Efficient Data Structures for Range Shortest Unique Substring Queries †


1
Department of Computer Science, University of Central Florida, Orlando, FL 32816, USA
2
Department of Computer Science, University of Wisconsin - Whitewater, Whitewater, WI 53190, USA
3
Life Sciences and Health, CWI, 1098 XG Amsterdam, The Netherlands
4
Center for Integrative Bioinformatics, Vrije Universiteit, 1081 HV Amsterdam, The Netherlands
*
Author to whom correspondence should be addressed.
†
An early version of this paper appeared in the Proceedings of SPIRE 2019.
Algorithms 2020, 13(11), 276; https://0-doi-org.brum.beds.ac.uk/10.3390/a13110276
Submission received: 9 September 2020
/
Revised: 23 October 2020
/
Accepted: 29 October 2020
/
Published: 30 October 2020
(This article belongs to the Special Issue Combinatorial Methods for String Processing)
{kind=link}
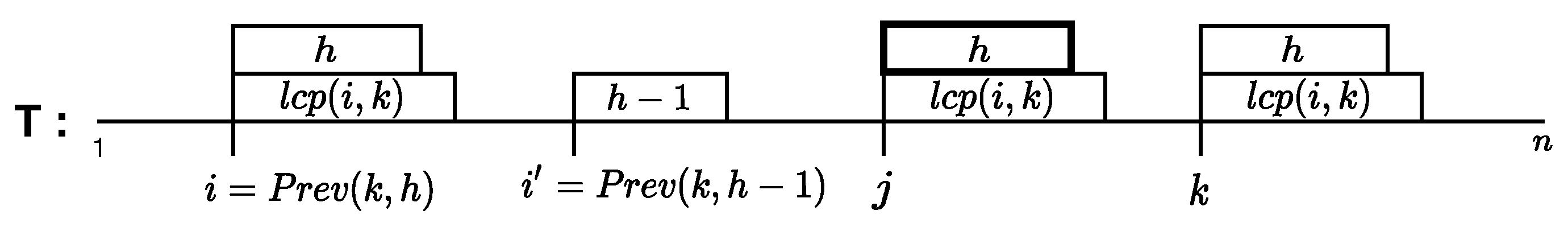{kind=link}
Abstract
:Let be a string of length n and be the substring of starting at position i and ending at position j. A substring of is a repeat if it occurs more than once in ; otherwise, it is a unique substring of . Repeats and unique substrings are of great interest in computational biology and information retrieval. Given string as input, the Shortest Unique Substring problem is to find a shortest substring of that does not occur elsewhere in . In this paper, we introduce the range variant of this problem, which we call the Range Shortest Unique Substring problem. The task is to construct a data structure over answering the following type of online queries efficiently. Given a range , return a shortest substring of with exactly one occurrence in . We present an -word data structure with query time, where is the word size. Our construction is based on a non-trivial reduction allowing for us to apply a recently introduced optimal geometric data structure [Chan et al., ICALP 2018]. Additionally, we present an -word data structure with query time, where is an arbitrarily small constant. The latter data structure relies heavily on another geometric data structure [Nekrich and Navarro, SWAT 2012].
1. Introduction
Finding regularities in strings is one of the main topics of combinatorial pattern matching and its applications [1]. Among the most well-studied types of string regularities is the notion of repeat. Let be a string of length n. A substring of is called a repeat if it occurs more than once in . The notion of unique substring is dual: it is a substring of that does not occur more than once in . Computing repeats and unique substrings has applications in computational biology [2,3] and information retrieval [4,5].
In this paper, we are interested in the notion of shortest unique substring. All of the shortest unique substrings of string can be computed in time using the suffix tree data structure [6,7]. Many different problems based on this notion have already been studied. Pei et al. [4] considered the following problem on the so-called position (or point) queries. Given a position i of , return a shortest unique substring of covering i. The authors gave an -time and -space algorithm, which finds the shortest unique substring covering every position of . Since then, the problem has been revisited and optimal -time algorithms have been presented by Ileri et al. [8] and Tsuruta et al. [9]. Several other variants of this problem have been investigated [10,11,12,13,14,15,16,17,18,19].
We introduce a natural generalization of the shortest unique substring problem. Specifically, our focus is on the range version of the problem, which we call the Range Shortest Unique Substring () problem. The task is to construct a data structure over to be able to answer the following type of online queries efficiently. Given a range , return a shortest substring of with exactly one occurrence (starting position) in ; i.e., , there is no , such that , and h is minimal. Note that this substring, , may end at a position . Further note that there may be multiple shortest unique substrings.
Range queries are a classic data structure topic [20,21,22]. A range query on an array of n elements over some set S, denoted by , takes two indices , a function f defined over arrays of elements of S, and outputs . Range query data structures have also been specifically considered for strings [23,24,25,26]. For instance, in bioinformatics applications we are often interested in finding regularities in certain regions of a DNA sequence [27,28,29,30,31]. In the Range–LCP problem, defined by Amir et al. [23], the task is to construct a data structure over to be able to answer the following type of online queries efficiently. Given a range , return such that the length of the longest common prefix of and is maximal among all pairs of suffixes within this range. The state of the art is an -word data structure supporting -time (polylogarithmic-time) queries [25] (see also [26,32]).
1.1. Main Problem and Main Results
An alphabet is a finite nonempty set of elements called letters. We fix a string over . The length of is denoted by . By , we denote the substring of starting at position i and ending at position j of . We say that another string has an occurrence in or, more simply, that occurs in if , for some i. Thus, we characterize an occurrence of by its starting position i in . A prefix of is a substring of of the form and a suffix of is a substring of of the form .
We next formally define the main problem considered in this paper.
- Problem
- Preprocess: String .
- Query: Range , where .
- Output: such that is a shortest string with exactly one occurrence in .
If the answer is trivial. So, in the rest we assume that .
Example 1.
Given and a query , we need to find a shortest substring of with exactly one occurrence in . The output here is , because is the shortest substring of with exactly one occurrence in .
Our main results are summarized below. We consider the standard word-RAM model of computations with w-bit machine words, where , for stating our results.
Theorem 1.
We can construct an -word data structure that can answer any query on in time.
Theorem 2.
We can construct an -word data structure that can answer any query on in time, where is an arbitrarily small constant.
1.2. Paper Organization
2. An -Word Data Structure
Our construction is based on ingredients, such as the suffix tree [7], heavy-light decomposition [34], and a geometric data structure for rectangle stabbing [35]. Let us start with some definitions.
Definition 1.
For a position and , we define and , as follows:
Intuitively, let x and y be the occurrences of right before and right after the position k, respectively. Subsequently, and . If x (resp., y) does not exist, then (resp., ).
Definition 2.
Let . We define , as follows:
Intuitively, denotes the length of the shortest substring that starts at position k with exactly one occurrence in .
Definition 3.
For a position , we define , as follows:
Example 2.(Running Example for Definition 3) Let and . We have that , , and . Thus, .
Intuitively, stores the set of candidate lengths for the shortest unique substrings starting at position k. We make the following observation.
Observation 1.
, for any .
Example 3.(Running Example for Observation 1) Let and . We have that . For and , , denoting substring . For and , , denoting substring .
The following combinatorial lemma is crucial for efficiency.
Lemma 1.
.
Proof.
The proof of Lemma 1 is deferred to Section 2.1. ☐
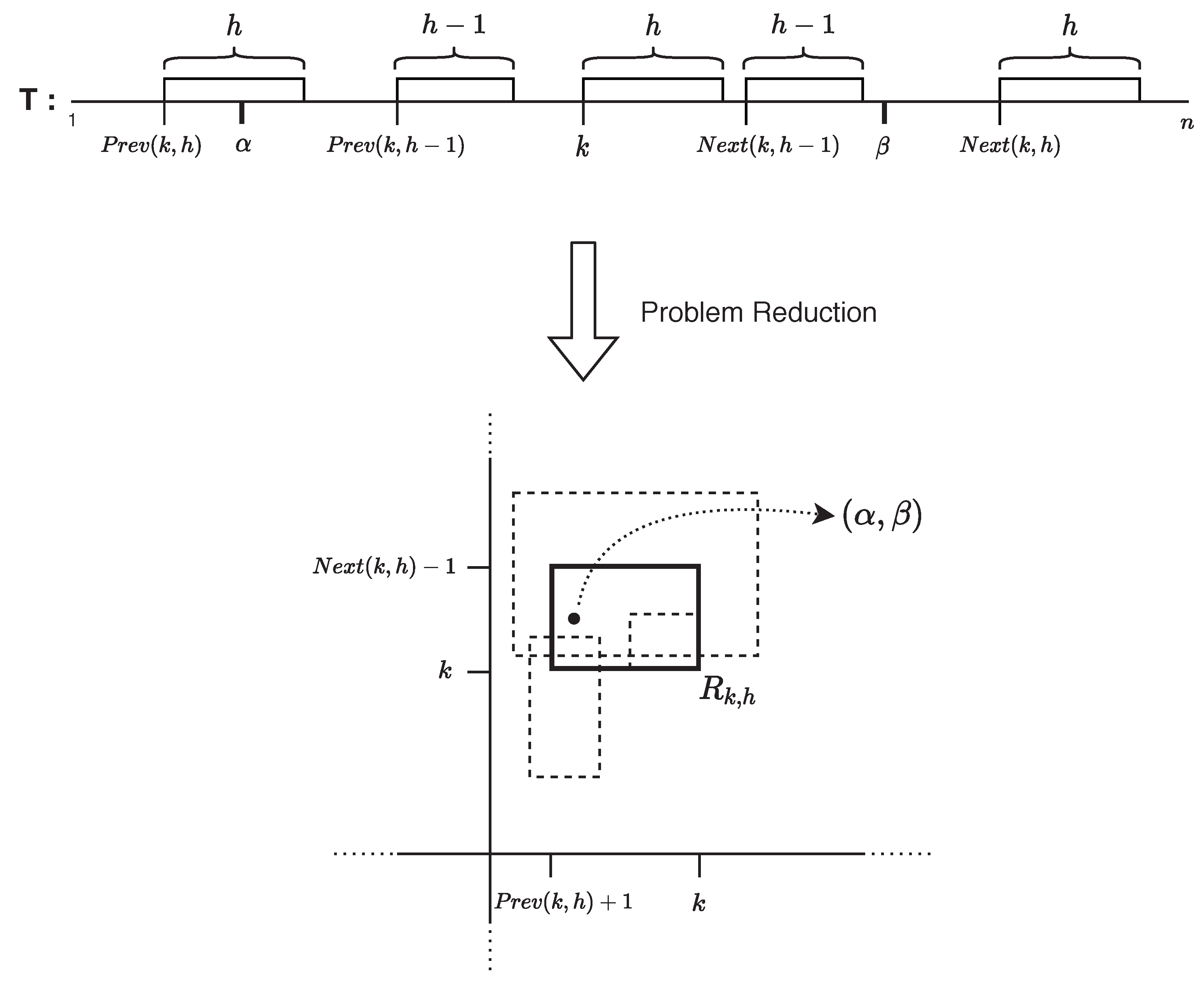
We are now ready to present our construction. By Observation 1, for a given query range , the answer that we are looking for is the pair with the minimum h under the following conditions: , , and . Equivalently, is the pair with the minimum h, such that , , and . We map each into a weighted rectangle with weight h, which is defined as follows:
Let be the set of all such rectangles, then the lowest weighted rectangle in stabbed by the point is . In short, an query on with an input range can be reduced to an equivalent top-1 rectangle stabbing query on a set of rectangles with input point . In the 2-d Top-1 Rectangle Stabbing problem, we preprocess a set of weighted rectangles in 2-d, so that given a query point q the task is to report the largest (or lowest) weighted rectangles containing q [35]. Similarly, here, the task is to report the lowest weighted rectangle in containing the point (see Figure 1 for an illustration). By Lemma 1, we have that . Therefore, by employing the optimal data structure for top-1 rectangle stabbing presented by Chan et al. [35], which takes -word space supporting -time queries, we arrive at the space-time trade-off of Theorem 1. This completes our construction.
2.1. Proof of Lemma 1
Let denote the length of the longest common prefix of the suffixes of starting at positions i and j in . Additionally, let S denote the set of all pairs, such that and , for all . The proof can be broken down into Lemma 2 and Lemma 3.
Lemma 2.
.
Proof.
Let us fix a position k. Let
Clearly we have that .
The following statements can be deduced by a simple contradiction argument:
- Let , where , then
- Let , where , then .
Figure 2 illustrates the proof for the first statement. The second one can be proved in a similar fashion.
Clearly, is proportional to the number of pairs, such that and . Similarly, is proportional to the number of pairs, such that and . Therefore, is proportional to the number of pairs, such that and , for all . This completes the proof of Lemma 2. ☐
Lemma 3.
.
Proof.
Consider the suffix tree data structure of string , which is a compact trie of the n suffixes of appended with a letter [7]. This suffix tree consists of leaves (one for each suffix of ) and at most n internal nodes. The edges are labeled with substrings of . Let u be the lowest common ancestor of the leaves corresponding to the strings and . Subsequently, the concatenation of the edge labels on the path from the root to u is exactly the longest common prefix of and . For any node u, we denote, by , the total number of leaf nodes of the subtree rooted at u.
We decompose the nodes in the suffix tree into light and heavy nodes. The root node is light and for any internal node, exactly one child is heavy. Specifically, the heavy child is the one having the largest number of leaves in its subtree (ties are broken arbitrarily). All other children are light. This tree decomposition is known as heavy-light decomposition. We have the following critical observation. Any path from the root to a leaf node contains many nodes; however, the number of light nodes is at most [34,36]. Additionally, corresponding to the leaves of the suffix tree, there are paths from the root to the leaves. Therefore, the sum of subtree sizes over all light nodes is .
We are now ready to complete the proof. Let denote the set of pairs , such that the lowest common ancestor of the leaves corresponding to suffixes and is u. Clearly, the paths from the root to the leaves that correspond to suffixes and pass from two distinct children of node u and then at least one of the two must be a light node. There are two cases. In the first case, both leaves are under the light children. In the second case, one leaf is under a light child and the other is under the heavy child. In both cases, we have at least one leaf under a light node. If we fix the leaf that is under the light node, we can enumerate the total number of pairs based on the subtree size of the light nodes. Therefore, is at most twice the sum of over all light children of u. Since , we can bound by the sum of over all light nodes in the suffix tree, which is . This completes the proof of Lemma 3. ☐
3. An -Word Data Structure
This section is dedicated to proving Theorem 2. For simplicity, we only focus on the computation of the length ℓ of the output .
Let be the suffix array of string of length n, which is a permutation of , such that if is the ith lexicographically smallest suffix of [37]. Further, let be the inverse suffix array of string of length n, which is a permutation of , such that . Moreover, of can be constructed in linear time and space [38,39].
We observe that an -time solution is straightforward with the aid of the suffix tree of as follows. First, identify those leaves corresponding to the suffixes starting within using the inverse suffix array of and mark them. Subsequently, for each marked leaf, identify its lowest ancestor node (and double mark it), such that a marked neighbor is also under it. This can be done via at most two -time Lowest Common Ancestor (LCA) queries over the suffix tree of while using additional space [22]. Afterwards, find the minimum over the string-depth of all double-marked nodes, add 1 to it, and report it as the length ℓ. The correctness is readily verified.
We employ the above procedure when , where is a parameter to be set later. We now consider the case when . Note that ℓ is the smallest element in . Let be the smallest number after and be the largest number before , such that and are multiples of . Subsequently, can be written as the union of and . Furthermore, can be written as , where
Our construction is based on a solution to the Orthogonal Range Predecessor/Successor in 2-d problem. A set of n points in an grid can be preprocessed into a linear-space data structure, such that the following queries can be answered in time per query [40]:
- .
We next show how to maintain additional structures, so that the smallest element in each of the above sets can be efficiently computed and, thus, the smallest among them can be reported as ℓ.
- Computing the Smallest Element in : for each , we compute and report the smallest among them. We handle each query in time , as follows: first find the leaf corresponding to the string position k in the suffix tree of , then the last (resp., first) leaf on its left (resp., right) side, such that the string position x (resp., y) corresponding to it is in , and report . To efficiently enable the computation of x (resp., y), we preprocess the suffix array into an -word data structure that can answer orthogonal range predecessor (resp., successor) queries in time [40].
- Computing the Smallest Element in : for each , we compute the smallest element in and report the smallest among them. The procedure is the following: find the leaf corresponding to the string position r in the suffix tree of and the last (resp., first) leaf on its left (resp., right) side, such that its corresponding string position x (resp., y) is in (via orthogonal range successor/predecessor queries as earlier). Subsequently, is the length of the longest prefix of with an occurrence d in . However, we need to verify whether occurrence d is unique and its . For this, find the two leftmost occurrences of after r, denoted by and (), via two orthogonal range successor queries. If does not exist, set . Then report if . Otherwise, report .
- Computing the Smallest Element in : for each , we compute the smallest element in and report the smallest among them. The procedure is analogous to that of ; i.e., find the length t of the longest prefix of with an occurrence d in . Then, find the two rightmost occurrences of before r, denoted by and (), via two orthogonal range successor queries. If does not exist, set . Subsequently, report if . Otherwise, report .
- Computing the Smallest Element in : the set can be written as , which is now dependent only on and . Therefore, our idea is to pre-compute and explicitly store the minimum element in for all pairs, where both a and b are multiples of , and for that the desired answer can be retrieved in constant time. The additional space needed is .
We set . The total space is then and total time is . Therefore, we arrive at Theorem 2.
4. Final Remarks
We introduced the Range Shortest Unique Substring () problem, the range variant of the Shortest Unique Substring problem. We presented a -word data structure with query time, where is the word size, for this problem. We also presented a -word data structure with query time, where is an arbitrarily small constant.
We leave the following related questions unanswered:
- Can we design an -word data structure for the problem with polylogarithmic query time?
- Can we design an efficient solution for the k mismatches/edits variation of the problem, perhaps using the framework of [41]?
Author Contributions
The initial draft of this paper was written by P.A. and S.V.T. S.P.P. wrote the introduction section and modified the whole draft. A.G. reviewed and edited the paper. All authors contributed to the manuscript equally by providing critical feedback and helping with the presentation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the U.S. National Science Foundation (NSF) under CCF-1703489.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lothaire, M. Applied Combinatorics on Words; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Schleiermacher, C.; Ohlebusch, E.; Stoye, J.; Choudhuri, J.V.; Giegerich, R.; Kurtz, S. REPuter: The manifold applications of repeat analysis on a genomic scale. Nucleic Acids Res. 2001, 29, 4633–4642. [Google Scholar] [CrossRef] [Green Version]
- Haubold, B.; Pierstorff, N.; Möller, F.; Wiehe, T. Genome comparison without alignment using shortest unique substrings. BMC Bioinform. 2005, 6, 123. [Google Scholar] [CrossRef] [Green Version]
- Pei, J.; Wu, W.C.; Yeh, M. On shortest unique substring queries. In Proceedings of the 29th IEEE International Conference on Data Engineering (ICDE 2013), Brisbane, Australia, 8–12 April 2013; pp. 937–948. [Google Scholar] [CrossRef]
- Khmelev, D.V.; Teahan, W.J. A Repetition Based Measure for Verification of Text Collections and for Text Categorization. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 104–110. [Google Scholar] [CrossRef]
- Gusfield, D. Algorithms on Strings, Trees, and Sequences: Computer Science and Computational Biology; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar] [CrossRef]
- Weiner, P. Linear Pattern Matching Algorithms. In Proceedings of the 14th Annual Symposium on Switching and Automata Theory (SWAT 1973), Iowa City, IA, USA, 15–17 October 1973; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Ileri, A.M.; Külekci, M.O.; Xu, B. Shortest Unique Substring Query Revisited. In Proceedings of the Combinatorial Pattern Matching—25th Annual Symposium (CPM 2014), Moscow, Russia, 16–18 June 2014; pp. 172–181. [Google Scholar] [CrossRef]
- Tsuruta, K.; Inenaga, S.; Bannai, H.; Takeda, M. Shortest Unique Substrings Queries in Optimal Time. In Proceedings of the 40th International Conference on Current Trends in Theory and Practice of Computer Science, Nový Smokovec, Slovakia, 26–29 January 2014; pp. 503–513. [Google Scholar] [CrossRef]
- Abedin, P.; Külekci, M.O.; V Thankachan, S. A Survey on Shortest Unique Substring Queries. Algorithms 2020, 13, 224. [Google Scholar] [CrossRef]
- Allen, D.R.; Thankachan, S.V.; Xu, B. A Practical and Efficient Algorithm for the k-mismatch Shortest Unique Substring Finding Problem. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics (BCB 2018), Washington, DC, USA, 29 August–1 September 2018; pp. 428–437. [Google Scholar] [CrossRef]
- Ganguly, A.; Hon, W.; Shah, R.; Thankachan, S.V. Space-Time Trade-Offs for the Shortest Unique Substring Problem. In Proceedings of the 27th International Symposium on Algorithms and Computation (ISAAC), Sydney, Australia, 12–14 December 2016; pp. 34:1–34:13. [Google Scholar] [CrossRef]
- Ganguly, A.; Hon, W.; Shah, R.; Thankachan, S.V. Space-time trade-offs for finding shortest unique substrings and maximal unique matches. Theor. Comput. Sci. 2017, 700, 75–88. [Google Scholar] [CrossRef]
- Inoue, H.; Nakashima, Y.; Mieno, T.; Inenaga, S.; Bannai, H.; Takeda, M. Algorithms and combinatorial properties on shortest unique palindromic substrings. J. Discret. Algorithms 2018, 52, 122–132. [Google Scholar] [CrossRef]
- Hon, W.; Thankachan, S.V.; Xu, B. In-place algorithms for exact and approximate shortest unique substring problems. Theor. Comput. Sci. 2017, 690, 12–25. [Google Scholar] [CrossRef]
- Mieno, T.; Inenaga, S.; Bannai, H.; Takeda, M. Shortest Unique Substring Queries on Run-Length Encoded Strings. In Proceedings of the 41st International Symposium on Mathematical Foundations of Computer Science MFCS, Kraków, Poland, 22–26 August 2016; pp. 69:1–69:11. [Google Scholar] [CrossRef]
- Schultz, D.W.; Xu, B. On k-Mismatch Shortest Unique Substring Queries Using GPU. In Proceedings of the 14th International Symposium, Bioinformatics Research and Applications, Beijing, China, 8–11 June 2018; pp. 193–204. [Google Scholar] [CrossRef]
- Mieno, T.; Köppl, D.; Nakashima, Y.; Inenaga, S.; Bannai, H.; Takeda, M. Compact Data Structures for Shortest Unique Substring Queries. In Proceedings of the 26th International Symposium, String Processing and Information Retrieval, Segovia, Spain, 7–9 October 2019; pp. 107–123. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, K.; Nakashima, Y.; Inenaga, S.; Bannai, H.; Takeda, M. Shortest Unique Palindromic Substring Queries on Run-Length Encoded Strings. In Proceedings of the 30th International Workshop Combinatorial Algorithms, Pisa, Italy, 23–25 July 2019; pp. 430–441. [Google Scholar] [CrossRef]
- Yao, A.C. Space-time Tradeoff for Answering Range Queries (Extended Abstract). In Proceedings of the Fourteenth Annual ACM Symposium on Theory of Computing (STOC ’82), San Francisco, CA, USA, 5–7 May 1982; pp. 128–136. [Google Scholar] [CrossRef]
- Berkman, O.; Vishkin, U. Recursive Star-Tree Parallel Data Structure. SIAM J. Comput. 1993, 22, 221–242. [Google Scholar] [CrossRef]
- Bender, M.A.; Farach-Colton, M. The LCA Problem Revisited. In Proceedings of the 4th Latin American Symposium, LATIN 2000: Theoretical Informatics, Punta del Este, Uruguay, 10–14 April 2000; pp. 88–94. [Google Scholar] [CrossRef]
- Amir, A.; Apostolico, A.; Landau, G.M.; Levy, A.; Lewenstein, M.; Porat, E. Range LCP. J. Comput. Syst. Sci. 2014, 80, 1245–1253. [Google Scholar] [CrossRef]
- Amir, A.; Lewenstein, M.; Thankachan, S.V. Range LCP Queries Revisited. In Proceedings of the 22nd International Symposium, String Processing and Information Retrieval, London, UK, 1–4 September 2015; pp. 350–361. [Google Scholar] [CrossRef]
- Abedin, P.; Ganguly, A.; Hon, W.; Nekrich, Y.; Sadakane, K.; Shah, R.; Thankachan, S.V. A Linear-Space Data Structure for Range-LCP Queries in Poly-Logarithmic Time. In Proceedings of the 24th International Conference, Computing and Combinatorics, Qing Dao, China, 2–4 July 2018; pp. 615–625. [Google Scholar] [CrossRef]
- Ganguly, A.; Patil, M.; Shah, R.; Thankachan, S.V. A Linear Space Data Structure for Range LCP Queries. Fundam. Inform. 2018, 163, 245–251. [Google Scholar] [CrossRef]
- Pissis, S.P. MoTeX-II: Structured MoTif eXtraction from large-scale datasets. BMC Bioinform. 2014, 15, 235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Almirantis, Y.; Charalampopoulos, P.; Gao, J.; Iliopoulos, C.S.; Mohamed, M.; Pissis, S.P.; Polychronopoulos, D. On avoided words, absent words, and their application to biological sequence analysis. Algorithms Mol. Biol. 2017, 12, 5:1–5:12. [Google Scholar] [CrossRef] [Green Version]
- Ayad, L.A.K.; Pissis, S.P.; Polychronopoulos, D. CNEFinder: Finding conserved non-coding elements in genomes. Bioinformatics 2018, 34, i743–i747. [Google Scholar] [CrossRef] [Green Version]
- Iliopoulos, C.S.; Mohamed, M.; Pissis, S.P.; Vayani, F. Maximal Motif Discovery in a Sliding Window. In Proceedings of the 25th International Symposium, String Processing and Information Retrieval, Lima, Peru, 9–11 October 2018; pp. 191–205. [Google Scholar] [CrossRef]
- Almirantis, Y.; Charalampopoulos, P.; Gao, J.; Iliopoulos, C.S.; Mohamed, M.; Pissis, S.P.; Polychronopoulos, D. On overabundant words and their application to biological sequence analysis. Theor. Comput. Sci. 2019, 792, 85–95. [Google Scholar] [CrossRef] [Green Version]
- Matsuda, K.; Sadakane, K.; Starikovskaya, T.; Tateshita, M. Compressed Orthogonal Search on Suffix Arrays with Applications to Range LCP. In Proceedings of the 31st Annual Symposium on Combinatorial Pattern Matching, Copenhagen, Denmark, 17–19 June 2020; pp. 23:1–23:13. [Google Scholar] [CrossRef]
- Abedin, P.; Ganguly, A.; Pissis, S.P.; Thankachan, S.V. Range Shortest Unique Substring Queries. In Proceedings of the 26th International Symposium, String Processing and Information Retrieval, Segovia, Spain, 7–9 October 2019; pp. 258–266. [Google Scholar] [CrossRef] [Green Version]
- Sleator, D.D.; Tarjan, R.E. A Data Structure for Dynamic Trees. In Proceedings of the 13th Annual ACM Symposium on Theory of Computing, Milwaukee, WI, USA, 11–13 May 1981; pp. 114–122. [Google Scholar] [CrossRef]
- Chan, T.M.; Nekrich, Y.; Rahul, S.; Tsakalidis, K. Orthogonal Point Location and Rectangle Stabbing Queries in 3-d. In Proceedings of the 45th International Colloquium on Automata, Languages, and Programming, Prague, Czech Republic, 9–13 July 2018; pp. 31:1–31:14. [Google Scholar] [CrossRef]
- Harel, D.; Tarjan, R.E. Fast Algorithms for Finding Nearest Common Ancestors. SIAM J. Comput. 1984, 13, 338–355. [Google Scholar] [CrossRef] [Green Version]
- Manber, U.; Myers, E.W. Suffix Arrays: A New Method for On-Line String Searches. SIAM J. Comput. 1993, 22, 935–948. [Google Scholar] [CrossRef]
- Farach, M. Optimal Suffix Tree Construction with Large Alphabets. In Proceedings of the 38th Annual Symposium on Foundations of Computer Science (FOCS ’97), Miami Beach, FL, USA, 19–22 October 1997; pp. 137–143. [Google Scholar] [CrossRef]
- Kärkkäinen, J.; Sanders, P.; Burkhardt, S. Linear work suffix array construction. J. ACM 2006, 53, 918–936. [Google Scholar] [CrossRef]
- Nekrich, Y.; Navarro, G. Sorted Range Reporting. In Proceedings of the 13th Scandinavian Symposium and Workshops (SWAT 2012), Helsinki, Finland, 4–6 July 2012; pp. 271–282. [Google Scholar] [CrossRef]
- Thankachan, S.V.; Aluru, C.; Chockalingam, S.P.; Aluru, S. Algorithmic Framework for Approximate Matching Under Bounded Edits with Applications to Sequence Analysis. In Proceedings of the 22nd Annual International Conference, Research in Computational Molecular Biology (RECOMB 2018), Paris, France, 21–24 April 2018; pp. 211–224. [Google Scholar] [CrossRef]
- Barton, C.; Héliou, A.; Mouchard, L.; Pissis, S.P. Linear-time computation of minimal absent words using suffix array. BMC Bioinform. 2014, 15, 388. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Illustration of the problem reduction: is the output of the problem with query range , where . is the lowest weighted rectangle in containing the point .
Figure 1.
Illustration of the problem reduction: is the output of the problem with query range , where . is the lowest weighted rectangle in containing the point .

Figure 2.
Let and . By contradiction, assume that there exists such that . Since , . This is a contradiction with . Thus, .
Figure 2.
Let and . By contradiction, assume that there exists such that . Since , . This is a contradiction with . Thus, .

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Abedin, P.; Ganguly, A.; Pissis, S.P.; Thankachan, S.V. Efficient Data Structures for Range Shortest Unique Substring Queries. Algorithms 2020, 13, 276. https://0-doi-org.brum.beds.ac.uk/10.3390/a13110276
AMA Style
Abedin P, Ganguly A, Pissis SP, Thankachan SV. Efficient Data Structures for Range Shortest Unique Substring Queries. Algorithms. 2020; 13(11):276. https://0-doi-org.brum.beds.ac.uk/10.3390/a13110276
Chicago/Turabian StyleAbedin, Paniz, Arnab Ganguly, Solon P. Pissis, and Sharma V. Thankachan. 2020. "Efficient Data Structures for Range Shortest Unique Substring Queries" Algorithms 13, no. 11: 276. https://0-doi-org.brum.beds.ac.uk/10.3390/a13110276
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.