
Pattern Recognition of the COVID-19 Pandemic in the United States: Implications for Disease Mitigation


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection and Processing
2.2. Spatial Pattern Analysis
2.3. Temporal Trend Analysis
2.4. K-Means Clustering and Principal Component Analysis
3. Results
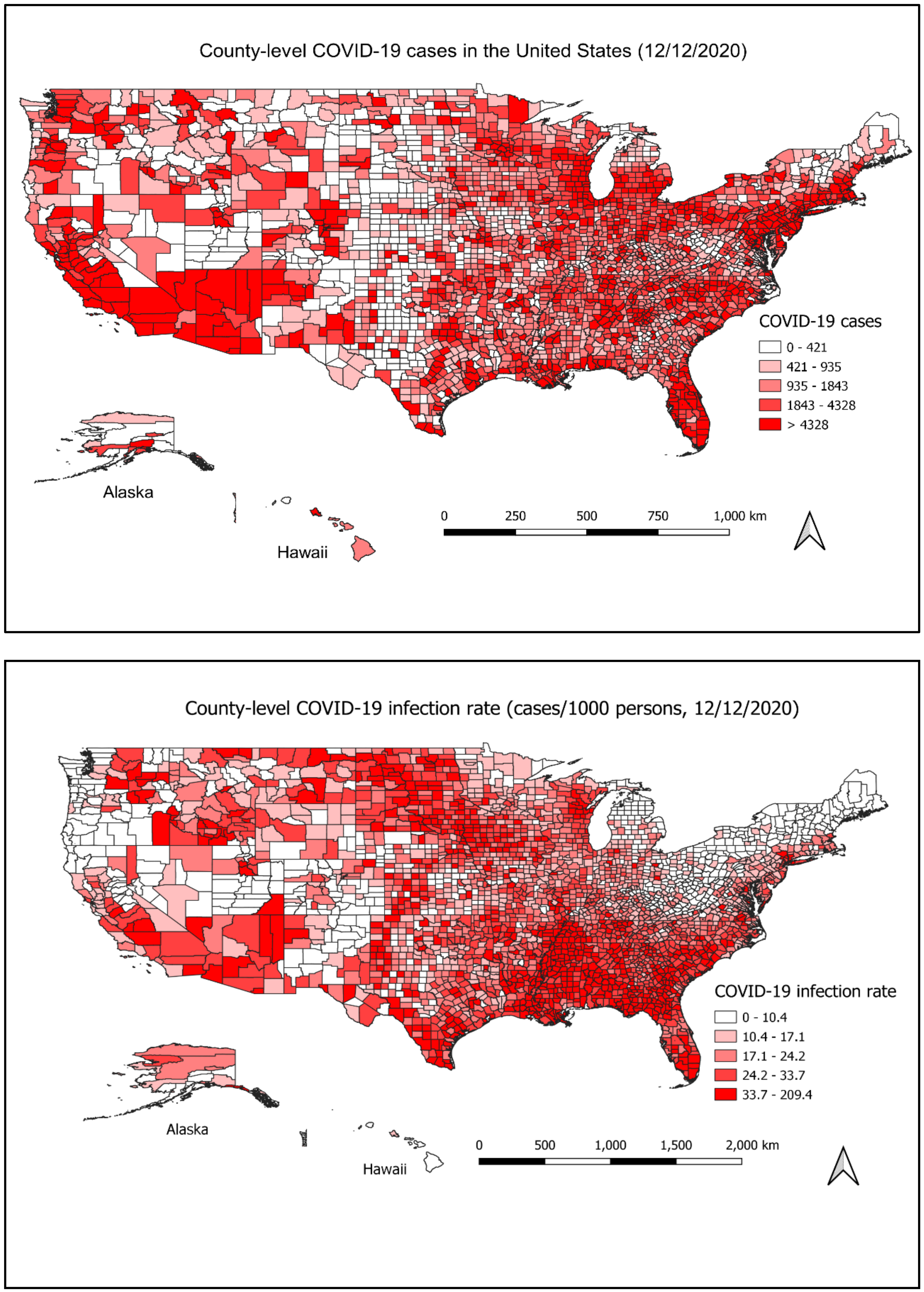
3.1. Spatial Distribution of COVID-19 Cases
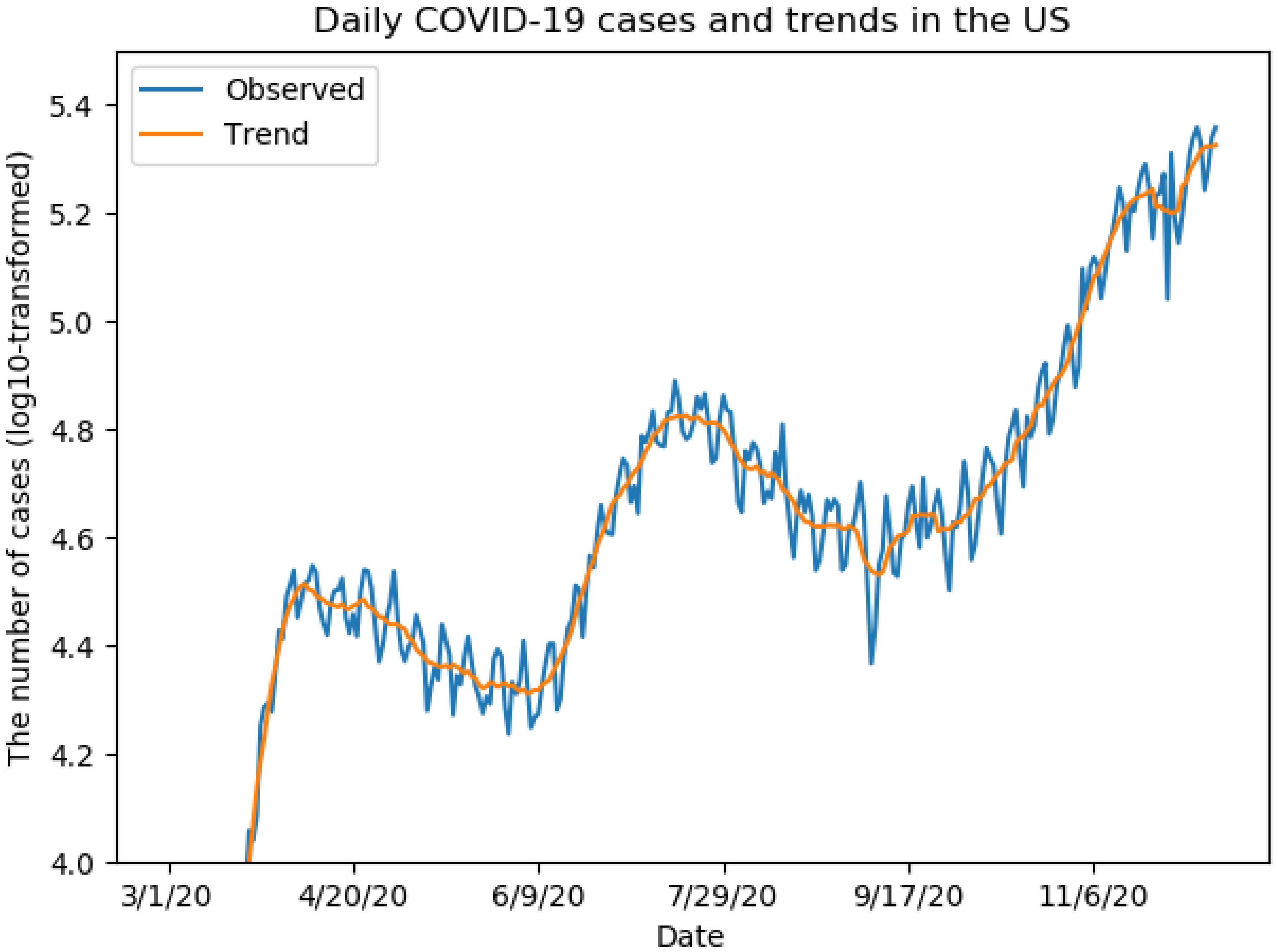
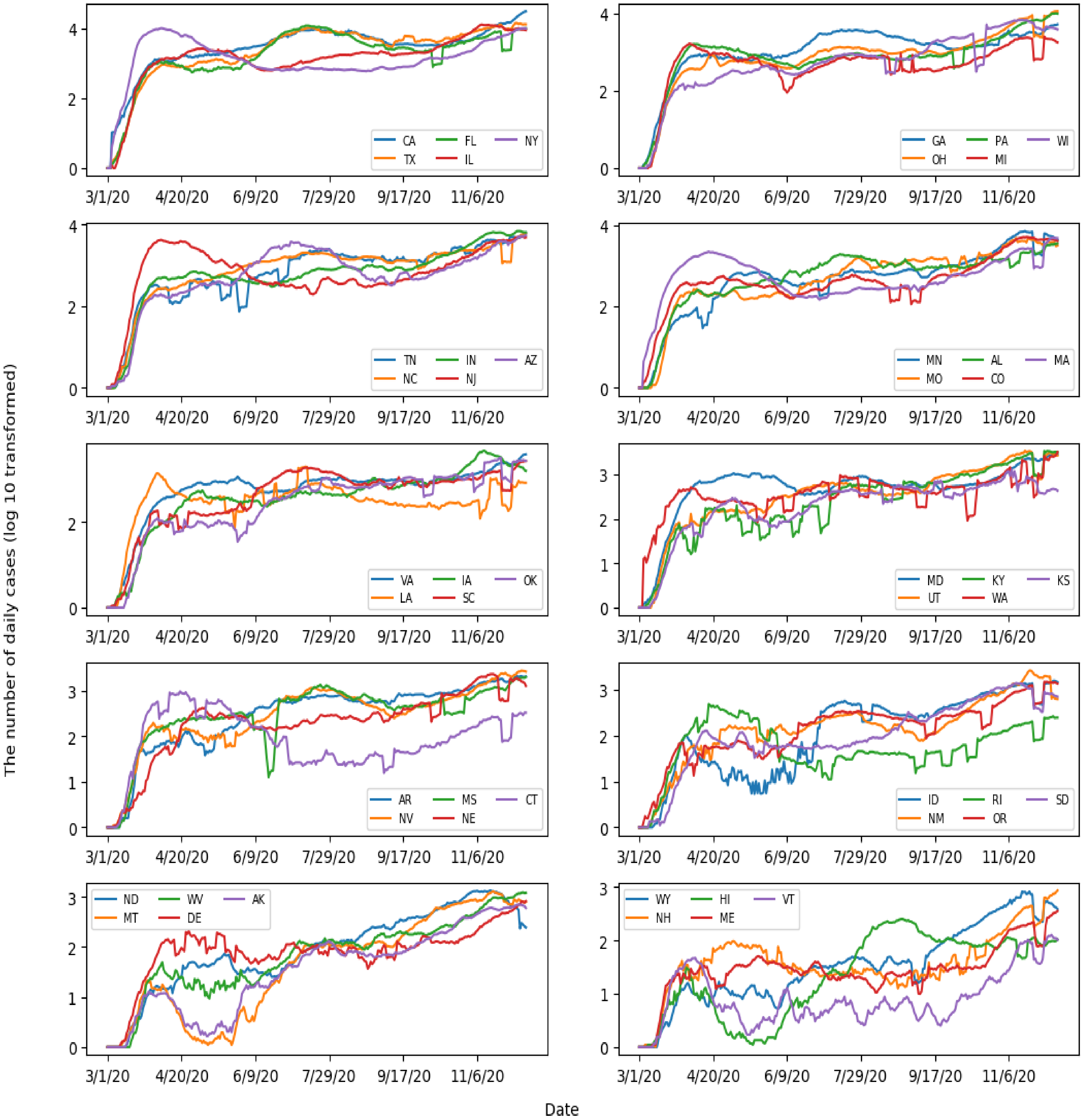
3.2. Temporal Trend of COVID-19 Cases
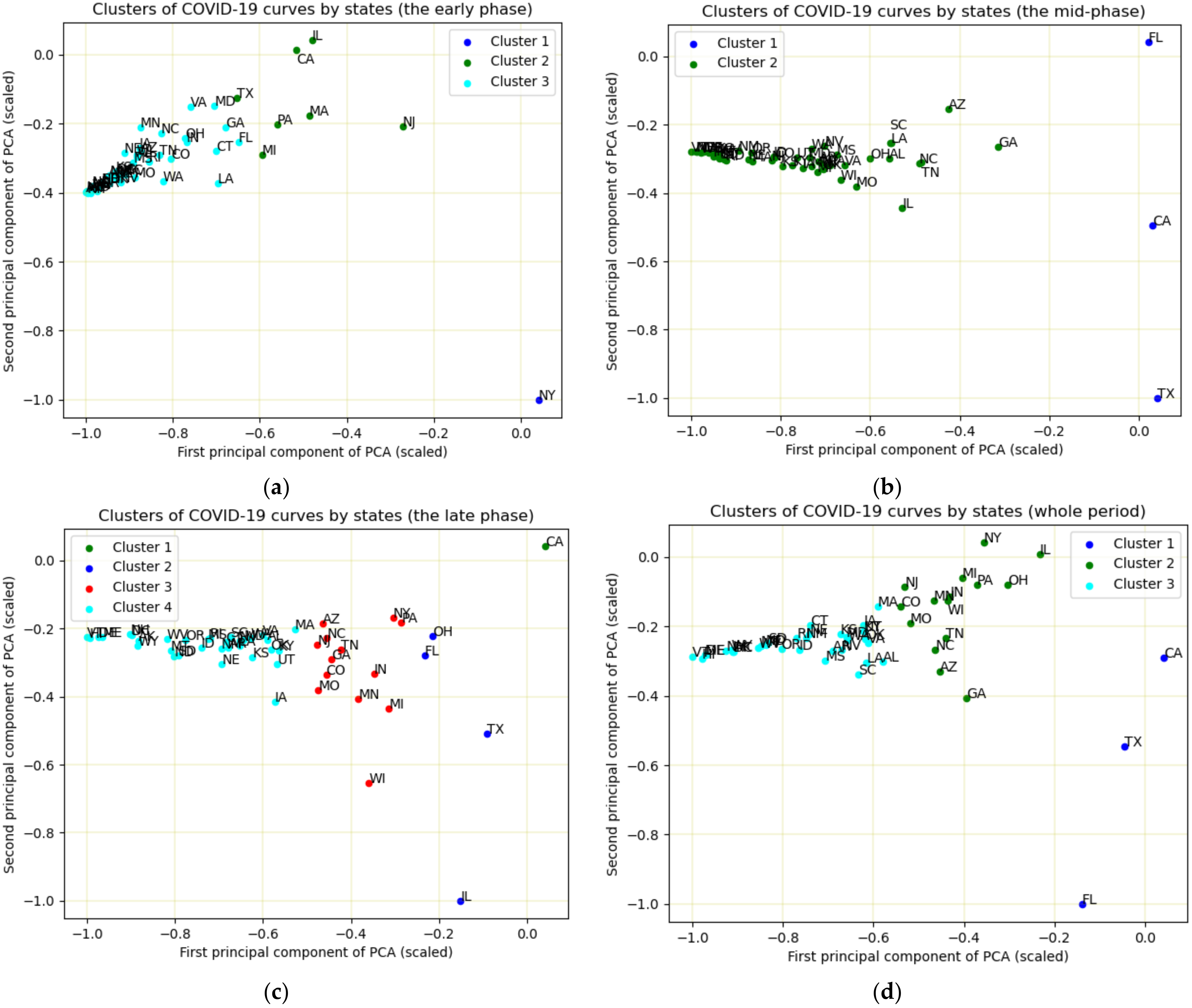
3.3. K-Means Clustering and PCA
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Code Availability Statement
References
- Wang, C.; Horby, P.W.; Hayden, F.G.; Gao, G.F. A novel coronavirus outbreak of global health concern. Lancet 2020, 395, 470–473. [Google Scholar] [CrossRef] [Green Version]
- Velavan, T.P.; Meyer, C.G. The COVID-19 epidemic. Trop. Med. Int. Health 2020, 25, 278. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Wu, T.; Liu, Q.; Yang, Z. The SARS-CoV-2 outbreak: What we know. Int. J. Infect. Dis. 2020, 94, 44–48. [Google Scholar] [CrossRef] [PubMed]
- Wiersinga, W.J.; Rhodes, A.; Cheng, A.C.; Peacock, S.J.; Prescott, H.C. Pathophysiology, transmission, diagnosis, and treatment of coronavirus disease 2019 (COVID-19): A review. JAMA 2020, 324, 782–793. [Google Scholar] [CrossRef]
- Holshue, M.L.; DeBolt, C.; Lindquist, S.; Lofy, K.H.; Wiesman, J.; Bruce, H.; Spitters, C.; Ericson, K.; Wilkerson, S.; Tural, A. First case of 2019 novel coronavirus in the United States. N. Engl. J. Med. 2020, 382, 929–936. [Google Scholar] [CrossRef] [PubMed]
- Cohen, M.L. Changing patterns of infectious disease. Nature 2000, 406, 762–767. [Google Scholar] [CrossRef] [PubMed]
- Rothman, K.J.; Greenland, S.; Lash, T.L. Modern Epidemiology; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2008. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Sajda, P. Machine learning for detection and diagnosis of disease. Annu. Rev. Biomed. Eng. 2006, 8, 537–565. [Google Scholar] [CrossRef] [Green Version]
- Fatima, M.; Pasha, M. Survey of machine learning algorithms for disease diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Liao, M.; Li, Y.; Kianifard, F.; Obi, E.; Arcona, S. Cluster analysis and its application to healthcare claims data: A study of end-stage renal disease patients who initiated hemodialysis. BMC Nephrol. 2016, 17, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Mclafferty, S. Disease cluster detection methods: Recent developments and public health implications. Ann. GIS 2015, 21, 127–133. [Google Scholar] [CrossRef]
- Desjardins, M.; Hohl, A.; Delmelle, E. Rapid surveillance of COVID-19 in the United States using a prospective space-time scan statistic: Detecting and evaluating emerging clusters. Appl. Geogr. 2020, 118, 102202. [Google Scholar] [CrossRef]
- Franch-Pardo, I.; Napoletano, B.M.; Rosete-Verges, F.; Billa, L. Spatial analysis and GIS in the study of COVID-19. A review. Sci. Total Environ. 2020, 739, 140033. [Google Scholar] [CrossRef]
- Kang, D.; Choi, H.; Kim, J.-H.; Choi, J. Spatial epidemic dynamics of the COVID-19 outbreak in China. Int. J. Infect. Dis. 2020, 94, 96–102. [Google Scholar] [CrossRef] [PubMed]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Johns Hopkins University. COVID-19 Data. Available online: https://github.com/CSSEGISandData/COVID-19 (accessed on 30 December 2020).
- US Census Bureau. The Boundary GIS Layer. Available online: https://www.census.gov/geographies/mapping-files/time-series/geo/carto-boundary-file.2018.html (accessed on 30 December 2020).
- Moran, P.A. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Scott, L.M.; Janikas, M.V. Spatial statistics in ArcGIS. In Handbook of Applied Spatial Analysis; Springer: New York, NY, USA, 2010; pp. 27–41. [Google Scholar]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A seasonal-trend decomposition. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Bergman, A.; Sella, Y.; Agre, P.; Casadevall, A. Oscillations in US COVID-19 incidence and mortality data reflect diagnostic and reporting factors. Msystems 2020, 5. [Google Scholar] [CrossRef] [PubMed]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Kodinariya, T.M.; Makwana, P.R. Review on determining number of Cluster in K-Means Clustering. Int. J. 2013, 1, 90–95. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding; Stanford: Stanford, CA, USA, 2006. [Google Scholar]
- Dunteman, G.H. Principal Components Analysis; Sage: Thousand Oaks, CA, USA, 1989. [Google Scholar]
- Van Rossum, G. Python Programming Language. In Proceedings of the USENIX Annual Technical Conference, Santa Clara, CA, USA, 20 June 2007; p. 36. [Google Scholar]
- Cordes, J.; Castro, M.C. Spatial analysis of COVID-19 clusters and contextual factors in New York City. Spat. Spat. Temporal Epidemiol. 2020, 34, 100355. [Google Scholar] [CrossRef]
- Frey, W. Who Lives in the Places Where Coronavirus is Hitting the Hardest; Brookings Institution: Princeton, NJ, USA, 2020. [Google Scholar]
- Lin, R.-G.; Sean, G. Los Angel Times: New COVID-19 Surge Spreading beyond Urban Areas to All Corners of California. Available online: https://www.latimes.com/california/story/2020-11-27/most-of-california-now-suffering-worst-coronavirus-case-rates-on-record (accessed on 30 December 2020).
- Lyu, W.; Wehby, G.L. Community Use Of Face Masks And COVID-19: Evidence From A Natural Experiment Of State Mandates In The US: Study examines impact on COVID-19 growth rates associated with state government mandates requiring face mask use in public. Health Aff. 2020, 39, 1419–1425. [Google Scholar] [CrossRef] [PubMed]
- Thompson, C.N.; Baumgartner, J.; Pichardo, C.; Toro, B.; Li, L.; Arciuolo, R.; Chan, P.Y.; Chen, J.; Culp, G.; Davidson, A. COVID-19 Outbreak—New York City, February 29–June 1, 2020. Morb. Mortal. Wkly. Rep. 2020, 69, 1725. [Google Scholar] [CrossRef] [PubMed]
- Kaiser Family Foundation. State Data and Policy Actions to Address Coronavirus. Available online: https://www.kff.org/report-section/state-data-and-policy-actions-to-address-coronavirus-sources/ (accessed on 30 December 2020).
- New York Forward. Phase 2 Industries. Available online: https://forward.ny.gov/phase-two-industries (accessed on 30 December 2020).
- The New York Times. When Is California Reopening? Available online: https://www.nytimes.com/article/coronavirus-california-reopening-phases.html (accessed on 30 December 2020).
- The New York Times. Texas Pauses Reopening as Virus Cases Soar Across the South and West. Available online: https://www.nytimes.com/2020/06/25/us/texas-coronavirus-cases-reopening-Greg-Abbott.html (accessed on 30 December 2020).
- CNN. Where Schools Are Reopening in the US. 2020. Available online: https://www.cnn.com/interactive/2020/health/coronavirus-schools-reopening/ (accessed on 30 December 2020).
- Garcia, G. Evaluation of Public Health Emergency Orders and Reported COVID-19 Rates in the Municipality of Anchorage, Alaska, June–August 2020. Available online: http://www.epi.alaska.gov/bulletins/docs/rr2021_01.pdf (accessed on 30 December 2020).
- WebMd. Coronavirus in Context: Why “Caution Fatigue” May Be Causing More COVID Cases. Available online: https://www.webmd.com/coronavirus-in-context/video/jacqueline-gollan (accessed on 30 December 2020).
- The New York Times. See Coronavirus Restrictions and Mask Mandates for All 50 States. Available online: https://www.nytimes.com/interactive/2020/us/states-reopen-map-coronavirus.html (accessed on 30 December 2020).
- Connecticut Official State Website. Latest Guidance. Available online: https://portal.ct.gov/Coronavirus/Covid-19-Knowledge-Base/Latest-Guidance (accessed on 30 December 2020).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Period | Clusters | States |
|---|---|---|
| The early phase (1 March–31 May) | 1 | NY |
| 2 | CA, IL, MA, MI, NJ, PA, TX | |
| 3 | The remaining states | |
| The middle phase (1 June–30 September) | 1 | CA, FL, TX |
| 2 | The remaining states | |
| The late phase (October–12 December) | 1 | CA |
| 2 | FL, IL, OH, TX | |
| 3 | AZ, CO, GA, IN, MI, MO, MN, NC, NJ, NY, PA, TN, WI | |
| 4 | The remaining states | |
| The whole period (1 March–12 December) | 1 | CA, FL, TX |
| 2 | AZ, CO, GA, IL, IN, MI, MN, MO, NC, NJ, NY, OH, TN, WI | |
| 3 | The remaining states |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Sha, S. Pattern Recognition of the COVID-19 Pandemic in the United States: Implications for Disease Mitigation. Int. J. Environ. Res. Public Health 2021, 18, 2493. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18052493
Wu J, Sha S. Pattern Recognition of the COVID-19 Pandemic in the United States: Implications for Disease Mitigation. International Journal of Environmental Research and Public Health. 2021; 18(5):2493. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18052493
Chicago/Turabian StyleWu, Jianyong, and Shuying Sha. 2021. "Pattern Recognition of the COVID-19 Pandemic in the United States: Implications for Disease Mitigation" International Journal of Environmental Research and Public Health 18, no. 5: 2493. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18052493