1. Introduction
Bridging studies are designed to fill the gap between two populations in terms of clinical trial data, such as toxicity, efficacy, comorbidities and doses. A bridging data package consists of selected data from the Clinical Data Package of the population in the new region, including pharmacokinetic, any pharmacodynamic, dose–toxicity or dose–efficacy data, and if appropriate, a bridging study to extrapolate the foreign dose–response data to the new region [
1].
According to the International Council for Harmonisation of Technical Requirements for Pharmaceuticals for Human Use E5 (ICH-E5) guidelines, data can be extrapolated from one region to another if “a bridging study [...] indicates that a different dose in the new region results in a safety and efficacy profile that is not substantially different from the one derived from the original region; it will often be possible to extrapolate the foreign data to the new region, with an appropriate dose adjustment, if this can be adequately justified (e.g., by pharmacokinetic and/or pharmacodynamic data)” [
1]. This is the reason why proposing a statistical tool evaluating the similarity between two foreign dose–response curves is of great interest. If this is proven, then, other clinical trials data can be used and extrapolated for the new region.
In Japan, the Pharmaceuticals and Medical Devices Agency (PMDA) recommends the re-evaluation of a drug if there are insufficient data from Japanese patients [
2]. Indeed, Phase I clinical trials in oncology, which aim to estimate the maximum tolerated dose (MTD), are often repeated. Ogura et al. [
3] pointed out that MTD differences between populations could be due to the different distribution of genetic polymorphisms in enzymes involved in drug metabolism or of biomarker incidences in different populations. In particular, in Japan, Phase I trials are repeated based on a physiological/metabolic paradigm: MTDs for Japanese patients are often lower than the ones of for Caucasian patients [
4]. Based on this assumption, Maeda and Kurokawa [
5] have performed an intensive study comparing the MTD of 21 molecularly targeted cancer drugs in Japanese versus Caucasian populations. They found out that this assumption does not hold well: in their study, the MTD was lower for Japanese patients in only two cases, there were no differences between the two populations with 10 drugs and MTD was incommensurable as the evaluated dose range acted different with nine drugs. Moreover, Mizugaki et al. [
6] have analyzed data of single-agent Phase I trials at the National Cancer Center Hospital between 1995 and 2012, comparing the dose-limiting toxicity (DLT) profiles and MTDs of Japanese trials with the trials from Caucasian populations.
Recently, methods for bridging dose-finding design have been proposed where previous population data were used to either calibrate the prior distribution of the Bayesian model parameter(s) or to choose the “working model” of the design for prospective trials [
7]. Liu et al. [
8] proposed using a Bayesian model to average the dose-finding method where the previous trial data were used to build three different skeletons which would then be averaged during the study. Moreover, Takeda and Morita recently defined an “historical-to-current” parameter that could describe the degree of borrowing from one population to the other [
9]. Ollier et al. [
10] proposed a bridging method where a borrowing parameter was estimated sequentially in a response adaptive design which quantifies the amount of reasonable borrowing according to the similarity between the two populations’ estimates. Usually, the proposed methods focus on one parameter, strictly related to the MTD and not on the full dose–toxicity response curve. All these methods were proposed with the purpose of using the foreign data to plan and conduct the future Phase I trial in the new region. Indeed, at this stage, the idea is to use the foreign data to calibrate model-based priors to be used in the new region trial. However, in most cases, the trial in the new region will not be planned this way, but rather by using the MTD information from the foreign region only, if available. The sophisticated statistical approach will not be used.
Another option is to compare the two dose–response curves estimated from each region and to evaluate how similar they are. In this case, the overall purpose is different from before; if the curves prove to be similar (under the uncertainty estimation), the new purpose will be to extrapolate other trial data—such as that of Phase II—to the new region and to avoid further repetition of clinical investigations. For dose–response curves, Bretz et al. [
11] introduced an asymptotic test to evaluate the difference of the
minimum efficient dose among several groups of subjects, according to a threshold. However, this method was built for later clinical phases and presents weaknesses when applied to a small sample size. By contrast, Bayesian methods could mitigate the issue of estimation based on a small sample size setting, since they do not rely on asymptotic approximations and prior distributions can be used to ensure more stability in computation. Thereafter, the degree of similarity could be considered directly at the posterior distributions level. Therefore, methods proposing to estimate the similarity between dose–toxicity curves should be proposed when there is the need to evaluate if the safety data can be extrapolated or not.
The aim of our work is to propose some Bayesian indicators that evaluate the distance and the similarity of (1) dose–toxicity curves, taking into account the variability, (2) the MTD posterior distributions, by extending and adapting the commensurability criterion initially proposed by Ollier et al. [
10]. These indicators were applied to several Phase I trials presented in Maeda and Kurokawa [
5] and Mizugaki et al. [
6], evaluating the similarity between Western dose–toxicity data to Eastern ones. The proposed tools should be used by trial stakeholders in order to decide if other trials data could be extrapolated from the new region, and, if so, to avoid the repetition of multiple clinical trials. In the next section, the original commensurability parameter is summarized along with the proposed extensions and the dose–toxicity model used. The case studies are described in
Section 3, while
Section 4 details the computational settings. The results are given in
Section 5, followed by a Discussion section.
2. Methods
In this section, we briefly recall the Bayesian commensurability measure used in Ollier et al. [
10], which was originally adopted into a power prior setting [
12]; we then propose extensions and modifications to this measure to be applied at the end of the study. We also introduce the Bayesian dose–toxicity model, which will be used for retrospective data analyses.
Let denote the Caucasian data, , the sample size of , and the binary outcome of the j-th patient which received dose . In a similar way, we can define , the Japanese data and associated parameters. Let us also set a model for the probability of toxicity vs dose; , where denotes a convenient monotonous link function parametrized by . The likelihood function for each population can be written as for .
2.1. Commensurability Distances
Ollier et al. [
10] suggested to consider the likelihood function as a distribution, divided by a normalization constant. This type of normalized likelihood can also be seen as the resulting Bayesian posterior distribution when constant (probably improper) priors are used for the analysis. Then, the authors defined a measure of “commensurability” between the two data-sets through a distance
, the Hellinger one, in the parameters space via the following relation
The commensurability measure, denoted by
, is then defined as
, with
. Values of
q higher than 1 will reduce the computed distance, while values lower than 1 will lead to a more conservative method, increasing the computed distance. In case of sequential trials, the authors proved that, when coupled with the power prior approach, a conservative value of
leads to a better result in terms of operating characteristics, as a percentage of the right MTD selection. However, at the end of the trial, we are interested in comparing the achieved results, without any discount in the resulting distance. Therefore, in this paper, we will focus on the original Hellinger distance, which is
. This computed distance is a positive number between 0 and 1, it tends towards the maximum value when the two datasets are quite different, and towards zero when they are close to each other. Each likelihood is divided by a normalization constant in order to ensure that it can be viewed as a probability distribution. The variance of the likelihood density depends on the sample size of the trial. To make the two likelihoods comparable in terms of precision (variance), if
,
is raised to a power of less than 1, otherwise,
is raised to a power of less than 1. Following this method, the variance of likelihood density of the trial with more patients is increased to almost fit the one of the trial with fewer patients. Practical examples are given in Ollier et al. [
10].
A straightforward modification of the distance in Equation (
1) was performed by changing the underlying flat prior into a proper one. The posterior distribution obtained with the weighted likelihood is then used in the Hellinger formula. Thus, denoted by
and by
the posterior distribution of
given
and
, respectively, we have
This modification will ensure more stability in computation when the likelihoods involve more than one parameter. When flat/constant priors are used for
, Equation (
2) is equivalent to Equation (
1). Even if, theoretically, two different priors can be chosen for the two trials, we suggest using a single one for the sake of comparability.
Both previous distances work at the parameter level. They check if the whole dose–toxicity curve is similar or not. Using a single parameter model for the dose–toxicity relationship, as a one parameter logistic model used in the continual reassessment method (CRM) [
13], is also equivalent to check the MTD distance. However, in models with more parameters, such as the Bayesian Logistic Regression Model (BLRM) [
14] where we have two parameters, intercept and slope, we check if the bivariate distribution of
is the same. Since the distance is difficult to interpret in case of the multidimensional parameters space, we propose a summary distance using the resulting posterior MTD distribution. In our setting, the MTD,
, is estimated as the dose linked to a pre-specified toxicity target
, that is,
, where
is the inverse function of
. The posterior MTD distribution,
, is obtained evaluating
through the posterior distribution of the parameter,
, for
. Therefore, we can define
Note that this distance always involves a one dimensional integral.
Previous distances focused on understanding the similarity of the whole dose–toxicity curve between two populations. However, even with different slopes and intercepts, two populations can still have the same MTD. Those differences should generally indicate a difference in responsiveness to a drug and it is important to know when MTDs are similar but not the underlying curves. Therefore, we propose to couple the distances, previously described, with a measure denoting the difference in MTD point estimations. We can build this measure as a percentage using the median of the posterior MTD distributions, such as
where
is the indicator function, which assumes the value 1 if the statement in parentheses is true and zero otherwise, and
with
, is the median of the posterior MTD distribution of Caucasians and Japanese, respectively. This formulation was chosen for its easy interpretation, indeed, we check how much the highest MTD differs in percentage in respect to the lowest one. For this reason, the formula implies the exponent
, which allows us to always have the highest estimate at the numerator, and the
term. Similarly to the three previous measures, Equation (
4) tends to zero when the two MTDs are very similar. However, this measure does not have an upper bound. We propose the use of the median since it is less impacted by outliers than the mean. The
maximum a posteriori is another possible candidate, that is
where
To summarize, the first three measures d, , and are bounded between 0 and 1. Even if they are not built as percentages, their interpretation could be strictly linked to the percentage. Otherwise, the last two measures and have a ratio-like measure, lower bounded at 0. In practice, they give the information on the number of times the maximum MTD is higher than the lowest one.
2.2. Dose–Toxicity Model
In this section, we describe the model selected for the link function
. Instead of the CRM, originally used in Ollier et al. [
10], which is better suited to prospective trials than retrospective analyses (retrospective CRM requires special techniques), we opted for a more flexible BLRM model, with two parameters, the intercept
and the (logarithm of the) slope
[
14]. The dose–toxicity relationship is represented by
where
,
denotes a reference dose and
assures a positive final slope in the model. In this case,
is equal to the logit function and the BLRM formulation is similar to the one of Zheng and Hampson [
15]. To close the Bayesian model, we suggest a bivariate normal distribution as prior for
.
Following the described model, the final MTD is estimated as
. In order to minimize the overdispersion generated by this formula, we compared the distribution of the log ratio of the MTD and the reference dose,
(instead of the real MTD). Therefore, we have also changed Equations (
4) and (
5), accordingly, to the new formulation (
) in order to preserve the original distance meaning, that is
and
.
Finally, in a previous sensitivity analysis (not shown), even when comparing the distribution of the log ratio of the MTD and the reference dose, we faced instability in computation due to the issue of outliers. We have found that truncating the posterior distribution of between the 10 and 90 percentiles gives a good compromise between preserving trial information and computation stability.
4. Settings
We chose , the target toxicity probability, to be used to define the MTD, which equals 0.3 for the three synthetic set examples, while it equals 0.25 for the real case studies. Most of real case studies followed an algorithm base allocation; therefore, it seemed more natural to have a threshold lower than 0.3, which is more frequently used when model based designs are adopted in oncology.
A non-informative bivariate prior distribution, commonly used in this setting, was chosen for the BLRM model as follows:
The hyperprior parameters of the bivariate prior were chosen after a preliminary sensitivity analysis (not shown) in order to ensure computational stability. In detail, this prior choice suggests a mean prior probability of toxicity at the reference dose, , of 0.1 and that the slope has the prior median centered at zero. Therefore, was chosen in the first half of the total dose panel for each example. In detail, 400 mg/day was set for the three synthetic examples, 1 mg/m2 for Erilubin, 900 mg/day for Lapatinib, 200 mg/day for Sorafenib, 30 mg/m2 for Ixabepilone, 8 mg/m2 for Edotecarin and 700 mg/m2 for E7070.
All distances were computed with
, which is why we focus on the square root of Equation (
1)–(
3) and on the original value for Equation (
4) and (
5). The reference doses selected are reported along with the results in
Table 3. All computations were performed in R, version 3.5.2. Monte Carlo approximations were adopted for all integrals involved, and uniform prior distribution on compact supports was set to approximate weighted likelihoods (as posterior distributions) in Equation (
4). Details can be found in R scripts in the
Supplementary Materials.
5. Results
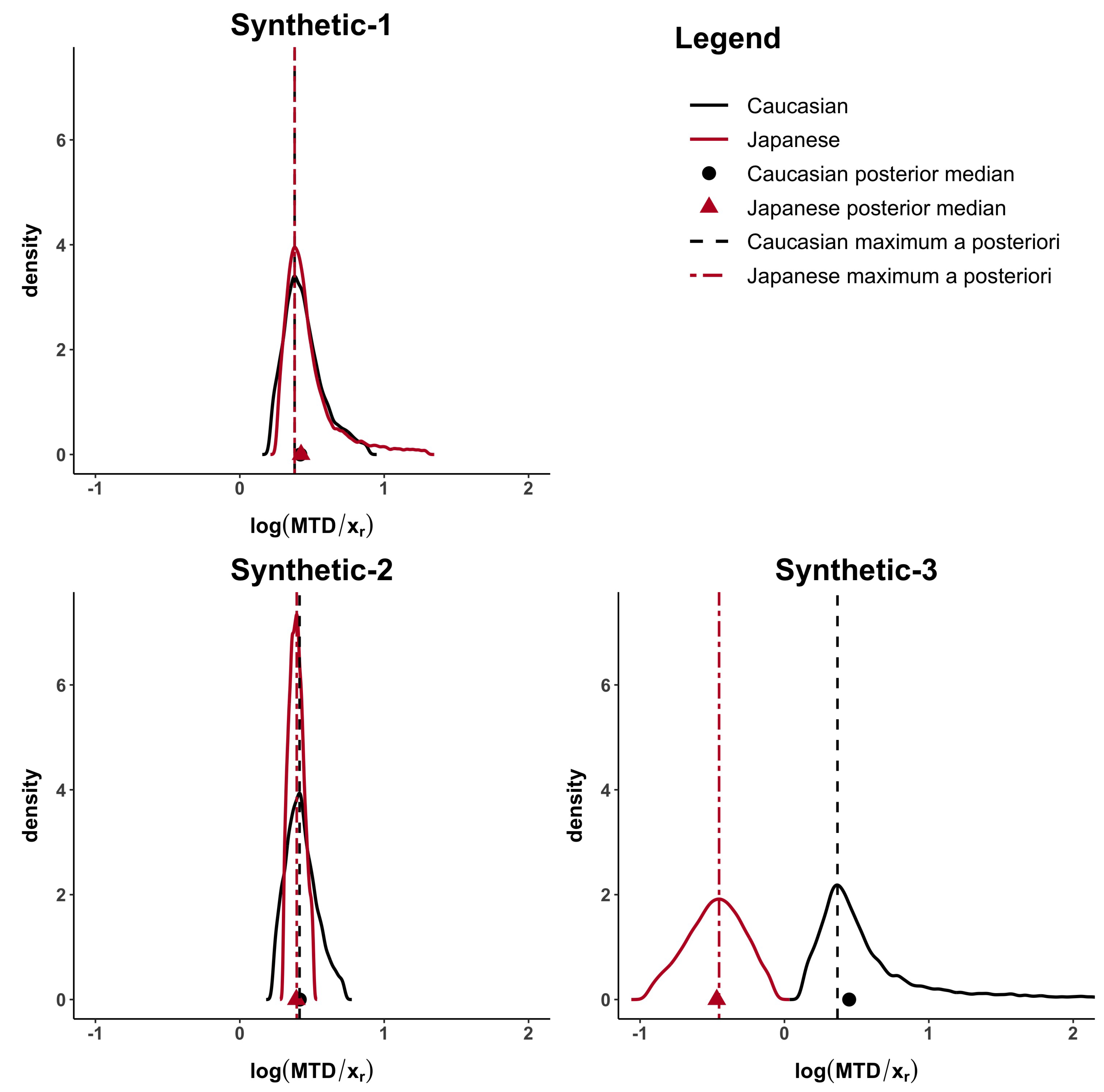
The computed distances under all the proposed methods are shown in
Table 3. When the MTD and the dose–toxicity curves are similar, like in synthetic-1 data,
d,
,
are lower than 0.23 and
. When only the MTDs are similar (synthetic-2 data) but not the dose–toxicity curves,
but
d,
,
are higher than 0.37. Finally, when both curves and MTDs (synthetic-3 data) differ
,
and
d,
,
are higher than 0.83.
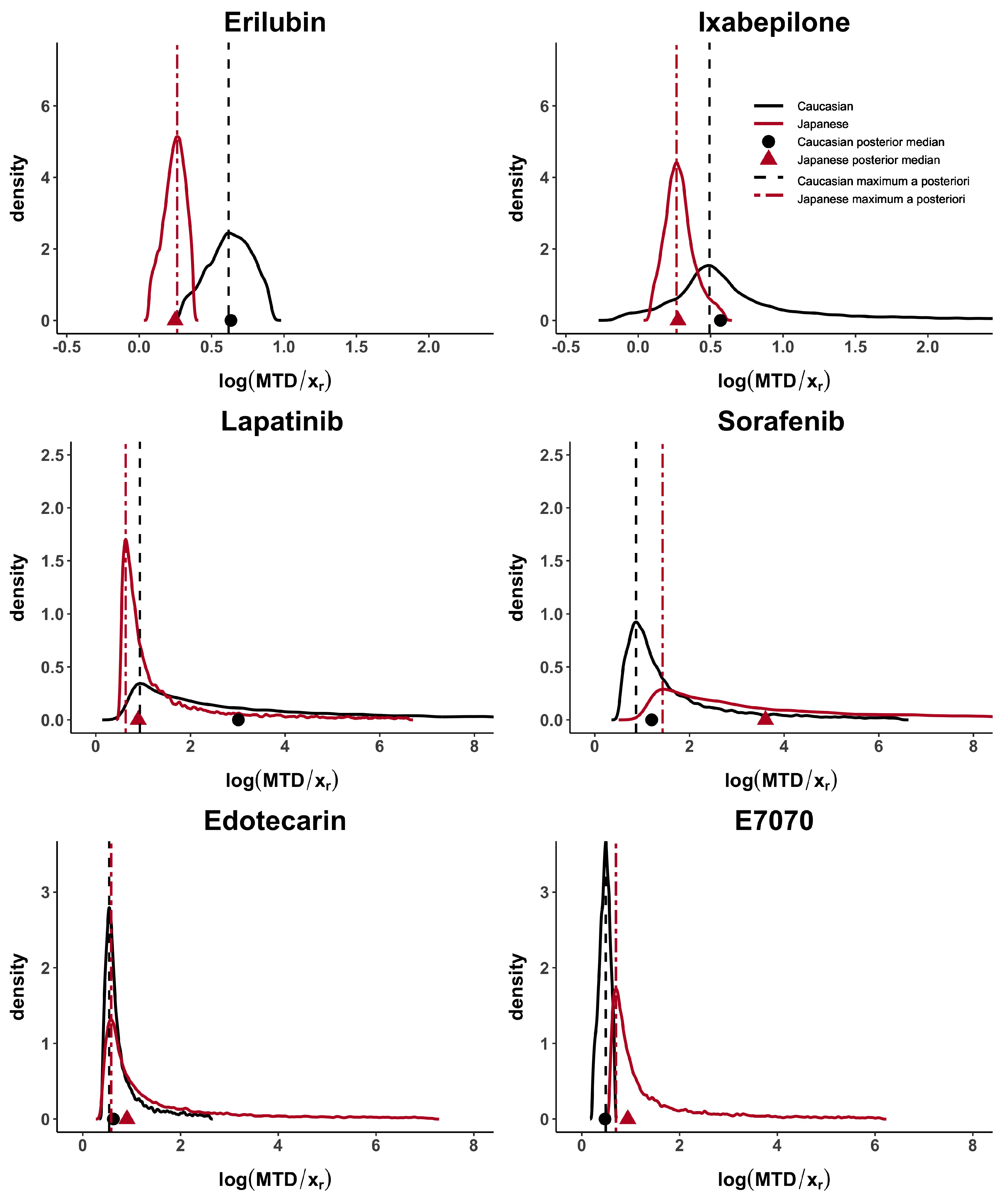
Taking these cases’ studies as reference, we then analyse the data from published papers with Caucasian and Japanese datasets. Erilubin has the highest values of
d,
and
, greater than 0.80, which suggests differences between the dose–toxicity curves. It is also shown in
Figure 1. Its values of
and
are around 0.45. Ixabepilone and E7070 have quite large
d,
and
, greater than 0.56 and they also have similar results in term of
. The value of
is different in these two examples and reflects the presence of unbalanced heavy tails in the E7070 case. The heavy tail concern is observed, in at least one population, in all examples except for Erilubin. The results obtained in
Table 3 show that
is directly impacted by this phenomenon. For example, Lapatinbib and Sorafenb have a very high value of
, greater than 7.29, whereas the maximum a posteriori,
, has more stable and usual results. Edotecarin has close values of
d,
and
, around 0.3, representing similar dose–toxicity curves.
Figure 2 and
Figure A1, in the
Appendix A, show how the Caucasian posterior distribution is different in the three synthetic examples even if it comes from the same Caucasian dataset. This behaviour is due to the variance adjustment given by
. In general, the posterior peak is preserved and the variance increases when the exponent is less than 1 (as in the synthetic-3 example).
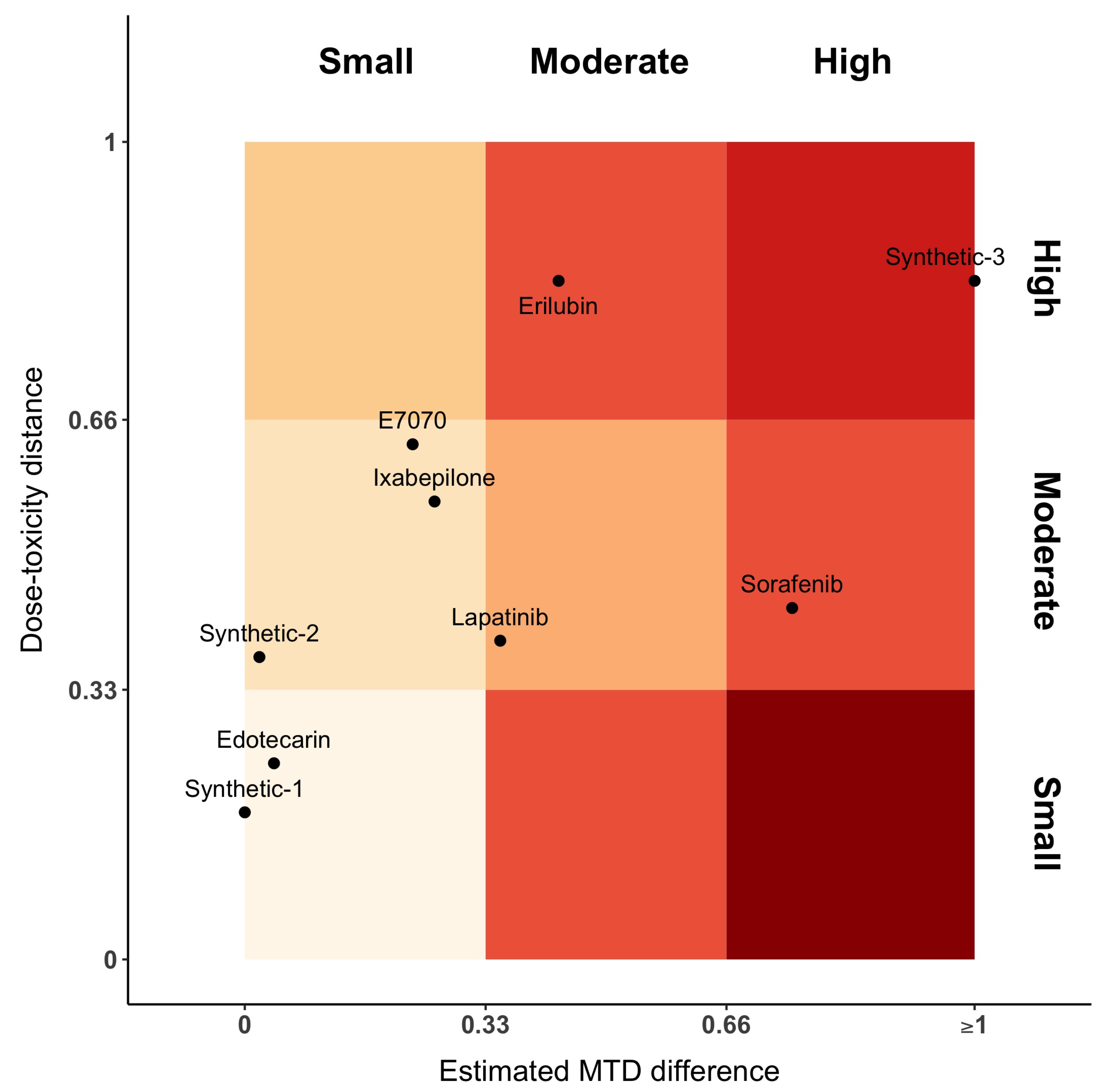
Figure 3 represents the distance between dose–toxicity curves,
, and maximum of the posterior MTD distribution,
. For the sake of interpretability, we have equally divided the axes into three parts, each one denoting a small, moderate or high distance, respectively. In this plot, Sorafenib has moderate distances between curves and high difference between MTDs. This is the opposite for Erilubin, where there is a moderate difference between MTD and a large distance between curves. When MTDs are similar or close (first column of the gradient), Edotecarin has similar dose–toxicity curves, while the distance between curves of Ixabepilone and E7070 is moderate. Lapatinib shows a moderate distance of both dose–toxicity curve and estimated MTDs.
6. Discussion
The aim of our work was to propose several Bayesian indicators to support further decisions when using a bridging data package [
1]. Bayesian methods permit the definition of a similarity degree based on posterior distribution, which do not rely on asymptotic approximations and can be used also in small sample size settings. Specifically, we proposed Bayesian indicators which evaluate the distance and the similarity of dose–toxicity curves and MTD. When evaluating a drug among different populations, assessing the dose–response curves similarity is of most importance, since, if it is proved, other clinical trial data can be used, as well as extrapolation from one population to the other. Maeda and Kurokawa [
5] pointed out the difficulty of defining a commensurability measure for different populations.
We presented and studied five criteria, where three of them, d, and , measure the similarity between dose–toxicity curves, and two of them, and , measure the distance between the median and the maximum a posteriori of the MTD posterior distributions. The first three measures are bounded between 0 and 1 and their interpretation could be linked to a proportion. The second ones, and have a ratio-like value with a lower bound at 0. In practice, they represent a relative risk measure.
Our approach allows for the identification and discussion of similarities and differences between dose–toxicity curves and MTDs. However, as small samples were used in these studies, estimation of the entire dose–toxicity curve, when only part of the doses in the panel were evaluated, is complex and leads to an estimation with high variability. This is reflected in the values of
d,
and
, which in our real case studies were above 0.2. When high differences between
d and
are observed, this is probably due to computational difficulties in Equation (
1), especially in computing the weighted likelihood without a stabilization term. In general,
is lower than
. This could be expected for two reasons: (i)
introduces, via the transformation, more variability (increased in the density estimation step); (ii)
is computed after truncating the posterior induced distribution of the MTD. Moreover, we showed that
, based on the maximum a posteriori, is more stable than
, which is based on the median, in the presence of unbalanced heavy tails. Therefore,
could be suggested as a more reliable measure in this setting. We have attempted the analysis while varying the variance matrix of the bivariate normal prior distribution and
was less stable (results not shown).
The MTD definition can vary according to the trial and to the population. Therefore, even if the same MTD is claimed in both Caucasian and Japanese populations, our analysis can identify differences. For instance, in the Japanese trial of Sorafenib, 400 mg/day is defined in the clinical trial as the MTD, but at the closest higher dose level, 600 mg/day, only one patient experienced toxicities (16.7%). Otherwise, in the Caucasian trial, three patients out of seven experienced toxicity at 600 mg/day (42.6%). Even if the two trials find the same MTD, the toxicity probability associated with each one differs. That is the reason why our results showed otherwise. Indeed, in the published clinical trials, there is a discrepancy between the method section defining the MTD and the real given MTD at the end of the trial. Our methods are based on data only and allow for evaluation of the actual similarity.
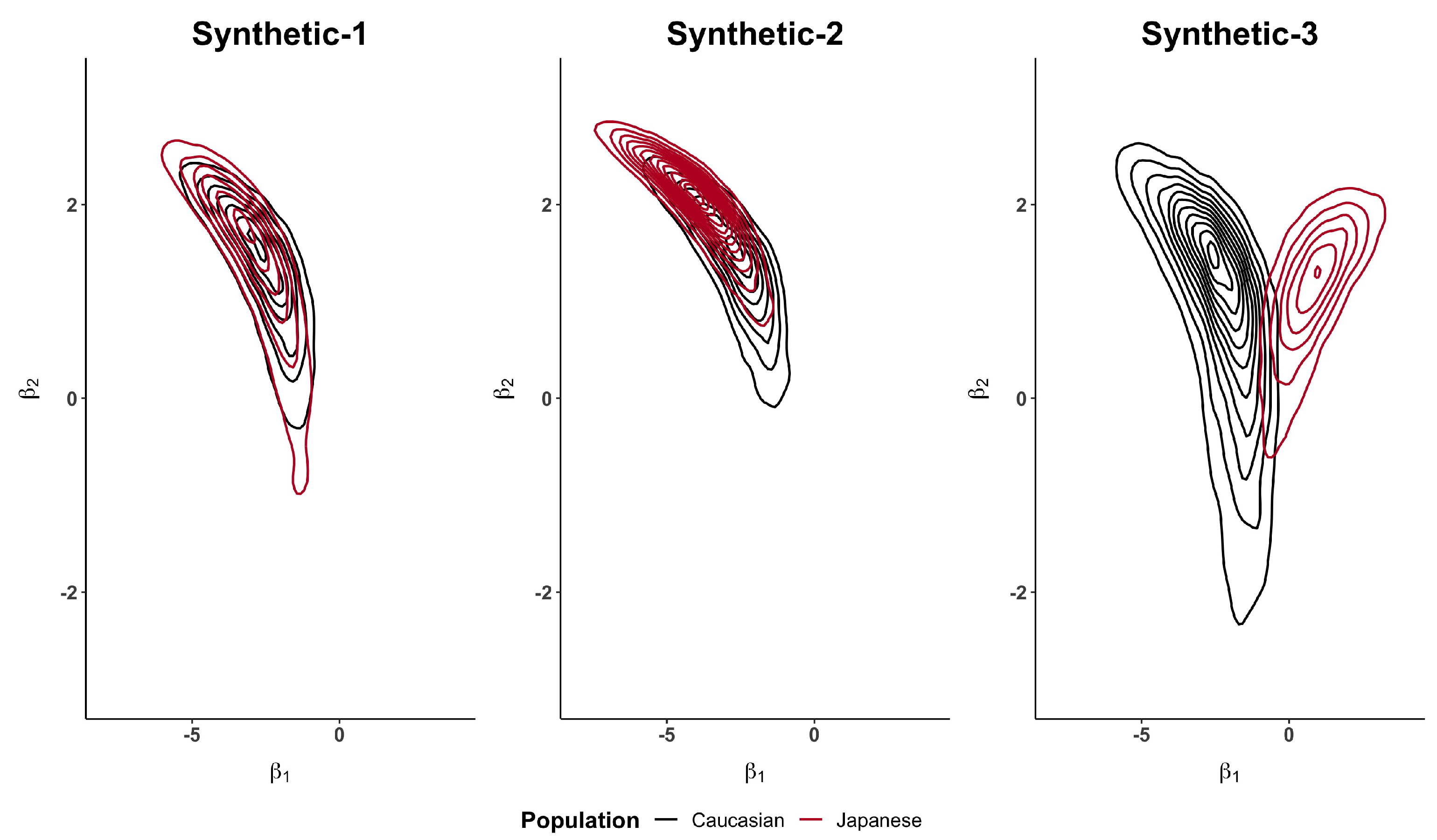
We decided to present the plot of the posterior densities (of the parameters and of the MTD) as it shows the super-position (or not) of the information. Plotting directly one-dimensional dose–response curves could, instead, be misleading and give hazardous interpretation.
A first limitation of our work is that we used published data, where the reporting can be sometimes incomplete in terms of DLTs and doses. For instance, in the paper of Burris et al. [
18], we had to re-compose the DLT table and the dose-allocation sequence. Therefore, some interpretation discrepancy can be found in our
Table 2. The issue of poor reporting in cancer trials was already raised by Zohar et al. [
28] and Comets and Zohar [
29]. As a second limitation, we did not provide fixed cut-offs for each criterion. In our opinion, the choice of the cut-offs depends on the application and on the quantity of information in the two trials. The more information we have, the more stringent cut-offs can be considered.
Figure 3 only represents a proposition on the way to display the results.
The criteria proposed in this manuscript may be extended to be used in other settings. For example, when several trials are available, a meta-analysis of the dose–toxicity curves or of the MTDs can be considered [
30,
31,
32]. In this case, pairwise distances can be previously estimated, in an empirical Bayes approach, and then be used to model the heterogeneity parameter(s) or to set prior distribution(s). Other extensions, which do not involve necessarily Phase I studies, could be considered: (i) in adults–children extrapolation; (ii) when we are interested to jointly evaluate efficacy and toxicity [
33]; (iii) when comparing outcomes (efficacy or toxicity) of the same drug in different indications; (iv) when dealing with similarities in subgroups; (v) in comparing historical control data with respect to the actual trial in randomized Phase III trials.
Being able to quantify distance and bridging between two populations at the end of early Phase I trials can be useful to better characterize the dose–toxicity relationship and differences. In case of small or acceptable differences, the extrapolation process can be considered, as suggested in the ICH-E5.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}