In this section, we set up the empirical model using Korean regional panel data for 16 provinces from 1998 to 2016. We include the cubic term of the income variable and age structure variables to estimate the IPAT augmented EKC model. By extending the model, we can verify the N-shaped EKC of CO2 emissions and assess the role of age structure, particularly population aging, on CO2 emissions.
4.1. Base Model
Based on Equation (6), our baseline estimation model includes total population (
P), per capita income (
y), and other exogenous variables (X), including socio-demographic factors. The baseline model takes the following form:
where
is per capita income,
is the oil price,
is total population,
is the ratio of manufacturing value-added to agriculture,
is the ratio of commercial value-added to agriculture,
is youth population,
is old population and
is the error term for region
i at time
t.
Equation (7) is represented in logarithmic form. We include a third-order polynomial of real per capita income at 2010 prices in order to explore the N-shaped EKC form. We include MAF and SVC as exogenous variables to incorporate the industrial structure of regions. Moreover, we add the oil price as the overall proxy of energy prices.
In terms of age distribution, we include both YOU and OLD variables to validate the robustness of the estimation. A0014 refers to the proportion of the total population that comprises youth aged between 0 to 14 years. P0014 is the youth dependency ratio, i.e., the ratio of the youth population to the working population.
For the OLD variable, O65 is the proportion of the population aged 65 and over in the total population. P65 is the dependency ratio of the old population, i.e., the ratio of the population aged 65 and over to the working population. Except for the dependent variable, CO2 emissions, all variables are taken from the Korean Statistical Information Service (KOSIS).
In summary, we construct a balanced panel data set comprising 304 observations from 16 regions for the period from 1998 to 2016.
Table 3 displays the average descriptive statistics of all variables for the entire period. Per capita CO
2 emissions have a large standard deviation between regions and are skewed to the right. In addition, the number of people over 65 years old was higher than that of 14-year-olds.
4.2. Panel Unit Root Test
Before estimating Equation (7), we perform panel unit root tests to verify the nonstationarity of variables. The three tests of LLC (Levin-Lin-Chu), IPS (Im-Pesaran-Shin), and MW (Maddala-Wu) [
29,
30,
31] are most widely used for panel unit root tests in empirical works. However, these “first generation” unit root tests assume that the individual time series in the panel are cross-sectionally independent. While this may be reasonably applied in the case of micro panel data with large N, it is a rather strong assumption in the case of macro and regional panel data.
To get rid of any cross-sectional dependency, [
32] develops new test statistics by including cross-section mean and its lagged value in cross-sectionally augmented Dickey–Fuller (CADF) regression with linear trends as follows:
where
is cross-section mean of
,
is the cross-section mean of
and
is the error term. CIPS (Cross-sectionally augmented IPS) test statistic is constructed as follows by taking averages of the t-value of coefficient
in the above CADF regression, where N and T refer to the cross-section and time series dimensions, respectively.
[
32] show that the limit distribution of the CIPS exists and is free of nuisance parameters. Additionally, the test has satisfactory power regardless of sample size and linear trends.
In our regional panel data set, the individual time series can also be somewhat correlated; thus, we use the CIPS test to account for any cross-sectional dependence.
Table 4 shows the result of the CIPS statistics. We perform the test including and excluding the linear trend in the specification based on Equation (8), for robustness. Based on the results, we cannot reject the null hypothesis of a unit root in both specifications for any variable. For CO
2 emissions (
lnC) and per capita income (
lny), we can reject the null hypothesis in one of the tests but there is no concrete evidence of stationarity. Therefore, we proceed to the cointegration test.
4.4. Panel Fully Modified OLS
In the empirical analysis with panel data, the nonstationarity of time-series is an important issue for the correction of statistical inference. To account for the nonstationarity property, many empirical works transform level variables into first-differenced variables [
20,
36,
37]. The estimated coefficient in the differenced regression model represents a short-run effect. However, the EKC hypothesis and the population–environment interaction are the long-run phenomena; thus, these estimated results are not suitable for the purpose [
25]. In order to conduct a correct statistical analysis and to account for long-run effects, we estimate Equation (7) by applying panel FMOLS of [
27,
28].
We built six models to estimate Equation (7). Models (1) and (2) are the basic models. We add a cubic term of per capita income () to reflect the EKC theory. Population (P) is derived from the IPAT model. Additionally, we include oil price (OP), manufacturing and commercial value-added ratio (MAF, SVC) as exogenous variables. The oil price represents the overall energy price of the regions. Manufacturing and commercial ratio represent industrial structure. To incorporate age distribution, Model (1) uses the proportion of the youth and the elderly to the total population (A0014, O65). However, Model (2) uses the dependency rate of the youth and the elderly (P0014, P65) for robustness.
Models (3) and (4) are similar to Models (1) and (2) except for the cubic term of per capita income. Models (3) and (4) represent a U-shaped or inverted U-shaped carbon–income relationship. Models (5) and (6) are estimated to check the robustness. Model (5) excludes the commercial value-added ratio, which is not significant in
Table 7. Furthermore, Model (6) excludes all industrial structure variables (
MAF and
SVC) for robustness.
All estimation results are summarized in
Table 7. The estimates can be interpreted in terms of elasticity because all variables are in logarithm form. Most estimates are highly statistically significant. In Models (1), (2), (5) and (6), the estimates of
y and
are positive, while that of
is negative; thus, we can expect an N-shaped curve of the carbon–income relationship in our sample. However, we find that the roots are imaginary. Thus, we cannot support inverted U-shaped or N-shaped curves. This may be mathematically interpreted as a monotonous increase in the carbon–income relationship.
Additionally, we run the regression models without the cubic term of per capita income to find the turning point, as indicated by Models (3) and (4) in
Table 7. The estimates of
y and
are negative and positive, which is indicative of a U-shaped curve. We identify the turning point incomes to be 10.0~10.3 million KRW (USD 8686~8886 in 2010) and they are found to be within our sample.
Next, we compare our results with two previous articles investigating Korean EKC. In [
15] verified the U-shaped EKC, which is consistent with our results. However, the researchers identified the turning point incomes to be much higher (at the level of USD 26,400~30,000). In [
16] investigated the EKC theory of CO
2 emissions in Korea using time-series analysis and found the turning points of USD 10,119 and USD 11,711 that triggered an inverted U-shaped curve. These turning point incomes exceed ours but are closer than those of [
15]. The two articles are references to our paper; however, they are not directly comparable due to differences in pollution emissions, methodology, and sample range.
Besides the income variables, the impacts of other exogenous variables are largely qualitatively consistent across Models (1) to (6). Oil price (OP), the proxy for general energy prices, exerts an adverse effect on CO2 emissions in Models (1) and (2). An increase in energy price leads to a decrease in fossil fuel consumption, thereby directly leading to a decrease in pollution emissions. Nonetheless, the estimated elasticity is rather small (at the level of −0.03~−0.04%). Moreover, the estimated elasticities lose their statistical significance in other models.
The estimated coefficient of the total population (P) is positive and significant, which is aligned with our expectations. The growing population raises the total energy consumption, thereby increasing environmental pollution. The results imply that a 1% increase in total population leads to an average of 0.9% increase in CO2 emissions. In the case of industrial structure, a higher manufacturing ratio seems to increase CO2 emission significantly. A 1% increase in manufacturing ratio leads to a 0.2%~0.3% increase in emissions. However, the effect of the commercial ratio is not statistically significant.
We now turn to the main goal of our analysis, which is to investigate the role of age structure on pollution emissions. The overall suggestion from Models (1) to (6) is that an increase in the elderly reduces CO2 emissions. In Models (1) and (3), we use the proportion of old people aged 65 and over in the total population and obtain estimated elasticities of −0.41% and −0.23%, respectively.
For a check on robustness, we use the old dependency ratio in Models (2) and (4) and estimate corresponding elasticities of −0.39% and −0.27%, respectively. Additionally, excluding industrial structure variables does not affect the estimates of the old dependency ratio in Model (6). The values differ slightly from each other but have the same effect qualitatively. These results are supported by previously mentioned literature [
4,
5,
17].
There are four possible explanations for these results. First, elderly people place higher value on environmental quality; this should lead to a positive correlation between population aging and air quality [
7,
8].
Second, since the elderly are less active than the young, an increase in the share of the older population can lead to a decrease in pollution. Old people tend to stay home longer than the young and this may decrease transportation demand [
4]. In [
20] showed that elderly people account for less CO
2 emissions in the transportation sector.
Third, even though they tend to stay home longer, their energy use intensity may be lower than that of young people, thereby leading to a potential decrease in energy consumption [
3,
6].
Fourth, aging may have an indirect effect on CO
2 through hindering economic growth. From previous studies, it is well known that aging reduces output growth, investment, and productivity. As economic activity is strongly correlated with emissions, aging may have reduced CO
2 emissions indirectly [
17,
21,
23,
24].
On the other hand, we find that the young population has a positive effect on CO2 emissions. Based on Models (1) and (3), a 1% increase in the proportion of young population results in a 0.22% and 0.42% increase in CO2 emissions respectively. The impact remains the same when using the youth dependency ratio in Models (2) and (4), where a 1% increase in youth dependency ratio leads to a 0.25% increase in emissions.
A possible explanation could be related to the “Nintendo-effect” [
3] whereby children usually watch more television, use personal computers, and are heavy game users. This may lead to an increase in electricity demand and hence, more CO
2 emissions.
Another explanation is related to household composition. Children and young population are raised by younger households, which are of have relatively larger size than aged households. Younger households are more active and drive more than other age groups; as a result, they emit more CO
2 emissions [
4,
5].
4.5. Time Series Fully Modified OLS
From the previous sections, we could verify that the age structure plays an important role in CO2 emissions on a regional level. However, one could criticize that regional analysis does not account for the CO2 emissions from transportation for commuting and fossil-fueled power generation. For example, many people in Seoul commute to Gyeonggi province and vice versa. Thus, they emit CO2 or other pollutants in at least two regions. Furthermore, Korea has a central power grid system and coal-powered generations, fossil fuel containing the most carbon, are mostly located in Gyeonggi, Chungnam and Gyeongnam. The distribution of present facilities does not depend on population age structure.
Against these backgrounds, we additionally estimate the nation-wide time-series regression model with two sector-specific dependent variables, CO2 emissions from the transportation sector and from the residential sector, for a robustness check. By doing this, we could embrace the aforementioned limitations.
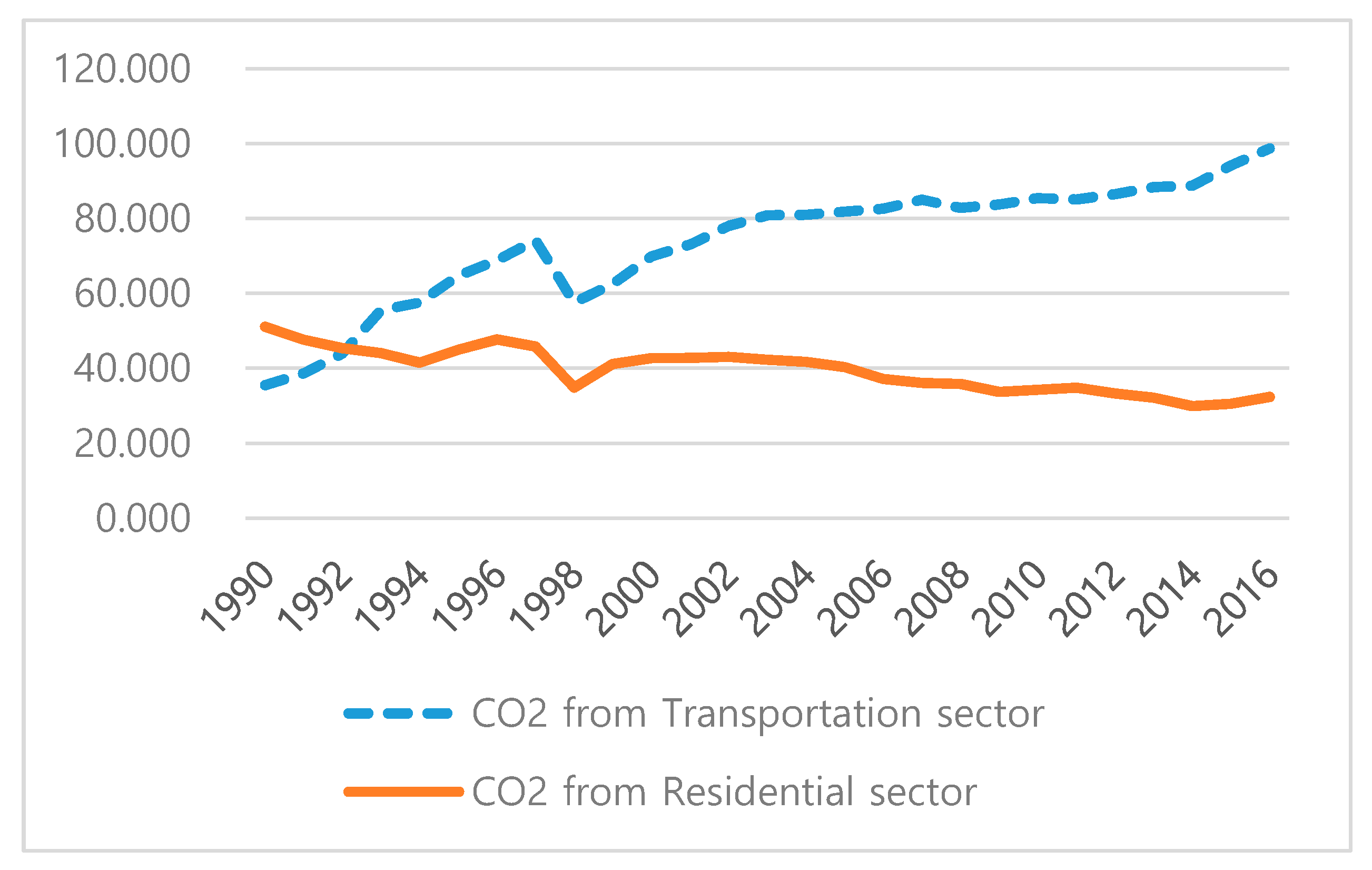
Figure 2 depicts CO
2 emissions from the transportation and residential sectors. In
Figure 2, we may notice that CO
2 emissions from the transportation sector (blue dashed line) are continuously increasing, but these from the residential sector (orange solid line) are decreasing.
For the nation-wide time series regression, we run Equation (6) using time series FMOLS [
38]. CO
2 emissions from the transportation and residential sectors are taken from GIR and other variables are taken from KOSIS. Data span is from 1990 to 2016 based on sector-specific CO
2 emissions.
Table 8 displays the results of time series FMOLS estimation where RES (1), RES (2) and RES (3) are results of FMOLS with residential sector CO
2 emissions and TR (4), TR (5) and TR (6) are results with transportation sector CO
2 emissions. We can verify that the effects of age structure variables,
A0014,
O65,
P0014, and
P65 on sector-specific CO
2 emissions are qualitatively the same as previously estimated panel models. The estimated values are somewhat larger than those of the panel models since the data is nationally aggregated and the size of the sample is much smaller.
The nonlinear relationship between CO2 emissions and per capita income found to be different from the sectors. The results of RES (1) to RES (3) indicate that there is a U-shaped curve between the two variables and the estimated turning point income is about USD 11,000. This indicates that there is a strong positive relationship between income and residential CO2 emissions. On the other hand, the results of TR (1) to TR (3) show the opposite relationship. We can find an inverted U-shaped curve between the two variables and the estimated turning point income is about USD 30,000.





{kind=link}
{kind=link}