
Understanding the Challenges and Uncertainties of Seroprevalence Studies for SARS-CoV-2

 ,
,
Abstract
:1. Introduction
2. Background
2.1. The Problem with Confirmed Cases
2.2. Seroprevalence Studies as A Solution
2.3. Uncertainty in Seroprevalence Studies
3. Key Challenges in Seroprevalence Studies
3.1. Populations and Generalization—Seroprevalence Among Whom?
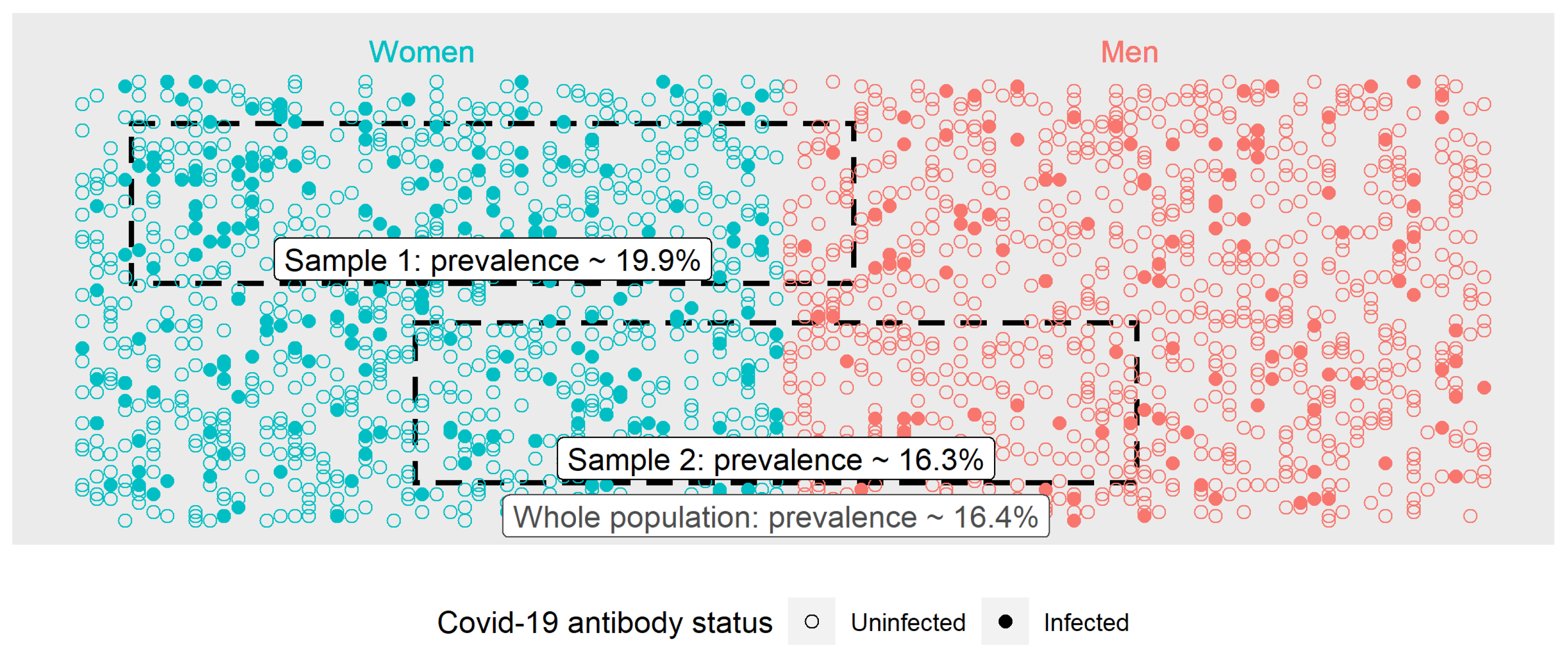
3.2. Selecting Appropriate Samples
3.3. Uncertainty from Sampling
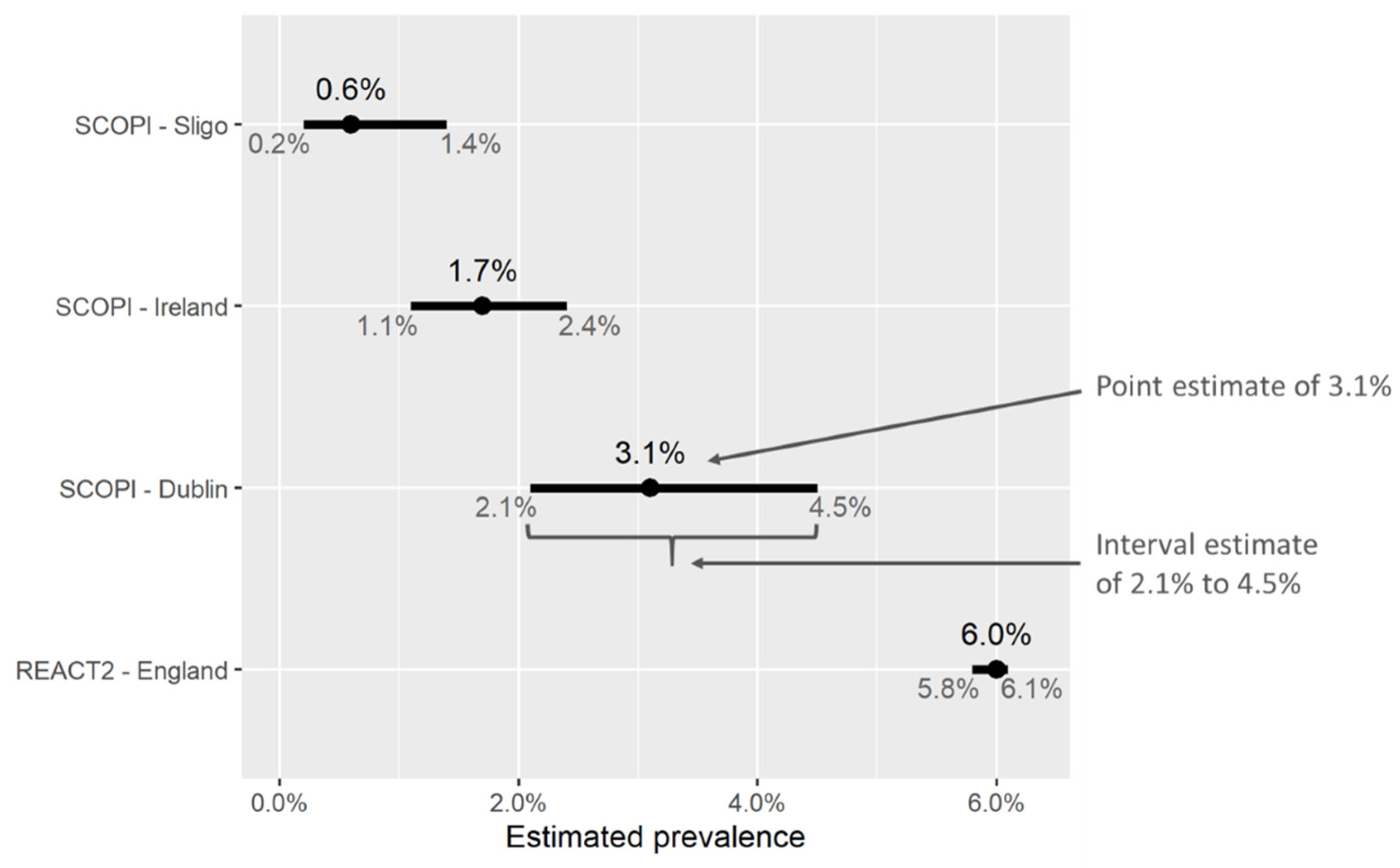
- A point estimate, i.e., a single “central” or “most likely” value for the percentage of people who are estimated to have been previously infected.
- An interval estimate, or a range of values surrounding the point estimate. This could be called a confidence/credible/uncertainty interval. They represent the range in which we expect the “true” value of prevalence to lie, with a reasonable degree of certainty, and we consider values outside this interval to be unlikely. Thus, a wider interval suggests a greater degree of uncertainty compared with a narrow one.
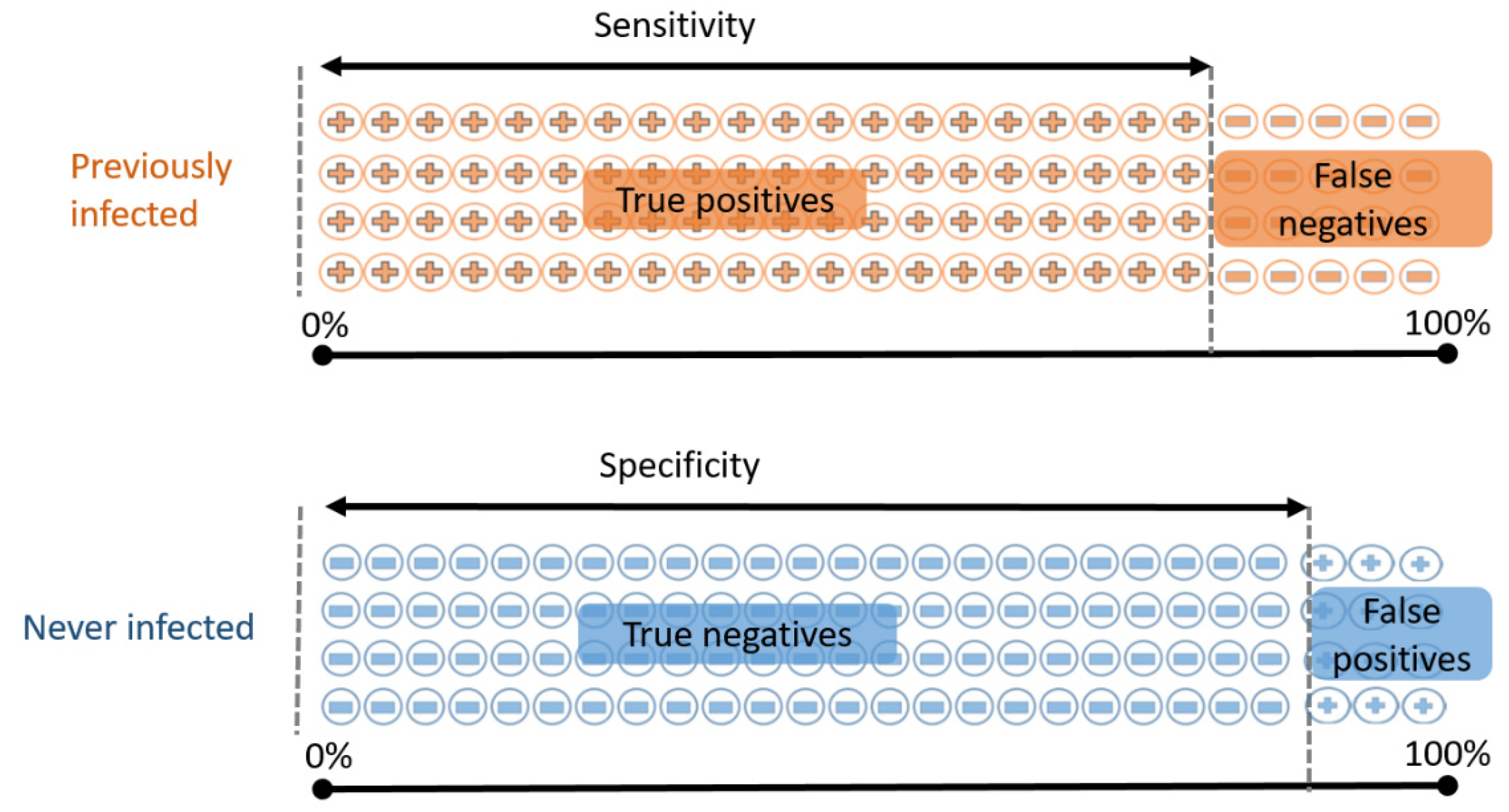
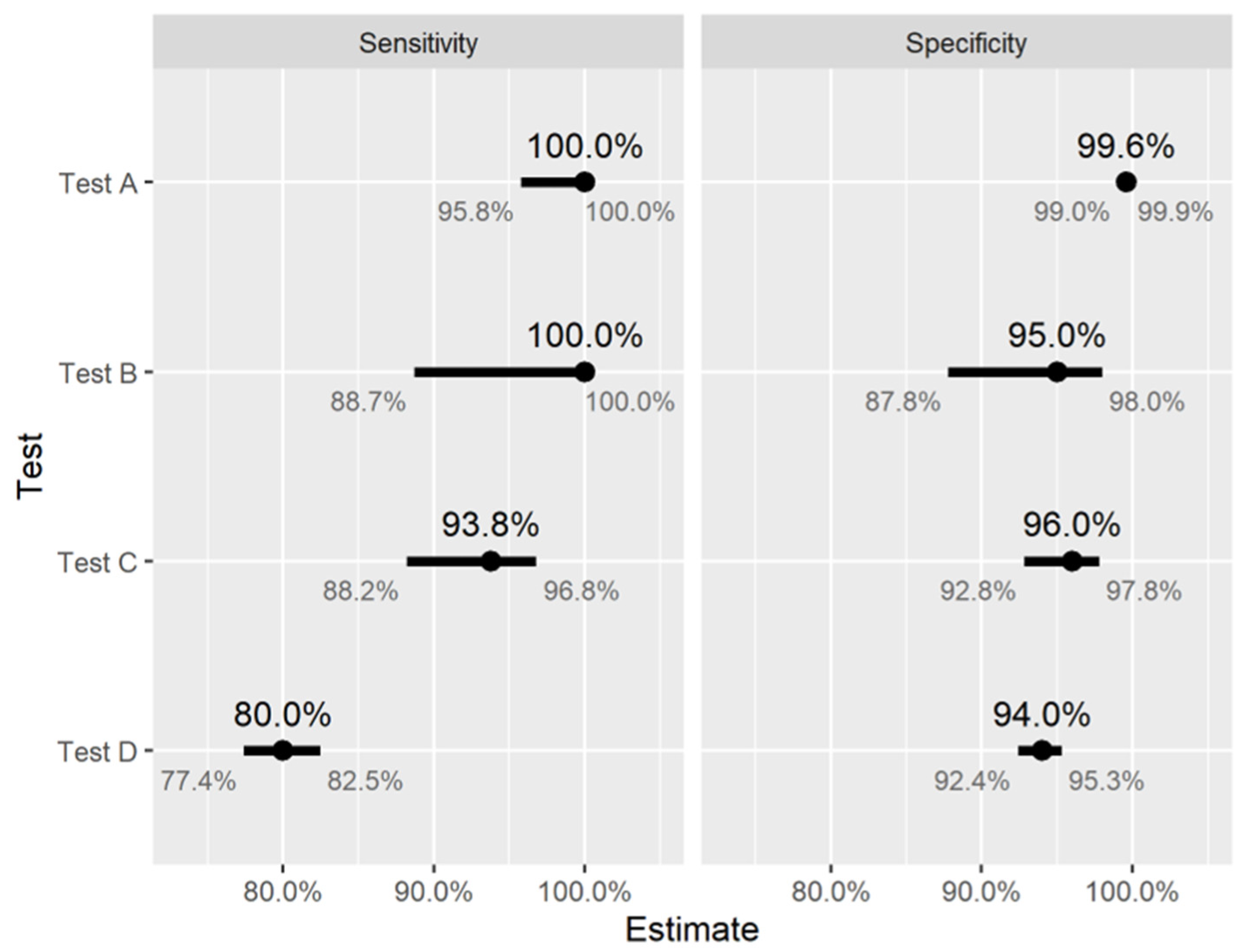
3.4. The Limitations of Antibody Tests
- Sensitivity: the proportion of previously infected people who will correctly test positive;
- Specificity: the proportion of never-infected people who will correctly test negative.
- If we test 100 people who have all previously been infected, we expect 80 of them to test positive.
- If we test 100 people who have never been infected, we expect 94 of them to test negative.
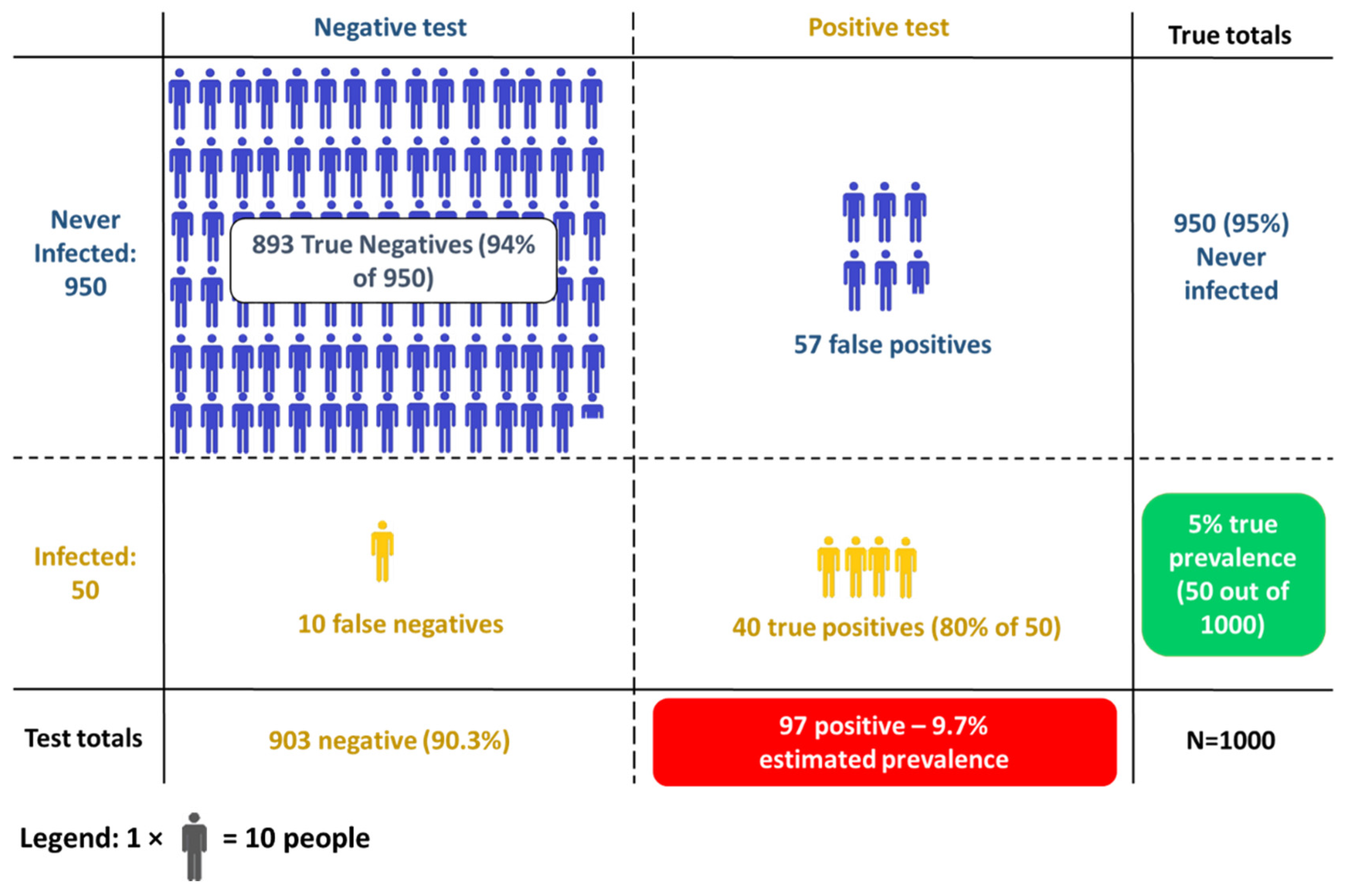
- Of the 50 people who have been infected, 40 correctly test positive (80% sensitivity)
- Of the 950 people who have not been infected, 893 correctly test negative (94% specificity), and thus 57 test positive.
3.5. Challenges When Correcting for Imperfect Test Performance
- Accept that this is a limitation of the study, and that the true prevalence might therefore differ from what was estimated in the study. In this case, we are estimating the proportion of the population who would test positive, using the same test.
- Try to adjust or correct the results to account for imperfect test accuracy (i.e., attempt to subtract the false positives and add the false negatives). In this case, we are estimating the proportion of the population who have SARS-CoV-2 antibodies in their blood.
- Population heterogeneity: factors such as age, sex, pre-existing conditions, and others may affect antibody response to COVID-19 infection [63], and thus influence test performance. Exposure to other circulating coronavirus may give rise to cross-reactive antibodies [64], which could affect test specificity; thus, geographic location may also be a meaningful source of heterogeneity.
- Patient history: disease severity and time since infection are likely to affect antibody levels [63]. If these factors differ between validation and seroprevalence studies, then test sensitivity may also differ.
- Sample collection, storage, and laboratory processing standards may affect test performance and also differ between studies.
3.6. Antibodies, Immunity, and Vaccines
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Havers, F.P.; Reed, C.; Lim, T.; Montgomery, J.M.; Klena, J.D.; Hall, A.J.; Fry, A.M.; Cannon, D.L.; Chiang, C.-F.; Gibbons, A.; et al. Seroprevalence of Antibodies to SARS-CoV-2 in 10 Sites in the United States, March 23–May 12, 2020. JAMA Intern. Med. 2020, 180, 1576–1586. [Google Scholar] [CrossRef] [PubMed]
- Russell, T.W.; Golding, N.; Hellewell, J.; Abbott, S.; Wright, L.; Pearson, C.A.B.; van Zandvoort, K.; Jarvis, C.I.; Gibbs, H.; Liu, Y.; et al. Reconstructing the Early Global Dynamics of Under-Ascertained COVID-19 Cases and Infections. BMC Med. 2020, 18, 332. [Google Scholar] [CrossRef] [PubMed]
- Flaxman, S.; Mishra, S.; Gandy, A.; Unwin, H.J.T.; Mellan, T.A.; Coupland, H.; Whittaker, C.; Zhu, H.; Berah, T.; Eaton, J.W.; et al. Estimating the Effects of Non-Pharmaceutical Interventions on COVID-19 in Europe. Nature 2020, 584, 257–261. [Google Scholar] [CrossRef] [PubMed]
- World Health Organisation. Diagnostic Testing for SARS-CoV-2. Available online: https://www.who.int/publications-detail-redirect/diagnostic-testing-for-sars-cov-2 (accessed on 19 January 2021).
- European Centre for Disease Control. Diagnostic Testing and Screening for SARS-CoV-2. Available online: https://www.ecdc.europa.eu/en/covid-19/latest-evidence/diagnostic-testing (accessed on 19 January 2021).
- Sethuraman, N.; Jeremiah, S.S.; Ryo, A. Interpreting Diagnostic Tests for SARS-CoV-2. JAMA 2020, 323, 2249. [Google Scholar] [CrossRef] [PubMed]
- Bendavid, E.; Mulaney, B.; Sood, N.; Shah, S.; Bromley-Dulfano, R.; Lai, C.; Weissberg, Z.; Saavedra-Walker, R.; Tedrow, J.; Bogan, A.; et al. COVID-19 Antibody Seroprevalence in Santa Clara County, California. Int. J. Epidemiol. 2021. [Google Scholar] [CrossRef] [PubMed]
- Offord, C. How (Not) to Do an Antibody Survey for SARS-CoV-2. Sci. Mag. 2020, 28, 2020. [Google Scholar]
- Buss, L.F.; Prete, C.A.; Abrahim, C.M.M.; Mendrone, A.; Salomon, T.; de Almeida-Neto, C.; França, R.F.O.; Belotti, M.C.; Carvalho, M.P.S.S.; Costa, A.G.; et al. Three-Quarters Attack Rate of SARS-CoV-2 in the Brazilian Amazon during a Largely Unmitigated Epidemic. Science 2021, 371, 288–292. [Google Scholar] [CrossRef]
- Sabino, E.C.; Buss, L.F.; Carvalho, M.P.S.; Prete, C.A.; Crispim, M.A.E.; Fraiji, N.A.; Pereira, R.H.M.; Parag, K.V.; da Silva Peixoto, P.; Kraemer, M.U.G.; et al. Resurgence of COVID-19 in Manaus, Brazil, despite High Seroprevalence. Lancet 2021, 397, 452–455. [Google Scholar] [CrossRef]
- Health Protection Surveillance Centre (Ireland). Epidemiology of COVID-19 in Ireland. Available online: https://www.hpsc.ie/a-z/respiratory/coronavirus/novelcoronavirus/casesinireland/epidemiologyofcovid-19inireland/ (accessed on 9 April 2021).
- Wu, S.L.; Mertens, A.N.; Crider, Y.S.; Nguyen, A.; Pokpongkiat, N.N.; Djajadi, S.; Seth, A.; Hsiang, M.S.; Colford, J.M.; Reingold, A.; et al. Substantial Underestimation of SARS-CoV-2 Infection in the United States. Nat. Commun. 2020, 11, 4507. [Google Scholar] [CrossRef]
- Böger, B.; Fachi, M.M.; Vilhena, R.O.; Cobre, A.F.; Tonin, F.S.; Pontarolo, R. Systematic Review with Meta-Analysis of the Accuracy of Diagnostic Tests for COVID-19. Am. J. Infect. Control 2020, 49, 21–29. [Google Scholar] [CrossRef]
- Kucirka, L.M.; Lauer, S.A.; Laeyendecker, O.; Boon, D.; Lessler, J. Variation in False-Negative Rate of Reverse Transcriptase Polymerase Chain Reaction–Based SARS-CoV-2 Tests by Time Since Exposure. Ann. Intern. Med. 2020, 173, 262–267. [Google Scholar] [CrossRef]
- Office for National Statistics (UK). COVID-19 Infection Survey: Methods and Further Information. Available online: https://www.ons.gov.uk/peoplepopulationandcommunity/healthandsocialcare/conditionsanddiseases/methodologies/covid19infectionsurveypilotmethodsandfurtherinformation (accessed on 9 April 2021).
- Faranda, D.; Castillo, I.P.; Hulme, O.; Jezequel, A.; Lamb, J.S.W.; Sato, Y.; Thompson, E.L. Asymptotic Estimates of SARS-CoV-2 Infection Counts and Their Sensitivity to Stochastic Perturbation. Chaos 2020, 30, 051107. [Google Scholar] [CrossRef]
- Rajgor, D.D.; Lee, M.H.; Archuleta, S.; Bagdasarian, N.; Quek, S.C. The Many Estimates of the COVID-19 Case Fatality Rate. Lancet Infect. Dis. 2020, 20, 776–777. [Google Scholar] [CrossRef] [Green Version]
- Deeks, J.J.; Dinnes, J.; Takwoingi, Y.; Davenport, C.; Spijker, R.; Taylor-Phillips, S.; Adriano, A.; Beese, S.; Dretzke, J.; Ferrante di Ruffano, L.; et al. Antibody Tests for Identification of Current and Past Infection with SARS-CoV-2. Cochrane Database Syst. Rev. 2020, 6, CD013652. [Google Scholar] [CrossRef]
- Isho, B.; Abe, K.T.; Zuo, M.; Jamal, A.J.; Rathod, B.; Wang, J.H.; Li, Z.; Chao, G.; Rojas, O.L.; Bang, Y.M.; et al. Persistence of Serum and Saliva Antibody Responses to SARS-CoV-2 Spike Antigens in COVID-19 Patients. Sci. Immunol. 2020, 5. [Google Scholar] [CrossRef]
- Gudbjartsson, D.F.; Norddahl, G.L.; Melsted, P.; Gunnarsdottir, K.; Holm, H.; Eythorsson, E.; Arnthorsson, A.O.; Helgason, D.; Bjarnadottir, K.; Ingvarsson, R.F.; et al. Humoral Immune Response to SARS-CoV-2 in Iceland. N. Engl. J. Med. 2020, NEJMoa2026116. [Google Scholar] [CrossRef]
- Foundation for Innovative New Diagnostics. SARS-CoV-2 Diagnostic Pipeline. Available online: https://www.finddx.org/covid-19/pipeline/ (accessed on 20 January 2021).
- Clapham, H.; Hay, J.; Routledge, I.; Takahashi, S.; Choisy, M.; Cummings, D.; Grenfell, B.; Metcalf, C.J.E.; Mina, M.; Barraquer, I.R.; et al. Seroepidemiologic Study Designs for Determining SARS-COV-2 Transmission and Immunity. Emerg. Infect. Dis. J. 2020, 26, 9. [Google Scholar] [CrossRef] [PubMed]
- Health Service Executive. SCOPI: COVID-19 Antibody Research Study—HSE.Ie. Available online: https://www.hse.ie/eng/services/news/newsfeatures/scopi-covid-19-research-project/ (accessed on 31 August 2020).
- Health Protection Surveillance Centre (Ireland). Preliminary Report of the Results of the Study to Investigate COVID-19 Infection in People Living in Ireland (SCOPI): A National Seroprevalence Study, June–July 2020; Health Protection Surveillance Centre: Dublin, Ireland, 2020. [Google Scholar]
- Allen, N.; Ni Riain, Ú.; Conlon, N.; Ferenczi, A.; Isidro Carrion Martin, A.; Domegan, L.; Walsh, C.; Doherty, L.; Fleming, C.; Bergin, L. Prevalence of Antibodies to SARS-CoV-2 in Irish Healthcare Workers; Health Protection Surveillance Centre: Dublin, Ireland, 2021. [Google Scholar]
- Bajema, K.L.; Wiegand, R.E.; Cuffe, K.; Patel, S.V.; Iachan, R.; Lim, T.; Lee, A.; Moyse, D.; Havers, F.P.; Harding, L.; et al. Estimated SARS-CoV-2 Seroprevalence in the US as of September 2020. JAMA Intern. Med. 2021, 181, 450. [Google Scholar] [CrossRef]
- Riley, S.; Atchison, C.; Ashby, D.; Donnelly, C.A.; Barclay, W.; Cooke, G.; Ward, H.; Darzi, A.; Elliott, P.; REACT study group. REal-Time Assessment of Community Transmission (REACT) of SARS-CoV-2 Virus: Study Protocol. Wellcome Open Res. 2020, 5, 200. [Google Scholar] [CrossRef]
- O’Driscoll, M.; Ribeiro Dos Santos, G.; Wang, L.; Cummings, D.A.T.; Azman, A.S.; Paireau, J.; Fontanet, A.; Cauchemez, S.; Salje, H. Age-Specific Mortality and Immunity Patterns of SARS-CoV-2. Nature 2020, 590, 140–145. [Google Scholar] [CrossRef]
- Ioannidis, J.P.A. Infection Fatality Rate of COVID-19 Inferred from Seroprevalence Data. Bull. World Health Organ. 2021, 99, 19F–33F. [Google Scholar] [CrossRef] [PubMed]
- Tilley, K.; Ayvazyan, V.; Martinez, L.; Nanda, N.; Kawaguchi, E.S.; O’Gorman, M.; Conti, D.; Gauderman, W.J.; Orman, S.V. A Cross-Sectional Study Examining the Seroprevalence of Severe Acute Respiratory Syndrome Coronavirus 2 Antibodies in a University Student Population. J. Adolesc. Health 2020, 67, 763–768. [Google Scholar] [CrossRef] [PubMed]
- Wilson, S.E.; Deeks, S.L.; Hatchette, T.F.; Crowcroft, N.S. The Role of Seroepidemiology in the Comprehensive Surveillance of Vaccine-Preventable Diseases. CMAJ 2012, 184, E70–E76. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehrotra, D.V.; Janes, H.E.; Fleming, T.R.; Annunziato, P.W.; Neuzil, K.M.; Carpp, L.N.; Benkeser, D.; Brown, E.R.; Carone, M.; Cho, I.; et al. Clinical Endpoints for Evaluating Efficacy in COVID-19 Vaccine Trials. Ann. Intern. Med. 2020, 174, 221–228. [Google Scholar] [CrossRef] [PubMed]
- Wheatley, A.K.; Juno, J.A.; Wang, J.J.; Selva, K.J.; Reynaldi, A.; Tan, H.-X.; Lee, W.S.; Wragg, K.M.; Kelly, H.G.; Esterbauer, R.; et al. Evolution of Immune Responses to SARS-CoV-2 in Mild-Moderate COVID-19. Nat. Commun. 2021, 12, 1162. [Google Scholar] [CrossRef] [PubMed]
- Public Health England. Weekly Coronavirus Disease 2019 (COVID-19) Surveillance Report. Available online: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/923668/Weekly_COVID19_Surveillance_Report_week_40.pdf (accessed on 1 December 2020).
- Thompson, C.P.; Grayson, N.E.; Paton, R.S.; Bolton, J.S.; Lourenço, J.; Penman, B.S.; Lee, L.N.; Odon, V.; Mongkolsapaya, J.; Chinnakannan, S.; et al. Detection of Neutralising Antibodies to SARS-CoV-2 to Determine Population Exposure in Scottish Blood Donors between March and May 2020. Eurosurveillance 2020, 25. [Google Scholar] [CrossRef]
- Slot, E.; Hogema, B.M.; Reusken, C.B.E.M.; Reimerink, J.H.; Molier, M.; Karregat, J.H.M.; IJlst, J.; Novotný, V.M.J.; van Lier, R.A.W.; Zaaijer, H.L. Low SARS-CoV-2 Seroprevalence in Blood Donors in the Early COVID-19 Epidemic in the Netherlands. Nat. Commun. 2020, 11, 5744. [Google Scholar] [CrossRef]
- He, D.; Fan, G.; Wang, X.; Li, Y.; Peng, Z. The New SARS-CoV-2 Variant and Reinfection in the Resurgence of COVID-19 Outbreaks in Manaus, Brazil. medRxiv 2021. [Google Scholar] [CrossRef]
- Keiding, N.; Louis, T.A. Perils and Potentials of Self-Selected Entry to Epidemiological Studies and Surveys. J. R. Stat. Soc. Ser. A 2016, 179, 319–376. [Google Scholar] [CrossRef]
- Rosenberg, E.S.; Tesoriero, J.M.; Rosenthal, E.M.; Chung, R.; Barranco, M.A.; Styer, L.M.; Parker, M.M.; John Leung, S.-Y.; Morne, J.E.; Greene, D.; et al. Cumulative Incidence and Diagnosis of SARS-CoV-2 Infection in New York. Ann. Epidemiol. 2020, 48, 23–29.e4. [Google Scholar] [CrossRef]
- Bendavid, E.; Mulaney, B.; Sood, N.; Shah, S.; Ling, E.; Bromley-Dulfano, R.; Lai, C.; Weissberg, Z.; Saavedra-Walker, R.; Tedrow, J.; et al. COVID-19 Antibody Seroprevalence in Santa Clara County, California. medRxiv 2020. [Google Scholar] [CrossRef]
- Cheung, K.L.; ten Klooster, P.M.; Smit, C.; de Vries, H.; Pieterse, M.E. The Impact of Non-Response Bias Due to Sampling in Public Health Studies: A Comparison of Voluntary versus Mandatory Recruitment in a Dutch National Survey on Adolescent Health. BMC Public Health 2017, 17, 276. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Locker, D.; Wiggins, R.; Sittampalam, Y.; Patrick, D.L. Estimating the Prevalence of Disability in the Community: The Influence of Sample Design and Response Bias. J. Epidemiol. Community Health 1981, 35, 208–212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beckett, L.A.; Scherr, P.A.; Evans, D.A. Population Prevalence Estimates from Complex Samples. J. Clin. Epidemiol. 1992, 45, 393–402. [Google Scholar] [CrossRef]
- Schisterman, E.F.; Cole, S.R.; Platt, R.W. Overadjustment Bias and Unnecessary Adjustment in Epidemiologic Studies. Epidemiology 2009, 20, 488–495. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, W.; Stanek, E.J.; Bertone-Johnson, E.R. Should Adjustment for Covariates Be Used in Prevalence Estimations? Epidemiol. Perspect. Innov. 2008, 5, 2. [Google Scholar] [CrossRef] [Green Version]
- Little, R.J.; Vartivarian, S. On Weighting the Rates in Non-Response Weights. Stat. Med. 2003, 22, 1589–1599. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geneletti, S.; Mason, A.; Best, N. Adjusting for Selection Effects in Epidemiologic Studies: Why Sensitivity Analysis Is the Only “Solution”. Epidemiology 2011, 22, 36–39. [Google Scholar] [CrossRef] [Green Version]
- Hoekstra, R.; Morey, R.D.; Rouder, J.N.; Wagenmakers, E.-J. Robust Misinterpretation of Confidence Intervals. Psychon. Bull. Rev. 2014, 21, 1157–1164. [Google Scholar] [CrossRef]
- Sim, J.; Reid, N. Statistical Inference by Confidence Intervals: Issues of Interpretation and Utilization. Phys. Ther. 1999, 79, 186–195. [Google Scholar] [CrossRef]
- Morey, R.D.; Hoekstra, R.; Rouder, J.N.; Lee, M.D.; Wagenmakers, E.-J. The Fallacy of Placing Confidence in Confidence Intervals. Psychon. Bull. Rev. 2016, 23, 103–123. [Google Scholar] [CrossRef] [Green Version]
- Ward, H.; Atchison, C.J.; Whitaker, M.; Ainslie, K.E.C.; Elliott, J.; Okell, L.C.; Redd, R.; Ashby, D.; Donnelly, C.A.; Barclay, W.; et al. Antibody Prevalence for SARS-CoV-2 in England Following First Peak of the Pandemic: REACT2 Study in 100,000 Adults. medRxiv 2020. [Google Scholar] [CrossRef]
- Gelman, A. Struggles with Survey Weighting and Regression Modeling. Stat. Sci. 2007, 22. [Google Scholar] [CrossRef] [Green Version]
- Altman, D.G.; Bland, J.M. Diagnostic Tests 3: Receiver Operating Characteristic Plots. BMJ 1994, 309, 188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kontou, P.I.; Braliou, G.G.; Dimou, N.L.; Nikolopoulos, G.; Bagos, P.G. Antibody Tests in Detecting SARS-CoV-2 Infection: A Meta-Analysis. Diagnostics 2020, 10, 319. [Google Scholar] [CrossRef]
- Lisboa Bastos, M.; Tavaziva, G.; Abidi, S.K.; Campbell, J.R.; Haraoui, L.-P.; Johnston, J.C.; Lan, Z.; Law, S.; MacLean, E.; Trajman, A.; et al. Diagnostic Accuracy of Serological Tests for Covid-19: Systematic Review and Meta-Analysis. BMJ 2020, m2516. [Google Scholar] [CrossRef]
- Brownstein, N.C.; Chen, Y.A. Predictive Values, Uncertainty, and Interpretation of Serology Tests for the Novel Coronavirus. Sci. Rep. 2021, 11, 5491. [Google Scholar] [CrossRef]
- Rogan, W.J.; Gladen, B. Estimating Prevalence from the Results of a Screening Test. Am. J. Epidemiol. 1978, 107, 71–76. [Google Scholar] [CrossRef]
- Reiczigel, J.; Földi, J.; Ózsvári, L. Exact Confidence Limits for Prevalence of a Disease with an Imperfect Diagnostic Test. Epidemiol. Infect. 2010, 138, 1674–1678. [Google Scholar] [CrossRef] [PubMed]
- Lang, Z.; Reiczigel, J. Confidence Limits for Prevalence of Disease Adjusted for Estimated Sensitivity and Specificity. Prev. Vet. Med. 2014, 113, 13–22. [Google Scholar] [CrossRef]
- Gelman, A.; Carpenter, B. Bayesian Analysis of Tests with Unknown Specificity and Sensitivity. J. R. Stat. Soc. C 2020, rssc.12435. [Google Scholar] [CrossRef]
- Flor, M.; Weiß, M.; Selhorst, T.; Müller-Graf, C.; Greiner, M. Comparison of Bayesian and Frequentist Methods for Prevalence Estimation under Misclassification. BMC Public Health 2020, 20, 1135. [Google Scholar] [CrossRef] [PubMed]
- U.S. Food & Drug Administration. EUA Authorized Serology Test Performance. Available online: https://www.fda.gov/medical-devices/coronavirus-disease-2019-covid-19-emergency-use-authorizations-medical-devices/eua-authorized-serology-test-performance (accessed on 2 September 2020).
- Post, N.; Eddy, D.; Huntley, C.; Schalkwyk, M.C.I.; van Shrotri, M.; Leeman, D.; Rigby, S.; Williams, S.V.; Bermingham, W.H.; Kellam, P.; et al. Antibody Response to SARS-CoV-2 Infection in Humans: A Systematic Review. PLoS ONE 2020, 15, e0244126. [Google Scholar] [CrossRef]
- Ng, K.W.; Faulkner, N.; Cornish, G.H.; Rosa, A.; Harvey, R.; Hussain, S.; Ulferts, R.; Earl, C.; Wrobel, A.G.; Benton, D.J.; et al. Preexisting and de Novo Humoral Immunity to SARS-CoV-2 in Humans. Science 2020, 370, 1339–1343. [Google Scholar] [CrossRef] [PubMed]
- Long, Q.-X.; Tang, X.-J.; Shi, Q.-L.; Li, Q.; Deng, H.-J.; Yuan, J.; Hu, J.-L.; Xu, W.; Zhang, Y.; Lv, F.-J.; et al. Clinical and Immunological Assessment of Asymptomatic SARS-CoV-2 Infections. Nat. Med. 2020, 26, 1200–1204. [Google Scholar] [CrossRef] [PubMed]
- Ibarrondo, F.J.; Fulcher, J.A.; Goodman-Meza, D.; Elliott, J.; Hofmann, C.; Hausner, M.A.; Ferbas, K.G.; Tobin, N.H.; Aldrovandi, G.M.; Yang, O.O. Rapid Decay of Anti–SARS-CoV-2 Antibodies in Persons with Mild Covid-19. N. Engl. J. Med. 2020, 383, 1085–1087. [Google Scholar] [CrossRef] [PubMed]
- Dan, J.M.; Mateus, J.; Kato, Y.; Hastie, K.M.; Yu, E.D.; Faliti, C.E.; Grifoni, A.; Ramirez, S.I.; Haupt, S.; Frazier, A.; et al. Immunological Memory to SARS-CoV-2 Assessed for up to 8 Months after Infection. Science 2021. [Google Scholar] [CrossRef]
- Health Information and Quality Authority (Ireland). Evidence Summary of Reinfection and the Duration of Antibody Responses Following SARS-CoV-2 Infection; Health Information and Quality Authority: Dublin, Ireland, 2020. [Google Scholar]
- Tillett, R.L.; Sevinsky, J.R.; Hartley, P.D.; Kerwin, H.; Crawford, N.; Gorzalski, A.; Laverdure, C.; Verma, S.C.; Rossetto, C.C.; Jackson, D.; et al. Genomic Evidence for Reinfection with SARS-CoV-2: A Case Study. Lancet Infect. Dis. 2021, 21, 52–58. [Google Scholar] [CrossRef]
- Lumley, S.F.; O’Donnell, D.; Stoesser, N.E.; Matthews, P.C.; Howarth, A.; Hatch, S.B.; Marsden, B.D.; Cox, S.; James, T.; Warren, F.; et al. Antibody Status and Incidence of SARS-CoV-2 Infection in Health Care Workers. N. Engl. J. Med. 2020, 384, 533–540. [Google Scholar] [CrossRef]
- Letizia, A.G.; Ge, Y.; Vangeti, S.; Goforth, C.; Weir, D.L.; Kuzmina, N.A.; Balinsky, C.A.; Chen, H.W.; Ewing, D.; Soares-Schanoski, A.; et al. SARS-CoV-2 Seropositivity and Subsequent Infection Risk in Healthy Young Adults: A Prospective Cohort Study. Lancet Respir. Med. 2021. [Google Scholar] [CrossRef]
- Office for National Statistics (UK). Coronavirus (COVID-19) Infection Survey, Antibody and Vaccination Data for the UK. Available online: https://www.ons.gov.uk/peoplepopulationandcommunity/healthandsocialcare/conditionsanddiseases/articles/coronaviruscovid19infectionsurveyantibodydatafortheuk/30march2021 (accessed on 6 April 2021).
- Hodgson, S.H.; Mansatta, K.; Mallett, G.; Harris, V.; Emary, K.R.W.; Pollard, A.J. What Defines an Efficacious COVID-19 Vaccine? A Review of the Challenges Assessing the Clinical Efficacy of Vaccines against SARS-CoV-2. Lancet Infect. Dis. 2021, 21, e26–e35. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Example 1: True Prevalence 2% | Example 2: True Prevalence 20% | |||||
|---|---|---|---|---|---|---|
| Negative | Positive | Total | Negative | Positive | Total | |
| Never infected | 921 | 59 | 980 | 752 | 48 | 800 |
| Previously Infected | 4 | 16 | 20 (2% true prevalence) | 40 | 160 | 200 (20% true prevalence) |
| Total | 925 | 75 (7.5% estimated prevalence) | 1000 | 792 | 208 (20.8% estimated prevalence) | 1000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McConnell, D.; Hickey, C.; Bargary, N.; Trela-Larsen, L.; Walsh, C.; Barry, M.; Adams, R. Understanding the Challenges and Uncertainties of Seroprevalence Studies for SARS-CoV-2. Int. J. Environ. Res. Public Health 2021, 18, 4640. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18094640
McConnell D, Hickey C, Bargary N, Trela-Larsen L, Walsh C, Barry M, Adams R. Understanding the Challenges and Uncertainties of Seroprevalence Studies for SARS-CoV-2. International Journal of Environmental Research and Public Health. 2021; 18(9):4640. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18094640
Chicago/Turabian StyleMcConnell, David, Conor Hickey, Norma Bargary, Lea Trela-Larsen, Cathal Walsh, Michael Barry, and Roisin Adams. 2021. "Understanding the Challenges and Uncertainties of Seroprevalence Studies for SARS-CoV-2" International Journal of Environmental Research and Public Health 18, no. 9: 4640. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18094640