Environmental Noise Classification Using Convolutional Neural Networks with Input Transform for Hearing Aids


Abstract
:1. Introduction
2. Previous Research
2.1. Conventional Noise Classification Algorithms
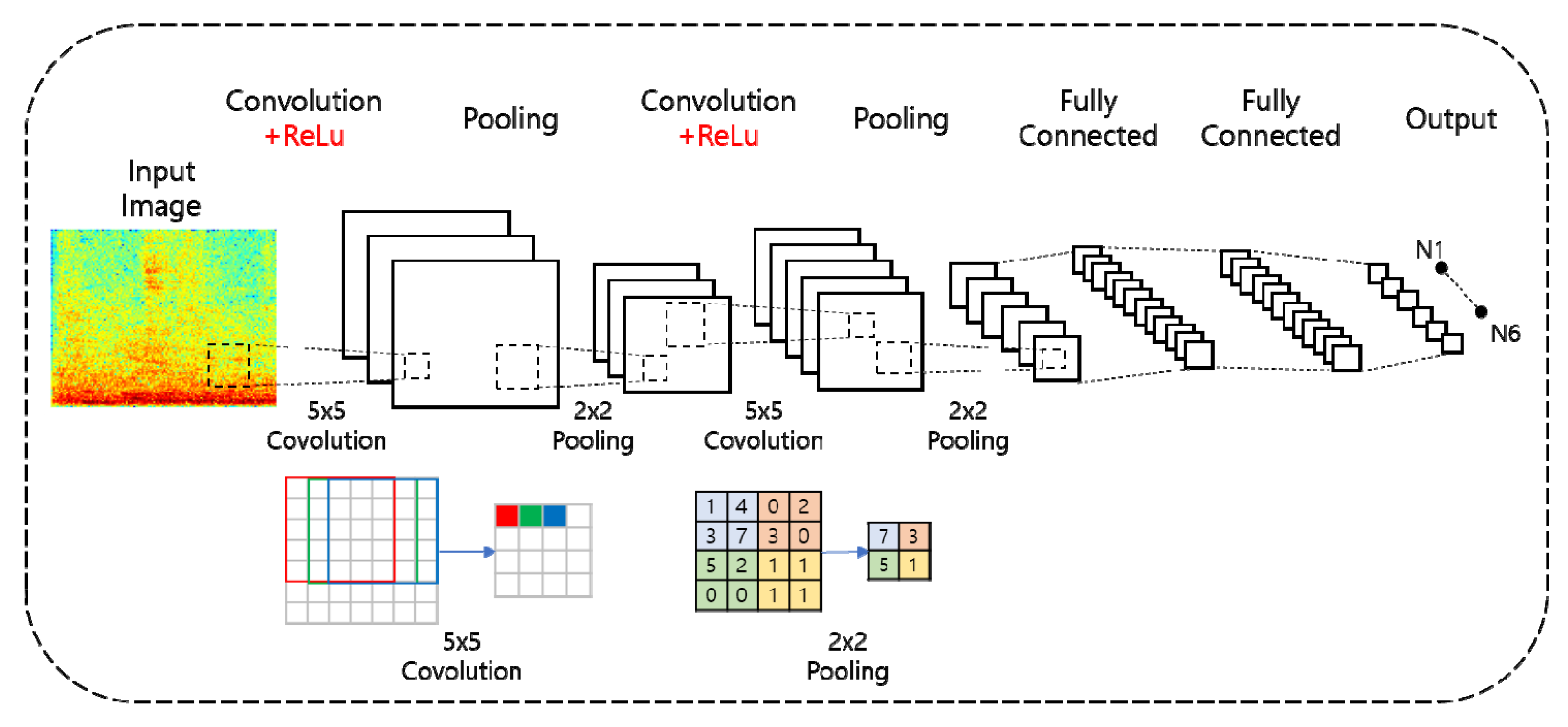
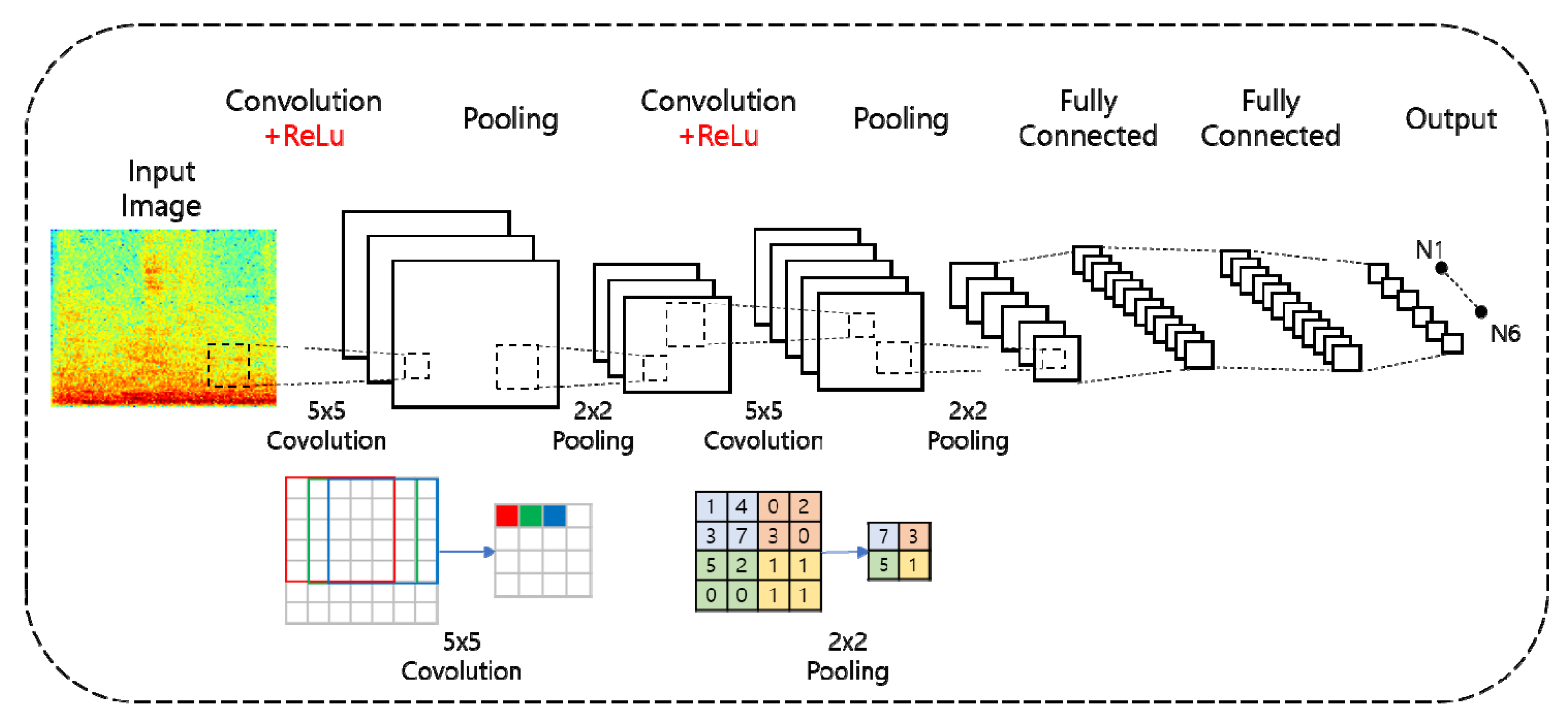
2.2. Convolutional Neural Networks
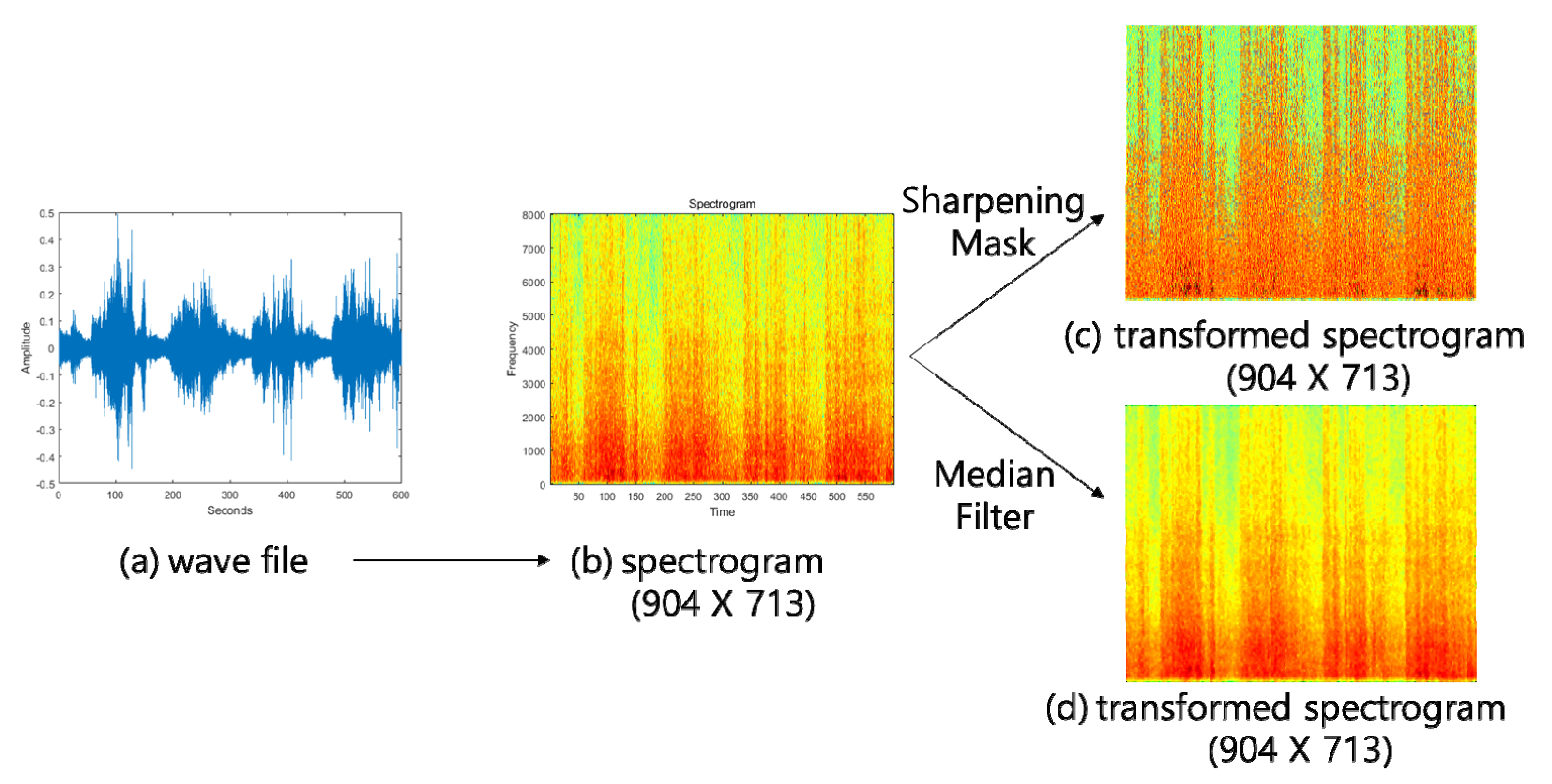
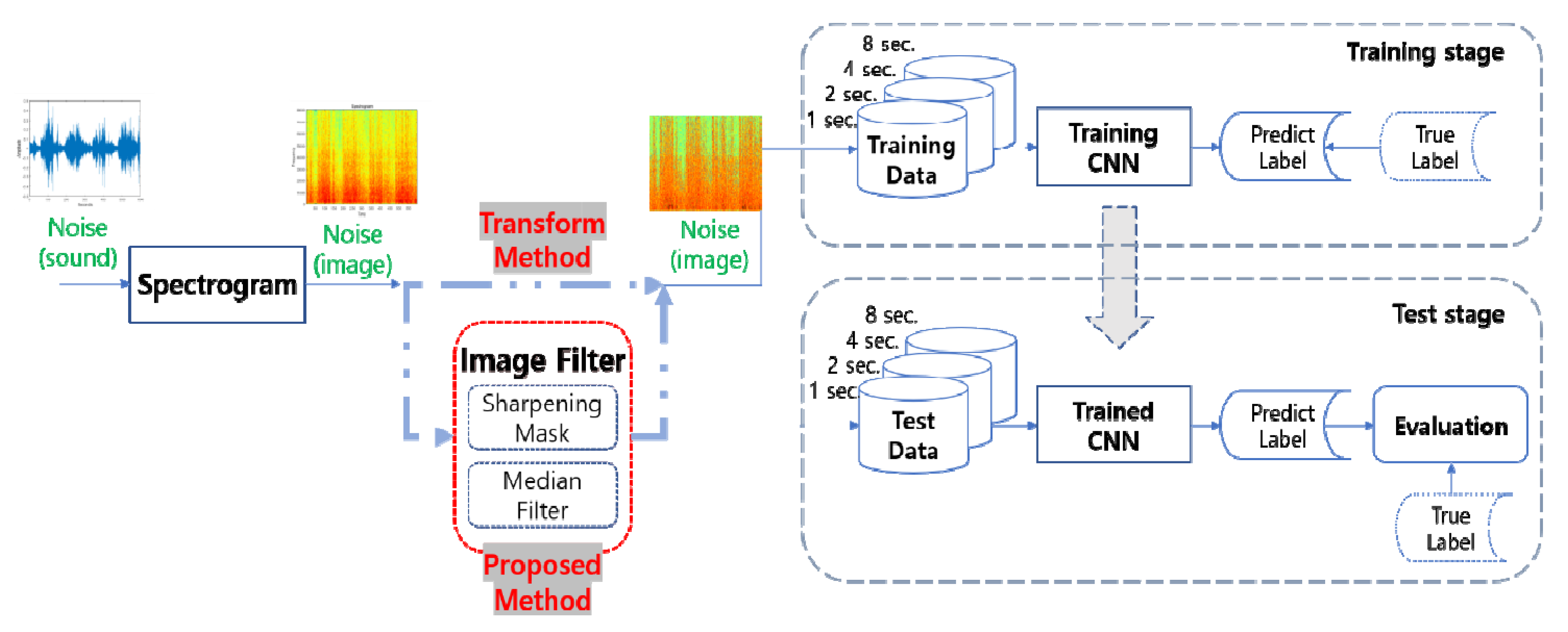
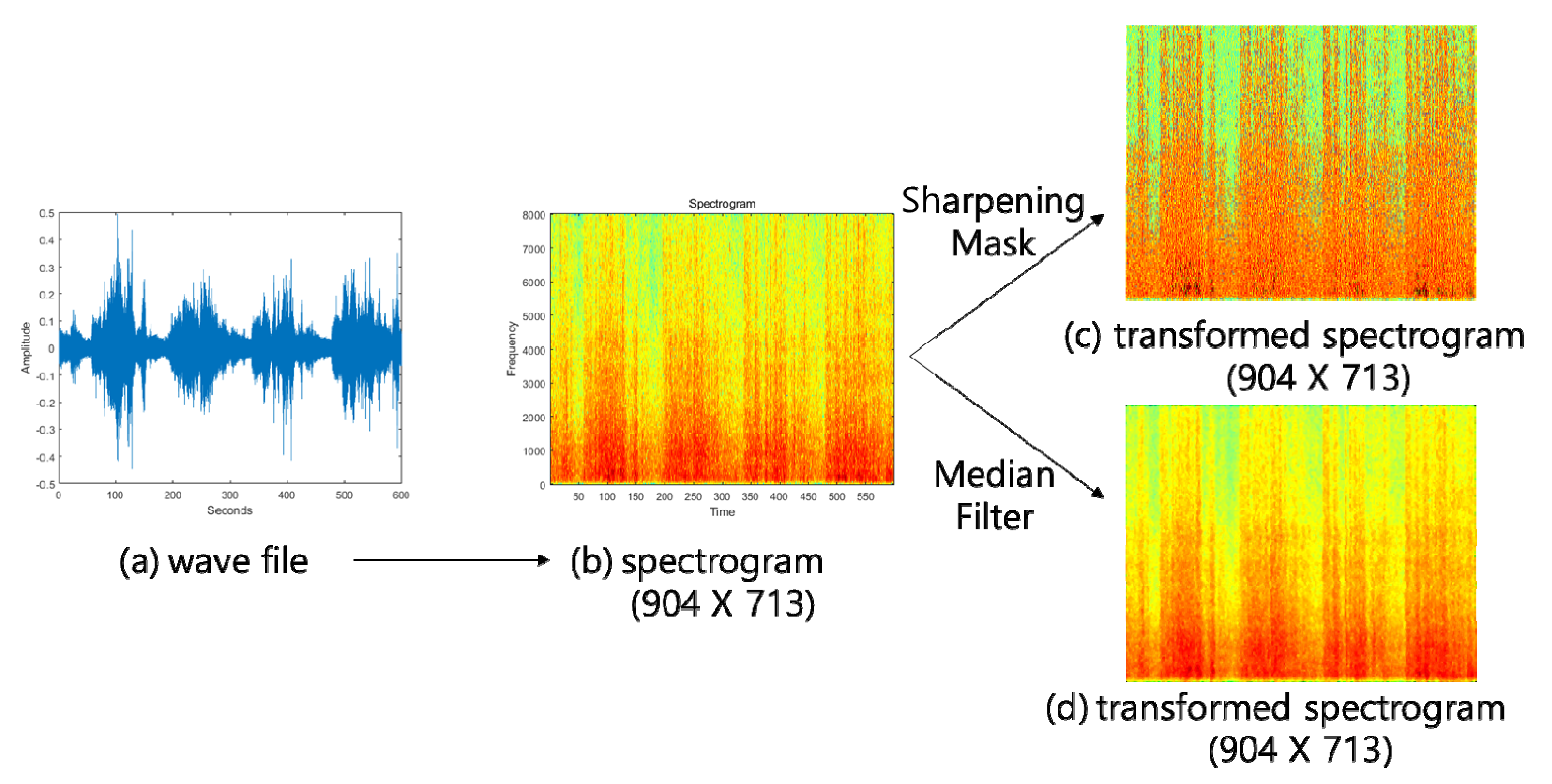
3. The Proposed Algorithm
4. Materials and Methods
4.1. Recording Environmental Noises
4.2. Experiment Data
5. Experimental Results
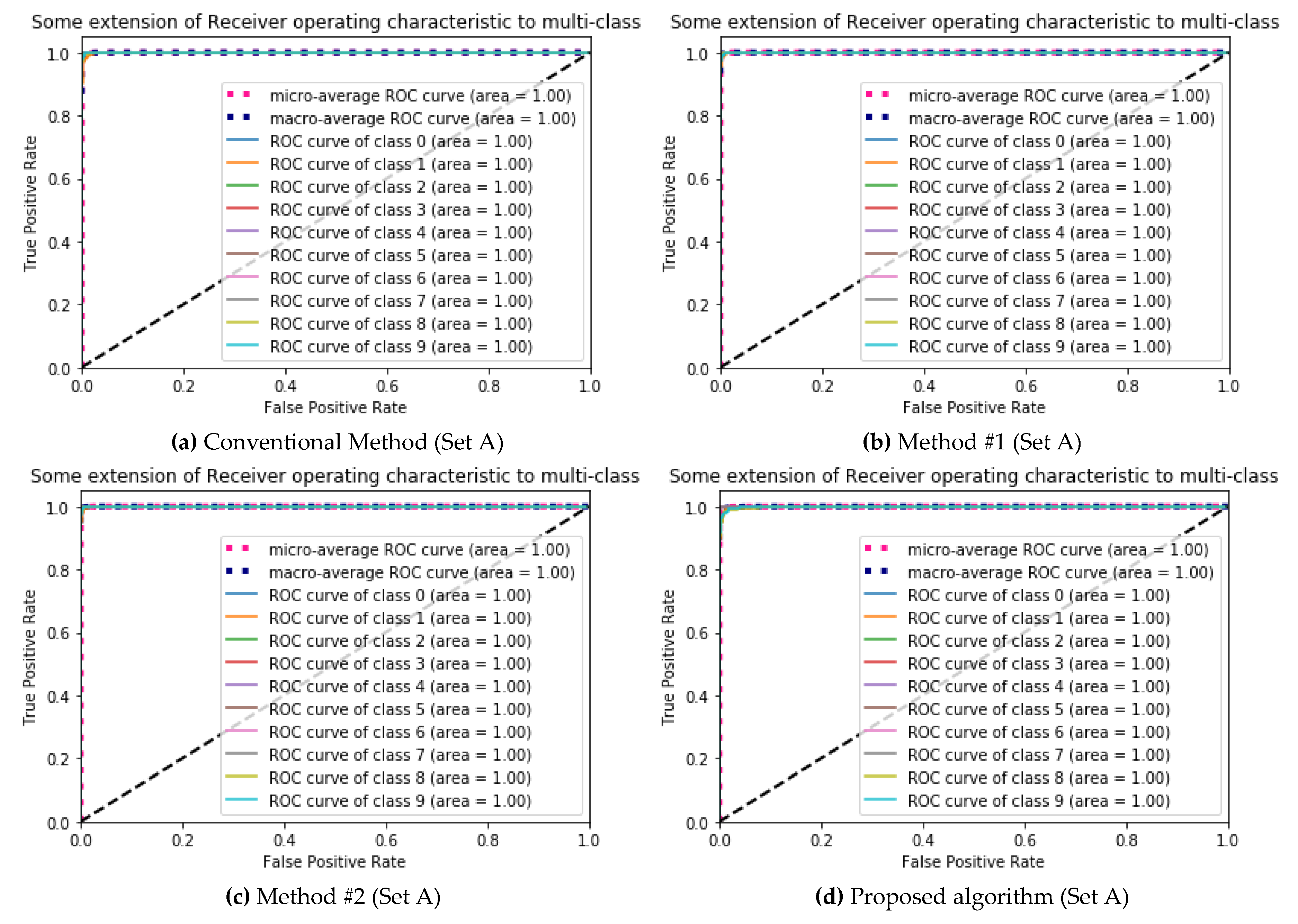
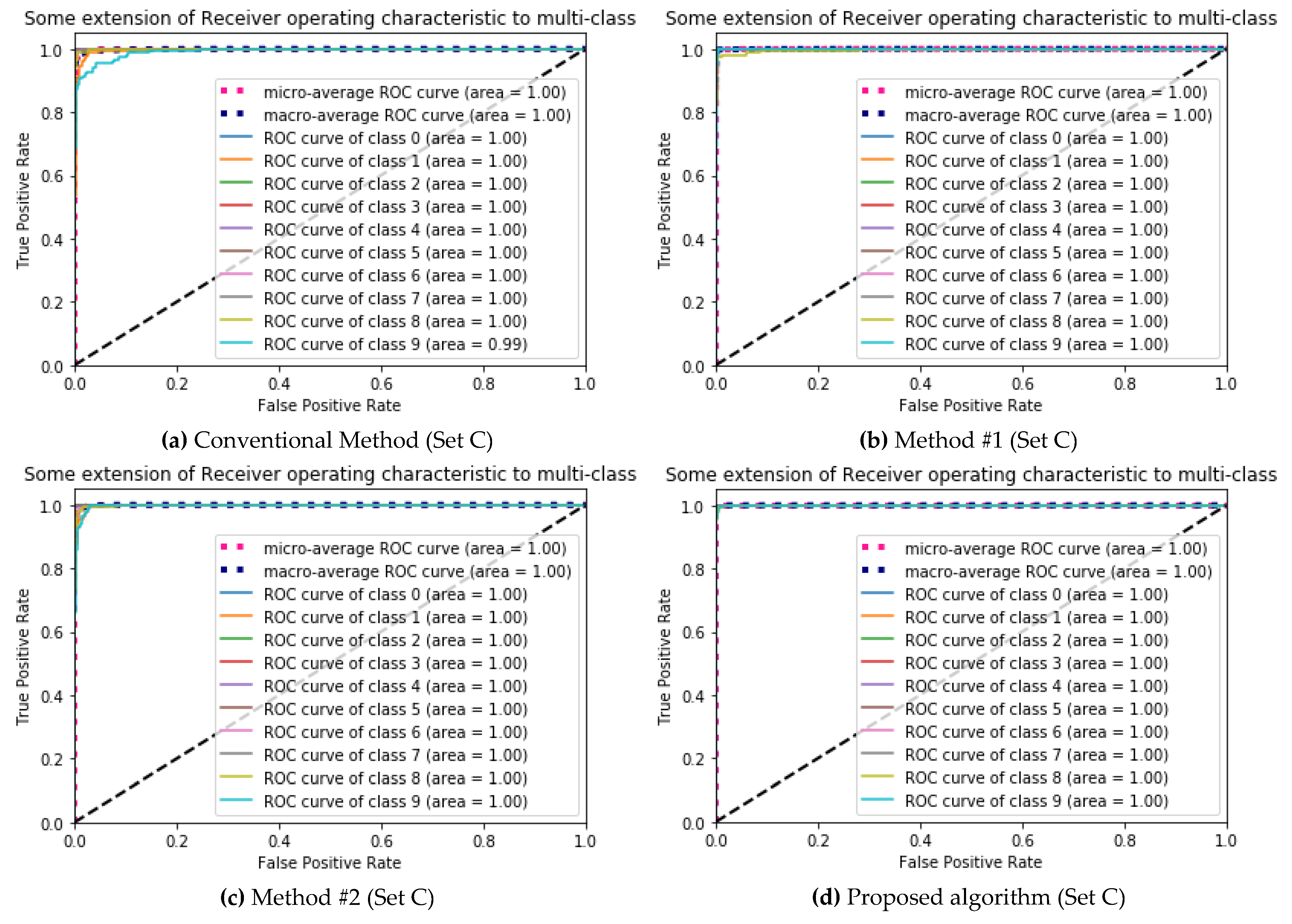
5.1. Performance Evaluations
5.2. Data Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Festen, J.M.; Plomp, R. Effects of fluctuating noise and interfering speech on the speech-reception threshold for impaired and normal hearing. J. Acoust. Soc. Am. 1990, 88, 1725–1736. [Google Scholar] [CrossRef] [PubMed]
- Hygge, S.; Rönnberg, J.; Larsby, B.; Arlinger, S. Normal-hearing and hearing-impaired subjects’ ability to just follow conversation in competing speech, reversed speech, and noise backgrounds. J. Speech Lang. Hear. Res. 1992, 35, 208–215. [Google Scholar] [CrossRef] [PubMed]
- Plomp, R. Auditory handicap of hearing impairment and the limited benefit of hearing aids. J. Acoust. Soc. Am. 1978, 63, 533–549. [Google Scholar] [CrossRef] [PubMed]
- Dillon, H. Hearing Aids; Hodder Arnold: London, UK, 2008. [Google Scholar]
- Seo, S.; Yook, S.; Nam, K.W.; Han, J.; Kwon, S.Y.; Hong, S.H.; Kim, D.; Lee, S.; Jang, D.P.; Kim, I.Y. Real time environmental classification algorithm using neural network for hearing aids. J. Biomed. Eng. Res. 2013, 34, 8–13. [Google Scholar] [CrossRef] [Green Version]
- Duquesnoy, A. Effect of a single interfering noise or speech source upon the binaural sentence intelligibility of aged persons. J. Acoust. Soc. Am. 1983, 74, 739–743. [Google Scholar] [CrossRef] [PubMed]
- Knudsen, L.V.; Öberg, M.; Nielsen, C.; Naylor, G.; Kramer, S.E. Factors influencing help seeking, hearing aid uptake, hearing aid use and satisfaction with hearing aids: A review of the literature. Trends Amplif. 2010, 14, 127–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cox, R.M.; McDaniel, D.M. Development of the Speech Intelligibility Rating (SIR) test for hearing aid comparisons. J. Speech Lang. Hear. Res. 1989, 32, 347–352. [Google Scholar] [CrossRef] [PubMed]
- Kates, J.M. Digital Hearing Aids; Plural publishing: San Diego, CA, USA, 2008. [Google Scholar]
- Nordqvist, P.; Leijon, A. An efficient robust sound classification algorithm for hearing aids. J. Acoust. Soc. Am. 2004, 115, 3033–3041. [Google Scholar] [CrossRef] [PubMed]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973. [Google Scholar]
- Dudani, S.A. The distance-weighted k-nearest-neighbor rule. IEEE Trans. Syst. Man Cybern. 1976, SMC-6, 325–327. [Google Scholar] [CrossRef]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 14, 5–16. [Google Scholar]
- Beale, H.D.; Demuth, H.B.; Hagan, M. Neural Network Design; Pws: Boston, MA, USA, 1996. [Google Scholar]
- Juang, B.H.; Rabiner, L.R. Hidden Markov models for speech recognition. Technometrics 1991, 33, 251–272. [Google Scholar] [CrossRef]
- Büchler, M.; Allegro, S.; Launer, S.; Dillier, N. Sound classification in hearing aids inspired by auditory scene analysis. EURASIP J. Adv. Signal Process. 2005, 2005, 387845. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Abdel-Hamid, O.; Mohamed, A.-R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks; Advances in Neural Information Processing Systems: Lake Tahoe, NV, USA, 2012; pp. 1097–1105. [Google Scholar]
- Yang, C.-C. Improving the overshooting of a sharpened image by employing nonlinear transfer functions in the mask-filtering approach. Opt.-Int. J. Light Electron Opt. 2013, 124, 2784–2786. [Google Scholar] [CrossRef]
- Hong, S.-W.; Kim, N.-H. A study on median filter using directional mask in salt & pepper noise environments. J. Korea Inst. Inf. Commun. Eng. 2015, 19, 230–236. [Google Scholar]
- Heinzel, G.; Rüdiger, A.; Schilling, R. Spectrum and Spectral Density Estimation by the Discrete Fourier Transform (DFT), Including a Comprehensive List of Window Functions and Some New at-Top Windows; Max-Planck-Institut für Gravitationsphysik: Hoanover, Germany, 2002. [Google Scholar]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test # | Set A | Set B | Set C | Set D | Test # | Set A | Set B | Set C | Set D |
| (1 s) | (2 s) | (4 s) | (8 s) | (1 s) | (2 s) | (4 s) | (8 s) | ||
| 1 | 98.98 | 98.6 | 97.93 | 95.2 | 1 | 98.95 | 99.13 | 98.87 | 97.6 |
| 2 | 98.92 | 98.66 | 97.8 | 95.07 | 2 | 98.9 | 99.03 | 99 | 98.27 |
| 3 | 98.8 | 98.43 | 97.4 | 95.73 | 3 | 98.88 | 99 | 98.8 | 97.87 |
| 4 | 98.87 | 98.66 | 98.27 | 95.2 | 4 | 98.9 | 99.2 | 98.73 | 98 |
| 5 | 98.78 | 98.6 | 98.27 | 94 | 5 | 98.95 | 98.83 | 98.73 | 98.13 |
| 6 | 98.61 | 98.7 | 98.13 | 96.4 | 6 | 98.95 | 98.46 | 97.8 | 95.87 |
| 7 | 98.73 | 98.86 | 98.27 | 94.8 | 7 | 98.9 | 98.86 | 98.73 | 98.13 |
| 8 | 98.58 | 98.83 | 98.47 | 93.87 | 8 | 98.92 | 98.6 | 99.2 | 96.13 |
| 9 | 98.83 | 98.63 | 96.47 | 95.73 | 9 | 98.82 | 98.96 | 98.6 | 97.87 |
| 10 | 98.8 | 99.26 | 98.27 | 96.4 | 10 | 98.87 | 98.9 | 97.93 | 95.73 |
| AVG 1 | 98.79 | 98.72 | 97.93 | 95.24 | AVG 1 | 98.9 | 98.9 | 98.64 | 97.36 |
| SD 2 | 0.12 | 0.23 | 0.6 | 0.87 | SD 2 | 0.04 | 0.23 | 0.44 | 1.02 |
| (a) Conventional Method(Spectrogram only) | (b) Method #1(Spectrogram + Sharpening Mask) | ||||||||
| Test # | Set A | Set B | Set C | Set D | Test # | Set A | Set B | Set C | Set D |
| (1 s) | (2 s) | (4 s) | (8 s) | (1 s) | (2 s) | (4 s) | (8 s) | ||
| 1 | 99.12 | 99.06 | 96.2 | 95.47 | 1 | 99.37 | 99.13 | 99.13 | 99.07 |
| 2 | 99.12 | 98.83 | 96 | 97.47 | 2 | 99.23 | 99.16 | 99.33 | 98.93 |
| 3 | 99.07 | 99 | 96.07 | 96.13 | 3 | 99.25 | 99.2 | 99.33 | 98.67 |
| 4 | 99.15 | 98.83 | 96.53 | 96.27 | 4 | 99.35 | 99.23 | 99.27 | 98.67 |
| 5 | 98.95 | 98.53 | 96.13 | 95.33 | 5 | 99.42 | 99.26 | 99.13 | 99.2 |
| 6 | 99.05 | 97.99 | 95.87 | 94.27 | 6 | 99.2 | 99.26 | 98.93 | 97.73 |
| 7 | 98.95 | 99.03 | 95.53 | 97.6 | 7 | 98.97 | 98.5 | 98.67 | 98.8 |
| 8 | 99.07 | 98.63 | 97.53 | 97.07 | 8 | 99.38 | 98.83 | 99.47 | 98.53 |
| 9 | 98.93 | 99.16 | 98 | 95.33 | 9 | 99.07 | 99.33 | 98.8 | 99.2 |
| 10 | 98.97 | 99 | 97.27 | 95.73 | 10 | 99.28 | 99.43 | 98.87 | 98.53 |
| AVG 1 | 99.04 | 98.81 | 96.51 | 96.07 | AVG 1 | 99.25 | 99.13 | 99.09 | 98.73 |
| SD 2 | 0.08 | 0.35 | 0.81 | 1.06 | SD 2 | 0.14 | 0.27 | 0.27 | 0.43 |
| (c) Method #2(Spectrogram + Median Filter) | (d) Proposed algorithm(Spectrogram + Sharpening Mask + Median Filter) | ||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 599 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 599 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 582.8 | 0 | 0.2 | 0.8 | 0.4 | 4 | 0.9 | 4.3 | 5.6 | 97.29 | N1 | 0 | 584.1 | 0 | 0.2 | 1 | 1.1 | 3.9 | 1.2 | 2.8 | 4.7 | 97.51 |
| N2 | 0 | 0 | 597.7 | 0 | 0 | 0 | 0 | 0 | 0.4 | 0.9 | 99.78 | N2 | 0 | 0 | 597.6 | 0 | 0 | 0 | 0 | 0 | 1.1 | 0.3 | 99.76 |
| N3 | 0 | 0 | 0 | 599 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N3 | 0 | 0 | 0 | 598.8 | 0 | 0 | 0 | 0 | 0 | 0.2 | 99.96 |
| N4 | 0 | 0.3 | 0.1 | 0.2 | 594.1 | 0.4 | 1.1 | 0.1 | 0.3 | 2.2 | 99.18 | N4 | 0 | 0.9 | 0 | 0 | 593.6 | 0.4 | 1.1 | 0.8 | 1.1 | 1.1 | 99.09 |
| N5 | 0.1 | 0.3 | 0 | 0 | 0.2 | 593.1 | 4 | 0.3 | 0 | 0.9 | 99.02 | N5 | 0.1 | 0.3 | 0 | 0 | 0 | 593.4 | 4.1 | 0.7 | 0 | 0.3 | 99.07 |
| N6 | 0 | 3.4 | 0 | 0.3 | 0 | 4.3 | 587.3 | 0.8 | 0 | 2.8 | 98.05 | N6 | 0 | 2.3 | 0 | 0 | 0 | 3.4 | 591.1 | 0.9 | 0 | 1.2 | 98.68 |
| N7 | 0 | 0.8 | 0 | 0 | 0 | 0 | 0.1 | 596.8 | 0.3 | 1 | 99.63 | N7 | 0 | 0.8 | 0 | 0 | 0 | 0.2 | 0.2 | 595.7 | 0 | 2 | 99.46 |
| N8 | 0 | 9.7 | 0.1 | 0 | 0.1 | 0.7 | 0 | 0 | 585.9 | 2.6 | 97.81 | N8 | 0 | 8.3 | 0 | 0 | 0 | 1.1 | 0 | 0 | 585.8 | 3.9 | 97.77 |
| N9 | 0.2 | 8 | 0.1 | 0.1 | 0.4 | 3.1 | 1.3 | 0.4 | 3.3 | 581.9 | 97.14 | N9 | 0.2 | 5.9 | 0.7 | 0 | 0.3 | 2.8 | 1.2 | 0.4 | 2.6 | 584.9 | 97.64 |
| Average Classification Accuracy | 98.79 | Average Classification Accuracy | 98.9 | ||||||||||||||||||||
| (a) Conventional Method (Set A) | (b) Method #1 (Set A) | ||||||||||||||||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 599 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 599 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 581.9 | 0 | 0.3 | 0.4 | 0.9 | 5.9 | 1.1 | 3.4 | 5 | 97.14 | N1 | 0 | 586.1 | 0 | 0.2 | 0.6 | 0.6 | 3.4 | 0.6 | 3.9 | 3.7 | 97.85 |
| N2 | 0 | 0 | 598.6 | 0 | 0 | 0 | 0 | 0 | 0.1 | 0.3 | 99.93 | N2 | 0 | 0 | 598.1 | 0 | 0 | 0 | 0 | 0 | 0.6 | 0.3 | 99.85 |
| N3 | 0 | 0 | 0 | 598.9 | 0 | 0 | 0 | 0 | 0 | 0.1 | 99.98 | N3 | 0 | 0.1 | 0 | 598.9 | 0 | 0 | 0 | 0 | 0 | 0 | 99.98 |
| N4 | 0 | 0.9 | 0 | 0 | 595.3 | 0.8 | 0.8 | 0.2 | 0.8 | 0.2 | 99.39 | N4 | 0 | 0.6 | 0 | 0 | 597 | 0 | 0 | 0.2 | 0.4 | 0.2 | 99.67 |
| N5 | 0.1 | 0.4 | 0 | 0 | 0.1 | 594.6 | 3.2 | 0.4 | 0 | 0.1 | 99.26 | N5 | 0 | 0.1 | 0 | 0 | 0 | 595.4 | 2.8 | 0 | 0 | 0.7 | 99.41 |
| N6 | 0 | 1.4 | 0 | 0.3 | 0 | 2.7 | 592.8 | 1 | 0 | 0.8 | 98.96 | N6 | 0 | 1.3 | 0 | 0.2 | 0 | 2.8 | 593 | 1.4 | 0 | 0.2 | 99 |
| N7 | 0 | 0.9 | 0 | 0 | 0.1 | 0 | 0.1 | 597.2 | 0 | 0.7 | 99.7 | N7 | 0 | 0.4 | 0 | 0 | 0 | 0 | 0.1 | 597.8 | 0 | 0.7 | 99.8 |
| N8 | 0 | 6.4 | 0.1 | 0 | 0.1 | 0.4 | 0 | 0 | 589 | 2.9 | 98.33 | N8 | 0 | 5.9 | 0 | 0 | 0.2 | 0.4 | 0 | 0 | 590.7 | 1.8 | 98.61 |
| N9 | 0 | 6.2 | 0.3 | 0 | 1.3 | 2 | 1.2 | 0.1 | 2.2 | 585.6 | 97.76 | N9 | 0 | 4.9 | 0.3 | 0 | 0.6 | 1.3 | 1.1 | 0.1 | 1.8 | 588.9 | 98.31 |
| Average Classification Accuracy | 99.04 | Average Classification Accuracy | 99.25 | ||||||||||||||||||||
| (c) Method #2 (Set A) | (d) Proposed algorithm (Set A) | ||||||||||||||||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 299 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 299 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 289 | 0 | 0.2 | 0.9 | 0.6 | 1.3 | 1 | 2.8 | 3.2 | 96.66 | N1 | 0 | 293.1 | 0 | 0 | 0.2 | 0.9 | 0.9 | 0.9 | 0.9 | 2.1 | 98.03 |
| N2 | 0 | 0 | 298.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0.8 | 99.74 | N2 | 0 | 0 | 298.4 | 0 | 0 | 0 | 0 | 0 | 0.1 | 0.4 | 99.81 |
| N3 | 0 | 0.1 | 0 | 298.9 | 0 | 0 | 0 | 0 | 0 | 0 | 99.96 | N3 | 0 | 0.2 | 0 | 298.4 | 0 | 0 | 0 | 0 | 0 | 0.3 | 99.81 |
| N4 | 0 | 0.2 | 0.1 | 0 | 294.3 | 0.2 | 0.4 | 0.9 | 1.3 | 1.4 | 98.44 | N4 | 0 | 0 | 0.2 | 0 | 295 | 0 | 0.8 | 0 | 0.3 | 2.7 | 98.66 |
| N5 | 0 | 0 | 0 | 0 | 0 | 297.2 | 1.6 | 0 | 0 | 0.2 | 99.41 | N5 | 0.2 | 0.7 | 0 | 0 | 0 | 296.3 | 1.3 | 0 | 0 | 0.4 | 99.11 |
| N6 | 0 | 0.2 | 0 | 0 | 0 | 1.8 | 297 | 0 | 0 | 0 | 99.33 | N6 | 0 | 0.3 | 0 | 0 | 0 | 1 | 296.2 | 0.3 | 0 | 1.1 | 99.07 |
| N7 | 0 | 0.4 | 0 | 0 | 0 | 0 | 0.1 | 298.4 | 0 | 0 | 99.81 | N7 | 0 | 0 | 0 | 0 | 0 | 0 | 0.2 | 298.7 | 0 | 0.1 | 99.89 |
| N8 | 0 | 4.9 | 0 | 0 | 0.4 | 0.4 | 0 | 0 | 291.6 | 1.7 | 97.51 | N8 | 0 | 3.3 | 0 | 0 | 0.8 | 1.1 | 0 | 0 | 290 | 3.8 | 96.99 |
| N9 | 0 | 4.1 | 0.8 | 0.1 | 0.6 | 0.7 | 2 | 0.6 | 2.2 | 288 | 96.32 | N9 | 0 | 1.7 | 0 | 0 | 0.7 | 1.7 | 1.1 | 0.8 | 1.1 | 292 | 97.66 |
| Average Classification Accuracy | 98.72 | Average Classification Accuracy | 98.9 | ||||||||||||||||||||
| (a) Conventional Method (Set B) | (b) Method #1 (Set B) | ||||||||||||||||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 299 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 299 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 292.3 | 0 | 0 | 0.2 | 0.8 | 1.2 | 0.6 | 2.7 | 2.1 | 97.77 | N1 | 0 | 291 | 0 | 0.2 | 0.3 | 0.4 | 1.2 | 0 | 2.6 | 3.2 | 97.32 |
| N2 | 0 | 0 | 298.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1 | 99.96 | N2 | 0 | 0 | 298.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0.2 | 99.93 |
| N3 | 0 | 0 | 0 | 298.8 | 0.2 | 0 | 0 | 0 | 0 | 0 | 99.93 | N3 | 0 | 0.1 | 0 | 298.7 | 0.1 | 0 | 0 | 0 | 0 | 0.1 | 99.89 |
| N4 | 0 | 0.6 | 0.2 | 0 | 295.9 | 0 | 0.2 | 0.2 | 0.4 | 1.4 | 98.96 | N4 | 0 | 0.1 | 0.1 | 0 | 296.4 | 0.1 | 0.8 | 0 | 0.3 | 1.1 | 99.15 |
| N5 | 0 | 0.4 | 0 | 0 | 0 | 296.2 | 2.1 | 0 | 0.1 | 0.1 | 99.07 | N5 | 0 | 0.4 | 0 | 0 | 0 | 297.4 | 1.1 | 0 | 0 | 0 | 99.48 |
| N6 | 0 | 0.2 | 0.1 | 0.1 | 0.1 | 2.7 | 295.3 | 0.2 | 0 | 0.2 | 98.77 | N6 | 0 | 0.3 | 0 | 0 | 0 | 1.8 | 296.3 | 0.2 | 0 | 0.3 | 99.11 |
| N7 | 0 | 0.2 | 0 | 0 | 0 | 0 | 0 | 298.6 | 0.1 | 0.1 | 99.85 | N7 | 0 | 0.1 | 0 | 0 | 0 | 0 | 0 | 298.3 | 0.1 | 0.4 | 99.78 |
| N8 | 0 | 6.4 | 0 | 0 | 0.4 | 0.1 | 0 | 0 | 289.7 | 2.3 | 96.88 | N8 | 0 | 2 | 0 | 0 | 0.2 | 0.3 | 0 | 0 | 294.2 | 2.2 | 98.4 |
| N9 | 0 | 5.4 | 0.3 | 0 | 0.4 | 0.7 | 0.6 | 0 | 1.8 | 289.8 | 96.92 | N9 | 0.1 | 2.2 | 0.1 | 0 | 0.4 | 0.6 | 0.3 | 0.2 | 1.3 | 293.7 | 98.22 |
| Average Classification Accuracy | 98.81 | Average Classification Accuracy | 99.13 | ||||||||||||||||||||
| (c) Method #2 (Set B) | (d) Proposed algorithm (Set B) | ||||||||||||||||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 150 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 150 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 144.7 | 0 | 0 | 0 | 0.4 | 0.8 | 0.4 | 2 | 1.7 | 96.44 | N1 | 0 | 146.4 | 0 | 0 | 0.1 | 0.3 | 0.8 | 0.1 | 0.3 | 1.9 | 97.63 |
| N2 | 0 | 0 | 149.1 | 0 | 0 | 0 | 0 | 0 | 0.3 | 0.6 | 99.41 | N2 | 0 | 0 | 149.6 | 0 | 0 | 0 | 0 | 0 | 0.2 | 0.2 | 99.7 |
| N3 | 0 | 0 | 0 | 149.7 | 0.3 | 0 | 0 | 0 | 0 | 0 | 99.78 | N3 | 0 | 0 | 0 | 150 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N4 | 0 | 0.6 | 0.3 | 0.1 | 145.7 | 0 | 0.2 | 0.9 | 0.7 | 1.6 | 97.11 | N4 | 0 | 0.6 | 0 | 0.1 | 146.3 | 0.2 | 0.7 | 0.2 | 0.4 | 1.4 | 97.56 |
| N5 | 0 | 0 | 0 | 0 | 0.1 | 149.7 | 0.1 | 0 | 0 | 0.1 | 99.78 | N5 | 0 | 0 | 0 | 0 | 0 | 149.4 | 0.6 | 0 | 0 | 0 | 99.63 |
| N6 | 0 | 0.6 | 0 | 0 | 0.1 | 2.8 | 146.2 | 0.3 | 0 | 0 | 97.48 | N6 | 0 | 0 | 0 | 0 | 0 | 1 | 148.9 | 0 | 0 | 0.1 | 99.26 |
| N7 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1 | 149.8 | 0 | 0.1 | 99.85 | N7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 150 | 0 | 0 | 100 |
| N8 | 0 | 2.4 | 0.6 | 0 | 0 | 0 | 0 | 0.2 | 145.2 | 1.6 | 96.81 | N8 | 0 | 4.3 | 0 | 0 | 0.1 | 0 | 0 | 0 | 144.1 | 1.4 | 96.07 |
| N9 | 0.2 | 7.4 | 0 | 0.1 | 0.2 | 0.6 | 0 | 0.6 | 2 | 138.9 | 92.59 | N9 | 0 | 2.6 | 0 | 0.1 | 0.3 | 0.8 | 0.8 | 0.1 | 0.4 | 144.9 | 96.59 |
| Average Classification Accuracy | 97.93 | Average Classification Accuracy | 98.64 | ||||||||||||||||||||
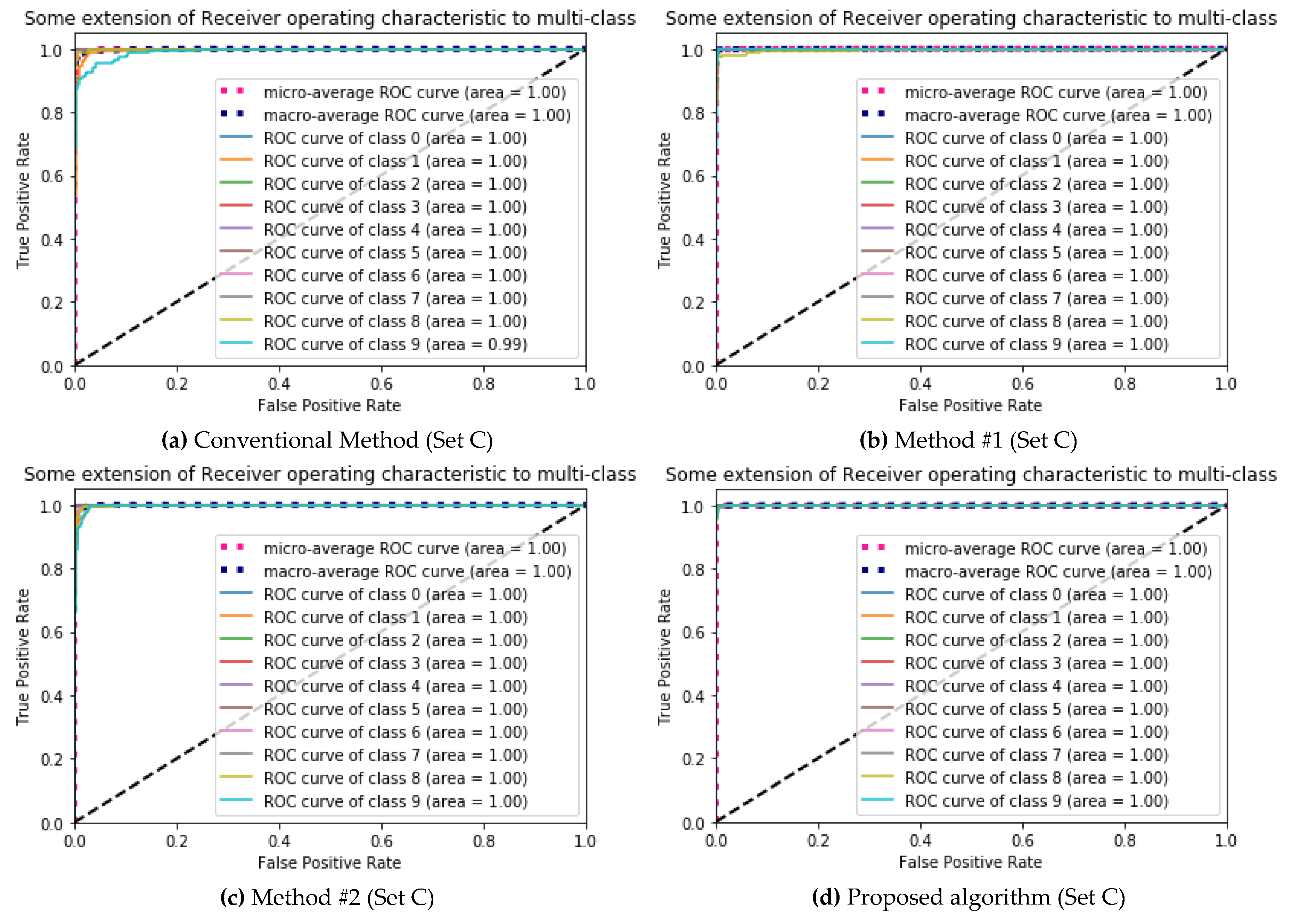
| (a) Conventional Method (Set C) | (b) Method #1 (Set C) | ||||||||||||||||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 150 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 150 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 136.2 | 0 | 0 | 0.7 | 0.2 | 2.6 | 0.7 | 3.6 | 6.1 | 90.81 | N1 | 0 | 147.4 | 0 | 0 | 0.2 | 0 | 0.6 | 0.1 | 0.7 | 0.9 | 98.37 |
| N2 | 0 | 0 | 148.8 | 0 | 0.1 | 0 | 0 | 0 | 0.6 | 0.6 | 99.19 | N2 | 0 | 0 | 149.6 | 0 | 0 | 0 | 0 | 0 | 0.2 | 0.2 | 99.7 |
| N3 | 0 | 0 | 0 | 149.8 | 0.2 | 0 | 0 | 0 | 0 | 0 | 99.85 | N3 | 0 | 0 | 0 | 149.9 | 0.1 | 0 | 0 | 0 | 0 | 0 | 99.93 |
| N4 | 0 | 0.3 | 0.3 | 1.8 | 142.7 | 0 | 0.6 | 0.3 | 2.2 | 1.8 | 95.11 | N4 | 0 | 0.3 | 0.1 | 0.2 | 147.1 | 0 | 0.2 | 0.3 | 0.1 | 1.1 | 98.37 |
| N5 | 0 | 0.4 | 0 | 0 | 0 | 148.6 | 0.8 | 0 | 0.2 | 0 | 99.04 | N5 | 0 | 0 | 0 | 0 | 0 | 149.4 | 0.6 | 0 | 0 | 0 | 99.63 |
| N6 | 0 | 0.6 | 0 | 0.2 | 0 | 3.4 | 145.1 | 0.3 | 0 | 0.3 | 96.74 | N6 | 0.1 | 0 | 0 | 0.1 | 0 | 1.4 | 147.9 | 0.1 | 0 | 0.1 | 98.74 |
| N7 | 0 | 0.1 | 0 | 0 | 0 | 0 | 0.1 | 148.8 | 0.1 | 0.9 | 99.19 | N7 | 0 | 0.1 | 0 | 0 | 0 | 0 | 0 | 149.7 | 0 | 0.2 | 99.78 |
| N8 | 0 | 4.8 | 0 | 0 | 0.4 | 0.2 | 0 | 0.2 | 141.8 | 2.6 | 94.52 | N8 | 0 | 1.7 | 0 | 0 | 0.1 | 0.1 | 0 | 0 | 147.1 | 0.7 | 98.3 |
| N9 | 0 | 5.4 | 1.2 | 0.6 | 0.2 | 0.2 | 1.8 | 0.8 | 3.8 | 136 | 90.67 | N9 | 0 | 1.4 | 0 | 0.1 | 0.3 | 0.1 | 0.3 | 0.3 | 0.2 | 146.9 | 98.07 |
| Average Classification Accuracy | 96.51 | Average Classification Accuracy | 99.09 | ||||||||||||||||||||
| (c) Method #2 (Set C) | (d) Proposed algorithm (Set C) | ||||||||||||||||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 64.6 | 0 | 0 | 0.3 | 0.4 | 1.4 | 0.1 | 3.2 | 4.9 | 86.07 | N1 | 0 | 69.3 | 0 | 0 | 0 | 0 | 2.3 | 0 | 1.9 | 1.4 | 92.44 |
| N2 | 0 | 0 | 74.2 | 0 | 0 | 0 | 0 | 0 | 0.1 | 0.7 | 98.96 | N2 | 0 | 0 | 74.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1 | 99.85 |
| N3 | 0 | 0 | 0 | 74.6 | 0.4 | 0 | 0 | 0 | 0 | 0 | 99.41 | N3 | 0 | 0 | 0 | 74.9 | 0.1 | 0 | 0 | 0 | 0 | 0 | 99.85 |
| N4 | 0 | 0.3 | 0.1 | 0 | 71.6 | 0.2 | 0 | 0.6 | 0.4 | 1.8 | 95.41 | N4 | 0 | 0 | 0.4 | 0.2 | 70.8 | 0.2 | 0.6 | 0.4 | 0.3 | 2 | 94.37 |
| N5 | 0 | 0.1 | 0 | 0 | 0 | 74.3 | 0.3 | 0 | 0.1 | 0.1 | 99.11 | N5 | 0 | 0 | 0 | 0 | 0 | 74.9 | 0.1 | 0 | 0 | 0 | 99.85 |
| N6 | 0 | 0 | 0 | 0 | 0 | 4.2 | 70 | 0.1 | 0 | 0.7 | 93.33 | N6 | 0 | 0 | 0 | 0 | 0 | 0.7 | 74.3 | 0 | 0 | 0 | 99.11 |
| N7 | 0 | 0 | 0 | 0 | 0 | 0.1 | 0 | 74.3 | 0 | 0.6 | 99.11 | N7 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1 | 74.9 | 0 | 0 | 99.85 |
| N8 | 0 | 2.1 | 0 | 0 | 2 | 0.2 | 0 | 0 | 69.2 | 1.4 | 92.3 | N8 | 0 | 2.1 | 0 | 0 | 0.3 | 0.1 | 0.1 | 0 | 70.6 | 1.8 | 94.07 |
| N9 | 0 | 3.7 | 0.1 | 0.1 | 0.1 | 0.6 | 0 | 0.6 | 3.3 | 66.6 | 88.74 | N9 | 0 | 2 | 0 | 0 | 0.7 | 0.6 | 0.1 | 0.3 | 0.7 | 70.7 | 94.22 |
| Average Classification Accuracy | 95.24 | Average Classification Accuracy | 97.36 | ||||||||||||||||||||
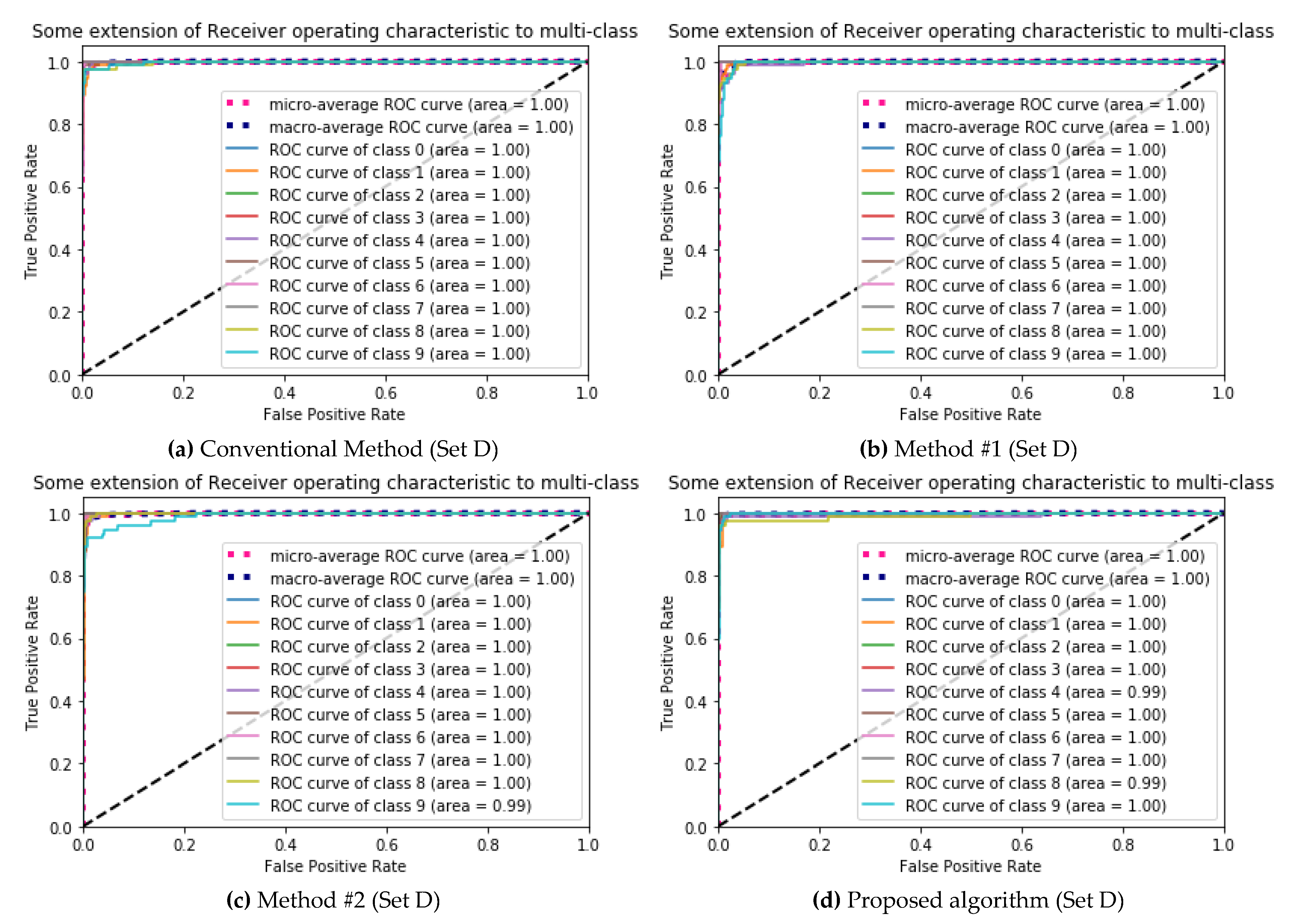
| (a) Conventional Method (Set D) | (b) Method #1 (Set D) | ||||||||||||||||||||||
| N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | N0 | N1 | N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | ACC | ||
| (%) | (%) | ||||||||||||||||||||||
| N0 | 75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | N0 | 75 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| N1 | 0 | 66.4 | 0 | 0 | 1 | 0.1 | 1.8 | 0 | 1.8 | 3.9 | 88.59 | N1 | 0 | 73.3 | 0 | 0 | 0.1 | 0.1 | 0.4 | 0 | 0.2 | 0.8 | 97.78 |
| N2 | 0 | 0 | 74.1 | 0 | 0 | 0 | 0 | 0 | 0 | 0.9 | 98.81 | N2 | 0 | 0 | 74.7 | 0 | 0 | 0 | 0 | 0 | 0.1 | 0.2 | 99.56 |
| N3 | 0 | 0 | 0 | 74.8 | 0.2 | 0 | 0 | 0 | 0 | 0 | 99.7 | N3 | 0 | 0 | 0 | 74.8 | 0.2 | 0 | 0 | 0 | 0 | 0 | 99.7 |
| N4 | 0 | 0.2 | 0.3 | 1.1 | 70.7 | 0.2 | 0.3 | 0 | 0.7 | 1.4 | 94.22 | N4 | 0 | 0.4 | 0.3 | 0 | 72.9 | 0.1 | 0 | 0 | 0.7 | 0.6 | 97.19 |
| N5 | 0 | 0 | 0 | 0 | 0 | 74.6 | 0.4 | 0 | 0 | 0 | 99.41 | N5 | 0 | 0 | 0 | 0 | 0 | 74.9 | 0.1 | 0 | 0 | 0 | 99.85 |
| N6 | 0 | 0 | 0 | 0 | 0 | 2.4 | 72.4 | 0 | 0 | 0.1 | 96.59 | N6 | 0 | 0 | 0 | 0 | 0 | 0.8 | 74.2 | 0 | 0 | 0 | 98.96 |
| N7 | 0 | 0 | 0 | 0 | 0 | 0 | 0.4 | 74.2 | 0 | 0.3 | 98.96 | N7 | 0 | 0 | 0 | 0 | 0 | 0 | 0.1 | 74.9 | 0 | 0 | 99.85 |
| N8 | 0 | 1.3 | 0.1 | 0 | 0.4 | 0.1 | 0 | 0 | 71 | 2 | 94.67 | N8 | 0 | 1.1 | 0 | 0 | 0.2 | 0.3 | 0 | 0 | 72.6 | 0.8 | 96.74 |
| N9 | 0 | 1.8 | 1.7 | 0.3 | 1 | 0.4 | 1.6 | 0.4 | 0.4 | 67.3 | 89.78 | N9 | 0 | 0.8 | 0 | 0 | 0.1 | 0.4 | 0.3 | 0.1 | 0 | 73.2 | 97.63 |
| Average Classification Accuracy | 96.07 | Average Classification Accuracy | 98.73 | ||||||||||||||||||||
| (c) Method #2 (Set D) | (d) Proposed algorithm (Set D) | ||||||||||||||||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, G.; Lee, S. Environmental Noise Classification Using Convolutional Neural Networks with Input Transform for Hearing Aids. Int. J. Environ. Res. Public Health 2020, 17, 2270. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17072270
Park G, Lee S. Environmental Noise Classification Using Convolutional Neural Networks with Input Transform for Hearing Aids. International Journal of Environmental Research and Public Health. 2020; 17(7):2270. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17072270
Chicago/Turabian StylePark, Gyuseok, and Sangmin Lee. 2020. "Environmental Noise Classification Using Convolutional Neural Networks with Input Transform for Hearing Aids" International Journal of Environmental Research and Public Health 17, no. 7: 2270. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17072270