
Predicting Survival in Veterans with Follicular Lymphoma Using Structured Electronic Health Record Information and Machine Learning

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
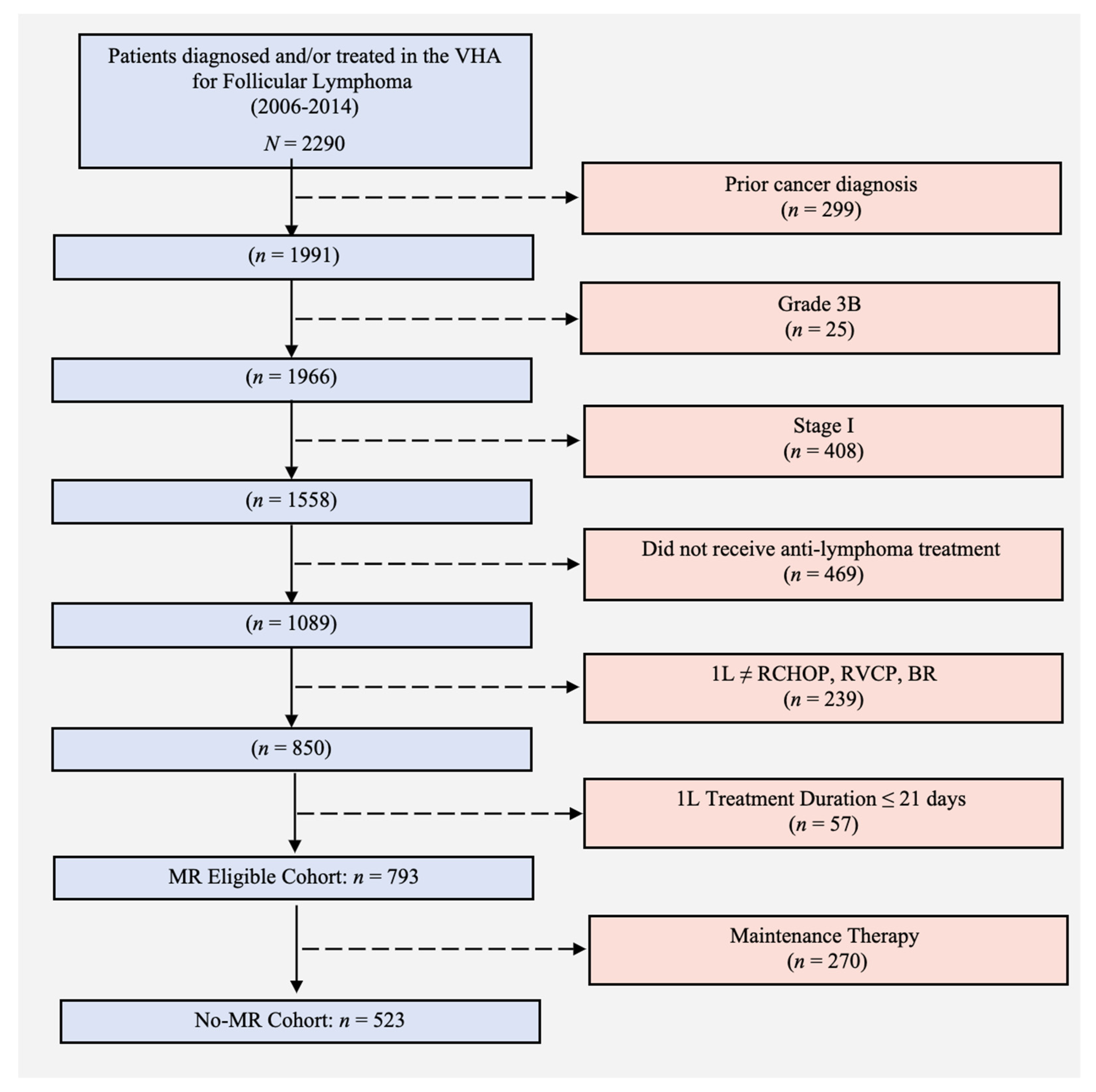
2.1. Cohort Selection
2.2. Feature Extractions
- A curated clinical set (“curated”) comprised patient demographics and disease-specific characteristics commonly recognized to be associated with survival, which were available in structured form in the VA Cancer Registry System or Corporate Data Warehouse (Table A1). Patient characteristics included age, sex, and modified Charlson comorbidity index; disease-specific characteristics included stage, grade, and lactate dehydrogenase at L1 initiation. We also included treatment used for L1.
- The second group (“labs”) included results of 33 lab values typically obtained prior to initiation of L1, extracted from the EHR lab domain. These data included most of the labs (available in 70% or more of patients) in the complete blood count and comprehensive metabolic panels (Table A1). We included medians and ranges of lab results for the period starting three months prior to start of L1 and ending just prior to start of L1. RSF handles missing data itself; for the Cox model, missing data were imputed by random forest imputation algorithm [27] using randomForestSRC R package [28].
- Finally, a larger group of variables (“ICD”) included any International Classification of Diseases (ICD) diagnostic codes present from one year prior to L1 initiation to three months prior to L1, with information indicating presence or absence of ICD codes as well as how many times each individual code was present during this nine-month period. There were 1841 ICD codes overall.
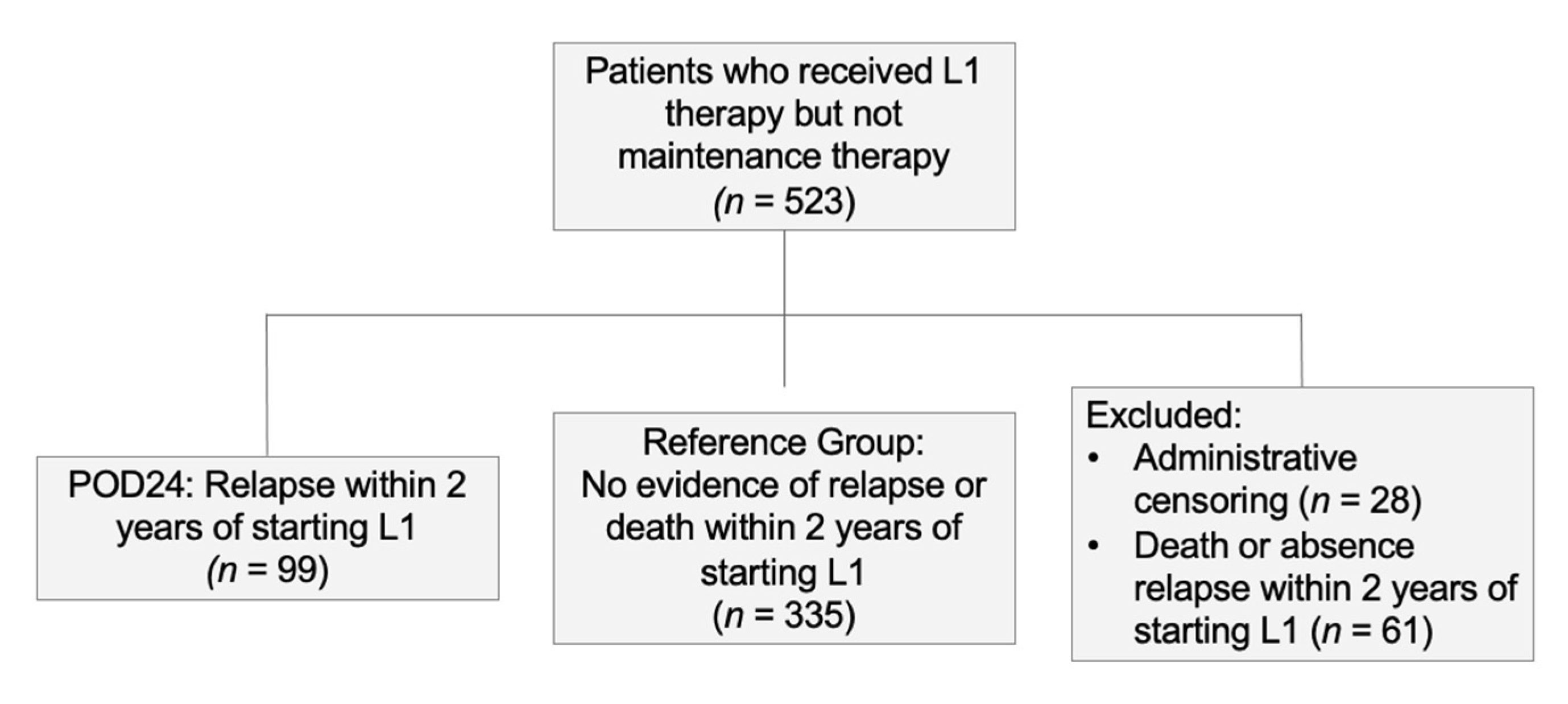
2.3. Outcomes
2.4. Models
- Bootstrap samples of the training data are selected to build the trees. For each bootstrap sample, about 2/3 of the observations are selected and 1/3 are left out.
- In each bootstrap sample, a survival tree is constructed. Each node, p candidate variables are randomly selected to build the tree. The split of the nodes maximizes the survival difference between daughter nodes; in this study, a log-rank splitting rule is used to determine the split of the nodes [18].
- The tree is grown to full size under the constraint that there should be at least one event with unique survival times at each terminal node.
- Survival curves are estimated for the out-of-bag observations and the average survival curves are calculated as the survival curve for each subject. The cumulative hazard functions in terminal nodes are time-dependent. Performance is assessed based on the testing set using the RSF model obtained from the training and parameter tuning process.
2.5. Use of RSF to Predict High or Low Risk
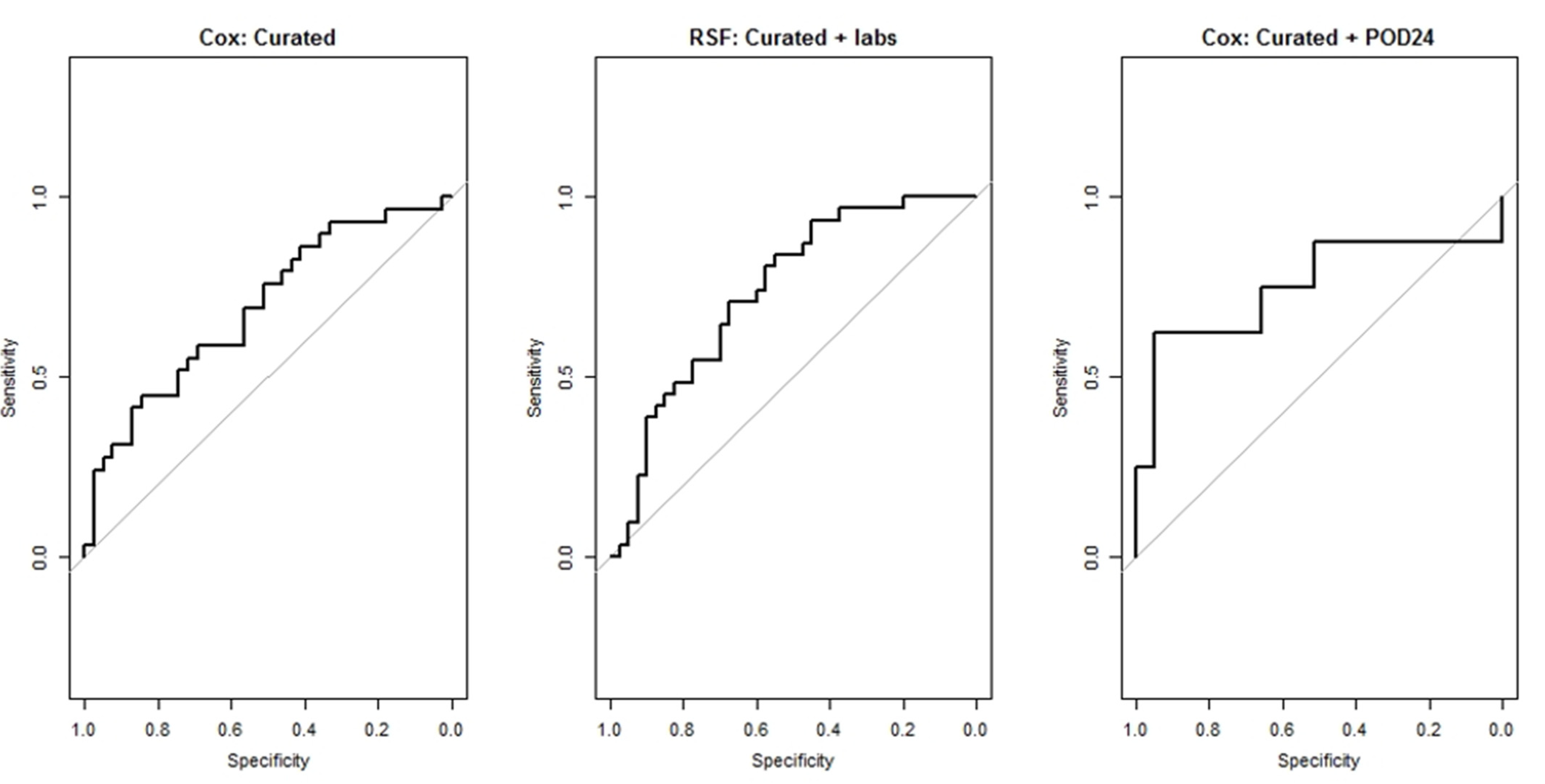
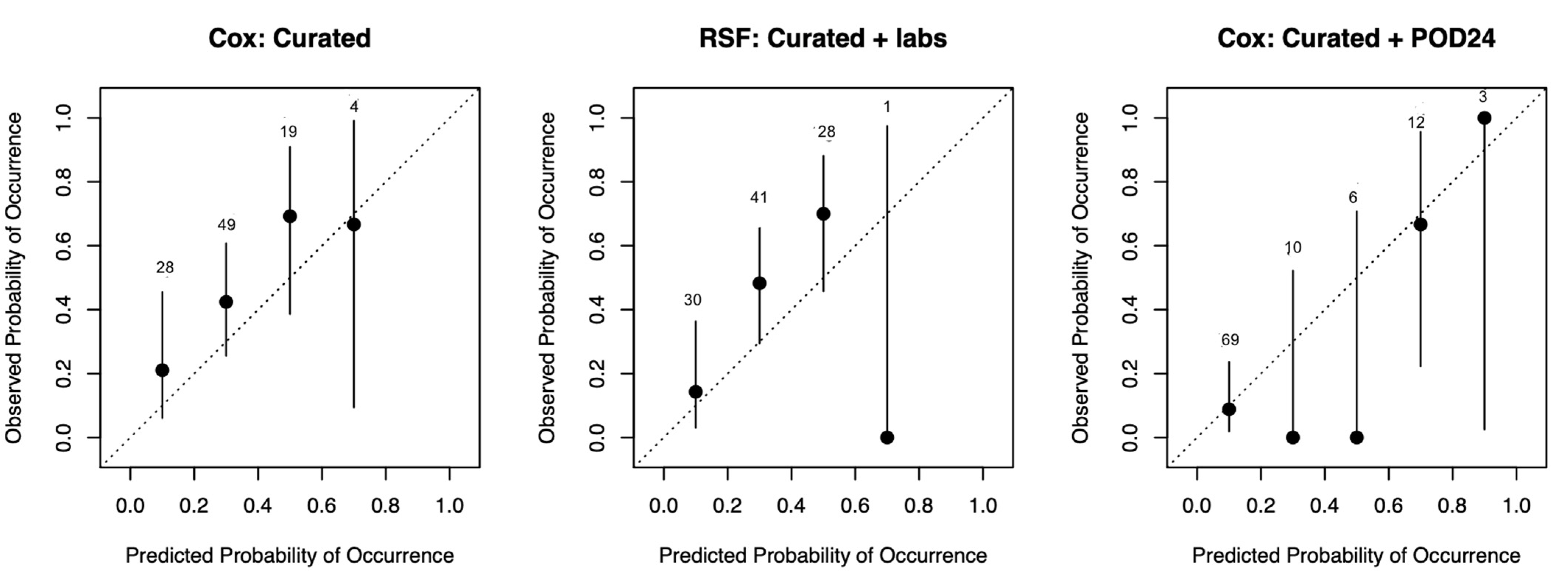
2.6. Model Performance Measures
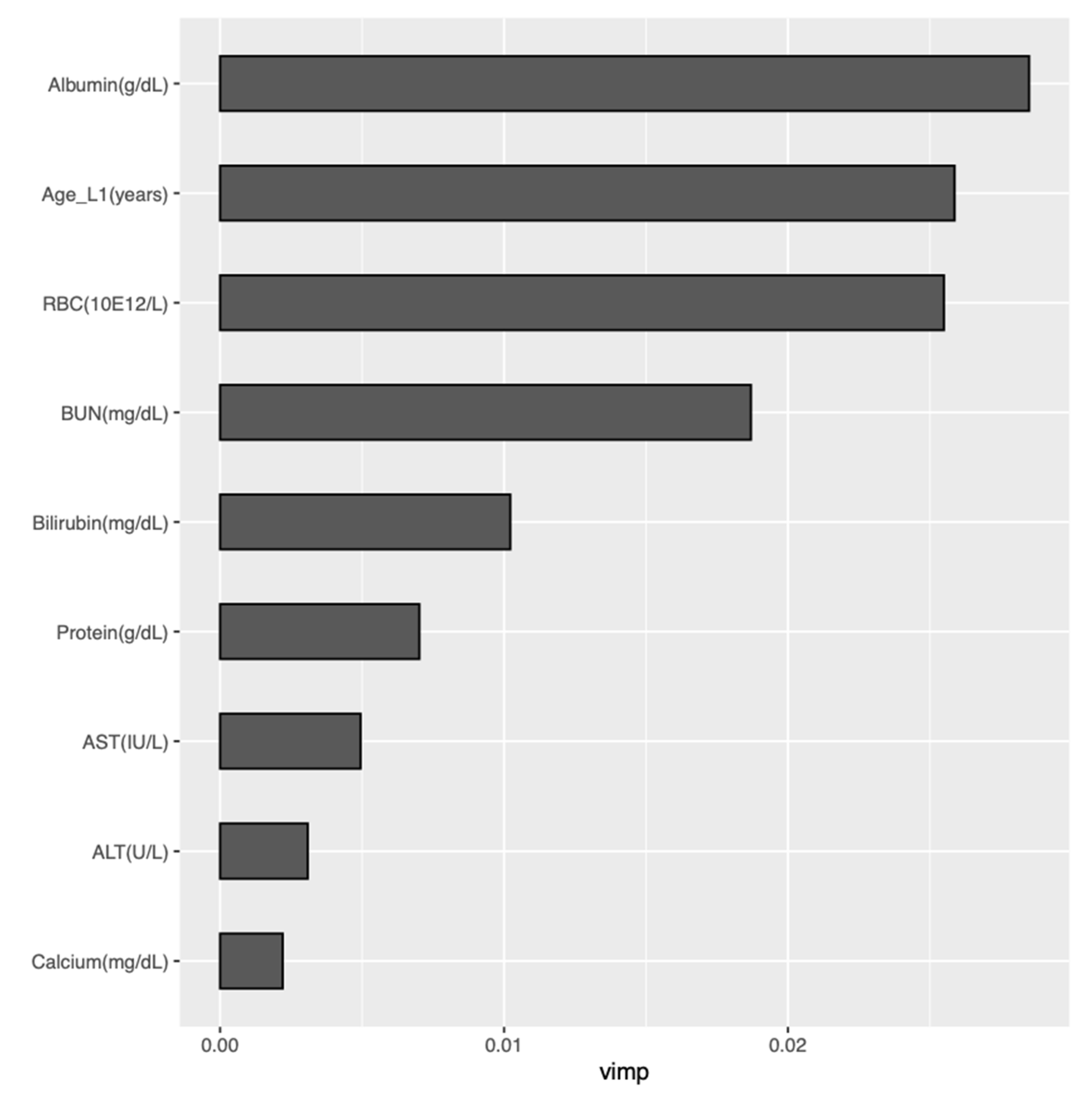
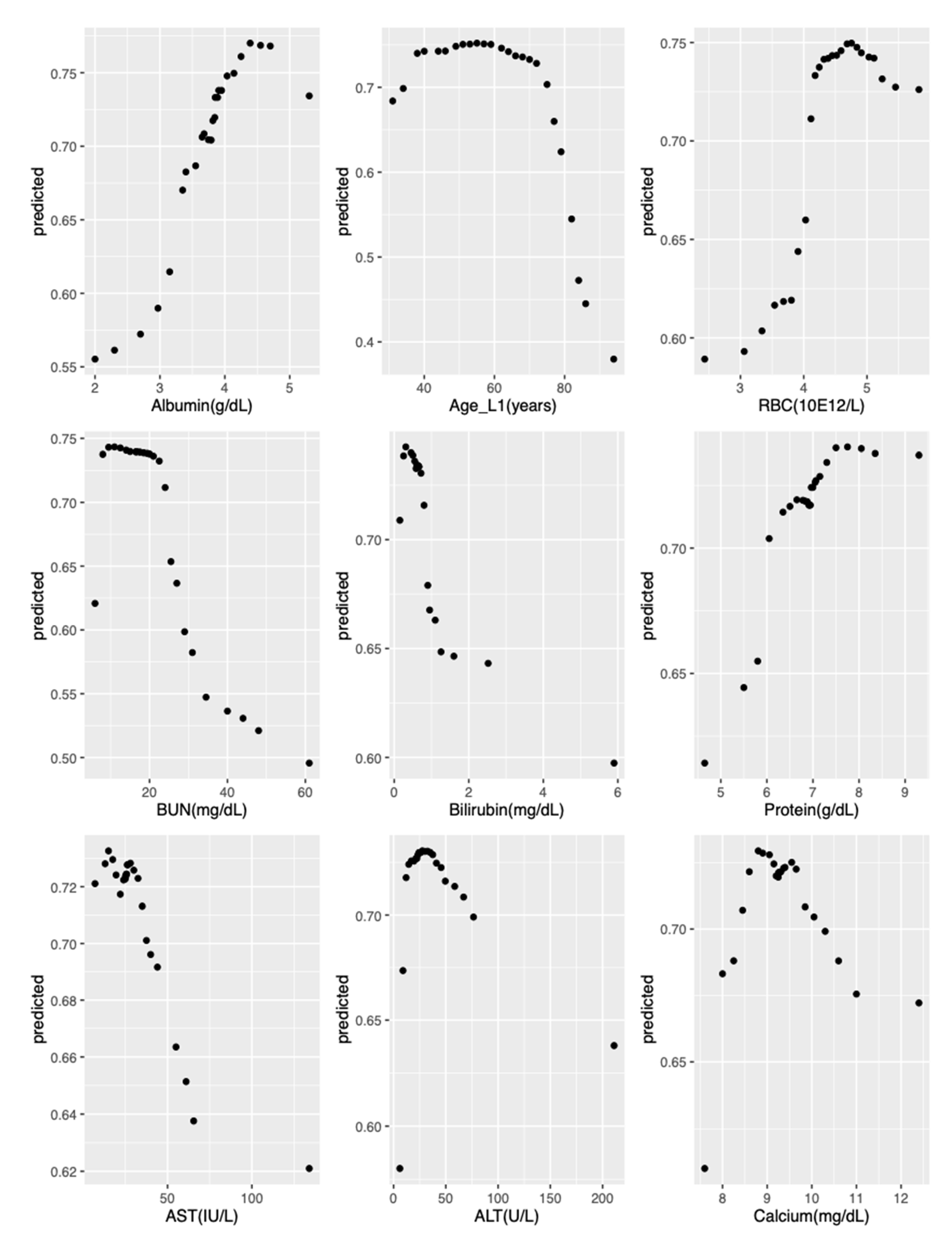
2.7. Model Interpretation
3. Results
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Clinical Rationale for Inclusion and Exclusion Criteria
Appendix B. RSF Parameter Tuning
- Nodesize: seq(100, 1000, by = 50)
- Ntree: seq(1, ncol(train_data), length.out = 100)
- Nsplit: c(1:9, seq(10, 100, by = 5))
Appendix C. Tables and Figure

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Labs Set |
| Alanine aminotransferase |
| Albumin |
| Alkaline phosphatase |
| Basophils |
| Basophils per 100 leukocytes |
| Bilirubin |
| Calcium |
| Carbon dioxide |
| Chloride |
| Creatinine |
| Eosinophils |
| Eosinophils per 100 leukocytes |
| Erythrocyte distribution width |
| Erythrocyte mean corpuscular hemoglobin |
| Erythrocyte mean corpuscular hemoglobin concentration |
| Erythrocyte mean corpuscular volume |
| Erythrocytes |
| Glomerular filtration rate per 1.73 square meters predicted |
| Glucose |
| Hematocrit |
| Lymphocytes |
| Lymphocytes per 100 leukocytes |
| Monocytes |
| Monocytes per 100 leukocytes |
| Neutrophils |
| Platelet mean volume |
| Platelets |
| Potassium |
| Protein |
| Sodium |
| Urea nitrogen |
| Curated Set |
| Sex |
| Race |
| Disease stage |
| Disease grade |
| Modified Charlson comorbidity index prior to first-line treatment |
| First-line treatment regimen |
| Age at first-line treatment initiation |
| Hemoglobin at first-line treatment initiation |
| Lactate dehydrogenase |
| Region of residence |
| Days from diagnosis to starting first-line treatment |
| Model | Curated (95% CI) |
|---|---|
| Cox | 0.59 (0.56–0.61) |
| Model | Curated (95% CI) | Curated + Labs (95% CI) | POD24 (95% CI) |
|---|---|---|---|
| Cox | 0.64 (0.61–0.66) | 0.64 (0.62–0.67) | 0.75 (0.73–0.78) |
| Model | Curated + Labs (95% CI) | Curated + ICD (95% CI) | Curated + ICD + Labs (95% CI) |
|---|---|---|---|
| Cox | 0.64 (0.62–0.67) | 0.57 (0.55–0.59) | 0.59 (0.55–0.63) |
| Labs | ICD | Labs + ICD | |||
|---|---|---|---|---|---|
| Variable | Times Retained | Variable | Times Retained | Variable | Times Retained |
| Urea nitrogen | 30 | Age at L1 | 30 | Age at L1 | 30 |
| Age at L1 initiation | 30 | Hemoglobin * | 30 | Albumin * | 30 |
| Albumin | 30 | 424.1 | 19 | Urea nitrogen * | 29 |
| Erythrocytes | 30 | v45.81 | 19 | Erythrocytes * | 27 |
| Chloride | 16 | 362.02 | 18 | v45.81 | 24 |
| Protein | 11 | 414.01 | 14 | 424.1 | 23 |
| Calcium | 10 | 250.80 | 13 | v81.1 | 14 |
| Lymphocytes | 6 | 782.3 | 13 | 305.03 | 13 |
| Carbon dioxide | 5 | v58.61 | 13 | v58.61 | 13 |
| Aspartate aminotransferase | 4 | v68.89 | 11 | 216.5 | 12 |
| Potassium | 4 | 305.03 | 10 | 414.01 | 12 |
| Northeast US residence | 4 | 443.9 | 7 | v68.89 | 12 |
| LDH | 3 | 366.15 | 4 | Potassium * | 11 |
| Sodium | 3 | 523.42 | 4 | 285.8 | 10 |
| Alanine aminotransferase | 2 | v58.83 | 3 | 362.02 | 10 |
| Alkaline phosphatase | 1 | v76.43 | 3 | 250.80 | 9 |
| Basophils | 1 | 173.9 | 2 | 782.3 | 9 |
| Bilirubin | 1 | 244.9 | 2 | 362.05 | 6 |
| Eosinophils | 1 | 427.31 | 2 | 443.9 | 6 |
| Hematocrit | 1 | 721.3 | 2 | Protein * | 6 |
| Neutrophils | 1 | v58.66 | 2 | 366.15 | 5 |
| Platelets | 1 | 250.00 | 1 | 427.31 | 5 |
| RCVP as L1 | 1 | 295.32 | 1 | v15.82 | 4 |
| Male sex | 1 | 300.02 | 1 | v49.89 | 4 |
| — | — | 427.89 | 1 | 340. | 3 |
| — | — | 428.0 | 1 | 371.5 | 3 |
| — | — | 715.00 | 1 | 785.2 | 3 |
| — | — | 721.2 | 1 | v43.1 | 3 |
| — | — | 722.0 | 1 | 295.32 | 2 |
| — | — | 724.3 | 1 | 362.01 | 2 |
| — | — | 785.2 | 1 | 726.73 | 2 |
| — | — | 998.83 | 1 | v16.1 | 2 |
| — | — | LDH* | 1 | v58.83 | 2 |
| — | — | v15.82 | 1 | v76.43 | 2 |
| — | — | v43.1 | 1 | 244.9 | 1 |
| — | — | v65.19 | 1 | 266.2 | 1 |
| — | — | v72.31 | 1 | 362.04 | 1 |
| — | — | v72.6 | 1 | 366.16 | 1 |
| — | — | — | — | 369.9 | 1 |
| — | — | — | — | 427.9 | 1 |
| — | — | — | — | 523.42 | 1 |
| — | — | — | — | 586. | 1 |
| — | — | — | — | 702.19 | 1 |
| — | — | — | — | 713.5 | 1 |
| — | — | — | — | 721.2 | 1 |
| — | — | — | — | 721.3 | 1 |
| — | — | — | — | 726.32 | 1 |
| — | — | — | — | 786.9 | 1 |
| — | — | — | — | 793.99 | 1 |
| — | — | — | — | 998.83 | 1 |
| — | — | — | — | Aspartate aminotransferase * | 1 |
| — | — | — | — | Chloride * | 1 |
| — | — | — | — | E878.2 | 1 |
| — | — | — | — | Glucose * | 1 |
| — | — | — | — | v43.3 | 1 |
| — | — | — | — | v65.19 | 1 |
| — | — | — | — | 72.31 | 1 |

References
- Jemal, A.; Bray, F.; Center, M.M.; Ferlay, J.; Ward, E.; Forman, D. Global cancer statistics. CA Cancer J. Clin. 2011, 61, 69–90. [Google Scholar] [CrossRef] [Green Version]
- Ekström-Smedby, K. Epidemiology and etiology of non-Hodgkin lymphoma—A review. Acta Oncol. 2006, 45, 258–271. [Google Scholar] [CrossRef] [Green Version]
- Monga, N.; Nastoupil, L.; Garside, J.; Quigley, J.; Hudson, M.; O’Donovan, P.; Parisi, L.; Tapprich, C.; Thieblemont, C. Burden of illness of follicular lymphoma and marginal zone lymphoma. Ann. Hematol. 2019, 98, 175–183. [Google Scholar] [CrossRef]
- Kahl, B.S. Follicular lymphoma: Are we ready for a risk-adapted approach? Hematol. Am. Soc. Hematol. Educ. Program 2017, 2017, 358–364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Teras, L.R.; DeSantis, C.E.; Cerhan, J.R.; Morton, L.M.; Jemal, A.; Flowers, C.R. 2016 US lymphoid malignancy statistics by World Health Organization subtypes. CA Cancer J. Clin. 2016, 66, 443–459. [Google Scholar] [CrossRef] [PubMed]
- Maurer, M.J.; Bachy, E.; Ghesquiéres, H.; Ansell, S.M.; Nowakowski, G.S.; Thompson, C.A.; Inwards, D.J.; Allmer, C.; Chassagne-Clément, C.; Nicolas-Virelizier, E.; et al. Early event status informs subsequent outcome in newly diagnosed follicular lymphoma. Am. J. Hematol. 2016, 91, 1096–1101. [Google Scholar] [CrossRef] [Green Version]
- Rummel, M.J.; Niederly, N.; Maschmeyer, G.; Banat, G.A.; von Grünhagen, U.; Losem, C.; Kofahl-Krause, D.; Heil, G.; Welslau, M.; Balser, C.; et al. Bendamustine plus rituximab versus CHOP plus rituximab as first-line treament for patients with indolent and mantle-cell lymphomas: An open-label, multicentre, randomised, phase 3 non-inferiority trial. Lancet 2013, 381, 1203–1210. [Google Scholar] [CrossRef]
- Flinn, I.W.; van der Jagt, R.; Kahl, B.; Wood, P.; Hawkins, T.; MacDonald, D.; Simpson, D.; Kolibaba, K.; Issa, S.; Chang, J.; et al. First-line treatment of patients with indolent non-Hodgkin lymphoma or mantle-cell lymphoma with bendamustine plus rituximab versus R-CHOP or R-CVP: Results of the BRIGHT 5-year follow-up study. J. Clin. Oncol. 2019, 37, 984–991. [Google Scholar] [CrossRef] [PubMed]
- Casulo, C.; Nastoupil, L.; Fowler, N.H.; Friedberg, J.W.; Flowers, C.R. Unmet needs in the first-line treatment of follicular lymphoma. Ann. Oncol. 2017, 28, 2094–2106. [Google Scholar] [CrossRef] [PubMed]
- Halabi, S.; Owzar, K. The importance of identifying and validating prognostic factors in oncology. Semin. Oncol. 2010, 37, e9–e18. [Google Scholar] [CrossRef] [Green Version]
- Solal-Céligny, P.; Roy, P.; Colombat, P.; White, J.; Armitage, J.O.; Arranz-Saez, R.; Au, W.Y.; Bellei, M.; Brice, P.; Caballero, D.; et al. Follicular Lymphoma International Prognostic Index. Blood 2004, 104, 1258–1265. [Google Scholar] [CrossRef] [Green Version]
- Van de Schans, S.A.M.; Steyerberg, E.W.; Nijziel, M.R.; Creemers, G.-J.; Janssen-Heijnen, M.L.; van Spronsen, D.J. Validation, revision and extension of the Follicular Lymphoma International Prognostic Index (FLIPI) in a population-based setting. Ann. Oncol. 2009, 20, 1697–1702. [Google Scholar] [CrossRef] [PubMed]
- Haybittle, J.L.; Blamey, R.W.; Elston, C.W.; Johnson, J.; Doyle, P.J.; Campbell, F.C.; Nicholson, R.I.; Griffiths, K. A prognostic index in primary breast cancer. Br. J. Cancer 1982, 45, 361–366. [Google Scholar] [CrossRef] [Green Version]
- Petersen, V.C.; Baxter, K.J.; Love, S.B.; Shepherd, N.A. Identification of objective pathological prognostic determinants and models of prognosis in Dukes‘ B colon cancer. Gut 2002, 51, 65–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Casulo, C.; Byrtek, M.; Dawson, K.L.; Zhou, X.; Farber, C.M.; Flowers, C.R.; Hainsworth, J.D.; Maurer, M.J.; Cerhan, J.R.; Link, B.K.; et al. Early relapse of follicular lymphoma after rituximab plus cyclophosphamide, doxorubicin, vincristine, and prednisone defines patients at high risk for death: An analysis from the National LymphoCare Study. J. Clin. Oncol. 2015, 33, 2516–2522. [Google Scholar] [CrossRef] [PubMed]
- Obermeyer, Z.; Emanuel, E.J. Predicting the future-big data, machine learning, and clinical medicine. NEJM 2016, 375, 1216–1219. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Ishwaran, H.; Kogalur, U.B.; Blackstone, E.H.; Lauer, M.S. Random survival forests. Ann. Appl. Stat. 2008, 2, 841–860. [Google Scholar] [CrossRef]
- Wang, H.; Li, G. A selective review on random survival forests for high dimensional data. Quant. Biosci. 2017, 36, 85–96. [Google Scholar] [CrossRef]
- Ishwaran, H.; Lu, M. Standard errors and confidence intervals for variable importance in random forest regression, classification, and survival. Stat. Med. 2018, 38, 558–582. [Google Scholar] [CrossRef]
- Dietrich, S.; Floegel, A.; Troll, M.; Kühn, T.; Rathmann, W.; Peters, A.; Sookthai, D.; von Bergen, M.; Kaaks, R.; Adamski, J.; et al. Random Survival Forest in practice: A method for modelling complex metabolomics data in time to event analysis. Int. J. Epidemiol. 2016, 45, 1406–1420. [Google Scholar] [CrossRef] [Green Version]
- LeBlanc, M. Regression trees. In Encyclopedia of Environmentrics; El-Shaarawi, A.H., Piegorsch, W.W., Zhang, H.H., Eds.; Wiley Online Library: Hoboken, NJ, USA, 2006. [Google Scholar] [CrossRef]
- Gupta, S.; Tran, T.; Luo, W.; Phung, D.; Kennedy, R.L.; Broad, A.; Campbell, D.; Kipp, D.; Singh, M.; Khasraw, M.; et al. Machine-learning prediction of cancer survival: A retrospective study using electronic administrative records and a cancer registry. BMJ Open 2014, 4, e004007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elfiky, A.A.; Pany, M.J.; Parikh, R.B.; Obermeyer, Z. Development and application of a machine learning approach to assess short-term mortality risk among patients with cancer starting chemotherapy. JAMA Netw. Open 2018, 1, e180926. [Google Scholar] [CrossRef] [Green Version]
- Parikh, R.B.; Manz, C.; Chivers, C.; Regli, S.H.; Braun, J.; Draugelis, M.E.; Schuchter, L.M.; Shulman, L.N.; Navathe, A.S.; Patel, M.S.; et al. Machine learning approaches to predict 6-month mortality among patients with cancer. JAMA Netw. Open 2019, 2, e1915997. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Halwani, A.S.; Rasmussen, K.M.; Patil, V.; Morreall, D.; Li, C.; Yong, C.; Burningham, Z.; Dawson, K.; Masaquel, A.; Henderson, K.; et al. Maintenance rituximab in Veterans with follicular lymphoma. Cancer Med. 2020, 9, 7537–7547. [Google Scholar] [CrossRef] [PubMed]
- Tang, F.; Ishwaran, H. Random forest missing data algorithms. Stat. Anal. Data Min. 2017, 10, 363–377. [Google Scholar] [CrossRef]
- Ishwaran, H.; Kogalur, U.B.; Fast Unified Random Forests for Survival, Regression, and Classification (RF-SRC). CRAN R-Project. Available online: https://cran.r-project.org/web/packages/randomForestSRC/randomForestSRC.pdf (accessed on 10 November 2020).
- Monfardini, S.; Banfi, A.; Bonadonna, G.; Rilke, F.; Milani, F.; Valagussa, P.; Lattuada, A. Improved five year survival after combined radiotherapy-chemotherapy for state I-II non-Hodgkin‘s lymphoma. Int. J. Radiat. Oncol. Biol. Phys. 1980, 6, 125–134. [Google Scholar] [CrossRef]
- Guadagnolo, B.A.; Li, S.; Neuberg, D.; Ng, A.; Hua, L.; Silver, B.; Stevenson, M.A.; Mauch, P. Long-term outcome and mortality trends in early-stage, Grade 1-2 follicular lymphoma treated with radiation therapy. Int. J. Radiat. Oncol. Biol. Phys. 2006, 64, 928–934. [Google Scholar] [CrossRef]
- Carreras, J.; Lopez-Guillermo, A.; Fox, B.C.; Colomo, L.; Martinez, A.; Roncador, G.; Montserrat, E.; Campo, E.; Banham, A.H. High numbers of tumor-infiltrating FOXP3-positive regulatory T cells are associated with improved overall survival in follicular lymphoma. Blood 2006, 108, 2957–2964. [Google Scholar] [CrossRef]
- Tibshirani, R. The lasso method for variable selection in the Cox model. Stat. Med. 1997, 16, 385–395. [Google Scholar] [CrossRef] [Green Version]
- Stackexchange. Available online: https://stats.stackexchange.com/questions/36015/prediction-in-cox-regression (accessed on 20 August 2020).
- Tay, K.; Simon, N.; Friedman, J.; Hastie, T.; Tibshirani, R.; Naraimhan, B. Regularized Cox Regression. Available online: https://cran.r-project.org/web/packages/glmnet/vignettes/Coxnet.pdf (accessed on 11 February 2021).
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random forests. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: Boston, MA, USA, 2012; pp. 157–175. [Google Scholar]
- Shi, Y.; Graves, J.A.; Garbett, S.P.; Zhou, Z.; Marathi, R.; Wang, X.; Harrell, F.E.; Lasko, T.A.; Denny, J.C.; Roden, D.M.; et al. A decision-theoretic approach to panel-based, preemptive genotyping. MDM Policy Prac. 2019, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Konerman, M.A.; Beste, L.A.; Van, T.; Liu, B.; Zhang, X.; Zhu, J.; Saini, S.D.; Su, G.L.; Nallamothu, B.K.; Ioannou, G.N.; et al. Machine learning models to predict disease progression among Veterans with hepatitis C virus. PLoS ONE 2019, 14, e0208141. [Google Scholar] [CrossRef] [PubMed]
- Gerds, T.A. Prediction Error Curves for Survival Models, R package pec version 1.1.5; CRAN: Vienna, Austria, 2009. [Google Scholar]
- Mogensen, U.B.; Ishwaran, H.; Gerds, T.A. Evaluating random forests for survival analysis using prediction error curves. J. Stat. Softw. 2012, 50, 1–23. [Google Scholar] [CrossRef]
- Uno, H.; Cai, T.; Pencina, M.J.; D’Agostino, R.B.; Wei, L.J. On the C-statistics for evaluating overall adequacy of risk prediction procedures with censored survival data. Stat. Med. 2011, 30, 1105–1117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruopp, M.D.; Perkins, N.J.; Whitcomb, B.W.; Schisterman, E.F. Youden Index and optimal cut-point estimated from observations affected by a lower limit of detection. Biomed. J. 2008, 50, 419–430. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harrell, F.E. “with Contributions from Many Others”. Harrell Miscellaneous. R Package Version 4.1-1. Available online: https://CRAN.R-project.org/package=Hmisc (accessed on 11 February 2021).
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Goldstein, A.; Kapelner, A.; Bleich, J.; Pitkin, E. Peeking inside the black box: Visualizing statistical learning with plots of individual conditional expectation. J. Comp. Graph. Stat. 2015, 45, 44–65. [Google Scholar] [CrossRef]
- R Core Team. R: A language and environment for statistical computing. R Foundation for Statistical Computing. Vienna, Austria. Available online: https://www.R-project.org (accessed on 11 February 2021).





| BR | RCHOP | RCVP | p-Value | |
|---|---|---|---|---|
| N | 120 | 235 | 168 | |
| Sex = male * (%) | 113 (94.2) | 220 (93.6) | 165 (98.2) | 0.085 |
| Race (%) | 0.177 | |||
| Hispanic | 3 (2.5) | 10 (4.3) | 3 (1.8) | |
| Non-Hispanic Black | 6 (5.0) | 26 (11.1) | 9 (5.4) | |
| Non-Hispanic White | 109 (90.8) | 194 (82.6) | 153 (91.1) | |
| Other | 2 (1.7) | 5 (2.1) | 3 (1.8) | |
| Disease stage (%) | 0.254 | |||
| II | 12 (10.0) | 42 (17.9) | 20 (11.9) | |
| III | 54 (45.0) | 97 (41.3) | 78 (46.4) | |
| IV | 54 (45.0) | 96 (40.9) | 70 (41.7) | |
| Disease grade (%) | <0.001 | |||
| 1 | 38 (31.7) | 55 (23.4) | 70 (41.7) | |
| 1–2 | 11 (9.2) | 7 (3.0) | 11 (6.5) | |
| 2 | 58 (48.3) | 76 (32.3) | 69 (41.1) | |
| 3 | 8 (6.7) | 63 (26.8) | 12 (7.1) | |
| 3a | 5 (4.2) | 34 (14.5) | 6 (3.6) | |
| Region of residence (%) | 0.110 | |||
| Midwest | 33 (27.5) | 60 (25.5) | 38 (22.6) | |
| Northwest | 17 (14.2) | 26 (11.1) | 36 (21.4) | |
| South | 46 (38.3) | 86 (36.6) | 53 (31.5) | |
| West | 24 (20.0) | 63 (26.8) | 41 (24.4) | |
| Pre-L1 CCI (mean [SD]) | 2.36 (2.56) | 2.51 (2.58) | 2.03 (2.33) | 0.161 |
| Age > 60 years at L1 (%) | 85 (70.8) | 149 (63.4) | 117 (69.6) | 0.259 |
| Hemoglobin at L1 < 12 g/dL (%) | 32 (26.7) | 76 (32.3) | 52 (31.0) | 0.544 |
| LDH at L1 > upper limit of normal | 39 (32.5) | 91 (38.7) | 48 (28.6) | 0.097 |
| Days from diagnosis to L1 (mean [SD]) | 227.47 (321.72) | 116.53 (314.30) | 168.35 (328.04) | 0.008 |
| Model (AUC) | Curated (95% CI) | Curated + Labs (95% CI) | Curated + ICD (95% CI) | Curated + ICD + Labs (95% CI) |
|---|---|---|---|---|
| Cox (regularized Cox denoted by *) | 0.64 (0.61–0.67) | 0.61 (0.59–0.64) * 0.71 (0.69–0.73) | * 0.69 (0.67–0.71) | * 0.73 (0.70–0.75) |
| RSF | 0.68 (0.65–0.70) | 0.73 (0.71–0.75) | 0.63 (0.61–0.65) | 0.71 (0.63–0.79) |
| Model (AUC) | Curated + POD24 (95% CI) |
|---|---|
| Cox | 0.74 (0.71–0.77) |
| Risk Group | N | Hazard Ratio (95% CI) | 5-Year Overall Survival (95% CI) |
|---|---|---|---|
| RSF Model | |||
| Low | 62 | 1 | 0.83 (0.73–0.94) |
| High | 43 | 4.39 (2.11–9.14) | 0.44 (0.30–0.63) |
| POD24 Model | |||
| Low | 61 | 1 | 0.87 (0.78–0.98) |
| High | 25 | 5.55 (3.27–9.35) | 0.41 (0.26–0.68) |
| Low-Risk | High-Risk | p-Value | |
|---|---|---|---|
| N | 62 | 43 | |
| Sex = male * (%) | 59 (95.2) | 40 (93.0) | 0.971 |
| Race (%) | 0.520 | ||
| Hispanic | 1 (1.6) | 1 (2.3) | |
| Non-Hispanic Black | 5 (8.1) | 1 (2.3) | |
| Non-Hispanic White | 52 (83.9) | 40 (93.0) | |
| Other | 2 (3.2) | 0 | |
| Unknown | 2 (3.2) | 1 (2.3) | |
| Disease stage (%) | 0.503 | ||
| II | 8 (12.9) | 5 (11.6) | |
| III | 26 (41.9) | 13 (30.2) | |
| IV | 24 (38.7) | 23 (53.5) | |
| Unknown | 4 (6.5) | 2 (4.7) | |
| Disease grade (%) | 0.208 | ||
| 1 | 13 (21.0) | 12 (27.9) | |
| 1–2 | 3 (4.8) | 0 | |
| 2 | 18 (29.0) | 7 (16.3) | |
| 3 | 8 (12.9) | 7 (16.3) | |
| 3a | 8 (12.9) | 3 (7.0) | |
| Unknown | 12 (19.4) | 14 (32.6) | |
| L1 treatment regimen (%) | 0.483 | ||
| BR | 13 (21.0) | 6 (14.0) | |
| RCHOP | 25 (40.3) | 22 (51.2) | |
| RCVP | 24 (38.7) | 15 (34.9) | |
| Region of residence (%) | 0.789 | ||
| Midwest | 11 (17.7) | 10 (23.3) | |
| Northwest | 6 (9.7) | 6 (14.0) | |
| South | 17 (27.4) | 8 (18.6) | |
| West | 13 (21.0) | 8 (18.6) | |
| Unknown | 15 (24.2) | 11 (25.6) | |
| Pre-L1 CCI (mean [SD]) | 2.37 (2.42) | 2.93 (2.81) | 0.284 |
| Days from diagnosis to L1 (mean [SD]) | 135.31 (310.77) | 102.49 (200.15) | 0.543 |
| Age > 60 years at L1 (%) | 37 (59.7) | 32 (79.1) | 0.061 |
| Hemoglobin at L1 (%) | <0.001 | ||
| <12 g/dL | 3 (4.8) | 26 (60.5) | |
| ≥12 g/dL | 58 (93.5) | 17 (39.5) | |
| Unknown | 1 (1.6) | 0 | |
| LDH at L1 (%) | 0.009 | ||
| ≤Upper limit of normal | 47 (75.8) | 21 (48.8) | |
| >Upper limit of normal | 9 (14.5) | 17 (39.5) | |
| Unknown | 6 (9.7) | 5 (11.6) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Patil, V.; Rasmussen, K.M.; Yong, C.; Chien, H.-C.; Morreall, D.; Humpherys, J.; Sauer, B.C.; Burningham, Z.; Halwani, A.S. Predicting Survival in Veterans with Follicular Lymphoma Using Structured Electronic Health Record Information and Machine Learning. Int. J. Environ. Res. Public Health 2021, 18, 2679. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18052679
Li C, Patil V, Rasmussen KM, Yong C, Chien H-C, Morreall D, Humpherys J, Sauer BC, Burningham Z, Halwani AS. Predicting Survival in Veterans with Follicular Lymphoma Using Structured Electronic Health Record Information and Machine Learning. International Journal of Environmental Research and Public Health. 2021; 18(5):2679. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18052679
Chicago/Turabian StyleLi, Chunyang, Vikas Patil, Kelli M. Rasmussen, Christina Yong, Hsu-Chih Chien, Debbie Morreall, Jeffrey Humpherys, Brian C. Sauer, Zachary Burningham, and Ahmad S. Halwani. 2021. "Predicting Survival in Veterans with Follicular Lymphoma Using Structured Electronic Health Record Information and Machine Learning" International Journal of Environmental Research and Public Health 18, no. 5: 2679. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18052679