In a dynamic programming application, intermediate results are generated from a search space with particular properties and will be far from random. While testing algorithm variants and constant factors on random data is always a good start, it is important to test all algorithms also in real-world scenarios. Due to the modular nature of algebraic dynamic programming, existing descriptions of bioinformatics applications that were already coded in GAP-L could be used for this work without modification. It is only their use with Pareto products that is new.
In our experiments, we will set also a focus on how the different components of the GAP-L programs, namely evaluation algebras, tree grammars and the input, influence the effectiveness of the implementations.
4.2. A Short Description of Tested Bioinformatics Applications
To achieve both a varied and a representative benchmark, we used, in total, four biosequence analysis problems already implemented with Bellman’s GAP. In each case, we use a two-dimensional Pareto product and, if suitable, also a three- or four-dimensional product, totaling seven main test cases shown in
Table 2. The applications Ali2D/3D, Fold2D/3D and Prob2D/4D address the task of RNA structure prediction, using the same tree grammar, but varying in the specified evaluation algebras. The application Gotoh performs sequence alignment under an affine gap model. More complete definitions are given later in this section.
For each application, realistic test sets were downloaded from biosequence databases, and a subset of inputs of different sizes were manually extracted. For detailed analysis, a number of different inputs of varying sizes were tested. Where applicable, only representative results of preferably large inputs will be shown to lower the amount of data presented in this article. For each dimension and application, we additionally tested different combinations of algebras for each input, yielding no significant variation in our test set. Therefore, only a representative subset of Pareto products is shown here. Only inputs were chosen for which profiling data could be extracted within 5 days of computation time. While 5 days seems to be a rather long time frame and sufficient for many applications, as we shall see, this poses a strong restriction on Pareto optimization with more than two dimensions.
Table 2.
Summary of test cases with essential properties and used databases as input. Element sizes are estimates only for the forward phase of the computation and are only valid for the used test system. They may vary on other systems or differ in reality due to memory padding. For the backward phase, string representations of candidates are added, so no general estimate can be made on their size.
Table 2.
Summary of test cases with essential properties and used databases as input. Element sizes are estimates only for the forward phase of the computation and are only valid for the used test system. They may vary on other systems or differ in reality due to memory padding. For the backward phase, string representations of candidates are added, so no general estimate can be made on their size.
| Application | Name | Dim. | Element Size (Byte) | Dataset |
|---|
| RNA Alignment Folding | Ali2D | 2 | 12 | Rfamseed alignments [31] |
| RNA Alignment Folding | Ali3D | 3 | 16 | Rfam seed alignments [31] |
| Gotoh’s algorithm | Gotoh2D | 2 | 8 | BAliBASE3.0 [32] |
| RNA Folding | Fold2D | 2 | 12 | Rfam seed alignments [31] |
| RNA Folding | Fold3D | 3 | 16 | Rfam seed alignments [31] |
| RNA Folding | Prob2D | 2 | 12 | RMDB [33] |
| RNA Folding | Prob4D | 4 | 28 | RMDB [33] |
The asymptotic complexity of the tested ADP applications can be described in terms of the initial input length n, as well as the runtime p and the space s of the Pareto computations per subproblem. The Pareto front is computed once per table entry; therefore, complexities multiply. The fold programs’ asymptotic complexity is in time and in space. The alignment program’s asymptotic complexity is in time and in space. The input length will be given as the number of bases (characters) in the input sequence for the remainder of this work.
Ali and Fold were tested on the the same inputs taken from Rfamseed alignments [
31], which contains alignments of sequences known to produce stable structures. No special attention was given to the nature of the optimal structures, only to input length.
The sequences and reactivities used to evaluate Prob originate from the RMDB [
33]. The selected dataset contains 146 sequences, but only three could be taken under the condition of length and that data for three different reactivities was available.
Gotoh2D was evaluated with BAliBASE 3.0 [
32]. Again, sequences were chosen solely on length.
Gotoh’s algorithm: The test case Gotoh2D is an implementation of Gotoh’s algorithm [
25] that solves the pairwise sequence alignment problem, also known as string edit distance, for affine gap costs. For Gotoh2D, the gap initiation cost is combined with the gap extension cost in a Pareto product, and the results are printed as an alignment string via a lexicographic product. See our introductory example in
Figure 1.
RNA folding: The RNA folding space is defined by the “Overdangle” grammar first described by Janssen
et al. [
34]. Depending on the application and the number of dimensions in the Pareto product, the folding space is evaluated with different algebras. For Fold2D, we use the minimum free energy (MFE), according to the Turner energy model [
35], combined with the maximum expected accuracy (MEA) that consists of the accumulation of base pairs’ probabilities computed with the partition function of the Turner model. For Fold3D, the maximization of the number of predicted base pairs (BP) is added to the Pareto product.
In Prob, we study the integration of reactivity data in RNA secondary prediction with Pareto optimization. The design of algebras is based on distance minimization between probing reactivities (SHAPE [
33,
36,
37], CMCT [
38] and DMS [
39,
40]), using an extended base pair distance following [
41]. For Prob2D, the MFE is combined with SHAPE, and for Prob4D, MFE, SHAPE, DMS and CMCT are used. A dot bracket string representation and a RNAshape representation of the candidates of the front are printed via a lexicographic product. A more detailed presentation of probing algebra products will be given in a yet unpublished work [
42].
RNA alignment folding: As in test case Ali, we study the behavior of Pareto fronts in an (re-)implementation of RNAalifold [
43,
44]. We analyze structure prediction with the MFE and MEA algebras and a covariance model algebra COVARfollowing the definitions of [
45]. For Ali2D, only MFE is combined with COVAR. For Ali3D, MFE, MEA and COVAR are combined into the Pareto product. Like for the single-sequence RNA folding, a dot bracket string representation and an RNAshape representation of the Pareto front candidates are added via a lexicographic product. It should be mentioned that alignment folding is defined over the same Overdangle grammar as the single sequence case, only now, the input alphabet is columns of aligned characters, including gap symbols. Accordingly, for this case, the Rfam seed alignments are left intact, while for Fold, only the first sequence is used.
4.3. Evaluation of Strategy SORT
Strategy SORT is evaluated in Experiments 1 and 2. Experiment 1 uses two random trials to evaluate the performance of Pareto front computations based on our sorting Algorithm 1–Algorithm 7. For this, we generate lists of sorted sublists of various lengths as inputs and measure their individual runtimes. The outcome is of interest for programmers who consider Pareto optimization, but not necessarily in a dynamic programming context. In an algebraic dynamic programming application, the case of simultaneously merging two or more sorted sublists can occur in Equations (
15) and (
16). Intermediate results are generated from a search space with particular properties and will be far-from-random datasets. In Experiment 2, we therefore look at our real-world applications, measuring runtimes for each sorting call on intermediate lists of the computations. The outcome is quite different from Experiment 1.
Experiment 1: Two randomized trials were conducted to confirm the viability of all sorted implementations. For this, we uniformly sample data points for
(Trial 1) and
20,000 (Trial 2) list elements over
sorted sublists.
M is fixed for each generated input. Trial 1 was ended at 200,990 tests, Trial 2 at 150,505. All list elements have a size of 22 bytes, bigger than most forward computation, but smaller than all backtracing elements in the next experiment set. The times of Algorithms 2–7 were compared against the corresponding times of Algorithm 1, both in total, for all points, as well as utilizing a separator (a separator in algorithmics is a borderline in the data space when one should switch from one algorithm variant to another for best efficiency) on
N and
M between the sets. All but one algorithm performs either in
or
, compared to
of Algorithm 1; thus, linear or logarithmic separators should be applied respectively. We tested various parameters of linear and logarithmic functions without the
y intercept, as well as constant separators by simple enumeration. In cases where visual inspection showed a possible discordance of this simple model, e.g., in
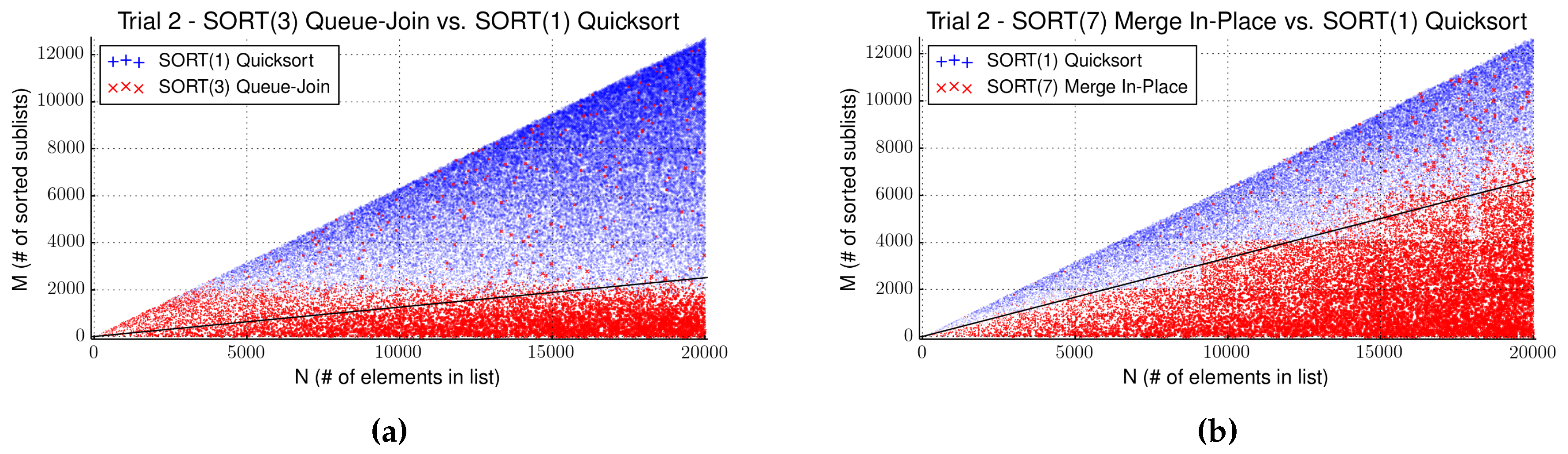
Figure 3a, we manually tested more complex models, however without any improvements. See
Table 3.
Figure 3.
Runtime gain of individual data points of for (a) Algorithm 3 and (b) Algorithm 7 against Algorithm 1 in Trial 2. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. Separators are indicated by a black line. In (b), please note that the distribution of red points is less dense above the separator than it is below.
Figure 3.
Runtime gain of individual data points of for (a) Algorithm 3 and (b) Algorithm 7 against Algorithm 1 in Trial 2. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. Separators are indicated by a black line. In (b), please note that the distribution of red points is less dense above the separator than it is below.
Table 3.
Maximal runtime gain of Algorithms 2–7 compared to Algorithm 1 for randomized uniform Trial Sets 1 and 2. The number of comparator calls was averaged over all data points, ignoring separators. Separators indicate where an algorithm becomes superior to Algorithm 1. Separators for runtime gain can operate solely on the total length of the input list N and the number of know nsorted sublists M. They are estimated to the nearest integer for linear separation and to two decimal places for logarithmic separation, in both cases assuming the simplest form without any offset variables.
Table 3.
Maximal runtime gain of Algorithms 2–7 compared to Algorithm 1 for randomized uniform Trial Sets 1 and 2. The number of comparator calls was averaged over all data points, ignoring separators. Separators indicate where an algorithm becomes superior to Algorithm 1. Separators for runtime gain can operate solely on the total length of the input list N and the number of know nsorted sublists M. They are estimated to the nearest integer for linear separation and to two decimal places for logarithmic separation, in both cases assuming the simplest form without any offset variables.
| Algorithm | Avg.Comparator Calls | Max. Saved Time (s) | Separator |
|---|
| Trial 1 |
| Algorithm 1 Quicksort | 26,692.7 | | |
| Algorithm 2 List-Join | 1,137,920.0 | - | No significant gain |
| Algorithm 3 Queue-Join | 21,780.1 | 29.0 | Always use Algorithm 3 |
| Algorithm 4 In-Join | 716,920.0 | - | Algorithm 4 never performs consistently better |
| Algorithm 5 Merge A | 18,043.2 | 11.3 | Use Algorithm 5 when |
| Algorithm 6 Merge B | 18,700.0 | 7.8 | Use Algorithm 6 when |
| Algorithm 7 Merge In-Place | 18,043.2 | 13.4 | Use Algorithm 7 when |
| Trial 2 |
| Algorithm 1 Quicksort | 222,480.0 | | |
| Algorithm 2 List-Join | 50,668,600.0 | - | No significant gain |
| Algorithm 3 Queue-Join | 181,884.0 | 33.2 | When |
| Algorithm 4 In-Join | 31,480,100.0 | - | Algorithm 4 never performs consistently better |
| Algorithm 5 Merge A | 157,102.0 | 44.9 | Use Algorithm 5 when |
| Algorithm 6 Merge B | 161,502.0 | 28.1 | Use Algorithm 6 when |
| Algorithm 7 Merge In-Place | 157,102.0 | 62.7 | Use Algorithm 7 when |
The clear winner in the first trial is Algorithm 3 (Queue-Join), outperforming Quicksort across all tested combinations, followed by Algorithms 5 and 7 with linear separators. In the second trial, Algorithm 3 moves down to third place, overtaken by Algorithms 5 and 7. The reason for this is the bad scaling behavior of Algorithm 3 that becomes apparent when comparing graphs for Algorithms 3 and 7. Both algorithms gain over Quicksort when
M is small relative to
N and sublists, hence, are long.
Figure 3 shows that Algorithm 7 (Merge In-Place) gains more than Algorithm 3 and, hence, performs better on the larger dataset.
For Algorithms 2 and 4, no noticeable gain could be found in any trial, which likely can be attributed to their inferior complexity, showing a drastic increase in comparator calls compared to Algorithm 1. All other algorithms average below Algorithm 1 on comparator calls. Algorithm 6 consistently performs worse than Algorithm 7, the additional tests not yielding any performance boost. In Trial 1, Algorithms 5–7 clearly outperform Algorithm 3 regarding comparator calls while showing longer runtimes. This difference can be explained by the number of memory operations executed by each algorithm. In a randomized setting, only a few elements will be initially placed correctly in the list. Algorithm 3 performs in guaranteed N moves, whereas Algorithms 5–7 take asymptotically moves for this case, amortizing the time needed to allocate new memory and destroying the old list on small data.
Experiment 2: Here, we test four dynamic programming applications in biosequence analysis as described earlier in this section. Algorithms 2–4 had exhibited a very bad time behavior in the randomized trials, which is also consistent within all new tested sets, therefore posing a strong limit on testable inputs.
All tests were executed in 2 steps. To achieve an accurate comparison of the sorting algorithms embedded in the application context, first, all implementations of SORT were tested excluding the runtime of the surrounding code, e.g., the iteration through the search space. After identifying the algorithm with the biggest time gain, possibly using a separator, a second test was performed comparing the full running times, including the full GAP-L programs, of all applications. Intermediate
N and
M or now not uniformly sampled, but arise from the properties of the input and ADP. A summary of the results is presented in
Table 4.
Table 4.
Summary of computation times and metadata of test cases. Left: Isolated sorting time gains over Algorithm 1. Input length and the final size of the resulting Pareto front are given. Input size denotes the number of characters in the input sequence. Middle: Total runtimes of sorting phase and full Pareto operators, including sorting for the best algorithm. Right: SORT(1) and SORT(7) show the full running times of the basic sorted (Algorithm 1, ) and the specialized sorted (Algorithm 7, ) implementations.
Table 4.
Summary of computation times and metadata of test cases. Left: Isolated sorting time gains over Algorithm 1. Input length and the final size of the resulting Pareto front are given. Input size denotes the number of characters in the input sequence. Middle: Total runtimes of sorting phase and full Pareto operators, including sorting for the best algorithm. Right: SORT(1) and SORT(7) show the full running times of the basic sorted (Algorithm 1, ) and the specialized sorted (Algorithm 7, ) implementations.
| Name | Input Size | Front Size | Gain (s) | Algorithm | Sort (s) | Pareto (s) | SORT(1) (s) | SORT(7) (s) |
|---|
| Ali2D | 509 | 487 | 59.1 | Algorithm 7 | 341.9 | 354.5 | 579.77 | 530.0 |
| Gotoh2D | 249 | 209,744 | 0 | Algorithm 7 | 0.1 | 0.1 | 29.42 | 30.3 |
| Fold2D | 509 | 15 | 26.8 | Algorithm 7 | 169.9 | 175.5 | 334.5 | 312.3 |
| Fold2D | 608 | 13 | 304.7 | Algorithm 7 | 1296.1 | 1305.8 | 2220.24 | 1833.3 |
| Prob2D | 185 | 9 | 0 | Algorithm 7 | 2.1 | 2.3 | 3.64 | 3.6 |
| Ali3D | 200 | 446 | 0.1 | Algorithm 7 | 0.3 | 1.2 | 4.97 | 4.88 |
| Fold3D | 404 | 165 | 40.7 | Algorithm 7 | 370.4 | 727.3 | 841.64 | 806.7 |
| Prob4D | 185 | 2327 | 125.1 | Algorithm 7 | 287.0 | 1947.9 | 2556.83 | 2469.8 |
Looking at the sorting performance alone, a clear speed up over Algorithm 1 could be achieved for most test cases. Exceptions are Ali3D and Prob2D, both of which have a very low overall computation time, and Gotoh2D. In all cases, Algorithm 7 (Merge In-Place) was the best performing algorithm. Furthermore, in contrast to the randomized trials, no separator was needed to optimize runtimes. Algorithm 5 performed second without any exceptions in the tested sets. While Algorithm 3 had appeared promising in the randomized trials, only for Prob4D could a separator be found, such that Algorithm 3 could achieve a runtime gain, even though it was significantly lower than that of Algorithm 7. Like in the randomized trials, Algorithm 6 performed consistently worse than Algorithms 2, 4, and 5, never achieving any gain.
Neither input size nor front size seem to be a good indicator on which algorithm works best. Most noticeably, the largest gain over Algorithm 1 was achieved with a final front size of 13 for Fold2D. For Ali3D, there was nearly no gain, despite a much larger final front size of 446. Prob4D and Ali3D were executed on similarly-sized inputs, but only one could achieve a significant gain. The reason for these observations is that no direct statements can be made about intermediate lists and front sizes from input size or final front size alone. Pareto fronts may grow and shrink in the course of the computation.
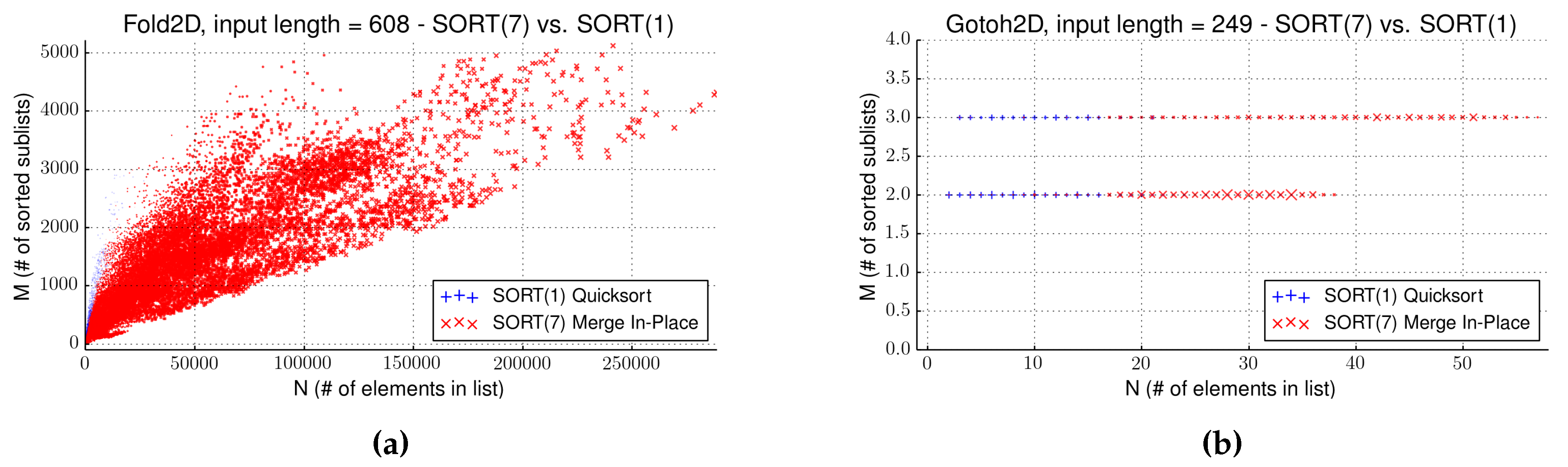
Most informative is the layout of the search space. In
Figure 4, the scatter plots for Fold2D, showing the best improvement, and Gotoh2D, with no improvement, are presented. In its moderate computation time and large final front size, Gotoh2D shows only very limited variance for intermediate results. The final Pareto front consists mostly of co-optimumsthat are only added in the last step of the computation and are not present for the sorting phases. Comparing the full computation times of Gotoh2D, the overall time variance is minimal. The reason for this is the problem decomposition of Gotoh2D. At most 3 sorted sublists are combined by the tree grammars, while the evaluation algebra also does not allow for much variation. In contrast, the grammars for the other applications have at least one rule that generates sublists of a length proportional to the input length. We will later revisit this analysis when comparing the runtime of all algorithms.
Comparing the total running time of the isolated sorting phases and full Pareto computations shows that for almost all cases, more than half of the total computation time is spent in the Pareto operators. Gotoh2D is again the only exception, following the same rationale as above. While the sorting phases seem to take up the most time of the computations for 2-dimensional cases, the gap grows larger for higher dimensions.
Figure 4.
Runtime gain of individual data points of Algorithm 7 against Algorithm 1 for the test cases (a) Fold2D and (b) Gotoh2D. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. Gotoh2D shows only very little variance in list sizes contrary to Fold2D, explaining the performance differences.
Figure 4.
Runtime gain of individual data points of Algorithm 7 against Algorithm 1 for the test cases (a) Fold2D and (b) Gotoh2D. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. Gotoh2D shows only very little variance in list sizes contrary to Fold2D, explaining the performance differences.
4.5. Comparing Two Sorting Strategies
In Experiment 4, we test the sorted variant of strategy EAGER on the same four ADP applications as before and compare it to the simplest version of SORT,
i.e., SORT(1), which uses the off-the-shelf Quicksort algorithm. Our goal is to find possible separators, where one method becomes better than the other, suggesting a data-dependent switch between methods (as we did in Experiment 1). Again, the tests were executed in 2 steps, first comparing the runtimes at the level of intermediate subproblems, excluding the runtime of the surrounding code, and afterwards comparing the full running times of the best implementations. As separators, linear and exponential separations based on values of
N and
M are considered, motivated by the asymptotic complexity of the compared implementations that differ in the factors of these two variables. A summary of the results is shown in
Table 5.
Table 5.
Summary of computation times and metadata of test cases. Left: Isolated sorting time gains over Algorithm 1 with the total sum of running times for Merge 1 or Merge 2, respectively (Sort). Input length and the final size of the resulting Pareto front are given. Input size denotes the number of characters in the input sequence. Right: SORT(1) and EAGER(sort) show the full running times of the basic sorted (Algorithm 1, ) and the Pareto-eager implementations (Merge 1 or Merge 2 respectively).
Table 5.
Summary of computation times and metadata of test cases. Left: Isolated sorting time gains over Algorithm 1 with the total sum of running times for Merge 1 or Merge 2, respectively (Sort). Input length and the final size of the resulting Pareto front are given. Input size denotes the number of characters in the input sequence. Right: SORT(1) and EAGER(sort) show the full running times of the basic sorted (Algorithm 1, ) and the Pareto-eager implementations (Merge 1 or Merge 2 respectively).
| Name | Input Size | Front Size | Gain (s) | Separator | Sort (s) | SORT(1) (s) | EAGER(sort) (s) |
|---|
| Ali2D | 509 | 487 | 220.46 | - | 220.1 | 579.77 | 356.11 |
| Gotoh2D | 249 | 209,744 | - | - | 0.1 | 29.42 | 29.83 |
| Fold2D | 608 | 13 | 762.16 | - | 542.3 | 2220.24 | 1054.39 |
| Prob2D | 185 | 9 | 0 | - | 1.7 | 3.64 | 2.76 |
| Ali3D | 200 | 446 | - | - | 4.3 | 4.97 | 8.04 |
| Fold3D | 404 | 165 | - | - | 5757.9 | 841.64 | 5810.36 |
| Prob4D | 185 | 2327 | - | - | 14,442.3 | 2556.83 | 14,552.12 |
There are two main observations. First of all, no separators are given for any case. The reason for this is that in no case could any improving separators be found. In all cases, one algorithm performs best for all data points. Secondly, with the exception of Gotoh2D, for two-dimensional definitions, EAGER(sorted) always performed best, whereas for higher dimensions, SORT(1) is superior without failure. The explanations for both facts are not entirely unrelated. The difference between dimensions is of course a result of the different underlying implementations of Merge 1 and Merge 2.
As before, we see that more than half of the full running times are spent in Pareto operators.
The two-dimensional case is very similar to the sorted case, only that we apply Pareto operators, as well as sorting the elements. In a way, Merge 1 works similar to a normal two-way merge sort with a merge step definition that is not in place, reflected by the complexity of . By the same arguments as before, Merge 1 is likely to perform better than executing a sorting in when . Conversely, if the number of sublists M is near the number of elements N and sublists are very short, the sorted case with Algorithm 1 will perform better. As intermediate lists are created by combining sub-results, the lengths of individual sub-results are likely to stay over a certain threshold that seems to be high enough in order for Merge 1 to perform well.
For higher dimensions, the situation changes, as now both algorithms perform in
, the complexity of the Pareto operations now dominating the sorting aspects of both implementations. However, the additional factors brought in by the different scenarios strongly favor the use of Algorithm 1 and a single operator step, compared to multiple smaller operator steps, each in
. This seems to be true already for small
N and, accordingly, only grows worse for longer candidate lists. The scatter plots in
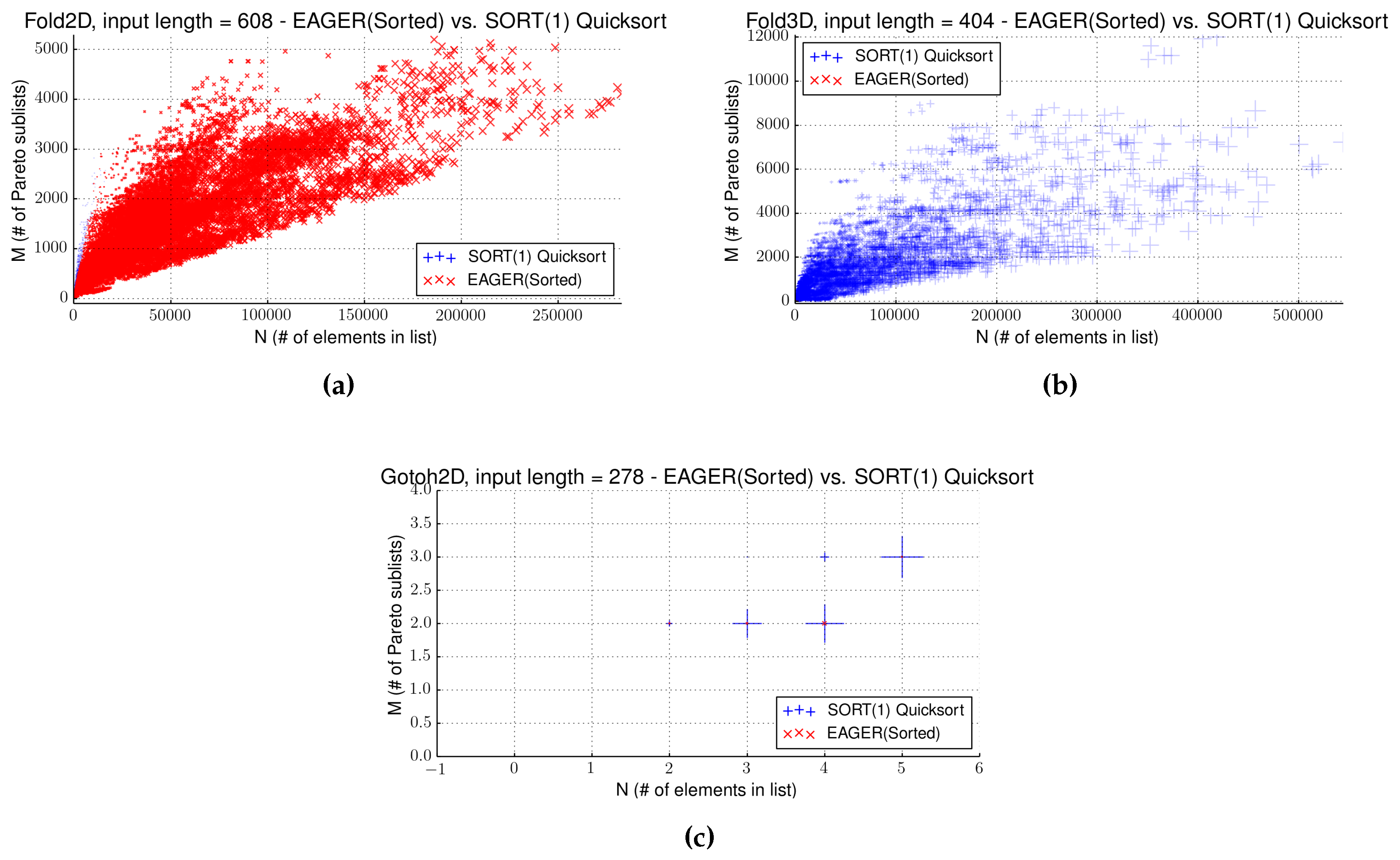
Figure 5a,b confirm this theory for both cases.
Figure 5.
Runtime gain of individual data points of SORT(1) against EAGER(sorted) for the test cases (a) Fold2D and (c) Gotoh2D and for (b) Fold3D. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. For the two-dimensional Fold2D, EAGER(sorted) performs best. For the three-dimensional Fold3D, SORT(1) always performed better. For Gotoh, the plot shows only limited variation and no winning algorithm.
Figure 5.
Runtime gain of individual data points of SORT(1) against EAGER(sorted) for the test cases (a) Fold2D and (c) Gotoh2D and for (b) Fold3D. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. For the two-dimensional Fold2D, EAGER(sorted) performs best. For the three-dimensional Fold3D, SORT(1) always performed better. For Gotoh, the plot shows only limited variation and no winning algorithm.
Like in the sorted scenario, Gotoh2D shows hardly any variation in the computation times. Of course, the same rationale as before applies to explain this behavior. As we can see in
Figure 5c, due to the Pareto condition, intermediate lists are even shorter and allow even fewer variations and with even less potential for better performing algorithms.
4.6. Putting It All Together
Now that all individual components have been established in the previous sections, it is time to combine the results of the previous experiments and relate them to strategy NOSORT. We write simply NOSORT for the variant using and NOSORT(B) using .
In Experiment 5, only full runtimes are considered, including all recursions of the ADP programs, production of output,
etc. A summary of all runtimes over all applications is presented in
Table 6. We will analyze the data in multiple steps, referencing results from previous subsections as needed.
Table 6.
Summary of benchmarks of all applications. Input and front sizes are given. We compare the full runtimes in seconds (s) for three strategies in overall six variants: the strategy (NOSORT) using , its multidimensional variant NOSORT(B) using , SORT(1) using Quicksort and , the specialized sorted case SORT(7), using Merge-in-place with , as well as EAGER (Sorted), using Merge 1 and Merge 2, and, finally, EAGER(Unsorted), using Merge 3. No algorithm can win in all cases.
Table 6.
Summary of benchmarks of all applications. Input and front sizes are given. We compare the full runtimes in seconds (s) for three strategies in overall six variants: the strategy (NOSORT) using , its multidimensional variant NOSORT(B) using , SORT(1) using Quicksort and , the specialized sorted case SORT(7), using Merge-in-place with , as well as EAGER (Sorted), using Merge 1 and Merge 2, and, finally, EAGER(Unsorted), using Merge 3. No algorithm can win in all cases.
| Name | Input | Front | NOSORT | NOSORT(B) | SORT(1) | SORT(7) | EAGER(Sort.) | EAGER(Uns.) |
|---|
| Ali2D | 509 | 487 | 667.84 | - | 579.77 | 529.98 | 356.11 | 775.77 |
| Gotoh2D | 249 | 209,744 | 29.19 | - | 29.42 | 30.32 | 29.83 | 29.75 |
| Fold2D | 509 | 15 | 154.12 | - | 334.53 | 312.28 | 216.54 | 228.29 |
| Fold2D | 608 | 13 | 631.43 | - | 2220.24 | 1833.31 | 1054.39 | 1279.03 |
| Prob2D | 185 | 9 | 2.05 | - | 3.64 | 3.6 | 2.76 | 2.36 |
| Ali3D | 200 | 446 | 5.43 | 4.93 | 4.97 | 4.88 | 8.04 | 4.85 |
| Fold3D | 404 | 165 | 314.52 | 704.03 | 841.64 | 806.67 | 5810.36 | 813.2 |
| Prob4D | 185 | 2327 | 1774.88 | 1227.13 | 2556.83 | 2449.83 | 14,552.12 | 2535.11 |
The most noticeable observation that can be made from the data is that with two exceptions, NOSORT performs best, both for two-dimensional and higher-dimensional cases. This replicates the results of the preliminary implementations done in [
21]. There, the authors suggest that this good behavior can be attributed to a positive randomization effect. When operating on sorted lists, extremal points of the Pareto fronts that are maximal in one dimension, but minimal in others, will be tested first. Such a point is unlikely to create domination over a new element, as it dominates only a rather small volume in the space of possible values. On unsorted lists, non-extremal points are on average encountered earlier, and thus, domination can be established earlier in the computations. Further tests seem to hint at this theory, but a proof appears hard to construct. In particular, we see two points in our measurements that challenge this hypothesis: (1) one would expect EAGER (unsorted) to beat EAGER (sorted) for the same reason, but this is not the case; and (2) EAGER (sorted) clearly beats NOSORT on problem Ali2D, which would then have to be attributed to a special property of its search space.
Although EAGER (unsorted) improves over EAGER (sorted) on multi-dimensional problems, it shows no significant advantage when compared to all other methods. It only wins by a small margin on problem Ali3D. In contrast, except for two cases with very small overall computation times like Ali3D and Gotoh2D, all other uses show a significant increase in running times. This behavior can likely be explained by differences in the implementation that were needed for the Pareto-eager strategies compared to the standard implementation of ADP, introducing new factors to the runtime that could not be amortized by removing candidates earlier on.
Let us now consider the problems Ali2D and Ali3D, where NOSORT could not perform best. For Ali2D, instead, EAGER (sorted) was consistently better. At the same time, both SORT strategies performed better than NOSORT, as well. This is a unique case within all other test cases. The two facts are not without a deeper connection, however. We already saw that for all cases, SORT(7) (using Merge-in-place) can improve the runtime compared to SORT(1) (using Quicksort). Only for the Ali problems, where SORT(1) already performs better than NOSORT, SORT(7) can increase the overall implementation time even more. Here, however, the two-dimensional sorted case EAGER (sorted) becomes the best. A likely reason for these particular measurement, with the only winning point of EAGER (sorted), is that sorting implementations all profit from the same properties of the search space that allow an effective merge of presorted lists. At least in this case, the Pareto eager implementation seems to benefit the strongest. The early reduction of candidate lists is the most likely reason for this good performance.
Altogether, our findings do not imply that the SORT strategies are without merit. Although EAGER (unsorted) beats it for Ali3D as an outlier, the good effect of the sorted implementation compared to the standard NOSORT can be seen here, as well. Due to its increased implementation complexity, EAGER (sorted) cannot really be preferred over SORT(7). EAGER (unsorted) is unlikely to scale well. For Ali3D and similar cases, and still for larger inputs, sorted SORT(7) can be expected to be the best option.
4.7. Influence of Search Space Properties and Dimensionality
Finally, we look at the effect of the search space decomposition and the performed evaluation. So far, our discussion lacks an explanation of why problems Ali2D and Ali3D behave differently from all other applications. For this, it is time to return to the layout of the search space.
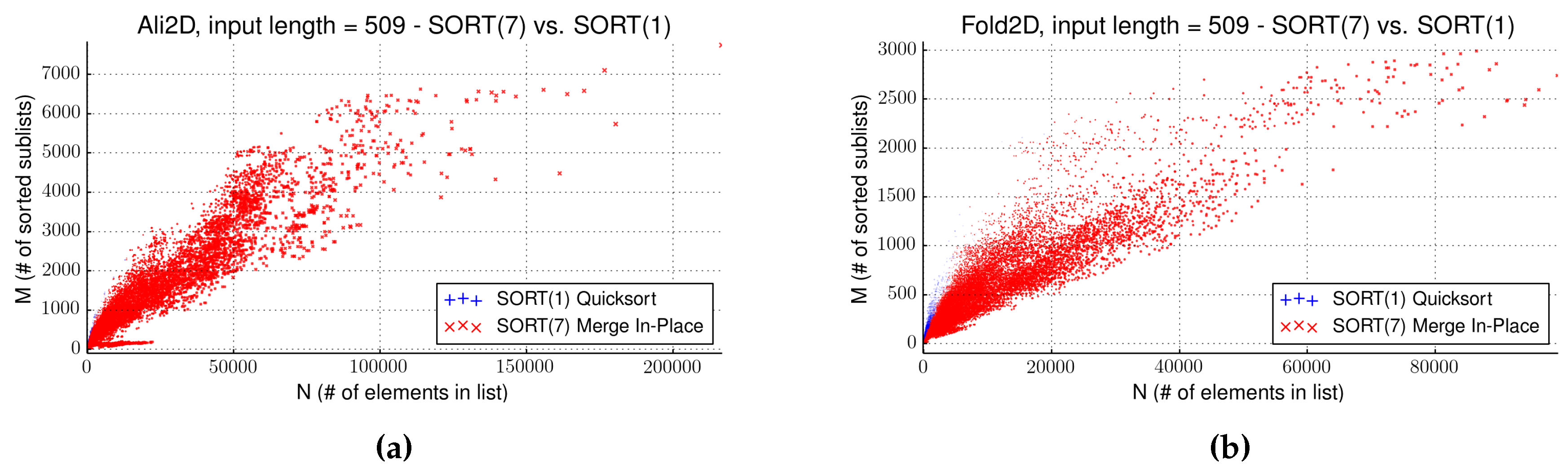
Figure 6 shows the plots of intermediate lists for the sorted cases of Ali2D and Fold2D. Ali2D and Fold2D were computed out of the same data and use the same tree grammar (
i.e., they perform the same search space decomposition), employing the same number of evaluation algebras. The difference in the distribution of data points is therefore caused by the qualitative influence of the evaluation algebras. They solve a different problem: Ali2D reads aligned sequences and folds them, Pareto-optimizing sequence similarity and free energy. Fold2D looks only at a single sequence (Yes, this is described by the same tree grammar in both problems. Only the terminal alphabet has been exchanged. Re-use of algorithm components is a big issue in ADP.) and folds it, Pareto-optimizing over free energy and chemical probing evidence.
Figure 6.
Runtime gain of individual data points of SORT(7) against SORT(1) for (a) Ali2D and (b) Fold2D. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. The point of interest here is not performance, but the observation that both problems produce intermediate results of significantly different sizes.
Figure 6.
Runtime gain of individual data points of SORT(7) against SORT(1) for (a) Ali2D and (b) Fold2D. Points are plotted when one algorithm performed better than the other with point sizes relative to the gained time. The point of interest here is not performance, but the observation that both problems produce intermediate results of significantly different sizes.
Empirically, we find (
Figure 6) that Fold2D generates smaller lists, with (in relation to) fewer sublists compared to Ali2D. This alone, however, cannot explain why for Ali2D, consistently, EAGER (sorted) performs best, while for Fold2D, the strategy NOSORT is considerably faster. This discrepancy must be related to the order and sortedness in which candidates are created, sortedness addressing how many elements are inverted in the lists upon creation.
Using different search space decompositions has an even more dramatic effect. This becomes apparent when taking another look at application Gotoh2D. We already saw in the previous section that Gotoh2D deviates strongly from all other cases, limiting the variation within intermediate candidate lists (see
Figure 4b and
Figure 5c). With all folding problems, the size of the search space depends on the input, and variance is high. The number of sublists also depends on input length. With sequence alignment, in contrast, the number of candidates in the search space only depends on the length of the sequences, not on their content, and the number of sublists is always ≤3. This reflects on the very limited time difference for not just the sorted and Pareto-eager implementation, but all tested algorithms.
The curse of dimensionality calls for its tribute. Of all applications, Prob4D was the only case to define a Pareto product over four dimensions, and because of this, it is also exhibiting very long intermediate lists. As such, Prob4D was the only case where the superior asymptotic complexity of the NOSORT(B) using resulted in an actual performance increase. It is interesting to note that Fold3D also exhibited similarly-sized intermediate lists for the largest input, but instead of improving runtimes, doubled the effort. In its complicated definition, employs high internal factors for runtime that can only be overcome for large inputs. Higher dimensional products are more likely to fulfil this property.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




