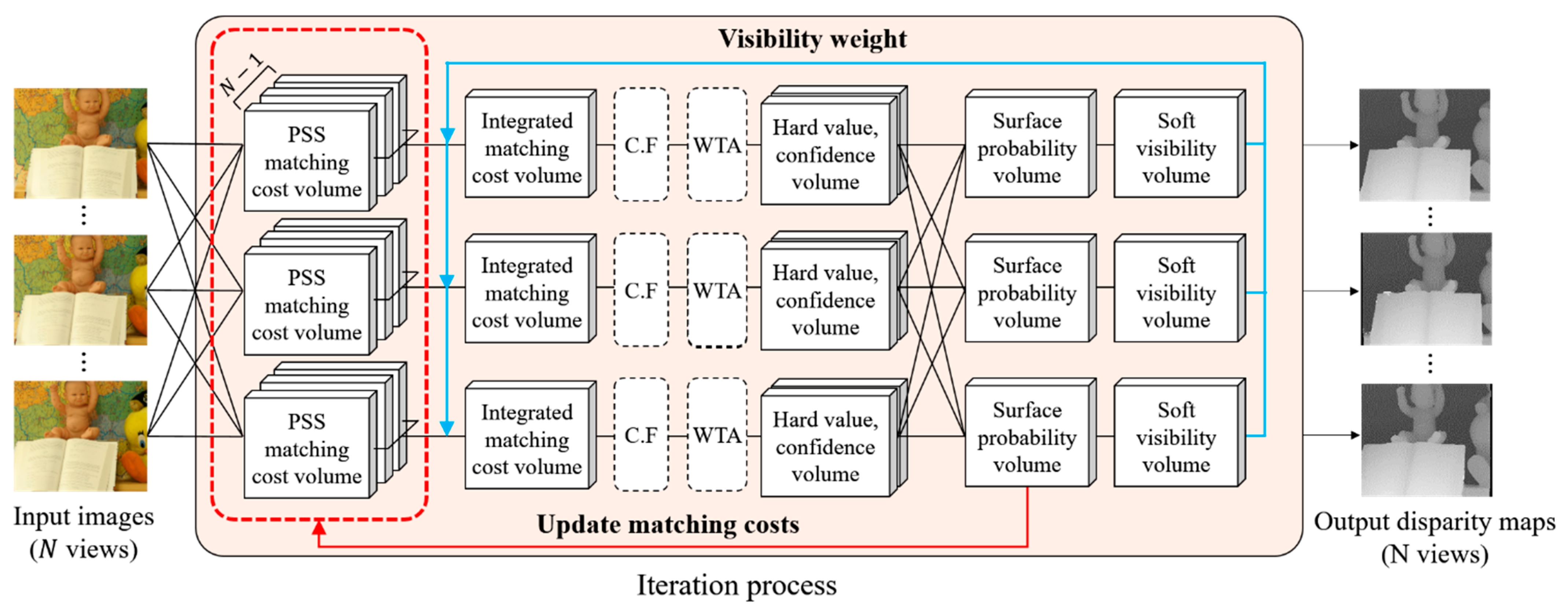
- A new cost update process is introduced in the pipeline of EnSoft3D to simultaneously refine the PSS matching costs and soft visibility of multiple views.
- (2)
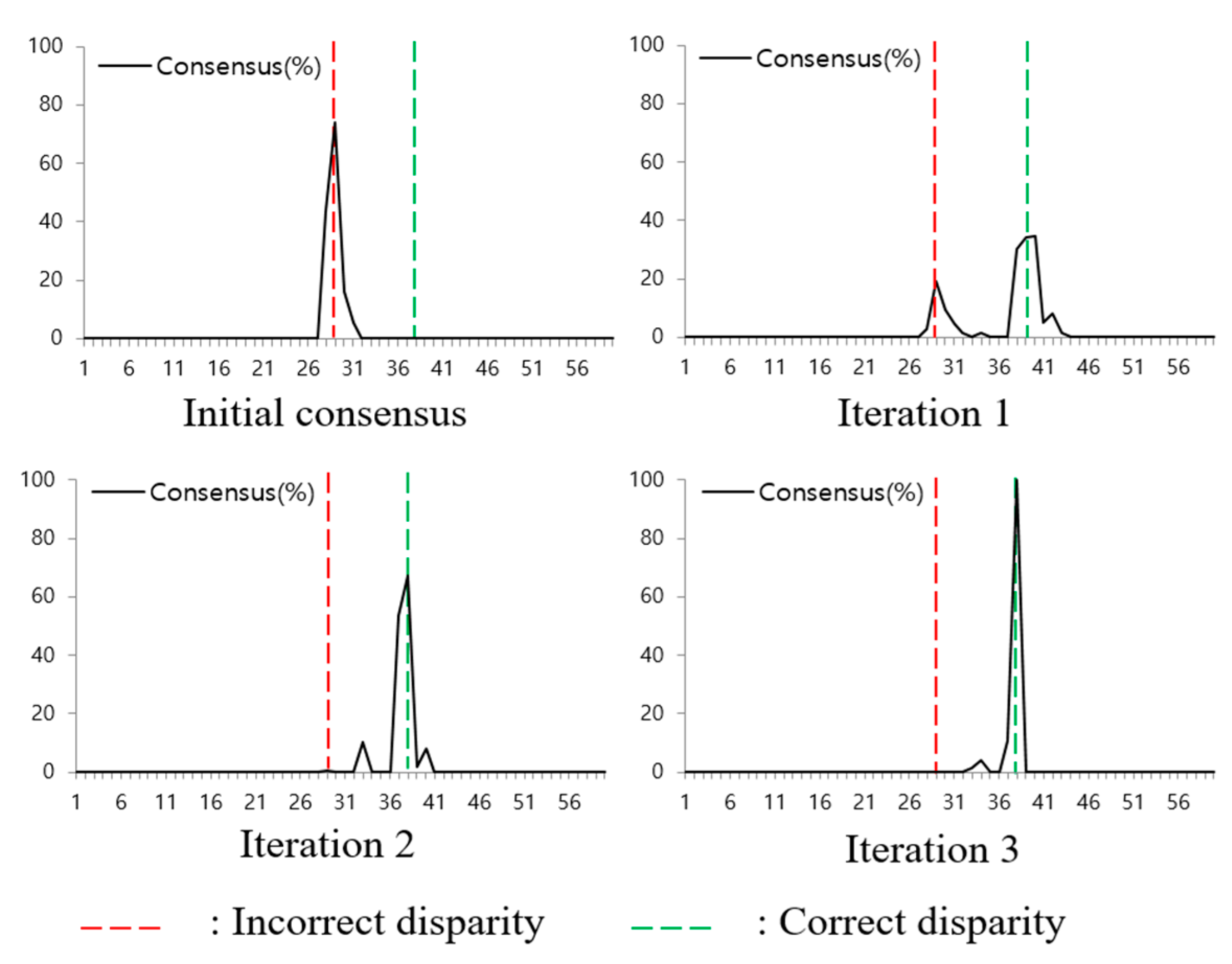
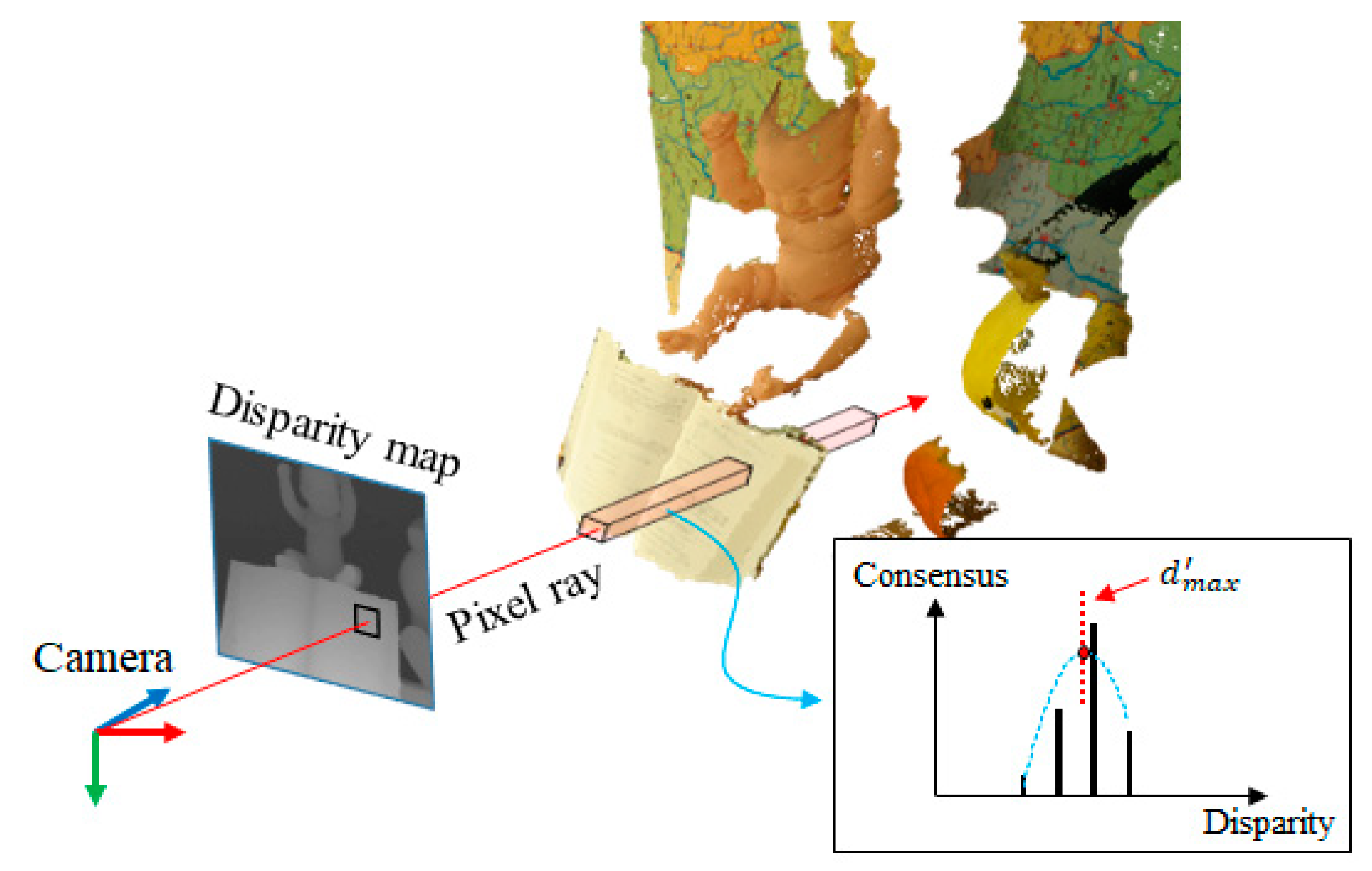
- The PSS matching cost is refined using the object surface consensus. The object surface is determined in sub-pixel accuracy from the surface consensus volumes.
- (3)
- An inverse Gaussian kernel is derived from the object surface. Then, the kernel is used to minimize the PSS matching costs around the surface.
2. Previous Works
3. Framework of Soft 3D Reconstruction
3.1. Initial Disparity Map Generation
3.2. Refinement of Disparity Cost Volume
4. Enhancement of Soft 3D Reconstruction
4.1. Object Surface Decision
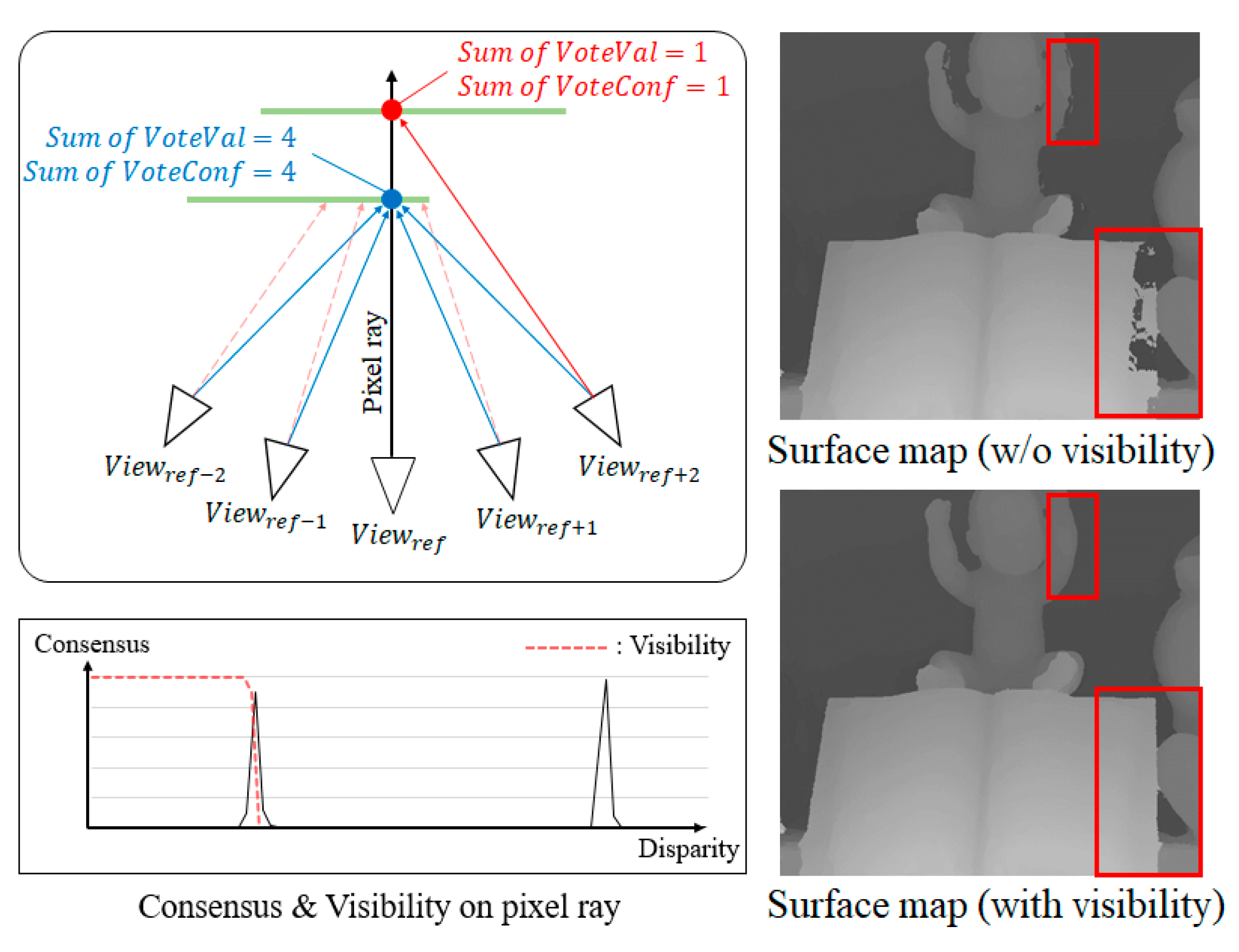
4.2. Update of Multi-View Matching Cost
4.3. New Matching Cost Integration
5. Experiment and Evaluation
5.1. Structured Dataset: Middlebury
5.1.1. D Reconstruction of Middlebury 2003 Dataset
5.1.2. D Reconstruction of Middlebury 2006 Dataset
5.1.3. View Synthesis of Middlebury 2006 Dataset
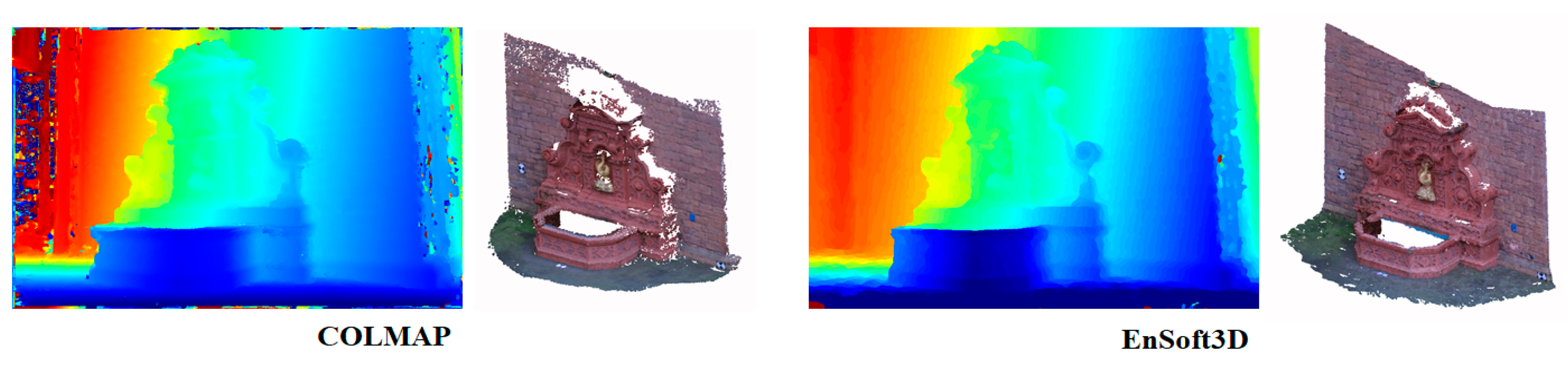
5.2. Unstructured Dataset: Fountain-P11, ETH3D Low Resolution Dataset
5.3. Runtime
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 807–814. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5525–5534. [Google Scholar]
- Zhang, H.T.; Yu, J.; Wang, Z.F. Probability contour guided depth map inpainting and superresolution using non-local total generalized variation. Multimed. Tools Appl. 2018, 77, 9003–9020. [Google Scholar] [CrossRef]
- Penner, E.; Zhang, L. Soft 3d reconstruction for view synthesis. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Collins, R.T. A space-sweep approach to true multi-image matching. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 18–20 June 1996; pp. 358–363. [Google Scholar]
- Ha, H.; Im, S.; Park, J.; Jeon, H.G.; Kweon, I.S. High-quality depth from uncalibrated small motion clip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5413–5421. [Google Scholar]
- Poggi, M.; Pallotti, D.; Tosi, F.; Mattoccia, S. Guided stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 979–988. [Google Scholar]
- Scharstein, D.; Szeliski, R. High-accuracy stereo depth maps using structured light. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Madison, WI, USA, 18–20 June 2003; pp. 195–202. [Google Scholar]
- Hirschmuller, H.; Scharstein, D. Evaluation of cost functions for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Schops, T.; Schonberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3260–3269. [Google Scholar]
- Strecha, C.; Hansen, W.V.; Gool, L.V.; Fua, P.; Thoennessen, U. On benchmarking camera calibration and multi-view stereo for high resolution imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Huynh, T.Q.; Ghanbari, M. The accuracy of PSNR in predicting video quality for different video scenes and frame rates. Telecommun. Syst. 2012, 49, 35–48. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Brownrigg, D.R. The weighted median filter. Commun. ACM 1984, 27, 807–818. [Google Scholar] [CrossRef]
- Ma, Z.; He, K.; Wei, Y.; Sun, J.; Wu, E. Constant time weighted median filtering for stereo matching and beyond. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 49–56. [Google Scholar]
- Hosni, A.; Bleyer, M.; Rhemann, C.; Gelautz, M.; Rother, C. Real-time local stereo matching using guided image filtering. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar]
- Chen, R.; Han, S.; Xu, J.; Su, H. Point-based multi-view stereo network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1538–1547. [Google Scholar]
- Manuel, M.G.V.; Manuel, M.M.J.; Edith, M.M.N.; Ivone, R.A.P.; Ramirez, S.R.E. Disparity map estimation with deep learning in stereo vision. In Proceedings of the Regional Consortium for Foundations, Research and Spread of Emerging Technologies in Computing Sciences (RCCS+SPIDTEC2), Juarez, MX, USA, 8–9 November 2018; pp. 27–40. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Kuhn, A.; Sormann, C.; Rossi, M.; Erdler, O.; Fraundorfer, F. DeepC-MVS: Deep confidence prediction for Multi-view stereo reconstruction. In Proceedings of the International Conference on 3D Vision (3DV), online, 25–28 November 2020; pp. 404–413. [Google Scholar]
- Kuhn, A.; Lin, S.; Erdler, O. Plane completion and filtering for multi-view stereo reconstruction. In Proceedings of the German Conference on Pattern Recognition (GCPR), Dortmund, Germany, 10–13 September 2019; pp. 18–32. [Google Scholar]
- Wang, K.; Shen, S. Mvdepthnet: Real-time multiview depth estimation neural network. In Proceedings of the International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 248–257. [Google Scholar]
- Huang, P.H.; Matzen, K.; Kopf, J.; Ahuja, N.; Huang, J.B. Deepmvs: Learning multi-view stereopsis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2821–2830. [Google Scholar]
- Im, S.; Jeon, H.G.; Lin, S.; Kweon, I.S. Dpsnet: End-to-end deep plane sweep stereo. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019; pp. 1–12. [Google Scholar]
- Wu, G.; Li, Y.; Huang, Y.; Liu, Y. Joint view synthesis and disparity refinement for stereo matching. Front. Comput. Sci. 2019, 13, 1337–1352. [Google Scholar] [CrossRef]
- Zhou, T.; Tucker, R.; Flynn, J.; Fyffe, G.; Snavely, N. Stereo magnification: Learning view synthesis using multiplane images. ACM Trans. Graph. 2018, 37, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Flynn, J.; Broxton, M.; Debevec, P.; DuVall, M.; Fyffe, G.; Overbeck, R.; Snavely, N.; Tucker, R. Deepview: View synthesis with learned gradient descent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2367–2376. [Google Scholar]
- Srinivasan, P.P.; Tucker, R.; Barron, J.T.; Ramamoorthi, R.; Ng, R.; Snavely, N. Pushing the boundaries of view extrapolation with multiplane images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 175–184. [Google Scholar]
- Kanade, T.; Okutomi, M. A stereo matching algorithm with an adaptive window: Theory and experiment. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 920–932. [Google Scholar] [CrossRef] [Green Version]
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the European conference on computer vision (ECCV), Stockholm, Sweden, 2–6 May 1994; pp. 151–158. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, Netherland, 8–16 October 2016; pp. 501–518. [Google Scholar]
- Middlebury Stereo Evaluation-Version 2. Available online: https://vision.middlebury.edu/stereo/eval/ (accessed on 26 September 2021).
- Huang, X.; Yuan, C.; Zhang, J. A systematic stereo matching framework based on adaptive color transformation and patch-match forest. J. Vis. Commun. Image Represent. In press.
- Li, H.; Gao, Y.; Huang, Z.; Zhang, Y. Stereo matching based on multi-scale fusion and multi-type support regions. J. Opt. Soc. Amer. A. JOSAA 2019, 36, 1523–1533. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Zhu, H.; Yu, S.; Shi, J. Stereo matching with fusing adaptive support weights. IEEE Access 2019, 7, 61960–61974. [Google Scholar] [CrossRef]
- Besse, F.; Rother, C.; Fitzgibbon, A.; Kautz, J. PMBP: PatchMatch belief propagation for correspondence field estimation. Int. J. Comput. Vis. 2013, 110, 2–13. [Google Scholar] [CrossRef]
- Li, Y.; Min, D.; Brown, M.S.; Do, M.N.; Lu, J. SPM-BP: Sped-up PatchMatch belief propagation for continuous MRFs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4006–4014. [Google Scholar]
- Taniai, T.; Matsushita, Y.; Naemura, T. Graph cut based continuous stereo matching using locally shared labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1613–1620. [Google Scholar]
- Mei, X.; Sun, X.; Dong, W.; Wang, H.; Zhang, X. Segment-tree based cost aggregation for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 313–320. [Google Scholar]
- Taniai, T.; Matsushita, Y.; Sato, Y.; Naemura, T. Continuous 3D label stereo matching using local expansion moves. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2725–2739. [Google Scholar] [CrossRef] [Green Version]
- Bleyer, M.; Rhemann, C.; Rother, C. PatchMatch stereo–stereo matching with slanted support windows. Available online: http://www.bmva.org/bmvc/2011/proceedings/paper14/paper14.pdf (accessed on 3 October 2021).
- Li, L.; Zhang, S.; Yu, X.; Zhang, L. PMSC: Patchmatch-based superpixel cut for accurate stereo matching. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 679–692. [Google Scholar] [CrossRef]
- Yang, Q.; Ji, P.; Li, D.; Yao, S.; Zhang, M. Fast stereo matching using adaptive guided filtering. Image Vis. Comput. 2014, 32, 202–211. [Google Scholar] [CrossRef]
- Yang, Q. Stereo matching using tree filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 834–846. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Fang, Y.; Min, D.; Sun, L.; Yang, S.; Yan, S. Cross-scale cost aggregation for stereo matching. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 965–976. [Google Scholar] [CrossRef] [Green Version]
- Hamzah, R.A.; Kadmin, A.F.; Hamid, M.S.; Ghani, S.F.A.; Ibrahim, H. Improvement of stereo matching algorithm for 3D surface reconstruction. Signal Process. Image Commun. 2018, 65, 165–172. [Google Scholar] [CrossRef]
- Luo, G.; Zhu, Y. Foreground removal approach for hole filling in 3D video and view synthesis. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2118–2131. [Google Scholar] [CrossRef]
- Oliveira, A.Q.; Walter, M.; Jung, C.R. An artifact-type aware dibr method for view synthesis. IEEE Signal Process. Lett. 2018, 25, 1705–1709. [Google Scholar] [CrossRef]
- Jain, A.K.; Tran, L.C.; Khoshabeh, R.; Nguyen, T.Q. Efficient stereo-to-multiview synthesis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 889–892. [Google Scholar]
- Tran, L.C.; Bal, C.; Pal, C.J.; Nguyen, T.Q. On consistent inter-view synthesis for autostereoscopic displays. 3D Res. 2012, 3, 1–10. [Google Scholar] [CrossRef]
- Ramachandran, G.; Rupp, M. Multiview synthesis from stereo views. In Proceedings of the International Conference on Systems, Signals and Image Processing (IWSSIP), Vienna, Austria, 11–13 April 2012; pp. 341–345. [Google Scholar]
- Zheng, E.; Dunn, E.; Jojic, V.; Frahm, J.M. Patchmatch based joint view selection and depthmap estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1510–1517. [Google Scholar]
- Hu, X.; Mordohai, P. Least commitment, viewpoint-based, multi-view stereo. In Proceedings of the International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission (3DIMPVT), Zurich, Switzerland, 13–15 October 2012; pp. 531–538. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Zaharescu, A.; Boyer, E.; Horaud, R. Topology-adaptive mesh deformation for surface evolution, morphing, and multiview reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 823–837. [Google Scholar] [CrossRef]
- Tylecek, R.; Šára, R. Refinement of surface mesh for accurate multi-view reconstruction. Int. J. Virtual Real. 2010, 9, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Jancosek, M.; Pajdla, T. Multi-view reconstruction preserving weakly-supported surfaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3121–3128. [Google Scholar]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 873–881. [Google Scholar]
- ETH3D Low-Resolution Many-View Benchmark. Available online: https://www.eth3d.net/low_res_many_view (accessed on 26 September 2021).
- Xue, T.; Owens, A.; Scharstein, D.; Geosele, M.; Szeliski, R. Multi-frame stereo matching with edges, planes, and superpixels. Image Vis. Comput. 2019, 91, 103771. [Google Scholar] [CrossRef]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Park, I.K. Deep self-guided cost aggregation for stereo matching. Pattern Recognit. Lett. 2018, 112, 168–175. [Google Scholar]
- Ma, N.; Men, Y.; Men, C.; Li, X. Accurate dense stereo matching based on image segmentation using an adaptive multi-cost approach. Symmetry 2016, 8, 159. [Google Scholar] [CrossRef]
- Yin, J.; Zhu, H.; Yuan, D.; Xue, T. Sparse representation over discriminative dictionary for stereo matching. Pattern Recognit. 2017, 71, 278–289. [Google Scholar] [CrossRef]
- Hamzah, R.A.; Ibrahim, H.; Hassan, A.H.A. Stereo matching algorithm based on per pixel difference adjustment, iterative guided filter and graph segmentation. J. Vis. Commun. Image Represent. 2017, 42, 145–160. [Google Scholar] [CrossRef]
- Zhang, K.; Li, J.; Li, Y.; Hu, W.; Sun, L.; Yang, S. Binary stereo matching. In Proceedings of the International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 356–359. [Google Scholar]
- Bricola, J.C.; Bilodeau, M.; Beucher, S. Morphological Processing of Stereoscopic Image Superimpositions for Disparity Map Estimation. Available online: https://hal.archives-ouvertes.fr/hal-01330139/ (accessed on 26 September 2021).
- Kitagawa, M.; Shimizu, I.; Sara, R. High accuracy local stereo matching using DoG scale map. In Proceedings of the Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 258–261. [Google Scholar]
- Mao, W.; Gong, M. Disparity filtering with 3D convolutional neural networks. In Proceedings of the 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 246–253. [Google Scholar]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intel. TPAMI 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. JMLR 2016, 17, 2287–2318. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cones (# of Disparity Plane: 80) | Err Threshold: 0.5 | Err Threshold: 1.0 | ||||
| Algorithm (Online rank) | nonocc | all | disc | nonocc | all | disc |
| EnSoft3D | 2.85 | 5.35 | 7.41 | 1.42 | 2.73 | 4.22 |
| PM-Forest (1) | 5.11 | 6.35 | 9.31 | 1.32 | 2.02 | 3.69 |
| Soft3D | 3.66 | 6.75 | 9.13 | 1.63 | 3.35 | 4.78 |
| PM-Huber (2) | 2.70 | 7.90 | 7.77 | 2.15 | 6.69 | 6.4 |
| ARAP (4) | 3.00 | 8.55 | 8.35 | 2.08 | 6.73 | 6.17 |
| GC+LocalExp (6) | 3.46 | 8.65 | 9.72 | 2.72 | 7.42 | 7.94 |
| PM-PM (7) | 3.51 | 8.86 | 9.58 | 2.18 | 6.43 | 6.37 |
| SubPixSearch (10) | 4.02 | 9.76 | 10.3 | 2.24 | 6.87 | 6.5 |
| PatchMatch (11) | 3.80 | 10.2 | 10.2 | 2.47 | 7.80 | 7.11 |
| LAMC-DSM (17) | 4.00 | 11.0 | 9.79 | 2.09 | 8.31 | 6.1 |
| C-SemiGlob (23) | 5.37 | 11.7 | 12.8 | 2.77 | 8.35 | 8.2 |
| IGSM (25) | 6.17 | 11.8 | 12.0 | 2.14 | 6.97 | 6.27 |
| ADCensus (28) | 6.58 | 12.4 | 11.9 | 2.42 | 7.25 | 6.95 |
| SemiGlob (30) | 4.93 | 12.5 | 13.5 | 3.06 | 9.75 | 8.9 |
| CrossLMF (46) | 7.55 | 13.5 | 14.5 | 2.34 | 7.82 | 6.8 |
| BSM (56) | 6.45 | 14.1 | 13.1 | 2.34 | 8.79 | 6.8 |
| SubPixDoubleBP (70) | 8.49 | 14.7 | 16.5 | 2.93 | 8.73 | 7.91 |
| AdaptLocalSeg (76) | 7.78 | 15.0 | 16.2 | 2.73 | 9.69 | 7.91 |
| HistAggrSlant (81) | 9.34 | 15.1 | 16.2 | 2.90 | 8.40 | 7.97 |
| CVW-RM (106) | 12.6 | 17.9 | 18.6 | 2.96 | 7.71 | 7.72 |
| MultiCamGC (113) | 12.0 | 18.8 | 21.2 | 4.89 | 11.8 | 12.1 |
| MVSegBP (130) | 14.4 | 21.2 | 24.5 | 5.29 | 11.3 | 14.5 |
| Teddy (# of disparity plane: 200) | Err threshold: 0.5 | Err threshold: 1.0 | ||||
| Algorithm (Online rank) | nonocc | all | disc | nonocc | all | disc |
| PM-Forest (1) | 4.95 | 5.45 | 11.3 | 1.91 | 2.29 | 5.47 |
| GC+LocalExp (3) | 5.16 | 7.73 | 14.2 | 3.33 | 4.88 | 8.87 |
| PM-Huber (5) | 5.53 | 9.36 | 15.9 | 3.38 | 5.56 | 10.7 |
| EnSoft3D | 6.77 | 9.94 | 17.4 | 3.86 | 4.85 | 10.9 |
| ARAP(8) | 5.52 | 10.7 | 15.6 | 3.01 | 6.47 | 9.51 |
| SubPixSearch (9) | 6.71 | 11.0 | 16.9 | 4.00 | 6.39 | 11.0 |
| Soft3D | 9.61 | 11.3 | 21.4 | 5.91 | 6.57 | 13.8 |
| PatchMatch (10) | 5.66 | 11.8 | 16.5 | 2.99 | 8.16 | 9.62 |
| PM-PM (11) | 5.21 | 11.9 | 15.9 | 3.00 | 8.27 | 9.88 |
| IGSM (13) | 9.02 | 12.1 | 21.3 | 4.08 | 5.98 | 11.4 |
| ADCensus (15) | 10.6 | 13.8 | 20.1 | 4.1 | 6.22 | 10.9 |
| LAMC-DSM (19) | 7.29 | 14.6 | 19 | 4.63 | 10.4 | 12.7 |
| BSM (21) | 11.2 | 15.2 | 24.2 | 5.74 | 8.95 | 14.8 |
| SubPixDoubleBP (26) | 10.1 | 16.4 | 21.3 | 3.45 | 8.38 | 10.0 |
| C-SemiGlob (36) | 9.82 | 17.4 | 22.8 | 5.14 | 11.8 | 13.0 |
| CrossLMF (37) | 11.1 | 17.5 | 24.1 | 5.50 | 10.6 | 14.2 |
| HistAggrSlant (40) | 11.2 | 17.6 | 22.5 | 3.44 | 8.82 | 9.77 |
| CVW-RM (48) | 15.0 | 17.9 | 26.2 | 4.70 | 6.94 | 12.1 |
| SemiGlob (56) | 11.0 | 18.5 | 26.1 | 6.02 | 12.2 | 16.3 |
| AdaptLocalSeg (80) | 12.9 | 20.0 | 26.5 | 5.32 | 11.9 | 14.5 |
| MVSegBP (93) | 15.9 | 21.5 | 29.8 | 6.53 | 11.3 | 14.8 |
| MultiCamGC (153) | 24.3 | 30.4 | 36.9 | 12.0 | 17.6 | 22.0 |
| Dataset | [37] | [38] | [39] | [40] | [41] | [42] | [43] | [35] | [44] | [45] | [46] | [47] | [36] | Soft3D | EnSoft3D |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aloe | 4.51 | 6.75 | 3.21 | 5.03 | 3.92 | 3.78 | 3.06 | 4.15 | 5.17 | 6.19 | 6.51 | 6.94 | 4.50 | 3.32 | 2.98 |
| Baby1 | 4.10 | 3.27 | 2.21 | 4.45 | 2.74 | 2.15 | 1.98 | 1.40 | 3.01 | 7.37 | 3.23 | 3.19 | 2.26 | 1.57 | 1.49 |
| Baby2 | 4.77 | 3.97 | 2.08 | 16.9 | 5.48 | 2.87 | 1.05 | 1.49 | 3.60 | 13.96 | 3.77 | 4.21 | 3.51 | 1.55 | 1.38 |
| Baby3 | 4.77 | 3.92 | 3.07 | 4.54 | 6.56 | 3.22 | 3.12 | 2.38 | 4.31 | 7.85 | 4.63 | 4.77 | 3.76 | 1.85 | 1.74 |
| Bowling1 | 14.1 | 12.1 | 4.14 | 16.5 | 5.37 | 5.30 | 2.06 | 3.92 | 7.58 | 17.17 | 5.71 | 6.38 | 5.76 | 3.29 | 1.56 |
| Bowling2 | 4.64 | 5.27 | 2.19 | 10.6 | 6.44 | 2.74 | 1.45 | 2.64 | 7.49 | 12.58 | 7.81 | 7.40 | 5.29 | 3.53 | 3.34 |
| Cloth1 | 1.68 | 1.17 | 0.71 | 0.68 | 0.78 | 0.89 | 0.60 | 0.71 | 0.77 | 0.96 | 1.65 | 1.09 | 0.66 | 0.41 | 0.34 |
| Cloth2 | 4.19 | 4.52 | 2.90 | 4.30 | 3.26 | 2.81 | 2.39 | 2.40 | 2.80 | 4.60 | 3.82 | 3.28 | 2.15 | 1.47 | 1.38 |
| Cloth3 | 2.88 | 2.15 | 1.66 | 2.54 | 1.62 | 1.91 | 1.57 | 1.01 | 2.06 | 2.55 | 2.48 | 2.73 | 1.68 | 0.99 | 0.94 |
| Cloth4 | 3.10 | 2.20 | 1.75 | 1.70 | 0.99 | 1.78 | 1.87 | 0.79 | 1.74 | 1.86 | 2.00 | 2.06 | 1.31 | 1.08 | 0.86 |
| Flowerpots | 9.28 | 8.80 | 4.60 | 12.5 | 10.8 | 5.56 | 2.49 | 1.81 | 9.32 | 15.51 | 8.87 | 9.71 | 8.97 | 4.87 | 2.59 |
| Lampshade1 | 13.5 | 8.67 | 12.6 | 10.9 | 5.96 | 9.70 | 1.50 | 1.63 | 9.85 | 10.96 | 9.91 | 14.80 | 6.37 | 10.5 | 1.95 |
| Lampshade2 | 16.5 | 17.2 | 10.0 | 16.2 | 21.7 | 11.1 | 0.99 | 1.76 | 9.52 | 12.69 | 10.65 | 16.93 | 6.42 | 13.9 | 1.27 |
| Rock1 | 4.15 | 2.60 | 2.19 | 2.96 | 1.60 | 2.35 | 1.80 | 1.28 | 2.52 | 3.63 | 3.61 | 4.06 | 2.22 | 1.16 | 1.04 |
| Rock2 | 1.82 | 1.68 | 1.46 | 2.38 | 1.49 | 1.64 | 1.20 | 0.94 | 2.00 | 2.91 | 2.50 | 2.76 | 1.75 | 1.02 | 0.89 |
| Wood1 | 1.52 | 4.19 | 0.48 | 4.66 | 1.30 | 0.87 | 0.73 | 3.36 | 5.16 | 10.53 | 4.55 | 4.95 | 2.95 | 2.16 | 2.14 |
| Wood2 | 0.70 | 0.49 | 0.36 | 2.38 | 4.62 | 0.56 | 0.37 | 0.42 | 3.43 | 5.95 | 2.75 | 2.53 | 2.42 | 0.45 | 0.36 |
| Average | 5.66 | 5.23 | 3.27 | 7.01 | 4.98 | 3.48 | 1.66 | 1.89 | 4.73 | 8.07 | 4.97 | 5.75 | 3.65 | 3.12 | 1.54 |
| Middlebury Dataset | [50] | [51] | [52] | [48] | [49] | Soft3D | EnSoft3D | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Art | 31.67 | 0.95 | 32.09 | 0.94 | 30.22 | 0.94 | 27.85 | 0.91 | 30.02 | 0.93 | 38.71 | 0.97 | 39.25 | 0.97 |
| Laundry | 31.66 | 0.95 | 31.63 | 0.95 | 31.32 | 0.94 | 28.85 | 0.93 | 29.99 | 0.94 | 38.33 | 0.97 | 38.59 | 0.98 |
| Cloth1 | 35.04 | 0.96 | 35.68 | 0.97 | 33.66 | 0.94 | - | - | - | - | 43.39 | 0.99 | 43.43 | 0.99 |
| Dolls | 31.61 | 0.95 | 31.95 | 0.94 | 30.90 | 0.94 | - | - | - | - | 41.96 | 0.98 | 42.02 | 0.98 |
| Books | 30.10 | 0.93 | 30.15 | 0.92 | 38.74 | 0.92 | - | - | - | - | 41.12 | 0.98 | 41.22 | 0.98 |
| Wood1 | 36.29 | 0.94 | 37.36 | 0.94 | - | - | - | - | - | - | 44.71 | 0.98 | 44.75 | 0.99 |
| Bowling1 | - | - | - | - | - | - | 31.97 | 0.95 | 32.23 | 0.95 | 42.33 | 0.98 | 45.08 | 0.99 |
| Bowling2 | - | - | - | - | - | - | 28.44 | 0.93 | 30.48 | 0.94 | 43.35 | 0.98 | 43.43 | 0.98 |
| Aloe | - | - | - | - | - | - | 29.91 | 0.92 | 29.35 | 0.92 | 38.75 | 0.97 | 38.89 | 0.98 |
| [53] | [54] | [55] | [56] | [57] | [58] | [59] | [32] | Soft3D | EnSoft3D | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (P80) | (P140) | (P200) | (P80) | (P140) | (P200) | ||||||||||
| Fountain | 2 cm | 0.769 | 0.754 | 0.731 | 0.712 | 0.732 | 0.824 | 0.693 | 0.827 | 0.496 | 0.711 | 0.789 | 0.532 | 0.741 | 0.810 |
| 10 cm | 0.929 | 0.930 | 0.838 | 0.832 | 0.822 | 0.973 | 0.838 | 0.975 | 0.964 | 0.983 | 0.987 | 0.980 | 0.991 | 0.993 | |
| Algorithm | Environments | Runtime (s) |
|---|---|---|
| PSMNet_ROB [62] | Nvidia GeForce GTX 1080 Ti /PCIe /SSE2 (CUDA, Python/PyTorch) | 0.55 |
| DSGCA [63] | i7-4770 @ 3.40 GHz; GTX 1080 GPU (Matlab) | 11.0 |
| ADSM [64] | 8 i7 cores; Nvidia GTX460 SE (CUDA, C/C++) | 35.8 |
| DDL [65] | 4 i7 cores @ 4.0 GHz (Matlab/C) | 112 |
| IGF [66] | 1 i5 Core @ 3.2 GHz (C++/OpenCV) | 132 |
| BSM [67] | Intel(R) Core(TM)2 Duo CPU P7370 @ 2.00GHz (C++/OpenCV) | 244 |
| ISM [47] | 1 i5 core @ 3.2 GHz (C/C++) | 330 |
| MPSV [68] | 1 i5 core @ 2.7 GHz (Python) | 594 |
| DogGuided [69] | 2 i5 cores @ 3.0 GHz (Matlab) | 630 |
| DF [70] | Matlab 2017 | 9999 |
| FASW [36] | Intel Core i5-6500 @ 3.2 GHz | 40.5 |
| Soft3D | Intel Core i9-10900K @ 3.7 GHz (C++/OpenCV) | 13.3 |
| EnSoft3D | Intel Core i9-10900K @ 3.7 GHz (C++/OpenCV) | 14.1 |
| Resolution of Middlebury Dataset | Runtime (Seconds) | ||||
|---|---|---|---|---|---|
| [71] | [72] | [61] | Soft3D | EnSoft3D | |
| Quad resolution (100–200 kP) | 8.2 | 16.4 | 10.1 | 12.1 | 13.3 |
| Half resolution (200–500 kP) | 68.1 | 139.2 | 35.8 | 33.0 | 34.4 |
| Original resolution (1–2 MP) | 458.7 | 1905.4 | 170.1 | 136.1 | 141.5 |
| Environments | Intel i7 | Intel i7+ GTX 1080 Ti | Intel i7 | Intel i9 | Intel i9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, M.-J.; Um, G.-M.; Yun, J.; Cheong, W.-S.; Park, S.-Y. Enhanced Soft 3D Reconstruction Method with an Iterative Matching Cost Update Using Object Surface Consensus. Sensors 2021, 21, 6680. https://0-doi-org.brum.beds.ac.uk/10.3390/s21196680
Lee M-J, Um G-M, Yun J, Cheong W-S, Park S-Y. Enhanced Soft 3D Reconstruction Method with an Iterative Matching Cost Update Using Object Surface Consensus. Sensors. 2021; 21(19):6680. https://0-doi-org.brum.beds.ac.uk/10.3390/s21196680
Chicago/Turabian StyleLee, Min-Jae, Gi-Mun Um, Joungil Yun, Won-Sik Cheong, and Soon-Yong Park. 2021. "Enhanced Soft 3D Reconstruction Method with an Iterative Matching Cost Update Using Object Surface Consensus" Sensors 21, no. 19: 6680. https://0-doi-org.brum.beds.ac.uk/10.3390/s21196680