Improved Prediction of Stream Flow Based on Updating Land Cover Maps with Remotely Sensed Forest Change Detection


Abstract
:1. Introduction
2. Materials and Methods
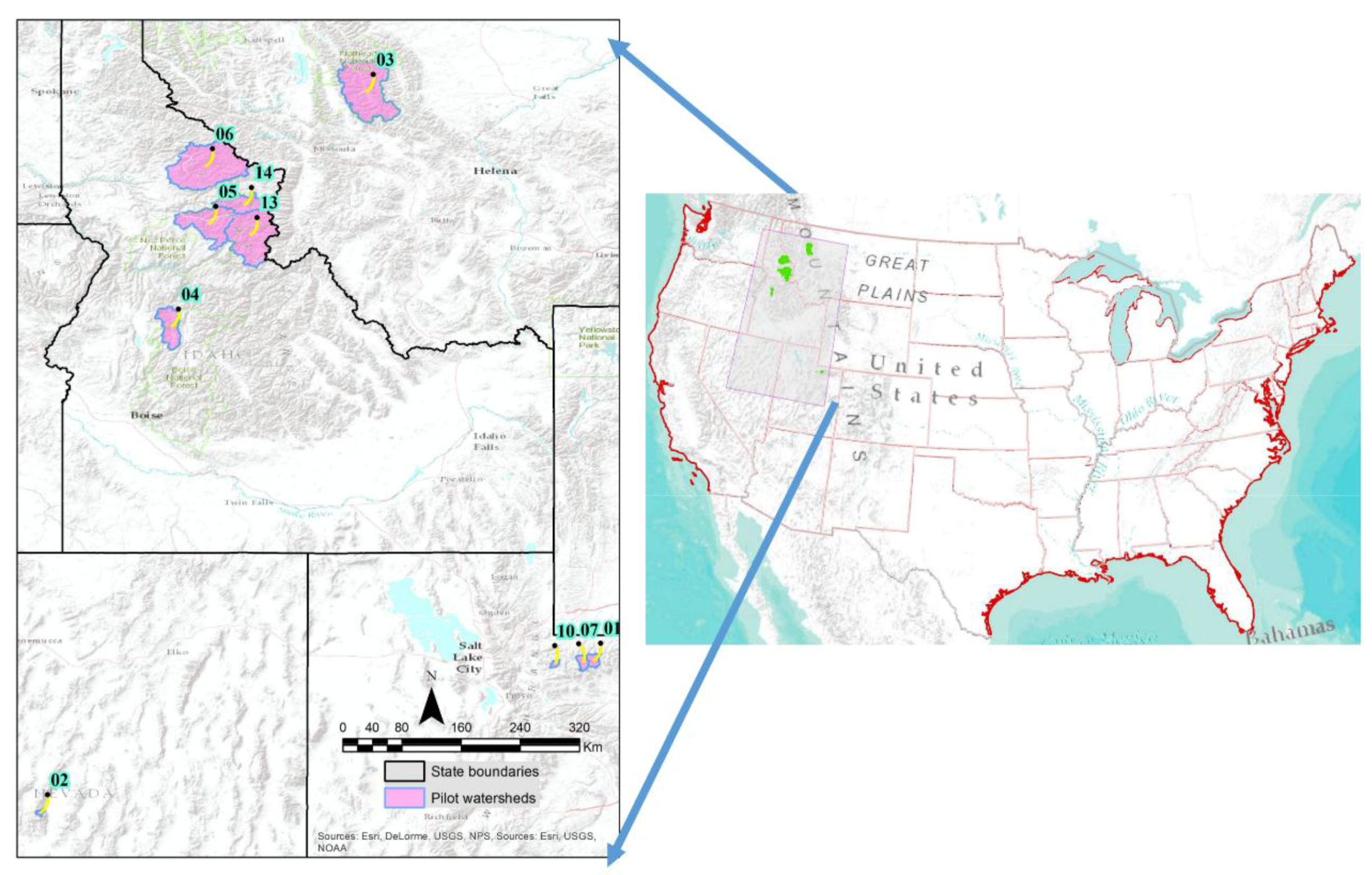
2.1. Study Area
2.2. The SWAT Model
2.3. SWAT’s Inputs and Principal Processes
2.3.1. Watershed Delineation
2.3.2. Climate Data
2.3.3. Land Cover Characteristics
2.3.4. Soil Characteristics
2.3.5. Hydrologic Response Units
2.3.6. Integration of Land Cover Change in SWAT
2.3.7. SWAT Simulations
2.3.8. Model Calibration
2.3.9. Model Validation
2.3.10. Improvement in SWAT Predictions
3. Results
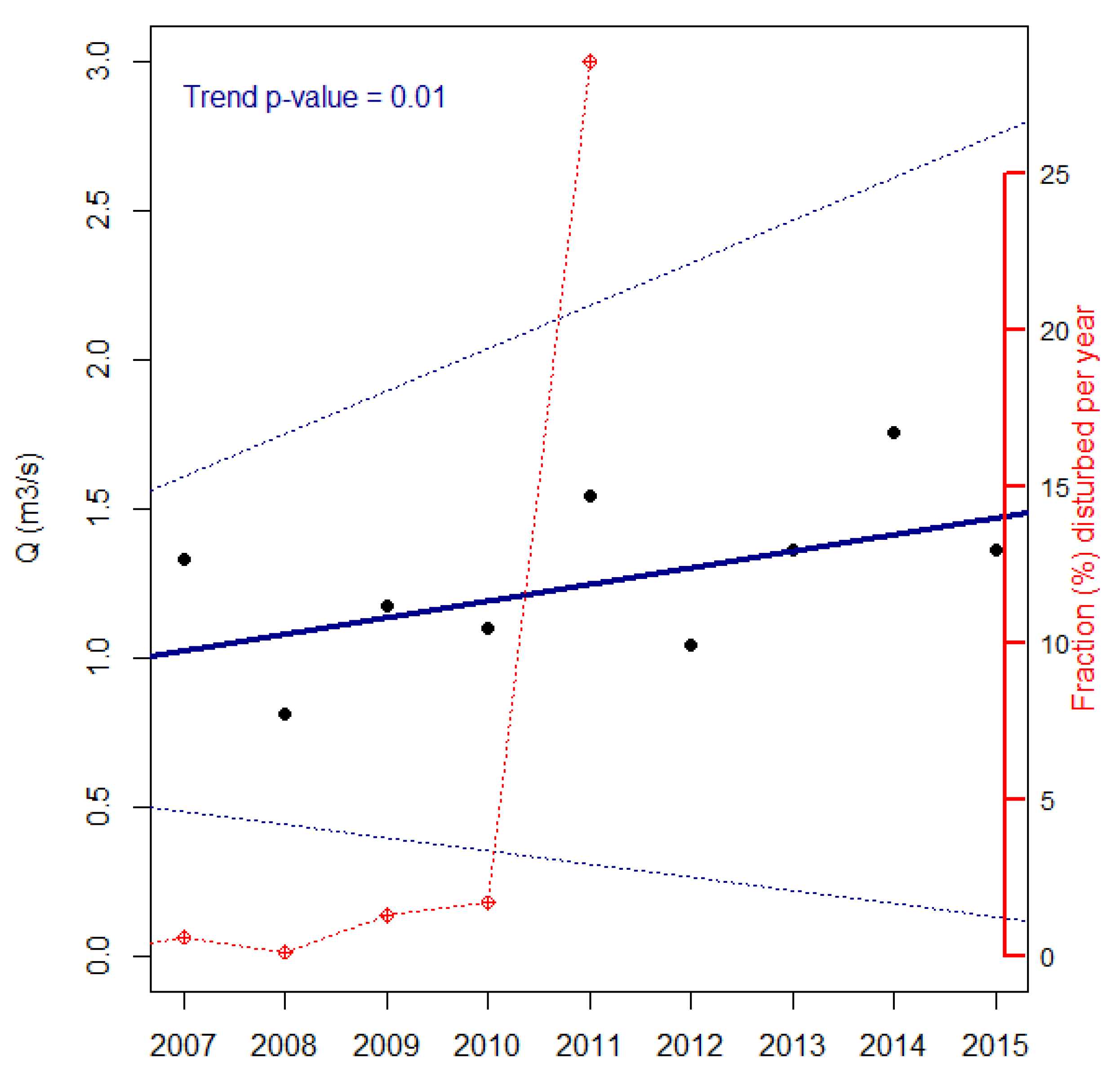
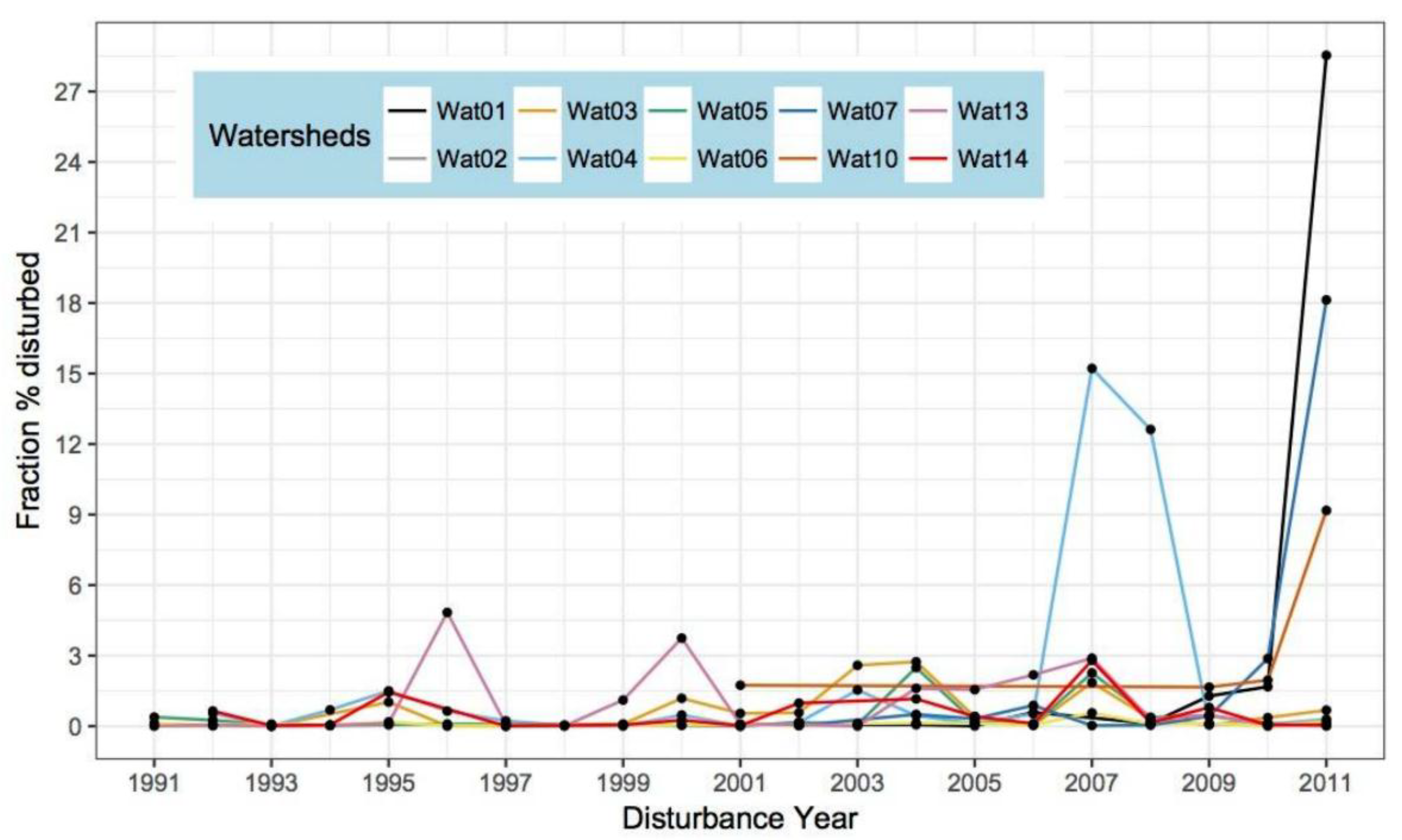
3.1. Disturbance Dynamics in the Pilot Watersheds
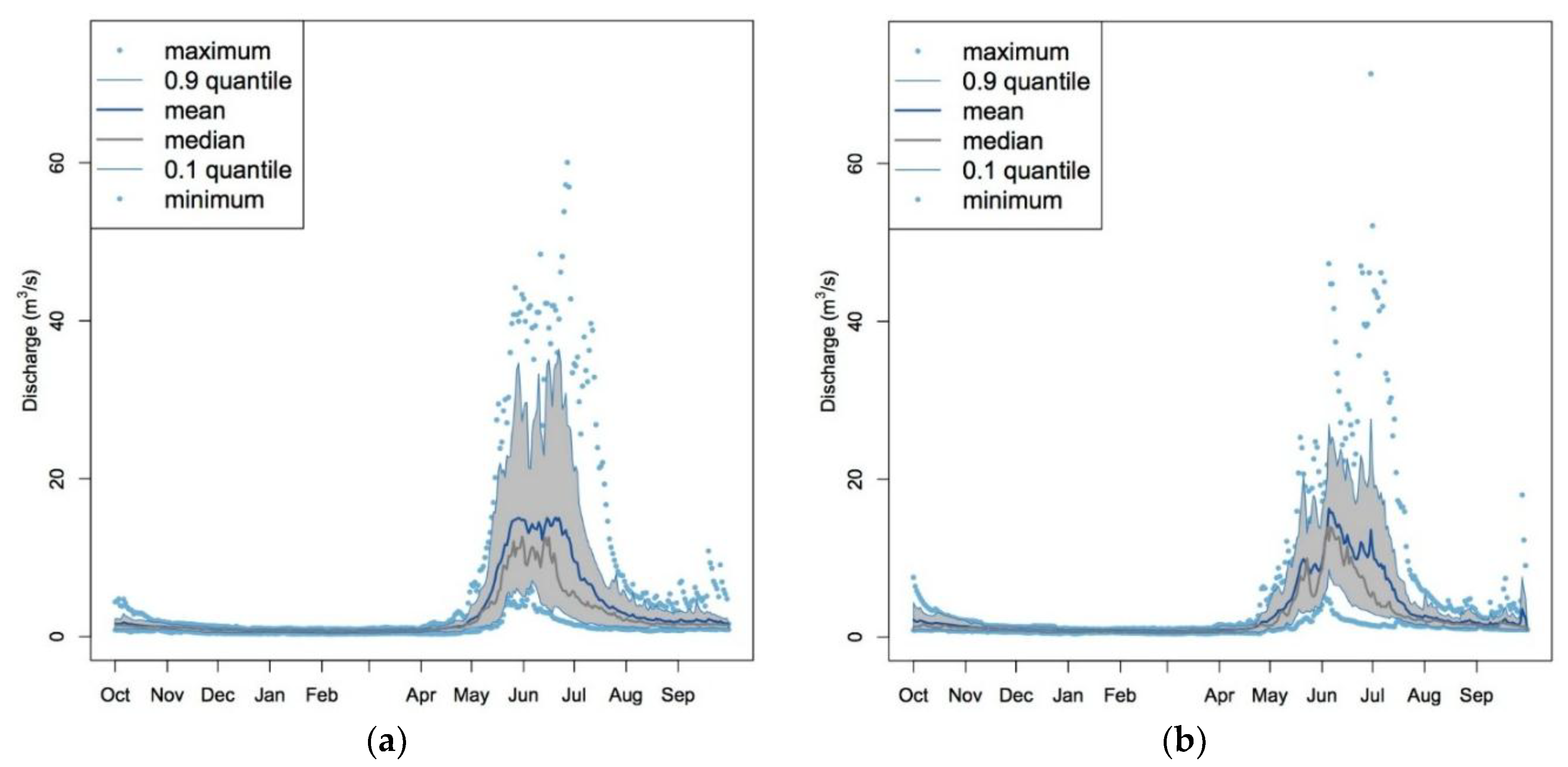
3.2. Major Impacts of Disturbance on Streamflows
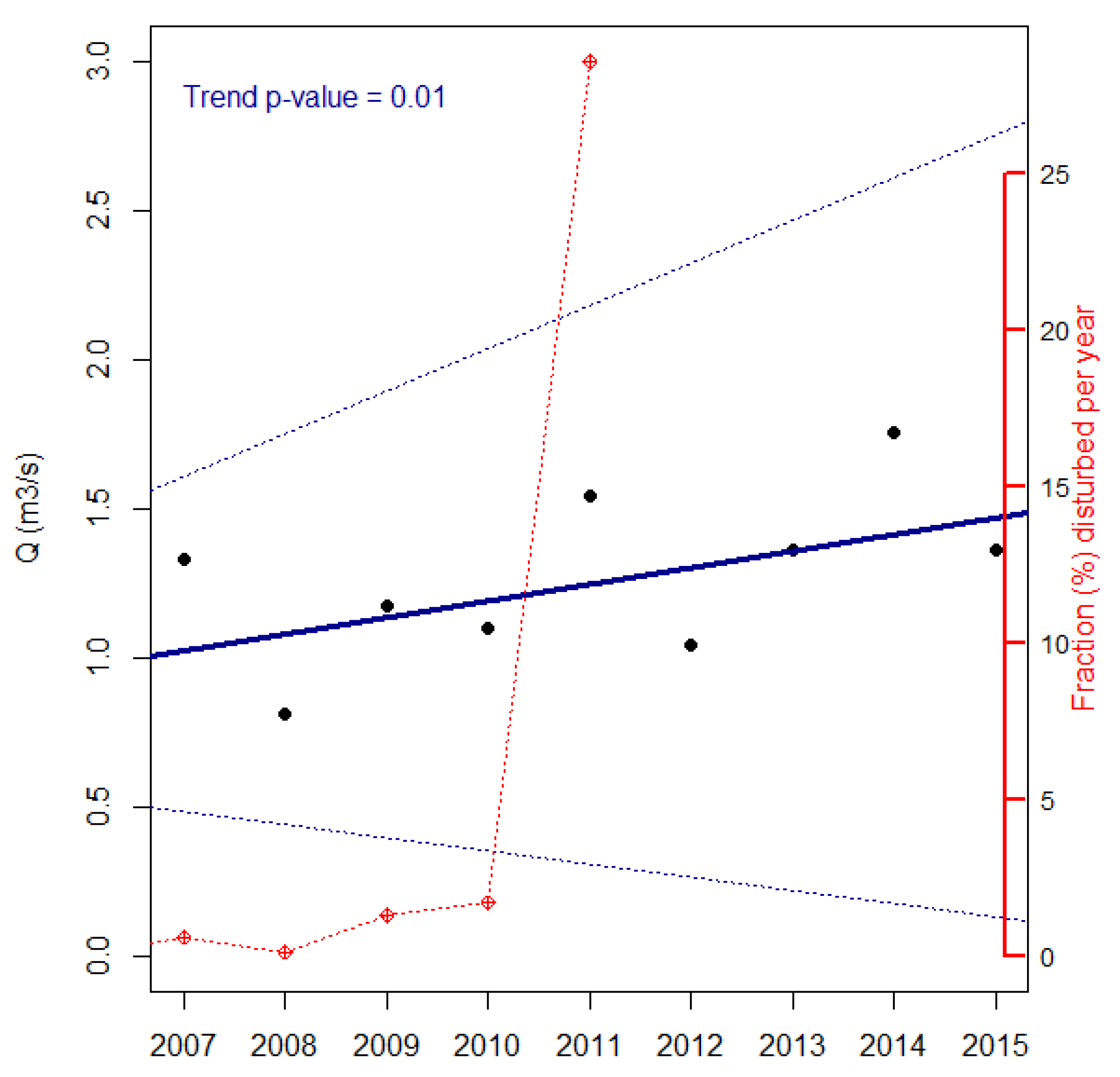
3.2.1. Insect Attacks
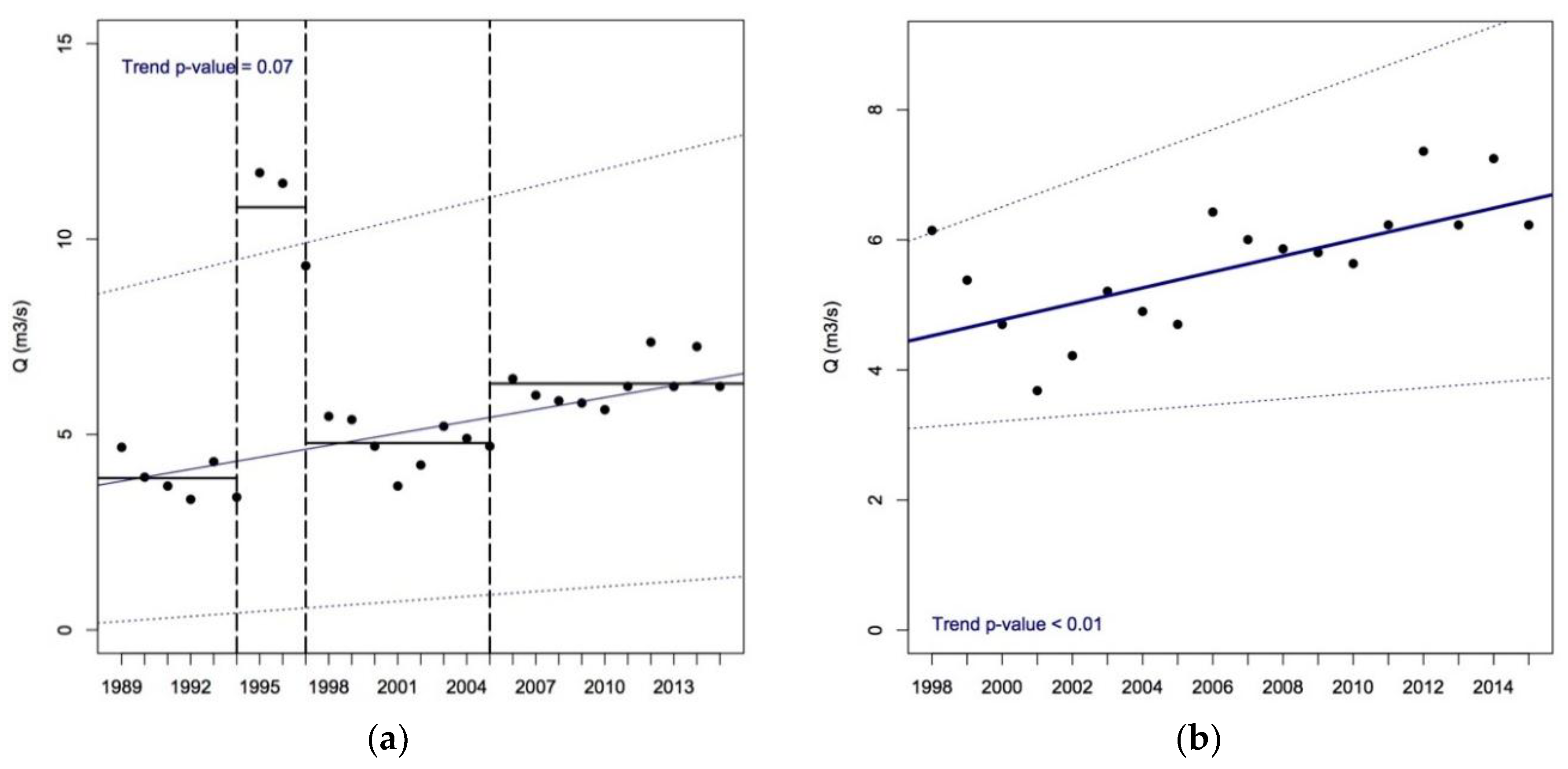
3.2.2. Forest Fires
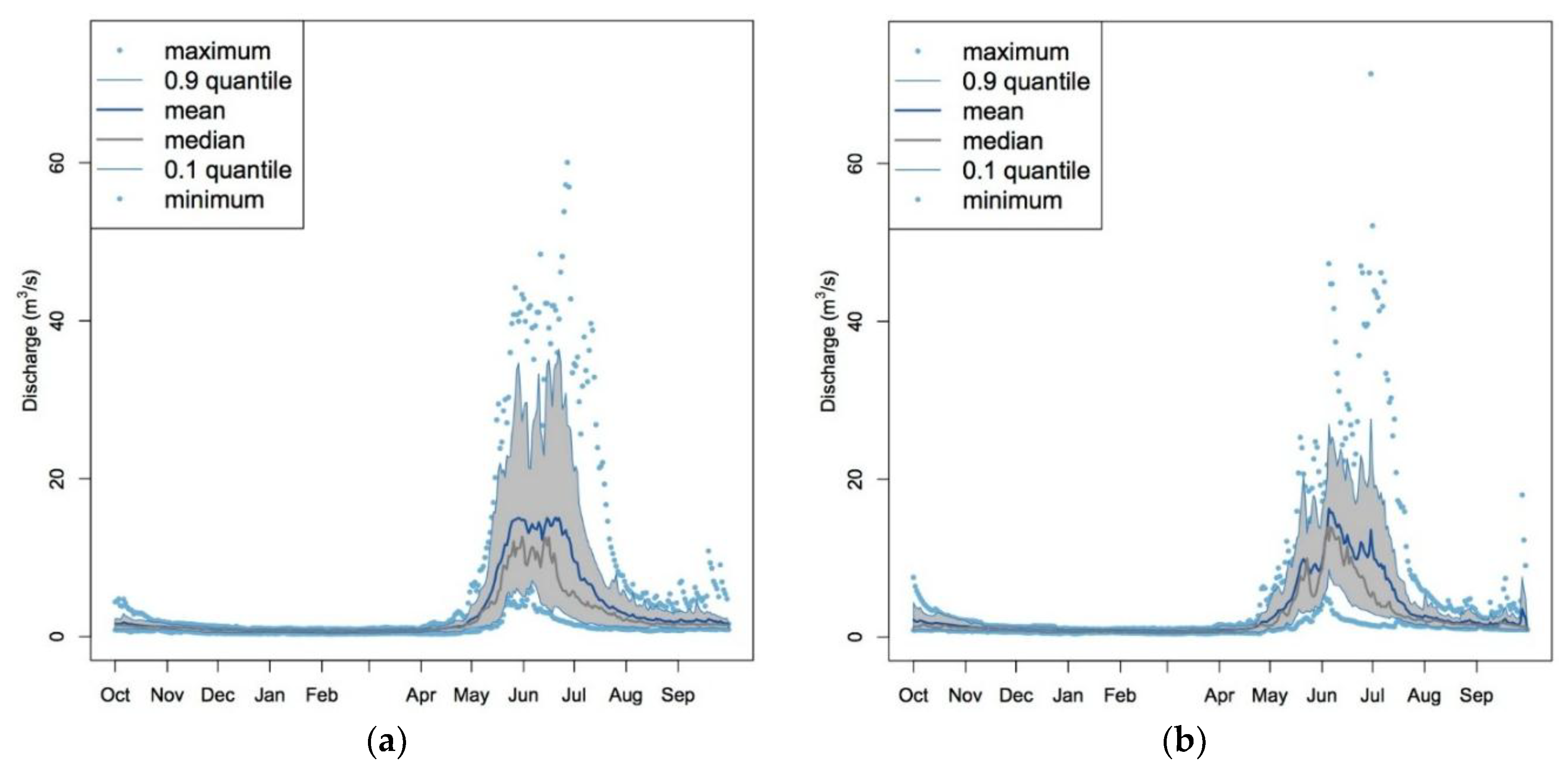
3.3. SWAT’s Outputs
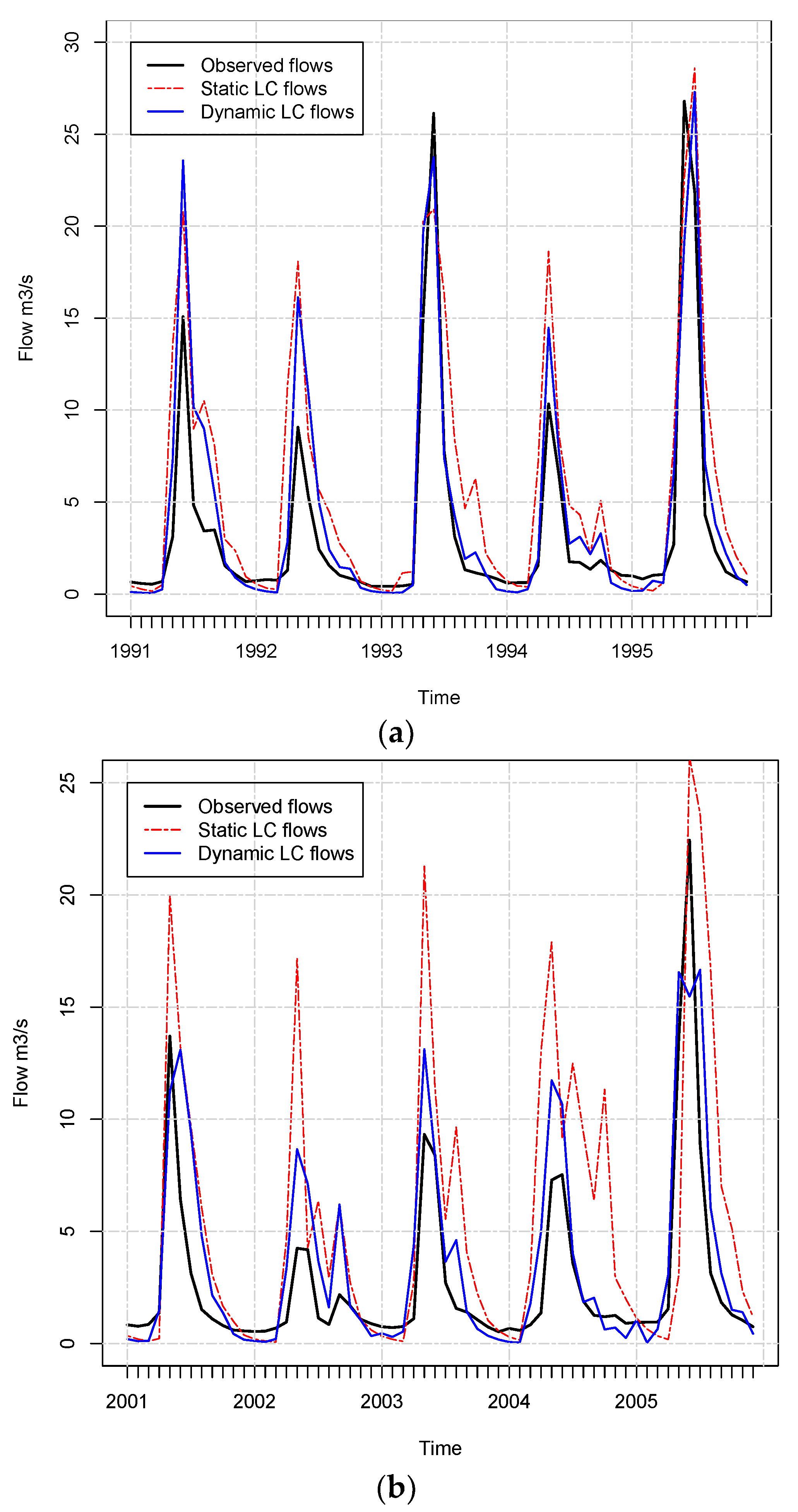
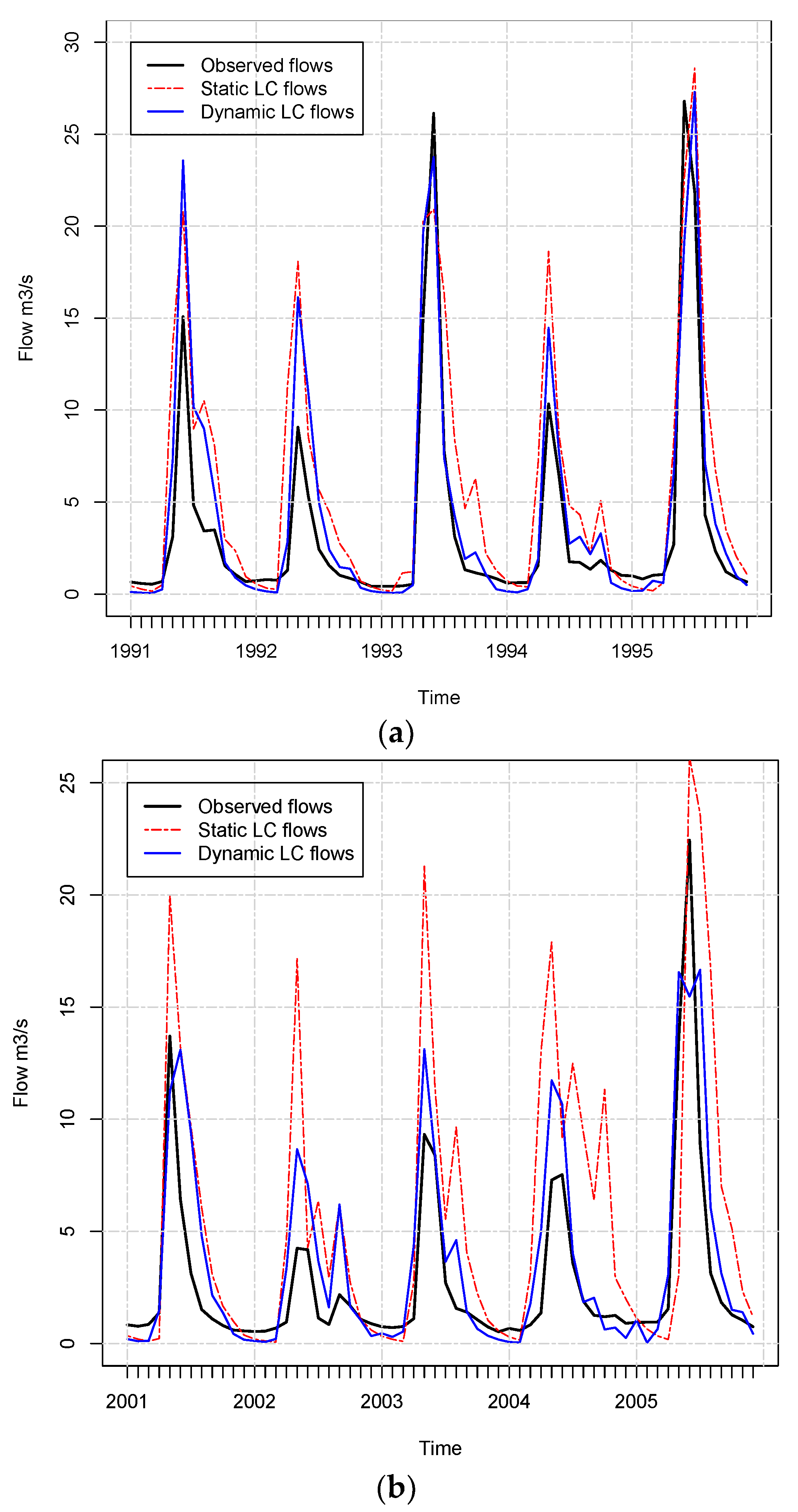
3.4. Annual Maps Provide Better Streamflow Estimates than Five-Year Maps
3.5. Source of the Improvement in Predictions
- HRU NLCD: initial number of HRU in the year 1991
- YEARS NLCD: number of datasets available for NLCD (1992, 2001, 2006, 2011)
- TOT.NLCD: total number of HRU participating in the simulation (Initial HRU × Years NLCD)
- HRU DISTURB: initial number of HRU in the year 1991 for the annual datasets
- YEARS DISTURB.: total number of years for which disturbances were mapped per watershed
- TOT.DISTURBED: total number of HRU participating in the simulation (Initial HRU × Years Disturb) for the annual maps
- DIFF-TOT HRU: difference between the total HRU for the annual maps and the total HRU for the five-year maps
- NSE Imp.: difference between the estimated NSE for five-year and annual maps
- RSR Imp.: difference between the estimated RSR for five-year and annual maps
4. Discussion
4.1. Using Annual Maps in SWAT Produce Better Streamflow Predictions
4.2. Updated Land Cover Helps Yield Prediction: The Relationship between Disturbance and Flow
4.3. Usefulness of SWAT Outputs in Forested Watersheds
5. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Luce, C.; Morgan, P.; Dwire, K.; Isaak, D.; Holden, Z. Rieman. In Climate Change, Forests, Fire, Water, and Fish: Building Resilient Landscapes, Streams, and Managers; Joint Fire Sciences Program GTR-RMRS-290; U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2012. [Google Scholar]
- Troendle, C.A.; King, R.M. The effect of timber harvest on the Fool Creek watershed, 30 years later. Water Resour. Res. 1985, 21, 1915–1922. [Google Scholar] [CrossRef]
- Brown, M.G.; Black, T.A.; Nesic, Z.; Foord, V.N.; Spittlehouse, D.L.; Fredeen, A.L.; Bowler, R.; Grant, N.J.; Burton, P.J.; Trofymow, J.A.; et al. Evapotranspiration and canopy characteristics of two lodgepole pine stands following mountain pine beetle attack. Hydrol. Process. 2014, 28, 3326–3340. [Google Scholar] [CrossRef]
- Cohen, W.B.; Healey, S.P.; Yang, Z.; Stehman, S.V.; Brewer, C.K.; Brooks, E.B.; Gorelick, N.; Huang, C.; Hughes, M.J.; Kennedy, R.E. How Similar Are Forest Disturbance Maps Derived from Different Landsat Time Series Algorithms? Forests 2017, 8, 98. [Google Scholar] [CrossRef]
- Brown, T.C.; Hobbins, M.T.; Ramirez, J.A. Spatial distribution of water supply in the coterminous United States1. J. Am. Water Resour. Assoc. 2008, 44, 1474–1487. [Google Scholar] [CrossRef]
- Ghaffari, G.; Keesstra, S.; Ghodousi, J.; Ahmadi, H. SWAT-simulated hydrological impact of land-use change in the Zanjanrood Basin, Northwest Iran. Hydrol. Process. 2010, 24, 892–903. [Google Scholar] [CrossRef]
- Ma, X.; Xu, J.; Luo, Y.; Prasad Aggarwal, S.; Li, J. Response of hydrological processes to land-cover and climate changes in Kejie watershed, south-west China. Hydrol. Process. 2009, 23, 1179–1191. [Google Scholar] [CrossRef] [Green Version]
- Matheussen, B.; Kirschbaum, R.L.; Goodman, I.A.; O’Donnell, G.M.; Lettenmaier, D.P. Effects of land cover change on streamflow in the interior Columbia River Basin (USA and Canada). Hydrol. Process. 2000, 14, 867–885. [Google Scholar] [CrossRef]
- Nie, W.; Yuan, Y.; Kepner, W.; Nash, M.S.; Jackson, M.; Erickson, C. Assessing impacts of Landuse and Landcover changes on hydrology for the upper San Pedro watershed. J. Hydrol. 2011, 407, 105–114. [Google Scholar] [CrossRef]
- Choi, W.; Deal, B.M. Assessing hydrological impact of potential land use change through hydrological and land use change modeling for the Kishwaukee River basin (USA). J. Environ. Manag. 2008, 88, 1119–1130. [Google Scholar] [CrossRef] [PubMed]
- Scanlon, B.R.; Reedy, R.C.; Stonestrom, D.A.; Prudic, D.E.; Dennehy, K.F. Impact of land use and land cover change on groundwater recharge and quality in the southwestern US. Glob. Change Biol. 2005, 11, 1577–1593. [Google Scholar] [CrossRef]
- Wu, K.; Johnston, C. Hydrologic comparison between a forested and a wetland/lake dominated watershed using SWAT. Hydrol. Process. 2008, 22, 1431–1442. [Google Scholar] [CrossRef]
- Fry, J.A.; Coan, M.J.; Homer, C.G.; Meyer, D.K.; Wickham, J.D. Completion of the National Land Cover Database (NLCD) 1992–2001 Land Cover Change Retrofit Product; US Geological Survey: Reston, VA, USA, 2009.
- Homer, C.; Dewitz, J.; Fry, J.; Coan, M.; Hossain, N.; Larson, C.; Herold, N.; McKerrow, A.; VanDriel, J.N.; Wickham, J. Completion of the 2001 national land cover database for the counterminous United States. Photogramm. Eng. Remote Sens. 2007, 73, 337–341. [Google Scholar]
- Di Luzio, M.; Srinivasan, R.; Arnold, J.G. A GIS-coupled hydrological model system for the watershed assessment of agricultural nonpoint and point sources of pollution. Trans. GIS 2004, 8, 113–136. [Google Scholar] [CrossRef]
- Devia, G.K.; Ganasri, B.P.; Dwarakish, G.S. A Review on Hydrological Models. Aquat. Procedia 2015, 4, 1001–1007. [Google Scholar] [CrossRef]
- Li, Z.; Liu, W.; Zhang, X.; Zheng, F. Impacts of land use change and climate variability on hydrology in an agricultural catchment on the Loess Plateau of China. J. Hydrol. 2009, 377, 35–42. [Google Scholar] [CrossRef]
- Hernandez, A.; Velázquez, S.; Jiménez, F.; Rivera, S. Dinamica del uso de la tierra y de la oferta hidrica en la cuenca Guacerique. Recur. Nat. Ambient. 2005, 21–27. [Google Scholar]
- Wang, X.; Melesse, A.M. Evaluation of the SWAT model’s snowmelt hydrology in a northwestern Minnesota watershed. Trans. ASAE 2005, 48, 1359–1376. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Andréfouët, S.; Cohen, W.B.; Gómez, C.; Griffiths, P.; Hais, M.; Healey, S.P.; Helmer, E.H.; Hostert, P.; Lyons, M.B.; et al. Bringing an ecological view of change to Landsat-based remote sensing. Front. Ecol. Environ. 2014, 12, 339–346. [Google Scholar] [CrossRef] [Green Version]
- Ruefenacht, B.; Finco, M.V.; Nelson, M.D.; Czaplewski, R.; Helmer, E.H.; Blackard, J.A.; Holden, G.R.; Lister, A.J.; Salajanu, D.; Weyermann, D.; et al. Conterminous US and Alaska forest type mapping using forest inventory and analysis data. Photogramm. Eng. Remote Sens. 2008, 74, 1379–1388. [Google Scholar] [CrossRef]
- PRISM Climate Group, Oregon State U. 30-Year Normals. Available online: http://www.prism.oregonstate.edu/normals/ (accessed on 5 May 2016).
- Schwarz, G.E.; Alexander, R.B. State Soil Geographic (STATSGO) Data Base for the Conterminous United States open file report 95-449; US Geological Survey: Reston, VA, USA, 1995.
- Dile, Y.T.; Daggupati, P.; George, C.; Srinivasan, R.; Arnold, J. Introducing a new open source GIS user interface for the SWAT model. Environ. Model. Softw. 2016, 85, 129–138. [Google Scholar] [CrossRef]
- Neitsch, S.L.; Williams, J.R.; Arnold, J.G.; Kiniry, J.R. Soil and Water Assessment Tool Theoretical Documentation Version 2009; Texas Water Resources Institute: College Station, TX, USA, 2011. [Google Scholar]
- Winchell, M.; Srinivasan, R.; Di Luzio, M.; Arnold, J. ArcSWAT Interface for SWAT2005 User’s Guide; Blackland Research Center, Texas Agricultural Experiment Station, United States Department of Agriculture: Temple, TX, USA, 2007. [Google Scholar]
- USDA. ArcSWAT. Available online: https://swat.tamu.edu/software/arcswat/ (accessed on 5 May 2016).
- NRCS. Geospatial Data Gateway. Available online: https://datagateway.nrcs.usda.gov/ (accessed on 5 May 2016).
- Arabi, M.; Govindaraju, R.S.; Hantush, M.M.; Engel, B.A. Role of watershed subdivision on modeling the effectiveness of best management practices with SWAT. JAWRA J. Am. Water Resour. Assoc. 2006, 42, 513–528. [Google Scholar] [CrossRef]
- Ahl, R.S.; Woods, S.W.; Zuuring, H.R. Hydrologic calibration and validation of swat in a snow-dominated rocky mountain watershed, montana, USA 1. JAWRA J. Am. Water Resour. Assoc. 2008, 44, 1411–1430. [Google Scholar] [CrossRef]
- NOAA Climate Data Online Search. Available online: https://www.ncdc.noaa.gov/cdo-web/search (accessed on 5 May2016).
- Huang, C.; Goward, S.N.; Masek, J.G.; Thomas, N.; Zhu, Z.; Vogelmann, J.E. An automated approach for reconstructing recent forest disturbance history using dense Landsat time series stacks. Remote Sens. Environ. 2010, 114, 183–198. [Google Scholar] [CrossRef]
- Healey, S.P.; Cohen, W.B.; Zhiqiang, Y.; Krankina, O.N. Comparison of Tasseled Cap-based Landsat data structures for use in forest disturbance detection. Remote Sens. Environ. 2005, 97, 301–310. [Google Scholar] [CrossRef]
- Schwind, B.; Brewer, K.; Quayle, B.; Eidenshink, J.C. Establishing a Nationwide Baseline of Historical Burn-Severity Data to Support Monitoring of Trends in Wildfire Effects and National Fire Policies. In Adcances in Threat Assessment and Their Application to Forest and Rangeland Management; Gen. Tech. Rep. PNW-GTR-802; Pye, J., Rauscher, M., Sands, Y., Lee, D., Beatty, J., Eds.; U.S. Department of Agriculture, Forest Service, Pacific Northwest and Southern Research Stations: Portland, OR, USA, 2010; pp. 381–396. [Google Scholar]
- Johnson, E.W.; Wittwer, D. Aerial detection surveys in the United States. Aust. For. 2008, 71, 212–215. [Google Scholar] [CrossRef]
- NRCS. Soil Survey Geographic (SSURGO) Database; USDA Natural Resources Conservation Service: Washington, DC, USA, 2004.
- Wang, X.; Melesse, A.M. Effects of STATSGO and SSURGO as inputs on SWAT model’s snowmelt simulation. J. Am. Water Resour. Assoc. 2006, 42, 1217–1236. [Google Scholar] [CrossRef]
- NRCS. National Engineering Handbook Hydrology Chapters. Available online: https://www.nrcs.usda.gov/wps/portal/nrcs/detailfull/national/water/manage/hydrology/?cid=stelprdb1043063 (accessed on 20 July 2017).
- Manguerra, H.B.; Engel, B.A. Hydrologic parameterization of watersheds for runoff prediction using SWAT. JAWRA J. Am. Water Resour. Assoc. 1998, 34, 1149–1162. [Google Scholar] [CrossRef]
- Fontaine, T.A.; Cruickshank, T.S.; Arnold, J.G.; Hotchkiss, R.H. Development of a snowfall–snowmelt routine for mountainous terrain for the soil water assessment tool (SWAT). J. Hydrol. 2002, 262, 209–223. [Google Scholar] [CrossRef]
- Pai, N.; Saraswat, D. SWAT2009_LUC: A tool to activate the land use change module in SWAT 2009. Trans. ASABE 2011, 54, 1649–1658. [Google Scholar] [CrossRef]
- Chen, X.; Vierling, L.; Rowell, E.; DeFelice, T. Using lidar and effective LAI data to evaluate IKONOS and Landsat 7 ETM+ vegetation cover estimates in a ponderosa pine forest. Remote Sens. Environ. 2004, 91, 14–26. [Google Scholar] [CrossRef]
- Gao, F.; Morisette, J.T.; Wolfe, R.E.; Ederer, G.; Pedelty, J.; Masuoka, E.; Myneni, R.; Tan, B.; Nightingale, J. An algorithm to produce temporally and spatially continuous MODIS-LAI time series. IEEE Geosci. Remote Sens. Lett. 2008, 5, 60–64. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Cohen, W.B.; Acker, S.A.; Parker, G.G.; Spies, T.A.; Harding, D. Lidar remote sensing of the canopy structure and biophysical properties of Douglas-fir western hemlock forests. Remote Sens. Environ. 1999, 70, 339–361. [Google Scholar] [CrossRef]
- Dennedy-Frank, P.J.; Muenich, R.L.; Chaubey, I.; Ziv, G. Comparing two tools for ecosystem service assessments regarding water resources decisions. J. Environ. Manag. 2016, 177, 331–340. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abbaspour, K.C. SWAT-CUP 2012. SWAT Calibration Uncertainty Program—A User Man; Swiss Federal Institute of Aquatic Science and Technology: Dübendorf, Switzerland, 2013. [Google Scholar]
- Arnold, J.G.; Moriasi, D.N.; Gassman, P.W.; Abbaspour, K.C.; White, M.J.; Srinivasan, R.; Santhi, C.; Harmel, R.D.; Van Griensven, A.; Van Liew, M.W. SWAT: Model use, calibration, and validation. Trans. ASABE 2012, 55, 1491–1508. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Gupta, H.V.; Sorooshian, S.; Yapo, P.O. Status of automatic calibration for hydrologic models: Comparison with multilevel expert calibration. J. Hydrol. Eng. 1999, 4, 135–143. [Google Scholar] [CrossRef]
- Hernandez, A.J. Dinámica del uso de la Tierra y de la Oferta Hídrica en la Cuenca del Río Guacerique, Tegucigalpa, Honduras; Centro Agronomico Tropical de Investigacion y Ensenanza: Turrialba, Costa Rica, 2003. [Google Scholar]
- Killick, R.; Eckley, I. Changepoint: An R package for changepoint analysis. J. Stat. Softw. 2014, 58, 1–19. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, S.; Sohl, T.L.; Young, C.J. Projecting the land cover change and its environmental impacts in the Cedar River Basin in the Midwestern United States. Environ. Res. Lett. 2013, 8, 024025. [Google Scholar] [CrossRef] [Green Version]
- Nejadhashemi, A.P.; Shen, C.; Wardynski, B.J.; Mantha, P.S. Evaluating the impacts of land use changes on hydrologic responses in the agricultural regions of Michigan and Wisconsin. In 2010 Pittsburgh, Pennsylvania, June 20–June 23, 2010; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2010; p. 1. [Google Scholar]
- Lin, Z.; Radcliffe, D.E.; Risse, L.M.; Romeis, J.J.; Jackson, C.R. Modeling phosphorus in the Lake Allatoona watershed using SWAT: II. Effect of land use change. J. Environ. Qual. 2009, 38, 121–129. [Google Scholar] [CrossRef] [PubMed]
- Brown, A.E.; Zhang, L.; McMahon, T.A.; Western, A.W.; Vertessy, R.A. A review of paired catchment studies for determining changes in water yield resulting from alterations in vegetation. J. Hydrol. 2005, 310, 28–61. [Google Scholar] [CrossRef]
- Zhang, L.; Dawes, W.R.; Walker, G.R. Response of mean annual evapotranspiration to vegetation changes at catchment scale. Water Resour. Res. 2001, 37, 701–708. [Google Scholar] [CrossRef] [Green Version]
- Hornbeck, J.W.; Adams, M.B.; Corbett, E.S.; Verry, E.S.; Lynch, J.A. Long-term impacts of forest treatments on water yield: A summary for northeastern USA. J. Hydrol. 1993, 150, 323–344. [Google Scholar] [CrossRef]
- Hewlett, J.D. Principles of Forest Hydrology; University of Georgia Press: Athens, GA, USA, 1982; ISBN 0-8203-2380-2. [Google Scholar]
- Chang, M. Forest Hydrology: An Introduction to Water and Forests; CRC Press: Boca Raton, FL, USA, 2006; ISBN 0-8493-5332-7. [Google Scholar]
- Zhao, F.R.; Meng, R.; Huang, C.; Zhao, M.; Zhao, F.A.; Gong, P.; Yu, L.; Zhu, Z. Long-term post-disturbance forest recovery in the greater Yellowstone ecosystem analyzed using Landsat time series stack. Remote Sens. 2016, 8, 898. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Healey, S.P.; Cohen, W.B.; Yang, Z.; Brewer, C.K.; Brooks, E.B.; Gorelick, N.; Hernandez, A.J.; Huang, C.; Hughes, M.J.; Kennedy, R.E.; et al. Mapping forest change using stacked generalization: An ensemble approach. Remote Sens. Environ. 2018, 204, 717–728. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit | Area (km2) | EL (m) Range | FTG > 25% † | SHG ‡ | Pcp (mm) ⊗ | T (°C) ⊗ | USGS Code | Long. | Lat. | Years of Record |
|---|---|---|---|---|---|---|---|---|---|---|
| Wat01 | 198.3 | 2496–4029 | FSMH–LP | B–C | 899.4 | 0.1 | 09289500 | 40°36′24″ | 110°31′35″ | 1933–2017 |
| Wat02 | 50.1 | 1912–3591 | PJ–AB | B | 536.8 | 4.2 | 10249300 | 38°53′15″ | 117°14′40″ | 1965–2017 |
| Wat03 | 3026.0 | 1096–2838 | FSMH–LP | B–D | 1145.2 | 2.5 | 12359800 | 47°58′44″ | 113°33′38″ | 1965–2017 |
| Wat04 | 855.0 | 1141–2787 | DF–FSMH | B | 990.4 | 3.2 | 13310700 | 44°59′13″ | 115°43′30″ | 1966–2017 |
| Wat05 | 1717.2 | 442–2445 | DF–FSMH | B–C | 1019.5 | 5.2 | 13336500 | 46°05′12″ | 115°30′50″ | 1911–2017 |
| Wat06 | 3360.9 | 509–2407 | FSMH–DF | B–C | 1401.8 | 4.9 | 13340600 | 46°50′26″ | 115°37′16″ | 1967–2017 |
| Wat07 | 177.2 | 2435–3924 | FSMH–LP | B | 984.3 | 0.5 | 9277800 | 40°33′27″ | 110°41′50″ | 1965–1994 |
| Wat10 | 62.7 | 2284–3484 | FSMH–LP | B | 1039.9 | 1.9 | 10153800 | 40°35′48″ | 111°05′48″ | 1963–1996 |
| Wat13 | 2552.7 | 671–2850 | DF–FSMH | B–C–D | 1061.6 | 3.6 | 13335690 | 46°07′18″ | 114°55′50″ | 1995–2006 |
| Wat14 | 941.3 | 660–2598 | FSMH | B–C–D | 1248.3 | 4.1 | 13335700 | 46°07′28″ | 114°55′58″ | 1995–2005 |
| Hydrologic Unit | NSE | PBIAS | RSR | |||
|---|---|---|---|---|---|---|
| NLCD | Annual | NLCD | Annual | NLCD | Annual | |
| Wat01 | 0.72 | 0.76 | −8 | −3.8 | 0.53 | 0.49 |
| Wat02 | 0.41 | 0.57 | −38.2 | 46.3 | 0.77 | 0.65 |
| Wat03 | −0.83 | 0.60 | −103.8 | −23.8 | 1.35 | 0.63 |
| Wat04 | −0.45 | 0.62 | 1.3 | −45.5 | 0.74 | 0.61 |
| Wat05 | −0.17 | 0.61 | 95.7 | −22.8 | 1.08 | 0.63 |
| Wat06 | 0.54 | 0.72 | −34.0 | 11.7 | 0.68 | 0.50 |
| Wat07 | 0.57 | 0.57 | 29.9 | 28.8 | 1.00 | 0.66 |
| Wat10 | 0.92 | 0.92 | −16.7 | −20.8 | 0.29 | 0.28 |
| Wat013 | 0.47 | 0.58 | −35.8 | 25.0 | 0.73 | 0.65 |
| Wat014 | 0.35 | 0.80 | 60.7 | −23.3 | 0.81 | 0.80 |
| Unit | HRU NLCD | Years NLCD | TOT NLCD | HRU Disturb. | Years Disturb. | TOT. Disturb. | DIFF–TOT HRU | NSE Imp. | RSR Imp. |
|---|---|---|---|---|---|---|---|---|---|
| Wat01 | 18 | 4 | 72 | 24 | 8 | 192 | 120 | 0.04 | 0.04 |
| Wat03 | 119 | 4 | 476 | 171 | 20 | 3420 | 2944 | 1.43 | 0.72 |
| Wat05 | 47 | 4 | 188 | 77 | 19 | 1463 | 1275 | 0.78 | 0.45 |
| Wat13 | 39 | 4 | 156 | 71 | 21 | 1491 | 1335 | 0.11 | 0.08 |
| Wat14 | 43 | 4 | 172 | 45 | 17 | 765 | 593 | 0.45 | 0.01 |
| Wat06 | 57 | 4 | 228 | 62 | 21 | 1302 | 1074 | 0.18 | 0.18 |
| Wat07 | 16 | 4 | 64 | 33 | 9 | 297 | 233 | 0.00 | 0.34 |
| Wat04 | 24 | 4 | 96 | 43 | 20 | 860 | 764 | 0.17 | 0.13 |
| Wat10 | 26 | 4 | 104 | 53 | 4 | 212 | 108 | 0.00 | 0.01 |
| Wat02 | 12 | 4 | 48 | 12 | 1 | 12 | −36 | 0.16 | 0.12 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernandez, A.J.; Healey, S.P.; Huang, H.; Ramsey, R.D. Improved Prediction of Stream Flow Based on Updating Land Cover Maps with Remotely Sensed Forest Change Detection. Forests 2018, 9, 317. https://0-doi-org.brum.beds.ac.uk/10.3390/f9060317
Hernandez AJ, Healey SP, Huang H, Ramsey RD. Improved Prediction of Stream Flow Based on Updating Land Cover Maps with Remotely Sensed Forest Change Detection. Forests. 2018; 9(6):317. https://0-doi-org.brum.beds.ac.uk/10.3390/f9060317
Chicago/Turabian StyleHernandez, Alexander J., Sean P. Healey, Hongsheng Huang, and R. Douglas Ramsey. 2018. "Improved Prediction of Stream Flow Based on Updating Land Cover Maps with Remotely Sensed Forest Change Detection" Forests 9, no. 6: 317. https://0-doi-org.brum.beds.ac.uk/10.3390/f9060317