Visualizing Inequality in Health and Socioeconomic Wellbeing in the EU: Findings from the SHARE Survey



Abstract
:1. Introduction
2. Literature Review
3. Methodology
3.1. First Stage
- (1)
- Select the group of descriptive variables. This group does not contribute to the indices and it is left unchanged. The kind of variables to be included in this group is usually related to socio-demographic information such as gender, age, education, employment, etc.
- (2)
- Thematic blocks: Group the rest of information in particular issues of interest yielding thematic blocks. For example, group the variables in four or five aspects to be studied.
- (3)
- For each thematic block, construct a composite index. To do so,
- (a)
- Variables within thematic blocks must be encoded. Here it can be of help to review some related literature with a view on how to treat each of the pertinent variables.
- (b)
- Transform all the included variables into binary variables, always maintaining the same polarity. For example, assign 1 to the worst-case scenario and 0 to the best-case scenario.
- Always maintain consistency. For categorical variables, when a scale is identical for two or more of them, the same cut-off must be designated for these variables. For example, this means that any question where the response options are “Poor”, “Fair”, “Good”, “Very good”, or “Excellent”, these variables must be transformed in the same manner using the same cut-off point.
- For quantitative variables, thresholds such as the median or even more restrictive percentiles can be used.
- (c)
- Leave binary variables unchanged.
- (d)
- Finally, construct the thematic index by adding all binarized variables and rescale to 0–10.
3.2. Second Stage
4. Data and Methods
- Country: 18 European countries and Israel;
- Gender: Male, Female;
- Ages: 55–60, 61–65, 66–75, 76+;
- Employment status: Employed, Not working;
- Marital status: Has no spouse, Has a spouse;
- Children: Has no children, Has one or more children;
- Education: No education, Primary, Secondary, University;
- Household in financial distress: Yes, No;
- Household receives benefits or has payments: Payments and no benefits, No benefits and no payments, Benefits and payments, Payments and no benefits.
4.1. Descriptive Variables
4.2. Index Creation
- Index 1: Self-perception. Life satisfaction; Life happiness; Self-perceived health; of health EURO depression scale; Satisfied doing no activities last year.
- Index 2: Physical health and nutrition. Number of chronic diseases; Number of nights spent in hospital; Living in a nursing home; Eyesight score; Hearing score; Ever smoked daily; How often eat fish, meat or poultry; How often eat vegetables; BMI; Max grip strength.
- Index 3: Mental agility. Self-rated reading; Self-rated writing; Score of memory test; Score of numeracy test; Score of orientation in time test; Score of words list learning test (both trials); Score of verbal fluency test.
- Index 4: Dependency. Global Activity Limitation Indicator (GALI); Number of mobility limitations; Number of difficulties in ADLs; Number of difficulties in IADLs; Physical inactivity.
4.2.1. Index 1: Self-Perception of Health
4.2.2. Index 2: Physical Health and Nutrition
4.2.3. Index 3: Mental Agility
4.2.4. Index 4: Dependency
4.3. Profile Construction
5. Results
5.1. Description of Profiles and Findings
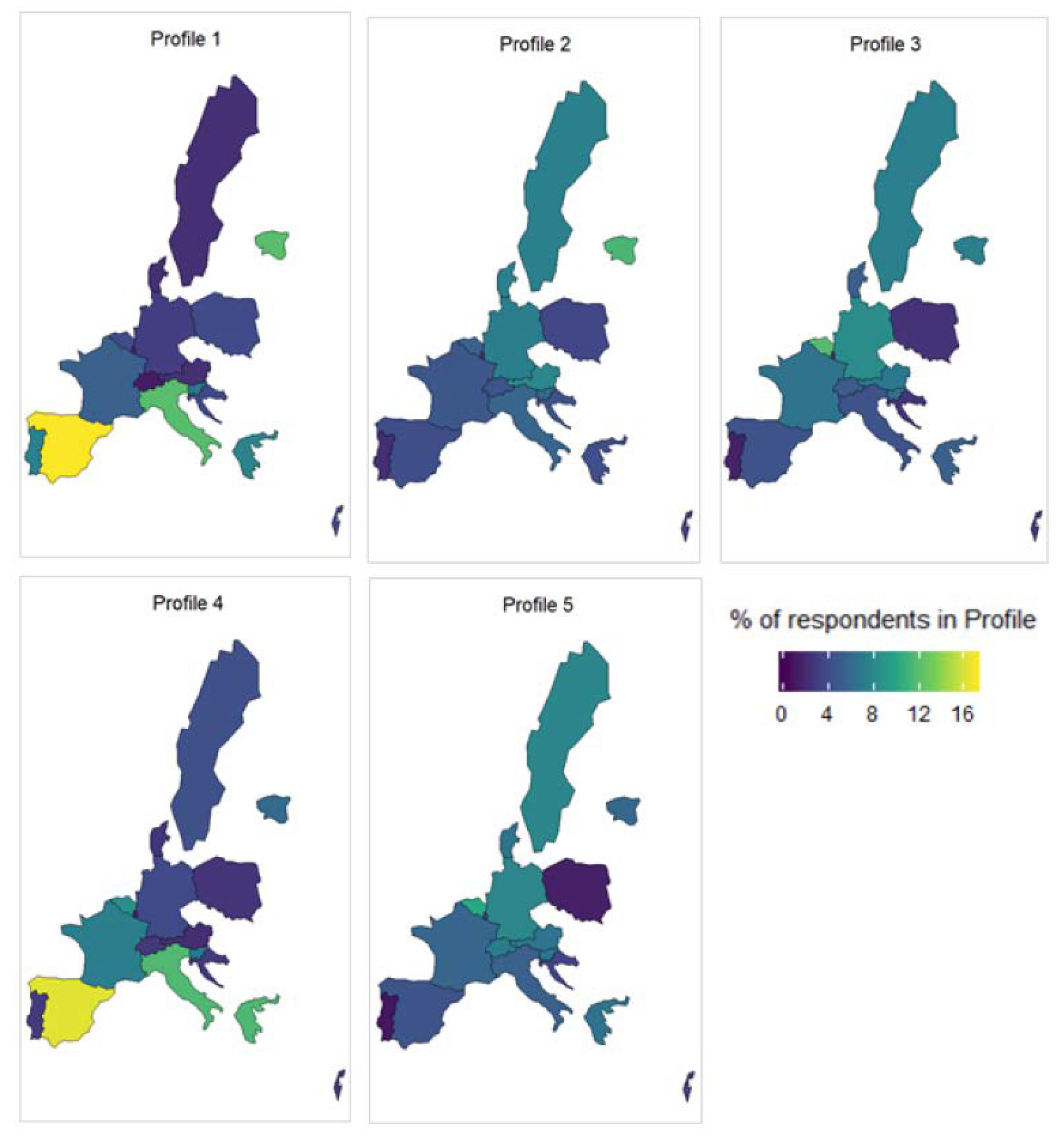
- Profile 1: Highest social vulnerability, lowest levels of health and socioeconomic wellbeing. Urgent need of social assistance. It is composed by 15.96% of the target population. Main characteristics: female; 76 years old or older; low education (primary or none); not working; likely lives alone; suffers from multiple limitations in ADL or IDAL; health-related payments or benefits; in financial distress; very negative self-perception of health; lack of autonomy; major difficulties in cognitive functions, with risk of suffering/developing serious health conditions.
- Profile 2: Medium-high social vulnerability. It is composed by 22.59% of the target population. Main characteristics: female; equally likely to belong to any age bracket; primary educated; not working; lives with a partner; few limitations in ADL or IADL; health-related payments or benefits; negative self-perception of health; lack of autonomy; with risk of suffering/developing serious health conditions.
- Profile 3: Medium-low social vulnerability. It is composed by 10.69% of the target population. Main characteristics: female; equally likely to belong to any age bracket; secondary educated; not working; lives with a partner; few limitations in ADL or IADL; health-related payments or benefits; with some negative aspects on self-perception of health; shows the highest score of suffering/developing serious health problems.
- Profile 4: High social vulnerability, low levels of health and socioeconomic wellbeing. Urgent need of social assistance. It is composed by 23.18% of the target population. Main characteristics: male; 70 years or older; primary educated; not working; lives with a partner; some limitations in ADL or IADL; health-related payments or benefits; likely in financial distress; shows the highest score of difficulties in cognitive functions; with risk of suffering/developing serious health problems.
- Profile 5: Low risk of social vulnerability, reasonable levels of health and socioeconomic wellbeing. Least need of social assistance. It is composed by 27.58% of the target population. Main characteristics: male; younger (55–65 years old); secondary or university educated; likely still working; lives with a partner; very unlikely to have limitations in ADL or IADL; no health-related benefits, some payments; shows the lowest scores in all wellbeing indices.
5.2. Profiles across the EU
6. Discussion
6.1. Key Messages and Implications
6.2. Strengths, Limitations, and Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Count | % of Total | Age | Age Prop. | Gender | Gender Prop. | Job Status | Job Status Prop. |
|---|---|---|---|---|---|---|---|---|
| 1 | 19,841,335 | 15.96% | 76+ | 50% | Female | 63% | Not working | 78% |
| 2 | 28,081,489 | 22.59% | 76+ | 26% | Female | 61% | Not working | 73% |
| 3 | 13,289,581 | 10.69% | 76+ | 23% | Female | 61% | Not working | 74% |
| 4 | 28,820,451 | 23.18% | 76+ | 30% | Male | 50% | Not working | 70% |
| 5 | 34,280,767 | 27.58% | 55-60 | 30% | Male | 53% | Not working | 57% |
| Cluster | Household in financial distress? | Financial distress prop. | Marital status | Marital status prop. | Education level | Education level prop. | Payments or benefits? | Payments or benefits prop. |
| 1 | Yes | 62% | Spouse | 59% | Primary | 57% | B & P | 71% |
| 2 | No | 63% | Spouse | 68% | Secondary | 42% | B & P | 69% |
| 3 | No | 67% | Spouse | 68% | Secondary | 46% | B & P | 72% |
| 4 | No | 56% | Spouse | 71% | Primary | 52% | B & P | 59% |
| 5 | No | 74% | Spouse | 76% | Secondary | 43% | B & P | 52% |
| Cluster | Index 1 mean | Index 1 median | Index 2 mean | Index 2 median | Index 3 mean | Index 3 median | Index 4 mean | Index 4 median |
| 1 | 5.56 | 5 | 3.77 | 4 | 7.85 | 8 | 5.55 | 6 |
| 2 | 5.73 | 5 | 2.87 | 2 | 2.22 | 2 | 3.52 | 4 |
| 3 | 1.27 | 2 | 4.43 | 4 | 1.6 | 2 | 3.08 | 2 |
| 4 | 1.05 | 2 | 2.24 | 2 | 5.18 | 4 | 2.39 | 2 |
| 5 | 0.86 | 0 | 1.31 | 1 | 1.02 | 2 | 1.3 | 0 |
| Cluster | Average ADL limitations | Proportion to global average ADL limitations | Average IADL limitations | Proportion to global average IADL limitations | ||||
| 1 | 0.87 | 3.2 | 1.88 | 3.4 | ||||
| 2 | 0.33 | 1.2 | 0.61 | 1.1 | ||||
| 3 | 0.20 | 0.7 | 0.41 | 0.7 | ||||
| 4 | 0.17 | 0.6 | 0.38 | 0.7 | ||||
| 5 | 0.04 | 0.1 | 0.07 | 0.1 | ||||

References
- Davies, R. Older people in Europe EU Policies and Programmes. Available online: https://epthinktank.eu/2014/05/22/older-people-in-europe-eu-policies-and-programmes/ (accessed on 21 September 2020).
- Ney, S. Active Aging Policy in Europe: Between Path Dependency and Path Departure. Ageing Int. 2005, 30, 325–342. [Google Scholar] [CrossRef]
- Baltes, M. The Many Faces of Dependency in Old Age; Cambridge University Press: New York, NY, USA, 1996. [Google Scholar]
- Albarrán, A.; Alonso, P.; Grané, A. Profile identification via weighted related metric scaling: An application to dependent Spanish children. J. R. Stat. Soc. Ser. A-Stat. Soc. 2015, 178, 1–26. [Google Scholar]
- Carrino, L.; Orso, C. Eligibility and Inclusiveness of Long-Term Care Institutional Frameworks in Europe: A Cross-Country Comparison. Available online: https://ssrn.com/abstract=2541246 (accessed on 21 September 2020).
- Tenand, M. Equity and Eficiency in Long-Term Care Policies: Empirical Evidence from France and The Netherlands. Ph.D. Thesis, PSL Research University, Paris, France, 2018. [Google Scholar]
- Barczyk, D.; Kredler, M. Long-term Care across Europe and the U.S.: The Role of Informal and Formal Care. Fisc. Stud. 2019, 40, 329–373. [Google Scholar] [CrossRef]
- Del Pozo-Rubio, R.; Moya-Martínez, P.; Ortega-Ortega, M.; Oliva-Moreno, J. Shadow and extended shadow cost sharing associated to informal long-term care: The case of Spain. Health Econ. Rev. 2020, 10, 12. [Google Scholar] [CrossRef] [PubMed]
- WHO. International Classification of Functioning, Disability and Health (ICF); WHO: Geneva, Switzerland, 2002. [Google Scholar]
- Huang, Z. Clustering large data sets with mixed numeric and categorical values. In Proceedings of the First Pacific Asia Knowledge Discovery and Data Mining Conference, Singapore, 23–24 February 1997; pp. 21–34. [Google Scholar]
- Maiti, D.; Awasthi, A. Exposure and the Level of Wellbeing and Progess: A Cross Country Analysis. Soc. Indic. Res. 2020, 147, 311–343. [Google Scholar] [CrossRef]
- Stiglitz, J.E.; Sen, A.; Fitoussi, J. The Measurement of Economic Performance and Social Progress: Reflections and Overview. Available online: https://spire.sciencespo.fr/notice/2441/5l6uh8ogmqildh09h4687h53k (accessed on 21 September 2020).
- White, S. Bringing Wellbeing into Development Practice; University of Bath: Bath, UK, 2009. [Google Scholar]
- Halleröd, B.; Seldén, D. The Multi-dimensional Characteristics of Wellbeing: How Different Aspects of Wellbeing Interact and Do Not Interact with Each Other. Soc. Indicicators Res. 2013, 113, 807–825. [Google Scholar] [CrossRef]
- Bache, I. How Does Evidence Matter? Understanding ‘What Works’ for Wellbeing. Soc. Indic. Res. 2019, 142, 1153–1173. [Google Scholar] [CrossRef] [Green Version]
- Weeranakin, P.; Promphakping, B. Local Meanings of Wellbeing and the Construction of Wellbeing Indicators. Soc. Indic. Res. 2018, 138, 689–703. [Google Scholar] [CrossRef]
- Linares-Luján, A.; Parejo-Moruno, F. Height, Literacy and Survival: A Composite Index of Wellbeing Based on Data from Military Recruitment (1880–1980). Soc. Indic. Res. 2019, 144, 999–1019. [Google Scholar] [CrossRef]
- Mori, K.; Kaiho, Y.; Tomata, Y.; Narita, M.; Tanji, F.; Sugiyama, K.; Sugawara, Y.; Tsuji, I. Sense of life worth living (ikigai) and incident functional disability in elderly Japanese: The Tsurugaya Project. J. Psychosom. Res. 2017, 95, 62–67. [Google Scholar] [CrossRef] [PubMed]
- Boyle, P.; Buchman, A.; Bennett, D. Purpose in life is associated with a reduced risk of incident disability among community-dwelling older persons. Am. J. Geriatr. Psychiatry 2010, 18, 1093–1102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Walker, A. Calidad de vida de las personas mayores. Análisis comparativo europeo. Rev. Española Geriatría Gerontol. 2004, 39, 8–17. [Google Scholar]
- Argyle, M. Is happiness a cause of health? Psychol. Health 1997, 12, 769–781. [Google Scholar] [CrossRef]
- Baltes, P.B.; Baltes, M.M. Psychological perspectives on successful aging: The model of selective optimization with compensation. In Successful Aging: Perspectives from the Behavioural Sciences; Baltes, P.B., Baltes, M.M., Eds.; Cambridge University Press: Cambridge, UK, 1990; pp. 1–34. [Google Scholar]
- Steptoe, A.; Deaton, A.; Stone, A. Subjective Wellbeing, Health and Ageing. Lancet 2015, 385, 640–648. [Google Scholar] [CrossRef] [Green Version]
- Albrecht, G.L.; Devlieger, P.J. Disability assumptions, concepts and theory: Reply to Tom Kock. Soc. Sci. Med. 2000, 50, 761–762. [Google Scholar] [CrossRef]
- Abellán, A. Percepción del estado de salud. Revista Multidisciplinar de Gerontología 2003, 13, 340–342. [Google Scholar]
- Cristea, M.; Noja, G.; Stefea, P.; Sala, A. The Impact of Population Aging and Public Health Support on EU Labor Markets. J. Environ. Res. Public Health 2020, 17, 1439. [Google Scholar] [CrossRef] [Green Version]
- Eurofound. Access to Care Services: Early Childhood Education and Care, Healthcare and Long-Term Care; Publications Office of the European Union: Luxembourg, 2020. [Google Scholar]
- Andersen, G.E. The Three Woorls of Wellfare Capitalism; Princeton University Press: Princeton, NJ, USA, 1990. [Google Scholar]
- Hlebec, V.; Srakar, A.; Majcen, B. Long-Term Care Determinants of Care Arrangements for Older People in Europe: Evidence from SHARE. Rev. Soc. Polit. 2019, 26, 135–152. [Google Scholar] [CrossRef]
- United Nations. Prevention and Control of Non-Communicable Diseases. Available online: https://www.who.int/nmh/events/2011/UN_resolution_prevention_control_ncds.pdf (accessed on 21 September 2020).
- Stolz, E.; Mayerl, H.; Freidl, W. Fluctuations in Frailty among Older Adults. Age Ageing 2019, 48, 547–552. [Google Scholar] [CrossRef]
- Gwozdz, W.; Sousa-Poza, A. Ageing, health and life satisfaction of the oldest old: An analysis for Germany. Soc. Indic. Res. 2010, 97, 397–417. [Google Scholar] [CrossRef] [Green Version]
- Chatterji, S.; Byles, J.; Cutler, D.; Seeman, T.; Verdes, E. Health, functioning, and disability in older adultspresent status and future implications. Lancet 2015, 385, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Verropoulou, G.; Tsimbos, C. Disability Trends among Older Adults in Ten European Countries over 2004–2013, Using Various Indicators and Survey of Health, Ageing and Retirement in Europe (SHARE) Data. Ageing Soc. 2016, 37, 2152–2182. [Google Scholar] [CrossRef]
- Real, T. Dependencia funcional, depresión y calidad de vida en ancianos institucionalizados. Inf. Psiquiátricas 2008, 192, 163–178. [Google Scholar]
- Gower, J. A general coefficient of similarity and some of its properties. Biometrics 1971, 27, 857–874. [Google Scholar] [CrossRef]
- Lloyd, S.P. Least square quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Huang, Z. A fast clustering algorithm to cluster very large categorical data sets in data mining. In Proceedings of the SIGMOD Workshop on Research Issues on Data Mining and Knowledge Discovery, Tucson, AZ, USA, 11 May 1997; pp. 1–8. [Google Scholar]
- Van de Velden, M.; Iodice-D’Enza, A.; Markos, A. Distance-based clustering of mixed data. Wires Comput. Stat. 2018, 11, e1456. [Google Scholar] [CrossRef]
- Foss, H.; Markatou, M.; Bonnie, R. Distance Metrics and Clustering Methods for Mixed-type Data. Int. Stat. Rev. 2019, 87, 80–109. [Google Scholar] [CrossRef]
- Huang, Z. Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Börsch-Supan, A. Survey of Health, Ageing and Retirement in Europe (SHARE). Available online: http://www.share-project.org/data-documentation/waves-overview/wave-6.html (accessed on 21 September 2020).
- Börsch-Supan, A.; Brandt, M.; Hunkler, C.; Kneip, T.; Korbmacher, J.; Malter, F.; Schaan, B.; Stuck, S.; Zuber, S. Data Resource Profile: The Survey of Health, Ageing and Retirement in Europe (SHARE). Int. J. Epidemiol. 2013, 42, 992–1001. [Google Scholar] [CrossRef]
- Albertini, M.; Arpino, B. Childlessness, parenthood and subjective wellbeing: The relevance of conceptualizing parenthood and childlessness as a continuum. In Proceedings of the European Population Conference 2018, Brussels, Belgium, 6–9 June 2018. [Google Scholar]
- Becchetti, L.; Conzo, P.; Pisani, F. Education, Health and Subjective Wellbeing in Europe. Available online: https://ssrn.com/abstract=2595705 (accessed on 21 September 2020).
- Havari, E.; Peracchi, F. Growing up in wartime—Evidence from the era of two world wars. Econ. Hum. Biol. 2014, 25, 9–32. [Google Scholar] [CrossRef]
- Côté-Sergent, A.; Fonseca, R.; Strumpf, E. Comparing the Education Gradient in Chronic Disease Incidence among the Elderly in Six OECD Countries. Available online: https://ideas.repec.org/p/lvl/criacr/1801.html (accessed on 21 September 2020).
- Hank, K. How “successful” do older Europeans age? Findings from SHARE. J. Gerontol. Ser. B Psychol. Sci. Soc. Sci. 2011, 66, 230–236. [Google Scholar] [CrossRef] [PubMed]
- Nie, P.; Sousa-Poza, A. Food Insecurity among Older Europeans: Evidence from the Survey of Health, Ageing, and Retirement in Europe. Available online: https://ideas.repec.org/p/zbw/hohdps/032016.html (accessed on 21 September 2020).
- Abeliansky, A.; Strulik, H. How we fall apart: Similarities of human aging in 10 European countries. Demography 2017, 55, 341–359. [Google Scholar] [CrossRef] [Green Version]
- Costa-Font, J.; Jimenez-Martin, S.; Vilaplana, C. Does Long-Term Care Subsidisation Reduce Unnecessary Hospitalisations? Available online: https://ssrn.com/abstract=2858807 (accessed on 21 September 2020).
- Balia, S.; Brau, R. A country for old men? Long-term home care utilization in Europe. Health Econ. 2014, 23, 1185–1212. [Google Scholar] [CrossRef] [PubMed]
- WHO. Women’s Mental Health: An Evidence Based Review; World Health Organization: Geneva, Switzerland, 2000. [Google Scholar]
- Acciai, F.; Hardy, M. Depression in later life: A closer look at the gender gap. Soc. Sci. Res. 2017, 68, 163–175. [Google Scholar] [CrossRef]
- Bonsang, E.; Skirbekk, V.; Staudinger, U.M. As You Sow, So Shall You Reap: Gender-Role Attitudes and Late-Life Cognition. Psychol. Sci. 2017, 28, 1201–1213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lima, A.L.B.; Espelt, A.; Lima, K.C.; Bosque-Prous, M. Activity limitation in elderly people in the European context of gender inequality: A multilevel approach. Cienc. Saude Coletiva 2018, 23, 2991–3000. [Google Scholar] [CrossRef]
- Avendano, M.; Jürges, H.; MacKenbach, J.P. Educational level and changes in health across Europe: Longitudinal results from SHARE. J. Eur. Soc. Policy 2009, 19, 301–316. [Google Scholar] [CrossRef]
- Bohácek, R.; Crespo, L.; Mira, P.; Pijoan-Mas, J. The Educational Gradient in Life Expectancy in Europe: Preliminary Evidence from SHARE. Available online: http://www.share-project.org/uploads/tx_sharepublications/WP_Series_22_2015_Bohacek_Crespo_Mira_Pijoan-Mas_03.pdf (accessed on 21 September 2020).
- Corsini, V. Highly Educated Men and Women Likely to Live Longer. Life Expectancy by Educational Attainment. In Eurostat—Statistics in Focus 24/2010; European Union: Brussels, Belgium, 2010; ISSN 1977-0316. [Google Scholar]
- Pappadà, G. A Comparative Analysis of Welfare Systems and the Health and Social Sector in Evidence from 16 European Countries. In Welfare for Wealth; The Risk Institute: Geneva, Switzerland, 2010. [Google Scholar]
- Muir, T. Measuring Social Protection for Long-Term Care; OECD Publishing: Paris, France, 2017. [Google Scholar]
- WHO. The Global Burden of Disease: 2004 Update; WHO: Geneva, Switzerland, 2004. [Google Scholar]
- Fernández, J.; Trigg, L.; Reinhard, H.; Micharikopoulos, D. European Long-Term Care Models and Compatibility with Social Investment Approaches, Social Protection Investment in LTC HORIZON 2020; SPRINT: Brussels, Belgium, 2018. [Google Scholar]
- Glanz, A.; Fernández, J. Social Investment in Long-Term Care—Key Recommendations from the SPRINT Project, Social Protection Investment in LTC HORIZON 2020; SPRINT: Brussels, Belgium, 2018. [Google Scholar]
- Colombo, F.; Llena-Nozal, A.; Mercier, J.; Tjadens, F. Help Wanted? Providing and Paying for Long-Term Care; OECD Publishing: Paris, France, 2011. [Google Scholar]
- Raman, R.; Sharma, L.; Akasapu, A. Fuzzy Clustering Technique for Numerical and Categorical dataset. Int. J. Comput. Sci. Eng. 2011, NCICT 2010, 75–80. [Google Scholar]



| Description | Values/Categories | Description | Values/Categories |
|---|---|---|---|
| Life satisfaction | Scale, 0–10 | Number of chronic diseases | From 0 to 13 |
| Satisfied doing no activities last year? | Scale, 0–10 | Number of nights spent in hospital in the past year | From 0 to 365 |
| Self-perceived health | Poor, Fair, Good, Very Good, Excellent | Living in a nursing home | Yes, No |
| Life happiness | Never, Rarely, Sometimes, Often | Eyesight score (based on test) | Poor, Fair, Good, Very Good, Excellent |
| EURO depression scale | Scale, 0–12 | Hearing score (based on test) | Poor, Fair, Good, Very Good, Excellent |
| Global Activity Limitation Indicator (GALI) | Limited, Not limited | Ever smoked cigarettes daily | Yes, No |
| Number of mobility limitations | From 0 to 10 | How often consume meat, fish or poultry | Less than once a week, Once a week, Twice a week, 3–6 times a week, Every day |
| Number of difficulties in activities of daily living (ADL) | From 0 to 6 | How often consume vegetables | Less than once a week, Once a week, Twice a week, 3–6 times a week, Every day |
| Number of difficulties in in instrumental activities of daily living (IADL) | From 0 to 9 | BMI | From 12.5 to 98.6 |
| Physical inactivity | Yes, No | Grip strength | From 1 to 92 |
| Self-rated reading skills | Poor, Fair, Good, Very Good, Excellent | Self-rated writing skills | Poor, Fair, Good, Very Good, Excellent |
| Score of memory test | Poor, Fair, Good, Very Good, Excellent | Score of numeracy test | scale, 0–5 |
| Score of verbal fluency test | From 0 to 97 | Score of orientation in time test | scale, 0–5 |
| Score of words list learning test—trial 1 | From 0 to 10 | Score of words list learning test—trial 2 | From 0 to 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grané, A.; Albarrán, I.; Lumley, R. Visualizing Inequality in Health and Socioeconomic Wellbeing in the EU: Findings from the SHARE Survey. Int. J. Environ. Res. Public Health 2020, 17, 7747. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17217747
Grané A, Albarrán I, Lumley R. Visualizing Inequality in Health and Socioeconomic Wellbeing in the EU: Findings from the SHARE Survey. International Journal of Environmental Research and Public Health. 2020; 17(21):7747. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17217747
Chicago/Turabian StyleGrané, Aurea, Irene Albarrán, and Roger Lumley. 2020. "Visualizing Inequality in Health and Socioeconomic Wellbeing in the EU: Findings from the SHARE Survey" International Journal of Environmental Research and Public Health 17, no. 21: 7747. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17217747