
Improved Duplication-Transfer-Loss Reconciliation with Extinct and Unsampled Lineages

1
Department of Computer Science & Engineering, University of Connecticut, Storrs, CT 06269, USA
2
Institute for Systems Genomics, University of Connecticut, Storrs, CT 06269, USA
*
Author to whom correspondence should be addressed.
Algorithms 2021, 14(8), 231; https://0-doi-org.brum.beds.ac.uk/10.3390/a14080231
Submission received: 27 May 2021
/
Revised: 1 August 2021
/
Accepted: 2 August 2021
/
Published: 5 August 2021
(This article belongs to the Special Issue Algorithms in Computational Biology)
Abstract
:Duplication-Transfer-Loss (DTL) reconciliation is a widely used computational technique for understanding gene family evolution and inferring horizontal gene transfer (transfer for short) in microbes. However, most existing models and implementations of DTL reconciliation cannot account for the effect of unsampled or extinct species lineages on the evolution of gene families, likely affecting their accuracy. Accounting for the presence and possible impact of any unsampled species lineages, including those that are extinct, is especially important for inferring and studying horizontal transfer since many genes in the species lineages represented in the reconciliation analysis are likely to have been acquired through horizontal transfer from unsampled lineages. While models of DTL reconciliation that account for transfer from unsampled lineages have already been proposed, they use a relatively simple framework for transfer from unsampled lineages and cannot explicitly infer the location on the species tree of each unsampled or extinct lineage associated with an identified transfer event. Furthermore, there does not yet exist any systematic studies to assess the impact of accounting for unsampled lineages on the accuracy of DTL reconciliation. In this work, we address these deficiencies by (i) introducing an extended DTL reconciliation model, called the DTLx reconciliation model, that accounts for unsampled and extinct species lineages in a new, more functional manner compared to existing models, (ii) showing that optimal reconciliations under the new DTLx reconciliation model can be computed just as efficiently as under the fastest DTL reconciliation model, (iii) providing an efficient algorithm for sampling optimal DTLx reconciliations uniformly at random, (iv) performing the first systematic simulation study to assess the impact of accounting for unsampled lineages on the accuracy of DTL reconciliation, and (v) comparing the accuracies of inferring transfers from unsampled lineages under our new model and the only other previously proposed parsimony-based model for this problem.
1. Introduction
Understanding how genes and species evolve is fundamental to our understanding of biology. In microbes, gene families evolve through complex evolutionary processes such as gene duplication, horizontal gene transfer (or simply transfer for short), homologous recombination, gene loss, and speciation. Duplication-Transfer-Loss (DTL) reconciliation is one of the most powerful computational techniques for studying microbial gene family evolution and for inferring evolutionary events such as transfer and gene duplication. Indeed, DTL reconciliation has been rigorously studied over the last several years [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18] and several different DTL reconciliation models and algorithms have been developed. At a fundamental level, algorithms for DTL reconciliation take as input a gene tree (i.e., evolutionary tree for a gene family) and a species tree (i.e., evolutionary tree for the corresponding collection of species) and reconcile any topological differences between the two by invoking gene duplication, transfer, gene loss, and speciation. Thus, the output is an embedding of the gene tree into the species tree, showing how that gene family evolved inside the species (or branches) represented in the species tree.
It is common knowledge that the vast majority of species that have ever existed on Earth have gone extinct without leaving any known surviving descendants. Furthermore, only a fraction of the existing microbial species diversity of Earth has ever been described and only a small subset of this diversity is represented in genetic sequence databases. Accounting for the presence and possible impact of such unsampled species lineages is important for understanding microbial gene family evolution and studying transfer since many genes in the species lineages represented in the reconciliation analysis are likely to have been acquired through transfer from unsampled lineages, including those that have gone extinct [10]. However, most models of DTL reconciliation, such as those implemented in Mowgli [3], CoRe-PA [19], Jane [20], AnGST [5], RANGER-DTL [7,17], Notung [8], PRIME-DLTRS [14], EUCALYPT [21], eMPRess [22], etc., do not explicitly account for the potential impact of unsampled lineages on evolutionary histories of gene families.
To the best of our knowledge, only two DTL reconciliation models currently exist that explicitly account for the impact of unsampled lineages: the probabilistic DTL reconciliation framework introduced by Szollosi et al. [10] and the parsimony-based model implemented in the software ecceTERA [16]. The model of Szollosi et al. [10] was used to demonstrate that a large fraction of detectable transfers are likely acquired from unsampled lineages. However, the underlying evolutionary model on which the probabilistic model of Szollosi et al. [10] is based makes several simplifying assumptions, for example, the assumption of an identical rate of transfer between any two species. The parsimony-based model of ecceTERA [16] addresses some of these limitations. In ecceTERA, transfers from unsampled lineages are modeled by adding a single lineage to the species tree (as an extra branch attached to the root of the species tree) such that this additional lineage represents all unsampled lineages. In particular, transfers can occur to or from this additional lineage, representing transfers to or from unsampled lineages, respectively. Among other limitations, this setup makes it difficult to infer the “location” on the species tree of an unsampled donor of a transfer and to customize transfer event costs based on phylogenetic distance. Furthermore, and perhaps most importantly, there has never been any systematic evaluation of the accuracy of transfers inferred as transferred from unsampled lineages or of the impact of accounting for transfers from unsampled lineages on overall reconciliation accuracy.
In this work, we introduce an extended DTL reconciliation model, building upon the widely-used parsimony-based DTL reconciliation framework of Bansal et al. [7,11], that accounts for unsampled species lineages in a more effective and useful manner than ecceTERA. The new model, which we refer to as the DTLx reconciliation model, has several important advantages over the model implemented in ecceTERA (and also the model implemented in [10]): First, our new model explicitly infers the location on the species tree of each unsampled lineage associated with an identified transfer event. Second, our model allows greater flexibility in assigning event costs to different types of transfer events (e.g., those from unsampled lineages), allowing for the costs to be fine tuned to the specific dataset or evolutionary scenario under consideration. Furthermore, third, the new model makes it possible to use variable transfer event costs based on the phylogenetic distance between donor and recipient species even when the donor is an unsampled species; this is important since transfers happen more frequently between more closely related species [23]. As an additional minor contribution, the DTLx reconciliation model also models transfer-loss events, which are currently only modeled in two other parsimonious DTL reconciliation frameworks, Mowgli [3] and ecceTERA [16].
We show how to compute optimal (most parsimonious) reconciliations under the DTLx reconciliation model in time, where m and n denote the number of leaves in the gene tree and species tree, respectively, matching the time complexity of the fastest known algorithms for any DTL reconciliation model. We provide an -time algorithm for sampling optimal reconciliations uniformly at random under the DTLx reconciliation model, thus making it possible to efficiently sample from the space of all optimal DTLx reconciliations, and perform the first systematic simulation study to assess the impact of accounting for unsampled lineages on the accuracy of DTL reconciliation. We also compare the accuracies of inferring transfers from unsampled lineages under our new model and the model implemented in ecceTERA (currently the only other parsimony-based model that accounts for unsampled lineages). Importantly, our experimental results, on both simulated and real data, suggest that models that account for unsampled lineages have only a small impact on overall reconciliation accuracy and that there is a clear trade-off between precision and recall of correctly detecting transfers from unsampled lineages. Encouragingly, we also find that DTLx reconciliation is capable of identifying at least some transfers from unsampled lineages with reasonable confidence and that it is able to identify the phylogenetic placement of the unsampled donors of such transfer events with high accuracy.
Our implementation of the DTLx reconciliation model is freely available open-source as the program RANGER-DTLx, downloadable from https://compbio.engr.uconn.edu/software/RANGER-DTLx/ (accessed on 3 August 2021).
The remainder of the manuscript is organized as follows: We provide basic preliminaries and introduce and formally define the DTLx reconciliation model in the next section. Our algorithms for computing and sampling optimal DTLx reconciliations appear in Section 3. Experimental results appear in Section 4 and concluding remarks in Section 5.
2. Definitions and Preliminaries
We follow basic definitions and notation from [7,11]. Given a tree , we denote its node, edge, and leaf sets by , , and , respectively. If is rooted, the root node of is denoted by , the parent of a node by , its set of children by , and the (maximal) subtree of rooted at by . If two nodes in have the same parent, they are called siblings. The set of internal nodes of , denoted , is defined to be . We define to be the partial order on where if is a node on the path between and . The partial order is defined analogously, that is, if is a node on the path between and . We say that is an ancestor of , or that is a descendant of if (note that, under this definition, every node is a descendant as well as an ancestor of itself). We say that and are incomparable if neither nor . Given a nonempty subset , we denote by the least common ancestor (LCA) of all the leaves L in tree ; that is, is the unique smallest upper bound of L under . Given , denotes the unique path from to in . Throughout this work, unless otherwise stated, the term “tree” refers to a rooted binary tree.
Throughout this work, we use and to denote the input gene tree and species tree, respectively. We assume that each leaf of the gene tree is labeled with the species from which that gene was sampled. This labeling defines a leaf-mapping that maps a leaf node to that unique leaf node , which has the same label as . We will implicitly assume that is well defined. Note that a gene tree may have more than one gene sampled from the same species, i.e., gene trees can be multi-labeled. We also point out that “species” in a species tree can, in fact, also represent distinct strains or genomes from the same species.
2.1. DTL Reconciliation
Given a rooted gene tree and a rooted species tree, Duplication-Transfer-Loss (DTL) reconciliation shows how the gene tree evolved within the species tree through speciation, gene duplication, transfer, and gene loss. Essentially, DTL reconciliation maps each node of the gene tree to a node or edge on the species tree and designates each internal node of the gene tree as representing either a speciation, duplication, or transfer event.
Computed DTL reconciliations can sometimes be time-inconsistent in that one or more inferred transfers may be inconsistent with any valid dating of the internal nodes of the species tree. The problem of finding an optimal time-consistent DTL reconciliation is NP-hard [4,24] and, consequently, DTL reconciliation algorithms often seek an optimal, not necessarily time-consistent, DTL reconciliation [4,5,7,11,13]. However, it is possible to perform additional filtering of computed optimal DTL reconciliations so that any time-inconsistent reconciliations are suppressed [8,21]. Time-consistent DTL reconciliations can also be computed efficiently if the input species tree can be fully dated [3,25]. In this work, we focus on computing optimal, not necessarily time-consistent, reconciliations with undated species trees, but the same techniques also extend to reconciliations with dated species trees.
Almost all existing DTL reconciliation models have some implicit limitations in how they handle transfer events. For example, nearly all DTL reconciliation models implicitly assume that transfer events are additive, i.e., that the transferred gene inserts itself as a new gene in the recipient species instead of replacing an existing homologous gene. Extensions of the DTL model that simultaneously model both additive and replacing transfers, referred to as the DTLR reconciliation model have also been proposed [26,27], but the problem of inferring optimal reconciliations under such models is known to be NP-hard [26,27]. Likewise, almost all existing DTL reconciliation models, except for [10,16], assume that transfer events only occur between branches, or species, represented on the given species tree. Thus, they often cannot correctly account for transfers from unsampled species lineages.
In the following, we introduce an extended version of the DTL reconciliation model that can explicitly model two additional types of transfer events, as defined below. Our approach builds upon initial ideas first briefly mentioned (but not further developed, formalized, implemented, or tested), in a previous 2012 paper [7].
Definition 1
(Transfer-Loss ()). A transfer-loss () event occurs when the descendants of the donor species lose all copies derived from the transferred gene.
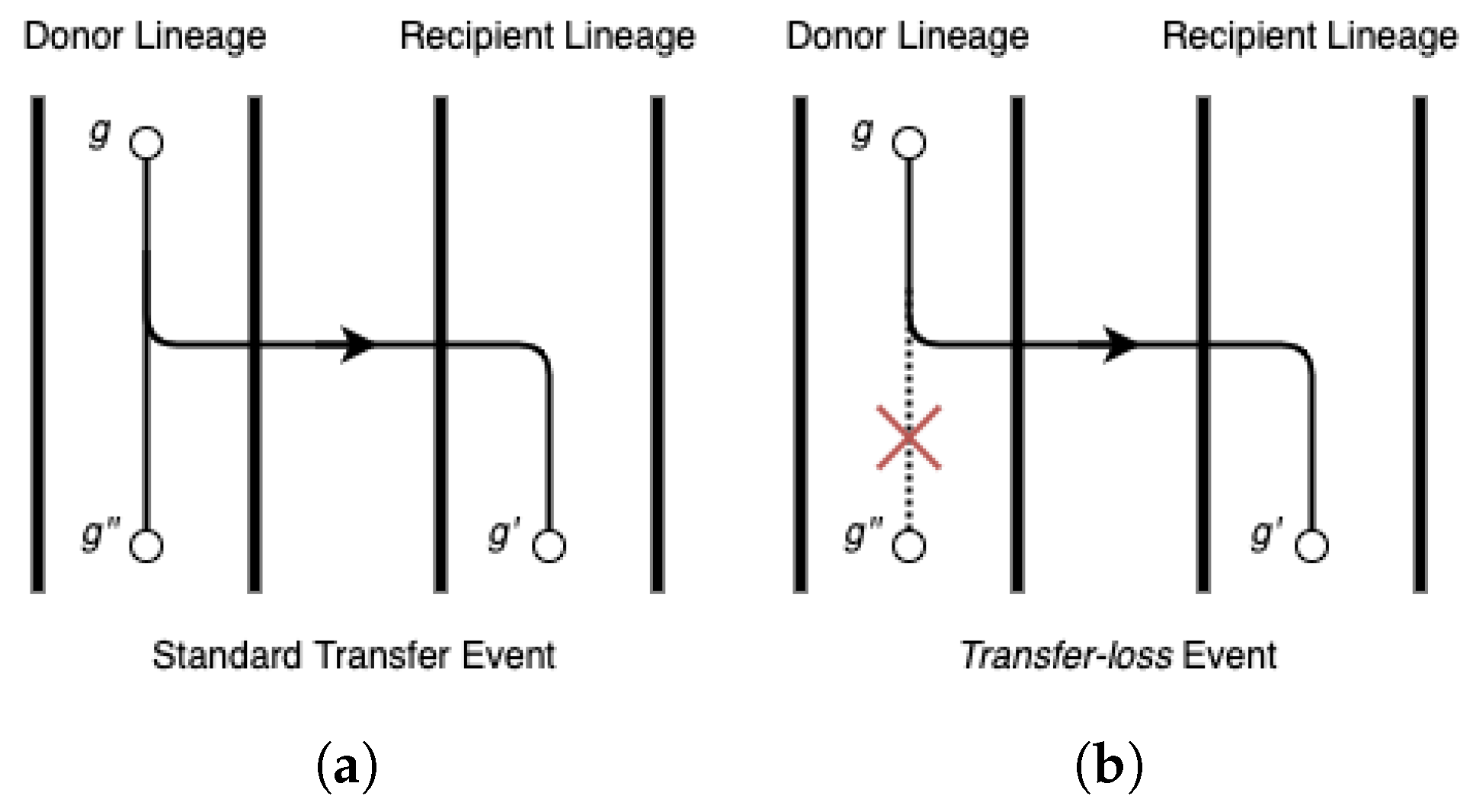
Figure 1 provides an illustration of a event and a detailed discussion occurs in Section 2.2 below. As noted earlier, events were also explicitly defined and handled in [3,16].
Definition 2
(Transfer from unsampled lineage ()). A transfer from unsampled lineage () event occurs when the donor species is not represented in the species tree.
In this work, unsampled lineages are representative any lineage not present in the species tree, including those that are extinct. We refer to transfer events that are neither events nor events as events. Thus, represents the “standard” transfer event type that is modeled by default in existing DTL reconciliation models.
2.2. Transfer-Loss Events
As shown in Figure 1, a event is equivalent to a standard transfer event with the exception that the donor lineage thereafter loses all copies derived from the gene that was transferred. events were first defined by Doyon et al. and implemented in their DTL reconciliation framework and software Mowgli [3]. The software ecceTERA [16] later inherited the same reconciliation framework. No other parsimony-based DTL reconciliation framework can currently handle events. Note that events do not represent a distinct biological event type; instead, they are simply standard transfer events followed later by one or more loss events that result in the donor lineage losing all copies derived from the gene that was transferred. Thus, the only reason to explicitly define events and distinguish them from standard transfer events is that most DTL reconciliation models and algorithms are not able to correctly handle evolutionary scenarios involving events. This difficulty in handling events stems from the fact that events are unary; unlike standard transfer events, they do not result in a bifurcation in the gene tree topology. Thus, there does not exist any node in the input gene tree that can represent a event. However, the DTL reconciliation model can be easily adapted to allow for events by explicitly augmenting edges in the input gene tree with additional nodes, referred to as hidden nodes. Each such hidden node simply subdivides the edge that they are augmented to, resulting in a non-binary node with a single child. This property allows hidden nodes to represent possible events, as the unary property is kept intact. More formally:
Definition 3
(Augmented gene tree and hidden nodes). Given a gene tree , an augmented gene tree is defined to be the tree obtained from by (i) selecting a subset of edges , and (ii) subdividing each edge in A by a hidden node such that each edge is replaced by the two edges and , where h is a new hidden node.
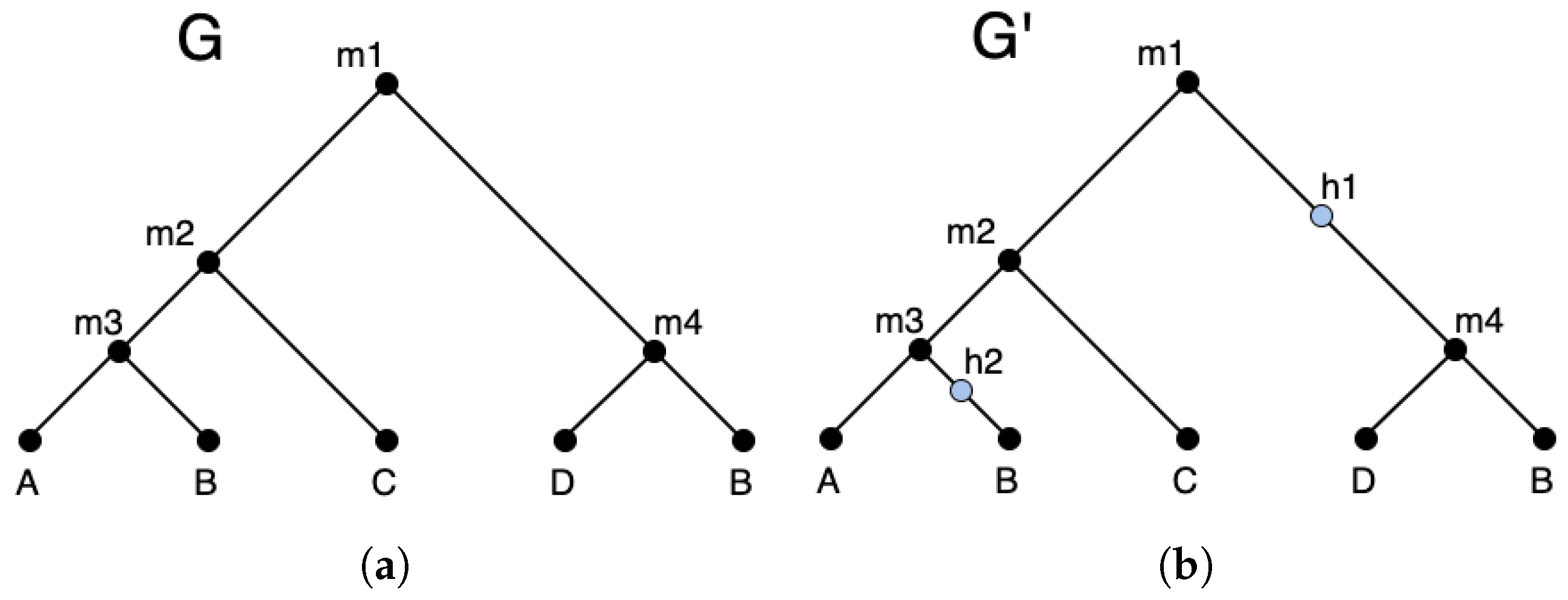
Figure 2 shows an example of an augmented gene tree. The hidden nodes in an augmented gene tree can be used to represent events. Thus, under the DTLx reconciliation framework, the reconciled gene tree is in fact a reconciled augmented gene tree, where each hidden node shown on that augmented gene tree represents a event.
2.3. Transfers from Unsampled Lineages
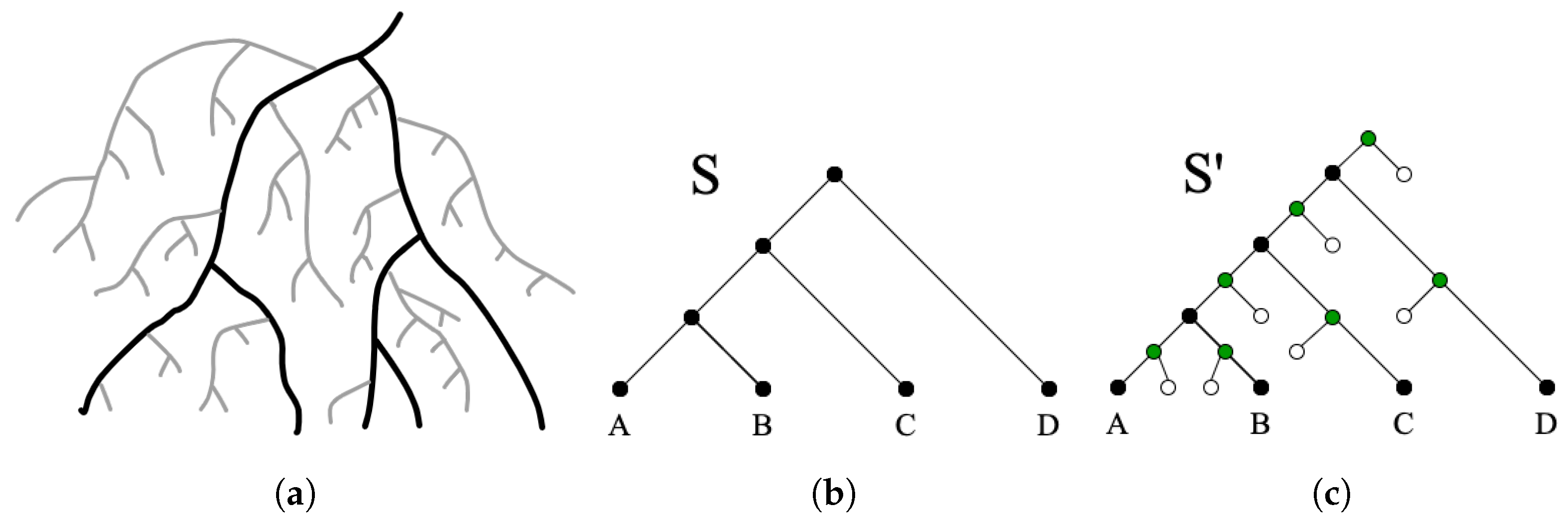
In most cases, it is difficult or impossible to achieve complete taxon sampling for the group of species under consideration. Unsampled taxa/lineages in the species tree can affect the accuracy of DTL reconciliation since transfers may have occurred from unsampled to sampled lineages. Even with complete taxon sampling, the species represented on a species tree are only those that have surviving descendant species. It is well-understood that the vast majority of species that have ever existed have gone extinct without leaving surviving descendants. This is depicted in Figure 3a. It is reasonable to expect that such extinct species lineages would have engaged in gene transfer with the species that are represented in the “visible” species tree [10]. However, conventional DTL reconciliation algorithms do not explicitly model transfers from such unsampled lineages (with the exception of [10,16], which include a simple mechanism to allow for such transfers).
We will show how transfers from unsampled species can be detected and correctly handled by appropriately augmenting the input species tree with additional edges that represent unsampled lineages and then leveraging events to allow for transfers from these additional edges to the rest of the species tree. Formally, we define the augmented species tree, denoted , as follows:
Definition 4
(Augmented species tree and extra nodes, leaves, and edges). Given the species tree , the augmented species tree is defined to be the tree obtained from by (i) subdividing each edge in by a new extra node such that each edge is replaced by the two edges and , where e is the new extra node, and connecting e by an edge to a new extra leaf, and (ii) creating a new root node r and connecting r by an edge to and by another edge to a new extra leaf. Each edge of connecting an extra node with an extra leaf is called an extra edge.
Figure 3c show an example of an augmented species tree. We use to denote the set of all extra leaves in . The extra edges in represent unsampled lineages and the new DTLx model allows for transfers to originate from these extra edges of , and any transfer that originates at an extinct edge is labeled as a event.
2.4. DTLx Reconciliation
A DTLx reconciliation of and shows how a suitably augmented version of evolved inside the augmented species tree through speciation, gene duplication, transfer, , , and loss events. A formal definition of DTLx reconciliation appears below and it specifies what constitutes a biologically valid DTLx reconciliation of and .
Definition 5
(DTLx Reconciliation). A DTLx reconciliation for and is an eleven-tuple
, where represents the leaf mapping from to , denotes the augmented gene tree, denotes the augmented species tree, : maps each node of to a node of , the sets Σ, Δ, Θ, , and partition into speciation, duplication, , , and events, respectively; Ξ is the subset of that represents transfer edges, and specifies the recipient species for each transfer event, subject to the following constraints:
Augmented gene tree constraint
- can be obtained from by suppressing each node of with exactly one child.
Mapping constraints
- 2.
- If , then = .
- 3.
- If (i.e., g is not a hidden node of ) and and denote the children of in , then,
- (a)
- , and ,
- (b)
- At least one of and is a descendant of .
- 4.
- If (i.e., g is a hidden node of ) and denotes it’s unique child, then and are incomparable.
Event constraints
- 5.
- Given any edge , if and only if and are incomparable.
- 6.
- If and and denote the children of in , then,
- (a)
- only if and and are incomparable,
- (b)
- only if , ,
- (c)
- if and only if either or ,
- (d)
- If and , then and must be incomparable and must be a descendant of , i.e., .
- 7.
- If and denotes it’s unique child, then,
- (a)
- , and
- (b)
- and are incomparable, and
- (c)
- if and only if .
Constraint 1 specifies how the gene tree can be augmented with hidden nodes so that any inferred and events can be shown in the final reconciliation. Constraint 2 ensures that the mapping is consistent with the leaf-mapping . Because is equivalent to , the leaf mappings of into must be equivalent to those of into . Constraints 3a and 4 impose on the temporal constraints implied by . Constraint 3b implies that any non-hidden internal node in may represent at most one transfer event. Constraint 5 determines the edges of that are , , or edges. Constraints 6a–c state the conditions under which a non-hidden internal node of may represent a speciation, duplication, and transfer, respectively. Constraint 6d specifies which species may be designated as the recipient species for any given event. Constraint 7a ensures that only those hidden nodes that represent a valid or event can appear in . Constraint 7b specifies which species may be designated as the recipient species for any given or event. Finally, Constraint 7c differentiates from events and requires that any event must originate along an extra edge (representing unsampled lineages) of the augmented species tree.
Figure 4 shows examples of DTLx reconciliations and illustrates how allowing for and events can lead to improved reconciliations.
Given a DTLx reconciliation , one can directly count the minimum number of gene losses implied by similarly as under the DTL reconciliation model [7], but with two additional considerations: First, any losses associated with and events (i.e., associated with hidden nodes of ) must be appropriately counted. Furthermore, second, losses must be counted using the original, unaugmented species tree , rather than using , except in cases where a gene tree node maps to an extra leaf. Specifically, to count the minimum number of losses that occur along an edge of the gene tree, we must count the number of non-extra species lineages in the species tree that branch off from the path , and also account for any extra edges along the path. To facilitate this counting, we define the loss-distance between two nodes , where , denoted , as follows:
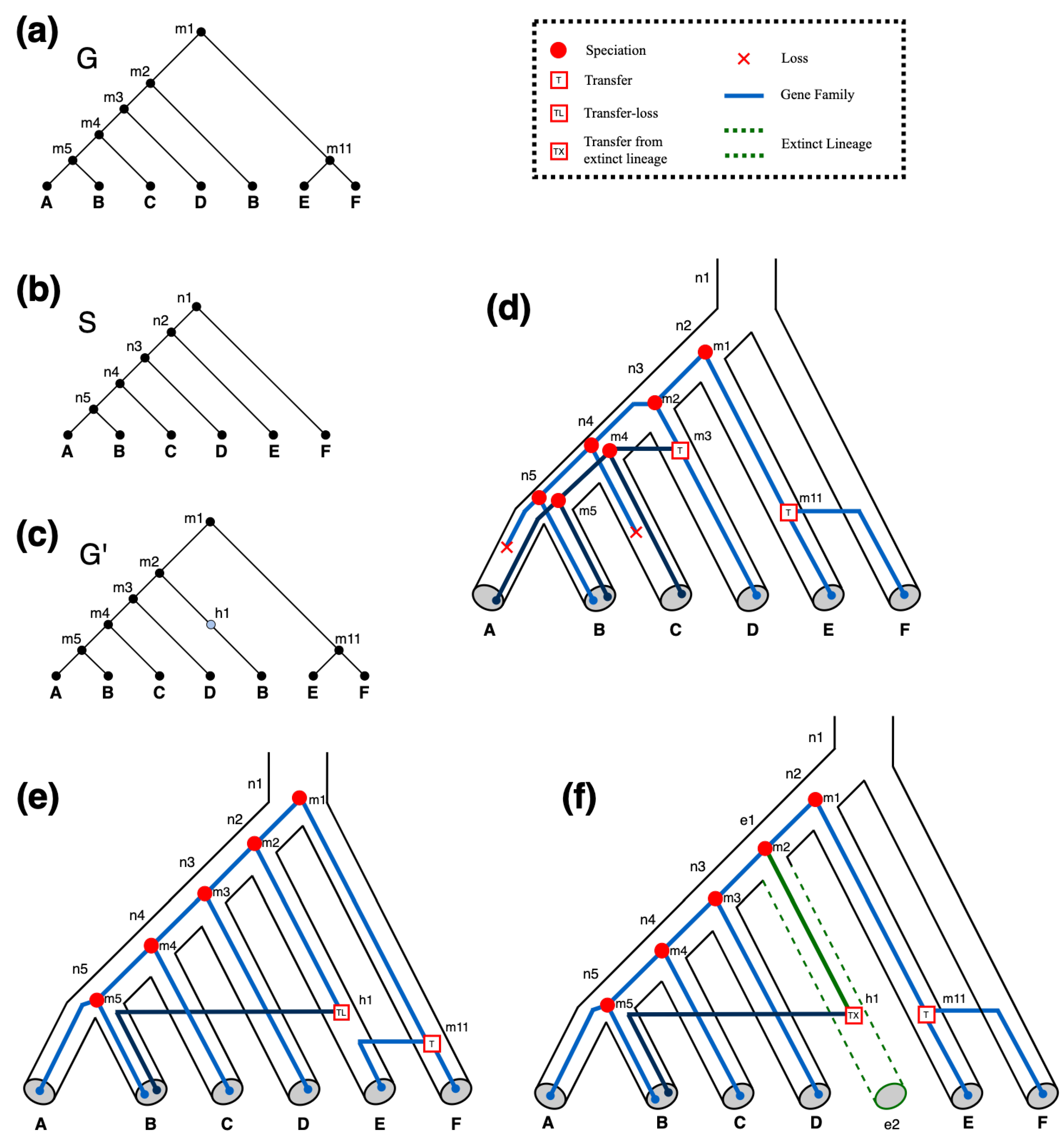
For example, in the species tree shown in Figure 4f, and .
Definition 6
(Losses). Given a DTLx reconciliation for and , let and if , and otherwise. The minimum number of losses at node (or, more accurately, the minimum number of losses incurred along the child edge(s) of ) is defined to be:
- ;
- ;
- ;
- .
The total number of losses associated with reconciliation α, denoted , is defined to be .
Note that the implicit gene loss (of the donor’s copy of the gene) associated with or events is not counted in the definition of losses above. Instead, and events can be assigned a higher event cost than a standard transfer event (see next paragraph) to account for these implicit losses.
In the DTLx reconciliation framework, each event other than speciation (which is considered a null event) is assigned a positive cost. Let , , , , and denote the costs associated with duplication, transfer, , , and loss events, respectively. The reconciliation cost of a DTLx reconciliation of and is then defined as follows.
Definition 7
(Reconciliation cost). Given a DTLx reconciliation for and , the reconciliation cost associated with α is the total cost of all events invoked by α. Specifically, the reconciliation cost is given by .
Given and , along with specific event costs, the computational objective is to find a DTLx reconciliation of and with minimum reconciliation cost (i.e., a most parsimonious DTLx reconciliation of and ). This yields the following problem statement.
Problem 1
(Optimal DTLx reconciliation (O-DTLx) problem). Given and , along with , , , , and , the O-DTLx problem is to find a DTLx reconciliation for and with minimum reconciliation cost.
It is well-understood that there can exist a very large number of optimal DTL reconciliations for any given gene tree and species tree and that this number can grow exponentially in the sizes of the input trees [11,12]. One of the most efficient and widely used approaches for handling multiple optima and exploring the diversity of optimal reconciliations is to generate optimal reconciliations uniformly at random from the space of all optimal reconciliations [11,17]. Such random sampling for the efficient exploration of the space of multiple optima and makes it possible to distinguish well-supported and poorly-supported aspects of an optimal reconciliation. This motivates the following problem statement.
Problem 2
(Optimal DTLx reconciliation sampling (O-DTLx-Sampling) problem). Given and , along with , , , , and , let denote the set of all optimal DTLx reconciliations for and (i.e., with minimum reconciliation cost). The O-DTLx-Sampling problem is to compute an optimal DTLx reconciliation from in such a way that each DTLx reconciliation in has an equal probability of being computed.
We provide efficient algorithms for both the above problems in the following section.
3. Materials and Methods
Our algorithms for computing and sampling optimal DTLx reconciliations build upon corresponding dynamic programming algorithms for computing and sampling optimal DTL reconciliations as described in [7,11]. These algorithms for DTL reconciliation perform a nested post-order traversal of the gene tree and species tree and compute, at each step, an optimal solution to a subproblem. Specifically, given any and , the subproblem is defined to be cost of an optimal DTL reconciliation of the subtree with under the constraint that maps to . As shown in [7], optimal solutions for these subproblems can be efficiently computed based on previously computed optimal solutions for smaller subproblems, and the final optimal reconciliation cost for and is then simply .
Adapting this approach to computing DTLx reconciliations requires several modifications and extensions to the basic dynamic programming framework. In particular, (i) hidden nodes in the augmented gene tree must be handled differently in the dynamic programming framework than the other nodes, (ii) mappings to extra leaves in the species tree must be handled differently than mappings to other nodes, and (iii) the new evolutionary events and must be integrated into the cost calculations performed within the dynamic programming framework.
Recall that a DTLx reconciliation of and is a reconciliation between an augmented gene tree and the augmented species tree . Accordingly, our algorithms for computing optimal DTLx reconciliations perform a nested post order traversal of a fully augmented gene tree, denoted , and the augmented species tree . This fully augmented gene tree is defined as follows:
Definition 8
(Fully augmented gene tree). Given a gene tree , the fully augmented gene tree, denoted , is defined to be the tree obtained from by subdividing each edge in by a hidden node such that each edge is replaced by the two edges and , where h is a new hidden node.
The fully augmented gene tree thus contains all possible hidden nodes and allows the algorithms to consider the possibility of and events occurring along each edge of G. Hidden nodes of that are not ultimately labeled as representing a or event are suppressed to yield the final augmented gene tree .
Next, we present our algorithm for the O-DTLx problem.
3.1. An -Time Algorithm for O-DTLx
Following along the lines of the previous dynamic programming framework described above, we define the core subproblem of dynamic programming algorithm as follows: Given any and , we define to be cost of an optimal DTLx reconciliation of the subtree with under the constraint that maps to . Note that the hidden nodes of that are not used in a DTLx reconciliation do not contribute to the reconciliation cost of that reconciliation. These unused hidden nodes can therefore be trimmed out at the end to yield the final augmented gene tree . Thus, in accordance with the definition of DTLx reconciliation, the optimal reconciliation cost of reconciling and is given by .
For each non-hidden internal node of , i.e., if , we also define the following restricted subproblems: (i) denotes the cost of an optimal reconciliation of with under the constraint that maps to and . (ii) denotes the cost of an optimal reconciliation of with under the constraint that maps to and . Furthermore, (iii) denotes the cost of an optimal reconciliation of with under the constraint that maps to and .
Recall that only the hidden nodes of can represent and events. Accordingly, for each hidden node of , i.e., if , we define the following restricted subproblems: (i) denotes the cost of an optimal reconciliation of with under the constraint that maps to and . (ii) denotes the cost of an optimal reconciliation of with under the constraint that maps to and .
The algorithm executes a nested post order traversal of and to compute the value of for each and . The base cases for the dynamic programming table are initialized as follows:
For internal nodes of , can be computed based on the values of the restricted subproblems, defined above, as follows:
where denotes the unique child of in the case where is a hidden node (i.e., ).
Note that, when , the value of is the minimum of the restricted subproblem values computed at and . Essentially, if equals , , or , then it means that the hidden node is not required (i.e., it need not represent any event) in an optimal reconciliation corresponding to that value of .
For each and , optimal values for the applicable restricted subproblems represented by , , , , and can be computed based on previously computed values of as shown below. For ease of presentation and to help compute these values more efficiently, we also define, for each and , the following:
Now, consider any , and let . If then let . Then,
and
Similarly, if , i.e., is a hidden node, and represents the unique child of in , then,
and
The O-DTLx problem can now be easily solved using dynamic programming based on Equations (1)–(7). The pseudocode given in Algorithm 1, i.e., Algorithm Compute-O-DTLx, shows how this can be done within time by efficiently computing the values of , , and .
Observe that Algorithm 1 only computes the optimal reconciliation cost. However, as with any dynamic programming algorithm, it is straightforward to compute an actual reconciliation that achieves this optimal reconciliation cost through backtracking. Furthermore, observe that it is trivial to “trim down” any reconciliation of and constructed through backtracking by simply removing any hidden node in that is not assigned a or event in that reconciliation. This would yield the augmented gene tree , along with its reconciliation with , as required by the definition of DTLx reconciliation (Definition 5).
Theorem 1.
The O-DTLx problem can be solved in time, where and .
Proof.
It suffices to show that Algorithm 1 correctly computes the value of , for each and , within time.
Correctness: We will show that the values of , , , , , , , and are computed correctly for each and where applicable. For each , consider the values of , , and . These values are assigned correctly in accordance with their definitions during the execution of the ‘for’ loop in Steps 8–11. These values serve as the base case of our inductive argument.
Consider the case when , and . By the induction hypothesis, we may assume that the values of , , and have been computed correctly for each . Given the values of , the values of must also be computed correctly during the execution of the ‘for’ loop in Steps 33–35. Observe that the values of , , and , for any , are computed using these previously computed values in accordance with Equations (2), (6), and (7), which, in turn, are based directly on the definitions of the corresponding events given in Definition 5. Thus, these values are all computed correctly. Once the values are computed correctly, the remaining values of , , and would also be assigned correctly in Steps 18–22 and Steps 33–35, in accordance with their definitions.
Now, consider the case when , and . By the induction hypothesis, we may again assume that the values of , , , , , and have been computed correctly for each . Given the values of and , the values of and must also be computed correctly during the execution of the ‘for’ loop in Steps 33–35. Observe that the values of , , , and , for any , are computed using these previously computed values in accordance with Equations (2)–(5), which, in turn, are based directly on the definitions of the corresponding events given in Definition 5. Thus, these values are all computed correctly. Once the values are computed correctly, the remaining values of , and would also be assigned correctly in Steps 28–32 and Steps 33–35, in accordance with their definitions.
Induction completes the proof.
Time complexity: The time complexity of the Algorithm is dominated by the nested ‘for’ loops in Steps 12 through 35 that perform the nexted post-order traversal of the gene and species tree. It is easy to verify that each step within these nested ‘for’ loops requires only time. Thus, the time complexity of Algorithm 1 is .
| Algorithm 1 Compute-O-DTLx() |
| 1: Initialize and as outlined earlier. |
| 2: for each and do |
| 3: Initialize , , , and to ∞. |
| 4: if then |
| 5: Initialize , , and to ∞. |
| 6: if then |
| 7: Initialize and to ∞. |
| 8: for each do |
| 9: Initialize to 0 |
| 10: For each , initialize to and to 0. |
| 11: For each incomparable to , assign . |
| 12: for each in post-order do |
| 13: for each in post-order do |
| 14: if then |
| 15: Let denote the unique child of in . |
| 16: Compute and according to Equations (6) and (7), respectively. |
| 17: Compute according to Equation (2). |
| 18: if then |
| 19: . |
| 20: else |
| 21: . |
| 22: If s is an extra node then . If s is not an extra node then . |
| 23: if then |
| 24: Let . |
| 25: If then let . |
| 26: Compute , , and according to Equations (3), (4), and (5), respectively. |
| 27: Compute according to Equation (2). |
| 28: if then |
| 29: . |
| 30: else |
| 31: . |
| 32: If s is an extra node then . If s is not an extra node then . |
| 33: for each in pre-order do |
| 34: Let . |
| 35: , and . |
| 36: Return . |
3.2. An -Time Algorithm for O-DTLx-Sampling
As with any dynamic programming algorithm, Algorithm 1 can be easily extended to keep track of all optimal choices at each step of the algorithm and to use these optimal choices to (1) compute all possible optimal reconciliations, and/or (2) perform probabilistic backtracking to sample from the space of optimal reconciliations uniformly at random. Since there is often a very large number of optimal reconciliations [11,12], making it infeasible to enumerate all possible optimal reconciliations in practice, we will show how to perform probabilistic backtracking to sample from the space of optimal DTLx reconciliations uniformly at random. Our sampling algorithm builds on the very similar sampling algorithm previously developed for DTL reconciliation [11] and implemented in RANGER-DTL 2.0 [17]. Given the similarity with [11], here we only provide a high level description of the overall approach, focusing primarily on describing the handling of hidden nodes and and events.
The key idea that enables uniform random sampling is to keep track of the number of optimal DTLx reconciliations associated with each subproblem. Accordingly, we define the following: Given any and , let denote the number of optimal reconciliations for and such that maps to . Thus, is the number of distinct DTLx reconciliations of and , under the constraint that maps to , that have a reconciliation cost of exactly . These values can be easily computed alongside the corresponding values using the same overall dynamic programming framework as in Algorithm 1.
Analogous to , , and , we define, for each non-hidden internal node of (i.e., ), , , and . Similarly, analogous to and , we define, for each hidden node of (i.e., ), and .
The dynamic programming table for can be initialized as follows for each :
It is easy to see that, for internal nodes of , can be computed based on the values of the restricted counts defined above as follows:
where denotes the unique child of in the case where is a hidden node (i.e., ).
Now, for any , the values of , , and can be computed exactly as described in [11] for DTL reconciliation. It therefore suffices to show how to compute the values and when is a hidden node.
Suppose , i.e., is a hidden node, and represents the unique child of in . For any , let A denote the set of all mappings of that are optimal for , i.e., for any we must have . Likewise, let B denote the set of all mappings of that are optimal for , i.e., for any we must have . The values of and can then be computed as follows:
and
Together with the equations for , , and from [11], Equations (8)–(11) make it possible to compute all values alongside those of using the same nested post-order traversal used in Algorithm 1. However, as also described in [11], to compute the values, we need to keep track of all optimal mappings for the child/children of that yield the optimal reconciliation cost at . Thus, it is not possible to use the speedups enabled by precomputing the required values of , , and , leading to an increased overall time complexity of [11]. Furthermore, once all the values have been computed, it is straightforward to perform a probabilistic backtracking procedure, completely analogous to the one described in [11] for DTL reconciliation, to sample from the space of all optimal DTLx reconciliations for G and S uniformly at random. Thus, we have the following theorem.
Theorem 2.
The O-DTLx-Sampling problem can be solved in time, where and .
3.3. Assigning Event Costs for and
Based on analyses of simulated and biological datasets, DTL reconciliation often uses default event costs of 1, 2, and 3 for losses, duplications, and transfers, respectively, [5,16,17]. For events, it makes sense to use a cost equal to since a event implies one transfer and at least one loss. For events, a cost equal to that of a transfer event may be appropriate, since each event implies one transfer but not necessarily any other events (besides extinction or non-sampling). However, depending on the specific dataset being analyzed, e.g., based on the approximate age of the root of the species tree or on the extent of incomplete taxon sampling, it may make sense to assign a slightly higher cost for events, such as a cost equal to .
Theoretically, observe that if then, for every optimal DTLx reconciliation that invokes a transfer event, there exists a distinct and equally optimal DTLx reconciliation in which that transfer event is substituted by an equivalent event. Thus, assigning to be strictly greater than may make it easier to distinguish between transfer and events.
4. Results
To assess the accuracy and impact of our new DTLx reconciliation framework, we implemented our ODTLx-Sampling algorithm and applied it to both simulated and real datasets. We describe the results of this experimental evaluation below.
4.1. Results on Simulated Datasets
We used simulated datasets to systematically evaluate the accuracy of DTLx reconciliations and to compare its accuracy and functionality against ecceTERA, the only other parsimony-based reconciliation model that handles and events. Our implementation is built upon the open-source RANGER-DTL software package [17] and we refer to the new software implementation as RANGER-DTLx.
We used the recently developed phylogenetic tree simulation software ZOMBI [29] to evolve simulated gene trees with known ground-truth evolutionary histories containing explicit transfers from extinct lineages. ZOMBI tracks species lineages that eventually go extinct and allows for such lineages to participate in horizontal gene transfer events before going extinct. In our analysis, we simulated two datasets, each consisting of 500 gene tree/species tree pairs. Note that each of these 500 pairs consist of a unique (i.e., different) species tree and gene tree, where each of the species trees has exactly 50 taxa. The specific parameters used to generate the datasets are shown in Table 1. Notably, Dataset-2 has a higher rate of transfers and more events in the gene trees due to a higher extinction rate. For increased realism, the transfer rate was split evenly between additive and replacing transfers.
The final gene trees, obtained after pruning out all gene lineages with no surviving gene descendants, had, on average, 152.5 leaves, 11.6 duplications, 18.1 transfers, 3.0 events, and 121.7 speciations for Dataset-1, and 180.3 leaves, 10.5 duplications, 26.7 transfers, 5.7 events, and 142 speciations for Dataset-2. For reference, the unpruned gene trees showed on average, for Dataset-1, 16.1 losses and 42 extinctions, and for Dataset-2, 24.2 losses and 67.4 extinctions. Thus, Datasets 1 and 2 correspond to low and moderate rates, respectively, of the relevant evolutionary events.
We used these two simulated datasets to address the following three questions: (i) Does using DTLx reconciliation, i.e., RANGER-DTLx, improve upon the overall accuracy of DTL reconciliation in the presence of events? (ii) How well do RANGER-DTLx and ecceTERA detect events? Furthermore, (iii) How do RANGER-DTLx and ecceTERA compare in their ability to detect the phylogenetic location of the extinct donor of a event?
Comparing accuracies of DTL and DTLx reconciliation. Since both RANGER-DTLx and ecceTERA can account for additional evolutionary scenarios that cannot be correctly handled in traditional DTL reconciliation, it is reasonable to expect that both RANGER-DTLx and ecceTERA should result in greater overall reconciliation accuracy than traditional DTL reconciliation. We therefore applied RANGER-DTLx, ecceTERA, and RANGER-DTL (which implements the traditional DTL reconciliation framework) to both simulated datasets and evaluated the overall accuracies of the resulting reconciliations. Note that, for a fair comparison, we only compared reconciliation accuracy across the nodes present on the input gene trees, without inclusion of any hidden nodes inferred by RANGER-DTLx.
For an inferred reconciliation , let , , , , and denote the sets of speciation nodes, duplication nodes, standard transfer nodes, mappings for internal nodes of G, and transfer recipients for standard transfers, respectively. The sets , , , , and are defined analogously for the ground truth reconciliation . Overall accuracy is quantified through the following three metrics:
To account for multiple optimal reconciliations, we used the standard approach of assigning the most well supported mapping and event type for each of the three methods/software. Specifically, 100 random optimal reconciliations were sampled for each gene tree/species tree pair, for both RANGER-DTLx and RANGER-DTL, and each gene tree node was assigned the most frequently observed mapping and event type among the 100 samples [11]. A similar procedure was followed for ecceTERA, but based on the reconciliation graph computed by ecceTERA [12], rather than on uniform random sampling.
Recall that, unlike ecceTERA, our DTLx reconciliation framework allows for independent assignment of and event costs. We therefore tried two different costs for events in all our experiments: 3 and 4. We fixed the cost of a event at 4. The costs for other events were fixed as follows for all three methods: Loss cost = 1, duplication cost = 2, and transfer cost = 3, which correspond to the defaults used in RANGER-DTL and ecceTERA. Based on these costs, ecceTERA automatically assigns events a cost of 4 (equivalent to one transfer plus one loss), and events a cost of 3 (equivalent to one transfer event).
The results of our analysis appear in Table 2. As the table shows, RANGER-DTL, RANGER-DTLx with cost 4, and ecceTERA have nearly indistinguishable reconciliation accuracies across both datasets, while RANGER-DTLx with cost 3 shows slightly worse event and mapping accuracies but slightly better recipient accuracy. These results suggest that models that account for and events may not result in improved overall reconciliation accuracy compared to traditional DTL reconciliation, at least for low to moderate rates of events as in our datasets. Importantly, these results also show that allowing for and events does not worsen reconciliation accuracy, even when the rate of events is low (Dataset-1).
Accuracy of event detection. Next, we assessed how well RANGER-DTLx and ecceTERA can infer ground-truth events. We labelled transfers from unsampled lineages as ground truth events if, in the event log generated by ZOMBI, the gene survives in an extant lineage but the original copy goes extinct. While the original name of the internal gene tree node representing the extinct gene is absent from the input gene tree, we can verify if either method correctly detects this transfer by looking for a event with the same recipient as the ground truth transfer.
We first assessed how well events were detected, in terms of precision and recall, in a single random optimal reconciliation computed by each method. Table 3 shows the results of this analysis, which reveals several interesting insights. First, and perhaps most strikingly, we find that none of the methods shows high precision in detecting events, with ecceTERA and RANGER-DTLx with cost 3 both showing 10% precision in the two datasets, and RANGER-DTLx with cost 4 showing much higher, but still relatively low, precision of 17.24% in Dataset-1 and 29.41% in Dataset-2. Second, we find that RANGER-DTLx with cost 3 and ecceTERA, despite using effectively the same event costs, differ dramatically in the number of events they infer. For example, for Dataset-1, ecceTERA infers only 413 events across all 500 gene trees with recall and precision of 2.61% and 9.44%, respectively, and RANGER-DTLx with cost 3 infers 4515 events with recall and precision of 30.12% and 9.97%. Furthermore, third, these results show that there is a clear tradeoff between sensitivity and precision of event inference and suggest that RANGER-DTLx with cost 4 should be the method of choice for event inference if precision is more important than recall, while RANGER-DTLx with cost 3 should be used if recall is more important than precision. This experiment also highlights the utility of allowing for a user-specifiable cost for events as permitted under our model but not under ecceTERA.
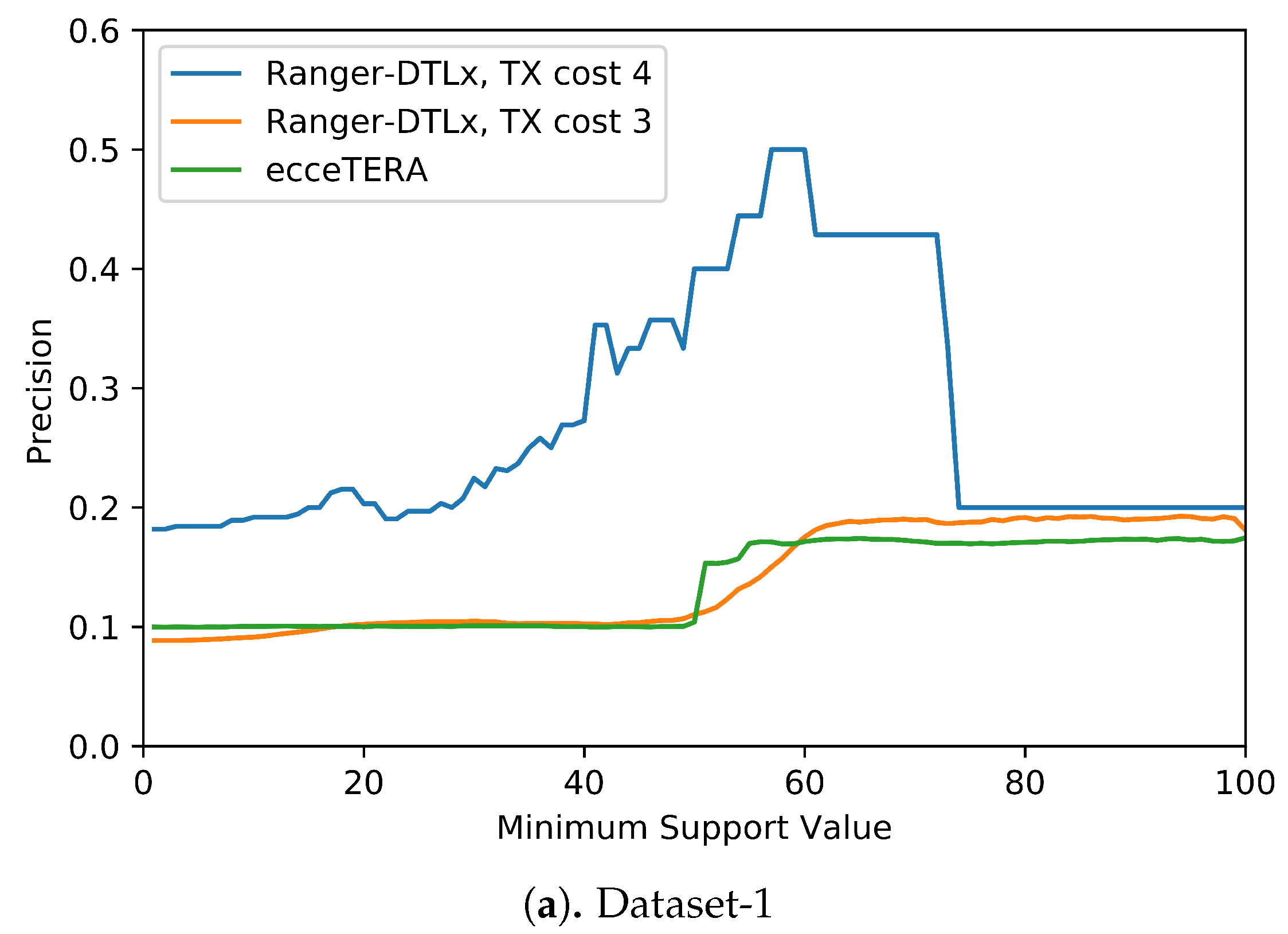
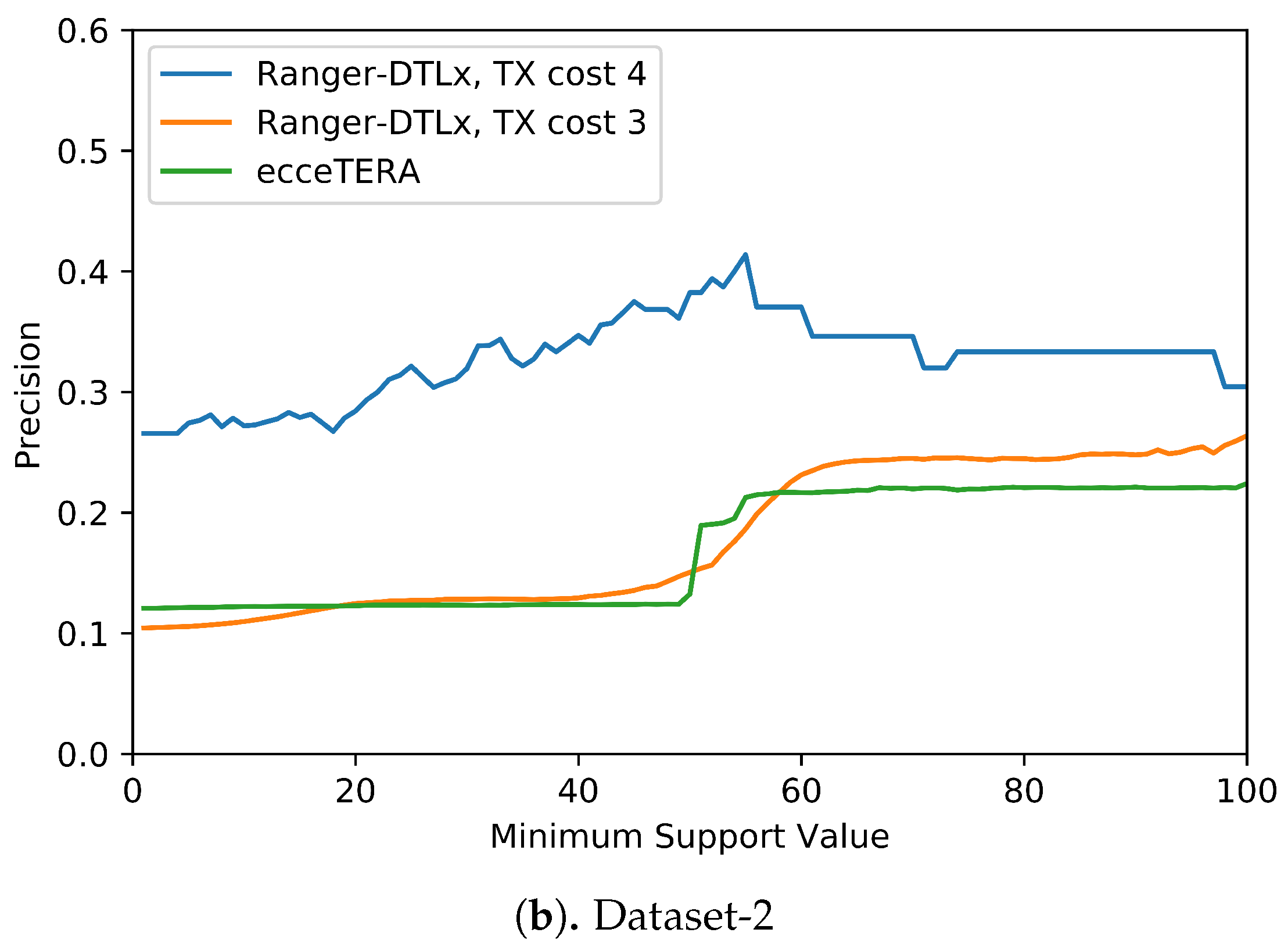
We also assessed if inferred events that have higher support (i.e., are inferred in at least some fraction of all optimal reconciliations for that gene tree) are more likely to be correct (i.e., show higher precision). Figure 5 shows the results of this analysis. These results suggest that higher support values do tend to result in greater precision. More precisely, we find that RANGER-DTLx with cost 3 and ecceTERA both shown similar trends in precision, with precision on Dataset-1 increasing from a low of about 0.1 for all inferred events irrespective of support to a high of about 0.18 if only considering events with 100% support, and precision on Dataset-2 increasing from about 0.1 for all inferred events irrespective of support to a high of approximately 0.25 if only considering events with 100% support. However, as expected, the increase in precision comes at the expense of recall (Table 4). For example, on Dataset-2, RANGER-DTLx with cost 3 infers a total of 14,134 distinct events with support among 100 optimal reconciliation samples but only 940 of these have 100% support, and the corresponding numbers for ecceTERA are 12,884 and 2088, respectively. Remarkably, as Figure 5 shows, RANGER-DTLx with cost 4 achieves a precision of almost 50% on Dataset-1 and over 40% on Dataset-2 when using a support threshold of about 55%. However, as Table 4 shows, the number of events inferred at that support level by RANGER-DTLx with cost 4 is relatively small. The small number of these events likely explains the drop in precision for RANGER-DTLx with cost 4 as the support threshold in increased past ∼60.
Phylogenetic placement of event donors. Identifying the locations on the species tree of unsampled lineages that served as donors for events can offer important insights regarding major unsampled species lineages and can help to better understand the evolutionary histories of gene families. By design, RANGER-DTLx identifies a specific edge/lineage in the species tree where any given event originates from. However, ecceTERA handles events by introducing a single unsampled branch existing outside of the species tree, which represents all unsampled lineages on the species tree and serves as the donor of all events. This makes it difficult to infer the location of unsampled donor lineages on the species tree using ecceTERA. To assess the accuracy of RANGER-DTLx in identifying/placing the unsampled species donor on the species tree, we used all events (across all 100 samples, regardless of support) inferred by RANGER-DTLx that mapped to the correct recipient species and computed the distance on the species tree between the inferred location of the donor and the actual location of the donor (as given by Zombi). This distance is defined as the number of edges between the inferred donor lineage and the true lineage on the full species tree (including extinct lineages) as simulated by Zombi. As Table 5 shows, RANGER-DTLx performs remarkably well at inferring the location of the unsampled species donor on the species tree, identifying the exact location for almost half the events when the event cost is 3. Results are worse for RANGER-DTLx with cost 4, but this is likely due to small sample sizes. These results also show that even when the donor lineage is not identified exactly, the inferred placement is often close to the actual placement of the unsampled donor. For completeness, results are also shown for ecceTERA and, as expected, the performance of ecceTERA is much worse than that of RANGER-DTLx, both for exact matches and average distance.
4.2. Biological Data
We also applied RANGER-DTLx to a real biological dataset of over 4500 gene trees from 100 broadly sampled, predominantly microbial, species [5]. Specifically, this dataset consisted of 4547 TreeFix-DTL-corrected gene trees [30] rooted using the OptRoot method implemented in RANGER-DTL 2.0 [17]. We partitioned this dataset into three subsets based on the number of taxa present in the gene trees: less than 50 taxa, between 50–100 taxa, and more than 100 taxa. These subsets represent 76.4% (3474), 16.8% (765), and 6.8% (308) of the total number of gene trees, respectively.
We measured the impact, in practice, of allowing for and events by (i) counting the number of gene trees for which the cost of an optimal reconciliation decreases when and are allowed, and (ii) counting the number of gene trees for which the cost of an optimal reconciliation does not decrease but for which there exist optimal reconciliations that invoke or events. We found that only 28 gene trees showed a reduction in reconciliation cost when reconciled using RANGER-DTLx with a cost of 4 as compared to using RANGER-DTL. This number increases to 76 when a smaller cost of 3 is used. However, as Table 6 shows, 50.7% of the gene trees, and nearly all of the gene trees with at least 50 leaves, had more optimal reconciliations even when using RANGER-DTLx with the higher cost of 4. This is a result of some (but not all) of the co-optimal reconciliations invoking and/or events. These results suggest that while and events clearly lead to more parsimonious reconciliations in some cases for many gene trees it may be difficult to confidently infer if and events have in fact occurred.
Runtime analysis. We also compared the runtimes of ecceTERA (undated version), RANGER-DTL, and RANGER-DTLx. Average runtimes for these methods on the three subsets of the biological dataset are shown in Table 7. As the table shoes, RANGER-DTL and ecceTERA are both extremely efficient, averaging a runtime of smaller than 1 s on all three subsets. As expected, given the increased complexity of the model, RANGER-DTLx takes longer than RANGER-DTL and ecceTERA on all three subsets but still remains highly efficient and scalable, averaging just a few seconds on even the subset with the largest gene trees. All timed experiments were run using a single core on a 2.8 GHz × 4 Intel Core i7 processor with 16 GB of RAM.
5. Discussion and Conclusions
In this work, we introduced an extension of the classical DTL reconciliation model, called the DTLx reconciliation model, that accounts for extinct or unsampled species lineages and allows for and events. The resulting method, RANGER-DTLx, handles these additional evolutionary events in a more functional manner compared to ecceERA, the only other parsimony-based model that also handles these events, while matching the time complexity of the fastest known algorithms for DTL reconciliation. Perhaps the most important contribution of this work is our systematic evaluation of the impact of accounting for and events and unsampled lineages on the accuracy of DTL reconciliation and of our ability to correctly detect events. This evaluation, using both simulated and biological data, reveals many new insights that are important for understanding and interpreting microbial gene family evolution and that can inform the development of more sophisticated reconciliation models: First, we find that DTLx reconciliation (i.e., both RANGER-DTLx and ecceTERA) does not noticeably result in improved overall reconciliation accuracy compared to the simpler DTL reconciliation model. Second, we find that there is a very clear tradeoff between the precision and recall of event detection, with precision remaining below 50% for even the most restrictive selection of events and generally staying below 20% for non-negligible values (say, >0.3) of recall. Furthermore, third, our results on the biological dataset indicate that while allowing for and events leads to more parsimonious reconciliations in some cases, for the majority of gene trees and events lead to co-optimal reconciliations that can make it difficult to confidently infer if and events have, in fact, occurred. Nonetheless, we do find that DTLx reconciliation is indeed capable of identifying at least some events with reasonable confidence and that RANGER-DTLx is actually able to find the phylogenetic placement of the unsampled donor of a event with fairly high accuracy.
Our experimental results suggest that it may be possible to use RANGER-DTLx to identify and locate major unsampled lineages on the tree of life and it would be interesting to further explore this application of the new DTLx reconciliation model. Several aspects of the proposed model could also be improved or evaluated further. In particular, though the proposed DTLx reconciliation model uses an undated species tree, the model can be easily extended to work with fully dated species trees. It is possible that the use of dated species trees may help to improve the precision and recall of event inference and this possibility should be explored further. In particular, the use of a dated species tree can help identify transfers that appear to be going forward in time (i.e., where the recipient of a transfer event appears to be more recent than its donor), suggesting the presence of events. Likewise, though RANGER-DTLx allows for the use of distance-dependant transfer costs, we did not evaluate the impact of using this feature in our current study. Using distance-dependent transfer costs (including and costs) may help to improve inference accuracy. Finally, our experimental study suggests that precise detection of events may be difficult to achieve using phylogenetic reconciliation alone, and that additional techniques may be needed to more accurately detect and account for events in microbial gene family evolution.
Author Contributions
Conceptualization, M.S.B.; Methodology, M.S.B. and S.W.; Software, S.W.; Validation, M.S.B. and S.W.; Formal Analysis, M.S.B. and S.W.; Investigation, S.W.; Resources, M.S.B.; Data Curation, M.S.B. and S.W.; Writing—Original Draft Preparation, S.W.; Writing—Review & Editing, M.S.B.; Visualization, S.W.; Supervision, M.S.B.; Project Administration, M.S.B.; Funding Acquisition, M.S.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by US National Science Foundation grants MCB 1616514 and IES 1615573 to M.S.B.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Our software implementation is freely available open-source as the program RANGER-DTLx from https://compbio.engr.uconn.edu/software/RANGER-DTLx/ (accessed on 3 August 2021). The simulated and real datasets used in this study are freely available from the same URL.
Conflicts of Interest
The authors declare no conflict of interest. The funding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Tofigh, A. Using Trees to Capture Reticulate Evolution: Lateral Gene Transfers and Cancer Progression. Ph.D. Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2009. [Google Scholar]
- Gorbunov, K.Y.; Liubetskii, V.A. Reconstructing genes evolution along a species tree. Molekuliarnaia Biologiia 2009, 43, 946–958. [Google Scholar] [CrossRef] [PubMed]
- Doyon, J.P.; Scornavacca, C.; Gorbunov, K.Y.; Szöllosi, G.J.; Ranwez, V.; Berry, V. An Efficient Algorithm for Gene/Species Trees Parsimonious Reconciliation with Losses, Duplications and Transfers. In Research in Computational Molecular Biology—Comparative Genomics; Tannier, E., Ed.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6398, pp. 93–108. [Google Scholar]
- Tofigh, A.; Hallett, M.T.; Lagergren, J. Simultaneous Identification of Duplications and Lateral Gene Transfers. IEEE/ACM Trans. Comput. Biol. Bioinform. 2011, 8, 517–535. [Google Scholar] [CrossRef]
- David, L.A.; Alm, E.J. Rapid evolutionary innovation during an Archaean genetic expansion. Nature 2011, 469, 93–96. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.Z.; Deng, F.; Wang, L. Simultaneous Identification of Duplications, Losses, and Lateral Gene Transfers. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 1515–1528. [Google Scholar] [CrossRef] [Green Version]
- Bansal, M.S.; Alm, E.J.; Kellis, M. Efficient algorithms for the reconciliation problem with gene duplication, horizontal transfer and loss. Bioinformatics 2012, 28, 283–291. [Google Scholar] [CrossRef]
- Stolzer, M.; Lai, H.; Xu, M.; Sathaye, D.; Vernot, B.; Durand, D. Inferring duplications, losses, transfers and incomplete lineage sorting with nonbinary species trees. Bioinformatics 2012, 28, 409–415. [Google Scholar] [CrossRef] [Green Version]
- Szollosi, G.J.; Boussau, B.; Abby, S.S.; Tannier, E.; Daubin, V. Phylogenetic modeling of lateral gene transfer reconstructs the pattern and relative timing of speciations. Proc. Natl. Acad. Sci. USA 2012, 109, 17513–17518. [Google Scholar] [CrossRef] [Green Version]
- Szollosi, G.J.; Tannier, E.; Lartillot, N.; Daubin, V. Lateral Gene Transfer from the Dead. Syst. Biol. 2013, 62, 386–397. [Google Scholar] [CrossRef]
- Bansal, M.S.; Alm, E.J.; Kellis, M. Reconciliation Revisited: Handling Multiple Optima when Reconciling with Duplication, Transfer, and Loss. J. Comput. Biol. 2013, 20, 738–754. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scornavacca, C.; Paprotny, W.; Berry, V.; Ranwez, V. Representing a Set of Reconciliations in a Compact Way. J. Bioinform. Comput. Biol. 2013, 11, 1250025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Libeskind-Hadas, R.; Wu, Y.C.; Bansal, M.S.; Kellis, M. Pareto-optimal phylogenetic tree reconciliation. Bioinformatics 2014, 30, i87–i95. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sjostrand, J.; Tofigh, A.; Daubin, V.; Arvestad, L.; Sennblad, B.; Lagergren, J. A Bayesian Method for Analyzing Lateral Gene Transfer. Syst. Biol. 2014, 63, 409–420. [Google Scholar] [CrossRef] [Green Version]
- Scornavacca, C.; Jacox, E.; Szöllosi, G.J. Joint amalgamation of most parsimonious reconciled gene trees. Bioinformatics 2015, 31, 841–848. [Google Scholar] [CrossRef] [Green Version]
- Jacox, E.; Chauve, C.; Szollosi, G.J.; Ponty, Y.; Scornavacca, C. ecceTERA: Comprehensive gene tree-species tree reconciliation using parsimony. Bioinformatics 2016, 32, 2056. [Google Scholar] [CrossRef]
- Bansal, M.S.; Kellis, M.; Kordi, M.; Kundu, S. RANGER-DTL 2.0: Rigorous reconstruction of gene-family evolution by duplication, transfer and loss. Bioinformatics 2018, 34, 3214–3216. [Google Scholar] [CrossRef]
- Kordi, M.; Bansal, M.S. Exact Algorithms for Duplication-Transfer-Loss Reconciliation with Non-Binary Gene Trees. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 16, 1077–1090. [Google Scholar] [CrossRef]
- Merkle, D.; Middendorf, M.; Wieseke, N. A parameter-adaptive dynamic programming approach for inferring cophylogenies. BMC Bioinform. 2010, 11, S60. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Conow, C.; Fielder, D.; Ovadia, Y.; Libeskind-Hadas, R. Jane: A new tool for the cophylogeny reconstruction problem. Algorithms Mol. Biol. 2010, 5, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donati, B.; Baudet, C.; Sinaimeri, B.; Crescenzi, P.; Sagot, M.F. EUCALYPT: Efficient tree reconciliation enumerator. Algorithms Mol. Biol. 2015, 10, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Santichaivekin, S.; Yang, Q.; Liu, J.; Mawhorter, R.; Jiang, J.; Wesley, T.; Wu, Y.C.; Libeskind-Hadas, R. eMPRess: A systematic cophylogeny reconciliation tool. Bioinformatics 2020, btaa978. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.; Gogarten, J.P.; Papke, R.T. Quantifying Homologous Replacement of Loci between Haloarchaeal Species. Genome Biol. Evol. 2012, 4, 1223–1244. [Google Scholar] [CrossRef] [Green Version]
- Ovadia, Y.; Fielder, D.; Conow, C.; Libeskind-Hadas, R. The Cophylogeny Reconstruction Problem Is NP-Complete. J. Comput. Biol. 2011, 18, 59–65. [Google Scholar] [CrossRef]
- Libeskind-Hadas, R.; Charleston, M. On the Computational Complexity of the Reticulate Cophylogeny Reconstruction Problem. J. Comput. Biol. 2009, 16, 105–117. [Google Scholar] [CrossRef]
- Hasić, D.; Tannier, E. Gene tree reconciliation including transfers with replacement is NP-hard and FPT. J. Comb. Optim. 2019, 38, 502–544. [Google Scholar] [CrossRef] [Green Version]
- Kordi, M.; Kundu, S.; Bansal, M.S. On Inferring Additive and Replacing Horizontal Gene Transfers Through Phylogenetic Reconciliation. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Niagara Falls, NY, USA, 7–10 September 2019; pp. 514–523. [Google Scholar] [CrossRef] [Green Version]
- Zhaxybayeva, O.; Gogarten, J.P. Horizontal gene transfer, gene histories, and the root of the tree of life. In Planetary Systems and the Origins of Life; Pudritz, R., Higgs, P., Stone, J., Eds.; Cambridge Astrobiology; Cambridge University Press: Cambridge, UK, 2007; pp. 178–192. [Google Scholar] [CrossRef]
- Davín, A.A.; Tricou, T.; Tannier, E.; de Vienne, D.N.; Szollosi, G.J. Zombi: A phylogenetic simulator of trees, genomes and sequences that accounts for dead linages. Bioinformatics 2019, 36, 1286–1288. [Google Scholar] [CrossRef] [PubMed]
- Bansal, M.S.; Wu, Y.C.; Alm, E.J.; Kellis, M. Improved gene tree error correction in the presence of horizontal gene transfer. Bioinformatics 2015, 31, 1211–1218. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Figure 1.
Illustration of the difference between (a) a standard transfer event and (b) a event.

Figure 2.
An example gene tree (a) and a possible augmented version with hidden nodes in blue (b).

Figure 3.
Representation of unsampled lineages on the species tree. (a) Illustration of the “coral” of life based on drawings by Darwin, where black lines represent lineages leading to extant species, and grey lines represent potential unsampled species; adapted from [28]. (b) Input species tree before augmentation. (c) Augmented species tree. Extra nodes are in green and extra leaves are in white. Leaves labeled A-D represent extant species. Unsampled lineages are represented by the edges connecting extra nodes and extra leaves.
Figure 3.
Representation of unsampled lineages on the species tree. (a) Illustration of the “coral” of life based on drawings by Darwin, where black lines represent lineages leading to extant species, and grey lines represent potential unsampled species; adapted from [28]. (b) Input species tree before augmentation. (c) Augmented species tree. Extra nodes are in green and extra leaves are in white. Leaves labeled A-D represent extant species. Unsampled lineages are represented by the edges connecting extra nodes and extra leaves.

Figure 4.
Impact of and events on optimal DTLx reconciliations. (a) and (b) are the input gene tree and input species tree , respectively. (c) An augmented version of containing a single hidden node as required by the reconciliations shown in Parts (e,f). (d) An optimal DTL reconciliation of and illustrating how the gene tree (blue lines) may have evolved within the species tree (tubes) without the use of or events. This DTL reconciliation invokes two transfer events and two losses. All reconciliations shown in this figure use event costs of 1, 2, 3, 4, and 3 for losses, duplications, transfers, , and events, respectively. Thus, we get a total reconciliation cost of 8 for this optimal DTL reconciliation. (e) An optimal reconciliation of G and S that uses events but not events. This reconciliation utilizes the hidden node h1 in to facilitate a event from species E to species B. It invokes one transfer event and one event, for a total reconciliation cost of 7. (f) An optimal DTLx reconciliation of G and S. This DTLx reconciliation utilizes the hidden node h1 in to facilitate a event. It invokes one transfer event and one event, for a total reconciliation cost of 6. Accordingly, the reconciliation shown in (f) makes use of an extra leaf and extra node on (dotted green tube).
Figure 4.
Impact of and events on optimal DTLx reconciliations. (a) and (b) are the input gene tree and input species tree , respectively. (c) An augmented version of containing a single hidden node as required by the reconciliations shown in Parts (e,f). (d) An optimal DTL reconciliation of and illustrating how the gene tree (blue lines) may have evolved within the species tree (tubes) without the use of or events. This DTL reconciliation invokes two transfer events and two losses. All reconciliations shown in this figure use event costs of 1, 2, 3, 4, and 3 for losses, duplications, transfers, , and events, respectively. Thus, we get a total reconciliation cost of 8 for this optimal DTL reconciliation. (e) An optimal reconciliation of G and S that uses events but not events. This reconciliation utilizes the hidden node h1 in to facilitate a event from species E to species B. It invokes one transfer event and one event, for a total reconciliation cost of 7. (f) An optimal DTLx reconciliation of G and S. This DTLx reconciliation utilizes the hidden node h1 in to facilitate a event. It invokes one transfer event and one event, for a total reconciliation cost of 6. Accordingly, the reconciliation shown in (f) makes use of an extra leaf and extra node on (dotted green tube).

Figure 5.
Impact of increasing support values on event accuracy. The support for an event is defined as the percentage of optimal solution space that the event appears in.
Figure 5.
Impact of increasing support values on event accuracy. The support for an event is defined as the percentage of optimal solution space that the event appears in.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Parameter settings used to generate simulated datasets using Zombi.
| Gene Tree Parameters | Species Tree Parameters | |||||
|---|---|---|---|---|---|---|
| Dataset | Duplication Rate | Transfer Rate | Loss Rate | Birth Rate | Extinction Rate | # Taxa (Leaves) |
| 1 | 0.022 | 0.04 | 0.01 | 0.1 | 0.025 | 50 |
| 2 | 0.020 | 0.06 | 0.008 | 0.1 | 0.032 | 50 |
Table 2.
Overall reconciliation accuracy. Average reconciliation accuracy, in terms of mapping accuracy and event assignment accuracy, is shown for each method. Event/mapping accuracy for a given input gene tree is calculated as the total number of correct events/mappings divided by the total number of internal nodes in that gene tree. The table also shows the accuracy of inferred recipients for transfer events. This recipient accuracy for each gene tree is calculated as the total number of correctly identified recipients divided by the total number of correctly identified transfers. Results are averaged across the 500 gene tree/species tree pairs in each dataset.
Table 2.
Overall reconciliation accuracy. Average reconciliation accuracy, in terms of mapping accuracy and event assignment accuracy, is shown for each method. Event/mapping accuracy for a given input gene tree is calculated as the total number of correct events/mappings divided by the total number of internal nodes in that gene tree. The table also shows the accuracy of inferred recipients for transfer events. This recipient accuracy for each gene tree is calculated as the total number of correctly identified recipients divided by the total number of correctly identified transfers. Results are averaged across the 500 gene tree/species tree pairs in each dataset.
| Dataset-1 | |||
| Event Accuracy | Mapping Accuracy | Recipient Accuracy | |
| RANGER-DTL | 0.961 | 0.937 | 0.682 |
| RANGER-DTLx, | 0.961 | 0.939 | 0.697 |
| RANGER-DTLx, | 0.917 | 0.895 | 0.716 |
| ecceTERA | 0.961 | 0.937 | 0.704 |
| Dataset-2 | |||
| Event Accuracy | Mapping Accuracy | Recipient Accuracy | |
| RANGER-DTL | 0.944 | 0.912 | 0.623 |
| RANGER-DTLx, | 0.944 | 0.912 | 0.637 |
| RANGER-DTLx, | 0.894 | 0.861 | 0.670 |
| ecceTERA | 0.945 | 0.910 | 0.650 |
Table 3.
Accuracy of event detection. The precision and recall for events inferred by each method are shown. A single optimal reconciliation is used per gene tree, and results are aggregated across all 500 gene tree/species tree pairs in each dataset.
Table 3.
Accuracy of event detection. The precision and recall for events inferred by each method are shown. A single optimal reconciliation is used per gene tree, and results are aggregated across all 500 gene tree/species tree pairs in each dataset.
| Dataset-1 | Dataset-2 | |||||
|---|---|---|---|---|---|---|
| s Returned | Recall | Precision | s Returned | Recall | Precision | |
| RANGER-DTLx, | 29 | 0.33% | 17.24% | 51 | 0.52% | 29.41% |
| RANGER-DTLx, | 4515 | 30.12% | 9.97% | 6740 | 29.94% | 12.73% |
| ecceTERA | 413 | 2.61% | 9.44% | 668 | 3.16% | 13.62% |
Table 4.
Number of events inferred by the different methods, along with their precision, are shown for different minimum support value cutoffs. Results are aggregated across all 500 gene tree/species tree pairs in each dataset and presented in the form , where b is the total number of distinct events inferred across 100 randomly sampled optimal reconciliations for RANGER-DTLx and across the entire optimal solution space for ecceTERA for each gene tree, and a is the number of these events that are correct.
Table 4.
Number of events inferred by the different methods, along with their precision, are shown for different minimum support value cutoffs. Results are aggregated across all 500 gene tree/species tree pairs in each dataset and presented in the form , where b is the total number of distinct events inferred across 100 randomly sampled optimal reconciliations for RANGER-DTLx and across the entire optimal solution space for ecceTERA for each gene tree, and a is the number of these events that are correct.
| Dataset-1 | Dataset-2 | |||||
|---|---|---|---|---|---|---|
| Support | RANGER-DTLx, | RANGER-DTLx, | ecceTERA | RANGER-DTLx, | RANGER-DTLx, | ecceTERA |
| >0 | 14,134 | 12,884 | ||||
| ≥25% | 11,141 | 12,252 | ||||
| ≥50% | ||||||
| ≥75% | ||||||
| =100% | ||||||
Table 5.
Accuracy of placing unsampled species donors on the species tree. All events inferred by each method, regardless of support, for which the recipient species was identified correctly were used for this analysis. The inferred unsampled donor is considered an exact match if the location of the donor lineage on the species tree is the same as the true location of the donor. Numbers for events considered and exact matches are aggregated across all 500 gene tree/species tree pairs in each dataset. The distance between the inferred and true locations of the donor is defined to be the number of edges between the inferred donor lineage and the true lineage on the full species tree (including extinct lineages) as simulated by Zombi.
Table 5.
Accuracy of placing unsampled species donors on the species tree. All events inferred by each method, regardless of support, for which the recipient species was identified correctly were used for this analysis. The inferred unsampled donor is considered an exact match if the location of the donor lineage on the species tree is the same as the true location of the donor. Numbers for events considered and exact matches are aggregated across all 500 gene tree/species tree pairs in each dataset. The distance between the inferred and true locations of the donor is defined to be the number of edges between the inferred donor lineage and the true lineage on the full species tree (including extinct lineages) as simulated by Zombi.
| Dataset-1 | Dataset-2 | |||||
|---|---|---|---|---|---|---|
| # Considered | Exact Matches | Average Distance | # Considered | Exact Matches | Average Distance | |
| RANGER-DTLx Cost 4 | 14 | 3 (21.4%) | 1.71 | 34 | 13 (38.2%) | 2.17 |
| RANGER-DTLx Cost 3 | 857 | 473 (55.2%) | 1.52 | 1475 | 689 (46.7%) | 2.03 |
| ecceTERA | 926 | 23 (2.5%) | 4.90 | 1554 | 36 (2.8%) | 6.21 |
Table 6.
Number of biological dataset gene trees that result in additional co-optimal reconciliations invoking and/or events. These results are based on event costs of 1, 2, 3, 4, and 4, for losses, duplications, transfers, , and , respectively.
Table 6.
Number of biological dataset gene trees that result in additional co-optimal reconciliations invoking and/or events. These results are based on event costs of 1, 2, 3, 4, and 4, for losses, duplications, transfers, , and , respectively.
| Dataset Size | Total # Gene Trees | Gene Trees with Additional Co-Optimal Solutions |
|---|---|---|
| <50 taxa | 3474 | 1350 (38.9%) |
| 50–100 taxa | 765 | 667 (87.2%) |
| >100 taxa | 308 | 292 (94.8%) |
Table 7.
Runtime comparison on the biological dataset.
| Dataset Size | RANGER-DTL | RANGER-DTLx | ecceTERA |
|---|---|---|---|
| <50 leaves | <1 s | s | <1 s |
| 50–100 leaves | <1 s | s | <1 s |
| >100 leaves | <1 s | s | <1 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Weiner, S.; Bansal, M.S. Improved Duplication-Transfer-Loss Reconciliation with Extinct and Unsampled Lineages. Algorithms 2021, 14, 231. https://0-doi-org.brum.beds.ac.uk/10.3390/a14080231
AMA Style
Weiner S, Bansal MS. Improved Duplication-Transfer-Loss Reconciliation with Extinct and Unsampled Lineages. Algorithms. 2021; 14(8):231. https://0-doi-org.brum.beds.ac.uk/10.3390/a14080231
Chicago/Turabian StyleWeiner, Samson, and Mukul S. Bansal. 2021. "Improved Duplication-Transfer-Loss Reconciliation with Extinct and Unsampled Lineages" Algorithms 14, no. 8: 231. https://0-doi-org.brum.beds.ac.uk/10.3390/a14080231
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.