
Sequential Recommendation through Graph Neural Networks and Transformer Encoder with Degree Encoding

 , , , , , and
, , , , , and
Abstract
:1. Introduction
- (1)
- We propose a novel framework GCNTRec to learn effective item representation in a user historical behavior sequence. Specifically:
- Using GCN to extract features from graphs constructed under heterogeneous information networks can mine richer adjacency relationships between nodes.
- The transformer encoder with degree encoding intends to learn an object-rich sequence feature representation, which involves capturing long-term preference information and improving the quality of locating the contextual information of a sequence.
- (2)
- The experimental results show that GCNTRec outperforms previous techniques on five widely used datasets.
2. Related Work
2.1. Traditional Recommendation Algorithm
2.1.1. Recommendation Algorithm Based on Collaborative Filtering
2.1.2. Recommendation Algorithm Based on Deep Learning
2.2. Sequence Recommendation Algorithm
2.2.1. Sequence Recommendation Algorithm Based on Markov Chain
2.2.2. Sequence Recommendation Algorithm Based on Recurrent Neural Network
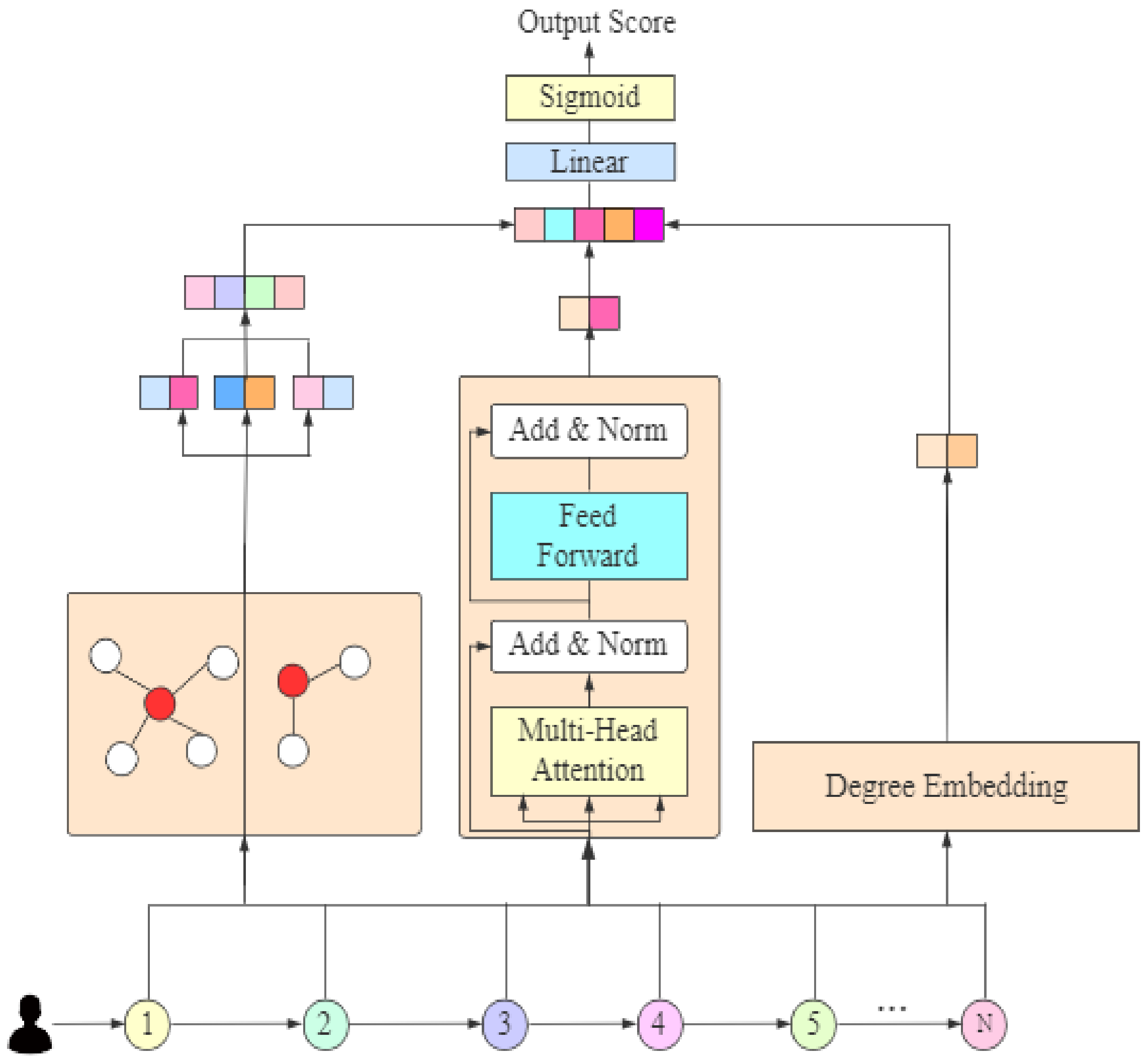
3. Our Model
3.1. Item Embedding
3.2. Graph Convolutional Network
3.3. Transformer
3.3.1. Degree Encoding
3.3.2. Transformer Encoder
3.4. User Feature Representation
| Algorithm 1 Sequential recommendation algorithm based on graph neural network and improved transformer. |
Input: The set of meta paths R; The set of graph data based on meta-path G; Item feature vector X; The adjacency matrix corresponding to the graph data A; The degree matrix corresponding to the graph data D; Target user behavior sequence L; Number of training cycles . Output:W, b model related parameters.
|
4. Experiments
4.1. Setup
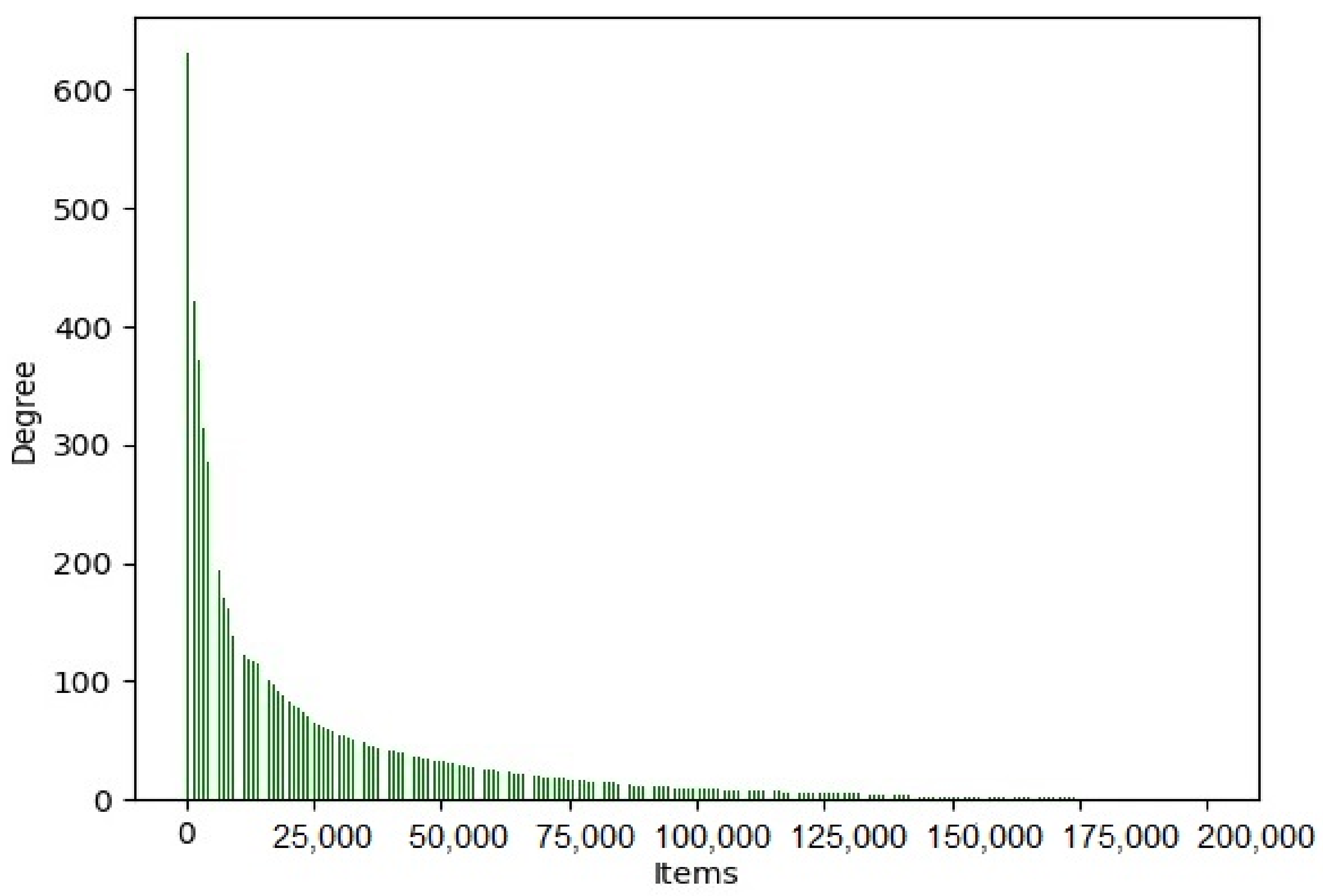
4.1.1. Datasets
4.1.2. Metrics
4.1.3. Baselines
4.1.4. Hyperparameters
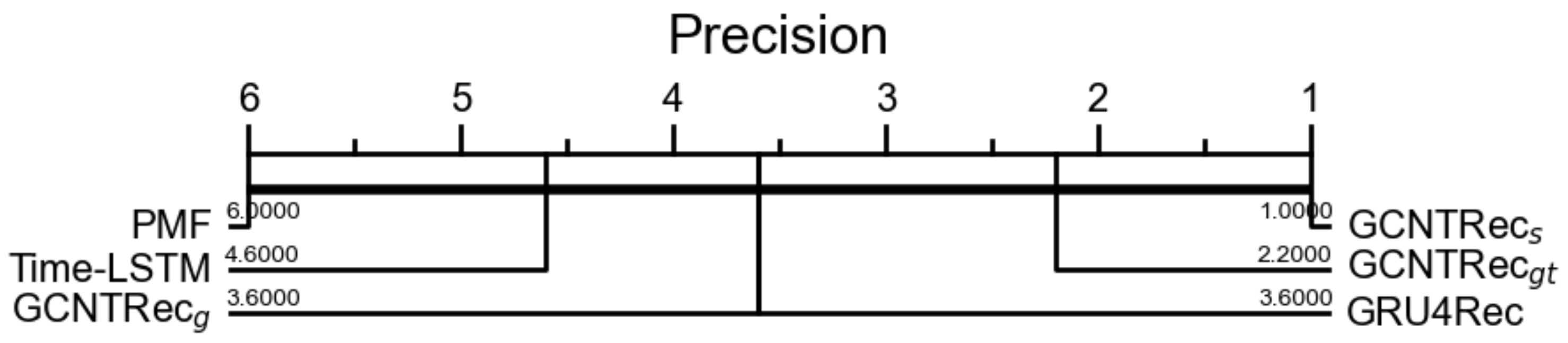
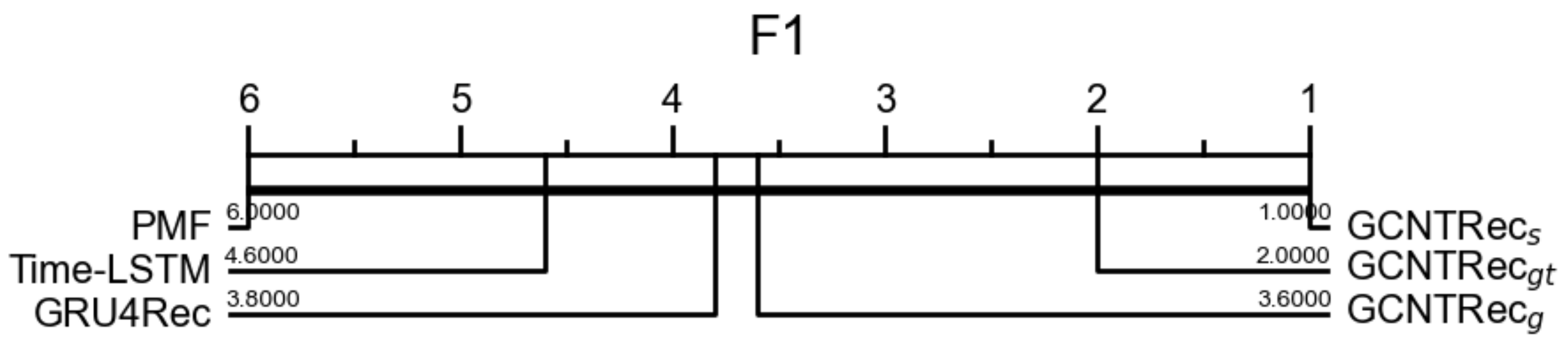
4.2. Results and Analysis
4.2.1. Overall Results
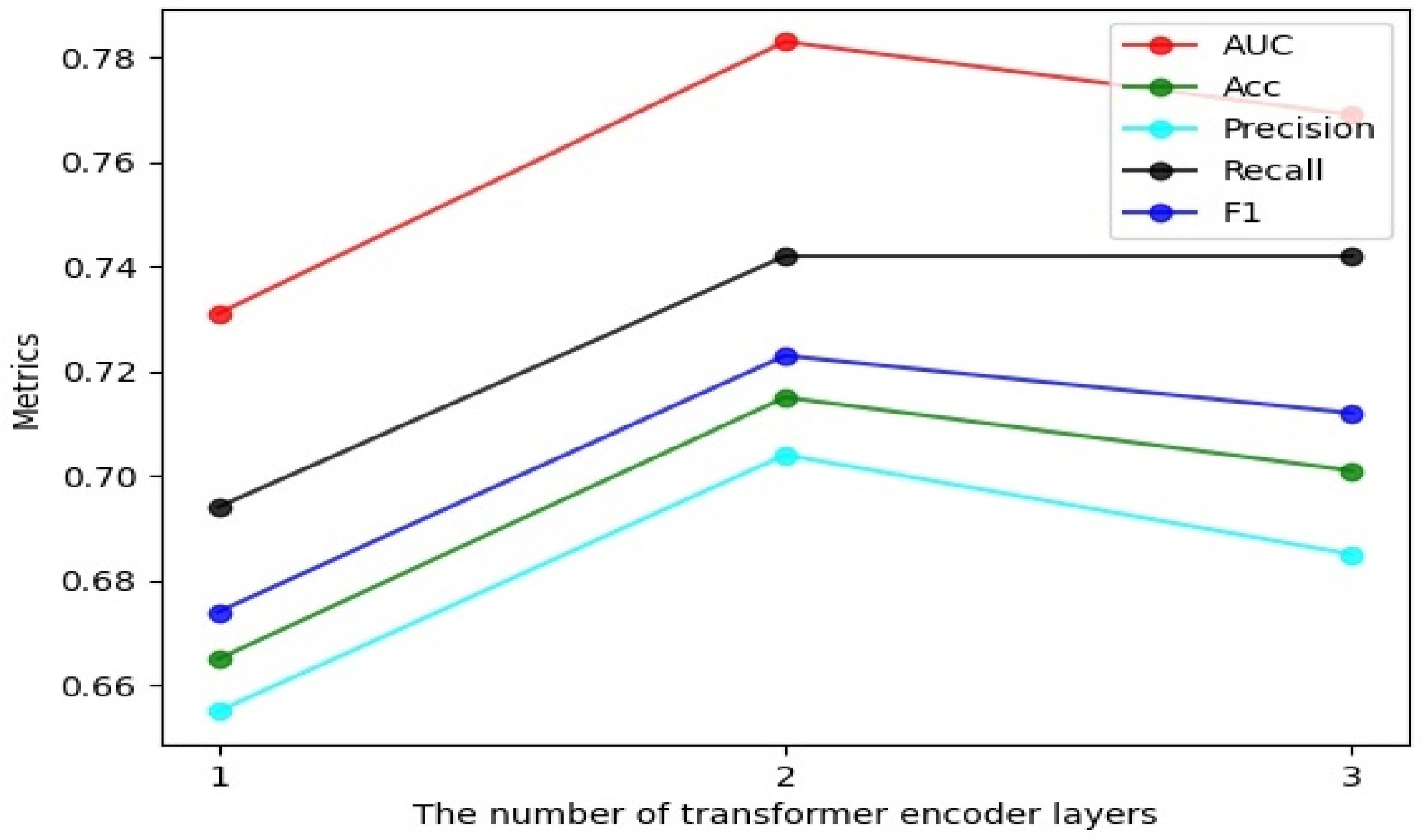
4.2.2. Effect of the Number of Transformer Encoder Layers
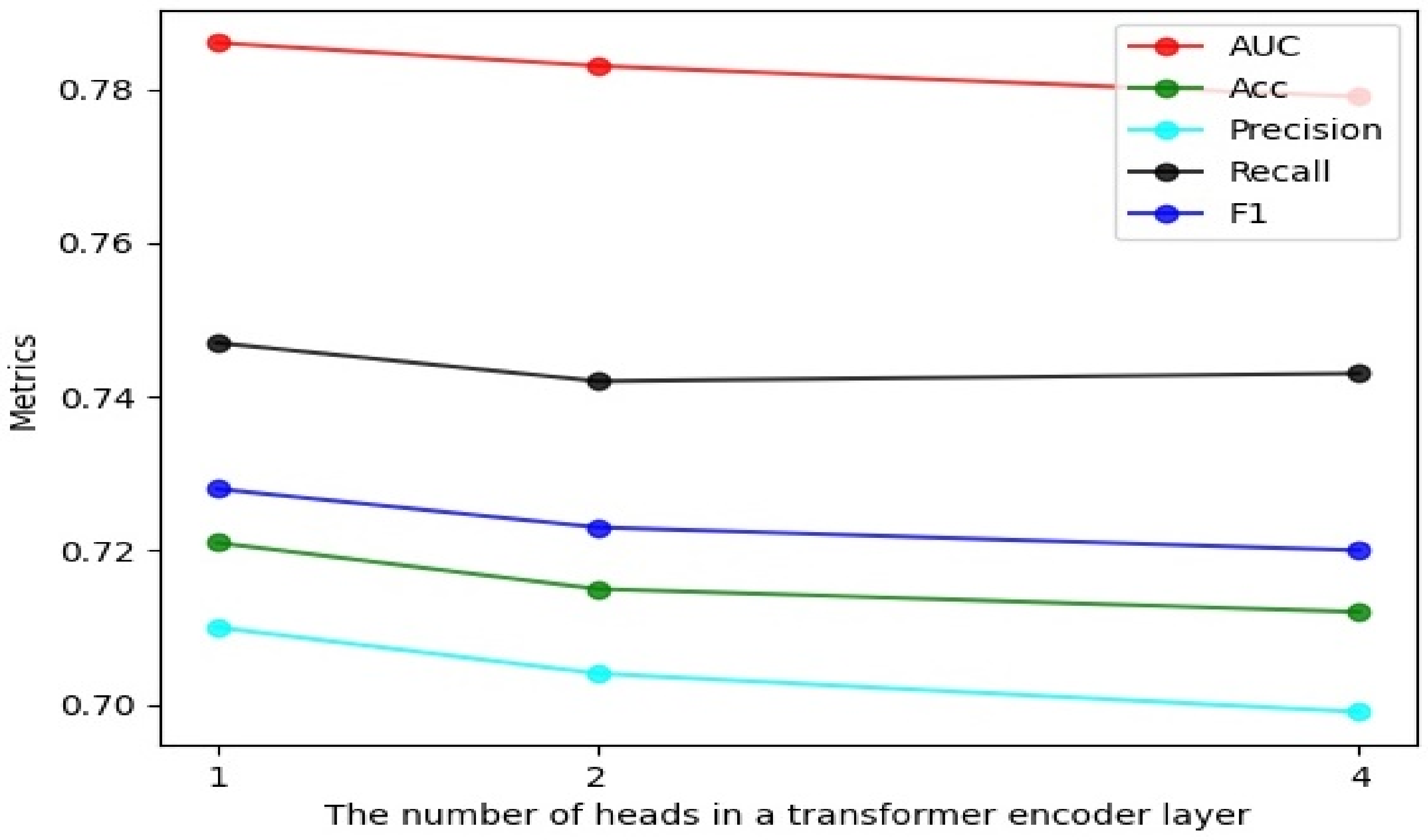
4.2.3. Effect of the Number of Heads in a Transformer Encoder Layer
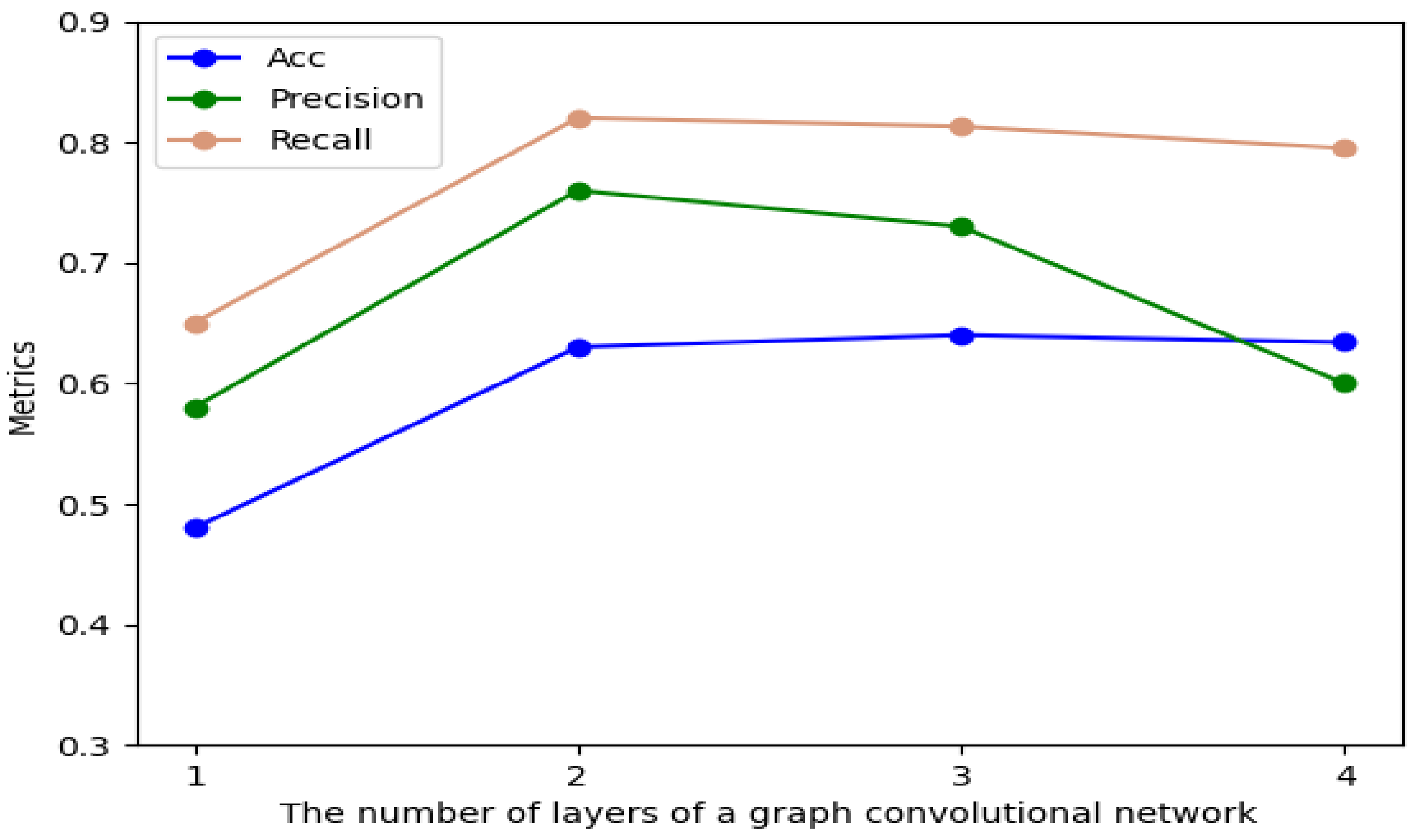
4.2.4. Effect of the Number of Layers of GCN
5. Discussions
5.1. Why Does GCTNRec Work?
- (1)
- Modeling data from a heterogeneous perspective: Most data scenarios in the real world are composed of multiple types of entities and various relationships between entities. Therefore, a heterogeneous graph used to describe each entity and the relationship between the entities contains rich information. Extracting the information from the heterogeneous graph will help us resolve the problem of sparse features of the entity itself.
- (2)
- Better sequence understanding through deep learning: Unlike traditional techniques, GCNTRec learns sequences with GCN and the transformer encoder. Characteristics of items in sequences, such as adjacent items in graphs and item orders in sequences, are considered in these models. Therefore, it can better evaluate the relevance of sequences and items to predict the next item.
- (3)
- Degree coding further enriches the characteristics of items in sequences: The degree of a node in a graph indicates the number of nodes adjacent to the node. The degree can reflect the influence level of a node in a graph. The higher the degree is, the more nodes are connected with the node. Therefore, the degree has a certain influence on the item feature representation for sequential recommendation tasks.
5.2. Threats to Validity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, NSW, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Pan, L.; Wang, X.; Li, C.; Li, J.; Tang, J. Course concept extraction in moocs via embedding-based graph propagation. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Taipei, Taiwan, 27 November–1 December 2017; pp. 875–884. [Google Scholar]
- Gan, M.; Xiao, K. R-RNN: Extracting User Recent Behavior Sequence for Click-Through Rate Prediction. IEEE Access 2019, 7, 111767–111777. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, H.; Liao, Y.; Wang, B.; Guan, Z.; Liu, H.; Cai, D. What to Do Next: Modeling User Behaviors by Time-LSTM. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 3602–3608. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Chen, S.X.; Wang, X.K.; Zhang, H.Y.; Wang, J.Q. Customer purchase prediction from the perspective of imbalanced data: A machine learning framework based on factorization machine. Expert Syst. Appl. 2021, 173, 114756. [Google Scholar] [CrossRef]
- Takimura, S.; Harakawa, R.; Ogawa, T.; Haseyama, M. Personalized tweet recommendation based on field-aware factorization machines with adaptive field organization. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017. [Google Scholar]
- Sarwar, B. Item-Based Collaborative Filtering Recommendation Algorithms. In Proceedings of the 10th International World Wide Web Conference (WWW10), Hong Kong, China, 1–5 May 2001. [Google Scholar]
- Xu, J.; He, X.; Li, H. Deep Learning for Matching in Search and Recommendation. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 1365–1368. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M. Wide & Deep Learning for Recommender Systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Zheng, Y.; Liu, S.; Li, Z.; Wu, S. Cold-start Sequential Recommendation via Meta Learner. arXiv 2020, arXiv:2012.05462. [Google Scholar]
- Jiang, S.; Qian, X.; Tao, M.; Yun, F. Personalized Travel Sequence Recommendation on Multi-Source Big Social Media. IEEE Trans. Big Data 2016, 2, 43–56. [Google Scholar] [CrossRef]
- Gong, J.; Wang, S.; Wang, J.; Feng, W.; Peng, H.; Tang, J.; Yu, P.S. Attentional graph convolutional networks for knowledge concept recommendation in moocs in a heterogeneous view. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 79–88. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Chen, Q.; Zhao, H.; Li, W.; Huang, P.; Ou, W. Behavior sequence transformer for e-commerce recommendation in alibaba. In Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, Anchorage, AK, USA, 5 August 2019; pp. 1–4. [Google Scholar]
- Zhao, H.; Yao, Q.; Li, J.; Song, Y.; Lee, D.L. Meta-graph based recommendation fusion over heterogeneous information networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 635–644. [Google Scholar]
- Pollard, S.B.; Mayhew, J.; Frisby, J.P. PMF: A stereo correspondence algorithm using a disparity gradient limit. Perception 1985, 14, 449. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jannach, D.; Ludewig, M. When Recurrent Neural Networks meet the Neighborhood for Session-Based Recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Users | Items | Records |
|---|---|---|---|
| MOOCS | 9986 | 1029 | 21,507 |
| Book-Crossing | 105,283 | 271,379 | 278,860 |
| Movielens-1m | 610 | 9742 | 108,375 |
| Steam | 12,393 | 5155 | 200,000 |
| Amazon Beauty | 1,210,271 | 1,249,274 | 2,023,070 |
| True | Predictions | |
|---|---|---|
| - | Positive | Negative |
| Positive | True positive (TP) | False negative (FN) |
| Negative | False positive (FP) | True negative (TN) |
| MOOCs | Book-Crossing | Movielens-1m | |||||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | Precision | AUC | Precision | AUC | Precision | ||||
| PMF | 0.757 | 0.658 | 0.667 | 0.643 | 0.564 | 0.591 | 0.830 | 0.745 | 0.758 |
| GRU4Rec | 0.812 | 0.719 | 0.730 | 0.716 | 0.625 | 0.651 | 0.873 | 0.789 | 0.806 |
| Time-LSTM | 0.829 | 0.744 | 0.752 | 0.691 | 0.606 | 0.621 | 0.881 | 0.797 | 0.815 |
| 0.885 | 0.790 | 0.825 | 0.708 | 0.609 | 0.650 | 0.887 | 0.805 | 0.824 | |
| 0.904 | 0.801 | 0.841 | 0.725 | 0.634 | 0.668 | 0.896 | 0.813 | 0.836 | |
| 0.923 | 0.828 | 0.858 | 0.769 | 0.685 | 0.712 | 0.919 | 0.835 | 0.859 | |
| Steam | Amazon Beauty | ||||||||
| AUC | Precision | AUC | Precision | ||||||
| PMF | 0.727 | 0.648 | 0.663 | 0.690 | 0.601 | 0.635 | |||
| GRU4Rec | 0.753 | 0.688 | 0.694 | 0.738 | 0.643 | 0.669 | |||
| Time-LSTM | 0.747 | 0.661 | 0.689 | 0.727 | 0.635 | 0.658 | |||
| 0.752 | 0.668 | 0.692 | 0.730 | 0.640 | 0.663 | ||||
| 0.766 | 0.684 | 0.708 | 0.741 | 0.652 | 0.676 | ||||
| 0.773 | 0.692 | 0.717 | 0.758 | 0.674 | 0.698 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Li, X.; Kou, X.; Zhang, J.; Zheng, S.; Wang, J.; Gong, J. Sequential Recommendation through Graph Neural Networks and Transformer Encoder with Degree Encoding. Algorithms 2021, 14, 263. https://0-doi-org.brum.beds.ac.uk/10.3390/a14090263
Wang S, Li X, Kou X, Zhang J, Zheng S, Wang J, Gong J. Sequential Recommendation through Graph Neural Networks and Transformer Encoder with Degree Encoding. Algorithms. 2021; 14(9):263. https://0-doi-org.brum.beds.ac.uk/10.3390/a14090263
Chicago/Turabian StyleWang, Shuli, Xuewen Li, Xiaomeng Kou, Jin Zhang, Shaojie Zheng, Jinlong Wang, and Jibing Gong. 2021. "Sequential Recommendation through Graph Neural Networks and Transformer Encoder with Degree Encoding" Algorithms 14, no. 9: 263. https://0-doi-org.brum.beds.ac.uk/10.3390/a14090263