
Accelerating In-Transit Co-Processing for Scientific Simulations Using Region-Based Data-Driven Analysis


Abstract
:1. Introduction
- An efficient method to determine the block importance of large-scale simulations. Calculating the importance of various regions of data was a time-consuming task in many related works. As such, only a few importance metrics tend to be used. The main goal of our proposed method is to provide researchers with a customizable and easy-to-use way to efficiently determine the importance of subsets of large-scale simulation data, even when using multiple complex analyses to determine such importance. To reach this goal, we have developed a scheme that uses a separate buffer to transform the data to a more suitable structure for analysis and strives to schedule importance analyses in a fashion that improves the cache hit rates. We also introduce the usage of an adaptive condition window; a custom range within which multiple condition parameters can vary. Using a condition window allows parameters to change based on the current constraints of the environment. For example, if a data transfer is too time-consuming, the parameters can be adapted to compress or remove more data in the coming time step.
- A flexible approach to accelerate in-transit co-processing. We observe that the effectiveness of a certain compression algorithm often depends on the underlying compressed data. By identifying the importance and the most suitable compression for each region of generated simulation data, we strive to minimize the data size and the in-transit data transfer time by combining the use of multiple compression methods integrated into a pipeline. The approach explored in this paper puts no additional restraints on the contents of the co-processing stage. It can be used in tandem with various visualization software, e.g., Paraview [18], VisIt [19], or OSPRay [20].
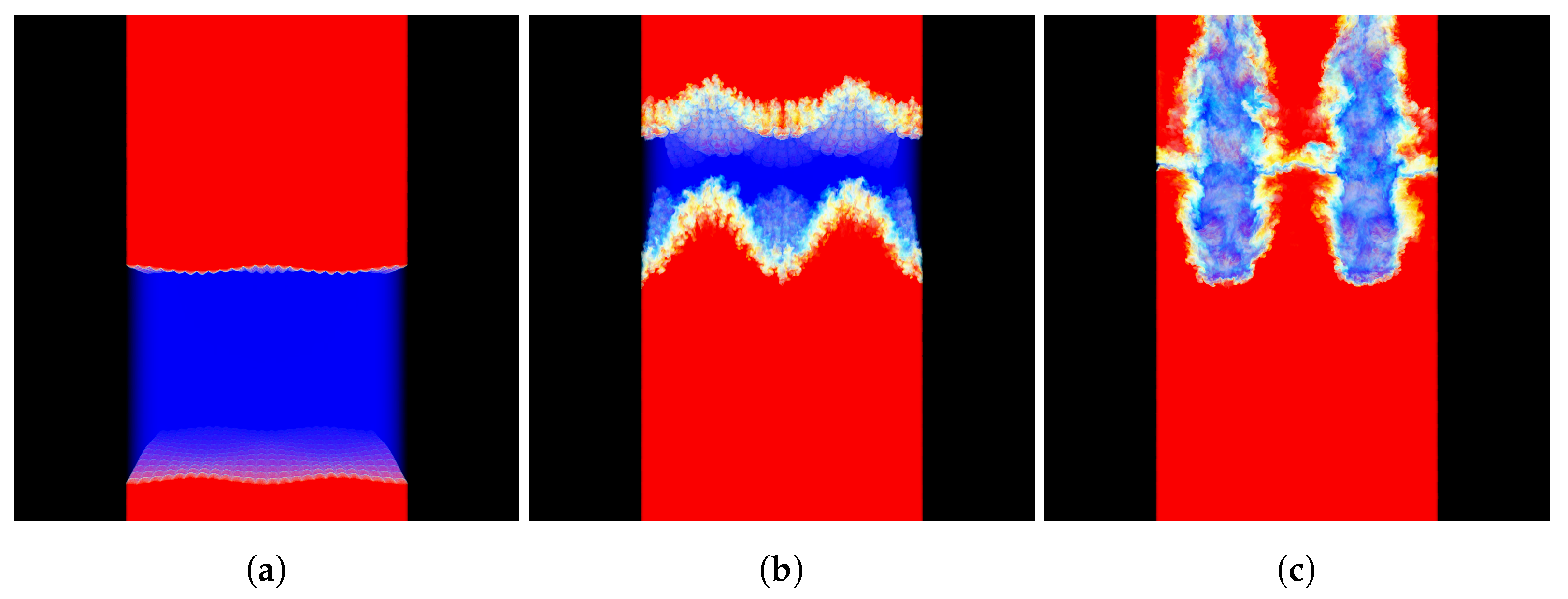
- A case study of how the in-transit co-processing of a Richtmyer–Meshkov instability (RMI) simulation can be accelerated using the proposed approach. The RMI simulation is performed using CNS3D, a state-of-the-art program for numerical fluid simulations.
2. Related Work
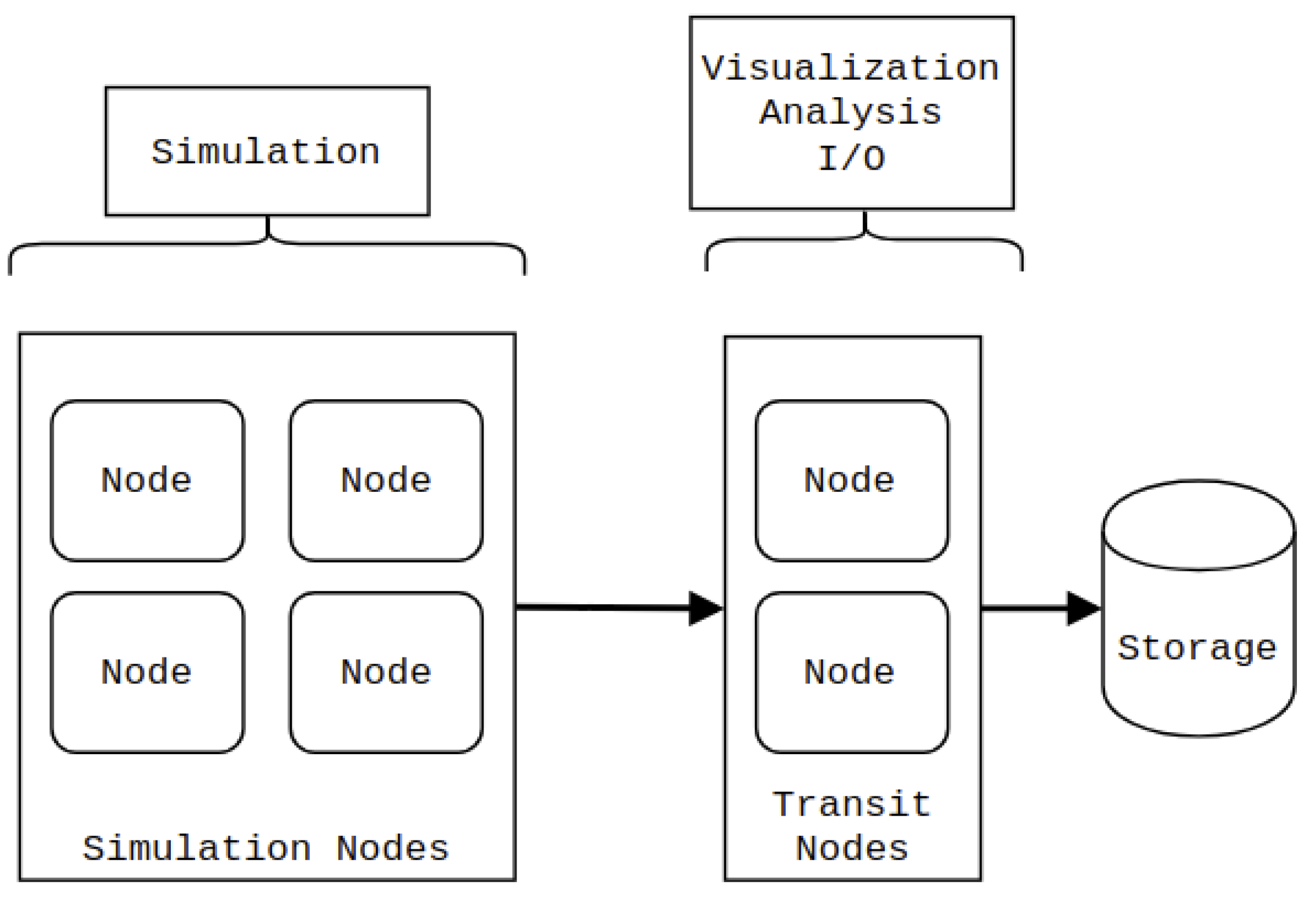
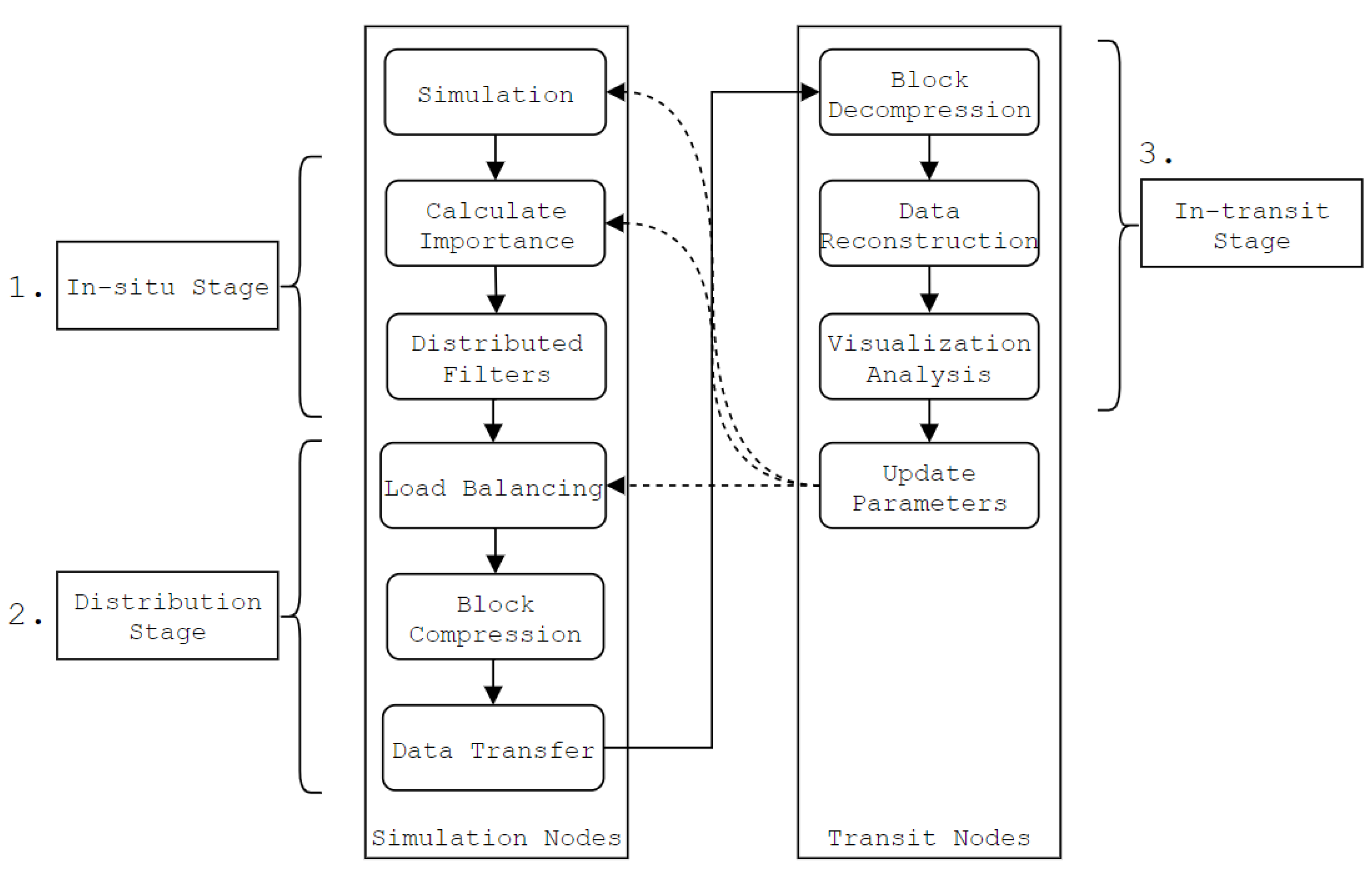
3. Adaptive In-Transit Co-Processing
- The in-situ stage (Section 3.1, Section 3.2, Section 3.3, Section 3.4), which consists of the proposed method. The block importance is calculated, and which compression method to use is determined on a per-block basis.
- The distribution stage (Section 3.5), where data is compressed, load balanced and transferred over the network to the transit nodes.
- The in-transit stage (Section 3.6), where compressed data is decompressed and restructured on the transit nodes.
3.1. Calculating Importance
| Algorithm 1 Scheme used to calculate the importance of all blocks. The importance is used to determine the action of each block. |
|
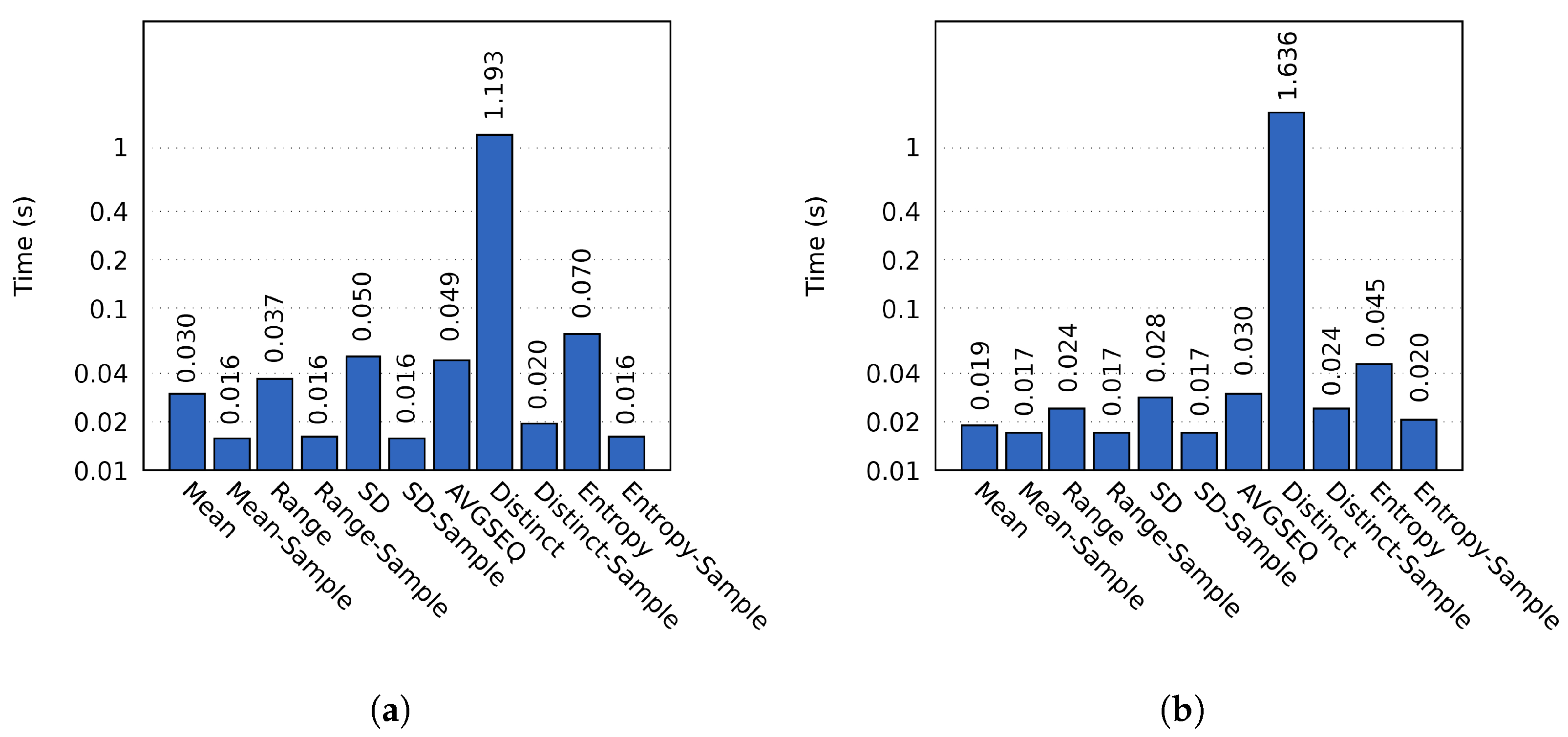
- Mean. Calculates the mean of all values in a block.
- Range. Calculates the range of the values in a block.
- SD. Calculates the standard deviation of the values in a block.
- AVGSEQ. Calculates the average sequence length of identical values in a block. This probe is only used on non-sampled data, as sampled data would not retain enough information about the average sequence length.
- Distinct. Calculates the number of distinct values compared to the total number of values in a block.
- Entropy. Calculates the entropy of a block [10].
3.2. Block Actions
- No Action (NONE). No reduction or compression is performed. Blocks have this action set by default. This action is mainly useful for blocks where the time overhead introduced by compression outweighs the speedup of data transfers.
- Skip. Blocks with this action are never allocated or sent to the transit nodes. This action is useful if, for example, a region of the simulated grid is not of interest. Using the Skip action can, as such, substantially reduce the data transfer and co-processing times in some scenarios.
- Run-Length Encoding (RLE). Blocks with the RLE action are compressed using RLE. Both the compression and decompression of data can be completed in one pass.
- LZ77. Block with this action are compressed using the LZ77 compression algorithm [32]. Compared to the RLE compression method, LZ77 can be used to more effectively compress repeating sequences of data. This means that its usefulness differs depending on the simulation as well as on each individual block.
- Homogeneous (HOMO). Blocks that are Homogeneous are allocated as a single value. Similarly to the Skip action, it can dramatically reduce the data transfer time. This action is useful for empty or homogeneous space, and can also be used to reduce regions that are not of interest. The main benefit that the Homogeneous action has over other types of compression and reduction algorithms is the compression time, which has a time complexity of .
3.3. Adaptive Condition Window
3.4. Advantages of the Pipeline Structure
- Ease of use. Using the structure of the proposed pipeline, each component (e.g., a filter or probe) is categorized and serves a clear purpose. In practice, it is easy to construct and understand the structure of the proposed pipeline. In contrast, some structures (e.g., decision trees) would not be intuitive without a visual interface.
- Gradual refinement. A new action can be assigned to a block after each filter has been applied. As filters are applied in sequence, this behavior enables a gradual refinement of the importance analysis. More advanced or time-consuming analyses can be limited to the relevant subsets of the simulation data. Although this behavior can be mirrored by other structures (e.g., a DAG or tree structure), it would be more complicated to create.
- Reusability. It is easy to reuse parts of a pipeline (e.g., filters or probes) in other applications as all parts of the pipeline are compartmentalized.
3.5. Data Distribution
3.6. In-Transit Co-Processing
4. Experimental Evaluation
4.1. Experiment Description
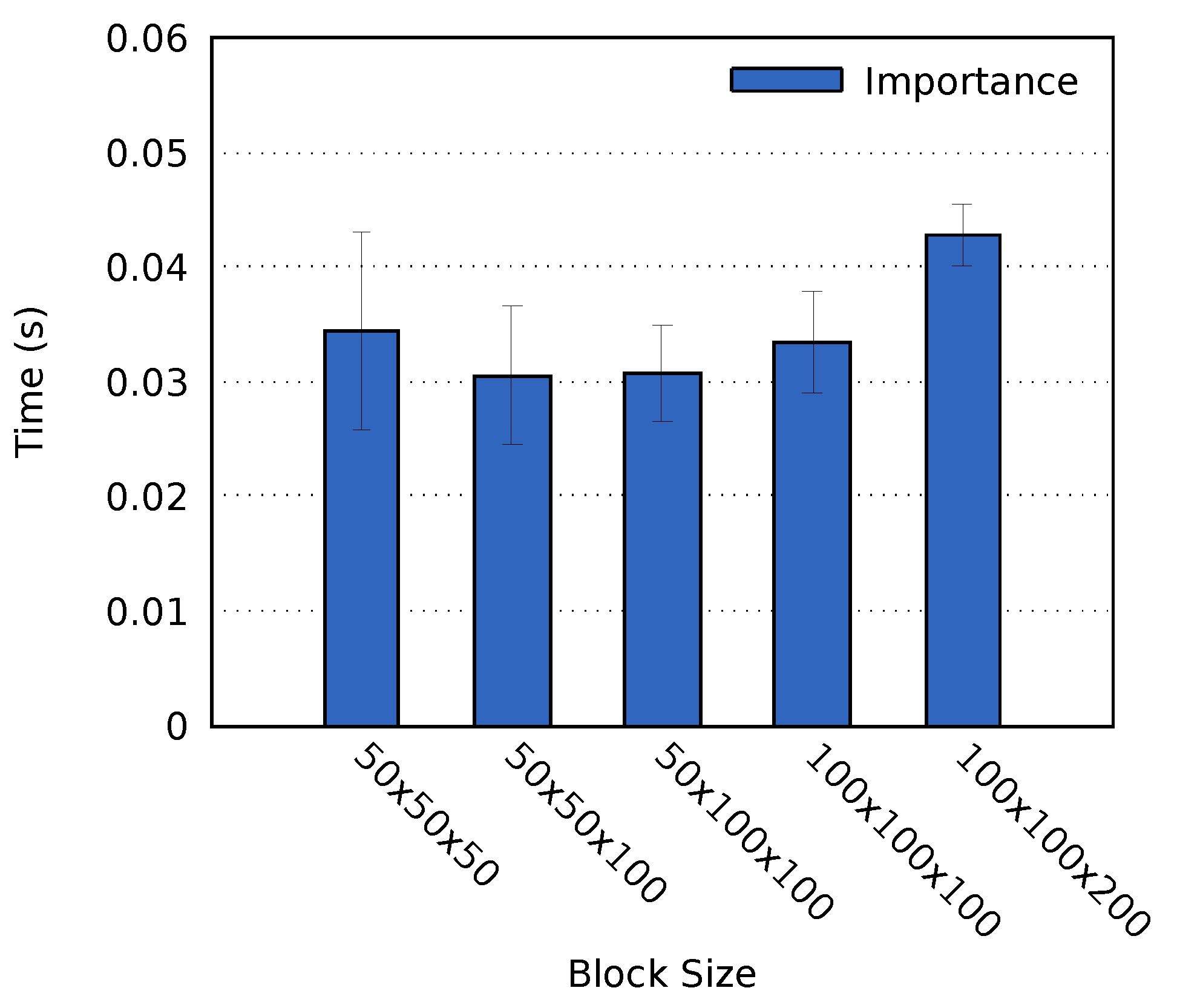
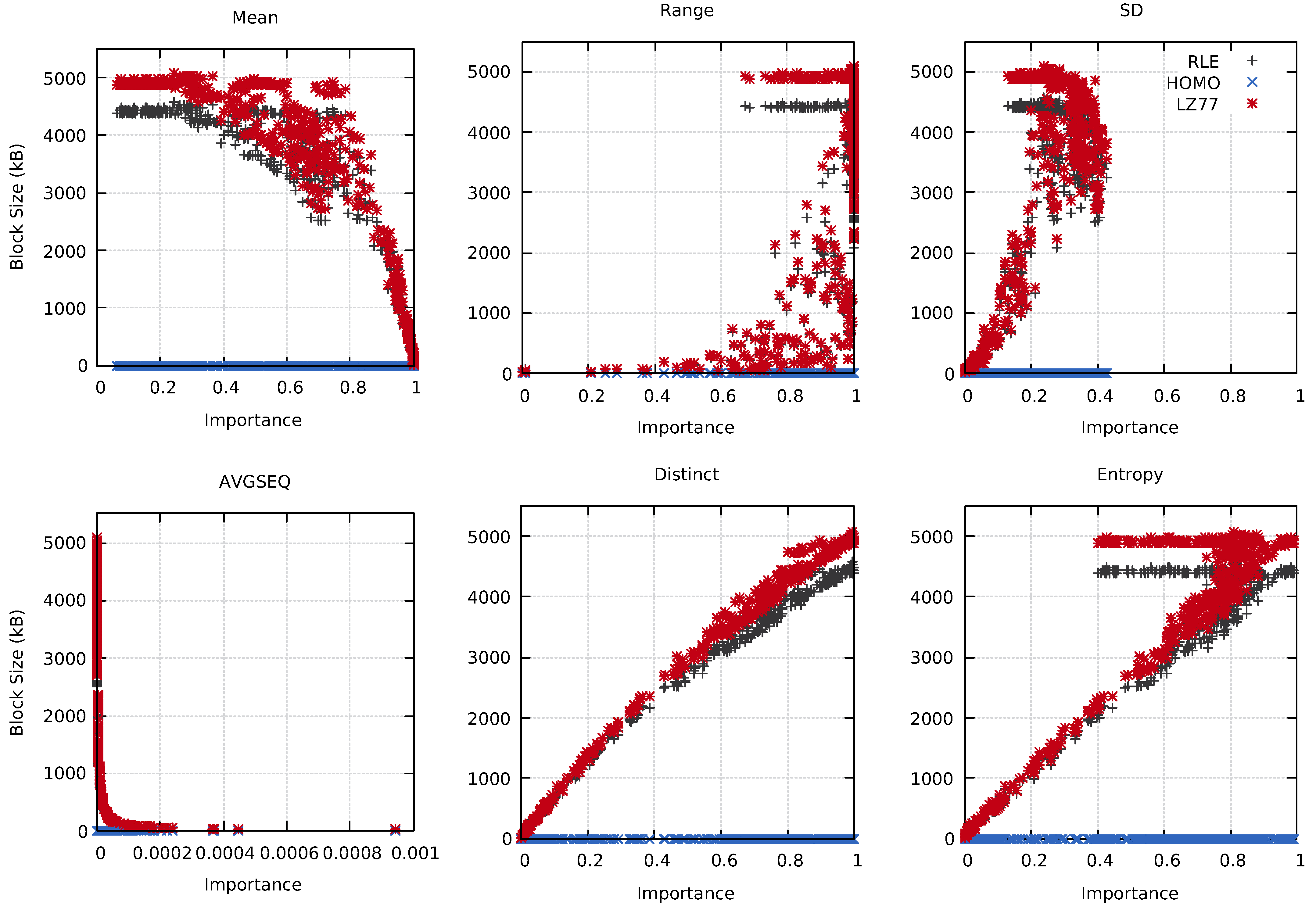
4.2. Block Size
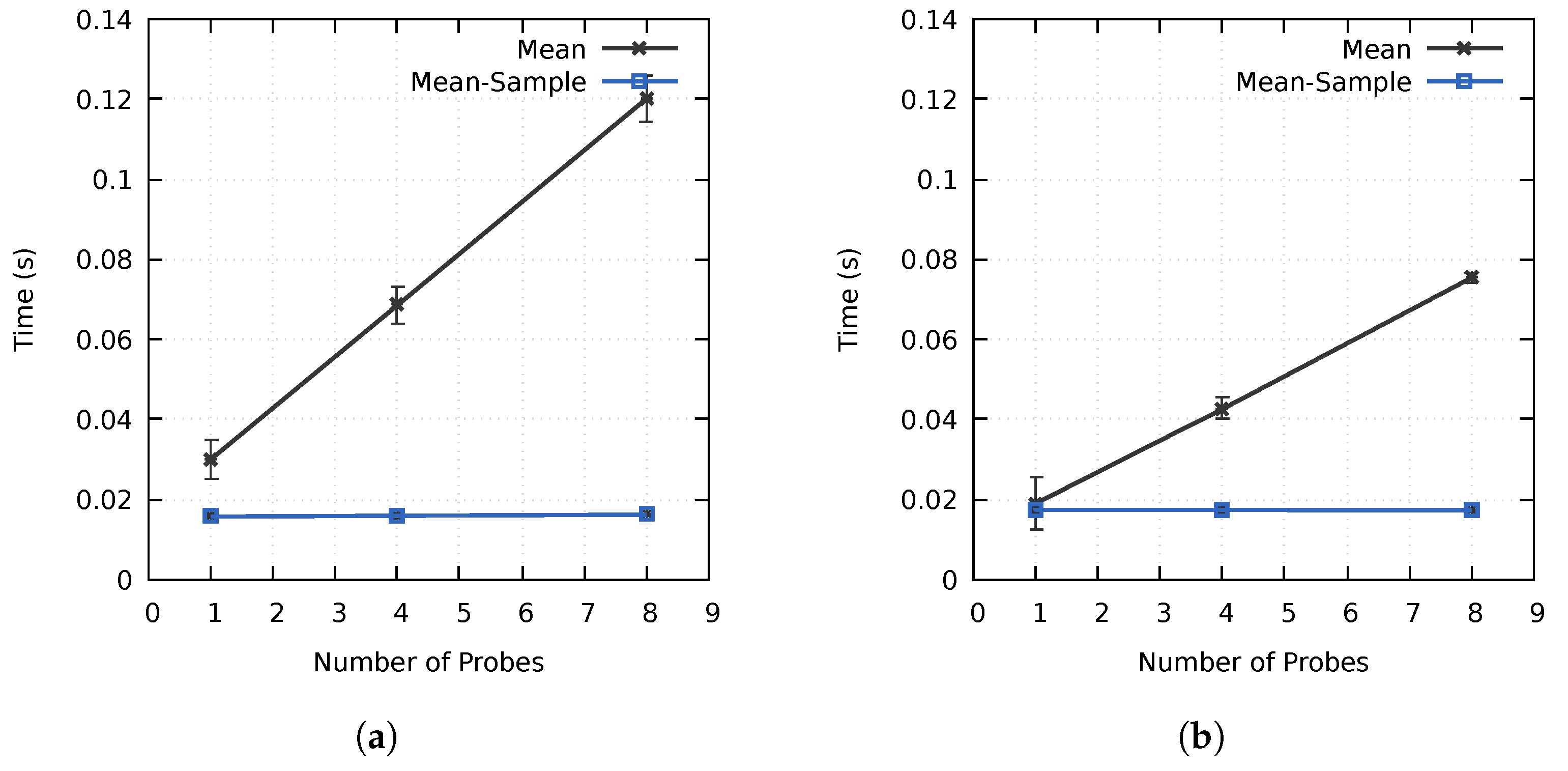
4.3. Performance of the Proposed Method
4.4. Evaluating the Proposed Approach
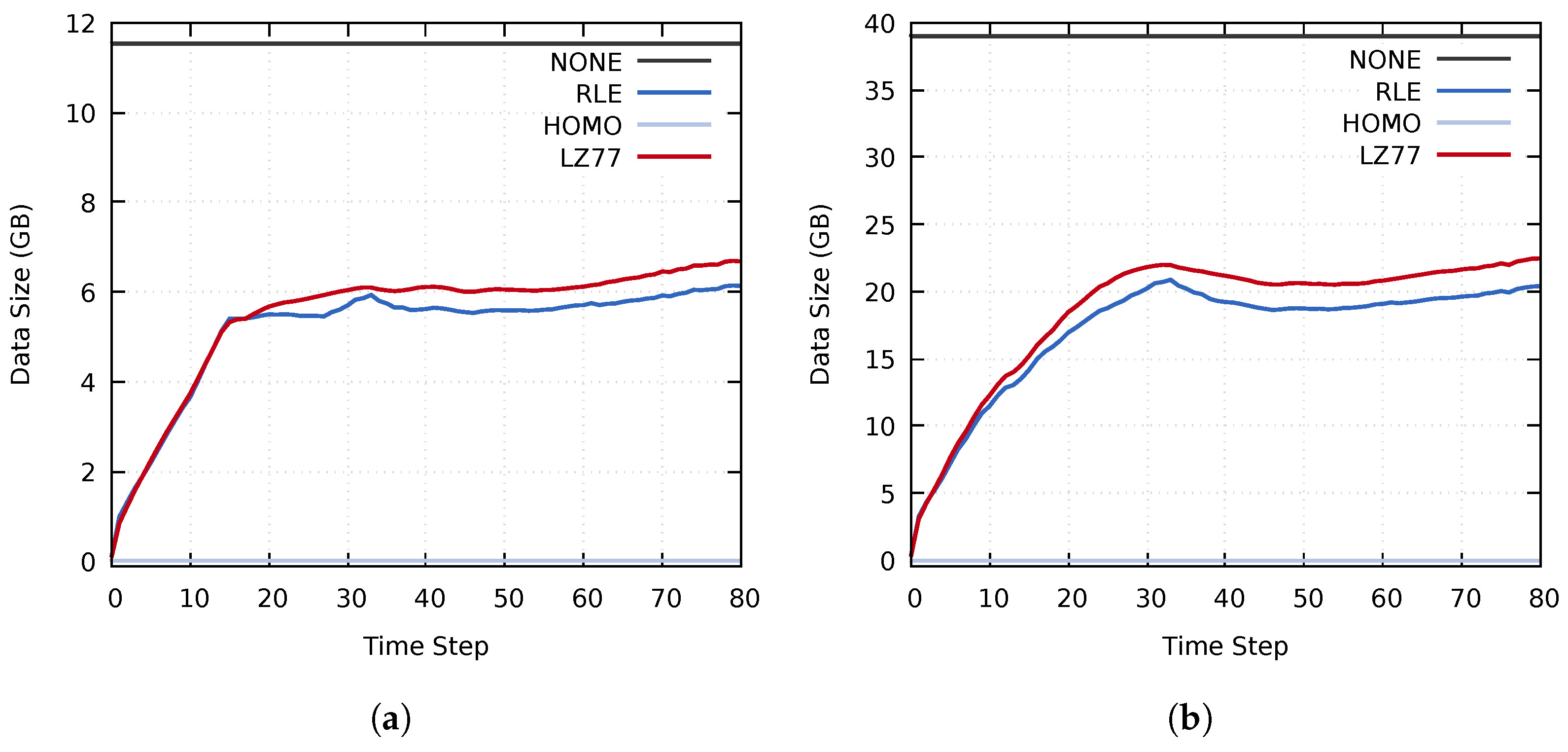
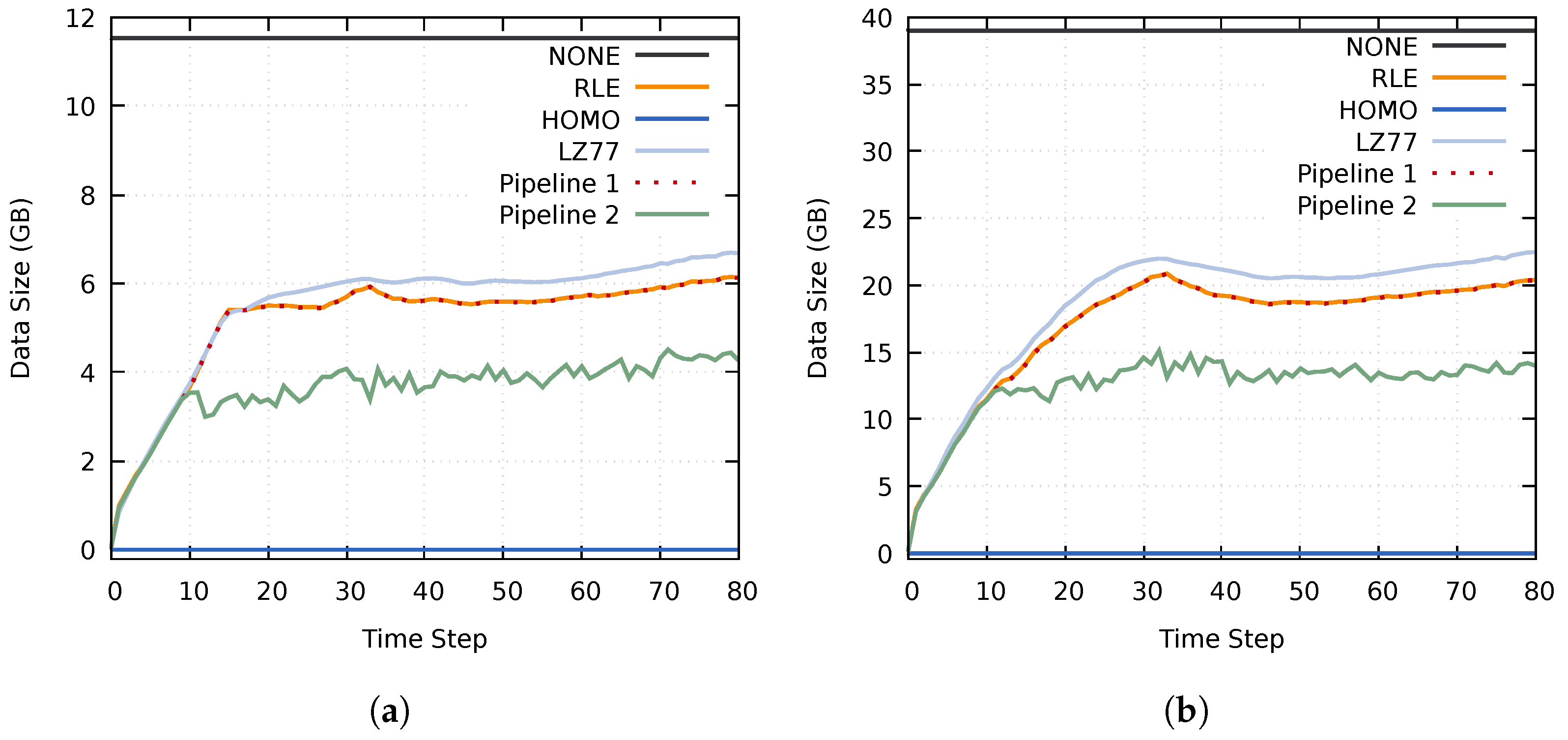
4.4.1. Compression Performance
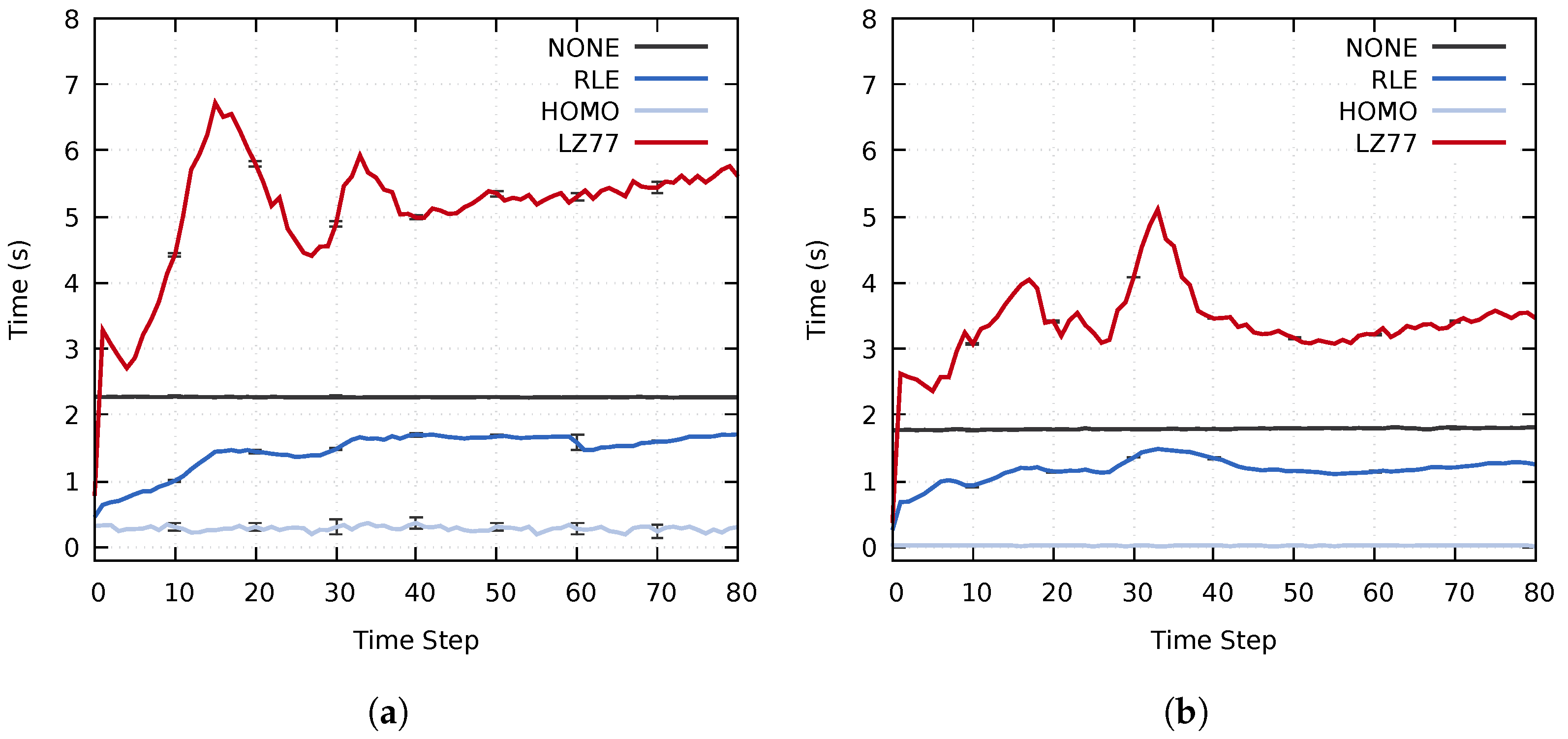
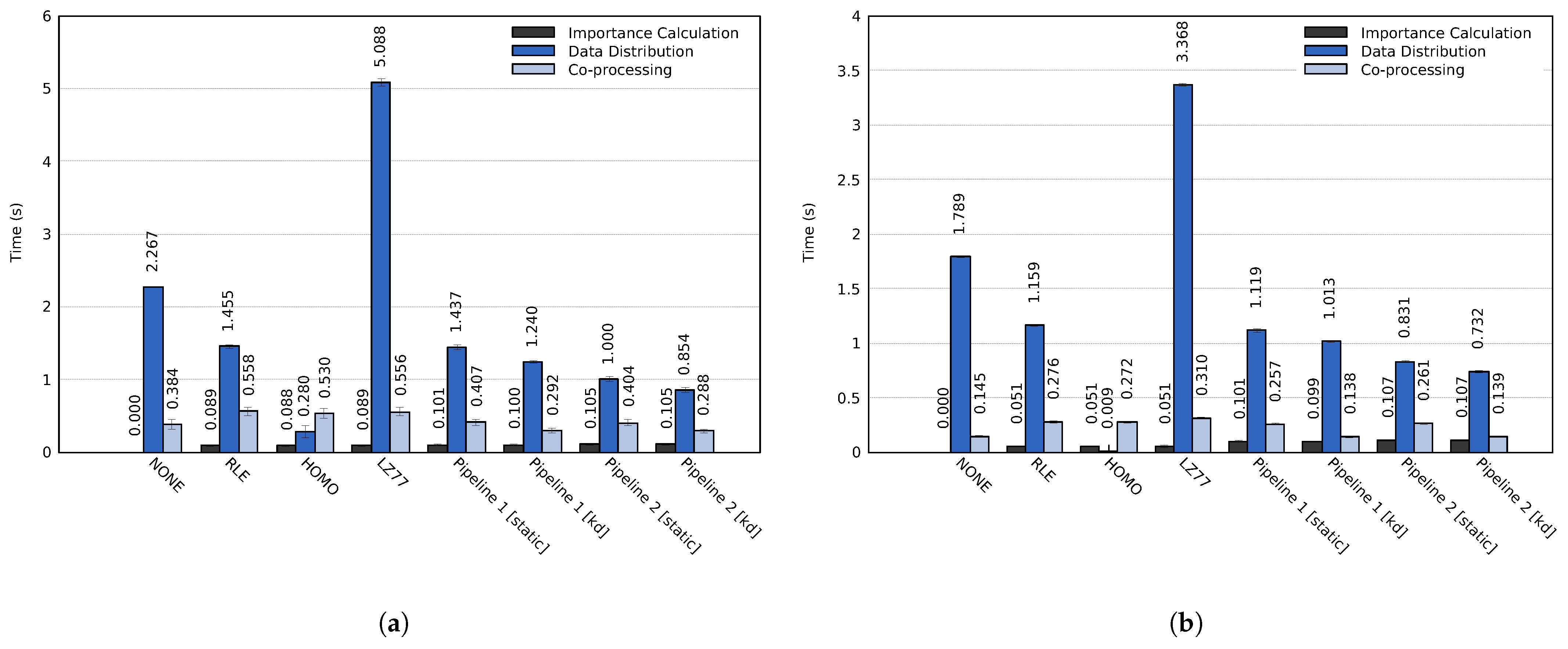
4.4.2. Assessing the Execution Times of the Proposed Approach
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moreland, K. The Tensions of In Situ Visualization. IEEE Comput. Graph. Appl. 2016, 36, 5–9. [Google Scholar] [CrossRef]
- Ma, K. In Situ Visualization at Extreme Scale: Challenges and Opportunities. IEEE Comput. Graph. Appl. 2009, 29, 14–19. [Google Scholar]
- Rivi, M.; Calori, L.; Muscianisi, G.; Slavnić, V. In-situ Visualization: State-of-the-Art and Some Use Cases. 2012. Available online: https://www.hpc.cineca.it/sites/default/files/In-situ_Visualization_State-of-the-art_and_Some_Use_Cases.pdf (accessed on 10 April 2021).
- Yu, H.; Wang, C.; Grout, R.W.; Chen, J.H.; Ma, K. In Situ Visualization for Large-Scale Combustion Simulations. IEEE Comput. Graph. Appl. 2010, 30, 45–57. [Google Scholar]
- Bennett, J.C.; Abbasi, H.; Bremer, P.; Grout, R.; Gyulassy, A.; Jin, T.; Klasky, S.; Kolla, H.; Parashar, M.; Pascucci, V.; et al. Combining in-situ and in-transit processing to enable extreme-scale scientific analysis. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC’12), Salt Lake City, UT, USA, 24–29 June 2012; pp. 1–9. [Google Scholar]
- Friesen, B.; Almgren, A.; Lukic, Z.; Weber, G.; Morozov, D.; Beckner, V.; Day, M. In situ and in-transit analysis of cosmological simulations. Comput. Astrophys. Cosmol. 2016, 3, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Flatken, M.; Wagner, C.; Gerndt, A. Distributed Post-processing and Rendering for Large-Scale Scientific Simulations. In Scientific Visualization: Uncertainty, Multifield, Biomedical, and Scalable Visualization; Springer: London, UK, 2014; pp. 381–398. [Google Scholar]
- Moreland, K.; Oldfield, R.; Marion, P.; Jourdain, S.; Podhorszki, N.; Vishwanath, V.; Fabian, N.; Docan, C.; Parashar, M.; Hereld, M.; et al. Examples of in Transit Visualization. In Proceedings of the 2nd International Workshop on Petascal Data Analytics: Challenges and Opportunities (PDAC’11), Seattle, WA, USA, 14 November 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1–6. [Google Scholar]
- Kress, J. In-Line vs. In-Transit In Situ: Which Technique to Use at Scale? Ph.D. Thesis, University of Oregon, Eugene, OR, USA, 2020. [Google Scholar]
- Dorier, M.; Sisneros, R.; Gomez, L.B.; Peterka, T.; Orf, L.; Rahmani, L.; Antoniu, G.; Bougé, L. Adaptive Performance-Constrained In Situ Visualization of Atmospheric Simulations. In Proceedings of the 2016 IEEE International Conference on Cluster Computing (CLUSTER), Taipei, Taiwan, 12–16 September 2016; pp. 269–278. [Google Scholar]
- Wang, C.; Yu, H.; Ma, K. Importance-Driven Time-Varying Data Visualization. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1547–1554. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nouanesengsy, B.; Woodring, J.; Patchett, J.; Myers, K.; Ahrens, J. ADR Visualization: A Generalized Framework for Ranking Large-Scale Scientific Data Using Analysis-Driven Refinement. In Proceedings of the 2014 IEEE 4th Symposium on Large Data Analysis and Visualization (LDAV), Paris, France, 9–10 November 2014; pp. 43–50. [Google Scholar]
- Berger, M.J.; Oliger, J. Adaptive mesh refinement for hyperbolic partial differential equations. J. Comput. Phys. 1984, 53, 484–512. [Google Scholar] [CrossRef]
- Schive, H.; ZuHone, J.A.; Goldbaum, N.J.; Turk, M.J.; Gaspari, M.; Cheng, C. gamer-2: A GPU-accelerated adaptive mesh refinement code—Accuracy, performance, and scalability. Mon. Not. R. Astron. Soc. 2018, 481, 4815–4840. [Google Scholar] [CrossRef] [Green Version]
- Shimokawabe, T.; Onodera, N. A High-Productivity Framework for Adaptive Mesh Refinement on Multiple GPUs. In Proceedings of the International Conference on Computational Science (ICCS 2019), Faro, Portugal, 12–14 June 2019; pp. 281–294. [Google Scholar]
- Biswas, A.; Dutta, S.; Pulido, J.; Ahrens, J. In Situ Data-Driven Adaptive Sampling for Large-Scale Simulation Data Summarization. In Proceedings of the Workshop on In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization (ISAV’18), Dallas, TX, USA, 12 November 2018; pp. 13–18. [Google Scholar]
- Dutta, S.; Biswas, A.; Ahrens, J. Multivariate Pointwise Information-Driven Data Sampling and Visualization. Entropy 2019, 21, 699. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fabian, N.; Moreland, K.; Thompson, D.; Bauer, A.C.; Marion, P.; Gevecik, B.; Rasquin, M.; Jansen, K.E. The ParaView Coprocessing Library: A scalable, general purpose in situ visualization library. In Proceedings of the 2011 IEEE Symposium on Large Data Analysis and Visualization, Providence, RI, USA, 23–24 October 2011; pp. 89–96. [Google Scholar]
- Childs, H.; Brugger, E.; Whitlock, B.; Meredith, J.; Ahern, S.; Bonnell, K.; Miller, M.; Weber, G.H.; Harrison, C.; Fogal, T.; et al. VisIt: An End-User Tool for Visualizing and Analyzing Very Large Data. In Proceedings of the SciDAC, Denver, CO, USA, 10–14 July 2011. [Google Scholar]
- Wald, I.; Johnson, G.; Amstutz, J.; Brownlee, C.; Knoll, A.; Günther, J.J.J.; Navratil, P. OSPRay—A CPU Ray Tracing Framework for Scientific Visualization. IEEE Trans. Vis. Comput. Graph. 2017, 23, 931–940. [Google Scholar] [CrossRef]
- Meagher, D. Geometric modeling using octree encoding. Comput. Graph. Image Process. 1982, 19, 129–147. [Google Scholar] [CrossRef]
- Kageyama, A.; Yamada, T. An approach to exascale visualization: Interactive viewing of in-situ visualization. Comput. Phys. Commun. 2014, 185, 79–85. [Google Scholar] [CrossRef] [Green Version]
- Ahrens, J.; Jourdain, S.; O’Leary, P.; Patchett, J.; Rogers, D.H.; Petersen, M. An Image-based Approach to Extreme Scale in Situ Visualization and Analysis. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’14), New Orleans, LA, USA, 16–21 November 2014; pp. 424–434. [Google Scholar]
- Woodring, J.; Ahrens, J.; Figg, J.; Wendelberger, J.; Habib, S.; Heitmann, K. In-situ Sampling of a Large-Scale Particle Simulation for Interactive Visualization and Analysis. In Proceedings of the Eurographics/IEEE-VGTC Symposium on Visualization (EuroVis 2011), Bergen, Norway, 31 May–3 June 2011; pp. 1151–1160. [Google Scholar]
- Landge, A.G.; Pascucci, V.; Gyulassy, A.; Bennett, J.C.; Kolla, H.; Chen, J.; Bremer, P. In-Situ Feature Extraction of Large Scale Combustion Simulations Using Segmented Merge Trees. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’14), New Orleans, LA, USA, 16–21 November 2014; pp. 1020–1031. [Google Scholar]
- Bremer, P.; Weber, G.; Tierny, J.; Pascucci, V.; Day, M.; Bell, J. Interactive Exploration and Analysis of Large-Scale Simulations Using Topology-Based Data Segmentation. IEEE Trans. Vis. Comput. Graph. 2011, 17, 1307–1324. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, H.; Zheng, F.; Wolf, M.; Eisenhauer, G.; Schwan, K.; Abbasi, H.; Liu, Q.; Podhorszki, N.; Klasky, S. Quality-Aware Data Management for Large Scale Scientific Applications. In Proceedings of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 816–820. [Google Scholar]
- Jin, T.; Zhang, F.; Sun, Q.; Bui, H.; Parashar, M.; Yu, H.; Klasky, S.; Podhorszki, N.; Abbasi, H. Using Cross-layer Adaptations for Dynamic Data Management in Large Scale Coupled Scientific Workflows. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC’13), Denver, CO, USA, 17–22 November 2013; pp. 74:1–74:12. [Google Scholar]
- Gu, J.; Loring, B.; Wu, K.; Bethel, E.W. HDF5 as a Vehicle for in Transit Data Movement. In Proceedings of the Workshop on In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization (ISAV’19), Denver, CO, USA, 18 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 39–43. [Google Scholar]
- Lindstrom, P. Fixed-Rate Compressed Floating-Point Arrays. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2674–2683. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Di, S.; Tao, D.; Li, S.; Li, S.; Guo, H.; Chen, Z.; Cappello, F. Error-Controlled Lossy Compression Optimized for High Compression Ratios of Scientific Datasets. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 438–447. [Google Scholar]
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef] [Green Version]
- Di, S.; Cappello, F. Fast Error-Bounded Lossy HPC Data Compression with SZ. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Chicago, IL, USA, 23–27 May 2016; pp. 730–739. [Google Scholar]
- Wang, G.; Xu, J.; He, B. A Novel Method for Tuning Configuration Parameters for Spark Based on Machine Learning. In Proceedings of the 18th International Conference on High Performance Computing and Communications (HPCC’16), Sydney, NSW, Australia, 12–14 December 2016; pp. 586–593. [Google Scholar]
- Wallden, M.; Markidis, S.; Okita, M.; Ino, F. Memory Efficient Load Balancing for Distributed Large-Scale Volume Rendering Using a Two-layered Group Structure. IEICE Trans. Inf. Syst. 2019, 102, 2306–2316. [Google Scholar] [CrossRef] [Green Version]
- Marchesin, S.; Mongenet, C.; Dischler, J. Dynamic Load Balancing for Parallel Volume Rendering. In Proceedings of the 6th Eurographics Conference on Parallel Graphics and Visualization, Groningen, The Netherlands, 6–7 June 2006; pp. 43–50. [Google Scholar]
- Zhang, J.; Guo, H.; Hong, F.; Yuan, X.; Peterka, T. Dynamic Load Balancing Based on Constrained K-D Tree Decomposition for Parallel Particle Tracing. IEEE Trans. Vis. Comput. Graph. 2018, 24, 954–963. [Google Scholar] [CrossRef]
- Bruder, V.; Frey, S.; Ertl, T. Prediction-based load balancing and resolution tuning for interactive volume raycasting. Vis. Inform. 2017, 1, 106–117. [Google Scholar] [CrossRef] [Green Version]
- Müller, C.; Strengert, M.; Ertl, T. Adaptive Load Balancing for Raycasting of Non-uniformly Bricked Volumes. Parallel Comput. 2007, 33, 406–419. [Google Scholar] [CrossRef]
- Lee, W.; Srini, V.P.; Park, W.; Muraki, S.; Han, T. An Effective Load Balancing Scheme for 3D Texture-Based Sort-Last Parallel Volume Rendering on GPU Clusters. IEICE Trans. Inf. Syst. 2008, 91, 846–856. [Google Scholar] [CrossRef] [Green Version]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Li, W.; Mueller, K.; Kaufman, A. Empty Space Skipping and Occlusion Clipping for Texture-based Volume Rendering. In Proceedings of the 14th IEEE Visualization 2003 (VIS’03), Seattle, WA, USA, 19–24 October 2003; pp. 317–324. [Google Scholar]
- Levoy, M. Efficient Ray Tracing of Volume Data. ACM Trans. Graph. 1990, 9, 245–261. [Google Scholar] [CrossRef]
- Matsui, M.; Ino, F.; Hagihara, K. Parallel Volume Rendering with Early Ray Termination for Visualizing Large-Scale Datasets. In Proceedings of the International Symposium on Parallel and Distributed Processing and Applications, Nanjing, China, 2–5 November 2005; pp. 245–256. [Google Scholar]
- Cybermedia Center. Osaka University » Blog Archive » OCTOPUS. 2019. Available online: http://www.hpc.cmc.osaka-u.ac.jp/en/octopus/ (accessed on 11 December 2019).
- Hahn, M.; Drikakis, D.; Youngs, D.L.; Williams, R.J.R. Richtmyer–Meshkov turbulent mixing arising from an inclined material interface with realistic surface perturbations and reshocked flow. Phys. Fluids 2011, 23, 046101. [Google Scholar] [CrossRef] [Green Version]
- Kokkinakis, I.W.; Drikakis, D.; Youngs, D.L. Vortex morphology in Richtmyer–Meshkov-induced turbulent mixing. Phys. D Nonlinear Phenom. 2020, 407, 132459. [Google Scholar] [CrossRef]
- Cohen, R.H.; Dannevik, W.P.; Dimits, A.M.; Eliason, D.E.; Mirin, A.A.; Zhou, Y.; Porter, D.H.; Woodward, P.R. Three-dimensional simulation of a Richtmyer–Meshkov instability with a two-scale initial perturbation. Phys. Fluids 2002, 14, 3692–3709. [Google Scholar] [CrossRef] [Green Version]
- Grinstein, F.F.; Gowardhan, A.A.; Wachtor, A.J. Simulations of Richtmyer–Meshkov instabilities in planar shock-tube experiments. Phys. Fluids 2011, 23, 034106. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ||||||
|---|---|---|---|---|---|---|
| This Work | [13,14,15] | [16,17] | ||||
| Processing approach | In-transit | In-situ | Post-hoc | In-situ | In-situ | In-situ |
| Supports custom importance metrics | ✔ | ✔ | ✔ | ✔ | ||
| Decisions based on multiple metrics | ✔ | ✔ | ||||
| Tracks time-varying data | ✔ | ✔ | ||||
| Used to compress unimportant data | ✔ | ✔ | ✔ | |||
| lossless/lossy | lossy | lossy | ||||
| Multiple compression methods | ✔ | — | — | — | ||
| Cluster A | Cluster B | |||
|---|---|---|---|---|
| Simulation Node | Transit Node | Simulation Node | Transit Node | |
| CPU | Xeon | Xeon Silver | Xeon Gold | Xeon Gold |
| E5-1650 v4 | 4110 | 6126 × 2 | 6126 × 2 | |
| 6 cores | 8 cores | 12 cores × 2 | 12 cores × 2 | |
| Memory (GB) | 128 | 96 | 192 | 192 |
| Node count | 16 | 2 | 32 | 4 |
| Processes | 16 | 2 | 64 | 8 |
| Software | GCC version 7.3.0 | ICC | ||
| OpenMPI version 3.1.0 | Intel MPI version 18.0.3 | |||
| < | <0.005 | <0.01 | <0.05 | <0.1 | |
|---|---|---|---|---|---|
| Mean | 71.9 | 98.5 | 100 | 100 | 100 |
| Range | 72.9 | 75.0 | 76.4 | 86.4 | 95.1 |
| SD | 71.9 | 99.4 | 100 | 100 | 100 |
| Distinct | 51.2 | 60.1 | 63.9 | 82.2 | 98.3 |
| Entropy | 50.2 | 56.4 | 61.3 | 85.4 | 99.7 |
| Cluster A | Cluster B | |||||||
|---|---|---|---|---|---|---|---|---|
| None | RLE | HOMO | LZ77 | None | RLE | HOMO | LZ77 | |
| Pipeline 1 | 1.62 | 1.29 | 0.55 | 3.51 | 1.55 | 1.19 | 0.26 | 2.98 |
| Pipeline 2 | 2.13 | 1.69 | 0.72 | 4.60 | 1.98 | 1.52 | 0.33 | 3.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walldén, M.; Okita, M.; Ino, F.; Drikakis, D.; Kokkinakis, I. Accelerating In-Transit Co-Processing for Scientific Simulations Using Region-Based Data-Driven Analysis. Algorithms 2021, 14, 154. https://0-doi-org.brum.beds.ac.uk/10.3390/a14050154
Walldén M, Okita M, Ino F, Drikakis D, Kokkinakis I. Accelerating In-Transit Co-Processing for Scientific Simulations Using Region-Based Data-Driven Analysis. Algorithms. 2021; 14(5):154. https://0-doi-org.brum.beds.ac.uk/10.3390/a14050154
Chicago/Turabian StyleWalldén, Marcus, Masao Okita, Fumihiko Ino, Dimitris Drikakis, and Ioannis Kokkinakis. 2021. "Accelerating In-Transit Co-Processing for Scientific Simulations Using Region-Based Data-Driven Analysis" Algorithms 14, no. 5: 154. https://0-doi-org.brum.beds.ac.uk/10.3390/a14050154