Nature-Inspired Optimization Algorithms for Text Document Clustering—A Comprehensive Analysis

 ,
,  ,
,  ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
2. Related Works
2.1. Krill Herd Algorithm (KHA)
2.2. Magnetic Optimization Algorithm (MOA)
2.3. Particle Swarm Optimization (PSO)
2.4. Social Spider Optimization (SSO)
2.5. Whale Optimization Algorithm (WOA)
2.6. Ant Colony Optimization (ACO)
2.7. Local Search Techniques
2.8. Bee Colony Optimization (BCO)
2.9. Generic Algorithm (GA)
2.10. Harmony Search (HS)
2.11. K-Means Clustering Technique
2.12. Other Algorithms
3. Procedures of the Text Clustering Problem
3.1. Problem Formulations
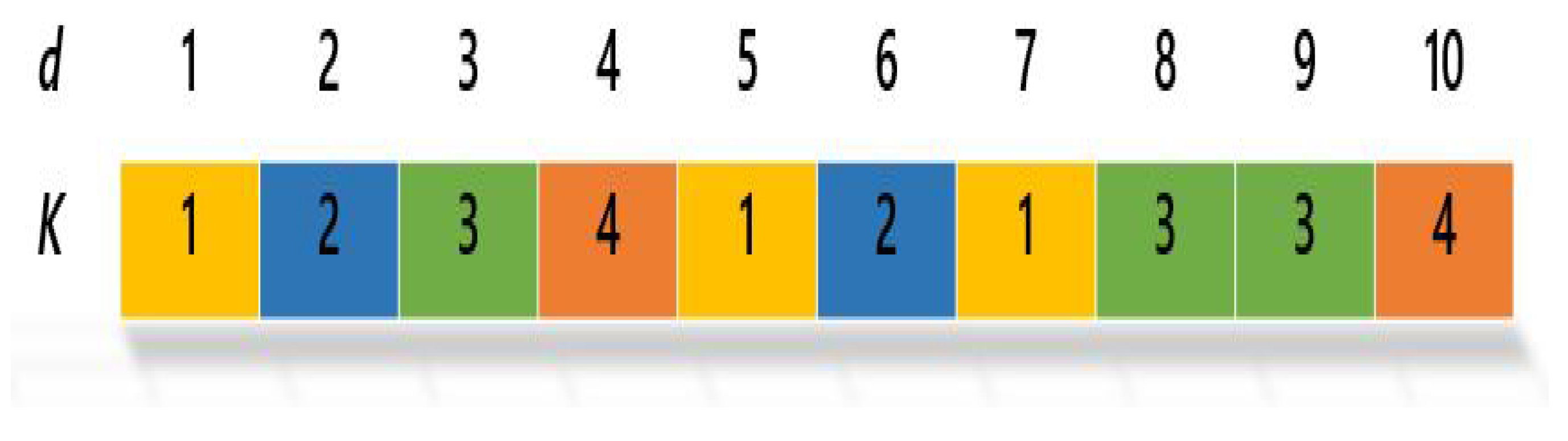
- A set of text documents (D/objects) is grouped into a established in advance number of clusters (K) [38].
- D can be given as a vector of objects , gives the object number two, i presents the number of the object and n is the number of total objects provided in D Reference [88].
- Each group contains a cluster centroid, called , which is represented as a vector of term weights of the words .
- is the cluster centroid, is the value of position two (feature) in the centroid of cluster number k, and t is the number of all unique centroid terms (features) in the given object.
3.2. Preprocessing Steps
3.2.1. Tokenization
3.2.2. Stop Words Removal
3.2.3. Stemming
3.3. Document Representation
3.4. Solution Representation of Clustering Problem
3.5. Fitness Function
4. Evaluation Measures
4.1. Accuracy Measure
4.2. Purity Measure
4.3. Entropy Measure
4.4. Precision Measure
4.5. Recall Measure
4.6. F-Measure
5. Experiments Results and Discussion
5.1. Document Dataset
- In dataset number 1 (DS1), 299 documents are given, which contains 1107 features. The documents in this dataset belong to 4 different clusters as given in Table 2.
- In dataset number 2 (DS2), 333 documents are given, which contains 2604 features. The documents in this dataset belong to 4 different clusters as given in Table 2.
- In dataset number 3 (DS3), 204 documents are given, which contains 4252 features. The documents in this dataset belong to 6 different clusters as given in Table 2.
- In dataset number 4 (DS4), 313 documents are given, which contains 3745 features. The documents in this dataset belong to 8 different clusters as given in Table 2.
- In dataset number 5 (DS5), 414 documents are given, which contains 4879 features. The documents in this dataset belong to 9 different clusters as given in Table 2.
- In dataset number 6 (DS6), 878 documents are given, which contains 5437 features. The documents in this dataset belong to 10 different clusters as given in Table 2.
- In dataset number 7 (DS7), 913 documents are given, which contains 3100 features. The documents in this dataset belong to 10 different clusters as given in Table 2.
5.2. Results and Discussion
6. Conclusions and Future Works
- The behavior of the selected clustering algorithm.
- The number of clusters.
- The initial clusters centroids.
- The selected features from the given documents for applying the clustering process.
- The dimension size of the given text documents
- The weighting score of the used features
Author Contributions
Funding
Conflicts of Interest
References
- Punitha, S.; Punithavalli, M. Performance evaluation of semantic based and ontology based text document clustering techniques. Procedia Eng. 2012, 30, 100–106. [Google Scholar] [CrossRef] [Green Version]
- Lu, Q.; Conrad, J.G.; Al-Kofahi, K.; Keenan, W. Legal document clustering with built-in topic segmentation. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Scotland, UK, 24–28 October 2011; pp. 383–392. [Google Scholar]
- Karypis, G.; Han, E.H.; Kumar, V. Chameleon: Hierarchical clustering using dynamic modeling. Computer 1999, 32, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, J. A parallel hybrid web document clustering algorithm and its performance study. J. Supercomput. 2004, 30, 117–131. [Google Scholar] [CrossRef]
- Bradley, P.S.; Fayyad, U.; Reina, C. Scaling EM (Expectation-Maximization) Clustering to Large Databases. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.9.2850&rep=rep1&type=pdf (accessed on 28 November 2020).
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Pearson Education India: London, UK, 2016. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. (CSUR) 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Karypis, M.S.G.; Kumar, V.; Steinbach, M. A Comparison of Document Clustering Techniques; TextMining Workshop at KDD2000 (May 2000). Available online: http://www.stat.cmu.edu/~rnugent/PCMI2016/papers/DocClusterComparison.pdf (accessed on 28 November 2020).
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965. [Google Scholar]
- Zhao, X.; Wang, C.; Su, J.; Wang, J. Research and application based on the swarm intelligence algorithm and artificial intelligence for wind farm decision system. Renew. Energy 2019, 134, 681–697. [Google Scholar] [CrossRef]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Wang, H.; Guo, W. An Optimization Model and Solution Algorithms for the Vehicle Routing Problem with a “Factory-in-a-Box”. IEEE Access 2020, 8, 134743–134763. [Google Scholar] [CrossRef]
- Slowik, A.; Kwasnicka, H. Nature inspired methods and their industry applications—Swarm intelligence algorithms. IEEE Trans. Ind. Inform. 2017, 14, 1004–1015. [Google Scholar] [CrossRef]
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm intelligence algorithms for feature selection: A review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef] [Green Version]
- Dulebenets, M.A.; Kavoosi, M.; Abioye, O.; Pasha, J. A self-adaptive evolutionary algorithm for the berth scheduling problem: Towards efficient parameter control. Algorithms 2018, 11, 100. [Google Scholar] [CrossRef] [Green Version]
- Anandakumar, H.; Umamaheswari, K. A bio-inspired swarm intelligence technique for social aware cognitive radio handovers. Comput. Electr. Eng. 2018, 71, 925–937. [Google Scholar] [CrossRef]
- Hussien, A.G.; Houssein, E.H.; Hassanien, A.E. A binary whale optimization algorithm with hyperbolic tangent fitness function for feature selection. In Proceedings of the 2017 IEEE Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 166–172. [Google Scholar]
- Abualigah, L.; Shehab, M.; Alshinwan, M.; Mirjalili, S.; Abd Elaziz, M. Ant Lion Optimizer: A Comprehensive Survey of Its Variants and Applications. In Archives of Computational Methods in Engineering; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Hussien, A.G.; Hassanien, A.E.; Houssein, E.H.; Bhattacharyya, S.; Amin, M. S-shaped binary whale optimization algorithm for feature selection. In Recent Trends in Signal and Image Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 79–87. [Google Scholar]
- Abualigah, L.; Shehab, M.; Alshinwan, M.; Alabool, H. Salp swarm algorithm: A comprehensive survey. Neural Comput. Appl. 2019, 32, 11195–11215. [Google Scholar] [CrossRef]
- Zahn, C.T. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Trans. Comput. 1971, 100, 68–86. [Google Scholar] [CrossRef] [Green Version]
- Mao, J.; Jain, A.K. Artificial neural networks for feature extraction and multivariate data projection. IEEE Trans. Neural Netw. 1995, 6, 296–317. [Google Scholar]
- Liao, S.H.; Wen, C.H. Artificial neural networks classification and clustering of methodologies and applications–literature analysis from 1995 to 2005. Expert Syst. Appl. 2007, 32, 1–11. [Google Scholar] [CrossRef]
- Forgy, E.W. Cluster analysis of multivariate data: Efficiency versus interpretability of classifications. Biometrics 1965, 21, 768–769. [Google Scholar]
- Paterlini, S.; Minerva, T. Evolutionary approaches for cluster analysis. In Soft Computing Applications; Springer: Berlin/Heidelberg, Germany, 2003; pp. 165–176. [Google Scholar]
- Sarkar, M.; Yegnanarayana, B.; Khemani, D. A clustering algorithm using an evolutionary programming-based approach. Pattern Recognit. Lett. 1997, 18, 975–986. [Google Scholar] [CrossRef]
- Cole, R.M. Clustering with Genetic Algorithms; University of Western Australia: Crawley, Australia, 1998. [Google Scholar]
- Cui, X.; Potok, T.E.; Palathingal, P. Document clustering using particle swarm optimization. In Proceedings of the 2005 IEEE Swarm Intelligence Symposium, SIS 2005, Pasadena, CA, USA, 8–10 June 2005; pp. 185–191. [Google Scholar]
- Runkler, T.A. Ant colony optimization of clustering models. Int. J. Intell. Syst. 2005, 20, 1233–1251. [Google Scholar] [CrossRef]
- Hussien, A.G.; Hassanien, A.E.; Houssein, E.H.; Amin, M.; Azar, A.T. New binary whale optimization algorithm for discrete optimization problems. Eng. Optim. 2020, 52, 945–959. [Google Scholar] [CrossRef]
- Hussien, A.G.; Oliva, D.; Houssein, E.H.; Juan, A.A.; Yu, X. Binary Whale Optimization Algorithm for Dimensionality Reduction. Mathematics 2020, 8, 1821. [Google Scholar] [CrossRef]
- Abualigah, L.; Abd Elaziz, M.; Hussien, A.G.; Alsalibi, B.; Jalali, S.M.J.; Gandomi, A.H. Lightning Search Algorithm: A Comprehensive Survey. Available online: https://0-link-springer-com.brum.beds.ac.uk/article/10.1007/s10489-020-01947-2 (accessed on 28 November 2020).
- Hussien, A.G.; Amin, M.; Wang, M.; Liang, G.; Alsanad, A.; Gumaei, A.; Chen, H. Crow search algorithm: Theory, recent advances, and applications. IEEE Access 2020, 8, 173548–173565. [Google Scholar] [CrossRef]
- Assiri, A.S.; Hussien, A.G.; Amin, M. Ant Lion Optimization: Variants, hybrids, and applications. IEEE Access 2020, 8, 77746–77764. [Google Scholar] [CrossRef]
- Hussien, A.G.; Amin, M.; Abd El Aziz, M. A comprehensive review of moth-flame optimisation: Variants, hybrids, and applications. J. Exp. Theor. Artif. Intell. 2020, 32, 705–725. [Google Scholar] [CrossRef]
- Purushothaman, R.; Rajagopalan, S.; Dhandapani, G. Hybridizing Gray Wolf Optimization (GWO) with Grasshopper Optimization Algorithm (GOA) for text feature selection and clustering. Appl. Soft Comput. 2020, 96, 106651. [Google Scholar] [CrossRef]
- Bharti, K.K.; Singh, P.K. Chaotic gradient artificial bee colony for text clustering. Soft Comput. 2016, 20, 1113–1126. [Google Scholar] [CrossRef]
- Forsati, R.; Keikha, A.; Shamsfard, M. An improved bee colony optimization algorithm with an application to document clustering. Neurocomputing 2015, 159, 9–26. [Google Scholar] [CrossRef]
- Hussien, A.G.; Hassanien, A.E.; Houssein, E.H. Swarming behaviour of salps algorithm for predicting chemical compound activities. In Proceedings of the 2017 IEEE Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 315–320. [Google Scholar]
- Abualigah, L.; Diabat, A.; Mirjalili, S.; Abd Elaziz, M.; Gandomi, A.H. The Arithmetic Optimization Algorithm. Comput. Methods Appl. Mech. Eng. 2020, in press. [Google Scholar]
- Abualigah, L.; Diabat, A.; Geem, Z.W. A Comprehensive Survey of the Harmony Search Algorithm in Clustering Applications. Appl. Sci. 2020, 10, 3827. [Google Scholar] [CrossRef]
- Abualigah, L. Group Search Optimizer: A Nature-Inspired Meta-Heuristic Optimization Algorithm with Its Results, Variants, and Applications. Available online: https://0-link-springer-com.brum.beds.ac.uk/article/10.1007/s00521-020-05107-y (accessed on 29 November 2020).
- Abualigah, L. Multi-Verse Optimizer Algorithm: A Comprehensive Survey of Its Results, Variants, and Applications. Available online: https://0-link-springer-com.brum.beds.ac.uk/article/10.1007/s00521-020-04839-1 (accessed on 29 November 2020).
- Rossi, R.G.; Marcacini, R.M.; Rezende, S.O. Benchmarking Text Collections for Classification and Clustering Tasks. Available online: http://repositorio.icmc.usp.br/bitstream/handle/RIICMC/6641/Relat%C3%B3rios%20T%C3%A9cnicas_395_2013.pdf?sequence=1 (accessed on 29 November 2020).
- Amer, A.A.; Abdalla, H.I. A set theory based similarity measure for text clustering and classification. J. Big Data 2020, 7, 1–43. [Google Scholar] [CrossRef]
- Nalawade, R.; Samal, A.; Avhad, K. Improved similarity measure for text classification and clustering. Int. Res. J. Eng. Technol. (IRJET) 2016, 3, 214–219. [Google Scholar]
- Yang, X.; Zhang, G.; Lu, J.; Ma, J. A kernel fuzzy c-means clustering-based fuzzy support vector machine algorithm for classification problems with outliers or noises. IEEE Trans. Fuzzy Syst. 2010, 19, 105–115. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.Y.; Liou, R.J.; Lee, S.J. A fuzzy self-constructing feature clustering algorithm for text classification. IEEE Trans. Knowl. Data Eng. 2010, 23, 335–349. [Google Scholar] [CrossRef]
- Onan, A. Hybrid supervised clustering based ensemble scheme for text classification. Kybernetes 2017, 46, 330–348. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Alavi, A.H. Krill herd: A new bio-inspired optimization algorithm. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 4831–4845. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. Hybrid clustering analysis using improved krill herd algorithm. Appl. Intell. 2018, 48, 4047–4071. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S.; Gandomi, A.H. A novel hybridization strategy for krill herd algorithm applied to clustering techniques. Appl. Soft Comput. 2017, 60, 423–435. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; AlBetar, M.A.; Hanandeh, E.S. A new hybridization strategy for krill herd algorithm and harmony search algorithm applied to improve the data clustering. In Proceedings of the 1st EAI International Conference on Computer Science and Engineering, Penang, Malaysia, 11–12 November 2016. [Google Scholar]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A.; Awadallah, M.A. A krill herd algorithm for efficient text documents clustering. In Proceedings of the 2016 IEEE Symposium on Computer Applications & Industrial Electronics (ISCAIE), Batu Feringghi, Malaysia, 30–31 May 2016; pp. 67–72. [Google Scholar]
- Abualigah, L.M.Q. Feature Selection and Enhanced Krill Herd Algorithm for Text Document Clustering; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Kushwaha, N.; Pant, M.; Kant, S.; Jain, V.K. Magnetic optimization algorithm for data clustering. Pattern Recognit. Lett. 2018, 115, 59–65. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A new feature selection method to improve the document clustering using particle swarm optimization algorithm. J. Comput. Sci. 2018, 25, 456–466. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; AI-Betar, M.A. Unsupervised feature selection technique based on harmony search. In Proceedings of the 2016 IEEE 7th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 13–14 July 2016. [Google Scholar]
- Janani, R.; Vijayarani, S. Text document clustering using spectral clustering algorithm with particle swarm optimization. Expert Syst. Appl. 2019, 134, 192–200. [Google Scholar] [CrossRef]
- Hasanzadeh, E.; Rokny, H.A.; Poyan, M. Text clustering on latent semantic indexing with particle swarm optimization (PSO) algorithm. Int. J. Phys. Sci. 2012, 7, 16–120. [Google Scholar] [CrossRef]
- Bharti, K.K.; Singh, P.K. Opposition chaotic fitness mutation based adaptive inertia weight BPSO for feature selection in text clustering. Appl. Soft Comput. 2016, 43, 20–34. [Google Scholar] [CrossRef]
- Lu, Y.; Liang, M.; Ye, Z.; Cao, L. Improved particle swarm optimization algorithm and its application in text feature selection. Appl. Soft Comput. 2015, 35, 629–636. [Google Scholar] [CrossRef]
- Chandran, T.R.; Reddy, A.; Janet, B. A social spider optimization approach for clustering text documents. In Proceedings of the 2016 IEEE 2nd International Conference on Advances in Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB), Chennai, India, 27–28 February 2016; pp. 22–26. [Google Scholar]
- Chandran, T.R.; Reddy, A.; Janet, B. Text clustering quality improvement using a hybrid social spider optimization. Int. J. Appl. Eng. Res. 2017, 12, 995–1008. [Google Scholar]
- Gopal, J.; Brunda, S. Text Clustering Algorithm Using Fuzzy Whale Optimization Algorithm. Int. J. Intell. Eng. Syst. 2019, 12. [Google Scholar] [CrossRef]
- Majhi, S.K. Fuzzy clustering algorithm based on modified whale optimization algorithm for automobile insurance fraud detection. Evol. Intell. 2019, 2, 1–12. [Google Scholar] [CrossRef]
- Cobo, A.; Rocha, R. Document management with ant colony optimization metaheuristic: A fuzzy text clustering approach using pheromone trails. In Soft Computing in Industrial Applications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 261–270. [Google Scholar]
- Nema, P.; Sharma, V. Multi-label text categorization based on feature optimization using ant colony optimization and relevance clustering technique. In Proceedings of the 2015 IEEE International Conference on Computers, Communications, and Systems (ICCCS), Kanyakumari, India, 2–3 November 2015; pp. 1–5. [Google Scholar]
- Forsati, R.; Moayedikia, A.; Jensen, R.; Shamsfard, M.; Meybodi, M.R. Enriched ant colony optimization and its application in feature selection. Neurocomputing 2014, 142, 354–371. [Google Scholar] [CrossRef] [Green Version]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A.; Alyasseri, Z.A.A.; Alomari, O.A.; Hanandeh, E.S. Feature selection with β-hill climbing search for text clustering application. In Proceedings of the 2017 IEEE Palestinian International Conference on Information and Communication Technology (PICICT), Gaza City, Palestine, 8–9 May 2017; pp. 22–27. [Google Scholar]
- Abualigah, L.M.; Sawaie, A.M.; Khader, A.T.; Rashaideh, H.; Al-Betar, M.A.; Shehab, M. β-hill climbing technique for the text document clustering. In New Trends in Information Technology (NTIT)–2017; University of Jordan: Amman, Jordan, 2017; p. 60. [Google Scholar]
- Saini, N.; Saha, S.; Bhattacharyya, P. Automatic scientific document clustering using self-organized multi-objective differential evolution. Cogn. Comput. 2019, 11, 271–293. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Hanandeh, E.S.; Khader, A.T.; Otair, M.A.; Shandilya, S.K. An Improved B-hill Climbing Optimization Technique for Solving the Text Documents Clustering Problem. Curr. Med. Imaging 2020, 16, 296–306. [Google Scholar] [CrossRef]
- Moayedikia, A.; Jensen, R.; Wiil, U.K.; Forsati, R. Weighted bee colony algorithm for discrete optimization problems with application to feature selection. Eng. Appl. Artif. Intell. 2015, 44, 153–167. [Google Scholar] [CrossRef] [Green Version]
- Abualigah, L.M.; Khader, A.T. Unsupervised text feature selection technique based on hybrid particle swarm optimization algorithm with genetic operators for the text clustering. J. Supercomput. 2017, 73, 4773–4795. [Google Scholar] [CrossRef]
- Abualigah, L.M.Q.; Hanandeh, E.S. Applying genetic algorithms to information retrieval using vector space model. Int. J. Comput. Sci. Eng. Appl. 2015, 5, 19. [Google Scholar]
- Forsati, R.; Mahdavi, M.; Shamsfard, M.; Meybodi, M.R. Efficient stochastic algorithms for document clustering. Inf. Sci. 2013, 220, 269–291. [Google Scholar] [CrossRef]
- Mohammad Abualigah, L.; Al-diabat, M.; Al Shinwan, M.; Dhou, K.; Alsalibi, B.; Said Hanandeh, E.; Shehab, M. Hybrid Harmony Search Algorithm to Solve the Feature Selection for Data Mining Applications. Recent Adv. Hybrid Metaheuristics Data Clust. 2020, 19–37. [Google Scholar] [CrossRef]
- Mahdavi, M.; Chehreghani, M.H.; Abolhassani, H.; Forsati, R. Novel meta-heuristic algorithms for clustering web documents. Appl. Math. Comput. 2008, 201, 441–451. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A. Multi-objectives-based text clustering technique using K-mean algorithm. In Proceedings of the 2016 IEEE 7th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 13–14 July 2016; pp. 1–6. [Google Scholar]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A novel weighting scheme applied to improve the text document clustering techniques. In Innovative Computing, Optimization and Its Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 305–320. [Google Scholar]
- Abualigah, L.M.; Khader, A.T.; Al-Betar, M.A.; Alomari, O.A. Text feature selection with a robust weight scheme and dynamic dimension reduction to text document clustering. Expert Syst. Appl. 2017, 84, 24–36. [Google Scholar] [CrossRef]
- Sarkar, S.; Roy, A.; Purkayastha, B. A comparative analysis of particle swarm optimization and K-means algorithm for text clustering using Nepali Wordnet. Int. J. Nat. Lang. Comput. (IJNLC) 2014, 3. [Google Scholar] [CrossRef]
- Romero, F.P.; Peralta, A.; Soto, A.; Olivas, J.A.; Serrano-Guerrero, J. Fuzzy optimized self-organizing maps and their application to document clustering. Soft Comput. 2010, 14, 857–867. [Google Scholar] [CrossRef]
- Rashaideh, H.; Sawaie, A.; Al-Betar, M.A.; Abualigah, L.M.; Al-Laham, M.M.; Ra’ed, M.; Braik, M. A grey wolf optimizer for text document clustering. J. Intell. Syst. 2018, 29, 814–830. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A combination of objective functions and hybrid krill herd algorithm for text document clustering analysis. Eng. Appl. Artif. Intell. 2018, 73, 111–125. [Google Scholar] [CrossRef]
- Prabha, K.A.; Visalakshi, N.K. Improved Particle Swarm Optimization Based K-Means Clustering. In Proceedings of the 2014 International Conference on IEEE Intelligent Computing Applications (ICICA), Coimbatore, India, 6–7 March 2014; pp. 59–63. [Google Scholar]
- Basu, T.; Murthy, C. A similarity assessment technique for effective grouping of documents. Inf. Sci. 2015, 311, 149–162. [Google Scholar] [CrossRef]
- Zhong, N.; Li, Y.; Wu, S.T. Effective pattern discovery for text mining. Knowl. Data Eng. IEEE Trans. 2012, 24, 30–44. [Google Scholar] [CrossRef] [Green Version]
- Bharti, K.K.; Singh, P.K. Hybrid dimension reduction by integrating feature selection with feature extraction method for text clustering. Expert Syst. Appl. 2015, 42, 3105–3114. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- De Vries, C.M. Document Clustering Algorithms, Representations and Evaluation for Information Retrieval. Ph.D. Thesis, Queensland University of Technology, Brisbane City, Australia, 2014. [Google Scholar]
- Forsati, R.; Mahdavi, M. Web text mining using harmony search. In Recent Advances in Harmony Search Algorithm; Springer: Berlin/Heidelberg, Germany, 2010; pp. 51–64. [Google Scholar]
- Kaur, S.P.; Madan, N. Document Clustering Using Firefly Algorithm. Artif. Intell. Syst. Mach. Learn. 2016, 8, 182–185. [Google Scholar]
- Kumar, L.; Bharti, K.K. A novel hybrid BPSO–SCA approach for feature selection. Nat. Comput. 2019, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Mahdavi, M.; Abolhassani, H. Harmony K-means algorithm for document clustering. Data Min. Knowl. Discov. 2009, 18, 370–391. [Google Scholar] [CrossRef]
- Del Buono, N.; Pio, G. Non-negative Matrix Tri-Factorization for co-clustering: An analysis of the block matrix. Inf. Sci. 2015, 301, 13–26. [Google Scholar] [CrossRef]
- Inbarani, H.H.; Bagyamathi, M.; Azar, A.T. A novel hybrid feature selection method based on rough set and improved harmony search. Neural Comput. Appl. 2015, 26, 1859–1880. [Google Scholar] [CrossRef]
- Bharti, K.K.; Singh, P.K. A three-stage unsupervised dimension reduction method for text clustering. J. Comput. Sci. 2014, 5, 156–169. [Google Scholar] [CrossRef]
- Chen, L.; Liu, M.; Wu, C.; Xu, A. A Novel Clustering Algorithm and Its Incremental Version for Large-Scale Text Collection. Inf. Technol. Control. 2016, 45, 136–147. [Google Scholar] [CrossRef]
- Singh, V.K.; Tiwari, N.; Garg, S. Document clustering using k-means, heuristic k-means and fuzzy c-means. In Proceedings of the Computational Intelligence and Communication Networks (CICN), 2011 International Conference on IEEE, Gwalior, India, 7–9 October 2011; pp. 297–301. [Google Scholar]
- Geem, Z.W.; Kim, J.H.; Loganathan, G.V. A new heuristic optimization algorithm: Harmony search. Simulation 2001, 76, 60–68. [Google Scholar] [CrossRef]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Zhou, C.; Gao, H.; Gao, L.; Zhang, W.G. Particle Swarm Optimization (PSO) Algorithm. Appl. Res. Comput. 2003, 12, 7–11. [Google Scholar]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef] [Green Version]
- Gandomi, A.H.; Yang, X.S.; Alavi, A.H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 2013, 29, 17–35. [Google Scholar] [CrossRef]
- Abualigah, L.; Shehab, M.; Alshinwan, M.; Alabool, H.; Abuaddous, H.Y.; Khasawneh, A.M.; Al Diabat, M. Ts-gwo: Iot tasks scheduling in cloud computing using grey wolf optimizer. In Swarm Intelligence for Cloud Computing; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020; pp. 127–152. [Google Scholar]
- Alomari, O.A.; Khader, A.T.; Al-Betar, M.A.; Abualigah, L.M. Gene selection for cancer classification by combining minimum redundancy maximum relevancy and bat-inspired algorithm. Int. J. Data Min. Bioinform. 2017, 19, 32–51. [Google Scholar] [CrossRef]
- Al-Sai, Z.A.; Abualigah, L.M. Big data and E-government: A review. In Proceedings of the 2017 IEEE 8th International Conference on Information Technology (ICIT), Amman, Jordan, 17–18 May 2017; pp. 580–587. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Method | Proposed | Dataset | Measure | Year |
|---|---|---|---|---|---|
| MKM [81] | K-means algorithm | Improved approach called multi-objective combining the similarity and distance measure for text clustering based on K-means | Seven different datasets | Accuracy F-measure | 2016 |
| LFW [82] | -hill climbing | Improve the -hill climbing algorithm the text clustering by providing a fair weighting value of the most important features for each document | LABIC datasets | F-measure Recall Precision Accuracy | 2018 |
| DDR [83] | PSO, LFW, K-means | A combination of three features algorithms for text document clustering based LFW approach the harmony search (HS), swarm optimization (PSO), and Genetic algorithm (GA), with dynamic dimension reduction and weight scheme | LABIC datasets | Accuracy F-measure | 2017 |
| MMKHA [52] | KHA | a new text clustering approach introduced based on the enhancement of KHA hybrid with multiple criteria function | LABIC datasets | ASDC Accuracy Precision Recall F-measure Purity Entropy | 2018 |
| H-KHA [53] | Harmony-KHA | A combination of the harmony search (HS) method and the KHA algorithm proposed to enhance the global search capability | UCI dataset | ASDC Precision Recall Accuracy F-measure | 2017 |
| KHA [56] | KHA | The first approach adopted the basic KHA, while the second approach uses the genetic operators instead of the KHA operators | CSTR Trec-5 Trec-6 Trec-7 Reuters 21,578 | Purity Entropy | 2016 |
| MHKHA [87] | MHKHA | hybrid KH algorithm is proposed for feature selection with a new weighting system, and a particular dimension reduction method. Four KHA algorithms are proposed for text clustering | CSTR SyskillWebert tr32- TREC-5 tr12- TREC-5 tr11- TREC-5 oh15 | Accuracy Purity Entropy Precision Recall F-measure | 2019 |
| MOAC [57] | MOA | This approach aims to select the best position of centroid particles, which is considered as the optimal cluster position | UCI | Accuracy Purity | 2018 |
| FSPSOTC [59] | PSO | Feature selection using the PSO algorithm, namely FSPSOTC, aims to solve the problem of feature selection in text clustering by building a new subset of informative features | LABIC | Precision Recall Accuracy F-measure Rank | 2017 |
| SCPSO [60] | PSO | The randomization is implemented with the initial population by considering the local and global optimization methods | Reuters 21,578 20 Newsgroup document TDT2 | Accuracy | 2019 |
| PSO + LSI [61] | PSO LSI | Text clustering based on the PSO algorithm and latent semantic indexing (PSO + LSI) | Reuters | F-measure time | 2012 |
| PM [62] | Binary PSO | Opposition chaotic fitness mutation A hybridization between binary PSO with a chaotic map, fitness based dynamic inertia weight, opposition-based learning, and mutation, is introduced for feature selection in text clustering | Reuters 21,578 Classic4 WebKB | Precision(P) Recall(R) F-score(F) | 2016 |
| Improved PSO [63] | PSO CHI | An improved PSO version was introduced to optimize the feature selection based on constant constriction factor and functional inertia weight | N.A Paired-sample | T-test | 2015 |
| ISSO [65] | SSO K-mean | Two-hybrid algorithms are presented based on SSO and K-means algorithms called SSO+K-means and K-means+SSO | PatentCorpus5000 | Cosine similarity F-Measure Accuracy | 2017 |
| SSO [64] | SSO K-mean | SSO utilizes the cooperative intelligence of spider social groups. According to spider gender, every spider tries to regenerate specific behavior and decreasing the local particles problems | Patent Corpus5000 | F-measure Precision Recall | 2016 |
| FCMWOA [66] | WOA FCM | A combination of Whale Optimization Algorithm (WOA) and Fuzzy C Means (FCM) is proposed for text clustering | Webkb Re0 20Newsgroup | Precision Recall F-measure | 2018 |
| AIFDS [67] | MWOA FCM | A modified WOA (MWOA) and FCM algorithm for text clustering. Further, an automobile insurance fraud detection system (AIFDS) is introduced | Iris Wine Seed Glass E-coli | CMC Sensitivity Specificity Accuracy | 2019 |
| CGABC [38] | Chaotic gradient artificial bee colony | Chaotic gradient artificial bee colony is proposed to enhance the performance of ABC search equation | Reuters 21,578, Classic4, and WebKB | Quality of solution and convergence speed | 2014 |
| ACO [68] | Ant colony optimization | Ant colony optimization is proposed to enhance the fuzzy document clustering issues | Accuracy | Pheromone trails | 2011 |
| MTACO [69] | Multi-label ACO | ACO is proposed to select the relevance function for the classification | webKB Yahoo RCV1 | classification | 2015 |
| RACO RACOFS [70] | EnRiched Ant Colony Optimization | RACO-based feature selection enRiched Ant Colony Optimization is proposed to to modify the pheromone values correctly and avoid premature convergence. RACO-based feature selection is introduced to find optimal solutions globally. | Monk1 Monk2 Post-operative BreastCancer Glass Vowel Wine Zoo | classification accuracy | 2014 |
| -FSTC [71] | -hill climbing technique | -hill climbing technique for text feature selection problem is proposed to improve the text clustering | Dmoz-Business and others | Accuracy Precision Recall F-measure | 2017 |
| -HC [72] | -hill climbing technique | -hill climbing technique is proposed to solve the text document clustering problem | ”Dmoz-Business” dataset | F-measure Precision Recall Accuracy | 2017 |
| IBCO [39] | An improved bee colony optimization algorithm | An improved bee colony optimization algorithm using dubbed IBCO is proposed to enhance clustering problem | Iris Wine Glass Wisconsin Breast Cancer Vowel | Classification Error Percentage (CEP) SICD | 2015 |
| SOM [85] | Optimization of SOM for document clustering | An optimization of SOM for document clustering has been presented to handle conceptual aspects in document clusters and to minimize training time | Reuters | F-measure training time | 2010 |
| H-FSPSOTC [76] | Hybrid method | Hybrid of particle swarm optimization algorithm with genetic operators have been proposed to solve the problem of feature selection | Reuters 21,578 20Newsgroups Reuters 21,578 20Newsgroups Dmoz-Business Dmoz-Science Reuters 21,578 20Newsgroups | Accuracy Precision Recall F-measure | 2017 |
| GWO–GOA [37] | Hybrid algorithm | GWO–GOA have been presented to improve meta-heuristic algorithms convergence levels | Reuters 21,578 20 newsgroups Reuters 21,578 20Newsgroups Dmoz-Business DMOZ-Science Reuters 21,578 20 Newsgroups | Accuracy Precision Recall F-measure Sensitivity Specificity | 2020 |
| TCP-GWO [86] | Improved grey wolf optimizer (GWO) | The grey wolf optimizer for TCP have been presented to address the problem of how to split text documents on the basis of GWO into homogeneous clusters | Dmoz-Business | Precision Recall F-measure rates | 2018 |
| FSHSTC [59] | Metaheuristic Harmony search (HS) | Harmony search (HS) algorithm have been proposed to solve the feature selection problem | Dmoz-Business and others | F-measure Accuracy | 2016 |
| Dataset | Number of | Source | ||
|---|---|---|---|---|
| Documents | Features | Clusters | ||
| DS1 | 299 | 1107 | 4 | Technical Reports |
| DS2 | 333 | 2604 | 4 | Web Pages |
| DS3 | 204 | 4252 | 6 | TREC |
| DS4 | 313 | 3745 | 8 | TREC |
| DS5 | 414 | 4879 | 9 | TREC |
| DS6 | 878 | 4537 | 10 | TREC |
| DS7 | 913 | 3100 | 10 | MEDLINE |
| Accuracy Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
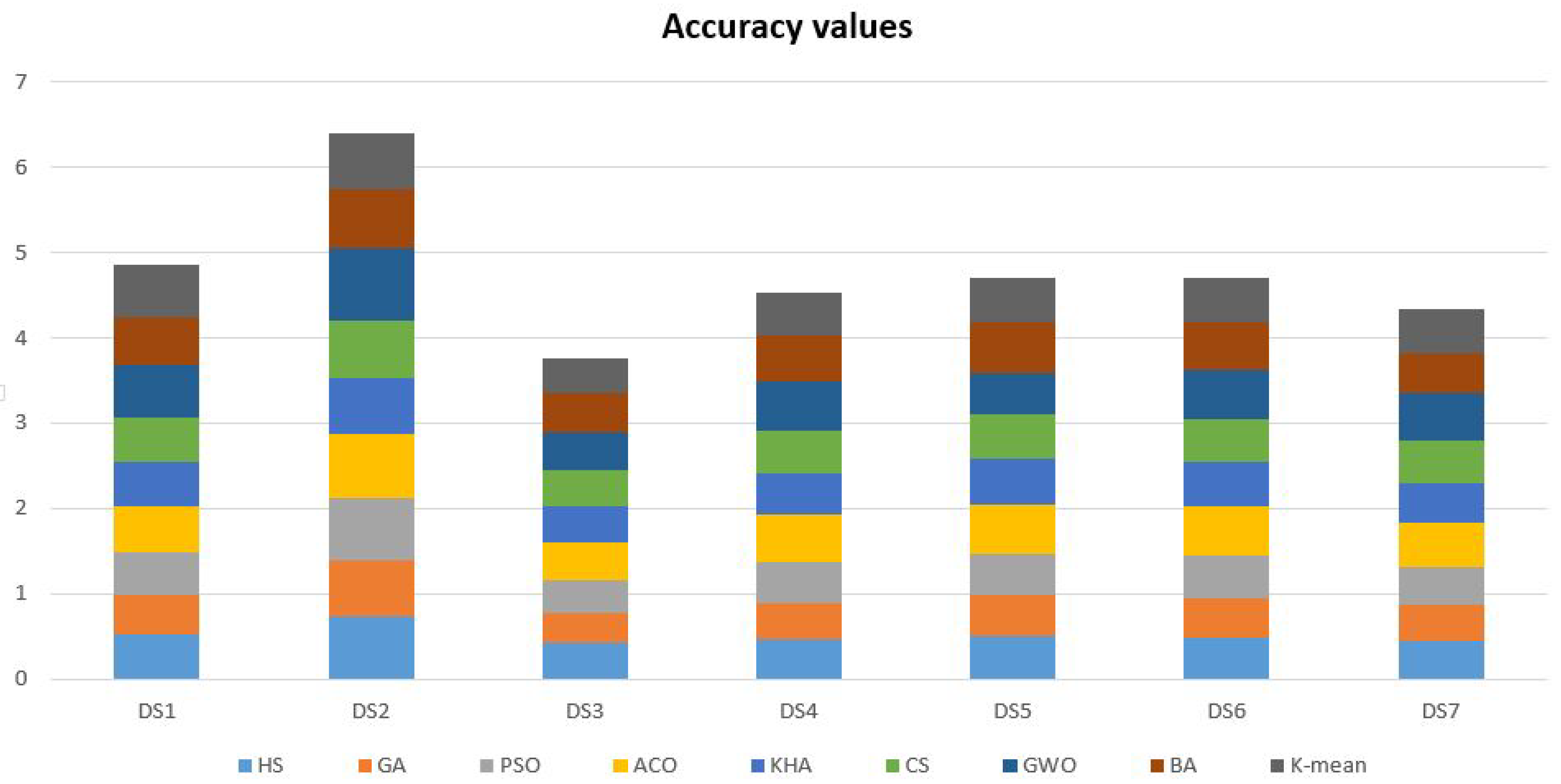
| DS1 | 0.521571 | 0.472742 | 0.498831 | 0.541639 | 0.521404 | 0.504682 | 0.622909 | 0.553512 | 0.620902 |
| DS2 | 0.727778 | 0.670421 | 0.725526 | 0.754805 | 0.649999 | 0.677476 | 0.843544 | 0.691741 | 0.659609 |
| DS3 | 0.426878 | 0.356863 | 0.368628 | 0.445097 | 0.425980 | 0.424509 | 0.444046 | 0.454167 | 0.412745 |
| DS4 | 0.467572 | 0.421912 | 0.473804 | 0.559265 | 0.487061 | 0.503514 | 0.569808 | 0.546485 | 0.505750 |
| DS5 | 0.497464 | 0.491048 | 0.488769 | 0.576623 | 0.540217 | 0.514372 | 0.483936 | 0.582661 | 0.530555 |
| DS6 | 0.493679 | 0.463895 | 0.494818 | 0.577961 | 0.510308 | 0.508542 | 0.584910 | 0.547836 | 0.528644 |
| DS7 | 0.437952 | 0.431106 | 0.450438 | 0.513801 | 0.453505 | 0.514732 | 0.549452 | 0.461172 | 0.530175 |
| Ranking Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 5 | 9 | 8 | 4 | 6 | 7 | 1 | 3 | 2 |
| DS2 | 3 | 7 | 4 | 2 | 9 | 6 | 1 | 5 | 8 |
| DS3 | 4 | 9 | 8 | 2 | 5 | 6 | 3 | 1 | 7 |
| DS4 | 8 | 9 | 7 | 2 | 6 | 5 | 1 | 3 | 4 |
| DS5 | 6 | 7 | 8 | 2 | 3 | 5 | 9 | 1 | 4 |
| DS6 | 8 | 9 | 7 | 2 | 5 | 6 | 1 | 3 | 4 |
| DS7 | 8 | 9 | 7 | 4 | 6 | 3 | 1 | 5 | 2 |
| Summation | 42 | 59 | 49 | 18 | 40 | 38 | 17 | 21 | 31 |
| Mean rank | 6.00 | 8.42857 | 7.00 | 2.57142 | 5.71428 | 5.42857 | 2.42857 | 3.00 | 4.42857 |
| Final ranking | 7 | 9 | 8 | 2 | 6 | 5 | 1 | 3 | 4 |
| Precision Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
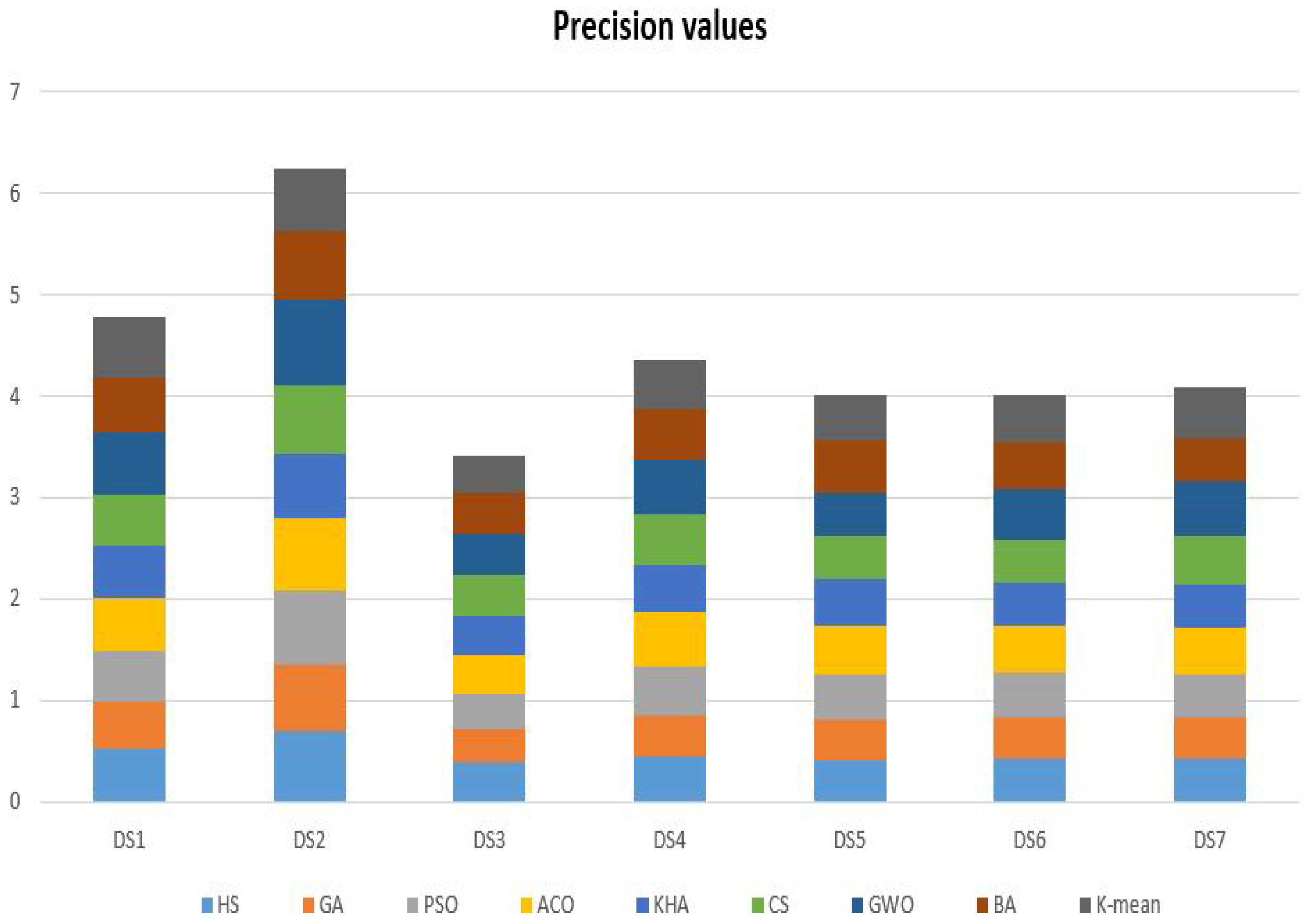
| DS1 | 0.516311 | 0.465179 | 0.506517 | 0.523483 | 0.510689 | 0.497316 | 0.626874 | 0.535501 | 0.598837 |
| DS2 | 0.695420 | 0.660070 | 0.722608 | 0.715740 | 0.648346 | 0.667253 | 0.850940 | 0.660592 | 0.620807 |
| DS3 | 0.394765 | 0.321445 | 0.339438 | 0.399019 | 0.386761 | 0.391978 | 0.413193 | 0.401748 | 0.369091 |
| DS4 | 0.452066 | 0.407555 | 0.478154 | 0.533171 | 0.461404 | 0.497471 | 0.544943 | 0.499450 | 0.487632 |
| DS5 | 0.409932 | 0.408273 | 0.444686 | 0.484433 | 0.458736 | 0.419713 | 0.417344 | 0.525953 | 0.448664 |
| DS6 | 0.425038 | 0.408469 | 0.437013 | 0.469521 | 0.425535 | 0.418595 | 0.504058 | 0.464550 | 0.451067 |
| DS7 | 0.421942 | 0.405116 | 0.426024 | 0.464437 | 0.418351 | 0.483816 | 0.537852 | 0.436314 | 0.494360 |
| Ranking Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 5 | 9 | 7 | 4 | 6 | 8 | 1 | 3 | 2 |
| DS2 | 4 | 7 | 2 | 3 | 8 | 5 | 1 | 6 | 9 |
| DS3 | 4 | 9 | 8 | 3 | 6 | 5 | 1 | 2 | 7 |
| DS4 | 8 | 9 | 6 | 2 | 7 | 4 | 1 | 3 | 5 |
| DS5 | 8 | 9 | 5 | 2 | 3 | 6 | 7 | 1 | 4 |
| DS6 | 7 | 9 | 5 | 2 | 6 | 8 | 1 | 3 | 4 |
| DS7 | 7 | 9 | 6 | 4 | 8 | 3 | 1 | 5 | 2 |
| Summation | 43 | 61 | 39 | 20 | 44 | 39 | 13 | 23 | 33 |
| Mean rank | 6.14285 | 8.71428 | 5.57142 | 2.85714 | 6.28571 | 5.57142 | 1.85714 | 3.28571 | 4.71428 |
| Final ranking | 7 | 9 | 5 | 2 | 8 | 5 | 1 | 3 | 4 |
| Recall Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 0.541343 | 0.476285 | 0.508354 | 0.536898 | 0.507354 | 0.476691 | 0.650435 | 0.561969 | 0.616213 |
| DS2 | 0.708215 | 0.662504 | 0.722580 | 0.737131 | 0.640515 | 0.658443 | 0.820237 | 0.665052 | 0.631951 |
| DS3 | 0.412106 | 0.346574 | 0.377370 | 0.409219 | 0.395009 | 0.414267 | 0.403324 | 0.392217 | 0.390691 |
| DS4 | 0.454048 | 0.419921 | 0.464152 | 0.541043 | 0.464823 | 0.496220 | 0.553784 | 0.516053 | 0.489738 |
| DS5 | 0.409845 | 0.408991 | 0.432807 | 0.467791 | 0.441765 | 0.409100 | 0.406372 | 0.522470 | 0.433629 |
| DS6 | 0.455282 | 0.428635 | 0.458360 | 0.500248 | 0.448898 | 0.437551 | 0.537407 | 0.489501 | 0.485761 |
| DS7 | 0.415760 | 0.404179 | 0.418950 | 0.482779 | 0.419679 | 0.484986 | 0.517571 | 0.430767 | 0.499522 |
| Ranking Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 4 | 9 | 6 | 5 | 7 | 8 | 1 | 3 | 2 |
| DS2 | 4 | 6 | 3 | 2 | 8 | 7 | 1 | 5 | 9 |
| DS3 | 2 | 9 | 8 | 3 | 5 | 1 | 4 | 6 | 7 |
| DS4 | 8 | 9 | 7 | 2 | 6 | 4 | 1 | 3 | 5 |
| DS5 | 6 | 8 | 5 | 2 | 3 | 7 | 9 | 1 | 4 |
| DS6 | 6 | 9 | 5 | 2 | 7 | 8 | 1 | 3 | 4 |
| DS7 | 8 | 9 | 7 | 4 | 6 | 3 | 1 | 5 | 2 |
| Summation | 38 | 59 | 41 | 20 | 42 | 38 | 18 | 26 | 33 |
| Mean rank | 5.42857 | 8.42857 | 5.85714 | 2.85714 | 6.00 | 5.42857 | 2.57142 | 3.71428 | 4.71428 |
| Final ranking | 5 | 9 | 7 | 2 | 8 | 5 | 1 | 3 | 4 |
| F-Measure Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
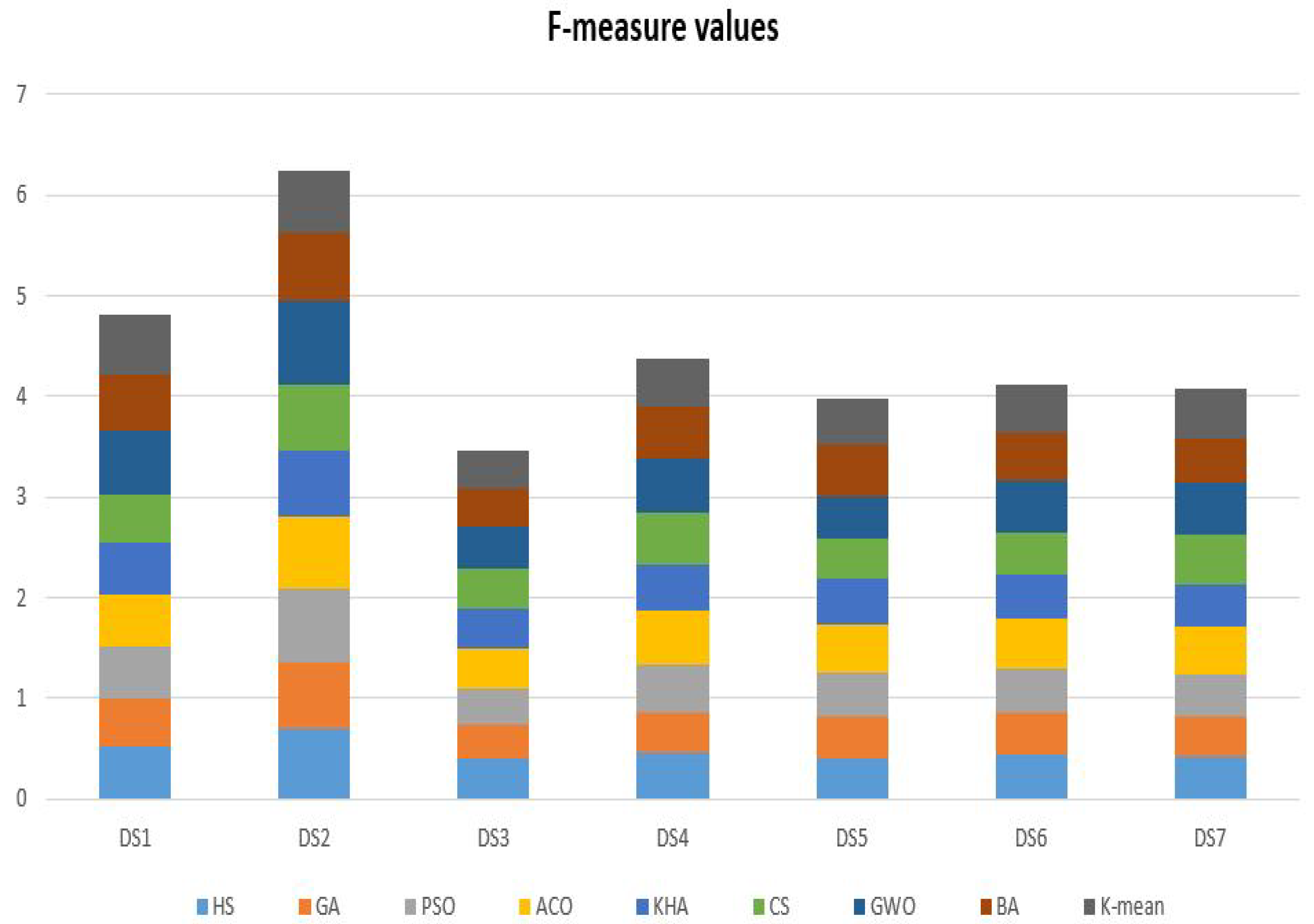
| DS1 | 0.526843 | 0.469324 | 0.509023 | 0.529366 | 0.507064 | 0.484753 | 0.637902 | 0.547258 | 0.606673 |
| DS2 | 0.701549 | 0.661178 | 0.722382 | 0.725740 | 0.643889 | 0.661381 | 0.835154 | 0.666718 | 0.625910 |
| DS3 | 0.402158 | 0.336810 | 0.356561 | 0.401984 | 0.389066 | 0.400461 | 0.410225 | 0.395514 | 0.377217 |
| DS4 | 0.452630 | 0.412758 | 0.470815 | 0.536117 | 0.462653 | 0.501921 | 0.548784 | 0.507005 | 0.487956 |
| DS5 | 0.409599 | 0.407297 | 0.438048 | 0.475219 | 0.449388 | 0.413829 | 0.411017 | 0.523684 | 0.440503 |
| DS6 | 0.439249 | 0.417510 | 0.447198 | 0.484020 | 0.436299 | 0.427266 | 0.519341 | 0.475981 | 0.467066 |
| DS7 | 0.418555 | 0.404324 | 0.422297 | 0.473309 | 0.418632 | 0.484100 | 0.527244 | 0.433272 | 0.496694 |
| Ranking Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 5 | 9 | 6 | 4 | 7 | 8 | 1 | 3 | 2 |
| DS2 | 4 | 7 | 3 | 2 | 8 | 6 | 1 | 5 | 9 |
| DS3 | 2 | 9 | 8 | 3 | 6 | 4 | 1 | 5 | 7 |
| DS4 | 8 | 9 | 6 | 2 | 7 | 4 | 1 | 3 | 5 |
| DS5 | 8 | 9 | 5 | 2 | 3 | 6 | 7 | 1 | 4 |
| DS6 | 6 | 9 | 5 | 2 | 7 | 8 | 1 | 3 | 4 |
| DS7 | 8 | 9 | 6 | 4 | 7 | 3 | 1 | 5 | 2 |
| Summation | 41 | 61 | 39 | 19 | 45 | 39 | 13 | 25 | 33 |
| Mean rank | 5.85714 | 8.71429 | 5.57143 | 2.71429 | 6.42857 | 5.57143 | 1.85714 | 3.57143 | 4.71428 |
| Final ranking | 7 | 9 | 5 | 2 | 8 | 5 | 1 | 3 | 4 |
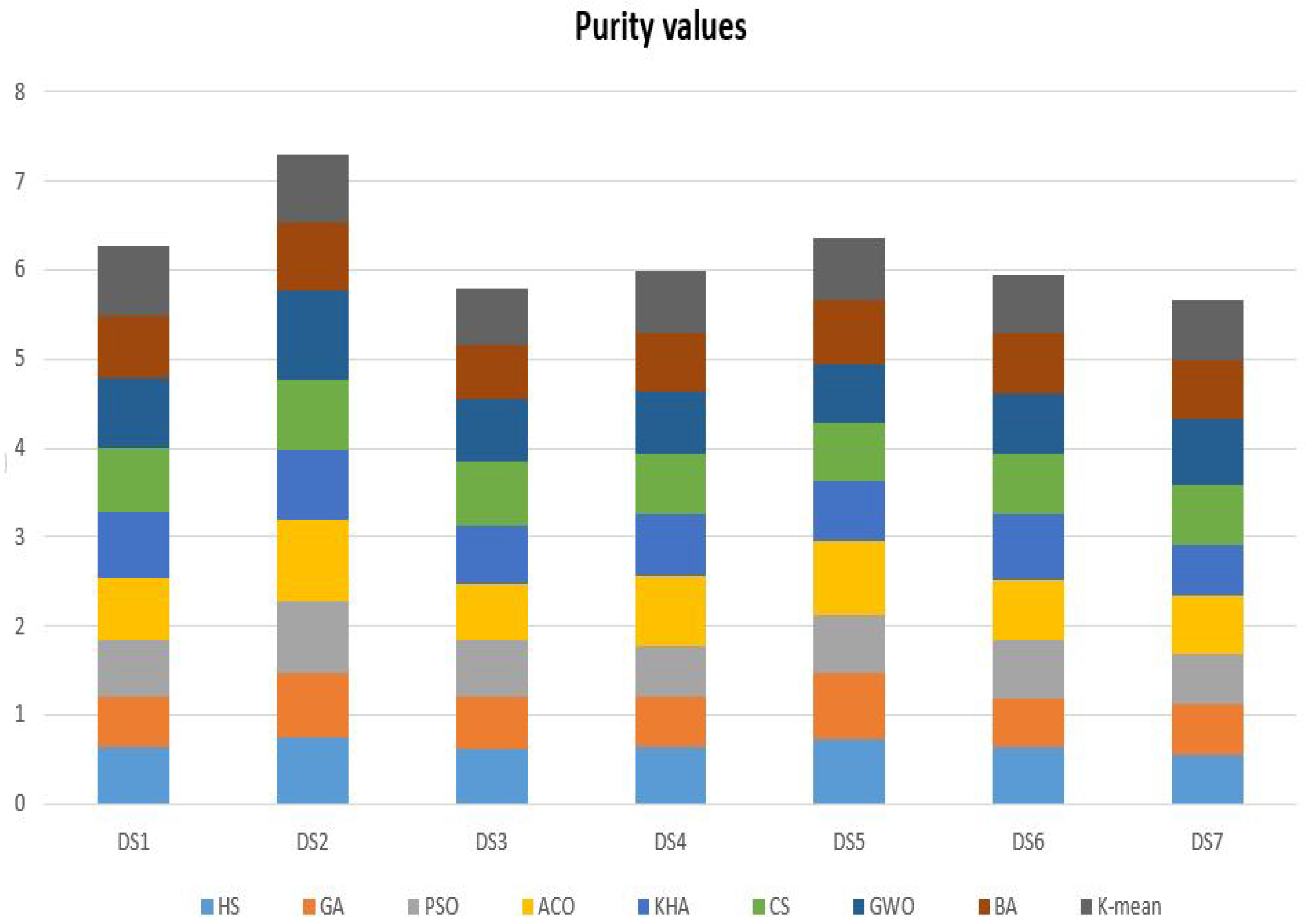
| Purity Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 0.636698 | 0.578385 | 0.632088 | 0.687157 | 0.753064 | 0.713239 | 0.781025 | 0.701243 | 0.778676 |
| DS2 | 0.743519 | 0.721757 | 0.806309 | 0.910619 | 0.798183 | 0.789050 | 0.989379 | 0.776432 | 0.754982 |
| DS3 | 0.626638 | 0.572274 | 0.629077 | 0.642075 | 0.667246 | 0.714183 | 0.693792 | 0.622121 | 0.632117 |
| DS4 | 0.630758 | 0.580626 | 0.557168 | 0.788665 | 0.708666 | 0.658809 | 0.718479 | 0.648318 | 0.688434 |
| DS5 | 0.718831 | 0.750700 | 0.661226 | 0.831996 | 0.661298 | 0.664520 | 0.648362 | 0.733289 | 0.683852 |
| DS6 | 0.633277 | 0.557320 | 0.644802 | 0.688866 | 0.729106 | 0.674527 | 0.678664 | 0.680488 | 0.656595 |
| DS7 | 0.542493 | 0.579877 | 0.564461 | 0.644539 | 0.583298 | 0.662628 | 0.750014 | 0.658338 | 0.663414 |
| Ranking Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 7 | 9 | 8 | 6 | 3 | 4 | 1 | 5 | 2 |
| DS2 | 8 | 9 | 3 | 2 | 4 | 5 | 1 | 6 | 7 |
| DS3 | 7 | 9 | 6 | 4 | 3 | 1 | 2 | 8 | 5 |
| DS4 | 7 | 8 | 9 | 1 | 3 | 5 | 2 | 6 | 4 |
| DS5 | 4 | 2 | 8 | 1 | 7 | 6 | 9 | 3 | 5 |
| DS6 | 8 | 9 | 7 | 2 | 1 | 5 | 4 | 3 | 6 |
| DS7 | 9 | 7 | 8 | 5 | 6 | 3 | 1 | 4 | 2 |
| Summation | 50 | 53 | 49 | 21 | 27 | 29 | 20 | 35 | 31 |
| Mean rank | 7.14285 | 7.57142 | 7.00 | 3.00 | 3.85714 | 4.14285 | 2.85714 | 5.00 | 4.42857 |
| Final ranking | 8 | 9 | 7 | 2 | 3 | 4 | 1 | 6 | 5 |
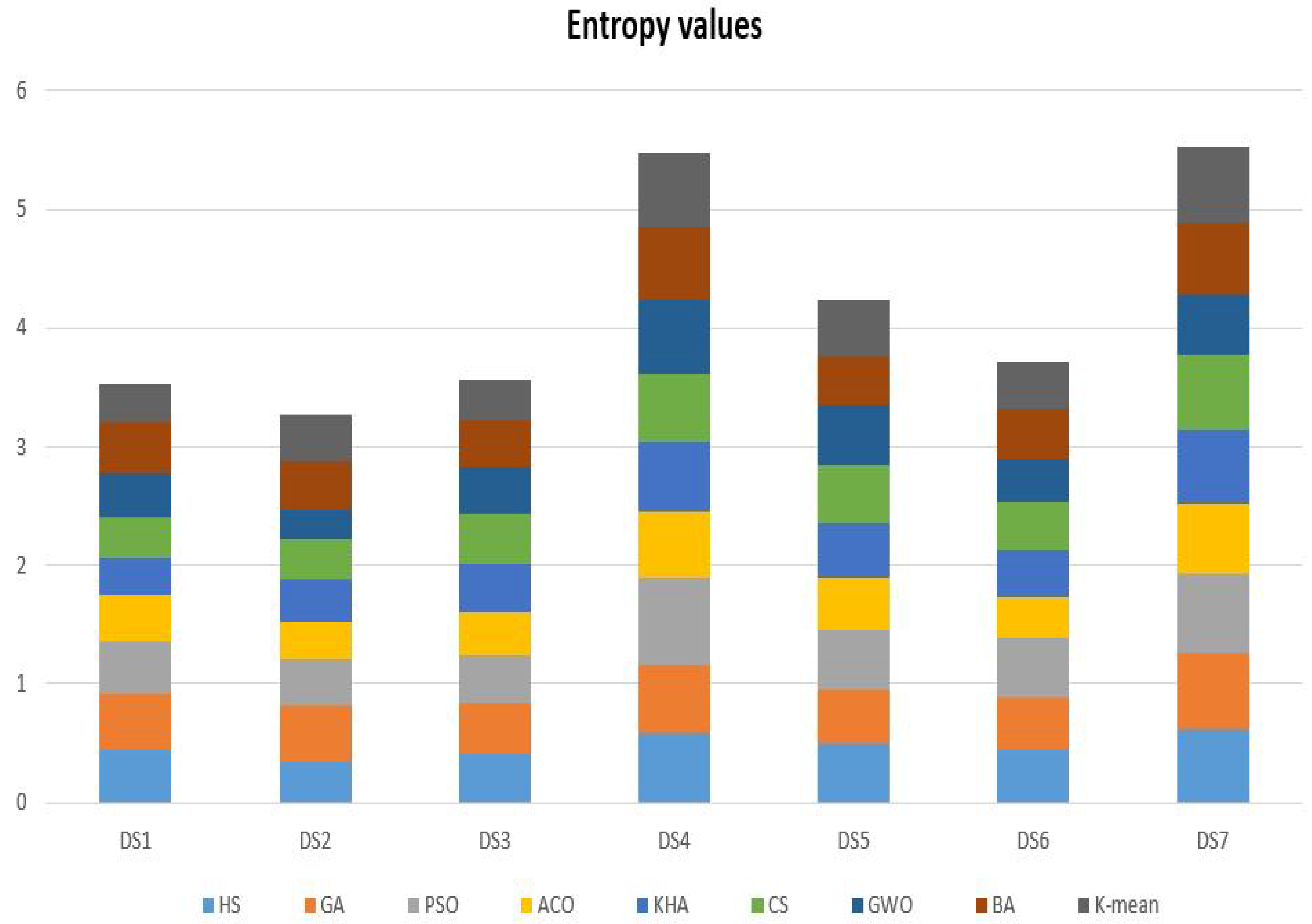
| Entropy Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 0.448296 | 0.465955 | 0.445373 | 0.388168 | 0.320995 | 0.335901 | 0.375879 | 0.421111 | 0.333152 |
| DS2 | 0.352708 | 0.464191 | 0.388575 | 0.324644 | 0.346803 | 0.346968 | 0.239784 | 0.411863 | 0.395838 |
| DS3 | 0.412584 | 0.423777 | 0.408261 | 0.357795 | 0.414517 | 0.419521 | 0.398005 | 0.391949 | 0.333981 |
| DS4 | 0.591471 | 0.575612 | 0.736625 | 0.546981 | 0.583180 | 0.580376 | 0.616758 | 0.619459 | 0.621091 |
| DS5 | 0.498653 | 0.447260 | 0.509601 | 0.440492 | 0.456882 | 0.491119 | 0.514431 | 0.404461 | 0.466960 |
| DS6 | 0.437201 | 0.453595 | 0.501121 | 0.349836 | 0.379381 | 0.407821 | 0.371808 | 0.416385 | 0.387643 |
| DS7 | 0.626637 | 0.641534 | 0.662544 | 0.580499 | 0.625289 | 0.634617 | 0.510802 | 0.609279 | 0.624934 |
| Ranking Dataset | Comparative Algorithms | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| HS | GA | PSO | ACO | KHA | CS | GWO | BA | K-Mean | |
| DS1 | 8 | 9 | 7 | 5 | 1 | 3 | 4 | 6 | 2 |
| DS2 | 5 | 9 | 6 | 2 | 3 | 4 | 1 | 8 | 7 |
| DS3 | 6 | 9 | 5 | 2 | 7 | 8 | 4 | 3 | 1 |
| DS4 | 5 | 2 | 9 | 1 | 4 | 3 | 6 | 7 | 8 |
| DS5 | 7 | 3 | 8 | 2 | 4 | 6 | 9 | 1 | 5 |
| DS6 | 7 | 8 | 9 | 1 | 3 | 5 | 2 | 6 | 4 |
| DS7 | 6 | 8 | 9 | 2 | 5 | 7 | 1 | 3 | 4 |
| Summation | 44 | 48 | 53 | 15 | 27 | 36 | 27 | 34 | 31 |
| Mean rank | 6.28571 | 6.85714 | 7.57142 | 2.14285 | 3.85714 | 5.14285 | 3.85714 | 4.85714 | 4.42857 |
| Final ranking | 7 | 8 | 9 | 1 | 2 | 6 | 2 | 5 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abualigah, L.; Gandomi, A.H.; Elaziz, M.A.; Hussien, A.G.; Khasawneh, A.M.; Alshinwan, M.; Houssein, E.H. Nature-Inspired Optimization Algorithms for Text Document Clustering—A Comprehensive Analysis. Algorithms 2020, 13, 345. https://0-doi-org.brum.beds.ac.uk/10.3390/a13120345
Abualigah L, Gandomi AH, Elaziz MA, Hussien AG, Khasawneh AM, Alshinwan M, Houssein EH. Nature-Inspired Optimization Algorithms for Text Document Clustering—A Comprehensive Analysis. Algorithms. 2020; 13(12):345. https://0-doi-org.brum.beds.ac.uk/10.3390/a13120345
Chicago/Turabian StyleAbualigah, Laith, Amir H. Gandomi, Mohamed Abd Elaziz, Abdelazim G. Hussien, Ahmad M. Khasawneh, Mohammad Alshinwan, and Essam H. Houssein. 2020. "Nature-Inspired Optimization Algorithms for Text Document Clustering—A Comprehensive Analysis" Algorithms 13, no. 12: 345. https://0-doi-org.brum.beds.ac.uk/10.3390/a13120345