Supervised SVM Transfer Learning for Modality-Specific Artefact Detection in ECG

 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
2.1.1. Polysomnographic Dataset (PSG)
2.1.2. Handheld Dataset (HH)
“If the annotator is able to confidently distinguish all R-peaks in the signal, then the signal is labelled as clean. Otherwise, it is labelled as contaminated.”
2.1.3. Capacitively Coupled Dataset (CC)
2.2. Preprocessing
2.3. Features
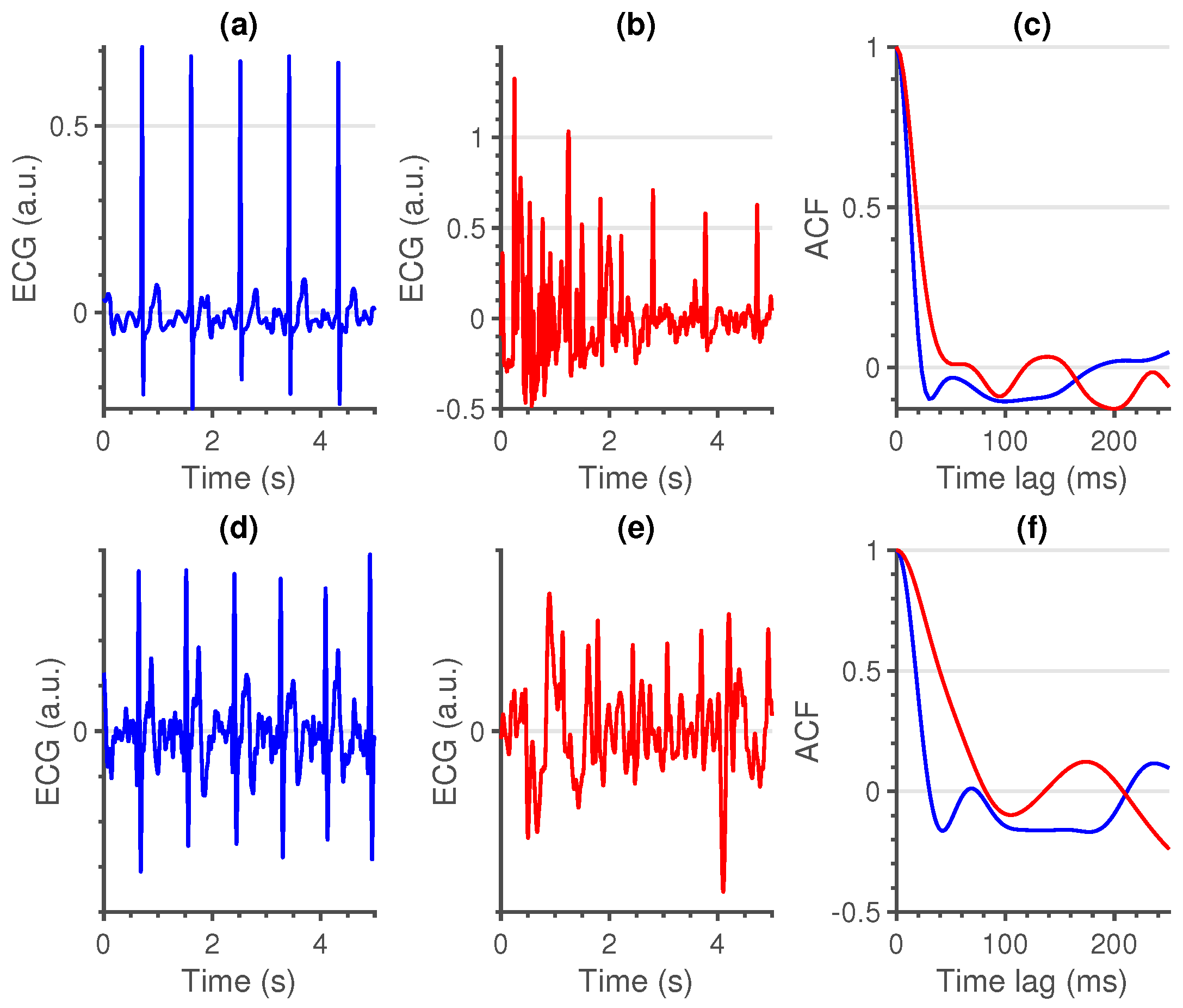
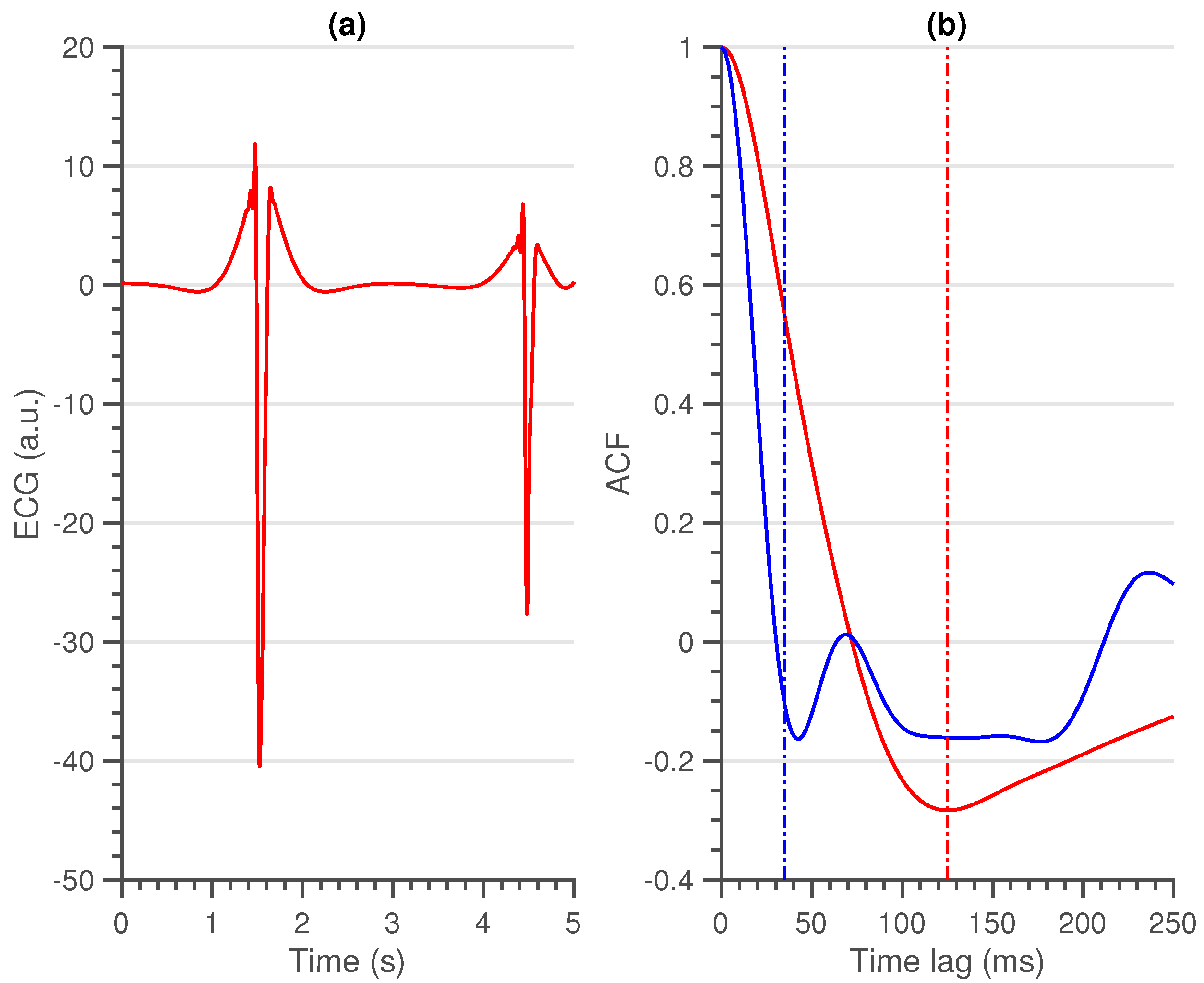
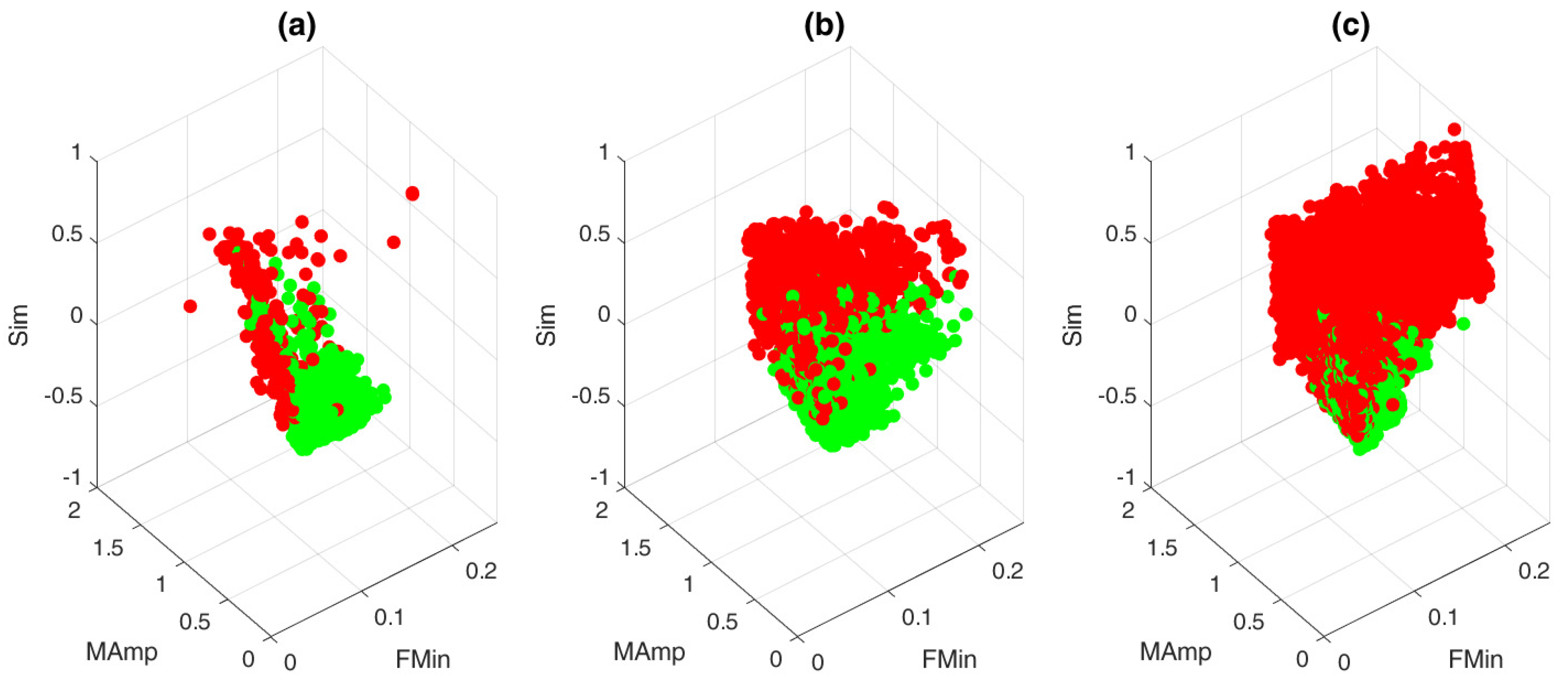
- First (local) minimum (FMin): As the QRS-complex consists of three opposite deflections, we can assume that by shifting the QRS-complex, we reach a time lag where the opposite deflections overlap. Due to the high amplitude of the QRS-complex, this shift should coincide with the first local minimum in the ACF.A large shift, could be an indication of a flat line, while a small shift could be an indication of a sharp, high amplitude, artefact. In Figure 2, a large, wide artefact is depicted. This results in a large FMin, which indicates that the lag is a lot larger than is normally expected.To derive a feature for the entire segment, we first selected the location of every first local minimum for all sliding windows. Afterwards, the overall minimum of the whole segment was computed. This results in a single value per segment.
- Maximum amplitude at 35 ms (MAmp): For the previous feature, we look at the shift that results in a local minimum. We do not make an assumption as to where this local minimum should be. Furthermore, we do not look at the amplitude of the ACF at this time lag. For the second feature, we make the assumption that the first local minimum of an average clean segment is around 35 ms. This time lag was empirically defined in [14]. We take the amplitude of the ACF at this time lag as second feature.High amplitudes, as well as large time lags of the previous feature, could indicate a flat line. They could also indicate a technical artefact with a high amplitude and large width (Figure 2).To have a general feature for the entire segment, we select the amplitude at 35 ms in the ACF of all sliding windows and we take the maximum over all obtained values.
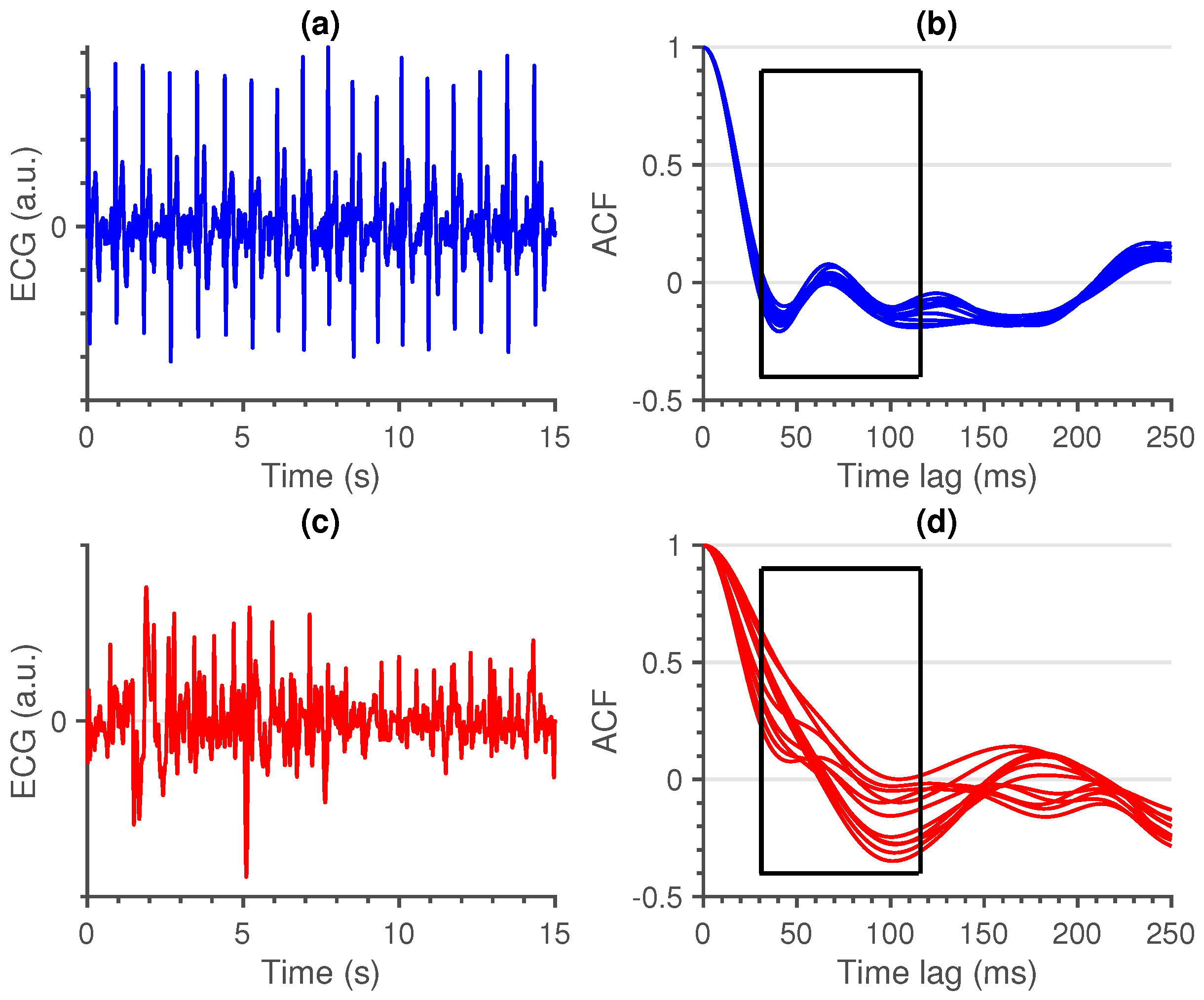
- Similarity (Sim): An ECG signal is a very repetitive, quasi-stationary, signal. While the heart rate may differ along the signal, the morphology of the heartbeat remains comparable. Therefore, it is safe to assume that a measure of similarity would be a good indication of the quality of an ECG signal.From the ACF’s of all sliding windows, we selected the interval between time lags 30 and 115 ms. The boundaries of these intervals were empirically defined. The amplitudes before 30 ms could be of interest, but are already taken into account in the first two features. Additionally, we observed no added value in terms of classification performance by extending the interval beyond 115 ms. Hereafter, we computed the pairwise euclidean distance between all the ACF’s in this interval and used the maximum of these distances as a measure of similarity. We can observe the difference between a clean and a noisy non-contact ECG signal in Figure 3.A large value of this feature indicates the presence of a divergent ACF. It could also be an indication of variable ECG morphologies within that segment. In essence, the larger the value of this feature, the less similar the ACF’s in that interval are and the more likely that the quasi-stationarity, that is expected in an ECG signal, is destroyed by the presence of an artefact.
2.4. Classification
2.4.1. Base Classifier
2.4.2. Transfer Learning
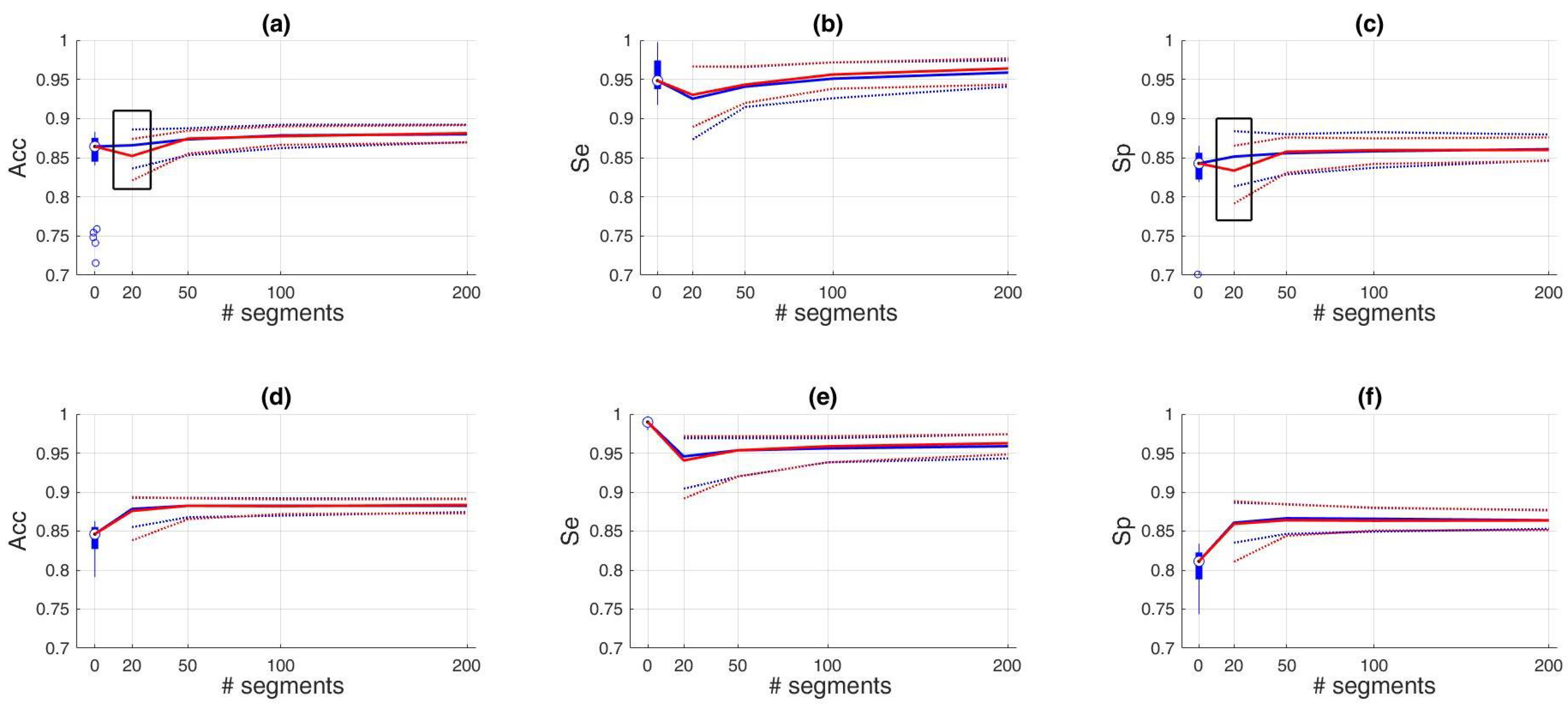
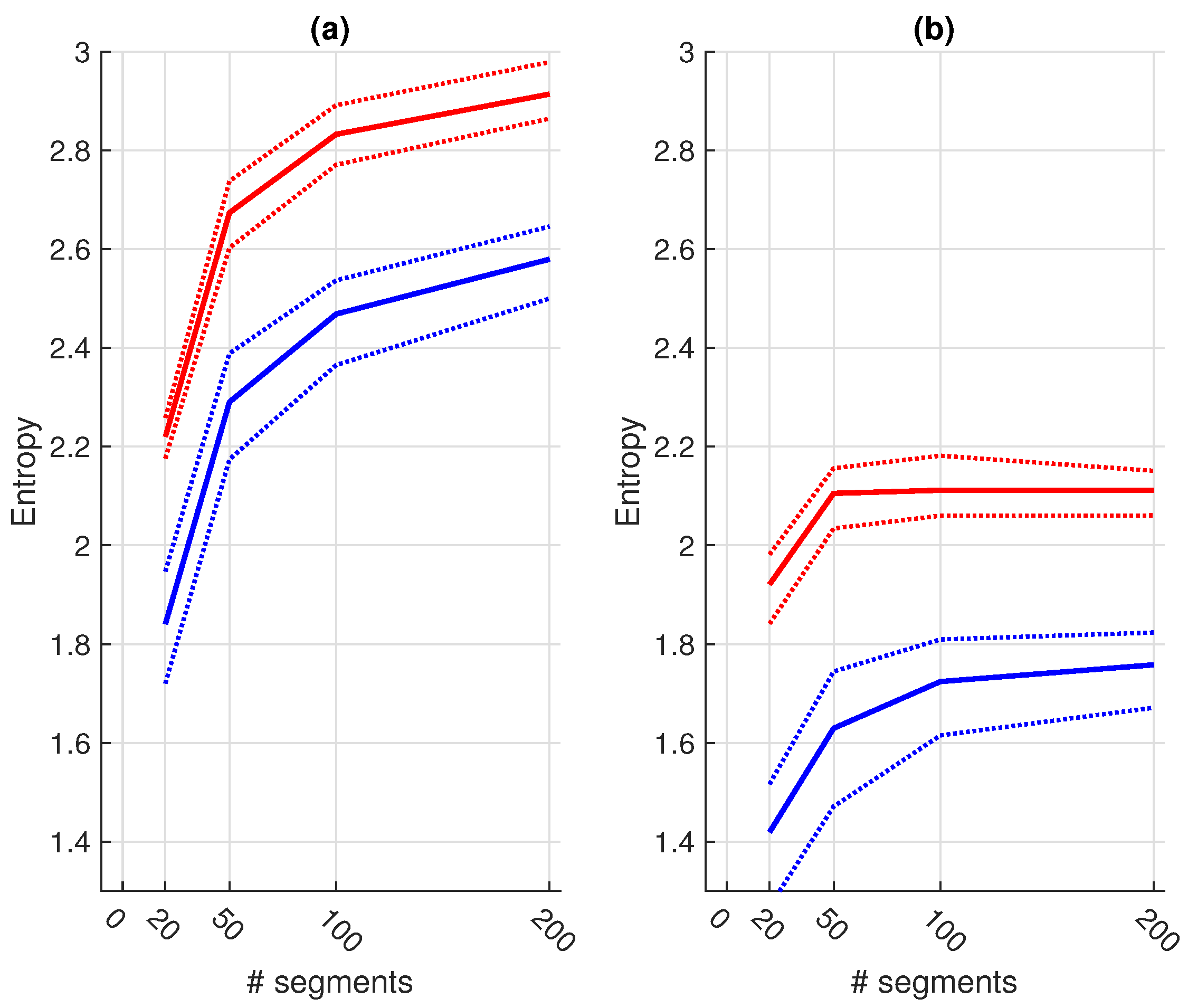
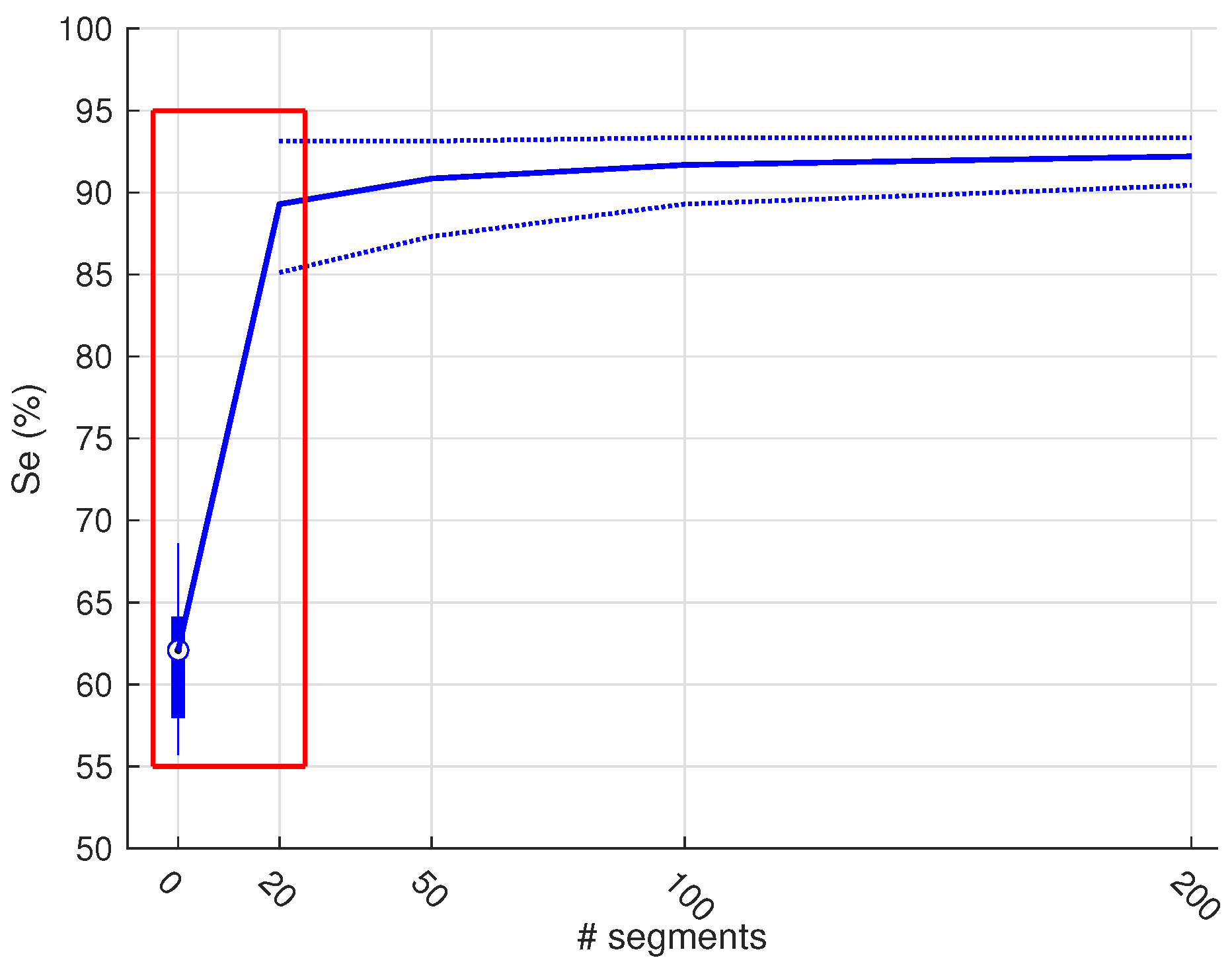
2.4.3. Subset Selection
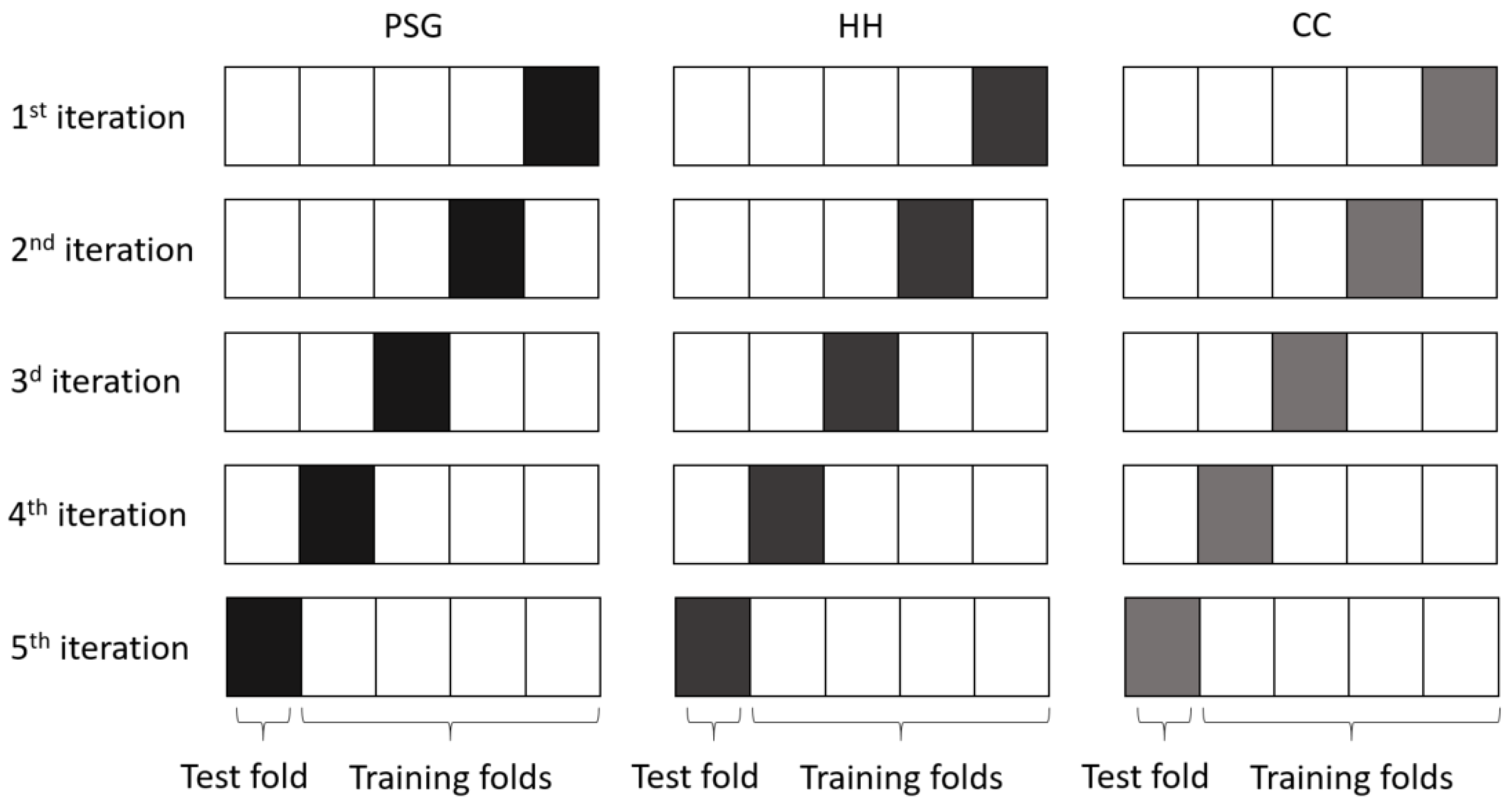
2.5. Performance Evaluation
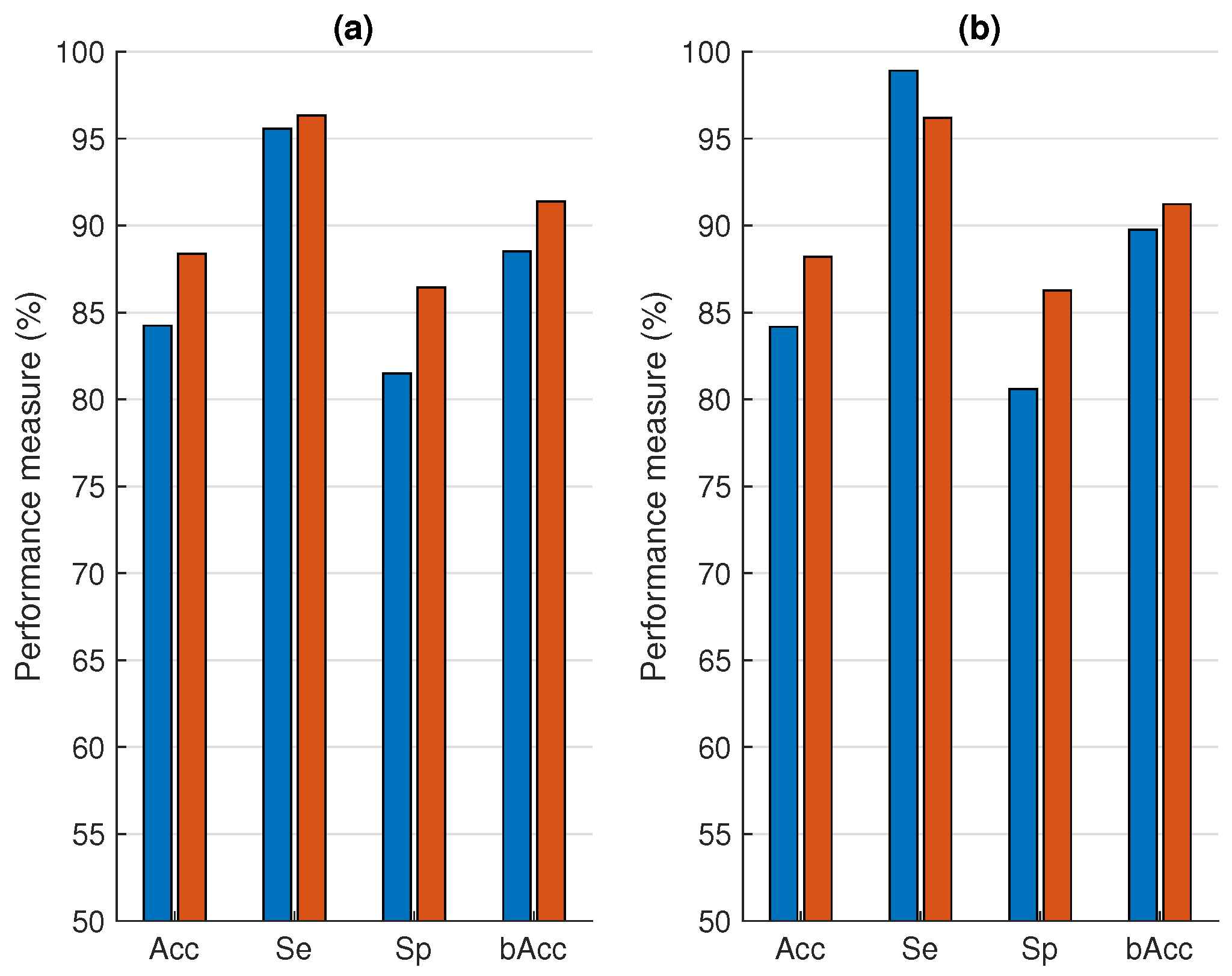
3. Results
4. Discussion
4.1. Features and Base Classifier
4.2. Transfer Learning
Subset Selection
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lipski, J.; Larry, C.; Jaime, E.; Michael, M.; Simon, D. Value of Holter Monitoring in Assessing Cardiac Arrhythmias in Symptomatic Patients. Am. J. Cardiol. 1976, 37, 102–107. [Google Scholar] [CrossRef]
- Bansal, A.; Joshi, R. Portable out-of-hospital electrocardiography: A review of current technologies. J. Arrhythm. 2018, 34, 129–138. [Google Scholar] [CrossRef]
- Azuaje, F.; Clifford, G.; McSharry, P. Advanced Methods and Tools for ECG Data Analysis; Artech: Norwood, MA, USA, 2006. [Google Scholar]
- Dagres, N.; Kottkamp, H.; Piorkowski, C.; Weis, S.; Arya, A.; Sommer, P.; Bode, K.; Gerds-Li, J.; Kremastinos, D.; Hindricks, G. Influence of The Duration of Holter Monitoring on The Detection of Arrhythmia Recurrences After Catheter Ablation of Atrial Fibrillation: Implications for Patient Follow-Up. Int. J. Cardiol. 2010, 139, 305–306. [Google Scholar] [CrossRef] [PubMed]
- Kinlay, S.; Leitch, J.W.; Neil, A.; Chapman, B.L.; Hardy, D.B.; Fletcher, P.J. Cardiac Event Recorders Yield More Diagnoses and Are More Cost-effective than 48-Hour Holter Monitoring in Patients with Palpitations: A Controlled Clinical Trial. Ann. Intern. Med. 1996, 124, 16–20. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.J.; Hwang, S.H.; Yoon, H.N.; Lee, W.K.; Park, K.S. Heart Rate Variability Monitoring during Sleep Based on Capacitively Coupled Textile Electrodes on a Bed. Sensors 2015, 15, 11295–11311. [Google Scholar] [CrossRef] [PubMed]
- Wartzek, T.; Czaplik, M.; Antink, C.H. UnoViS: The MedIT Public Unobtrusive Vital Signs Database. Health Inf. Sci. Syst. 2015, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Castro, I.; Varon, C.; Moeyersons, J.; Gomez, A.V.; Morales, J.; Deviaene, M.; Torfs, T.; Van Huffel, S.; Puers, R.; Van Hoof, C. Data Quality Assessment of Capacitively-Coupled ECG Signals. In Proceedings of the 2019 Computing in Cardiology (CinC), Singapore, 8–11 September 2019; pp. 1–4. [Google Scholar]
- Wartzek, T.; Eilebrecht, B.; Lem, J.; Lindner, H.; Leonhardt, S.; Walter, M. ECG on the Road: Robust and Unobtrusive Estimation of Heart Rate. IEEE Trans. Biomed. Eng. 2011, 58, 3112–3120. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.M.; Kim, K.K.; Park, K.S. Wavelet approach to artifact noise removal from Capacitive coupled Electrocardiograph. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; pp. 2944–2947. [Google Scholar] [CrossRef]
- Wedekind, D.; Malberg, H.; Zaunseder, S. Cascaded output selection for processing of capacitive electrocardiograms by means of independent component analysis. In Proceedings of the 2013 Workshop on Sensor Data Fusion: Trends, Solutions, Applications (SDF), Bonn, Germany, 9–11 October 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Schumm, J.; Axmann, S.; Arnrich, B.; Tröster, G. Automatic Signal Appraisal for Unobtrusive ECG Measurements. Int. J. Bioelectromagn. 2010, 12, 158–164. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Moeyersons, J.; Smets, E.; Morales, J.; Villa, A.; De Raedt, W.; Testelmans, D.; Buyse, B.; Van Hoof, C.; Willems, R.; Van Huffel, S.; et al. Artefact Detection and Quality Assessment of Ambulatory ECG Signals. Comput. Methods Prog. Biomed. 2019, 182, 105050. [Google Scholar] [CrossRef] [PubMed]
- De Cooman, T.; Vandecasteele, K.; Varon, C.; Hunyadi, B.; Cleeren, E.; Van Paesschen, W.; Van Huffel, S. Personalizing Heart Rate-Based Seizure Detection Using Supervised SVM Transfer Learning. Front Neurol. 2020, 11, 145. [Google Scholar] [CrossRef] [PubMed]
- Varon, C.; Testelmans, D.; Buyse, B.; Suykens, J.A.K.; Van Huffel, S. Robust Artefact Detection in Long-Term ECG Recordings Based on Autocorrelation Function Similarity and Percentile Analysis. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 3151–3154. [Google Scholar]
- Clifford, G.D.; Liu, C.; Moody, B.; Lehman, L.H.; Silva, I.; Li, Q.; Johnson, A.E.; Mark, R.G. AF classification from a short single lead ECG recording: The PhysioNet/computing in cardiology challenge 2017. In Proceedings of the 2017 Computing in Cardiology (CinC), Rennes, France, 24–27 September 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Castro, I.D.; Patel, A.; Torfs, T.; Puers, R.; Van Hoof, C. Capacitive Multi-Electrode Array with Real-Time Electrode Selection for Unobtrusive ECG and BIOZ Monitoring. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 5621–5624. [Google Scholar]
- Castro, I.D.; Varon, C.; Torfs, T.; Van Huffel, S.; Puers, R.; Van Hoof, C. Evaluation of a Multichannel Non-Contact ECG System and Signal Quality Algorithms for Sleep Apnea Detection and Monitoring. Sensors 2018, 18, 577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clifford, G.D.; Behar, J.; Li, Q.; Rezek, I. Signal Quality Indices and Data Fusion for Determining Clinical Acceptability of Electrocardiograms. Physiol. Meas. 2012, 33, 1419–1433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Box, G.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1976.
- Sollich, P. Bayesian Methods for Support Vector Machines: Evidence and Predictive Class Probabilities. Mach. Learn. 2000, 46. [Google Scholar] [CrossRef]
- De Cooman, T.; Varon, C.; Van de Vel, A.; Ceulemans, B.; Lagae, L.; Van Huffel, S. Semi-Supervised One-Class Transfer Learning for Heart Rate Based Epileptic Seizure Detection. In Proceedings of the 2017 Computing in Cardiology (CinC), Rennes, France, 24–27 September 2017; pp. 1–4. [Google Scholar]
- De Brabanter, K.; De Brabanter, J.; Suykens, J.A.K.; De Moor, B. Optimized Fixed-Size Kernel Models for Large Data Sets. Comput. Stat. Data Anal. 2010, 54, 1484–1504. [Google Scholar] [CrossRef]
- Girolami, M. Orthogonal series density estimation and the kernel eigenvalue problem. Neural Comput. 2002, 14, 669–688. [Google Scholar] [CrossRef] [PubMed]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The Balanced Accuracy and Its Posterior Distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Yang, J.; Yan, R.; Hauptmann, A.G. Adapting SVM Classifiers to Data with Shifted Distributions. In Proceedings of the Seventh IEEE International Conference on Data Mining Workshops (ICDMW 2007), Omaha, NE, USA, 28–31 October 2007; pp. 69–76. [Google Scholar]
- Tong, S.; Koller, D. Support Vector Machine Active Learning with Applications to Text Classification. J. Mach. Learn. Res. 2001, 45–66. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Data Source | Sampling Frequency (Hz) | Scenario | # Segments |
|---|---|---|---|---|
| PSG | University hospitals Leuven | 200 | During sleep | 9132 |
| HH | CinC Challenge of 2017 [20] | 300 | Unknown | 3857 |
| CC | Recordings of system presented in [8] | 512 | Static car seat | 2500 |
| Bed | 2500 | |||
| Office chair | 1520 | |||
| Driving a car | 480 | |||
| UnoVis database [7] | 512 | Bed | 1000 | |
| Driving a car | 1000 | |||
| Armchair | 1000 |
| PSG | HH | CC | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Se | Sp | bAcc | Se | Sp | bAcc | Se | Sp | bAcc | |
| PSG | |||||||||
| HH | |||||||||
| CC | |||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moeyersons, J.; Morales, J.; Villa, A.; Castro, I.; Testelmans, D.; Buyse, B.; Van Hoof, C.; Willems, R.; Van Huffel, S.; Varon, C. Supervised SVM Transfer Learning for Modality-Specific Artefact Detection in ECG. Sensors 2021, 21, 662. https://0-doi-org.brum.beds.ac.uk/10.3390/s21020662
Moeyersons J, Morales J, Villa A, Castro I, Testelmans D, Buyse B, Van Hoof C, Willems R, Van Huffel S, Varon C. Supervised SVM Transfer Learning for Modality-Specific Artefact Detection in ECG. Sensors. 2021; 21(2):662. https://0-doi-org.brum.beds.ac.uk/10.3390/s21020662
Chicago/Turabian StyleMoeyersons, Jonathan, John Morales, Amalia Villa, Ivan Castro, Dries Testelmans, Bertien Buyse, Chris Van Hoof, Rik Willems, Sabine Van Huffel, and Carolina Varon. 2021. "Supervised SVM Transfer Learning for Modality-Specific Artefact Detection in ECG" Sensors 21, no. 2: 662. https://0-doi-org.brum.beds.ac.uk/10.3390/s21020662