
Spatio-Temporal Characteristics of PM2.5 Concentrations in China Based on Multiple Sources of Data and LUR-GBM during 2016–2021


Abstract
:1. Introduction
- (1)
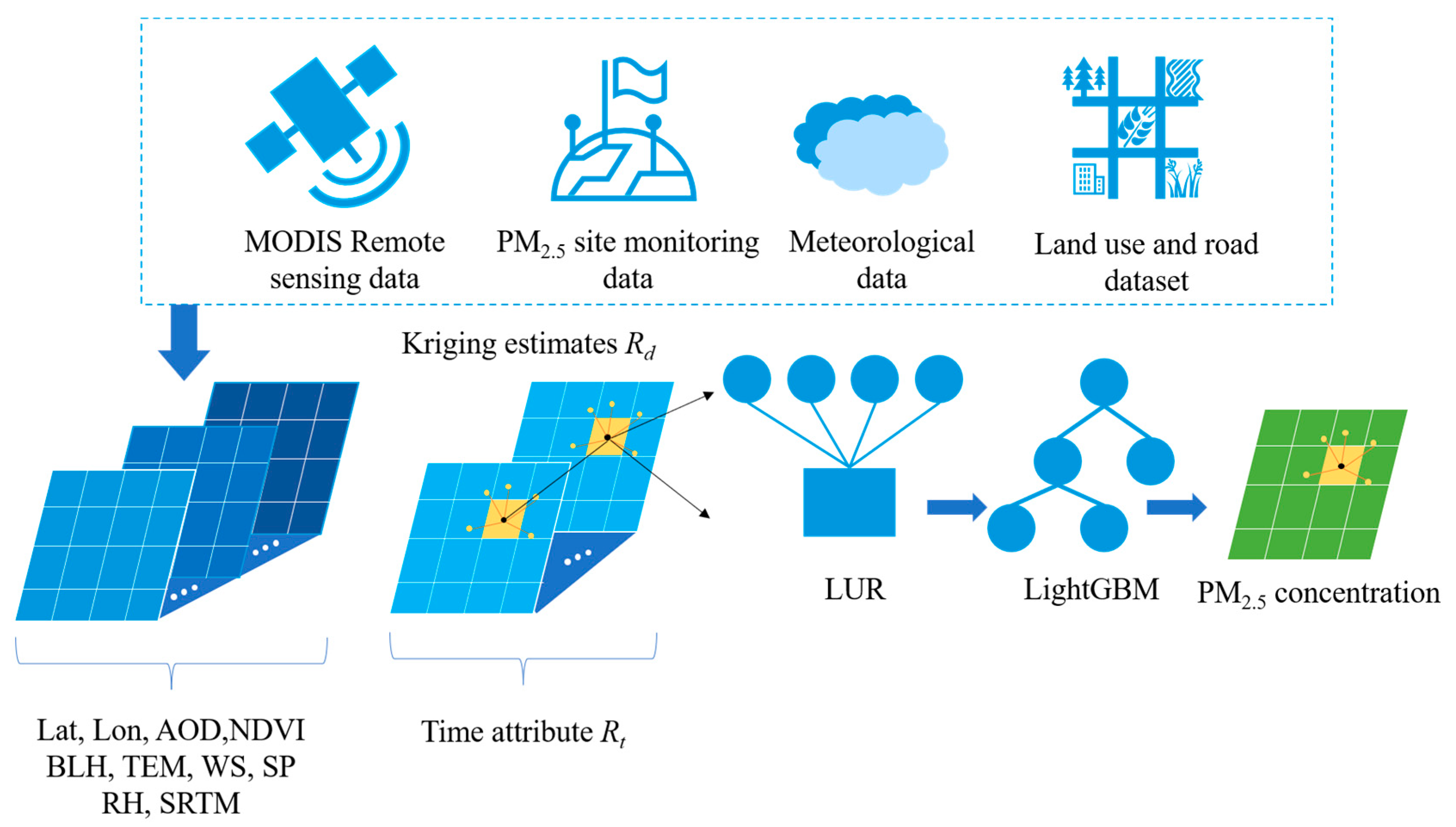
- This study uses an integrated approach combining the LUR model, Kriging method and LightGBM model to improve the daily concentration estimates of PM2.5 in the Chinese region from 2016 to 2021. AOD data, latitude and longitude information, meteorological observation elements, land use and road data are used to estimate PM2.5 concentrations. Specifically, the accuracy of PM2.5 change prediction is improved by stepwise selection of LUR models to identify important predictor variables, and then five machine learning algorithms (BPNN, DNN, RF, XGBoost and LightGBM) are used to build prediction models.
- (2)
- The hybrid spatial prediction model proposed in this paper combines the strengths of LUR in identifying the most influential emission predictors. A hybrid spatial prediction model built by identifying the most influential emission predictors combined with LightGBM’s strength in estimating non-linear trends will be more widely effective than traditional machine learning estimation methods. Validated by R2, RMSE and MAE metrics, the results show that LUR-GBM performs better.
- (3)
- The spring, summer, autumn, winter and 2016–2021 average concentrations are modelled, and the spatial and temporal characteristics of regional PM2.5 concentrations in China are analysed.
2. Data Sources
2.1. MODIS Remote Sensing Data
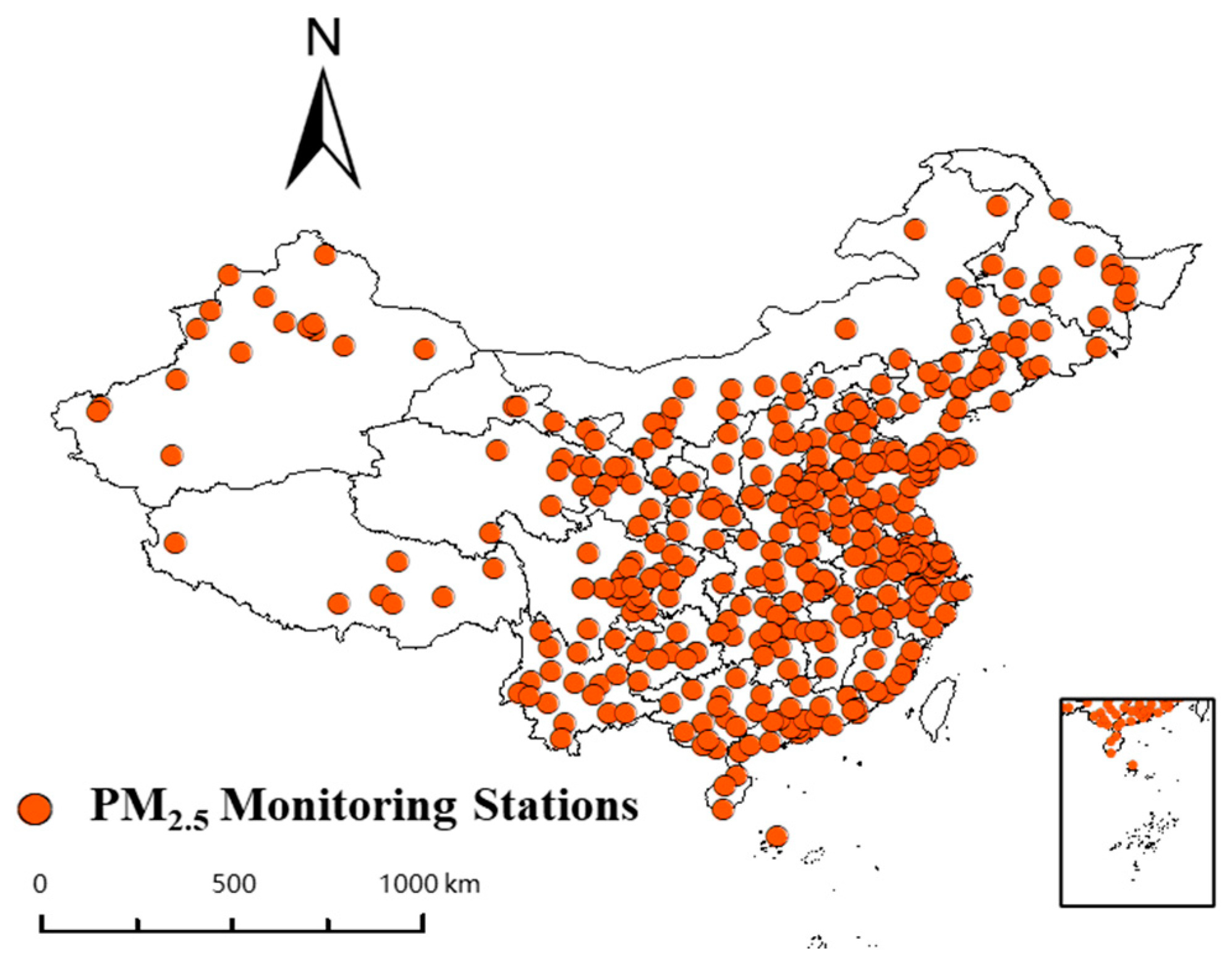
2.2. PM2.5 Site Monitoring Data
2.3. Meteorological Data
2.4. Land Use and Road Dataset
3. Methods
3.1. LightGBM
3.2. LUR Model
3.3. Kriging
3.3.1. Regionalised Variables
3.3.2. Variance Functions
3.3.3. Equation Solving
3.4. LUR-GBM Model
3.5. Accuracy Evaluation
4. Results and Analysis
4.1. Correlation Analysis of PM2.5 Concentrations and Impact Factors
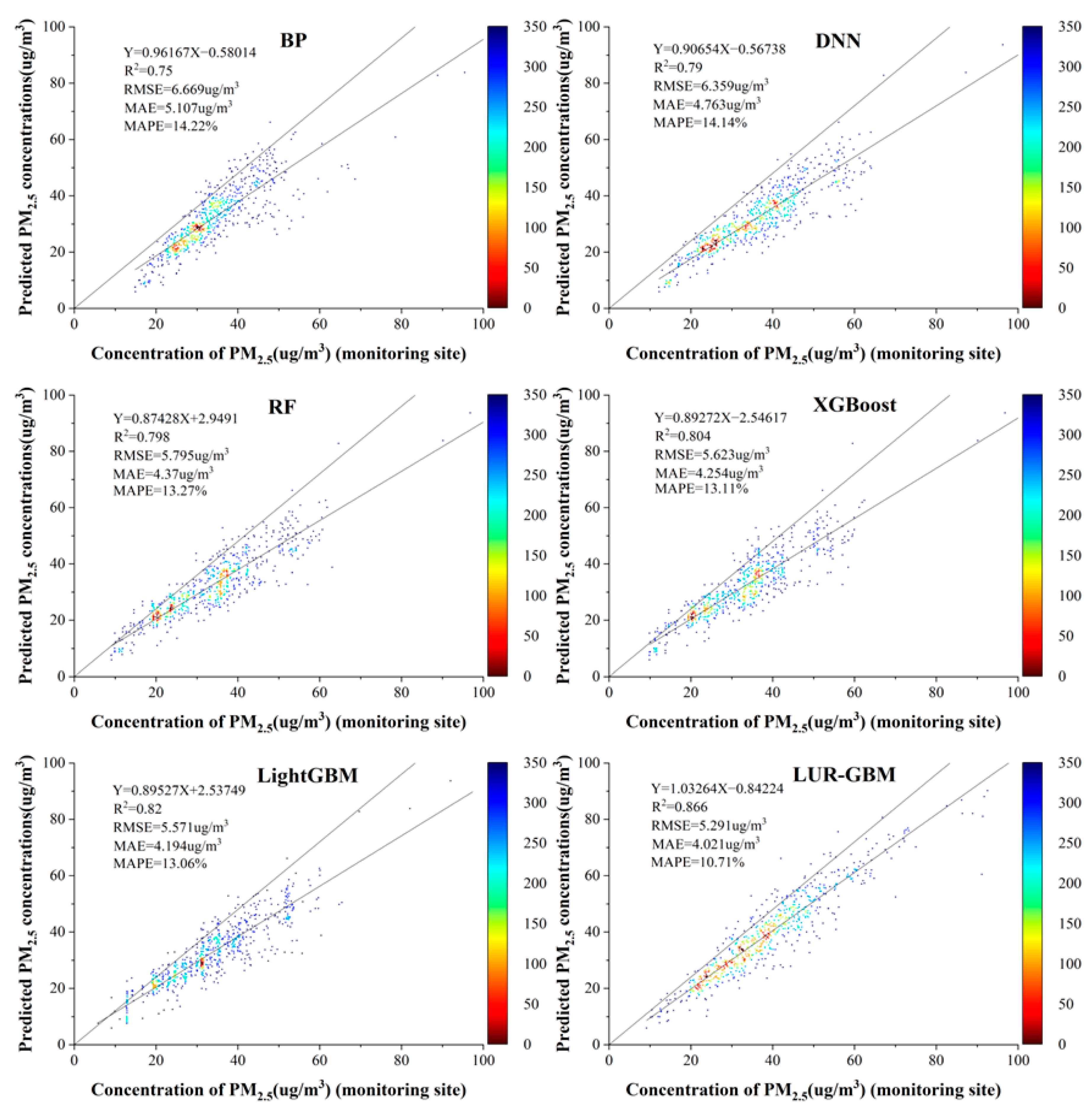
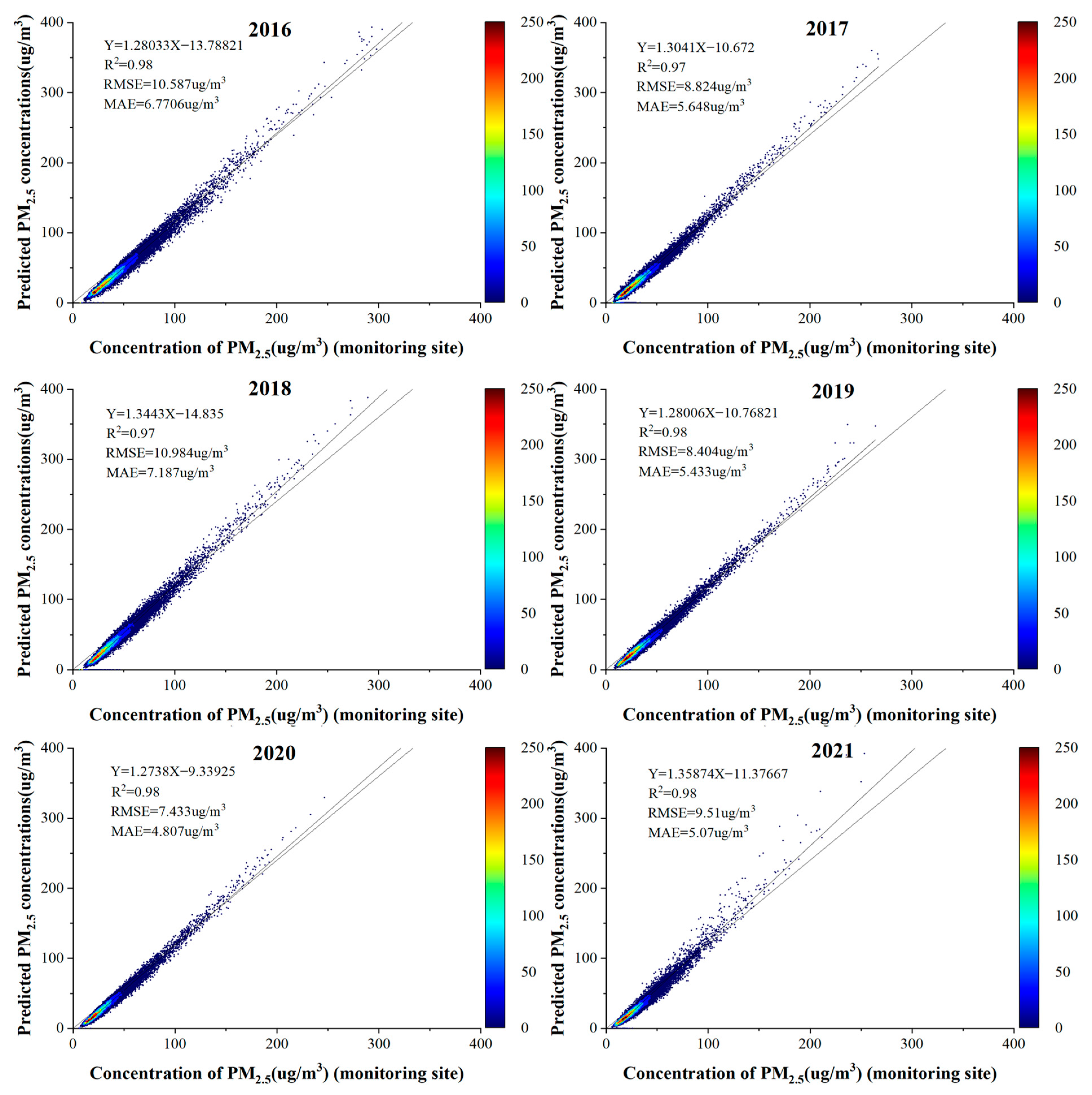
4.2. Model Performance
4.3. Spatial and Temporal Distribution Characteristics of PM2.5 Mass Concentration in China
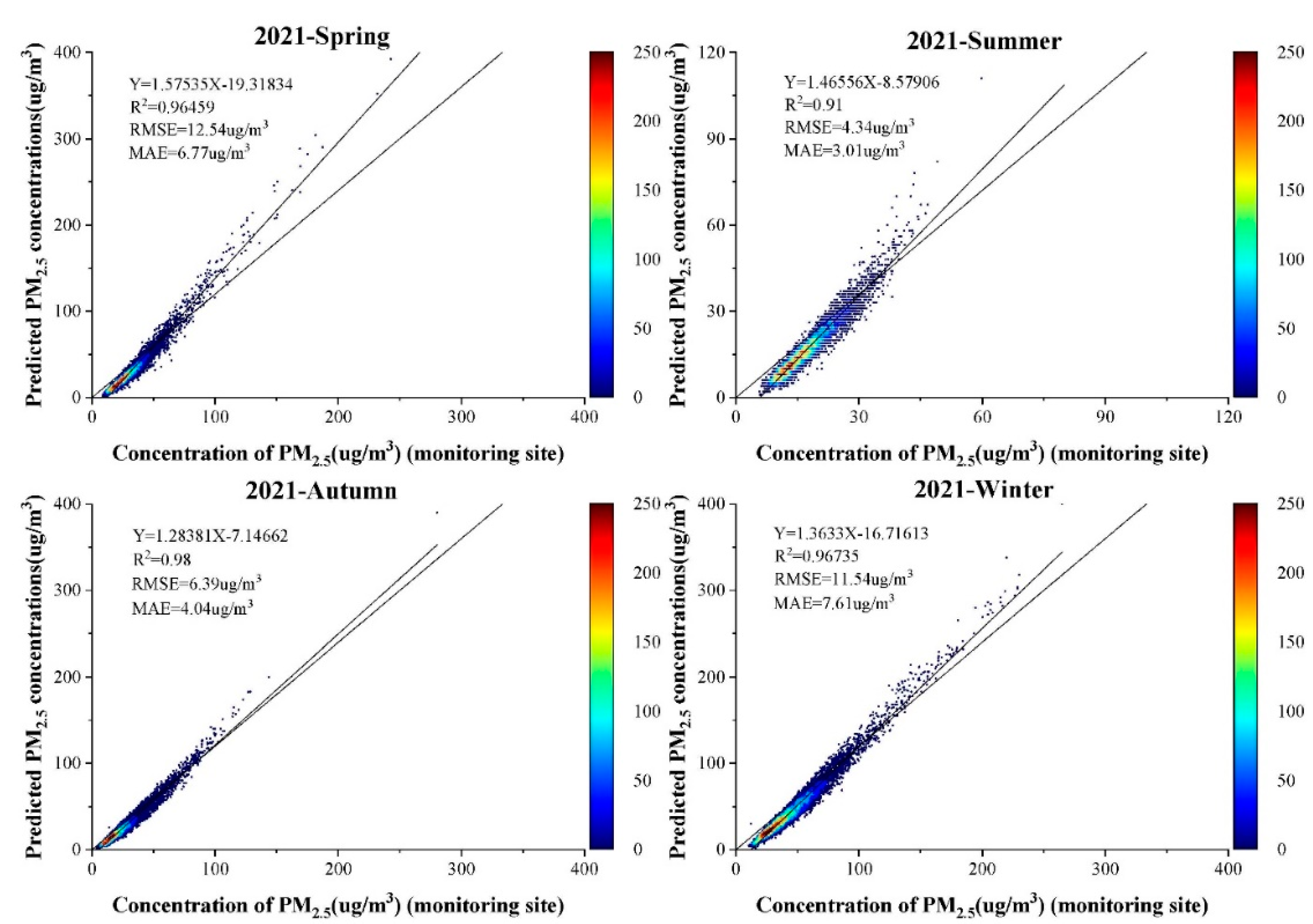
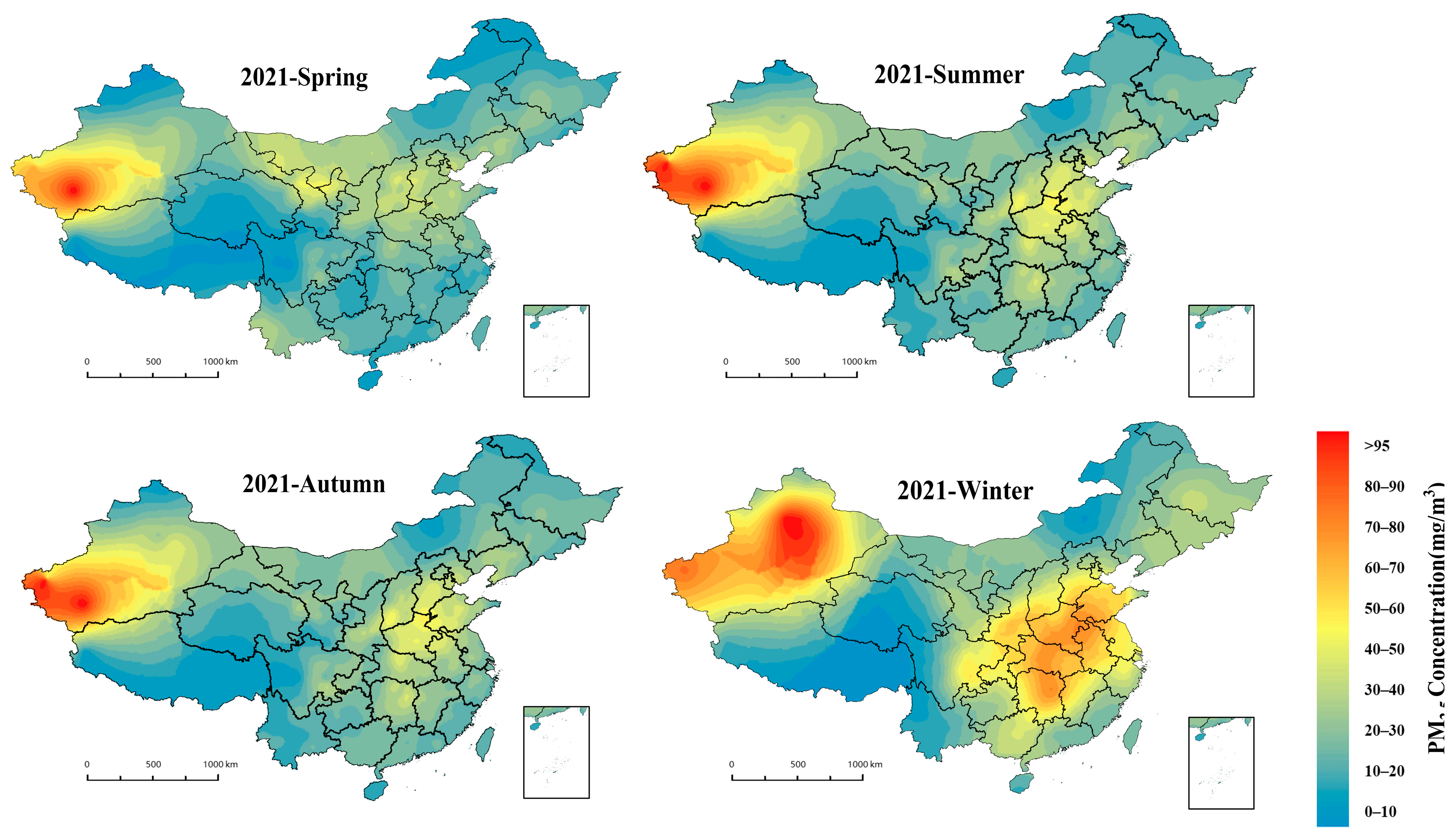
4.3.1. Seasonal Distribution Characteristics
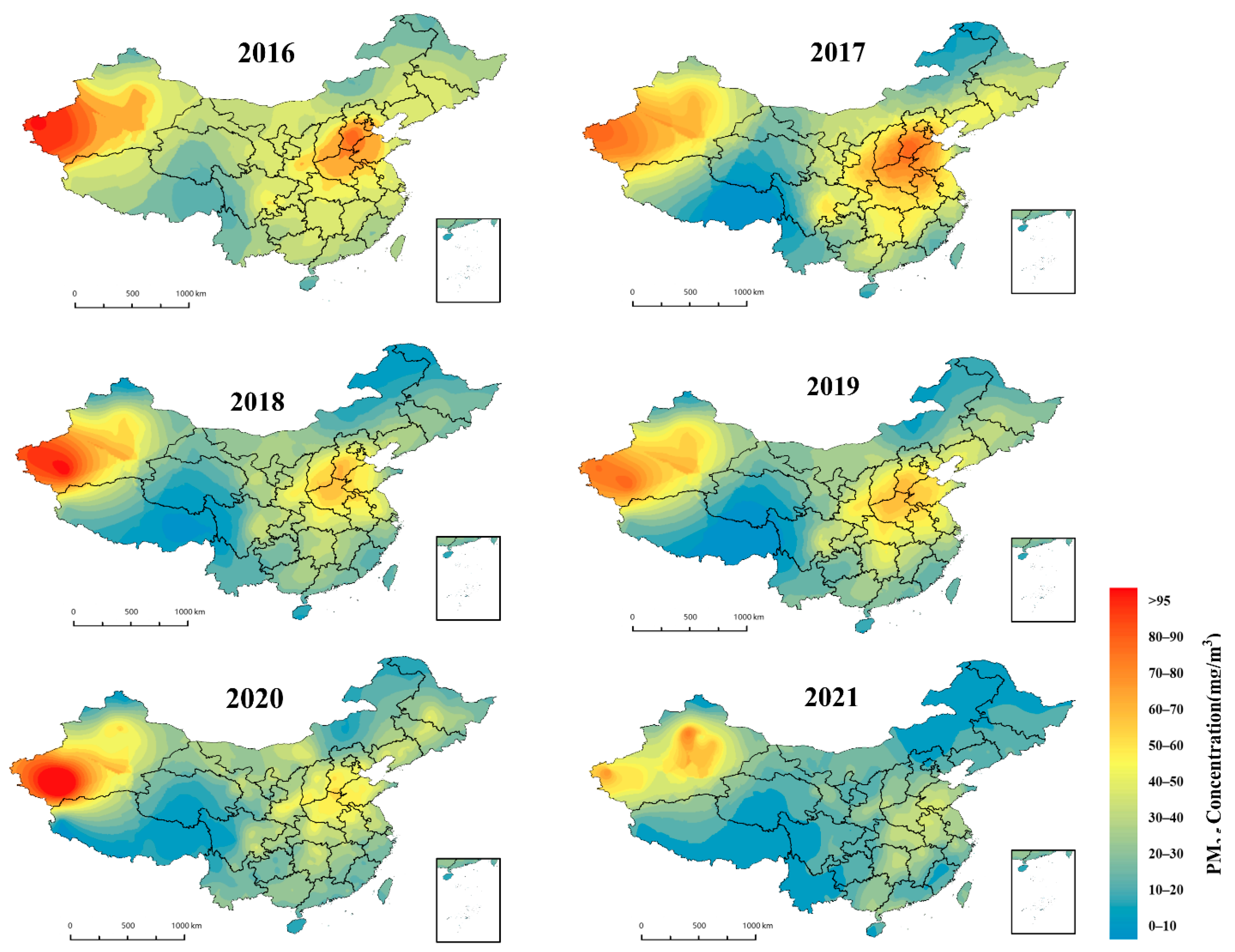
4.3.2. Spatial and Temporal Distribution of PM2.5 Concentrations in China
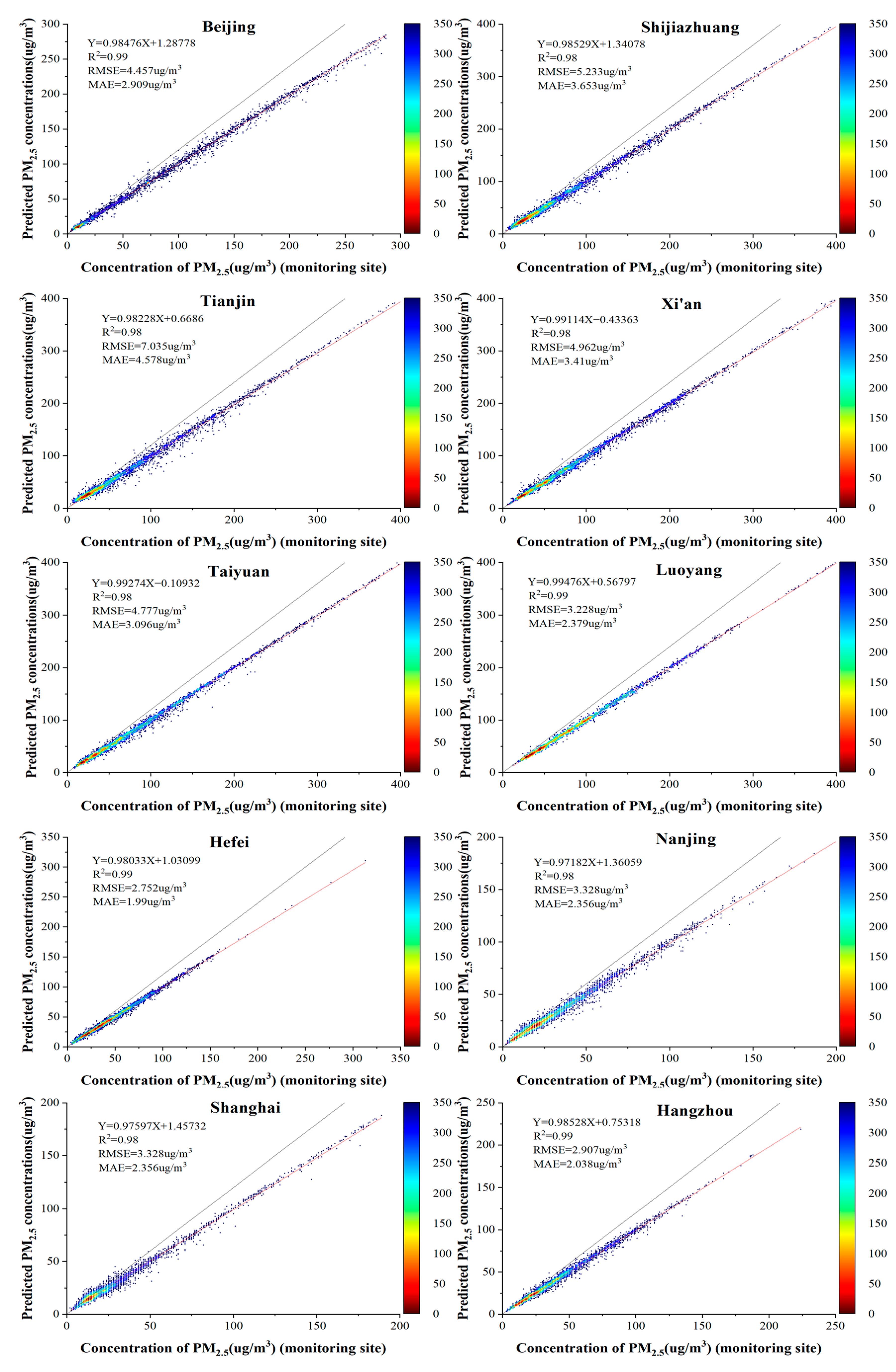
4.4. Fitting Assessment of PM2.5 Concentrations in Typical Chinese Cities
5. Discussion
- (1)
- To verify that the PM2.5 concentration prediction based on the LUR-GBM model was more accurate, validation was carried out from the perspective of different datasets and different control models. In terms of cross-sectional datasets, by predicting PM2.5 concentrations based on sample-based datasets, site-based datasets and time-based datasets, the LUR-GBM model was found to have the highest prediction accuracy with sample-based datasets. In particular, compared to the PM2.5 concentration prediction based on the station dataset, the result of the sample dataset-based prediction improved R2 by 7.69%, reduced RMSE by 13.81% and reduced MAE by 16.77%. Compared to the PM2.5 concentration prediction based on the time dataset, the result of the sample dataset-based prediction improved R2 by 10.11%, reduced RMSE by 9.05% and reduced MAE by 15.76%. From the models, the LUR-GBM model had improved prediction accuracy over BPNN, DNN, RF, XGBoost and LightGBM. Compared to the BPNN model, the LUR-GBM model improved R2 by 42.63%, reduced RMSE by 41.15% and reduced MAE by 48.45% on average. Compared to the DNN model, the LUR-GBM model improved R2 by an average of 16.31%, reduced RMSE by 34.23% and reduced MAE by 42.37%. Compared to the RF model, the LUR-GBM model improved R2 by 12.99%, reduced RMSE by 33.22% and reduced MAE by 34.20%. Compared to the XGBoost model, the LUR-GBM model improved R2 by an average of 10.29%, reduced RMSE by 23.31% and reduced MAE by 22.54%. Compared to the LightGBM model, the LUR-GBM model improved R2 by an average of 7.33%, reduced RMSE by 7.46% and reduced MAE by 10.47%.
- (2)
- The distribution of PM2.5 concentrations in China is characterised by high winter and low summer, falling in spring and rising in autumn. In winter, PM2.5 pollution is most severe in areas such as the Fenwei Plain. In spring, PM2.5 concentrations are higher in northern China than in southern regions. In autumn, PM2.5 pollution is most severe in eastern China and Xinjiang. In summer, air quality is better throughout the country, except in Xinjiang.
- (3)
- A further decrease was found in the national average PM2.5 concentration from 47 ug/m3 to 30 ug/m3 from 2016 to 2021. Seriously polluted areas are concentrated in the Fenwei Plain, Eastern China and Western Xinjiang. In terms of the spatial distribution of PM2.5 concentrations, China’s pollution regions as a whole are characterised by higher levels in the east than in the west. North China is the most polluted region, mainly including southern Hebei, northern Henan and western Shandong. This was followed by greater air pollution in Central China, the Sichuan Basin and Xinjiang. Southern China has the lowest PM2.5 concentration and the best air quality.
- (4)
- PM2.5 concentration predictions for ten typical cities in heavily polluted regions of China were studied and discussed and found to be less accurate in northern cities than in southern cities. Hangzhou and Hefei had the highest forecast accuracy, while Shijiazhuang and Tianjin had a lower forecast accuracy.
6. Conclusions
- (1)
- Improve joint prevention and control mechanisms in different regions. The formation and sources of PM2.5 are complex, and it is difficult to control a single source and a single city to radically reduce the pollution. Analysis of the spatial distribution of PM2.5 on a regional scale can further provide reliable information to support the establishment of improved regional joint prevention and control mechanisms in order to better address urban air pollution.
- (2)
- Fine-grained regulation of pollution levels by zoning. Pollution prevention and control measures are formulated according to the different geographical features, meteorological conditions and economic development of different regions, taking into account local conditions. Differential control management for heavily polluted areas and general areas. The relevant government departments should speed up the improvement of early warning and treatment of heavily polluted areas.
- (3)
- Implementation of seasonal differentiation of control. This study found significant differences in PM2.5 concentrations between seasons, requiring the implementation of targeted prevention and control measures. Measures such as reducing pollution through artificial precipitation, imposing restrictions on motor vehicles and reasonable heating.
- (4)
- Strengthen the control of pollution at the source. There is a need to increase energy restructuring and energy conservation and emission reduction efforts to prevent and control air pollution at the source. Rational allocation of functional tasks of agency staff to areas with different PM2.5 levels through predictive warning. Timely release of information on pollution sources to achieve the transformation from governance to prevention.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhan, Y.; Luo, Y.; Deng, X.; Chen, H.; Grieneisen, M.L.; Shen, X.; Zhang, M. Spatiotemporal prediction of continuous daily PM2.5 concentrations across China using a spatially explicit machine learning algorithm. Atmos. Environ. 2017, 155, 129–139. [Google Scholar] [CrossRef]
- Lu, X.; Wang, J.; Yan, Y.; Zhou, L.; Ma, W. Estimating hourly PM2.5 concentrations using Himawari-8 AOD and a DBSCAN-modified deep learning model over the YRDUA, China. Atmos. Pollut. Res. 2021, 12, 183–192. [Google Scholar] [CrossRef]
- Roth, G.; Mensah, G.; Johnson, C. Global Burden of Cardiovascular Diseases and Risk Factors, 1990–2019. J. Am. Coll. Cardiol. 2020, 76, 2982–3021. [Google Scholar] [CrossRef]
- Cheng, Z.; Luo, L.; Wang, S.; Wang, Y.; Sharma, S.; Shimadera, H.; Hao, J. Status and characteristics of ambient PM2.5 pollution in global megacities. Environ. Int. 2016, 89, 212–221. [Google Scholar] [CrossRef] [PubMed]
- Han, L.; Zhou, W.; Li, W. Growing Urbanization and the Impact on Fine Particulate Matter (PM2.5) Dynamics. Sustainability 2018, 10, 1696. [Google Scholar] [CrossRef] [Green Version]
- World Health Organization. Ambient Air Pollution: A Global Assessment of Exposure and Burden of Disease; World Health Organization: Geneva, Switzerland, 2016; pp. 1–131. [Google Scholar]
- Yang, D.; Ye, C.; Wang, X.; Lu, D.; Xu, J.; Yang, H. Global distribution and evolvement of urbanization and PM2.5(1998–2015). Atmos. Environ. 2018, 182, 171–178. [Google Scholar] [CrossRef]
- Maji, K.; Dikshit, A.; Arora, M.; Deshpande, A. Estimating premature mortality attributable to PM2.5 exposure and benefit of air pollution control policies in China for 2020. Sci. Total Environ. 2018, 612, 683–693. [Google Scholar] [CrossRef]
- Huang, K.; Xiao, Q.; Meng, X.; Geng, G.; Wang, Y.; Lyapustin, A.; Liu, Y. Predicting monthly high-resolution PM2.5 concentrations with random forest model in the North China Plain. Environ. Pollut. 2018, 242, 675–683. [Google Scholar] [CrossRef]
- Chen, C.; Wang, Y.; Yeh, H.; Lin, T.; Huang, C.; Wu, C. Estimating monthly PM2.5 concentrations from satellite remote sensing data, meteorological variables, and land use data using ensemble statistical modeling and a random forest approach. Environ. Pollut. 2021, 291, 118159. [Google Scholar] [CrossRef]
- Gupta, P.; Christopher, S. Particulate matter air quality assessment using integrated surface, satellite, and meteorological products: 2. A neural network approach. J. Geophys. Res.-Atmos. 2009, 114, 1–14. [Google Scholar] [CrossRef]
- Cobourn, W. An enhanced PM2.5 air quality forecast model based on nonlinear regression and back-trajectory concentrations. Atmos. Environ. 2010, 44, 3015–3023. [Google Scholar] [CrossRef]
- Hu, X.; Waller, L.; Al-Hamdan, M.; Crosson, W.; Estes, M., Jr.; Estes, S.; Liu, Y. Estimating ground-level PM2.5 concentrations in the southeastern US using geographically weighted regression. Environ. Res. 2013, 121, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Liu, Y.; Zhao, Q.; Liu, M.; Zhou, Y.; Bi, J. Satellite-derived high resolution PM2.5 concentrations in Yangtze River Delta Region of China using improved linear mixed effects model. Atmos. Environ. 2016, 133, 156–164. [Google Scholar] [CrossRef]
- Li, T.; Shen, H.; Zeng, C.; Yuan, Q.; Zhang, L. Point-surface fusion of station measurements and satellite observations for mapping PM2.5 distribution in China: Methods and assessment. Atmos. Environ. 2017, 152, 477–489. [Google Scholar] [CrossRef] [Green Version]
- Dai, H.; Huang, G.; Zeng, H.; Yang, F. PM2.5 Concentration Prediction Based on Spatiotemporal Feature Selection Using XGBoost-MSCNN-GA-LSTM. Sustainability 2021, 13, 12071. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Regional VOCs Gathering Situation Intelligent Sensing Method Based on Spatial-Temporal Feature Selection. Atmosphere 2022, 13, 483. [Google Scholar] [CrossRef]
- Zaman, N.; Kanniah, K.; Kaskaoutis, D.; Latif, M. Evaluation of Machine Learning Models for Estimating PM2.5 Concentrations across Malaysia. Appl. Sci. 2021, 11, 7326. [Google Scholar] [CrossRef]
- Yang, W.; Deng, M.; Xu, F.; Wang, H. Prediction of hourly PM2. 5 using a space-time support vector regression model. Atmos. Environ. 2018, 181, 12–19. [Google Scholar] [CrossRef]
- Kianian, B.; Liu, Y.; Chang, H. Imputing Satellite-Derived Aerosol Optical Depth Using a Multi-Resolution Spatial Model and Random Forest for PM2.5 Prediction. Remote Sens. 2021, 13, 126. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, Q.; Ban, J.; Liu, Z.; Zhang, Y.; Ma, R.; Li, S.; Li, T. Estimating the daily PM2. 5 concentration in the Beijing-Tianjin-Hebei region using a random forest model with a 0.01° × 0.01° spatial resolution. Environ. Int. 2020, 134, 105297. [Google Scholar] [CrossRef]
- Goudarzi, G.; Hopke, P.; Yazdani, M. Forecasting PM2. 5 concentration using artificial neural network and its health effects in Ahvaz, Iran. Chemosphere 2021, 283, 131285. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, L. A Locally Weighted Neural Network Constrained by Global Training for Remote Sensing Estimation of PM2.5. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Chen, X.; Kong, P.; Jiang, P.; Wu, Y. Estimation of PM2.5 Concentration Using Deep Bayesian Model Considering Spatial Multiscale. Remote Sens. 2021, 13, 4545. [Google Scholar] [CrossRef]
- Han, F.; Li, J. Spatial Pattern and Spillover of Abatement Effect of Chinese Environmental Protection Tax Law on PM2.5 Pollution. Int. J. Environ. Res. Public Health 2022, 19, 1440. [Google Scholar] [CrossRef]
- Yuan, Q.; Xu, H.; Li, T.; Shen, H.; Zhang, L. Estimating surface soil moisture from satellite observations using a generalized regression neural network trained on sparse ground-based measurements in the continental US. J. Hydrol. 2020, 580, 124351. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Prediction of Air Pollutant Concentration Based on One-Dimensional Multi-Scale CNN-LSTM Considering Spatial-Temporal Characteristics: A Case Study of Xi’an, China. Atmosphere 2021, 12, 1626. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, H.; Xu, X.; Han, M.; Zuo, P. A balanced social LSTM for PM2. 5 concentration prediction based on local spatiotemporal correlation. Chemosphere 2022, 291, 133124. [Google Scholar] [CrossRef]
- Mo, Y.; Booker, D.; Zhao, S.; Tang, J.; Jiang, H.; Shen, J.; Zhang, G. The application of land use regression model to investigate spatiotemporal variations of PM2. 5 in Guangzhou, China: Implications for the public health benefits of PM2.5 reduction. Sci. Total Environ. 2021, 778, 146305. [Google Scholar] [CrossRef]
- Di, Q.; Kloog, I.; Koutrakis, P.; Lyapustin, A.; Wang, Y.; Schwartz, J. Assessing PM2. 5 exposures with high spatiotemporal resolution across the continental United States. Environ. Sci. Technol. 2016, 50, 4712–4721. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Gong, W.; Wang, W.; Ji, Y.; Zhu, Z.; Huang, Y. Ground Level PM2.5 Estimates over China Using Satellite-Based Geographically Weighted Regression (GWR) Models Are Improved by Including NO2 and Enhanced Vegetation Index (EVI). Int. J. Environ. Res. Public Health 2016, 13, 1215. [Google Scholar] [CrossRef]
- Han, S.; Sun, B.; Zhang, T. Mono-and polycentric urban spatial structure and PM2. 5 concentrations: Regarding the dependence on population density. Habitat Int. 2020, 104, 102257. [Google Scholar] [CrossRef]
- Chen, B.; Song, Z.; Pan, F.; Huang, Y. Obtaining vertical distribution of PM2. 5 from CALIOP data and machine learning algorithms. Sci. Total Environ. 2022, 805, 150338. [Google Scholar] [CrossRef] [PubMed]
- Niu, Z.; Zhang, F.; Chen, J.; Yin, L.; Wang, S.; Xu, L. Carbonaceous species in PM2. 5 in the coastal urban agglomeration in the Western Taiwan Strait Region, China. Atmos. Res. 2013, 122, 102–110. [Google Scholar] [CrossRef]
- Both, A.; Balakrishnan, A.; Joseph, B.; Marshall, J. Spatiotemporal aspects of real-time PM2. 5: Low-and middle-income neighborhoods in Bangalore, India. Environ. Sci. Technol. 2011, 45, 5629–5636. [Google Scholar] [CrossRef] [PubMed]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Liu, T. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Processing Syst. 2017, 30, 1–9. [Google Scholar]
- Tang, R.; Ning, Y.; Li, C.; Feng, W.; Chen, Y.; Xie, X. Numerical Forecast Correction of Temperature and Wind Using a Single-Station Single-Time Spatial LightGBM Method. Sensors 2022, 22, 193. [Google Scholar] [CrossRef]
- Montagne, D.; Hoek, G.; Nieuwenhuijsen, M.; Lanki, T.; Pennanen, A.; Portella, M.; Brunekreef, B. The association of LUR modeled PM2.5 elemental composition with personal exposure. Sci. Total Environ. 2014, 493, 298–306. [Google Scholar] [CrossRef]
- Hoek, G.; Beelen, R.; De Hoogh, K.; Vienneau, D.; Gulliver, J.; Fischer, P.; Briggs, D. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos. Environ. 2008, 42, 7561–7578. [Google Scholar] [CrossRef]
- Sampson, P.; Richards, M.; Szpiro, A.; Bergen, S.; Sheppard, L.; Larson, T.; Kaufman, J. A regionalized national universal kriging model using Partial Least Squares regression for estimating annual PM2.5 concentrations in epidemiology. Atmos. Environ. 2013, 75, 383–392. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Griffith, D.; Shu, H. Temperature prediction based on a space–time regression-kriging model. J. Appl. Stat. 2020, 47, 1168–1190. [Google Scholar] [CrossRef]
- Zeng, H.; Shao, B.; Bian, G.; Dai, H.; Zhou, F. A hybrid deep learning approach by integrating extreme gradient boosting-long short-term memory with generalized autoregressive conditional heteroscedasticity family models for natural gas load volatility prediction. Energy Sci. Eng. 2022, 3, 21. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Zeng, H.; Zhou, F. PM2.5 volatility prediction by XGBoost-MLP based on GARCH models. J. Clean Prod. 2022, 356, 131898. [Google Scholar] [CrossRef]
- Ministry of Ecology and Environment of the People’s Republic of China. Second National Pollution Source Census Bulletin. Available online: https://www.mee.gov.cn/xxgk2018/xxgk/xxgk01/202006/W020200610353985963290.pdf (accessed on 19 April 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Variable Name | Unit | Variable Description |
|---|---|---|---|
| Land type | cro | % | Cropland |
| for | % | Forest | |
| gra | % | Grass | |
| wat | % | Water | |
| ind | % | Industrial and residential | |
| sem | % | Seminatural | |
| Terrain and landforms | altitude | m | Altitude |
| Population | pop | people | Population |
| Road traffic | hig | m | Highway |
| maj | m | Major road | |
| hm | m | Sum of highway and Major road | |
| min | m | Minor road | |
| Meteorological elements | GST | °C | 0 cm Surface temperature |
| SSD | h | Sunshine hours | |
| PRS | hPa | Pressure | |
| TEM | °C | Temperature | |
| RHU | % | Relative humidity | |
| PRE | mm | Precipitation | |
| WIN | m/s | Wind speed |
| Independent Variable | Pearson Correlation | p | Independent Variable | Pearson Correlation | p |
|---|---|---|---|---|---|
| cro | 0.343 | 0.003 | pop | 0.310 | 0.021 |
| wat | −0.059 | 0.002 | altitude | −0.559 | 0.000 |
| for | −0.379 | 0.000 | GST | 0.178 | 0.000 |
| gra | −0.299 | 0.000 | SSD | 0.018 | 0.000 |
| ind | 0.322 | 0.000 | PRS | 0.302 | 0.000 |
| sem | −0.134 | 0.000 | TEM | 0.523 | 0.000 |
| hig | −0.084 | 0.000 | RHU | −0.215 | 0.001 |
| maj | 0.187 | 0.002 | PRE | −0.346 | 0.004 |
| hm | 0.177 | 0.000 | WIN | 0.415 | 0.000 |
| min | 0.125 | 0.002 |
| Based on Samples | Based on Sites | Based on Time | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | R2 | RMSE | MAE | R2 | RMSE | MAE | |
| BPNN | 0.76 | 11.27 | 8.35 | 0.65 | 11.26 | 9.34 | 0.56 | 13.28 | 9.69 |
| DNN | 0.84 | 10.33 | 8.05 | 0.78 | 11.09 | 8.86 | 0.77 | 10.43 | 7.67 |
| RF | 0.86 | 9.19 | 6.08 | 0.81 | 11.03 | 7.46 | 0.79 | 11.27 | 8.03 |
| XGBoost | 0.88 | 7.34 | 4.79 | 0.83 | 10.54 | 6.78 | 0.81 | 9.86 | 6.93 |
| LightGBM | 0.91 | 6.56 | 4.56 | 0.85 | 8.32 | 5.76 | 0.83 | 7.86 | 5.49 |
| LUR-GBM | 0.98 | 6.43 | 4.17 | 0.91 | 7.46 | 5.01 | 0.89 | 7.07 | 4.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Spatio-Temporal Characteristics of PM2.5 Concentrations in China Based on Multiple Sources of Data and LUR-GBM during 2016–2021. Int. J. Environ. Res. Public Health 2022, 19, 6292. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph19106292
Dai H, Huang G, Wang J, Zeng H, Zhou F. Spatio-Temporal Characteristics of PM2.5 Concentrations in China Based on Multiple Sources of Data and LUR-GBM during 2016–2021. International Journal of Environmental Research and Public Health. 2022; 19(10):6292. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph19106292
Chicago/Turabian StyleDai, Hongbin, Guangqiu Huang, Jingjing Wang, Huibin Zeng, and Fangyu Zhou. 2022. "Spatio-Temporal Characteristics of PM2.5 Concentrations in China Based on Multiple Sources of Data and LUR-GBM during 2016–2021" International Journal of Environmental Research and Public Health 19, no. 10: 6292. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph19106292