
Heating and Lighting Load Disaggregation Using Frequency Components and Convolutional Bidirectional Long Short-Term Memory Method


Abstract
:1. Introduction
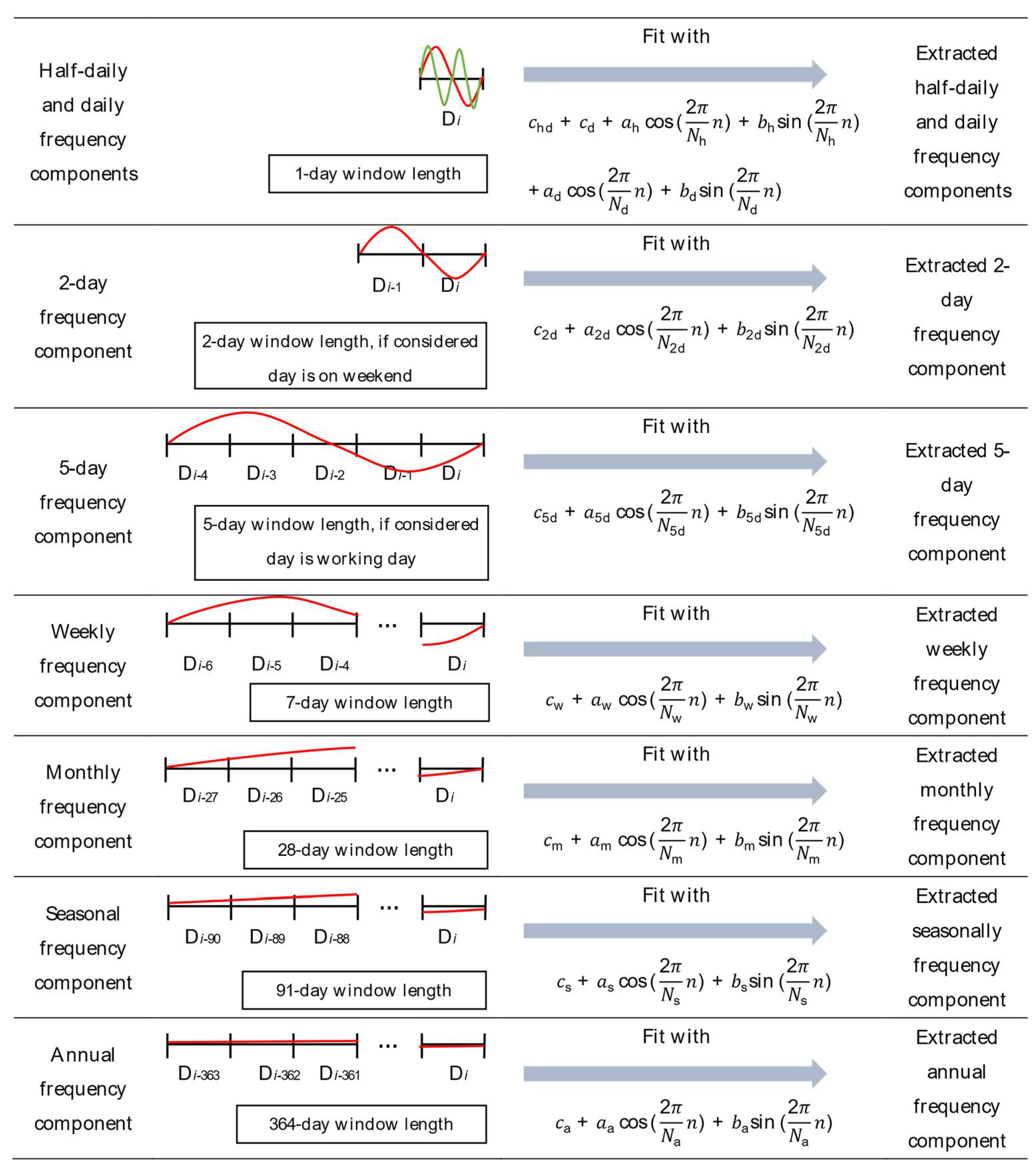
2. Selection of Target Frequency Components for Fourier Series Decomposition and Correlational Analysis
2.1. Description of Available Datasets
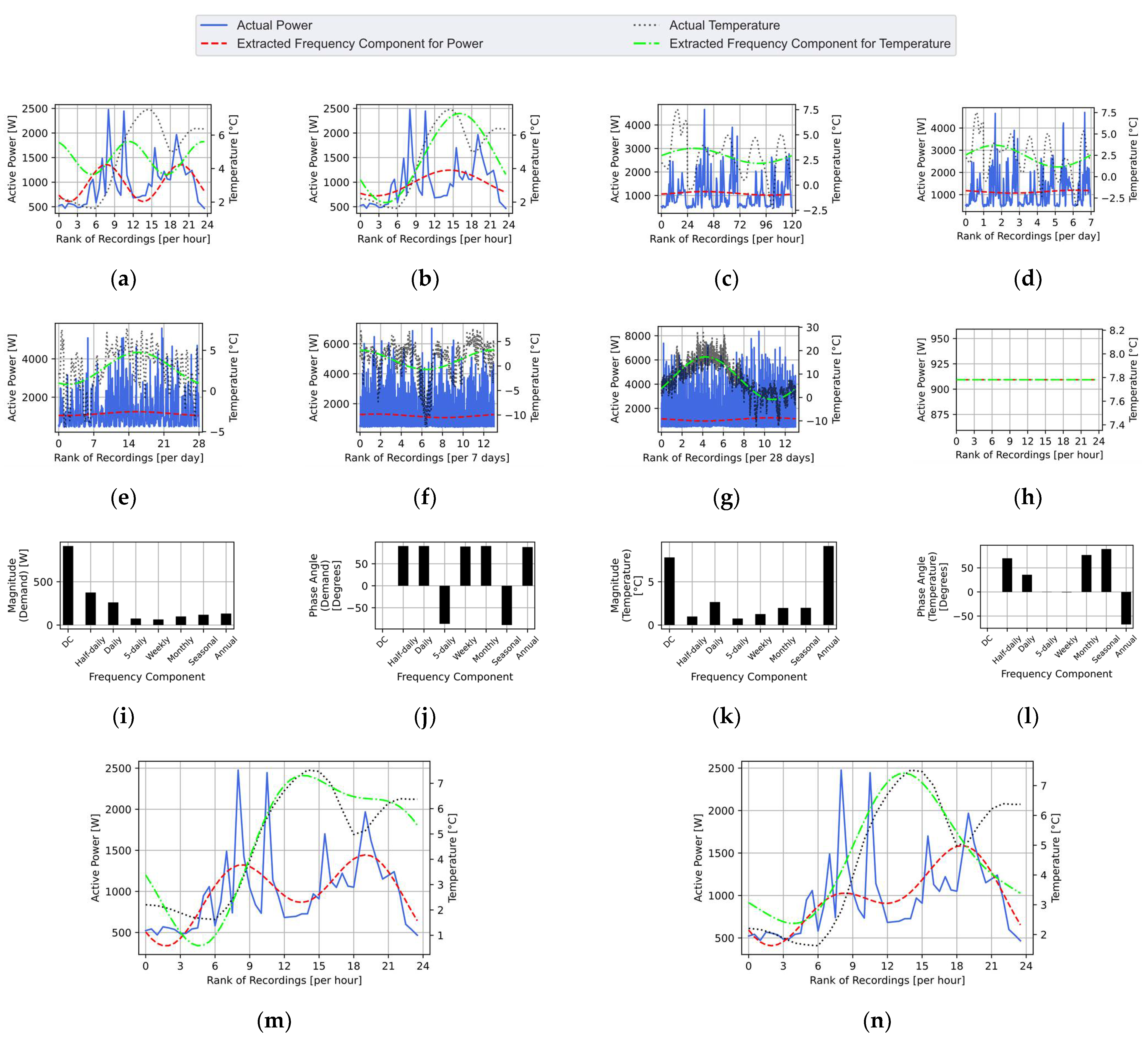
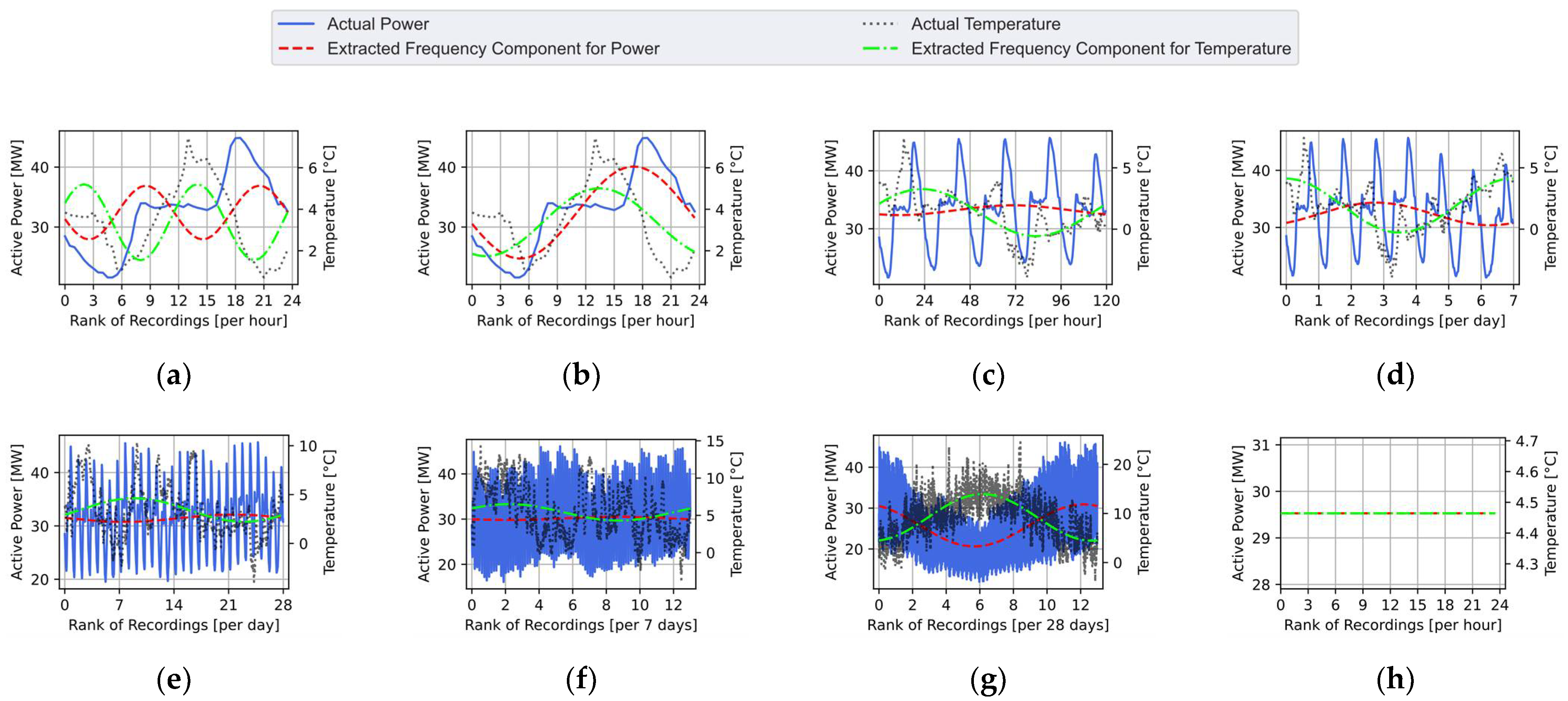
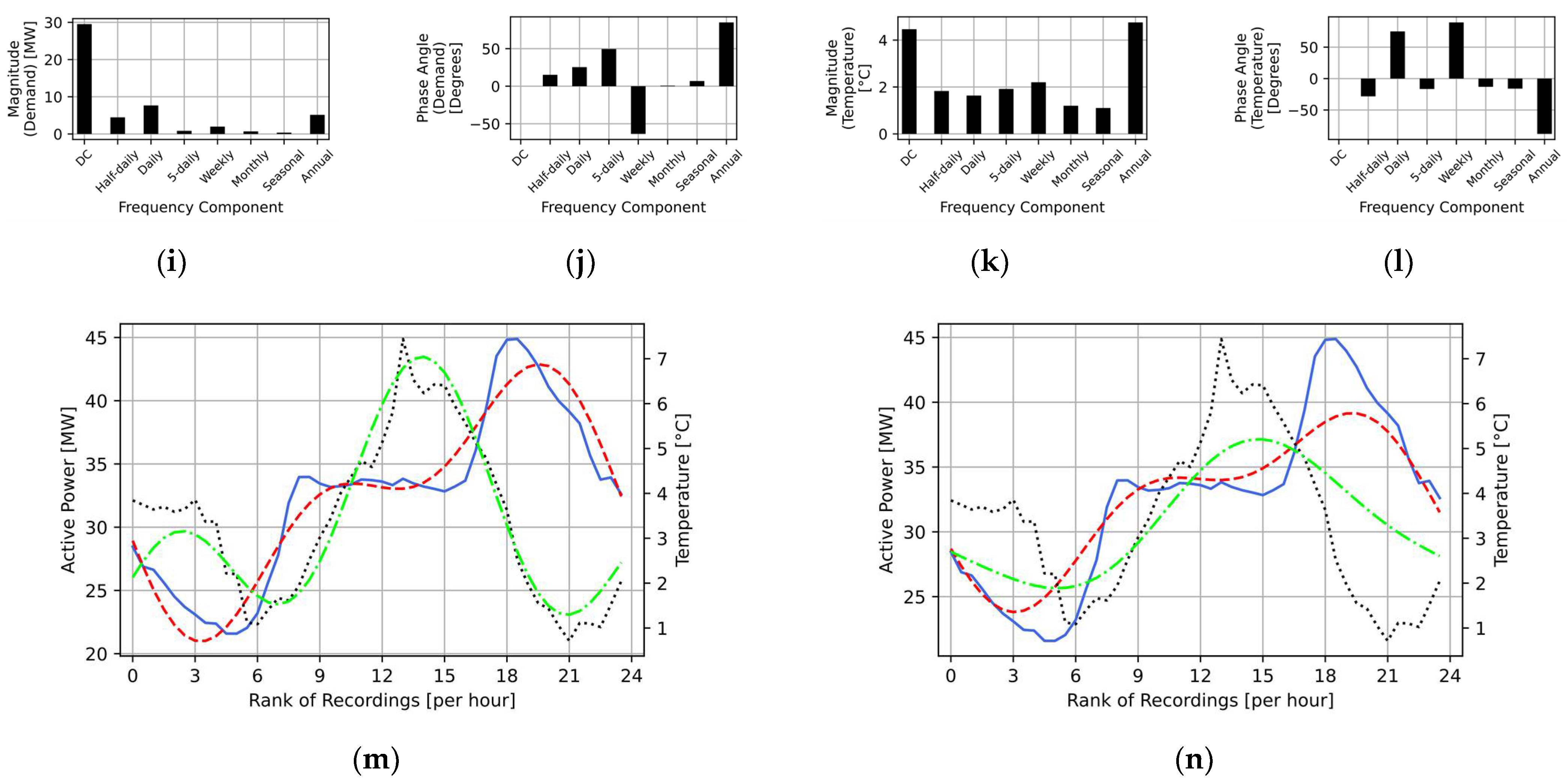
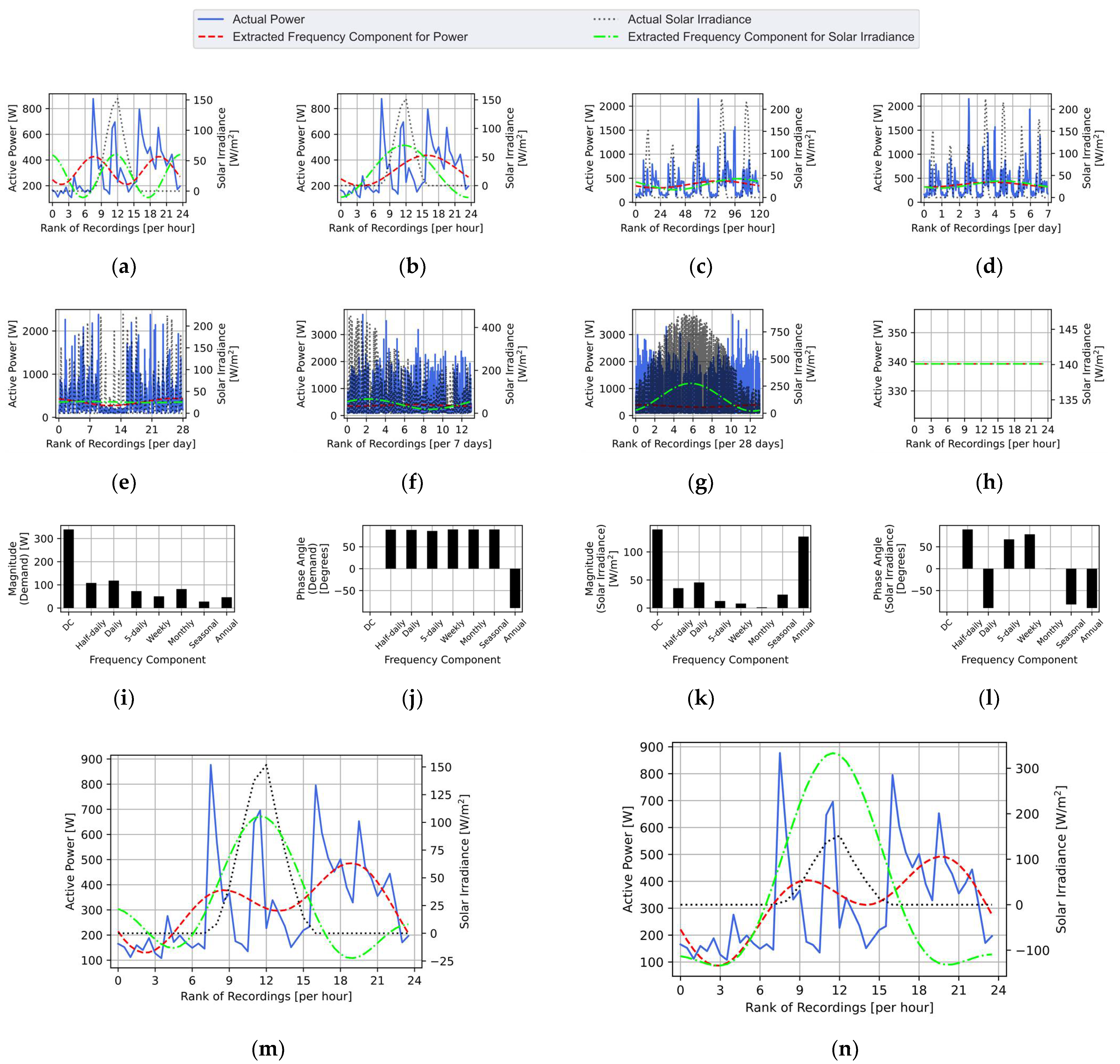
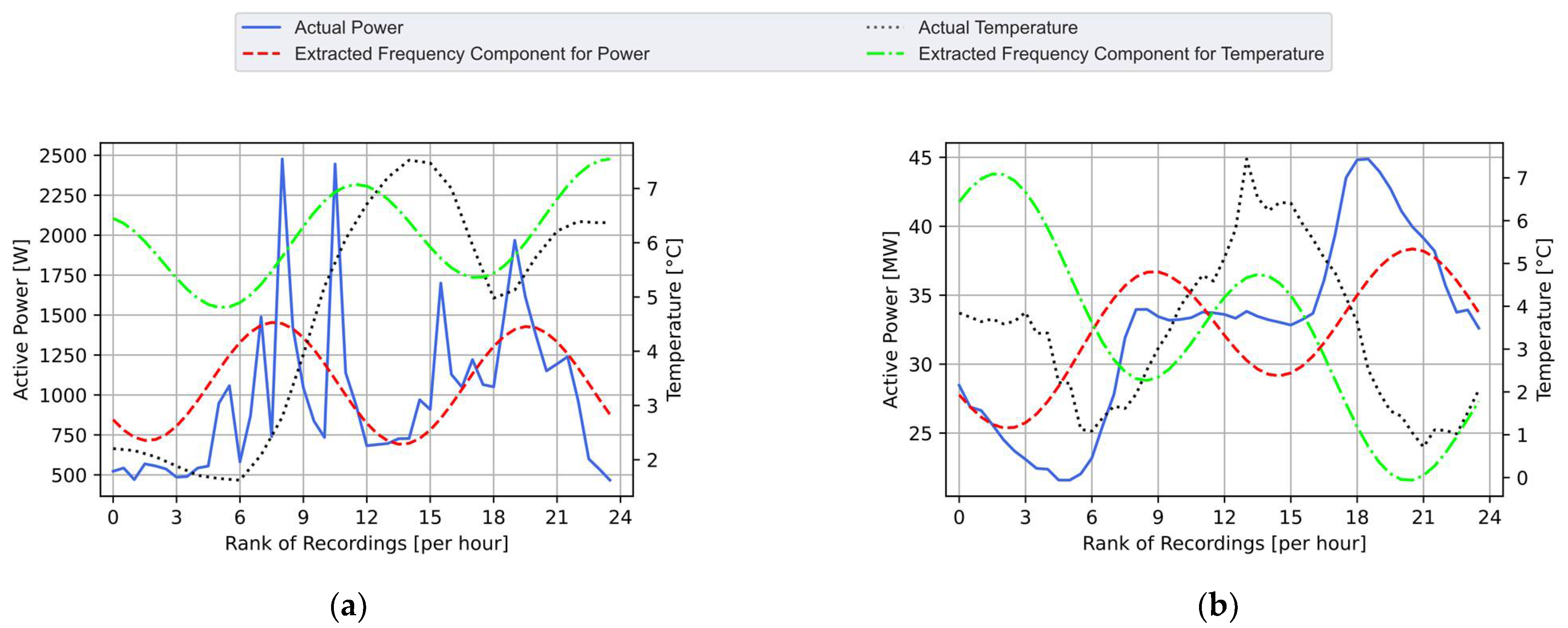
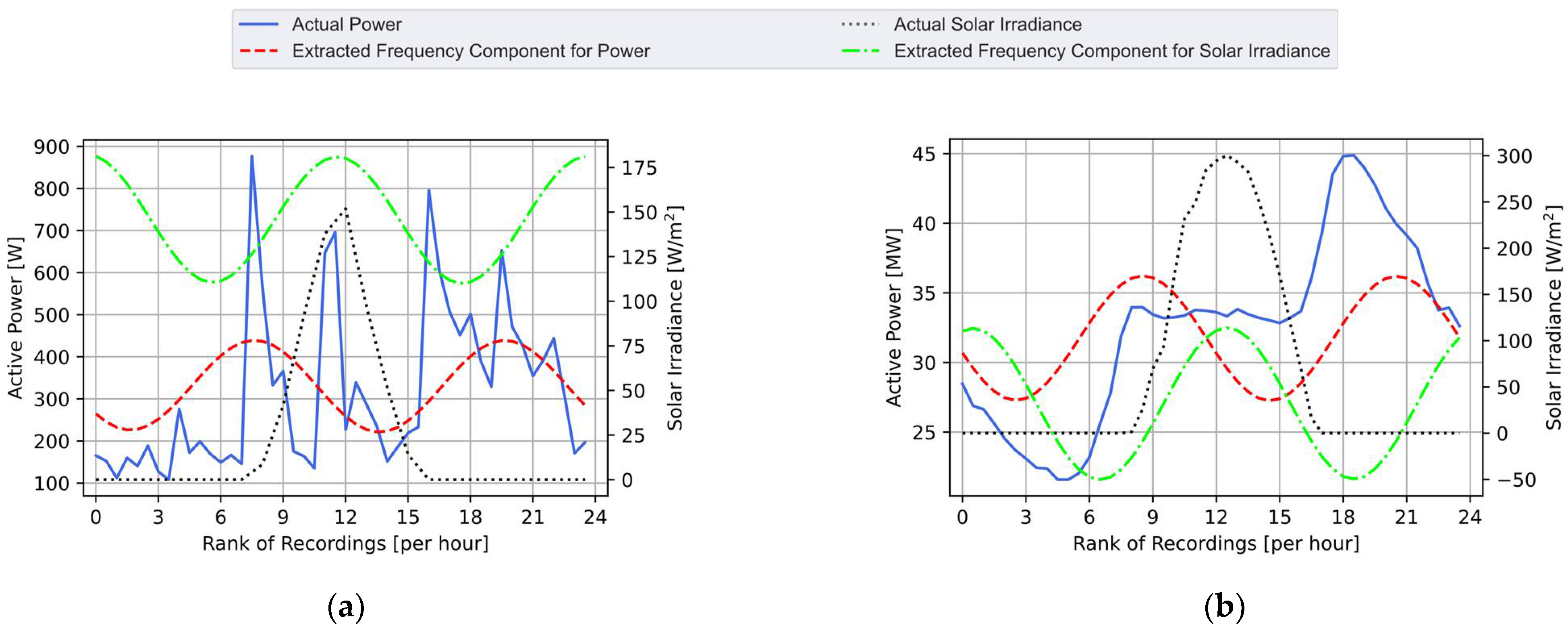
2.2. Disaggregation through Targeted Single-Components Fourier Series Decomposition
2.3. Extraction of the Strongly Correlated Components
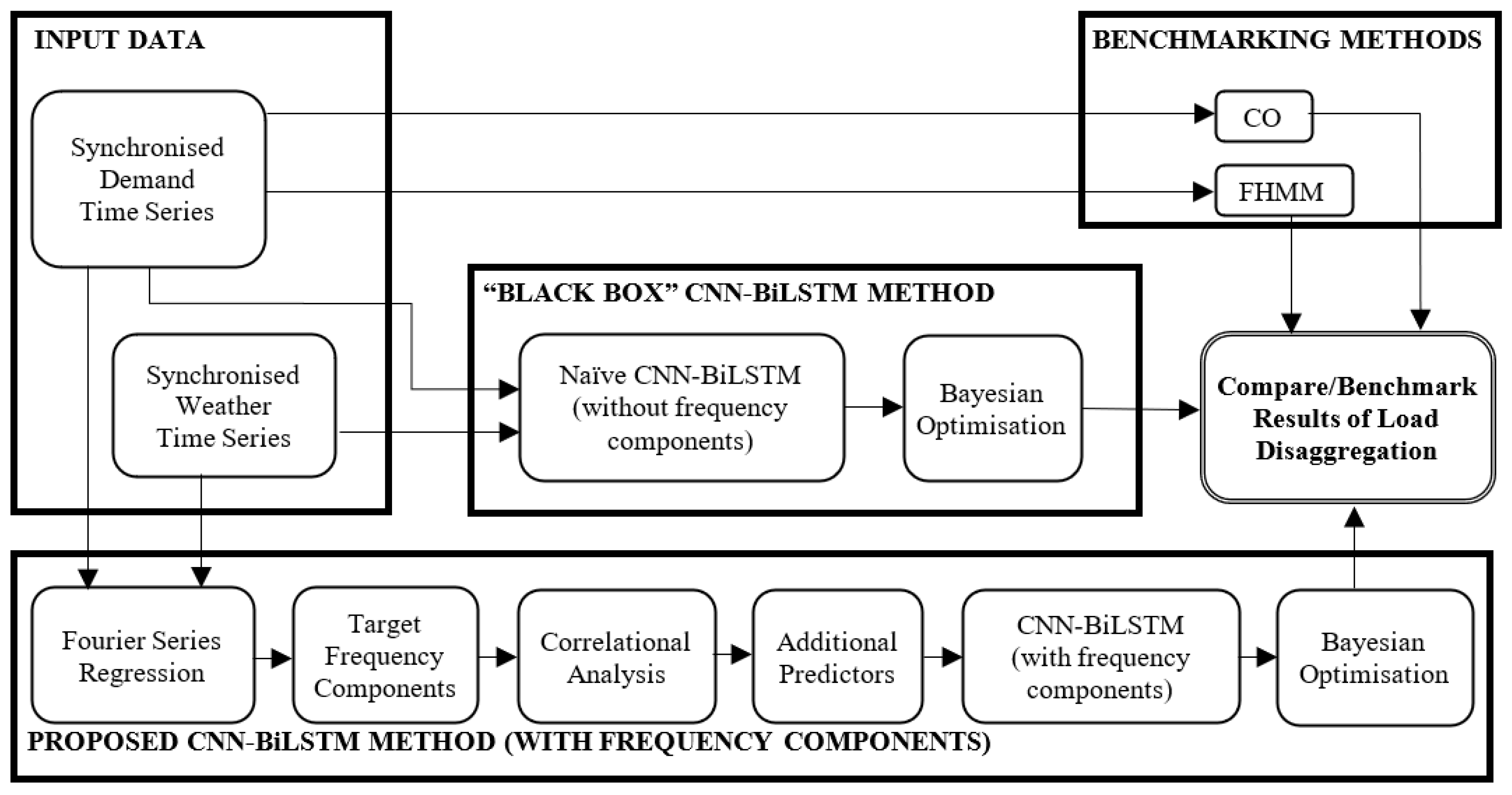
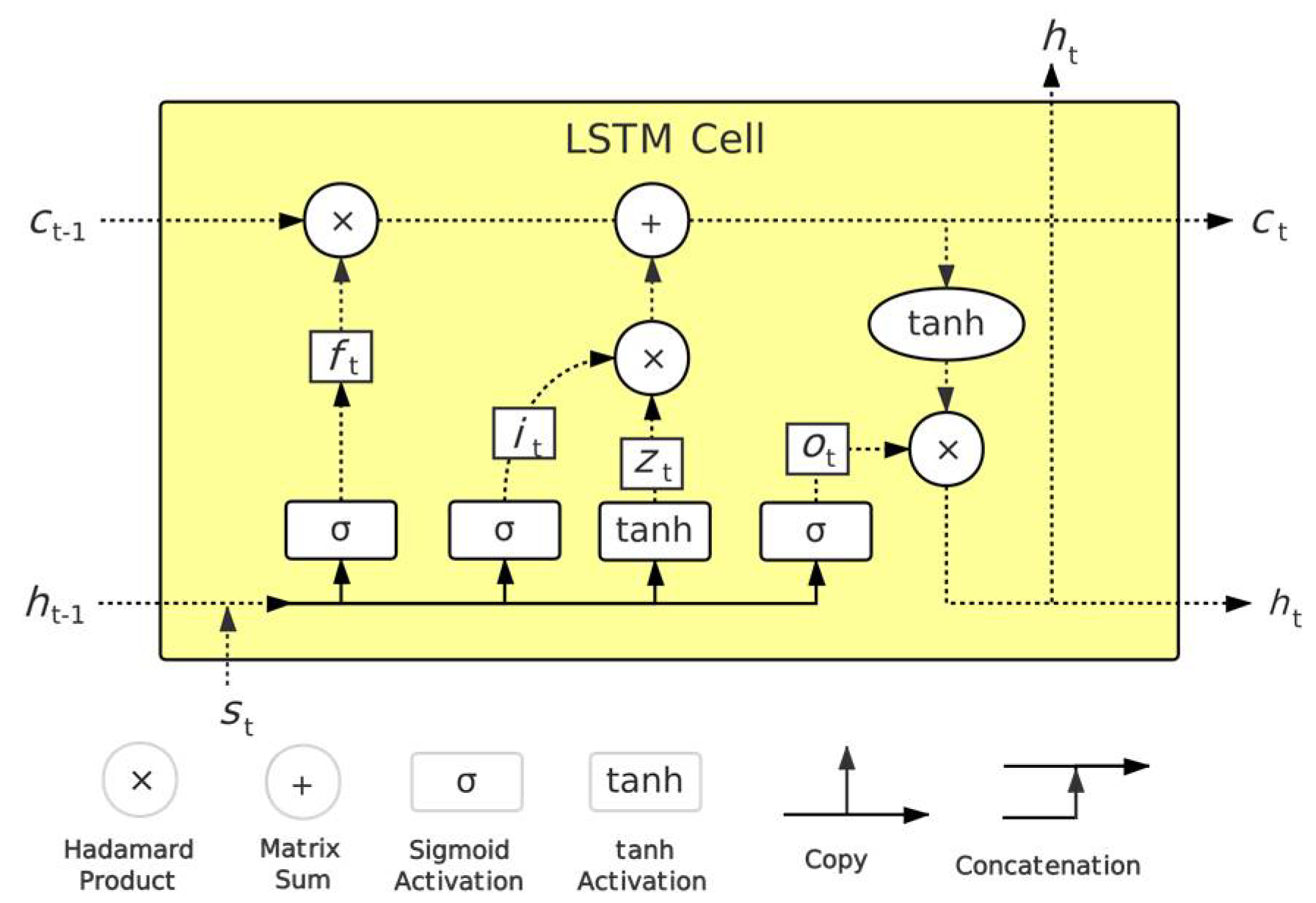
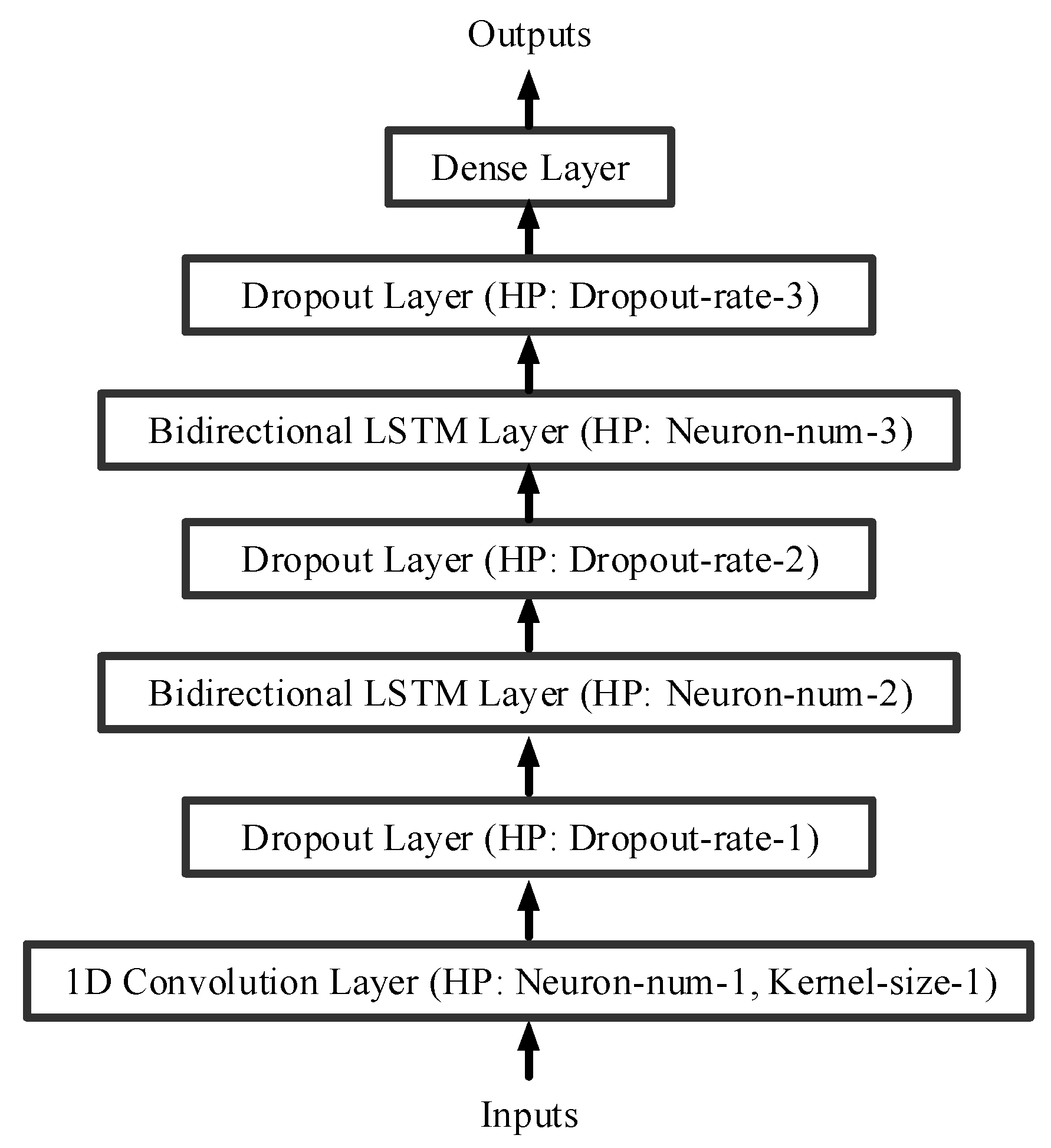
3. Neural Network Load Disaggregation Model
3.1. CNN-BiLSTM Load Disaggregation Model
3.2. Tuning of Model Hyperparameter: Bayesian Optimisation (BO)
- Fit the GP using D1:t = ((x1, y1), (x2, y2), …, (xt, yt));
- Determine xt+1 = argmaxxt+1 (UCB(μt(xt+1), σt(xt+1)));
- Evaluate yt+1 = f(xt+1);
- Insert (xt+1, yt+1) into D1:t and obtain D1:t+1.
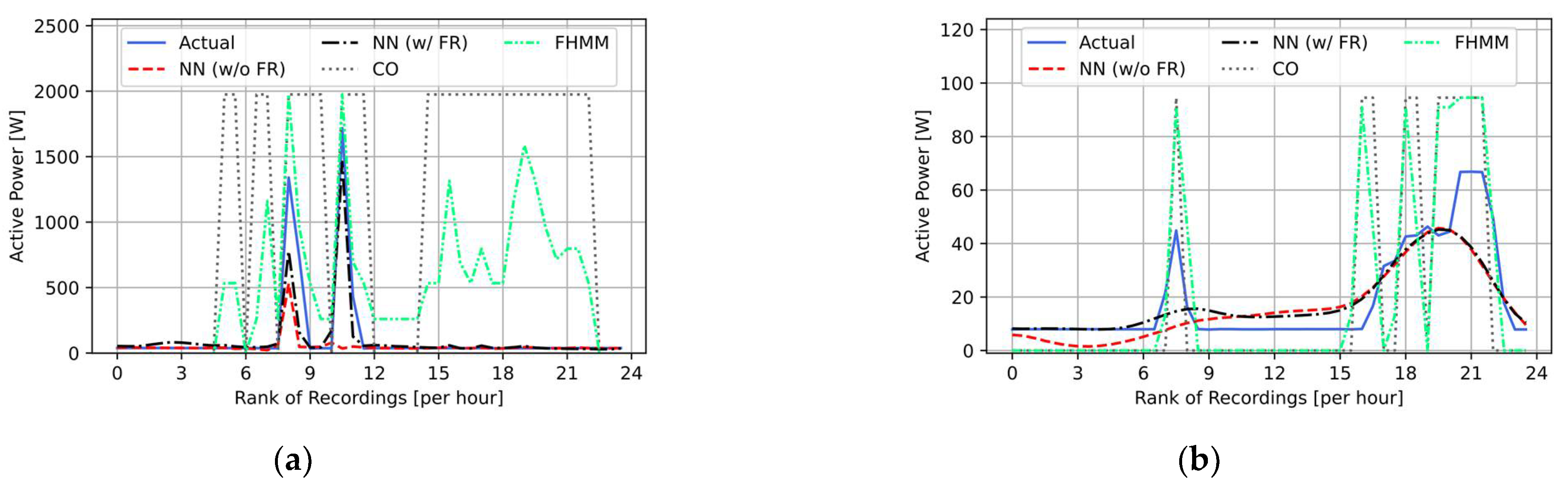
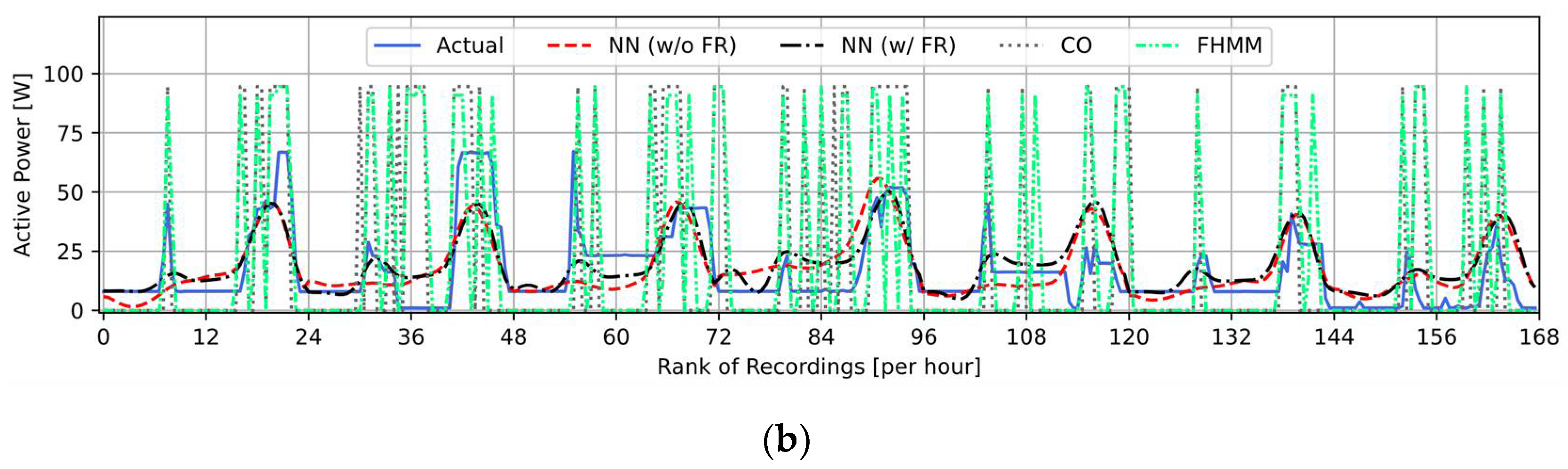
3.3. Load Disaggregation Results and the Benefits of Using Fourier Series Regression
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Papaefthymiou, G.; Hasche, B.; Nabe, C. Potential of Heat Pumps for Demand Side Management and Wind Power Integration in the German Electricity Market. IEEE Trans. Sustain. Energy 2012, 3, 636–642. [Google Scholar] [CrossRef]
- Yao, E.; Samadi, P.; Wong, V.W.S.; Schober, R. Residential Demand Side Management Under High Penetration of Rooftop Photovoltaic Units. IEEE Trans. Smart Grid 2016, 7, 1597–1608. [Google Scholar] [CrossRef]
- Quek, Y.T.; Woo, W.L.; Logenthiran, T. Load Disaggregation Using One-Directional Convolutional Stacked Long Short-Term Memory Recurrent Neural Network. IEEE Syst. J. 2020, 14, 1395–1404. [Google Scholar] [CrossRef]
- Kelly, J.D. Disaggregation of Domestic Smart Meter Energy Data. Ph.D. Thesis, University of London, London, UK, 2017. [Google Scholar]
- Kaselimi, M.; Doulamis, N.; Voulodimos, A.; Protopapadakis, E.; Doulamis, A. Context Aware Energy Disaggregation Using Adaptive Bidirectional LSTM Models. IEEE Trans. Smart Grid 2020, 11, 3054–3067. [Google Scholar] [CrossRef]
- He, K.; Stankovic, L.; Liao, J.; Stankovic, V. Non-Intrusive Load Disaggregation Using Graph Signal Processing. IEEE Trans. Smart Grid 2018, 9, 1739–1747. [Google Scholar] [CrossRef] [Green Version]
- Altrabalsi, H.; Stankovic, V.; Liao, J.; Stankovic, L. Low-complexity energy disaggregation using appliance load modelling. AIMS Energy 2016, 4, 884–905. [Google Scholar] [CrossRef]
- Liao, J.; Elafoudi, G.; Stankovic, L.; Stankovic, V. Non-intrusive appliance load monitoring using low-resolution smart meter data. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 535–540. [Google Scholar]
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Kolter, J.Z.; Jaakkola, T. Approximate Inference in Additive Factorial HMMs with Application to Energy Disaggregation. In Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, La Palma, Spain, 21–23 April 2012; pp. 1472–1482. [Google Scholar]
- Bonfigli, R.; Principi, E.; Fagiani, M.; Severini, M.; Squartini, S.; Piazza, F. Non-intrusive load monitoring by using active and reactive power in additive Factorial Hidden Markov Models. Appl. Energy 2017, 208, 1590–1607. [Google Scholar] [CrossRef]
- Leeb, S.B.; Shaw, S.R.; Kirtley, J.L. Transient event detection in spectral envelope estimates for nonintrusive load monitoring. IEEE Trans. Power Deliv. 1995, 10, 1200–1210. [Google Scholar] [CrossRef] [Green Version]
- Chang, H.-H. Non-Intrusive Demand Monitoring and Load Identification for Energy Management Systems Based on Transient Feature Analyses. Energies 2012, 5, 4569–4589. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Le, T.-T.-H.; Kim, H. Nonintrusive Load Monitoring Based on Advanced Deep Learning and Novel Signature. Comput. Intell. Neurosci. 2017, 2017, 4216281. [Google Scholar] [CrossRef] [PubMed]
- Kelly, J.; Knottenbelt, W. Neural NILM: Deep Neural Networks Applied to Energy Disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Korea, 4–5 November 2015; pp. 55–64. [Google Scholar]
- Sun, M.; Zhang, T.; Wang, Y.; Strbac, G.; Kang, C. Using Bayesian Deep Learning to Capture Uncertainty for Residential Net Load Forecasting. IEEE Trans. Power Syst. 2020, 35, 188–201. [Google Scholar] [CrossRef] [Green Version]
- Sadeghianpourhamami, N.; Ruyssinck, J.; Deschrijver, D.; Dhaene, T.; Develder, C. Comprehensive feature selection for appliance classification in NILM. Energy Build. 2017, 151, 98–106. [Google Scholar] [CrossRef] [Green Version]
- Schirmer, P.A.; Mporas, I. Statistical and Electrical Features Evaluation for Electrical Appliances Energy Disaggregation. Sustainability 2019, 11, 3222. [Google Scholar] [CrossRef] [Green Version]
- Zou, M.; Fang, D.; Djokic, S.; Hawkins, S. Assessment of wind energy resources and identification of outliers in on-shore and off-shore wind farm measurements. In Proceedings of the 3rd International Conference on Offshore Renewable Energy (CORE), Glasgow, UK, 29–30 August 2018. [Google Scholar]
- Makonin, S.; Ellert, B.; Bajić, I.V.; Popowich, F. Electricity, water, and natural gas consumption of a residential house in Canada from 2012 to 2014. Sci. Data 2016, 3, 160037. [Google Scholar] [CrossRef] [Green Version]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef] [Green Version]
- Gelaro, R.; McCarty, W.; Suárez, M.J.; Todling, R.; Molod, A.; Takacs, L.; Randles, C.; Darmenov, A.; Bosilovich, M.G.; Reichle, R.; et al. The Modern-Era Retrospective Analysis for Research and Applications, Version 2 (MERRA-2). J. Clim. 2017, 30, 5419–5454. [Google Scholar] [CrossRef] [PubMed]
- Zou, M.; Fang, D.; Harrison, G.; Djokic, S. Weather Based Day-Ahead and Week-Ahead Load Forecasting using Deep Recurrent Neural Network. In Proceedings of the IEEE 5th International forum on Research and Technology for Society and Industry (RTSI), Firenze, Italy, 9–12 September 2019; pp. 341–346. [Google Scholar]
- Kato, T.; Uemura, M. Period Analysis using the Least Absolute Shrinkage and Selection Operator (Lasso). Publ. Astron. Soc. Jpn. 2012, 64, 122. [Google Scholar] [CrossRef] [Green Version]
- Incremona, A.; Nicolao, G.D. Spectral Characterization of the Multi-Seasonal Component of the Italian Electric Load: A LASSO-FFT Approach. IEEE Control Syst. Lett. 2020, 4, 187–192. [Google Scholar] [CrossRef]
- Goertzel, G. An Algorithm for the Evaluation of Finite Trigonometric Series. Am. Math. Mon. 1958, 65, 34. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Wang, X.; Su, J.; Tang, B.; Wu, S. A Labeling Method for Financial Time Series Prediction Based on Trends. Entropy 2020, 22, 1162. [Google Scholar] [CrossRef]
- Zou, M.; Fang, D.; Djokic, S.; Di Giorgio, V.; Langella, R.; Testa, A. Evaluation of Wind Turbine Power Outputs with and without Uncertainties in Input Wind Speed and Wind Direction Data. IET Renew. Power Gener. 2020, 14, 2801–2809. [Google Scholar] [CrossRef]
- Mahfoud, S.; Mani, G. Financial forecasting using genetic algorithms. Appl. Artif. Intell. 1996, 10, 543–566. [Google Scholar] [CrossRef]
- Hauke, J.; Kossowski, T. Comparison of Values of Pearson’s and Spearman’s Correlation Coefficients on the Same Sets of Data. Quaest. Geogr. 2011, 30, 87–93. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin, Germany, 2006. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Chen, G. A Gentle Tutorial of Recurrent Neural Network with Error Backpropagation. arXiv 2016, arXiv:1610.02583. [Google Scholar]
- Hochreiter, S.; Schmidhuber, j. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, Fully Connected Deep Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Duvenaud, D.K. Automatic Model Construction with Gaussian Processes. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2014. [Google Scholar]
- Srinivas, N.; Krause, A.; Kakade, S.; Seeger, M. Gaussian process optimization in the bandit setting: No regret and experimental design. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 1015–1022. [Google Scholar]
- Batra, N.; Kelly, J.; Parson, O.; Dutta, H.; Knottenbelt, W.; Rogers, A.; Singh, A.; Srivastava, M. NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring. In Proceedings of the 5th International Conference on Future Energy Systems (ACM e-Energy), Cambridge, UK, 11–13 June 2014. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temperature Reconstruction | MAE [°C] | RMSE [°C] | Demand Reconstruction | MAE [W] | RMSE [W] | EO [Wh] | EO [%] | EU [Wh] | EU [%] | ET [Wh] | ET [%] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Conv. Fourier | 0.901 | 1.182 | Conv. Fourier | 253.281 | 383.512 | 3039.368 | 24.736 | 3039.368 | 26.850 | 0.000 | 0.000 |
| Proposed FSR | 0.506 | 0.652 | Proposed FSR | 233.751 | 347.824 | 2805.014 | 25.009 | 2805.014 | 22.638 | 0.000 | 0.000 |
| Temperature Reconstruction | MAE [°C] | RMSE [°C] | Demand Reconstruction | MAE [MW] | RMSE [MW] | EO [MWh] | EO [%] | EU [MWh] | EU [%] | ET [MWh] | ET [%] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Conv. Fourier | 1.085 | 1.287 | Conv. Fourier | 1.766 | 2.427 | 21.192 | 5.131 | 21.192 | 5.806 | 0.000 | 0.000 |
| Proposed FSR | 0.464 | 0.567 | Proposed FSR | 1.447 | 1.768 | 17.361 | 4.507 | 17.361 | 4.419 | 0.000 | 0.000 |
| Solar Irradiance Reconstruction | MAE [W/m2] | RMSE [W/m2] | Demand Reconstruction | MAE [W] | RMSE [W] | EO [Wh] | EO [%] | EU [Wh] | EU [%] | ET [Wh] | ET [%] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Conv. Fourier | 121.469 | 131.259 | Conv. Fourier | 117.872 | 160.147 | 1414.469 | 41.507 | 1414.469 | 33.464 | 0.000 | 0.000 |
| Proposed FSR | 15.713 | 19.009 | Proposed FSR | 110.304 | 155.998 | 1323.643 | 39.530 | 1323.643 | 30.881 | 0.000 | 0.000 |
| Solar Irradiance Reconstruction | MAE [W/m2] | RMSE [W/m2] | Demand Reconstruction | MAE [MW] | RMSE [MW] | EO [MWh] | EO [%] | EU [MWh] | EU [%] | ET [MWh] | ET [%] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Conv. Fourier | 43.117 | 51.570 | Conv. Fourier | 1.766 | 2.427 | 21.192 | 5.131 | 21.192 | 5.806 | 0.000 | 0.000 |
| Proposed FSR | 27.481 | 31.472 | Proposed FSR | 1.447 | 1.768 | 17.361 | 4.507 | 17.361 | 4.419 | 0.000 | 0.000 |
| Half Daily | Daily | 5 Days’ | Weekly | Monthly | Seasonal | Annual | |
|---|---|---|---|---|---|---|---|
| Figure 3 | −0.3677 | 0.8849 | 1.0000 | −1.0000 | 1.0000 | −1.0000 | −1.0000 |
| Figure 4 | −0.9145 | 0.5363 | 0.2553 | −1.0000 | −1.0000 | −1.0000 | −1.0000 |
| Figure 5 | −0.4814 | 0.4251 | 0.9946 | −0.7414 | −1.0000 | −1.0000 | 1.0000 |
| Figure 6 | −0.4816 | 0.3672 | −0.2561 | 1.0000 | 1.0000 | −1.0000 | −1.0000 |
| Constraints | AMPds2, w/o FR | AMPds2, w/FR | UK-DALE, w/o FR | UK-DALE, w/FR | |
|---|---|---|---|---|---|
| Neuron-num-1 | (8:1:16) | 13 | 8 | 9 | 12 |
| Kernel-size-1 | (3:2:7) | 5 | 5 | 5 | 5 |
| Dropout-rate-1 | (0.05:0.05:0.5) | 0.2 | 0.15 | 0.25 | 0.4 |
| Neuron-num-2 | (48:8:128) | 88 | 120 | 80 | 56 |
| Dropout-rate-2 | (0.05:0.05:0.5) | 0.45 | 0.45 | 0.3 | 0.3 |
| Neuron-num-3 | (48:8:128) | 64 | 80 | 128 | 120 |
| Dropout-rate-3 | (0.05:0.05:0.5) | 0.2 | 0.2 | 0.1 | 0.35 |
| Adam learning rate | (0.0005, 0.001, 0.005) | 0.0005 | 0.0005 | 0.0005 | 0.005 |
| MAE [W] | RMSE [W] | EO [Wh] | EO [%] | EU [Wh] | EU [%] | ET [Wh] | ET [%] | ||
|---|---|---|---|---|---|---|---|---|---|
| AMPds2 | NN, w/o FR | 78.295 | 292.132 | 80.115 | 15.857 | 1798.954 | 74.131 | −1718.839 | −58.624 |
| NN, w/FR | 50.393 | 131.612 | 342.627 | 53.778 | 866.815 | 37.772 | −524.188 | −17.878 | |
| CO | 1027.054 | 1375.749 | 24,129.788 | 952.398 | 519.509 | 130.410 | 23,610.280 | 805.276 | |
| FHMM | 414.752 | 562.774 | 9624.049 | 361.166 | 330.011 | 123.492 | 9294.038 | 316.992 | |
| UK-DALE | NN, w/o FR | 11.213 | 13.616 | 267.908 | 75.557 | 1.213 | 12.301 | 266.695 | 73.18 |
| NN, w/FR | 6.996 | 8.77 | 159.78 | 52.472 | 8.126 | 13.558 | 151.654 | 41.613 | |
| CO | 23.810 | 33.603 | 268.930 | 434.256 | 302.508 | 100.000 | −33.578 | −9.214 | |
| FHMM | 19.924 | 27.290 | 203.949 | 243.845 | 274.236 | 97.663 | −70.287 | −19.287 |
| MAE [W] | RMSE [W] | EO [kWh] | EO [%] | EU [kWh] | EU [%] | ET [kWh] | ET [%] | ||
|---|---|---|---|---|---|---|---|---|---|
| AMPds2 | NN, w/o FR | 166.332 | 375.100 | 7.341 | 121.448 | 20.602 | 47.061 | −13.261 | −26.617 |
| NN, w/FR | 142.235 | 318.995 | 8.449 | 81.054 | 15.446 | 39.205 | −6.997 | −14.043 | |
| CO | 1005.172 | 1327.605 | 165.334 | 367.322 | 3.535 | 73.462 | 161.799 | 324.747 | |
| FHMM | 509.442 | 731.393 | 82.869 | 185.445 | 2.717 | 52.897 | 80.152 | 160.875 | |
| UK-DALE | NN, w/o FR | 9.164 | 12.055 | 0.887 | 83.941 | 0.652 | 39.020 | 0.235 | 8.620 |
| NN, w/FR | 8.128 | 11.219 | 0.931 | 77.321 | 0.434 | 28.485 | 0.497 | 18.221 | |
| CO | 25.017 | 36.611 | 2.486 | 245.737 | 1.717 | 100.000 | 0.769 | 28.185 | |
| FHMM | 22.692 | 33.526 | 2.454 | 214.682 | 1.358 | 85.660 | 1.096 | 40.172 |
| MAE [W] | RMSE [W] | EO [kWh] | EO [%] | EU [kWh] | EU [%] | ET [kWh] | ET [%] | ||
|---|---|---|---|---|---|---|---|---|---|
| AMPds2 | NN, w/o FR | 136.966 | 341.062 | 43.591 | 139.917 | 74.748 | 46.948 | −31.157 | −16.367 |
| NN, w/FR | 133.853 | 332.633 | 45.178 | 106.736 | 70.472 | 47.602 | −25.294 | −13.287 | |
| CO | 956.996 | 1306.700 | 805.931 | 507.231 | 20.914 | 66.433 | 785.017 | 412.364 | |
| FHMM | 465.163 | 699.053 | 385.334 | 240.339 | 16.567 | 55.149 | 368.767 | 193.711 | |
| UK-DALE | NN, w/o FR | 9.911 | 13.077 | 11.729 | 91.101 | 5.640 | 34.214 | 6.089 | 20.722 |
| NN, w/FR | 9.233 | 12.298 | 11.528 | 89.319 | 4.649 | 28.268 | 6.879 | 23.433 | |
| CO | 23.889 | 34.634 | 21.635 | 236.850 | 20.219 | 100.000 | 1.417 | 4.826 | |
| FHMM | 22.039 | 32.162 | 22.021 | 204.723 | 16.591 | 89.216 | 5.430 | 18.499 |
| FSR (Minute) | BO (Minute) | CNN-BiLSTM (Minute) | CO (Second) | FHMM (Second) | |
|---|---|---|---|---|---|
| MV level dataset | 59 | - | - | - | - |
| AMPds 2 | 15 | (1097, 934) | (15, 14) | 5.4 | 5.1 |
| UK-DALE | 31 | (1230, 750) | (6, 12) | 12.1 | 11.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, M.; Zhu, S.; Gu, J.; Korunovic, L.M.; Djokic, S.Z. Heating and Lighting Load Disaggregation Using Frequency Components and Convolutional Bidirectional Long Short-Term Memory Method. Energies 2021, 14, 4831. https://0-doi-org.brum.beds.ac.uk/10.3390/en14164831
Zou M, Zhu S, Gu J, Korunovic LM, Djokic SZ. Heating and Lighting Load Disaggregation Using Frequency Components and Convolutional Bidirectional Long Short-Term Memory Method. Energies. 2021; 14(16):4831. https://0-doi-org.brum.beds.ac.uk/10.3390/en14164831
Chicago/Turabian StyleZou, Mingzhe, Shuyang Zhu, Jiacheng Gu, Lidija M. Korunovic, and Sasa Z. Djokic. 2021. "Heating and Lighting Load Disaggregation Using Frequency Components and Convolutional Bidirectional Long Short-Term Memory Method" Energies 14, no. 16: 4831. https://0-doi-org.brum.beds.ac.uk/10.3390/en14164831