
Deep Learning-Based Channel Estimation for mmWave Massive MIMO Systems in Mixed-ADC Architecture


1
School of Computer Science and Cyber Engineering, Guangzhou University, Guangzhou 510006, China
2
School of Electronic and Information Engineering, Chongqing Three Gorges University, Chongqing 404000, China
3
School of Electronics and Information Engineering, South China Normal University, Foshan 528000, China
4
School of Artificial Intelligence, Nanjing University of Information Science and Technology, Nanjing 210044, China
5
National Mobile Communications Research Laboratory, Southeast University, Nanjing 210096, China
*
Author to whom correspondence should be addressed.
Sensors 2022, 22(10), 3938; https://0-doi-org.brum.beds.ac.uk/10.3390/s22103938
Submission received: 20 April 2022
/
Revised: 15 May 2022
/
Accepted: 19 May 2022
/
Published: 23 May 2022
(This article belongs to the Special Issue Cell-Free Ultra Massive MIMO in 6G and Beyond Networks)
Abstract
:Millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems can significantly reduce the number of radio frequency (RF) chains by using lens antenna arrays, because it is usually the case that the number of RF chains is often much smaller than the number of antennas, so channel estimation becomes very challenging in practical wireless communication. In this paper, we investigated channel estimation for mmWave massive MIMO system with lens antenna array, in which we use a mixed (low/high) resolution analog-to-digital converter (ADC) architecture to trade-off the power consumption and performance of the system. Specifically, most antennas are equipped with low-resolution ADC and the rest of the antennas use high-resolution ADC. By utilizing the sparsity of the mmWave channel, the beamspace channel estimation can be expressed as a sparse signal recovery problem, and the channel can be recovered by the algorithm based on compressed sensing. We compare the traditional channel estimation scheme with the deep learning channel-estimation scheme, which has a better advantage, such as that the estimation scheme based on deep neural network is significantly better than the traditional channel-estimation algorithm.
1. Introduction
Millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) technology can significantly improve data transmission rate with wider bandwidth and higher spectral efficiency, becoming one of the key technologies for the sixth generation (6G) wireless communication [1]. However, digital beamforming and full-resolution ADCs are not suitable in mmWave massive MIMO system, due to the power consumption of ADCs scales being exponential with the number of quantization bits, leading to high hardware cost, power consumption and system complexity. Therefore, the use of current high-speed and high-resolution ADCs (8–12 bits) for each antenna array would become a great burden to the base station (BS) [2,3,4]. Consequently, the use of low-cost and low-resolution ADCs (1–4 bits) is promoted as a potential solution to this problem.
1.1. Related Works
In order to reap the maximum benefits of mmWave massive MIMO, the researchers have proposed hybrid precoding, which involves a massive number of antennas attached with a few RF chains [5,6], which effectively improved the energy efficiency of systems. In addition, the authors of [7] utilized the lens antenna array at the BS in the mmWave massive MIMO system, in which signals from different directions can be concentrated on different antennas, and the spatial channel can be converted into a beamspace channel. Thus, the mmWave beamspace channel is sparse and there are only a few main propagation path gains. By selecting a small number of main beams, the number of RF chains required by the massive MIMO system can be significantly reduced [8,9]. Unfortunately, the beam selection requires the BS to obtain the channel state information (CSI), and this is difficult to achieve, especially when the number of RF links is limited. Furthermore, the performance of hybrid precoding systems relies heavily on the precise control of the analog components, and also the selection of the optimal beam will be more difficult if the beam width is small.
In parallel, there is a common solution to replace high-resolution ADCs with low-resolution ADC (1–4 bits), which means the deployment of pure low-resolution ADCs at the BS. However, low-resolution ADCs are prone to severe non-linear distortion, which inevitably causes several problems, including high pilot overhead for channel estimation [10], the system performance loss and signal detection [11]. In order to balance the cost and performance of the system, a mmWave massive MIMO system with a mixed ADC architecture was proposed in [12,13], which replaces the low-resolution ADCs with the partial high-resolution ADCs on the original basis. As reported in [14], channel estimation in a mixed-resolution ADC architecture is easier to process than in a pure low-resolution ADC system. The authors of [15] derived a closed-form approximation of the reachable rate of massive MIMO uplink under Rician fading channels with mixed-ADC. The work in [16] analyzed the sum-rate performance of the multi-user massive MIMO relaying system equipped with mixed-ADC architecture in the BS. Authors of [17] proposed the channel estimation algorithm for uplinking massive MIMO systems with mixed-ADC architecture. For ease of understanding, the advantages and limitations of the two solutions mentioned above are summarized in Table 1.
Different from using mixed-ADC architecture to reduce cost, another research direction focuses on using the sparsity of the mmWave channel to estimate the channel by using some classical schemes based on compressed sensing (CS) [18,19,20,21]. Specifically, the work in [18] used the orthogonal matching pursuit (OMP) algorithm to detect the dominant entries of multiple channel paths. The authors of [19] proposed a simultaneous weighted orthogonal matching pursuit (SWOMP) channel estimation scheme. Furthermore, the authors of [20] proposed stage wise orthogonal matching pursuit. Using the sparse characteristics of the mmWave channel, the work in [21] designed a compressive sampling matching pursuit, which aims to reduce system complexity. Unfortunately, the estimation accuracy of the greedy algorithm is not ideal in the low signal-to-noise ratio (SNR) range. As a powerful sparse signal recovery algorithm, the approximate message passing (AMP) algorithm was proposed in [22], which can be used to estimate the beamspace channel, but it is difficult to find the optimal solution for the shrinkage parameters of the algorithm.
Deep learning (DL) has achieved great success in speech recognition and image processing. The advantages of DL are expected to bring changes to the communication system. Compared with traditional methods, DL can reveal the internal characteristics of end-to-end collected data or signals, so as to better solve various complicated problems encountered in wireless communication [23,24,25,26,27]. Inspired by the powerful learning ability of deep neural networks (DNNs), some methods based on DL have been applied to channel estimation and achieved good results. For example, the work in [28] applied to channel estimation in the wireless downlink transmission system, which is superior to the traditional scheme in estimation accuracy and energy acquisition. The use of neural networks can help improve channel estimation performance was also demonstrated in [29], where the method was designed by the structure of the minimum mean squared error (MMSE) channel estimator. In addition, the authors of [30] proposed a framework based on DL for direction-of-arrival estimation and the massive MIMO system. In [31], the authors proposed an iterative channel estimation scheme, in which a denoising neural network is used to update the estimated channel in each iteration. The authors in [32] proposed a two-stage massive MIMO channel estimation process based on DL, including pilot-aided and data-aided estimation stages. In [33], a deep neural network based on long short-term memory (LSTM) was introduced to develop a more effective CSI feedback channel compression and recovery method. To improve the estimation accuracy, the authors of [34] developed a learned AMP (LAMP) network for channel estimation. Compared with the original AMP algorithm, the estimation accuracy of both algorithms is improved.
1.2. Contributions
In this paper, we investigate channel estimation for mmWave massive MIMO system with lens antenna array, in which we use a mixed (low/high) resolution ADC architecture. To the best of our knowledge, there is no previous work exploring a mixed-ADC architecture of mmWave massive MIMO system and how to estimate CSI based on the DL method. We first study that the mixed-ADC architecture is practically useful because it can provide performance comparable to the ideal high-resolution ADC architecture, while reducing the complexity and power consumption of signal processing. Specifically, the main contributions of this work can be summarized as follows:
- We study the DL-based channel estimation for a mmWave massive MIMO system with mixed-ADC architecture, where most antennas are equipped with low-resolution ADC and the rest of the antennas use high-resolution ADC. In terms of spectral efficiency, the results showed that the mixed-ADC architecture is practically useful and it can provide performance comparable to the ideal high-resolution ADC architecture.
- We compare the performance of traditional beamspace channel estimation algorithms and DL-based schemes in mixed-ADC architecture. By applying the sparsity of the mmWave channel, the DL-based channel estimation scheme performs significantly better than the conventional channel estimation algorithm and its complexity outperforms the conventional estimation algorithm.
- We evaluate the effect of different quantization bits of low-resolution ADC in the mixed-ADC architecture on the channel estimation and the sum rate. The results show that when the number of quantization is about 4 bit, the estimation error with the mixed-ADC architecture is small compared to that with the high-resolution ADC.
Notation: We use boldface letters to denote vectors and capitals to denote matrices. For matrix , is the th entry of . represent ’s transpose, complex conjugate. Moreover, a circularly symmetric complex Gaussian random vector with zero mean and covariance matrix is denoted , is the identity matrix of size n, ⊗ is the Kronecker product and is the Euclidean norm.
2. System Model
We consider a time division duplex (TDD) mmWave massive MIMO system, in which the BS is equipped with N antennas and RF chains, serving K single antenna users simultaneously In this section, we first introduce the traditional mmWave massive MIMO channel and the space channel after adding the lens antenna array. In the second section, we introduce the mixed resolution ADC architecture. Finally, we express the beamspace channel estimation problem as the sparse signal recovery problem.
2.1. Beamspace Channel Model
We start with the traditional massive MIMO mmWave channel, and in this work, we adopt the Saleh–Valenzuela channel model, which is widely used in the frequency domain. The channel vector with the size of between the kth user and the BS can be expressed as
where N is the total number of antennas, is the number of resolvable paths and , and are the complex gain, azimuth and elevation on the lth path, respectively. is the array steering vector, which depends on the array geometry, and denotes the lth path component. For a typical uniform planar arrays (UPAs) with antennas, the array steering vector can be expressed as
where and is the wavelength of the carrier, and d is the antenna spacing usually satisfying in mmWave communications. Then, we can define and , respectively, as the spatial angles for UPAs configuration [35].
Traditional channels in the spatial domain can be converted to beam spatial channels by using a lens antenna array. In fact, the lens antenna array plays the role of the spatial discrete Fourier transform (DFT) matrix U of size . For UPA configuration, the matrix U can be expressed as
where for and for are the spatial direction corresponding to the azimuth and elevation predefined by the lens antenna array, respectively. Therefore, the beamspace channel vector with a size of between the kth user and BS with N antennas can be written as
where represents the lth path component in the beamspace channel.
2.2. Mixed Resolution ADC Architecture
In this section, we consider a mixed resolution ADC architecture on the part of the lens antenna array. We divide the antenna into two parts, where the antennas are connected to the high-resolution ADC, and the antenna is connected to lower ADC. In order to facilitate calculation, the antenna number and in the simulation are integers, and the coefficient is also limited to a certain rational number. In this experiment, is set to 0.25, so we can redivide the channel matrix and rewrite the above Formula (4) as
where represents the channel matrix associated with antennas connected to a high resolution ADC, and represents the channel matrix associated with antennas connected to a low resolution ADC.
Due to the reciprocity of the TDD channel, after the pilot sequence is transmitted to BS, the user can obtain the downlink channel through the estimated uplink channel. This paper adopts the widely used orthogonal pilot transmission strategy, and the channel estimation of each user is independent, so the subscript k in Formula (4) can be omitted.
Assuming that all users transmit known pilot sequences through instance Q for channel estimation, the measured signal with a size of passing through the RF chains at the qth instant can be expressed as
where is the beam-selection network, is the pilot transmitted symbol at the qth instant, is the effective noise vector, where is the noise vector with representing the noise power.
After the pilot transmission of Q instances, we can obtain the overall measurement vector by assuming for as
where is the overall combining matrix, and is the effective noise vector for Q instants.
2.3. Problem Formulation
According to Formula (7), we can now recover channel from and . Due to the limited scattering at mmWave frequency, there are only a few propagation paths, and the beam space channel is approximately sparse. This problem can be solved by the sparse signal recovery algorithm in compressed sensing (CS), in which matrix in Formula (7) can be regarded as the sensing matrix in CS.
where is the number of non-zero elements of is the error tolerance parameter.
Because the -norm minimization problem is a NP-hard problem in practice, so in many cases, the -norm optimization problem will be converted to a higher-dimension norm problem, such as replacing -norm with -norm for the convex optimization problem. At present, some traditional greedy algorithms are commonly used to solve this problem; for example, the OMP [18] and compressive sampling matching pursuit (CoSaMP) [21]. However, using these greedy algorithms it is difficult to find the global optimal solution and the estimation accuracy is not ideal.
3. Traditional Channel Estmation Algorithems
3.1. Compressed Sensing
Compressed sensing is a new technology for finding sparse solutions of underdetermined linear systems. By using the characteristics of signal sparsity, compared with Nyquist theory, the technology can restore the original signal to be recognized from fewer measured values. The theory mainly includes three parts: signal-sparse representation, reconstruction conditions and signal recovery algorithm. Suppose a signal can be sparsely represented by an orthonormal basis , i.e,
where is a sparse column vector, the sparse coefficient of is K and K is far less than N. Consider a linear measurement process; is represented by an orthonormal basis and a coefficient vector , and the measured value can be written as
where represents the measurement matrix, and is the sensing matrix.
In general, taking the sparse of the reconstructed signal in a certain transform domain as a priori information, the original signal is observed with the measurement matrix, and the complete measured signal is reconstructed from the observed value combined with the reconstruction algorithm.
3.2. OMP (Orthogonal Matching Pursuit)
Orthogonal Matching Pursuit is one of the classic algorithms in the field of compressed sensing. It is the basis of many commonly used efficient algorithms. This algorithm has the characteristics of simplicity and efficiency. The essence of the OMP algorithm is to select the columns in the sensor matrix by greedy iteration so that the selected column is most related to the current redundant vector in the process of each iteration, subtract the relevant part from the original signal vector, and iterate repeatedly until the number of iterations reaches the sparsity K, and then stop the iteration.
We define as a sensing matrix and is the column of , observation vector and sparsity K, the initialization residual . The initial iterated index collection , and initial value of iteration . To solve the first problem, we attempt to look for an iterative index as follows:
Adds the index of the most relevant dictionary element found to the index set, while the set of reconstructed atoms in the sensing matrix is updated:
Update the residual:
After executing K cycles, the reconstructed sparse coefficient can be obtained. For more specific OMP algorithm flow, please refer to Algorithm 1.
| Algorithm 1 OMP Algorithm in mmWave Channels |
|
3.3. AMP (Approximate Message Passing)
The approximate message passing (AMP) algorithm is an iterative compressed sensing approach based on a probability graph to predict the next iteration through state evolution and to de-noise through soft threshold iteration. In this section, we will describe how the AMP algorithm estimates the beamspace channel, as shown in Algorithm 2.
| Algorithm 2 AMP Algorithm in mmWave Channels |
|
In Algorithm 2, in Step 6 is a tuning parameter and usually takes a fixed value during iteration, the term in Step 3 is called Onsager Correction, which is introduced into the AMP algorithm to accelerate the convergence. The key step of the AMP algorithm is step 6, in which the estimated channel is obtained by soft threshold shrinking function during the iteration. The shrinkage function is non-linear element-wise operation, due to the sparsity of the channel, the channel vector updated in each iteration will be more sparse. For the i th element of input vector , we have
where is the phase of complex-valued element , is the fixed parameter in the T iteration, and is updated with iteration process in Step 5. In addition, b is obtained by calculating the element-wise derivatives of the shrinkage function at the input vector r in Step 7.
Although the AMP algorithm can effectively deal with massive sparse signal problems, and performs well in many traditional channel-estimation algorithm schemes, for sparse beamspace channel estimation, many problems still exist, such as that the AMP algorithm has a high requirement for i.i.d. sub-Gaussian matrix A. Otherwise, the algorithm itself is prone to divergence. There are two key problems that restrict the performance of the AMP algorithm: (1) The shrinkage parameters in the AMP algorithm usually take the same value in the whole iterative process; (2) the general AMP algorithm cannot make full use of the prior distribution of beamspace channels.
4. AI Channel Estmation Algorithems
4.1. Deep Learning
Deep learning is a kind of representation learning method based on data in machine learning. Its basis is the neural network. In DL, training data consisting of feature and label pairs are used to train the parameters of the deep neural network, which aims to accurately predict the unknown label associated with the newly acquired feature . Depth networks accept and process it in many layers, each of which usually consists of a linear transformation followed by a simple non-linear transformation. Unlike traditional shallow learning, in-depth learning emphasizes the depth of the model structure, usually with five, six or even ten layers of hidden nodes, and transforms the feature representation of samples in the original space into a new feature space through layer-by-layer feature transformation, which makes classification or prediction easier.
In general, the label space is discrete; for example, is an audio or a picture; is a class of cat, dog, or some other type. However, for the sparse linear problem in beam space, label is continuous, but before that, some authors have demonstrated that a well-constructed deep neural network can predict such tags accurately.
4.2. LAMP Network
Recently, the authors of [34] proposed a LAMP network scheme based on the classical AMP algorithm. The results showed that the contraction parameters of the AMP algorithm can only take the same value during the iterative process. Therefore, it essence is to map each iteration of the AMP algorithm to each layer of the LAMP network and optimize the non-linear parameters in each iteration.
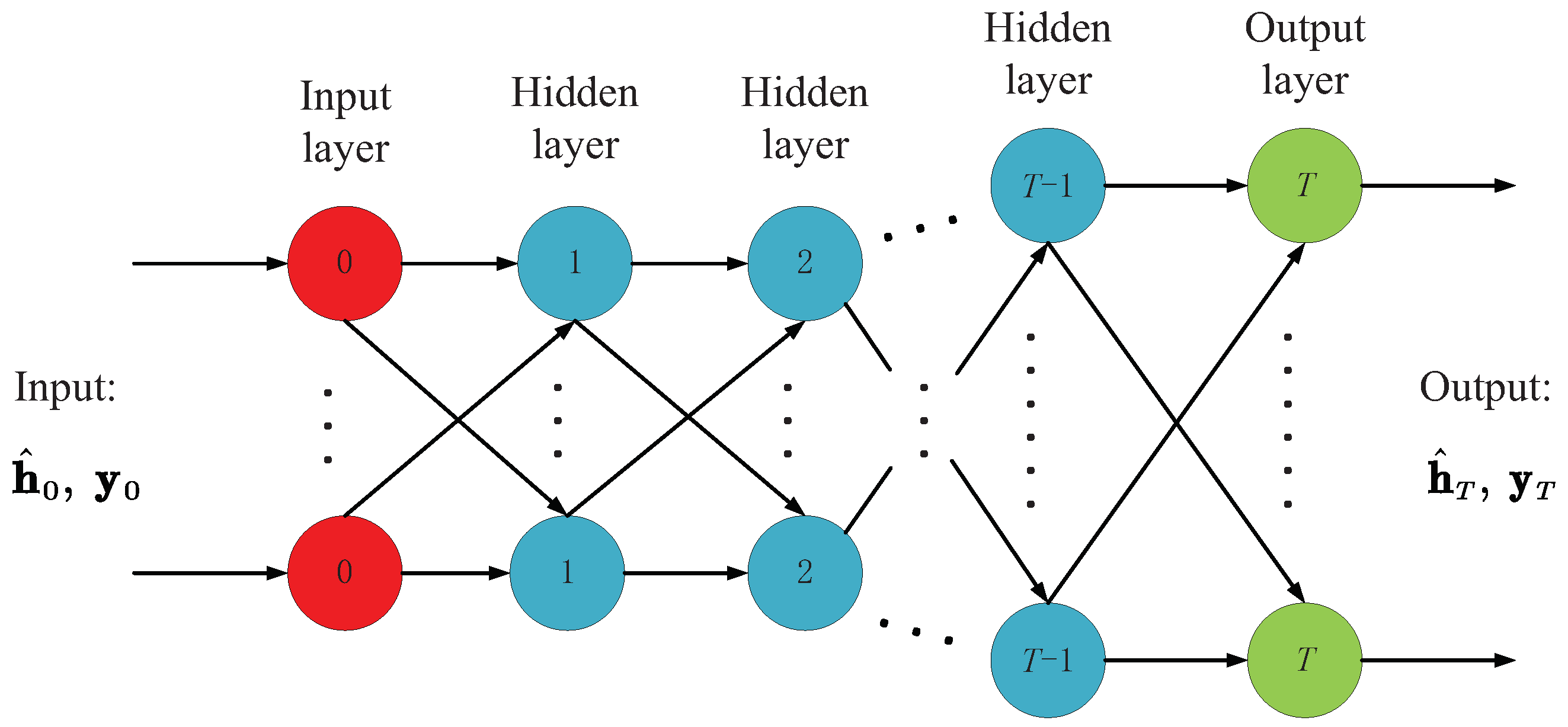
Figure 1 shows the network structure of the LAMP scheme with a total of T layers. Specifically, the LAMP network processes signals in the same way as the AMP algorithm, where the input of tth layer is and . It is worth mentioning that is the measurement signal, and both and are th layer outputs, so the processing of signals in tth layer can be summarized as follows:
where
From the above Formulas (16) and (19), we see the LAMP network involved in the learnable parameters compared with Algorithm 2. In the tth iteration, operations involving are replaced by , and the shrinkage function of the AMP algorithm plays a role in the non-linear activation function in the conventional DNN. It is worth noting that selecting in the AMP algorithm is only for the convenience of formula derivation. If enough training data are given, the LAMP network can use DNN’s powerful learning ability to find better shrinking parameters. Thus, the performance of the original AMP algorithm can be further improved by optimizing the linear transformation coefficient and non-linear shrinking parameter .
4.3. GM-LAMP Network
The LAMP network solves the problem of taking fixed shrinkage parameters in the AMP algorithm, but it does not make good use of prior information on the beamspace channel. The GM-LAMP network proposed by [36] solves this problem. The GM-LAMP network derives a new shrinking function by considering the Gaussian mixing distribution of the elements of the beamspace channel. Before that, we first introduce the expression of the probability density function of the element in the beamspace channel:
where is a set of all the parameters, is the probability of the kth Gaussian component and is the number of Gaussian components in the Gaussian mixture distribution. and represent the mean and variance of the kth Gaussian component, respectively. denotes the probability density function of the k th Gaussian component.
It is interesting that when the mean and variance of Gaussian components are zero, the probability density function of Gaussian distribution can be rewritten as
where the is the Dirac delta function, which means that the variable will be exactly zero. Therefore, the sparsity of beam space channel can be described as a special case by using Gaussian mixture distribution. Finally, the Gaussian Mixed Shrinkage Function considering the prior distribution of the beamspace channel can be written as
where a set of all distribution parameters can also be called as the shrinkage parameters.
GM-LAMP network is still based on AMP algorithm, and it has T uniform layers, in which the input and output of each layer are the same as that of LAMP network, and the difference from LAMP network is that its soft threshold shrinkage function is replaced by the Gaussian mixture shrinkage function. The channel estimation for the tth layer can be written as
where the linear transformation coefficient is and the non-linear shrinkage parameter is the variable that can be optimized in the training stage.
The GM-LAMP network is mainly divided into two stages: offline training and online estimation. During the offline training phase, a large amount of known training data are provided to optimize the overall trainable variable by minimizing the loss function. In the online estimation phase, the new measurement data can be input into the trained GM-LAMP network and the corresponding channel estimates can be obtained directly.
In the offline training stage, supervised learning is adopted to train the GM-LAMP network, and the training dataset can be expressed as , where is the input of the GM-LAMP network, is the corresponding label and D represents the number of the training data.
In order to avoid over-fitting, a layer-by-layer training method is adopted. Specifically, the whole training process can be divided into T training subroutines according to sequence. For the tth training subprocess, its objective is to optimize trainable variable of the layer. In this simulation, we refer to the GM-LAMP algorithm that was first proposed in the literature [36]. In the model training stage, the huber loss is used to define two loss functions of linear transformation coefficient and non-linear shrinkage parameter :
where , , is a hyperparameter, is the output of linear transformation operation in Formula (23), and is the output of non-linear contraction operation in Formula (24). Based on these two loss functions, the training sub-process at the tth layer can be divided into linear training to minimize and non-linear training to minimize .
Algorithm 3 represents the specific layer-by-layer training method of the GM-LAMP network that was provided in [36]. To avoid the trapped-in local optimization caused by over-fitting, we firstly adopt the separate optimization method in step 2, and then jointly optimize the method in step 3 and 4, which are set to and , respectively. Then the training is carried out in sequence from the 1th layer to the th layer. For the training sub-process of the tth layer, the training variable is set to the value of the training variable of the th layer before training. Steps 7–8 indicate that the linear transformation coefficient is optimized separately, and then and are optimized jointly. Similarly, steps 9–10 indicate that the non-linear shrinkage parameter is optimized separately first, and then , and are optimized jointly.
| Algorithm 3 Layer-by-Layer Training Method |
|
A trained GM-LAMP network can be obtained after optimizing the overall trainable variables of T layers. In the online estimation phase, the corresponding estimates can be directly generated by inputting new measurement signals into the trained GM-LAMP network.
4.4. Complexity Analysis
In this subsection, we perform the complexity analysis of the channel estimation algorithms used in the simulation process. Considering the OMP algorithm, when the sparsity of the channel vector is set to K, the computational complexity in the atom selection step is about , and the computational complexity of the k-th iteration is at least . Therefore, we ignore trivial operations; the computational complexity can be calculated as . In addition, since the LAMP network and GM-LAMP network are constructed that both are based on the AMP algorithm, the computational complexity of the AMP algorithm, LAMP network and GM-LAMP network is roughly the same values that equals to .
5. Numerical Results
In this section, we compare the performance of traditional beamspace channel estimation algorithms and DL-based schemes in mixed-ADC architecture. Specifically, DL-based schemes include the LAMP network and the GM-LAMP network. This experiment provides a widely used Saleh–Valenzuela channel model.
5.1. Parameter Setting
In our simulations, we consider that the BS is deployed a lens antenna array, where the numbers of antennas and RF chains are set to and , individually. The number of single-antenna users is set to , and the number of measurements is set to . For the the Saleh–Valenzuela channel model, we set the same channel parameters for each user k, where the number of channel paths , the complex gain on the lth path satisfies for , and the range of azimuth and elevation on each path is between and . In order to train and test the LAMP network and the GM-LAMP network, we generate 80,000, 2000 and 2000 samples as the training, the validation and the testing set based on the above setup, respectively. Then the number of training layers is set as for both network schemes, where the number of nodes in each layer depends on the number of measurements M and the number of dimensions N of the beamspace channel. Finally, we use the normalized mean square error (NMSE) to quantify the accuracy of channel estimation for each user, which is mathematically defined as
where is the recovered channel matrix using the channel estimation algorithms.
5.2. Simulation Results on the Saleh–Valenzuela Channel Model
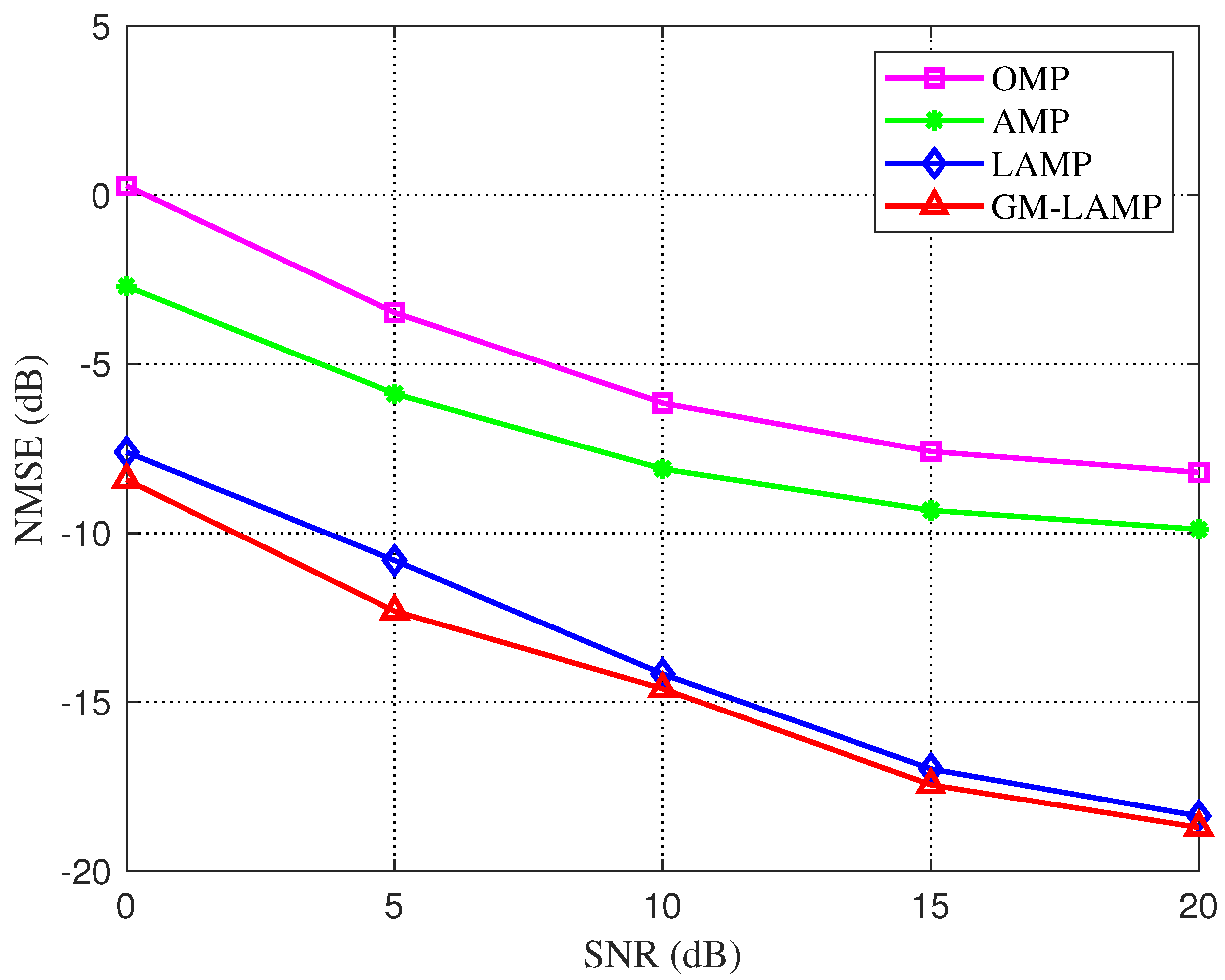
Figure 2 shows the NMSE performance comparison of various algorithms under the considered UPA and mixed-resolution ADC quantization architecture. It can be seen from the figure that the performance of the traditional two algorithms is poor, and in general, the performance of the AMP algorithm is better than the OMP algorithm. For the DL-based LAMP network and GM-LAMP network, the performance of the scheme has been greatly improved. In addition, considering the prior distribution of beamspace channels, the GM-LAMP network has better channel estimation accuracy than the LAMP network.
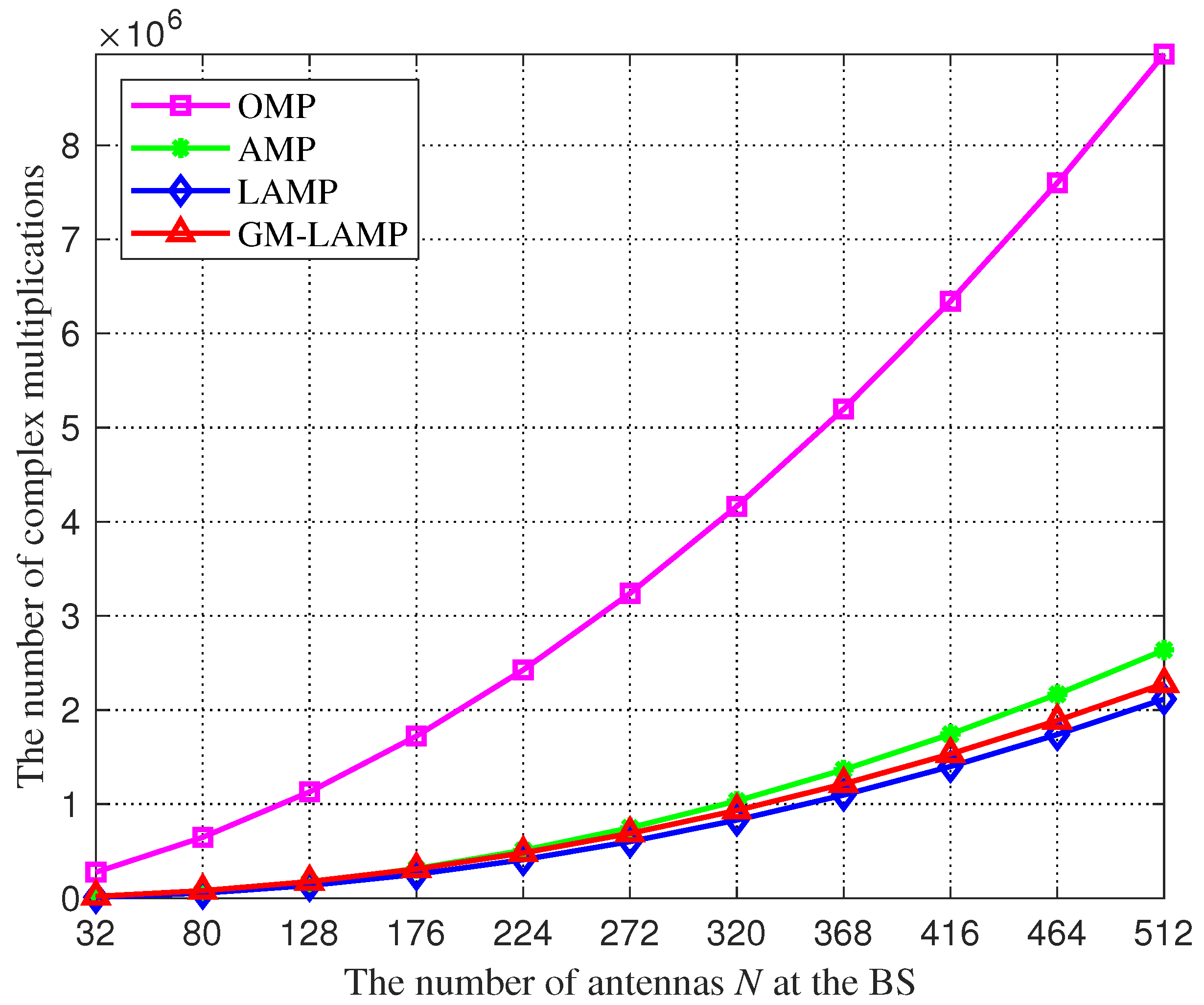
Figure 3 shows a comparison of the complexity of the above four kinds of channel estimation schemes. We can find that the traditional OMP algorithm requires more complex multipliers than other schemes, because the OMP algorithm is a kind of greed-tracking algorithm, the number of complex multiplications increases exponentially with the number of antennas, so the OMP algorithm has an excessive demand on the number of antennas. In addition, thanks to the powerful learning of DNNs, the LAMP network and GM-LAMP network can converge faster than the AMP algorithm. Therefore, the complex multiplier required by the LAMP network and GM-LAMP network is smaller than that required by the AMP algorithm.
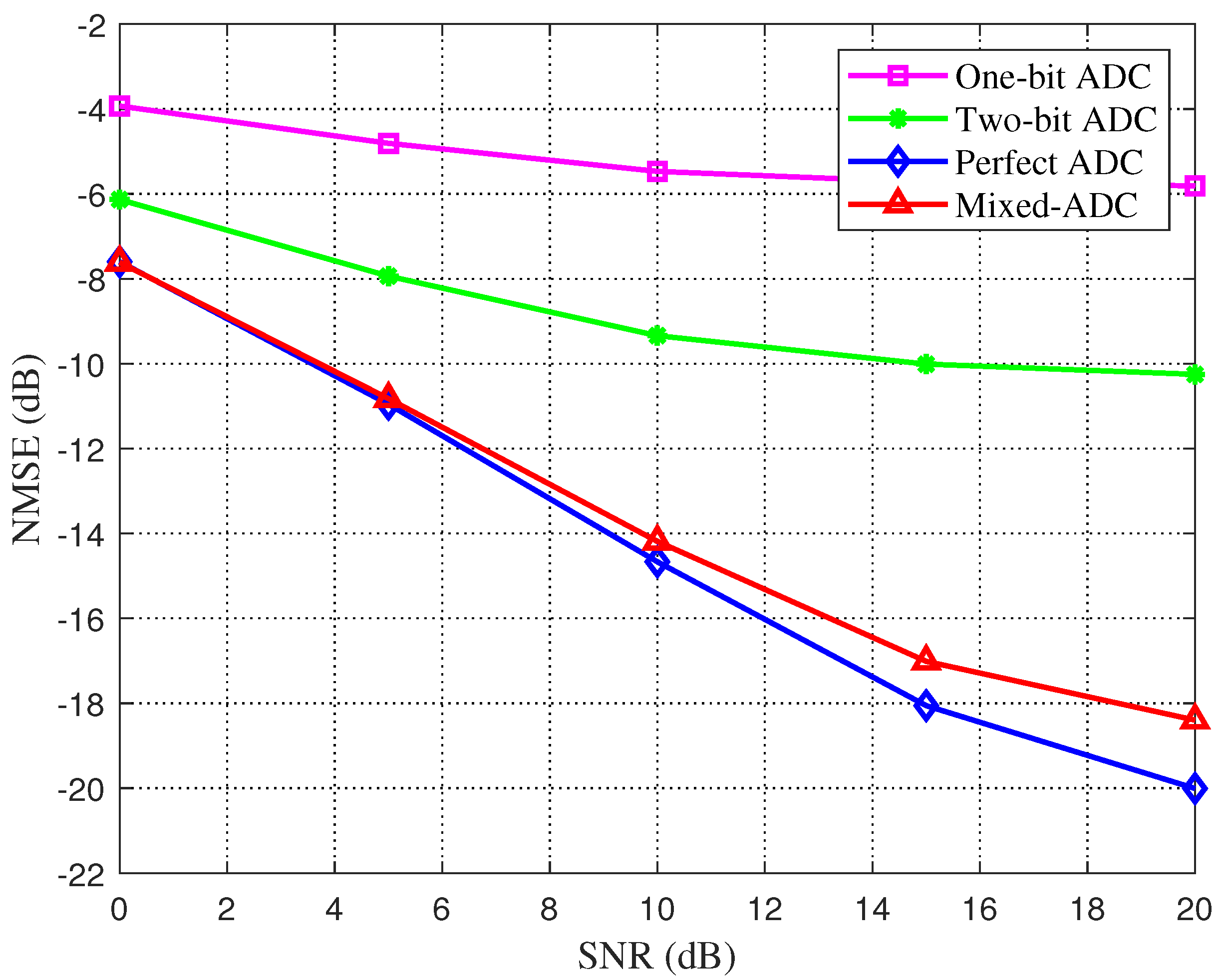
Next, we discuss the effects of resolution of ADC and channel sparsity on NMSE performance for two schemes based on DL. Figure 4 shows the performance changes of LAMP network schemes with different resolution ADC quantization. It can be seen that lower estimation error can be obtained by using higher-resolution ADC quantization, and the estimation performance after using mixed resolution ADC is better than four-bit ADC. With the increase in SNR, the performance difference between mixed resolution ADC and other low-resolution ADCs increases.
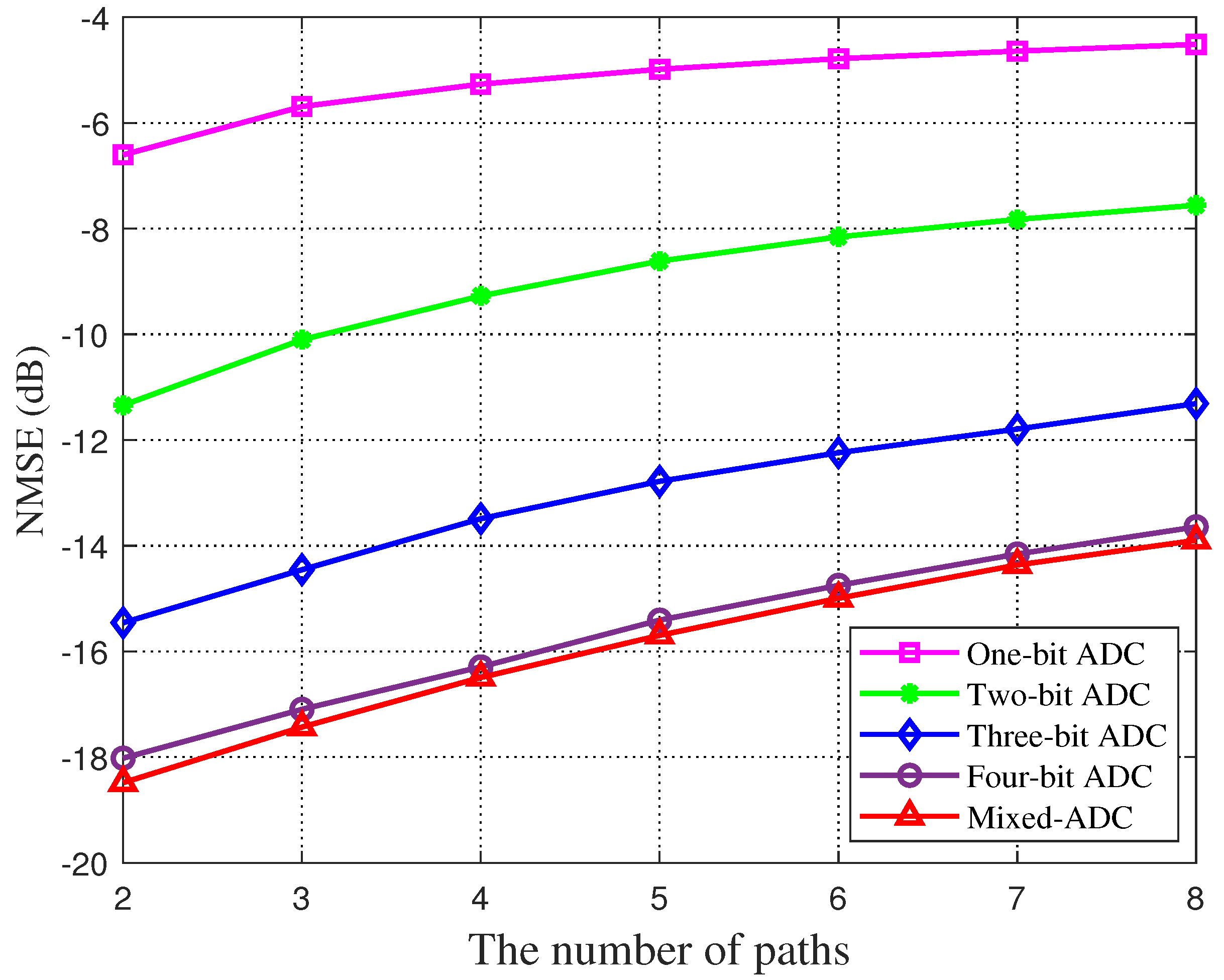
Figure 5 plots the variation of estimation error in low-resolution ADCs from one to four bits and mixed resolution after adopting the GAMP network scheme. The sparsity in this figure is equivalent to the number of channel paths (). With the increase in sparsity, the channel estimation performance of all quantization resolutions will decline. It can be seen from the four curves in the comparison that the higher the resolution, the smaller the estimation error.
In addition, we evaluate the effects of NMSE and SNR on the total rate of beam selection in beamspace channel estimation. In this simulation, we reference the parameters of [37] to model the estimated beamspace channel in case of imperfect CSI as
where is the error parameter, denotes the error matrix, whose elements satisfies the independent and identical distribution of the zero means and variance error, i.e., , NMSE), and denotes the channel matrix with perfect CSI for K users. In order to demonstrate the effectiveness of this work, we use the results provided in [37]; that is, AI beam selection with perfect CSI as the benchmark.
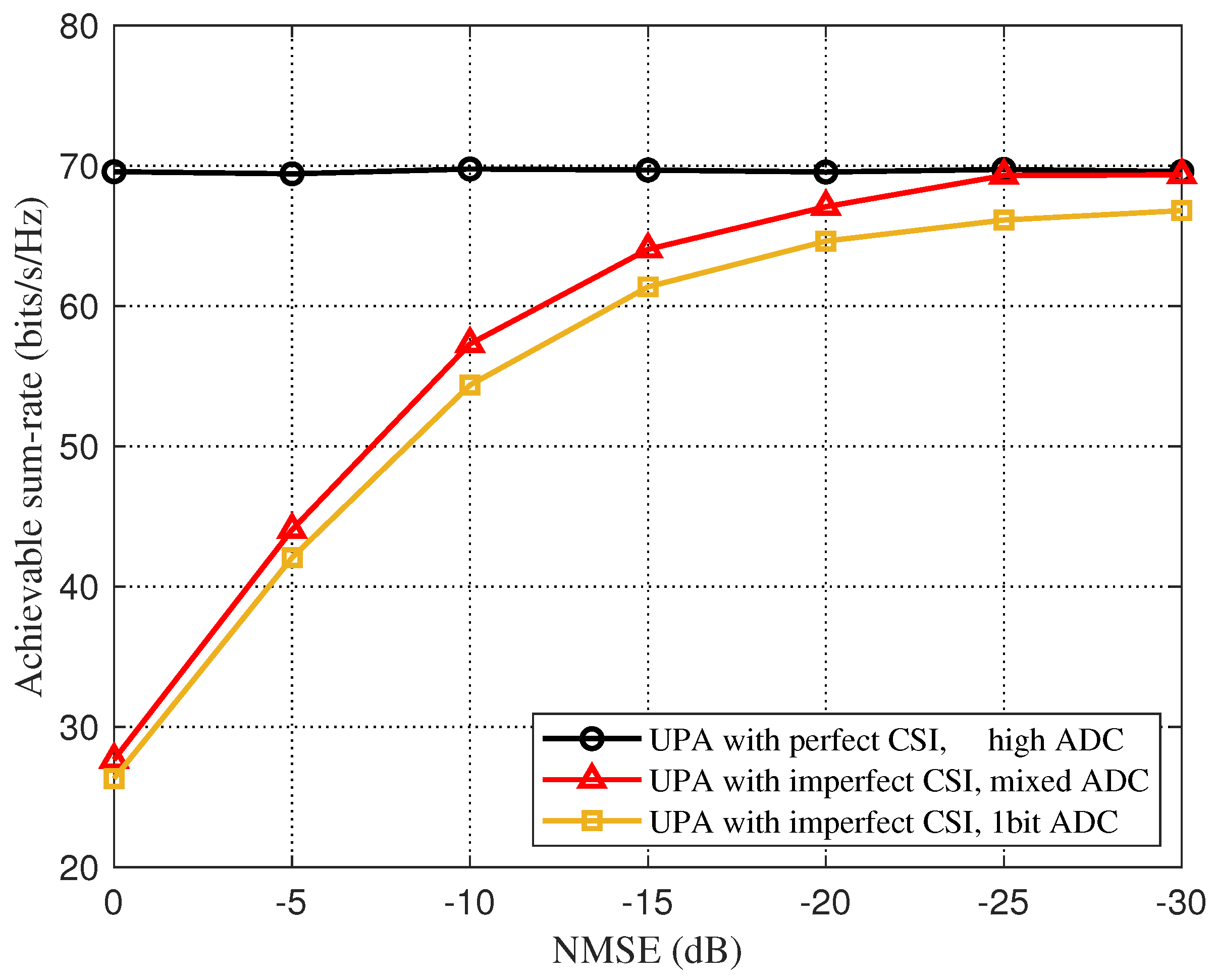
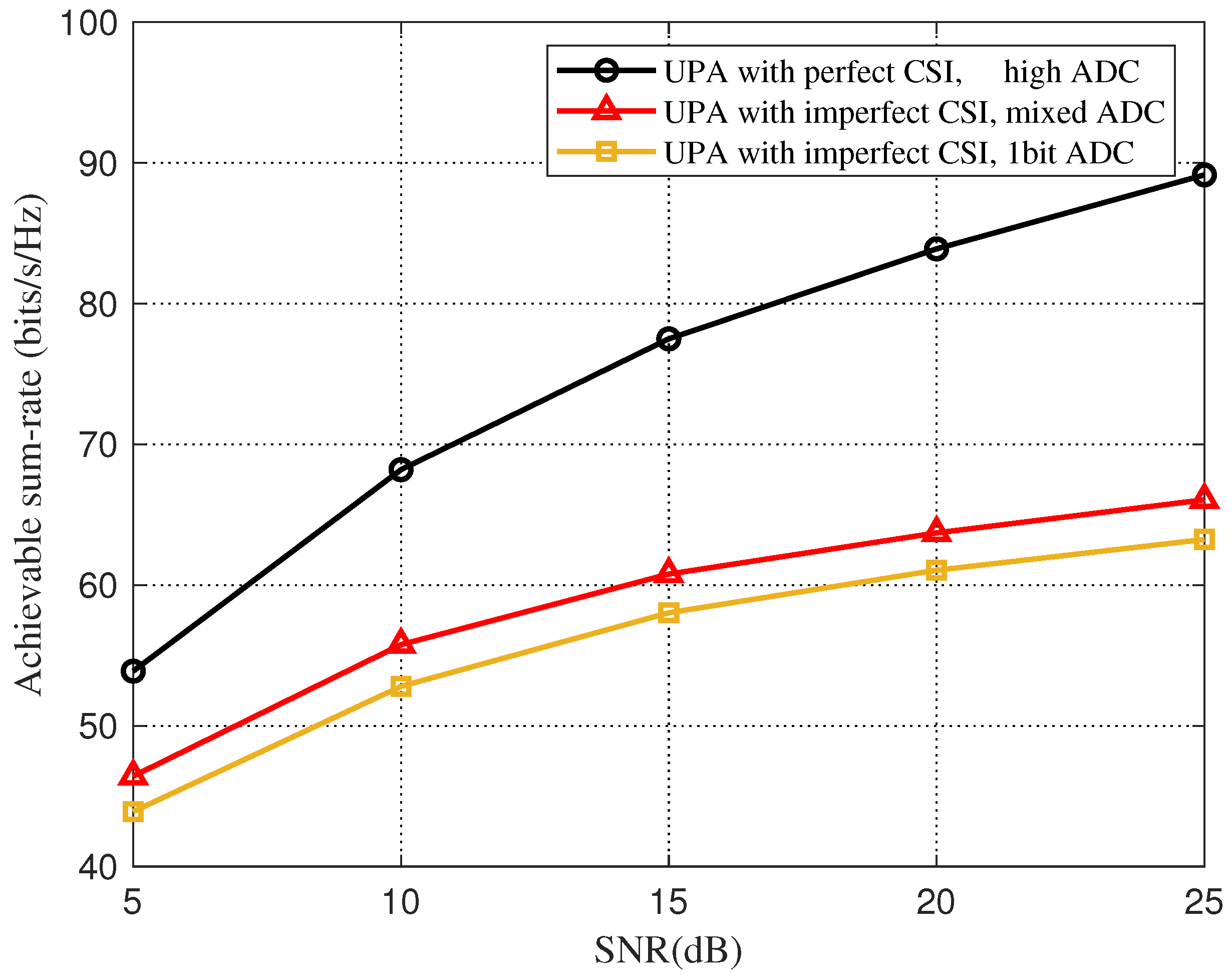
In Figure 6, we consider UPA based on the Saleh-Valenzuela channel model, and compare the sum-rate between an imperfect CSI and a perfect CSI with a downlink SNR of 10 dB. As shown in Figure 6, for the imperfect CSI under the mixed-resolution ADC architecture, when the NMSE is about −23 dB, the total rate-loss due to beam selection is less than 5% compared to the perfect CSI, and the beam-selection rate quantized by a one-bit ADC is always quite different from that of the mixed-resolution ADC. Figure 7 shows the effect of the change of SNR on the total rate of beam selection for an imperfect CSI and a perfect CSI when the NMSE is set to −10 dB. We can clearly see that with the increase in SNR, the beam selection rate of all three increases, but the gap between the rate of imperfect CSI and perfect CSI gradually increases.
6. Conclusions
In this paper, the channel estimation for a mmWave massive MIMO system with a mixed-resolution ADC architecture was investigated, where the BS deployed the lens antenna arrays. By using the sparsity of the mmWave channel, the beamspace channel estimation can be expressed as a sparse signal-recovery problem, and the channel can be recovered by the algorithm based on compressed sensing. We compare the traditional channel-estimation scheme with the channel-estimation scheme using DL. Simulation results showed that the performance of the DNN-based estimation scheme is significantly better than that of the traditional estimation scheme in the same configuration. Furthermore, the performance gap between using mixed-resolution ADC and using high-resolution ADC is slowly closing as the SNR increases. In future work, we will investigate the performance of IRS-assisted mmWave massive MIMO systems with mixed-ADC architectures, which aims to study the channel estimation problems in cascaded channels.
Author Contributions
W.T. conceived and designed the idea. R.Z. and X.W. performed the experiments and analyzed the data. W.N. and T.L. gave valuable suggestions on the structuring of the paper and assisted in the revising and proofreading. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Natural Science Foundation of Guangdong Province of China under Grant 2020A1515010484, the Guangzhou Science and Technology Planning Project under Grant 202102020879, the 2023 Guangzhou Basic Research Program Municipal School (College) Joint Funding Project, the 2022 Joint Research Fund for Guangzhou University and Hong Kong University of science and technology, the open research fund of National Mobile Communications Research Laboratory, Southeast University under Grant 2021D03, the National Nature Science Foundation of China under Grant 62101274, the Nature Science Foundation of Jiangsu Province under Grant BK20210640, and Scientific Research Cultivation Project for Young Scholars of South China Normal University under Grant 21KJ07.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to extend their gratitude to the anonymous reviewers and the editors for their valuable and constructive comments, which have greatly improved the quality of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Giordani, M.; Polese, M.; Mezzavilla, M.; Rangan, S.; Zorzi, M. Toward 6G networks: Use cases and technologies. IEEE Commun. Mag. 2020, 58, 55–61. [Google Scholar] [CrossRef]
- Fozi, M.; Sharafat, A.R.; Bennis, M. Fast MIMO Beamforming via Deep Reinforcement Learning for High Mobility mmWave Connectivity. IEEE J. Sel. Areas Commun. 2022, 40, 127–142. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, J.; Ma, S.; Wen, C.K.; Jin, S. Large System Achievable Rate Analysis of RIS-Assisted MIMO Wireless Communication With Statistical CSIT. IEEE Trans. Wirel. Commun. 2021, 20, 5572–5585. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, J.; Jin, Y.; Ai, B. Wireless powered IoE for 6G: Massive access meets scalable cell-free massive MIMO. China Commun. 2020, 17, 92–109. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, R. Millimeter wave MIMO with lens antenna array: A new path division multiplexing paradigm. IEEE Trans. Commun. 2016, 64, 1557–1571. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, R.; Chen, Z.N. Electromagnetic lens-focusing antenna enabled massive MIMO: Performance improvement and cost reduction. IEEE J. Sel. Areas Commun. 2014, 32, 1194–1206. [Google Scholar] [CrossRef] [Green Version]
- Brady, J.; Behdad, N.; Sayeed, A.M. Beamspace MIMO for millimeter-wave communications: System architecture, modeling, analysis, and measurements. IEEE Trans. Antennas Propag. 2013, 61, 3814–3827. [Google Scholar] [CrossRef]
- Gao, X.; Dai, L.; Chen, Z.; Wang, Z.; Zhang, Z. Near-optimal beam selection for beamspace mmWave massive MIMO systems. IEEE Commun. Lett. 2016, 20, 1054–1057. [Google Scholar] [CrossRef]
- Amadori, P.V.; Masouros, C. Low RF-complexity millimeter-wave beamspace-MIMO systems by beam selection. IEEE Trans. Commun. 2015, 63, 2212–2223. [Google Scholar] [CrossRef]
- Mo, J.; Schniter, P.; Heath, R.W. Channel estimation in broadband millimeter wave MIMO systems with few-bit ADCs. IEEE Trans. Signal Process. 2017, 66, 1141–1154. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, L.; Sun, S.; Wang, Z. On the spectral efficiency of massive MIMO systems with low-resolution ADCs. IEEE Commun. Lett. 2016, 20, 842–845. [Google Scholar] [CrossRef] [Green Version]
- Tan, W.; Li, S.; Zhou, M. Spectral and energy efficiency for uplink massive MIMO systems with mixed-ADC architecture. Phys. Commun. 2022, 50, 101516. [Google Scholar] [CrossRef]
- Zhou, M.; Zhang, Y.; Qiao, X.; Tan, W.; Yang, L. Analysis and optimization for downlink cell-free massive MIMO system with mixed DACs. Sensors 2021, 21, 2624. [Google Scholar] [CrossRef] [PubMed]
- Liang, N.; Zhang, W. Mixed-ADC massive MIMO uplink in frequency-selective channels. IEEE Trans. Commun. 2016, 64, 4652–4666. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, L.; He, Z.; Jin, S.; Li, X. Performance analysis of mixed-ADC massive MIMO systems over Rician fading channels. IEEE J. Sel. Areas Commun. 2017, 35, 1327–1338. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Xu, J.; Xu, W.; Jin, S.; Dong, X. Multiuser massive MIMO relaying with mixed-ADC receiver. IEEE Signal Process. Lett. 2016, 24, 76–80. [Google Scholar] [CrossRef]
- Yuan, J.; He, Q.; Matthaiou, M.; Quek, T.Q.; Jin, S. Toward massive connectivity for IoT in mixed-ADC distributed massive MIMO. IEEE Internet Things J. 2019, 7, 1841–1856. [Google Scholar] [CrossRef]
- Venugopal, K.; Alkhateeb, A.; Heath, R.W.; Prelcic, N.G. Time-domain channel estimation for wideband millimeter wave systems with hybrid architecture. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 6493–6497. [Google Scholar]
- Rodríguez-Fernández, J.; González-Prelcic, N.; Venugopal, K.; Heath, R.W. Frequency-Domain Compressive Channel Estimation for Frequency-Selective Hybrid Millimeter Wave MIMO Systems. IEEE Trans. Wirel. Commun. 2018, 17, 2946–2960. [Google Scholar] [CrossRef] [Green Version]
- Lee, D. MIMO OFDM channel estimation via block stagewise orthogonal matching pursuit. IEEE Commun. Lett. 2016, 20, 2115–2118. [Google Scholar] [CrossRef]
- Jayanthi, P.; Ravishankar, S. Sparse channel estimation for MIMO-OFDM systems using compressed sensing. In Proceedings of the 2016 IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 20–21 May 2016; pp. 1060–1064. [Google Scholar]
- Donoho, D.L.; Maleki, A.; Montanari, A. Message passing algorithms for compressed sensing: I. motivation and construction. In Proceedings of the 2010 IEEE information theory workshop on information theory (ITW 2010, Cairo), Cairo, Egypt, 6–8 January 2010; pp. 1–5. [Google Scholar]
- Qin, Z.; Ye, H.; Li, G.Y.; Juang, B.H.F. Deep learning in physical layer communications. IEEE Wirel. Commun. 2019, 26, 93–99. [Google Scholar] [CrossRef] [Green Version]
- O’shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Liang, F.; Shen, C.; Wu, F. An iterative BP-CNN architecture for channel decoding. IEEE J. Sel. Top. Signal Process. 2018, 12, 144–159. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Kim, N.I.; Lee, W.; Cho, D.H. Deep learning-aided SCMA. IEEE Commun. Lett. 2018, 22, 720–723. [Google Scholar] [CrossRef]
- He, H.; Wen, C.K.; Jin, S.; Li, G.Y. Model-driven deep learning for MIMO detection. IEEE Trans. Signal Process. 2020, 68, 1702–1715. [Google Scholar] [CrossRef]
- Kang, J.M.; Chun, C.J.; Kim, I.M. Deep-learning-based channel estimation for wireless energy transfer. IEEE Commun. Lett. 2018, 22, 2310–2313. [Google Scholar] [CrossRef]
- Neumann, D.; Wiese, T.; Utschick, W. Learning the MMSE channel estimator. IEEE Trans. Signal Process. 2018, 66, 2905–2917. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Yang, J.; Huang, H.; Song, Y.; Gui, G. Deep learning for super-resolution channel estimation and DOA estimation based massive MIMO system. IEEE Trans. Veh. Technol. 2018, 67, 8549–8560. [Google Scholar] [CrossRef]
- He, H.; Wen, C.K.; Jin, S.; Li, G.Y. Deep learning-based channel estimation for beamspace mmWave massive MIMO systems. IEEE Wirel. Commun. Lett. 2018, 7, 852–855. [Google Scholar] [CrossRef] [Green Version]
- Chun, C.J.; Kang, J.M.; Kim, I.M. Deep learning-based channel estimation for massive MIMO systems. IEEE Wirel. Commun. Lett. 2019, 8, 1228–1231. [Google Scholar] [CrossRef]
- Wang, T.; Wen, C.K.; Jin, S.; Li, G.Y. Deep learning-based CSI feedback approach for time-varying massive MIMO channels. IEEE Wirel. Commun. Lett. 2018, 8, 416–419. [Google Scholar] [CrossRef] [Green Version]
- Borgerding, M.; Schniter, P.; Rangan, S. AMP-inspired deep networks for sparse linear inverse problems. IEEE Trans. Signal Process. 2017, 65, 4293–4308. [Google Scholar] [CrossRef]
- Tan, W.; Yang, X.; Ma, S. Spectral Efficiency of Massive MIMO With LMMSE Receivers Under Finite Dimensional Channels. IEEE Wirel. Commun. Lett. 2021, 11, 18–22. [Google Scholar] [CrossRef]
- Wei, X.; Hu, C.; Dai, L. Deep learning for beamspace channel estimation in millimeter-wave massive MIMO systems. IEEE Trans. Commun. 2020, 69, 182–193. [Google Scholar] [CrossRef]
- Gao, X.; Dai, L.; Han, S.; Chih-Lin, I.; Heath, R.W. Energy-efficient hybrid analog and digital precoding for mmWave MIMO systems with large antenna arrays. IEEE J. Sel. Areas Commun. 2016, 34, 998–1009. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
LAMP network structure with a total of T layers.

Figure 2.
NMSE performance comparison of each channel estimation scheme for UPAs based on the Saleh-Valenzuela channel model in the mixed resolution ADC architecture.
Figure 2.
NMSE performance comparison of each channel estimation scheme for UPAs based on the Saleh-Valenzuela channel model in the mixed resolution ADC architecture.

Figure 3.
The number of complex multiplications against the number of antennas N.

Figure 4.
Channel estimation error is a function of SNR. Variations of estimation errors in different resolution ADCs quantification in LAMP network schemes are plotted.
Figure 4.
Channel estimation error is a function of SNR. Variations of estimation errors in different resolution ADCs quantification in LAMP network schemes are plotted.

Figure 5.
Channel estimation error is a function of channel sparsity. Variations of estimation errors in different resolution ADCs quantification in GAMP network schemes are plotted.
Figure 5.
Channel estimation error is a function of channel sparsity. Variations of estimation errors in different resolution ADCs quantification in GAMP network schemes are plotted.

Figure 6.
Total rate for beam selection against different NMSE for the beamspace channel estimation.
Figure 6.
Total rate for beam selection against different NMSE for the beamspace channel estimation.

Figure 7.
Total rate for beam selection against different SNR for the beamspace channel estimation.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Multiple solutions to the problem of overwhelming hardware costs and power consumption in mmWave massive MIMO system.
Table 1.
Multiple solutions to the problem of overwhelming hardware costs and power consumption in mmWave massive MIMO system.
| Solutions | Advantages | Limitations |
|---|---|---|
| Lens antenna arrays | Significant reduction in the number of RF chains by adopting a hybrid precoding scheme. | Beam selection requires the BS to obtain the CSI of beamspace, and system performance is vulnerable to bandwidth. |
| Low-resolution ADCs | Reduce power consumption by reducing the high resolution of the ADCs to low resolution. | Low-resolution ADCs are prone to severe non-linear distortion. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, R.; Tan, W.; Nie, W.; Wu, X.; Liu, T. Deep Learning-Based Channel Estimation for mmWave Massive MIMO Systems in Mixed-ADC Architecture. Sensors 2022, 22, 3938. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103938
AMA Style
Zhang R, Tan W, Nie W, Wu X, Liu T. Deep Learning-Based Channel Estimation for mmWave Massive MIMO Systems in Mixed-ADC Architecture. Sensors. 2022; 22(10):3938. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103938
Chicago/Turabian StyleZhang, Rui, Weiqiang Tan, Wenliang Nie, Xianda Wu, and Ting Liu. 2022. "Deep Learning-Based Channel Estimation for mmWave Massive MIMO Systems in Mixed-ADC Architecture" Sensors 22, no. 10: 3938. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103938
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.