
Load Balancing Strategies for Slice-Based Parallel Versions of JEM Video Encoder

 , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Description of the New Characteristics of the Joint Exploration Test Model (JEM)
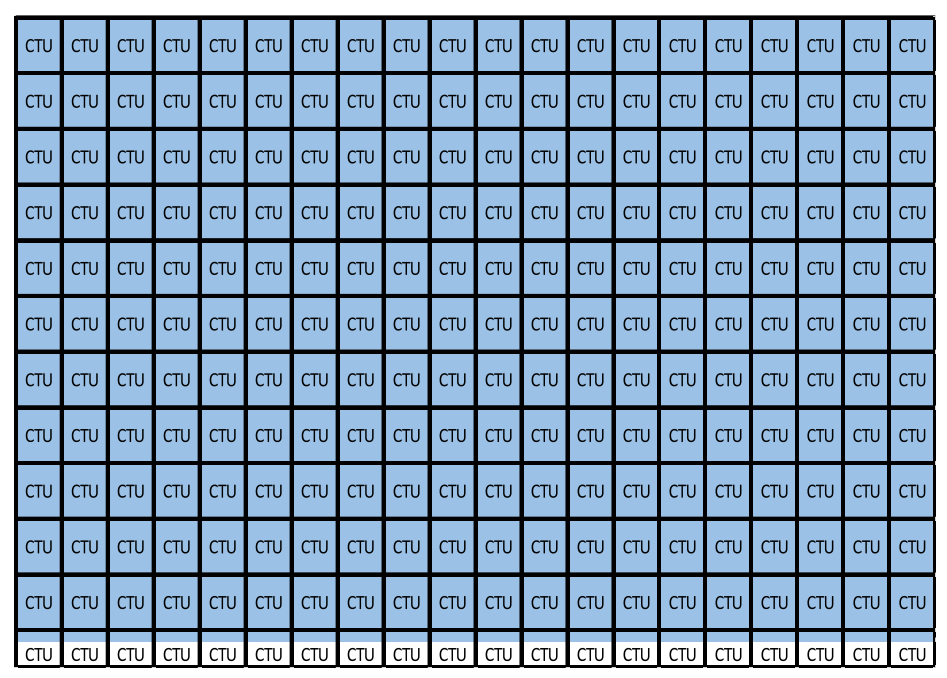
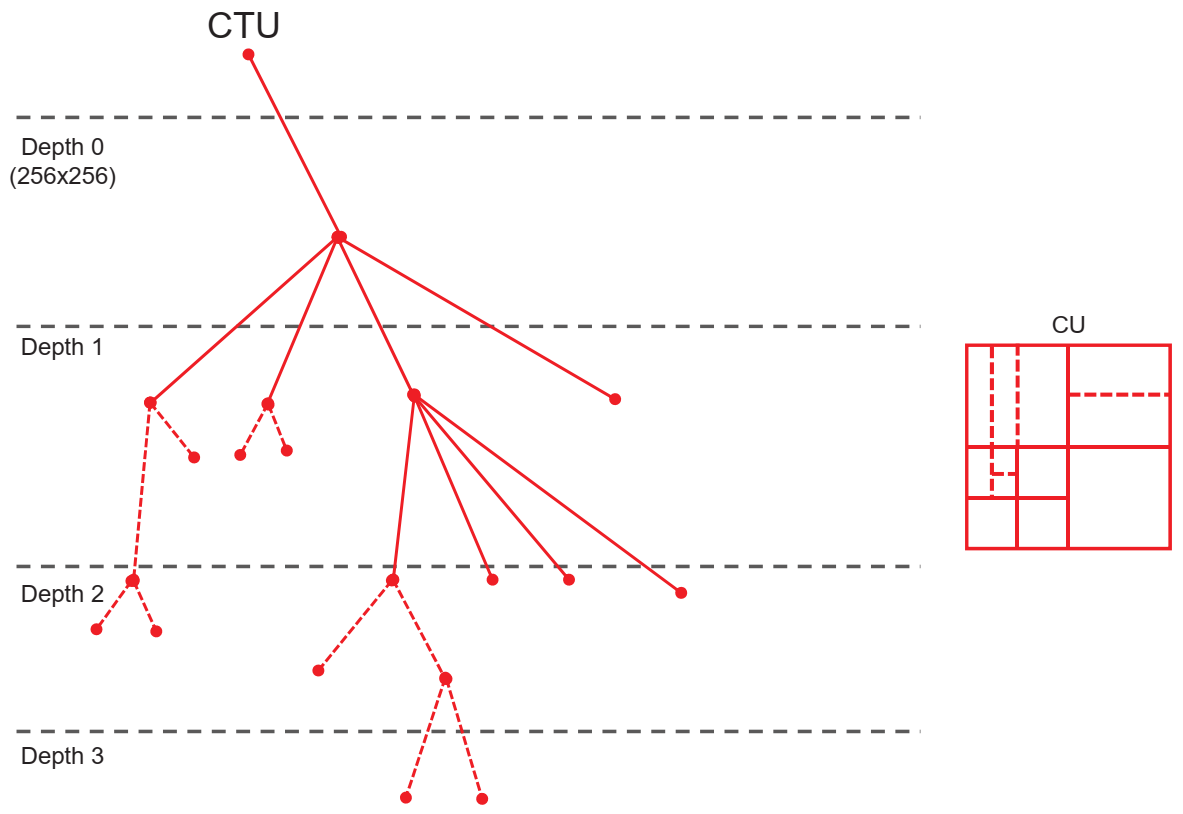
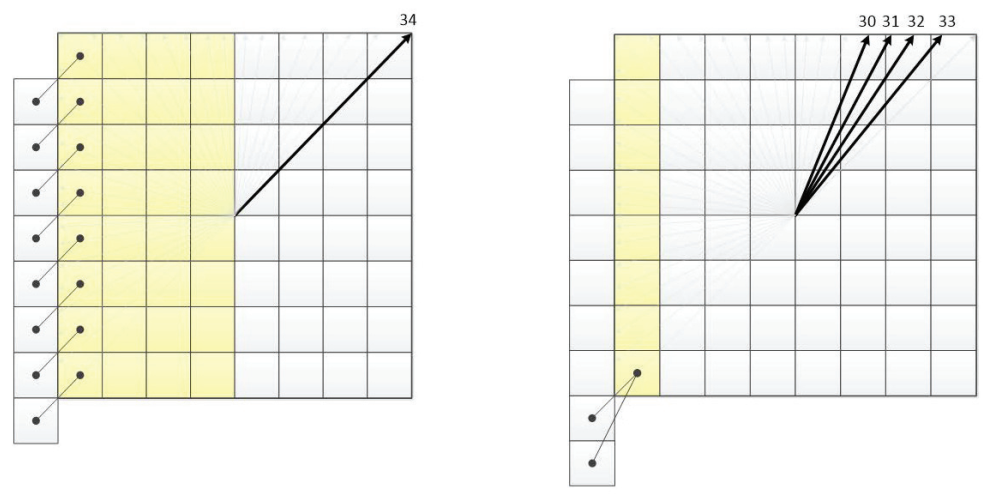
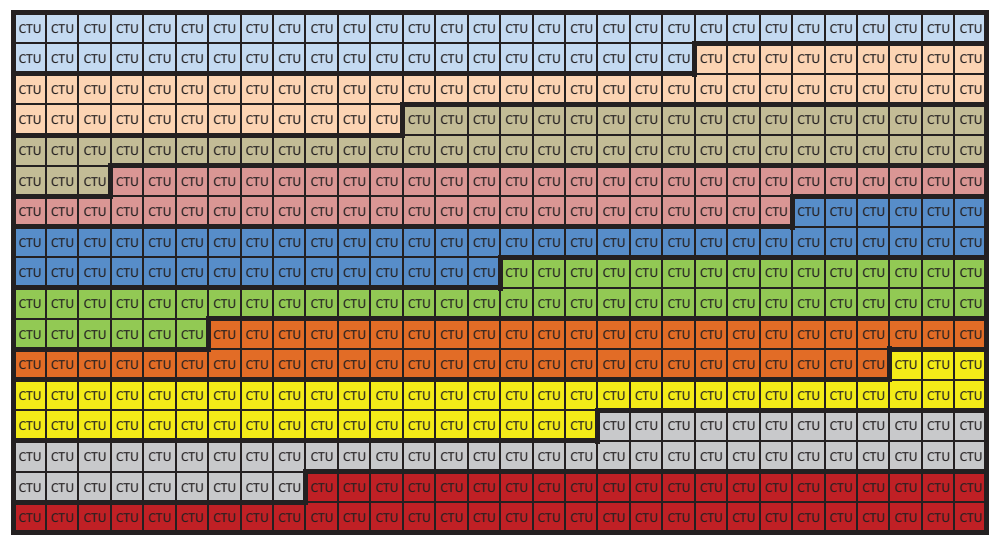
2.1. Picture Partitioning
- CTU size: The root node size of a quadtree; the same concept as in HEVC.
- MinQTSize: The minimum allowed size of the leaf node in the quadtree.
- MaxBTSize: The maximum allowed size of the root node in the binary tree.
- MaxBTDepth: The maximum allowed depth of the binary tree.
- MinBTSize: The minimum allowed size of the leaf node in the binary tree.
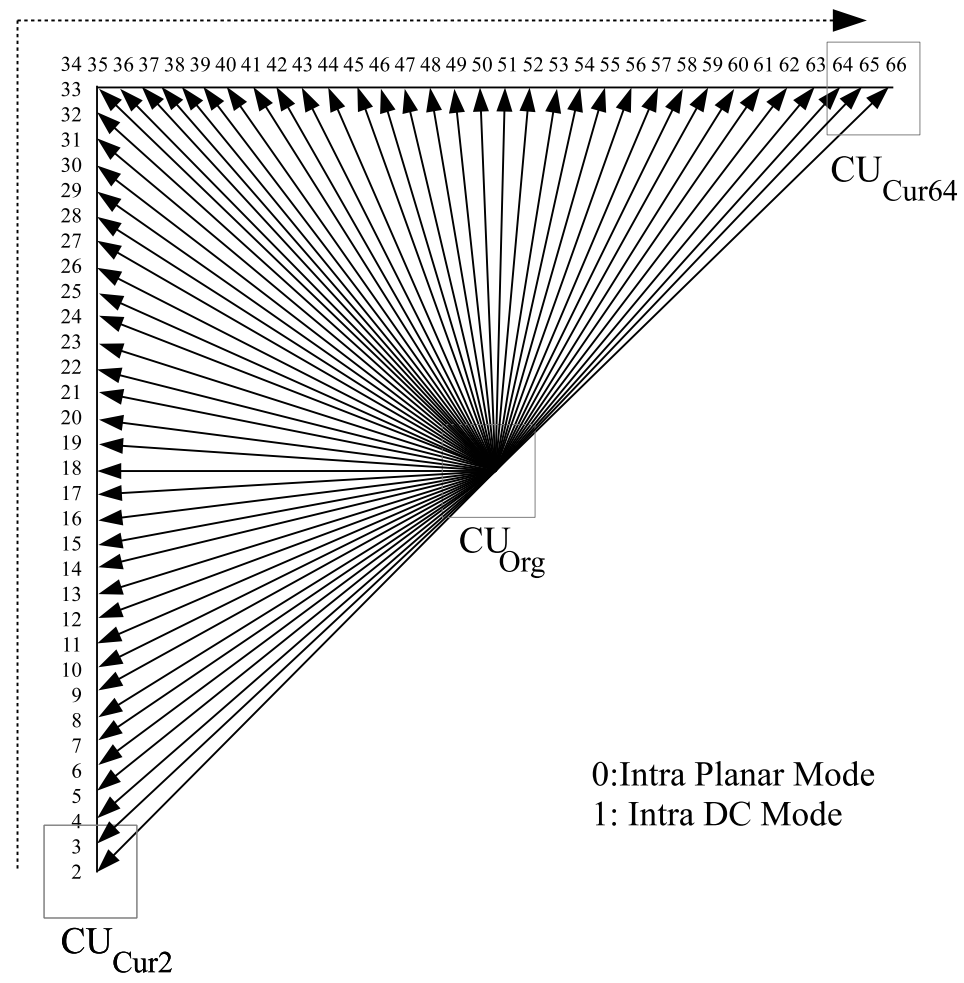
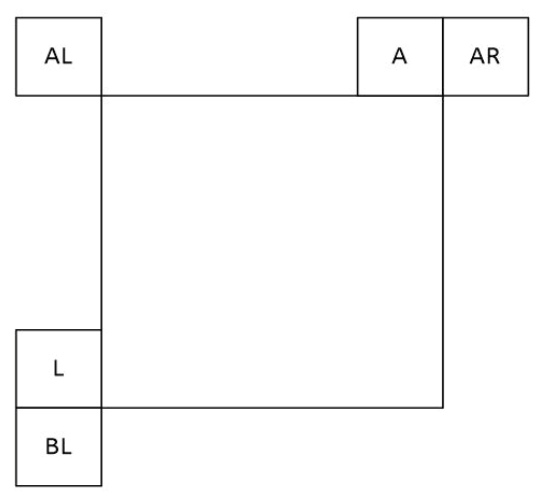
2.2. Spatial Prediction
3. Parallel Approaches
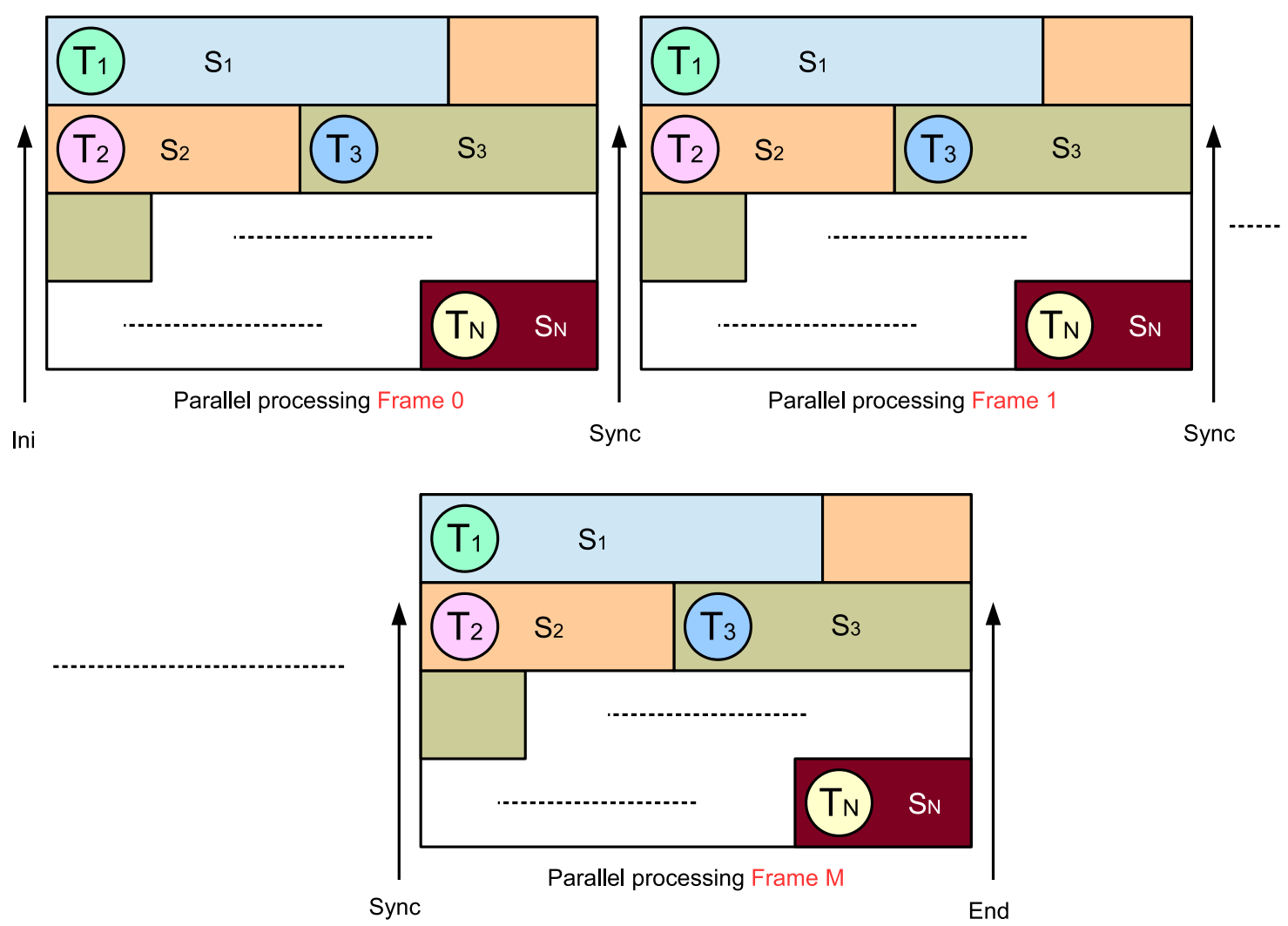
3.1. Synchronous Algorithm: JEM-SP-Sync
| Algorithm 1 JEM-SP-Sync: Slice-based parallel algorithm with synchronization processes. |
|
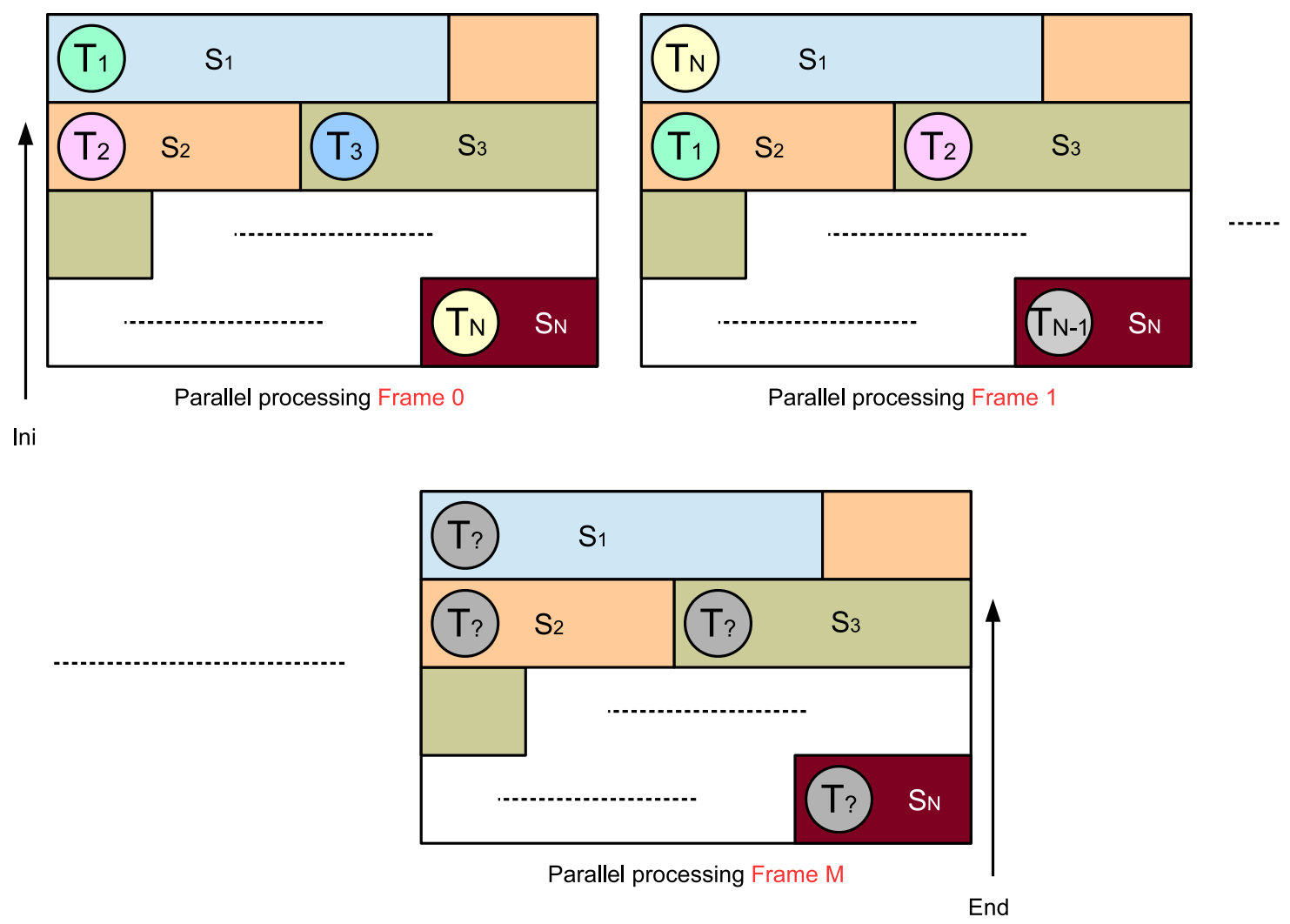
3.2. Asynchronous Algorithm: JEM-SP-ASync
| Algorithm 2 JEM-SP-ASync: Slice-based parallel algorithm without synchronization processes. |
|
4. Experimental Results
5. Conclusions
List of Acronyms
- –
- AI—All Intra
- –
- AVC—Advanced Video Coding
- –
- CB—Coding Blocks
- –
- CCLM—Cross Component Linear Model
- –
- CTU—Coding Tree Unit
- –
- CU—Coding Unit
- –
- HEVC—High Efficiency Video Coding
- –
- JCT-VC—Joint Collaborative Team on Video Coding
- –
- JEM—Joint Exploration test Model
- –
- JVET—Joint Video Exploration Team
- –
- ME—Motion Estimation
- –
- MMLM—Multiple Model CCLM Mode
- –
- MPEG—Moving Picture Expert Group
- –
- MPM—Most Probable Modes
- –
- MV—Motion Vectors
- –
- NALU—Network Abstraction Layer Unit
- –
- PDPC—Position Dependent intra-Prediction Component
- –
- PSNR—Peak Signal to Noise Ratio
- –
- PU—Prediction Unit
- –
- QP—Quantization Parameter
- –
- QTBT—Quadtree Plus Binary Tree
- –
- R/D—Rate/Distortion
- –
- RDO—Rate Distortion Optimization
- –
- TU—Transform Unit
- –
- VCEG—Video Coding Expert Group
- –
- VoD—Video on Demand
- –
- VVC—Versatile Video Coding
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sullivan, G.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) standard. Circuits Syst. Video Technol. IEEE Trans. 2012, 22, 1648–1667. [Google Scholar] [CrossRef]
- ITU-T.; ISO/IEC JTC 1. Advanced Video Coding for Generic Audiovisual Services. Available online: https://www.itu.int/rec/T-REC-H.264-201610-S (accessed on 30 September 2021).
- Ohm, J.; Sullivan, G.; Schwarz, H.; Tan, T.K.; Wiegand, T. Comparison of the Coding Efficiency of Video Coding Standards - Including High Efficiency Video Coding (HEVC). Circuits Syst. Video Technol. IEEE Trans. 2012, 22, 1669–1684. [Google Scholar] [CrossRef]
- Cisco. Cisco Visual Networking Index: Forecast and Methodology, 2017–2022. Technical Report. 2019. Available online: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/white-paper-c11-741490.html (accessed on 30 September 2021).
- Chen, J.; Alshina, E.; Sullivan, G.J.; Ohm, J.R.; Boyce, J. Algorithm Description of Joint Exploration Test Model 7. Available online: https://mpeg.chiariglione.org/standards/exploration/future-video-coding/n17055-algorithm-description-joint-exploration-test-model (accessed on 30 September 2021).
- Bross, B. Versatile Video Coding (Draft 2). Available online: https://mpeg.chiariglione.org/standards/mpeg-i/versatile-video-coding (accessed on 30 September 2021).
- Alshina, E.; Alshin, A.; Choi, K.; Park, M. Performance of JEM 1 tools analysis. Technical report. In Proceedings of the JVET-B0044 3rd 2nd JVET Meeting, San Diego, CA, USA, 20–26 February 2016. [Google Scholar]
- Schwarz, H.; Rudat, C.; Siekmann, M.; Bross, B.; Marpe, D.; Wiegand, T. Coding Efficiency Complexity Analysis of JEM 1.0 coding tools for the Random Access Configuration. Technical report. In Proceedings of the JVET-B0044 3rd 2nd JVET Meeting, San Diego, CA, USA, 20–26 February 2016. [Google Scholar]
- Karczewicz, M.; Alshina, E. JVET AHG Report: Tool Evaluation (AHG1). Available online: http://phenix.it-sudparis.eu/jvet/doc_end_user/documents/4_Chengdu/wg11/JVET-D0001-v4.zip (accessed on 30 September 2021).
- Grois, D.; Nguyen, T.; Marpe, D. Performance Comparison of AV1, JEM, VP9, and HEVC Encoders. Available online: https://www.researchgate.net/publication/319925128_Performance_comparison_of_AV1_JEM_VP9_and_HEVC_encoders_Conference_Presentation (accessed on 30 September 2021).
- García-Lucas, D.; Cebrián-Márquez, G.; Díaz-Honrubia, A.J.; Cuenca, P. Acceleration of the integer motion estimation in JEM through pre-analysis techniques. J. Supercomput. 2018, 75, 1–12. [Google Scholar] [CrossRef]
- Bjontegaard, G. Calculation of average PSNR differences between RD-curves. In Technical Report VCEG-M33; Video Coding Experts Group (VCEG): Austin, TX, USA, April 2001. [Google Scholar]
- López-Granado, O.; Migallón, H.; Martínez-Rach, M.; Galiano, V.; Malumbres, M.P.; Van Wallendael, G. A highly scalable parallel encoder version of the emergent JEM video encoder. J. Supercomput. 2019, 74, 1429–1442. [Google Scholar] [CrossRef]
- Sullivan, G.; Ohm, J.R. Meeting Report of the 6th meeting of the Joint Video Exploration Team (JVET). Technical report. In Proceedings of the Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Hobart, AU, USA, 31 March–7 April 2017. [Google Scholar]
- Chen, J.; Sullivan, G.; Ohm, J.R. Algorithm Description of Joint Exploration Test Model 7 (JEM 7). Technical report. In Proceedings of the Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11-JVET-G1001-v1, Turin, IT, USA, 13–21 July 2017. [Google Scholar]
- Sze, V.; Budagavi, M.; Sullivan, G. High Efficiency Video Coding (HEVC); Springer: New York City, NY, USA, 2014; pp. 1–375. [Google Scholar]
- ITU-T.; ISO/IEC. Algorithm Description of Joint Exploratory Test Model (JEM); Technical Report; Joint Video Exploration Team (JVET): Geneva, Switzerland, May 2015. [Google Scholar]
- Zhang, X.; Liu, S.; Lei, S. Intra mode coding in HEVC standard. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Seregin, V.; Zhao, X.; Said, A.; Karczewicz, M. Neighbor based intra most probable modes list derivation. Technical Report JVET-C0055, Joint Video Exploration Team (JVET). In Proceedings of the 3rd Meeting, Geneva, CH, USA, 26–27 January 2016. [Google Scholar]
- Piñol, P.; Migallón, H.; López-Granado, O.; Malumbres, M.P. Slice-based parallel approach for HEVC encoder. J. Supercomput. 2015, 71, 1882–1892. [Google Scholar] [CrossRef]
- JEM Reference Software. 2017. Available online: https://jvet.hhi.fraunhofer.de/svn/svn_HMJEMSoftware/tags/HM-16.6-JEM-7.0rc1/ (accessed on 30 September 2021).
- GCC, the GNU Compiler Collection. Free Software Foundation, Inc. 2009–2012. Available online: http://gcc.gnu.org (accessed on 30 September 2021).
- OpenMP ARB (Architecture Review Boards). OpenMP Application Program Interface, Version 3.1. 2011. Available online: http://www.openmp.org (accessed on 30 September 2021).
- Suehring, K. JVET common test conditions and software reference configurations. In Proceedings of the Technical Report JVET-B1010, Joint Video Exploration Team (JVET), San Diego, CA, USA, 15–21 October 2016. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | HEVC | JEM |
|---|---|---|
| CTU size | ||
| CTU partition | Quad-Tree with separate tress for CU, PU and TU | Quad-Tree+Binary-Tree QTBT (shared by CU, PU, TU) |
| Inter-Prediction | No bi-directional | Bi-directional allowed for and sizes |
| Max transform unit size |
| Characteristics | HEVC | JEM |
|---|---|---|
| Intra-modes | 33 | 67 |
| List MPMs | 3 | 6 |
| N° of Neighbors for MPMs derivation | 2 | 5 |
| Interpolation filters | 2-tap Linear | 4-tap Cubic or Gaussian |
| Boundary filter samples | 1 | 4 |
| Video Seq. | Acronym | Resolution | Rate (Hz) | N. Frames | Time (s) |
|---|---|---|---|---|---|
| Park Scene | PARK | 1920 × 1080 | 24 | 120 | 5 |
| Four People | FOUR | 1280 × 720 | 60 | 120 | 2 |
| Party Scene | PART | 832 × 480 | 50 | 120 | 2.4 |
| BQ Square | BQSQ | 416 × 240 | 60 | 120 | 2 |
| Resolution | Horizontal CTUs | Vertical CTUs | Number of CTUs | ||
|---|---|---|---|---|---|
| 1920 × 1080 | 15 | 15 | 8.4 | 9 | 135 |
| 1280 × 720 | 10 | 10 | 5.6 | 6 | 60 |
| 832 × 480 | 6.5 | 7 | 3.8 | 4 | 28 |
| 416 × 240 | 3.25 | 4 | 1.9 | 2 | 8 |
| Number of Slices (and Threads) | ||||||||
|---|---|---|---|---|---|---|---|---|
| N. CTUs | 2 | 4 | 5 | 7 | 8 | 10 | 11 | 12 |
| Slice size (in CTUs) | ||||||||
| 135 | 67.5 | 33.8 | 27.0 | 19.3 | 16.9 | 13.5 | 12.3 | 11.3 |
| 60 | 30.0 | 15.0 | 12.0 | 8.6 | 7.5 | 6.0 | 5.5 | 5.0 |
| 28 | 14.0 | 7.0 | 5.6 | 4.0 | 3.5 | 2.8 | 2.5 | 2.3 |
| 8 | 4.0 | 2.0 | 1.6 | 1.1 | 1.0 | 0.8 | 0.7 | 0.7 |
| Slice size (in CTUs) rounded up | ||||||||
| 135 | 68 | 34 | 27 | 20 | 17 | 14 | 13 | 12 |
| 60 | 30 | 15 | 12 | 9 | 8 | 6 | 6 | 5 |
| 28 | 14 | 7 | 6 | 4 | 4 | 3 | 3 | 3 |
| 8 | 4 | 2 | 2 | 2 | 1 | 1 | 1 | 1 |
| Number of Slices (and Threads) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Number of CTUs | 2 | 4 | 5 | 7 | 8 | 10 | 11 | 12 |
| Diff. in Size of the Last Slice | ||||||||
| 135 | −1 | −1 | 0 | −5 | −1 | −5 | −8 | −9 |
| 60 | 0 | 0 | 0 | −3 | −4 | 0 | −6 | 0 |
| 28 | 0 | 0 | −2 | 0 | −4 | −2 | −5 | −8 |
| 8 | 0 | 0 | −2 | −6 | 0 | −2 | -3 | −4 |
| Slice | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| size | QP | (0–68) | (68–135) | |||||||
| 68 | 22 | 53% | 47% | |||||||
| 27 | 53% | 47% | ||||||||
| 32 | 53% | 47% | ||||||||
| 37 | 53% | 47% | ||||||||
| (0–45) | (45–90) | (90–135) | ||||||||
| 45 | 22 | 37% | 36% | 28% | ||||||
| 27 | 37% | 36% | 28% | |||||||
| 32 | 37% | 35% | 27% | |||||||
| 37 | 37% | 36% | 27% | |||||||
| (0–34) | (34–68) | (68–102) | (102–135) | |||||||
| 34 | 22 | 27% | 27% | 29% | 18% | |||||
| 27 | 27% | 26% | 29% | 17% | ||||||
| 32 | 27% | 26% | 30% | 16% | ||||||
| 37 | 28% | 25% | 31% | 16% | ||||||
| (0–27) | (27–54) | (54–81) | (81–108) | (108–135) | ||||||
| 27 | 22 | 22% | 21% | 22% | 23% | 13% | ||||
| 27 | 22% | 21% | 22% | 23% | 12% | |||||
| 32 | 22% | 21% | 22% | 24% | 11% | |||||
| 37 | 23% | 19% | 23% | 26% | 10% | |||||
| (0–23) | (23–46) | (46–69) | (69–92) | (92–115) | (115–135) | |||||
| 23 | 22 | 18% | 20% | 17% | 19% | 18% | 7% | |||
| 27 | 17% | 21% | 17% | 20% | 19% | 6% | ||||
| 32 | 18% | 21% | 16% | 21% | 19% | 6% | ||||
| 37 | 18% | 20% | 16% | 22% | 19% | 5% | ||||
| (0–20) | (20–40) | (40–60) | (60–80) | (80–100) | (100–120) | (120–135) | ||||
| 20 | 22 | 15% | 17% | 17% | 15% | 17% | 16% | 4% | ||
| 27 | 15% | 17% | 17% | 15% | 17% | 15% | 4% | |||
| 32 | 15% | 17% | 17% | 15% | 18% | 15% | 3% | |||
| 37 | 16% | 17% | 16% | 16% | 18% | 14% | 3% | |||
| (0–17) | (17–34) | (34–51) | (51–68) | (68–85) | (85–102) | (102–119) | (119–135) | |||
| 17 | 22 | 14% | 14% | 13% | 14% | 14% | 15% | 13% | 4% | |
| 27 | 13% | 14% | 13% | 14% | 14% | 16% | 13% | 4% | ||
| 32 | 14% | 14% | 12% | 14% | 14% | 16% | 12% | 4% | ||
| 37 | 14% | 14% | 12% | 13% | 14% | 17% | 12% | 3% | ||
| (0–15) | (15–30) | (30–45) | (45–60) | (60–75) | (75–90) | (90–105) | (105–120) | (120–135) | ||
| 15 | 22 | 12% | 13% | 12% | 12% | 11% | 12% | 13% | 11% | 4% |
| 27 | 12% | 13% | 12% | 12% | 11% | 12% | 13% | 11% | 4% | |
| 32 | 12% | 13% | 12% | 12% | 11% | 13% | 13% | 10% | 3% | |
| 37 | 12% | 14% | 12% | 11% | 11% | 13% | 14% | 10% | 3% |
| Slice | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| size | QP | (0–30) | (30–60) | ||||||
| 30 | 22 | 56% | 44% | ||||||
| 27 | 56% | 44% | |||||||
| 32 | 56% | 44% | |||||||
| 37 | 57% | 43% | |||||||
| (0–20) | (20–40) | (40–60) | |||||||
| 20 | 22 | 31% | 52% | 17% | |||||
| 27 | 30% | 54% | 15% | ||||||
| 32 | 31% | 54% | 15% | ||||||
| 37 | 32% | 54% | 14% | ||||||
| (0–15) | (15–30) | (30–45) | (45–60) | ||||||
| 15 | 22 | 25% | 31% | 32% | 11% | ||||
| 27 | 25% | 31% | 34% | 10% | |||||
| 32 | 26% | 31% | 34% | 9% | |||||
| 37 | 27% | 31% | 33% | 9% | |||||
| (0–12) | (12–24) | (24–36) | (36–48) | (48–60) | |||||
| 12 | 22 | 19% | 24% | 29% | 19% | 8% | |||
| 27 | 18% | 25% | 30% | 20% | 8% | ||||
| 32 | 18% | 26% | 29% | 19% | 7% | ||||
| 37 | 19% | 26% | 29% | 19% | 7% | ||||
| (0–10) | (10–20) | (20–30) | (30–40) | (40–50) | (50–60) | ||||
| 10 | 22 | 14% | 18% | 24% | 27% | 11% | 5% | ||
| 27 | 13% | 18% | 25% | 28% | 10% | 5% | |||
| 32 | 13% | 18% | 26% | 29% | 10% | 5% | |||
| 37 | 14% | 18% | 25% | 28% | 10% | 5% | |||
| (0–9) | (9–18) | (18–27) | (27–36) | (36–45) | (45–54) | (54–60) | |||
| 9 | 22 | 12% | 16% | 22% | 22% | 17% | 8% | 3% | |
| 27 | 12% | 16% | 23% | 22% | 17% | 7% | 3% | ||
| 32 | 12% | 16% | 23% | 22% | 17% | 7% | 3% | ||
| 37 | 13% | 16% | 23% | 22% | 17% | 7% | 2% | ||
| (0–8) | (8–16) | (16–24) | (24–32) | (32–40) | (40–48) | (48–56) | (56–60) | ||
| 8 | 22 | 11% | 15% | 16% | 19% | 22% | 8% | 6% | 2% |
| 27 | 11% | 15% | 17% | 19% | 23% | 8% | 6% | 2% | |
| 32 | 12% | 15% | 17% | 18% | 23% | 7% | 5% | 2% |
| Slice | ||||||||
|---|---|---|---|---|---|---|---|---|
| size | QP | (0–14) | (14–28) | |||||
| 14 | 22 | 52% | 48% | |||||
| 27 | 51% | 49% | ||||||
| 32 | 51% | 49% | ||||||
| 37 | 51% | 49% | ||||||
| (0–10) | (10–20) | (20–28) | ||||||
| 10 | 22 | 36% | 40% | 24% | ||||
| 27 | 35% | 41% | 23% | |||||
| 32 | 35% | 42% | 22% | |||||
| 37 | 35% | 43% | 22% | |||||
| (0–7) | (7–14) | (14–21) | (21–28) | |||||
| 7 | 22 | 25% | 27% | 27% | 21% | |||
| 27 | 24% | 27% | 28% | 21% | ||||
| 32 | 24% | 27% | 29% | 19% | ||||
| 37 | 25% | 26% | 30% | 19% | ||||
| (0–6) | (6–12) | (12–18) | (18–24) | (24–28) | ||||
| 6 | 22 | 22% | 22% | 23% | 20% | 12% | ||
| 27 | 22% | 22% | 24% | 20% | 12% | |||
| 32 | 21% | 21% | 25% | 20% | 12% | |||
| 37 | 21% | 21% | 25% | 20% | 13% | |||
| (0–5) | (5–10) | (10–15) | (15–20) | (20–25) | (25–28) | |||
| 5 | 22 | 18% | 19% | 19% | 21% | 15% | 8% | |
| 27 | 17% | 19% | 19% | 23% | 14% | 8% | ||
| 32 | 17% | 19% | 19% | 24% | 13% | 9% | ||
| 37 | 17% | 19% | 18% | 24% | 13% | 9% | ||
| (0–4) | (4–8) | (8–12) | (12–16) | (16–20) | (20–24) | (24–28) | ||
| 4 | 22 | 15% | 14% | 16% | 15% | 18% | 11% | 12% |
| 27 | 14% | 14% | 15% | 15% | 19% | 11% | 12% | |
| 32 | 14% | 15% | 14% | 15% | 20% | 10% | 12% | |
| 37 | 14% | 15% | 13% | 15% | 21% | 9% | 12% |
| Slice Size | QP | (0–4) | (4–8) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 4 | 22 | 56% | 44% | ||||||
| 27 | 57% | 43% | |||||||
| 32 | 58% | 42% | |||||||
| 37 | 61% | 39% | |||||||
| (0–3) | (3–6) | (6–8) | |||||||
| 3 | 22 | 51% | 31% | 18% | |||||
| 27 | 51% | 31% | 18% | ||||||
| 32 | 53% | 29% | 18% | ||||||
| 37 | 56% | 27% | 17% | ||||||
| (0–2) | (2–4) | (4–6) | (6–8) | ||||||
| 2 | 22 | 35% | 21% | 26% | 18% | ||||
| 27 | 36% | 20% | 25% | 18% | |||||
| 32 | 38% | 20% | 24% | 18% | |||||
| 37 | 40% | 21% | 22% | 17% | |||||
| (0–1) | (1–2) | (2–3) | (3–4) | (4–5) | (5–6) | (6–7) | (7–8) | ||
| 1 | 22 | 18% | 18% | 16% | 5% | 13% | 13% | 14% | 4% |
| 27 | 20% | 17% | 15% | 5% | 13% | 12% | 14% | 4% | |
| 32 | 22% | 17% | 15% | 5% | 12% | 12% | 14% | 4% | |
| 37 | 22% | 17% | 16% | 5% | 11% | 11% | 13% | 4% |
| Time (s.) | Time per Frame (s.) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Video seq. | Reso- lution | QP 22 | QP 27 | QP 32 | QP 37 | QP 22 | QP 27 | QP 32 | QP 37 |
| PARK | 1920 × 1080 | 163,395 | 114,688 | 78,010 | 50,474 | 1362 | 956 | 650 | 421 |
| FOUR | 1280 × 720 | 46,805 | 33,763 | 24,928 | 18,272 | 390 | 281 | 208 | 152 |
| PART | 832 × 480 | 43,844 | 36,796 | 29,754 | 22,121 | 365 | 307 | 248 | 184 |
| BQSQ | 416 × 240 | 9896 | 8099 | 6265 | 5010 | 82 | 67 | 52 | 42 |
| Parallel Efficiency | |||||
|---|---|---|---|---|---|
| Video sequence | NoT | QP 22 | QP 27 | QP 32 | QP 37 |
| BQSQ | 2 | 85.0% | 85.2% | 82.6% | 79.1% |
| 3 | 61.5% | 61.3% | 59.4% | 57.2% | |
| 4 | 67.6% | 65.2% | 62.5% | 60.3% | |
| 8 | 61.7% | 56.7% | 52.2% | 51.1% | |
| PART | 2 | 94.1% | 96.1% | 96.9% | 94.1% |
| 3 | 77.3% | 76.3% | 76.0% | 75.5% | |
| 4 | 86.1% | 83.1% | 82.4% | 78.9% | |
| 5 | 79.6% | 78.7% | 75.6% | 74.2% | |
| 6 | 73.1% | 69.0% | 66.0% | 64.6% | |
| 7 | 74.2% | 70.9% | 67.8% | 64.7% | |
| 8 | 65.4% | 61.8% | 59.2% | 56.8% | |
| 10 | 72.5% | 70.4% | 68.4% | 67.1% | |
| FOUR | 2 | 88.4% | 88.1% | 86.3% | 85.3% |
| 3 | 62.2% | 60.1% | 57.9% | 60.1% | |
| 4 | 74.5% | 70.9% | 70.7% | 71.5% | |
| 5 | 65.0% | 62.9% | 63.8% | 65.3% | |
| 6 | 59.6% | 56.1% | 55.1% | 55.5% | |
| 7 | 61.0% | 57.8% | 57.8% | 58.3% | |
| 8 | 55.5% | 50.2% | 50.1% | 51.2% | |
| 9 | 59.6% | 56.8% | 57.0% | 57.8% | |
| 10 | 59.5% | 54.5% | 54.7% | 56.3% | |
| 11 | 53.8% | 50.1% | 49.9% | 50.8% | |
| 12 | 55.7% | 51.7% | 49.5% | 49.3% | |
| PARK | 2 | 91.7% | 92.9% | 92.1% | 93.9% |
| 3 | 87.9% | 89.0% | 89.8% | 91.0% | |
| 4 | 88.6% | 88.3% | 84.3% | 81.6% | |
| 5 | 89.8% | 87.0% | 84.3% | 80.1% | |
| 6 | 82.1% | 80.0% | 78.8% | 78.6% | |
| 7 | 83.6% | 82.4% | 78.0% | 78.1% | |
| 8 | 84.5% | 80.8% | 77.0% | 73.1% | |
| 9 | 86.3% | 84.1% | 79.3% | 78.2% | |
| 10 | 81.9% | 77.9% | 73.3% | 69.4% | |
| 11 | 78.5% | 75.5% | 72.6% | 70.2% | |
| 12 | 77.0% | 73.2% | 66.9% | 63.7% | |
| Computational Time (s.) | |||||
|---|---|---|---|---|---|
| Video sequence | NoT | QP 22 | QP 27 | QP 32 | QP 37 |
| BQSQ | 2 | 5882 | 4751 | 3857 | 3215 |
| 3 | 5415 | 4402 | 3577 | 2964 | |
| 4 | 3694 | 3694 | 3694 | 3694 | |
| 8 | 2026 | 2026 | 2026 | 2026 | |
| PART | 2 | 23,305 | 19,153 | 15,346 | 11,753 |
| 3 | 18,911 | 16,069 | 13,053 | 9763 | |
| 4 | 12,733 | 11,070 | 9030 | 7007 | |
| 5 | 11,012 | 9347 | 7867 | 5964 | |
| 6 | 9991 | 8887 | 7518 | 5703 | |
| 7 | 8445 | 7412 | 6266 | 4882 | |
| 8 | 8384 | 7444 | 6287 | 4864 | |
| 10 | 6051 | 5224 | 4349 | 3295 | |
| FOUR | 2 | 26,479 | 19,172 | 14,441 | 10,709 |
| 3 | 25,103 | 18,716 | 14,362 | 10,141 | |
| 4 | 15,705 | 11,898 | 8809 | 6385 | |
| 5 | 14,407 | 10,732 | 7818 | 5595 | |
| 6 | 13,085 | 10,034 | 7547 | 5484 | |
| 7 | 10,960 | 8348 | 6158 | 4476 | |
| 8 | 10,545 | 8410 | 6218 | 4464 | |
| 9 | 8727 | 6606 | 4860 | 3512 | |
| 10 | 7861 | 6200 | 4558 | 3244 | |
| 11 | 7909 | 6128 | 4546 | 3269 | |
| 12 | 7007 | 5440 | 4194 | 3089 | |
| PARK | 2 | 95,117 | 66,946 | 45,846 | 29,237 |
| 3 | 66,202 | 46,565 | 31,348 | 20,128 | |
| 4 | 49,218 | 35,234 | 25,017 | 16,821 | |
| 5 | 38,857 | 28,583 | 20,025 | 13,708 | |
| 6 | 35,411 | 25,915 | 17,845 | 11,654 | |
| 7 | 29,830 | 21,576 | 15,453 | 10,048 | |
| 8 | 25,811 | 19,243 | 13,695 | 9396 | |
| 9 | 22,458 | 16,426 | 11,831 | 7804 | |
| 10 | 21,319 | 15,965 | 11,511 | 7916 | |
| 11 | 20,207 | 14,978 | 10,567 | 7110 | |
| 12 | 18,894 | 14,159 | 10,507 | 7188 | |
| Parallel Efficiency | |||||
|---|---|---|---|---|---|
| Video sequence | NoT | QP 22 | QP 27 | QP 32 | QP 37 |
| BQSQ | 2 | 93.1% | 96.1% | 95.0% | 96.7% |
| 3 | 93.7% | 92.6% | 94.6% | 95.2% | |
| 4 | 92.7% | 92.7% | 94.8% | 95.7% | |
| 8 | 86.2% | 88.3% | 88.8% | 88.9% | |
| PART | 2 | 98.3% | 98.6% | 99.4% | 99.0% |
| 3 | 95.3% | 96.3% | 97.1% | 97.9% | |
| 4 | 94.4% | 95.1% | 96.7% | 96.4% | |
| 5 | 93.3% | 95.2% | 94.6% | 93.2% | |
| 6 | 92.6% | 93.4% | 93.0% | 92.2% | |
| 7 | 92.0% | 91.2% | 94.2% | 93.3% | |
| 8 | 91.3% | 91.3% | 92.1% | 92.5% | |
| 10 | 91.9% | 90.0% | 93.7% | 90.8% | |
| FOUR | 2 | 97.9% | 98.9% | 97.2% | 98.8% |
| 3 | 95.2% | 94.5% | 94.3% | 95.2% | |
| 4 | 95.0% | 92.3% | 94.1% | 94.9% | |
| 5 | 97.8% | 93.9% | 94.7% | 94.6% | |
| 6 | 93.9% | 93.1% | 92.7% | 91.6% | |
| 7 | 95.3% | 93.8% | 93.3% | 93.5% | |
| 8 | 94.1% | 92.2% | 92.6% | 91.0% | |
| 9 | 95.0% | 93.8% | 92.9% | 93.0% | |
| 10 | 92.6% | 91.2% | 91.8% | 90.0% | |
| 12 | 89.9% | 89.5% | 87.6% | 88.4% | |
| PARK | 2 | 98.5% | 98.2% | 97.4% | 98.1% |
| 3 | 95.4% | 95.1% | 93.1% | 94.7% | |
| 4 | 94.0% | 94.2% | 90.5% | 94.6% | |
| 5 | 94.2% | 95.7% | 92.9% | 93.1% | |
| 6 | 94.7% | 93.6% | 89.9% | 93.4% | |
| 7 | 93.6% | 91.2% | 93.2% | 94.2% | |
| 8 | 93.7% | 93.4% | 91.8% | 92.7% | |
| 9 | 94.2% | 92.6% | 91.2% | 92.9% | |
| 10 | 93.3% | 92.4% | 91.8% | 89.1% | |
| 11 | 92.4% | 92.2% | 87.9% | 89.9% | |
| 12 | 89.5% | 89.4% | 88.5% | 88.5% | |
| Computational Time (s.) | |||||
|---|---|---|---|---|---|
| Video sequence | NoT | QP 22 | QP 27 | QP 32 | QP 37 |
| BQSQ | 2 | 5368 | 4215 | 3354 | 2629 |
| 3 | 3556 | 2915 | 2244 | 1781 | |
| 4 | 2695 | 2695 | 2695 | 2695 | |
| 8 | 1449 | 1449 | 1449 | 1449 | |
| PART | 2 | 22,302 | 18,668 | 14,968 | 11,172 |
| 3 | 15,343 | 12,730 | 10,216 | 7532 | |
| 4 | 11,613 | 9677 | 7693 | 5737 | |
| 5 | 9403 | 7729 | 6288 | 4748 | |
| 6 | 7891 | 6568 | 5332 | 3997 | |
| 7 | 6807 | 5761 | 4513 | 3386 | |
| 8 | 6000 | 5039 | 4040 | 2990 | |
| 10 | 4769 | 4087 | 3176 | 2435 | |
| FOUR | 2 | 23,893 | 17,072 | 12,822 | 9247 |
| 3 | 16,392 | 11,909 | 8811 | 6401 | |
| 4 | 12,311 | 9143 | 6624 | 4811 | |
| 5 | 9569 | 7195 | 5263 | 3862 | |
| 6 | 8306 | 6046 | 4482 | 3325 | |
| 7 | 7019 | 5140 | 3818 | 2791 | |
| 8 | 6220 | 4578 | 3367 | 2509 | |
| 9 | 5473 | 4000 | 2983 | 2182 | |
| 10 | 5057 | 3703 | 2714 | 2029 | |
| 12 | 4341 | 3144 | 2370 | 1723 | |
| PARK | 2 | 82,978 | 58,401 | 40,028 | 25,722 |
| 3 | 57,119 | 40,202 | 27,935 | 17,760 | |
| 4 | 43,445 | 30,449 | 21,543 | 13,332 | |
| 5 | 34,683 | 23,956 | 16,803 | 10,840 | |
| 6 | 28,754 | 20,416 | 14,461 | 9007 | |
| 7 | 24,939 | 17,967 | 11,961 | 7656 | |
| 8 | 21,809 | 15,356 | 10,624 | 6805 | |
| 9 | 19,275 | 13,767 | 9508 | 6034 | |
| 10 | 17,512 | 12,408 | 8499 | 5666 | |
| 11 | 16,084 | 11,304 | 8064 | 5105 | |
| 12 | 15,207 | 10,695 | 7347 | 4750 | |
| Bitrate (Kbps) | |||||||
|---|---|---|---|---|---|---|---|
| Video sequence | NoT and sequence | Slice size | QP 22 | QP 27 | QP 32 | QP 37 | |
| BQSQ | 2 | 4 | Seq. | 13,024 | 8652 | 5578 | 3474 |
| Par. | 12,579 | 8361 | 5356 | 3370 | |||
| Diff. | −3.4% | −3.4% | −4.0% | −3.0% | |||
| 4 | 2 | Seq. | 13,366 | 8855 | 5736 | 3563 | |
| Par. | 12,640 | 8410 | 5393 | 3398 | |||
| Diff. | −5.4% | −5.0% | −6.0% | −4.6% | |||
| 8 | 1 | Seq. | 13,508 | 9113 | 5898 | 3644 | |
| Par. | 12,826 | 8548 | 5495 | 3483 | |||
| Diff. | −5.0% | −6.2% | −6.8% | −4.4% | |||
| PART | 2 | 14 | Seq. | 45,454 | 28,760 | 17,506 | 9660 |
| Par. | 45,291 | 28,643 | 17,362 | 9675 | |||
| Diff. | −0.4% | −0.4% | −0.8% | 0.2% | |||
| 4 | 7 | Seq. | 46,018 | 29,001 | 17,678 | 9736 | |
| Par. | 45,499 | 28,794 | 17,468 | 9750 | |||
| Diff. | −1.1% | −0.7% | −1.2% | 0.1% | |||
| 8 | 4 | Seq. | 46,559 | 29,558 | 17,833 | 9810 | |
| Par. | 45,689 | 28,919 | 17,552 | 9814 | |||
| Diff. | −1.9% | −2.2% | −1.6% | 0.0% | |||
| FOUR | 2 | 30 | Seq. | 27,225 | 16,817 | 10,498 | 6513 |
| Par. | 26,866 | 16,631 | 10,398 | 6464 | |||
| Diff. | −1.3% | −1.1% | −1.0% | −0.8% | |||
| 4 | 15 | Seq. | 27,717 | 17,160 | 10,738 | 6671 | |
| Par. | 27,182 | 16,871 | 10,575 | 6595 | |||
| Diff. | −1.9% | −1.7% | −1.5% | −1.1% | |||
| 8 | 8 | Seq. | 28,180 | 17,397 | 10,960 | 6831 | |
| Par. | 27,506 | 17,106 | 10,746 | 6719 | |||
| Diff. | −2.4% | −1.7% | −1.9% | −1.6% | |||
| PARK | 2 | 68 | Seq. | 49,209 | 26,911 | 14,227 | 7118 |
| Par. | 49,084 | 26,873 | 14,222 | 7132 | |||
| Diff. | −0.3% | −0.1% | 0.0% | 0.2% | |||
| 4 | 34 | Seq. | 49,288 | 26,987 | 14,284 | 7154 | |
| Par. | 49,218 | 26,983 | 14,301 | 7182 | |||
| Diff. | −0.1% | 0.0% | 0.1% | 0.4% | |||
| 8 | 17 | Seq. | 49,452 | 27,135 | 14,395 | 7232 | |
| Par. | 49,468 | 27,166 | 14,436 | 7271 | |||
| Diff. | 0.0% | 0.1% | 0.3% | 0.5% | |||
| PSNR (dB) | |||||||
|---|---|---|---|---|---|---|---|
| Video sequence | NoT and slices | Slice size | QP 22 | QP 27 | QP 32 | QP 37 | |
| BQSQ | 2 | 4 | Seq. | 42.7616 | 38.6735 | 34.9935 | 31.4817 |
| Par. | 42.9435 | 38.8538 | 35.2465 | 31.7929 | |||
| Diff. | 0.4% | 0.5% | 0.7% | 1.0% | |||
| 4 | 2 | Seq. | 42.6559 | 38.5985 | 34.9282 | 31.3503 | |
| Par. | 42.9435 | 38.8538 | 35.2465 | 31.7929 | |||
| Diff. | 0.7% | 0.7% | 0.9% | 1.4% | |||
| 8 | 1 | Seq. | 42.6338 | 38.4881 | 34.7934 | 31.2209 | |
| Par. | 42.9312 | 38.8410 | 35.2348 | 31.7715 | |||
| Diff. | 0.7% | 0.9% | 1.3% | 1.8% | |||
| PART | 2 | 14 | Seq. | 42.1050 | 38.0071 | 34.2767 | 30.7610 |
| Par. | 42.1459 | 38.0528 | 34.4646 | 30.9932 | |||
| Diff. | 0.1% | 0.1% | 0.5% | 0.8% | |||
| 4 | 7 | Seq. | 42.0037 | 37.9629 | 34.188 | 30.6701 | |
| Par. | 42.1434 | 38.0467 | 34.455 | 30.9788 | |||
| Diff. | 0.3% | 0.2% | 0.8% | 1.0% | |||
| 8 | 4 | Seq. | 41.8932 | 37.7962 | 34.1187 | 30.5650 | |
| Par. | 42.1409 | 38.0440 | 34.4525 | 30.9748 | |||
| Diff. | 0.6% | 0.7% | 1.0% | 1.3% | |||
| FOUR | 2 | 30 | Seq. | 45.1104 | 42.6808 | 39.9899 | 37.1100 |
| Par. | 45.1828 | 42.7848 | 40.1469 | 37.3029 | |||
| Diff. | 0.2% | 0.2% | 0.4% | 0.5% | |||
| 4 | 15 | Seq. | 45.0631 | 42.6244 | 39.9007 | 36.9927 | |
| Par. | 45.1802 | 42.7800 | 40.1387 | 37.2943 | |||
| Diff. | 0.3% | 0.4% | 0.6% | 0.8% | |||
| 8 | 8 | Seq. | 45.0372 | 42.6250 | 39.8448 | 36.9191 | |
| Par. | 45.1785 | 42.7756 | 40.1334 | 37.2841 | |||
| Diff. | 0.3% | 0.4% | 0.7% | 1.0% | |||
| PARK | 2 | 68 | Seq. | 42.4621 | 39.5641 | 36.8565 | 34.2881 |
| Par. | 42.5295 | 39.6277 | 36.9372 | 34.3736 | |||
| Diff. | 0.2% | 0.2% | 0.2% | 0.2% | |||
| 4 | 34 | Seq. | 42.4194 | 39.5221 | 36.8147 | 34.2439 | |
| Par. | 42.5264 | 39.6253 | 36.9344 | 34.3672 | |||
| Diff. | 0.3% | 0.3% | 0.3% | 0.4% | |||
| 8 | 17 | Seq. | 42.3886 | 39.4936 | 36.7939 | 34.2173 | |
| Par. | 42.5215 | 39.6188 | 36.9288 | 34.3554 | |||
| Diff. | 0.3% | 0.3% | 0.4% | 0.4% | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Migallón, H.; López-Granado, O.; Martínez-Rach, M.O.; Galiano, V.; Malumbres, M.P. Load Balancing Strategies for Slice-Based Parallel Versions of JEM Video Encoder. Algorithms 2021, 14, 320. https://0-doi-org.brum.beds.ac.uk/10.3390/a14110320
Migallón H, López-Granado O, Martínez-Rach MO, Galiano V, Malumbres MP. Load Balancing Strategies for Slice-Based Parallel Versions of JEM Video Encoder. Algorithms. 2021; 14(11):320. https://0-doi-org.brum.beds.ac.uk/10.3390/a14110320
Chicago/Turabian StyleMigallón, Héctor, Otoniel López-Granado, Miguel O. Martínez-Rach, Vicente Galiano, and Manuel P. Malumbres. 2021. "Load Balancing Strategies for Slice-Based Parallel Versions of JEM Video Encoder" Algorithms 14, no. 11: 320. https://0-doi-org.brum.beds.ac.uk/10.3390/a14110320