Re-Pair in Small Space †
by
 , , , ,
, , , ,
Dominik Köppl
1,* ,
,
Tomohiro I
2 ,
,
Isamu Furuya
3,
Yoshimasa Takabatake
2,
Kensuke Sakai
2 and
Keisuke Goto
4 1
M&D Data Science Center, Tokyo Medical and Dental University, Tokyo 113-8510, Japan
2
Kyushu Institute of Technology, Fukuoka 820-8502, Japan
3
Graduate School of IST, Hokkaido University, Hokkaido 060-0814, Japan
4
Fujitsu Laboratories Ltd., Kawasaki 211-8588, Japan
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in the Prague Stringology Conference 2020: Prague, Czech Republic, 31 August–2 September 2020 and at the Data Compression Conference 2020: Virtual Conference, 24–27 March 2020.
Algorithms 2021, 14(1), 5; https://0-doi-org.brum.beds.ac.uk/10.3390/a14010005
Submission received: 29 November 2020
/
Revised: 18 December 2020
/
Accepted: 18 December 2020
/
Published: 25 December 2020
(This article belongs to the Special Issue Combinatorial Methods for String Processing)
Abstract
:Re-Pairis a grammar compression scheme with favorably good compression rates. The computation of Re-Pair comes with the cost of maintaining large frequency tables, which makes it hard to compute Re-Pair on large-scale data sets. As a solution for this problem, we present, given a text of length n whose characters are drawn from an integer alphabet with size , an time algorithm computing Re-Pair with bits of working space including the text space, where is a fixed user-defined constant and is the sum of and the number of non-terminals. We give variants of our solution working in parallel or in the external memory model. Unfortunately, the algorithm seems not practical since a preliminary version already needs roughly one hour for computing Re-Pair on one megabyte of text.
1. Introduction
Re-Pair [1] is a grammar deriving a single string. It is computed by replacing the most frequent bigram in this string with a new non-terminal, recursing until no bigram occurs more than once. Despite this simple-looking description, both the merits and the computational complexity of Re-Pair are intriguing. As a matter of fact, Re-Pair is currently one of the most well-understood grammar schemes.
Besides the seminal work of Larsson and Moffat [1], there are a couple of articles devoted to the compression aspects of Re-Pair: Given a text T of length n whose characters are drawn from an integer alphabet of size , the output of Re-Pair applied to T is at most bits with when represented naively as a list of character pairs [2], where denotes the empirical entropy of the k-th order. Using the encoding of Kieffer and Yang [3], Ochoa and Navarro [4] could improve the output size to at most bits. Other encodings were recently studied by Ganczorz [5]. Since Re-Pair is a so-called irreducible grammar, its grammar size, i.e., the sum of the symbols on the right-hand side of all rules, is upper bounded by ([3], Lemma 2), which matches the information-theoretic lower bound on the size of a grammar for a string of length n. Comparing this size with the size of the smallest grammar, its approximation ratio has as an upper bound [6] and as a lower bound [7]. On the practical side, Yoshida and Kida [8] presented an efficient fixed-length code for compressing the Re-Pair grammar.
Although conceived of as a grammar for compressing texts, Re-Pair has been successfully applied for compressing trees [9], matrices [10], or images [11]. For different settings or for better compression rates, there is a great interest in modifications to Re-Pair. Charikar et al. [6] (Section G) gave an easy variation to improve the size of the grammar. Another variant, proposed by Claude and Navarro [12], runs in a user-defined working space ( bits) and shares with our proposed solution the idea of a table that (a) is stored with the text in the working space and (b) grows in rounds. The variant of González et al. [13] is specialized to compressing a delta-encoded array of integers (i.e., by the differences of subsequent entries). Sekine et al. [14] provided an adaptive variant whose algorithm divides the input into blocks and processes each block based on the rules obtained from the grammars of its preceding blocks. Subsequently, Masaki and Kida [15] gave an online algorithm producing a grammar mimicking Re-Pair. Ganczorz and Jez [16] modified the Re-Pair grammar by disfavoring the replacement of bigrams that cross Lempel–Ziv-77 (LZ77) [17] factorization borders, which allowed the authors to achieve practically smaller grammar sizes. Recently, Furuya et al. [18] presented a variant, called MR-Re-Pair, in which a most frequent maximal repeat is replaced instead of a most frequent bigram.
1.1. Related Work
In this article, we focus on the problem of computing the grammar with an algorithm working in text space, forming a bridge between the domain of in-place string algorithms, low-memory compression algorithms, and the domain of Re-Pair computing algorithms. We briefly review some prominent achievements in both domains:
In-place string algorithms: For the LZ77 factorization, Kärkkäinen et al. [19] presented an algorithm computing this factorization with words on top of the input space in time for a variable , achieving words with time. For the suffix sorting problem, Goto [20] gave an algorithm to compute the suffix array [21] with bits on top of the output in time if each character of the alphabet is present in the text. This condition was improved to alphabet sizes of at most n by Li et al. [22]. Finally, Crochemore et al. [23] showed how to transform a text into its Burrows–Wheeler transform by using of additional bits. Due to da Louza et al. [24], this algorithm was extended to compute simultaneously the longest common prefix (LCP) array [21] with bits of additional working space.
Low-memory compression algorithms: Simple compression algorithms like run-length compression can be computed in-place and online on the text in linear time. However, a similar result for LZ77 is unknown: A trivial algorithm working with constant number of words (omitting the input text) computes an LZ77 factor starting at by linearly scanning for the longest previous occurrence for , thus taking quadratic time. A trade-off was proposed by Kärkkäinen et al. [19], who needed bits of working space and time for a selectable parameter . For the particular case of for an arbitrary constant , Kosolobov [25] could improve the running time to for the same space of bits. Unfortunately, we are unaware of memory-efficient algorithms computing other grammars such as longest-first substitution (LFS) [26], where a modifiable suffix tree is used for computation.
Re-Pair computation: Re-Pair is a grammar proposed by Larsson and Moffat [1], who presented an algorithm computing it in expected linear time with words of working space, where is the number of non-terminals (produced by Re-Pair). González et al. [13] (Section 4) gave another linear time algorithm using bytes of working space, where p is the maximum number of distinct bigrams considered at any time. The large space requirements got significantly improved by Bille et al. [27], who presented a randomized linear time algorithm taking words on top of the rewritable text space for a constant with . Subsequently, they improved their algorithm in [28] to include the text space within the words of the working space. However, they assumed that the alphabet size was constant and , where w is the machine word size. They also provided a solution for running in expected linear time. Recently, Sakai et al. [29] showed how to convert an arbitrary grammar (representing a text) into the Re-Pair grammar in compressed space, i.e., without decompressing the text. Combined with a grammar compression that can process the text in compressed space in a streaming fashion, this result leads to the first Re-Pair computation in compressed space.
In a broader picture, Carrascosa et al. [30] provided a generalization called iterative repeat replacement (IRR), which iteratively selects a substring for replacement via a scoring function. Here, Re-Pair and its variant MR-Re-Pair are specializations of the provided grammar IRR-MO (IRR with maximal number of occurrences)selecting one of the most frequent substrings that have a reoccurring non-overlapping occurrence. (As with bigrams, we only count the number of non-overlapping occurrences.)
1.2. Our Contribution
In this article, we propose an algorithm that computes the Re-Pair grammar in time (cf. Theorems 1 and 2) with bits of working space including the text space, where is a fixed user-defined constant and is the sum of the alphabet size and the number of non-terminals .
We can also compute the byte pair encoding [31], which is Re-Pair with the additional restriction that the algorithm terminates before no longer holds. Hence, we can replace with in the above space and time bounds.
Given that the characters of the text are drawn from a large integer alphabet with size the algorithm works in-place. (We consider the alphabet as not effective, i.e., a character does not have to appear in the text, as this is a common setting in Unicode texts such as Japanese text. For instance, could be such an alphabet size.) In this setting, we obtain the first non-trivial in-place algorithm, as a trivial approach on a text T of length n would compute the most frequent bigram in time by computing the frequency of each bigram for every integer i with , keeping only the most frequent bigram in memory. This sums up to total time and can be for some texts since there can be different bigrams considered for replacement by Re-Pair.
To achieve our goal of total time, we first provide a trade-off algorithm (cf. lemBatchedCount) finding the d most frequent bigrams in time for a trade-off parameter d. We subsequently run this algorithm for increasing values of d and show that we need to run it times, which gives us time if d is increasing sufficiently fast. Our major tools are appropriate text partitioning, elementary scans, and sorting steps, which we visualize in Section 2.5 by an example and practically evaluate in Section 2.6. When , a different approach using word-packing and bit-parallel techniques becomes attractive, leading to an time algorithm, which we explain in Section 3. Our algorithm can be parallelized (Section 5), used in external memory (Section 6), or adapted to compute the MR-Re-Pair grammar in small space (Section 4). Finally, in Section 7, we study several heuristics that make the algorithm faster on specific texts.
1.3. Preliminaries
We use the word RAM model with a word size of for an integer . We work in the restore model [32], in which algorithms are allowed to overwrite the input, as long as they can restore the input to its original form.
Strings: Let T be a text of length n whose characters are drawn from an integer alphabet of size . A bigram is an element of . The frequency of a bigram B in T is the number of non-overlapping occurrences of B in T, which is at most . For instance, the frequency of the bigram in the text consisting of na’s is .
Re-Pair: We reformulate the recursive description in the Introduction by dividing a Re-Pair construction algorithm into turns. Stipulating that is the text after the i-th turn with and with , Re-Pair replaces one of the most frequent bigrams (ties are broken arbitrarily) in with a non-terminal in the i-th turn. Given this bigram is , Re-Pair replaces all occurrences of bc with a new non-terminal in and sets with to produce . Since , Re-Pair terminates after turns such that contains no bigram occurring more than once.
2. Sequential Algorithm
A major task for producing the Re-Pair grammar is to count the frequencies of the most frequent bigrams. Our work horse for this task is a frequency table. A frequency table in of length f stores pairs of the form , where bc is a bigram and x the frequency of bc in . It uses bits of space since an entry stores a bigram consisting of two characters from and its respective frequency, which can be at most . Throughout this paper, we use an elementary in-place sorting algorithm like heapsort:
Lemma 1
([33]). An array of length n can be sorted in-place in time.
2.1. Trade-Off Computation
Using the frequency tables, we present a solution with a trade-off parameter:
Lemma 2.
Given an integer d with , we can compute the frequencies of the d most frequent bigrams in a text of length n whose characters are drawn from an alphabet of size σ in time using bits.
Proof.
Our idea is to partition the set of all bigrams appearing in T into subsets, compute the frequencies for each subset, and finally, merge these frequencies. In detail, we partition the text into substrings such that each substring has length d (the last one has a length of at most d). Subsequently, we extend to the left (only if ) such that and overlap by one text position, for . By doing so, we take the bigram on the border of two adjacent substrings and for each into account. Next, we create two frequency tables F and , each of length d for storing the frequencies of d bigrams. These tables are at the beginning empty. In what follows, we fill F such that after processing , F stores the most frequent d bigrams among those bigrams occurring in while acts as a temporary space for storing candidate bigrams that can enter F.
With F and , we process each of the substrings as follows: Let us fix an integer j with . We first put all bigrams of into in lexicographic order. We can perform this within the space of in time since there are at most d different bigrams in . We compute the frequencies of all these bigrams in the complete text T in time by scanning the text from left to right while locating a bigram in in time with a binary search. Subsequently, we interpret F and as one large frequency table, sort it with respect to the frequencies while discarding duplicates such that F stores the d most frequent bigrams in . This sorting step can be done in time. Finally, we clear and are done with . After the final merge step, we obtain the d most frequent bigrams of T stored in F.
Since each of the merge steps takes time, we need: time. For , we can build a large frequency table and perform one scan to count the frequencies of all bigrams in T. This scan and the final sorting with respect to the counted frequencies can be done in time. □
2.2. Algorithmic Ideas
With Lemma 2, we can compute in time with additional bits of working space on top of the text for a parameter d with . (The variable used in the abstract and in the introduction is interchangeable with , i.e., .) In the following, we show how this leads us to our first algorithm computing Re-Pair:
Theorem 1.
We can compute Re-Pair on a string of length n in time with bits of working space including the text space as a rewritable part in the working space, where is a fixed constant and is the sum of the alphabet size σ and the number of non-terminal symbols.
In our model, we assume that we can enlarge the text from bits to bits without additional extra memory. Our main idea is to store a growing frequency table using the space freed up by replacing bigrams with non-terminals. In detail, we maintain a frequency table F in of length for a growing variable , which is set to in the beginning. The table F takes bits, which is bits for . When we want to query it for a most frequent bigram, we linearly scan F in time, which is not a problem since (a) the number of queries is and (b) we aim for as the overall running time. A consequence is that there is no need to sort the bigrams in F according to their frequencies, which simplifies the following discussion.
Frequency table F: With lemBatchedCount, we can compute F in time. Instead of recomputing F on every turn i, we want to recompute it only when it no longer stores a most frequent bigram. However, it is not obvious when this happens as replacing a most frequent bigram during a turn (a) removes this entry in F and (b) can reduce the frequencies of other bigrams in F, making them possibly less frequent than other bigrams not tracked by F. Hence, the variable i for the i-th turn (creating the i-th non-terminal) and the variable k for recomputing the frequency table F the -st time are loosely connected. We group together all turns with the same and call this group the k-th round of the algorithm. At the beginning of each round, we enlarge and create a new F with a capacity for bigrams. Since a recomputation of F takes much time, we want to end a round only if F is no longer useful, i.e., when we no longer can guarantee that F stores a most frequent bigram. To achieve our claimed time bounds, we want to assign all m turns to different rounds, which can only be done if grows sufficiently fast.
Algorithm outline: At the beginning of the k-th round and the i-th turn, we compute the frequency table F storing bigrams and keep additionally the lowest frequency of F as a threshold , which is treated as a constant during this round. During the computation of the i-th turn, we replace the most frequent bigram (say, ) in the text with a non-terminal to produce . Thereafter, we remove bc from F and update those frequencies in F, which were decreased by the replacement of bc with and add each bigram containing the new character into F if its frequency is at least . Whenever a frequency in F drops below , we discard it. If F becomes empty, we move to the -st round and create a new F for storing frequencies. Otherwise (F still stores an entry), we can be sure that F stores a most frequent bigram. In both cases, we recurse with the -st turn by selecting the bigram with the highest frequency stored in F. We show in Algorithm 1 the pseudo code of this outlined algorithm. We describe in the following how we update F and how large can become at least.
| Algorithm 1: Algorithmic outline of our proposed algorithm working on a text T with a growing frequency table F. The constants and are explained in Section 2.3. The same section shows that the outer while loop is executed times. |
 |
2.3. Algorithmic Details
Suppose that we are in the k-th round and in the i-th turn. Let be the lowest frequency in F computed at the beginning of the k-th round. We keep as a constant threshold for the invariant that all frequencies in F are at least during the k-th round. With this threshold, we can assure in the following that F is either empty or stores a most frequent bigram.
Now suppose that the most frequent bigram of is , which is stored in F. To produce (and hence advancing to the -st turn), we enlarge the space of from to and replace all occurrences of bc in with a new non-terminal . Subsequently, we would like to take the next bigram of F. For that, however, we need to update the stored frequencies in F. To see this necessity, suppose that there is an occurrence of abcd with two characters in . By replacing with ,
- 1.
- the frequencies of ab and cd decrease by one (for the border case a = b = c (resp. b = c = d), there is no need to decrement the frequency of ab (resp. cd)), and
- 2.
- the frequencies of and increase by one.
Updating F. We can take care of the former changes (1) by decreasing the respective bigram in F (in the case that it is present). If the frequency of this bigram drops below the threshold , we remove it from F as there may be bigrams with a higher frequency that are not present in F. To cope with the latter changes (2), we track the characters adjacent to after the replacement, count their numbers, and add their respective bigrams to F if their frequencies are sufficiently high. In detail, suppose that we have substituted bc with exactly h times. Consequently, with the new text we have additionally bits of free space (the free space is consecutive after shifting all characters to the left), which we call D in the following. Subsequently, we scan the text and put the characters of appearing to the left of each of the h occurrences of into D. After sorting the characters in D lexicographically, we can count the frequency of for each character preceding an occurrence of in the text by scanning D linearly. If the obtained frequency of such a bigram is at least as high as the threshold , we insert into F and subsequently discard a bigram with the currently lowest frequency in F if the size of F has become . In the case that we visit a run of ’s during the creation of D, we must take care of not counting the overlapping occurrences of . Finally, we can count analogously the occurrences of for all characters succeeding an occurrence of .
Capacity of F: After the above procedure, we update the frequencies of F. When F becomes empty, all bigrams stored in F are replaced or have a frequency that becomes less than . Subsequently, we end the k-th round and continue with the ()-st round by (a) creating a new frequency table F with capacity and (b) setting the new threshold to the minimal frequency in F. In what follows, we (a) analyze in detail when F becomes empty (as this determines the sizes and ) and (b) show that we can compensate the number of discarded bigrams with an enlargement of F’s capacity from bigrams to bigrams for the sake of our aimed total running time.
Next, we analyze how many characters we have to free up (i.e., how many bigram occurrences we have to replace) to gain enough space for storing an additional frequency. Let be the number of bits needed to store one entry in F, and let be the minimum number of characters that need to be freed to store one frequency in this space. To understand the value of , we look at the arguments of the minimum function in the definition of and simultaneously at the maximum function in our aimed working space of bits (cf. Theorem 1):
- 1.
- The first item in this maximum function allows us to spend bits for each freed character such that we obtain space for one additional entry in F after freeing characters.
- 2.
- The second item allows us to use additional bits after freeing up c characters. This additional treatment helps us to let grow sufficiently fast in the first steps to save our time bound, as for sufficiently small alphabets and large text sizes, , which means that we might run the first turns with and, therefore, already spend time. Hence, after freeing up characters, we have space to store one additional entry in F.
With , we have the sufficient condition that replacing a constant number of characters gives us enough space for storing an additional frequency.
If we assume that replacing the occurrences of a bigram stored in F does not decrease the other frequencies stored in F, the analysis is now simple: Since each bigram in F has a frequency of at least two, . Since , this lets grow exponentially, meaning that we need rounds. In what follows, we show that this is also true in the general case.
Lemma 3.
Given that the frequency of all bigrams in F drops below the threshold after replacing the most frequent bigram bc, then its frequency has to be at least , where is the number of frequencies stored in F.
Proof.
If the frequency of bc in is x, then we can reduce at most frequencies of other bigrams (both the left character and the right character of each occurrence of bc can contribute to an occurrence of another bigram). Since a bigram must occur at least twice in to be present in F, the frequency of bc has to be at least for discarding all bigrams of F. □
Suppose that we have enough space available for storing the frequencies of bigrams, where is a constant (depending on and ) such that F and the working space of Lemma 2 with can be stored within this space. With and Lemma 3 with , we have:
where we use the equivalence to estimate the two arguments of the maximum function.
Since we let grow by a factor of at least for each recomputation of F, , and therefore, after steps. Consequently, after reaching , we can iterate the above procedure a constant number of times to compute the non-terminals of the remaining bigrams occurring at least twice.
Time analysis: In total, we have rounds. At the start of the k-th round, we compute F with the algorithm of Lemma 2 with on a text of length at most in time with . Summing this up, we get:
In the i-th turn, we update F by decreasing the frequencies of the bigrams affected by the substitution of the most frequent bigram bc with . For decreasing such a frequency, we look up its respective bigram with a linear scan in F, which takes time. However, since this decrease is accompanied with a replacement of an occurrence of bc, we obtain total time by charging each text position with time for a linear search in F. With the same argument, we can bound the total time for sorting the characters in D to overall time: Since we spend time on sorting h characters preceding or succeeding a replaced character and time on swapping a sufficiently large new bigram composed of and a character of with a bigram with the lowest frequency in F, we charge each text position again with time. Putting all time bounds together gives the claim of Theorem 1.
2.4. Storing the Output In-Place
Finally, we show that we can store the computed grammar in text space. More precisely, we want to store the grammar in an auxiliary array A packed at the end of the working space such that the entry stores the right-hand side of the non-terminal , which is a bigram. Thus, the non-terminals are represented implicitly as indices of the array A. We therefore need to subtract bits of space from our working space after the i-th turn. By adjusting in the above equations, we can deal with this additional space requirement as long as the frequencies of the replaced bigrams are at least three (we charge two occurrences for growing the space of A).
When only bigrams with frequencies of at most two remain, we switch to a simpler algorithm, discarding the idea of maintaining the frequency table F: Suppose that we work with the text . Let be a text position, which is one in the beginning, but will be incremented in the following turns while holding the invariant that does not contain a bigram of frequency two. We scan linearly from left to right and check, for each text position j, whether the bigram has another occurrence with , and if so,
- (a)
- append to A,
- (b)
- replace and with a new non-terminal to transform to , and
- (c)
- recurse on with until no bigram with frequency two is left.
The position , which we never decrement, helps us to skip over all text positions starting with bigrams with a frequency of one. Thus, the algorithm spends time for each such text position and time for each bigram with frequency two. Since there are at most n such bigrams, the overall running time of this algorithm is .
Remark 1
(Pointer machine model). Refraining from the usage of complicated algorithms, our algorithm consists only of elementary sorting and scanning steps. This allows us to run our algorithm on a pointer machine, obtaining the same time bound of . For the space bounds, we assume that the text is given in n words, where a word is large enough to store an element of or a text position.
2.5. Step-by-Step Execution
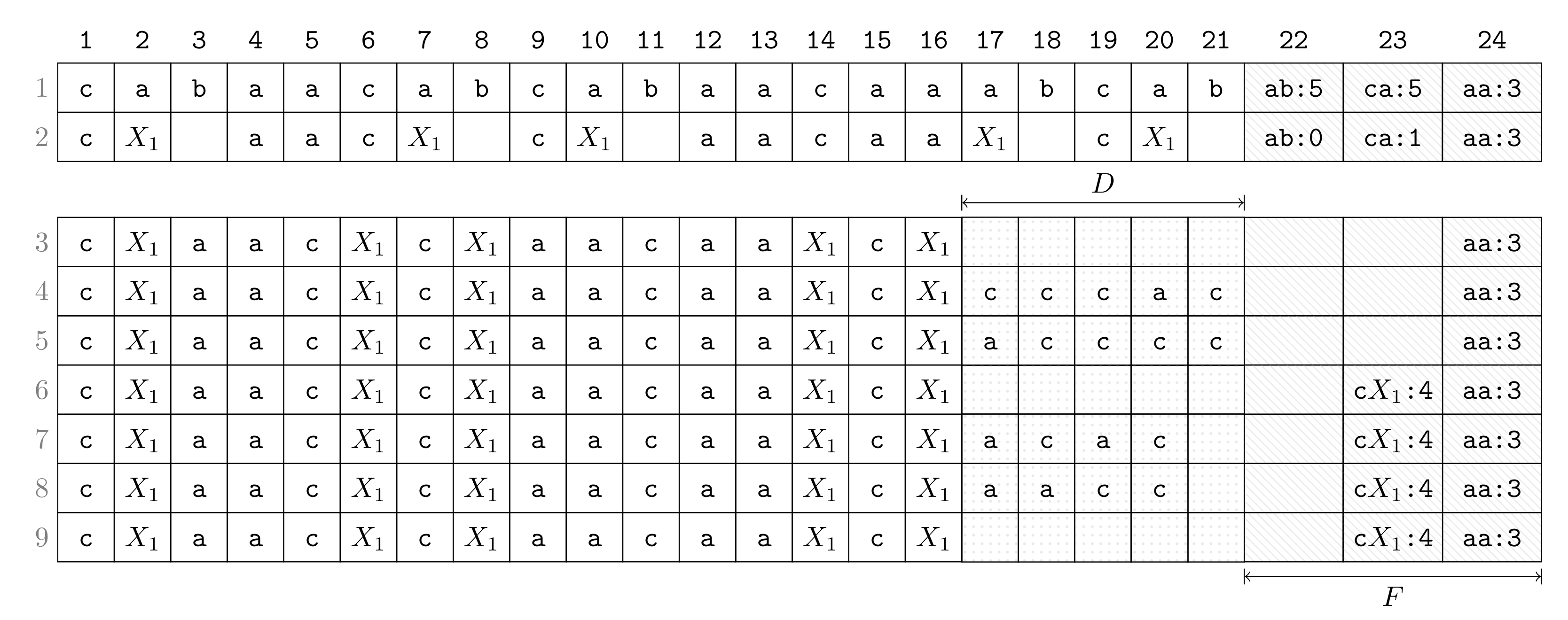
Here, we present an exemplary execution of the first turn (of the first round) on the input . We visualize each step of this turn as a row in Figure 1. A detailed description of each row follows:
- Row 1:
- Suppose that we have computed F, which has the constant number of entries (in the later turns when the size becomes larger, F will be put in the text space). The highest frequency is five achieved by and . The lowest frequency represented in F is three, which becomes the threshold for a bigram to be present in F such that bigrams whose frequencies drop below are removed from F. This threshold is a constant for all later turns until F is rebuilt (in the following round). During Turn 1, the algorithm proceeds now as follows:
- Row 2:
- Choose as a bigram to replace with a new non-terminal (break ties arbitrarily). Replace every occurrence of with while decrementing frequencies in F according to the neighboring characters of the replaced occurrence.
- Row 3:
- Remove from F every bigram whose frequency falls below the threshold. Obtain space for D by aligning the compressed text (the process of Row 2 and Row 3 can be done simultaneously).
- Row 4:
- Scan the text and copy each character preceding an occurrence of in to D.
- Row 5:
- Sort characters in D lexicographically.
- Row 6:
- Insert new bigrams (consisting of a character of D and ) whose frequencies are at least as large as the threshold.
- Row 7:
- Scan the text again and copy each character succeeding an occurrence of in to D (symmetric to Row 4).
- Row 8:
- Sort all characters in D lexicographically (symmetric to Row 5).
- Row 9:
- Insert new bigrams whose frequencies are at least as large as the threshold (symmetric to Row 6).
2.6. Implementation
At https://github.com/koeppl/repair-inplace, we provide a simplified implementation in C++17. The simplification is that we (a) fix the bit width of the text space to 16 bit and (b) assume that is the byte alphabet. We further skip the step increasing the bit width of the text from to . This means that the program works as long as the characters of fit into 16 bits. The benchmark, whose results are displayed in Table 1, was conducted on a Mac Pro Server with an Intel Xeon CPU X5670 clocked at 2.93 GHz running Arch Linux. The implementation was compiled with gcc-8.2.1 in the highest optimization mode -O3. Looking at Table 1, we observe that the running time is super-linear to the input size on all text instances, which we obtained from the Pizza&Chili corpus (http://pizzachili.dcc.uchile.cl/). We conducted the same experiments with an implementation of Gonzalo Navarro (https://users.dcc.uchile.cl/~gnavarro/software/repair.tgz) in Table 2 with considerably better running times while restricting the algorithm to use 1 MB of RAM during execution. Table 3 gives some characteristics about the used data sets. We see that the number of rounds is the number of turns plus one for every unary string with an integer since the text contains only one bigram with a frequency larger than two in each round. Replacing this bigram in the text makes F empty such that the algorithm recomputes F after each turn. Note that the number of rounds can drop while scaling the prefix length based on the choice of the bigrams stored in F.
3. Bit-Parallel Algorithm
In the case that is (and therefore, ), a word-packing approach becomes interesting. We present techniques speeding up the previously introduced operations on chunks of characters from time to time. In the end, these techniques allow us to speed up the sequential algorithm of Theorem 1 from time to the following:
Theorem 2.
We can compute Re-Pair on a string of length n in time with bits of working space including the text space, where is a fixed constant and is the sum of the alphabet size σ and the number of non-terminal symbols.
Note that the time factor is due to the popcount function [34] (Algorithm 1), which has been optimized to a single instruction on modern computer architectures. Our toolbox consists of several elementary instructions shown in Figure 2. There, can be computed in constant time algorithm using bits [35] (Section 5). The last two functions in Figure 2 are explained in Figure 3.
3.1. Broadword Search
First, we deal with accelerating the computation of the frequency of a bigram in T by exploiting broadword search thanks to the word RAM model. We start with the search of single characters and subsequently extend this result to bigrams:
Lemma 4.
We can count the occurrences of a character in a string of length in time.
Proof.
Let q be the largest multiple of fitting into a computer word, divided by . Let be a string of length q. Our first task is to compute a bit mask of length marking the occurrences of a character in S with a ‘1’. For that, we follow the constant time broadword pattern matching of Knuth [36] (Section 7.1.3); see https://github.com/koeppl/broadwordsearch for a practical implementation. Let H and L be two bit vectors of length having marked only the most significant or the least significant bit, respectively. Let and denote the q times concatenation of H and L, respectively. Then, the operations in Figure 4 yield an array X of length q with:
where each entry of X has bits.
To obtain the number of occurrences of c in S, we use the popcount operation returning the number of zero bits in X and divide the result by . The popcount instruction takes time ([34] Algorithm 1). □
Having Lemma 4, we show that we can compute the frequency of a bigram in T in time. For that, we interpret of length n as a text of length . Then, we partition T into strings fitting into a computer word and call each string of this partition a chunk. For each chunk, we can apply Lemma 4 by treating a bigram as a single character. The result is, however, not the frequency of the bigram c in general. For computing the frequency a bigram , we distinguish the cases and .
Case : By applying Lemma 4 to find the character in a chunk S (interpreted as a string of length on the alphabet ), we obtain the number of occurrences of bc starting at odd positions in S. To obtain this number for all even positions, we apply the procedure to with . Additional care has to be taken at the borders of each chunk matching the last character of the current chunk and the first character of the subsequent chunk with b and c, respectively.
Case : This case is more involving as overlapping occurrences of bb can occur in S, which we must not count. To this end, we watch out for runs of b’s, i.e., substrings of maximal lengths consisting of the character b (here, we consider also maximal substrings of b with length one as a run). We separate these runs into runs ending either at even or at odd positions. We do this because the frequency of bb in a run of b’s ending at an even (resp. odd) position is the number of occurrences of bb within this run ending at an even (resp. odd) position. We can compute these positions similarly to the approach for by first (a) hiding runs ending at even (resp. odd) positions and then (b) counting all bigrams ending at even (resp. odd) positions. Runs of b’s that are a prefix or a suffix of S are handled individually if S is neither the first nor the last chunk of T, respectively. That is because a run passing a chunk border starts and ends in different chunks. To take care of those runs, we remember the number of b’s of the longest suffix of every chunk and accumulate this number until we find the end of this run, which is a prefix of a subsequent chunk. The procedure for counting the frequency of bb inside S is explained with an example in Figure 5. With the aforementioned analysis of the runs crossing chunk borders, we can extend this procedure to count the frequency of bb in T. We conclude:
Lemma 5.
We can compute the frequency of a bigram in a string T of length n whose characters are drawn from an alphabet of size σ in time.
3.2. Bit-Parallel Adaption
Similarly to Lemma 2, we present an algorithm computing the d most frequent bigrams, but now with the word-packed search of Lemma 5.
Lemma 6.
Given an integer d with , we can compute the frequencies of the d most frequent bigrams in a text of length n whose characters are drawn from an alphabet of size σ in time using bits.
Proof.
We allocate a frequency table F of length d. For each text position i with , we compute the frequency of in time with Lemma 5. After computing a frequency, we insert it into F if it is one of the d most frequent bigrams among the bigrams we have already computed. We can perform the insertion in time if we sort the entries of F by their frequencies, obtaining total time. □
Studying the final time bounds of Equation (1) for the sequential algorithm of Section 2, we see that we spend time in the first turn, but spend less time in later turns. Hence, we want to run the bit-parallel algorithm only in the first few turns until becomes so large that the benefits of running Lemma 2 outweigh the benefits of the bit-parallel approach of Lemma 6. In detail, for the k-th round, we set and run the algorithm of Lemma 6 on the current text if d is sufficiently small, or otherwise the algorithm of Lemma 2. In total, we obtain:
where is the sum of the alphabet size and the number of non-terminals, and .
To obtain the claim of Theorem 2, it is left to show that the k-th round with the bit-parallel approach uses time, as we now want to charge each text position with time with the same amortized analysis as after Equation (1). We target time for:
- (1)
- replacing all occurrences of a bigram,
- (2)
- shifting freed up text space to the right,
- (3)
- finding the bigram with the highest or lowest frequency in F,
- (4)
- updating or exchanging an entry in F, and
- (5)
- looking up the frequency of a bigram in F.
Let and q be the largest multiple of x fitting into a computer word, divided by x. For Item (1), we partition T into substrings of length q and apply Item (1) to each such substring S. Here, we combine the two bit vectors of Figure 5 used for the two popcount calls by a bitwise OR and call the resulting bit vector Y. Interpreting Y as an array of integers of bit width x, Y has q entries, and it holds that if and only if is the second character of an occurrence of the bigram we want to replace. (Like in Item (1), the case in which the bigram crosses a boundary of the partition of T is handled individually). We can replace this character in all marked positions in S by a non-terminal using x bits with the instruction , where L with is the bit vector having marked only the least significant bit. Subsequently, for Item (2), we erase all characters with and move them to the right of the bit chunk S sequentially. In the subsequent bit chunks, we can use word-packed shifting. The sequential bit shift costs time, but on an amortized view, a deletion of a character is done at most once per original text position.
For the remaining points, our trick is to represent F by a minimum and a maximum heap, both realized as array heaps. For the space increase, we have to lower (and ) adequately. Each element of an array heap stores a frequency and a pointer to a bigram stored in a separate array B storing all bigrams consecutively. A pointer array P stores pointers to the respective frequencies in both heaps for each bigram of B. The total data structure can be constructed at the beginning of the k-th round in time and hence does not worsen the time bounds. While B solves Item (5), the two heaps with P solve Items (3) and (4) even in time.
In the case that we want to store the output in working space, we follow the description of Section 2.4, where we now use word-packing to find the second occurrence of a bigram in in time.
4. Computing MR-Re-Pair in Small Space
We can adapt our algorithm to compute the MR-Re-Pair grammar scheme proposed by Furuya et al. [18]. The difference to Re-Pair is that MR-Re-Pair replaces the most frequent maximal repeat instead of the most frequent bigram, where a maximal repeat is a reoccurring substring of the text whose frequency decreases when extending it to the left or to the right. (Here, we naturally extended the definition of frequency from bigrams to substrings meaning the number of non-overlapping occurrences.) Our idea is to exploit the fact that a most frequent bigram corresponds to a most frequent maximal repeat ([18], Lemma 2). This means that we can find a most frequent maximal repeat by extending all occurrences of a most frequent bigram to their left and to their right until all are no longer equal substrings. Although such an extension can be time consuming, this time is amortized by the number of characters that are replaced on creating an MR-Re-Pair rule. Hence, we conclude that we can compute MR-Re-Pair in the same space and time bounds as our algorithms (Theorems 1 and 2) computing the Re-Pair grammar.
5. Parallel Algorithm
Suppose that we have p processors on a concurrent read concurrent write (CRCW) machine, supporting in particular parallel insertions of elements and frequency updates in a frequency table. In the parallel setting, we allow us to spend bits of additional working space such that each processor has an extra budget of bits. In our computational model, we assume that the text is stored in p parts of equal lengths, which we can achieve by padding up the last part with dummy characters to have characters for each processor, such that we can enlarge a text stored in bits to bits in time without extra memory. For our parallel variant computing Re-Pair, our working horse is a parallel sorting algorithm:
Lemma 7
([37]). We can sort an array of length n in parallel time with bits of working space. The work is .
The parallel sorting allows us to state Lemma 2 in the following way:
Lemma 8.
Given an integer d with , we can compute the frequencies of the d most frequent bigrams in a text of length n whose characters are drawn from an alphabet of size σ in time using bits. The work is .
Proof.
We follow the computational steps of lemBatchedCount, but (a) divide a scan into p parts, (b) conduct a scan in parallel but a binary search sequentially, and (c) use lemSortPar for the sorting. This gives us the following time bounds for each operation:
| Operation | Lemma 2 | Parallel |
| fill with bigrams | ||
| sort lexicographically | ||
| compute frequencies of | ||
| merge with F |
The merge steps are conducted in the same way, yielding the bounds of this lemma. □
In our sequential model, we produce by performing a left shift of the gained space after replacing all occurrences of a most frequent bigram with a new non-terminal such that we accumulate all free space at the end of the text. As described in our computational model, our text is stored as a partition of p substrings, each assigned to one processor. Instead of gathering the entire free space at T’s end, we gather free space at the end of each of these substrings. We bookkeep the size and location of each such free space (there are at most p many) such that we can work on the remaining text like it would be a single continuous array (and not fragmented into p substrings). This shape allows us to perform the left shift in time, while spending bits of space for maintaining the locations of the free space fragments.
For , exchanging Lemma 2 with Lemma 8 in Equation (1) gives:
It is left to provide an amortized analysis for updating the frequencies in F during the i-th turn. Here, we can charge each text position with time, as we have the following time bounds for each operation:
| Operation | Sequential | Parallel |
| linearly scan F | ||
| linearly scan | ||
| sort D with |
The first operation in the above table is used, among others, for finding the bigram with the lowest or highest frequency in F. Computing the lowest or highest frequency in F can be done with a single variable pointing to the currently found entry with the lowest or highest frequency during a parallel scan thanks to the CRCW model. In the concurrent read exclusive write (CREW) model, concurrent writes are not possible. A common strategy lets each processor compute the entry of the lowest or highest frequency within its assigned range in F, which is then merged in a tournament tree fashion, causing additional time.
Theorem 3.
We can compute Re-Pair in time with processors on a CRCW machine with bits of working space including the text space, where is a fixed constant and is the sum of the alphabet size σ and the number of non-terminal symbols. The work is .
6. Computing Re-Pair in External Memory
This part is devoted to the first external memory (EM) algorithms computing Re-Pair, which is another way to overcome the memory limitation problem. We start with the definition of the EM model, present an approach using a sophisticated heap data structure, and another approach adapting our in-place techniques.
For the following, we use the EM model of Aggarwal and Vitter [38]. It features fast internal memory (IM) holding up to M data words and slow EM of unbounded size. The measure of the performance of an algorithm is the number of input and output operations (I/Os) required, where each I/O transfers a block of B consecutive words between memory levels. Reading or writing n contiguous words from or to disk requires I/Os. Sorting n contiguous words requires I/Os. For realistic values of n, B, and M, we stipulate that .
A simple approach is based on an EM heap maintaining the frequencies of all bigrams in the text. A state-of-the-art heap is due to Jiang and Larsen [39] providing insertion, deletion, and the retrieval of the maximum element in I/Os, where N is the size of the heap. Since , inserting all bigrams takes at most I/Os. As there are at most n additional insertions, deletions, and maximum element retrievals, this sums to at most I/Os. Given Re-Pair has m turns, we need to scan the text m times to replace the occurrences of all m retrieved bigrams, triggering I/Os.
In the following, we show an EM Re-Pair algorithm that evades the use of complicated data structures and prioritizes scans over sorting. This algorithm is based on our Re-Pair algorithm. It uses Lemma 2 with such that F and can be kept in RAM. This allows us to perform all sorting steps and binary searches in IM without additional I/O. We only trigger I/O operations for scanning the text, which is done times, since we partition T into d substrings. In total, we spend at most scans for the algorithm of Lemma 2. For the actual algorithm having m turns, we update Fm times, during which we replace all occurrences of a chosen bigram in the text. This gives us m scans in total. Finally, we need to reason about D, which we create m times. However, D may be larger than M, such that we may need to store it in EM. Given that is D in the i-th turn, we sort D in EM, triggering I/Os. With the converse of Jensen’s inequality ([40], Theorem B) (set there ), we obtain total I/Os for all instances of D. We finally obtain:
Theorem 4.
We can compute Re-Pair with I/Os in external memory.
The latter approach can be practically favorable to the heap based approach if and , or if the EM space is also of major concern.
7. Heuristics for Practicality
The achieved quadratic or near-quadratic time bounds (Theorems 1 and 2) seem to convey the impression that this work is only of purely theoretic interest. However, we provide here some heuristics, which can help us to overcome the practical bottleneck at the beginning of the execution, where only of bits of working space are available. In other words, we want to study several heuristics to circumvent the need to call Lemma 2 with a small parameter d, as such a case means a considerable time loss. Even a single call of Lemma 2 with a small d prevents the computation of Re-Pair of data sets larger than 1 MiB within a reasonable time frame (cf. Section 2.6). We present three heuristics depending on whether our space budget on top of the text space is within:
- 1.
- bits,
- 2.
- bits, or
- 3.
- bits.
Heuristic 1. If is small enough such that we can spend bits, then we can count the frequencies of all bigrams in a table of bits in time. Whenever we reach a that lets grow outside of our budget, we have spent time in total for reaching from as the costs for replacements can be amortized by twice of the text length.
Heuristic 2. Suppose that we are allowed to use bits in addition to the bits of the text . We create an extra array F of length with the aim that stores the frequency of in . We can fill the array in scans over , costing us time. The largest number stored in F is the most frequent bigram in T.
Heuristic 3. Finally, if the distribution of bigrams is skewed, chances are that one bigram outnumbers all others. In such a case, we can use the following algorithm to find this bigram:
Lemma 9.
Given there is a bigram in () whose frequency is higher than the sum of frequencies of all other bigrams, we can compute in time using bits.
Proof.
We use the Boyer–Moore majority vote algorithm [41] for finding the most frequent bigram in time with bits of working space. □
A practical optimization of updating F as described in Section 2.3 could be to enlarge F beyond instead of keeping its size. There, after a replacement of a bigram with a non-terminal , we insert those bigrams containing into F whose frequencies are above while discarding bigrams of the lowest frequency stored in F to keep the size of F at . Instead of discarding these bigrams, we could just let F grow. We can let F grow by using the space reserved for the frequency table computed in Lemma 2 (remember the definition of the constant ). By doing so, we might extend the lifespan of a round.
8. Conclusions
In this article, we propose an algorithm computing Re-Pair in-place in sub-quadratic time for small alphabet sizes. Our major tools are simple, which allows us to parallelize our algorithm or adapt it in the external memory model.
Author Contributions
Conceptualization: K.G.; formal analysis: T.I., I.F., Y.T., and D.K.; visualization: K.S.; writing: T.I. and D.K. All authors read and agreed to the published version of the manuscript.
Funding
This work is funded by the JSPS KAKENHI Grant Numbers JP18F18120 (Dominik Köppl), 19K20213 (Tomohiro I), and 18K18111 (Yoshimasa Takabatake) and the JST CREST Grant Number JPMJCR1402 including the AIP challenge program (Keisuke Goto).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Larsson, N.J.; Moffat, A. Offline Dictionary-Based Compression. In Proceedings of the 1999 Data Compression Conference, Snowbird, UT, USA, 29–31 March 1999; pp. 296–305. [Google Scholar]
- Navarro, G.; Russo, L.M.S. Re-Pair Achieves High-Order Entropy. In Proceedings of the 2008 Data Compression Conference, Snowbird, UT, USA, 25–27 March 2008; p. 537. [Google Scholar]
- Kieffer, J.C.; Yang, E. Grammar-based codes: A new class of universal lossless source codes. IEEE Trans. Inf. Theory 2000, 46, 737–754. [Google Scholar] [CrossRef]
- Ochoa, C.; Navarro, G. RePair and All Irreducible Grammars are Upper Bounded by High-Order Empirical Entropy. IEEE Trans. Inf. Theory 2019, 65, 3160–3164. [Google Scholar] [CrossRef]
- Ganczorz, M. Entropy Lower Bounds for Dictionary Compression. Proc. CPM 2019, 128, 11:1–11:18. [Google Scholar]
- Charikar, M.; Lehman, E.; Liu, D.; Panigrahy, R.; Prabhakaran, M.; Sahai, A.; Shelat, A. The smallest grammar problem. IEEE Trans. Inf. Theory 2005, 51, 2554–2576. [Google Scholar] [CrossRef]
- Bannai, H.; Hirayama, M.; Hucke, D.; Inenaga, S.; Jez, A.; Lohrey, M.; Reh, C.P. The smallest grammar problem revisited. arXiv 2019, arXiv:1908.06428. [Google Scholar] [CrossRef]
- Yoshida, S.; Kida, T. Effective Variable-Length-to-Fixed-Length Coding via a Re-Pair Algorithm. In Proceedings of the 2013 Data Compression Conference, Snowbird, UT, USA, 20–22 March 2013; p. 532. [Google Scholar]
- Lohrey, M.; Maneth, S.; Mennicke, R. XML tree structure compression using RePair. Inf. Syst. 2013, 38, 1150–1167. [Google Scholar] [CrossRef]
- Tabei, Y.; Saigo, H.; Yamanishi, Y.; Puglisi, S.J. Scalable Partial Least Squares Regression on Grammar-Compressed Data Matrices. In Proceedings of the SIGKDD, San Francisco, CA, USA, 13–17 August 2016; pp. 1875–1884. [Google Scholar]
- de Luca, P.; Russiello, V.M.; Ciro-Sannino, R.; Valente, L. A study for Image compression using Re-Pair algorithm. arXiv 2019, arXiv:1901.10744. [Google Scholar]
- Claude, F.; Navarro, G. Fast and Compact Web Graph Representations. TWEB 2010, 4, 16:1–16:31. [Google Scholar] [CrossRef]
- González, R.; Navarro, G.; Ferrada, H. Locally Compressed Suffix Arrays. ACM J. Exp. Algorithmics 2014, 19, 1. [Google Scholar] [CrossRef]
- Sekine, K.; Sasakawa, H.; Yoshida, S.; Kida, T. Adaptive Dictionary Sharing Method for Re-Pair Algorithm. In Proceedings of the 2014 Data Compression Conference, Snowbird, UT, USA, 26–28 March 2014; p. 425. [Google Scholar]
- Masaki, T.; Kida, T. Online Grammar Transformation Based on Re-Pair Algorithm. In Proceedings of the 2016 Data Compression Conference (DCC), Snowbird, UT, USA, 30 March–1 April 2016; pp. 349–358. [Google Scholar]
- Ganczorz, M.; Jez, A. Improvements on Re-Pair Grammar Compressor. In Proceedings of the 2017 Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017; pp. 181–190. [Google Scholar]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef] [Green Version]
- Furuya, I.; Takagi, T.; Nakashima, Y.; Inenaga, S.; Bannai, H.; Kida, T. MR-RePair: Grammar Compression based on Maximal Repeats. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 508–517. [Google Scholar]
- Kärkkäinen, J.; Kempa, D.; Puglisi, S.J. Lightweight Lempel-Ziv Parsing. In Proceedings of the International Symposium on Experimental Algorithms, Rome, Italy, 5–7 June 2013; Volume 7933, pp. 139–150. [Google Scholar]
- Goto, K. Optimal Time and Space Construction of Suffix Arrays and LCP Arrays for Integer Alphabets. In Proceedings of the Prague Stringology Conference 2019, Prague, Czech Republic, 26–28 August 2019; pp. 111–125. [Google Scholar]
- Manber, U.; Myers, E.W. Suffix Arrays: A New Method for On-Line String Searches. SIAM J. Comput. 1993, 22, 935–948. [Google Scholar] [CrossRef]
- Li, Z.; Li, J.; Huo, H. Optimal In-Place Suffix Sorting. In Proceedings of the International Symposium on String Processing and Information Retrieval, Lima, Peru, 9–11 October 2018; Volume 11147, pp. 268–284. [Google Scholar]
- Crochemore, M.; Grossi, R.; Kärkkäinen, J.; Landau, G.M. Computing the Burrows-Wheeler transform in place and in small space. J. Discret. Algorithms 2015, 32, 44–52. [Google Scholar] [CrossRef]
- da Louza, F.A.; Gagie, T.; Telles, G.P. Burrows-Wheeler transform and LCP array construction in constant space. J. Discret. Algorithms 2017, 42, 14–22. [Google Scholar] [CrossRef] [Green Version]
- Kosolobov, D. Faster Lightweight Lempel-Ziv Parsing. In Proceedings of the International Symposium on Mathematical Foundations of Computer Science, Milano, Italy, 24–28 August 2015; Volume 9235, pp. 432–444. [Google Scholar]
- Nakamura, R.; Inenaga, S.; Bannai, H.; Funamoto, T.; Takeda, M.; Shinohara, A. Linear-Time Text Compression by Longest-First Substitution. Algorithms 2009, 2, 1429–1448. [Google Scholar] [CrossRef]
- Bille, P.; Gørtz, I.L.; Prezza, N. Space-Efficient Re-Pair Compression. In Proceedings of the 2017 Data Compression Conference (DCC), Snowbird, UT, USA, 4–7 April 2017; pp. 171–180. [Google Scholar]
- Bille, P.; Gørtz, I.L.; Prezza, N. Practical and Effective Re-Pair Compression. arXiv 2017, arXiv:1704.08558. [Google Scholar]
- Sakai, K.; Ohno, T.; Goto, K.; Takabatake, Y.; I, T.; Sakamoto, H. RePair in Compressed Space and Time. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 518–527. [Google Scholar]
- Carrascosa, R.; Coste, F.; Gallé, M.; López, G.G.I. Choosing Word Occurrences for the Smallest Grammar Problem. In Proceedings of the International Conference on Language and Automata Theory and Applications, Trier, Germany, 24–28 May 2010; Volume 6031, pp. 154–165. [Google Scholar]
- Gage, P. A New Algorithm for Data Compression. C Users J. 1994, 12, 23–38. [Google Scholar]
- Chan, T.M.; Munro, J.I.; Raman, V. Selection and Sorting in the “Restore” Model. ACM Trans. Algorithms 2018, 14, 11:1–11:18. [Google Scholar] [CrossRef]
- Williams, J.W.J. Algorithm 232—Heapsort. Commun. ACM 1964, 7, 347–348. [Google Scholar]
- Vigna, S. Broadword Implementation of Rank/Select Queries. In Proceedings of the International Workshop on Experimental and Efficient Algorithms, Provincetown, MA, USA, 30 May–1 June 2008; Volume 5038, pp. 154–168. [Google Scholar]
- Fredman, M.L.; Willard, D.E. Surpassing the Information Theoretic Bound with Fusion Trees. J. Comput. Syst. Sci. 1993, 47, 424–436. [Google Scholar] [CrossRef] [Green Version]
- Knuth, D.E. The Art of Computer Programming, Volume 4, Fascicle 1: Bitwise Tricks & Techniques; Binary Decision Diagrams, 12th ed.; Addison-Wesley: Boston, MA, USA, 2009. [Google Scholar]
- Batcher, K.E. Sorting Networks and Their Applications. In Proceedings of the AFIPS Spring Joint Computer Conference, Atlantic City, NJ, USA, 30 April–2 May 1968; Volume 32, pp. 307–314. [Google Scholar]
- Aggarwal, A.; Vitter, J.S. The Input/Output Complexity of Sorting and Related Problems. Commun. ACM 1988, 31, 1116–1127. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Larsen, K.G. A Faster External Memory Priority Queue with DecreaseKeys. In Proceedings of the 2019 Annual ACM-SIAM Symposium on Discrete Algorithms, San Diego, CA, USA, 6–9 January 2019; pp. 1331–1343. [Google Scholar]
- Simic, S. Jensen’s inequality and new entropy bounds. Appl. Math. Lett. 2009, 22, 1262–1265. [Google Scholar] [CrossRef] [Green Version]
- Boyer, R.S.; Moore, J.S. MJRTY: A Fast Majority Vote Algorithm. In Automated Reasoning: Essays in Honor of Woody Bledsoe; Automated Reasoning Series; Springer: Dordrecht, The Netherlands, 1991; pp. 105–118. [Google Scholar]
- Köppl, D.; Furuya, I.; Takabatake, Y.; Sakai, K.; Goto, K. Re-Pair in Small Space. In Proceedings of the Prague Stringology Conference 2020, Prague, Czech Republic, 31 August–2 September 2020; pp. 134–147. [Google Scholar]
- Köppl, D.; I, T.; Furuya, I.; Takabatake, Y.; Sakai, K.; Goto, K. Re-Pair in Small Space (Poster). In Proceedings of the 2020 Data Compression Conference, Snowbird, UT, USA, 24–27 March 2020; p. 377. [Google Scholar]
Figure 1.
Step-by-step execution of the first turn of our algorithm on the string . The turn starts with the memory configuration given in Row 1. Positions 1 to 21 are text positions, and Positions 22 to 24 belong to F (, and it is assumed that a frequency fits into a text entry). Subsequent rows depict the memory configuration during Turn 1. A comment on each row is given in Section 2.5.
Figure 1.
Step-by-step execution of the first turn of our algorithm on the string . The turn starts with the memory configuration given in Row 1. Positions 1 to 21 are text positions, and Positions 22 to 24 belong to F (, and it is assumed that a frequency fits into a text entry). Subsequent rows depict the memory configuration during Turn 1. A comment on each row is given in Section 2.5.

Figure 2.
Operations used in Figures 4 and 5 for two bit vectors X and Y. All operations can be computed in constant time. See Figure 3 for an example of rmSufRun and rmPreRun.
Figure 2.
Operations used in Figures 4 and 5 for two bit vectors X and Y. All operations can be computed in constant time. See Figure 3 for an example of rmSufRun and rmPreRun.

Figure 3.
Step-by-step execution of and introduced in Figure 2 on a bit vector X.
Figure 3.
Step-by-step execution of and introduced in Figure 2 on a bit vector X.

Figure 4.
Matching all occurrences of a character in a string S fitting into a computer word in constant time by using bit-parallel instructions. For the last step, special care has to be taken when the last character of S is a match, as shifting X bits to the right might erase a ‘1’ bit witnessing the rightmost match. In the description column, X is treated as an array of integers with bit width . In this example, , c has the bit representation 010 with , and .
Figure 4.
Matching all occurrences of a character in a string S fitting into a computer word in constant time by using bit-parallel instructions. For the last step, special care has to be taken when the last character of S is a match, as shifting X bits to the right might erase a ‘1’ bit witnessing the rightmost match. In the description column, X is treated as an array of integers with bit width . In this example, , c has the bit representation 010 with , and .

Figure 5.
Finding a bigram bb in a string S of bit length q, where q is the largest multiple of fitting into a computer word, divided by . In the example, we represent the strings M, B, E, and X as arrays of integers with bit width and write and for and , respectively. Let for be the frequency of a bigram bc with as described in Section 3.1, where the function find returns the output described in Figure 4. Each of the popcount queries gives us one occurrence as a result (after dividing the returned number by ), thus the frequency of bb in S, without looking at the borders of S, is two. As a side note, modern computer architectures allow us to shrink the or blocks to single bits by instructions like _pext_u64 taking a single CPU cycle.
Figure 5.
Finding a bigram bb in a string S of bit length q, where q is the largest multiple of fitting into a computer word, divided by . In the example, we represent the strings M, B, E, and X as arrays of integers with bit width and write and for and , respectively. Let for be the frequency of a bigram bc with as described in Section 3.1, where the function find returns the output described in Figure 4. Each of the popcount queries gives us one occurrence as a result (after dividing the returned number by ), thus the frequency of bb in S, without looking at the borders of S, is two. As a side note, modern computer architectures allow us to shrink the or blocks to single bits by instructions like _pext_u64 taking a single CPU cycle.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Experimental evaluation of our implementation and the implementation of Navarro described in Section 2.6. Table entries are running times in seconds. The last line is the benchmark on the unary string .
Table 1.
Experimental evaluation of our implementation and the implementation of Navarro described in Section 2.6. Table entries are running times in seconds. The last line is the benchmark on the unary string .
| Data Set | Our Implementation | Implementation of Navarro | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Prefix Size in KiB | ||||||||||
| 64 | 128 | 256 | 512 | 1024 | 64 | 128 | 256 | 512 | 1024 | |
| Escherichia_Coli | 20.68 | 130.47 | 516.67 | 1708.02 | 10,112.47 | 0.01 | 0.02 | 0.07 | 0.18 | 0.29 |
| cere | 13.69 | 90.83 | 443.17 | 2125.17 | 9185.58 | 0.01 | 0.02 | 0.04 | 0.16 | 0.22 |
| coreutils | 12.88 | 75.64 | 325.51 | 1502.89 | 5144.18 | 0.01 | 0.05 | 0.05 | 0.14 | 0.29 |
| einstein.de.txt | 19.55 | 88.34 | 181.84 | 805.81 | 4559.79 | 0.01 | 0.04 | 0.08 | 0.10 | 0.25 |
| einstein.en.txt | 21.11 | 78.57 | 160.41 | 900.79 | 4353.81 | 0.01 | 0.02 | 0.05 | 0.21 | 0.51 |
| influenza | 41.01 | 160.68 | 667.58 | 2630.65 | 10,526.23 | 0.03 | 0.02 | 0.05 | 0.11 | 0.36 |
| kernel | 20.53 | 101.84 | 208.08 | 1575.48 | 5067.80 | 0.01 | 0.04 | 0.09 | 0.18 | 0.27 |
| para | 20.90 | 175.93 | 370.72 | 2826.76 | 9462.74 | 0.01 | 0.01 | 0.08 | 0.12 | 0.35 |
| world_leaders | 11.92 | 21.82 | 167.52 | 661.52 | 1718.36 | 0.01 | 0.01 | 0.06 | 0.11 | 0.25 |
| 0.35 | 0.92 | 3.90 | 14.16 | 61.74 | 0.01 | 0.01 | 0.05 | 0.05 | 0.12 | |
Table 2.
Experimental evaluation of the implementation of Navarro. Table entries are running times in seconds.
Table 2.
Experimental evaluation of the implementation of Navarro. Table entries are running times in seconds.
| Data Set | Prefix Size in KiB | ||||
|---|---|---|---|---|---|
| 64 | 128 | 256 | 512 | 1024 | |
| Escherichia_Coli | 0.01 | 0.02 | 0.07 | 0.18 | 0.29 |
| cere | 0.01 | 0.02 | 0.04 | 0.16 | 0.22 |
| coreutils | 0.01 | 0.05 | 0.05 | 0.14 | 0.29 |
| einstein.de.txt | 0.01 | 0.04 | 0.08 | 0.10 | 0.25 |
| einstein.en.txt | 0.01 | 0.02 | 0.05 | 0.21 | 0.51 |
| influenza | 0.03 | 0.02 | 0.05 | 0.11 | 0.36 |
| kernel | 0.01 | 0.04 | 0.09 | 0.18 | 0.27 |
| para | 0.01 | 0.01 | 0.08 | 0.12 | 0.35 |
| world_leaders | 0.01 | 0.01 | 0.06 | 0.11 | 0.25 |
Table 3.
Characteristics of our data sets used in Section 2.6. The number of turns and rounds are given for each of the prefix sizes 128, 256, 512, and 1024 KiB of the respective data sets. The number of turns reflecting the number of non-terminals is given in units of thousands. The turns of the unary string are in plain units (not divided by thousand).
Table 3.
Characteristics of our data sets used in Section 2.6. The number of turns and rounds are given for each of the prefix sizes 128, 256, 512, and 1024 KiB of the respective data sets. The number of turns reflecting the number of non-terminals is given in units of thousands. The turns of the unary string are in plain units (not divided by thousand).
| Data Set | Turns/1000 | Rounds | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Prefix Size in KiB | Prefix Size in KiB | ||||||||||
| Escherichia_Coli | 4 | 1.8 | 3.2 | 5.6 | 10.3 | 18.1 | 6 | 9 | 9 | 12 | 12 |
| cere | 5 | 1.4 | 2.8 | 5.0 | 9.2 | 15.1 | 13 | 14 | 14 | 14 | 14 |
| coreutils | 113 | 4.7 | 6.7 | 10.2 | 16.1 | 26.5 | 15 | 15 | 15 | 14 | 14 |
| einstein.de.txt | 95 | 1.7 | 2.8 | 3.7 | 5.2 | 9.7 | 14 | 14 | 15 | 16 | 16 |
| einstein.en.txt | 87 | 3.3 | 3.5 | 3.8 | 4.5 | 8.6 | 16 | 15 | 15 | 15 | 17 |
| influenza | 7 | 2.5 | 3.7 | 9.5 | 13.4 | 22.1 | 11 | 12 | 14 | 13 | 15 |
| kernel | 160 | 4.5 | 8.0 | 13.9 | 24.5 | 43.7 | 10 | 11 | 14 | 14 | 13 |
| para | 5 | 1.8 | 3.2 | 5.8 | 10.1 | 17.6 | 12 | 12 | 13 | 13 | 14 |
| world_leaders | 87 | 2.6 | 4.3 | 6.1 | 10.0 | 42.1 | 11 | 11 | 11 | 11 | 14 |
| 1 | 15 | 16 | 17 | 18 | 19 | 16 | 17 | 18 | 19 | 20 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Köppl, D.; I, T.; Furuya, I.; Takabatake, Y.; Sakai, K.; Goto, K. Re-Pair in Small Space. Algorithms 2021, 14, 5. https://0-doi-org.brum.beds.ac.uk/10.3390/a14010005
AMA Style
Köppl D, I T, Furuya I, Takabatake Y, Sakai K, Goto K. Re-Pair in Small Space. Algorithms. 2021; 14(1):5. https://0-doi-org.brum.beds.ac.uk/10.3390/a14010005
Chicago/Turabian StyleKöppl, Dominik, Tomohiro I, Isamu Furuya, Yoshimasa Takabatake, Kensuke Sakai, and Keisuke Goto. 2021. "Re-Pair in Small Space" Algorithms 14, no. 1: 5. https://0-doi-org.brum.beds.ac.uk/10.3390/a14010005
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.