Modelling Vector Transmission and Epidemiology of Co-Infecting Plant Viruses
by
 ,
,
Linda J. S. Allen
1,*, 
Vrushali A. Bokil
2,
Nik J. Cunniffe
3,
Frédéric M. Hamelin
4,
Frank M. Hilker
5 and
Michael J. Jeger
6 1
Department of Mathematics and Statistics, Texas Tech University, Lubbock, TX 79409, USA
2
Department of Mathematics, Oregon State University, Corvallis, OR 97331, USA
3
Department of Plant Sciences, University of Cambridge, Cambridge CB2 3EA, UK
4
IGEPP, Agrocampus Ouest, INRA, Université de Rennes 1, Université Bretagne-Loire, 35000 Rennes, France
5
Institute of Environmental Systems Research, School of Mathematics/Computer Science, Osnabrück University, 49069 Osnabrück, Germany
6
Centre for Environmental Policy, Imperial College London, Ascot SL5 7PY, UK
*
Author to whom correspondence should be addressed.
Viruses 2019, 11(12), 1153; https://0-doi-org.brum.beds.ac.uk/10.3390/v11121153
Submission received: 5 November 2019
/
Revised: 3 December 2019
/
Accepted: 6 December 2019
/
Published: 13 December 2019
(This article belongs to the Special Issue Plant Virus Transmission by Vectors)
Abstract
:Co-infection of plant hosts by two or more viruses is common in agricultural crops and natural plant communities. A variety of models have been used to investigate the dynamics of co-infection which track only the disease status of infected and co-infected plants, and which do not explicitly track the density of inoculative vectors. Much less attention has been paid to the role of vector transmission in co-infection, that is, acquisition and inoculation and their synergistic and antagonistic interactions. In this investigation, a general epidemiological model is formulated for one vector species and one plant species with potential co-infection in the host plant by two viruses. The basic reproduction number provides conditions for successful invasion of a single virus. We derive a new invasion threshold which provides conditions for successful invasion of a second virus. These two thresholds highlight some key epidemiological parameters important in vector transmission. To illustrate the flexibility of our model, we examine numerically two special cases of viral invasion. In the first case, one virus species depends on an autonomous virus for its successful transmission and in the second case, both viruses are unable to invade alone but can co-infect the host plant when prevalence is high.
1. Introduction
Transmission is a key element in understanding the epidemiology of plant virus diseases, particularly those transmitted by arthropod vectors [1,2,3,4]. In general, four modes of transmission, non-persistent, semi-persistent, persistent-circulative and persistent-propagative, can be distinguished. Each of these modes has a characteristic time period for acquisition from infected plants, retention in the vector, and inoculation to healthy plants [5], although some virus groups such as the torradoviruses do not fit neatly into these categories [6]. Other aspects important for arthropod transmission include transovarial and transtadial transmission, and the “helper strategy” [3] in which a helper virus can be transmitted by the vector but the dependent virus can only be transmitted in the presence of the helper, a strategy modelled by Zhang et al. [7].
Co-infection of hosts by two or more plant viruses is common in both agricultural crops [8,9] and natural plant communities [10,11]. Because of this, the literature on co-infection by plant viruses is extensive, although often not related to transmission. Indeed, extending epidemiological models to go beyond a single pathogen species was relatively-recently highlighted as a key challenge in modeling plant diseases in [12] (challenge 4). Co-infection almost always leads to interactions between viruses during transmission and within-plant processes that can strongly influence disease development in individual plants and ultimately spread in a plant population. The strength and direction of interactions can vary with both negative and facilitating effects, involving within-cell processes, cell-to-cell movement, vector acquisition and inoculation, symptom development and virulence, and yield loss. Reports on cellular interactions have been the most prevalent, mostly for replication rates and virus titre, but some studies have shown clear interactions with vectors over short (epidemiological) and long-term (evolutionary) time scales [13].
Most experimental studies on the relationship between co-infection and transmission have been done for viruses with non-persistent transmission by aphids. Syller [14] reviewed the literature on “simultaneous” transmission of plant viruses by vectors, emphasizing the acquisition component of transmission with little consideration of inoculation. The use of the term “simultaneous” is ambiguous—what seems to be suggested is that two different virus particles can be acquired instantaneously by a vector during a single probe where there is spatial separation between two viruses. However, for non-persistent transmission, with a following probe [15] on the same or different plant, one of the viruses can become detached and no longer be available for inoculation. Transmission can present a real bottleneck in the virus life cycle [16]. In a subsequent review, Syller and Grupa [17] differentiate between simultaneous inoculation (which they call co-infection) and sequential inoculation (which they call super-infection). They claim that synergistic interactions within-plants most often arise between unrelated viruses. Synergism is defined as a facilitative effect in which accumulation of one or both viruses in the host plant increases; in the case of the effect on just one virus, it has been called asymmetric synergism [18]. Synergism has also been used to describe more severe disease symptoms than induced by either virus alone. Syller and Grupa [17] concentrate more on antagonistic effects, such as cross protection [19] or, as has been termed “super-infection exclusion” in which related viruses or virus strains are used preventively to exclude more virulent strains. Mascia and Gallitelli [20] note the contributions that mathematical modeling could make “in forecasting challenges deriving from the great variety of pathways of synergistic and antagonistic interactions” (p. 176).
Co-infection can cover scenarios ranging from two viruses (or virus strains)/one vector through to many viruses/many vectors, but with some nuances. There is an extensive literature on co-infection across this range. Some representative but not exhaustive publications are noted in Table 1, together with some key messages. Many publications acknowledge that there are several or many (in the case of aphids) vector species for a given plant virus, but the experiments reported only involve one vector. Similarly, the same virus and vector can infect more than one host (cucumber mosaic virus is an extreme example) and hence cause more than one disease. Co-infection with virus strains differing in virulence (or other characteristic) can lead to the same set of interactions and consequences as found with virus species. A good example of two strains of the same virus species with shared vector species is potato virus Y (PVY) [21,22,23] on potato and other hosts [15]. There are many examples of two co-infecting virus species with a shared vector species [24,25,26]. Similarly, there are many cases where two co-infecting viruses have quite different vectors taxonomically [27]. Co-infection is manifested in more complex situations with multiple viruses and vectors such as with grapevine leafroll disease [28,29] and sweet potato virus disease (SPVD) [30]. At an even higher level of complexity, the ecological networks formed by multiple co-infecting viruses and multiple hosts were analyzed by McLeish et al. [31].
In this paper, we formulate a general epidemiological model for one vector species and one plant species that allows for co-infection of the host plant by two virus species or strains. The model is used to investigate the role of vector transmission on co-infection, specifically acquisition and inoculation, as well as antagonistic and synergistic interactions. The basic reproduction number provides a condition for invasion of a single virus infection. For co-infection, we derive a new invasion threshold. Given that a single virus can persist in the host plant, the invasion threshold highlights some key epidemiological parameters for successful co-infection. In addition, we investigate the roles of the vector acquisition and inoculation parameters when one virus depends on an autonomous virus for its successful transmission, or when both viruses are unable to invade alone but can facilitate co-infection if they occur in high enough prevalences. We also explicitly test when the simplifications—which are almost always left implicit—in models which do not explicitly include the infection status of vectors lead to potentially misleading results.
2. Materials and Methods
2.1. Modelling
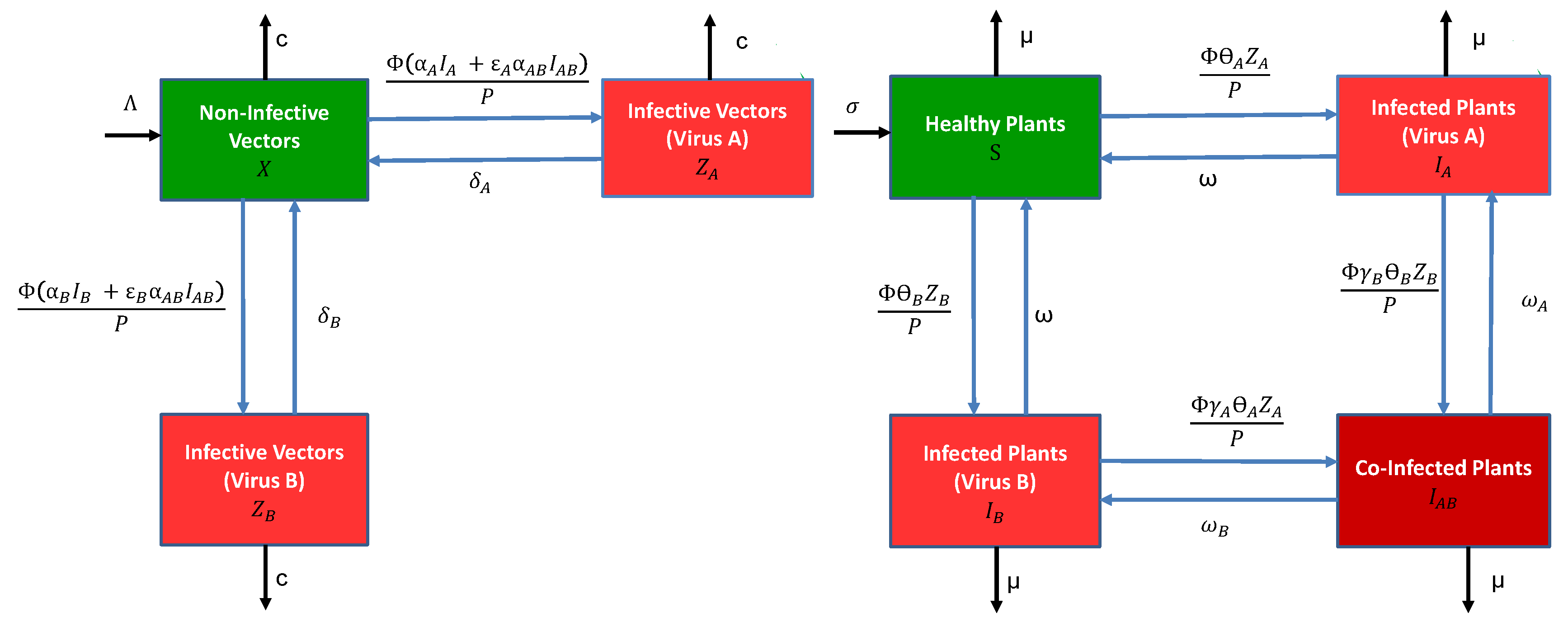
The general epidemiological model for vectors and plants consists of a system of differential equations with either infection by a single virus, or co-infection by two viruses (species or strains). For simplicity, we refer to the two viruses as virus A and virus B. We make several simplifying assumptions. The two viruses are not transmitted vertically in the plant population (no transmission by seeds or other propagating material) nor in the vector (no transovarial transmission). The plants can be infected by a single virus or co-infected by both viruses. The vectors are only inoculative with a single virus; namely, we assume that acquisition of the first virus precludes inoculation by a second virus by the same vector for as long as the vector retains the first virus. This assumption applies to both modes of transmission. For non-persistent transmission, it may arise because stylet receptor sites are saturated by the first virus. For persistent-circulative transmission, it may be due to a phenomenon similar to “super-infection exclusion” taking place in the vector [16], or simply that the first virus moves back to the salivary glands faster than the second. In addition, the latent stages in the vector and plant are ignored. The following compartmental diagrams in Figure 1 illustrate the rates of change between the vector and plant stages. The vector and plant models are described in more detail below.
The vector model has three stages, the density of non-infective vectors, the density of infective vectors carrying virus A and the density of infective vectors carrying virus B (for vectors, “infective” more accurately means “inoculative”). The total vector density is . The parameters net vector birth rate, per capita vector death rate, number of plants visited per unit time by a single vector, probability a non-infective vector acquires a single virus from an infected plant , , per plant visit and per capita vector recovery rate from virus . The parameters and multiplying the acquisition probability are the conditional probabilities that either virus A or B are acquired, given that acquisition is from a co-infected plant, . All of the parameters are non-negative. They are summarised in Table 2. With these assumptions, as well as the assumption of frequency-dependent transmission with P being the total plant population density, the vector model takes the following form:
The plant model consists of four stages, density of healthy plants, and three different classes for infection, , and , equal to the density of infected plants carrying only virus A, virus B or both viruses, respectively. The total plant population density is . The parameters for the plant model include net planting rate, per capita rate of harvesting/mortality, probability an infective vector inoculates a healthy plant with virus per plant visit, per capita recovery rate in a plant infected with a single virus, and per capita viral recovery rate of virus i in a co-infected plant , . The parameters and denote the synergistic or antagonistic interactions between the viruses within the plant when infective vectors inoculate a plant carrying a different virus, i.e., account for the probability of a second infection being either increased or reduced relative to a healthy plant. The plant model is
The parameters and , , reflect the fact that vector acquisition or inoculation with co-infection may differ from a single virus infection [24,25,30]. The acquisition of a single virus from a co-infected plant may be greater or less than acquisition from a plant infected with a single virus (e.g., or ). In addition, the inoculation of a second virus into an infected plant may be greater or less than inoculation of a healthy plant (e.g., or ).
2.2. Invasion Thresholds
Two important disease threshold parameters are derived from models (1) and (2), the basic reproduction number and the invasion reproduction number. The density of non-infective vectors at the disease-free equilibrium (DFE) in the vector model (1) is and the density of healthy plants at the DFE plant model (2) is . The basic reproduction number can be computed from the next generation matrix approach [32,33,34,35,36] (Appendix A). Here it is defined as the maximum of two reproduction numbers,
The two terms in the preceding definition are basic reproduction numbers corresponding to infection with either virus A or virus B, and , respectively. If the basic reproduction number for virus A exceeds the value of one, then virus A can invade the disease-free vector-plant system and if , then virus B can invade. An epidemiological interpretation of is that if one vector inoculative with virus A is introduced into a healthy vector-plant system, it will inoculate and infect plants at a rate of during the period of time the vector is infective. From an infected plant, a non-infective vector will acquire the virus at a rate during the period of time the plant is infected. If the product of these two expressions exceeds the value of one, then one infective vector (or infected plant) will generate more than one infective vector (or infected plant), resulting in an epidemic. In general, if , then either virus A or B can invade the vector-plant system.
An invasion reproduction number can be derived if the system is already infected with a single virus. We consider whether virus B can invade when the system is at the virus A equilibrium, i.e., . The endemic equilibrium values for with virus A are . These endemic values can be expressed in terms of the basic reproduction number :
To determine whether virus B can invade, we apply the next generation matrix approach to derive an invasion matrix from which an invasion reproduction number can be computed (Appendix B). We assume that the vector-plant system is at the virus A equilibrium, defined in (4), with the remaining states , , and set equal to zero. An invasion matrix for the system (1)–(2) is defined as follows:
where , , and . A mathematical definition of the invasion reproduction number is the spectral radius of the invasion matrix, that is, . An epidemiological interpretation of is the average number of new states, , or , that are produced after introduction of an average of one infective vector or infected plant containing virus B, , or , into the system infected with virus A. If , then virus B can invade and if , then virus B cannot invade. Each element in matrix can be interpreted in terms of producing new infective vectors or infected plants, or . For example, the entry in the second row and first column,
can be interpreted as the average number of new infected plants that are produced when one infective vector is introduced into the vector-plant system (where virus A has already invaded).
Since the invasion matrix (5) has non-negative entries, an increase (or a decrease) in any matrix entry also increases (or decreases) the invasion reproduction number [37]. In particular, if the inoculation probability for virus B increases so does the invasion reproduction number. The direction of change for the invasion reproduction number is not as straightforward if the vector visitation rate or parameters related to virus A are changed, as the equilibrium values and also change.
2.3. Formal Reduction to a Model That Does Not Track Vectors Explicitly
The vector-plant system can be reduced to a simplified plant model, where the vectors are not explicitly included (Appendix C). If the vector recovery rates, and , are sufficiently large, then the vector population dynamics occur on a faster time scale than the plant population dynamics. The differential equations for the vector model (1) and the plant host model (2) can be approximated by another plant model without the vector variables:
where parameters for . To distinguish the two sets of models, we will refer to the simplified plant model (6) as the vector-implicit model and to the vector-plant model (1) and (2) as the vector-explicit model.
The vector-implicit model retains the inoculation and acquisition terms. At the DFE, the basic reproduction number is the same as in (3). But the equilibrium for virus A differs from the vector-explicit model,
An invasion matrix for the vector-implicit model when can be computed by a method similar to the computation of the invasion matrix in (5) (Appendix C). Invasion of virus B (via plants infected with virus B, or ) is successful if the spectral radius of the following invasion matrix exceeds the value of one:
where .
3. Results
The effect of vector transmission on virus establishment in the vector-explicit model is examined in several numerical examples. In addition, the conditions for invasion of a second virus in the vector-explicit model are compared to the vector-implicit model.
3.1. Only One Virus Can Invade in Absence of the Other
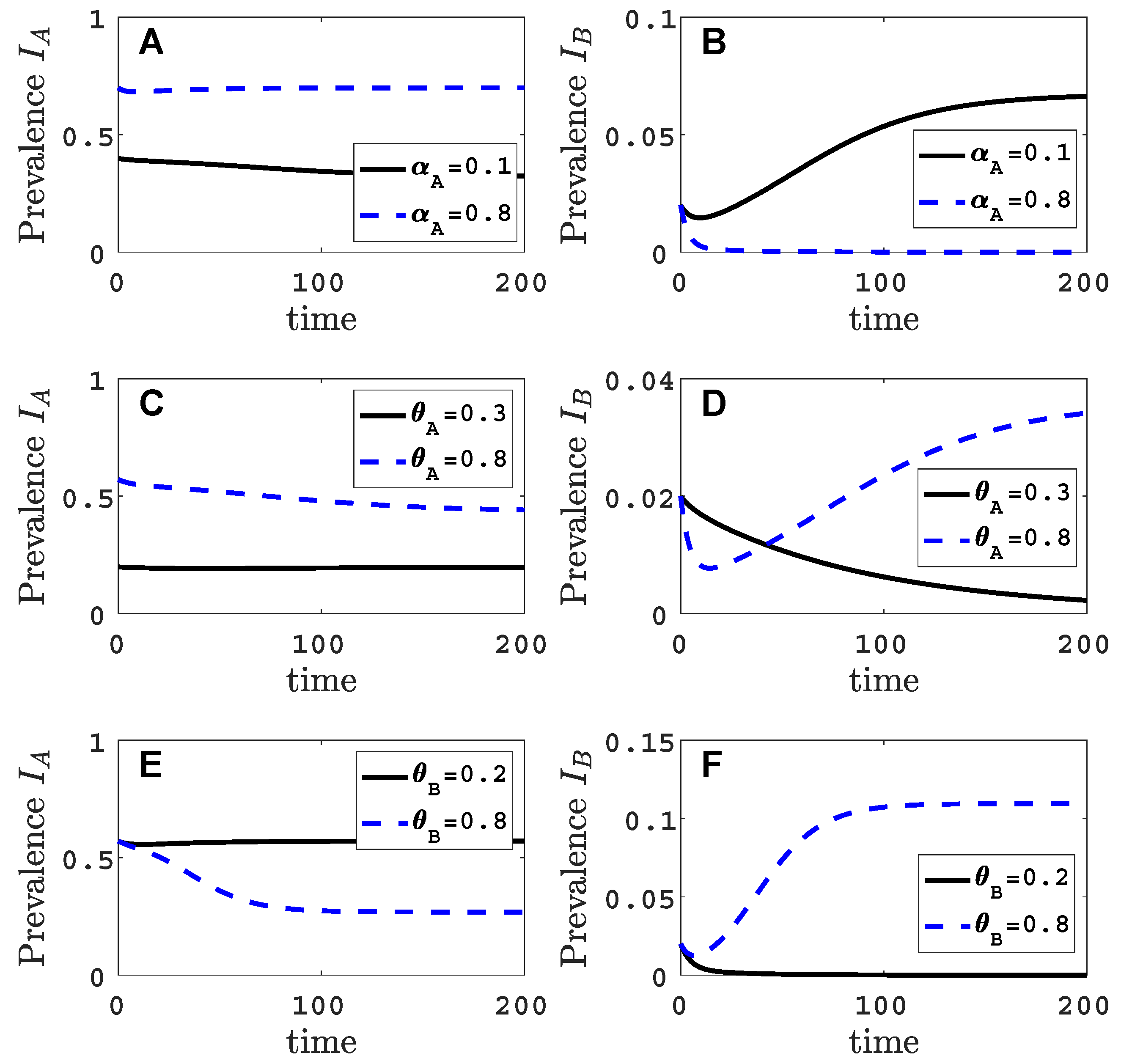
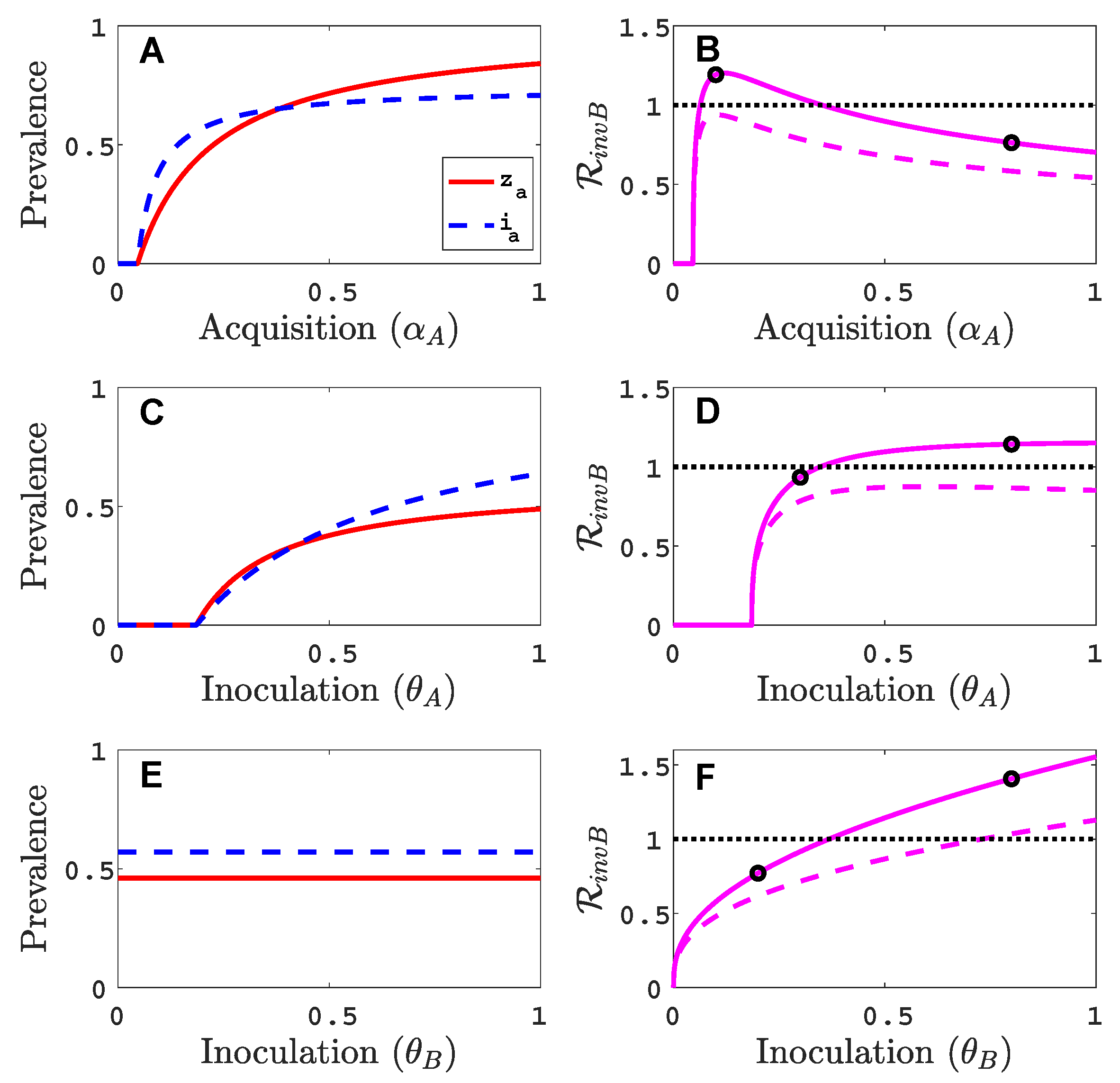
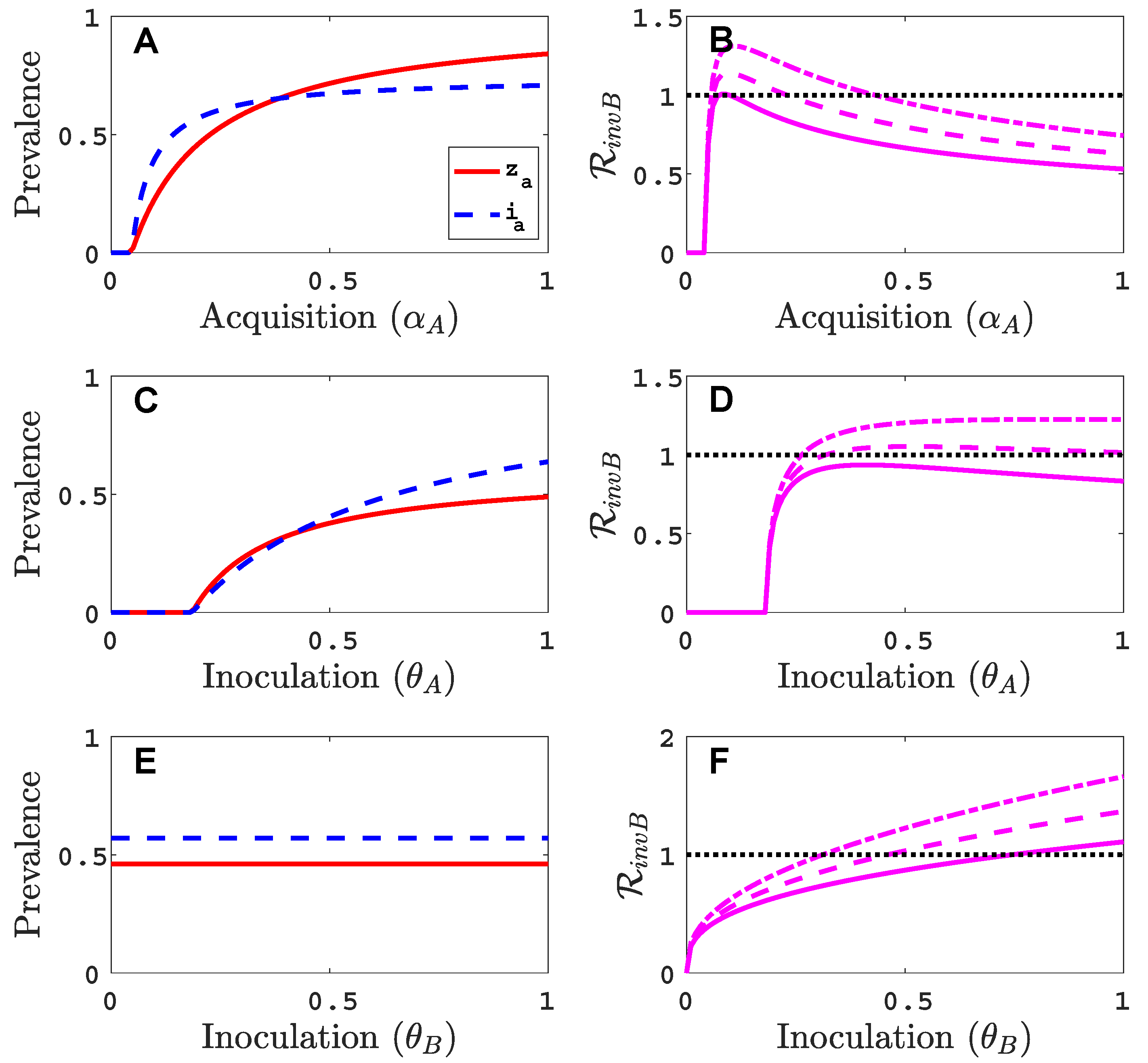
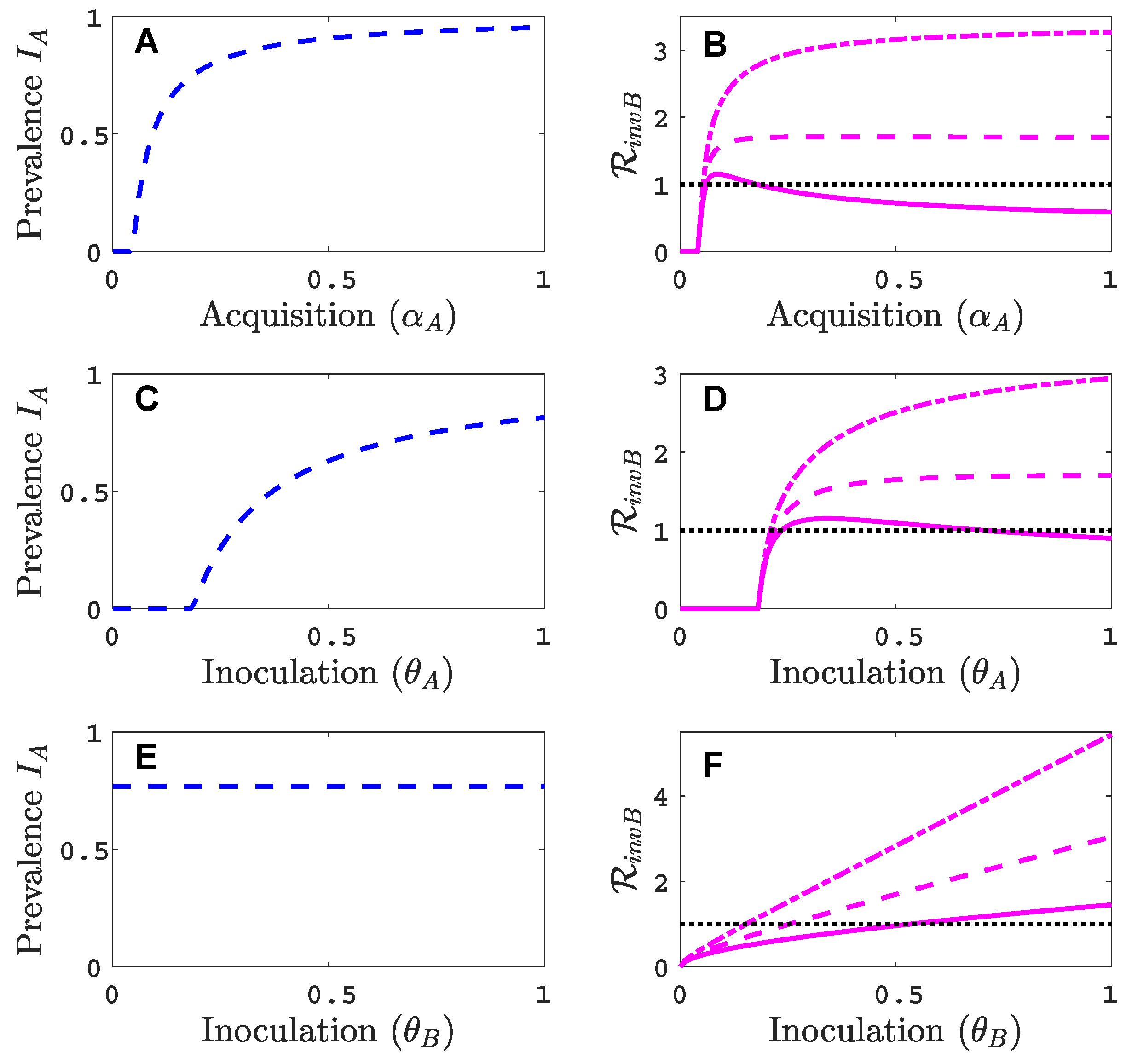
We assume that virus A can invade and persist in the vector-explicit model but not virus B. In particular, the acquisition probability of virus B is set to zero, , and all other acquisition and inoculation probabilities are positive. We investigate the invasion reproduction number as a function of the remaining acquisition and inoculation parameters, , and , whose values lie in . Table 2 is a summary of the default parameter values. The parameter values are chosen consistent with those summarised by Jeger et al. [5], but based on a time unit of one month. For each of the acquisition or inoculation parameters, Figure 2 shows a graph of the equilibrium prevalences for infective vectors and infected plants with virus A (with and ) and the invasion reproduction curves. Two different invasion reproduction curves are graphed, one with (solid invasion curve) and the other with (dashed invasion curve). Parameter denotes the inoculation success of virus B on a plant infected with virus A, relative to a healthy plant. Small values of decrease the likelihood of a successful invasion of virus B.
As the acquisition probability increases (Figure 2A,B), there is initially an increase in the invasion reproduction number but then it decreases as approaches one. From the invasion matrix in (5), it can be seen that some of the matrix entries increase and some decrease with an increase in , resulting in potential increases or decreases in the invasion reproduction number. The equilibrium prevalences and increase with which provide more opportunities for an infective vector to inoculate infected plants and more opportunities for an infected plant to become inoculated from infective vectors . But the density of healthy plants, in matrix (5), and the density of non-infective vectors, in matrix (5), decrease with increases in which provide fewer opportunities for to inoculate healthy plants or for non-infective vectors to acquire virus B from a co-infected plant . For a relative inoculation success ratio of (solid invasion curve), the invasion reproduction number exceeds the threshold value of one for a range of values but for (dashed invasion curve), the invasion reproduction number never exceeds the value of one.
As the inoculation probability increases in Figure 2C,D, a similar effect on the invasion reproduction number could occur as for but the decrease in the invasion reproduction number is not seen for these parameter values. The reduction in healthy plants and non-infective vectors is not as severe as for . Changes in the inoculation probability do not affect equilibrium prevalences and . Therefore, as increases, so does the invasion reproduction number (Figure 2E,F). Similarly, for large values of , the invasion reproduction number increases (Figure A1 in Appendix B).
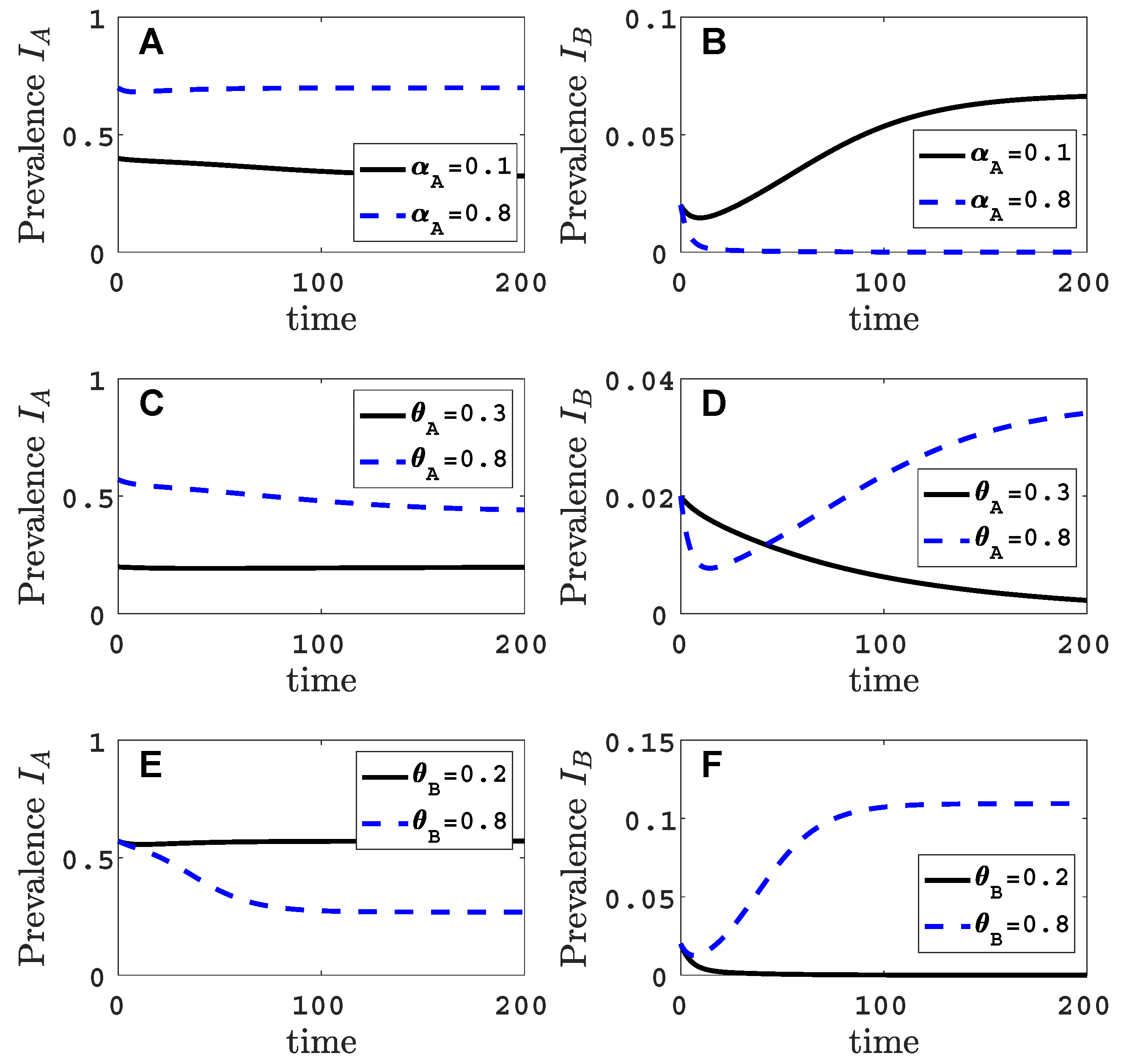
Parameter values in Figure 2, indicated by the black circles on the invasion curves, represent either a successful () or an unsuccessful () invasion of virus B. For these parameter values, the infection prevalence of viruses A and B in the plant population are graphed as functions of time in Figure A2 (Appendix B).
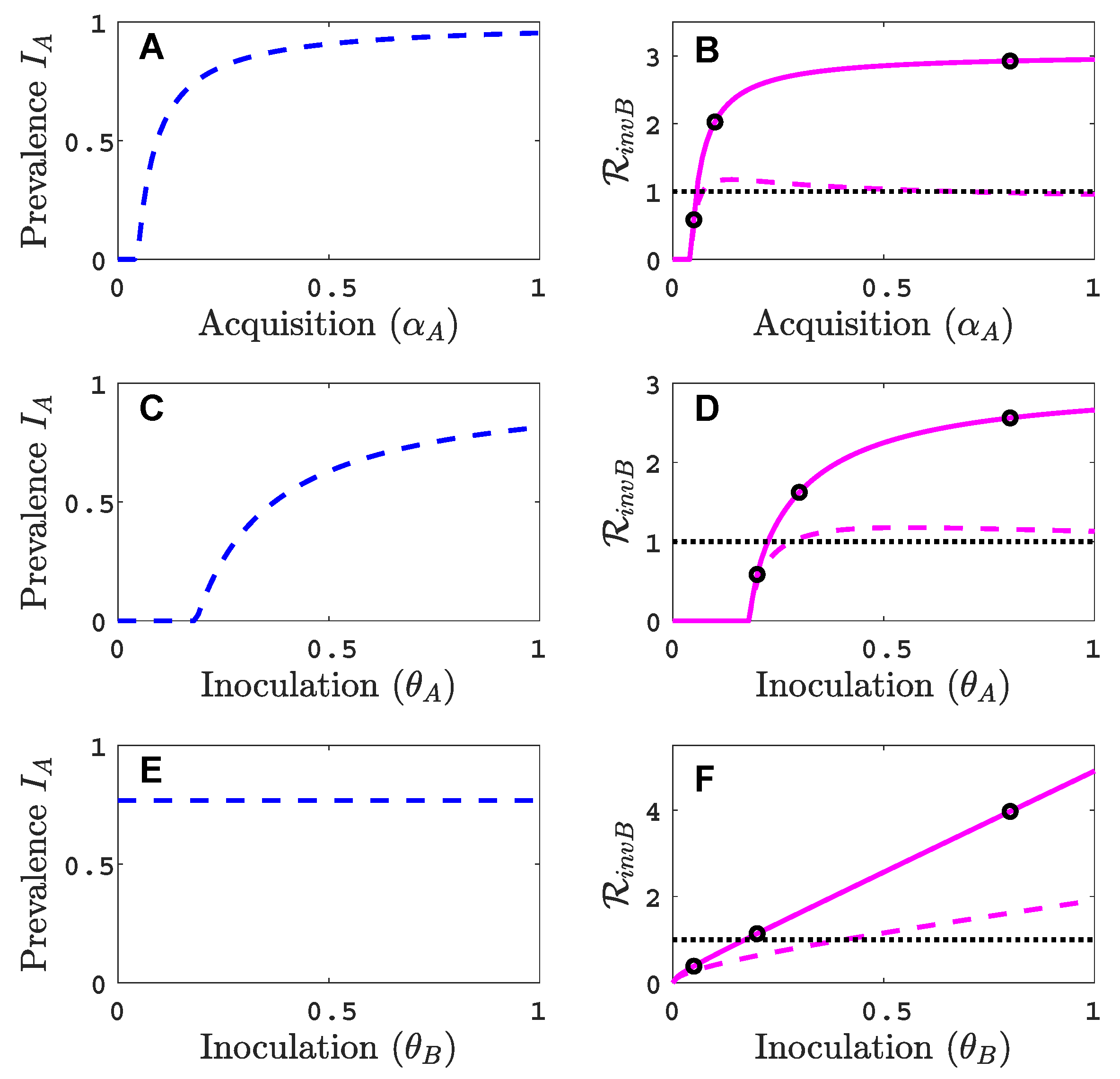
3.2. Comparison with Results of Model That Does Not Track Vectors Explicitly
The dynamics of the vector-implicit model in Figure 3 are compared to the vector-explicit model when the same parameter values as in Figure 2 are applied. The differences in the invasion matrices and the virus A equilibrium values in the two models impact the invasion outcome. For the default parameter values in Table 2, the infected plant prevalences and the invasion reproduction values are larger in the vector-implicit model than in the vector-explicit model. The vector-implicit model predicts greater likelihood of co-infection than in the vector-explicit model. The differences may be attributed to the fact that the assumptions which led to the reduction to a plant model do not hold for all transmission classes. One of the assumptions in the vector-implicit model is that the infective vector life cycle is short, such as in non-persistent transmission. But in these examples, the parameter values for the vectors’ infective period, and , are equal to 10 days, characteristic of persistent-circulative transmission [5]. These differences between the vector-explicit model and the vector-implicit model illustrate the importance of considering the mode of vector transmission in models of vectored plant viruses.
In Appendix C, additional invasion reproduction curves are graphed for different values of the relative inoculation success of viruses A and B, and in Figure A3 and as a function of vector recovery in Figure A5. Also, the infection prevalence of viruses A and B in the plant population for parameter values indicated by the black circles in Figure 3 are graphed as functions of time in Figure A4.
3.3. Neither Virus Can Invade in Absence of the Other
In this example, we assume neither virus can invade the vector-explicit model in the absence of the other virus, i.e., and . There is only the disease-free equilibrium (DFE), which is always locally stable, and, for certain parameter values, we found numerically up to two co-infection equilibria. One of the latter is stable, so that the vector-explicit model is bistable. In the following analysis, we define and as the initial prevalences of virus A and virus B in the plant population, i.e., and , respectively. For these prevalences, we will assume the following initial conditions of the plant population
where . For the initial conditions of the vector population, we assume
where , and which accounts for the fact that the initial prevalences of the viruses in the vectors cannot add beyond one because there is no co-infection.
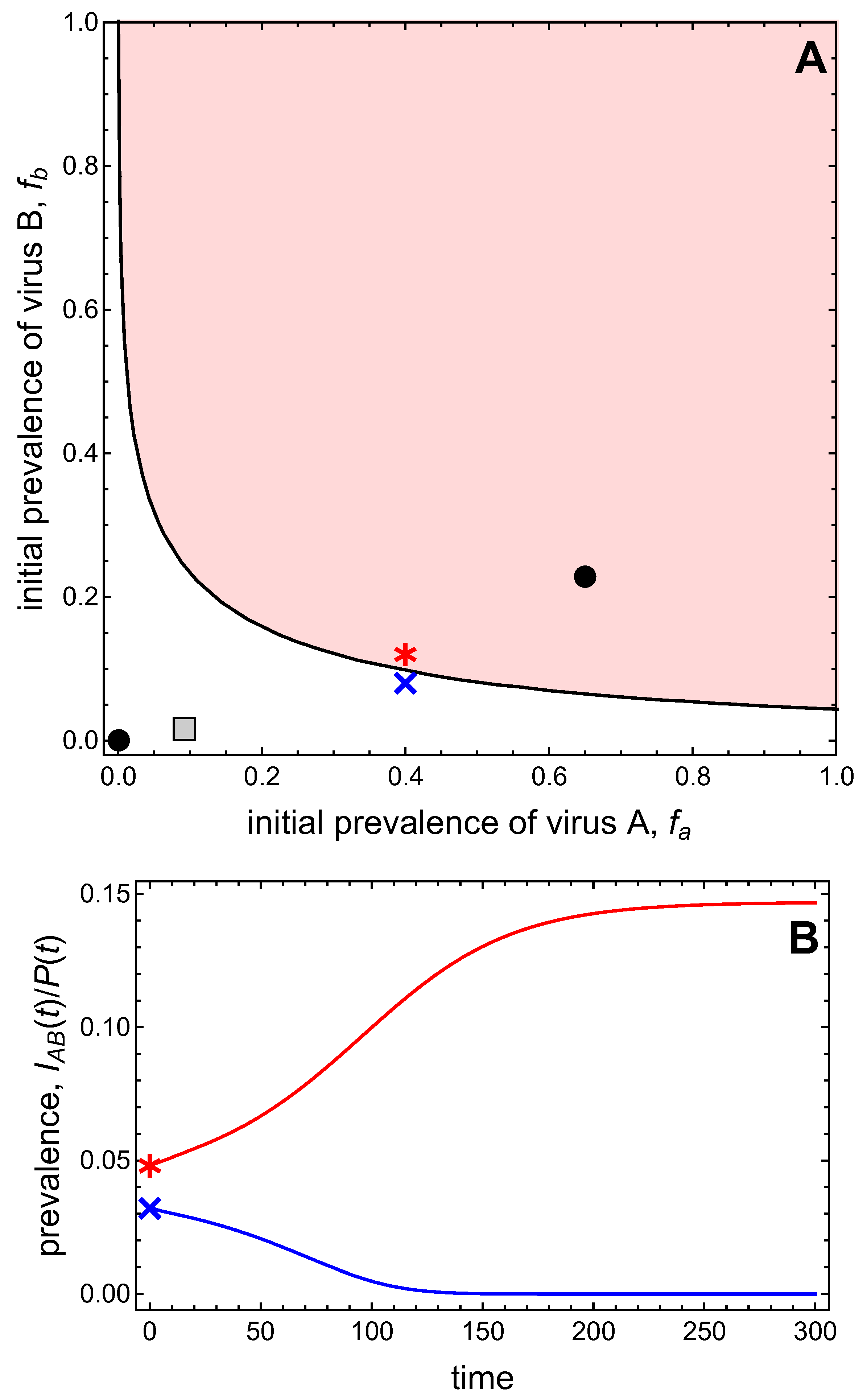
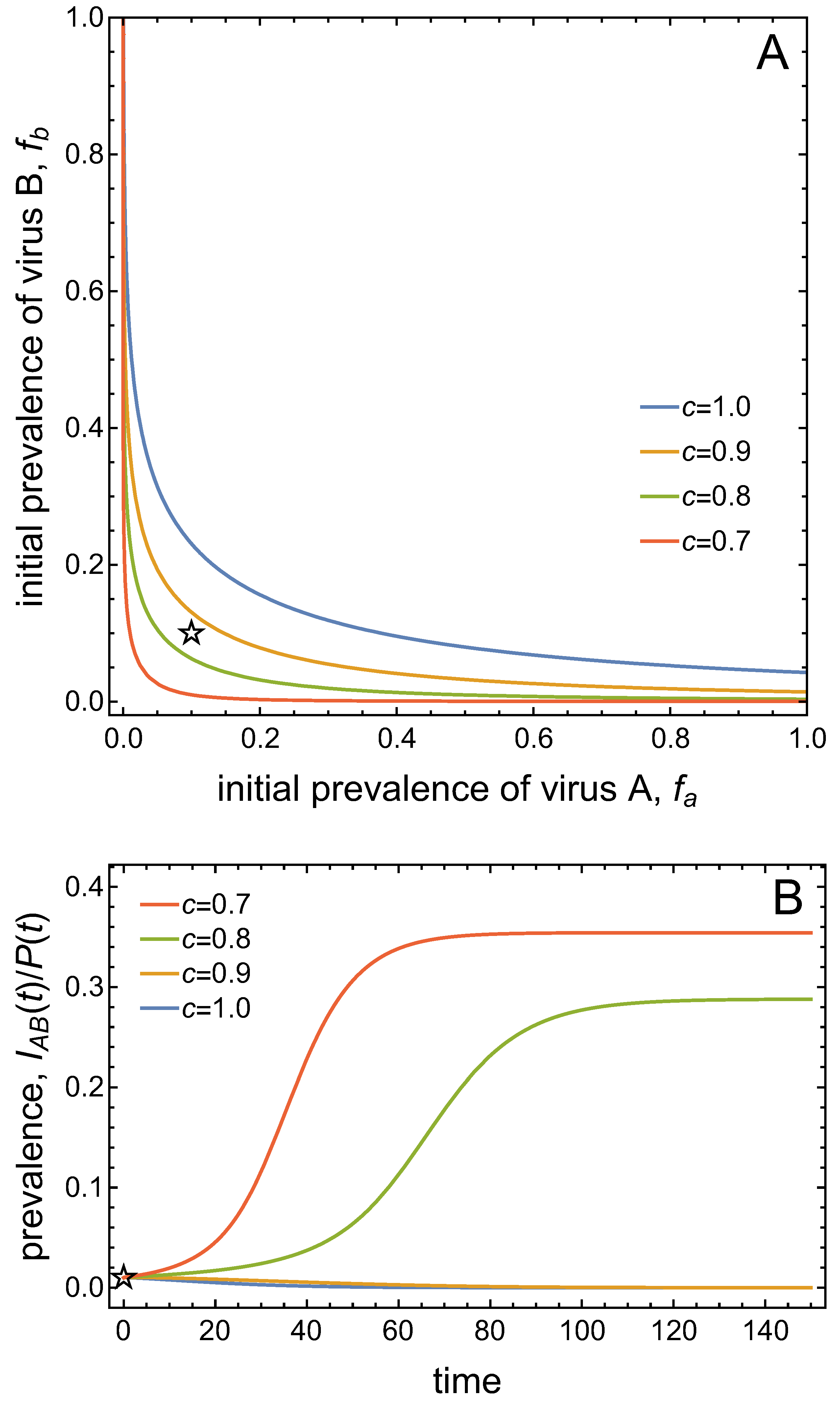
Figure 4A presents the bistable scenario and graphs the basins of attraction for the two stable equilibria as a function of the initial prevalences of virus A and virus B. In this graph, the origin represents the DFE, and the point representing the stable co-infection equilibrium indicates the virus prevalences at this equilibrium. The basin of attraction of an equilibrium is the set of initial conditions that will lead to that equilibrium in the long-run. As the system is bistable, there are two basins of attraction: one for the DFE which comprises smaller initial virus prevalences, and one for the co-infection state which comprises larger initial virus prevalences. The two basins of attraction are separated by a curve, the so-called separatrix. The time plots in Figure 4B illustrate that initial virus prevalences on one side of the separatrix approach the DFE in the long-run, while initial virus prevalences from the other side approach the co-infection state in the long-run.
Figure 5A shows the separatrix for varying values of the vector mortality, c. The basin of attraction of the co-infection equilibrium expands in size when vector mortality is decreased. The size of the basin of attraction is also a measure of the resilience of the corresponding equilibrium, because the larger the basin of attraction, the more resistant the equilibrium against perturbations. That is, decreasing vector mortality enhances the resilience of the co-infection equilibrium, whereas increasing vector mortality enhances the resilience of the DFE. Now consider a given initial condition marked by the star in Figure 5A. Depending on the value of vector mortality, the same initial condition leads either to the disappearance of both viruses from the system (for larger vector mortalities) or to co-infection (for smaller vector mortalities). This is shown in Figure 5B. Notably, there is no gradual transition between these different outcomes. Instead, there is a rather drastic establishment of co-infection at high prevalence levels once both viruses can persist.
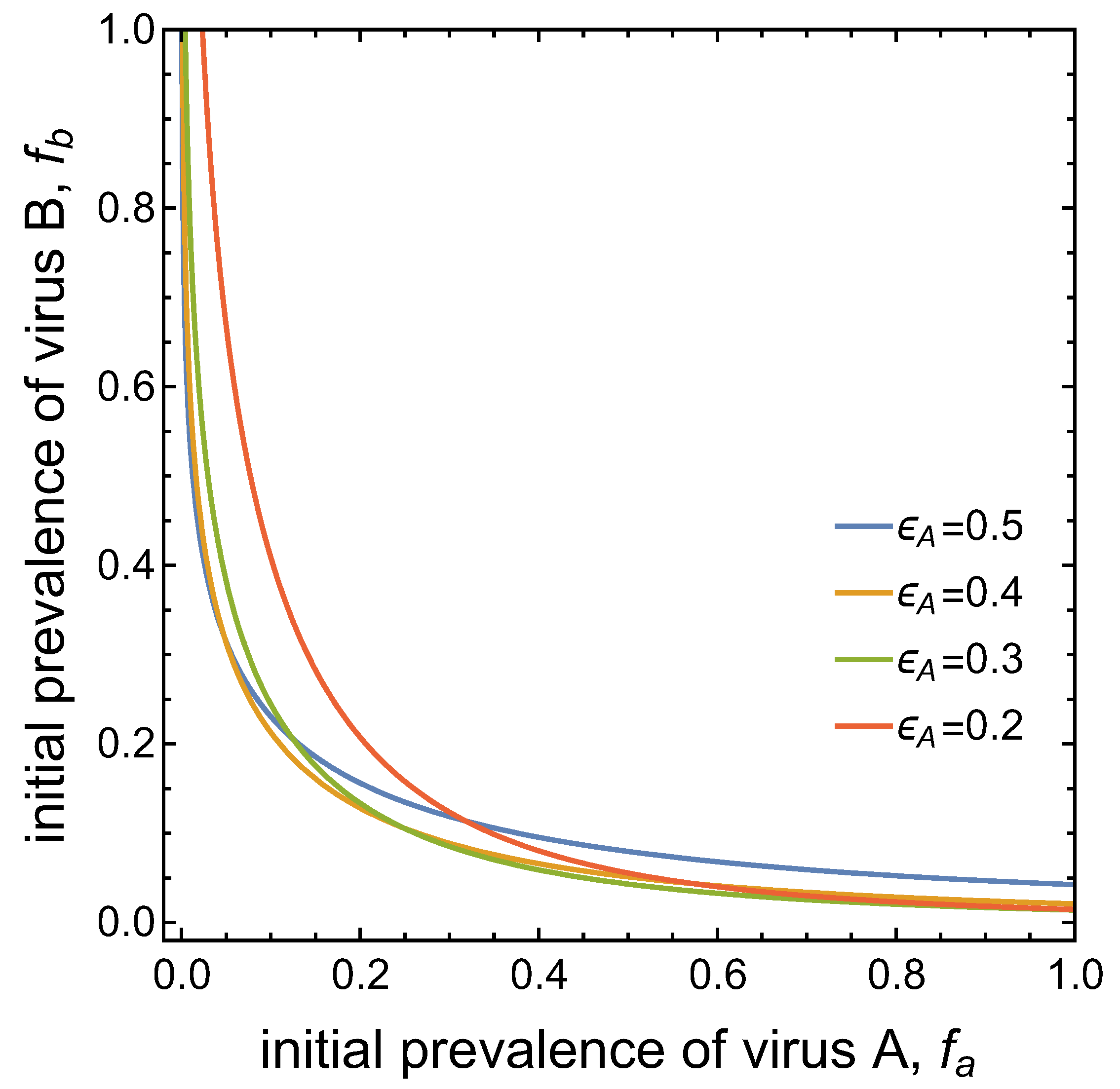
Note that the separatrix between the two basins of attraction is asymmetric for the set of parameter values considered thus far. This is due to the different transmission potentials of the two viruses, as expressed by the different values of and (when ). Figure 6 demonstrates that the ‘asymmetry’ in the basins of attraction can be ‘reversed’ when, for instance, the value of is decreased. This increases the conditional probability of vectors to acquire virus B from co-infected plants. That is, an advantage for virus B in the competition for vectors can compensate for the disadvantages of virus B assumed in the other parameter values.
4. Discussion
Co-infections are pervasive in plant virus epidemiology; yet, mathematical models keeping track of co-infections often leave vector dynamics implicit. This is understandable since (i) keeping track of co-infections makes the models less tractable mathematically, (ii) modeling vector dynamics explicitly may not be necessary relative to the research question addressed, and (iii) the biological knowledge or the data may be too scarce to reasonably increase the model’s complexity [38]. Moreover, it is well known [10,39,40] that vector-implicit models may reasonably approximate vector-explicit models when vector dynamics can be considered to be fast with respect to epidemiological dynamics in the plant host population (such as in non-persistent transmission). Although see [41] for a different model of non-persistent transmission of viruses that goes beyond differential equations to track the epidemiological effects of vector dynamics.
However, we have showed that vector-implicit and vector-explicit models may yield qualitatively different results (Figure 2 and Figure 3). The default parameter set we considered were appropriate for persistent-circulative transmission with vector infective periods of about 10 days (Table 2), and the qualitative difference in the models’ outcomes highlights a key biological feature of the vector-explicit model that is not accounted for in its vector-implicit analogue. This key feature is competition for vectors [16]. Competition occurs because we assumed one vector cannot be inoculative with two viruses at the same time at the point of inoculation. This assumption may reflect the fact that the first acquired virus saturates stylet receptor sites in non-persistent transmission, or that it precludes second inoculation of other viruses as long as the vector retains the first virus. The latter phenomenon would resemble the so-called “super-infection exclusion” usually associated with the host plant rather than with the vector [16]. Nevertheless, competitive exclusion (or pre-emptive competition) of one virus by another can also occur within vectors [42,43,44,45]. This way, infective vectors are only able to inoculate one virus at the point of inoculation. Therefore, viruses indirectly compete for vectors. However, the vector-implicit model is valid only if the vector recovery rate is sufficiently large, meaning that the vector loses the virus very quickly after acquisition (as is the case in non-persistent viruses). Therefore, it is very unlikely that a virus cannot be transmitted because the vector had already acquired another virus. These results highlight the importance of the mode of vector transmission in models of vectored plant viruses.
To illustrate the implications of our model, we considered two distinct special cases with two viruses (or virus strains) denoted A and B:
- i
- Virus A is able to complete a full infection cycle, invade a disease-free population and settle at an endemic equilibrium in the absence of virus B. By contrast, virus B can systematically infect a plant but cannot be acquired by a vector in the absence of co-infection in the host plant. Successful invasion of virus B depends on a complex relation between vector acquisition and inoculation rates, the relative inoculation success of viruses A and B and the prevalence of infected hosts and infective vectors carrying virus A.
- ii
- Virus A and virus B can both complete their infection cycles but are unable to invade a disease-free population in the absence of the other virus. The only biologically feasible endemic equilibrium is a co-infection equilibrium. The system will approach the co-infection equilibrium if the initial prevalences of virus A and B are sufficiently large, i.e., if the initial condition is in the basin of attraction of the co-infection equilibrium. Otherwise, if the initial virus prevalences are so low that the initial condition is in the basin of attraction of the disease-free equilibrium, both viruses will disappear from the system. The separatrix between these two different outcomes represents a curve of tipping points. On either side of these tipping points, we have contrasting dynamics, namely a disease-free versus a co-infected system. We have seen that increased vector mortality rates (e.g., due to vector control programs) moves the separatrix by making the co-infection equilibrium less resilient. This could lead to an abrupt (rather than gradual) extinction of co-infection.
In this paper, we have formulated a general epidemiological model for potential co-infection in a host plant by two virus species or strains. We used the model to investigate the effects of vector transmission on co-infection, specifically acquisition and inoculation, as well as antagonistic and synergistic interactions between viruses. We showed that reducing the model to a vector-implicit model can lose some of the key features gained when the vector is included explicitly (such as competition for vector). We derived a new invasion threshold that determines whether or not a second virus can invade a host population in which a first virus had successfully established. The invasion threshold highlights the key epidemiological parameters that are important for successful co-infection. However, the invasion threshold only applies near the virus A equilibrium when the invading virus B species/strain is at low prevalence levels. The dynamics of the models away from the virus A equilibrium can be quite complex and exhibit bistability, where both the virus A equilibrium and the co-infection equilibrium are stable. In this case, the initial prevalences of viruses A and B determine whether virus B can successfully invade. We also investigated the potential for co-infection and the conditions that need to be satisfied when one virus depends on an autonomous virus for its successful transmission or when both viruses are unable to invade alone. For persistent-circulative transmission, competition between viruses/virus strains, either direct or indirect, as they move through the vector is identified as a key and challenging area for further research that would improve modeling attempts to predict the epidemiological consequences of co-infection.
Author Contributions
M.J.J. and F.M.H. (Frédéric M. Hamelin) designed the study; L.J.S.A.,V.A.B., N.J.C., F.M.H. (Frédéric M. Hamelin), F.M.H. (Frank M. Hilker), and M.J.J. developed the models; L.J.S.A. formally analyzed the models; L.J.S.A., V.A.B., F.M.H. (Frédéric M. Hamelin), and F.M.H. (Frank M. Hilker) performed the visualization and model validation; L.J.S.A.,V.A.B., N.J.C., F.M.H. (Frédéric M. Hamelin), F.M.H. (Frank M. Hilker), and M.J.J. drafted the manuscript; all authors approve the manuscript.
Funding
This work was initiated during the Multiscale Vectored Plant Viruses Working Group at the National Institute for Mathematical and Biological Synthesis, supported by the National Science Foundation through NSF Award #DBI-1300426, with additional support from The University of Tennessee, Knoxville. This material is based upon research supported by the Thomas Jefferson Fund of the Embassy of France in the United States and the FACE Foundation.
Acknowledgments
L.J.S.A. thanks Texas Tech University for support. N.J.C. thanks Girton College, University of Cambridge for support. The authors thank the reviewers for their helpful suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Basic Reproduction Number
Linearization of the system of equations for the infected states in models (1) and (2) and evaluated at the DFE, , , with the remaining states equal to zero, yields the following Jacobian matrix:
The two matrices on the diagonal are used to calculate and . For example, the next generation matrix for virus A is
where
Matrix includes the rate of new infections and includes all of the other transfer rates. We define the basic reproduction number as
which is the product of the off-diagonal elements in the next generation matrix. The basic reproduction number is often defined as the spectral radius of the next generation matrix, the square root of this value, [36]. Both definitions have been applied in vector-host epidemic models [32,34,35,36]. Roberts and Heesterbeek [34] call the expression in (A1) the type reproduction number, whereas Heffernan et al. [32] call it the basic reproduction number and van den Driessche [35] calls it the target reproduction number. The terms “type” or “target” reproduction numbers are used in relation to a particular stage or type, where control measures may be targeted. The two expressions, with or without the square root, are equal at the threshold value of one. We choose the definition in (A1) for its simplicity and its straightforward epidemiological interpretation. The two expressions and represent the average infective period of a plant or a vector, respectively. The entry in the first row and second column is the average number of infective vectors produced by one infected plant during the plants’ infective period and the entry in the second row first column is the average number of infected plants produced by one infective vector during the vectors’ infective period. Therefore,
Appendix B. Invasion Reproduction Number
The system of equations for the infected states are linearized about the virus A endemic equilibrium. This leads to the Jacobian matrix,
Matrix is a stable matrix for the states (provided ), C is a matrix, O is a zero matrix, and is the invasion matrix for virus B. For simplicity, let and . The two diagonal block matrices in J are defined as
and
Invasion of virus B can be determined by computing the eigenvalues of matrix . Invasion is successful if matrix is unstable, i.e., if matrix has an eigenvalue with positive real part. However, computation of the three eigenvalues yield complicated expressions in terms of all of the parameters and do not give a simple criterion for invasion. An alternative is to compute an invasion reproduction matrix.
To compute the invasion reproduction number, we define . An invasion reproduction number is defined as the spectral radius of the matrix ,
If , then virus B can invade the system. Equivalent thresholds can also be defined using the next generation matrix approach, such as type or target reproduction numbers [34,35,36].
We define matrix as the rate of new infections,
and matrix represents other transitions,
The recovery of virus B from a co-infected plant, , is counted as a new infection in matrix Therefore, the invasion reproduction number is the spectral radius of the following matrix,
where and The invasion reproduction number is the largest positive root of the characteristic equation of matrix a cubic equation. Instead of writing the complex expression for the invasion reproduction number, we interpret how the nonzero entries in the invasion matrix affect the invasion reproduction number.
Equilibrium prevalences of virus A in the plant population do not depend on the relative inoculation success of viruses A or B, parameters or , but the invasion reproduction curves do depend on these parameters through the two matrix entries in (A4) in the last row. In Figure A1, three invasion reproduction curves are graphed for the relative inoculation success ratios and for As increases, so do the invasion curves.
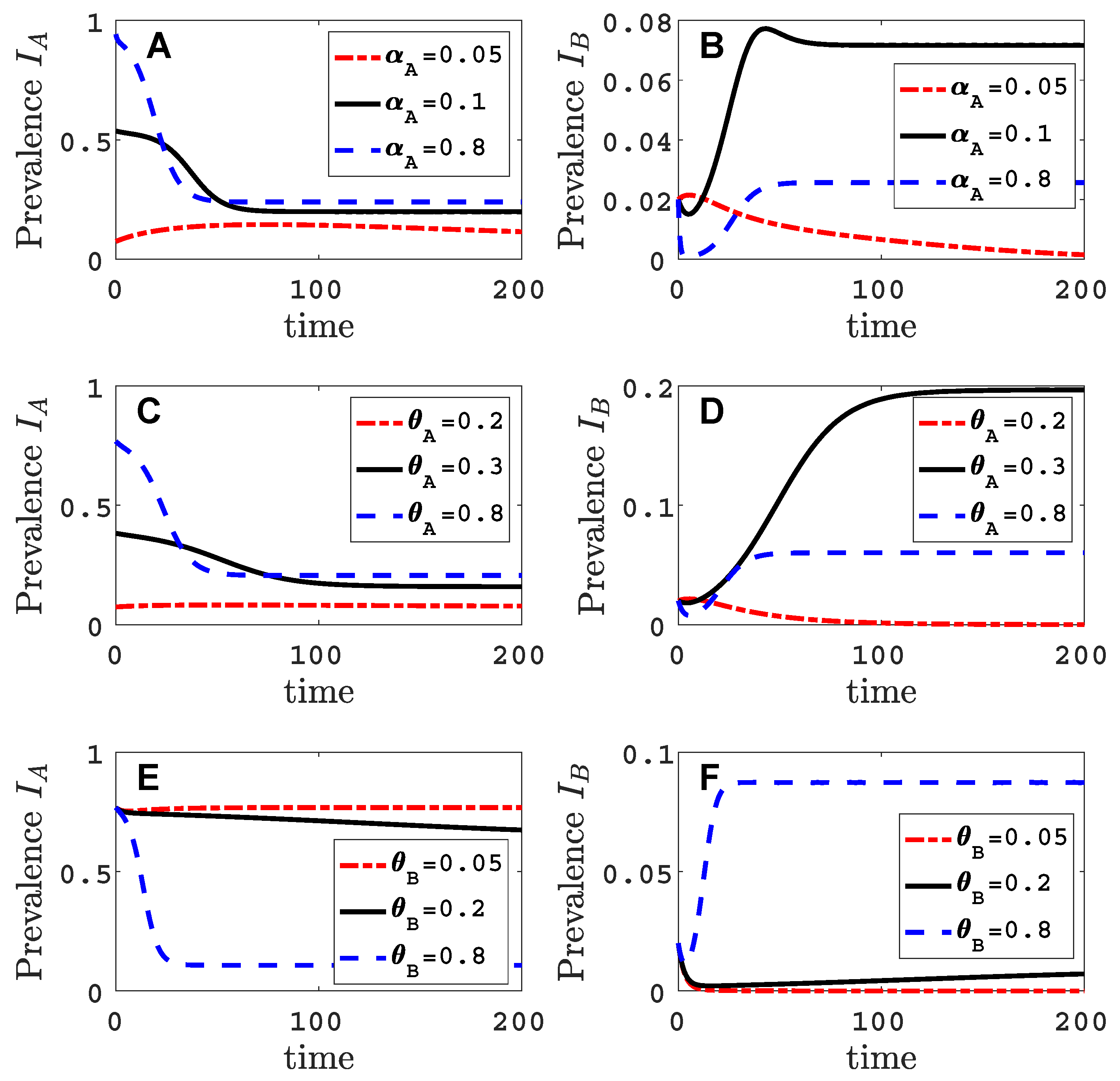
Figure A2 illustrates the time course of a successful invasion () and an unsuccessful invasion () of virus B, corresponding to the two sets of parameter values indicated by the black circles on the solid invasion curve in Figure 2.
Figure A1.
For the vector-explicit model, virus A equilibrium prevalences for the vector and for the host are graphed in (A,C,E) and the corresponding invasion reproduction curves are graphed in (B,D,F) as a function of acquisition and inoculation parameters. The parameter values are the same as in Figure 2 with the exception that in panels B, D and F parameters and (solid curve), 0.5 (dashed curve), 1 (dashed-dot curve).
Figure A1.
For the vector-explicit model, virus A equilibrium prevalences for the vector and for the host are graphed in (A,C,E) and the corresponding invasion reproduction curves are graphed in (B,D,F) as a function of acquisition and inoculation parameters. The parameter values are the same as in Figure 2 with the exception that in panels B, D and F parameters and (solid curve), 0.5 (dashed curve), 1 (dashed-dot curve).

Figure A2.
The time courses of one successful and one unsuccessful invasion of virus B are graphed for the vector-explicit model. The virus A host prevalences are graphed in panels (A,C,E) and the virus B host prevalences are graphed in panels (B,D,F) for the two sets of parameter values identified by black circles in Figure 2. The initial condition is perturbed slightly from the virus A equilibrium, . Parameter values for the graphs in panels (A–F) are the same as in Figure 2A–F with .
Figure A2.
The time courses of one successful and one unsuccessful invasion of virus B are graphed for the vector-explicit model. The virus A host prevalences are graphed in panels (A,C,E) and the virus B host prevalences are graphed in panels (B,D,F) for the two sets of parameter values identified by black circles in Figure 2. The initial condition is perturbed slightly from the virus A equilibrium, . Parameter values for the graphs in panels (A–F) are the same as in Figure 2A–F with .
Appendix C. Reduction to a Vector-Implicit Model
The vector dynamics generally occur on a faster time scale than the plant dynamics. We use this assumption to make a quasi-steady-state approximation for vector abundances [39]. Consider the vector model (1), where the total vector population is . Assume that the vector recovery rates, and , are large (short infective vector life cycle). Summing the differential equations for X, and leads to the following differential equation for V:
Thus, . For , it follows that is approximately constant, an assumption applied in our model. Replace X by in the differential equations for and and divide by or :
In particular, and due to the short life cycle of infective vectors. In addition, we assumed . This latter assumption holds if the vector visitation rate is much smaller than the vector death rate plus recovery rate , . Solving the right-hand sides of the differential equations for and leads to
Let for . The vector-implicit model (Equation (6) in the main text) is
The vector parameters appear in the transmission coefficients. For example, the transmission coefficients from a co-infected plant when are
The basic reproduction number and the invasion matrix for the plant model are calculated by a method similar to that used for the vector-explicit model. The basic reproduction number for the vector-implicit model is the same as in (3). The virus A equilibrium is distinct from the equilibrium for the vector-explicit model in (4),
The invasion matrix for virus B, given , has the following form (matrix (8) in the main text):
where . The invasion reproduction number is the largest positive root of the quadratic characteristic equation of matrix . Alternately, a successful invasion can be assessed directly from the trace and determinant of the non-negative matrix [46]. That is,
if and only if .
Condition (A8) for invasion of virus B simplifies in the case that virus B cannot invade alone and there is no plant recovery, i.e., if () and in the plant population, . Under these assumptions, condition (A8) can be expressed as
The preceding condition shows that the invasion success of virus B increases if the parameters related to virus B are larger than those related to virus A, , or if is large.
For the parameter values and and the same parameter values as in Figure A1, the equilibrium prevalences for plants infected with virus A and three invasion reproduction curves are graphed for the vector-implicit model in Figure A3. In Figure A4, the time courses of two successful invasions () and one unsuccessful invasion () are graphed for the vector-implicit model and for parameter values as in Figure 3.
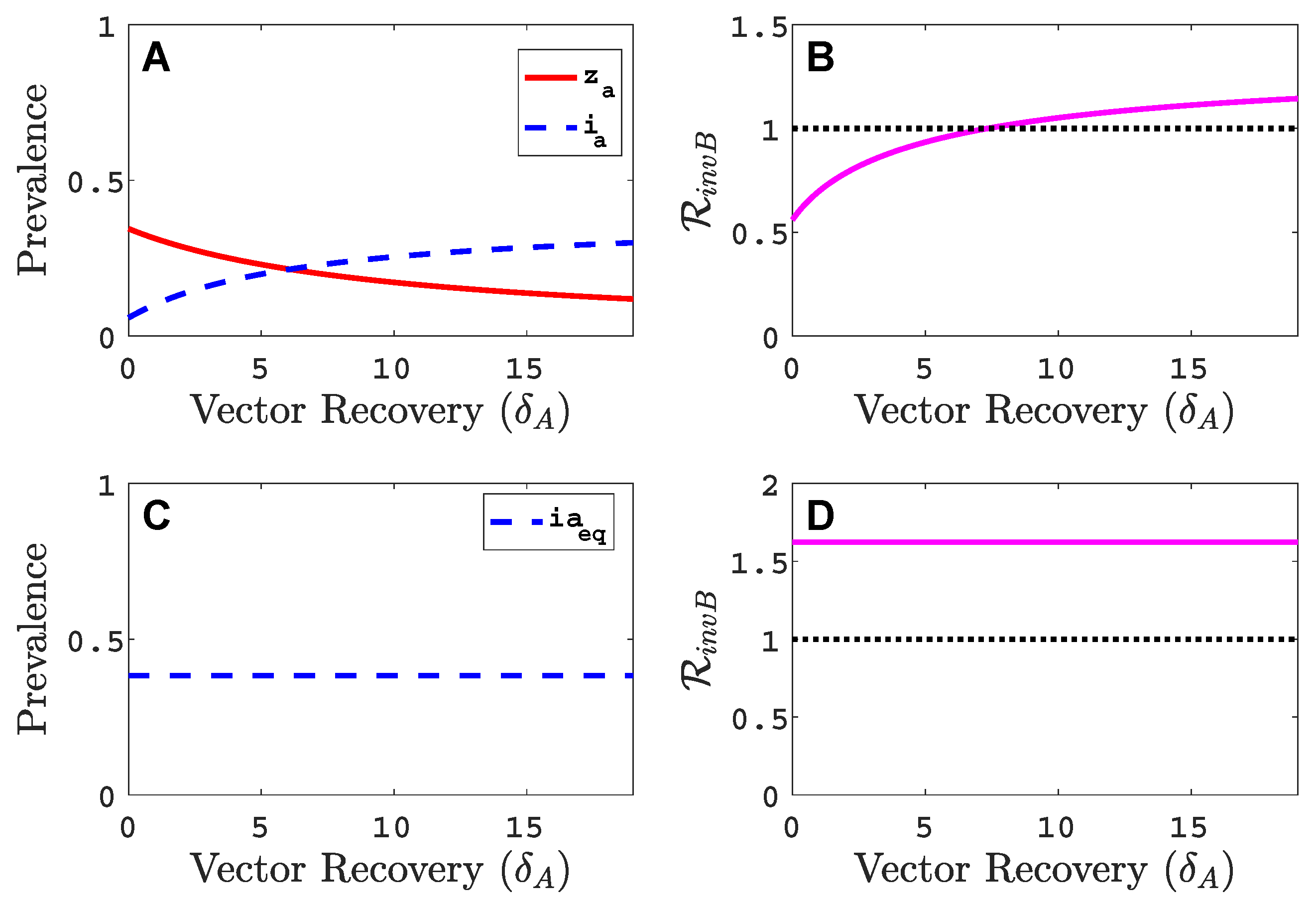
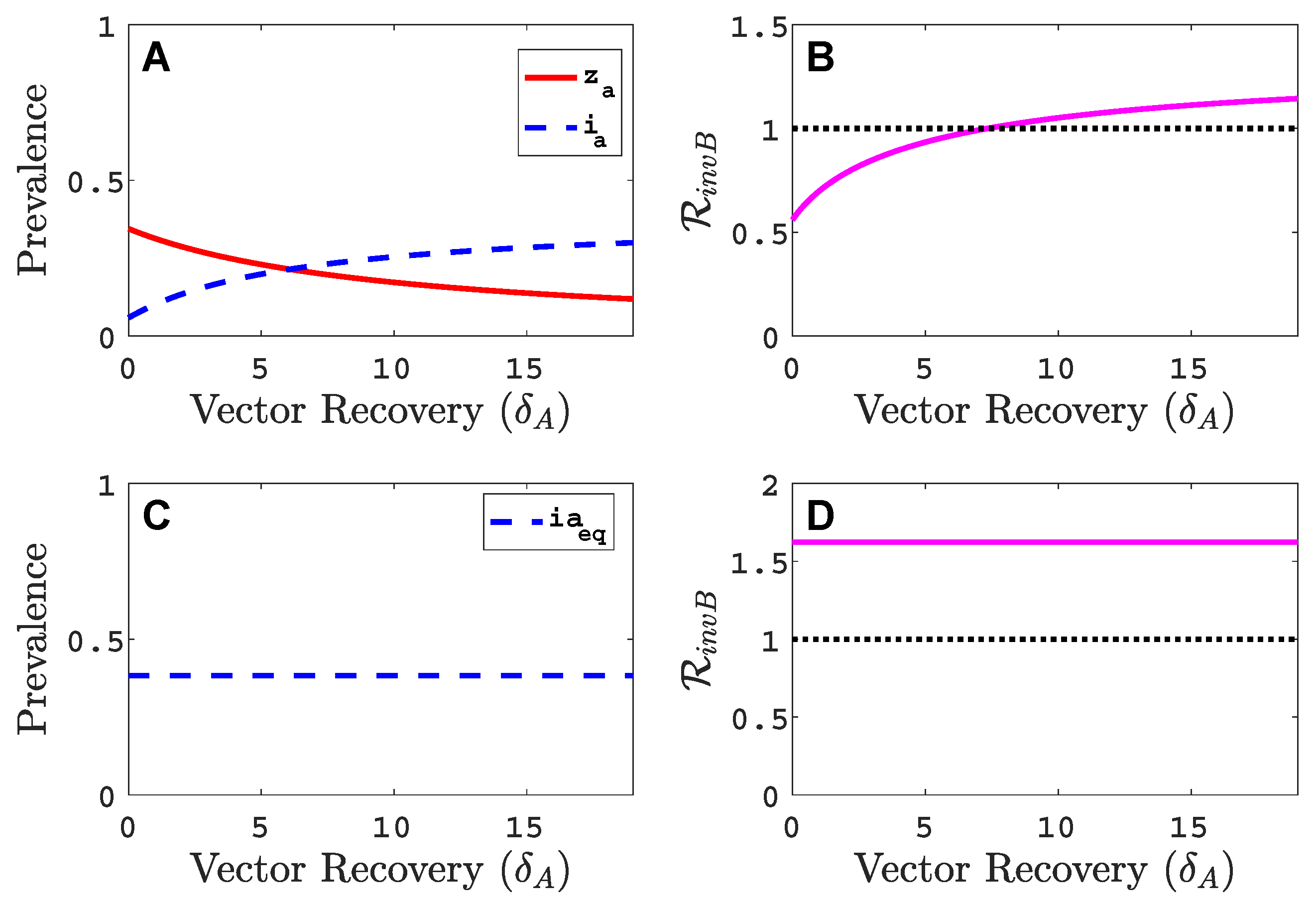
If the vector recovery rate is increased (infective period of vector is shortened) there is better agreement between the vector-implicit and vector-explicit models. That is, if the vector-explicit model predicts no invasion of virus B so does the vector-implicit model and vice versa. In addition, the values of the host equilibrium prevalences for the two models are in closer agreement for large values of . We can see this if we fix the composite parameter constant in the vector-implicit model but vary and . The virus A prevalence and the invasion reproduction number in the vector-implicit model does not change as and change but this is not the case for the virus A prevalence and the invasion reproduction number in the vector-explicit model (see Figure A5). The invasion reproduction number in the vector-implicit model predicts species B invasion success but in the vector-explicit model, a successful invasion occurs only if is sufficiently large. In the example in Figure A5, and with other parameter values as in Table 2. Panels A and B in Figure A5 are the results for the vector-explicit model and panels C and D are for the vector-implicit model. The invasion curve where in the vector-explicit model predicts a successful invasion only if
Figure A3.
For the vector-implicit model, the virus A host equilibrium prevalences are graphed in panels (A,C,E) and the corresponding invasion reproduction curves are graphed in panels (B,D,F) as a function of acquisition and inoculation parameters. Parameter values are as in Figure 3A–F with the exception that in panels B, D and F the parameter values for and for (solid curve), 0.5 (dashed curve), 1 (dashed-dot curve).
Figure A3.
For the vector-implicit model, the virus A host equilibrium prevalences are graphed in panels (A,C,E) and the corresponding invasion reproduction curves are graphed in panels (B,D,F) as a function of acquisition and inoculation parameters. Parameter values are as in Figure 3A–F with the exception that in panels B, D and F the parameter values for and for (solid curve), 0.5 (dashed curve), 1 (dashed-dot curve).

Figure A4.
The time courses of two successful invasions and one unsuccessful invasion of virus B are graphed for the vector-implicit model. The virus A host prevalences are graphed in panels (A,C,E) and the virus B host prevalences are graphed in panels (B,D,F) for the three sets of parameter values identified by the black circles in Figure 3. The initial condition is perturbed slightly from the virus A equilibrium, . Parameter values are as in Figure 3A–F with .
Figure A4.
The time courses of two successful invasions and one unsuccessful invasion of virus B are graphed for the vector-implicit model. The virus A host prevalences are graphed in panels (A,C,E) and the virus B host prevalences are graphed in panels (B,D,F) for the three sets of parameter values identified by the black circles in Figure 3. The initial condition is perturbed slightly from the virus A equilibrium, . Parameter values are as in Figure 3A–F with .

Figure A5.
Comparison of the virus A equilibrium prevalences and invasion reproduction numbers in the vector-explicit model in (A,B) to the vector-implicit model in (C,D) as a function of vector recovery rate . Parameter values are , , , , and other parameter values as in Table 2.
Figure A5.
Comparison of the virus A equilibrium prevalences and invasion reproduction numbers in the vector-explicit model in (A,B) to the vector-implicit model in (C,D) as a function of vector recovery rate . Parameter values are , , , , and other parameter values as in Table 2.
References
- Gray, S.M.; Banerjee, N. Mechanisms of arthropod transmission of plant and animal viruses. Microbiol. Mol. Biol. Rev. 1999, 63, 128–148. [Google Scholar] [PubMed]
- Blanc, S. Virus transmission–gettin. In Viral Transport in Plants; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–28. [Google Scholar]
- Brault, V.; Uzest, M.; Monsion, B.; Jacquot, E.; Blanc, S. Aphids as transport devices for plant viruses. C. R. Biol. 2010, 333, 524–538. [Google Scholar] [CrossRef] [PubMed]
- Bragard, C.; Caciagli, P.; Lemaire, O.; Lopez-Moya, J.; MacFarlane, S.; Peters, D.; Susi, P.; Torrance, L. Status and prospects of plant virus control through interference with vector transmission. Annu. Rev. Phytopathol. 2013, 51, 177–201. [Google Scholar] [CrossRef] [PubMed]
- Jeger, M.; Van Den Bosch, F.; Madden, L.; Holt, J. A model for analysing plant-virus transmission characteristics and epidemic development. Math. Med. Biol. A J. IMA 1998, 15, 1–18. [Google Scholar] [CrossRef]
- Verbeek, M.; van Bekkum, P.J.; Dullemans, A.M.; van der Vlugt, R.A. Torradoviruses are transmitted in a semi-persistent and stylet-borne manner by three whitefly vectors. Virus Res. 2014, 186, 55–60. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.S.; Holt, J.; Colvin, J. Mathematical models of host plant infection by helper-dependent virus complexes: Why are helper viruses always avirulent? Phytopathology 2000, 90, 85–93. [Google Scholar] [CrossRef] [Green Version]
- Mahuku, G.; Lockhart, B.E.; Wanjala, B.; Jones, M.W.; Kimunye, J.N.; Stewart, L.R.; Cassone, B.J.; Sevgan, S.; Nyasani, J.O.; Kusia, E.; et al. Maize lethal necrosis (MLN), an emerging threat to maize-based food security in sub-Saharan Africa. Phytopathology 2015, 105, 956–965. [Google Scholar] [CrossRef] [Green Version]
- Legg, J.; Jeremiah, S.; Obiero, H.; Maruthi, M.; Ndyetabula, I.; Okao-Okuja, G.; Bouwmeester, H.; Bigirimana, S.; Tata-Hangy, W.; Gashaka, G.; et al. Comparing the regional epidemiology of the cassava mosaic and cassava brown streak virus pandemics in Africa. Virus Res. 2011, 159, 161–170. [Google Scholar] [CrossRef]
- Seabloom, E.W.; Hosseini, P.R.; Power, A.G.; Borer, E.T. Diversity and composition of viral communities: Coinfection of barley and cereal yellow dwarf viruses in California grasslands. Am. Nat. 2009, 173, E79–E98. [Google Scholar] [CrossRef] [Green Version]
- Susi, H.; Barrès, B.; Vale, P.F.; Laine, A.L. Co-infection alters population dynamics of infectious disease. Nat. Commun. 2015, 6, 5975. [Google Scholar] [CrossRef] [Green Version]
- Cunniffe, N.J.; Koskella, B.; Metcalf, C.J.E.; Parnell, S.; Gottwald, T.R.; Gilligan, C.A. Thirteen challenges in modelling plant diseases. Epidemics 2015, 10, 6–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Escriu, F.; Fraile, A.; García-Arenal, F. The evolution of virulence in a plant virus. Evolution 2003, 57, 755–765. [Google Scholar] [CrossRef]
- Syller, J. Biological and molecular events associated with simultaneous transmission of plant viruses by invertebrate and fungal vectors. Mol. Plant Pathol. 2014, 15, 417–426. [Google Scholar] [CrossRef] [PubMed]
- Moury, B.; Fabre, F.; Senoussi, R. Estimation of the number of virus particles transmitted by an insect vector. Proc. Natl. Acad. Sci. USA 2007, 104, 17891–17896. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gallet, R.; Michalakis, Y.; Blanc, S. Vector-transmission of plant viruses and constraints imposed by virus–vector interactions. Curr. Opin. Virol. 2018, 33, 144–150. [Google Scholar] [CrossRef] [PubMed]
- Syller, J.; Grupa, A. Antagonistic within-host interactions between plant viruses: Molecular basis and impact on viral and host fitness. Mol. Plant Pathol. 2016, 17, 769–782. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.S.; Holt, J.; Colvin, J. Synergism between plant viruses: A mathematical analysis of the epidemiological implications. Plant Pathol. 2001, 50, 732–746. [Google Scholar] [CrossRef]
- Zhang, X.S.; Holt, J. Mathematical models of cross protection in the epidemiology of plant-virus diseases. Phytopathology 2001, 91, 924–934. [Google Scholar] [CrossRef] [Green Version]
- Mascia, T.; Gallitelli, D. Synergies and antagonisms in virus interactions. Plant Sci. 2016, 252, 176–192. [Google Scholar] [CrossRef]
- Srinivasan, R.; Hall, D.G.; Cervantes, F.A.; Alvarez, J.M.; Whitworth, J.L. Strain specificity and simultaneous transmission of closely related strains of a Potyvirus by Myzus persicae. J. Econ. Entomol. 2012, 105, 783–791. [Google Scholar] [CrossRef]
- Carroll, J.; Smith, D.; Gray, S. Preferential acquisition and inoculation of PVYNTN over PVYO in potato by the green peach aphid Myzus persicae (Sulzer). J. Gen. Virol. 2016, 97, 797. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mondal, S.; Wenninger, E.J.; Hutchinson, P.J.; Whitworth, J.L.; Shrestha, D.; Eigenbrode, S.D.; Bosque-Pérez, N.A. Comparison of transmission efficiency of various isolates of Potato virus Y among three aphid vectors. Entomol. Exp. Et Appl. 2016, 158, 258–268. [Google Scholar] [CrossRef]
- Lacroix, C.; Seabloom, E.W.; Borer, E.T. Environmental nutrient supply alters prevalence and weakens competitive interactions among coinfecting viruses. New Phytol. 2014, 204, 424–433. [Google Scholar] [CrossRef] [PubMed]
- Salvaudon, L.; De Moraes, C.M.; Mescher, M.C. Outcomes of co-infection by two potyviruses: Implications for the evolution of manipulative strategies. Proc. R. Soc. B Biol. Sci. 2013, 280, 20122959. [Google Scholar] [CrossRef] [Green Version]
- Holt, J.; Chancellor, T. Simulation modelling of the spread of rice tungro virus disease: The potential for management by roguing. J. Appl. Ecol. 1996, 33, 927–936. [Google Scholar] [CrossRef]
- Peñaflor, M.F.G.; Mauck, K.E.; Alves, K.J.; De Moraes, C.M.; Mescher, M.C. Effects of single and mixed infections of Bean pod mottle virus and Soybean mosaic virus on host-plant chemistry and host–vector interactions. Funct. Ecol. 2016, 30, 1648–1659. [Google Scholar] [CrossRef]
- Naidu, R.A.; Maree, H.J.; Burger, J.T. Grapevine leafroll disease and associated viruses: A unique pathosystem. Annu. Rev. Phytopathol. 2015, 53, 613–634. [Google Scholar] [CrossRef]
- Blaisdell, G.K.; Cooper, M.L.; Kuhn, E.J.; Taylor, K.A.; Daane, K.M.; Almeida, R.P. Disease progression of vector-mediated Grapevine leafroll-associated virus 3 infection of mature plants under commercial vineyard conditions. Eur. J. Plant Pathol. 2016, 146, 105–116. [Google Scholar] [CrossRef] [Green Version]
- Untiveros, M.; Fuentes, S.; Salazar, L.F. Synergistic interaction of Sweet potato chlorotic stunt virus (Crinivirus) with carla-, cucumo-, ipomo-, and potyviruses infecting sweet potato. Plant Dis. 2007, 91, 669–676. [Google Scholar] [CrossRef] [Green Version]
- McLeish, M.; Sacristán, S.; Fraile, A.; García-Arenal, F. Coinfection Organizes Epidemiological Networks of Viruses and Hosts and Reveals Hubs of Transmission. Phytopathology 2019, 109, 1003–1010. [Google Scholar] [CrossRef]
- Heffernan, J.M.; Smith, R.J.; Wahl, L.M. Perspectives on the basic reproductive ratio. J. R. Soc. Interface 2005, 2, 281–293. [Google Scholar] [CrossRef] [PubMed]
- Diekmann, O.; Heesterbeek, J.A.P.; Metz, J.A. On the definition and the computation of the basic reproduction ratio R 0 in models for infectious diseases in heterogeneous populations. J. Math. Biol. 1990, 28, 365–382. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roberts, M.; Heesterbeek, J. A new method for estimating the effort required to control an infectious disease. Proc. R. Soc. Lond. Ser. B Biol. Sci. 2003, 270, 1359–1364. [Google Scholar] [CrossRef] [PubMed]
- Van den Driessche, P. Reproduction numbers of infectious disease models. Infect. Dis. Model. 2017, 2, 288–303. [Google Scholar] [CrossRef] [PubMed]
- Van den Driessche, P.; Watmough, J. Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission. Math. Biosci. 2002, 180, 29–48. [Google Scholar] [CrossRef]
- Ortega, J.M. Matrix Theory: A Second Course; Plenum Press: New York, NY, USA; London, UK, 1987. [Google Scholar]
- Hilker, F.M.; Allen, L.J.; Bokil, V.A.; Briggs, C.J.; Feng, Z.; Garrett, K.A.; Gross, L.J.; Hamelin, F.M.; Jeger, M.J.; Manore, C.A.; et al. Modeling virus coinfection to inform management of maize lethal necrosis in Kenya. Phytopathology 2017, 107, 1095–1108. [Google Scholar] [CrossRef]
- Keeling, M.J.; Rohani, P. Modeling Infectious Diseases in Humans and Animals; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Hamelin, F.M.; Allen, L.J.; Prendeville, H.R.; Hajimorad, M.R.; Jeger, M.J. The evolution of plant virus transmission pathways. J. Theor. Biol. 2016, 396, 75–89. [Google Scholar] [CrossRef] [Green Version]
- Donnelly, R.; Cunniffe, N.J.; Carr, J.P.; Gilligan, C.A. Pathogenic modification of plants enhances long-distance dispersal of nonpersistently transmitted viruses to new hosts. Ecology 2019, e02725. [Google Scholar] [CrossRef] [Green Version]
- Gildow, F.E.; Rochow, W.F. Transmission interference between two isolates of barley yellow dwarf virus in Macrosiphum avenae. Phytopathology 1980, 70, 122–126. [Google Scholar] [CrossRef]
- Cohen, S.; Duffus, J.E.; Liu, H.Y. Acquisition, interference, and retention of cucurbit leaf curl viruses in whiteflies. Phytopathology 1989, 79, 109–113. [Google Scholar] [CrossRef]
- Ng, J.C.; Chen, A.Y. Acquisition of Lettuce infectious yellows virus by Bemisia tabaci perturbs the transmission of Lettuce chlorosis virus. Virus Res. 2011, 156, 64–71. [Google Scholar] [CrossRef] [PubMed]
- Seabloom, E.W.; Borer, E.T.; Gross, K.; Kendig, A.E.; Lacroix, C.; Mitchell, C.E.; Mordecai, E.A.; Power, A.G. The community ecology of pathogens: Coinfection, coexistence and community composition. Ecol. Lett. 2015, 18, 401–415. [Google Scholar] [CrossRef] [PubMed]
- Allen, L.J. Introduction to Mathematical Biology; Pearson/Prentice Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
Figure 1.
Compartmental diagrams (left) for the vector model and (right) the host plant model, described by the differential Equations (1) and (2), respectively. Meanings of the symbols for model parameters are summarised in Table 2.
Figure 1.
Compartmental diagrams (left) for the vector model and (right) the host plant model, described by the differential Equations (1) and (2), respectively. Meanings of the symbols for model parameters are summarised in Table 2.
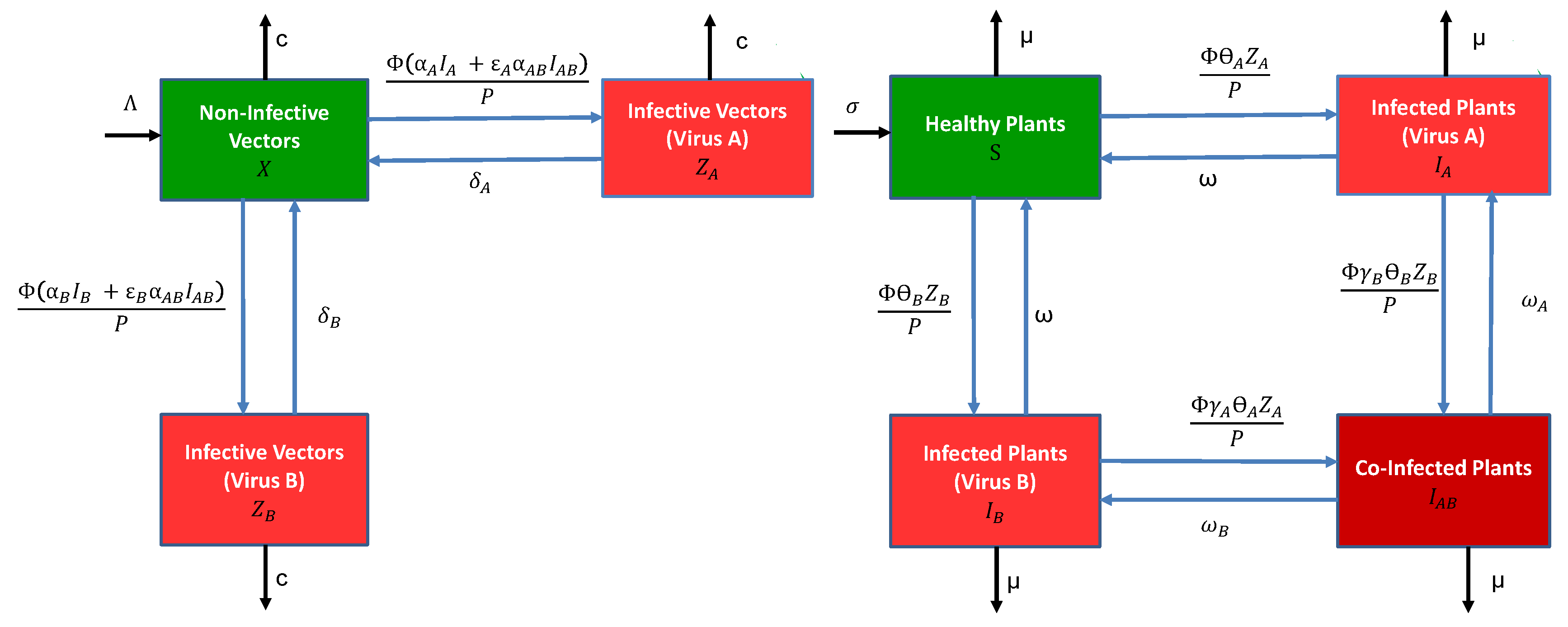
Figure 2.
For the vector-explicit model, the virus A equilibrium prevalences for the vector and for the host are graphed in panels (A,C,E) and the corresponding invasion reproduction numbers are graphed in panels (B,D,F) as a function of acquisition () or inoculation ( and ) parameters. Virus B may invade the virus A equilibrium if the invasion reproduction number is greater than the threshold value one. The parameters values that are not varied are fixed at their default values (see Table 2): per month per unit area, per month, per month, , , , , per month, per month, (1000 per year per unit area), , and . Parameter values for the two invasion reproduction curves in (B,E,F) are for the solid curve and for the dashed curve. (B) The two black circles on the solid curve are at values of ; (D) ; (F) . The invasion reproduction number is as defined in (5).
Figure 2.
For the vector-explicit model, the virus A equilibrium prevalences for the vector and for the host are graphed in panels (A,C,E) and the corresponding invasion reproduction numbers are graphed in panels (B,D,F) as a function of acquisition () or inoculation ( and ) parameters. Virus B may invade the virus A equilibrium if the invasion reproduction number is greater than the threshold value one. The parameters values that are not varied are fixed at their default values (see Table 2): per month per unit area, per month, per month, , , , , per month, per month, (1000 per year per unit area), , and . Parameter values for the two invasion reproduction curves in (B,E,F) are for the solid curve and for the dashed curve. (B) The two black circles on the solid curve are at values of ; (D) ; (F) . The invasion reproduction number is as defined in (5).

Figure 3.
For the vector-implicit model, the virus A host equilibrium prevalences are graphed in panels (A,C,E) and the corresponding invasion reproduction numbers are graphed in panels (B,D,F) as a function of the acquisition () and inoculation ( and ) parameters. The same parameter values are applied as in the vector-explicit model in Figure 2. The three black circles on the solid curve in (B) are at values of ; in (D) ; (F) . The invasion reproduction number equals as defined in (8).
Figure 3.
For the vector-implicit model, the virus A host equilibrium prevalences are graphed in panels (A,C,E) and the corresponding invasion reproduction numbers are graphed in panels (B,D,F) as a function of the acquisition () and inoculation ( and ) parameters. The same parameter values are applied as in the vector-explicit model in Figure 2. The three black circles on the solid curve in (B) are at values of ; in (D) ; (F) . The invasion reproduction number equals as defined in (8).

Figure 4.
(A) The basins of attraction of the disease-free equilibrium (DFE) (white region) and the co-infected equilibrium (shaded region) are graphed as a function of the initial frequency of virus A and frequency of virus B in the plant population. See Equations (9) and (10) for the initial conditions. The points mark the prevalences of virus A and B in the plant population at the DFE (at the origin) and the stable co-infection equilibrium (in the interior). The gray square marks the relative frequency of virus A and B in the vector population at the stable co-infection equilibrium. The blue cross and red asterisk indicate initial conditions in different basins of attraction, for which time plots show convergence either to the DFE () or to the co-infection equilibrium () in (B). Parameter values are such that and .
Figure 4.
(A) The basins of attraction of the disease-free equilibrium (DFE) (white region) and the co-infected equilibrium (shaded region) are graphed as a function of the initial frequency of virus A and frequency of virus B in the plant population. See Equations (9) and (10) for the initial conditions. The points mark the prevalences of virus A and B in the plant population at the DFE (at the origin) and the stable co-infection equilibrium (in the interior). The gray square marks the relative frequency of virus A and B in the vector population at the stable co-infection equilibrium. The blue cross and red asterisk indicate initial conditions in different basins of attraction, for which time plots show convergence either to the DFE () or to the co-infection equilibrium () in (B). Parameter values are such that and .

Figure 5.
(A) The changes in the size of the basins of attraction for the DFE and the co-infected equilibrium are graphed as a function of the initial frequency of virus A and of virus B when the death rate of vectors decreases from to , with values of . The boundary separating the two basins of attraction at is closest to the origin = DFE and at is furthest from the origin. Other parameter values are as in Figure 4. The star symbol marks the initial condition for the disease progress curves in (B), which shows the time series of the prevalence of co-infected plants for varying levels of per-capita plant mortality, c. Initial conditions are fixed at (9) and (10) with initial virus prevalences in the plant population.
Figure 5.
(A) The changes in the size of the basins of attraction for the DFE and the co-infected equilibrium are graphed as a function of the initial frequency of virus A and of virus B when the death rate of vectors decreases from to , with values of . The boundary separating the two basins of attraction at is closest to the origin = DFE and at is furthest from the origin. Other parameter values are as in Figure 4. The star symbol marks the initial condition for the disease progress curves in (B), which shows the time series of the prevalence of co-infected plants for varying levels of per-capita plant mortality, c. Initial conditions are fixed at (9) and (10) with initial virus prevalences in the plant population.
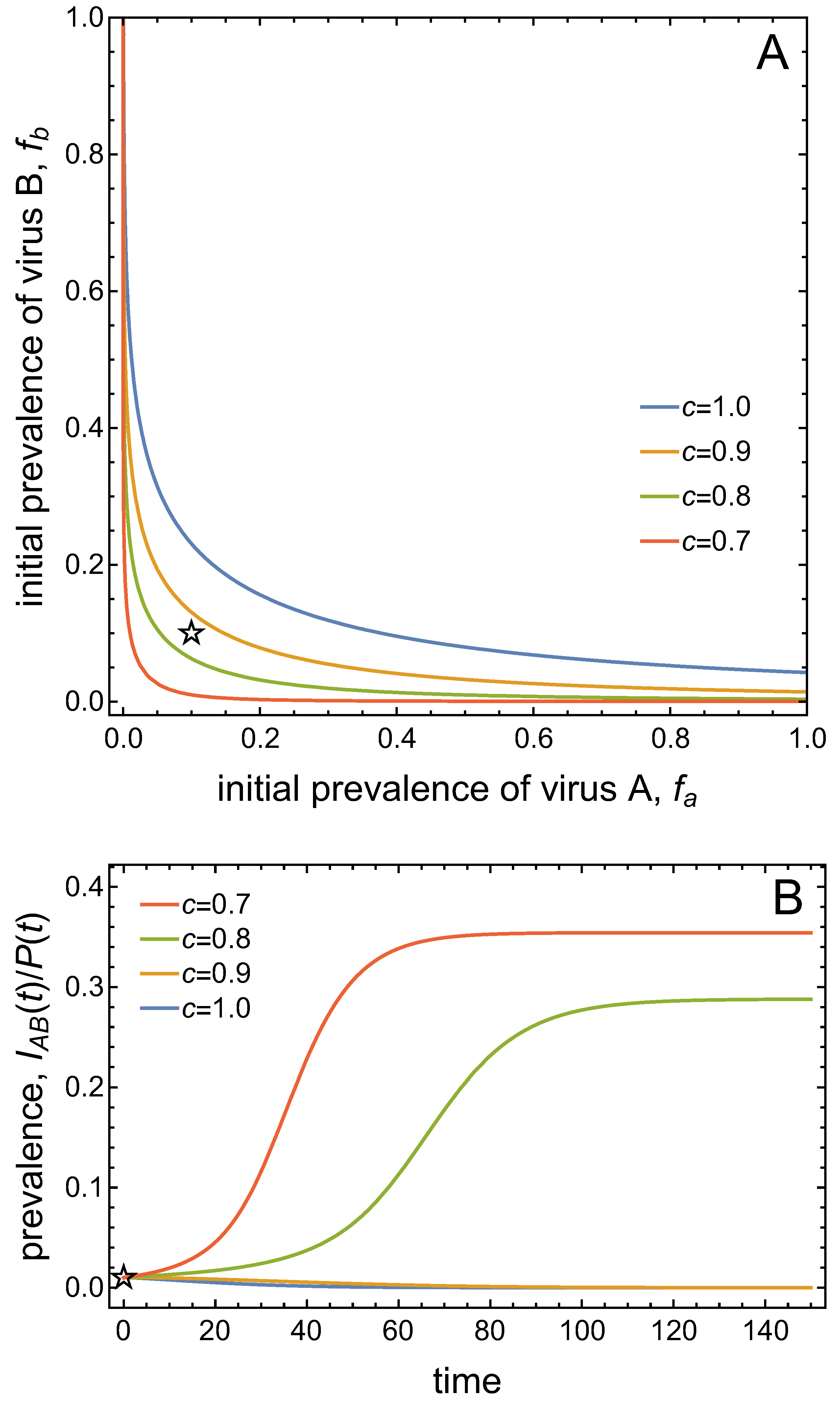
Figure 6.
Basins of attraction for the DFE and the co-infection equilibrium for different values of and . The blue curve with corresponds to the separatrix shown in Figure 4 with . Decreasing , i.e. increasing , reverses the asymmetry in the basins of attraction.
Figure 6.
Basins of attraction for the DFE and the co-infection equilibrium for different values of and . The blue curve with corresponds to the separatrix shown in Figure 4 with . Decreasing , i.e. increasing , reverses the asymmetry in the basins of attraction.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of some representative experimental work on co-infection at different levels of complexity.
Table 1.
Summary of some representative experimental work on co-infection at different levels of complexity.
| Pathosystem | Authors | Key Message | |
|---|---|---|---|
| Two virus strains | Potato virus Y (PYV)—Myzus persicae (host Capsicum annuum) | Moury et al. [15] | Two strains were equally transmissible and competition was studied to estimate the size of bottlenecks imposed by vector transmission. If there was a cost of virulence, modelling showed that virulent strains would go extinct. |
| compared with other strains—Myzus persicae | Srinivasan et al. [21] | Previous work had suggested some specificity in transmission of strains. The rate of infection for was higher than for other strains, a vector-related outcome as this was not observed with mechanical transmission. | |
| compared with —Myzus persicae | Carroll et al. [22] | The necrotic strain was transmitted more efficiently than the wild-type. Co-infection would more likely result from inoculation by multiple aphids feeding on plants infected with the different strains rather than by single aphids feeding on multiple plants infected with the different strains. | |
| Two virus species—common vector | Barley yellow dwarf virus/cereal yellow dwarf virus—Rhopalosiphum padi | Lacroix et al. [24] | The co-inoculation of BYDV-PAV lowered the CYDV-RPV infection rate but only at low nutrient supply rates. Broader environmental and nutritional factors can alter co-infection interactions and outcomes. |
| Watermelon mosaic virus/zucchini yellow mosaic virus—Aphis gossypii | Salvaudon et al. [25] | ZYMV accumulated at similar rates in single and mixed infections, whereas WMV was much reduced in the presence of ZYMV. ZYMV also induced host changes that gave strong vector preference for infected plants; whereas WMV did not, although it was still readily acquired from mixed infections. | |
| Rice tungro spherical virus/rice tungro bacilliform virus—Nephottetix virescens | Holt and Chancellor [26] | Infection by each virus alone results in less pronounced symptoms. RTBV is retained in the vector for a longer period. When a vector carries both viruses, co-inoculation is common. When inoculative with RSTV alone the infection probability is higher. | |
| Two virus species—multiple vector species | Bean pod mottle virus—Epilachna varivestis/soybean mosaic virus—Aphis glycines | Penaflor et al. [27] | Singly-infected plants with either BPMV or SMV increased soybean palatability, potentially enhancing acquisition of BPMV from BPMV plants and secondary infection of BPMV from SMV plants. BPMV infection had little effect on A. glycines, whereas SMV infection reduced aphid population growth but increased the preference for infected plants. With co-infection, effects on population growth were reversed and aphids showed a preference for co-infected plants. |
| Multiple virus species—multiple vector species | Grapevine leafroll-associated viruses (GLRaVs)—mealybugs/scale insects | Naidu et al. [28] | The exact role of GLRaVs in disease etiology remains unclear. With mealybugs, transmission is of a semi-persistent manner with a lack of vector-virus specificity. |
| Blaisdell et al. [29] | Co-infections of GLRaVs are frequent in grapevines although with some spatial separation with implications for transmission and epidemiology. | ||
| Sweet potato chlorotic stunt virus/sweet potato feathery mottle virus/multiple viruses—multiple vector species | Untiveros et al. [30] | Six viruses from the same or different virus families interacted synergistically with sweet potato virus disease, with increased disease symptoms, virus accumulation and movement in plants, and reduced yield of storage roots. All inoculations were made by grafting; no conclusions can be drawn on vector transmission effects. | |
| Multiple virus species—multiple vector species, multiple hosts | Ecological networks formed by multiple co-infecting viruses in multiple hosts | McLeish et al. [31] | Co-infection networks were found to lead to strong non-random associations compared with single infections. Single infections were mostly related to habitat parameters, whereas co-infections were more related to ecological heterogeneity and ecosystem-level processes. |
Table 2.
Summary of model parameters for plants and vectors. All parameters are non-negative.
| Vector | Default Values | Default Values | |
|---|---|---|---|
| Parameters | Section 3.1 and Section 3.2, Appendix B and Appendix C | Section 3.3 | |
| vector birth rate | 10/month/area | 1/month/area | |
| c | per capita vector natural death rate | 1/month | 1/month |
| number of plants visited/time by a vector | 1/day | 8.33/day | |
| per capita infective vector recovery rate from virus A | 3/month | 0.66/day | |
| per capita infective vector recovery rate from virus B | 3/month | 1.33/day | |
| probability non-infective vector acquires virus A from per plant visit | 0.2 | 0.005 | |
| probability non-infective vector acquires virus B from per plant visit | 0 | 0.005 | |
| probability non-infective vector acquires a single virus, A or B, from per plant visit | 0.5 | 0.15 | |
| conditional probability of acquiring virus A from a co-infected plant , given a successful acquisition | 0.5 | 0.5 | |
| conditional probability of acquiring virus B from co-infected plant , given a successful acquisition () | 0.5 | 0.5 | |
| Plant | Default Values | Default Values | |
| Parameters | Section 3.1 and Section 3.2, Appendix B and Appendix C | Section 3.3 | |
| per capita mortality and or harvest of plants | 1/year | 1/year | |
| seeding or planting rate | 1000/year/area | 100/year/area | |
| probability an infective vector with virus A inoculates a healthy plant per visit | 0.8 | 0.8 | |
| probability an infective vector with virus B inoculates a healthy plant per visit | 0.5 | 0.5 | |
| relative inoculation success of virus A (as compared to a heathy plant) in a plant , infected with a single virus B | 0.9 | 0.5 | |
| relative inoculation success of virus B (as compared to a healthy plant) in a plant , infected with a single virus A | 0.25, 0.9 | 0.5 | |
| per-capita viral A or B loss rate in a plant infected with single virus | 0 | 0.001/day | |
| per-capita viral B loss rate (A is retained) from a co-infected plant | 0 | 0.001/day | |
| per-capita viral A loss rate (B is retained) from a co-infected plant | 0 | 0.001/day | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Allen, L.J.S.; Bokil, V.A.; Cunniffe, N.J.; Hamelin, F.M.; Hilker, F.M.; Jeger, M.J. Modelling Vector Transmission and Epidemiology of Co-Infecting Plant Viruses. Viruses 2019, 11, 1153. https://0-doi-org.brum.beds.ac.uk/10.3390/v11121153
AMA Style
Allen LJS, Bokil VA, Cunniffe NJ, Hamelin FM, Hilker FM, Jeger MJ. Modelling Vector Transmission and Epidemiology of Co-Infecting Plant Viruses. Viruses. 2019; 11(12):1153. https://0-doi-org.brum.beds.ac.uk/10.3390/v11121153
Chicago/Turabian StyleAllen, Linda J. S., Vrushali A. Bokil, Nik J. Cunniffe, Frédéric M. Hamelin, Frank M. Hilker, and Michael J. Jeger. 2019. "Modelling Vector Transmission and Epidemiology of Co-Infecting Plant Viruses" Viruses 11, no. 12: 1153. https://0-doi-org.brum.beds.ac.uk/10.3390/v11121153
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.