Person Re-Identification across Data Distributions Based on General Purpose DNN Object Detector


 ,
,
Abstract
:1. Introduction
2. Related Work
3. Theory Overview
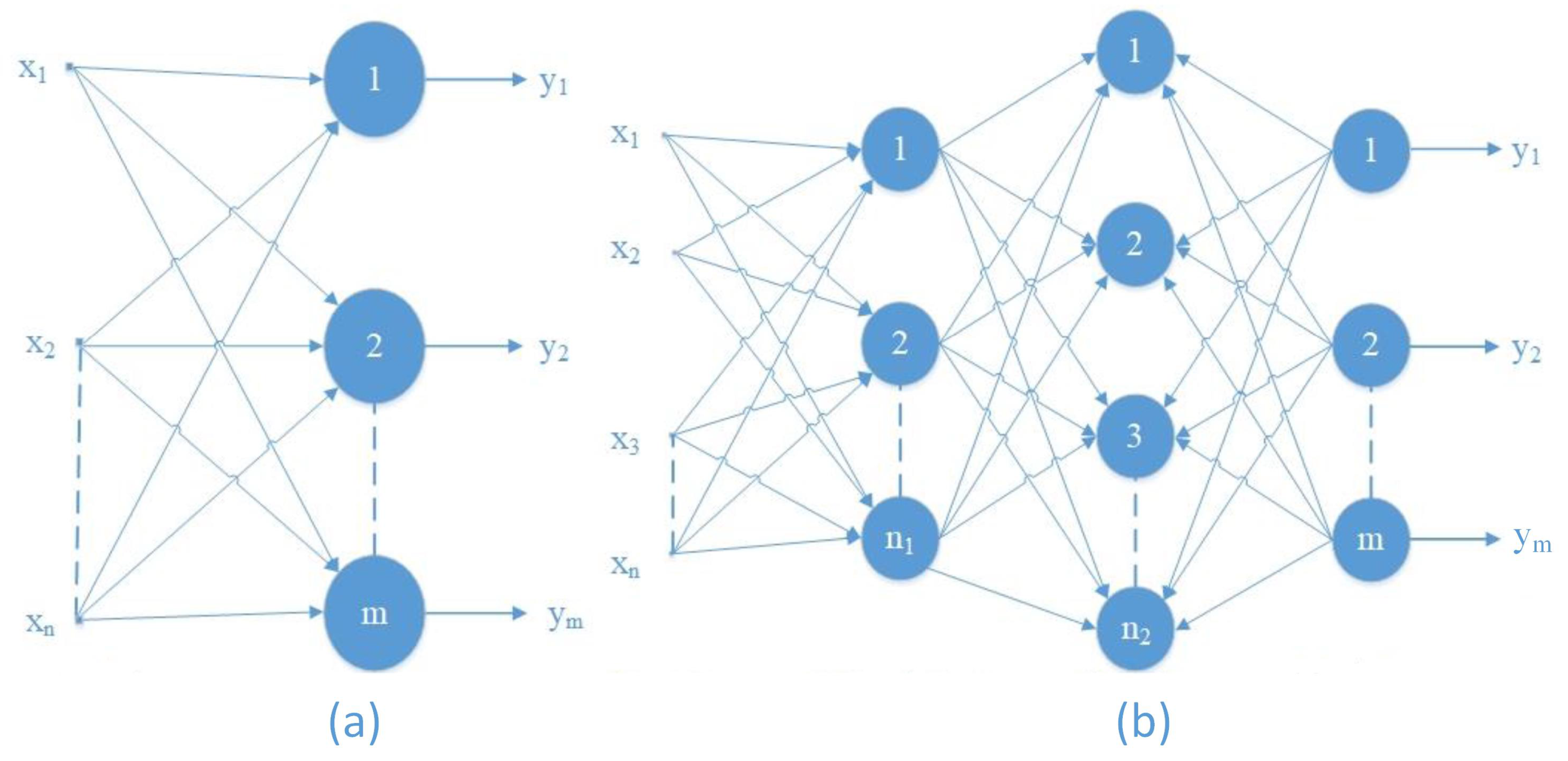
3.1. Fully Connected Neural Networks
- The input layer. It receives information, signals, features, or measurements made in the external environment. Network inputs are usually set to maximum values. As a result of the normalization stage, the numerical accuracy of the network’s mathematical operations increases.
- The hidden, intermediate, or invisible layers. These layers are composed of neurons that are responsible for extracting the patterns associated with the analyzed process. Most of the internal processing of the neural network takes place at the level of these layers. There may be one or more hidden layers in a network.
- The output layer. This layer is responsible for producing and presenting the network’s final outputs, which were obtained after the processing performed by the previous layers.
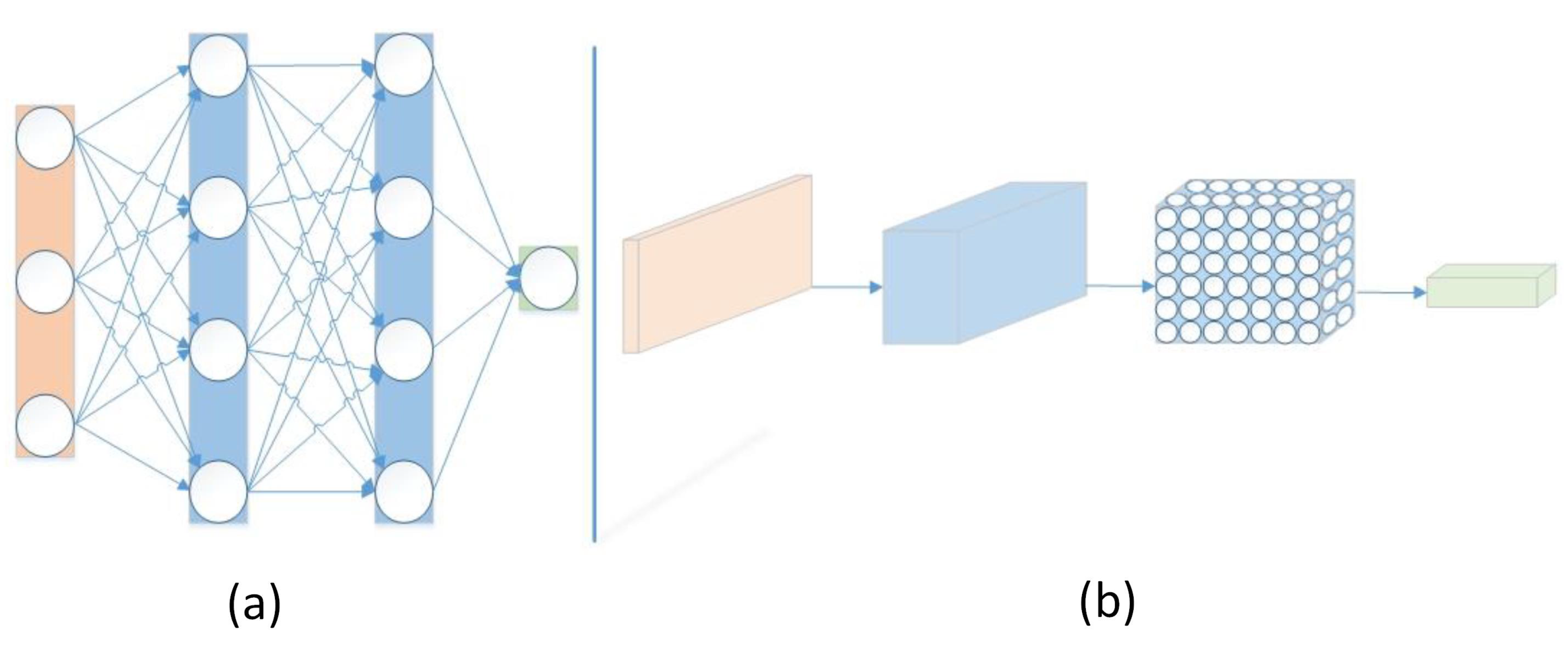
3.2. Convolutional Neural Networks
- Input layer. At this layer’s level, the pixel values from an image of various widths and heights are stored, using three color channels (R—Red, G—Green, B—Blue).
- Convolution layer. It calculates the output of neurons that are connected to the input regions. The third dimension of the output changes depending on the number of filters (kernels) used in the convolution operation.
- RELU layer. This layer applies an input data activation function, such as , with the threshold 0. The operations that take place at this layer do not change the size of the input data.
- Pooling layer. It performs the subsampling operation along the spatial dimensions (width and height, respectively).
- Fully Connected (FC) layer. This layer calculates the results for each class. Unlike all other layers, the neurons in this layer are connected to all of the previous layers’ neurons.
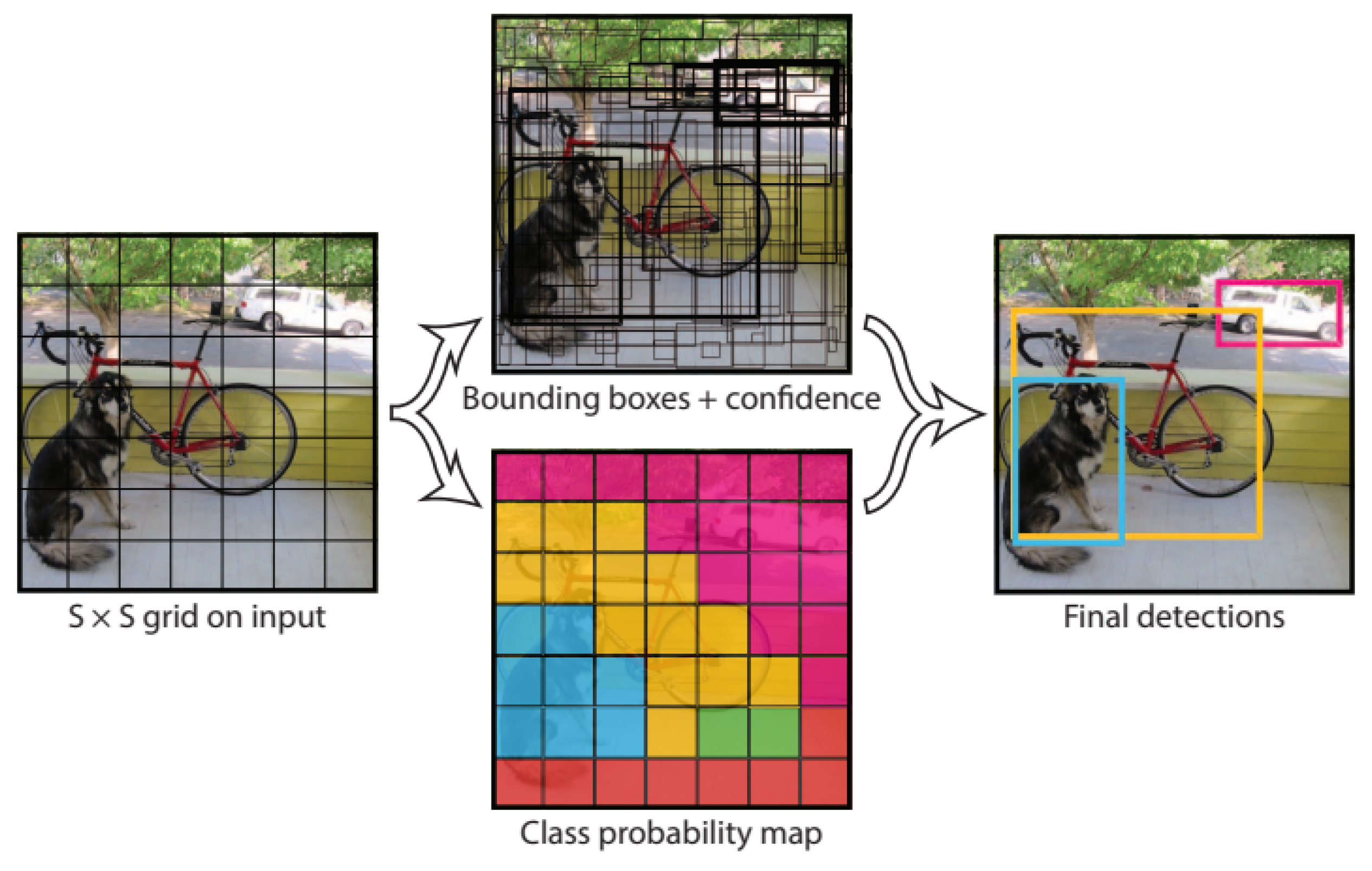
3.3. YOLO Model
- (x, y), which represent the coordinates of the center of the bounding box;
- (w, h), which represent the dimensions: the weight, and respectively, the height of the bounding box; and,
- the prediction’s confidence, representing the Intersection Over Union (IOU) ratio between the predicted and the real bounding box.
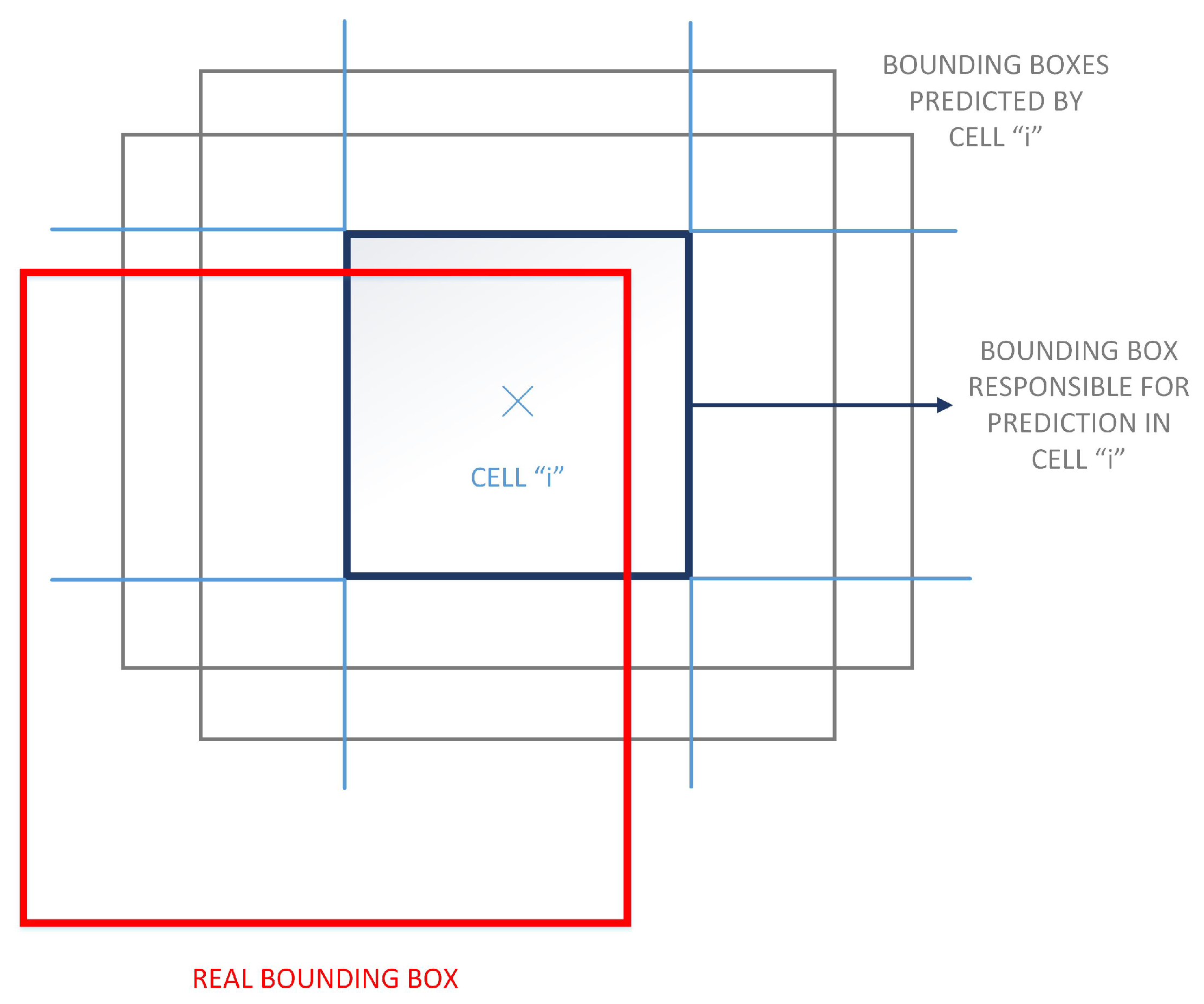
3.3.1. Darknet Architecture
- indicates if there is an object in cell i;
- refers to the bounding box j in cell i, which is responsible for the prediction. This is the bounding box with the highest IOU relatively to the real bounding box (described in Figure 5).
- represents the confidence score of the responsible predictor, from cell i;
- represents the predicted confidence score;
- defines the conditional probability that the cell i contains an object from class c; and,
- represents the scaling parameter that leads to the increasing of the loss function according to the coordinates’ predictions of bounding boxes. YOLO model uses the parameter
- represents the scaling parameter that leads to the decreasing of the loss function, according to the predictions for the confidence score of the bounding boxes that do not contain objects. This system uses the scaling parameter
3.3.2. YOLO Third Version
4. Proposed Method
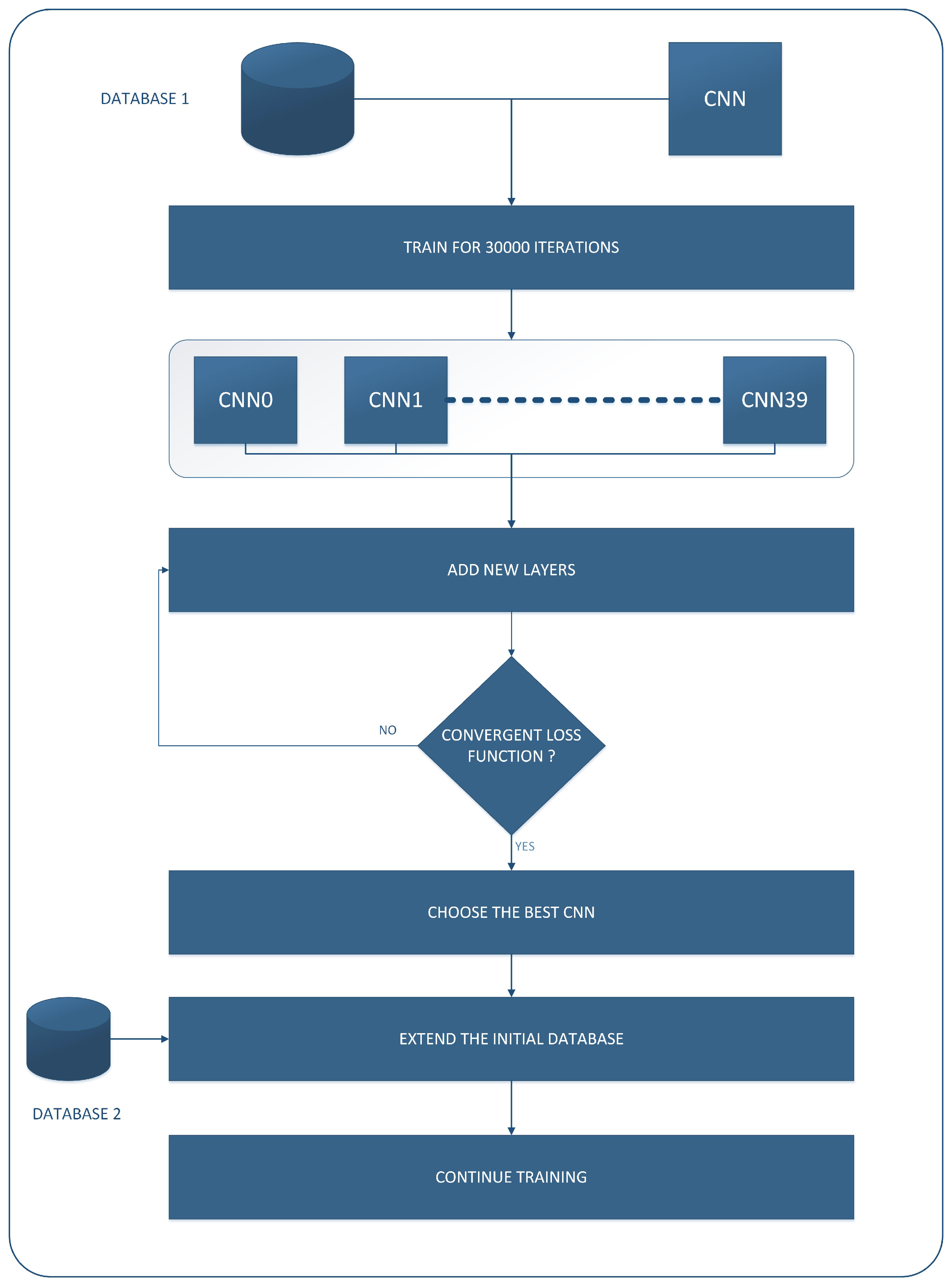
4.1. Algorithm Description
4.2. Image Databases
- eliminating all the images that contain two or more persons;
- eliminating all the images in which a person is partially hidden by other object, or is not fully captured on camera; and,
- we eliminate all of the blurred images and the out of focus ones, in order to remove noise from database.
4.3. First Training Phase
4.4. Second Training Phase
4.4.1. Proposed Neural Network Architecture
4.4.2. Triplet Loss
- Anchor image. This is the image from the batch, which will pass through the network.
- Positive image. It is an image similar to the anchor image (practically, from the same class).
- Negative image. This must be dissimilar to the anchor image, belonging to another class.
4.4.3. Re-Identification Layer
- margin. This parameter is used in the computation of the triplet loss, according to Equation (20). If not provided, this parameter has the default value 0.
- type of triplets. Three types of triplets can be used in our algorithm: hard triplets, semihard triplets, and moderate positives triplets. Those three methods are described in Table 4. If not provided, this parameter will take the default value, i.e., hard triplets.
- number of samples. This parameter is used only when it comes to moderate positives triplets. In this case, the number of positive, respectively, negative samples are different from the number of batches.
5. Experimental Results
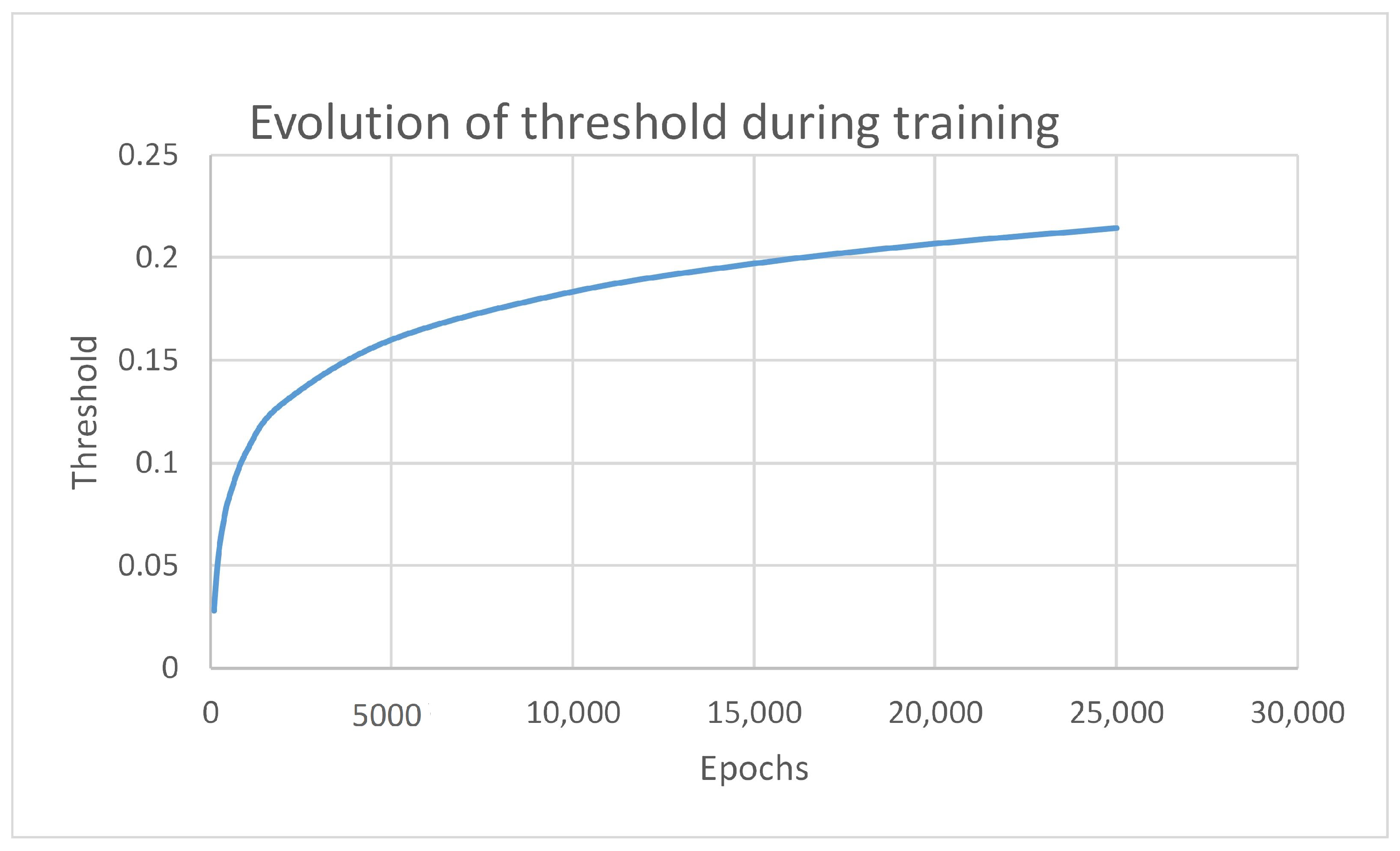
5.1. Testing Algorithm
- ID. This column is generated automatically and also incrementally. It represents a sequence of unique and consecutive numbers, being present in any database.
- LABEL. This value is, in fact, an Universally Unique Identifiers (UUID). It is a 128 bits identifier, which consists of a total of 32 hexadecimal digits. Each time the system generates a new label, it considers that a feature vector belonging to a new person is being introduced in the database. If the system connects with an existing person in the database, the associated label is copied and assigned to the newly entered person.
- TRUE_LABEL. This column represents the true identity of a person. The value is extracted from the .txt files that accompany the test images. It must be provided to the system in the testing stage.
- NORM. This value represents the l2-norm of the feature vector and it is computed based on Equation (26).
- FEATURES. This column stores the feature vector. This vector represents the output generated by the neural network. It is an 128-dimensional vector, based on which we finally made the association between the persons from the database.
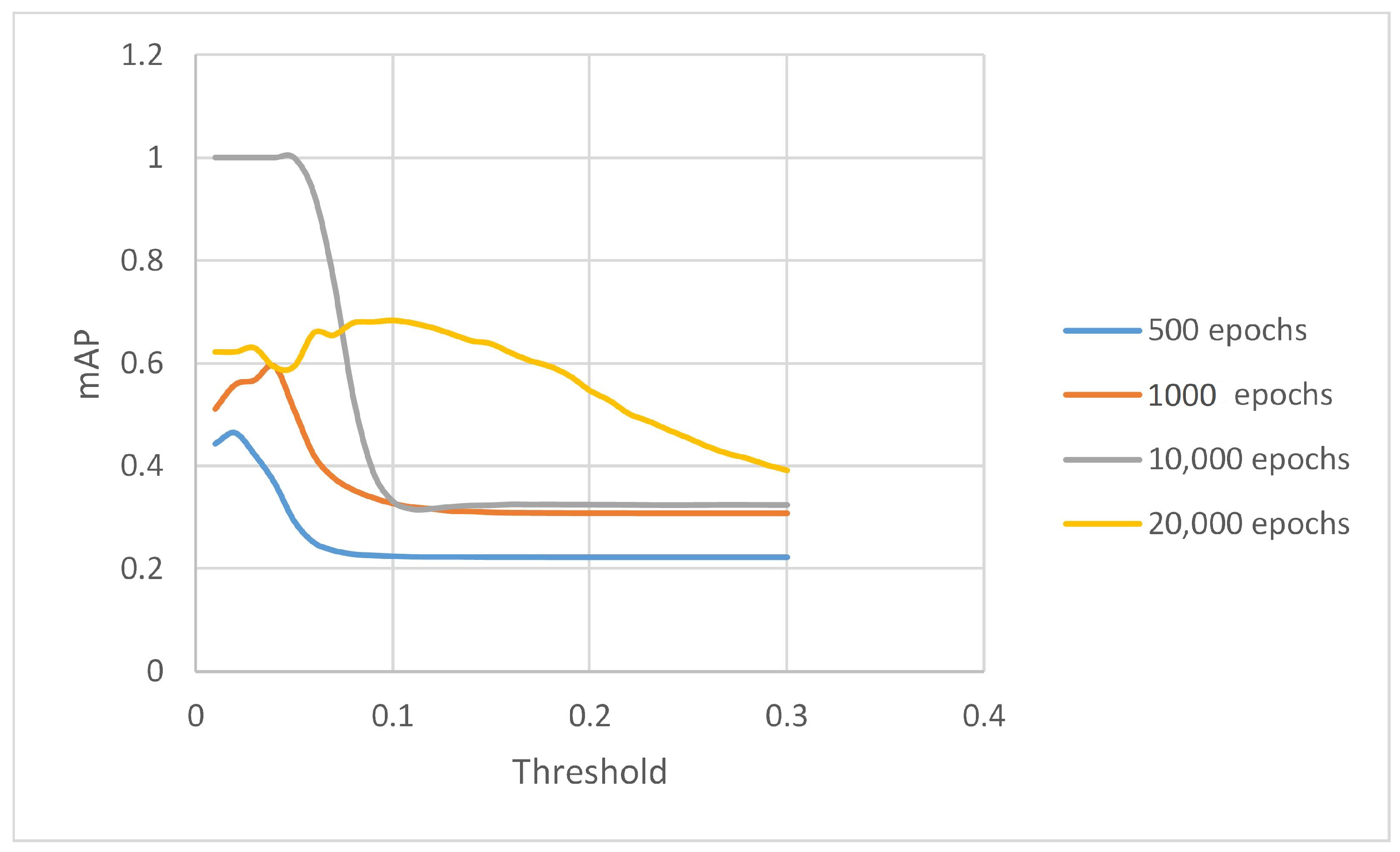
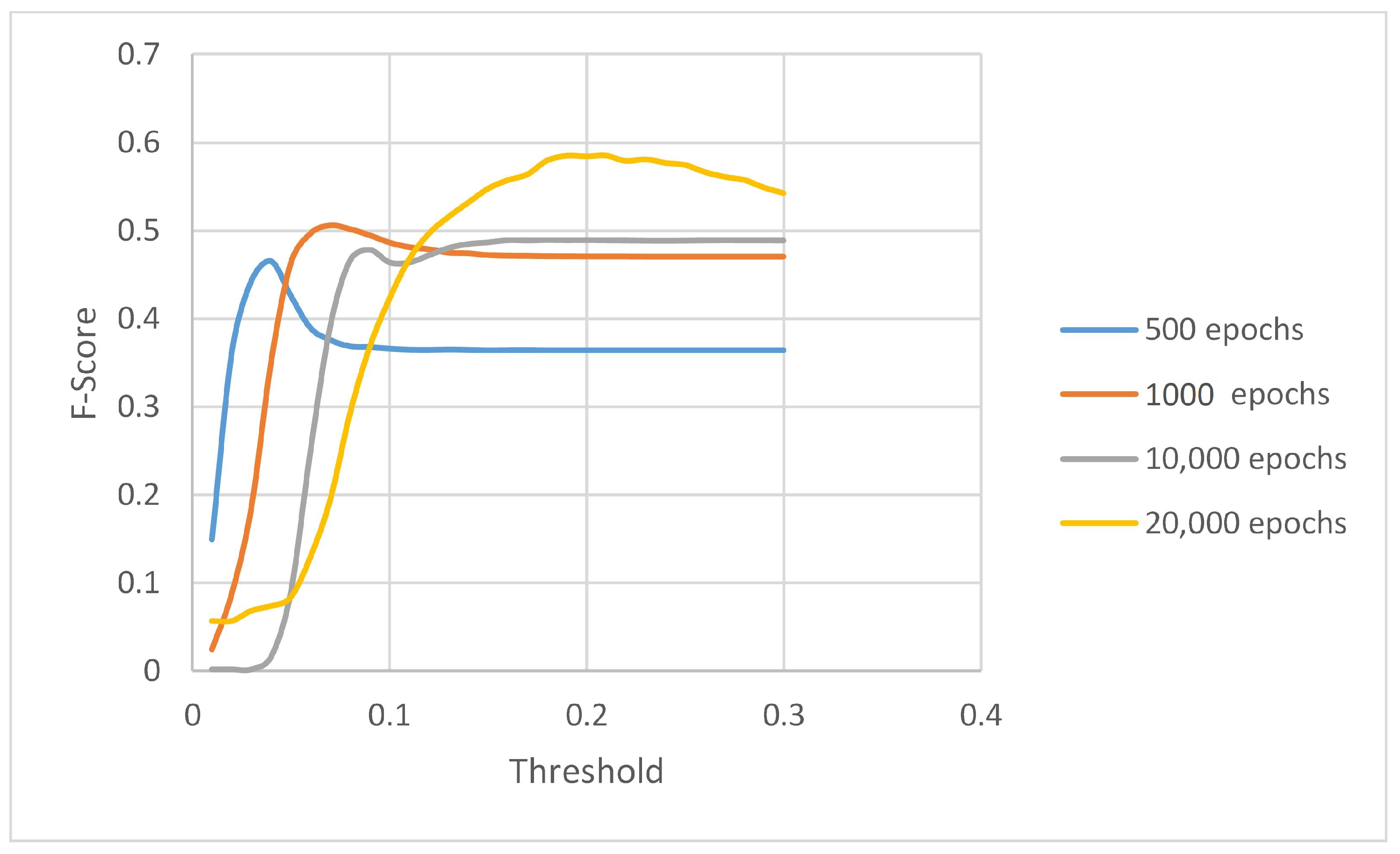
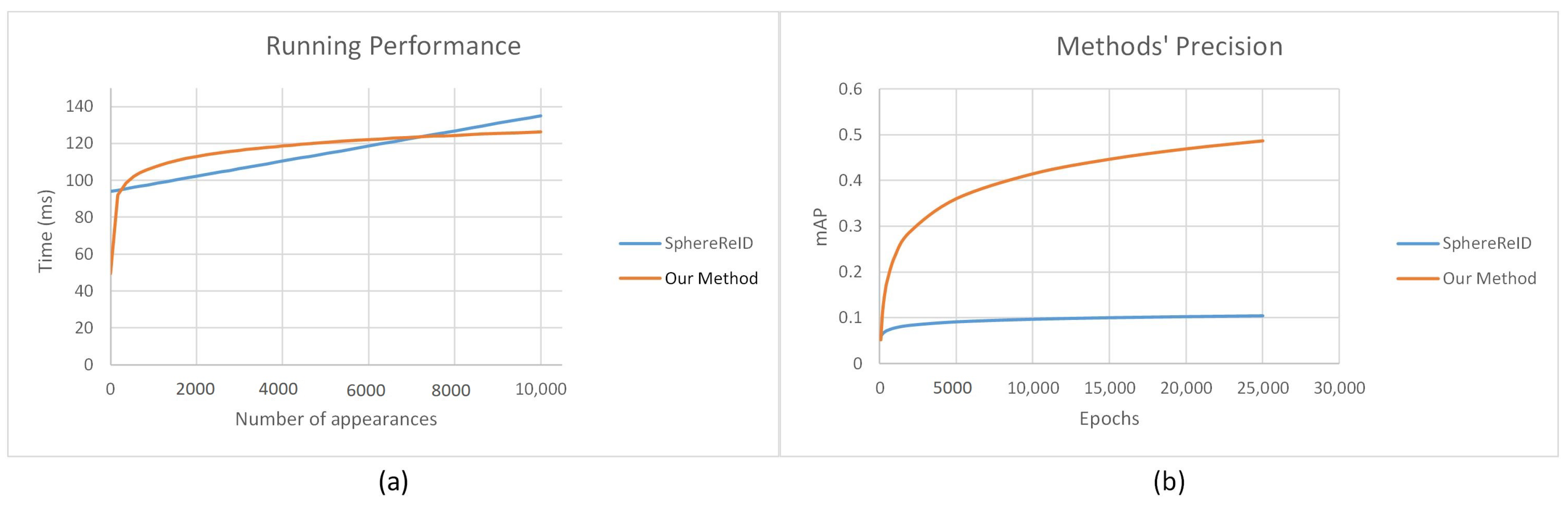
5.2. Results
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| DNN | Deep Neural Network |
| CNN | Convolutional Neural Network |
| FC | Fully Connected |
| MLP | Multi Layer Perceptrons |
| R-CNN | Region based Convolutional Neural Network |
| RoI | Region of Interest |
| IOU | Intersection Over Union |
| ORDBMS | Object-Relational Database Management System |
| MVCC | Multi-Version Concurrency Control |
| ODBC | Open Database Connectivity |
| TCP | Transmission Control Protocol |
| IP | Internet Protocol |
| UUID | Universally Unique Identifiers |
| mAP | mean Average Precision |
References
- Arca, S.; Campadelli, P.; Lanzarotti, R. A face recognition system based on automatically determined facial fiducial points. Pattern Recognit. 2006, 39, 432–443. [Google Scholar] [CrossRef]
- Ghenescu, V.; Mihaescu, R.E.; Carata, S.V.; Ghenescu, M.T.; Barnoviciu, E.; Chindea, M. Face detection and recognition based on general purpose dnn object detector. In Proceedings of the 2018 International Symposium on Electronics and Telecommunications (ISETC), Timisoara, Romania, 8–9 November 2018; pp. 1–4. [Google Scholar]
- Lalonde, M.; Foucher, S.; Gagnon, L.; Pronovost, E.; Derenne, M.; Janelle, A. A system to automatically track humans and vehicles with a PTZ camera. In Visual Information Processing XVI; Ur Rahman, Z., Reichenbach, S.E., Neifeld, M.A., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2007; Volume 6575, pp. 9–16. [Google Scholar] [CrossRef]
- Choi, W.; Pantofaru, C.; Savarese, S. A general framework for tracking multiple people from a moving camera. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1577–1591. [Google Scholar] [CrossRef] [PubMed]
- Kim, C.; Lee, J.; Han, T.; Kim, Y.M. A hybrid framework combining background subtraction and deep neural networks for rapid person detection. J. Big Data 2018, 5, 22. [Google Scholar] [CrossRef]
- Gong, S.; Cristani, M.; Loy, C.C.; Hospedales, T.M. The re-identification challenge. In Person Re-Identification; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–20. [Google Scholar]
- Zheng, M.; Karanam, S.; Radke, R.J. Towards Automated Spatio-Temporal Trajectory Recovery in Wide-Area Camera Networks. IEEE Trans. Biom. Behav. Identity Sci. 2020. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C. pp. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 14 December 2020).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bedagkar-Gala, A.; Shah, S.K. A survey of approaches and trends in person re-identification. Image Vis. Comput. 2014, 32, 270–286. [Google Scholar] [CrossRef]
- Gray, D.; Brennan, S.; Tao, H. Evaluating appearance models for recognition, reacquisition, and tracking. In Proceedings of the IEEE International Workshop on Performance Evaluation for Tracking and Surveillance (Pets), Rio de Janeiro, Brazil, 14 October 2007; Citeseer: Princeton, NJ, USA, 2007; Volume 3, pp. 1–7. [Google Scholar]
- Li, W.; Wang, X. Locally aligned feature transforms across views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3594–3601. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 868–884. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 17–35. [Google Scholar]
- Zheng, M.; Karanam, S.; Radke, R.J. RPIfield: A new dataset for temporally evaluating person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1893–1895. [Google Scholar]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person Re-identification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1367–1376. [Google Scholar]
- Khan, F.M.; Brèmond, F. Multi-shot person re-identification using part appearance mixture. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 605–614. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. arXiv 2020, arXiv:2001.04193. [Google Scholar]
- Gao, H.; Chen, S.; Zhang, Z. Parts semantic segmentation aware representation learning for person re-identification. Appl. Sci. 2019, 9, 1239. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Zha, Y.; Min, W.; Yuan, Z. Person Re-identification Algorithm Based on Logistic Regression Loss Function. J. Phys. Conf. Ser. 2019, 1176, 032041. [Google Scholar] [CrossRef]
- Luo, Y.; Wong, Y.; Kankanhalli, M.; Zhao, Q. G -Softmax: Improving Intraclass Compactness and Interclass Separability of Features. IEEE Trans. Neural Networks Learn. Syst. 2019, 31, 685–699. [Google Scholar] [CrossRef] [PubMed]
- Shrestha, A.; Mahmood, A. Enhancing Siamese Networks Training with Importance Sampling. In Proceedings of the 11th International Conference on Agents and Artificial Intelligence (ICAART 2019), Prague, Czech Republic, 19–21 February 2019; pp. 610–615. Available online: https://www.scitepress.org/Papers/2019/73717/73717.pdf (accessed on 14 December 2020). [CrossRef]
- Liu, Z.; Qin, J.; Li, A.; Wang, Y.; Van Gool, L. Adversarial binary coding for efficient person re-identification. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 700–705. [Google Scholar]
- Zhao, Y.; Jin, Z.; Qi, G.J.; Lu, H.; Hua, X.S. An Adversarial Approach to Hard Triplet Generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 508–524. [Google Scholar]
- Zhang, Y.; Zhong, Q.; Ma, L.; Xie, D.; Pu, S. Learning incremental triplet margin for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9243–9250. [Google Scholar]
- Shi, H.; Yang, Y.; Zhu, X.; Liao, S.; Lei, Z.; Zheng, W.; Li, S. Embedding Deep Metric for Person Re-identification: A Study Against Large Variations. In Computer Vision—ECCV 2016; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 732–748. Available online: https://arxiv.org/pdf/1611.00137.pdf (accessed on 14 December 2020). [CrossRef]
- Manmatha, R.; Wu, C.Y.; Smola, A.; Krahenbuhl, P. Sampling Matters in Deep Embedding Learning. 2017; pp. 2859–2867. Available online: https://arxiv.org/pdf/1706.07567.pdf (accessed on 14 December 2020). [CrossRef] [Green Version]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K. Part-Aligned Bilinear Representations for Person Re-identification. arXiv 2018, arXiv:1804.07094. [Google Scholar]
- Ristani, E.; Tomasi, C. Features for Multi-Target Multi-Camera Tracking and Re-Identification. arXiv 2018, arXiv:1803.10859. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond Triplet Loss: A Deep Quadruplet Network for Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Fan, X.; Jiang, W.; Luo, H.; Fei, M. SphereReID: Deep Hypersphere Manifold Embedding for Person Re-Identification. J. Vis. Commun. Image Represent. 2019, 60. [Google Scholar] [CrossRef] [Green Version]
- Kumar, D.; Siva, P.; Marchwica, P.; Wong, A. Unsupervised Domain Adaptation in Person re-ID via k-Reciprocal Clustering and Large-Scale Heterogeneous Environment Synthesis. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 2–5 March 2020; pp. 2645–2654. [Google Scholar]
- Alom, M.Z.; Taha, T.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.; Hasan, M.; Essen, B.; Awwal, A.; Asari, V. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Carata, S.; Mihaescu, R.; Barnoviciu, E.; Chindea, M.; Ghenescu, M.; Ghenescu, V. Complete Visualisation, Network Modeling and Training, Web Based Tool, for the Yolo Deep Neural Network Model in the Darknet Framework. In Proceedings of the 2019 IEEE 15th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 5–7 September 2019; pp. 517–523. [Google Scholar]
- Wu, D.; Zheng, S.J.; Bao, W.Z.; Zhang, X.P.; Yuan, C.A.; Huang, D.S. A novel deep model with multi-loss and efficient training for person re-identification. Neurocomputing 2019, 324, 69–75. [Google Scholar] [CrossRef]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1335–1344. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Frames | ID’s | Annotated Box | Boxes per ID | Cameras |
|---|---|---|---|---|---|
| VIPeR [12] | 632 | 1264 | 2 | 2 | |
| CUHK02 [13] | 1816 | 7264 | 4 | 10 | |
| CUHK03 [14] | 1360 | 13,164 | 9.7 | 10 | |
| Market-1501 [15] | 1501 | 25,259 | 19.9 | 6 | |
| MARS [16] | 1261 | 1,067,516 | 846.5 | 6 | |
| DukeMTMC-reID [17] | 1852 | 36,441 | 19.7 | 8 | |
| RPIField [18] | 601,581 | 112 | 601,581 | 5371.2 | 12 |
| PRW-v16.04.20 [19] | 11,816 | 932 | 34,304 | 36.8 | 6 |
| Type of Layer | Input Dimensions | Number of Filters | Size | Stride | Output Dimensions |
|---|---|---|---|---|---|
| Convolutional | 52 × 52 × 128 | 128 | 3 | 2 | 26 × 26 × 128 |
| Convolutional | 26 × 26 × 128 | 64 | 1 | 1 | 26 × 26 × 64 |
| Fully Connected | 26 × 26 × 64 | - | - | - | 1024 |
| Dropout | 1024 | - | - | - | 1024 |
| Fully Connected | 1024 | - | - | - | 128 |
| Dropout | 128 | - | - | - | 128 |
| Re-Identification | 128 | - | - | - | - |
| Distance Metric | Equation |
|---|---|
| Euclidean Distance | |
| 1—cosine similarity |
| Type of Triplets | Algorithm |
|---|---|
| Hard negative | Initialization: |
| Set network parameters: | |
| For number of batches: | |
| For number of negative samples: | |
| Compute based on (28) and (26) | |
| Find for the most similar negative sample using (22) | |
| Compute based on (28) and (26) | |
| Compute the triplet loss using (20) | |
| Compute the cost function based on (25) | |
| Semi-hard negatives | Initialization: |
| Set network parameters: | |
| For number of batches: | |
| Compute based on (28) and (26) | |
| For number of negative samples | |
| Compute based on (28) and (26) | |
| Choose all the triplets that correspond to (24) | |
| Compute the number of semi-hard negative triplets for | |
| For | |
| Compute the triplet loss according to (20) | |
| Compute the partial cost function based on (25) | |
| Compute the cost function by summing all the partial functions. | |
| Moderate Positives | Initialization: |
| Set network parameters: | |
| For number of batches: | |
| For number of negative samples: | |
| Compute based on (28) and (26) | |
| Find for the most similar negative sample using (22) | |
| For , number of positive samples: | |
| Compute based on (28) and (26) | |
| Find for the most different positive sample using (23) | |
| Check if the first part of the condition from (24) is fulfilled for and | |
| If the condition is met, compute the triplet loss using (20) | |
| Compute the cost function based on (25) |
| Algorithm for Finding the Most Similar Feature Vector from the Database |
|---|
| Initialization: |
| Set parameters from PostgreSQL database: |
| Compute , as being the L1-norm of new feature vector based on (27) |
| Sort vectors ascending, according to L1-norm |
| Select most similar feature vectors, according to L1-norm |
| for |
| Compute the distance , based on (28) and (26) |
| Compute the distance as being the minimum distance between the new feature vector and the others k vectors, |
| based on (22). |
| NETWORK | LEARNING | MOMENTUM | EPOCHS TRAINED | mAP | F-Score |
|---|---|---|---|---|---|
| ID | RATE | ||||
| 1 | 0.90 | 10,000 | 0.540167 | 0.599489 | |
| 20,000 | 0.526794 | 0.58512 | |||
| 30,000 | 0.565535 | 0.592613 | |||
| 3 | 0.90 | 10,000 | 0.348933 | 0.37761 | |
| 20,000 | 0.298821 | 0.460086 | |||
| 30,000 | 0.394028 | 0.501042 | |||
| 5 | 0.91 | 10,000 | 0.482261 | 0.568995 | |
| 20,000 | 0.535748 | 0.578173 | |||
| 30,000 | 0.487742 | 0.604684 | |||
| 6 | 0.91 | 10,000 | 0.353856 | 0.485571 | |
| 20,000 | 0.411061 | 0.504279 | |||
| 30,000 | 0.5 | 0.577131 | |||
| 7 | 0.91 | 10,000 | 0.533333 | 0.397199 | |
| 20,000 | 0.46791 | 0.464961 | |||
| 30,000 | 0.527403 | 0.479184 | |||
| 13 | 0.93 | 10,000 | 0.577577 | 0.614993 | |
| 20,000 | 0.551397 | 0.568058 | |||
| 30,000 | 0.54831 | 0.587156 | |||
| 15 | 0.93 | 10,000 | 0.270189 | 0.425431 | |
| 20,000 | 0.324363 | 0.489367 | |||
| 30,000 | 0.536048 | 0.49375 | |||
| 19 | 0.94 | 10,000 | 0.257972 | 0.41014 | |
| 20,000 | 0.300079 | 0.461632 | |||
| 30,000 | 0.281992 | 0.43265 | |||
| 21 | 0.95 | 10,000 | 0.315037 | 0.475352 | |
| 20,000 | 0.329039 | 0.489486 | |||
| 30,000 | 0.376514 | 0.538335 | |||
| 22 | 0.95 | 10,000 | 0.400224 | 0.473076 | |
| 20,000 | 0.529153 | 0.56472 | |||
| 30,000 | 0.4909 | 0.544563 | |||
| 25 | 0.96 | 10,000 | 0.460402 | 0.585877 | |
| 20,000 | 0.438733 | 0.571622 | |||
| 30,000 | 0.439295 | 0.5609 | |||
| 34 | 0.98 | 10,000 | 0.480484 | 0.576851 | |
| 20,000 | 0.570223 | 0.599062 | |||
| 30,000 | 0.51923 | 0.545269 | |||
| 39 | 0.99 | 10,000 | 0.311738 | 0.475305 | |
| 20,000 | 0.372743 | 0.472351 | |||
| 30,000 | 0.428161 | 0.557936 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mihaescu, R.-E.; Chindea, M.; Paleologu, C.; Carata, S.; Ghenescu, M. Person Re-Identification across Data Distributions Based on General Purpose DNN Object Detector. Algorithms 2020, 13, 343. https://0-doi-org.brum.beds.ac.uk/10.3390/a13120343
Mihaescu R-E, Chindea M, Paleologu C, Carata S, Ghenescu M. Person Re-Identification across Data Distributions Based on General Purpose DNN Object Detector. Algorithms. 2020; 13(12):343. https://0-doi-org.brum.beds.ac.uk/10.3390/a13120343
Chicago/Turabian StyleMihaescu, Roxana-Elena, Mihai Chindea, Constantin Paleologu, Serban Carata, and Marian Ghenescu. 2020. "Person Re-Identification across Data Distributions Based on General Purpose DNN Object Detector" Algorithms 13, no. 12: 343. https://0-doi-org.brum.beds.ac.uk/10.3390/a13120343