
Sampling Trade-Offs in Duty-Cycled Systems for Air Quality Low-Cost Sensors

 , and
, and
Abstract
:1. Introduction
- Describe the prototype node used to simulate the duty cycle strategies;
- Perform a multiple linear regression, k-nearest neighbors, and support vector regression calibration of O, NO, and NO sensors, assuming high data availability;
- Simulate different sensor sampling strategies, showing their impact on the goodness-of-fit of the calibration, as well as the implications of the resulting duty cycles.
2. Related Work
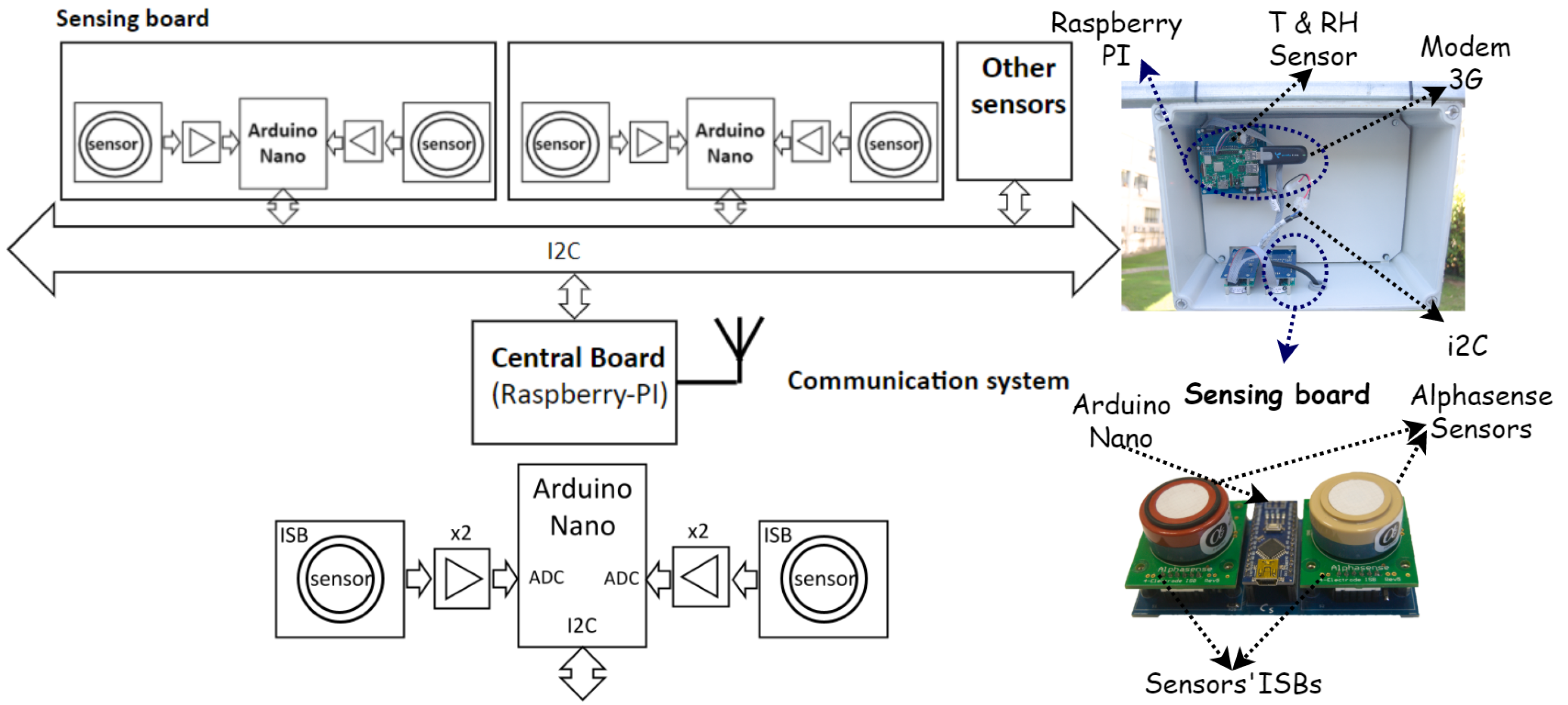
3. Sensing Node: The Captor Node
3.1. CAPTOR Node
3.2. Low-Cost Sensors
3.3. Datasets
4. Sensor Data Gathering Pipeline
4.1. Pre-Processing
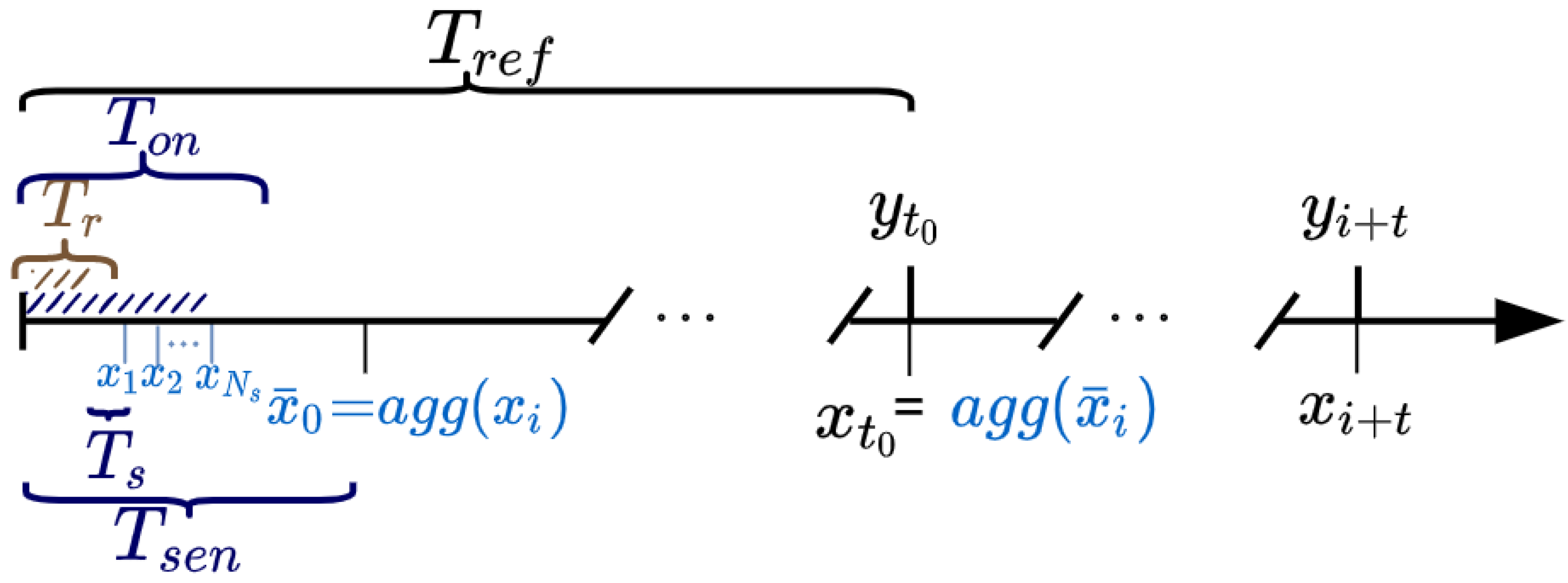
4.1.1. Sensor Sampling
4.1.2. Filtering
4.1.3. Aggregation
4.2. Machine Learning-Based Sensor Calibration
5. Results
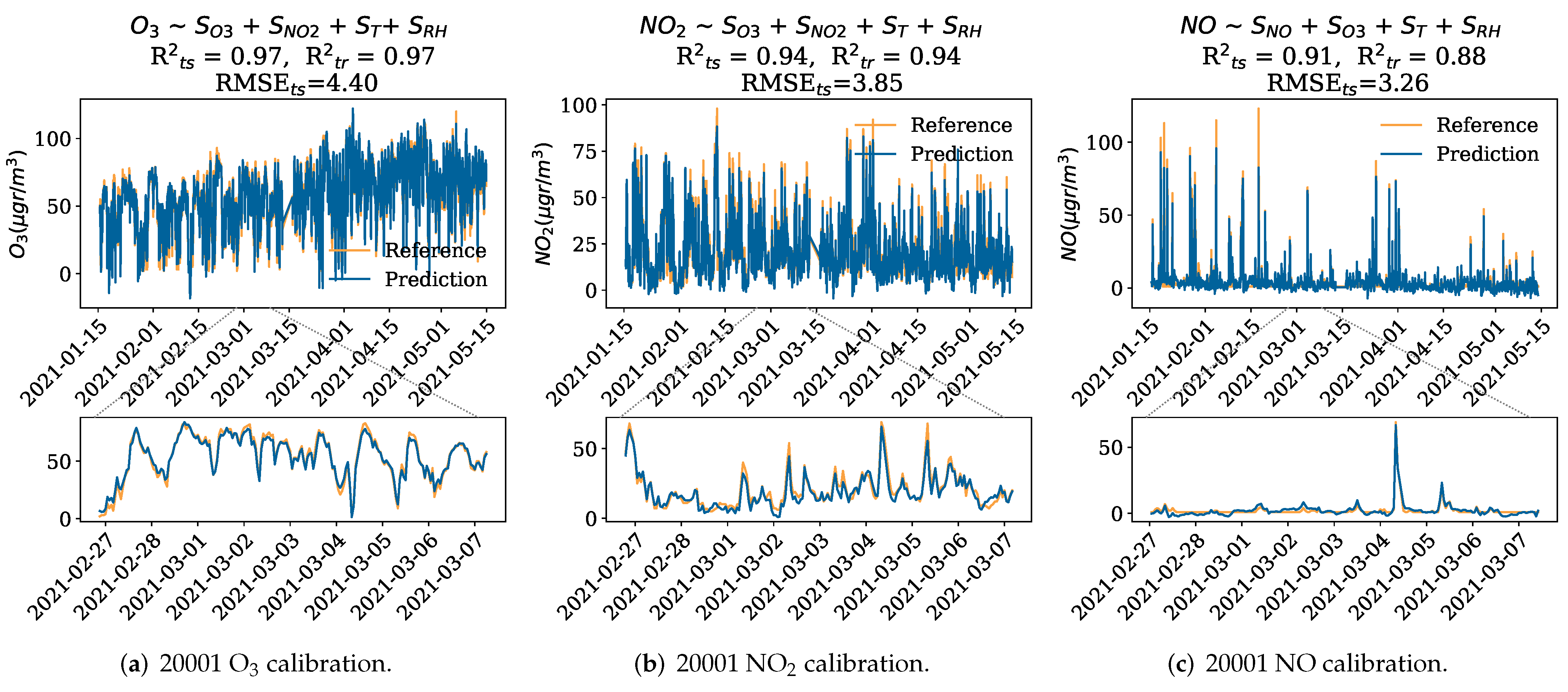
- We perform sensor in-situ calibration for the O, NO and NO sensors, using the best subsets of sensors found by forward stepwise feature selection using 10-fold cross-validation (CV). We perform this experiment using the raw sensors’ signals (), therefore assuming no energy consumption restrictions. We compare three in-situ calibration models: multiple linear regression, k-nearest neighbors and support vector regression;
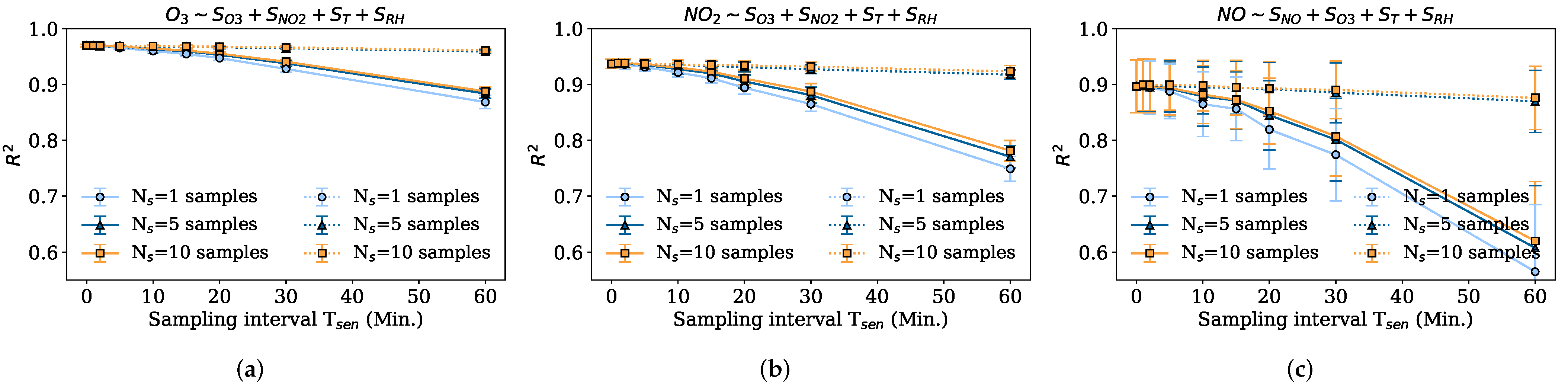
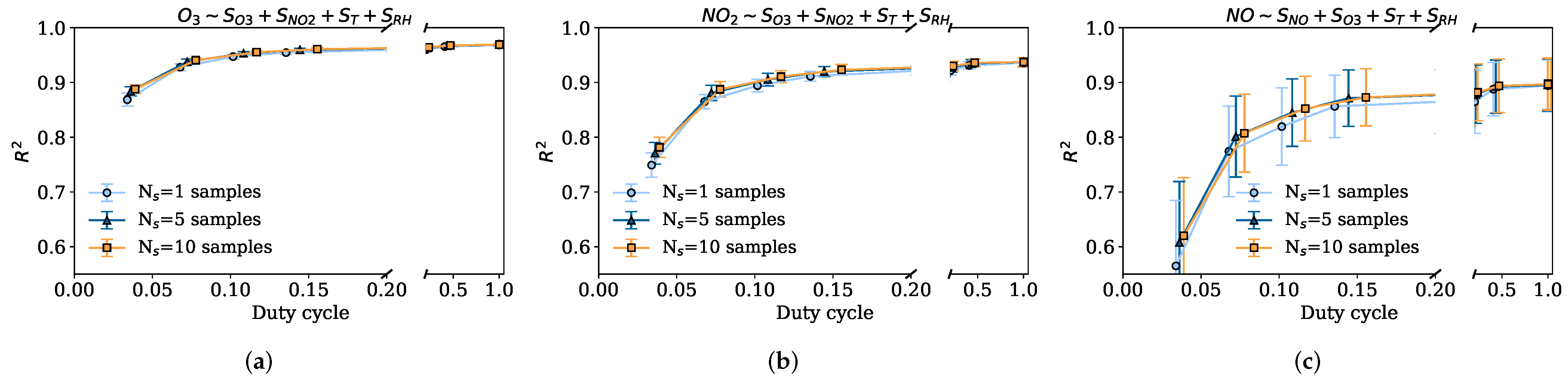
- We investigate the impact of the sensor sampling parameters on the sensor calibration accuracy and power consumption. To this end, we compare different sampling periods for the sensing node , as well as different numbers of samples collected in these periods . We also consider sensor response periods. To carry out this experiment, we use the raw two-second signals from the sensors and simulate the different sampling settings by subsampling these raw signals. A 10-fold CV is performed for every sampling setting, discussing the resulting goodness-of-fit metrics, duty cycles, and power consumption implications.
5.1. Machine Learning-Based Calibration
5.2. Sensor Sampling Impact
5.2.1. Impact of Node Sampling Period
5.2.2. Impact of Duty Cycle DC: Data Quality
5.2.3. Impact of Duty Cycle DC: Power Consumption
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Anastasi, G.; Conti, M.; Di Francesco, M.; Passarella, A. Energy conservation in wireless sensor networks: A survey. Ad Hoc Netw. 2009, 7, 537–568. [Google Scholar] [CrossRef]
- Fasolo, E.; Rossi, M.; Widmer, J.; Zorzi, M. In-network aggregation techniques for wireless sensor networks: A survey. IEEE Wirel. Commun. 2007, 14, 70–87. [Google Scholar] [CrossRef]
- Morawska, L.; Thai, P.K.; Liu, X.; Asumadu-Sakyi, A.; Ayoko, G.; Bartonova, A.; Bedini, A.; Chai, F.; Christensen, B.; Dunbabin, M.; et al. Applications of low-cost sensing technologies for air quality monitoring and exposure assessment: How far have they gone? Environ. Int. 2018, 116, 286–299. [Google Scholar] [CrossRef] [PubMed]
- Barcelo-Ordinas, J.M.; Doudou, M.; Garcia-Vidal, J.; Badache, N. Self-Calibration Methods for Uncontrolled Environments in Sensor Networks: A Reference Survey. Ad Hoc Netw. 2019, 88, 142–159. [Google Scholar] [CrossRef] [Green Version]
- Maag, B.; Zhou, Z.; Thiele, L. A Survey on Sensor Calibration in Air Pollution Monitoring Deployments. IEEE Internet Things J. 2018, 5, 4857–4870. [Google Scholar] [CrossRef] [Green Version]
- Ripoll, A.; Viana, M.; Padrosa, M.; Querol, X.; Minutolo, A.; Hou, K.M.; Barcelo-Ordinas, J.M.; García-Vidal, J. Testing the performance of sensors for ozone pollution monitoring in a citizen science approach. Sci. Total Environ. 2019, 651, 1166–1179. [Google Scholar] [CrossRef]
- Mijling, B.; Jiang, Q.; Jonge, D.D.; Bocconi, S. Field calibration of electrochemical NO2 sensors in a citizen science context. Atmos. Meas. Tech. 2018, 11, 1297–1312. [Google Scholar] [CrossRef] [Green Version]
- Ferrer-Cid, P.; Barcelo-Ordinas, J.M.; Garcia-Vidal, J.; Ripoll, A.; Viana, M. A Comparative Study of Calibration Methods for Low-Cost Ozone Sensors in IoT Platforms. IEEE Internet Things J. 2019, 6, 9563–9571. [Google Scholar] [CrossRef] [Green Version]
- Nowack, P.; Konstantinovskiy, L.; Gardiner, H.; Cant, J. Machine learning calibration of low-cost NO2 and PM10 sensors: Non-linear algorithms and their impact on site transferability. Atmos. Meas. Tech. 2021, 14, 5637–5655. [Google Scholar] [CrossRef]
- Bigi, A.; Mueller, M.; Grange, S.K.; Ghermandi, G.; Hueglin, C. Performance of NO, NO2 low cost sensors and three calibration approaches within a real world application. Atmos. Meas. Tech. 2018, 11, 3717–3735. [Google Scholar] [CrossRef] [Green Version]
- De Vito, S.; Esposito, E.; Salvato, M.; Popoola, O.; Formisano, F.; Jones, R.; Di Francia, G. Calibrating chemical multisensory devices for real world applications: An in-depth comparison of quantitative machine learning approaches. Sens. Actuators B Chem. 2018, 255, 1191–1210. [Google Scholar] [CrossRef] [Green Version]
- Si, M.; Xiong, Y.; Du, S.; Du, K. Evaluation and calibration of a low-cost particle sensor in ambient conditions using machine-learning methods. Atmos. Meas. Tech. 2020, 13, 1693–1707. [Google Scholar] [CrossRef] [Green Version]
- Mead, M.I.; Popoola, O.; Stewart, G.; Landshoff, P.; Calleja, M.; Hayes, M.; Baldovi, J.; McLeod, M.; Hod gson, T.; Dicks, J.; et al. The use of electrochemical sensors for monitoring urban air quality in low-cost, high-density networks. Atmos. Environ. 2013, 70, 186–203. [Google Scholar] [CrossRef] [Green Version]
- Han, P.; Mei, H.; Liu, D.; Zeng, N.; Tang, X.; Wang, Y.; Pan, Y. Calibrations of Low-Cost Air Pollution Monitoring Sensors for CO, NO2, O3, and SO2. Sensors 2021, 21, 256. [Google Scholar] [CrossRef] [PubMed]
- Astudillo, G.D.; Garza-Castañon, L.E.; Avila, L.I.M. Design and evaluation of a reliable low-cost atmospheric pollution station in urban environment. IEEE Access 2020, 8, 51129–51144. [Google Scholar] [CrossRef]
- Concas, F.; Mineraud, J.; Lagerspetz, E.; Varjonen, S.; Liu, X.; Puolamäki, K.; Nurmi, P.; Tarkoma, S. Low-cost outdoor air quality monitoring and sensor calibration: A survey and critical analysis. ACM Trans. Sens. Netw. (TOSN) 2021, 17, 1–44. [Google Scholar] [CrossRef]
- Ali, S.; Glass, T.; Parr, B.; Potgieter, J.; Alam, F. Low cost sensor with IoT LoRaWAN connectivity and machine learning-based calibration for air pollution monitoring. IEEE Trans. Instrum. Meas. 2020, 70, 1–11. [Google Scholar] [CrossRef]
- Becnel, T.; Tingey, K.; Whitaker, J.; Sayahi, T.; Lê, K.; Goffin, P.; Butterfield, A.; Kelly, K.; Gaillardon, P.E. A distributed low-cost pollution monitoring platform. IEEE Internet Things J. 2019, 6, 10738–10748. [Google Scholar] [CrossRef]
- Chowdhury, M.R.; De, S.; Shukla, N.K.; Biswas, R.N. Energy-efficient air pollution monitoring with optimum duty-cycling on a sensor hub. In Proceedings of the 2018 Twenty Fourth National Conference on Communications (NCC), Hyderabad, India, 25–28 February 2018; pp. 1–6. [Google Scholar]
- Espinosa, G.R.; Montrucchio, B.; Giusto, E.; Rebaudengo, M. Low-cost PM Sensor Behaviour Based on Duty-Cycle Analysis. In Proceedings of the 2021 26th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vasteras, Sweden, 7–10 September 2021; pp. 1–8. [Google Scholar]
- Fekih, M.A.; Bechkit, W.; Rivano, H. On the Data Analysis of Participatory Air Pollution Monitoring Using Low-cost Sensors. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), Athens, Greece, 5–8 September 2021; pp. 1–7. [Google Scholar]
- Chiavassa, P.; Gandino, F.; Giusto, E. An investigation on duty-cycle for particulate matter monitoring with light-scattering sensors. In Proceedings of the 2021 6th International Conference on Smart and Sustainable Technologies (SpliTech), Split & Bol, Croatia, 8–11 September 2021; pp. 1–6. [Google Scholar]
- Rebeiro-Hargrave, A.; Fung, P.L.; Varjonen, S.; Huertas, A.; Sillanpaa, S.; Luoma, K.; Hussein, T.; Petäjä, T.; Timonen, H.; Limo, J.; et al. City wide participatory sensing of air quality. Front. Environ. Sci. 2021, 587. [Google Scholar] [CrossRef]
- Williams, D.E. Low Cost Sensor Networks: How Do We Know the Data Are Reliable? ACS Sens. 2019, 4, 2558–2565. [Google Scholar] [CrossRef] [Green Version]
- Spinelle, L.; Gerboles, M.; Villani, M.G.; Aleixandre, M.; Bonavitacola, F. Field calibration of a cluster of low-cost commercially available sensors for air quality monitoring. Part B: NO, CO and CO2. Sens. Actuators B Chem. 2017, 238, 706–715. [Google Scholar] [CrossRef]
- Esposito, E.; De Vito, S.; Salvato, M.; Fattoruso, G.; Di Francia, G. Computational intelligence for smart air quality monitors calibration. In Proceedings of the International Conference on Computational Science and Its Applications, Trieste, Italy, 3–6 July 2017; pp. 443–454. [Google Scholar]
- Zaidan, M.A.; Motlagh, N.H.; Fung, P.L.; Lu, D.; Timonen, H.; Kuula, J.; Niemi, J.V.; Tarkoma, S.; Petäjä, T.; Kulmala, M.; et al. Intelligent calibration and virtual sensing for integrated low-cost air quality sensors. IEEE Sens. J. 2020, 20, 13638–13652. [Google Scholar] [CrossRef]
- Ferrer-Cid, P.; Barcelo-Ordinas, J.M.; Garcia-Vidal, J.; Ripoll, A.; Viana, M. Multi-sensor data fusion calibration in IoT air pollution platforms. IEEE Internet Things J. 2020, 7, 3124–3132. [Google Scholar] [CrossRef]
- Munir, S.; Mayfield, M.; Coca, D.; Jubb, S.A.; Osammor, O. Analysing the performance of low-cost air quality sensors, their drivers, relative benefits and calibration in cities—A case study in Sheffield. Environ. Monit. Assess. 2019, 191, 94. [Google Scholar] [CrossRef] [Green Version]
- Cui, H.; Zhang, L.; Li, W.; Yuan, Z.; Wu, M.; Wang, C.; Ma, J.; Li, Y. A new calibration system for low-cost Sensor Network in air pollution monitoring. Atmos. Pollut. Res. 2021, 12, 101049. [Google Scholar] [CrossRef]
- Sahu, R.; Nagal, A.; Dixit, K.K.; Unnibhavi, H.; Mantravadi, S.; Nair, S.; Simmhan, Y.; Mishra, B.; Zele, R.; Sutaria, R.; et al. Robust statistical calibration and characterization of portable low-cost air quality monitoring sensors to quantify real-time O3 and NO2 concentrations in diverse environments. Atmos. Meas. Tech. 2021, 14, 37–52. [Google Scholar] [CrossRef]
- Support Circuits (PPB): ISB Individual Sensor Board Datasheet. Available online: https://www.alphasense.com/products/support-circuits-air/ (accessed on 20 November 2021).
- Alphasense OX-B431 Sensor Datasheet. Available online: https://www.alphasense.com/products/ozone/ (accessed on 20 November 2021).
- Alphasense NO2-B43F Sensor Datasheet. Available online: https://www.alphasense.com/products/nitrogen-dioxide/ (accessed on 20 November 2021).
- Alphasense NO-B4 Sensor Datasheet. Available online: https://www.alphasense.com/products/nitric-oxide-safety/ (accessed on 20 November 2021).
- Reference Station Data Website of the Regional Government of Catalonia, Spain. Available online: https://mediambient.gencat.cat/es/05_ambits_dactuacio/atmosfera/qualitat_de_laire/vols-saber-que-respires/descarrega-de-dades/descarrega-dades-automatiques/index.html (accessed on 20 November 2021).
- Zenodo’s Captor Data Website. Available online: https://zenodo.org/record/5770589 (accessed on 20 November 2021).
- Marathe, S.; Nambi, A.; Swaminathan, M.; Sutaria, R. CurrentSense: A novel approach for fault and drift detection in environmental IoT sensors. In Proceedings of the International Conference on Internet-of-Things Design and Implementation, Charlottesvle, VA, USA, 18–21 May 2021; pp. 93–105. [Google Scholar]
- Sun, L.; Westerdahl, D.; Ning, Z. Development and evaluation of a novel and cost-effective approach for low-cost NO2 sensor drift correction. Sensors 2017, 17, 1916. [Google Scholar] [CrossRef]
- Ferrer-Cid, P.; Barcelo-Ordinas, J.M.; Garcia-Vidal, J. Volterra Graph-Based Outlier Detection for Air Pollution Sensor Networks. IEEE Trans. Netw. Sci. Eng. 2022. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Pollutants | Sampling Period () |
|---|---|---|
| Mijling et al. [7] | NO | 1 min |
| Sahu et al. [31] | O, NO | 1 min |
| Ali et al. [17] | CO, NO, PM | 1 min |
| Becnel et al. [18] | CO, NO, PM PM, PM | 1 min |
| Nowack et al. [9] | NO, PM | 30 s |
| Bigi et al. [10] | NO, NO | 20 s |
| De Vito et al. [11] | NO, O, NO | 20 s |
| Si et al. [12] | PM | 6 s |
| Mead et al. [13] | NO | 5 s |
| Han et al. [14] | O, NO, CO, SO | 2 s |
| Mead et al. [13] | CO, NO | 1 s |
| Astudillo et al. [15] | O, CO | 1 s |
| Node Label | Sensor | Deployment Period | |
|---|---|---|---|
| 20001 | O | 2021/01/15–2021/05/15 | 2 s |
| NO | 2021/01/15–2021/05/15 | 2 s | |
| NO | 2021/01/15–2021/05/15 | 2 s | |
| 20002 | O | 2021/01/15–2021/05/15 | 2 s |
| NO | 2021/01/15–2021/05/15 | 2 s |
| Parameter | Definition |
|---|---|
| Required time to take a sensor measure | |
| Sensing node sampling period | |
| Number of samples taken every sampling period | |
| Sensor response time before valid measurements | |
| Reference data period | |
| DC | Sampling strategy duty cycle |
| Time the microcontroller is switched on to collect sensor samples |
| Target Sensor | Best Subset |
|---|---|
| O | O, NO, T, and RH |
| NO | NO, O, T, and RH |
| NO | NO, O, T, and RH |
| Sensor | DC = 1.00 | DC = 0.10 | DC = 0.03 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MLR | KNN | SVR | MLR | KNN | SVR | MLR | KNN | SVR | |
| 20001 O | 0.97 | 0.96 | 0.98 | 0.95 | 0.94 | 0.96 | 0.87 | 0.86 | 0.88 |
| 20001 NO | 0.94 | 0.94 | 0.96 | 0.89 | 0.90 | 0.92 | 0.75 | 0.77 | 0.78 |
| 20001 NO | 0.90 | 0.95 | 0.97 | 0.82 | 0.89 | 0.90 | 0.56 | 0.66 | 0.60 |
| 20002 O | 0.97 | 0.96 | 0.98 | 0.94 | 0.93 | 0.95 | 0.84 | 0.84 | 0.85 |
| 20002 NO | 0.92 | 0.92 | 0.94 | 0.88 | 0.89 | 0.91 | 0.74 | 0.76 | 0.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferrer-Cid, P.; Garcia-Calvete, J.; Main-Nadal, A.; Ye, Z.; Barcelo-Ordinas, J.M.; Garcia-Vidal, J. Sampling Trade-Offs in Duty-Cycled Systems for Air Quality Low-Cost Sensors. Sensors 2022, 22, 3964. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103964
Ferrer-Cid P, Garcia-Calvete J, Main-Nadal A, Ye Z, Barcelo-Ordinas JM, Garcia-Vidal J. Sampling Trade-Offs in Duty-Cycled Systems for Air Quality Low-Cost Sensors. Sensors. 2022; 22(10):3964. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103964
Chicago/Turabian StyleFerrer-Cid, Pau, Julio Garcia-Calvete, Aina Main-Nadal, Zhe Ye, Jose M. Barcelo-Ordinas, and Jorge Garcia-Vidal. 2022. "Sampling Trade-Offs in Duty-Cycled Systems for Air Quality Low-Cost Sensors" Sensors 22, no. 10: 3964. https://0-doi-org.brum.beds.ac.uk/10.3390/s22103964