1. Introduction
A number of emergency department-based syndromic surveillance systems and early warning systems for early detection of adverse disease events have been implemented since the year 2000. Syndromic surveillance is defined as the ongoing systematic collection, analysis, and interpretation of “syndrome”-specific data for early detection of public health aberrations [
1]. The Korea Centers for Disease Control and Prevention (KCDC) has also implemented an emergency department-based syndromic surveillance system. The system was designed to identify illness clusters before diagnoses are confirmed and reported to public health agencies. The system is connected to a considerable number of emergency departments from 17 provinces and cities in Korea and has been used to monitor the daily status of five different syndromes.
The incidence of infectious disease has been growing in relation to population growth, density, and climate change [
2,
3]. Therefore, a number of statistical methodologies have been proposed for syndromic surveillance systems based on the collected historical time series data using a computer database system. These statistical methodologies can be classified into two major areas such as statistical detection and time series forecasting methods [
4,
5].
To design upgraded and enhanced functions of the system for the early warning of adverse disease events, we survey many suitable algorithms for syndromic surveillance, and analyze and evaluate some algorithms. According to our survey, the CUmulative SUM (CUSUM) [
6,
7] and the Early Aberration Reporting System (EARS) [
7] statistical detection approaches and the autoregressive integrated moving average (ARIMA) [
8] and Holt-Winters [
9,
10] time series forecasting approaches have been used in a large number of papers and applications.
Ronald et al. [
7] applied the CUSUM algorithm to adaptive regression residuals and compared it with EARS (C1, C2, and C3) based on a simulation data for syndromic surveillance. In their study, the CUSUM method with adaptive regression residuals showed better results than EARS. Recently, Gabriel et al. [
11] compared 21 statistical algorithms for temporal outbreak detection. However, these studies did not include time series forecasting methods.
Allard et al. [
5] and Reis et al. [
12] presented the integer-valued autoregressive (INAR) and ARIMA time series models for a syndromic surveillance system. Howard et al. [
13] compared three different time series models, namely the non-adaptive regression, adaptive regression, and Holt-Winters approaches utilizing real bio-surveillance time series.
Unfortunately, those studies did not compare both the statistical detection and time series forecasting algorithm categories. Therefore, the aim of this study is to define the advantages and disadvantages of these methods based on time series data on trends, seasonality, and random outbreaks.
In order to address the aforementioned issues, this paper carries out an experimental study based on simulated time series to evaluate state-of-the-art algorithms. In addition, it contributes a limited case of real-world data related to diarrhea infection. Towards achieving these goals, simulated time series data based on a negative binomial method which takes into account not only trends and seasonality, but also randomly occurring outbreaks were generated guided by the recent work of Angela et al. [
14]. On the other hand, because the methodologies considered in this study generally fall into two main categories (statistical and forecasting methods), different evaluation metrics were used.
Statistical detection methods are commonly evaluated using: true positive rate (sensitivity), true negative rate (specificity), positive predictive value (PPV), negative predictive value (NPV), and F1 score. In contrast, time series forecasting methods were mostly evaluated by the root-mean-square error (RMSE), mean absolute percentage error (MAPE) and mean absolute deviation (MAD). Therefore, this study used: PPV, NPV, F1 score, a “symmetric” mean absolute percentage error (sMAPE), RMSE, and MAD.
This paper is organized as follows. We briefly present a description of the evaluation framework, selected methods, and evaluation metrics used to compare the algorithms in
Section 2.
Section 3 presents the process of simulating the data and evaluating the experimental results. Finally,
Section 4 concludes the experimental result and comparison, as well as discussing the advantages and disadvantages of the selected methods.
2. Methods and Materials
2.1. Outbreak Detection Algorithms and Evaluation Metrics
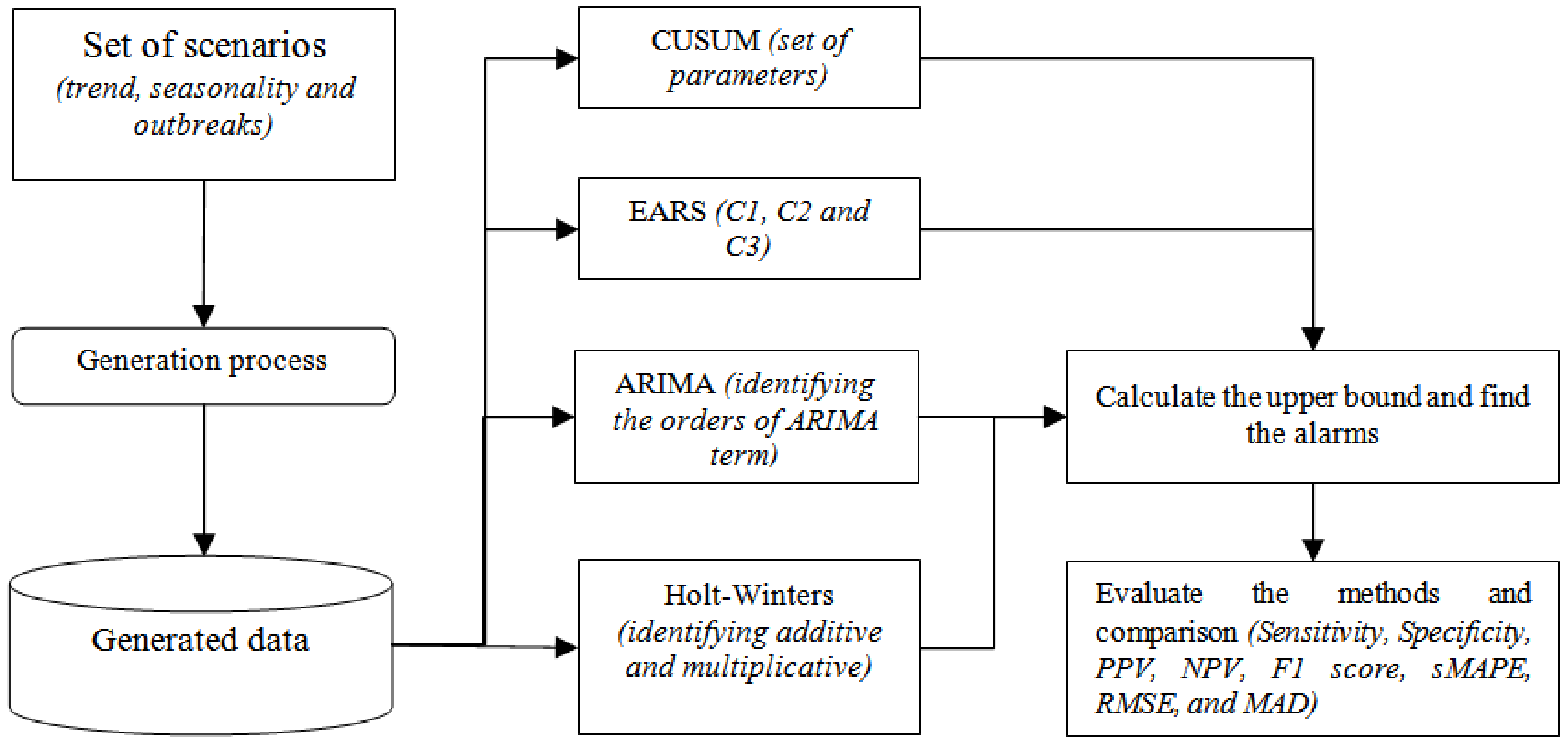
The overall framework of this study is shown in
Figure 1. Firstly, we generated time series data using several combinations of seasonality and trends for syndromic surveillance following the same procedure as in Angela et al. [
14]. In the second part, four different approaches of syndromic surveillance (CUSUM, EARS, ARIMA, and Holt-Winters) were analyzed using the generated data. Finally, the four approaches were compared using the selected evaluation metrics. Also, real-life diarrhea syndromic surveillance data were used in the final step where daily and weekly data were fed into the selected algorithms in order to detect alarms related to diarrhea infection. However, since the real-world data of the syndromic diarrhea did not include an attribute that defined the state of the outbreak, the performances of the algorithms in this case were evaluated based on sMAPE, RMSE, and MAD as evaluation metrics.
In order to implement the widely used CUSUM algorithm developed in 1954 by Page et al. [
15], as well as variants of the EARS algorithm, the “R surveillance package” [
16]—a popularly used open source toolkit—was used. The package comprised assorted algorithms such as standardized variables transformations (anscombe and rossi) [
6], and the generalized linear model (glm) [
17] for time-varying expectations. The analysis was carried out based on the default settings incorporated in the package.
In the case of the ARIMA [
18] and Holt-Winters methods [
19], a different package was used, namely, the R forecast package which is dedicated to time series forecast analysis [
20,
21]. The package is sophisticated enough to automatically select between ARIMA and Holt-Winters as forecasting models depending on whether the time-series includes trends or seasonality.
As referred in the introduction, the previous related studies mostly used sensitivity, specificity, PPV, NPV, and F1 score as evaluation metrics to measure the performances of outbreak detection algorithms, and RMSE, MAPE, and MAD metrics for time series forecasting methods. Particularly, RMSE, MAPE and MAD metrics were found to be suitable when the datasets did not include a variable for the state of the outbreak. However, due to the fact that even with the existence of outbreak state in the data the results of sensitivity, specificity, PPV, NPV, and F1 are inconsistent and disagreeable, in this paper, we applied the “symmetric” MAPE (sMAPE) method proposed by Armstrong which was used in an M3 forecasting competition [
22]. Therefore, the evaluation metrics used in this paper are: sensitivity, specificity, PPV, NPV, F1 score, sMAPE, RMSE and MAD.
2.2. Data Simulation
This section describes the details of generating the simulated data. In essence, the data generation process was carried out in a similar way to that of Angela et al. [
14]. In the process, baseline time series counts without outbreaks were generated based on a negative binomial model of mean (
) and variance (
) with a dispersion parameter (
).
The formula for the baseline simulation is defined as:
where theta (
) is the baseline frequency of reports, beta (
) is the time trend, gamma1 (
) is the seasonality, gamma2 (
) is the biannual seasonality, m = 0 formally corresponds to no seasonality, m = 1 corresponds to annual seasonality, and m = 2 shows biannual seasonality.
The time series generation process was guided by 42 different parameter combinations as shown in
Table S1 in the Supplementary Materials. For each case of these parameter combinations the simulation was replicated 100 times to generate data for
n = 624 weeks in each individual run. Thereafter, in each replica, the simulated data were split into three parts. The first part spans the period from week 1 to week 312 to represent training time series, followed by the data from week 313 through week 575 as the baseline, and the final data from week 576 to week 624 were left to resemble time series of the current week.
Outbreaks in baseline weeks: For each scenario, we included four outbreaks with start times chosen randomly among the baseline weeks (weeks 313–575). We took the values of k to be 2, 3, 5 or 10. Where the parameter k resembles the number of outbreaks.
Outbreaks in current weeks: For each scenario, we included one outbreak with start time chosen randomly among the last 49 weeks (weeks 576–624). We choose the values of k to be in the range 1–10.
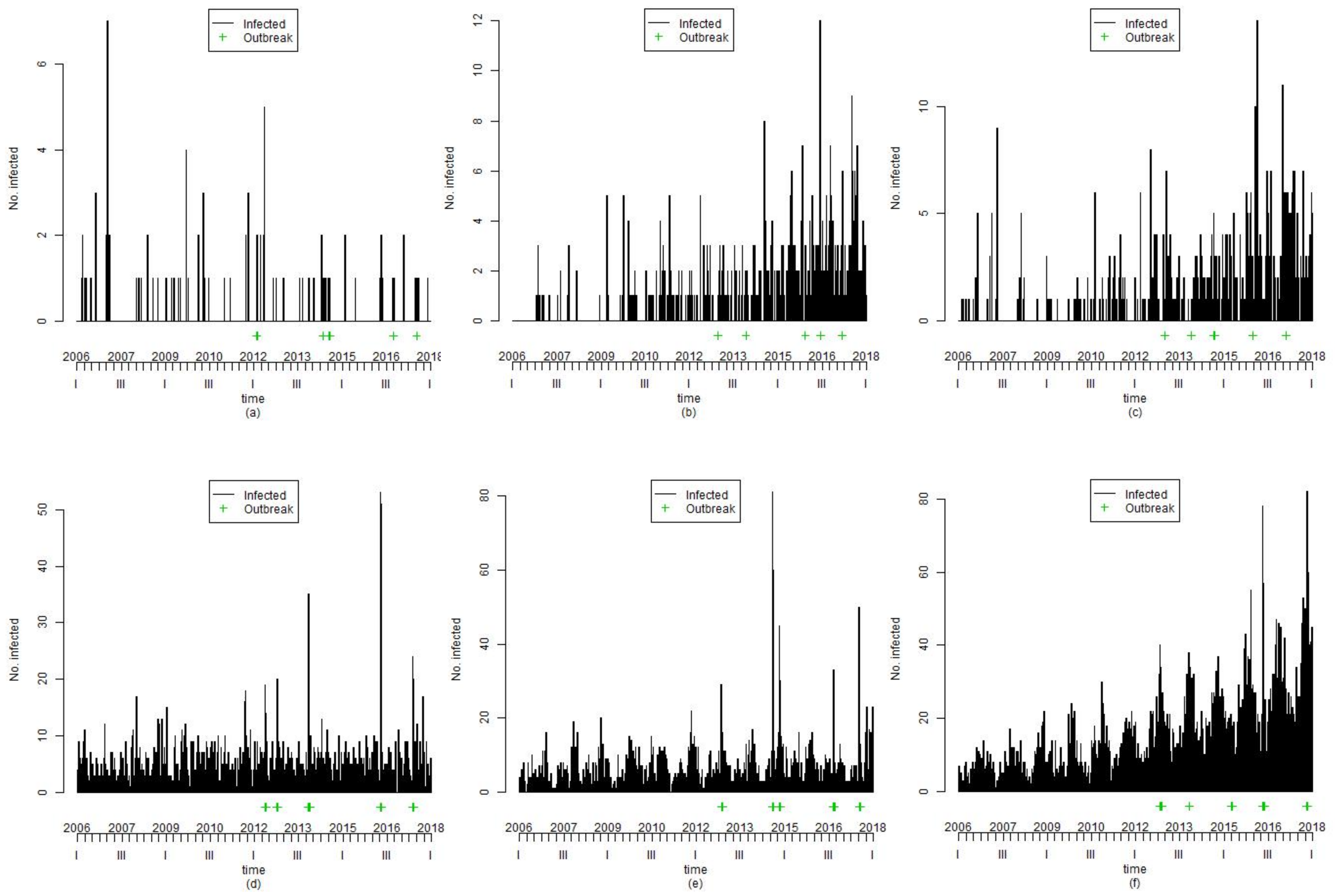
Finally, because of this data generation, 4200 series were prepared to analyze the outbreak detection for the syndromic surveillance system. The value 4200 was obtained by multiplying the 42 scenarios by 100 replications. As an example of the data generated by the above-mentioned procedure, we present the data of six selected scenarios as follows: (1) Scenario 8 comprises the baseline frequency (
= −2), and annual seasonality (m = 1 and
); (2) Scenario 10 comprises the baseline frequency (
= −2), and trend (
); (3) Scenario 12 comprises the baseline frequency (
= −2), trend (
), and biannual seasonality (m = 2,
and
); (4) Scenario 13 comprises only the baseline frequency (
= 1.5); (5) Scenario 15 comprises the baseline frequency (
= 1.5), and biannual seasonality (m = 2,
and
); and (6) Scenario 17 comprises the baseline frequency (
= 1.5), trend (
), and annual seasonality (m = 1 and
), as shown in
Figure 2. In the figure, each graph of a scenario consists of an x-axis, which represents time, a y-axis, which represents the number of infections, a line that represents infections, and a green-colored plus sign to represent outbreaks.
3. Results
3.1. The Results of CUSUM
The underlying mechanism of the CUSUM algorithm is to account for the accumulation of deviations between previous and current values of a given time series. Since the algorithm needs a guide to count the deviations, it requires a parameter, h, to show the upper bound of the time series, and an additional parameter, k, to represent the tolerated shift from the mean of the underlying monitored time-series. For the purposes of our experiments, the default settings of these parameters in the “R surveillance package” were used. However, since the default parameters assume a time series without trends and seasonality, in this paper, trend and seasonality were added into a generalized linear model resulting in a new model named “glm with trend” which requires an additional parameter, namely, “trans = ‘rossi’”, which indicates a version of the CUSUM algorithm that deals with trends, and seasonality [
6]. Then, we calculated the evaluation metrics for each of the 42 scenarios in a similar way to that of Angela et al. [
14].
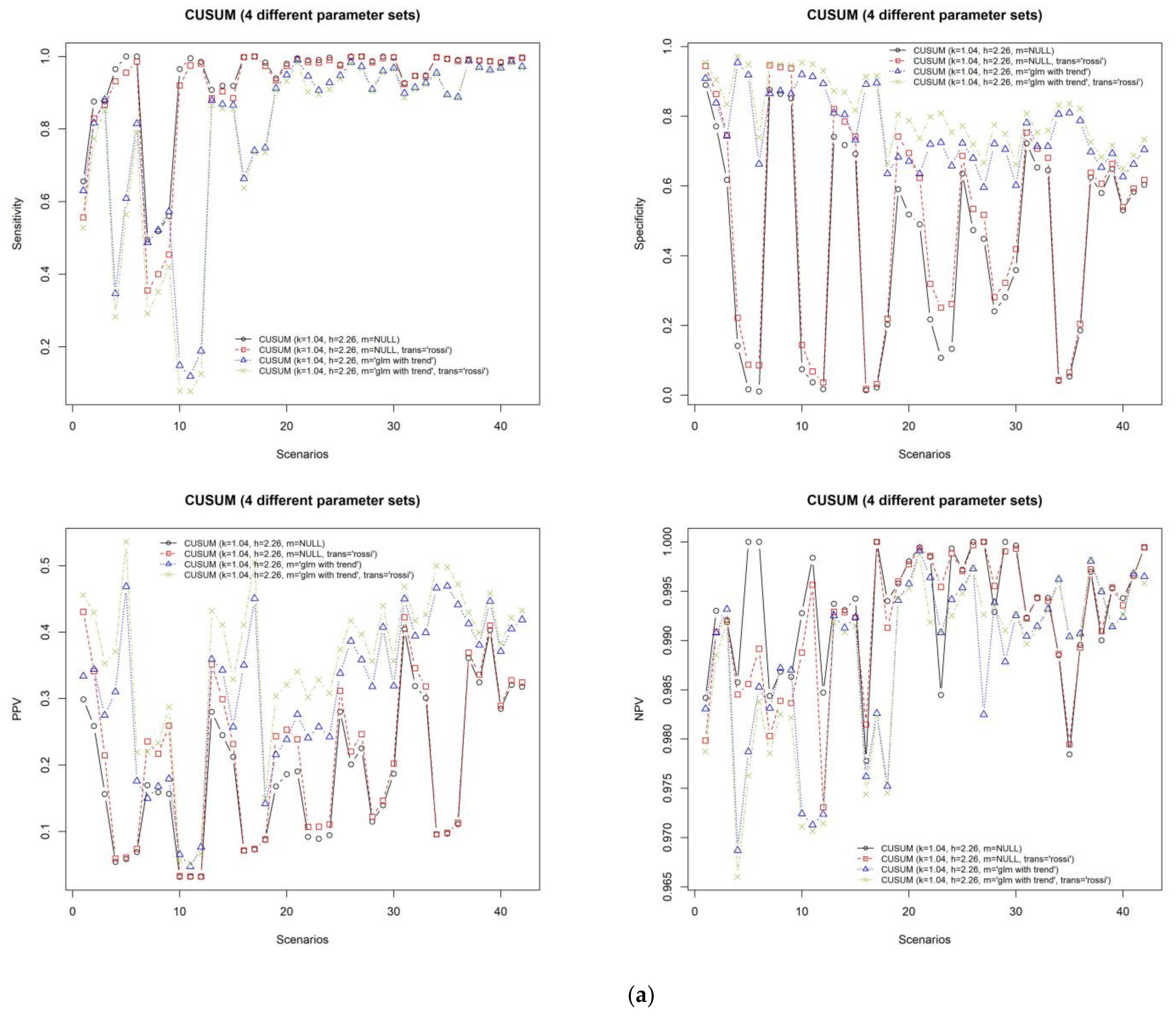
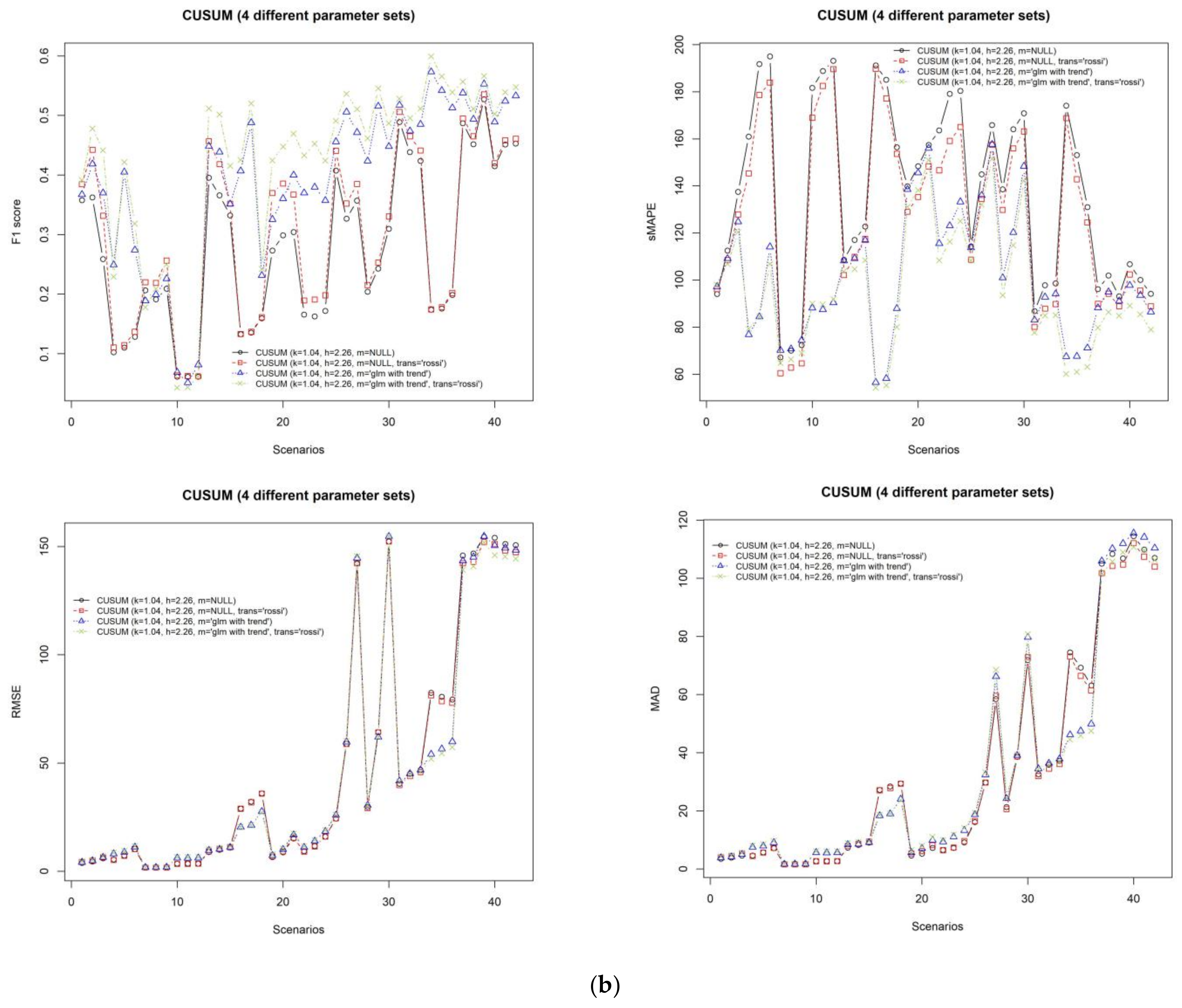
In order to determine which parameter configuration will result in a better performance of CUSUM, the performances of the four sets of parameters are measured by the eight different evaluation metrics as illustrated in
Figure 3a,b. The “rossi” and “glm with trend” (k = 1.04, h = 2.26, m = “glm with trend” and trans = “rossi”) algorithms showed good results compared with other CUSUM algorithms.
For the best CUSUM algorithm, average sensitivity is equal to 0.77, specificity is equal to 0.81, PPV is equal to 0.36, and NPV is equal to 0.99. According to this result, although it provides many false alarms, the true outbreak detection rate is high. Also, its average F1 score is equal to 0.424. The F1 score shows the trade-off between sensitivity and PPV. If the F1 score is close to 1, it shows good performance in detecting the outbreaks without false alarms.
The metrics of RMSE and MAD are meant to measure the differences between the predicted number of infections by a given outbreak detection algorithm and the actual number of observed infections. Higher values of these metrics indicate poor performance of a given algorithm. From
Figure 3a,b, however, it is evident that even though the values of these two metrics were slightly higher, the algorithm still revealed good performances in terms of sensitivity, specificity, PPV, NPV, and F1 score. Therefore, we suggested sMAPE evaluation metric to address this problem. When the sMAPE value is closer to 0, it indicates that the selected method shows good performance. Additionally, this evaluation metric is agreeable to evaluate the selected methods because the correlation between F1 score and sMAPE was −0.7. This means that if the F1 score is high, sMAPE will be low.
The average sMAPE of the best CUSUM algorithms is equal to 95.76, the average RMSE is equal to 45.16, and MAD is equal to 32.58.
3.2. The Results of EARS C1, C2 and C3
The C1, C2, and C3 of the EARS are among the most commonly used syndromic surveillance techniques. Although they were meant to follow similar detection approach like CUSUM, they instead compute number of counts from the recent past [
7]. In addition, C1, and C2 utilize Shewhart control charts that use a moving sample average and sample standard deviation to standardize each observation.
In order to evaluate these methods, the R surveillance package was used and the performances were observed and reflected in
Figure 4a,b.
Figure 4a shows the results of sensitivity, specificity, PPV, and NPV when C1, C2, and C3 were compared using the synthetic dataset across all of the scenarios. Equally, in terms of the performance values of F1 score, RMSE, SMAPE, and MAD, EARS C3 was the best method, as shown in
Figure 4b.
3.3. Performance Evaluation of CUSUM, EARS C3, ARIMA and Holt-Winters
In
Section 3.1 and
Section 3.2 the best settings required for CUSUM algorithm and EARS C3 to perform well are demonstrated. In this section, the all algorithms considered in this paper are compared. Namely, we compared the CUSUM, EARS C3, ARIMA, and Holt-Winters approaches. ARIMA and Holt-Winters are widely used for the purposes of time series forecasting in different research domains. The ARIMA algorithm requires parameters such as the autoregressive (AR), moving average (MA), and knowledge of whether the mode of its operation is integrated or not. On the other hand, Holt-Winters algorithm only requires the definition of additive and multiplicative seasonality. Fortunately, however, the underlying forecast library of the R language includes a function that automatically selects the ARIMA or Holt-Winter algorithm based on the underlying characteristics of the time series [
21].
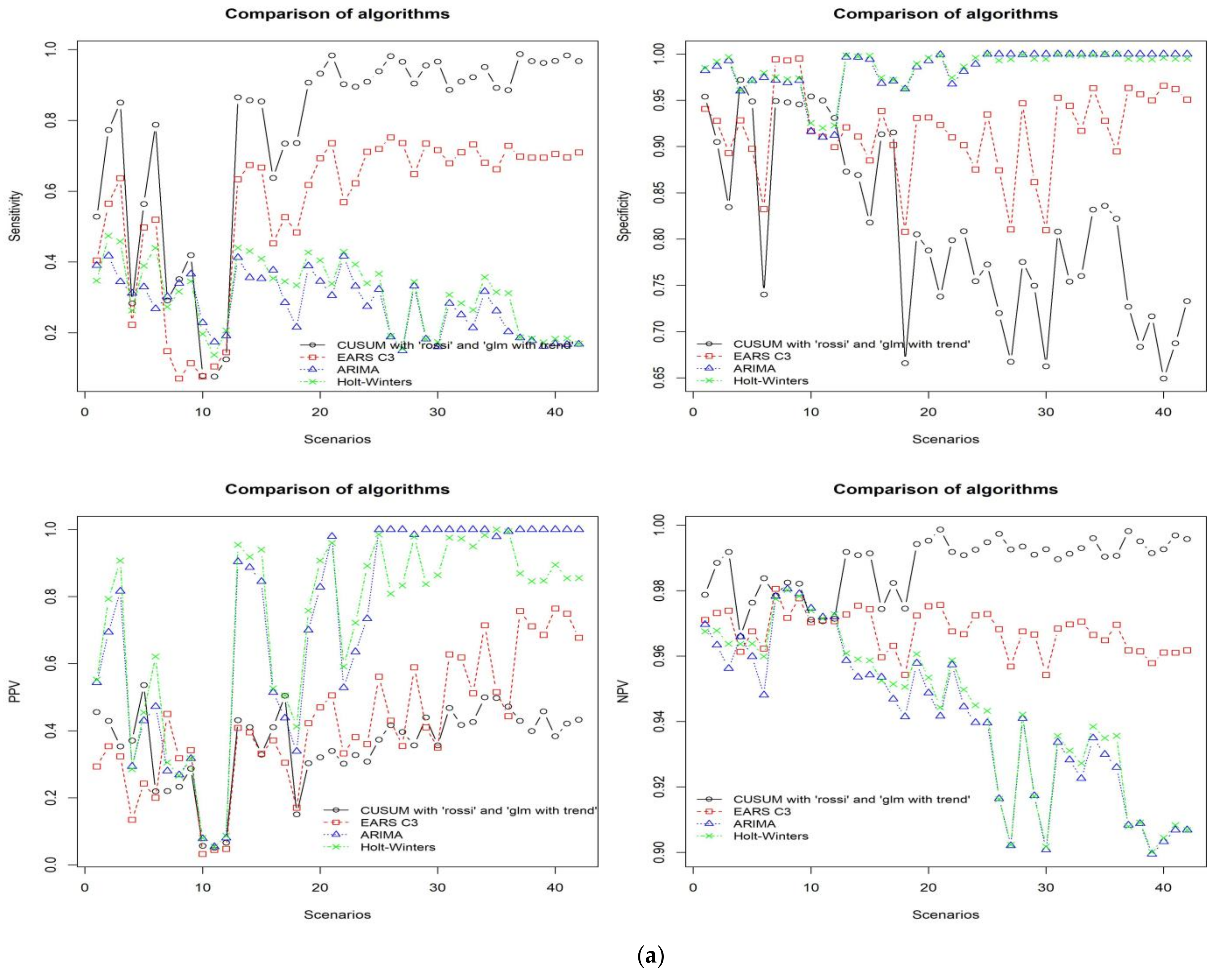
Figure 5a,b show the performance results of the four algorithms using the simulated data set across all scenarios. The graphs in
Figure 5a show the comparative results of the algorithms in terms of sensitivity, specificity, PPV, and NPV. This figure shows that although the best setting for CUSUM shows outstanding results in terms of sensitivity and NPV, specificity and PPV were comparatively low. In contrast, both ARIMA and Holt-Winters achieved higher average values in terms of specificity (0.984, and 0.985) and PPV (0.941 and 0.944), respectively, and lower average values in terms of sensitivity (0.277 and 0.305), and NPV (0.729 and 0.718), in that order.
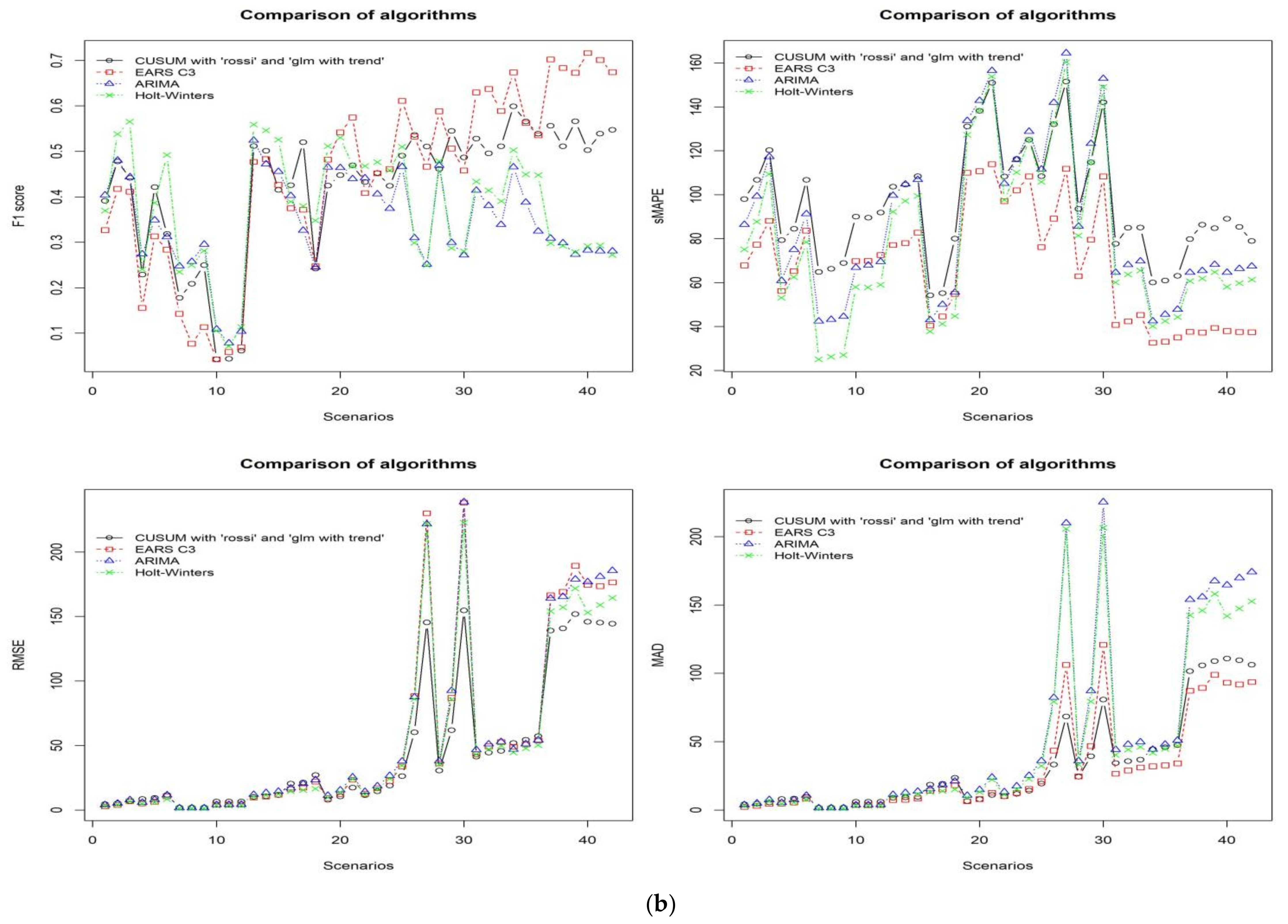
Figure 5b shows the comparison of the algorithms in terms of F1 score, sMAPE, RMSE, and MAD. From these graphs the ARIMA and Holt-Winters approaches did not show competing performance against EARS C3 and CUSUM.
EARS C3 indicates average results for sensitivity, specificity, NPV, and PPV. Even though EARS C3 showed fewer false alarms than the best CUSUM, its true outbreak detection rate is low. However, the EARS C3 algorithm is the best approach to detect outbreaks for average F1 score and sMAPE metrics.
We also compared the methods depending on the characteristics of time series data as shown in
Table 1. Our generated data can be divided into six groups based on the combination of scenarios. In this case, EARS C3 model also showed the best performance for all groups, except the time series with the trend and annual seasonality grouped according to F1 score and sMAPE metrics. The best CUSUM (rossi and glm with trend) algorithm indicated the best performance for the remaining group.
In
Table 2, the data is divided into seven groups based on baseline frequency and dispersion parameters. ARIMA and Holt-Winter showed good performance when the baseline frequency was less than 1.5 and the dispersion was parameter less than 2. EARS C3 performed well in other cases.
3.4. Comparison of Selected Methods for Diarrhea Syndromic Surveillance
In this section, we run the selected algorithms using real world syndromic diarrhea surveillance data (2013–2017) obtained from the Korea Centers for Disease Control and Prevention. Datasets of the years 2013 through 2016 were used as a baseline data. The data from 2017 were designated as current data in order to evaluate the algorithms. Daily and weekly data are illustrated in
Figures S1 and S2 in the Supplementary Materials.
Figures S3 and S4 in the Supplementary Materials show the experimental results. In each figure the dashed blue line indicates an upper bound calculated by the underling algorithm. This is there to indicate if the current value referred to in the figure by the black lines surpassed this upper bound, and an alarm was raised. The small red triangular shapes indicate the alarm. In
Figures S3 and S4, the black lines represent the actual cases of infectious diarrhea. The dashed-blue line indicates the upper bound calculated by the algorithm. Therefore, whenever number of actual infectious diarrhea surpasses the upper-bound, an alarm is raised, indicating a possibility of an outbreak. In this case, however, since the real-life diarrhea syndromic surveillance data do not include outbreak variable, the sMAPE, RMSE, and MAD evaluation metrics were used in this section. Fortunately, we found that the sMAPE metric is highly correlated with F1 score from the analysis of simulated data. According to sMAPE metric, the result of real data analysis showed same performance as the simulated data. EARS C3 also showed the best performance, as shown in
Table 3. The result of the CUSUM (rossi and glm with trend) algorithm evaluated by RMSE and MAD indicated outstanding performance.
4. Discussion
The aim of surveillance system is to provide two main objectives, which are to maximize true outbreak detection rate and minimize false alarm rate. We analyzed most widely used four algorithms for early detection of infectious disease outbreaks in public health using simulated and real data. In order to compare the performances of the selected algorithms, we used several evaluation metrics. However, although algorithms that provide high sensitivity such as CUSUM and EARS were able to detect the majority of the outbreaks, algorithms that showed high specificity or PPV such as ARIMA and Holt-Winters detected fewer outbreaks. Furthermore, none of the algorithms considered in this study showed good results consistently across the all evaluation metrics.
Nevertheless, the F1 score metric demonstrates the trade-off between sensitivity and specificity in the surveillance system. Also, we compared sMAPE, RMSE and MAD evaluation metrics for time series forecasting methods to the F1 score, and the sMAPE is highly correlated with the F1 score. The EARS C3 algorithm’s performance, which was evaluated by the F1 score and sMAPE, was better than other algorithms for most of the scenarios.
In the CUSUM approach, we chose four different algorithms and set the default h and k parameters in a similar way as in [
11]. However, the one difference is that we added the trend variable into “glm” model of CUSUM. Thereafter, the result of CUSUM (rossi and glm with trend) algorithm was much improved, such that average specificity increased by 0.33, PPV increased by 0.14, F1 score increased by 0.12, and sMAPE decreased by 32.6. The best CUSUM algorithm showed better results than the ARIMA and Holt-Winter algorithms and comparable results with the EARS C3 algorithm. In addition, the CUSUM model indicated the best performance when the data has trend and annual seasonality.
Practically, the CUSUM algorithm is good for detecting disease outbreaks, but it provides many false alarms in normal conditions except when the data has trends and annual seasonality. This is the disadvantage of CUSUM algorithm. The aim of an early outbreak detection method is to identify the largest possible number of outbreaks without false alarms [
11].
For the ARIMA and Holt-Winters algorithms, the F1 score and sMAPE are lower than other algorithms. However, these algorithms can detect outbreaks very well on data that have a baseline frequency less than 1.5 ( < 1.5) and a dispersion parameter of less than 2 ( < 2). This means that these algorithms are more suitable to detect disease outbreaks that rarely cause infections in public health.
This study analyzed real data collected from the KCDC. The data represent historical cases of infectious diarrhea between 2013 and 2017. The results of the selected algorithms are similar to the simulated data because the real data show no trends and biannual seasonality.
5. Conclusions
This study compared the most useful four methods for early outbreak detection in syndromic surveillance systems based on multiple types of simulated data and real data. In the results, we used several evaluation metrics to compare the selected algorithms, but it is difficult to compare the selected algorithms because those algorithms have their own advantages and disadvantages. The four algorithms are compared according to the time series data type (trends, seasonality, and baseline infections), and the algorithms can be selected according to various data types.
The main conclusions from the results are that CUSUM (rossi and glm with trend) showed better performance compared to the other variants of CUSUM algorithm, particularly when the data show trends and annual seasonality. Additionally, if the baseline for infectious disease is less than 1.5 and its dispersion is small, ARIMA and Holt-Winter algorithms are good approaches to detect outbreaks of this kind of disease. For the EARS C1, C2, and C3 algorithms, C3 showed better performance than the other EARSs. It also showed good performance compared with other algorithms for the most of the scenarios. However, the EARS C3 algorithm is more suitable for outbreak detection when it considers both true outbreak detection rate and false alarm rate. Finally, we studied the selected approaches on the real data and the results were same as for the simulated data.
The contributions of this study are that we suggest sMAPE evaluation metrics for evaluating the performance of syndromic surveillance analysis when the data do not include the outbreak state variable, and we demonstrated that the “glm with trend variable” CUSUM algorithm is better than other default CUSUM algorithms.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}