1. Introduction
Studies of nutrition and physical activity behaviour in the past decade have recognised the importance of the environment in understanding health and health related behaviour [
1,
2,
3,
4]. Within nutritional research, an increased focus has been placed on measuring the impact of the food environment on health outcomes such as Body Mass Index (BMI) [
5,
6,
7,
8], body weight [
9,
10], obesity [
11,
12] and diet [
3,
10,
13]. The environmental exposure is often conceptualised through and measured within neighbourhoods. However, the spatial extent of neighbourhoods has proven difficult for researchers to define, and the result is a great variation in the definitions of neighbourhood used to study the environmental exposure [
2].
The method used to define a neighbourhood is essential for researchers to ensure that measured exposure reaches optimal agreement with the actual exposure. However, for researchers to achieve this result, they must scrutinise the behaviour carefully to fully understand the phenomenon. The way a neighbourhood is defined should reflect the context of its application [
14]. Therefore, when measuring the food environment, researchers must make qualified assumptions about where people shop or dine, the distance people are willing to travel for shopping or dining and other individual preferences [
2].
Applying neighbourhoods to measuring food exposure creates a manageable concept to analyse the effect of the exposure. However, variations in neighbourhood definitions indicate that not all definitions manage to conceive and measure the actual exposure equally well [
3,
15]. Giles-Corti
et al. found little agreement among previous studies on the appropriate distance from home, work or school to search for a relationship to physical activity [
16]. A study in Seattle found that 49% of participants had greater exposure to supermarkets outside their home neighbourhood [
17]. Similar results were found in Minnesota, where the participants had more than twice the exposure at work than at home [
11].
That defining neighbourhoods presents challenges seems evident, and several studies appear to agree on several suggested challenges [
9,
15,
18,
19,
20]. Ball
et al. [
1] explain that (1) people live and function in multiple contexts and settings; (2) people live and work in multiple geographic areas; and (3) different types of environmental influences exist, including built, natural, social, cultural and policy environments. Consequently, methods used for defining neighbourhoods must comply with individual behavioural characteristics. Focus on the individual is conceptualised by Rainham
et al. through the change from a place-based to a people-based perspective with individual-based measures [
21].
Previous studies reveal numerous examples that contradict the people-based approach through application of administrative divisions as the spatial extent for a neighbourhood [
18,
22]. Census tracts [
23,
24,
25,
26], zip codes [
22] or parishes are used as a spatial representation of a neighbourhood for analysis of exposure to the food environment.
Neighbourhoods based on buffers also rely strongly on the location of the home but also offer an individual measurement. However, the difference is small for people living close to one another. The buffer method is widely used [
16] to create neighbourhood definitions for residences [
5,
9,
24,
27], schools [
13,
28,
29,
30,
31,
32,
33] and work locations [
9]. The buffer distances and methods varies between fixed distances or a travel time constraint and either Euclidian or network distances [
27].
Administrative divisions and buffers applied to the residential location adhere to a conceptual and analytic platform, where place is the central element in studying human behaviour. From the place-based perspective, all behaviour is located and centralised around the home. The importance of people’s closeness and sense of belonging to a certain community and place is challenged by today’s society. No matter what one believes, human mobility has increased substantially in the last century, and connectivity now makes activities and places more dynamic.
The problem is that each individual is unique and consequently must be assumed to have their own concept of neighbourhood. Complexity and heterogeneity of human mobility no longer appear to correspond to the use of residential neighbourhoods. Exposure to the food environment occurs in multiple environments, but to measure the impact of people’s individual exposure in multiple environments is challenging.
Technologies for tracking individuals’ behaviour have been available for more than a decade. However, development of lightweight, low-cost and accurate Global Position System (GPS) devices and assisted GPS in smartphones has boosted the use of tracking within behavioural nutrition research. GPS provides an individual measurement of space-time information about people’s behaviour. The outcome of GPS tracking can potentially consist of millions of data entries, which must be handled and conceptualised to resemble a neighbourhood. Common methods for simplifying neighbourhoods (or activity spaces) from GPS data are standard deviational ellipses (SD ellipses) and home range (minimum convex polygon) [
21,
34]. The derived activity spaces are individual and not dependent on a fixed location. Commuting routes and leisure time activities are therefore also included.
Although many studies utilise neighbourhood as a concept, few studies explore how neighbourhoods are defined or which definition is most suitable for the study. A variety of neighbourhood definitions are applied in relation to measuring the impact of the food environment.
Therefore, the aims of this study are (1) to compare different definitions of neighbourhoods for analysis of exposure to healthy/unhealthy food options, where supermarket exposure is perceived to be healthy and fast food exposure to be unhealthy; (2) to investigate the differences in neighbourhood area size and in the number of food outlets by type within neighbourhoods; and (3) to discuss the influence of the neighbourhood definition on the measure of exposure.
2. Methods
2.1. Study Area and Sample
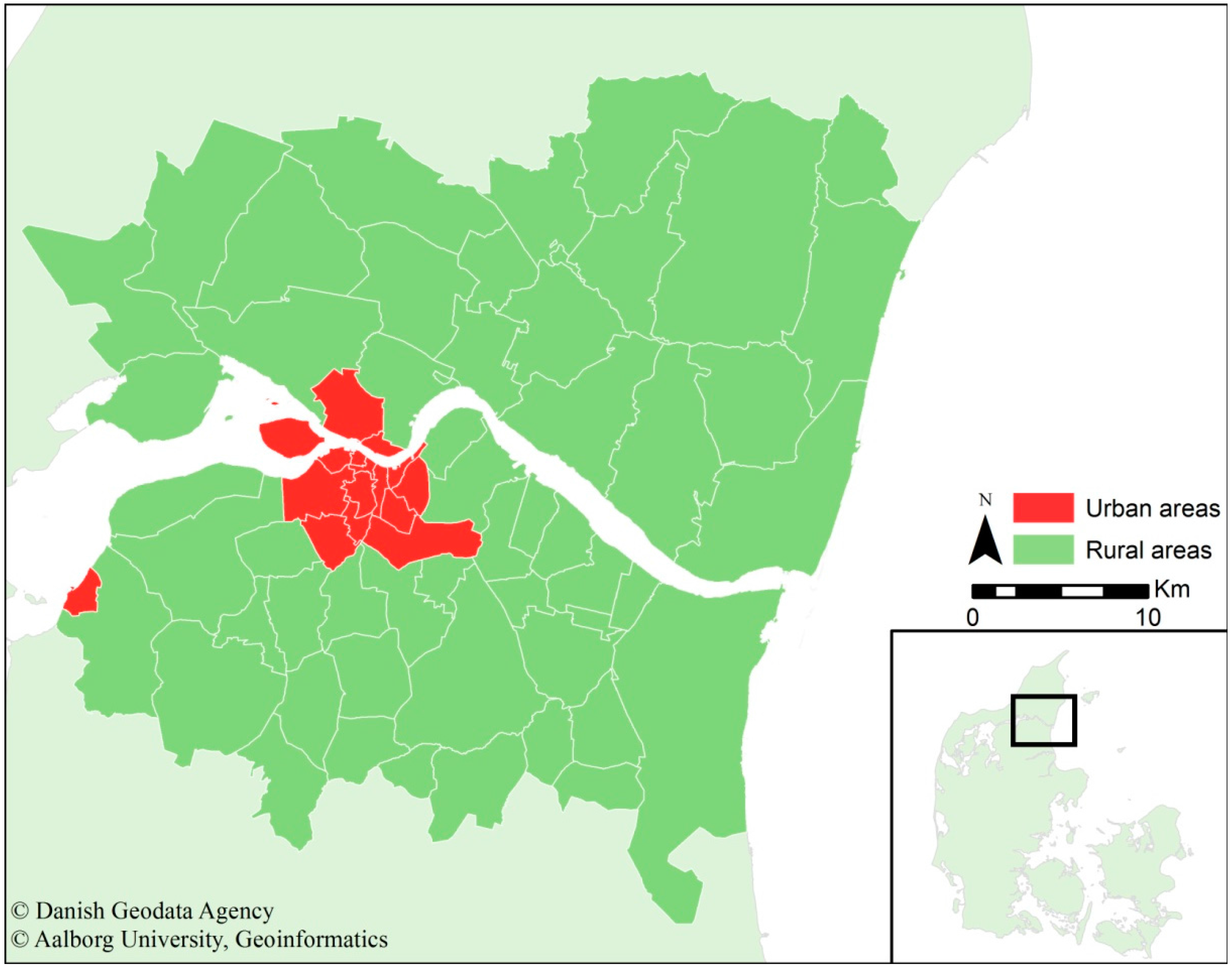
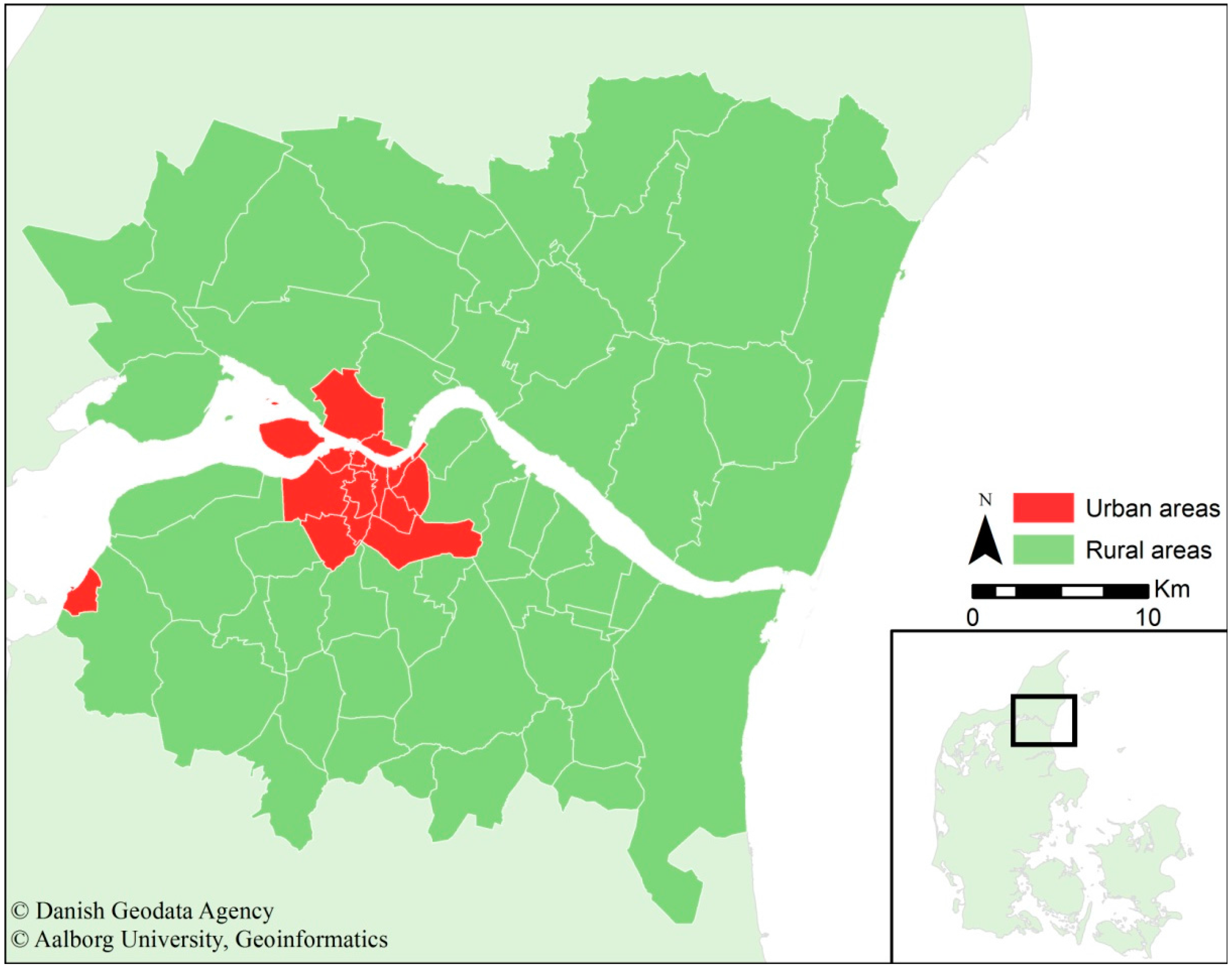
The study area consists of 65 parishes (15 urban and 50 rural) in Northern Jutland (Denmark) centralised around Aalborg as the largest city in the region. The population in the study area is approximately 230,000, and of that number, approximately 120,000 live in Aalborg. The study area is approximately 1552 km
2, of which Aalborg, with its high-density housing (mean ≈ 1700 people/km
2) only comprises 68.3 km
2 (≈4.4%). The remaining areas consists of small villages with populations up to 7000 and low-density housing (mean ≈ 85 people/km
2). The study area’s spatial extent, relative location in Denmark and the divide in urban and rural areas are presented in
Figure 1. Northern Jutland consists of 11 municipalities, five of which are defined as peripheral regions. Peripheral regions are characterised by, among other factors, a lower average income than the national average, a lower amount of commuting traffic and low or negative population growth. However, Aalborg attracts many young people and is the economic centre of the region. In Northern Jutland, approximately 50% of all people aged 16 to 25 lives in Aalborg, whereas these people are only approximately 17% of the entire population.
Figure 1.
Presentation of the study area, the relative location in Denmark and the division between urban and rural areas.
Figure 1.
Presentation of the study area, the relative location in Denmark and the division between urban and rural areas.
The study involves a random sample of 223 people selected from a population of 7277 people enrolled in school in Aalborg. Respondents were distributed between six school locations. The sample has a higher proportion of female (57%) than male (43%) participants. The participants’ ages range from 16 to 23 years old, with an average age of 17.7 years. Each person was tracked by the Global Positioning System (GPS) for one week of their typical school schedule. The GPS devices used in this study are the Lommy Phoenix and are approximately the same size as a mobile phone. The participants were asked to carry the device at all possible times during the week. All subjects provided their informed consent for inclusion before they participated in the study and could opt out at any time by turning off the GPS device. The tracking resulted in 8.22 million records for the 223 participants. The number of loggings registered for each person varied from 579 to 128,679, with an average of 36,523.
A threshold of 30 h (equal to waking hours for two days) of tracking was set as a minimum for the participants to be included in the study. The final sample consists of 187 people (36 were excluded). The final sample population includes 110 women (58.8%) and 77 men (41.2%) from 16 to 23 years old (the mean age is 17.3 years old). The final sample includes 93 people who live in a rural area and 94 people who live in an urban area.
2.2. GPS Data Preparation
GPS tracking is subject to several technical limitations when measuring space-time data [
19,
35]. Connection to an adequate amount of satellites is critical because lack of such a connection can result in inaccurate position data or complete loss of data for a period. The errors can be categorised as (1) outliers, either in attribute values for number of satellites, horizontal delusion of precision (HDOP) and time to fix (TTF), or extreme positions (e.g., on equator); or (2) scatter, in the form of unnatural linear point patterns [
35]. The unnatural linear point patterns are detected by little or no change in the direction between three or more subsequent loggings, and the location of these loggings are outside a 50 m buffer on the road network. Detection of outliers and scatter found 341,741 loggings that were perceived as erroneous data.
The GPS devices were set to register the location at 7 s intervals, which was the lowest interval possible for the devices used. However, due to external conditions (i.e., visibility to satellites and time to establish a fix), the logging interval varies up to 60 s. Calculation of several neighbourhood definitions assumes an even time interval between loggings (e.g., SD ellipses) because they are based on statistical assumptions. Spatial linear interpolation between subsequent loggings was applied to create an even time interval of 1 s between each logging. However, a 60 s threshold is set because the GPS creates a duplicate of the previous logging if it cannot obtain three consecutive measurements with a HDOP less than 30 in 60 s. The consequence can be large time leaps, for which it is difficult to estimate or guess the location. The interpolation results in a data set consisting of 60.18 million loggings, which corresponds to an average of three days and 17.4 h of active tracking for each participant.
2.3. Neighbourhood Definitions
2.3.1. Administrative Divisions
Division of the land into smaller areas is used administratively on several levels in most countries, and previous studies refer to census tracts and zip codes used for spatial analysis. The purposes of the administrative division vary, but none were created for research purposes. The consequence of using administrative divisions as measures of exposure to the food environment implies that all individuals within these divisions will be exposed solely to the food outlets within those boundaries. Thus, it relies on people to have a strong residential connection.
This study uses parishes because they are the smallest official administrative division in Denmark. The area size of parishes within the study varies from 0.65 to 110.49 km2 (mean = 23.85 km2), the population ranges from 98 to 12,544 people and the population density varies from 14.39 to 9097 people/km2. People were assigned to the parish in which their residence is located.
2.3.2. Buffers
Buffers are used to create a circular area at a specified distance, and they are quick to calculate, easy to understand and easy to compare because the area size is equal for all study subjects. Simple buffers are based on Euclidian distances, whereas buffers that are more complex are based on network analysis. The buffer distance should be appropriate for examining nutrition-related behaviours for the target group involved. Little agreement exists on the appropriate distance, and multiple distances are applied in research [
16]. This study applies two distances for defining the buffer size. A distance of 800 m was selected because it is approximately equal to a 10 min walk (5 km/h). Second, a distance of 1600 m (≈1 mile) was selected because it is frequently used in other studies [
5,
9,
13,
16,
24,
28,
29,
32]. A study of adults in England demonstrated that more than 95% of usual walking destinations were within 1600 m of the home [
36]. This study calculates buffers on the home and school addresses. A third neighbourhood definition is defined by combining the buffers for home and school.
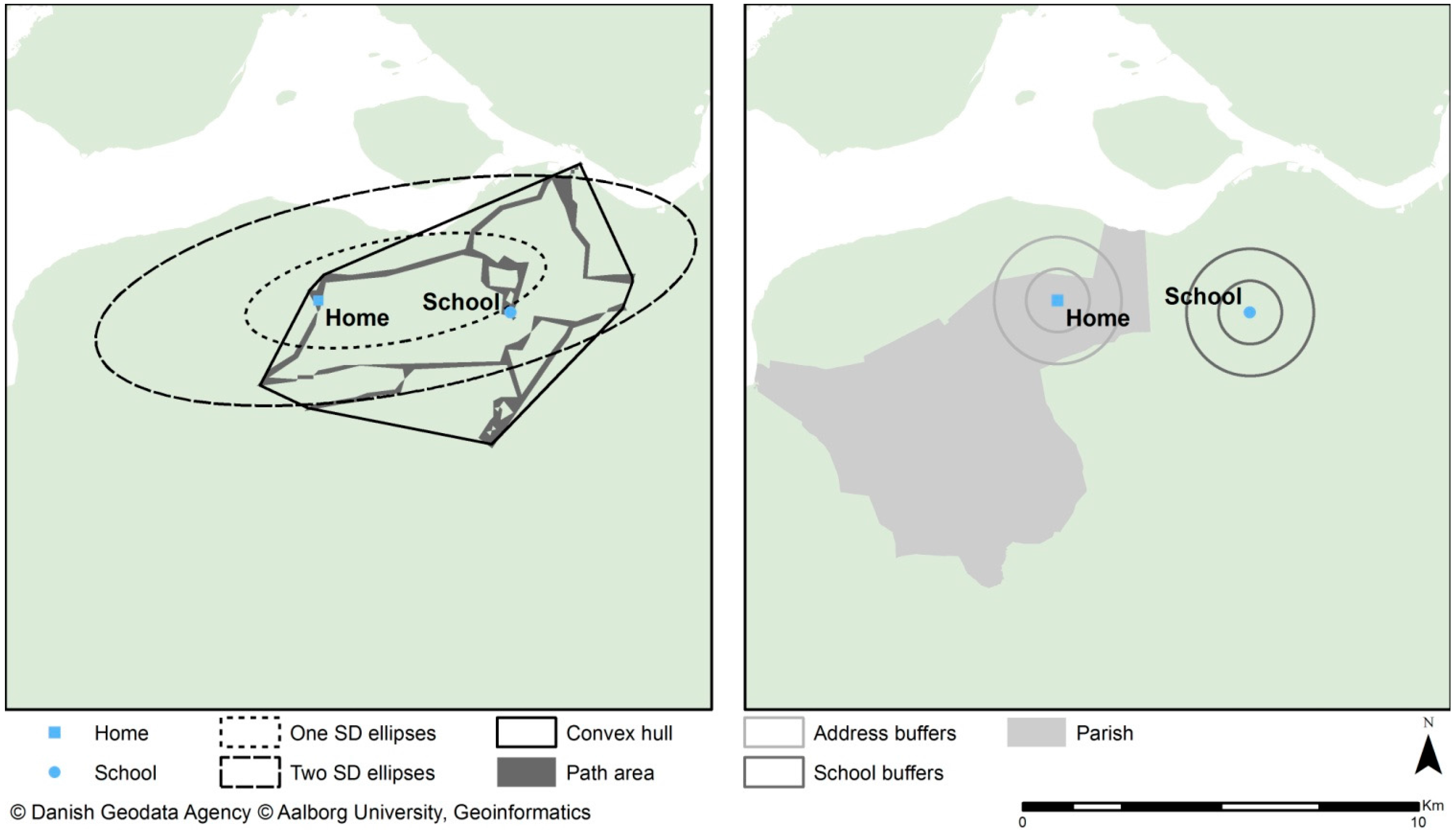
2.3.3. Convex Hull (Minimum Bounding Geometry)
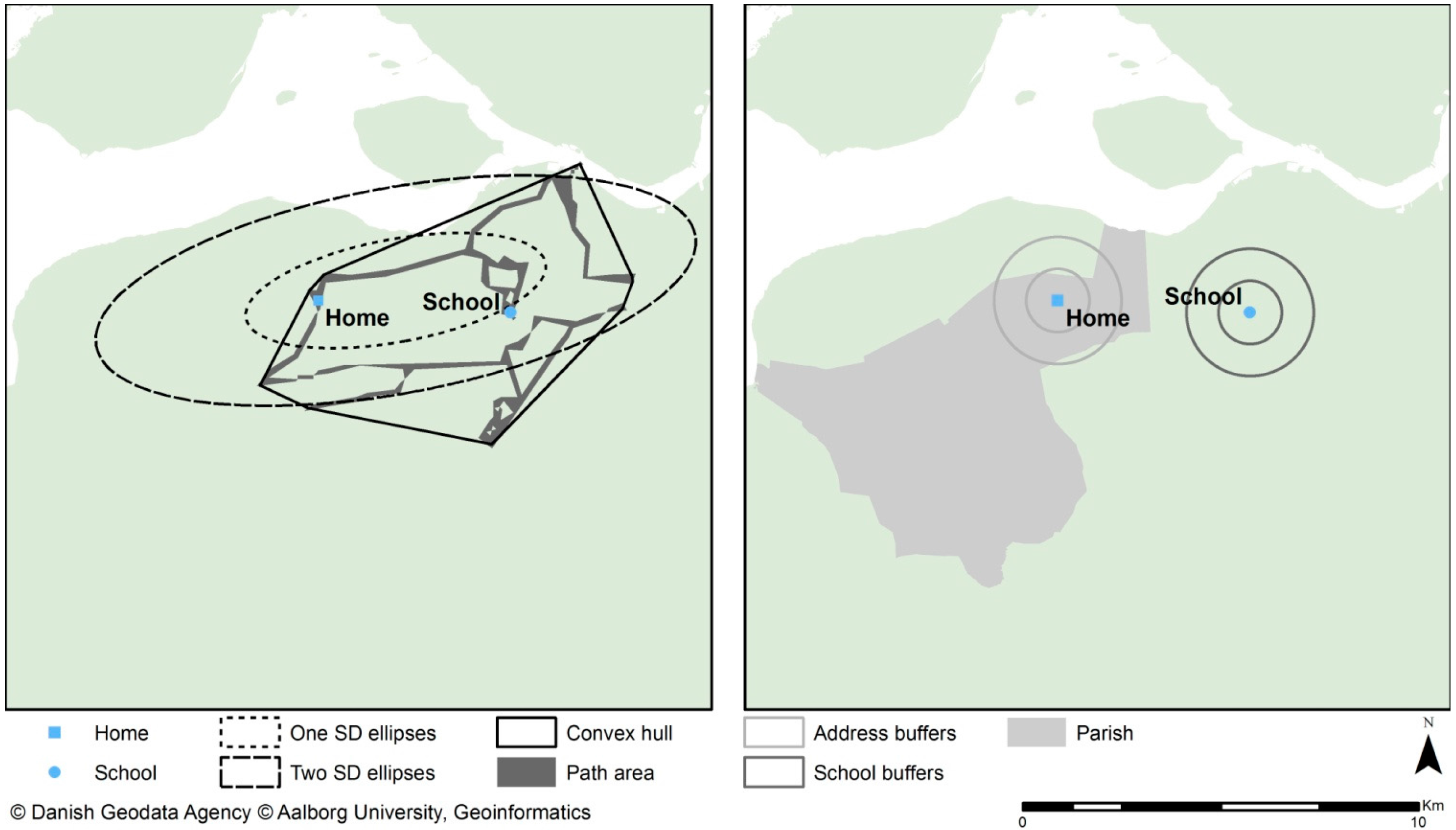
The convex hull area is created to represent the minimum bounding geometry enclosing all the GPS loggings for each individual. The convex hull represents the maximum area in which the individuals engaged in activities.
2.3.4. Standard Deviational Ellipses
The standard deviational (SD) ellipses are created by calculating the standard deviation in the x-coordinates and y-coordinates from the mean centre of the coordinates. The ellipses do not represent the maximum area in which the individual could engage in activities but rather the area in which the individual is likely to be regularly involved in activities. This study applies one and two SD ellipses, which implies that approximately 68% and 95% or more of the GPS loggings are positioned within the one or two SDs, respectively. The position of each GPS logging is a weight in calculating the ellipses extent. The GPS loggings therefore must represent an individual’s whereabouts, which is performed through interpolation on the space-time data.
2.3.5. Path Area
The GPS loggings are used to create the path area represents the participants’ travel patterns. For each GPS logging, the nearest road or path segment was determined through a near analysis. On the road and path segments, a 50 m buffer was applied. The buffer is needed to capture the exposure to food outlets, for which spatial location often has an offset of 5–30 m from roads.
Figure 2 presents a spatial comparison of the neighbourhood definitions.
Figure 2.
Visual representation of neighbourhood spatial extent and definition.
Figure 2.
Visual representation of neighbourhood spatial extent and definition.
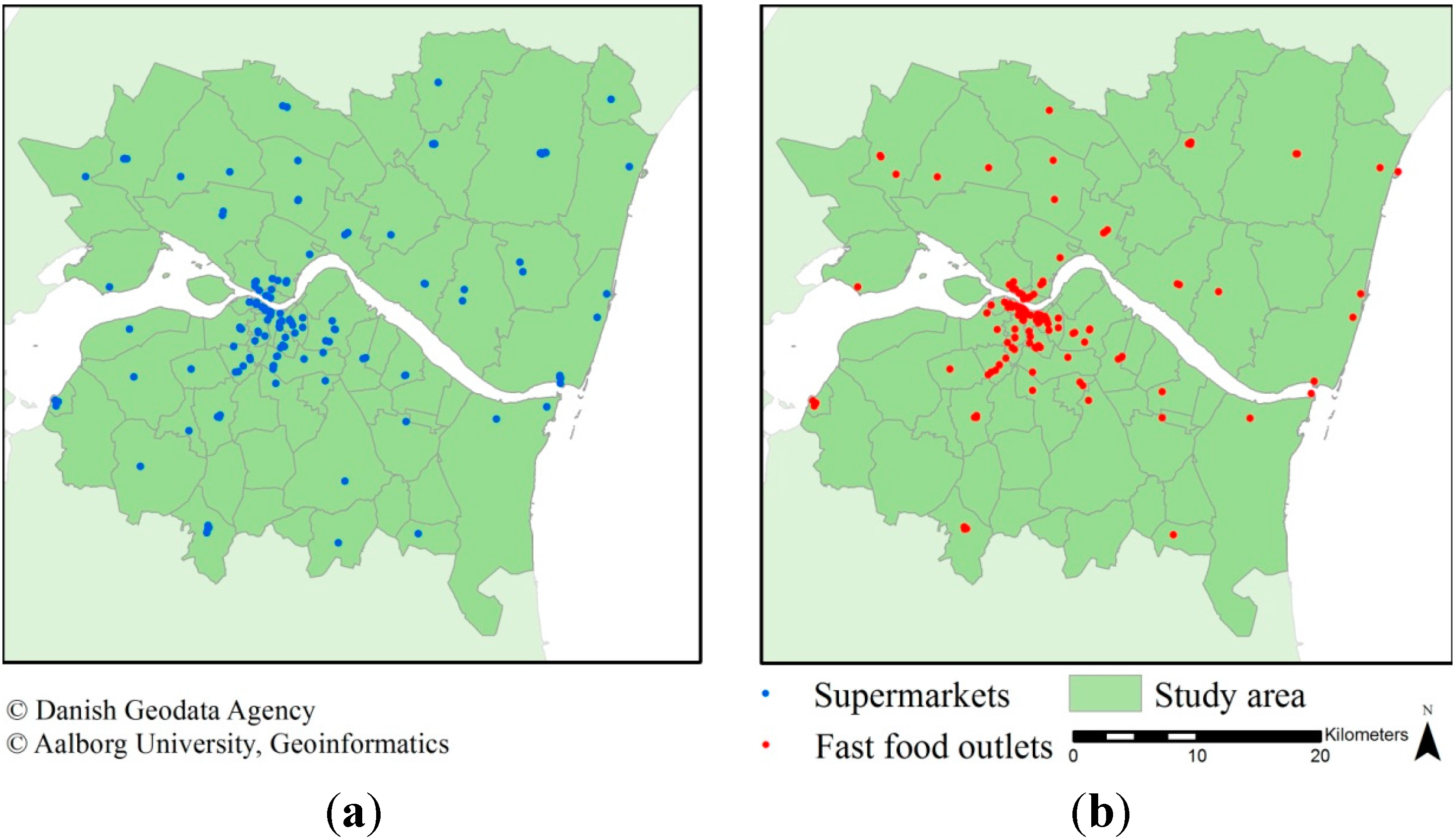
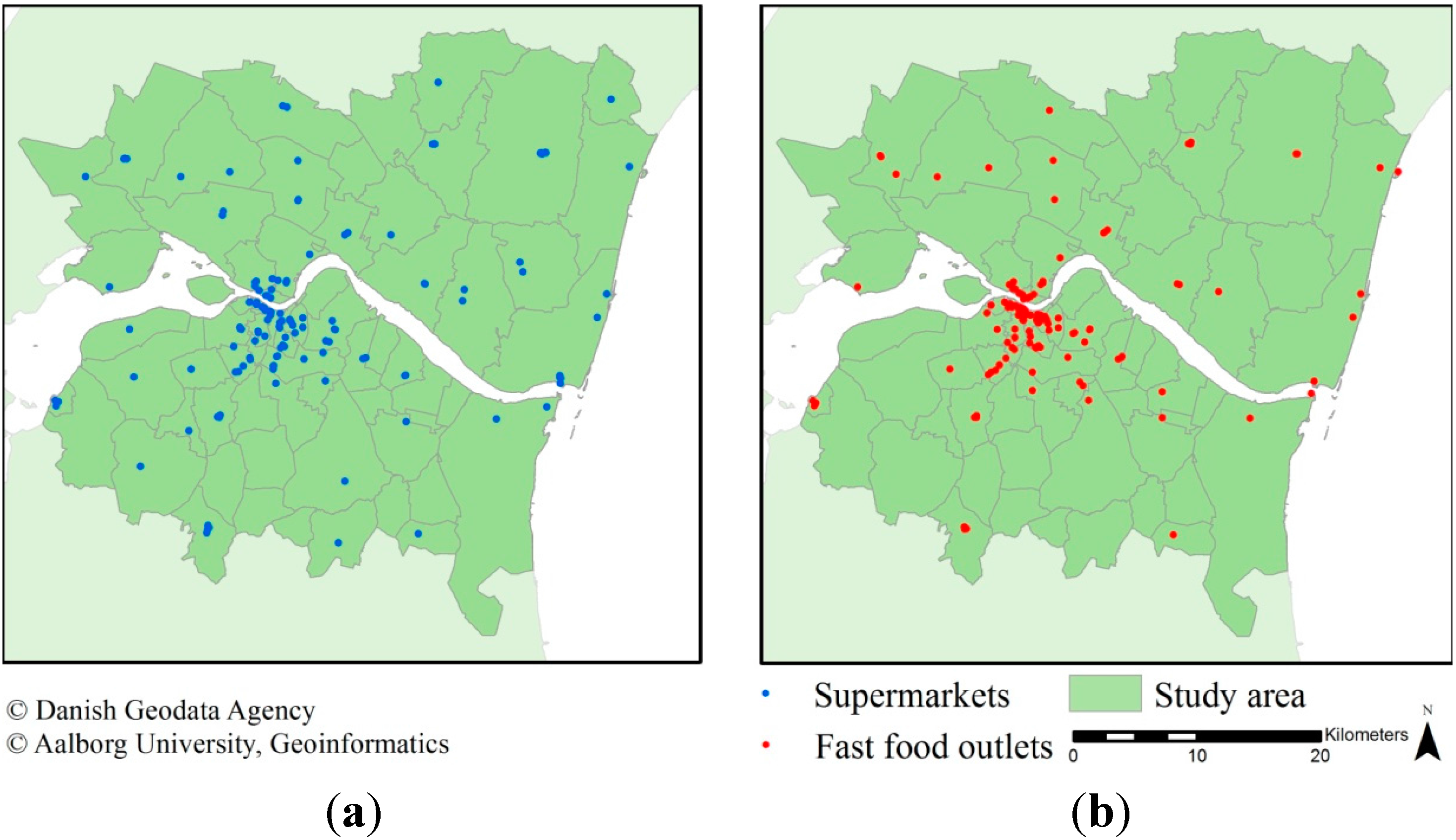
2.4. Food Outlet Data
Data on fast food outlets and supermarkets were retrieved from the national business register (CVR) and the national food safety and hygiene regulation register (Smiley). The spatial and semantic validity has been described in previous research [
37]. A pre-classification method of the business type based on the outlets name was applied as described in [
37]. This resulted in 144 supermarkets (including discount) and 154 fast food outlets in the study area. The addresses in CVR were geocoded based on address reference data in the Universal Transverse Mercator (UTM) projection obtained from the Danish Geodata Agency. The Smiley register contains World Geodetic System 84 (WGS84) coordinates for approximately 95% of entries, which were transformed into UTM and used as their locations. The remaining records are geocoded by the address using reference data from the Danish Geodata Agency. The distribution of the supermarkets and fast food outlets is depicted in
Figure 3.
Figure 3.
The spatial distribution of (a) supermarkets; and (b) fast food outlets within the study area.
Figure 3.
The spatial distribution of (a) supermarkets; and (b) fast food outlets within the study area.
2.5. Statistical Analysis
This study compares the mean values for food outlets exposure in each neighbourhood to analyse differences. Consequently, the null hypothesis is that any difference between the groups is a result of sampling error, and the actual differences between the means are effectively zero. The Welch two-sample t-test is applied to compare two groups, and the one-way ANOVA (F-test) is applied for comparing three or more groups.
One-way ANOVA assumes that the data are sampled from populations that follow a Gaussian distribution. Although this assumption is not very important with large samples, it is important with small sample sizes and particularly with unequal sample sizes. One-way ANOVA assumes that all the groups have the same standard deviation. This assumption is not very important when all the groups have the same or almost the same number of individuals. The sample sizes in this study are equal for all one-way ANOVA tests.
The one-way ANOVA compares several groups but does not inform about groups having significantly different means. The differences between groups might be due to errors in the sampling whereas others might not be. Therefore, a post hoc comparison test is conducted to examine the differences between pairs of each of the neighbourhood types. This identifies pairs of neighbourhoods that have significantly large differences, which are not the result of sampling errors. This is calculated using Tukey’s HSD (honest significant difference) test. Tukey’s HSD test is weak, meaning it is less likely to detect significant results. The test assumes normality for each group of data, the observations are independent within and among groups and there is homogeneity of variance. The test is quite robust to violations of normality and to some extent violations of homogeneity of variance for large samples. Tukey’s HSD test requires previous calculation of one-way ANOVA and is calculated using Equation (1).
M1 and
M2 are the means of the neighbourhood groups,
MSw is the mean square within groups from the one-way ANOVA and
n is the number per group.
The Welch
t-test is used to test the hypothesis that two independent or unpaired groups of data have equal means. The test is an adaption of the students’
t-test, but it is used when the variance possibly is unequal. The test compares urban and rural samples, which are non-overlapping. The test assumes the data are independent. The Welch
t-test is calculated using Equation (2), where
is the group means,
Si is the group variance and
Ni is the group sample size.
All statistical analyses are calculated using R [
38].
4. Discussion
4.1. Place Based vs. People Based Neighbourhood Definitions
The understanding of place as a concept stretches from the individual adhering to their own unique place determined by their everyday life and behaviour to the claim that the individual unconsciously relates their behaviour and choices to more structured patterns based on social and physical environment characteristics [
2]. However, often the discussion about place is ignored due to pragmatic considerations, such as data only being accessible in administrative units. Administrative divisions as the concept for place are therefore often the natural choice for many researchers without considering the administrative divisions’ ability to encapsulate the relevant behaviour. The consequence is a wrong assumption or generalisation that all individuals have equal behaviour patterns, limiting the exposure to a confined area and limiting diversity in food supply choices.
This study reveals that the administrative divisions are not a suitable neighbourhood type to capture the measured behaviour. This finding is supported by the fact that only 12.8% (24 of 187) of the participants attend school in their residential parish, and the exposures to supermarkets and fast food outlets around the schools are more than three and six times higher, respectively, than in the parishes. This fact coincides with previous studies that found similar relationships between exposures near home and school [
11,
15,
17]. However, the differences between home and school neighbourhoods are significantly more distinctive for participants living in a rural area and attending schools in urban areas.
The place-based neighbourhood definitions do not take into account the diversity in individual behaviour. This problem is most likely the result of assuming people carry out most of their activities in their residential location, which is contradicted by the high mobility in the participant sample. The participants in this study are young adults, and most have a high mobility level even without the ability to drive a car. The participant’s mobility must be taken into account because it weakens the influence of residential neighbourhoods. However, other studies with low mobility group samples, such as the elderly and the disadvantaged people, are probably more sensitive to the residential neighbourhood exposure [
20].
The use of the term neighbourhood in food environment research adheres to spaces defined by fixed boundaries, such as administrative units, or a fixed distance, such as buffers, that define a school or residential neighbourhood [
4]. When referring to individual-measured areas, a more appropriate term instead of neighbourhood is “activity spaces” as suggested by Zenk and colleagues [
39]. This division between terms can potentially improve researchers’ understanding of the differences between the place-based and person-based exposure measures.
Defining individual activity spaces is advantageous for providing increased specificity in a multiple space exposure measurement. However, as Ball and colleagues note, the collection of activity space attribute data can be time and labour intensive because the individual activity spaces do not align spatially with existing administrative divisions [
1]. The activity spaces defined by the individual’s behaviour most likely vary in area size, which increases the complexity of analysis when comparing different individuals’ exposure. Moreover, comparisons across different studies are very difficult if the activity spaces vary in area size. The equal size of neighbourhoods based on buffers makes them easier to compare between studies in different countries. However, the buffers are limited to a few locations, and as this study reveals, the buffers and the administrative divisions have similar problems in capturing exposure during commuting or leisure time activities. The researcher’s perception is that the use of multiple-location buffers provides a much better basis for measuring exposure than single-area buffers and administrative divisions. Applying buffers on either home or school only provides one piece in the complex puzzle of measuring the complete exposure. Many studies have limited the research area to a residential/school neighbourhood (for example, a 1 km buffer) [
5,
9,
13,
16,
24,
27,
28,
29,
30,
31,
32,
33] or administratively defined boundaries [
22,
23,
24,
25,
26]. The studies thereby only consider data inside the sample area of interest. Data in adjacent areas are not implemented, which could be problematic because the effect of exposure across study boundaries is not considered. Another problem with the buffer areas created is how to define a relevant distance since found associations may vary depending on this definition [
4]. To bypass these problems, researchers should consider measuring actual activity spaces, which is possible using GPS.
4.2. Implications for Research
The neighbourhoods’ ability to capture the activity measured by GPS varies, particularly for those neighbourhood types that are confined to one or two locations and enclose a smaller percentage of the measured activity. The parishes are typically more than eight times larger in area than the address 800 m buffer and two times the 1600 m buffer, but they enclose only 1% more and 2.5% less, respectively, of the measured activity. This finding indicates that most activity around the residential locations is tied very closely (within 800 m) to the home, whereas an enlargement of the residential neighbourhood to a 1600 m buffer or a parish has little effect on capturing more of the measured activity. Approximately 85% of the measured activities are near the home or school, but the final 15% poses a challenge for researchers to measure because it constitutes the behaviours that are most affected by individual preferences.
Individual characteristics as confounders are crucial to take into account personal preferences when analysing relationships between the food environment and health outcomes [
1,
2]. However, not all preferences can be adjusted through common confounders such as income, ethnicity and education level. Consequently, methods used for defining neighbourhoods must accommodate the individual behavioural characteristics [
20]. However, to achieve this effect, researchers must carefully scrutinise the behaviour to be measured to fully understand the phenomenon. The way a space is defined should reflect the context in which it is applied [
14]. Therefore, to measure the exposure to food environment, researchers must make qualified assumptions about where people shop, the distance they are willing to travel to shop and other individual preferences [
2]. Thus, paying attention to the individual is important when developing studies of the interaction between the population and the environment. As Larson and Story concluded, most food environment studies have methodological problems that reduce the credibility of their findings [
40]. Problems occur with assessing the physical access to food sources in the environment [
4] and linking access to a food source with food purchases and intake. Further analysis of individual behaviour could potentially be used to link the food source exposure to individual food purchasing through analysing movement and stop flows in space-time data.
The results of this study are consistent with several other studies [
1,
2,
15,
20,
21] advocating for more individual-based neighbourhood definitions taking into account multiple environments for exposure beyond home, school or work communities. Exposure during commuting time and leisure activities are particularly difficult to incorporate when the neighbourhoods are place based. Kwan further questions the use of arbitrary definitions of neighbourhoods instead of considering the actual spaces in which individuals’ exposure occur [
41]. The main objections to the static and administrative bounded spatial definitions in ecological exposure measures found in this study and accentuated by Kwan are: (1) the assumption that the residential neighbourhoods are the most relevant in affecting food exposure; and (2) individuals who live in the same spatial areas experience the same level of exposure, regardless of time spent in the area and residential locations within the area [
41]. The results from this study contradict the assumptions since individuals also spend a substantial time outside their residential neighbourhood, and the variance of individual activity space sizes illustrates the variety in individuals’ exposure.
Comparisons between urban and rural samples (t-tests) clearly reveal differences in exposure to supermarkets and fast food outlets in some neighbourhoods. Tukey’s HSD test similarly reveals that more neighbourhood types are significantly different in the rural sample than in the urban sample. Hence, a separation between urban and rural samples would create more homogenous samples. Individual activity spaces will vary depending on factors such as income, personal mobility (ability to drive, access to a vehicle, walking disabilities, etc.), age and other individual preferences. People living in rural areas are more likely to travel to a more populated area because these areas often provide greater access to work opportunities, food or cultural events, for example. On the other hand, urban residents are less likely to commute to rural areas, as their needs are mostly satisfied in the cities. The daily activity spaces of rural residents are presumably larger if they have no restrictions on their movement or travel abilities.
4.3. Limitations
The activity data measured by GPS clearly indicates that participants are using multiple locations and are thereby not restricted to their immediate residential environments. The survey period of one week is a short time frame for analysis of the participants’ behaviour. Short tracking periods could include locations, which might be visited infrequently and vice versa [
20]. This phenomenon is the shortcoming of GPS technologies because recording consecutive involvement at such a level for longer periods is difficult. The development of tracking technologies is a fast growing field, and technologies such as Bluetooth, Wi-Fi and cellular phone networks could potentially be used to track participants in a way that requires less involvement from the individuals [
42], mostly because all these technologies are included in most mobile phones today and therefore do not require participants to carry and maintain additional devices. The development of these technologies provides a promising improvement for empirical place research [
21].
This study used GPS devices set to measure at seven-second intervals, which was the minimum interval available between loggings. A seven-second interval between registrations is a short time and discharges the battery faster than at a higher interval. A low interval between registrations is preferable for some uses, but the logging interval could probably be 15 s or more to measure the extent of the activity spaces. However, some problems occur with a high registration frequency. Activity measured by GPS can experience periods with loss of data that interferes with the registration interval. Activity space measures as standard deviational ellipses are calculated from the centre of gravity of the measured point locations and uneven intervals between registrations therefore affect the extent of the calculated spaces. Several methods have been proposed for resolving this issue by estimating missing data [
39] or interpolation between registrations. Further, studies’ ability to measure individuals’ use of food retailers is dependent on a low interval between registrations. To detect stops at food retailers, several consecutive registrations at the same location are needed. Determining a maximum interval between registrations is difficult without further research, but a large interval between registrations results in a smaller dataset that is easier to analyse. Studies that apply GPS to measure activity must consider the accuracy required (interval between registrations) and the expected travel types and speed of participants.
The individual based neighbourhoods are better at capturing multiple space activity, but the measured exposure could be an exaggeration, which could be the case for the convex hull and two SD ellipses when compared to path area. The neighbourhood type convex hull has a large mean area size, particularly for the rural samples. Comparing convex hull with path area, which are both based on GPS tracking, reveals a 25% higher supermarket exposure for the convex hull neighbourhood type. However, if the area sizes for both neighbourhood types are used to adjust the exposure, then the exposure in path area is twice that of the convex hull. Path area is more focused on where the actual activity has occurred, but it does not capture deviant activities that would happen at other times than the single week when the activity was tracked. Therefore, whether the path area may underestimate the exposure remains unclear. To answer this question, researchers must delve into the understanding of people’s behaviour. Second, studying the relationship between measured exposure and the actual choices of food buying is relevant because this research could broaden the insight to defining a proper neighbourhood for measuring exposure to food outlets.
Any study of this type must use the appropriate spatial area to measure the exposure. However, many studies have applied place-based neighbourhoods with little focus on identifying these areas [
41]. Among the most discussed methodological issues in research applying spatial data is the Modifiable Area Unit Problem (MAUP). MAUP refers to the issue that the areal units to which data are assigned might influence results. Neighbourhoods based on administrative divisions or buffers are highly susceptible to the MAUP. The place-based neighbourhoods allow little variation between individuals compared to the person-based neighbourhoods (
Table 1). Large differences exist between individual activity spaces such as the convex hull and standard deviational ellipses where the standard deviation for each type of activity space is larger than the mean area size. This finding clearly indicates a large spread between individual activity spaces. Considering the actual spatial and temporal exposure would allow for a more accurate measure of exposure and address the MAUP [
41]. This result would allow individuals to have individual exposure measures although they live in the same neighbourhood.



{kind=link}
{kind=link}
{kind=link}