Adopting Machine Learning and Spatial Analysis Techniques for Driver Risk Assessment: Insights from a Case Study

 , ,
, ,
Abstract
:1. Introduction
2. Data and Methods
2.1. Selection of Study Area
2.2. Data Collection
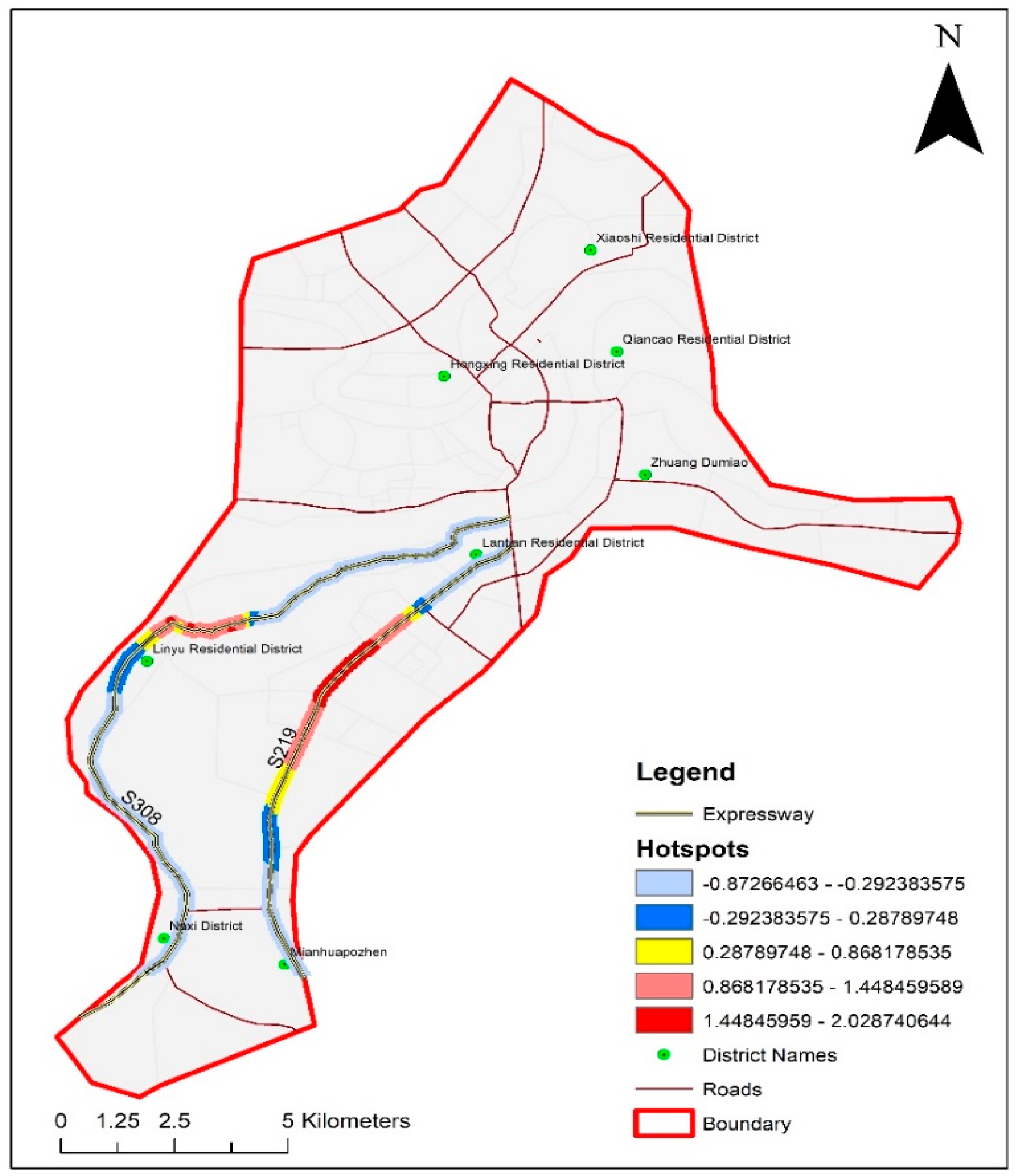
2.3. GIS-Based Analysis for Violation Hotspots
2.4. Traffic Violation Prediction Using ML
2.4.1. K Nearest Neighbors (KNN)
2.4.2. Support Vector Machine (SVM)
2.4.3. CN2 Rule Inducer
2.5. Performance Evaluation Metrics for ML Models
3. Results and Discussions
3.1. Analysis of Descriptive Statistics
3.2. Mapping of Violation Hotspots
3.3. ML Model’s Comparison for Violation Prediction
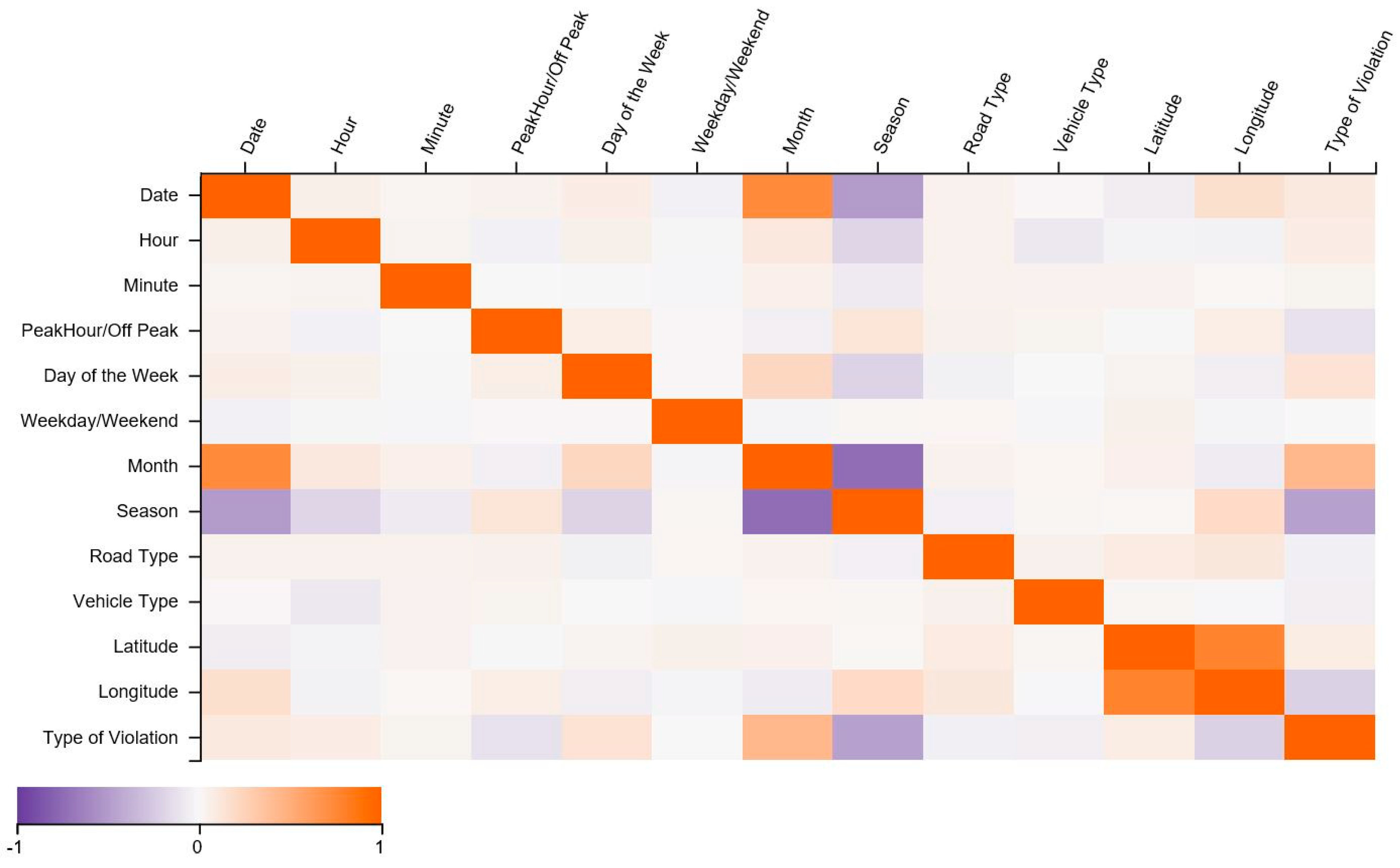
3.4. Spearman Correlation Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | IF Condition | Then Class | Distribution | Probabilities (%) | Rule Quality | Length |
|---|---|---|---|---|---|---|
| 1 | Latitude ≥ 28.85656 | Illegal parking | [12, 0, 0, 0] | 81:6:6:6 | 0.929 | 1 |
| 2 | Latitude ≤ 28.83151 and Season = Autumn | Illegal parking | [16, 0, 0, 0] | 85:5:5:5 | 0.944 | 2 |
| 3 | Latitude ≥ 28.83693 and Latitude ≤ 28.84196 and Season ≠ Summer | Illegal parking | [20, 0, 0, 0] | 88:4:4:4 | 0.955 | 3 |
| 4 | Latitude ≤ 28.83151 and Day of Week = Sunday | Illegal parking | [4, 0, 0, 0] | 62:12:12:12 | 0.833 | 2 |
| 5 | Lattitude ≤ 28.83151 and Day of Week = Tuesday | Illegal parking | [3, 2, 0, 0] | 44:33:11:11 | 0.571 | 2 |
| 6 | Lattitude ≤ 28.83151 and Season = Winter | Overspeeding | [0, 60, 0, 0] | 2:95:2:2 | 0.984 | 2 |
| 7 | Month ≥ 12.0 and Lattitude ≥ 28.84942 | Overspeeding | [0, 22, 0, 0] | 4:88:4:4 | 0.958 | 2 |
| 8 | Lattitude ≥ 28.83693 and Minute ≥ 55.0 | Overspeeding | [0, 3, 0, 0] | 14:57:14:14 | 0.8 | 2 |
| 9 | Day of Week = Sunday and Hour ≥ 14.0 | Violation of prohibited markings | [0, 0, 76, 5] | 1:1:91:7 | 0.928 | 3 |
| 10 | Month ≤ 2.0 and Vehicle type = Taxi/Passenger Car and Day of Week = Monday | Violation of prohibited markings | [0, 0, 35, 12] | 2:2:71:25 | 0.735 | 3 |
| 11 | Month ≤ 2.0 and Day of Week = Monday | Violation of prohibited markings | [0, 0, 100, 79] | 1:1:55:44 | 0.558 | 2 |
| 12 | Month ≤ 2.0 and Day of Week = Sunday | Violation of prohibited markings | [0, 0, 35, 36] | 1:1:48:49 | 0.493 | 2 |
| 13 | Month ≤ 2.0 and Day of Week = Tuesday | Violation of prohibited markings | [0, 0, 16, 23] | 2:2:40:56 | 0.415 | 2 |
| 14 | Season = Autumn and Month ≥ 10.0 | Violation of prohibited markings | [0, 0, 4, 0] | 12:12:62:1 | 0.833 | 3 |
| 15 | Hour ≥ 17.0 and Season = Spring | Wrongway driving | [0, 0, 2, 151] | 1:1:2:97 | 0.981 | 2 |
| 16 | Day of Week = Wednesday and Season = Spring | Wrongway driving | [0, 0, 4, 113] | 1:1:4:94 | 0.958 | 2 |
| 17 | Day of Week = Saturday and Peak/Off Peak ≠ Peak | Wrongway driving | [1, 0, 7, 121] | 2:1:6:92 | 0.931 | 2 |
| 18 | Season ≠ Winter and Day of Week = Friday | Wrongway driving | [3, 0, 6, 141] | 3:1:5:92 | 0.934 | 2 |
| 19 | Day of Week = Thursday and Season = Spring | Wrongway driving | [0, 0, 7, 104] | 1:1:7:91 | 0.929 | 2 |
| 20 | Day of Week = Sunday and Hour ≥ 10.0 | Wrongway driving | [0, 0, 2, 105] | 1:1:3:95 | 0.972 | 3 |
| 21 | Season ≠ Winter | Wrongway driving | [39, 9, 70, 209] | 12:3:21:63 | 0.638 | 1 |
| 22 | Month ≤ 2.0 and Day of Week = Thursday | Wrongway driving | [0, 0, 1, 24] | 3:3:7:86 | 0.926 | 2 |
| 23 | Month ≤ 2.0 and Month ≥ 2.0 | Wrongway driving | [0, 0, 16, 107] | 1:1:13:85 | 0.864 | 2 |
| 24 | Month ≤ 5.0 and Day of Week = Friday | Wrongway driving | [2, 0, 21, 29] | 5:2:39:54 | 0.556 | 2 |
| 25 | Month ≤ 5.0 and Day of Week = Tuesday | Wrongway driving | [0, 0, 23, 23] | 2:2:48:48 | 0.5 | 2 |
| 26 | Day_of_Week = Monday and Hour ≤ 11.0 | Wrongway driving | [2, 2, 19, 25] | 6:6:38:50 | 0.52 | 2 |
| 27 | Month ≤ 5.0 and Day of Week = Saturday | Wrongway driving | [0, 0, 15, 12] | 3:3:52:42 | 0.448 | 2 |
| 28 | Month ≤ 2.0 and Hour ≥ 17.0 | Wrongway driving | [0, 0, 13, 10] | 4:4:52:41 | 0.44 | 2 |
| 29 | Day of Week = Wednesday | Wrongway driving | [8, 3, 10, 12] | 24:11:30:135 | 0.371 | 1 |
| 30 | TRUE | Wrongway driving | [57, 91, 358, 1502] | 3:5:18:75 | 0.747 |
References
- National Bureau of Statistics of China. China Statistical Yearbook 2012; China Statistics Press: Beijing, China, 2012.
- Jamal, A.; Rahman, M.T.; Al-Ahmadi, H.M.; Mansoor, U. The dilemma of road safety in the eastern province of Saudi Arabia: Consequences and prevention strategies. Int. J. Environ. Res. Public Health 2020, 17, 157. [Google Scholar] [CrossRef] [Green Version]
- Petridou, E.; Moustaki, M. Human factors in the causation of road traffic crashes. Eur. J. Epidemiol. 2000, 16, 819–826. [Google Scholar] [CrossRef]
- Stutts, J.; Reinfurt, D.; Staplin, L.; Rodgman, E. The Role of Driver Distraction in Traffic Crashes. 2001. Available online: https://www.forces-nl.org/download/distraction.pdf (accessed on 8 June 2020).
- Shin, D.S.; Park, M.H.; Jeong, B.Y. Human factors and severity of injury of delivery truck crashes registered for work-related injuries in South Korea. Ind. Eng. Manag. Syst. 2018, 17, 302–310. [Google Scholar] [CrossRef]
- Jamal, A.; Subhan, F. Public perception of autonomous car: A case study for Pakistan. Adv. Transp. Stud. 2019, 49, 145–154. [Google Scholar]
- Chu, W.; Wu, C.; Atombo, C.; Zhang, H.; Özkan, T. Traffic climate, driver behaviour, and accidents involvement in China. Accid. Anal. Prev. 2019, 122, 119–126. [Google Scholar] [CrossRef] [PubMed]
- Rezapour Mashhadi, M.M.; Saha, P.; Ksaibati, K. Impact of traffic enforcement on traffic safety. Int. J. Police Sci. Manag. 2017, 19, 238–246. [Google Scholar] [CrossRef]
- Alonso, F.; Esteban, C.; Montoro, L.; Useche, S.A. Knowledge, perceived effectiveness and qualification of traffic rules, police supervision, sanctions and justice. Cogent Soc. Sci. 2017, 3, 1393855. [Google Scholar] [CrossRef]
- Bălan, C.; Micle, M.; Săucan, D.; Udrea, A. Educaţie Pentru Sănătate-Suport de curs Adresat Persoanelor din Sistemul Naţional de Educaţie Implicat în Pilotarea Ofertelor Educaţionale Extracuriculare şi Extraşcolare, în AMD CALUGĂRU, STOICA EUGEN, A; Fundaţia Tineri pentru Tineri: Bucureşti, Romania, 2010. [Google Scholar]
- Harris, P.B.; Houston, J.M. Recklessness in context: Individual and situational correlates to aggressive driving. Environ. Behav. 2010, 42, 44–60. [Google Scholar] [CrossRef] [Green Version]
- Banks, W.W.; Shaffer, J.W.; Masemore, W.C.; Fisher, R.S.; Schmidt, C.W., Jr.; Zlotowitz, H.I. The relationship between previous driving record and driver culpability in fatal, multiple-vehicle collisions. Accid. Anal. Prev. 1977, 9, 9–13. [Google Scholar] [CrossRef]
- Lui, K.-J.; Marchbanks, P.A. A study of the time between previous traffic infractions and fatal automobile crashes, 1984–1986. J. Saf. Res. 1990, 21, 45–51. [Google Scholar] [CrossRef]
- Factor, R. The effect of traffic tickets on road traffic crashes. Accid. Anal. Prev. 2014, 64, 86–91. [Google Scholar] [CrossRef] [PubMed]
- Chandraratna, S.; Stamatiadis, N.; Stromberg, A. Crash involvement of drivers with multiple crashes. Accid. Anal. Prev. 2006, 38, 532–541. [Google Scholar] [CrossRef] [PubMed]
- Useche, S.; Serge, A.; Alonso, F. Risky behaviors and stress indicators between novice and experienced drivers. Am. J. Appl. Psychol. 2015, 3, 11–14. [Google Scholar]
- Hayakawa, H.; Fischbeck, P.S.; Fischhoff, B. Traffic accident statistics and risk perceptions in Japan and the United States. Accid. Anal. Prev. 2000, 32, 827–835. [Google Scholar] [CrossRef]
- Holubowycz, O.T.; Kloeden, C.N.; McLean, A.J. Age, sex, and blood alcohol concentration of killed and injured drivers, riders, and passengers. Accid. Anal. Prev. 1994, 26, 483–492. [Google Scholar] [CrossRef]
- Oh, C.; Kang, Y.; Kim, W. Assessing the safety benefits of an advanced vehicular technology for protecting pedestrians. Accid. Anal. Prev. 2008, 40, 935–942. [Google Scholar] [CrossRef]
- Zhang, J.; Lindsay, J.; Clarke, K.; Robbins, G.; Mao, Y. Factors affecting the severity of motor vehicle traffic crashes involving elderly drivers in Ontario. Accid. Anal. Prev. 2000, 32, 117–125. [Google Scholar] [CrossRef]
- Valent, F.; Schiava, F.; Savonitto, C.; Gallo, T.; Brusaferro, S.; Barbone, F. Risk factors for fatal road traffic accidents in Udine, Italy. Accid. Anal. Prev. 2002, 34, 71–84. [Google Scholar] [CrossRef]
- De Winter, J.C.F.; Dodou, D. The Driver Behaviour Questionnaire as a predictor of accidents: A meta-analysis. J. Saf. Res. 2010, 41, 463–470. [Google Scholar] [CrossRef]
- Zahid, M.; Chen, Y.; Jamal, A. Freeway Short-Term Travel Speed Prediction Based on Data Collection Time-Horizons: A Fast Forest Quantile Regression Approach. Sustainability 2020, 12, 646. [Google Scholar] [CrossRef] [Green Version]
- Zahid, M.; Chen, Y.; Jamal, A.; Memon, M.Q. Short Term Traffic State Prediction via Hyperparameter Optimization Based Classifiers. Sensors 2020, 20, 685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jamal, A.; Rahman, M.T.; Al-Ahmadi, H.M.; Ullah, I.M.; Zahid, M. Intelligent Intersection Control for Delay Optimization: Using Meta-Heuristic Search Algorithms. Sustainability 2020, 12, 1896. [Google Scholar] [CrossRef] [Green Version]
- Pour-Rouholamin, M.; Zhou, H. Analysis of driver injury severity in wrong-way driving crashes on controlled-access highways. Accid. Anal. Prev. 2016, 94, 80–88. [Google Scholar] [CrossRef] [PubMed]
- Ponnaluri, R.V. The odds of wrong-way crashes and resulting fatalities: A comprehensive analysis. Accid. Anal. Prev. 2016, 88, 105–116. [Google Scholar] [CrossRef] [PubMed]
- Kemel, E. Wrong-way driving crashes on French divided roads. Accid. Anal. Prev. 2015, 75, 69–76. [Google Scholar] [CrossRef]
- Lucidi, F.; Mallia, L.; Lazuras, L.; Violani, C. Personality and attitudes as predictors of risky driving among older drivers. Accid. Anal. Prev. 2014, 72, 318–324. [Google Scholar] [CrossRef]
- Zhang, G.; Yau, K.K.W.; Gong, X. Traffic violations in Guangdong Province of China: Speeding and drunk driving. Accid. Anal. Prev. 2014, 64, 30–40. [Google Scholar] [CrossRef]
- Tseng, C.-M. Operating styles, working time and daily driving distance in relation to a taxi driver’s speeding offenses in Taiwan. Accid. Anal. Prev. 2013, 52, 1–8. [Google Scholar] [CrossRef]
- Tseng, C.-M.; Yeh, M.-S.; Tseng, L.-Y.; Liu, H.-H.; Lee, M.-C. A comprehensive analysis of factors leading to speeding offenses among large-truck drivers. Transp. Res. Part F Traffic Psychol. Behav. 2016, 38, 171–181. [Google Scholar] [CrossRef]
- Tselentis, D.I.; Vlahogianni, E.I.; Yannis, G. Driving safety efficiency benchmarking using smartphone data. Transp. Res. Part C Emerg. Technol. 2019, 109, 343–357. [Google Scholar] [CrossRef]
- Eboli, L.; Mazzulla, G.; Pungillo, G. Combining speed and acceleration to define car users’ safe or unsafe driving behaviour. Transp. Res. Part C Emerg. Technol. 2016, 68, 113–125. [Google Scholar] [CrossRef]
- Jovanović, D.; Šraml, M.; Matović, B.; Mićić, S. An examination of the construct and predictive validity of the self-reported speeding behavior model. Accid. Anal. Prev. 2017, 99, 66–76. [Google Scholar] [CrossRef] [PubMed]
- Warner, H.W.; Åberg, L. Drivers’ beliefs about exceeding the speed limits. Transp. Res. Part F Traffic Psychol. Behav. 2008, 11, 376–389. [Google Scholar] [CrossRef]
- Kim, A.-R.; Rhee, S.-Y.; Jang, H.-W. Lane detection for parking violation assessments. Int. J. Fuzzy Log. Intell. Syst. 2016, 16, 13–20. [Google Scholar] [CrossRef] [Green Version]
- Toledo, T.; Musicant, O.; Lotan, T. In-vehicle data recorders for monitoring and feedback on drivers’ behavior. Transp. Res. Part C Emerg. Technol. 2008, 16, 320–331. [Google Scholar] [CrossRef]
- Eboli, L.; Mazzulla, G.; Pungillo, G. How to define the accident risk level of car drivers by combining objective and subjective measures of driving style. Transp. Res. Part F Traffic Psychol. Behav. 2017, 49, 29–38. [Google Scholar] [CrossRef]
- Zhang, G.; Yau, K.K.W.; Chen, G. Risk factors associated with traffic violations and accident severity in China. Accid. Anal. Prev. 2013, 59, 18–25. [Google Scholar] [CrossRef]
- Zahid, M.; Chen, Y.; Khan, S.; Jamal, A.; Ijaz, M.; Ahmed, T. Predicting Risky and Aggressive Driving Behavior among Taxi Drivers: Do Spatio-Temporal Attributes Matter? Int. J. Environ. Res. Public Health 2020, 17, 3937. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Garber, N.J.; Srinivasan, R. Risk assessment of elderly drivers at intersections: Statistical modeling. Transp. Res. Rec. 1991, 1325, 17–22. [Google Scholar]
- Yilmaz, V.; Çelik, H.E. Risky driving attitudes and self-reported traffic violations among Turkish drivers: The case of Eskişehir. Doğuş Üniversitesi Derg. 2011, 7, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Radwan, E.; Abou-Senna, H. Pedestrian-vehicle conflict analysis at signalized intersections using micro-simulation. In Proceedings of the 17th International Conference Road Safety On Five Continents (RS5C 2016), Rio de Janeiro, Brazil, 17–19 May 2016. [Google Scholar]
- Nanni, L.; Lumini, A.; Ferrara, M.; Cappelli, R. Combining biometric matchers by means of machine learning and statistical approaches. Neurocomputing 2015, 149, 526–535. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, H.; Zhou, Y.; Fu, C.; Zhu, Q. Investigating Effects of Temporal and Locational Factors on Traffic Violations of Taxi Drivers: Data from Off-Site Enforcement Camera System. In Proceedings of the 19th COTA International Conference of Transportation Professionals, Nanjing, China, 6–8 July 2019; pp. 356–366. [Google Scholar]
- Alver, Y.; Demirel, M.C.; Mutlu, M.M. Interaction between socio-demographic characteristics: Traffic rule violations and traffic crash history for young drivers. Accid. Anal. Prev. 2014, 72, 95–104. [Google Scholar] [CrossRef] [PubMed]
- Precht, L.; Keinath, A.; Krems, J.F. Identifying the main factors contributing to driving errors and traffic violations–Results from naturalistic driving data. Transp. Res. Part F Traffic Psychol. Behav. 2017, 49, 49–92. [Google Scholar] [CrossRef]
- Machado-León, J.L.; de Oña, J.; de Oña, R.; Eboli, L.; Mazzulla, G. Socio-economic and driving experience factors affecting drivers’ perceptions of traffic crash risk. Transp. Res. Part F Traffic Psychol. Behav. 2016, 37, 41–51. [Google Scholar] [CrossRef]





| K (Number of Neighbors) | Metric | Weight |
|---|---|---|
| 3 | Euclidean | Distance |
| 5 | Euclidean | Distance |
| 7 | Manhattan | Distance |
| 10 | Euclidean | Uniform |
| 12 | Mahalanobis | Distance |
| Model Parameters | Parameter Value |
|---|---|
| α1 | 0.04 |
| α2 | 0.04 |
| Minimum rule coverage | 1 |
| Maximum rule coverage | 7 |
| Variable | Percentage of Total Violations (%) | Frequency | Variable Type |
|---|---|---|---|
| Wrongway driving | 74.94 | 1501 | Response |
| Violation of Prohibited Markings | 17.87 | 358 | Response |
| Overspeeding | 4.54 | 91 | Response |
| Illegal Parking | 2.65 | 53 | Response |
| Vehicles Type | |||
| Private Car | 58.46 | 1171 | Predictor |
| Taxi | 23.27 | 466 | Predictor |
| Van | 9.54 | 191 | Predictor |
| Small Truck | 6.19 | 124 | Predictor |
| Bus | 2.55 | 51 | Predictor |
| Seasons | |||
| Spring | 54.72 | 1096 | Predictor |
| Winter | 34.4 | 689 | Predictor |
| Summer | 7.79 | 156 | Predictor |
| Autumn | 3.1 | 62 | Predictor |
| Week | |||
| Weekdays | 68.3 | 1368 | Predictor |
| Weekends | 31.7 | 635 | Predictor |
| Hours of the Day | |||
| Peak Hours (9:00 a.m.–11:00 a.m., 15:00 p.m.–17:00 p.m.) | 47.98 | 961 | Predictor |
| Off Peak Hours (11:00 a.m.–15:00 p.m., 17:00 p.m.–9:00 a.m.) | 52.02 | 1042 | Predictor |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zahid, M.; Chen, Y.; Jamal, A.; Al-Ofi, K.A.; Al-Ahmadi, H.M. Adopting Machine Learning and Spatial Analysis Techniques for Driver Risk Assessment: Insights from a Case Study. Int. J. Environ. Res. Public Health 2020, 17, 5193. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17145193
Zahid M, Chen Y, Jamal A, Al-Ofi KA, Al-Ahmadi HM. Adopting Machine Learning and Spatial Analysis Techniques for Driver Risk Assessment: Insights from a Case Study. International Journal of Environmental Research and Public Health. 2020; 17(14):5193. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17145193
Chicago/Turabian StyleZahid, Muhammad, Yangzhou Chen, Arshad Jamal, Khalaf A. Al-Ofi, and Hassan M. Al-Ahmadi. 2020. "Adopting Machine Learning and Spatial Analysis Techniques for Driver Risk Assessment: Insights from a Case Study" International Journal of Environmental Research and Public Health 17, no. 14: 5193. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17145193