Geocoding Error, Spatial Uncertainty, and Implications for Exposure Assessment and Environmental Epidemiology

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
2.1.1. Residential Address Data
2.1.2. Air Pollution Data
2.1.3. Socioeconomic Position Data
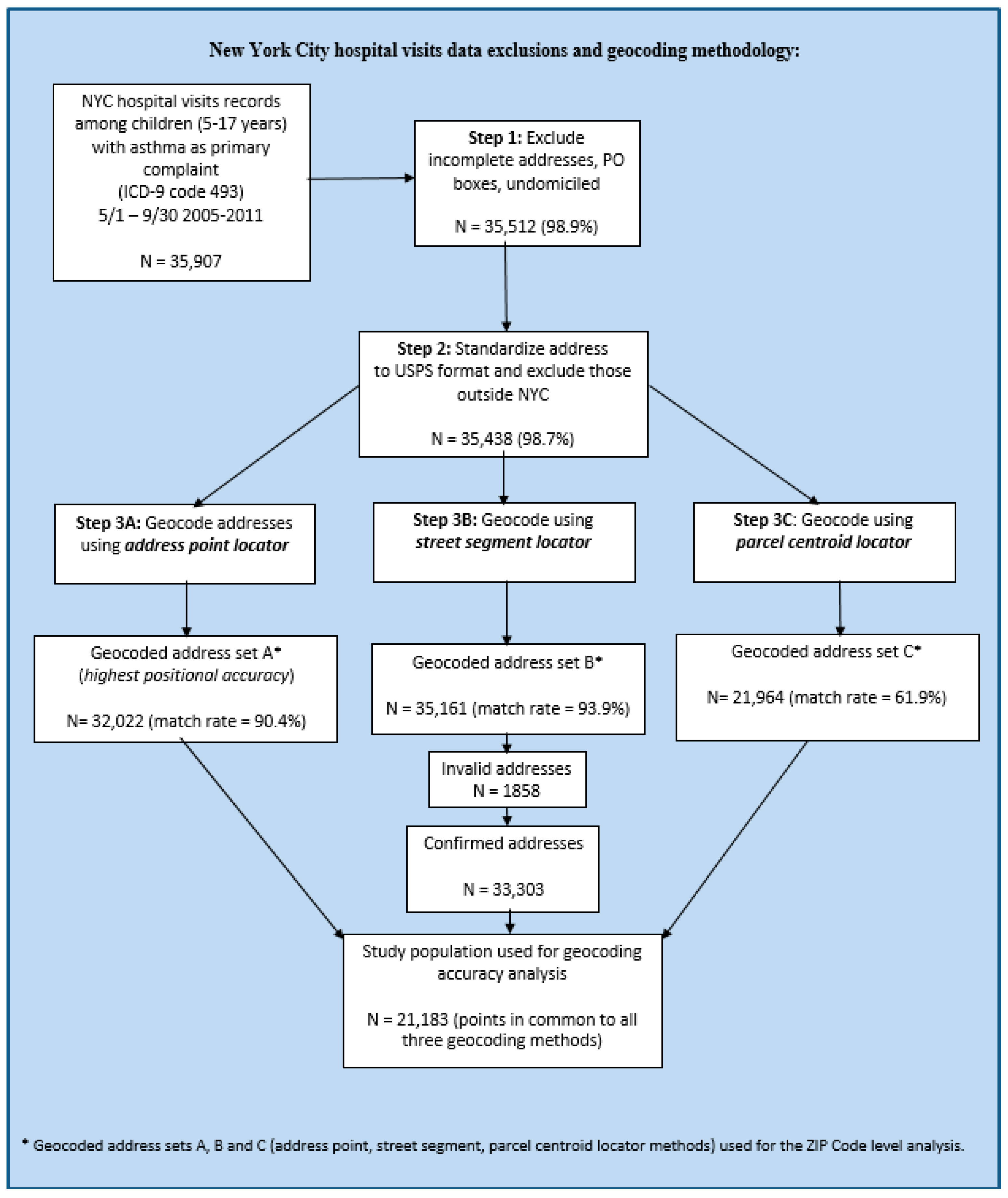
2.2. Geocoding Methods
2.3. Geocoding Error Measurement
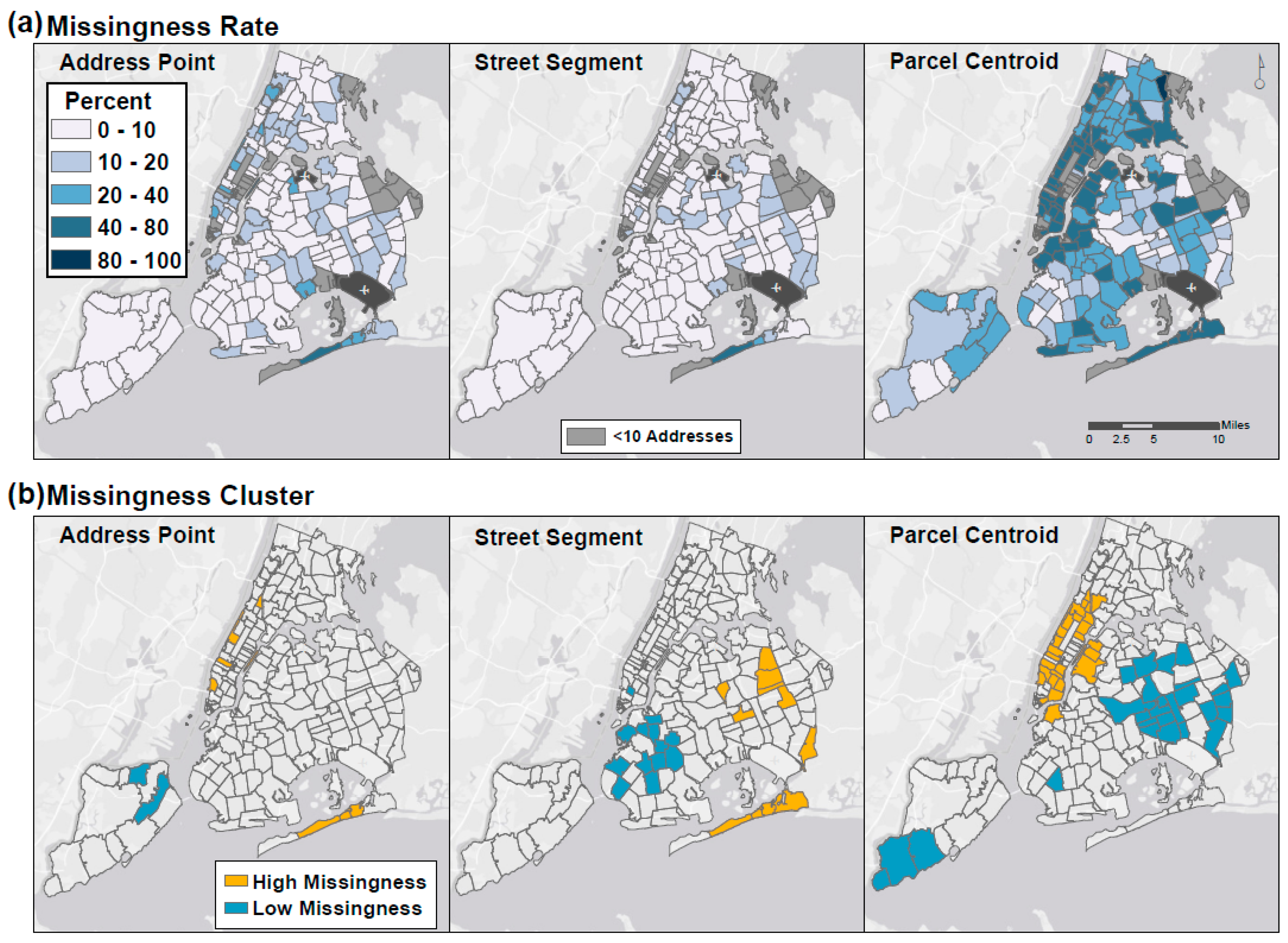
2.3.1. Missingness and Spatial Patterning in Missingness
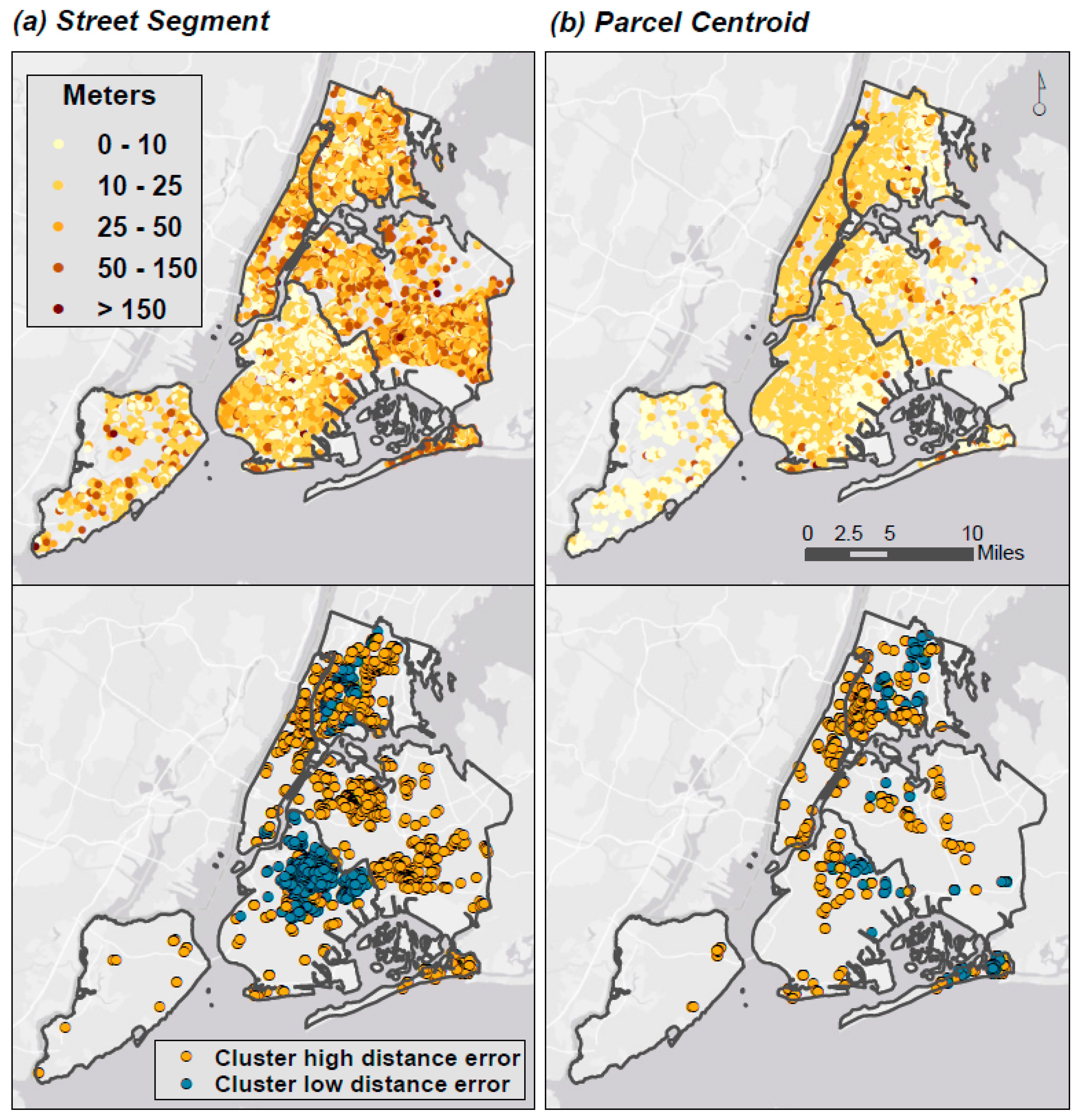
2.3.2. Distance Error
2.3.3. Directional Error
2.4. Exposure Assignment Impacts
2.4.1. Air Pollution Exposure Assignment
2.4.2. Socioeconomic Position Exposure Assignment
2.4.3. Spatial Clustering in NO2 Exposure Estimates
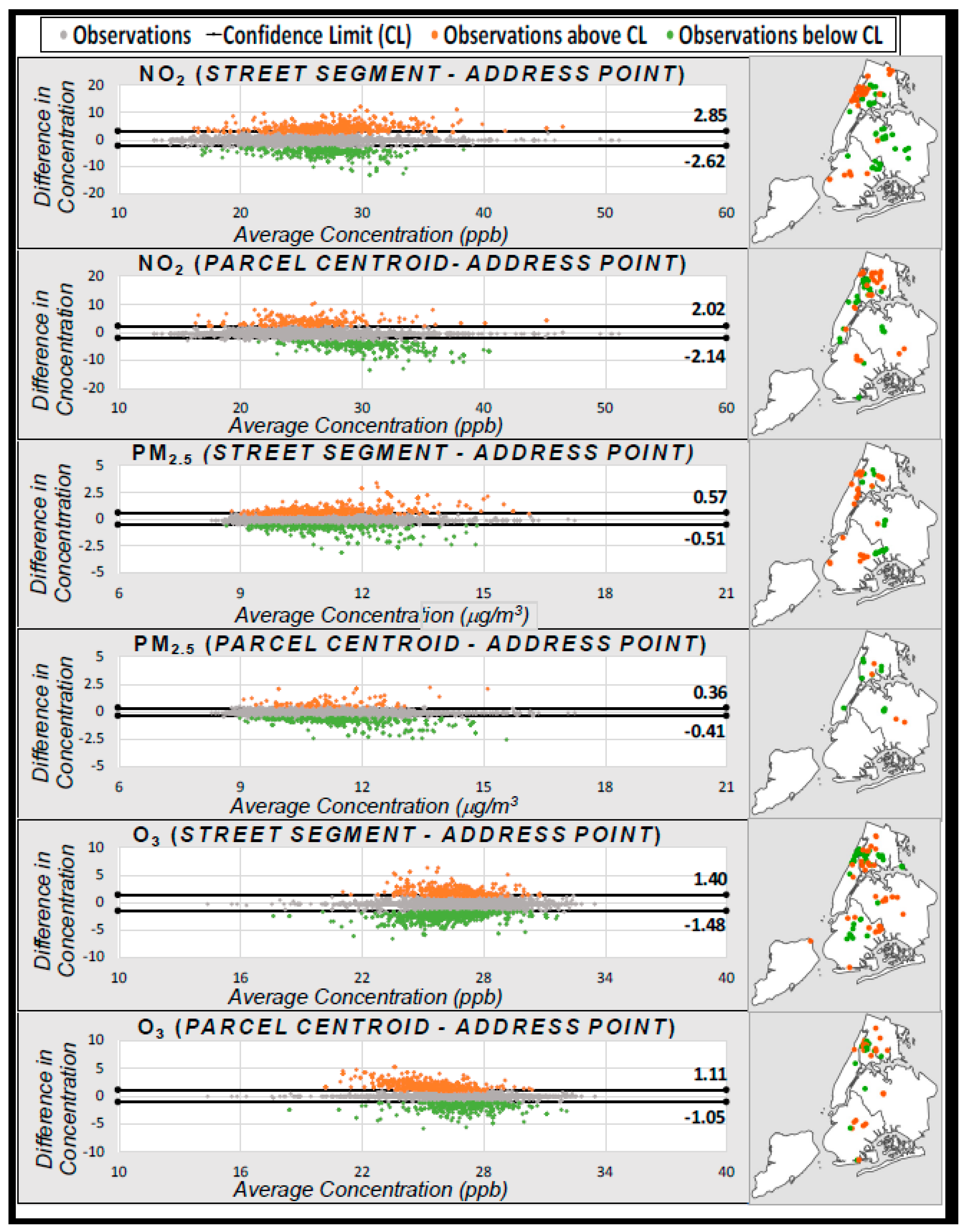
2.4.4. Differential Error in Air Pollution Exposure Estimates
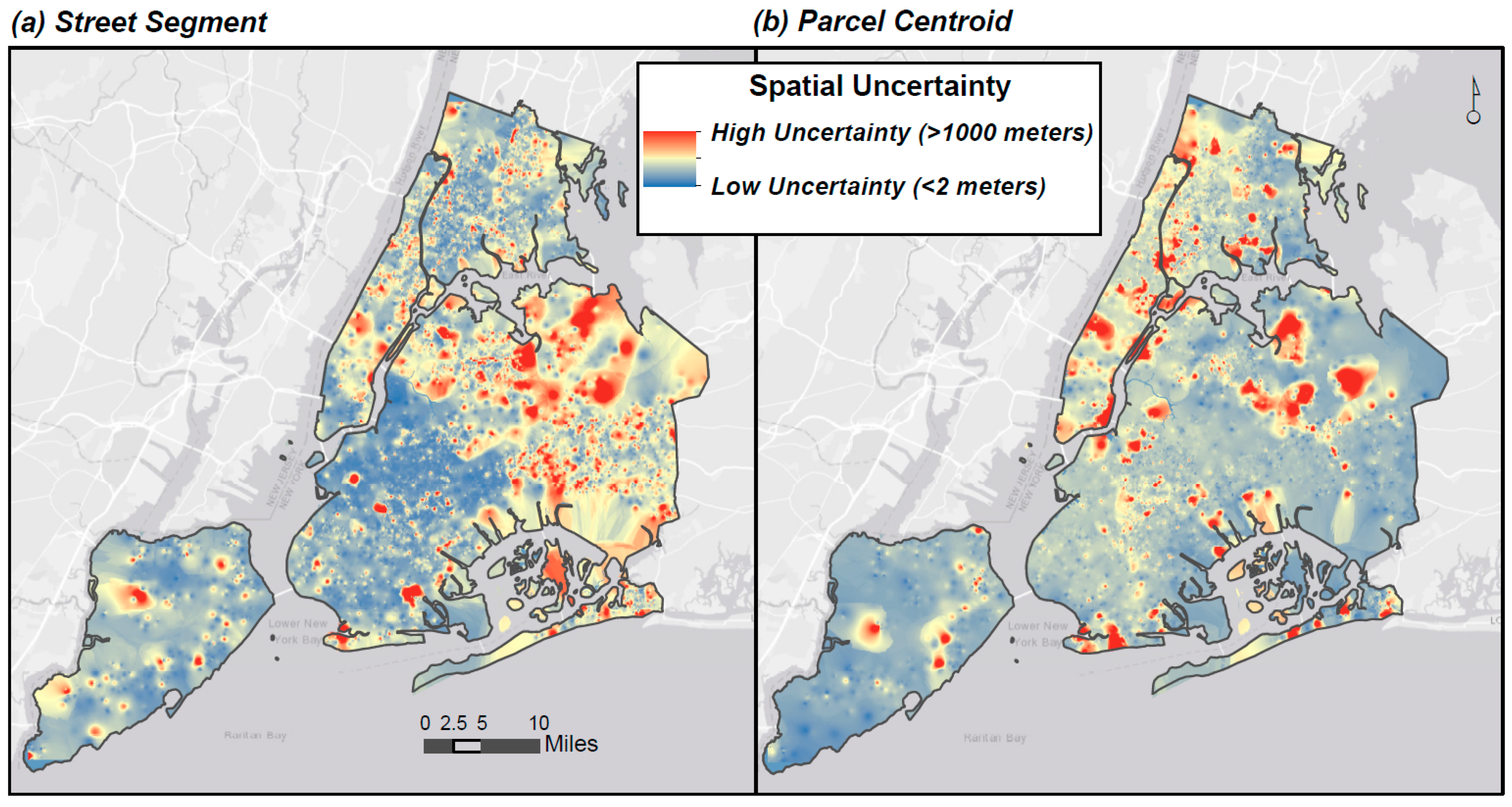
2.4.5. Spatial Uncertainty Surfaces
3. Results
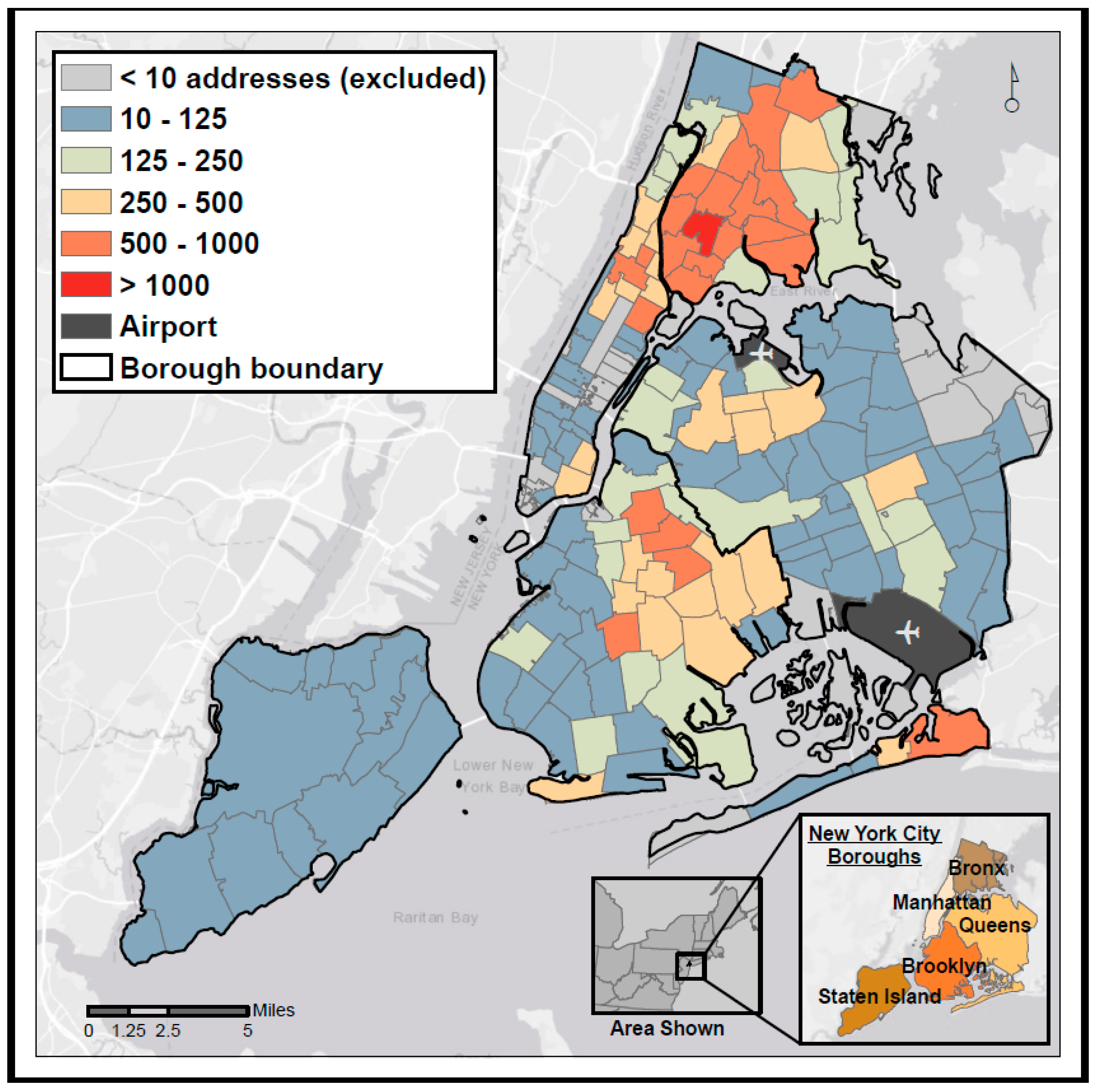
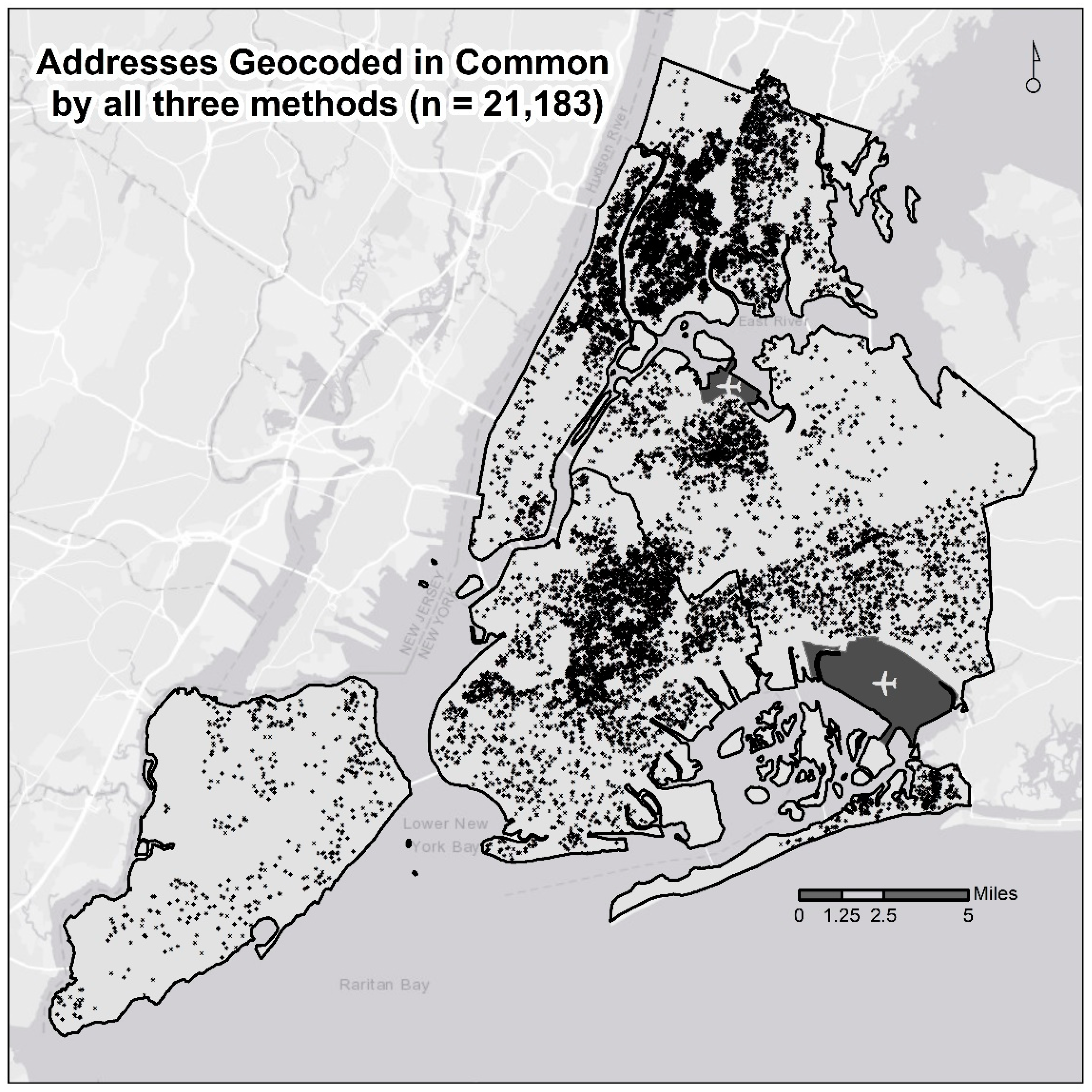
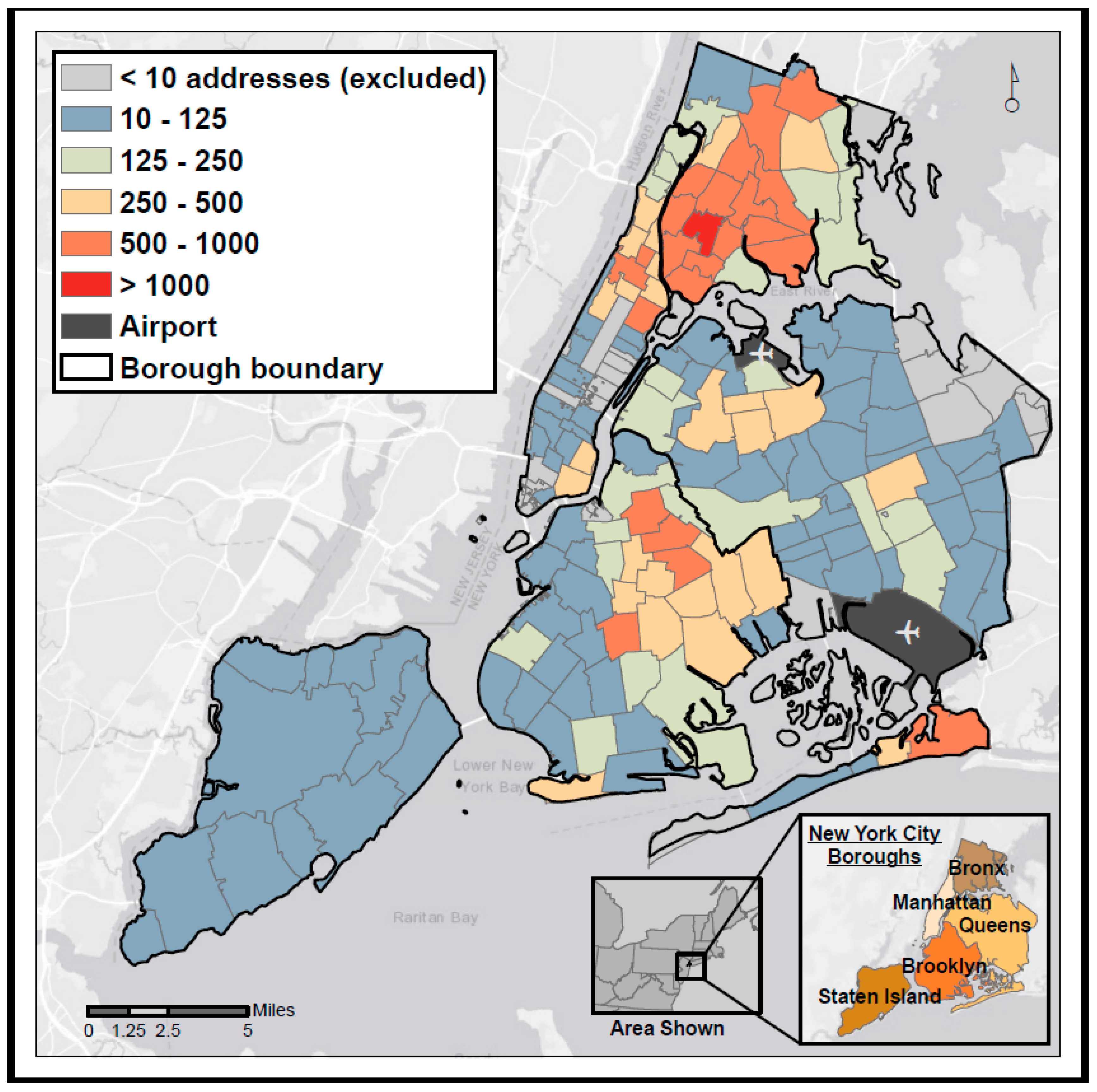
3.1. Missingness
3.2. Distance Error
3.3. Directional Error
3.4. Impacts on Air Pollution Exposure Estimates
3.5. Impacts on SEP Indicator Assignment
3.5.1. Census Area Assignment
3.5.2. Differential Accuracy in Pollution Exposure Estimates by SEP
3.6. Geocoding Uncertainty Surfaces
4. Discussion
4.1. Strengths
4.2. Limitations
4.3. Suggestions/Recommendations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Detailed Geocoding Methods
Appendix A.1. Address Cleaning
Appendix A.2. Address Locators
- The Address Point locator is based on USPS postal delivery point locations, which allows for precise assignment of latitude and longitude coordinates at the front door, or mail delivery point, of individual building footprints or parcels.This layer provides the highest degree of positional accuracy for residential exposure assignment, but is the most restrictive, in that it requires complete and exact address formatting.
- The Parcel Centroid locator matches each address to the corresponding tax Parcel Centroid, based on NYC tax parcel boundaries as determined by the NYC Department of Finance.Once the locator matches an address to a tax parcel, the geocode is assigned a latitude and longitude corresponding to the Parcel Centroid. This method provides a precise match with the information in tax records, but—because parcel lots vary widely with respect to size and buildings configuration—the positional accuracy of geocoded points varies substantially.
- The Street Segment locator matches addresses to Street Segments, assigning coordinates based on the interpolated position of the address number along the Street Segment address range.The locator first matches address records by street name, and then uses the address number range to interpolate an address point location along the appropriate side of the street center line (i.e., even- vs. odd-numbered side of the street). For example, the address 1250 Manhattan Blvd. would be located at the approximate midpoint of the Street Segment with numeric range of 1200–1298 Manhattan Blvd., on the even-numbered side of the street. Positional accuracy is dependent on Street Segment length and building density. Because the addresses successfully matched in this layer are not validated against real-world address data (i.e., interpolated points along a Street Segment may be located on vacant lots, or the address may not exist in an official database (i.e., USPS deliverable addresses)), we used the ZP4 software to verify that these addresses were eligible for mail delivery and excluded any non-confirmed records.
Appendix A.3. Side Offsets for Street Segment Locators

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Locator Setting | Address Point | Parcel Centroid | Street Segment |
|---|---|---|---|
| Style 1 | US Address–Single House | US Address–Single House | US Address–Dual Ranges |
| Reference data | NYC Open Data Address Points https://data.cityofnewyork.us/City-Government/NYC-Address-Points/g6pj-hd8k | NYC Tax Parcel polygons http://www1.nyc.gov/site/planning/data-maps/open-data/dwn-pluto-mappluto.page | TeleAtlas StreetMaps Premium 2013 https://doc.arcgis.com/en/streetmap-premium/get-started/overview.htm |
| Minimum match score 2 | 85 | 85 | 85 |
| Minimum candidate score 2 | 75 | 75 | 75 |
| Spelling sensitivity 2 | 80 | 80 | 80 |
| Side Offset 2 | 0 | 0 | 20 |

References
- Schinasi, L.H.; Benmarhnia, T.; De Roos, A.J. Modification of the association between high ambient temperature and health by urban microclimate indicators: A systematic review and meta-analysis. Environ. Res. 2018, 161, 168–180. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Greenblatt, R.; Levy, M.Z.; Himes, B.E. Enhancing Electronic Health Record Data with Geospatial Information. AMIA Summits Transl. Sci. Proc. 2017, 2017, 123–132. [Google Scholar] [PubMed]
- Xie, S.; Himes, B.E. Approaches to Link Geospatially Varying Social, Economic, and Environmental Factors with Electronic Health Record Data to Better Understand Asthma Exacerbations. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Bethesda, MD, USA, 2018; Volume 2018, pp. 1561–1570. [Google Scholar]
- Casey, J.A.; Schwartz, B.S.; Stewart, W.F.; Adler, N.E. Using Electronic Health Records for Population Health Research: A Review of Methods and Applications. Annu. Rev. Public Health 2016, 37, 61–81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hoek, G. Methods for Assessing Long-Term Exposures to Outdoor Air Pollutants. Curr. Environ. Health Rep. 2017, 4, 450–462. [Google Scholar] [CrossRef]
- Tripathy, S.; Tunno, B.J.; Michanowicz, D.R.; Kinnee, E.; Shmool, J.L.; Gillooly, S.; Clougherty, J.E. Hybrid land use regression modeling for estimating spatio-temporal exposures to PM2.5, BC, and metal components across a metropolitan area of complex terrain and industrial sources. Sci. Total Environ. 2019, 673, 54–63. [Google Scholar] [CrossRef] [PubMed]
- Parvez, F.; Wagstrom, K. A hybrid modeling framework to estimate pollutant concentrations and exposures in near road environments. Sci. Total Environ. 2019, 663, 144–153. [Google Scholar] [CrossRef]
- Cayo, M.R.; Talbot, T.O. Positional error in automated geocoding of residential addresses. Int. J. Health Geogr. 2003, 2, 10. [Google Scholar] [CrossRef] [Green Version]
- Jones, R.R.; DellaValle, C.T.; Flory, A.R.; Nordan, J.A.; Hoppin, J.N.; Hofmann, H.; Chen, J.; Giglierano, C.F.; Lynch, L.E.; Beane Freeman, G.; et al. Accuracy of residential geocoding in the Agricultural Health Study. Int. J. Health Geogr. 2014, 13, 37. [Google Scholar] [CrossRef] [Green Version]
- Zandbergen, P.A.; Green, J.W. Error and bias in determining exposure potential of children at school locations using proximity-based GIS techniques. Environ. Health Perspec. 2007, 115, 1363. [Google Scholar] [CrossRef] [Green Version]
- Gilboa, S.M.; Mendola, P.; Olshan, A.F.; Harness, C.; Loomis, D.; Langlois, P.H.; Savitz, D.A.; Herring, A.H. Comparison of residential geocoding methods in population-based study of air quality and birth defects. Environ. Res. 2006, 101, 256–262. [Google Scholar] [CrossRef]
- Han, D.; Bonner, M.R.; Nie, J.; Freudenheim, J.L. Assessing bias associated with geocoding of historical residence in epidemiology research. Geospat. Health 2013, 7, 369–374. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oliver, M.N.; Matthews, K.A.; Siadaty, M.; Hauck, F.R.; Pickle, L.W. Geographic bias related to geocoding in epidemiologic studies. Int. J. Health Geogr. 2005, 4, 29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zimmerman, D.L.; Fang, X.; Mazumdar, S. Spatial clustering of the failure to geocode and its implications for the detection of disease clustering. Stat. Med. 2008, 27, 4254–4266. [Google Scholar] [CrossRef]
- Zandbergen, P.A. A comparison of address point, parcel and street geocoding techniques. Comput. Environ. Urban Syst. 2008, 32, 214–232. [Google Scholar] [CrossRef]
- Schootman, M.; Sterling, D.A.; Struthers, J.; Yan, Y.; Laboube, T.; Emo, B.; Higgs, G. Positional accuracy and geographic bias of four methods of geocoding in epidemiologic research. Ann. Epidemiol. 2007, 17, 464–470. [Google Scholar] [CrossRef]
- Zimmerman, D.L.; Li, J.; Fang, X. Spatial autocorrelation among automated geocoding errors and its effects on testing for disease clustering. Stat. Med. 2010, 29, 1025–1036. [Google Scholar] [CrossRef] [Green Version]
- Burra, T.; Jerrett, M.; Burnett, R.; Anderson, M. Conceptual and practical issues in the detection of local disease clusters: A study of mortality in Hamilton, Ontario. Can. Geogr. 2002, 46, 160–171. [Google Scholar] [CrossRef]
- Whitsel, E.A.; Quibrera, P.M.; Smith, R.L.; Catellier, D.J.; Liao, D.; Henley, A.C.; Heiss, G. Accuracy of commercial geocoding: Assessment and implications. Epidemiol. Persp. Innov. 2006, 3, 8. [Google Scholar] [CrossRef] [Green Version]
- Zandbergen, P.A.; Hart, T.C.; Lenzer, K.E.; Camponovo, M.E. Error propagation models to examine the effects of geocoding quality on spatial analysis of individual-level datasets. Spat. Spatio Temporal Epidemiol. 2012, 3, 69–82. [Google Scholar] [CrossRef] [Green Version]
- Karimi, H.A.; Durcik, M.; Rasdorf, W. Evaluation of uncertainties associated with geocoding techniques. Comput. Aided Civ. Infrastruct. Eng. 2004, 19, 170–185. [Google Scholar] [CrossRef]
- Lane, K.J.; Scammell, M.K.; Levy, J.I.; Fuller, C.H.; Parambi, R.; Zamore, W.; Mwamburi, M.; Brugge, D. Positional error and time-activity patterns in near-highway proximity studies: An., exposure misclassification analysis. Environ. Health 2013, 12, 75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Horst, M.A.; Coco, A.S. Observing the spread of common illnesses through a community: Using Geographic Information Systems (GIS) for surveillance. J. Am. Board Fam. Med. 2010, 23, 32–41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mazumdar, S.; Rushton, G.; Smith, B.J.; Zimmerman, D.L.; Donham, K.J. Geocoding accuracy and the recovery of relationships between environmental exposures and health. Int. J. Health Geogr. 2008, 7, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jacquez, G.M. A research agenda: Does geocoding positional error matter in health GIS studies? Spat. Spatio Temporal Epidemiol. 2012, 3, 7–16. [Google Scholar] [CrossRef] [Green Version]
- Schwartz, B.S.; Stewart, W.F.; Godby, S.; Pollak, J.; Dewalle, J.; Larson, S.; Mercer, D.G.; Glass, T.A. Body mass index and the built and social environments in children and adolescents using electronic health records. Am. J. Prev. Med. 2011, 41, 17–28. [Google Scholar] [CrossRef]
- Zimmerman, D.L.; Li, J. The effects of local street network characteristics on the positional accuracy of automated geocoding for geographic health studies. Int. J. Health Geogr. 2010, 9, 10. [Google Scholar] [CrossRef] [Green Version]
- Jacquemin, B.; Lepeule, J.; Boudier, A.; Arnould, C.; Benmerad, M.; Chappaz, C.; Ferran, J.; Kauffmann, F.; Morelli, X.; Pin, I.; et al. Impact of geocoding methods on associations between long-term exposure to urban air pollution and lung function. Environ. Health Perspect. 2013, 121, 1054–1060. [Google Scholar] [CrossRef] [Green Version]
- Goldman, G.T.; Mulholland, J.A.; Russell, A.G.; Srivastava, A.; Strickland, M.J.; Klein, M.; Waller, L.A.; Tolbert, P.E.; Edgerton, E.S. Ambient Air Pollutant Measurement Error: Characterization and Impacts in a Time-Series Epidemiologic Study in Atlanta. Environ. Sci. Technol. 2010, 44, 7692–7698. [Google Scholar] [CrossRef] [Green Version]
- Chun, Y.; Griffith, D.A. Impacts of positional error on spatial statistics confidence intervals. In Proceedings of the Spatial Accuracy, East Lansing, MI, USA, 8–11 July 2014. [Google Scholar]
- Chun, Y.; Kwan, M.-P.; Griffith, D.A. Uncertainty and context in GIScience and geography: Challenges in the era of geospatial big data. Int. J. Geogr. Inform. Sci. 2019, 33, 1131–1134. [Google Scholar] [CrossRef] [Green Version]
- Griffith, D.A. Uncertainty and Context in Geography and GIScience: Reflections on Spatial Autocorrelation, Spatial Sampling, and Health Data. Ann. Am. Assoc. Geogr. 2018, 108, 1499–1505. [Google Scholar] [CrossRef]
- Zhang, Z.; Manjourides, J.; Cohen, T.; Hu, Y.; Jiang, Q. Spatial measurement errors in the field of spatial epidemiology. Int. J. Health Geogr. 2016, 15, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sheffield, P.E.; Zhou, J.; Shmool, J.L.; Clougherty, J.E. Ambient ozone exposure and children’s acute asthma in New York City: A case-crossover analysis. Environ. Health 2015, 14, 25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clougherty, J.E.; Kheirbek, I.; Eisl, H.M.; Ross, Z.; Pezeshki, G.; Gorczynski, J.E.; Johnson, S.; Markowitz, S.; Kass, D.; Matte, T. Intra-urban spatial variability in wintertime street-level concentrations of multiple combustion-related air pollutants: The New York City Community Air Survey (NYCCAS). J. Expo. Sci. Environ. Epidemiol. 2013, 23, 232–240. [Google Scholar] [CrossRef] [PubMed]
- Matte, T.D.; Ross, Z.; Kheirbek, I.; Eisl, H.; Johnson, S.; Gorczynski, J.E.; Kass, D.; Markowitz, S.; Pezeshki, G.; Clougherty, J.E. Monitoring intraurban spatial patterns of multiple combustion air pollutants in New York City: Design and implementation. J. Expo. Sci. Environ. Epidemiol. 2013, 23, 223–231. [Google Scholar] [CrossRef] [PubMed]
- NYCCAS. The New York City Community Air Survey 2008–2015; NYCCAS: New York, NY, USA, 2017.
- Hoek, G.; Beelen, R.; De Hoogh, K.; Vienneau, D.; Gulliver, J.; Fischer, P.; Briggs, D. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos. Environ. 2008, 42, 7561–7578. [Google Scholar] [CrossRef]
- Shmool, J.L.; Bobb, J.F.; Ito, K.; Elston, B.; Savitz, D.A.; Ross, Z.; Matte, T.D.; Johnson, S.; Dominici, F.; Clougherty, J.E. Area-level socioeconomic deprivation, nitrogen dioxide exposure, and term birth weight in New York City. Environ. Res. 2015, 142, 624–632. [Google Scholar] [CrossRef] [Green Version]
- Krieger, N.; Chen, J.T.; Waterman, P.D.; Soobader, M.-J.; Subramanian, S.V.; Carson, R. Geocoding and Monitoring of US Socioeconomic Inequalities in Mortality and Cancer Incidence: Does the Choice of Area-based Measure and Geographic Level Matter? The Public Health Disparities Geocoding Project. Am. J. Epidemiol. 2002, 156, 471–482. [Google Scholar] [CrossRef]
- Villanueva, C.; Aggarwal, B. The Association Between Neighborhood Socioeconomic Status and Clinical Outcomes Among Patients 1 Year After Hospitalization for Cardiovascular Disease. J. Commun. Health 2013, 38, 690–697. [Google Scholar] [CrossRef] [Green Version]
- New York State Department of Health. New York State Community Health Indicator Reports—About Socio-Economic Status Indicators, [Cited 2019; Percentage of Population Who Live Below the Federally Determined Guidelines for Poverty]. Available online: https://www.health.ny.gov/statistics/chac/indicators/about_ses.htm (accessed on 12 March 2020).
- United States Census Bureau. American Community Survey S1701, Poverty Status in the Past 12 Months, 2008–2012; United States Census Bureau: Sutran, MD, USA, 2012.
- Shmool, J.L.; Kinnee, E.; Sheffield, P.E.; Clougherty, J.E. Spatio-temporal ozone variation in a case-crossover analysis of childhood asthma hospital visits in New York City. Environ. Res. 2016, 147, 108–114. [Google Scholar] [CrossRef] [Green Version]
- Ratcliffe, J.H. On the accuracy of TIGER-type geocoded address data in relation to cadastral and census areal units. Int. J. Geogr. Inform. Sci. 2001, 15, 473–485. [Google Scholar] [CrossRef]
- Anselin, L. Local Indicators of Spatial Association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- ESRI. ArcGIS Desktop: Release 10.5; Environmental Systems Research Institute: Redlands, CA, USA, 2016. [Google Scholar]
- U.S. Census Bureau. American Housing Survey for the United States, 2011; U.S. Census Bureau: Sutran, MD, USA, 2013.
- Jenness, J. Polar Plots and Circular Statistics: Extension for ArcGIS; Jenness Enterprises: Flagstaff, AZ, USA, 2014. [Google Scholar]
- Berens, P. CircStat: A MATLAB Toolbox for Circular Statistics. J. Stat. Softw. 2009, 31, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Mutwiri, R.M.; Mwambi, H.; Slotow, R. Approaches for testing uniformity hypothesis in angular data of mega-herbivores. Int. J. Sci. Res. 2016, 5, 1202–1207. [Google Scholar]
- Ross, Z.; Ito, K.; Johnson, S.; Yee, M.; Pezeshki, G.; Clougherty, J.E.; Savitz, D.; Matte, T. Spatial and temporal estimation of air pollutants in New York City: Exposure assignment for use in a birth outcomes study. Environ. Health 2013, 12, 51. [Google Scholar] [CrossRef] [Green Version]
- Bland, J.M.; Altman, D.G. Measuring Agreement in Method Comparison Studies. Stat. Meth. Med. Res. 1999, 8, 135–160. [Google Scholar] [CrossRef]
- NCSS. NCSS 11 Statistical Software; NCSS LLC.: Kaysville, UT, USA, 2016. [Google Scholar]
- Bland, J.M.; Altman, D.G. Applying the right statistics: Analyses of measurement studies. Ultrasound Obstet. Gynecol. Off. J. Int. Soc. Ultrasound Obstet. Gynecol. 2003, 22, 85–93. [Google Scholar] [CrossRef]
- Giavarina, D. Understanding Bland Altman analysis. Biochem. Med. 2015, 25, 141–151. [Google Scholar]
- Koutsopoulos, K.; de Miguel Gonzalez, R.; Donert, K. Geospatial Challenges in the 21st Century; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- MacEachren, A.M.; Robinson, A.; Hopper, S.; Gardner, S.; Murray, R.; Gahegan, M.; Hetzler, E. Visualizing geospatial information uncertainty: What we know and what we need to know. Cartogr. Geogr. Inform. Sci. 2005, 32, 139–160. [Google Scholar] [CrossRef] [Green Version]
- Hope, S.; Hunter, G. Testing the effects of positional uncertainty on spatial decision-making. Int. J. Geogr. Inform. Sci. 2007, 21, 645–665. [Google Scholar] [CrossRef]
- Lee, M.; Chun, Y.; Griffith, D.A. Spatial Data Analysis Uncertainties Introduced by Selected Sources of Error. In Advances in Geocomputation; Springer: Berlin/Heidelberg, Germany, 2017; pp. 303–313. [Google Scholar]
- Davis, C.A.; Fonseca, F.T. Assessing the certainty of locations produced by an address geocoding system. Geoinformatica 2007, 11, 103–129. [Google Scholar] [CrossRef]
- Strickland, M.J.; Siffel, C.; Gardner, B.R.; Berzen, A.K.; Correa, A. Quantifying geocode location error using GIS methods. Environ. Health 2007, 6, 10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zandbergen, P.A. Geocoding quality and implications for spatial analysis. Geogr. Compass 2009, 3, 647–680. [Google Scholar] [CrossRef]
- Karner, A.A.; Eisinger, D.S.; Niemeier, D.A. Near-roadway air quality: Synthesizing the findings from real-world data. Environ. Sci. Technol. 2010, 44, 5334–5344. [Google Scholar] [CrossRef] [PubMed]
- Hart, T.C.; Zandbergen, P.A. Reference data and geocoding quality: Examining completeness and positional accuracy of street geocoded crime incidents. Polic. Int. J. Police Strateg. Manag. 2013, 36, 263–294. [Google Scholar] [CrossRef]
- Quinn, J.W.; Mooney, S.J.; Sheehan, D.M.; Teitler, J.O.; Neckerman, K.M.; Kaufman, T.K.; Lovasi, G.S.; Bader, M.D.; Rundle, A.G. Neighborhood physical disorder in New York City. J. Maps 2016, 12, 53–60. [Google Scholar] [CrossRef] [Green Version]
- Lu, G.Y.; Wong, D.W. An adaptive inverse-distance weighting spatial interpolation technique. Comput. Geosci. 2008, 34, 1044–1055. [Google Scholar] [CrossRef]
- Roberts, E.A.; Sheley, R.L.; Lawrence, R.L. Using sampling and inverse distance weighted modeling for mapping invasive plants. West N. Am. Nat. 2004, 64, 4. [Google Scholar]
- Li, J.; Heap, A.D. A review of spatial interpolation methods for environmental scientists. Environ. Sci. 2008, 23, 137–145. [Google Scholar]
- Zandbergen, P.A. Influence of street reference data on geocoding quality. Geocarto Int. 2011, 26, 35–47. [Google Scholar] [CrossRef]
- Gan, W.Q.; McLean, K.; Brauer, M.; Chiarello, S.A.; Davies, H.W. Modeling population exposure to community noise and air pollution in a large metropolitan area. Environ. Res. 2012, 116, 11–16. [Google Scholar] [CrossRef]
- Ribeiro, M.C.; Pereira, M.J. Modelling local uncertainty in relations between birth weight and air quality within an urban area: Combining geographically weighted regression with geostatistical simulation. Environ. Sci. Pollut. Res. Int. 2018, 25, 25942–25954. [Google Scholar] [CrossRef] [PubMed]

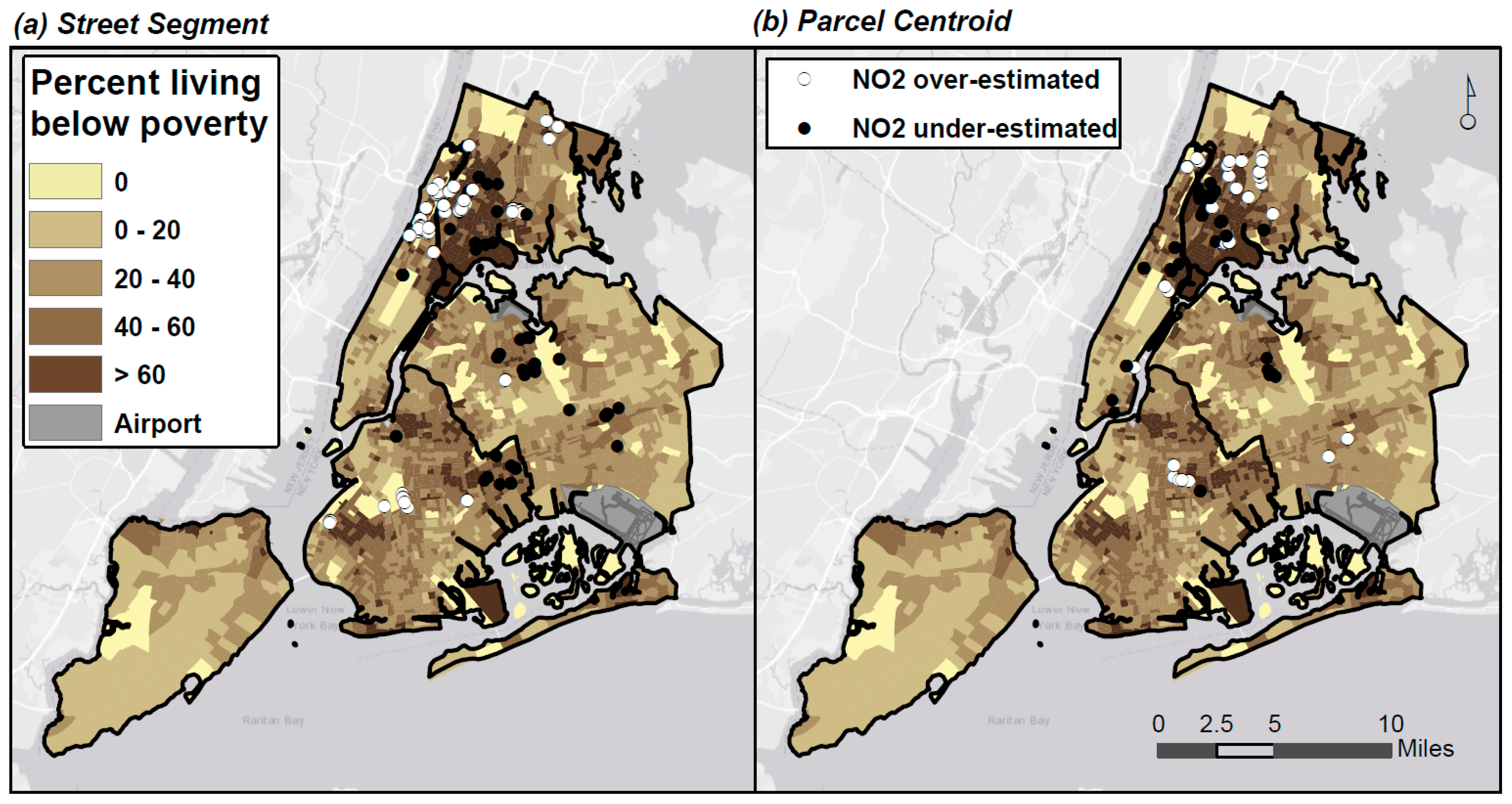
| Error Type | Frequency (%) | Mean NO2 (+/− SD) (ppb) | Mean Percent Below Federal Poverty Level (+/− SD) |
|---|---|---|---|
| Street Segment geocodes over-estimating NO2 | 855 (4.0%) | 30.4 ± 4.18 | 25.9 ± 11.5 |
| Street Segment geocodes under-estimating NO2 | 519 (2.5%) | 24.8 ± 3.0 | 26.9 ± 12.8 |
| Parcel Centroid geocodes over-estimating NO2 | 426 (2.0%) | 28.9 ± 4.3 | 28.6 ± 12.2 |
| Parcel Centroid geocodes under-estimating NO2 | 584 (2.8%) | 25.5 ± 3.0 | 30.9 ± 12.6 |
| Total Frequency (%) Average (+/−SD) | 2384 (11.3%) | 25.6 ± 3.2 | 28.1 ± 12.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kinnee, E.J.; Tripathy, S.; Schinasi, L.; Shmool, J.L.C.; Sheffield, P.E.; Holguin, F.; Clougherty, J.E. Geocoding Error, Spatial Uncertainty, and Implications for Exposure Assessment and Environmental Epidemiology. Int. J. Environ. Res. Public Health 2020, 17, 5845. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17165845
Kinnee EJ, Tripathy S, Schinasi L, Shmool JLC, Sheffield PE, Holguin F, Clougherty JE. Geocoding Error, Spatial Uncertainty, and Implications for Exposure Assessment and Environmental Epidemiology. International Journal of Environmental Research and Public Health. 2020; 17(16):5845. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17165845
Chicago/Turabian StyleKinnee, Ellen J., Sheila Tripathy, Leah Schinasi, Jessie L. C. Shmool, Perry E. Sheffield, Fernando Holguin, and Jane E. Clougherty. 2020. "Geocoding Error, Spatial Uncertainty, and Implications for Exposure Assessment and Environmental Epidemiology" International Journal of Environmental Research and Public Health 17, no. 16: 5845. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17165845