
Analyzing Twitter Data to Evaluate People’s Attitudes towards Public Health Policies and Events in the Era of COVID-19


Abstract
:1. Introduction
1.1. Evidence-Based Health Policy
1.2. Sentiment Analysis
1.3. Research Goals
2. Materials and Methods
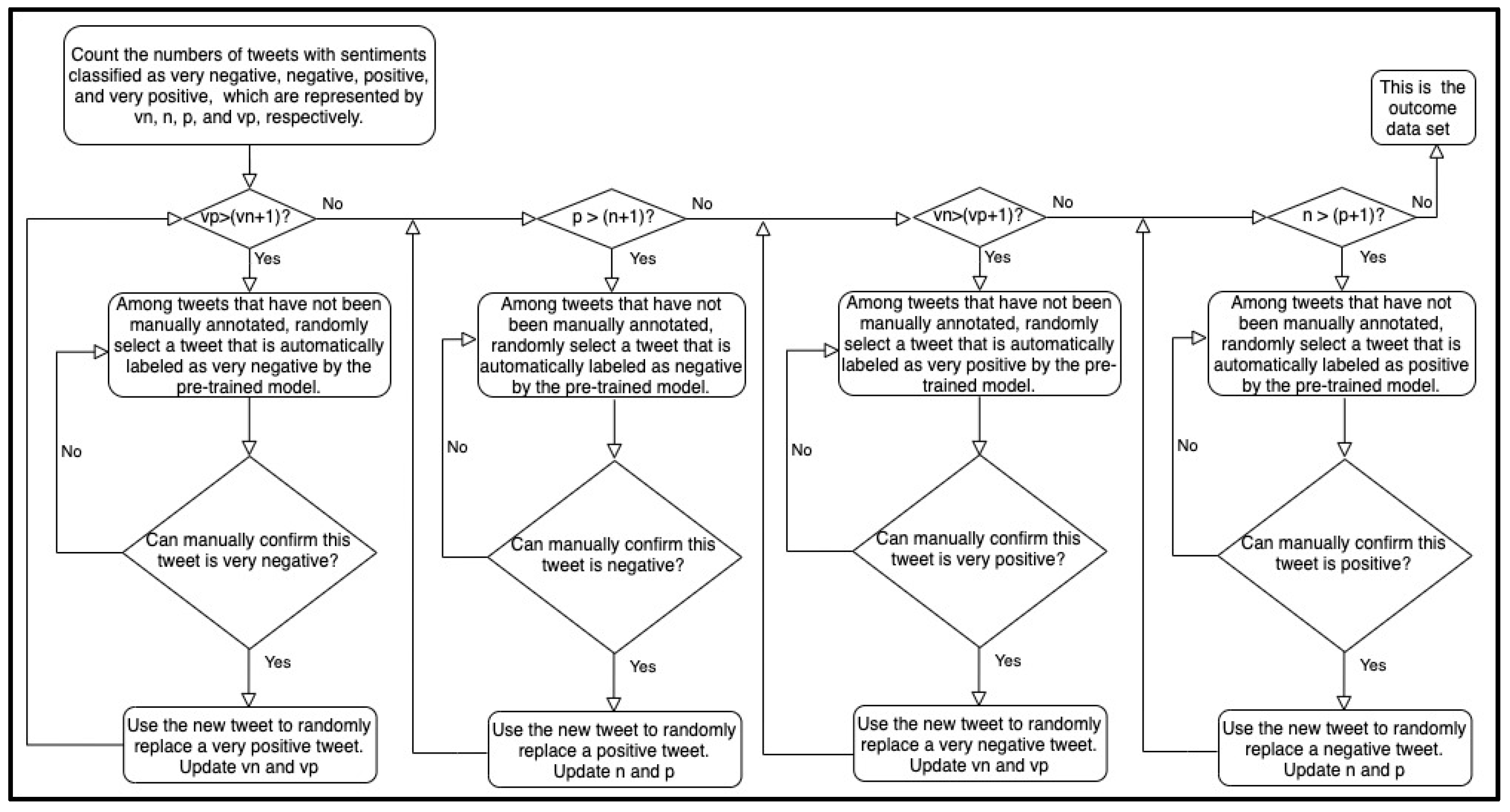
2.1. Data Preparation
2.2. Sentiment Analysis Model Training
2.3. Sentiment Analysis
2.4. Research Design
3. Results
3.1. Sentiment Analysis Results
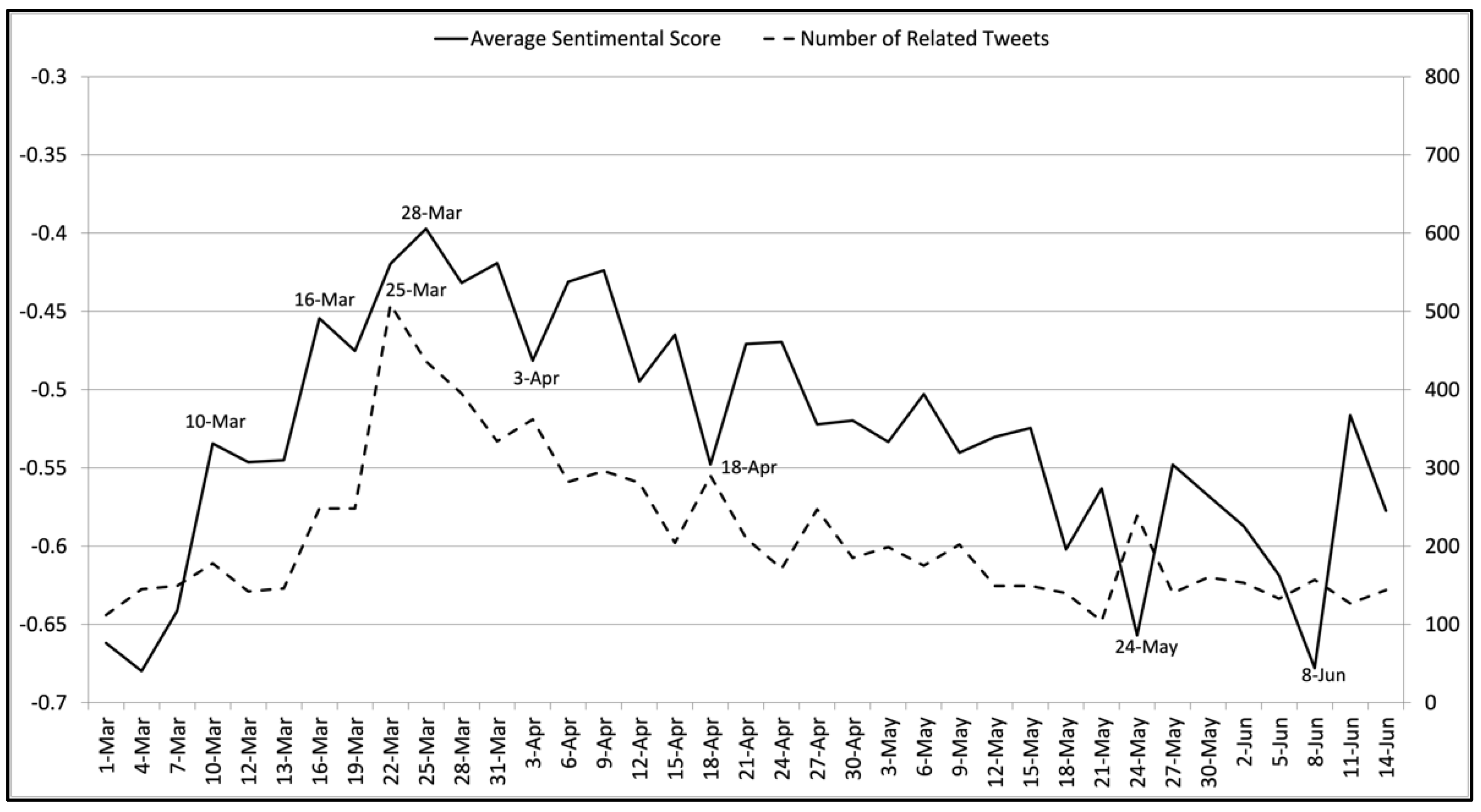
3.1.1. Analysis Results of the Stay-at-Home Policy
3.1.2. Analysis Results of the Social Distancing Policy
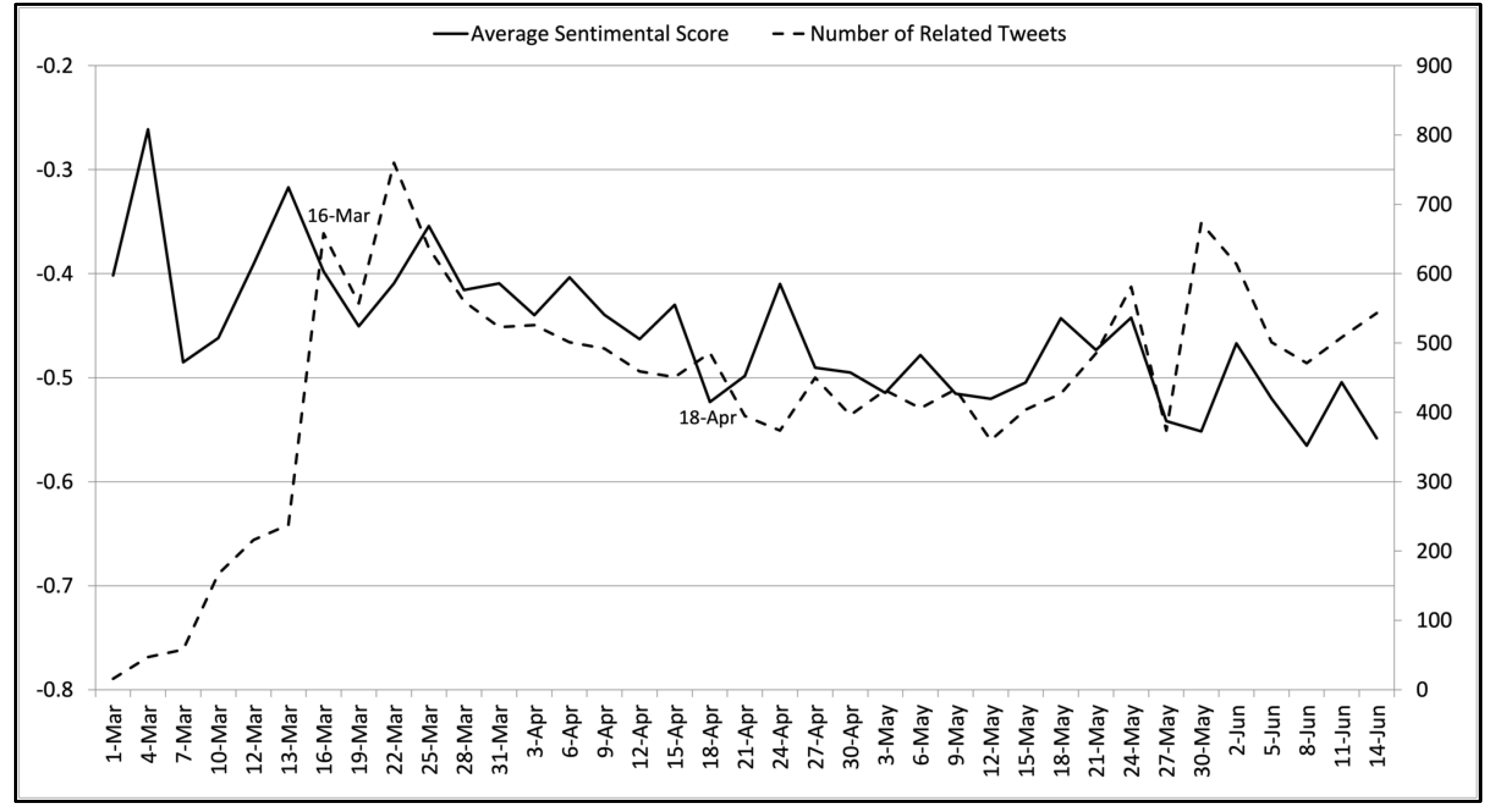
3.1.3. Analysis Results of the Mask Wearing Policy
3.2. Preprocessing Approach Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anderson, L.M.; Brownson, R.C.; Fullilove, M.T.; Teutsch, S.M.; Novick, L.F.; Fielding, J.; Land, G.H. Evidence-based public health policy and practice: Promises and limits. Am. J. Prev. Med. 2005, 28, 226–230. [Google Scholar] [CrossRef] [PubMed]
- Brownson, R.C.; Fielding, J.E.; Maylahn, C.M. Evidence-based public health: A fundamental concept for public health practice. Annu. Rev. Public Health 2009, 30, 175–201. [Google Scholar] [CrossRef] [Green Version]
- Brownson, R.C.; Chriqui, J.F.; Stamatakis, K.A. Understanding evidence-based public health policy. Am. J. Public Health 2009, 99, 1576–1583. [Google Scholar] [CrossRef] [PubMed]
- Vanagas, G.; Bala, M.; Lhachimi, S.K. Editorial: Evidence-based public health 2017. Biomed Res. Int. 2017, 2017, 2607397. [Google Scholar] [CrossRef] [PubMed]
- Kohatsu, N.D.; Robinson, J.G.; Torner, J.C. Evidence-based public health: An evolving concept. Am. J. Prev. Med. 2004, 27, 417–421. [Google Scholar] [CrossRef]
- Aarons, G.A.; Hurlburt, M.; Horwitz, S.M.C. Advancing a conceptual model of evidence-based practice implementation in public service sectors. Adm. Policy Ment. Health 2011, 38, 4–23. [Google Scholar] [CrossRef] [Green Version]
- Gibbert, W.S.; Keating, S.M.; Jacobs, J.A.; Dodson, E.; Baker, E.; Diem, G.; Giles, W.; Gillespie, K.N.; Grabauskas, V.; Shatchkute, A.; et al. Training the workforce in evidence-based public health: An evaluation of impact among US and international practitioners. Prev. Chronic Dis. 2013, 10, E148. [Google Scholar] [CrossRef] [Green Version]
- Carter, S.M.; Rychetnik, L.; Dietetics, P.D.; Lloyd, B.; Kerridge, I.H.; Baur, L.; Bauman, A.; Hooker, C.; Zask, A. Evidence, ethics, and values: A framework for health promotion. Am. Intern. Med. 2011, 101, 465–472. [Google Scholar] [CrossRef]
- Lim, J.H.; Cho, D.W. Specular reflection probability in the certainty grid representation. J. Dyn. Syst. Meas. Control. Trans. ASME 1994, 116, 512–520. [Google Scholar] [CrossRef]
- Feinstein, A.R. Clinical epidemiology, I: The populational experiments of nature and of man in human illness. Ann. Intern. Med. 1968, 69, 807–820. [Google Scholar] [CrossRef]
- Rychetnik, L.; Hawe, P.; Waters, E.; Barratt, A.; Frommer, M. A glossary for evidence based public health. J. Epidemiol. Community Health 2004, 58, 538–545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huston, A.C. From research to policy and back. Child Dev. 2008, 79, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Greenlick, M.R.; Goldberg, B.; Lopes, P.; Tallon, J. Health policy roundtable—View from the state legislature: Translating research into policy. Health Serv. Res. 2005, 40, 337–346. [Google Scholar] [CrossRef]
- Spangler, K.J.; Caldwell, L.L. The implications of public policy related to parks, recreation, and public health: A focus on physical activity. J. Phys. Act. Health 2007, 4, S64–S71. [Google Scholar] [CrossRef] [PubMed]
- McGowan, A.; Schooley, M.; Narvasa, H.; Rankin, J.; Sosin, D.M. Symposium on public health law surveillance: The nexus of information technology and public health law. J. Law Med. Ethics 2003, 31, 41–42. [Google Scholar] [CrossRef]
- Al-garadi, M.A.; Khan, M.S.; Varathan, K.D.; Mujtaba, G.; Al-Kabsi, A.M. Using online social networks to track a pandemic: A systematic review. J. Biomed. Inform. 2016, 62, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Saunders, G.H.; Christensen, J.H.; Gutenberg, J.; Pontoppidan, N.H.; Smith, A.; Spanoudakis, G.; Bamiou, D.E. Application of big data to support evidence-based public health policy decision-making for hearing. Ear Hear. 2020, 41, 1057–1063. [Google Scholar] [CrossRef]
- Dunn, A.G.; Mandl, K.D.; Coiera, E. Social media interventions for precision public health: Promises and risks. NPJ Digit. Med. 2018, 1, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Sinnenberg, L.; Buttenheim, A.M.; Padrez, K.; Mancheno, C.; Ungar, L.; Merchant, R.M. Twitter as a tool for health research: A systematic review. Am. J. Public Health 2017, 107, e1–e8. [Google Scholar] [CrossRef]
- Zhang, H.; Wheldon, C.; Tao, C.; Dunn, A.G.; Guo, Y.; Huo, J.; Bian, J. How to improve public health via mining social media platforms: A case study of human papillomaviruses (HPV). In Social Web and Health Research; Springer: Berlin/Heidelberg, Germany, 2019; pp. 207–231. ISBN 9783030147143. [Google Scholar]
- Merchant, R.M.; Elmer, S.; Lurie, N. Integrating social media into emergency-preparedness efforts. N. Engl. J. Med. 2011, 365, 289–291. [Google Scholar] [CrossRef] [Green Version]
- Ratkiewicz, J.; Meiss, M.; Conover, M.; Gonçalves, B.; Flammini, A.; Menczer, F. Detecting and tracking political abuse in social media. In Proceedings of the International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; pp. 297–304. [Google Scholar]
- Lampos, V.; De Bie, T.; Cristianini, N. Flu detector-tracking epidemics on twitter. In Lecture Notes in Computer Science; Balcázar, J.L., Bonchi, F., Gionis, A., Sebag, M., Eds.; Springer: Berlin/Heidelberg, Heidelberg, 2010; Volume 6323, pp. 599–602. ISBN 3642159389. [Google Scholar]
- Center, P.R. Sizing up Twitter Users. Available online: https://www.pewresearch.org/internet/2019/04/24/sizing-up-twitter-users/ (accessed on 9 June 2021).
- Top 10 Twitter Statistics—Updated May 2020. Available online: https://zephoria.com/twitter-statistics-top-ten/ (accessed on 14 June 2020).
- Twitter Usage Statistics. Available online: https://www.internetlivestats.com/twitter-statistics/ (accessed on 14 June 2020).
- Colditz, J.B.; Chu, K.H.; Emery, S.L.; Larkin, C.R.; James, A.E.; Welling, J.; Primack, B.A. Toward real-time infoveillance of twitter health messages. Am. J. Public Health 2018, 108, 1009–1014. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, N.; Siddique, J. Personality assessment using Twitter tweets. Procedia Comput. Sci. 2017, 112, 1964–1973. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, L. A survey of opinion mining and sentiment analysis. In Mining Text Data; Aggarwal, C.C., Zhai, C., Eds.; Springer: Boston, MA, USA, 2012; pp. 415–462. ISBN 9781461432234. [Google Scholar]
- Vinodhini, G.; Chandrasekaran, R. Sentiment analysis and opinion mining: A survey. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 282–292. [Google Scholar] [CrossRef] [Green Version]
- Bhavitha, B.K.; Rodrigues, A.P.; Chiplunkar, N.N. Comparative study of machine learning techniques in sentimental analysis. In Proceedings of the International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 10–11 March 2017; pp. 216–221. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Cámara, E.; Martín-Valdivia, M.T.; Ureña-López, L.A.; Montejo-Ráez, A.R. Sentiment analysis in Twitter. Nat. Lang. Eng. 2014, 20, 1–28. [Google Scholar] [CrossRef]
- Ji, X.; Chun, S.A.; Wei, Z.; Geller, J. Twitter sentiment classification for measuring public health concerns. Soc. Netw. Anal. Min. 2015, 5, 13. [Google Scholar] [CrossRef] [PubMed]
- Chew, C.; Eysenbach, G. Pandemics in the age of Twitter: Content analysis of tweets during the 2009 H1N1 outbreak. PLoS ONE 2010, 5, e14118. [Google Scholar] [CrossRef] [PubMed]
- Du, J.; Xu, J.; Song, H.; Liu, X.; Tao, C. Optimization on machine learning based approaches for sentiment analysis on HPV vaccines related tweets. J. Biomed. Semant. 2017, 8, 9. [Google Scholar] [CrossRef] [Green Version]
- Du, J.; Xu, J.; Song, H.Y.; Tao, C. Leveraging machine learning-based approaches to assess human papillomavirus vaccination sentiment trends with Twitter data. BMC Med. Inform. Decis. Mak. 2017, 17 (Suppl. 2), 69. [Google Scholar] [CrossRef]
- Daniulaityte, R.; Chen, L.; Lamy, F.R.; Carlson, R.G.; Thirunarayan, K.; Sheth, A. “When ‘Bad’ is ‘Good’”: Identifying personal communication and sentiment in drug-related Tweets. JMIR Public Health Surveill. 2016, 2, e162. [Google Scholar] [CrossRef] [Green Version]
- Cole-Lewis, H.; Varghese, A.; Sanders, A.; Schwarz, M.; Pugatch, J.; Augustson, E. Assessing electronic cigarette-related tweets for sentiment and content using supervised machine learning. J. Med. Internet Res. 2015, 17, e208. [Google Scholar] [CrossRef] [PubMed]
- Gabarron, E.; Dorronzoro, E.; Rivera-Romero, O.; Wynn, R. Diabetes on Twitter: A sentiment analysis. J. Diabetes Sci. Technol. 2019, 13, 439–444. [Google Scholar] [CrossRef] [PubMed]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; Alqarni, S.M.; Alamoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A sentiment analysis approach to predict an individual’s awareness of the precautionary procedures to prevent covid-19 outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2021, 18, 218. [Google Scholar] [CrossRef] [PubMed]
- Singh, M.; Kumar, A.; Shivam, J. Sentiment analysis on the impact of coronavirus in social life using the BERT model. Soc. Netw. Anal. Min. 2021, 11, 33. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public perception of the COVID-19 pandemic on twitter: Sentiment analysis and topic modeling study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef] [PubMed]
- Manguri, H.K.; Ramadhan, N.R.; Mohammed, R.A.P. Twitter sentiment analysis on worldwide COVID-19 outbreaks. Kurdistan J. Appl. Res. 2020, 5, 54–65. [Google Scholar] [CrossRef]
- Chun, S.A.; Li, A.C.Y.; Toliyat, A.; Geller, J. Tracking citizen’s concerns during COVID-19 pandemic. In Proceedings of the Annual International Conference on Digital Government Research, Seoul, Korea, 17–19 June 2020; pp. 322–323. [Google Scholar]
- Vijay, T.; Chawla, A.; Dhanka, B.; Karmakar, P. Sentiment Analysis on COVID-19 Twitter Data. In Proceedings of the IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Jaipur, India, 1–3 December 2020; pp. 1–7. [Google Scholar]
- Tweepy. Available online: https://www.tweepy.org/ (accessed on 26 June 2020).
- DocOnce Preprocess.py. Available online: https://github.com/doconce/preprocess/ (accessed on 28 March 2021).
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–14 June 2014; pp. 55–60. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.Y.; Ghuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Washington, DC, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Transcript—CDC Media Telebriefing: Update on COVID-19. Available online: https://www.cdc.gov/media/releases/2020/t0309-covid-19-update.html (accessed on 15 March 2021).
- Pidd, H. Did Dominic Cummings Break the Law on Lockdown Rules? Available online: https://www.theguardian.com/politics/2020/may/24/did-dominic-cummings-break-the-law-on-lockdown-rules (accessed on 15 March 2021).
- Collins, M.; Jackson, D.; Fritze, J.; Subramanian, C. Social Distancing through August? Donald Trump Suggests it May Be Needed to Help Confront Coronavirus. Available online: https://www.usatoday.com/story/news/politics/2020/03/16/coronavirus-trump-says-social-distancing-may-needed-through-august/5061517002/ (accessed on 15 March 2021).
- Chavez, N.; Andone, D.; Maxouris, C. CDC Recommends Americans Wear Face Masks Voluntarily in Public but Some Officials Say They Felt “Pressured” to Draft New Guidelines. Available online: https://www.cnn.com/2020/04/03/health/us-coronavirus-friday/index.html (accessed on 15 March 2021).
- Mangan, D.; Wilkie, C. Vice President Mike Pence Tours Mayo Clinic without Coronavirus Mask even though He Was Told to Wear One. Available online: https://www.cnbc.com/2020/04/28/coronavirus-mike-pence-tours-mayo-clinic-without-mask.html (accessed on 15 March 2021).
- Aiken, K. The Best Coronavirus Face Mask Materials, According to a New Study. Available online: https://www.huffpost.com/entry/best-coronavirus-face-mask-materials-new-study_l_5e99b576c5b6a92100e63129 (accessed on 21 March 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Sample Tweet |
|---|---|
| Very negative | The U.S. response to the coronavirus pandemic (it is that, just not acknowledged yet) is *shameful*. For the richest country in the world to fumble this badly is inexcusable. #COVID19 #coronavirus #pandemic |
| Negative | #coronavirus again exposing how there is no civilisation anywhere in the world. |
| Neutral | If you ever went to a party at the greenhouse, you’re immune to the coronavirus |
| Positive | Maybe the Masked Singer had the right idea #SocialDistancing #Isolation #COVID19 #Coronavirus |
| Very positive | #Erie County (275k pop.): 3.6% #COVID19 positive test rate (1054 tests, 38 positives w/.38% of pop. tested). PA (12M pop.): 18% positive test rate (120,153 tests, 21,655 pos. w/1% of pop. tested). Fewer tested, yes. But especially happy to be an Erie County resident right now. |
| Level | Sample Tweet |
|---|---|
| Very negative | A dull, simple-minded and stereotypical tale of drugs, death and mind-numbing indifference on the inner-city streets. |
| Negative | A sleek advert for youthful anomie that never quite equals the sum of its pretensions. |
| Neutral | So here it is: It’s about a family of sour immortals. |
| Positive | Any movie that makes hard work seem heroic deserves a look. |
| Very positive | A good music documentary, probably one of the best since The Last Waltz. |
| Data Set | Very Negative | Negative | Neutral | Positive | Very Positive |
|---|---|---|---|---|---|
| Mar01 | 35 | 331 | 212 | 115 | 7 |
| Mar01-Updated-1 | 26 | 237 | 212 | 201 | 24 |
| Mar01-Updated-2 | 21 | 223 | 212 | 223 | 21 |
| MarAprMay-1 | 37 | 296 | 233 | 121 | 13 |
| MarAprMay-2 | 19 | 271 | 269 | 128 | 13 |
| MarAprMay-3 | 17 | 259 | 277 | 132 | 15 |
| MarAprMay-all | 73 | 826 | 779 | 381 | 41 |
| Method | MarAprMay-1 | MarAprMay-2 | MarAprMay-3 | |||
|---|---|---|---|---|---|---|
| ASSE | MSE | ASSE | MSE | ASSE | MSE | |
| Pretrained | 0.346 | 0.783 | 0.283 | 0.731 | 0.293 | 0.767 |
| Original early trained | 0.156 | 0.810 | 0.106 | 0.769 | 0.152 | 0.781 |
| Updated-Early-1 | 0.036 | 0.699 | 0.052 | 0.753 | 0.025 | 0.707 |
| Updated-Early-2 | 0.030 | 0.721 | 0.037 | 0.672 | 0.026 | 0.645 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, M.H.; Wang, Y. Analyzing Twitter Data to Evaluate People’s Attitudes towards Public Health Policies and Events in the Era of COVID-19. Int. J. Environ. Res. Public Health 2021, 18, 6272. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18126272
Tsai MH, Wang Y. Analyzing Twitter Data to Evaluate People’s Attitudes towards Public Health Policies and Events in the Era of COVID-19. International Journal of Environmental Research and Public Health. 2021; 18(12):6272. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18126272
Chicago/Turabian StyleTsai, Meng Hsiu, and Yingfeng Wang. 2021. "Analyzing Twitter Data to Evaluate People’s Attitudes towards Public Health Policies and Events in the Era of COVID-19" International Journal of Environmental Research and Public Health 18, no. 12: 6272. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18126272