1. Introduction
Many ecological and forest management studies are based on knowledge about tree species within a region of interest. Such knowledge can be used for the precise analysis of natural conditions [
1], the development of ecological models [
2], and for conservation and restoration decision-making [
3]. Accompanied by other characteristics, such as tree age and height, crown width, and tree species information can be leveraged for timber volume [
4,
5] and biomass estimation [
6].
A commonly used approach for forest type data gathering is field-based measurement, which has the obvious drawbacks of acquisition cost and difficulty. Many studies are now focused on the automatization of land-cover survey through the use of remote sensing-derived data. This approach is more preferable when analysing vast territories. For instance, the creation of large-scale maps has been described in [
7,
8]. For such tasks, both low spatial resolution and high resolution data can be used. Examples of frequently leveraged data sources with resolution lower than 30 m is Landsat satellite imagery [
9,
10]. Promising results have been shown in studies, both for single image and time-series data [
11,
12,
13]. Nevertheless, some tasks require more precise data with higher resolution. Multispectral images with high resolution strive to provide more thorough land-cover analysis. Many studies have performed forest survey based on Sentinel images with spatial resolution adjusted to 10 m [
14]. For instance, one of the open source packages for Sentinel data analysis is eo-learn project [
15].
Recently, image classification algorithms have demonstrated high prediction accuracy in a variety of applied tasks. Algorithms based on machine learning methods are now commonly used for land-cover mapping—particularly for forest species prediction—using satellite imagery. Classical methods, such as Random Forest [
16], Support Vector Machine [
17], and Linear Regression, usually work with feature vectors, where each value corresponds to some spectral band or combination of bands (in the case of vegetation indices) [
18,
19]. Deep neural network approaches have proved to be more capable for many land-cover tasks [
20,
21,
22]. In [
23], a CNN was compared with XGBoost [
24]. In [
25], a CNN approach was examined for tree mapping, through the use of airplane-based RGB and LiDAR data. In [
26], neural-based hierarchical approach was implemented to improve forest species classification.
In contrast with typical image classification tasks (such as in the Imagenet data set), land-cover tasks involve spatial data. Vast study regions are usually supplied, with a reference map covering the entire area. Classes within this area may not be evenly distributed in many cases [
27]. Moreover, classes of vegetation types of land-cover are often imbalanced within the study region. In many works, the analysed territory can be covered by a single satellite tile (e.g., the size for Sentinel-2 is
km
). Therefore, researchers must choose both how to select the training and validation regions and how to organize the training procedure to deal with imbalanced classes and a spatial distribution that is usually far from uniform. Sampling approach is vital for the remote sensing domain as simple image partition into tiles is ineffective for vast territories [
28]. The training procedure depends on whether we use a pixel-wise [
29] or object-wise approach [
10,
18]. In a pixel-wise approach, each pixel is ascribed a particular class label and the goal is to predict this label using a feature description of the pixel. In an object-wise approach, a set of pixels is considered as a single object. In some classical machine learning methods, a combination of the two approaches has also been considered [
19]. An alternative approach to classical pixel- or object-wise has been provided in [
25] for a CNN tree classification task using airplane-based data. During the described patch-wise training procedure, the model strove to predict one label for a whole input image of size
pixels. However, for some semantic segmentation tasks with lower spatial resolution, the input image can include pixels with different labels and, therefore, the aforementioned approach is not always applicable. The same issue was faced in [
21], where patch-wise approach was implemented for CNN for a land-cover classification task using RapidEye satellite imagery. Some patches with mixed labels were excluded, in order to solve the problem. In our study, we aim to provide sampling approach for medium resolution satellite imagery for forest species classification. In contrast to [
25], we focus on the particular area within a patch and do not exclude from training patches with mixed labels as in [
21].
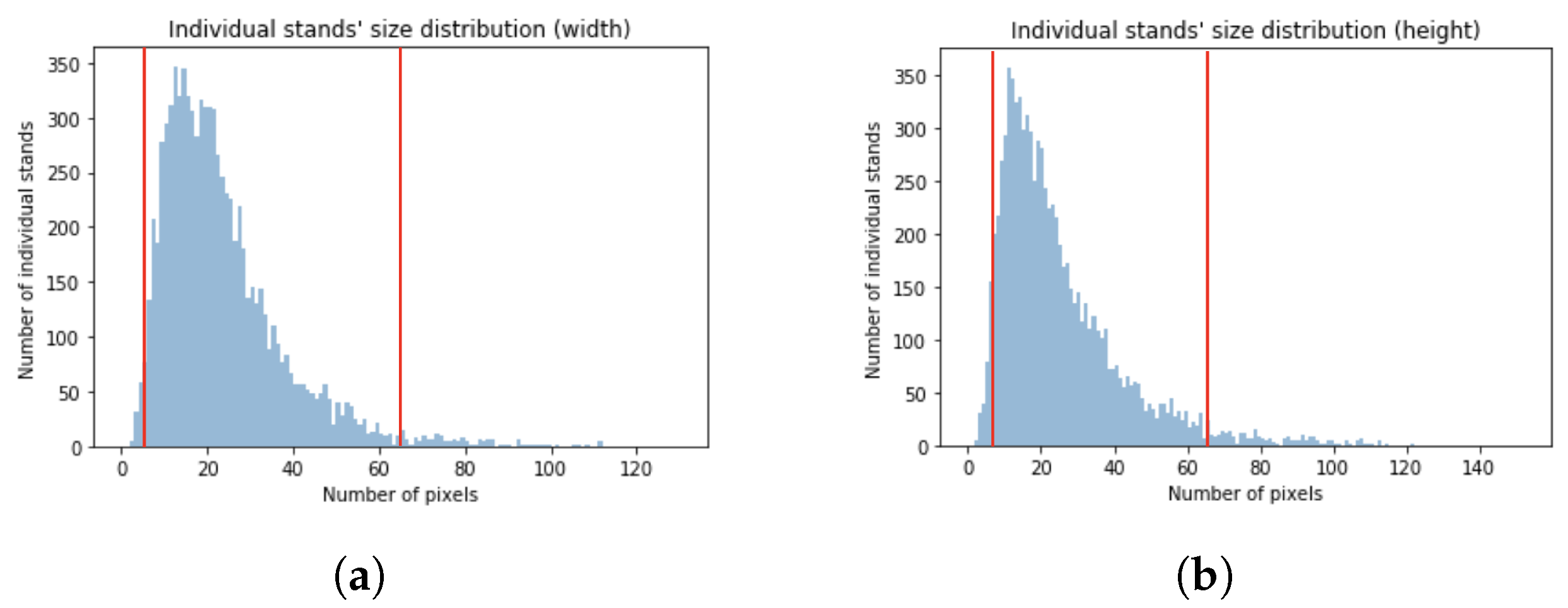
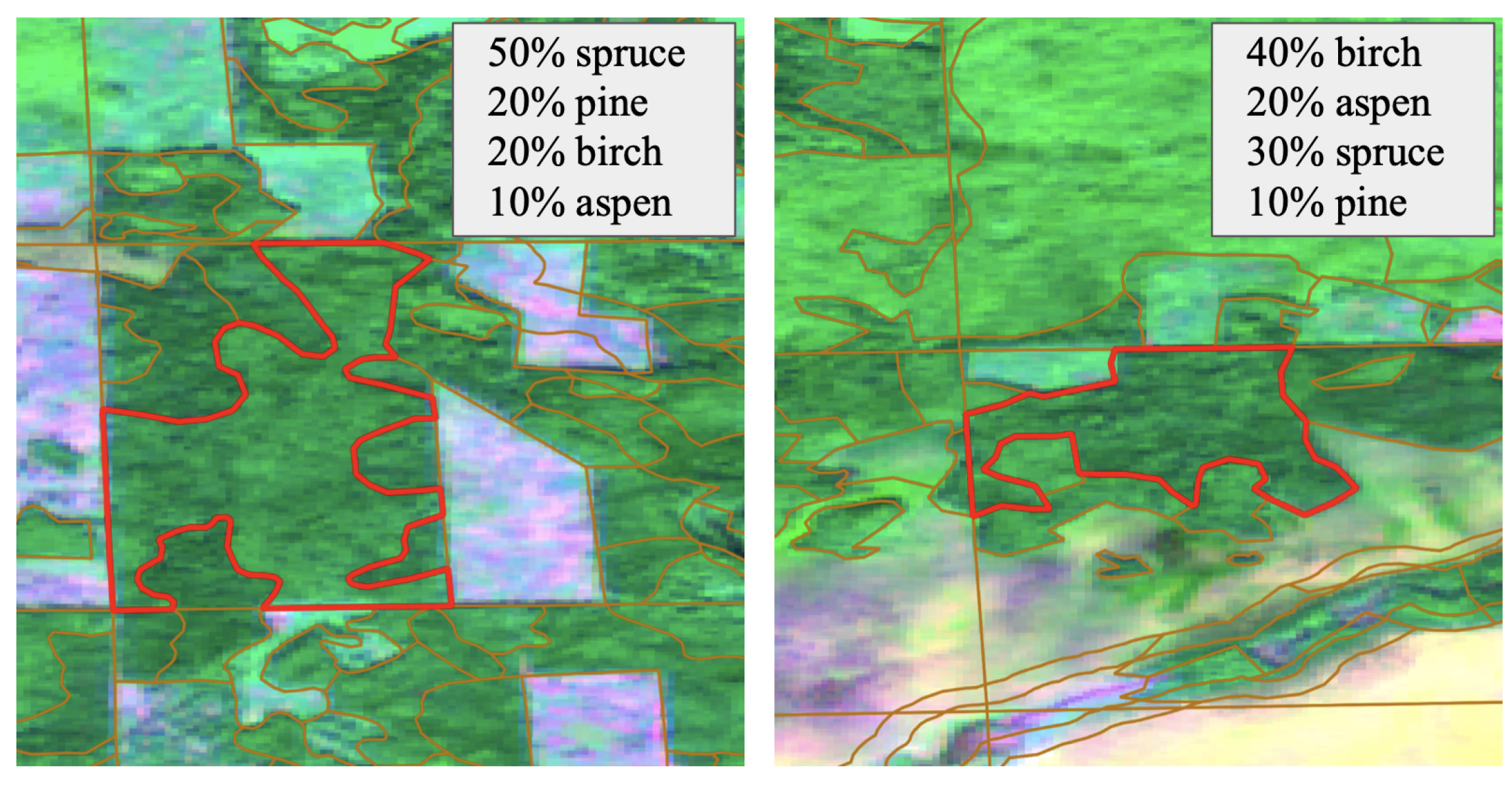
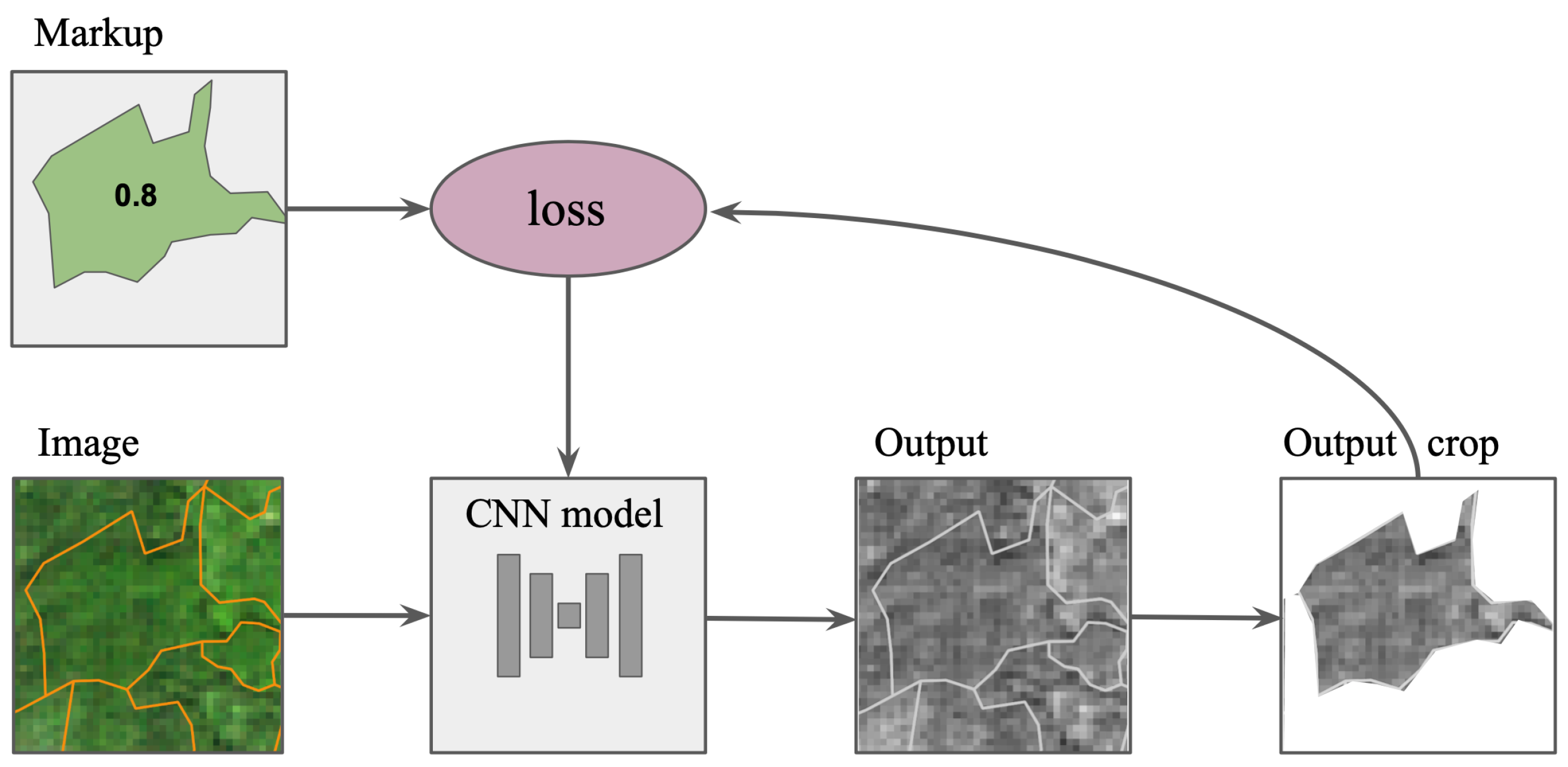
Another important issue is markup limitations. Field-based measurements are commonly used as reference data. Vast territories are often split into small aggregated areas comprised of groups of trees called individual stands [
30]. These stands are not necessarily homogeneous but, in some cases, the percentages of different tree species within the stand is available [
26]. The location of the non-dominant trees is unknown. In such cases, machine learning algorithms are often trained to predict the dominant class even for regions with mixed forest species [
31], or just areas with a single dominant tree species are selected [
32]. This raises the issue of weak markup adjustment. Among weakly supervision tasks, this one belongs to inexact supervision when only coarse-grained labels are given [
33]. Weakly supervised images occur both in the general domain [
34,
35] and in specific tasks such as medical images segmentation [
36]. These studies involve new neural network architectures or frameworks development to decrease requirements for labor-intensive data labeling. In the remote sensing domain weakly supervised learning was also considered in different tasks such as cropland segmentation using low spatial resolution satellite data [
37], cloud detection through high resolution images [
38], and detection of red-attacked trees with very high resolution areal images [
39]. However, in the field of forest species classification, the weak markup problem requires additional analysis according to data specificity (both satellite and field-based). In this study, we propose a CNN-based approach to extract more homogeneous areas from the traditional forest inventory data that includes only species’ content within stands and does not provide each species’ location. We focus on semantic segmentation problem using high resolution multispectral satellite data. The approach is particularly based on the Co-teaching paradigm presented in [
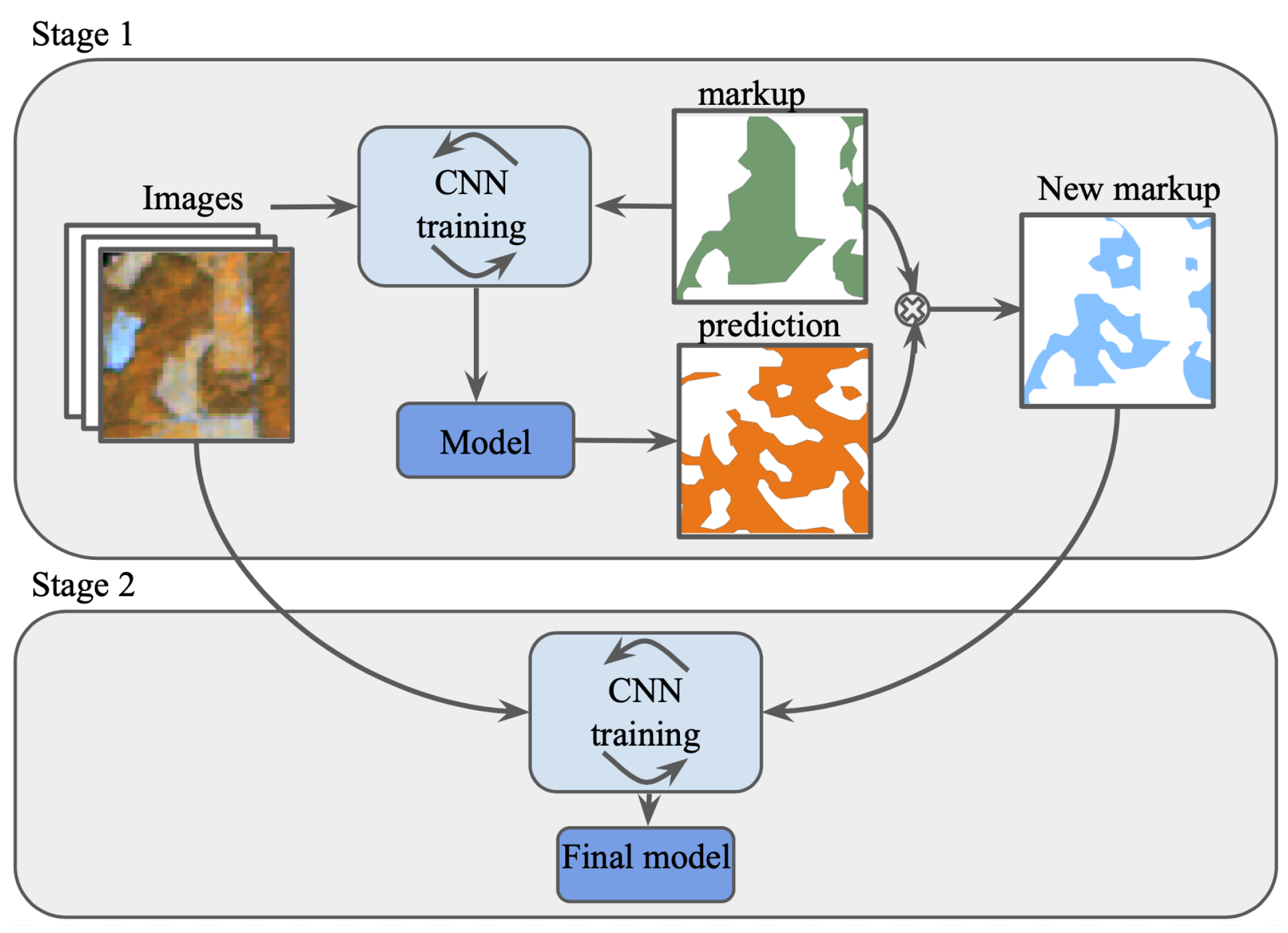
40] where two neural networks are trained, and small-loss instances are selected as clean data for image classification task. In contrast, we split the data adjustment and training process into two separate stages and implement this pipeline for the semantic segmentation task.
In this study, we aim to explore a deep neural network approach for forest type classification in Russian boreal forests using Sentinel-2 images. We set the following objectives:
to develop a novel approach for forest species classification using convolutional neural networks (CNN) combining pixel- and object-wise approaches during the training procedure, and compare it with a typically used approach for semantic segmentation; and
to provide a strategy for weak markup improvements and examine forest type classification both as a problem of (a) dominant class estimation for non-homogeneous individual stands and (b) more precise homogeneous classification.
4. Discussion
4.1. Sampling Approach for Species Classification
The analysis showed that the sampling procedure is highly essential for the forest species classification task. The same approach can be implemented for other problems where maps of vast territories are used and some classes are distributed not uniformly. The proposed object-wise sampling approach for CNN leads to better results than the commonly used approach where patches are chosen randomly within the entire satellite image.
It is worth mentioning the reason why a classical patch-wise approach was not considered suitable for our problem. It implies that we can choose the patch size small enough to include just the pixels of one class. However, in our case, there are two obstacles to implement this. The first being that individual stands are not of rectangular shape and, therefore, the patch size must be rather small. The other point is that individual stands are not homogeneous and we do not know the spatial distributions within stands. Therefore, a random small patch within an individual stand may turn out to, in fact, be a set of pixels of a minor class. This makes the approach described in [
21] inappropriate in the presented case.
Another alternative approach to classical pixel- and object-wise classification for remote sensing applications (e.g., airplane-based) has been discussed in [
25]. It should be noted that, despite the apparent similarity of airplane and satellite-derived remote sensing data, they have substantive differences. The main difference is spatial resolution. The relevant observation field can vary by 100 times (e.g.,
m for UAV and 10 m for satellite images). Thus, the approach have to be modified.
4.2. Markup Adjustment
Clear markup is essential for remote sensing tasks. In some cases, non-homogeneous areas are excluded from training set [
32]. Another approach is to use plots with different species and ascribed it by the dominant species class [
31]. It is reasonable to move further in the direction of an automatic markup adjustment, in order to make the data clearer without extra manual labeling. The next step of the study can be label adjustment for all classes, not only for conifer and deciduous. The weighted loss function adjustment can also be considered to improve homogeneous areas detection.
Weakly supervised learning is now applied in different remote sensing tasks. They vary by the target objects and remote sensing data properties such as spatial resolution and spectral bands number. In our study, we focus on 10 m spatial resolution and 10 multispectral bands. In cases of very high spatial resolution and just RGB bands such as in [
39] markup constraints differ significantly. Particular tasks also pose some limitations and additional opportunities for a weakly supervised learning approach [
38]. Therefore, remote sensing datasets can differ drastically from such datasets as MNIST or CIFAR considered in [
40]. Another difference is that the forest species classification is considered as a semantic segmentation task instead of an image classification task, such as in the case of noisy labels problem in [
40].
Markup adjustment can be also studied in the case with machine learning algorithms instead of neural network based such as methods described in [
57,
58,
59].
The main error source in such land cover tasks is diversity within each forest species. Spectral characteristics vary drastically for different tree age and depend on environmental conditions. Therefore, markup adjustment and optimal sampling choice are promising approaches to improve model performance. Another error source is mixed border pixels of neighboring individual stands. In the case of 10 m spatial resolution, even for homogeneous forest stands, spectral characteristics on the border can be affected by other species outside this stand. A possible approach to address this problem for homogeneous stands is to consider just inner pixels remote from the border.
One of the potential limitations is the time and computational cost for markup adjustment model training. In our case, we used the same CNN architecture to perform this stage. We trained the model for markup adjustment and the final segmentation model sequentially. In future studies, an alternative approach can be developed and implemented to perform markup adjustment on the fly for remote sensing tasks.
In this study, we considered forest species classification. However, the proposed approach can be transferred in future studies for other tasks where samples are grouped, and for a group, label distribution is known. The described approach is also applicable for other neural network architectures. Therefore, experiments with new state-of-the-art architectures can be conducted using the same method. Both the sampling and markup adjustment approaches are transferable to new satellite data sources. We considered multispectral Sentinel-2 imagery with a spatial resolution of 10 m. However, it can also be implemented for high-resolution multispectral data such as WorldView or just RGB images such as base maps.
Vegetation indices are significant for environmental tasks as they provide relevant surface characteristics. Therefore, they are widely used as features for classical machine learning methods. However, in the case of deep neural networks, it is assumed that neural networks can learn non-linear connections between raw input data and use prior information for more general characteristics extraction. In our study, we considered only multispectral satellite bands. However, future studies might include vegetation indices or supplementary materials such as digital elevation or canopy height models to achieve higher results and reduce training time.
It is promising to study different augmentation techniques combined with improved markup and the object-wise sampling approach. For example, the object-based augmentation described in [
60] can further be implemented to create more variable training samples with different homogeneous stands.
Precise forest species classification can also be implemented in ecological and environmental studies, as large forest patches have been proved to affect human health [
61]. Detailed forest characteristics can be helpful for such analysis.















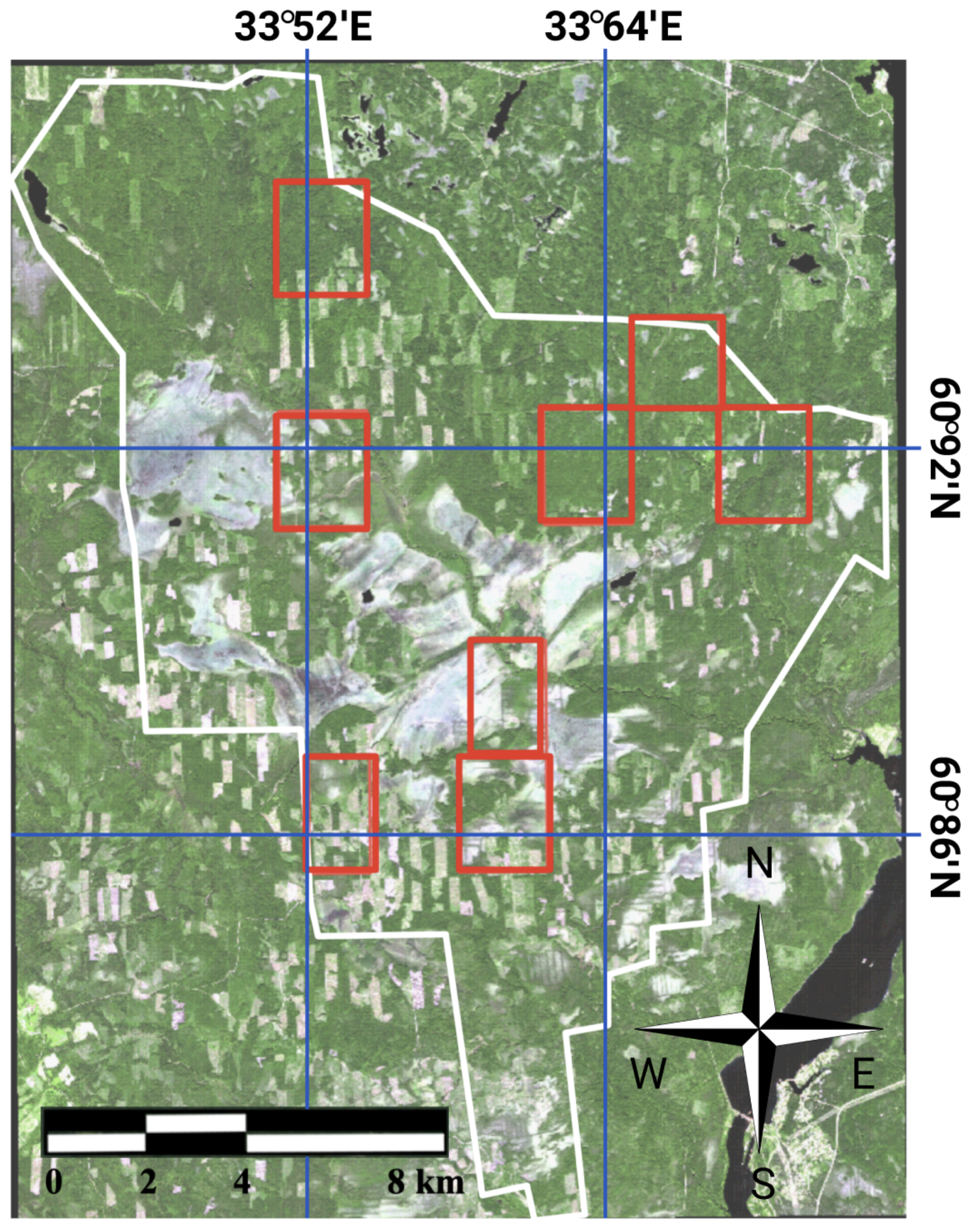
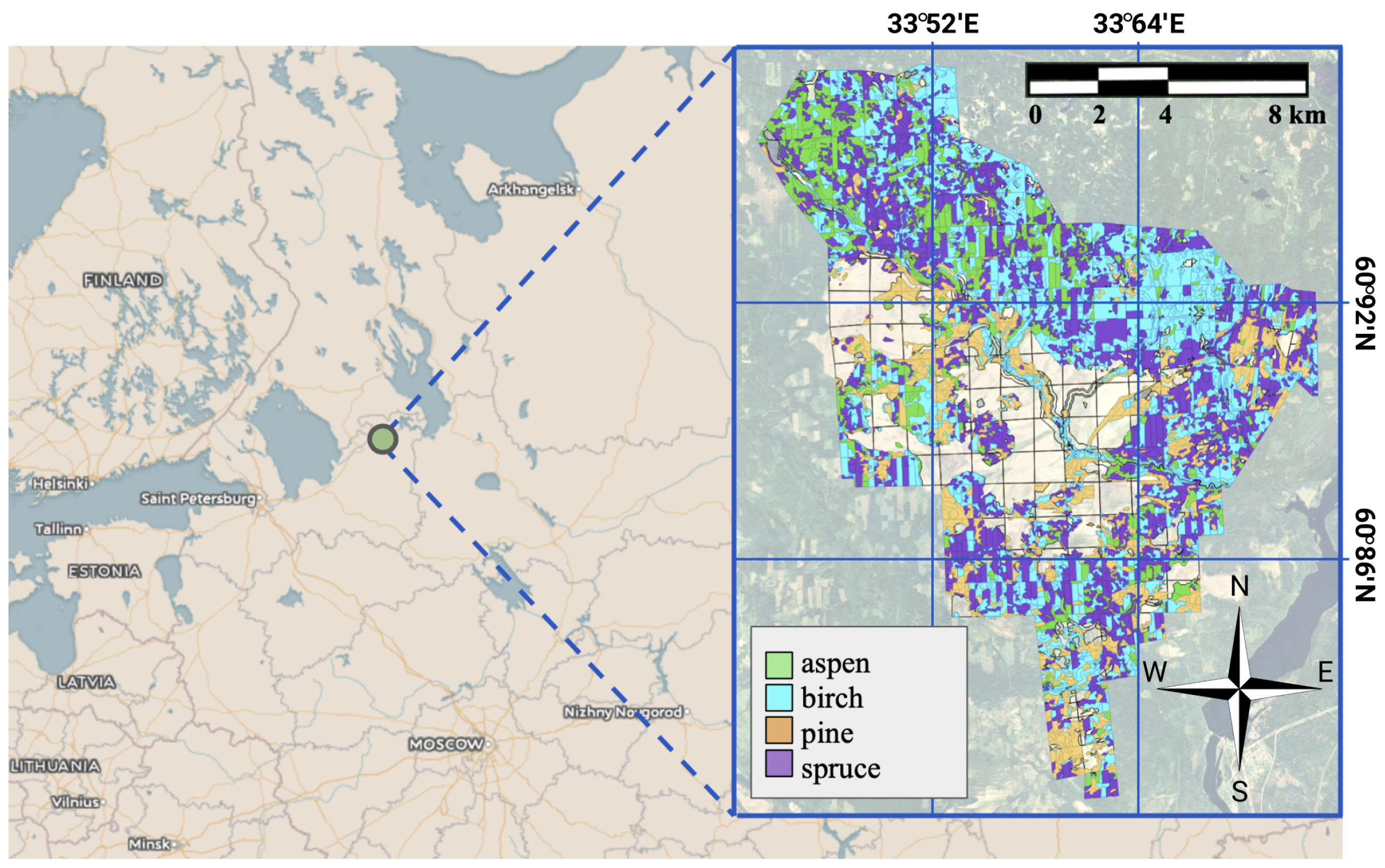{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}