
Recognition of Unipolar and Generalised Split Graphs

1
Department of Statistics, University of Oxford, 1 South Parks Road, Oxford OX1 3TG, United Kingdom
2
Department of Computer Science, University of Oxford, Wolfson Building, Parks Road, Oxford OX 13QD, United Kingdom
*
Author to whom correspondence should be addressed.
Algorithms 2015, 8(1), 46-59; https://0-doi-org.brum.beds.ac.uk/10.3390/a8010046
Submission received: 4 July 2014
/
Accepted: 26 January 2015
/
Published: 13 February 2015
{kind=link}
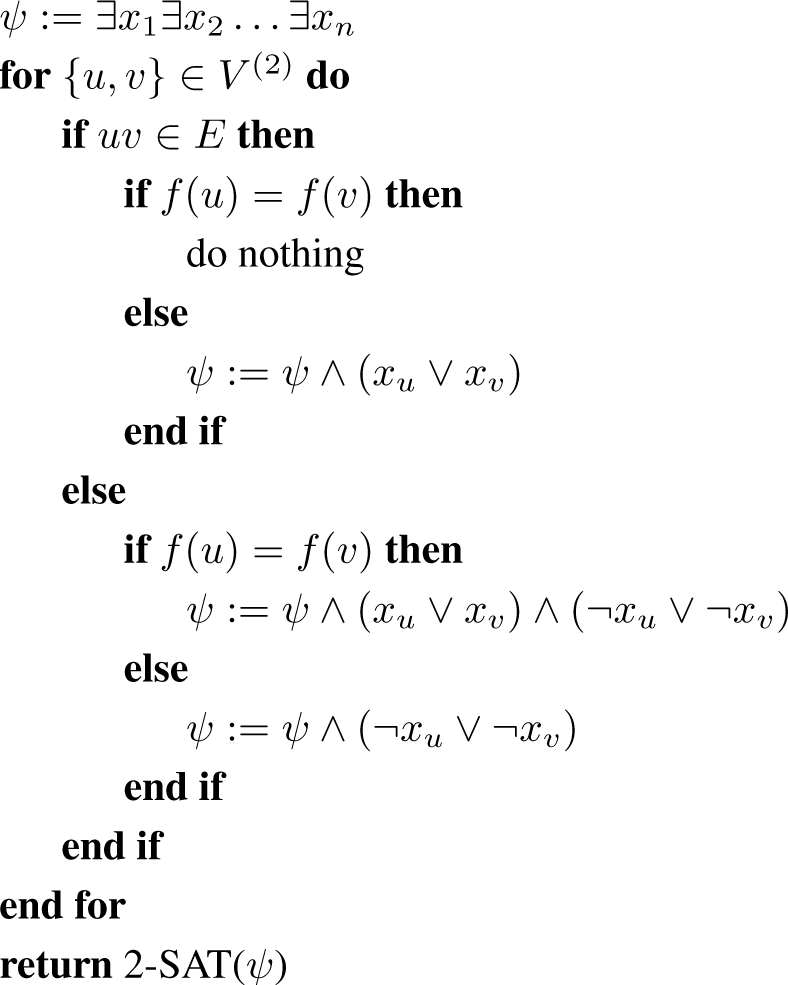{kind=link}
{kind=link}
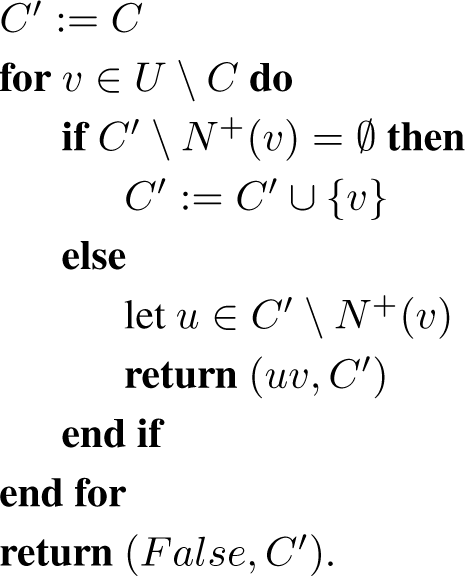{kind=link}
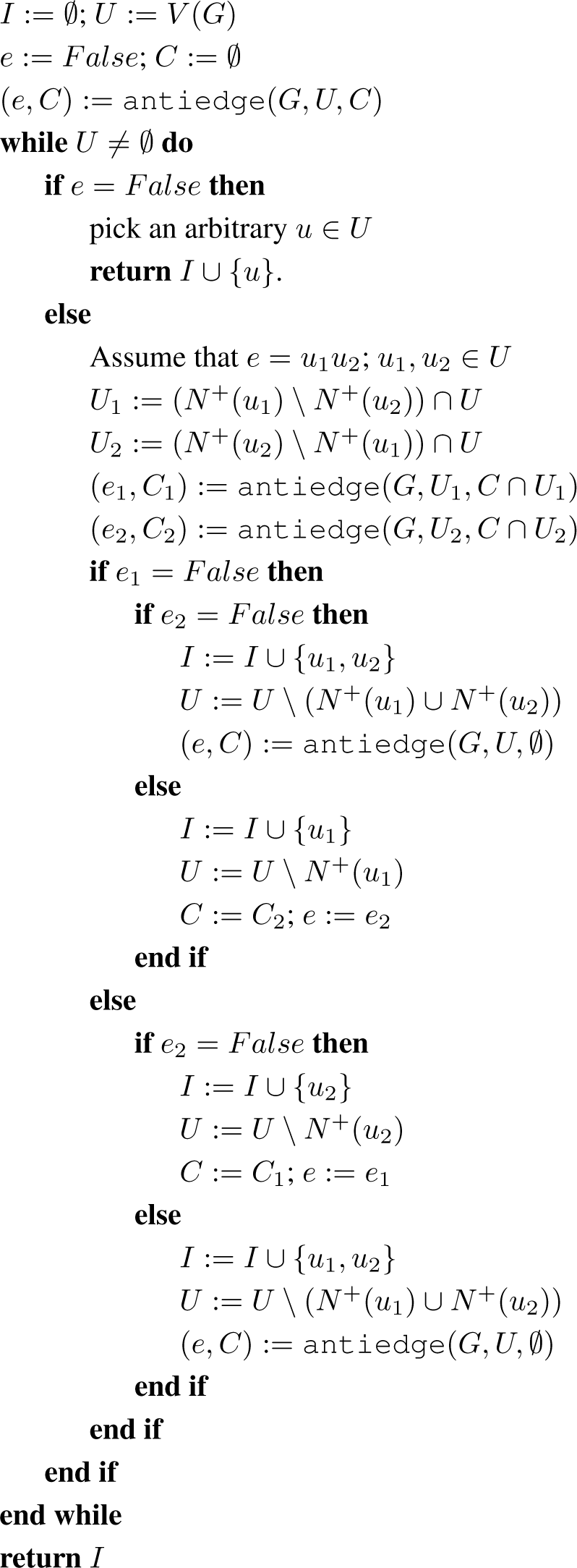{kind=link}
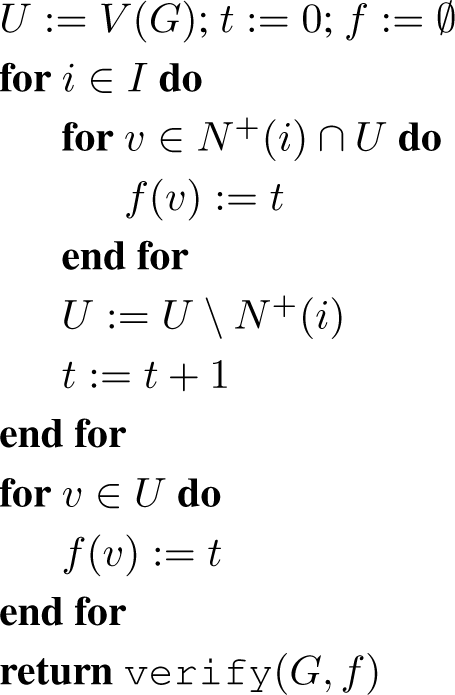{kind=link}
{kind=link}
{kind=link}
Abstract
:A graph is unipolar if it can be partitioned into a clique and a disjoint union of cliques, and a graph is a generalised split graph if it or its complement is unipolar. A unipolar partition of a graph can be used to find efficiently the clique number, the stability number, the chromatic number, and to solve other problems that are hard for general graphs. We present an O(n2)-time algorithm for recognition of n-vertex generalised split graphs, improving on previous O(n3)-time algorithms.
1. Introduction
1.1. Definition and Motivation
A graph is unipolar if for some k ≥ 0 its vertices admit a partition into k + 1 cliques {C}ki=0 so that there are no edges between Ci and Cj for 1 ≤ i < j ≤ k. A graph G is a generalised split graph if either G or its complement G is unipolar. All generalised split graphs are perfect; and Prömel and Steger [1] show that almost all perfect graphs are generalised split graphs. Perfect graphs can be recognised in polynomial time [2,3], and there are many NP-hard problems which are solvable in polynomial time for perfect graphs, including the stable set problem, the clique problem, the colouring problem, the clique covering problem and their weighted versions [4]. If the input graph is restricted to be a generalised split graph, then there are much more efficient algorithms for the problems above [5]. In this paper we address the problem of efficiently recognising generalised split graphs, and finding a witnessing partition.
Previous recognition algorithms for unipolar graphs include [6] which achieves O(n3) running time, [7] with O(n2m) time and [5] with O(nm+nm′) time, where n and m are respectively the number of vertices and edges of the input graph, and m′ is the number of edges added after a triangulation of the input graph. Note that almost all unipolar graphs and almost all generalised split graphs have (1 + o(1))n2/4 edges (see our paper “Random perfect graphs”, which is under preparation). Further, by testing whether G or
is unipolar, each of the mentioned algorithms above recognises generalised split graphs in O(n3) time. The algorithm in this paper has running time O(n2).
This leads to polynomial-time algorithms for the problems mentioned above (stable set, clique, colouring, and so on) which have O(n2.5) expected running time for a random perfect graph Rn and an exponentially small probability of exceeding this time bound. Here we assume that Rn is sampled uniformly from the perfect graphs on vertex set [n] = {1, 2, … n}.
1.2. Notation
We use V (G), E(G), v(G) and e(G) to denote V, E, |V | and |E| for a graph G = (V, E). We let N(v) denote the neighbourhood of a vertex v, and let N+(v) denote N(v) ∪ {v}, also called the closed neighbourhood of v. If G = (V, E) and S ⊆ V, then G[S] denotes the subgraph induced by S. Let
be the set of all unipolar graphs and let
be the set of all generalised split graphs. Fix
. If V0, V1 ⊆ V with V0 ∩ V1 = ∅ and V0 ∪ V1 = V are such that V0 is a clique and V1 is a disjoint union of cliques, then the ordered pair (V0, V1) will be called a unipolar representation of G or just a representation of G. For each unipolar representation R = (V0, V1) we call V0 the central clique of R, and we call the maximal cliques of V1 the side cliques of R. A graph is unipolar iff it has a unipolar representation.
Definition 1.1. Let R = (V0, V1) be a unipolar representation of a graph G. A partition of V (G) is a block decomposition of G with respect to R if the intersection of each part of B with V1 is either a side clique or ∅.
1.3. Plan of the Paper
Assume that G is an input graph throughout. The algorithm for recognising unipolar graphs has three stages. In the first stage a sufficiently large maximal independent set is found. The second stage constructs a partition of V (G), such that is a block decomposition for some unipolar representation if
The third stage generates a 2-CNF formula which is satisfiable iff
is a block decomposition for some unipolar representation. The formula is constructed in such a way that a satisfying assignment of the variables corresponds to a representation of G, and the algorithm returns either a representation of G, or reports
.
We describe the third stage first (in Section 2) as it is short and includes a natural transformation to 2-SAT. In Section 3 we discuss the first stage of finding large independent sets. In Section 4 we present the second stage when we seek to build a block decomposition. Finally, in Section 5, we briefly discuss random perfect graphs and algorithms for them using the algorithm described above.
1.4. Data Structures
The most commonly used data type for this algorithm is the set. We assume that the operation A ∩ B takes O(min(|A|, |B|)) time, A ∪ takes O(|A| + |B|) time, A \ B takes O(|A|) time and a ∈ A takes O(1) time. These properties can be achieved by using hashtables to implement sets.
Functions will always be of the form f : [m] → A for some m, where [m] = {1, 2, … m}. Therefore functions can be implemented with simple arrays, hence the lookup and assignment operations are assumed to require O(1) time.
2. Verification of Block Decomposition
2.1. 2-SAT
Let x1, …, xn be n boolean variables. A 2-clause is an expression of the form y1 ∨ y2, where each yj is a variable, xi, or the negation of a variable, ¬xi. There are 4n2 possible 2-clauses. The problem of deciding whether or not a formula of the form ψ = ∃x1∃x2 … ∃xn(c1 ∧ c2 ∧ … ∧ cm), where each cj is a 2-clause, is satisfiable is called 2-SAT. The problem 2-SAT is solvable in O(n + m) time – [8,9], where n is the number of variables and m is the number of clauses in the input formula.
2.2. Transformation to 2-SAT
Let G = (V, E) be a graph with vertex set V = [n]. In this subsection we show how to test if a partition of V is a block decomposition for some unipolar representation, in which case we must have
. Let be the partition of V we want to test. From each block of , we seek to pick out some vertices to form the central clique V0 of a representation, with the remaining vertices in the blocks forming the side cliques. Suppose that
= m, and
is represented by a surjective function f : V → [m], so that
= {f−1[i] : i ∈ [m. Let {xv : v ∈ V } be Boolean variables. We use Algorithm 1 to construct a formula ψ (x1, … xn), so that each satisfying assignment of {xv} corresponds to a representation of G.
Algorithm 1.
verify(G, f)

There is an exception: the first time a clause is added to ψ it should be added without the preceding sign for conjunction. The following lemma is easy to check.
Lemma 2.1. The formula ψ is satisfiable iff is a block decomposition for some representation. Indeed an assignment Φ : {xv : v ∈ V} → {0, 1} satisfies ψ if and only if R = (V0, V1) is a representation of G and is a block decomposition of G with respect to R, where Vi = {v ∈ V : Φ(v) = 1 − i}.
Proof. Suppose Φ is a satisfying assignment and let V0, V1 be as above. If u and v are both in V0, then uv ∈ E, since otherwise Φ contains a clause ¬xu ∨ ¬xv. If u and v are in V1, then either uv ∈ E and f(u) = f(v) or uv ∉ E and f(u) ≠ f(v), because in the other two cases ϕ contains the clause xu ∨ xv. This means that the vertices in V1 are grouped into cliques by their value of f. For the other direction, it is sufficient to verify that each generated clause is satisfied, which is a routine check. □
At most a constant number of operations are performed per pair {u, v}, so O(n2) time is spent preparing ψ. The formula ψ can have at most 2 clauses per pair {u, v}, so the length of ψ is also O(n2), and since 2-SAT can be solved in linear time, the total time for this step is O(n2).
3. Independent Set
3.1. Maximum Independent Set of a Unipolar Graph
Let α(G) be the maximum size of an independent set in a graph G. Let
and let R be a unipolar representation of G. Observe that for any representation R of G, the number s(R, G) of side cliques satisfies s(R, G) ≤ α(G) ≤ s(R, G) + 1. We deduce that for every two representations R1 and R2 of G we have |s(R1, G) − s(R2, G)| ≤ 1.
If for example G is Kn or its complement, then the number s(R, G) depends on R. However, this is not necessarily the case for all graphs, see Figure 1. It can be shown that the number of n-vertex unipolar graphs with a unique representation is,
and that the number of n-vertex unipolar graphs G with a unique representation R and such that
for a constant δ > 0 (see our paper “Random perfect graphs”, which is under preparation).
3.2. Independent Set Algorithm
It is well known that calculating α(G) for a general graph is NP-hard. For
let s(G) = maxR s(R, G), where the maximum is over all representations R of G. For
set s(G) = 0. In this section we see how to find a maximal independent set I, such that if
, then |I| ≥ s(G) (≥ α(G) − 1).
The idea is to start with G and with I = Ø; and as long as the remaining graph has two non-adjacent vertices, say v1 and v2, pick r = 1 or 2 of these vertices to add to I, and delete from G the closed neighbourhood of the added vertices. We do this in such a way that a given representation R of G yields a representation with r less side cliques, or (only when r = 2) with one less side clique and the central clique removed.
Observe that the main body of Algorithm 2 is a while loop. An alternative way of seeing the algorithm is that instead of the loop there is a recursive call to indep(G[U]) at the end of the iteration and the algorithm returns the union of the vertices found during this iteration and the recursively retrieved set. A recursive interpretation is clearer to work with for inductive proofs.
Algorithm 2.
indep(G)
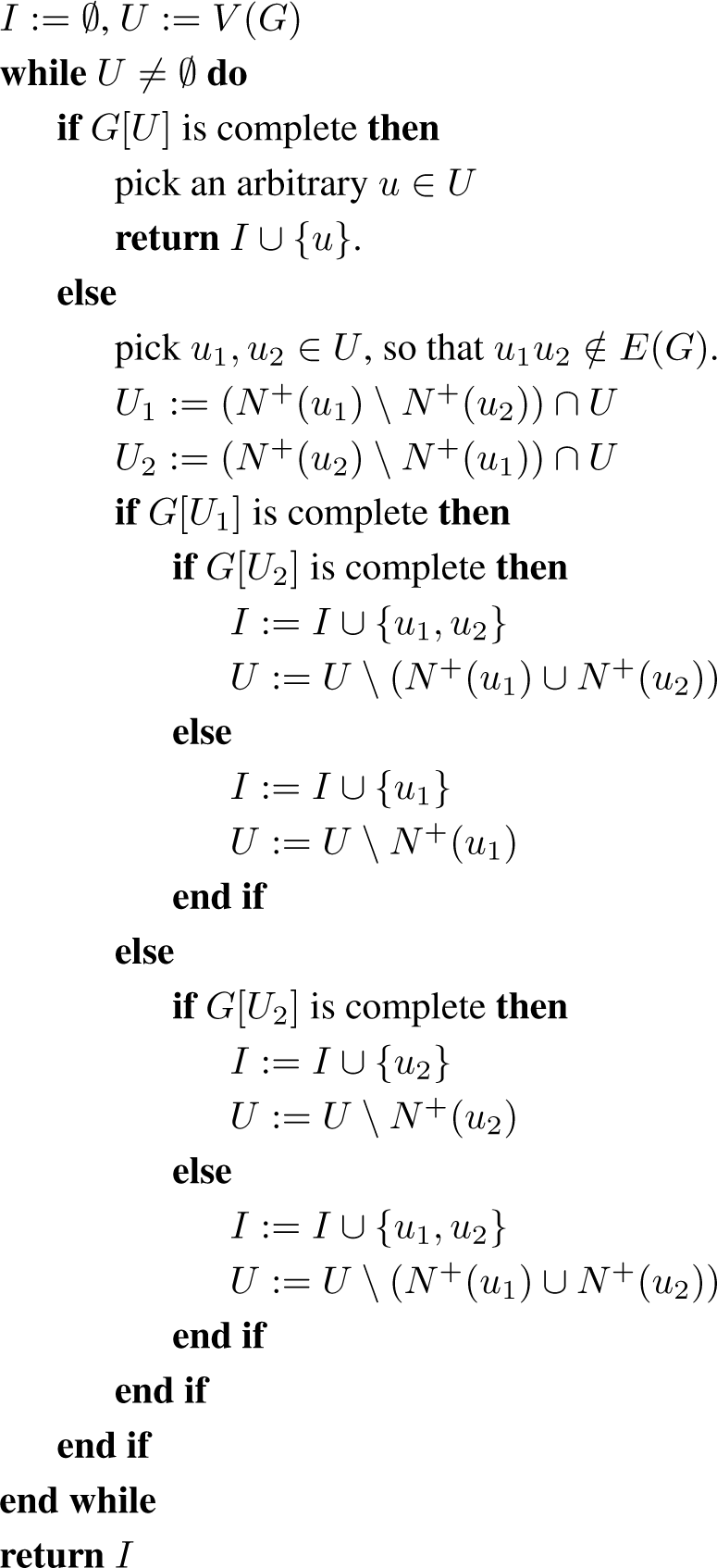
3.3. Correctness
Lemma 3.1. Algorithm 2 always returns a maximal independent set I.
Proof. This is easy to see, since each vertex deleted from U is adjacent to a vertex put in I.
Lemma 3.2. If Algorithm 2 returns I, then |I| ≥ s(G).
Proof. If
, then the statement holds, because s(G) = 0. From now on assume that
We argue by induction on v(G). It is trivial to see that the lemma holds for v(G) = 1. Let v(G) > 1 and assume that the lemma holds for smaller graphs. If G is complete, then |I| = 1 = s(G).
Fix an arbitrary unipolar representation R of G. We show that |I| ≥ s(R, G). If G is not complete, the algorithm selects two non-adjacent vertices u and v. The vertices u and v are either in different side cliques or one of them is in the central clique and the other is in a side clique.
We start with the case when u and v are contained in side cliques. After inspecting their neighbourhoods, the algorithm removes from U either one or both of them along with their neighbourhood. Suppose that it removes r of them, where r is 1 or 2. Let G′ and R′ be the graph and the representation induced by the remaining vertices. By the induction hypothesis, if I′ is the recursively retrieved set, then |I′| ≥ s(R′, G′). Let I be the independent set returned at the end of the algorithm, so that |I′| + r = |I|. Both u and v see all the vertices in their corresponding side clique, and see no vertices from different side cliques, so after removing r of them with their neighbours, the number of side cliques in the representation decreases by precisely r, and hence s(R, G) = s(R′, G′) + r. Now |I| = |I0| + r ≥ s(R0, G0) + r = s(R, G).
Now w.l.o.g. assume that u belongs to a side clique and v belongs to the central clique. Then N+(u) contains the side clique of u and perhaps parts of the central clique. Therefore, N+(u) \ N+(v) is a subset of the side clique of u, and hence it is a clique. If N+(v) \ N+(u) is a not clique, then the algorithm continues recursively with G[V \ N+(u)]; and using the same arguments as above with r = 1, we guarantee correct behaviour. Now assume that N+(v) \ N+(u) is a clique. Then N+(v) \ N+(u) can intersect at most one side clique, because the vertices in different side cliques are not adjacent. In this case N+(v) ∪ N+(u) completely covers the side clique of u, completely covers the central clique, and it may intersect one additional side clique. Hence s(R, G) = s(R′, G′) + 1 or s(R, G) = s(R′, G′) + 2, where G′ and R′ are the induced graph and representation after the removal of N+(v) ∪ N+(u). If I′ is the recursively obtained independent set, from the induction hypothesis we deduce that |I| = |I|′ + 2 ≥ s(R′, G′) + 2 ≥ s(R, G).
3.4. Time Complexity
In this form the algorithm takes more than O(n2) time, because checking whether an induced subgraph is complete is slow. However, we can maintain a set of vertices, C, which we have seen to induce a complete graph. We will create an efficient procedure to check if a subgraph is complete, and to return some additional information to be used for future calls if the subgraph is not complete.
Algorithm 3.
antiedge(G, U, C)

The following lemma summarises the behaviour of Algorithm 3.
Lemma 3.3. Let C ⊆ U and suppose that G[C] is complete. If G[U] is complete, then antiedge(G, U, C) returns (F alse, U); if not, then it returns (uv, C0) such that
- is complete
Proof. Easy checking. □
Algorithm 4.
indep(G)

Lemma 3.4. Let U and C be the sets stored in the respective variables at the beginning of an iteration of the main loop of Algorithm 4, and let U′ and C′ be the sets stored at the beginning of the next iteration, if the algorithm does not terminate meanwhile. The following loop invariants hold:
- G[C] is complete and C ⊆ U
- U′ \ C′ ⊆ U \ C.
A loop invariant is a condition which is true at the beginning of each iteration of a loop.
Proof. Observe that the initial values of U and C, which are V and Ø respectively, guarantee by Lemma 3.3 that the values after the call to Algorithm 3 satisfy condition (1). Therefore, (1) holds for the first iteration. Concerning future iterations, observe that (1) guarantees the precondition of Lemma 3.3, which it turn guarantees (1) for the next iteration. We deduce that (1) does indeed give a loop invariant. By proving this we have proved that the preconditions of Lemma 3.3 are always met; and so we can use Lemma 3.3 throughout.
If e = False, then there is no next iteration, hence condition (2) is automatically correct. Now assume that e = u1u2. Depending on e1 and e2 there are two cases for how many vertices are excluded.
Case 1: one vertex is excluded. W.l.o.g. assume that u1 is excluded, so U′ = U \N+(u1), C∩U2 ⊆ C0 and C ⊆ N+(u) ∪ N+(u2). Then
Case 2: two vertices are excluded. Now
, and
We have shown that condition (2) holds at the start of the next iteration, and so it gives a loop invariant as claimed. □
A vertex v is absorbed if it is processed during the loop of Algorithm 3 and then appended to the result set, C′.
Corollary 3.5. A vertex can be absorbed once at most.
Proof. Let U, C, U′ and C′ be as before. Observe that if, during the iteration, vertex v is absorbed in a call to Algorithm 3, then v ∈ U \ C and v ∉ U′ \ C′. The Corollary now follows from the second invariant in Lemma 3.4. □
Lemma 3.6. Algorithm 4 takes O(n2) time.
Proof. The total running time of each iteration of the main loop of Algorithm 4 besides calling Algorithm 3 is O(n). The set U decreases by at least one vertex on each iteration, so the time spent outside of Algorithm 3 is O(n2).
From Corollary 3.5 at most n vertices are absorbed and O(n) steps are performed each time, so in total O(n2) time is spent in all calls to Algorithm 3 for absorbing vertices.
Assume that v is processed by Algorithm 3 for the first time, but it is not absorbed and it is tested against a set C1. Since v is not absorbed, we may assume that Algorithm 3 has returned the pair of vertices vu. At least one of u and v is removed (along with its neighbourhood) from U and moved to I. If v is removed from U, then no more time can be spent on it by Algorithm 3, hence the total time spent on v by Algorithm 3 is O(n). Now assume that u is removed. We have that C1 ⊆ N+(u) and each vertex in N+(u) is removed from U. Hence, if v is processed again by Algorithm 3, it will be tested against a set C2 with C1 ∩ C2 = Ø, and therefore |C1| + |C2| = |C1 ∪ C2| = O(n). As we saw before, if v is absorbed or removed from U, then it cannot be processed again by Algorithm 3; and thus the running time spent on v is again O(n). If v is not removed from U, then C2 is removed from U. Hence, if v is processed again by Algorithm 3, v will be tested against a set C3 with |C1| + |C2| + |C3| = |C1 ∪ C2 ∪ C3| = O(n), and so on. Thus, we see that over all these tests, each vertex is tested at most once for adjacency to v, and so the total time spent on v is O(n).
4. Building Blocks and Recognition
4.1. Block Creation Algorithm
In this subsection we present a short algorithm for creating a partition of V (G) using an independent set I and then checking if this partition is a block decomposition using Algorithm 1 from Section 2.
Algorithm 5.
test(G, I)

Lemma 4.1. Suppose that I ⊆ V (G) is an independent set with |I| ≥ s(G) − 1 and V0 ∩ I = Ø for some unipolar representation R = (V0, V1) of G. Then test(G, I) returns True.
Proof. On each step of the main loop a vertex from i ∈ I is selected. Since V0 ∩ I = Ø, the vertex i is a part of some side clique, say C. Now C ∩ N+(j) = Ø for each j ∈ I \ {i}, so C ⊆ U. Also C ⊆ N+(i), and hence C ⊆ N+(i) ∩ U. Vertex i does not see vertices from other side cliques, so N+(i) ∩ U is correctly marked as a separate block.
Since |I| ≥ s(G) − 1, at most one side clique is not represented in I. If there is an unrepresented side clique, say C, then none of the previously created blocks can claim any vertex from it, and hence C ⊆ U. We have shown that when the main loop ends, either U ∩ V1 = Ø or U ∩ V1 is a side clique; so U is correctly marked as a separate block. The set U also contains all remaining vertices, so f is partition of V into blocks, and hence Algorithm 1 returns True.
4.2. Block Decomposition Algorithm
By Lemmas 3.1 and 3.2 Algorithm 4 returns a maximal independent set I of size at least s(G). Thus, Lemma 4.1 suggests a naive algorithm for recognition for
– try test(G, I \ i) for each i ∈ I and return True if any attempt succeeds. The proposed algorithm is correct, since |I ∩ V0| ≤ 1. The running time is O(|I|n2) = O(n3), while we aim for O(n2). However, with relatively little effort we can localize I ∩ V0 to at most 2 candidates from I.
Algorithm 6.
blocks(G, I)

Algorithm 7.
recognise(G)

4.3. Correctness
Lemma 4.2. Algorithm 7 returns True on input G iff
.
Proof. First assume that
and let R = (V0, V1) be an arbitrary representation of G. Let I = indep(G). By Lemma 3.2, |I| ≥ s(G) ≥ s(R, G). Since V0 is a clique and I is an independent set, we have |V0 ∩ I| ≤ 1.
Case 1: V0 ∩ I = Ø. Observe that Algorithm 6 returns test(G, I′), where I′ is either I or I \ {v} for some v ∈ I, hence |I0| ≥ |I| − 1 ≥ s(G) − 1; I′ ⊆ I ⊆ V1, so test(G, I′) = True from Lemma 4.1.
Case 2: V0 ∩ I = {c}. Algorithm 6 starts by calculating the set C, where C = I if there is no v ∈ V with |N+(v) ∩ I| = 2, and otherwise
Assume that |N+(v) ∩ I| = 2 for some v ∈ V. If v ∈ V, then c ∈ N+(v), because V0 is a clique. If v ∈ V1, then N+(v) can intersect at most one vertex from I ∩V1 and at most one vertex from I ∩V0 = {c} and since |N+(v)∩I| = 2, we have c ∈ N+(v). For each v ∈ V if |N+(v)∩I| = 2, then c ∈ N+(v)∩I, so c belongs to their intersection. If no v ∈ V exists with |N+(v) ∩ I| = 2, then C = I, but c ∈ I, so again c ∈ C. We deduce that if V0 ∩ I = {c}, then c ∈ C and |C| > 0.
If |C| = 1 or |C| = 2 then test(G, I \ {i}) is tested individually for each vertex i ∈ C, but c ∈ C and test(G, I \ {c}) = True by Lemma 4.1.
If |C| > 2, then there is no v ∈ V with |N+(v) ∩ I| = 2. Either |I| = s(R, G) or |I| = s(R, G) + 1, so either all side cliques are represented by vertices of I, or at most one is not represented, say S. We can handle both cases simultaneously by saying that S = Ø in the former case. We have that I is a maximal independent set, but no vertex of I \ {c} can see a vertex of S, because they belong to different side cliques, so c is connected to all vertices of S and therefore {c} ∪ S is a clique. Let T = N(c) ∩ (V1 \ S). Then |N+(v) ∩ I| = 2 for each v ∈ T, but no such vertex exists by assumption, so T = Ø. Now N(c) ∩ V1 = S, and V1 is a union of disjoint cliques, so V1 ∪ {c} is also a union of disjoint cliques. Hence R′ = (V0 \ {c}, V1 ∪ {c}) is a representation of G, so from Lemma 4.1 test(G, I) = True.
On the contrary, if
, then there is no representation for G, hence Algorithm 5 cannot generate a block decomposition of G, and therefore Algorithm 5 will return False. □
4.4. Time Complexity
Lemma 4.3. Algorithm 7 takes O(n2) time.
Proof. Algorithm 5 loops over a subset of V and intersects two subsets of V, so the time for each step is bounded by O(n), and since the number of steps is O(n), O(n2) time is spent in the loop. Then it performs one more operation in O(n) time, so the total time spent for preparation is O(n2). Then Algorithm 5 calls Algorithm 1, which takes O(n2) time, so the total running time of Algorithm 5 is O(n2).
While building C, Algorithm 6 handles O(n) sets with size O(n), so it spends O(n2) time in the first stage. Depending on the size of C, Algorithm 6 calls Algorithm 5 once or twice, but in both cases it takes O(n2) time, so the total running time of Algorithm 6 is O(n2). The total time spent for recognition is the time spent for Algorithm 6 plus the time spent for Algorithm 4, and since both are O(n2), the total running time for recognition is O(n2). □
5. Algorithms for Random Perfect Graphs
Grötschel, Lovász, and Schrijver [4] show that the stable set problem, the clique problem, the colouring problem, the clique covering problem and their weighted versions are computable in polynomial time for perfect graphs. The algorithms rely on the Lovász sandwich theorem, which states that for every graph G we have
, where ϑ(G) is the Lovász number. The Lovász number can be approximated via the ellipsoid method in polynomial time, and for perfect graphs we know that ω(G) = χ(G), hence ϑ(G) is an integer and its precise value can be found. Therefore χ(G) and ω(G) can be found in polynomial time for perfect graphs, though these are NP-hard problems for general graphs. Further, α(G) and χ(G) (the clique covering number) can be computed from the complement of G (which is perfect). The weighted versions of these parameters can be found in a similar way using the weighted version of the Lovász number,
.
These results tell us more about computational complexity than algorithm design in practice. On the other hand, the problems above are much more easily solvable for generalised split graphs. We know that the vast majority of the n-vertex perfect graphs are generalised split graphs [1]. One can first test if the input perfect graph is a generalised split graph using the algorithm in this paper and if so, apply a more efficient solution.
Eschen and Wang [5] show that, given a generalised split graph G with n vertices together with a unipolar representation of G or
, we can efficiently solve each of the following four problems: find a maximum clique, find a maximum independent set, find a minimum colouring, and find a minimum clique cover.
It is sufficient to show that this is the case when G is unipolar, as otherwise we can solve the complementary problem in the complement of G. Finding a maximum size stable set and minimum clique cover in a unipolar graph is equivalent to determining whether there exists a vertex in the central clique such that no side clique is contained in its neighbourhood, which is trivial and can be done very efficiently. Suppose there are k side cliques. If there is such a vertex v, then a maximum size stable set (of size k + 1) consists of v and from each side clique a vertex not adjacent to v, and a minimum size clique cover is formed by the central clique and the k side cliques. If not, then a maximum size stable set (of size k) consists of a vertex from each side clique, and a minimum clique cover is formed by extending the k side cliques to maximal cliques (which then cover C0).
Let us focus on finding a maximum clique and minimum colouring of a unipolar graph G with a representation R. If R contains k side cliques, C1, … Ck, then
where C0 is the central clique. Therefore, in order to find a maximum clique or a minimum colouring, it is sufficient to solve the corresponding problem in each of the co-bipartite graphs induced by the central clique and a side clique. The vertices outside a clique in a co-bipartite graph form a cover in the complementary bipartite graph, and the vertices coloured with the same colour in a proper colouring of a co-bipartite graph form a matching in the complementary bipartite graph. By König’s theorem it is easy to find a minimum cover using a given maximum matching, and therefore finding a maximum clique and a minimum colouring in a co-bipartite graph is equivalent to finding a maximum matching in the complementary bipartite graph. For colourings, we explicitly find a minimum colouring in each co-bipartite graph G[C0 ∪ Ci], and such colourings can be fitted together using no more colours, since C0 is a clique cutset. Assume that
contains ni vertices and mi edges, so each ni ≤ n and
We could use the Hopcroft–Karp algorithm for maximum matching in
time to find time bound
The approach of Eschen and Wang [5] is very similar, and they give more details, but unfortunately there is a problem with their analysis, and a corrected version of their analysis yields O(n3.5/log n) time, instead of the claimed O(n2.5/log n). In order to see the problem consider the case when the input graph is a split graph with an equitable partition.
Given a random perfect graph Rn, we run our recognition algorithm in time O(n2). If we have a generalised split graph, with a representation, we solve each of our four optimisation problems in time O(n2.5), if not, which happens with probability e−Ω(n), we run the methods from [4]. This simple idea yields a polynomial-time algorithm for each problem with low expected running time, and indeed the probability that the time bound is exceeded is exponentially small.
Acknowledgments
We thank the referees for a careful reading.
Nikola Yolov is supported by the EPSRC Doctoral Training Grant and a studentship from the Department of Computer Science of University of Oxford. The APC is covered by Oxford University’s RCUK open-access block grant.
Author Contributions
Joint work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Prömel, H.J.; Steger, A. Almost all Berge graphs are perfect. Comb. Probab. Comput. 1992, 1, 53–79. [Google Scholar]
- Cornuéjols, G.; Liu, X.; Vušković, K. A polynomial algorithm for recognizing perfect graphs, Proceedings of the 44th Annual IEEE Symposium on Foundations of Computer Science, Berkeley, CA, USA, 26–29 October 2013; pp. 20–27.
- Chudnovsky, M.; Cornuéjols, G.; Liu, X.; Seymour, P.; Vušković, K. Recognizing Berge graphs. Combinatorica 2005, 25, 143–186. [Google Scholar]
- Grötschel, M.; Lovász, L.; Schrijver, A. Polynomial algorithms for perfect graphs. North-Holl. Math. Stud. 1984, 88, 325–356. [Google Scholar]
- Eschen, E.M.; Wang, X. Algorithms for unipolar and generalized split graphs. Discrete Appl. Math. 2014, 162, 195–201. [Google Scholar]
- Tyshkevich, R.; Chernyak, A. Algorithms for the canonical decomposition of a graph and recognizing polarity. Izvestia Akad. Nauk BSSR Ser. Fiz.-Mat. Nauk 1985, 6, 16–23. [Google Scholar]
- Churchley, R.; Huang, J. Solving partition problems with colour-bipartitions. Graphs Comb. 2014, 30, 353–364. [Google Scholar]
- Even, S.; Itai, A.; Shamir, A. On the complexity of timetable and multicommodity flow problems. SIAM J. Comput. 1976, 5, 691–703. [Google Scholar]
- Aspvall, B.; Plass, M.F.; Tarjan, R.E. A linear-time algorithm for testing the truth of certain quantified boolean formulas. Inf. Process. Lett. 1979, 8, 121–123. [Google Scholar]
Figure 1.
For the graph G1 (left) we have s(R, G1) = α(G1) for all representations R, and for the graph G2 (right) we have s(R, G2) = α(G2) + 1 for all representations R.
Figure 1.
For the graph G1 (left) we have s(R, G1) = α(G1) for all representations R, and for the graph G2 (right) we have s(R, G2) = α(G2) + 1 for all representations R.

© 2015 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
McDiarmid, C.; Yolov, N. Recognition of Unipolar and Generalised Split Graphs. Algorithms 2015, 8, 46-59. https://0-doi-org.brum.beds.ac.uk/10.3390/a8010046
AMA Style
McDiarmid C, Yolov N. Recognition of Unipolar and Generalised Split Graphs. Algorithms. 2015; 8(1):46-59. https://0-doi-org.brum.beds.ac.uk/10.3390/a8010046
Chicago/Turabian StyleMcDiarmid, Colin, and Nikola Yolov. 2015. "Recognition of Unipolar and Generalised Split Graphs" Algorithms 8, no. 1: 46-59. https://0-doi-org.brum.beds.ac.uk/10.3390/a8010046