

Algorithms, Volume 13, Issue 7 (July 2020) – 21 articles
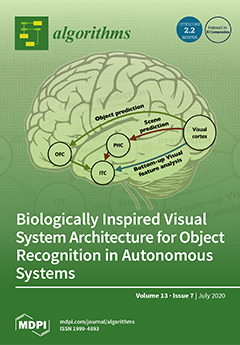
Cover Story (view full-size image):
Convolutional neural networks (CNNs) opened the way to unprecedented performance in computer vision tasks. Nevertheless, the sensitivity of CNNs to noise, light conditions, and the wholeness of data, indicate that CNNs still lacks the robustness needed for autonomous robotics. In an attempt to bring computer vision algorithms closer to the capabilities of a human operator, the mechanisms of the human visual system were analyzed. Studies show that the human brain continuously generates predictions based on prior knowledge of the world. These predictions generate contextual hypotheses that bias the outcome of the recognition process. In addition, the brain updates its knowledge based on the gaps between its predictions and the visual feedback. A biologically inspired algorithm was designed that integrates the concepts behind these top-down prediction and learning mechanisms with bottom-up CNNs. View this
[...] Read more.
- Issues are regarded as officially published after their release is announced to the table of contents alert mailing list.
- You may sign up for e-mail alerts to receive table of contents of newly released issues.
- PDF is the official format for papers published in both, html and pdf forms. To view the papers in pdf format, click on the "PDF Full-text" link, and use the free Adobe Reader to open them.
Previous Issue
Next Issue