1. Introduction
Infectious diseases have been the object of study throughout the history of mankind. Multiple disciplines have contributed to the understanding of these health phenomena, in particular the sources and types of infections, as well as the negative consequences on the population.
From an epidemiological and health perspective, humanity has experienced a series of infectious disease events, including Cholera, Malaria, and AIDS [
1]. Infectious diseases have an epidemic potential due to the dissemination of microorganisms, generally viruses that develop in a host and later seek another living being to continue with their survival process [
2,
3]. Therefore, the spread of this type of disease occurs through contact between living beings, humans or animals, which present significant loads of pathogenic microorganisms. Consequently, when massive infections occur, we are facing an epidemic outbreak. The concept of an epidemic is established when the infectious outbreak affects a specific geographic area and a pandemic is related to an event spread over extensive continental areas [
4].
An example of the above is the current COVID-19 pandemic context, the study of the spread of diseases being of interest [
5,
6]. The beginning of the pandemic was registered in the city of Wuhan, China [
7]. The consequences of the COVID-19 pandemic have been evidenced in a series of dimensions, including the collapse of health systems in some countries, the stoppage of production, the impoverishment of communities, unemployment, among other social and economical consequences [
8].
In this sense, the current and historical contributions of mathematical models are important. The compartmental models are useful to establish in a simple way the projections and evolution of infectious diseases. They are characterized by compartmentalizing the population depending on whether the disease generates immunity or not [
3]. One of the classic compartmental mathematical models is SIR, developed by Kermack and Mc Kendrick in 1927 for the understanding of epidemics [
9], and the current use of computational simulations is of great relevance to analyze the behavior, in this case, of SARS-CoV2 (see, for instance, [
10]). The SIR model compartmentalizes or divides the population into Susceptible (S), Infected (I), and Removed (R). This compartmentalization allows for analyzing the population with these states and is useful to determine projections in relation to the total number of patients and the duration of the disease [
11]. The SIR model approach is eminently deterministic; however, it has also been used from a stochastic perspective, improving the representation of the dynamics of infectious diseases through the probability of the appearance of epidemic outbreaks [
11]. There are other mathematical models in epidemiology that have been developed from the SIR model, adding variables such as exposure and the effect of quarantine measures such as the SEIR and SEQIJR model, respectively [
12]. With this, nations and governments can count on information to establish mitigation measures for the consequences of the virus, such as: safeguarding employment, strengthening health system responses, developing community actions, among other measures.
However, these models are limited when the extension and heterogeneity of the data are wide, so they fail to detect changes in the population structure and the variation in contact dynamics over time [
12].
On the other hand, globalization and high population concentration have led to the inclusion of other ways of representing the spread of infectious diseases. Models with stochastic approximations have the advantage of establishing probabilities of person-to-person contact [
3]. One of them is the network model, which is based on the theory of graphs studied from the observations of Leonhard Euler with the problem of the seven bridges. The model proposes the formation of individuals (nodes) and their relationship with others (edge), so the result is a network [
12] (see, for instance,
Figure 1).
To build a network model, the variables that are relevant to the spread of a disease are established. Among the multiple models developed, sociocentric studies stand out, which allow a broad exploration of the complete network that is generated to understand the spread of a pathogen. Therefore, network models are useful to understand the development of different infectious diseases [
13]. It is not new, especially if the spread of an epidemic disease in network structures is studied, which in an abstract way is the main object of graph theory; see, for instance, in [
14], where the authors use the model as a predictive tool, to emulate the dynamics of Ebola virus disease in Liberia, and in [
15] where the transmission connectivity networks of people infected with highly contagious Middle East respiratory syndrome coronavirus (MERS-CoV) in Saudi Arabia were assessed to identify super-spreading events among the infected patients between 2012 and 2016. The relevance of these studies is related to the possibility of preventing nodes (people) from continuing to infect, an issue that is treated in [
16] with the graph protection methods proposed by Wijayanto and Murata. Deepening in this line of studies, there have been included new mathematical models with variables related to the behavior of people associated with information and emotions during epidemics [
17]. Likewise, dynamic models have covered the influence of the infectious disease itself on the network of contacts and, therefore, changes in the dynamics of spread of the epidemic over time [
12].
In general, network models can be analyzed through static graphics such as snapshots. However, for an adequate approximation and correcting the loss of data generated by the snapshot, data modeling techniques must be used including the weighting of the edges and, consequently, better estimated, given the information obtained from the relationships between individuals and the spreading of the disease [
12].
In the current context, organized information has an important value for the management of epidemics. The databases elaborated from the information of individuals can contribute in the characterization and knowledge of a determined area, which are important in order to know the evolution of the diseases [
18].
In the case of infectious pathologies, depending on the type of database, it is possible to determine through the variables whether two or more individuals are linked to each other, such as people who live in the same neighborhood or work in the same place. Given the characteristics of network models and the obtaining of information through complex databases, it is relevant to use these models, in particular, with approximations that incorporate weighting on the edges.
For all the above, there are challenges around the possibility of representing and understanding the evolution of infectious diseases through a network model using databases. The relevance of this type of research contribution is based on the possibility of having tools that favor measures to prevent the spread of this type of disease, an issue that takes on greater social and scientific value due to the context of the SARS-CoV2 pandemic. Consequently, the aim of this article is to develop a spreading stochastic model of some disease from a database, particularly using variables that link individuals in a given territory, the probability of contagion among them, and, therefore, the spread of the disease through edge-weighted graphs (or edge-weighted networks). For the purposes of this manuscript, a database is understood as a matrix whose columns are the variables, while the rows correspond to the responses of the subjects in relation to the variables consulted.
Our proposal provides an edge-weighted graph obtained from a database that contains enough information about the individuals that belong to a population. With this graph, we use a graph-based SIR model in which each individual is represented by a vertex in an edge-weighted graph. At time
t, each vertex
is in a state
belonging to
, where
and
represent the three discrete states: susceptible (S), infected (I), and recovered (R). We choose predetermined values for the parameters of the model changing only one of them at a time, observing the effects on the epidemic. These parameters are: the order of the graph, the mean degree of its vertices, the representative factor of the disease, the numbers of relation variables of database, and the numbers of classes (for the last parameters, see
Section 3). The initial population contains one infected individual and all the simulations were done on a random and scale-free graph. The recovery rate is fixed in
. We have studied the effects of these parameters on two characteristics of the disease: the number of total infected and the duration of the disease. Finally, we tested our model with real COVID-19 data from Olmué City (Chili). The database was obtained from the epidemiological surveillance system of the Chilean Ministry of Health.
The paper is organized as follows:
Section 2 contains generalities about graph theory and the SIR model.
Section 3 is divided into two parts: first, we give the construction of the graph from a database. In the second part, we describe the Graph-based SIR model. In
Section 4, we ran the different simulations of the spread of a disease on two different types of graphs and analyzed the effects of each parameter on the end of the disease and the number of infected. In
Section 5, we give a deterministic approach to the Graph-based SIR model. In
Section 6, we tested our model with database COVID-19 from Olmué City (Chili). Finally, in
Section 7, we provide a discussion about the results of the
Section 4,
Section 5 and
Section 6.
3. Model Description
This section is divided into two parts. A part dedicated to build a graph from a database and the second one to describe the dynamics of the disease on the graph-based SIR model.
To begin, we need some basic elements to understand what follows. First, we will understand by variable the characteristic assigned to a person from a predetermined set of values which can be a numerical measure, a category or a classification—for instance, income, age, weight, occupation, address, etc. Second, we will understand by database a matrix whose columns are variables, while the rows correspond to the responses of the subjects in relation to the variables consulted.
3.1. Graph from a Database
Let us consider a database, denoted by
, that stores information on
N individuals of a population. Let
V be the set of the persons registered in the database, equivalent
where
is a person registered in
for
.
Let
be a person registered in
for
. We set
where
K is the number of elements of the set
. (
K is the number of variables in
),
is a variable in
for
, and
is the response of the person
to the variable
.
As we want to study the link between the people who are registered in through the variables of this database, we must identify which are the variables that allow us to establish these links that promote the spread of the disease. For example, if two people are the same age, they do not necessarily meet and spread the virus unlike two people who live in the same city.
Definition 7. We will say that is a relationship variable if and only if it allows us to assume that some person meets another. In another case, we will say that is a characteristic variable.
The above allows us to define the following sets:
Let us denote by and the cardinality of and , respectively. Notice that .
Definition 8. We will say that a person is related to a person if and only if there exists for such that and .
It is clear that, if is related to , then is related to , this is to say that the relation is a symmetric relation.
The previous definition allows us to construct a graph G of links given by the relationship variables of the . G will be considered as an undirected graph without loops or multiple edges.
On the other hand, it is possible that is not unique because more than one variable may coincide. This induces us to define the weight of the link between and .
3.2. Weighting Variables
In order to define the weight of each link between two vertices, we assume that each has an associated inherent weight; this is to say, it is possible to discriminate some hierarchical order between the variables. Let be the weight associated with the variable for .
On the other hand, to better understand the definition that follows and its consequences, suppose that X is a set of 100 people. If we define the relationship in the set: person Q is related to person W if and only if they are the same age, then we could group the people in the set by age. In addition, an interesting fact is that thanks to this relationship everyone would be part of a group and no one could be in two groups at the same time. These types of relations defined on a set are called equivalence relations and each defined group is called equivalence class.
Definition 9. We will say that, for , is related to , denoted by , if and only if .
Lemma 1. The relation defined on is an equivalence relation.
Thanks to the relation , we can consider the different equivalence classes which are composed of the variables that have the same weight. Hence, we have the same number of classes as different weights.
Definition 10. Let be the different classes that are defined by the different weights and its respective cardinalities. Hence,for all . 3.3. Weighted Link
The aim in this subsection is to introduce the definition of weight link.
Let
such that
is related to
. We set
We denoted by the cardinality of the set H. Notice that is simply the number of times that one person is related to another (or the number of variables that matches between them). Since our proposal considers undirected graph, we have that .
Definition 11. Let be such that is related to and the weight of the variable in which and match, for . We will say thatis the weight of the link between and . Finally, the weighted adjacency matrix of
G is the
matrix
, where
The idea of having a graph with weights in its edges is to be able to differentiate or measure, in some way, the strength or closeness between individuals. For example, it is not the same saying that two individuals share the same city than saying they share the same house they live in; it follows that the latter makes the relationship closer and consequently the contagion of the disease is intuitively more likely.
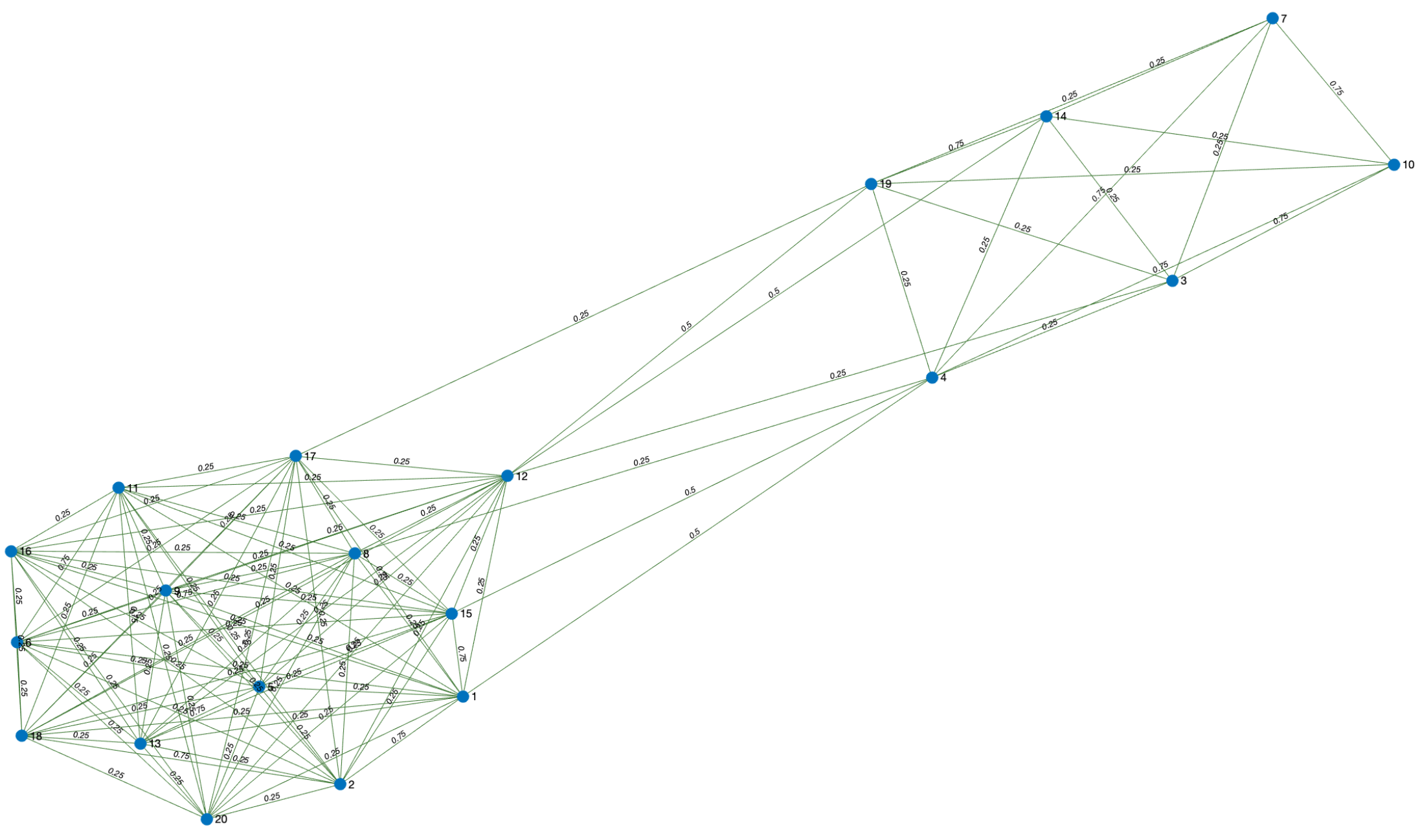
Example 1. In the following example, Table 1 simulates a database with 20 registered people. The data hosted correspond to the city in which they live (City), workplace (considering school and university as a workplace), gender (Gen.), age, extracurricular activity (EC activity), address, if they drink alcohol (Drin.), if they are smokers (Sm.), and marital status (MS). Let us consider A and B two different cities, and h different people’s addresses. Moreover, in the table, Y = Yes, N = No, IC = in couple, M = married, S = single, W = widower. From Table 1, we have that , where = , = Workplace, = E.P. activity, = Address, = Sm., = Dri., = Gen., = M.S. and = Age. Then, by Definition 7, we obtain the sets: - 1
and
- 2
.
In our criteria, the hierarchical order of the variables in descending form is , and . Moreover, we consider that the variables and have the same weight. Hence, , , and are the different classes that are defined by the different weights. Hence, by Definition 10 To construct the graph, we must resort to Definition 8. For instance, person 17 is related to all the people who live in city A or who work at Workplace 8 or who have music as an extra curricular activity or whose address is k. With respect to the weights of the edges, Equation (6) in Definition 11 gives us the answer. For instance, person 6 matches person 11 in the answers of the variables and , this is to say, both people live in city A and have the same workplace. Then, the edge has weight . Figure 2 shows the obtained graph. 3.4. Graph-Based SIR Model
Having described a population with a network model, the spreading of an epidemic is modeled by a dynamic system that uses the graph (in our case an edge-weighted graph) as its support. The class of chosen model is the probabilistic cellular automata (see [
25]), this is to say, the model in which the events happen at times
, where
is the discretization interval. In this work, we use a graph-based SIR model in which each individual is represented by a vertex in an edge-weighted graph. At time
t, each vertex
is in a state
belonging to
, where
and
represent the three discrete states: susceptible (S), infected (I), and recovered (R).
Let
G be the edge-weighted graph obtained from a database
and
. We set
At time , the vertex will change state according to probabilistic rules:
- 1
The probability (
) that a susceptible vertex
is infected by one of its neighbors is given by
where
is a purely biological factor and representative of the disease.
- 2
The probability (
) that a infected vertex
at time
t will recover is given by
where
is the recovery rate.
Moreover, we assume that the disease is present for a certain period of time and, when individuals recover, they are immune.
Remark 2. Notice that the expression (8) can be deduced from the infection model called q-influence, assuming . (see [26,27]). 4. Simulation of Disease Spread
In this section, we choose predetermined values for the parameters changing only one of them at a time, observing the effects on the epidemic. For a given type of graph, these parameters are: the order of the graph (
), the mean degree of its vertices (
), the representative factor of the disease (
), the amount of relation variables of database (
), and the amount of classes (
). The initial population contains one infected individual and all the simulations were done on a random and scale-free graph and considering
. Moreover, the software in which the simulations were run correspond to Matlab in its R2020b version. Finally, the source code of our analysis and network files are accessible through the Github link:
https://github.com/RonaldManriquez/Spread-of-disease.git (accessed on 20 February 2021).
We want to study the effects of these parameters on two characteristics of the disease: the number of total infected and the duration of the disease. We have reparameterized the number of total infected while the duration of the disease is simply the end of it, this is to say, when the infected are 0.
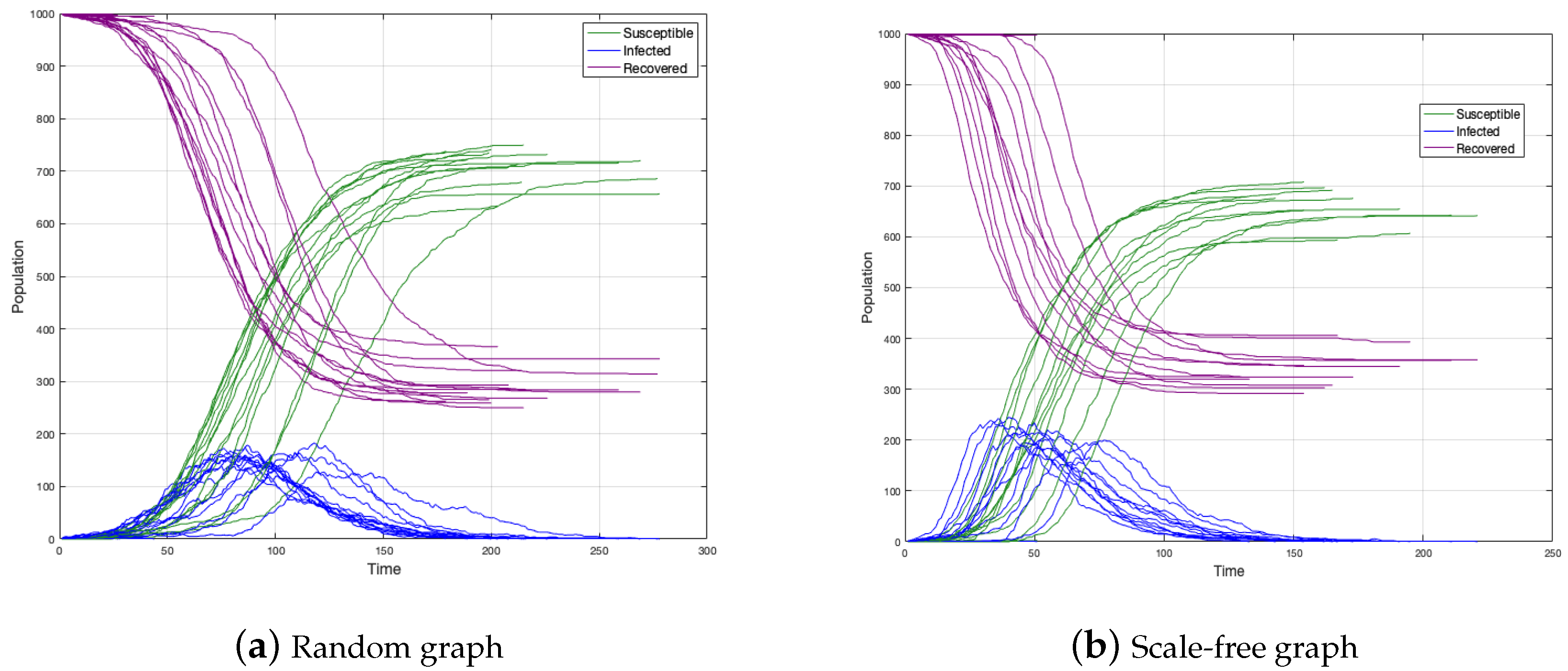
We simulated 30 epidemic spreadings on two graphs: a random graph and a scale-free graph to see how epidemics differ from each other (see
Figure 3a,b).
In both cases, the number of total infected is between 600 and 750 individuals and the duration of the disease around 150–200 time units. We concluded then that epidemics do not differ from each other. In a simple analysis, the peak in the scale-free graph occurs before the case of the random graph. Perhaps the above is because, in the scale-free graph, the disease spreading is faster.
4.1. Order of the Graph
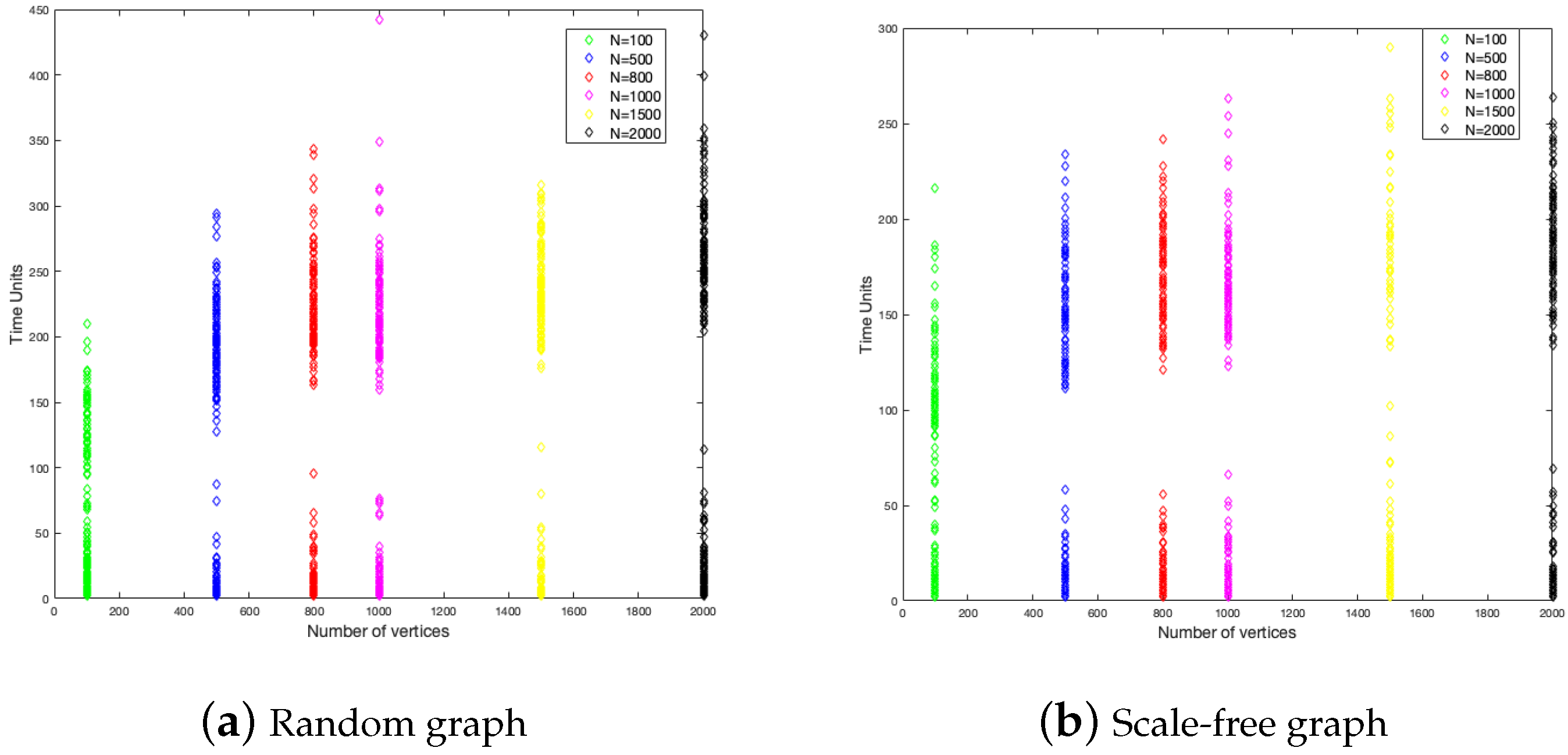
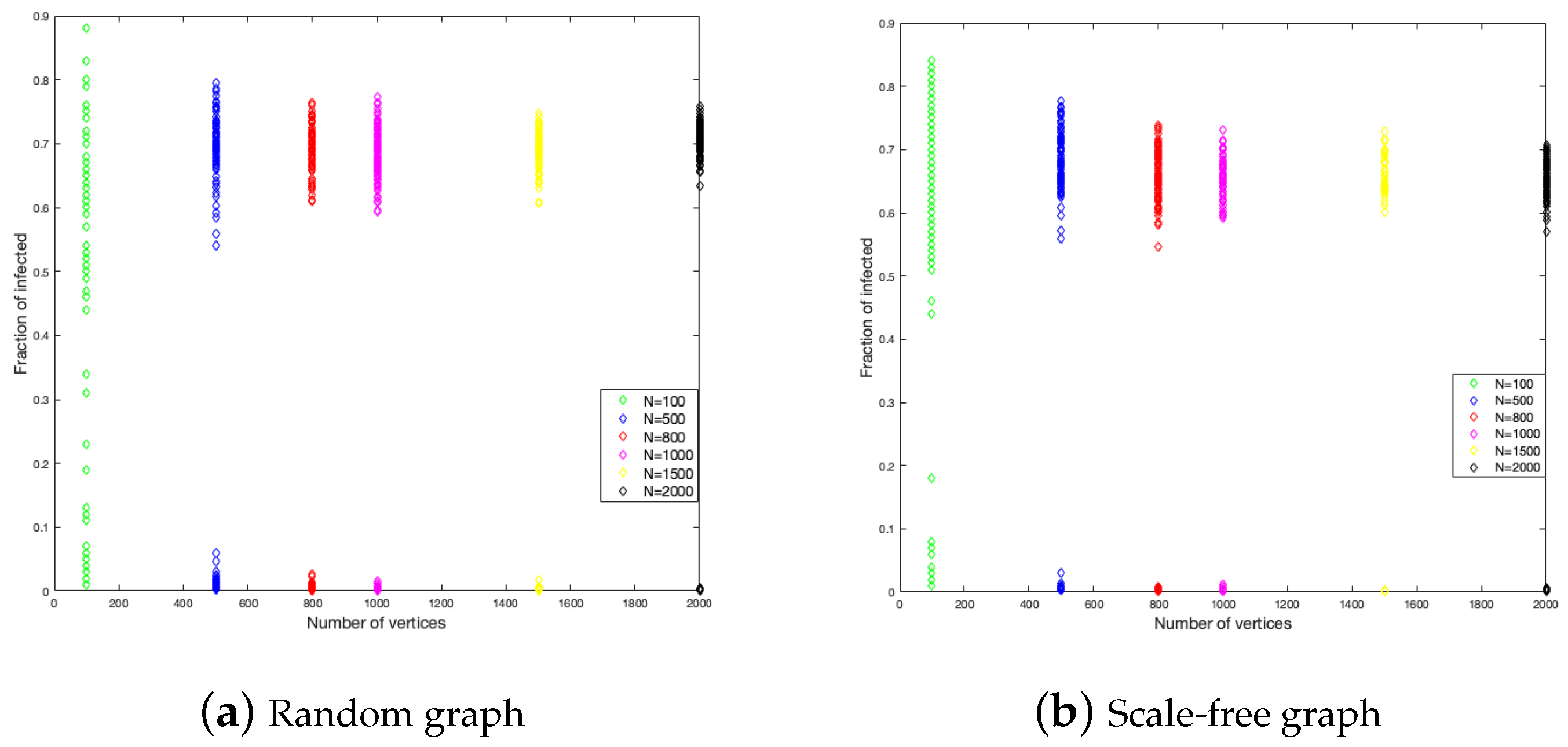
To study the graph size influence on the duration of the disease and the fraction of infected, we have considered six different sizes of graphs, these are 100, 500, 800, 1000, 1500, and 2000. In each one of them, we did 200 simulations. The results are shown in
Figure 4 and
Figure 5.
Figure 4 shows that the end of the disease is farther for the random graph than the scale-free graph. The random graph has around 350 time units as a maximum, while the scale-free graph has around 250 time units. This is to say, in the last case, the disease epidemic is shorter. This is a constant for each size of the graph.
With respect to the fraction of the infected, the random graph is more homogeneous in the numbers of individuals that get infected with a little influence from the size, while, in the scale-free graph, the fraction of infected is decreasing when the size is increasing.
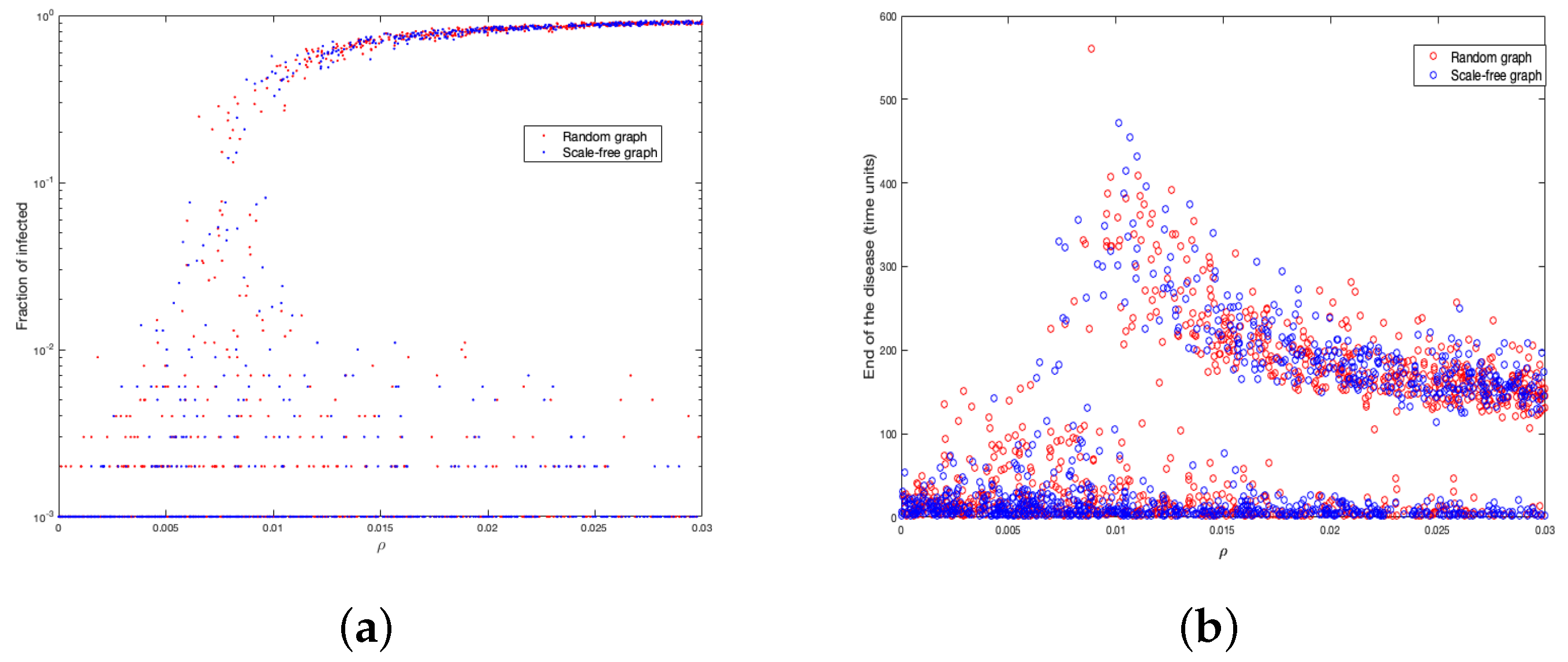
4.2. Representative Factor of the Disease ()
In this subsection, we study how the representative factor of the disease (
) affects the two epidemic parameters we are interested in. We did 1000 simulations with values of
randomly sampled from a uniform distribution between 0 and
. In
Figure 6a, we show the change of the fraction of infected in function of
and in
Figure 6b the variation of end of the disease according to
.
Notice that, from , the fraction of infected tends more clearly to 1, while near , close to 1% of the population is infected. On the other hand, when is close to , the disease has a longer duration (very close to the value by settings).
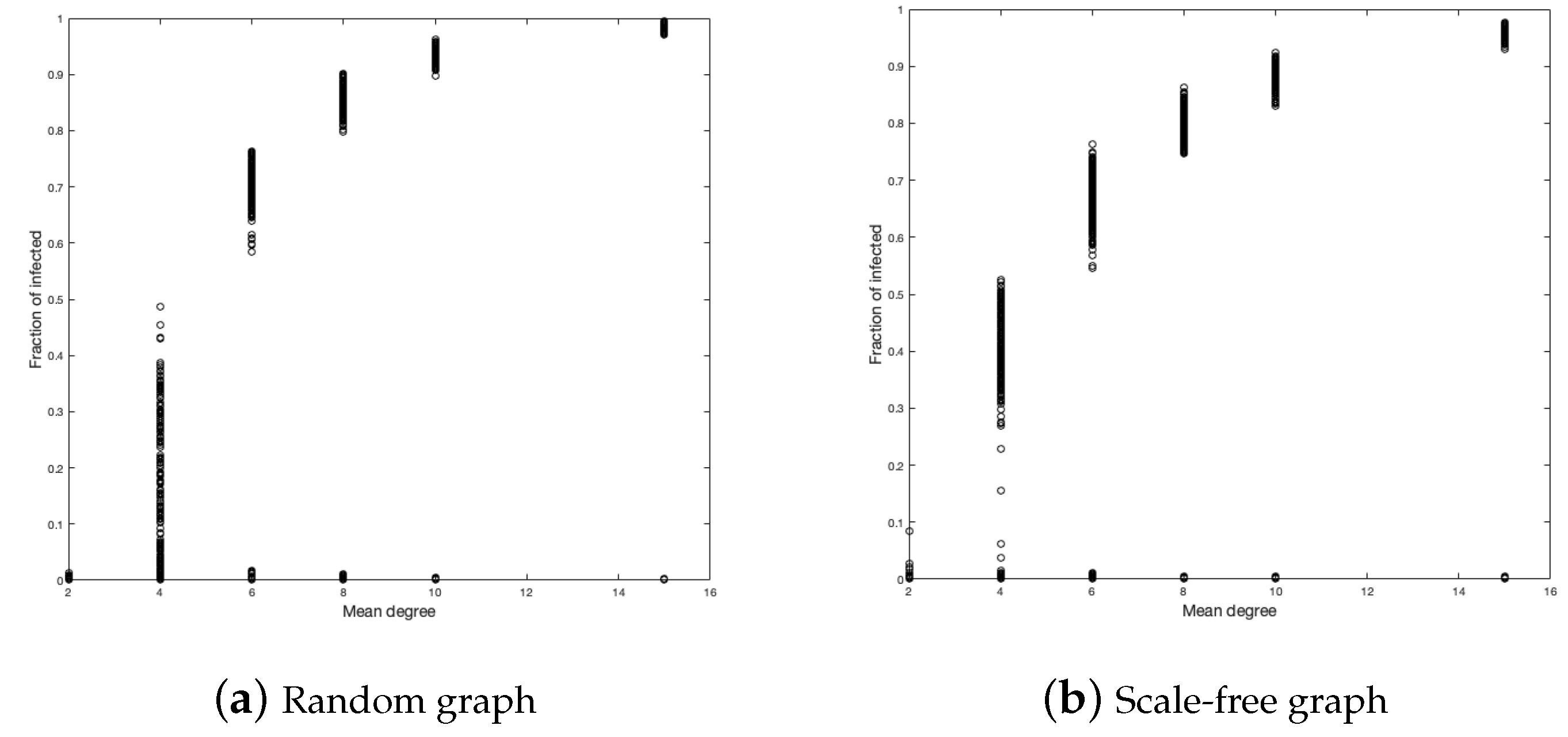
4.3. The Mean Degree of Vertices
The next variable to study is the mean degree of each vertex of the graph. For this purpose, we ran 500 simulations for each graph with a mean of degree equal to 2, 4, 6, 8, 10, and 15.
Figure 7 and
Figure 8 show the fractions of infected and the duration of the disease.
For the random graph, in the fraction of infected, it is clear that, the larger the average number of contacts, the more infected we will have. This should not be strange because the more contacts, the more likely you are to be infected. The case for is curious since it presents greater heterogeneity in the simulations.
In the case of the scale-free graph, something similar happens to the case of the random graph. The case
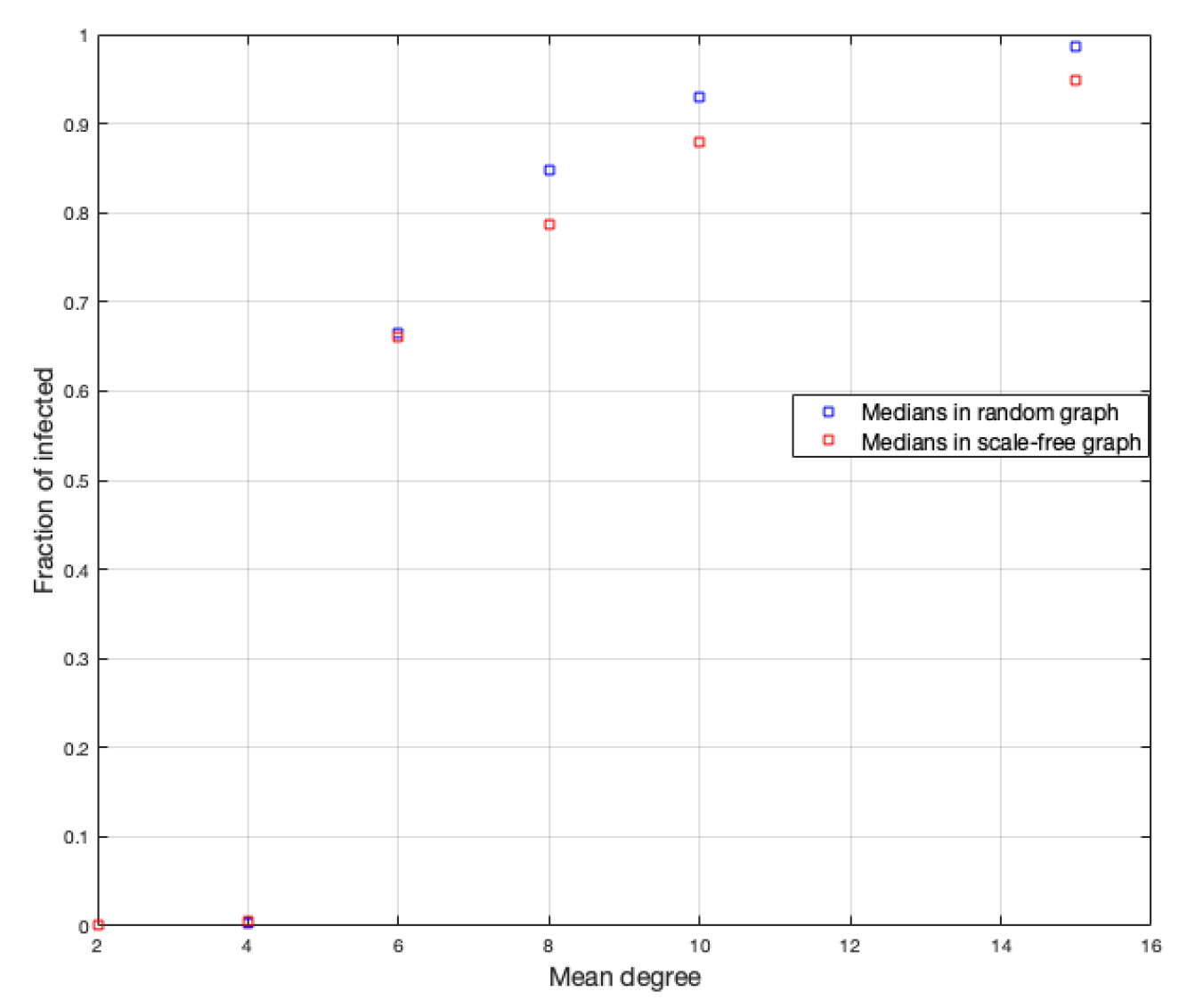
is also the most heterogeneous, but to a lesser degree than in the case of the random graph. We calculate the medians of each simulation for each
d to better see the influence from the mean value of the vertices on the infected fraction, as shown in
Figure 9. (We choose the median to reduce the bias of extreme data close to zero).
Regarding the duration of the disease, we have in the scale-free graph that, as the average number of neighbors (d) increases, the duration of the disease decreases, but not as fast as in the case of the random graph and also the duration is lower in each vertex average with respect to the random graph.
4.4. Amount of Relation Variables
Studying the effects of this parameter is important because it is a factor that is not always considered when it comes to modeling the spread of diseases on networks. It is clear that, by changing the amount of variables, the weights assigned to them and consequently the weights assigned to the links of the graph also change. To see this effect, first let’s see how the link weights change when modifying the amount of variables.
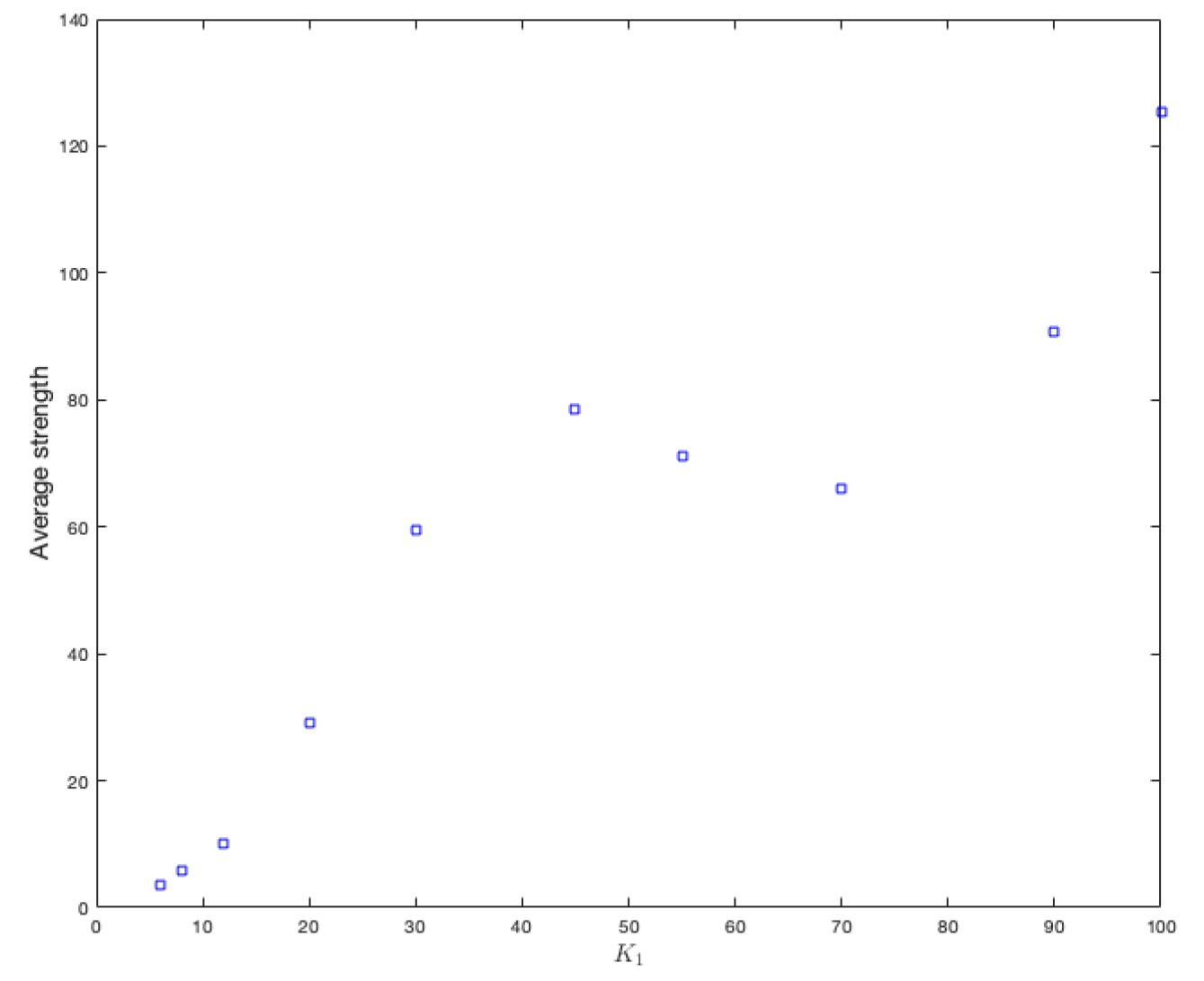
As this assignment is independent from the type of graph, we have only made the changes on a random graph. Our focus was placed on the variation of the average strength that each vertex has, considering 10 different values for
, these are
, and 100. To properly observe the effect on the strength of the vertices, we calculate the average strengths of the vertices for each value of
.
Figure 10 shows the results. It can be clearly seen that increasing the amount of variables increases the strength of each vertex.
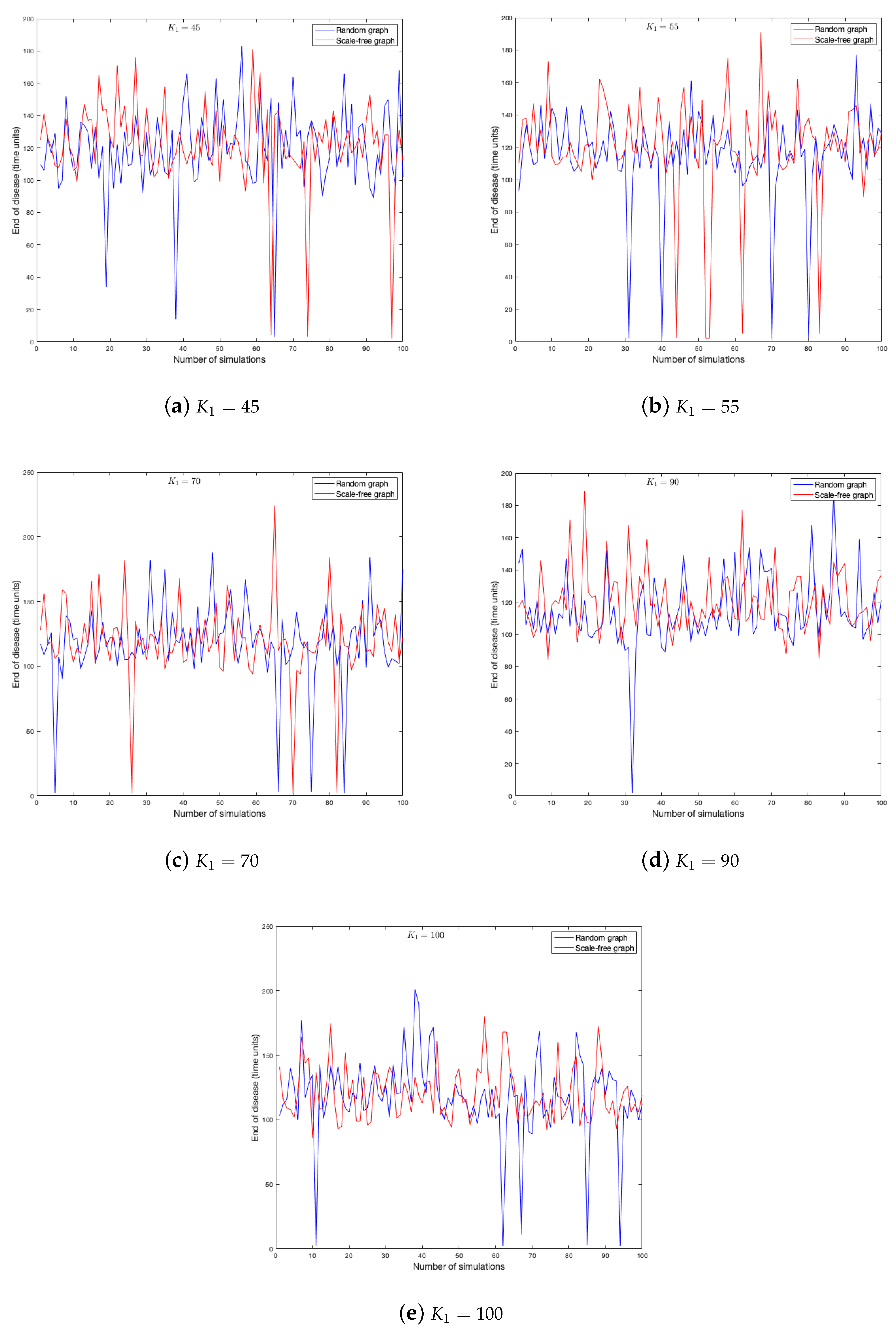
As the probability of being infected depends on the strength of the neighbors, it is clear that this parameter has effects on the spread of a disease in a graph. One hundred simulations were run on each graph.
Figure 11 and
Figure 12 show the duration of the disease in random and scale-free graph for each value of
.
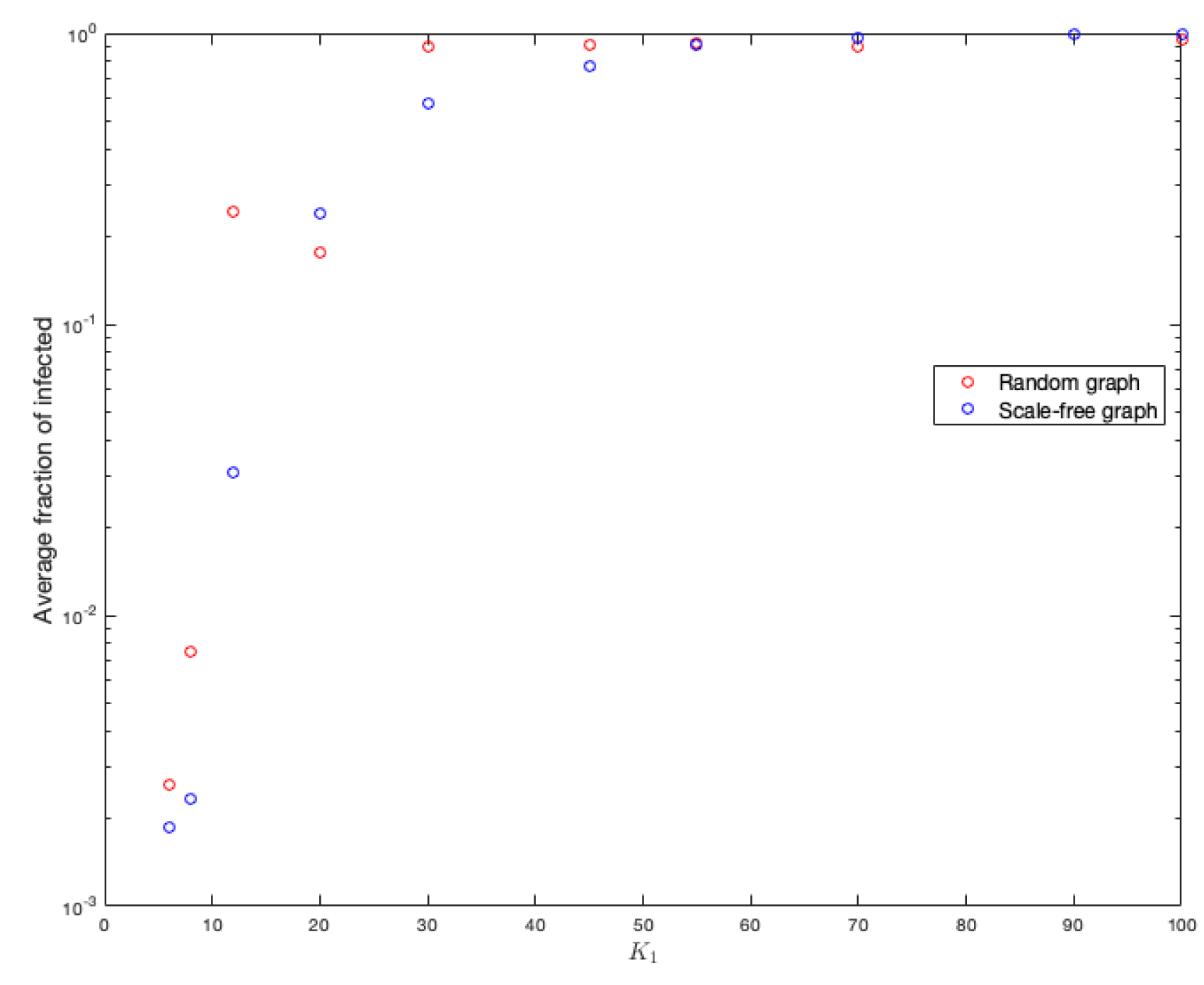
Figure 13 shows the effects of this parameter on the fraction of infected.
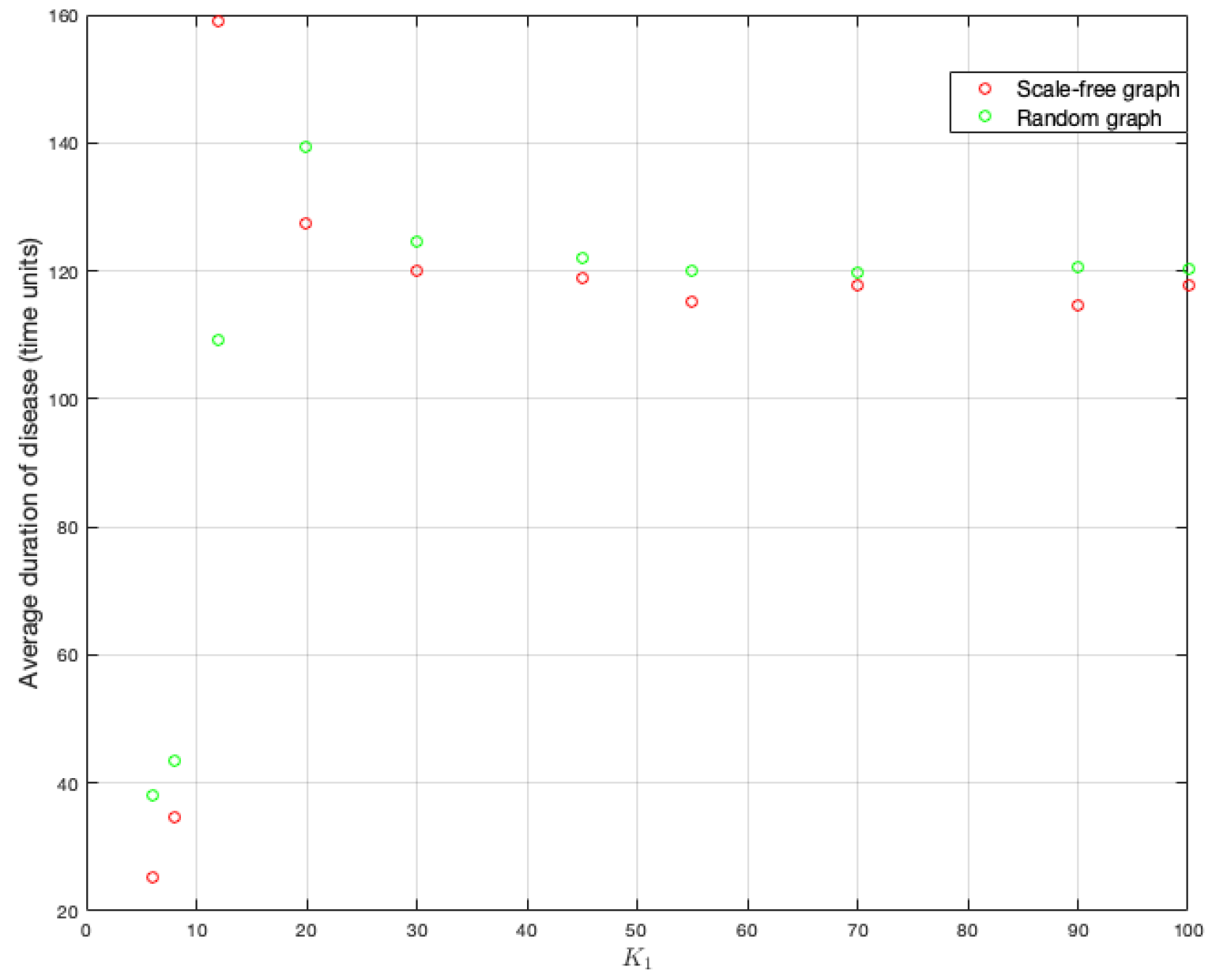
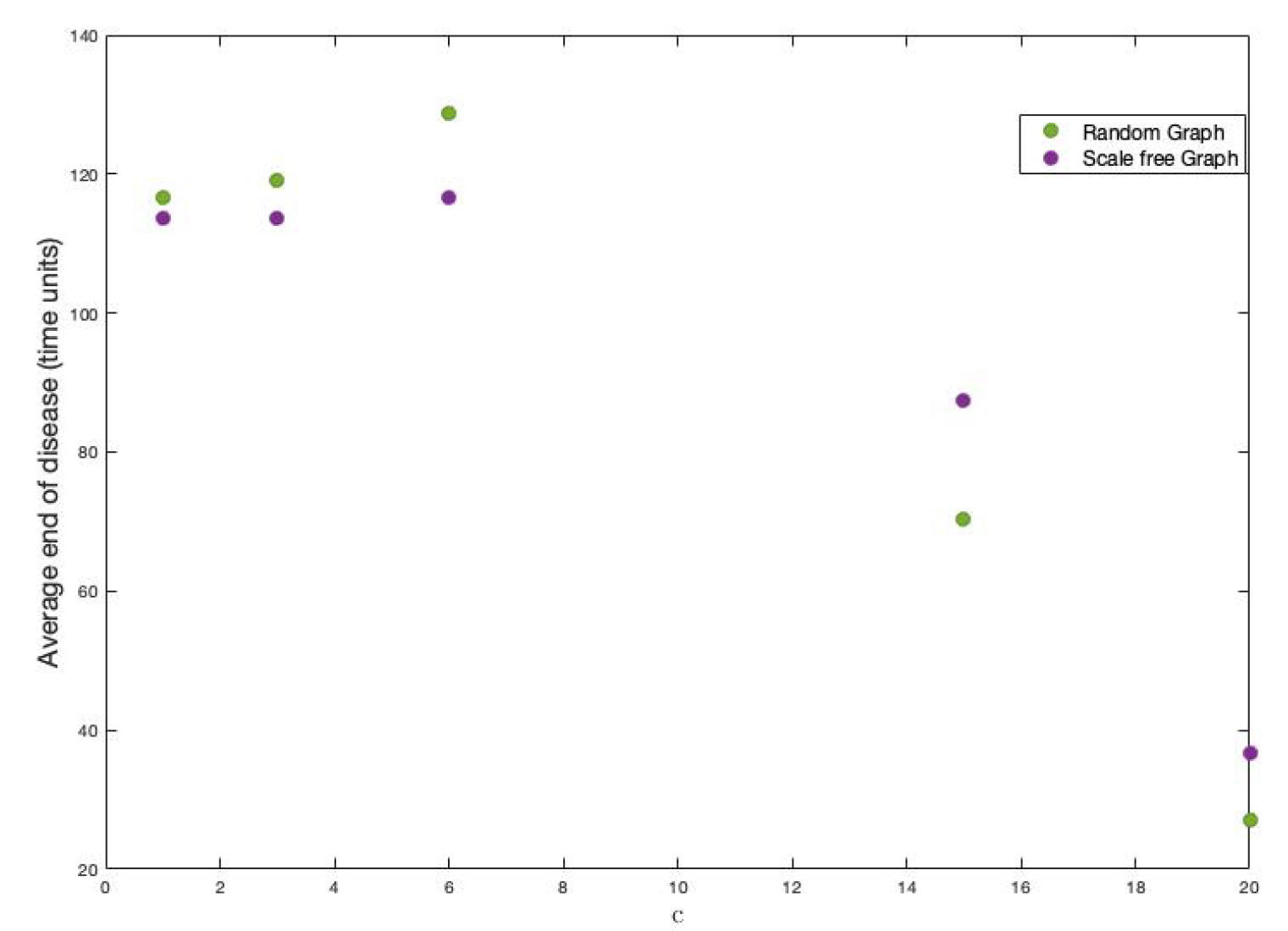
To better understand the figures above, we compute end-of-disease averages for each
value. It can be observed in
Figure 14 that scale-free graph has a shorter duration on average (as it has been verified when studying the effects of other parameters). There is also a tendency to stabilize around 120 time units on average.
On the other hand, in the same way, to better study and see the effects of this parameter on the fraction of infected, the means of each simulation were calculated for each value of
.
Figure 13 shows the results.
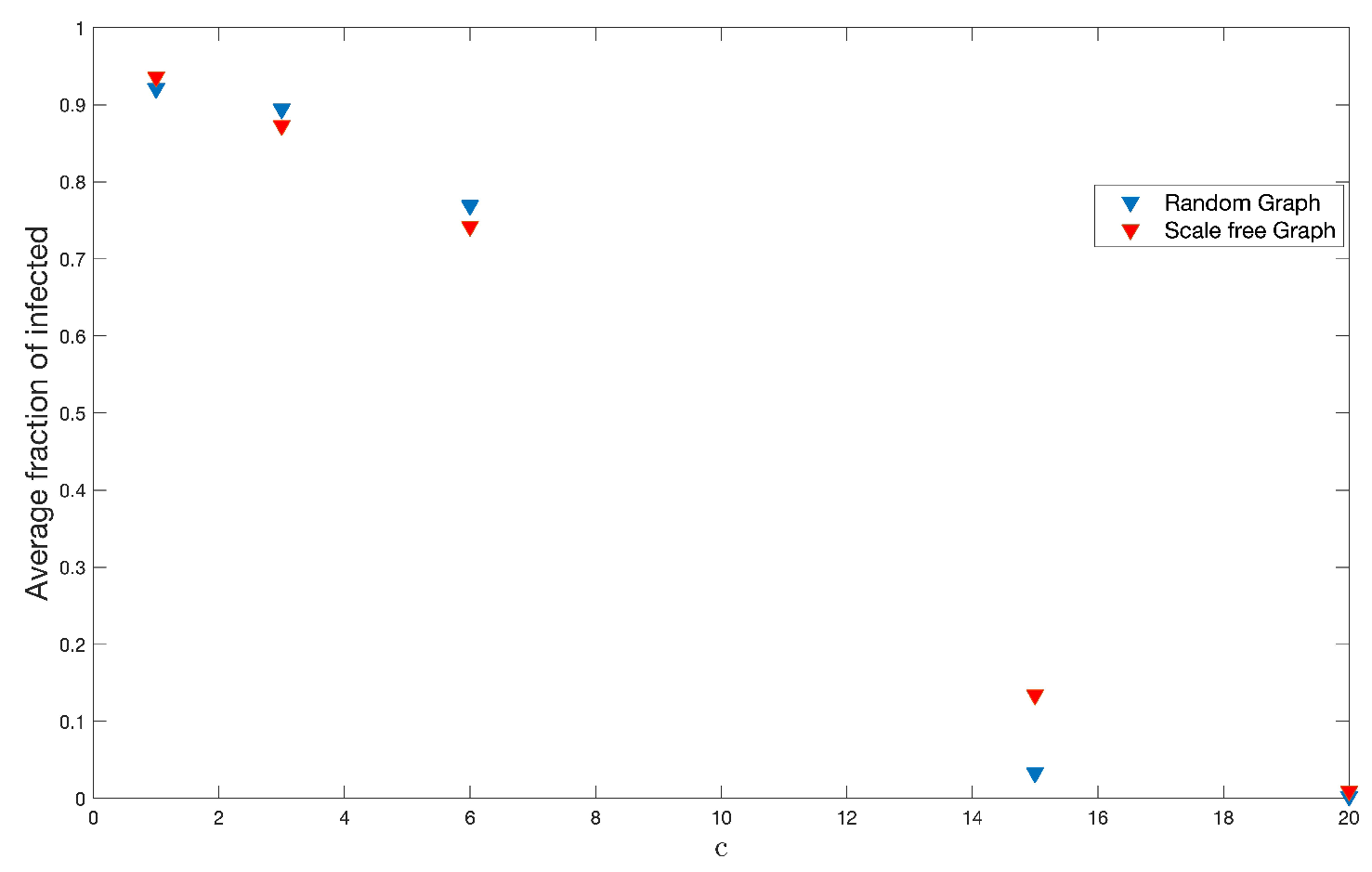
Notice that the number of infected is slightly higher in random graphs.
4.5. The Amount of Classes
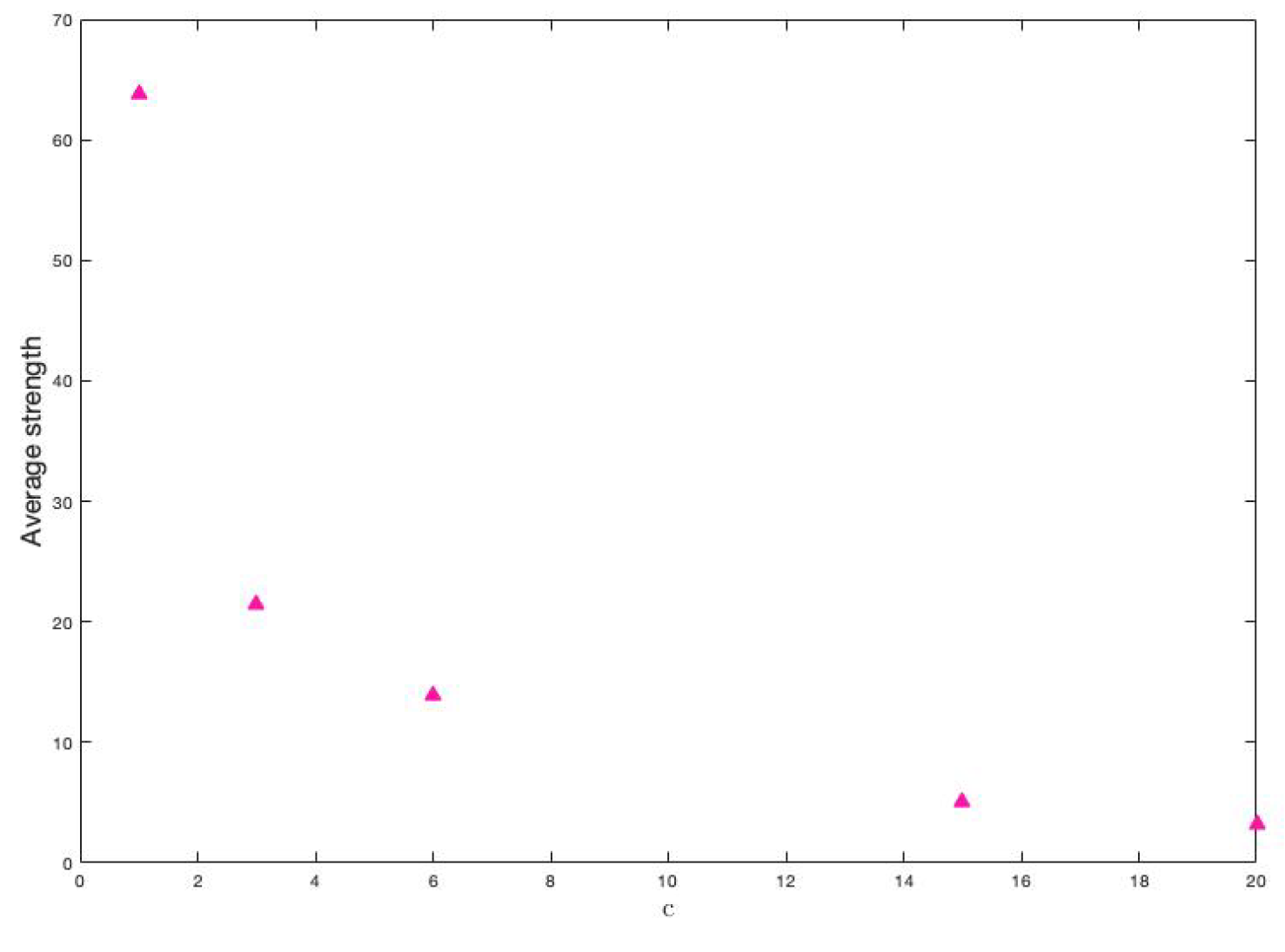
The amount of different classes is also a parameter that our proposal considers. Although this is a factor that is determined exclusively by the researcher, we want to study its direct influence on the two characteristics of the disease. Notice that, only by changing the amount of variables, their weights’ assignment change and, consequently, the weights of the links in the graph change as well. The same happens if the amount of classes changes. To see this effect, let’s first see how the weights link change when the amount of classes changes. We have considered the following values for
c:
and 20. The average of these strengths is seen in
Figure 15.
It is clear that, if the amount of classes tends to be the number of variables, then the average strength of the vertices decreases. It is also observed that the decrease is possibly exponential.
On the other hand, we have done 200 simulations for each one of these different values of
c on each type of graph used throughout this work and, with this, to see the effects on the fraction of infected and the end of the disease.
Figure 16 and
Figure 17 show the results.
5. Deterministic Approximation
Despite the previous conclusions, with respect to the different simulations, we will show an approximation of Susceptible, Infected, and Recovered curves through a differential equation system. The idea is to obtain a differential equation system with the parameters that define the graph.
Let
be the number of infected individuals between two consecutive (discrete) times, i.e.,
where
is an estimate of the mean value of strength of infected neighbors for every susceptible individual. In order to get
, we assume that
m is the neighbors average and that a proportion of these neighbors, we say
, is infected. On the other hand,
is the average strength of the graph. Then,
Replacing the Equation (
12) in (
10) and as
, then
Dividing by
and taking the limit as
, we obtain
In the same way, we obtain the equations
We can see that the Equations (
14)–() are the same as those defined for the SIR model. From there, we can see that
.
If the previous deductions are done on a not edge-weighted graph, then we obtain that . If is the average of weights, then . It is clear that, if , then we are in the case where the graph is not an edge-weighted graph.
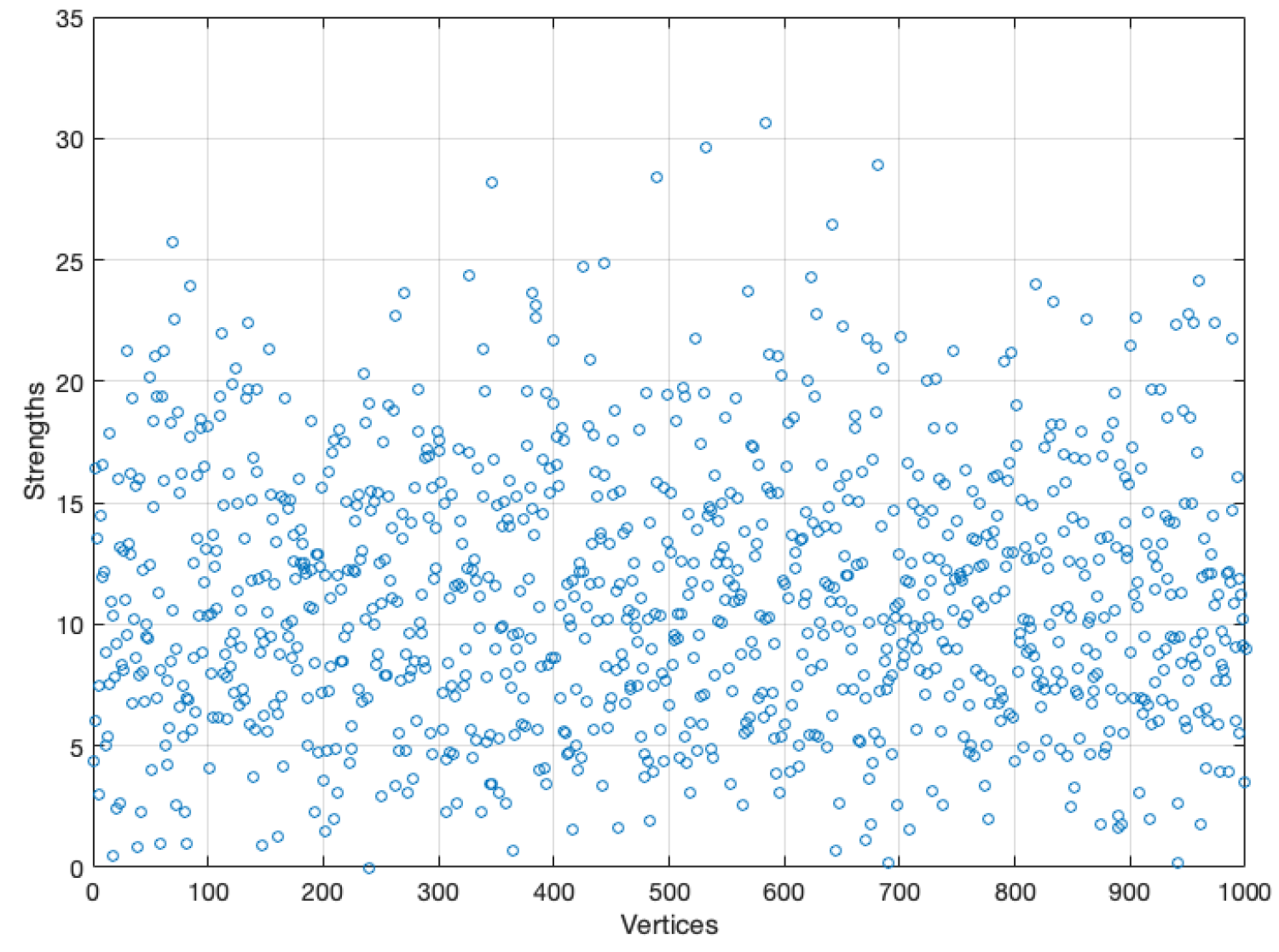
The above is valid only if the population is mixed, the graph has a fixed contact structure, and all vertices have approximately the same number of neighbors and approximately the same strength. However, the last condition is a stronger condition and certainly; it is not true, even to assume
can be a mistake because
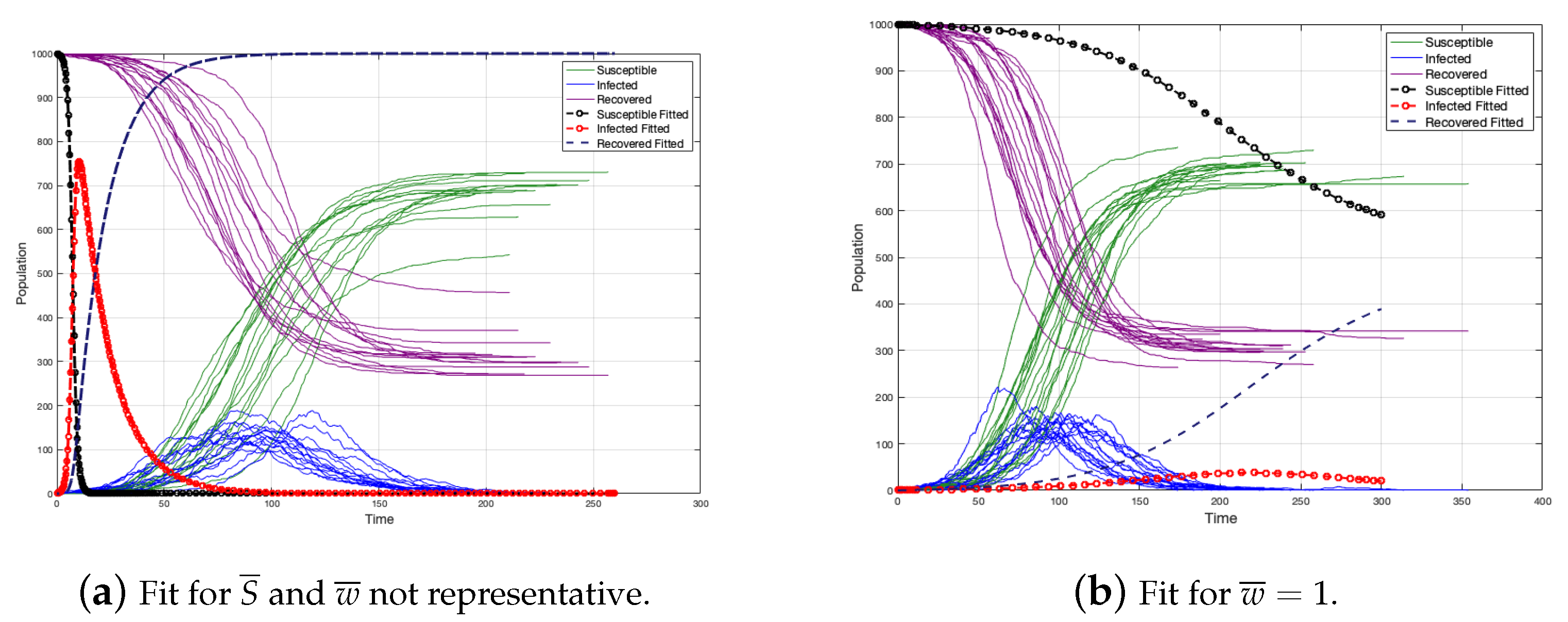
could be unrepresentative. For instance, in
Section 4, the average strengths are not representative in the initial simulation since the strengths are strongly heterogeneous (see
Figure 18).
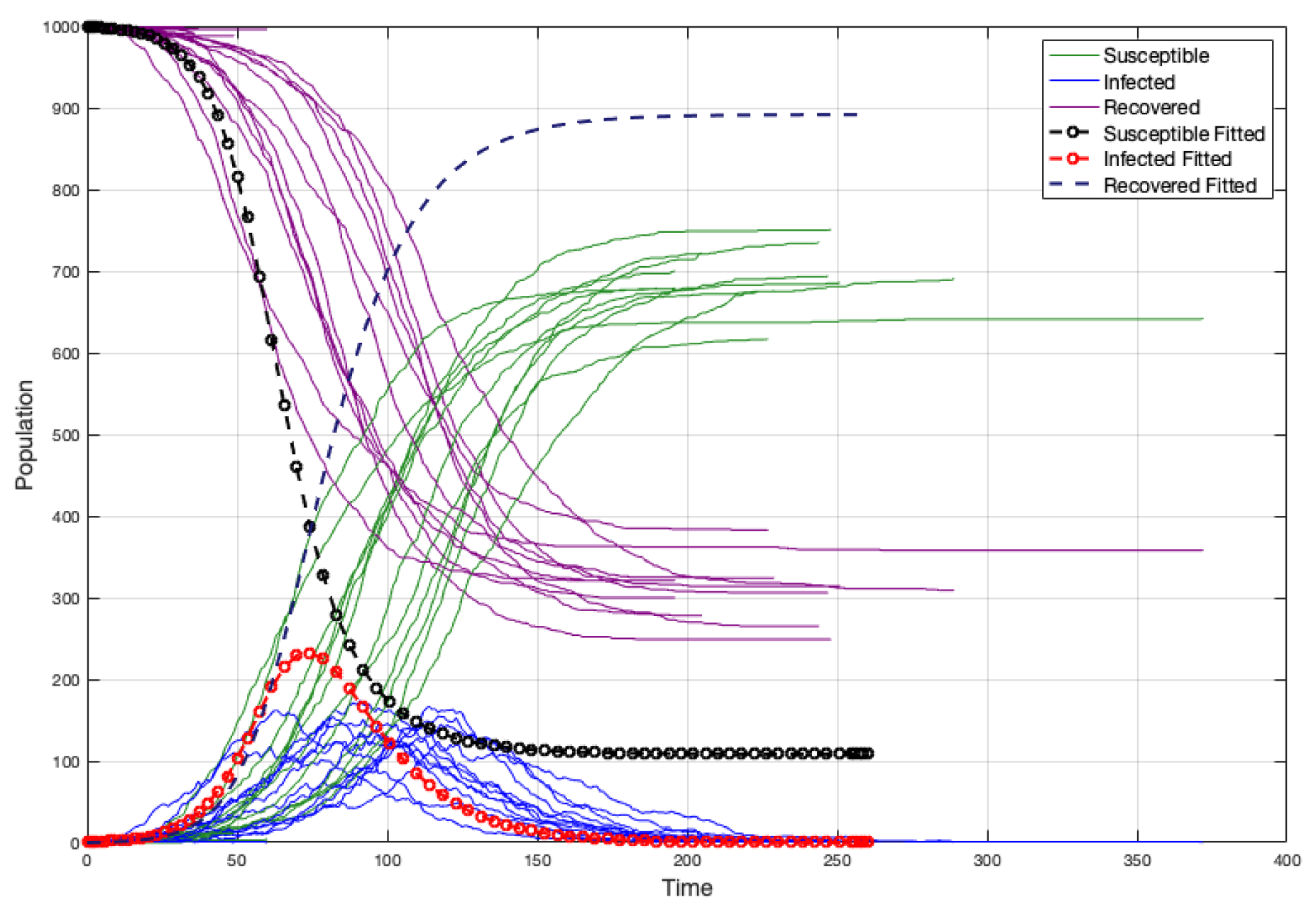
When the strength and weight average are not representative, there is an overestimation of the infected individuals and the duration of the disease is lower. (see
Figure 19a). Moreover, if we consider
like in the case of the non edge-weighted graph, we have a sub-estimation of the infected individuals and the duration of the disease is upper (see
Figure 19b). Certainly, without considering
, the fit is better, but not really good (because
is not a good representative) (see
Figure 20).
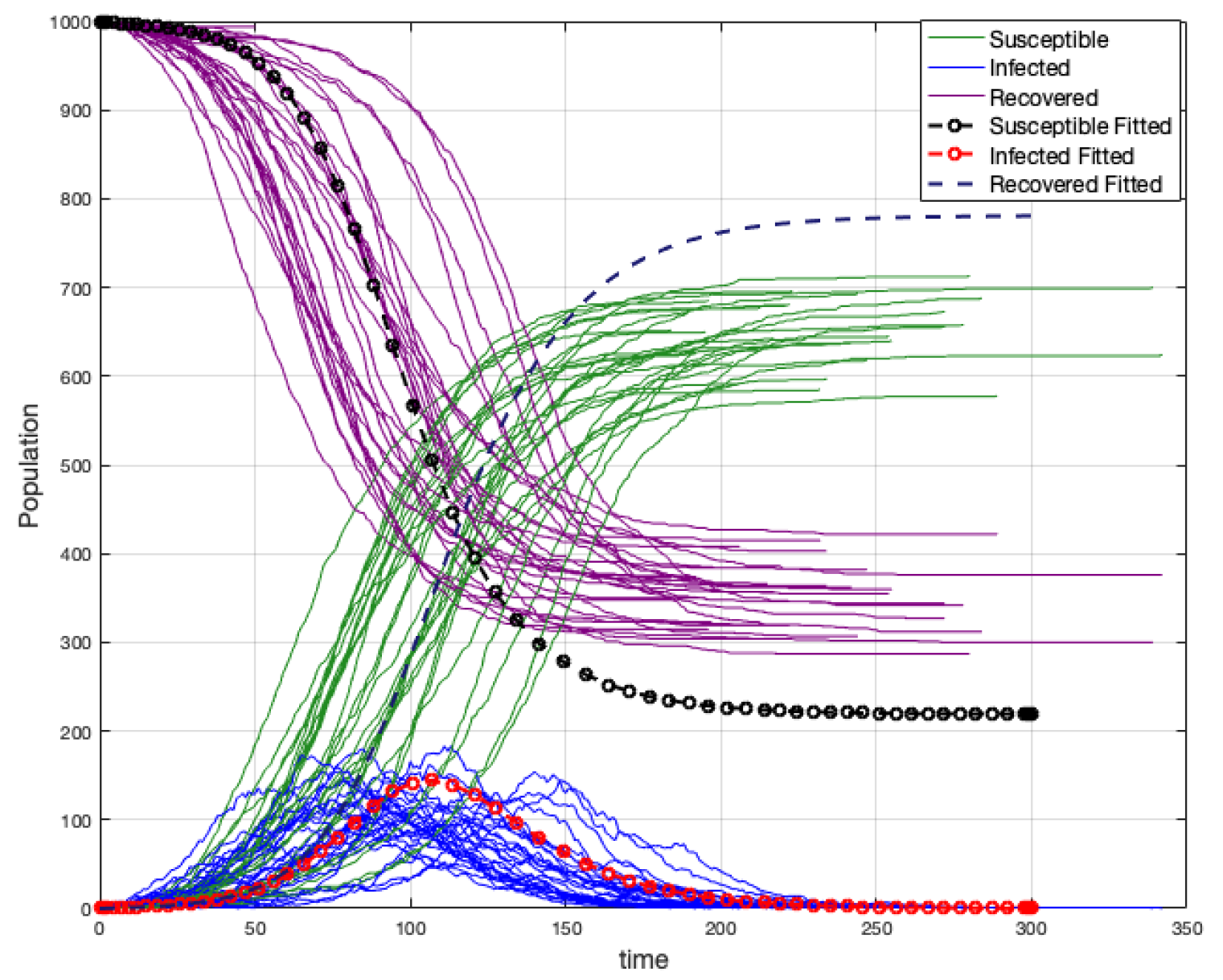
After many simulations (1000), we have noticed that a simple approximation to
is the average between
and
m, in the case where the strength of vertices is not strongly homogeneous (see
Figure 21). Thus, if
, we have
A similar problem is treated in [
28] in the case of a non edge-weighted graph, where a graph has a heterogeneous distribution degree of vertex (scale-free graph).
6. Modeling
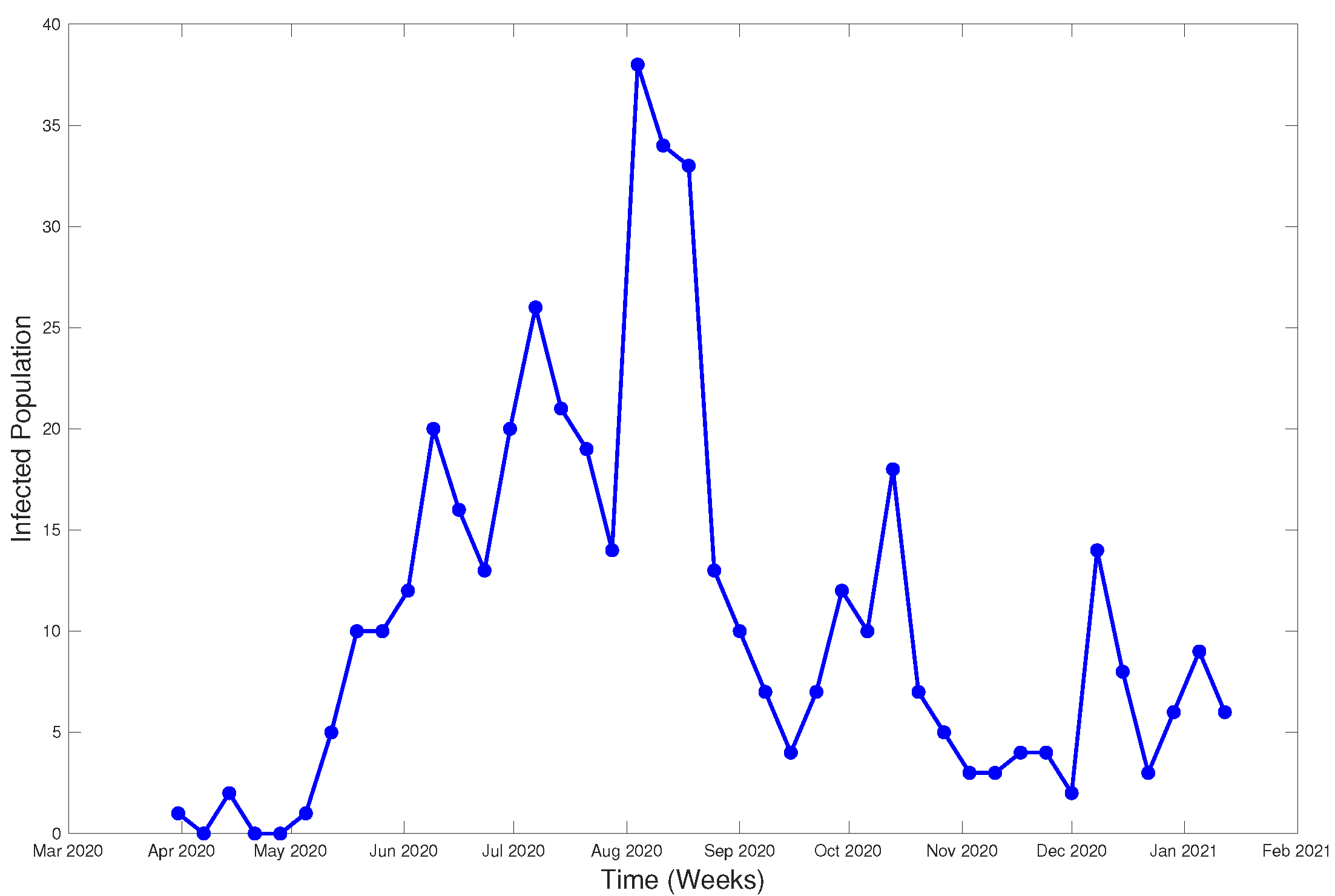
The modeled data were obtained from the database of the Epidemiological Surveillance System of the Chilean Ministry of Health, with the approval of the ethics committee of the Faculty of Medicine of the University of Valparaíso (Act No. 15/2020). This system is the official system of the country and allows health management of notifiable diseases, including COVID-19. For the purposes of this study, the database from Olmué city (Valparaíso Region) was used, which included reported cases (positive or negative) and their contacts from 3 March 2020 to 15 January 2021 with
n = 3866 registered persons.
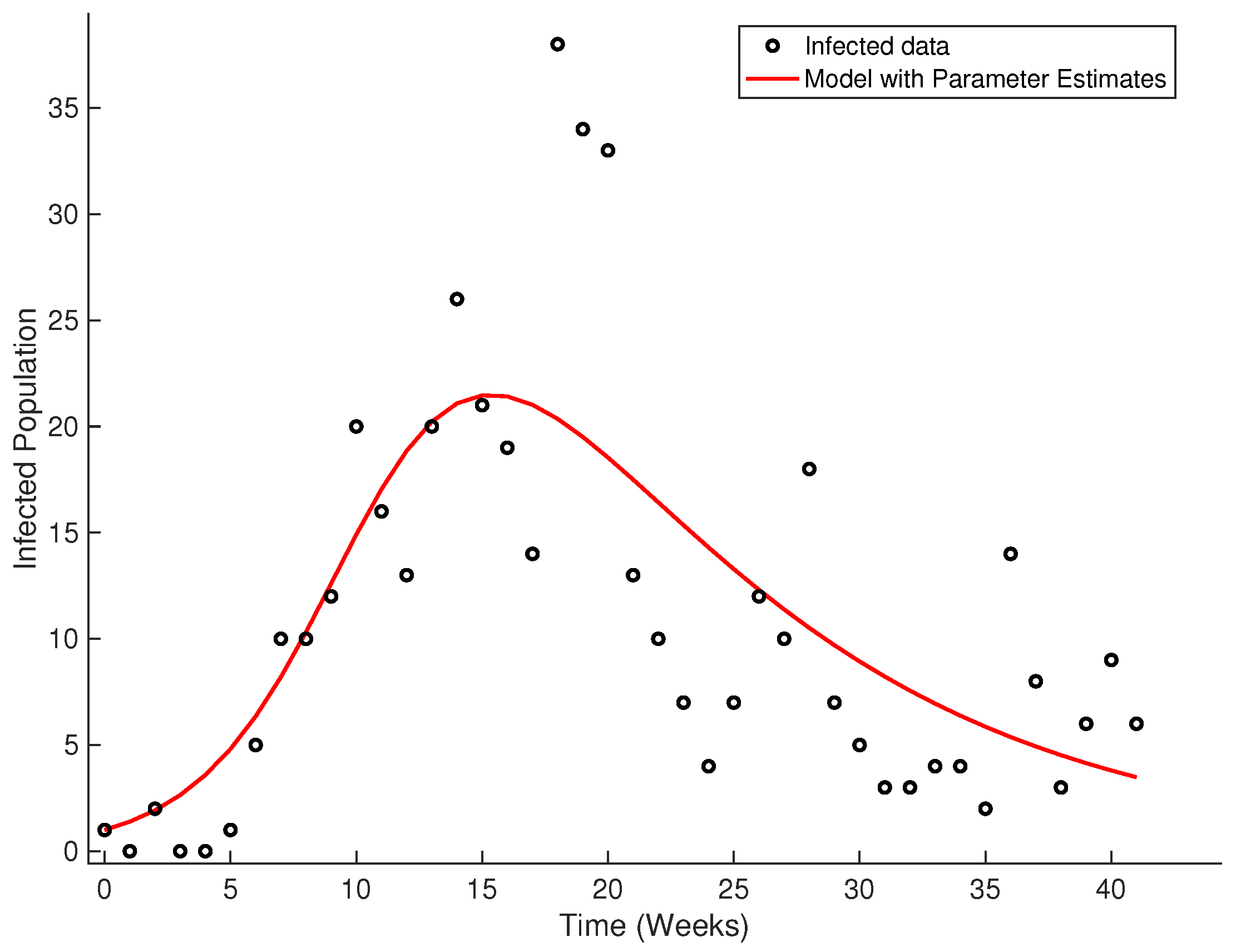
Figure 22 shows the evolution of the infected per week.
To fit a curve to the data following the SIR model, we used the classic method of least squares. The values for the
and
parameters are
and
, respectively.
Figure 23 shows the fitted curve.
On the other hand, from the total of variables included in the database (), seven of them are relationship variables (). They are: full address (), the street where the people live (), town (), place of work (), workplace section (), health facility where they were treated (), and the region of the country where the test was taken to confirm, or not, the contagion ().
In our criteria, the hierarchical order of the seven variables in descending form is
. Moreover, we consider that the variables
and
have the same weight. In the same way, we also consider the variables
and
with equal weight. Hence,
,
,
and
are the different classes that are defined by the different weights. Hence, by Definition 10,
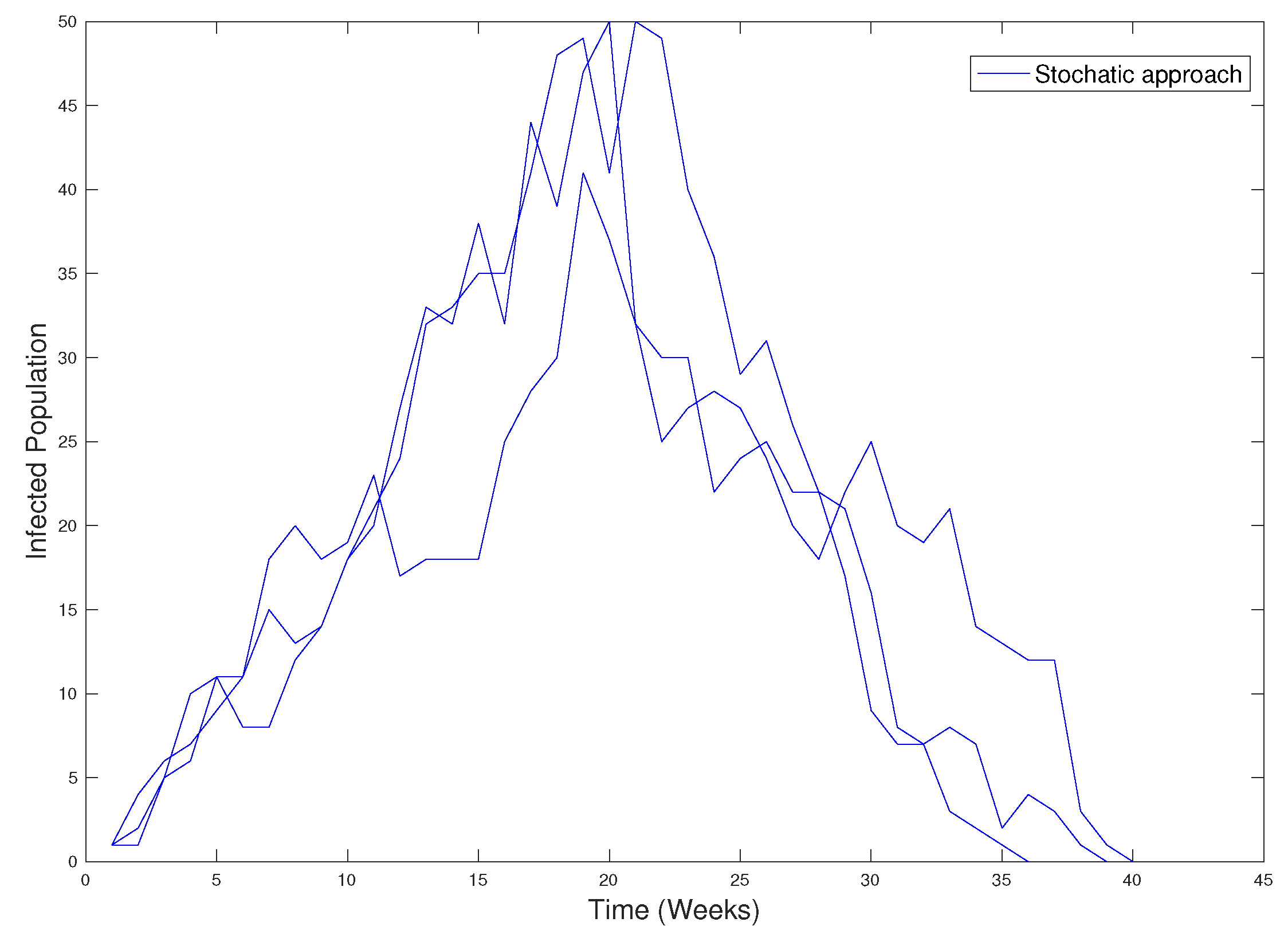
We have run some simulations of the spread of the disease on the graph obtained from the data base of the city of Olmué, considering the recovery rate
and
. The results are in
Figure 25.
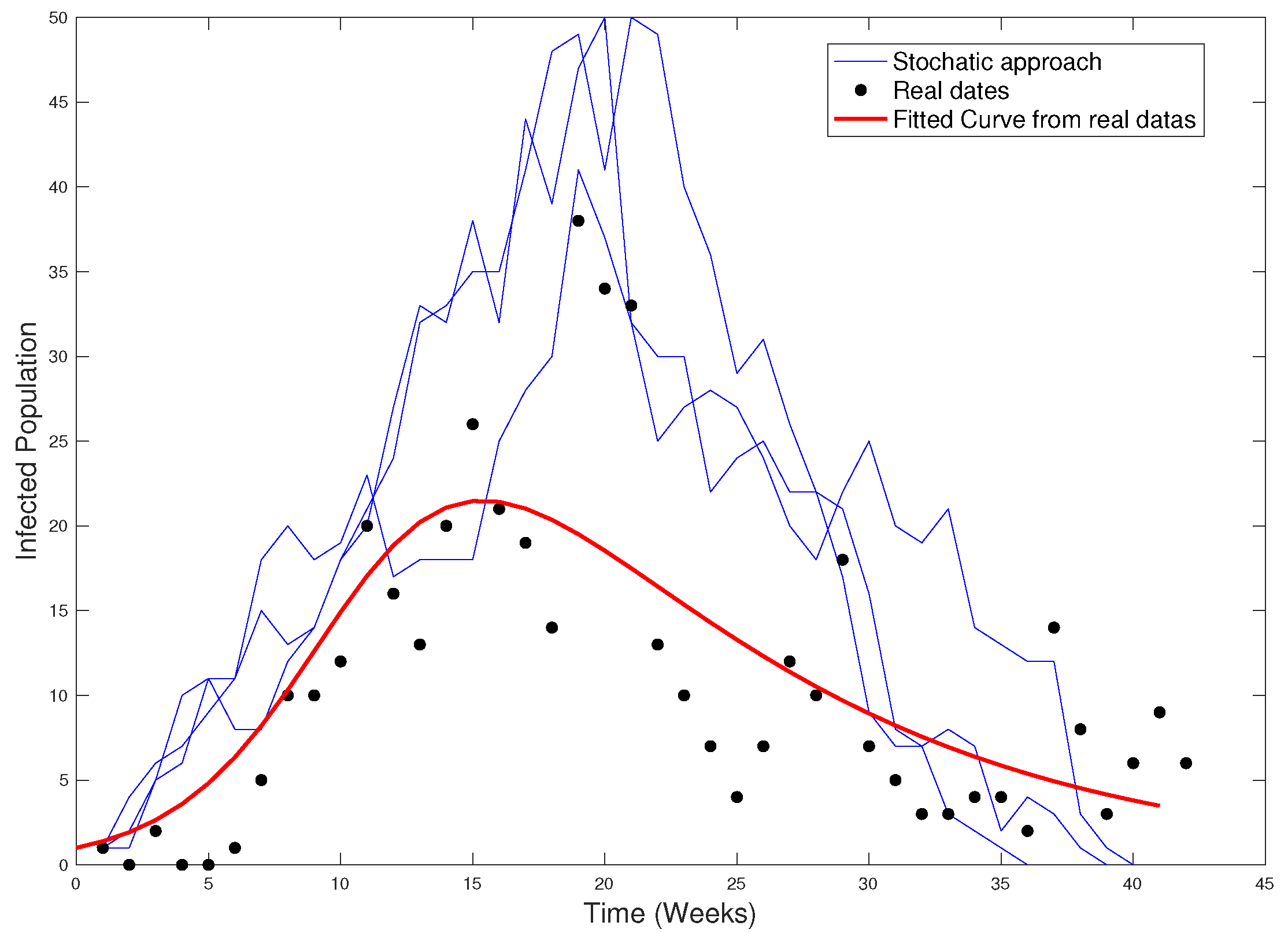
Figure 26 shows the real data, the fitted curve, and the stochastic approach.
Notice that, in this case, it is not possible a deterministic approximation like in
Section 5 because the average strength is not a good representative.
7. Discussion
Our proposal confirms the possibility of obtaining an edge-weighted graph from individuals registered in a database. The decision to incorporate weights on its edges is an attempt to quantify the ties between individuals. An important assumption for the quantification of these weights is to recognize a certain value in each variable or a certain hierarchical order between them, that is, to identify which variable (s) is (are) more important than others and defining an order. In this way, it is possible to define the so-called classes of variables (that is, each class is defined by variables that have the same value or defined hierarchical order), since it is possible that two or more variables have the same value or hierarchical order. This is similar to the stated by Enright & Raymond, who hold that the weighting of the edges is relevant for a more comprehensive understanding of the disease dissemination processes, without losing information provided by the network [
12]. In particular, this research provides an approach that relates population groups and discrimination variables of greater or lesser force for the spread of diseases, which allows for understanding the level of interaction between people. This, for Keeling & Eames, is paramount for understanding infectious diseases [
29].
Consequently, for the case study (Olmué city), the model was adjusted to the spread of the disease, both in the number of people with COVID-19 and the duration of the disease. This shows that both the theoretical and practical development are useful from a public health perspective. This is relevant due to the weighting of the relationship variables.
Likewise, our proposal of weighted graphs obtained from a database would be useful for health organizations and scientific teams as a tool for the modeling of infectious diseases through a database in order to establish priority variables in the understanding of these health events, in public health surveillance, and in the establishment of measures for the prevention of infections with greater certainty [
16,
30]. For this reason, it is important to have standardized databases that allow the evolution of health problems to be analyzed with a greater degree of complexity [
31]. As an example, the COVID-19 database could contain other relationship variables that would allow us to know the interaction between people who are susceptible to get infected or who are sick with SARS-COV2. In summary, we believe it is relevant to continue with data collection efforts in a systematic way by scientific and governmental organizations [
32].
Our work coincides with the stated by Keeling & Eames regarding the integration of complex networks and their limitations in relation to having an adequate volume of data to represent infectious diseases [
29]. However, the limitations that the authors mention are diminishing, since, for the management of infectious diseases, most of the countries make greater efforts in the systematization of information [
33], as well as the COVID-19 pandemic has reaffirmed these actions.
After performing simulations to study each effect of the parameters described, we can point out that, regardless of the parameter that is intervened, the durations of the diseases are shorter on scale-free graphs than on random ones. This may be due to the heterogeneity and recognition of infectious disease propagators provided by free-scale graphs [
29]. For its part, the number or fraction of infected is always greater on random graphs than on scale-free graphs. The only parameter in which this was not evident is for the purely biological disease factor
. This would be generated because the random network does not discriminate the level of targeted contacts and gives the chance of contagion [
29]. An interesting fact is the case where we vary the amount of classes. If the class number tends to be the same as the amount of variables, the average strength increases, and this means that the fraction of infected also increases.
We believe that it would be very interesting, and complementary to our proposal, to carry out simulations on other types of graphs, for example graphs of small worlds and their different variations. It is very likely that the spread of diseases on these graphs differ from the results obtained on the graphs used in this work. Studying the effects of other parameters on the disease would also be beneficial. For example, we believe that an interesting factor would be the number of initial infected and what it happens if they are neighbors or to what extent the disease spreads more with respect to the distance between them. In this same sense, varying the strength of the infected vertex would also give us new information.
The deterministic approach is undoubtedly a useful tool, but it lacks being generic, in the sense that in order to make use of it, some fairly strong assumptions are necessary, they are the homogeneity in the number of neighbors and the average strength for each vertex. Therefore, in scale-free graphs, we cannot use this approximation since the average of neighbors by vertices is not representative from the reality of the graph.
The importance of having accurate models able to explain the spread of epidemics and resemble reality lies in understanding it for the development of effective defense strategies against contagious diseases. Current demands drive progress in this field, which will undoubtedly continue to grow. It is important to mention that these types of contributions are only one dimension in the understanding of epidemic events. In this sense, for a holistic approach, it is necessary to include analyses of different disciplines such as the social, biological, and health sciences and, above all, the meanings that populations give to pandemics.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}