Rapid Detection and Quantification of Adulterants in Fruit Juices Using Machine Learning Tools and Spectroscopy Data

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples
2.2. Adulteration
2.3. Near-Infrared Spectroscopy (NIR)
2.4. Data Analysis
3. Results and Discussion
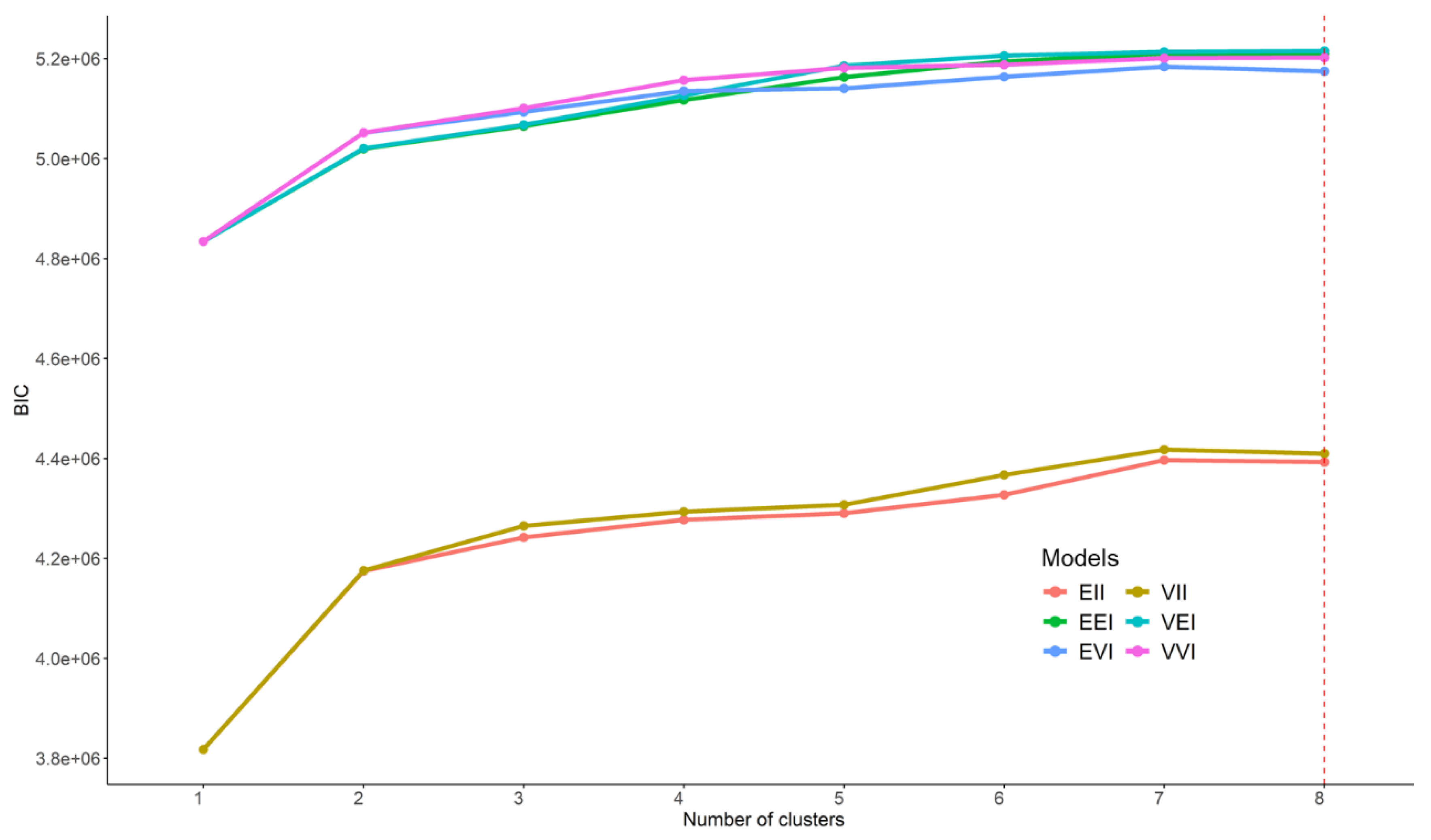
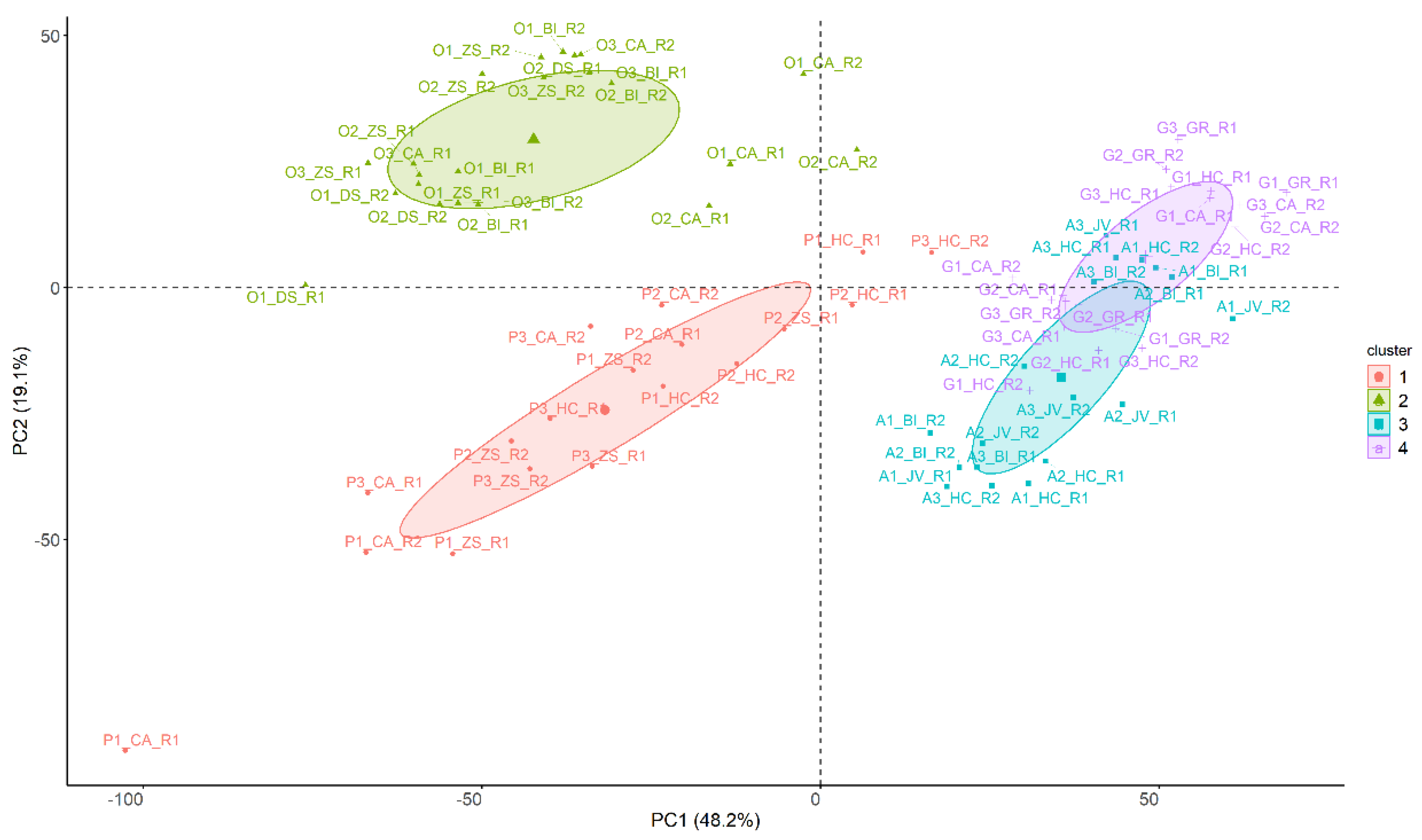
3.1. Unsupervised Analysis
3.2. Supervised Analysis
3.2.1. Classification Models
Linear Discriminant Analysis (LDA)
Support Vector Machine (SVM) with Gaussian Kernel
Random Forest (RF)
3.2.2. Regression Models
Partial Least Squares Regression (PLS)
Support Vector Regression (SVR)
Random Forest Regression
3.3. Application Development
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Spink, J.; Moyer, D.C. Defining the public health threat of food fraud. J. Food Sci. 2011, 76, R157–R163. [Google Scholar] [CrossRef] [PubMed]
- Boggia, R.; Casolino, M.C.; Hysenaj, V.; Oliveri, P.; Zunin, P. A screening method based on UV-Visible spectroscopy and multivariate analysis to assess addition of filler juices and water to pomegranate juices. Food Chem. 2013, 140, 735–741. [Google Scholar] [CrossRef] [PubMed]
- Moore, J.C.; Spink, J.; Lipp, M. Development and application of a database of food ingredient fraud and economically motivated adulteration from 1980 to 2010. J. Food Sci. 2012, 77, R118–R126. [Google Scholar] [CrossRef]
- European Parliament. European Parliament Directive 2012/12/EU of the European Parliament and of the Council of 19 April 2012 Amending Council Directive 2001/112/EC Relating to Fruit Juices and Certain Similar Products Intended for Human Consumption; European Parliament: Luxembourg, 2012; pp. 1–11. [Google Scholar]
- IMARC Group Fruit Juice Market Size, Share, Trends & Forecast 2021–2026. 2021. Available online: https://www.imarcgroup.com/fruit-juice-manufacturing-plant (accessed on 19 January 2022).
- Dalmia, A. Rapid measurement of food adulteration with minimal sample preparation and no chromatography using ambient ionization mass spectrometry. J. AOAC Int. 2017, 100, 573–575. [Google Scholar] [CrossRef] [PubMed]
- Różańska, A.; Dymerski, T.; Namieśnik, J. Novel analytical method for detection of orange juice adulteration based on ultra-fast gas chromatography. Monatsh. Chem. 2018, 149, 1615–1621. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- An, J.A.; Lee, J.; Park, J.; Auh, J.H.; Lee, C. Authentication of pomegranate juice using multidimensional analysis of its metabolites. Food Sci. Biotechnol. 2021, 30, 1635–1643. [Google Scholar] [CrossRef]
- Tang, F.; Hatzakis, E. NMR-Based analysis of pomegranate juice using untargeted metabolomics coupled with nested and quantitative approaches. Anal. Chem. 2020, 92, 11177–11185. [Google Scholar] [CrossRef]
- Marchetti, L.; Pellati, F.; Benvenuti, S.; Bertelli, D. Use of 1H NMR to detect the percentage of pure fruit juices in blends. Molecules 2019, 24, 2592. [Google Scholar] [CrossRef] [Green Version]
- Liang, Y.L.; Ding, Y.J.; Liu, X.; Zhou, P.F.; Ding, M.X.; Yin, J.J.; Song, Q.H. A duplex PCR–RFLP–CE for simultaneous detection of mandarin and grapefruit in orange juice. Eur. Food Res. Technol. 2021, 247, 1–7. [Google Scholar] [CrossRef]
- Pardo, M.A. Evaluation of a dual-probe real time PCR system for detection of mandarin in commercial orange juice. Food Chem. 2015, 172, 377–384. [Google Scholar] [CrossRef]
- Maione, C.; De Paula, E.S.; Gallimberti, M.; Batista, B.L.; Campiglia, A.D.; Barbosa, F.; Barbosa, R.M. Comparative study of data mining techniques for the authentication of organic grape juice based on ICP-MS analysis. Expert Syst. Appl. 2016, 49, 60–73. [Google Scholar] [CrossRef]
- Borges, E.M.; Volmer, D.A.; Brandelero, E.; Gelinski, J.M.L.N.; Gallimberti, M.; Barbosa, F. Monitoring the authenticity of organic grape juice via chemometric analysis of elemental data. Food Anal. Methods 2016, 9, 362–369. [Google Scholar] [CrossRef]
- Yeganeh-Zare, S.; Farhadi, K.; Amiri, S. Rapid detection of apple juice concentrate adulteration with date concentrate, fructose and glucose syrup using HPLC-RID incorporated with chemometric tools. Food Chem. 2022, 370, 131015. [Google Scholar] [CrossRef] [PubMed]
- Shojaee AliAbadi, M.H.; Karami-Osboo, R.; Kobarfard, F.; Jahani, R.; Nabi, M.; Yazdanpanah, H.; Mahboubi, A.; Nasiri, A.; Faizi, M. Detection of lime juice adulteration by simultaneous determination of main organic acids using liquid chromatography-tandem mass spectrometry. J. Food Compos. Anal. 2022, 105, 104223. [Google Scholar] [CrossRef]
- Li, S.; Hu, Y.; Liu, W.; Chen, Y.; Wang, F.; Lu, X.; Zheng, W. Untargeted volatile metabolomics using comprehensive two-dimensional gas chromatography-mass spectrometry—A solution for orange juice authentication. Talanta 2020, 217, 121038. [Google Scholar] [CrossRef]
- Vaclavik, L.; Schreiber, A.; Lacina, O.; Cajka, T.; Hajslova, J. Liquid chromatography–mass spectrometry-based metabolomics for authenticity assessment of fruit juices. Metabolomics 2011, 8, 793–803. [Google Scholar] [CrossRef]
- Dhaulaniya, A.S.; Balan, B.; Yadav, A.; Jamwal, R.; Kelly, S.; Cannavan, A.; Singh, D.K. Development of an FTIR based chemometric model for the qualitative and quantitative evaluation of cane sugar as an added sugar adulterant in apple fruit juices. Food Addit. Contam.—Part A Chem. Anal. Control. Expo. Risk Assess. 2020, 37, 539–551. [Google Scholar] [CrossRef]
- Jha, S.N.; Gunasekaran, S. Authentication of sweetness of mango juice using Fourier transform infrared-attenuated total reflection spectroscopy. J. Food Eng. 2010, 101, 337–342. [Google Scholar] [CrossRef]
- Downey, G.; Kelly, J.D.; León, L. Detection of apple juice adulteration using near-infrared transflectance spectroscopy. Appl. Spectrosc. 2005, 59, 593–599. [Google Scholar]
- Ellis, D.I.; Ellis, J.; Muhamadali, H.; Xu, Y.; Horn, A.B.; Goodacre, R. Rapid, high-throughput, and quantitative determination of orange juice adulteration by Fourier-transform infrared spectroscopy. Anal. Methods 2016, 8, 5581–5586. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Rodriguez-Saona, L.E.; Giusti, M.M. Midinfrared spectroscopy for juice authentication-rapid differentiation of commercial juices. J. Agric. Food Chem. 2007, 55, 4443–4452. [Google Scholar] [CrossRef] [PubMed]
- Vardin, H.; Tay, A.; Ozen, B.; Mauer, L. Authentication of pomegranate juice concentrate using FTIR spectroscopy and chemometrics. Food Chem. 2008, 108, 742–748. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Calle, J.L.P.; Ferreiro-González, M.; Ruiz-Rodríguez, A.; Fernández, D.; Palma, M. Detection of adulterations in fruit juices using machine learning methods over FT-IR spectroscopic data. Agronomy 2022, 12, 683. [Google Scholar] [CrossRef]
- Xie, L.; Ye, X.; Liu, D.; Ying, Y. Quantification of glucose, fructose and sucrose in bayberry juice by NIR and PLS. Food Chem. 2009, 114, 1135–1140. [Google Scholar] [CrossRef]
- Šnurkovič, P. Quality assessment of fruit juices by NIR spectroscopy. Acta Univ. Agric. Silvic. Mendel. Brun. 2013, 61, 803–812. [Google Scholar] [CrossRef] [Green Version]
- Xie, L.J.; Ye, X.Q.; Liu, D.H.; Ying, Y. Bin Application of principal component-radial basis function neural networks (PC-RBFNN) for the detection of water-adulterated bayberry juice by near-infrared spectroscopy. J. Zhejiang Univ. Sci. B 2008, 9, 982–989. [Google Scholar] [CrossRef] [Green Version]
- Jahani, R.; Yazdanpanah, H.; van Ruth, S.M.; Kobarfard, F.; Alewijn, M.; Mahboubi, A.; Faizi, M.; Aliabadi, M.H.S.; Salamzadeh, J. Novel application of near-infrared spectroscopy and chemometrics approach for detection of lime juice adulteration. Iran. J. Pharm. Res. 2020, 19, 34–44. [Google Scholar] [CrossRef]
- Ma, H.L.; Wang, J.W.; Chen, Y.J.; Cheng, J.L.; Lai, Z.T. Rapid authentication of starch adulterations in ultrafine granular powder of Shanyao by near-infrared spectroscopy coupled with chemometric methods. Food Chem. 2017, 215, 108–115. [Google Scholar] [CrossRef]
- Ríos-Reina, R.; Camiña, J.M.; Callejón, R.M.; Azcarate, S.M. Spectralprint techniques for wine and vinegar characterization, authentication and quality control: Advances and projections. TrAC—Trends Anal. Chem. 2021, 134, 116121. [Google Scholar] [CrossRef]
- Li, S.; Zhang, X.; Shan, Y.; Su, D.; Ma, Q.; Wen, R.; Li, J. Qualitative and quantitative detection of honey adulterated with high-fructose corn syrup and maltose syrup by using near-infrared spectroscopy. Food Chem. 2017, 218, 231–236. [Google Scholar] [CrossRef]
- Ferreiro-González, M.; Espada-Bellido, E.; Guillén-Cueto, L.; Palma, M.; Barroso, C.G.; Barbero, G.F. Rapid quantification of honey adulteration by visible-near infrared spectroscopy combined with chemometrics. Talanta 2018, 188, 288–292. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Li, Y.; Wei, W.; Peng, Y. Detection of adulteration with duck meat in minced lamb meat by using visible near-infrared hyperspectral imaging. Meat Sci. 2019, 149, 55–62. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Tan, C.; Lin, Z.; Wu, T. Detection of melamine adulteration in milk by near-infrared spectroscopy and one-class partial least squares. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2017, 173, 832–836. [Google Scholar] [CrossRef]
- Zhang, L.G.; Zhang, X.; Ni, L.J.; Xue, Z.B.; Gu, X.; Huang, S.X. Rapid identification of adulterated cow milk by non-linear pattern recognition methods based on near infrared spectroscopy. Food Chem. 2014, 145, 342–348. [Google Scholar] [CrossRef]
- Borin, A.; Ferrão, M.F.; Mello, C.; Maretto, D.A.; Poppi, R.J. Least-squares support vector machines and near infrared spectroscopy for quantification of common adulterants in powdered milk. Anal. Chim. Acta 2006, 579, 25–32. [Google Scholar] [CrossRef]
- Peris, M.; Escuder-Gilabert, L. Electronic noses and tongues to assess food authenticity and adulteration. Trends Food Sci. Technol. 2016, 58, 40–54. [Google Scholar] [CrossRef] [Green Version]
- Esteki, M.; Shahsavari, Z.; Simal-Gandara, J. Gas Chromatographic Fingerprinting Coupled to Chemometrics for Food Authentication. Food Rev. Int. 2020, 36, 384–427. [Google Scholar] [CrossRef]
- Rasekh, M.; Karami, H. Application of electronic nose with chemometrics methods to the detection of juices fraud. J. Food Process. Preserv. 2021, 45, e15432. [Google Scholar] [CrossRef]
- Qiu, S.; Wang, J.; Gao, L. Discrimination and characterization of strawberry juice based on electronic nose and tongue: Comparison of different juice processing approaches by LDA, PLSR, RF, and SVM. J. Agric. Food Chem. 2014, 62, 6426–6434. [Google Scholar] [CrossRef]
- Aliaño-González, M.J.; Ferreiro-González, M.; Espada-Bellido, E.; Palma, M.; Barbero, G.F. A screening method based on Visible-NIR spectroscopy for the identification and quantification of different adulterants in high-quality honey. Talanta 2019, 203, 235–241. [Google Scholar] [CrossRef]
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016; ISBN 978-3-319-24277-4. [Google Scholar]
- Kassambara, A.; Mundt, F. Factoextra: Extract and Visualize the Results of Multivariate Data Analyses. R Package Version 1.0.7. 2020. Available online: https://CRAN.R-project.org/package=factoextra (accessed on 20 February 2022).
- Stevens, A.; Ramirez-Lopez, L. An Introduction to the Prospectr Package. R Package Version 0.2.4. 2022. Available online: https://cran.r-project.org/web/packages/prospectr/prospectr.pdf (accessed on 20 February 2022).
- Scrucca, L.; Fop, M.; Murphy, T.B.; Raftery, A.E. mclust 5: Clustering, classification and density estimation using gaussian finite mixture models. R J. 2016, 8, 289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuhn, M. Caret: Classification and Regression Training. 2020. Available online: https://cran.r-project.org/web/packages/caret/caret.pdf (accessed on 20 February 2022).
- Chang, W.; Cheng, J.; Allaire, J.J.; Xie, Y.; McPherson, J. Shiny: Web Application Framework for R. 2020. Available online: https://cran.r-project.org/web/packages/shiny/index.html (accessed on 20 February 2022).
- Finn, B.; Harvey, L.M.; McNeil, B.; McNeil, B. Near-infrared spectroscopic monitoring of biomass, glucose, ethanol and protein content in a high cell density baker’s yeast fed-batch bioprocess. Yeast 2006, 23, 507–517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Calle, J.L.P.; Ferreiro-González, M.; Ruiz-Rodríguez, A.; Barbero, G.F.; Álvarez, J.Á.; Palma, M.; Ayuso, J. A methodology based on FT-IR data combined with random forest model to generate spectralprints for the characterization of high-quality vinegars. Foods 2021, 10, 1411. [Google Scholar] [CrossRef] [PubMed]
- Men, H.; Fu, S.; Yang, J.; Cheng, M.; Shi, Y.; Liu, J. Comparison of SVM, RF and ELM on an electronic nose for the intelligent evaluation of paraffin samples. Sensors 2018, 18, 285. [Google Scholar] [CrossRef] [Green Version]
- Géron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow, 2nd ed.; Rachel Roumeliotis, N.T., Ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]



{kind=link}
{kind=link}
| Employed Value | Training Set | Test Set | |||
|---|---|---|---|---|---|
| Model | Hyperparameters | Accuracy (%) | Kappa | Accuracy (%) | Kappa |
| LDA | - | 100 | 1 | 97.67 | 0.9648 |
| SVM | C = 2 γ = 9.766 × 10−4 | 100 | 1 | 88.37 | 0.8139 |
| RF | mtry = 65 Number of trees = 500 | 100 | 1 | 97.67 | 0.9648 |
| Model | Hyperparameter | Training Set Performance | Test Set Performance |
|---|---|---|---|
| PLS | 11 principal components | RMSE = 3.644 R2 = 0.951 | RMSE = 4.388 R2 = 0.931 |
| SVR | C = 22.63 Y = 5.52 × 10−3 | RMSE = 1.446 R2 = 0.994 | RMSE = 1.683 R2 = 0.989 |
| RF | mtry = 6 Number of trees = 500 | RMSE = 2.571 R2 = 0.983 | RMSE = 7.223 R2 = 0.851 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calle, J.L.P.; Barea-Sepúlveda, M.; Ruiz-Rodríguez, A.; Álvarez, J.Á.; Ferreiro-González, M.; Palma, M. Rapid Detection and Quantification of Adulterants in Fruit Juices Using Machine Learning Tools and Spectroscopy Data. Sensors 2022, 22, 3852. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103852
Calle JLP, Barea-Sepúlveda M, Ruiz-Rodríguez A, Álvarez JÁ, Ferreiro-González M, Palma M. Rapid Detection and Quantification of Adulterants in Fruit Juices Using Machine Learning Tools and Spectroscopy Data. Sensors. 2022; 22(10):3852. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103852
Chicago/Turabian StyleCalle, José Luis P., Marta Barea-Sepúlveda, Ana Ruiz-Rodríguez, José Ángel Álvarez, Marta Ferreiro-González, and Miguel Palma. 2022. "Rapid Detection and Quantification of Adulterants in Fruit Juices Using Machine Learning Tools and Spectroscopy Data" Sensors 22, no. 10: 3852. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103852