
Exploring Factors for Predicting Anxiety Disorders of the Elderly Living Alone in South Korea Using Interpretable Machine Learning: A Population-Based Study


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Source
2.2. Measurement and Definition of Variables
2.3. Development of Machine Learning Using Stacking Ensemble
2.3.1. Base Model: Support Vector Machine (SVM)
2.3.2. Base Model: Random Forest
2.3.3. Base Model: LightGBM
2.3.4. Base Model: Adaboost
- Train weak learner using distribution .
- Get weak hypothesis
- Aim: select with low weighted error:
- Choose
- Update, forwhere is a normalization factor (chosen so that will be a distribution).
2.4. Meta Model: XGBoost
2.5. Validation of Model’s Predictive Performance
| True positive = It is actually an anxiety disorder, and the predicted outcome is an anxiety disorder. | (2) |
| False negative = It is actually an anxiety disorder, but the predicted outcome is normal. | |
| False positive = It is actually normal, and the predicted outcome is an anxiety disorder. | |
| True negative = It is actually normal, and the predicted outcome is normal. | |
| Recall = TP/(TP + FN) | |
| Precision = TP/(TP + FP) | |
| Accuracy = (TP + TN)/(TP + FP + FN + TN) | |
| F1-score = 2 * (Recall * Precision)/(Recall + Precision) |
3. Results
3.1. General Characteristics of Subjects
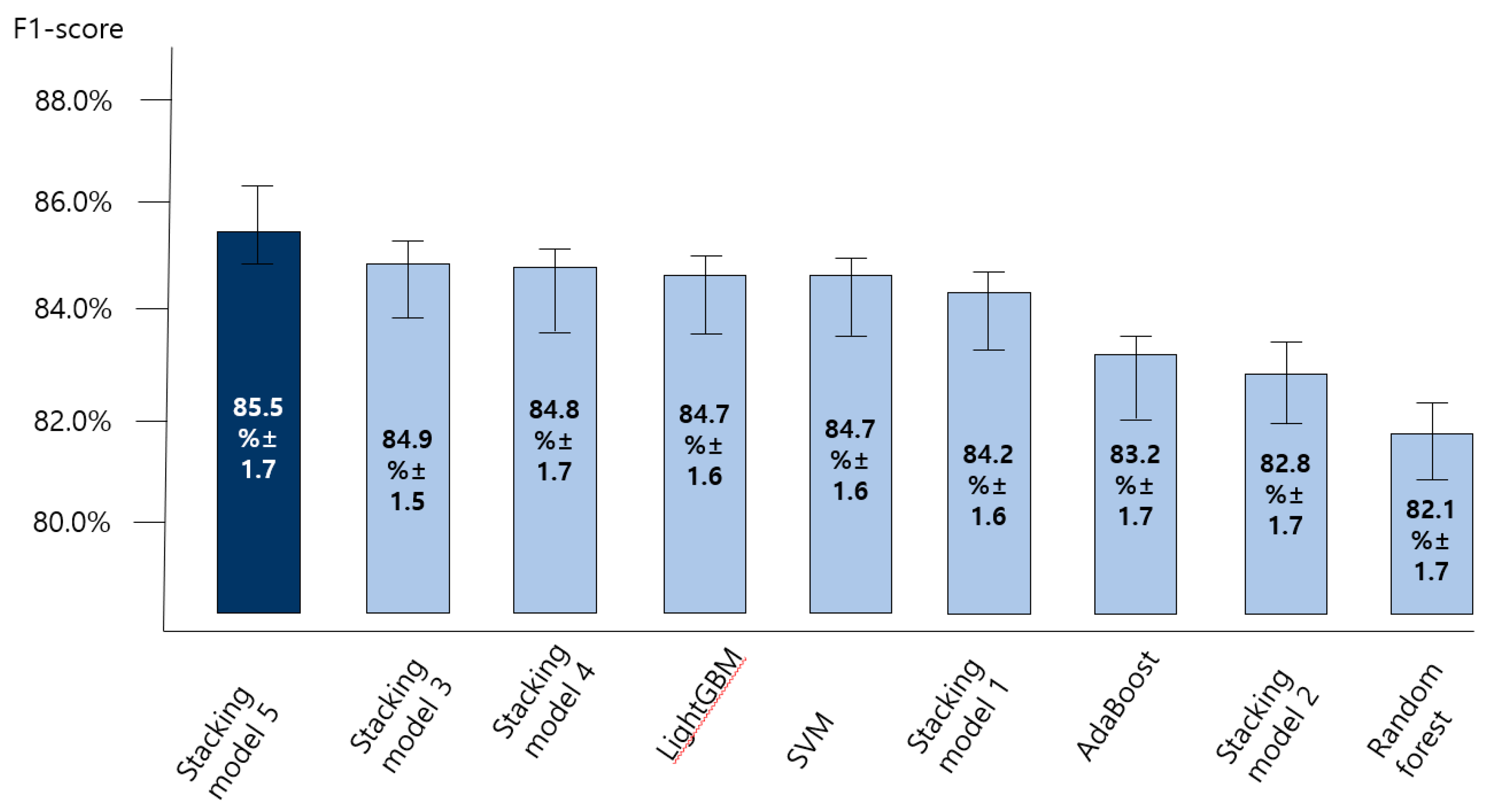
3.2. Comparing the Accuracy of Predictive Models for the Anxiety Disorder in Old Age
3.3. Exploring Predictors and High-Risk Groups for the Anxiety Disorder in Old Age
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Baxter, A.J.; Scott, K.M.; Vos, T.; Whiteford, H.A. Global prevalence of anxiety disorders: A systematic review and meta-regression. Psychol. Med. 2013, 43, 897. [Google Scholar] [CrossRef] [PubMed]
- Kessler, R.C.; Berglund, P.; Demler, O.; Jin, R.; Merikangas, K.R.; Walters, E.E. Lifetime prevalence and age-of-onset distributions of DSM-IV disorders in the National Comorbidity Survey Replication. Arch. Gen. Psychiatry 2005, 62, 593–602. [Google Scholar] [CrossRef] [Green Version]
- Ministry of Health & Welfare. National Mental Health Statistics 2019; Ministry of Health & Welfare: Sejong, Korea, 2020.
- Remes, O.; Brayne, C.; Van Der Linde, R.; Lafortune, L. A systematic review of reviews on the prevalence of anxiety disorders in adult populations. Brain Behav. 2016, 6, e00497. [Google Scholar] [CrossRef]
- Gum, A.M.; King-Kallimanis, B.; Kohn, R. Prevalence of mood, anxiety, and substance-abuse disorders for older Americans in the national comorbidity survey-replication. Am. J. Geriatr. Psychiatry 2009, 17, 769–781. [Google Scholar] [CrossRef]
- Subramanyam, A.A.; Kedare, J.; Singh, O.P.; Pinto, C. Clinical practice guidelines for geriatric anxiety disorders. Indian J. Psychiatry 2018, 60 (Suppl. 3), S371. [Google Scholar] [CrossRef]
- Rangara, J.; Pelissolo, A. Anxiety disorders in the elderly: Clinical and therapeutic aspects. Psychol. Neuropsychiatr. Vieil. 2006, 4, 179–187. [Google Scholar]
- Sable, J.A.; Jeste, D.V. Anxiety disorders in older adults. Curr. Psychiatry Rep. 2001, 3, 302–307. [Google Scholar] [CrossRef] [PubMed]
- Fan, X.; Xie, X.; Zhang, C.; Kong, W.; Zhou, C.; Biao, D.U. Systematic review of tandospirone and buspirone in treatment of patients with generalized anxiety disorder. Drug Eval. Res. 2017, 40, 400–405. [Google Scholar]
- Park, S.A.; Song, J.K. The effect of social anxiety on psychological adaptation. Korean Psychol. J. Cult. Soc. Issues 2005, 40, 400–405. [Google Scholar]
- Kim, C.T. An exploratory study on phenomenological hermeneutics of every day’ anxiety of university student. J. Welf. Adm. 2013, 23, 23–45. [Google Scholar]
- Choi, I.; Suh, K.H.; Kim, Y.S. The psychosocial factors affecting suicidal ideation of the elderly. Health Soc. Sci. 2009, 25, 33–56. [Google Scholar]
- Chatterjee, A.; Gerdes, M.W.; Martinez, S.G. Identification of risk factors associated with obesity and overweight—A machine learning overview. Sensors 2020, 20, 2734. [Google Scholar] [CrossRef] [PubMed]
- Byeon, H. Associations between adolescents’ earphone usage in noisy environments, hearing loss, and self-reported hearing problems in a nationally representative sample of South Korean middle and high school students. Medicine 2021, 100, e24056. [Google Scholar] [CrossRef] [PubMed]
- Navada, A.; Ansari, A.N.; Patil, S.; Sonkamble, B.A. Overview of use of decision tree algorithms in machine learning. In Proceedings of the 2011 IEEE control and system graduate research colloquium, Shah Alam, Malaysia, 27–28 June 2011; pp. 37–42. [Google Scholar] [CrossRef]
- Adhikari, R. A neural network based linear ensemble framework for time series forecasting. Neurocomputing 2015, 157, 231–242. [Google Scholar] [CrossRef]
- Al-Sarem, M.; Saeed, F.; Al-Mekhlafi, Z.G.; Mohammed, B.A.; Al-Hadhrami, T.; Alshammari, M.T.; Alreshidi, A.; Alshammari, T.S. An Optimized Stacking Ensemble Model for Phishing Websites Detection. Electronics 2021, 10, 1285. [Google Scholar] [CrossRef]
- Divina, F.; Gilson, A.; Gomez-Vela, F.; Garcia Torres, M.; Torres, J.F. Stacking ensemble learning for short-term electricity consumption forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef] [Green Version]
- Panwar, H.; Gupta, P.K.; Siddiqui, M.K.; Morales-Menendez, R.; Bhardwaj, P.; Singh, V. A deep learning and grad-CAM based color visualization approach for fast detection of COVID-19 cases using chest X-ray and CT-Scan images. Chaos Soliton Fractals 2020, 140, 110190. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. Proc. IEEE Int. Conf. Comput. Vis. 2017, 618–626. [Google Scholar]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine learning interpretability: A survey on methods and metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, D.; Geng, N.; Wang, Y.; Yin, Y.; Jin, Y. Stacking-based ensemble learning of decision trees for interpretable prostate cancer detection. Appl. Soft Comput. 2019, 77, 188–204. [Google Scholar] [CrossRef]
- Lee, J.H. Development of the Korean Form of Zung’s Self-Rating Anxiety Scale. Yeungnam Univ. J. Med. 1996, 13, 279–294. [Google Scholar] [CrossRef]
- Zung, W.W. A rating instrument for anxiety disorders. Psychosomatics 1971, 12, 371–379. [Google Scholar] [CrossRef]
- Julian, L.J. Measures of anxiety. Arthritis Care Res. 2011, 63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carriere, I.; Ryan, J.; Norton, J.; Scali, J.; Stewart, R.; Ritchie, K.; Ancelin, M.L. Anxiety and mortality risk in community-dwelling elderly people. Br. J. Psychiatry 2013, 203, 303–309. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clarke, D.M.; Currie, K.C. Depression, anxiety and their relationship with chronic diseases: A review of the epidemiology, risk and treatment evidence. Med. J. Aust. 2009, 190, S54–S60. [Google Scholar] [CrossRef] [PubMed]
- Sami, M.B.; Nilforooshan, R. The natural course of anxiety disorders in the elderly: A systematic review of longitudinal trials. Int. Psychogeriatr. 2015, 27, 1061. [Google Scholar] [CrossRef]
- Bryant, C.; Jackson, H.; Ames, D. The prevalence of anxiety in older adults: Methodological issues and a review of the literature. J. Affect. Disord. 2008, 109, 233–250. [Google Scholar] [CrossRef]
- Domènech-Abella, J.; Mundó, J.; Haro, J.M.; Rubio-Valera, M. Anxiety, depression, loneliness and social network in the elderly: Longitudinal associations from The Irish Longitudinal Study on Ageing (TILDA). J. Affect. Disord. 2019, 246, 82–88. [Google Scholar] [CrossRef] [Green Version]
- Saunders, J.B.; Aasland, O.G.; Babor, T.F.; De LaFuente, J.R.; Grant, M. Development of the alcohol use disorders identification test (AUDIT): WHO collaborative project on earlydetection of persons with harmful alcohol consumption-II. Addiction 1993, 88, 791–804. [Google Scholar] [CrossRef]
- Rosenberg, M. Rosenberg self-esteem scale (RSE). Acceptance and commitment therapy. Meas. Package 1965, 61, 18. [Google Scholar]
- Daneshfaraz, R.; Aminvash, E.; Ghaderi, A.; Abraham, J.; Bagherzadeh, M. SVM performance for predicting the effect of horizontal screen diameters on the hydraulic parameters of a vertical drop. Appl. Sci. 2021, 11, 4238. [Google Scholar] [CrossRef]
- Furey, T.S.; Cristianini, N.; Duffy, N.; Bednarski, D.W.; Schummer, M.; Haussler, D. Support vector machine classification and validation of cancer tissue samples using microarray expression data. Bioinformatics 2000, 16, 906–914. [Google Scholar] [CrossRef] [PubMed]
- Byeon, H. Predicting the swallow-related quality of life of the elderly living in a local community using support vector machine. Int. J. Environ. Res. Public Health 2019, 16, 4269. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Gao, Y.; Jiao, D. Multi-label classification based on random forest algorithm for non-intrusive load monitoring system. Processes 2019, 7, 337. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Xiao, Y.; Wu, J.; Lin, Z.; Zhao, X. A deep learning-based multi-model ensemble method for cancer prediction. Comput. Methods Programs Biomed. 2018, 153, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Xie, O.; Liu, Z.T.; Ding, X.W. Electroencephalogram emotion recognition based on a stacking classification model. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 5544–5548. [Google Scholar] [CrossRef]
- Lin, F.; Jiang, J.; Fan, J.; Wang, S. A stacking model for variation prediction of public bicycle traffic flow. Intell. Data Anal. 2018, 22, 911–933. [Google Scholar] [CrossRef]
- Yadav, D.C.; Pal, S. To generate an ensemble model for women thyroid prediction using data mining techniques. Asian Pac. J. Cancer Prev. 2019, 20, 1275–1281. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Byeon, H. Exploring factors associated with the social discrimination experience of children from multicultural families in South Korea by using stacking with non-linear algorithm. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 125–130. [Google Scholar] [CrossRef]
- Green, M.J.; Benzeval, M. The development of socioeconomic inequalities in anxiety and depression symptoms over the lifecourse. Soc. Psychiatry Psychiatr. Epidemiol. 2013, 48, 1951–1961. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, K.T.; Choi, S.; Park, M.; Park, S.; Go, S.H.; Park, H. The effect of family structures and psycho-social factors on suicidal ideation of senior citizens. Korean J. Gerontol. Soc. Welfare 2011, 52, 205–228. [Google Scholar] [CrossRef]
- Singh, A.; Misra, N. Loneliness, depression and sociability in old age. Ind. Psychiatry J. 2009, 18, 51–55. [Google Scholar] [CrossRef] [PubMed]
- Statistics Korea. Senior Statistics; Statistics Korea: Daejeon, Korea, 2021.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Anxiety Disorder | p | |
|---|---|---|---|
| No (n = 1290) | Yes (n = 268) | ||
| Residential area | 0.621 | ||
| Urban | 981 (83.1) | 200 (16.9) | |
| Rural | 309 (82.0) | 68 (18.0) | |
| Highest level of education | <0.001 | ||
| Middle school graduation or less | 804 (79.6) | 206 (20.4) | |
| High school graduation or more | 486 (88.7) | 62 (11.3) | |
| Mean monthly household income | 0.001 | ||
| <KRW 2 million | 739 (80.1) | 184 (19.9) | |
| ≥KRW 2 million and <KRW 3 million | 248 (84.9) | 44 (15.1) | |
| ≥KRW 3 million | 303 (88.3) | 40 (11.7) | |
| Subjective loneliness | <0.001 | ||
| Very rare | 653 (95.1) | 34 (4.9) | |
| Occasionally lonely | 530 (82.9) | 109 (17.1) | |
| Often lonely | 100 (47.6) | 110 (52.4) | |
| Mostly lonely | 7 (31.8) | 15 (68.2) | |
| Subjective satisfaction with help from neighbors | <0.001 | ||
| Yes | 915 (85.7) | 153 (14.3) | |
| No | 375 (76.5) | 115 (23.5) | |
| Self-esteem, the experience of suicidal urge over the past year | <0.001 | ||
| Yes | 66 (47.1) | 74 (52.9) | |
| No | 1224 (86.3) | 194 (13.7) | |
| Subjective trust satisfaction with neighbors | <0.001 | ||
| Yes | 1153 (85.7) | 193 (14.3) | |
| No | 137 (64.6) | 75 (35.4) | |
| Alcohol use disorder | <0.001 | ||
| Normal drinker | 685 (83.8) | 132 (16.2) | |
| High-risk drinker | 225 (80.9) | 53 (19.1) | |
| Alcohol use disorder | 5 (38.5) | 8 (61.5) | |
| Subjective satisfaction of the living environment of the neighborhood | <0.001 | ||
| Yes | 1032 (85.9) | 169 (14.1) | |
| No | 258 (72.3) | 99 (27.7) | |
| Subjective satisfaction of the safety level of the neighborhood | <0.001 | ||
| Yes | 1104 (85.9) | 181 (14.1) | |
| No | 186 (68.1) | 87 (31.9) | |
| Subjective satisfaction of the medical service of the region | 0.007 | ||
| Yes | 947 (84.4) | 175 (15.6) | |
| No | 343 (78.7) | 93 (21.3) | |
| Regular club activities | 0.001 | ||
| Yes | 421 (87.7) | 59 (12.3) | |
| No | 869 (80.6) | 209 (19.4) | |
| Your and your family’s experience of being a victim of a crime over the past year | <0.001 | ||
| Yes | 28 (56.0) | 22 (44.0) | |
| No | 1206 (84.5) | 221 (15.5) | |
| Awareness of mental health promotion services provided by public health centers and/or mental health promotion centers | 0.662 | ||
| Yes | 330 (82.1) | 72 (17.9) | |
| No | 960 (83.0) | 196 (17.0) | |
| Experiences of using mental health promotion services provided by public health centers and/or mental health promotion centers | 0.372 | ||
| Yes | 95 (79.8) | 24 (20.2) | |
| No | 1195 (83.0) | 244 (17.0) | |
| Age, mean ± SD | 67.77 ± 5.53 | 69.01 ± 5.50 | 0.001 |
| Subjective frequency of communication with other family members, mean ± SD | 6.40 ± 1.53 | 5.22 ± 1.91 | <0.001 |
| Subjective frequency of communication with neighbors and friends, mean ± SD | 6.18 ± 1.56 | 5.23 ± 1.79 | <0.001 |
| Self esteem scale, mean ± SD | 29.28 ± 3.21 | 26.13 ± 3.35 | <0.001 |
| Subjective frequency of communication with neighbors and friends (10 points scale) | 5.90 ± 1.54 | 5.16 ± 1.84 | <0.001 |
| Job/income instability (10-point scale) | 5.07 ± 1.84 | 5.86 ± 2.14 | <0.001 |
| Instability of preparation for old age (10-point scale) | 6.29 ± 2.16 | 7.27 ± 1.71 | <0.001 |
| Living safety instability (10-point scale) | 4.66 ± 2.04 | 5.34 ± 1.87 | <0.001 |
| Physical health instability (10-point scale) | 6.17 ± 2.14 | 7.02 ± 2.08 | <0.001 |
| Cognitive health instability (10-point scale) | 4.86 ± 2.11 | 6.33 ± 1.95 | <0.001 |
| Family relationship and dissolution instability (10-point scale | 3.79 ± 2.23 | 5.31 ± 2.14 | <0.001 |
| Instability in family support and caregiving (10-point scale) | 3.71 ± 2.28 | 4.45 ± 2.47 | <0.001 |
| Instability in relationship with neighbors (10-point scale) | 3.45 ± 2.17 | 4.27 ± 2.15 | <0.001 |
| Online privacy infringement and personal information leakage instability (10-point scale) | 3.76 ± 2.37 | 3.49 ± 2.31 | 0.094 |
| Instability in the spread of high-risk new infectious disease (10-point scale) | 6.35 ± 1.96 | 6.74 ± 1.66 | 0.003 |
| Economic recession and growth slowdown instability (10-point scale) | 6.42 ± 1.87 | 6.69 ± 1.80 | 0.032 |
| Environmental destruction and natural disaster instability (10-point scale) | 5.47 ± 1.88 | 5.66 ± 1.61 | 0.130 |
| Political and international relations instability | 5.63 ± 1.92 | 5.28 ± 2.02 | 0.993 |
| Crime instability such as abuse and violence (10-point scale) | 5.28 ± 2.02 | 5.73 ± 2.03 | 0.001 |
| Social safety net vulnerability instability (10-point scale) | 5.37 ± 2.03 | 5.79 ± 1.97 | 0.002 |
| Low fertility and aging instability (10-point scale) | 5.38 ± 2.12 | 5.75 ± 2.06 | 0.010 |
| Instability in conflicts between classes, groups, and generations (10-point scale) | 5.03 ± 2.02 | 5.33 ± 2.01 | 0.027 |
| Path | Characteristics | LFP-Score |
|---|---|---|
| 1 | The elderly who often (or mostly) felt subjective loneliness, had an SES score of 26 or less, and had a subjective communication with their family of 4 or less (on a 10-point scale) | 0.14 |
| 2 | The elderly who sometimes felt subjective loneliness, perceived that they had a bad family relationship (or very bad), and were victims of a crime, or had their family member who was a victim of a crime over the past year | 0.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Byeon, H. Exploring Factors for Predicting Anxiety Disorders of the Elderly Living Alone in South Korea Using Interpretable Machine Learning: A Population-Based Study. Int. J. Environ. Res. Public Health 2021, 18, 7625. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18147625
Byeon H. Exploring Factors for Predicting Anxiety Disorders of the Elderly Living Alone in South Korea Using Interpretable Machine Learning: A Population-Based Study. International Journal of Environmental Research and Public Health. 2021; 18(14):7625. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18147625
Chicago/Turabian StyleByeon, Haewon. 2021. "Exploring Factors for Predicting Anxiety Disorders of the Elderly Living Alone in South Korea Using Interpretable Machine Learning: A Population-Based Study" International Journal of Environmental Research and Public Health 18, no. 14: 7625. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18147625