
Multiagent Hierarchical Cognition Difference Policy for Multiagent Cooperation


1
School of Artificial Intelligence, University of Chinese Academy of Sciences, Beijing 100049, China
2
Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China
*
Author to whom correspondence should be addressed.
Algorithms 2021, 14(3), 98; https://0-doi-org.brum.beds.ac.uk/10.3390/a14030098
Submission received: 22 February 2021
/
Revised: 18 March 2021
/
Accepted: 18 March 2021
/
Published: 21 March 2021
(This article belongs to the Special Issue Reinforcement Learning Algorithms)
Abstract
:Multiagent cooperation is one of the most attractive research fields in multiagent systems. There are many attempts made by researchers in this field to promote cooperation behavior. However, several issues still exist, such as complex interactions among different groups of agents, redundant communication contents of irrelevant agents, which prevents the learning and convergence of agent cooperation behaviors. To address the limitations above, a novel method called multiagent hierarchical cognition difference policy (MA-HCDP) is proposed in this paper. It includes a hierarchical group network (HGN), a cognition difference network (CDN), and a soft communication network (SCN). HGN is designed to distinguish different underlying information of diverse groups’ observations (including friendly group, enemy group, and object group) and extract different high-dimensional state representations of different groups. CDN is designed based on a variational auto-encoder to allow each agent to choose its neighbors (communication targets) adaptively with its environment cognition difference. SCN is designed to handle the complex interactions among the agents with a soft attention mechanism. The results of simulations demonstrate the superior effectiveness of our method compared with existing methods.
1. Introduction
Grouping and effective communication are important methods to promote multiagent cooperative behavior. Agents in nature such as ants, social animals, and humans tend to cooperate and generate complex cooperative strategies by grouping and exchanging information. Naturally, the behaviors of grouping and exchanging information also apply to multiagent systems, especially in scenarios that require cooperation, such as smart grid control [1], resource management [2], and games [3,4].
Recently, deep reinforcement learning (DRL) has shown great potential in many domains, such as games [5,6] and robotics [7,8]. Inspired by the powerful perception and learning ability of DRL, researchers have made continuous attempts to apply DRL to multiagent reinforcement learning (MARL) to promote multiagent cooperative behaviors in environments with many agents [9,10,11,12,13,14,15]. Based on the common paradigm of centralized learning with decentralized execution, some MARL algorithms learn centralized critics for multiple agents and determine the decentralized action. However, when these methods are applied to environments with a large number of agents, they have their limitations. Some MARL algorithms [9,10] ignore different underlying influences brought by different groups of observation. Although some algorithms based on attention mechanism [16,17,18] partially consider the influences of groups, they do not take communication relationship among the agents into consideration. Furthermore, some algorithms [14,19,20] deal with the communication relationship between agents, but they do not consider the problem of communication redundancy, making it unsuitable for environments with a large number of agents.
To address the limitations above, we propose a novel method called multiagent hierarchical cognition difference policy (MA-HCDP) to handle state representations of different group of agents and filter irrelevant agents to promote agents’ cooperation behavior. In general, MA-HCDP can divide agents into different groups, filter out irrelevant agents in these groups, and handle the interactions among the remaining agents, in that order. Corresponding to the three functions is three networks in MA-HCDP, including a hierarchical group network (HGN), a cognition difference network (CDN), and a soft communication network (SCN). Specifically, HGN is responsible for extracting high-dimensional state representations of different groups including friend groups, enemy groups, and object groups. Then, the agents’ understanding of the environment is extracted based on the group-level state representations obtained from SCN and posterior distributions of variational autoencoder (VAE) [21] in CDN. Next, the differences between distributions of the agents are calculated with Kullback–Leibler (KL) divergence [22]. If the difference is large, these agents are defined as irrelevant agents and filtered out. SCN is responsible for the weight distribution of the agents to handle the influence of different neighbors. SCN expands the agents’ communication field with the chain propagation characteristics of graph neural networks (GNN). The main contributions and novelties are summarized as follows:
- A novel method, called MA-HCDP, is proposed to promote cooperation behaviors in environments with many agents.
- A hierarchical group network based on prior knowledge is designed to extract high-dimensional group-level state representation.
- A cognition difference network based on a variational autoencoder is designed to allow each agent to choose its neighbors adaptively to communicate.
- The effectiveness of MA-HCDP is evaluated in different tasks including cooperative navigation and group containment. Compared with existing methods, MA-HCDP shows a significant improvement in all the tasks, especially for the tasks with numerous agents.
The rest of this paper is organized as follows. In Section 2, we present the related works. In Section 3, we describe the background. In Section 4, we give the design procedure of the proposed method MA-HCDP, including HGN, CDN, and SCN. In Section 5, representative simulations are carried out in several scenarios. In Section 6, the discussion for the simulation results is presented. Finally, conclusions are summarized in Section 7.
2. Related Works
The multiagent deep deterministic policy gradient (MADDPG) [9] is extended from the deep deterministic policy gradient (DDPG) [7] to multiagent systems for mixed cooperative–competitive environments. A counterfactual multiagent (COMA) [10] computes a counterfactual advantage function to handle the problem of multiagent credit assignment. They adopt a common paradigm of centralized learning with decentralized execution (CTDE) to enhance cooperative behaviors of agents. Although MADDPG and COMA can improve the agents’ cooperation ability, they do not consider the complex interactions among the agents. They aggregate observations of all the agents and never distinguish different groups of agents, thus limiting the cooperation of agents.
To address the limitation, the agent grouping method [12] employs a two-level graph neural network to model the interagent and intergroup relationships effectively. However, it ignores the communication relationship between the agents in the same group. The authors of [13] designed a two-level attention network to distinguish the different semantic meanings of observation. Nonetheless, it does not consider the communication contents.
To deal with the problem of communication, a feedforward deep neural network is adopted in [14] to map all agents’ inputs to their actions. Each agent can have access to an implicit communication channel to receive other agents’ states. A bidirectionally coordinated network (BiCNet) [19] based on the actor–critic model adopts bidirectional recurrent networks to achieve mutual communication between agents. Master–slave [20] is a communication architecture for real-time strategy games, where the action of each slave agent consists of information from the slave agents and master agent. Although these methods can promote cooperation behaviors of agents, they need the global states of the environment during the training, which is not applicable in partially observable environments. Furthermore, these methods take all the communication among the agents into consideration, but they ignore the influence of redundant communication caused by too many communication objects.
To address this issue, some methods based on the attention mechanism appeared [15,16,17,18]. Nonetheless, each agent within the communication range will be assigned an attention coefficient with attention mechanism. The total amount of communication is not decreased since irrelevant agents can still obtain the attention coefficients and be included in the total communication amount. The soft attention mechanism usually assigns small but nonzero attention coefficients to irrelevant agents, which weakens the attention assigned to the significant agents.
Based on the above analyses, MA-HCDP is proposed to handle state representations of different group of agents and filter irrelevant agents to promote agents’ cooperation behavior. To the best of our knowledge, none of existing work in MARL tackles simultaneously the problem of agents grouping, redundant communication information processing, and agent interaction processing like our MA-HCDP.
3. Background
In this section, the definition of partially observable Markov games (POMG) is presented firstly to describe the decision process of agents in partially observable environments. Then, the preliminary of reinforcement learning (RL) methods applied in MA-HCDP is introduced, including basic concepts and the actor–critic framework of RL and PPO. Moreover, the attention mechanism for handling the interaction among the agents is presented. Finally, the basic idea of variational autoencoding is introduced.
3.1. Partially Observable Markov Games
In this paper, agents need to cooperate with each other to complete different tasks in partially observable environments, which are considered as partially observable Markov games that are an extension of Markov games [23]. They are defined by environment state , action spaces where N is the number of agents, is the action of agent i at time t, and observation spaces . Each agent i learns a policy , which maps each agent’s observation to a distribution over its set of actions. Then, the next states are produced according to the transition function . Each agent i obtains rewards as a function of the state space and action spaces: . The goal of each agent is to maximize following expected discounted returns with the policy :
where represents the expectation. represents the reward that agent i obtains at time t and denotes the discount factor determining the importance of future rewards. If , the agent will be completely myopic and only learn about actions that produce an immediate reward. If , the agent will evaluate each of its actions based on the sum total of all of its future rewards.
3.2. Reinforcement Learning
Reinforcement learning [24] is adopted to solve special POMG problems where . It is a machine learning approach to solve sequential decision-making problems. Policy gradient methods are the popular choice for a variety of RL tasks. The policy realized by a neural network with parameters is denoted as a policy . Its objective is to directly adjust the parameters of the policy in order to maximize the objective by taking steps in the direction of :
The actor–critic framework is one of the most effective RL frameworks. The key feature of the framework lies in two functions: policy function and value function. The policy function is known as the actor function, because it is used to select actions. The value function is known as the critic, because it criticizes the actions made by the actor. They reinforce each other. Specifically, the actor selects actions, then the actions is evaluated by the critic. Then, the critic updates the actor toward the right direction. This mutual reinforcement behavior enables policies to converge faster.
The proximal policy optimization algorithm (PPO) [25] is a novel policy gradient method. Considering the advantage of the actor–critic framework, we adopt PPO based on the actor–critic framework as the basic training algorithm in this paper. The objective function of PPO changes from (2) to (4) for a single-agent environment:
denotes the likelihood ratio. denotes the policy of the agent before k steps. Then, the objective function is optimized according to the following equations:
where is the generalized advantage estimate (GAE) and clips in the interval .
To train agents to learn cooperative behaviors, PPO is extended to multiagent environments in MA-HCDP, and the details are introduced in Section 4.4.
3.3. Attention Mechanism
The attention mechanism has been adopted in many fields [26,27,28]. For the attention mechanism, its inputs are composed of several input vectors and a target vector . The attention weight is related to a user-defined function . P is a weighted sum of each vector according to the normalized attention weight :
Note that since
the attention weight vector denotes a probability distribution.
In this paper, the attention mechanism is enhanced to handle the relationship among the agents. The input vectors are the hidden states of the neighbor agents. The target vectors are the states of the center agent. The user-defined function is a feedforward neural network. The details are presented in Section 4.
3.4. Variational Autoencoder
The variational autoencoder [21] is a probabilistic latent variable model that relates an observed variable vector x to a latent variable vector z by a posterior distribution . In this paper, the posterior distribution represents the understanding of the environment for agents. It can be adopted as a basis to judge whether communication is needed between agents. The details are presented in Section 4.
4. Multiagent Hierarchical Cognition Difference Policy
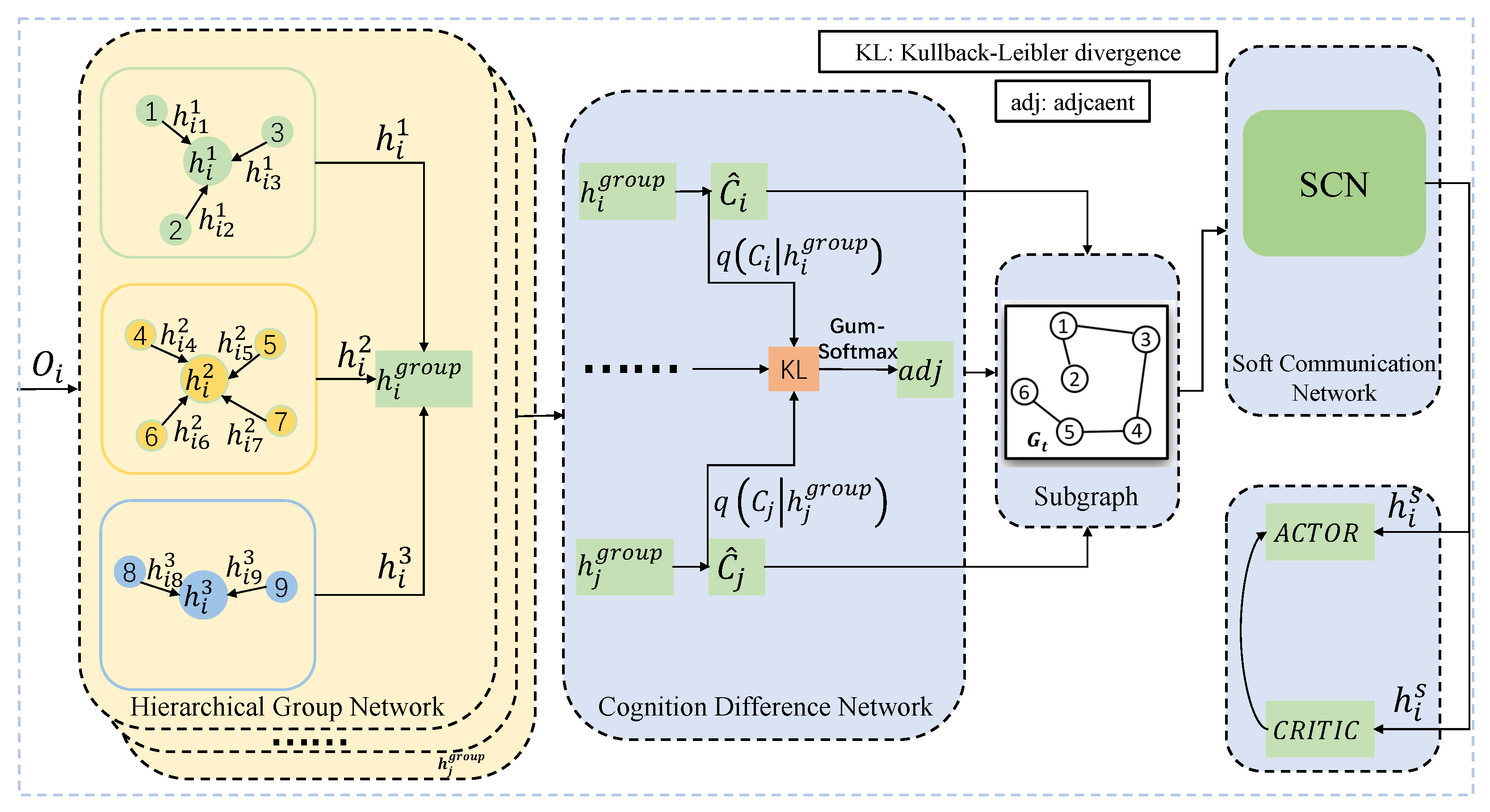
In this section, a multiagent hierarchical cognition difference policy (MA-HCDP) is proposed as shown in Figure 1, including a hierarchical group network (HGN), a cognition difference network (CDN), and a soft communication network (SCN). First, HGN uses prior knowledge or data to cluster all the agents into different groups (including a friendly group, enemy group, and object group) and adopts attention mechanism [27] to extract different high-dimensional state representations of different groups. Then, CDN is responsible for filtering irrelevant agents to reduce redundant information. Next, the filtered communication status among the agents is modeled as a graph G according to the CDN results. SCN is responsible for the weight distribution of the filtered agents to handle different neighbors’ influence. Finally, the captured states of different groups are subsequently used to update the critic and actor network.
4.1. Hierarchical Group Network
In this part, the influence of neighbor agents is analyzed firstly. Then, details of the hierarchical group network are presented.
In partially observable environments with many agents, there are many neighbors within the agents’ observation range. In general, these neighbors can be divided into different groups based on prior knowledge, including a friend group, enemy group, and object group (obstacles or common goal). For instance, agents can be categorized into two groups, the friend group (agents) and the object group (obstacles or common goals), in a cooperative task. Different state representations of different groups have different influences on agents’ policies. If an agent does not distinguish between states of the different groups, the influence of the states of different groups on the agent will be stacked together, thereby affecting its policy. Therefore, a hierarchical group network (HGN) is proposed to handle the different influences of state representations of different groups on the agent, which is shown in Figure 1.
In this paper, the other entities such as agents or obstacles within observation range of each agent i are categorized into H groups, and agent i is set as the center of each group. Note that agent i has a local observation where , is the number of entities in group h, and . is the own state of agent i.
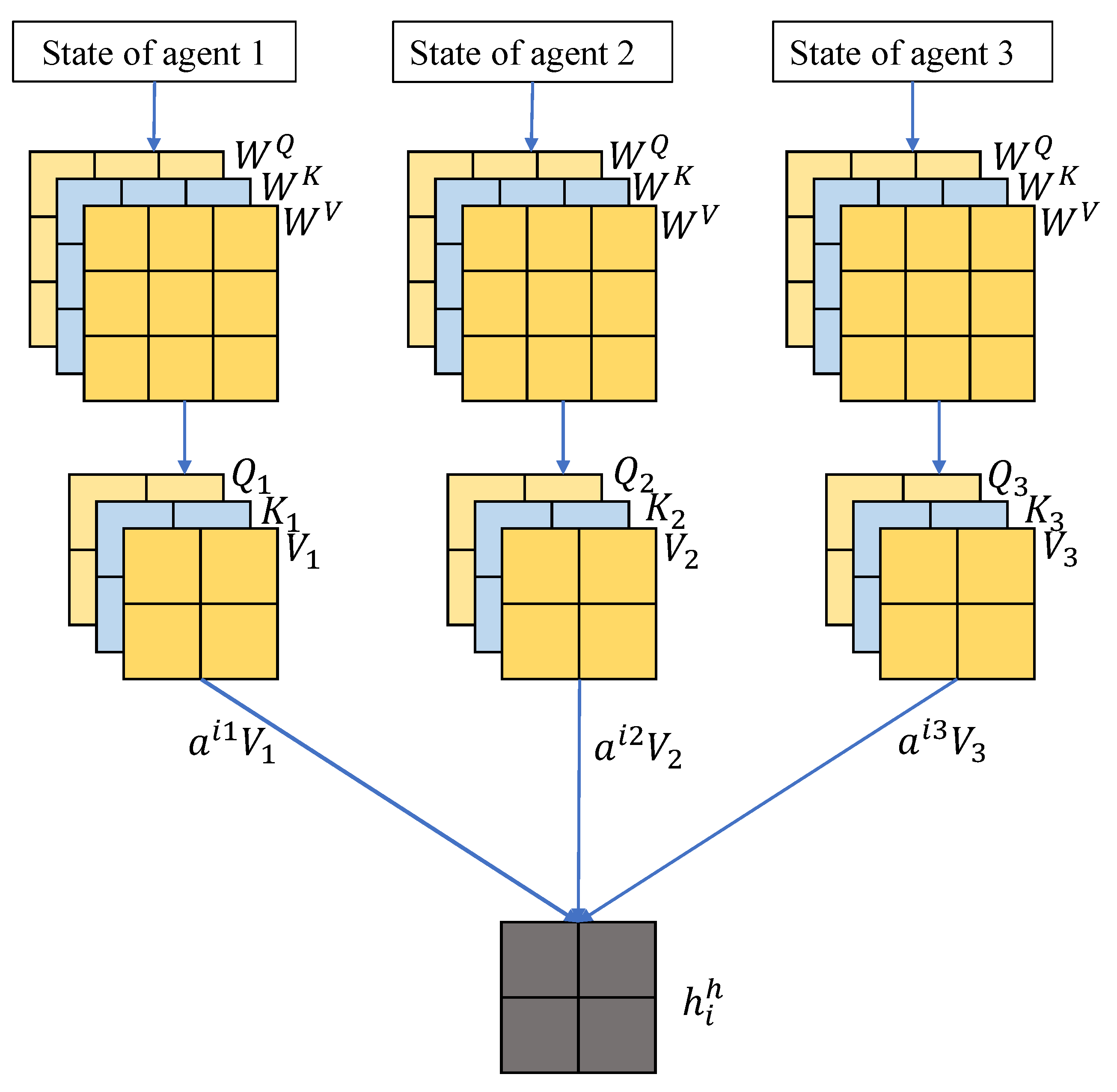
Then, the attention mechanism is adopted by agent i to obtain different state representations of different groups. It can enable agents to handle the states of the other entities in a group effectively. As shown in Figure 2, by using linear weight matrices , , , the states of entity j in group h for agent i are transformed to a different space including , and . After receiving the pair from the entities in group h, the attention coefficient from entity j in group h to agent i is computed. Then, the state representations of entities in group h for agent i are aggregated according to attention coefficients :
where is the dimensionality of and is the aggregated states from other entities in group h with nonlinear activation function .
After state representation of all groups are obtained, they are aggregated to form a high-dimensional group-level state representation for agents’ policy learning.
With HGN, the entities are divided into different groups, which enables the agents to handle the state of different groups separately. The attention mechanism in HGN allows the agents to process the different influence of the other entities in a group, which helps the agents to understand the environment more effectively.
4.2. Cognition Difference Network
In this part, we first analyze the importance of redundant agents. Then, the design process of the cognition difference network is presented.
In environments with a large number of agents, if an agent communicates with all of its neighbors of the groups, redundant information will affect the agent’s decision. When the number of agents in the environment increases, the communication among agents become more complicated, which makes the influence of redundant information more serious. Therefore, it is necessary for the agents to process redundant information.
Artificial rules [11] or a soft attention mechanism [15,16,17,18] are often used to process communication among the agents. The methods with artificial rules require strong prior knowledge of the environment and may not be suitable for application in complex environments. The methods with a soft attention mechanism assign attention coefficients to all agents within the communication range. The total amount of communication is not decreased since irrelevant agents can still obtain the attention coefficient and be included in the total communication amount. The soft attention mechanism usually assigns small but nonzero attention coefficients to irrelevant agents, which essentially weakens the attention assigned to the significant agents. Therefore, a cognition difference network (CDN) is designed to filter redundant agents to reduce redundant information.
First, we construct the communication status between agents as a graph, where each node represents a single agent, and all nodes are connected in pairs by default. represents the communication status between the agents. In particular, is a set of the agents. denotes the edge set at time t. is a set of group state representations at time t, , , where L represents the state representation dimension of each node. Moreover, represents a set of neighbors of node i at time t in the graph. Agent if where is communication range and is a two-dimensional Euclidean norm. As indicated by (9), there is a time-varying adjacency matrix where if otherwise .
where denotes a two-dimensional Euclidean norm that can calculate the distance between two agents.
Then, we introduce definitions of cognitive difference based on an assumption below to filter neighbor agents more effectively.
Definition 1.
The cognition of an agent is its understanding of the local environment. It contains the states of all entities within its observation range, or the high-level hidden states or distributions extracted from these states (e.g., learned with deep neural networks (DNNs)).
Definition 2.
The cognition difference is the difference of high-level hidden states or distributions between the agents measured by n-dimensional norm or distribution measures.
Assumption 1.
The cognition of each agent can be represented by a vector or a distribution obeying Gaussian distribution.
Under the above definitions and assumption, if the cognition difference between agent i and agent j is relatively large, agents’ perceptions of the environment are quite different. In other words, the state of agent j is noise or disturbance to agent i, which will affect the policy of agent i, so agent i does not need to communicate with agent j.
After analyzing the role of the cognition difference, we need to solve two problems, including the representation of the cognition and the measurement of the cognition difference.
The representation of the cognition of agent i is denoted as cognition vector ; it is based on the states of all entities within its observation range. The common methods are to adopt directly multilayer perception (MLP) [9,10,11] or a graph convolution network (GCN) [15,29,30] to extract features of the observations as the cognition vector . However, the cognitive vectors extracted by these methods are essentially the result of single-valued mapping from vector to vector. These methods cannot fully decouple the observations’ factors, such as position or velocity. Therefore, the cognition vector extracted by MLP or GCN is not appropriate for the cognition of the environment.
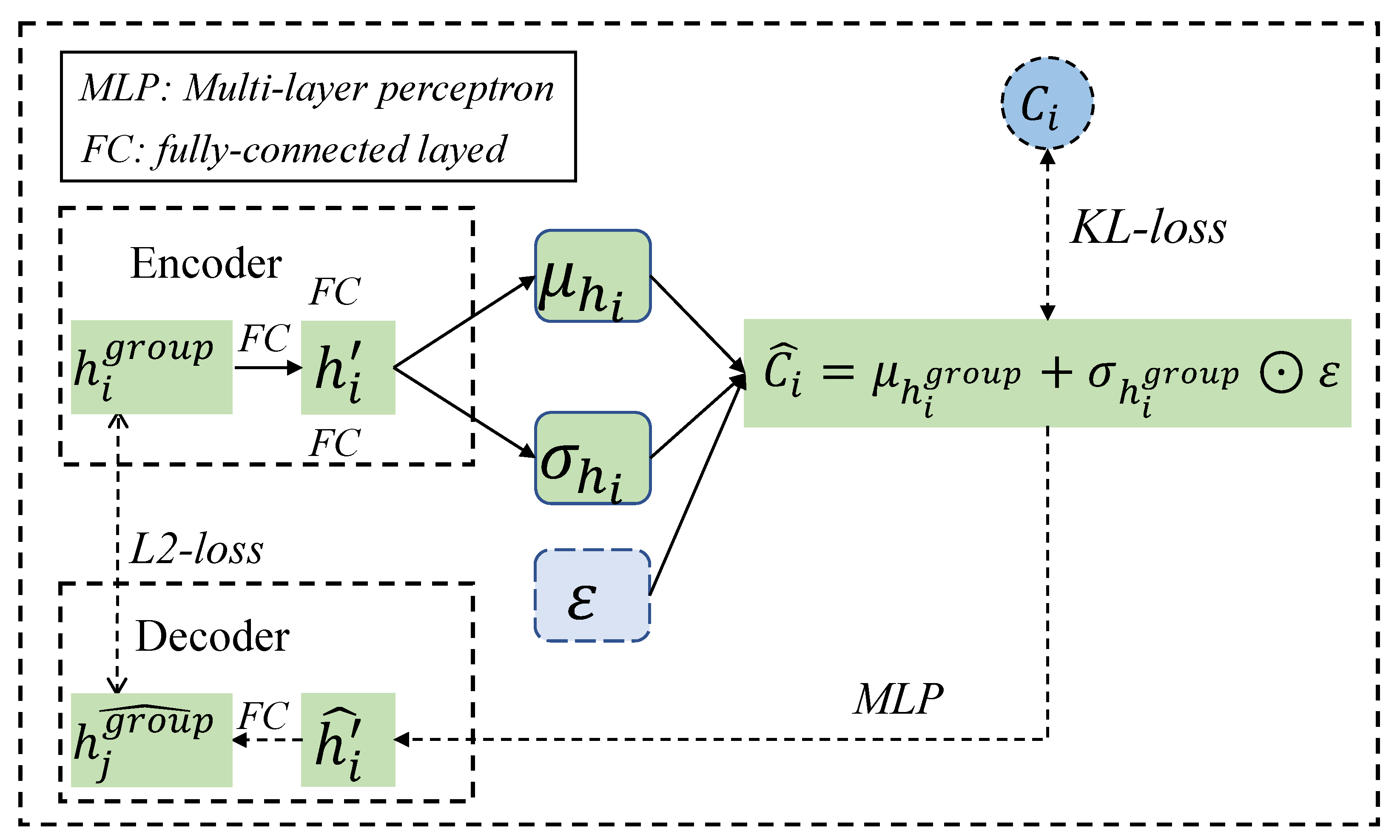
In order to effectively represent the cognitive vector, we adopt a probability distribution method. Specifically, the cognition vector is sampled with posterior distribution from group states and is inferred with:
where is a reconstruction process from the cognition vector . is the cogniton representation for agent i.
However, the above equation is diffcult to calculate directly. Hence, we approximate by another tractable distribution . The restriction is that needs to be close to . We achieve it by minimizing the following KL divergence:
which is equal to the maximum of the evidence lower bound (ELBO) [31]:
Note that the former is the reconstruction likelihood, and the latter is used to ensure that and the true prior distribution are as similar as possible. This process can be modeled as a VAE [21] as shown in Figure 3. Specifically, a mapping from to is obtained in the encoder of VAE where are the parameters of DNNs. Next, we adopt the “reparameterization trick” to sample from a unit Gaussian. Then, with mean and variance is generated: where . A distribution mapping from back to is learned in the decoder of the VAE. Based on the above analyses, the loss function for training the VAE is:
where is the result of the cognition representation of agent i and the learned distribution is an approximation of .
For the measurement of difference, since is sampled from the learned distribution, the distribution is more general in the environment’s cognition than . Therefore, we choose the difference between the distributions as the cognition difference. To calculate the cognition difference between agent i and agent j, KL divergence is adopted to calculate a score that measures the difference.
We need to output a one-hot vector based on the cognition difference to determine whether the edge between agent i and j exist in the graph or which agents need to be communicated. However, the backpropagation of gradients cannot be achieved in the process of outputting the one-hot vector due to the sampling process. Therefore, the Gumbel-Softmax function [32] is adopted to solve it:
where represents the Gumbel-Softmax function.
With the cognition difference and the sample process of Gumbel-Softmax, we can get a subgraph for agent i, where agent i only connects with agents that need to communicate.
With CDN, the agent understanding for the environment is obtained via VAE. Then, agents that have different understanding for the environment are defined as irrelevant agents and filtered out, which can reduce redundant information to enable agents to cooperate better.
4.3. Soft Communication Network
In this part, the influence of filtered neighbor agents is analyzed. Then, details of the soft communication network are presented. Furthermore, the process of enlarging the communication field is described.
Actually, in addition to processing redundant agents, the filtered neighbor agents of agent i need to be treated differently to promote cooperation. Different neighbors have different cognition of the environment, and this will have different influences on agent i. For instance, to an agent, agents closer to it may have more influence than agents further away, which means the agent should take into the influence of different agents. Therefore, the graph attention mechanism [33] is adopted in SCN to enable agents to handle the filtered neighbor agents’ states differently.
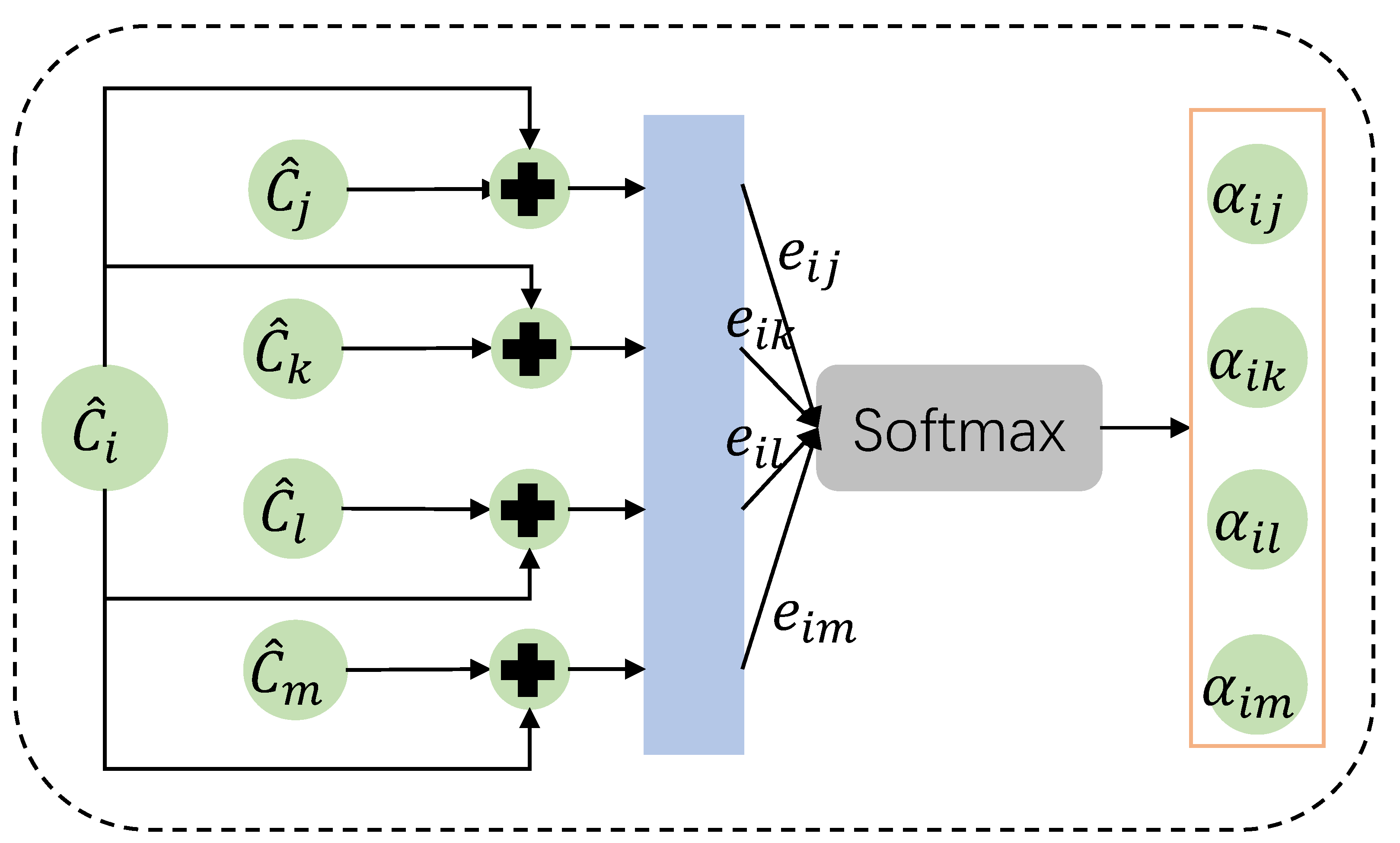
Specifically, SCN operates on graph-structured data and obtains the features of each graph node by aggregating the states of its neighbors. As shown in Figure 4, the attention coefficient from agent j to agent i and its normalized form are calculated with the hidden states of the agents:
where is a linear learnable matrix, is a single-layer feedforward neural network, and is a nonlinear activation function. [33] shows that the import of multihead attention is helpful to stabilize the learning process of the attention coefficients. Therefore, the aggregation states of agent i with multihead attention at t is given by:
where denotes the filtered neighbor agents for agent i. is the concatenation operator and M denotes the number of the heads. is the weight matrix of the mth linear transformation and is the normalized attention coefficient of the mth attention head.
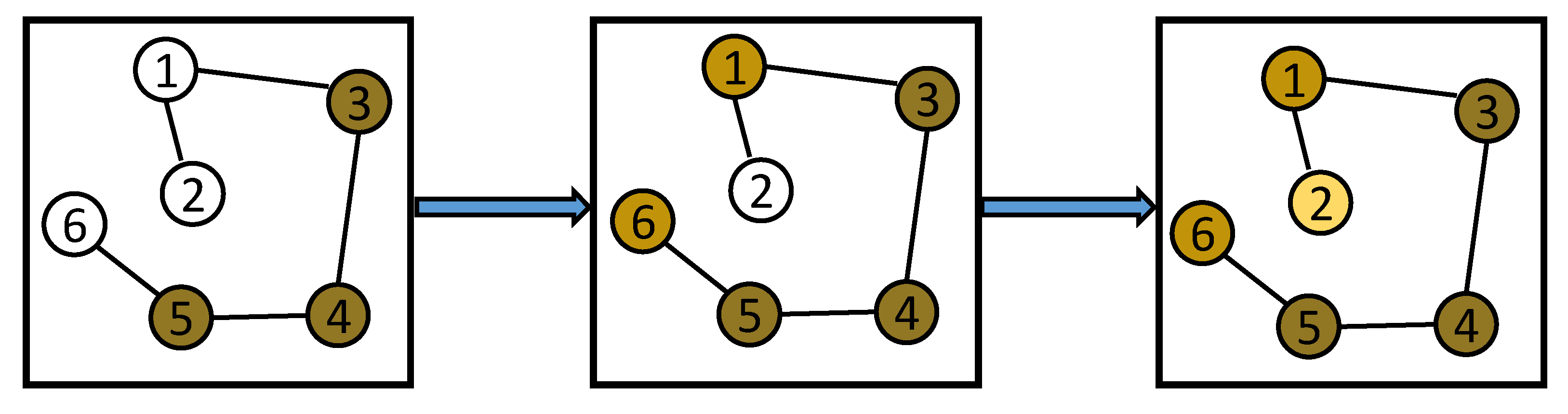
Moreover, the chain propagation characteristic of the graph convolution is adopted in SCN to enlarge the communication field. As described in Figure 5, agent 4 can get the states from its neighbors (agent 3 and agent 5) with one SCN layer. With two layers, agent 4 further obtains the states of its neighbors’ neighbors (agent 1 and agent 6). By stacking a third layer, agent 4 can finally obtain all the agents’ states. Therefore, multiple SCN layers can be utilized to enlarge the communication field of agent 4. Although multiple stacked SCN layers can take more additional structure information from the neighbor nodes of the center node into consideration, the cost of computing is greatly increased. Therefore, the number of SCN layers is set to three in this paper.
With SCN, each agent can handle different cognition of different neighbor agents. The communication field is enlarged with the chain propagation characteristic of graph, which promotes cooperation behaviors of the agents.
4.4. Training Method
After extraction by SCN, is utilized to optimize the policy of agents. PPO is adopted to train the agents based on an actor–critic framework. With HGN, the agent can obtain high-dimensional state representation of different groups. Owing to CDN and SCN, each agent can choose the agents to communicate with and assign different weights to them. The objective function of PPO as shown in (4) is changed as (21) after extracted from CDN and SCN. Then, PPO is trained by minimizing a total loss , which is conducted by the weighted summation of value loss , action loss , action entropy , and cognition difference loss :
where is the weight coefficient of the loss function. The action entropy is specially designed to encourage exploration for agents by penalizing the entropy of actor . The implementation details are presented in Algorithm 1.
| Algorithm 1 MA-HCDP. |
| Input: agent’s state Initialization: Initialize actor , critic , and old actor network
|
5. Simulation Results and Analysis
5.1. Simulation Settings
In this section, the performance of MA-HCDP is evaluated in two tasks, including cooperative navigation and group containment. The cooperative navigation task is designed to evaluate the effectiveness of MA-HCDP in handling states of differnt groups of agents. The group containment tasks is designed to verify the performance of MA-HCDP in reducing redundant communication information.
For all the tasks, the only way to obtain more information from the other agents is through limited communication. The map side length is 2 m, the detection range is 0.5 m, and the communication range is 1 m. The radius of an agent is 0.05 m and the radius of an obstacle is 0.1 m. The action space is discrete and each agent is able to control unit acceleration or deceleration in X and Y directions. The boundary condition for the environment is the four sides of the map. Each agent obtains for crossing the boundary.
where x is the abscissa or ordinate of the agent.
These tasks are implemented based on [9], where the agents can move around with a double integrator dynamics model. The details of the tasks will be presented in the following sections.
As baseline algorithms for comparing the performance, MADDPG [9] and TRANSFER [15] are taken into consideration to compare with our method MA-HCDP. MADDPG needs the state of all the agents during training to construct its critic network. It neither considers the influence of different groups nor the influence of redundant communication contents. TRANSFER adopts GCN and the soft attention mechanism to deal with the different influence of agents, but it ignores the influence of redundant communication contents.
A workstation is utilized for training and testing throughout the simulations, in which the processor is Intel(R) Xeon 8280L(2.6 GHz), the graphics card is Nvidia TITAN RTX GPU(24 G), and the RAM size is 128 GB. These simulations are implemented in the multiagent particle environment (MAPE) [9], and these algorithms are trained with PyTorch 1.0. The parameters of the training process, the network, and MA-HCDP are given in Table 1. Specifically, the learning rate is a hyperparameter used in the training of neural networks. The max gradient normalization is used to clip the gradient to avoid exploding gradients. The episode, batch size, PPO epoch, the coefficient of value loss, policy loss, entropy, and VAE are hyperparameters used in the training of PPO. The number of attention heads in HGN is a hyperparameter used for the multihead attention mechanism of HGN.
5.2. Cooperative Navigation
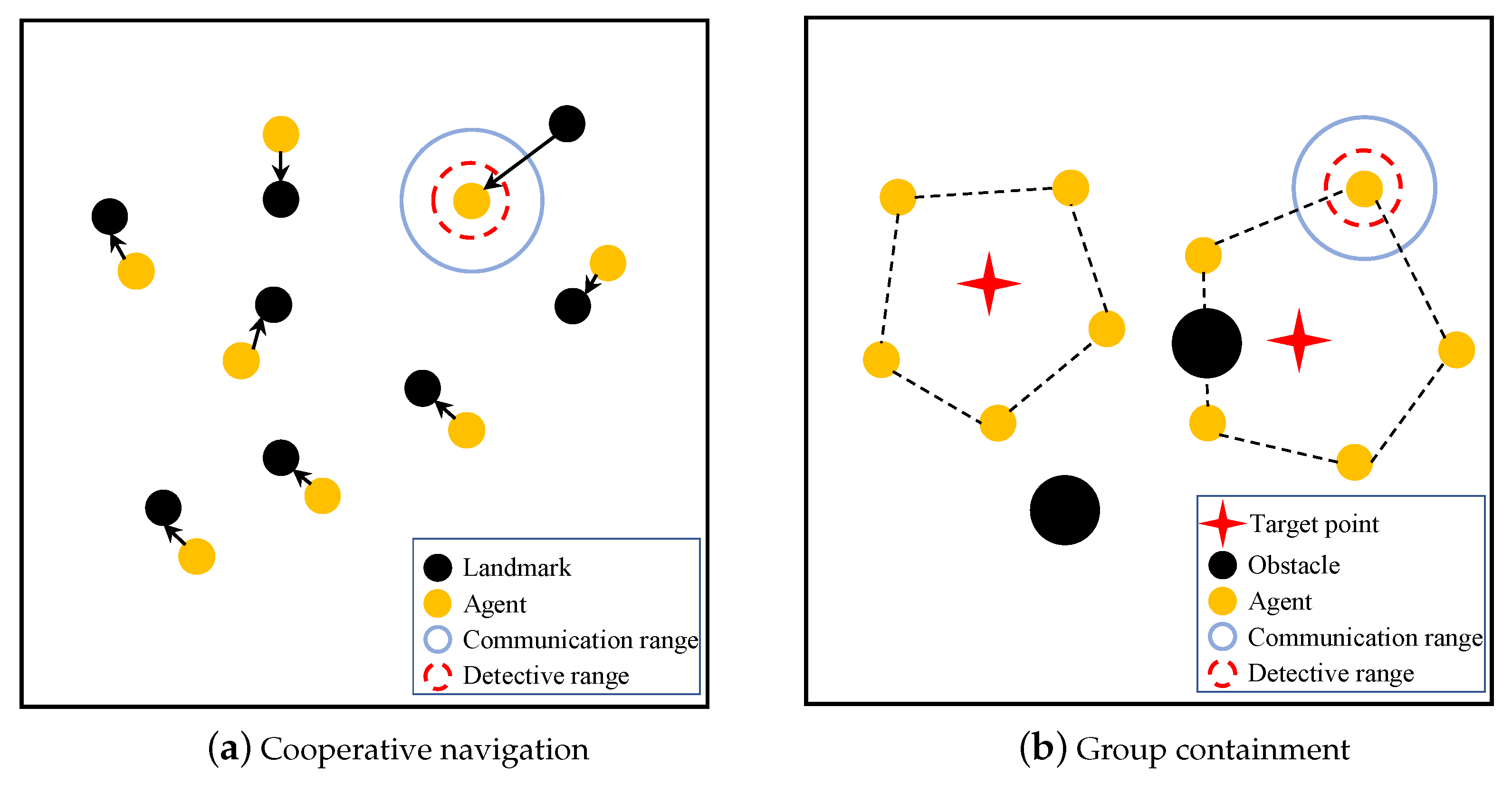
For the cooperative navigation, there are N agents and N landmarks in the environment as shown in Figure 6a. The objective is for the agents to deploy themselves in a manner such that every agent reaches a distinct landmark. Note that we do not assign a particular landmark to each agent, but instead let the agents communicate with each other and develop a consensus as to who goes where. The compound reward function for this task is defined as follows:
where is the distance reward and is the collision reward. represents the radius of agent i and represents the goal position of agent i. The closer the agent is to the goal point, the greater is.
In this paper, there are four different scenarios with different numbers of agents. Specifically, these scenarios include scenario (a) with 6 agents, scenario (b) with 15 agents, scenario (c) with 20 agents, and scenario (d) with 29 agents. MA-HCDP is compared with MADDPG and TRANSFER in these scenarios.
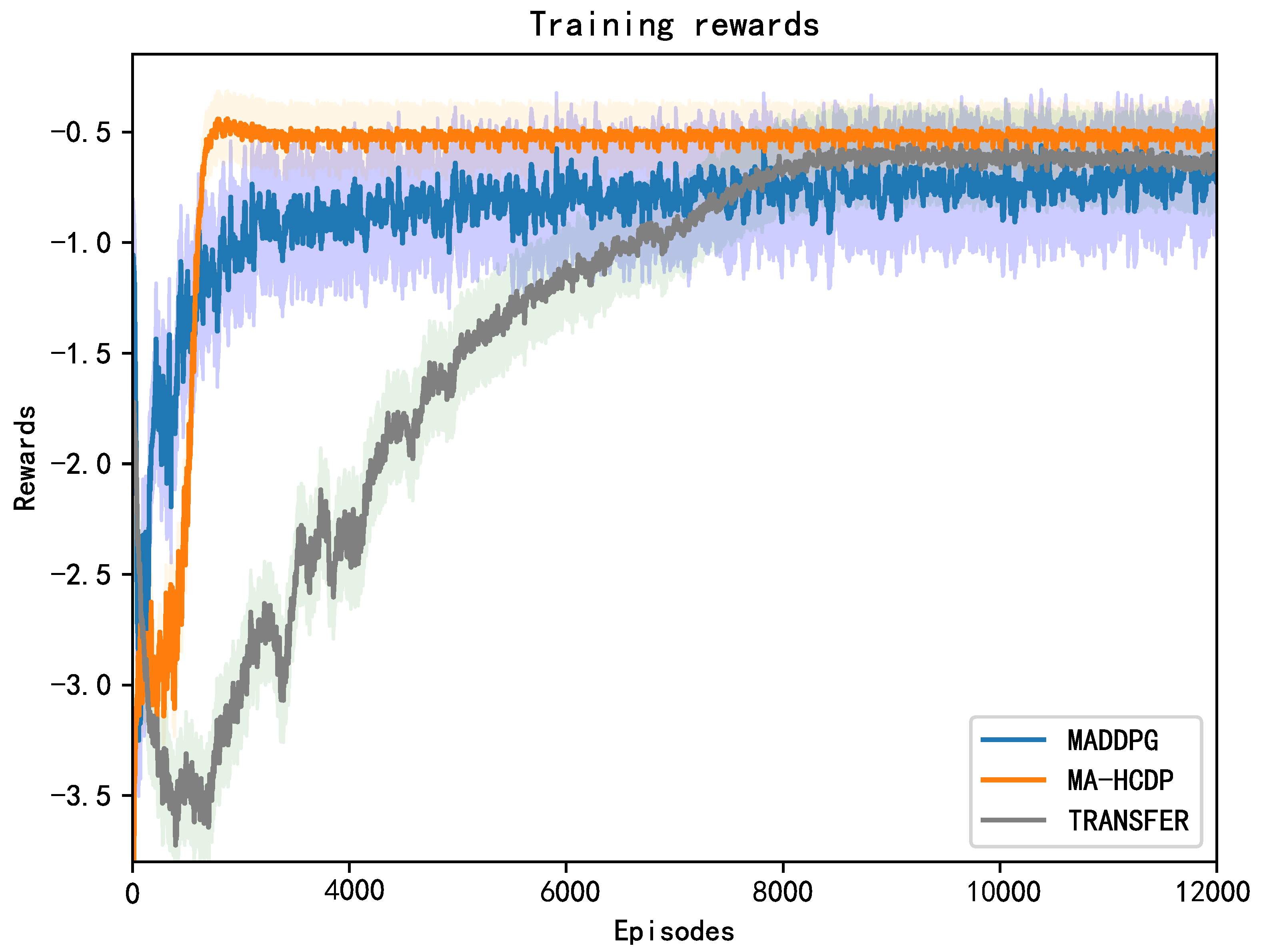
The learning curves of all the approaches in terms of mean rewards are presented in Figure 7. The coordinate name of the x-axis indicates the time spent in training. The longer the time, the slower the method will converge. The coordinate name of the x-axis represents the reward obtained in an episode. The higher the reward, the better the performance of the method. As shown in Figure 7, MA-HCDP has a higher convergence rate and higher performance than MADDPG and TRANSFER. The results indicate that different influences of observations of different groups of agents can be handled by MA-HCDP. It demonstrates that the redundant communication information can be filtered effectively by MA-HCDP, which enable agents to learn more appropriate policy in fewer training episodes. Note that MADDPG converges faster than TRANSFER but converges to a minimum value. As a comparison, TRANSFER converges slower but obtain higher rewards than MADDPG. Although TRANSFER considers the influence of communication among different agents, it ignores the influence of redundant communication, which make agents trained with TRANSFER obtain higher rewards and converge slower than MADDPG. Due to the ignorance of the influence of redundant communication, although the agent trained by TRANSFER can learn appropriate policy, its performance and convergence speed are both weaker than MA-HCDP. The above analysis shows the effectiveness of our method in dealing with the influence of different groups of agents and redundant communication.
In addition to the training process data, the simulation results of 100 independent simulations for each scenario are presented in Table 2. The t-test value is adopted to evaluate the effectiveness of our method statistically. According to the mean value, standard deviation and the sample data for 100 tests, we calculate the t value of MA-HCDP and the other methods on the same test scenario. “+” and “=” indicate that the index values obtained by the algorithm in this paper are superior and equal to the results of the other methods in the same test scenario in the two-tailed t-test with a significance level of .
As indicated by Table 2, our method obtains 18 optimal measurements during all the test scenarios. Note that the success rate of MADDPG in four scenarios is zero. This is because MADDPG does not consider the communication relationship among the agents and cannot handle partially observable environments. There is no significant performance difference between our method and TRANSFER in terms of success rate. The reason is that the task is simple, so TRANSFER and MA-HCDP can successfully complete the task. Despite this, our method is better than TRANSFER in terms of rewards and steps in scenarios with large number of agents. When the number of agents is equal to six, all methods except MADDPG present a similar performance. When the number of agents increases, our proposed MA-HCDP can obtain more rewards and take fewer steps than TRANSFER to complete the task. The reason is that agents need to communicate with more neighbor agents as the number of agents increases, and MA-HCDP can filter out redundant agents to promote multiagent cooperation behavior.
5.3. Group Containment
For the group containment, there are n agents and m landmarks in the environment as shown in Figure 6b. The relationship between n and m is defined as where represents a set of positive integers. Based on the above restriction, two scenarios including 6 agents with 2 landmarks and 10 agents with 2 landmarks are designed to evaluate the performance of our scheme. In these scenarios, all the agents must be divided into two groups and distributed evenly around the two landmarks without collision. The compound reward function for this task is defined as follows:
where is the position of agent i and is the position of goal. represents the Hungarian algorithm, which is a combination optimization algorithm. The Hungarian algorithm is adopted to calculate the mean distance between the agents and the goal positions. With the reward setting, the distance reward for each agent is related to the other agents.
In this paper, there are two different scenarios with different number of agents for the group containment tasks. Specifically, these scenarios include scenario (a) with 6 agents and scenario (b) with 10 agents. MA-HCDP is compared with MADDPG and TRANSFER in these scenarios.
The simulation results of MA-HCDP and TRANSFER are presented in Table 3. MA-HCDP obtain 12 optimal measurements during four scenarios and outperforms than TRANSFER and MADDPG in terms of steps and rewards. In this kind of competitive scenario, where there is a high demand for communication effectiveness, CDN in MA-HCDP can filter out unrelated agents, and SCN can process the information of filtered agents with attention weights to promote cooperation.
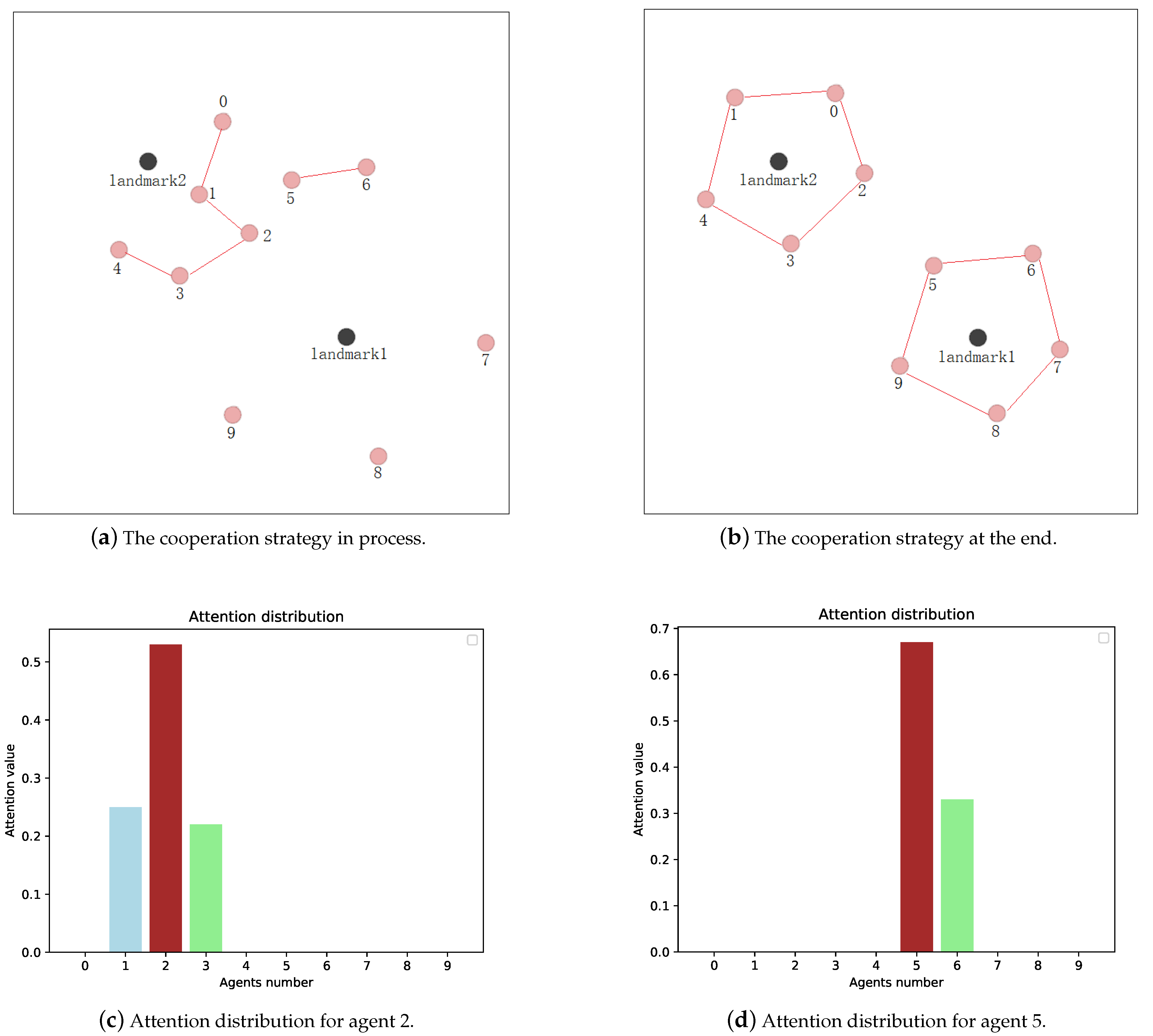
To further demonstrate the effectiveness of our method, we present the attention value distribution of agents in Figure 8. Take agent 2 and agent 5 in Figure 8a as an example. As shown in Figure 8, we can obtain the attention value distribution for agent 2 (Figure 8c) and agent 5 (Figure 8d). Note that agent 2 only communicates with agent 1 and agent 3, and agents 5 communicates with agent 6. The reason why agents 2 and 5 do not communicate is that agent 2 needs to go around landmark 1, while agent 5 needs to go around landmark 2. They have different perceptions of the environment and goals, so there is no need for communication. Based on the communication status, the attention coefficients are only assigned to those agents communicating with agent 2 and agent 5. Moreover, since different agents have different influences, they are assigned different attention coefficients. It demonstrates that MA-HCDP can filter out unrelated agents and process the information of different agents to promote cooperation.
6. Discussion
In addition to the analyses above, there are some phenomena worth analyzing. Note that MADDPG converges faster than TRANSFER but converges to a minimum value. As shown in Table 2, the success rate of MADDPG is zero. This phenomenon may be caused by the limitation of MADDPG. Although MADDPG can obtain the state of all the agents during training, too much information makes the agents fall into a locally optimal situation and unable to learn appropriate policy. As a comparison, TRANSFER converges slower but obtains higher rewards than MADDPG. Although TRANSFER considers the influence of communication among different agents, it ignores the influence of redundant communication, which makes agents trained with TRANSFER obtain higher rewards and converge slower than MADDPG. Therefore, although the agents trained by TRANSFER can learn appropriate policy, its performance and convergence speed are both worse than our MA-HCDP.
As shown in Figure 8, agent 2 and agent 5 are both within the communication range of each other, but due to inconsistent cognition of the environment, there is no communication between them. Although agent 2 can obtain information from agent 0 and agent 4 and be influenced by them, the attention value from agent 0 and agent 4 to agent 2 is zero because the information and influence are obtained indirectly. Specifically, the adjacent matrix for agent 2 is:
The state of agent 2 after stacked SCN layers are related to agent 0, agent 1, agent 3, and agent 4. Agent 2 communicates with agents outside the communication range indirectly through stacked SCN layers, rather than directly communicating with those agents. Therefore, the attention value from agent 0 and agent 4 to agent 2 is zero.
In addition to the above discussions, there are several limitations and possible validations for this study that may be addressed as future directions. HCN is responsible for dividing agents into different groups, but the grouping of the agents depends on prior knowledge. When the environment becomes too complex, it is a challenge to group the agents with prior knowledge. There is a certain difference between simulation environments and realistic environments. How to make methods that perform well in simulation environments also work well in realistic environment is a problem that we are working hard to study.
7. Conclusions
In this paper, we present a novel reinforcement learning method MA-HCDP for multiagent cooperation in environments with a large number of agents. Its key feature lays in a hierarchical group network (HGN), a cognition difference network (CDN), and a soft communication network (SCN). Specifically, HGN is responsible for dividing agents into different groups and extracting high-dimensional state representations of these groups. CDN is designed to extract the agents’ understanding of the environment with VAE and filtering out irrelevant agents with KL divergence. SCN is responsible for handling different cognition of different neighbor agents with the attention mechanism and enlarging the communication field. Simulation results indicate that MA-HCDP can handle influences of different groups of agents and redundant communication and perform a satisfying strategy and adapt to environments with many agents. Our method has a considerable increase in terms of rewards and convergence compared with MADDPG and TRANSFER. The proposed method can handle the redundant information well. As shown in Figure 8, if the agents’ information is redundant, there is no communicate between them, even if they are within the communication range of each other. Future work will take the adaptive grouping based on cognitive differences into consideration.
Author Contributions
Conceptualization, H.W.; methodology, H.W.; software, H.W.; validation, H.W.; formal analysis, H.W.; investigation, H.W.; resources, H.W.; data curation, H.W.; writing—original draft preparation, H.W.; writing—review and editing, H.W., Z.L., J.Y., and Z.P.; visualization, H.W.; supervision, Z.L.; project administration, Z.L.; funding acquisition, J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China under Grant 2018AAA0102402, in part by the external cooperation key project of the Chinese Academy of Sciences No. 173211KYSB20200002 and Innovation Academy for Light-duty Gas Turbine, Chinese Academy of Sciences, No.CXYJJ19-ZD-02 and No.CXYJJ20-QN-05.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MA-HCDP | Multiagent hierarchical cognition difference policy |
| HGN | Hierarchical group network |
| CDN | Cognition difference network |
| SCN | Soft communication network |
| VAE | Variational autoencoder |
| GNN | Graph neural networks |
| PPO | Proximal policy optimization |
| POMG | Partially observable Markov games |
| RL | Reinforcement learning |
References
- Yang, Y.; Hao, J.; Sun, M.; Wang, Z.; Fan, C.; Strbac, G. Recurrent Deep Multiagent Q-Learning for Autonomous Brokers in Smart Grid. IJCAI 2018, 18, 569–575. [Google Scholar]
- Li, X.; Zhang, J.; Bian, J.; Tong, Y.; Liu, T.Y. A Cooperative Multi-Agent Reinforcement Learning Framework for Resource Balancing in Complex Logistics Network. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. International Foundation for Autonomous Agents and Multiagent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 980–988. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Ye, D.; Chen, G.; Zhao, P.; Qiu, F.; Yuan, B.; Zhang, W.; Chen, S.; Sun, M.; Li, X.; Li, S.; et al. Supervised Learning Achieves Human-Level Performance in MOBA Games: A Case Study of Honor of Kings. IEEE Trans. Neural Netw. Learn. Syst. 2020, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates. arXiv 2016, arXiv:cs.RO/1610.00633. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, O.P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Foerster, J.N.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yang, Y.; Luo, R.; Li, M.; Zhou, M.; Zhang, W.; Wang, J. Mean Field Multi-Agent Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5567–5576. [Google Scholar]
- Ryu, H.; Shin, H.; Park, J. Multi-agent actor-critic with hierarchical graph attention network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7236–7243. [Google Scholar]
- Wu, S.; Pu, Z.; Yi, J.; Wang, H. Multi-agent Cooperation and Competition with Two-Level Attention Network. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2020; pp. 524–535. [Google Scholar]
- Sukhbaatar, S.; Szlam, A.; Fergus, R. Learning multiagent communication with backpropagation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2244–2252. [Google Scholar]
- Agarwal, A.; Kumar, S.; Sycara, K.; Lewis, M. Learning Transferable Cooperative Behavior in Multi-Agent Teams. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, Auckland, New Zealand, 9–13 May 2020; pp. 1741–1743. [Google Scholar]
- Jiang, J.; Lu, Z. Learning attentional communication for multi-agent cooperation. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 7254–7264. [Google Scholar]
- Iqbal, S.; Sha, F. Actor-Attention-Critic for Multi-Agent Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 2961–2970. [Google Scholar]
- Das, A.; Gervet, T.; Romoff, J.; Batra, D.; Parikh, D.; Rabbat, M.; Pineau, J. TarMAC: Targeted Multi-Agent Communication. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 1538–1546. [Google Scholar]
- Peng, P.; Wen, Y.; Yang, Y.; Yuan, Q.; Tang, Z.; Long, H.; Wang, J. Multiagent bidirectionally-coordinated nets: Emergence of human-level coordination in learning to play starcraft combat games. arXiv 2017, arXiv:1703.10069. [Google Scholar]
- Kong, X.; Xin, B.; Liu, F.; Wang, Y. Revisiting the Master-Slave Architecture in Multi-Agent Deep Reinforcement Learning. arXiv 2017, arXiv:cs.AI/1712.07305. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:stat.ML/1312.6114. [Google Scholar]
- Kullback, S. Information Theory and Statistics; Courier Corporation: Chelmsford, MA, USA, 1997. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 157–163. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Liu, Y.; Wang, W.; Hu, Y.; Hao, J.; Chen, X.; Gao, Y. Multi-agent game abstraction via graph attention neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7211–7218. [Google Scholar]
- Malysheva, A.; Kudenko, D.; Shpilman, A. MAGNet: Multi-agent Graph Network for Deep Multi-agent Reinforcement Learning. In Proceedings of the 2019 XVI International Symposium “Problems of Redundancy in Information and Control Systems” (REDUNDANCY), Moscow, Russia, 21–25 October 2019; pp. 171–176. [Google Scholar] [CrossRef]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Jang, E.; Gu, S.; Poole, B. Categorical Reparameterization with Gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
Figure 1.
Architecture of MA-HCDP. Suppose there are nine entities around agent i. HGN divides the entities into different groups and adopts attention mechanism to extract high-dimensional state representations. Then, CDN is responsible for filtering irrelevant agents to reduce redundant information. Next, the remaining agents are modeled as a graph G. SCN is responsible for the weight distribution of the remaining agents. Finally, the captured states of different groups are subsequently used to update critic and actor networks.
Figure 1.
Architecture of MA-HCDP. Suppose there are nine entities around agent i. HGN divides the entities into different groups and adopts attention mechanism to extract high-dimensional state representations. Then, CDN is responsible for filtering irrelevant agents to reduce redundant information. Next, the remaining agents are modeled as a graph G. SCN is responsible for the weight distribution of the remaining agents. Finally, the captured states of different groups are subsequently used to update critic and actor networks.

Figure 2.
Architecture of one group attention. Suppose there are three agents around agent i in a group. State representations of agents in group h for agent i are aggregated according to attention coefficients .
Figure 2.
Architecture of one group attention. Suppose there are three agents around agent i in a group. State representations of agents in group h for agent i are aggregated according to attention coefficients .

Figure 3.
Architecture of variational autoencode. The agent understanding for the environment is obtained via variational autoencoder (VAE). L2-loss is the reconstruction loss function and KL-Loss is the loss function for VAE training.
Figure 3.
Architecture of variational autoencode. The agent understanding for the environment is obtained via variational autoencoder (VAE). L2-loss is the reconstruction loss function and KL-Loss is the loss function for VAE training.

Figure 4.
Architecture of attention. Different states of neighbors of agent i () are concentrated with agent i; then, the attention coefficient is calculated. The normalized form of is , and it is used as the weight of state concentration.
Figure 4.
Architecture of attention. Different states of neighbors of agent i () are concentrated with agent i; then, the attention coefficient is calculated. The normalized form of is , and it is used as the weight of state concentration.

Figure 5.
Enlarging respective fields. With stacked layers, agent 4 first obtains the information of agents 3 and agent 5, then obtains the information of agents 1 and 6, and finally obtains the information of agent 2.
Figure 5.
Enlarging respective fields. With stacked layers, agent 4 first obtains the information of agents 3 and agent 5, then obtains the information of agents 1 and 6, and finally obtains the information of agent 2.

Figure 6.
The illustration of simulation tasks.

Figure 7.
Simulation result in cooperative navigation with six agents.

Figure 8.
Attention distribution.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameters of training.
| Parameters | Value |
|---|---|
| Learning rate | |
| Max gradient normalization | 2 |
| Discount factor | 0.99 |
| Coefficient of value loss function | 0.5 |
| Coefficient of policy loss function | 1 |
| Coefficient of entropy | 0.01 |
| Coefficient of VAE loss function | 0.01 |
| Episode | 20,000 |
| Batch size | 64 |
| PPO epoch | 4 |
| Number of attention heads in HGN | 3 |
Table 2.
Evaluation results of cooperative navigation.
| Method | Scenario (a) with 6 Agents | Scenario (b) with 15 Agents | |||||
|---|---|---|---|---|---|---|---|
| Success Rate | Steps | Rewards | Success Rate | Steps | Rewards | ||
| MADDPG | mean | 0 | 50 | −1.34 | 0 | 50 | −2.2 |
| t-test | N/A(+) | −557.9873(+) | 94.2665(+) | N/A(+) | −522.7875(+) | 181.5395(+) | |
| TRANSFER | mean | 100 | 14.2 | −0.52 | 97 | 17.18 | −0.61 |
| t-test | N/A(=) | −1.2035(=) | 1.2131(=) | 1.0801(=) | −5.7893(+) | 6.3189(+) | |
| MA-HCDP | mean | 100 | 14.01 | −0.49 | 99 | 14.82 | −0.53 |
| t-test | N/A | N/A | N/A | N/A | N/A | N/A | |
| Method | Scenario (c) with 20 agents | Scenario (d) with 29 agents | |||||
| Success rate | Steps | Rewards | Success rate | Steps | Rewards | ||
| MADDPG | mean | 0 | 50 | −3.48 | 0 | 50 | −3.91 |
| t-test | N/A(+) | −472.6488(+) | 322.5309(+) | N/A(+) | −413.4042(+) | 373.1337(+) | |
| TRANSFER | mean | 98 | 20.11 | −0.72 | 96 | 25.2 | −0.86 |
| t-test | 0.9201(=) | −21.1968(+) | 9.2276(+) | 1.1241(=) | −38.0417(+) | 42.0352(+) | |
| MA-HCDP | mean | 99 | 17.05 | −0.64 | 98 | 20.06 | −0.69 |
| t-test | N/A | N/A | N/A | N/A | N/A | N/A | |
Table 3.
Evaluation results of group containment.
| Method | Scenario (a) with 6 Agents | Scenario (b) with 10 Agents | |||||
|---|---|---|---|---|---|---|---|
| Success Rate | Steps | Rewards | Success Rate | Steps | Rewards | ||
| MADDPG | mean | 0 | 80 | −1.68 | 0 | 80 | −4.12 |
| t-test | N/A (+) | −583.7586 (+) | 252.3061 (+) | N/A (+) | −662.4380 (+) | 749.1802 (+) | |
| TRANSFER | mean | 93 | 16.3 | −0.66 | 91 | 14.28 | −0.82 |
| t-test | 87.3064 (+) | −38.9224 (+) | 32.3495 (+) | 103.8512 (+) | −33.4683 (+) | 36.2515 (+) | |
| MA-HCDP | mean | 100 | 14.2 | −0.56 | 100 | 12.9 | −0.68 |
| t-test | N/A | N/A | N/A | N/A | N/A | N/A | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, H.; Liu, Z.; Yi, J.; Pu, Z. Multiagent Hierarchical Cognition Difference Policy for Multiagent Cooperation. Algorithms 2021, 14, 98. https://0-doi-org.brum.beds.ac.uk/10.3390/a14030098
AMA Style
Wang H, Liu Z, Yi J, Pu Z. Multiagent Hierarchical Cognition Difference Policy for Multiagent Cooperation. Algorithms. 2021; 14(3):98. https://0-doi-org.brum.beds.ac.uk/10.3390/a14030098
Chicago/Turabian StyleWang, Huimu, Zhen Liu, Jianqiang Yi, and Zhiqiang Pu. 2021. "Multiagent Hierarchical Cognition Difference Policy for Multiagent Cooperation" Algorithms 14, no. 3: 98. https://0-doi-org.brum.beds.ac.uk/10.3390/a14030098
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.