
Improvement of a 1D Population Balance Model for Twin-Screw Wet Granulation by Using Identifiability Analysis

 , , ,
, , ,  and
and
Abstract
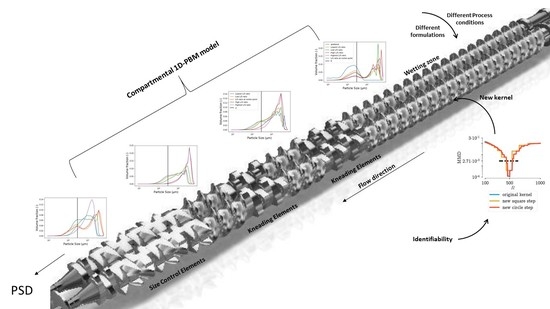
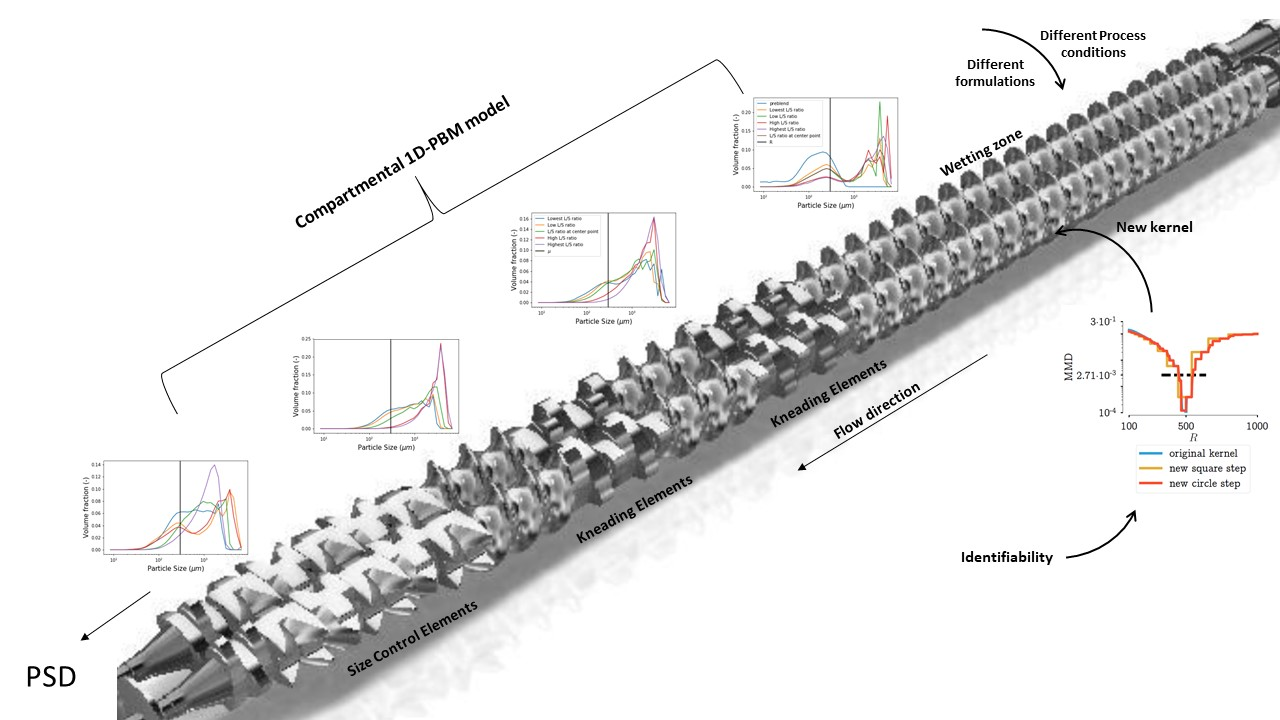
:
1. Introduction
2. Experimental Setup
2.1. Continuous Wet Granulation Experiments Using TSG
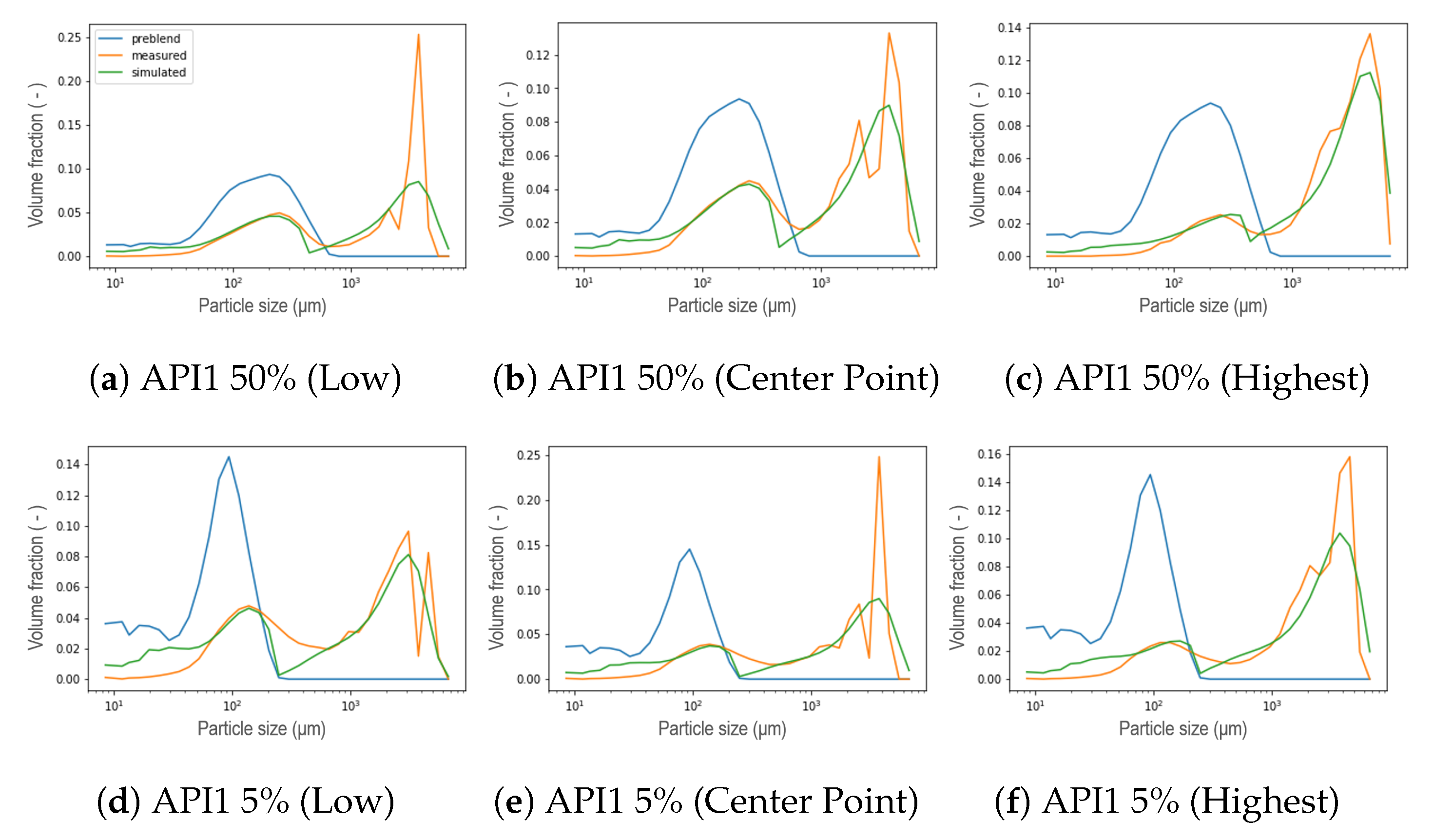
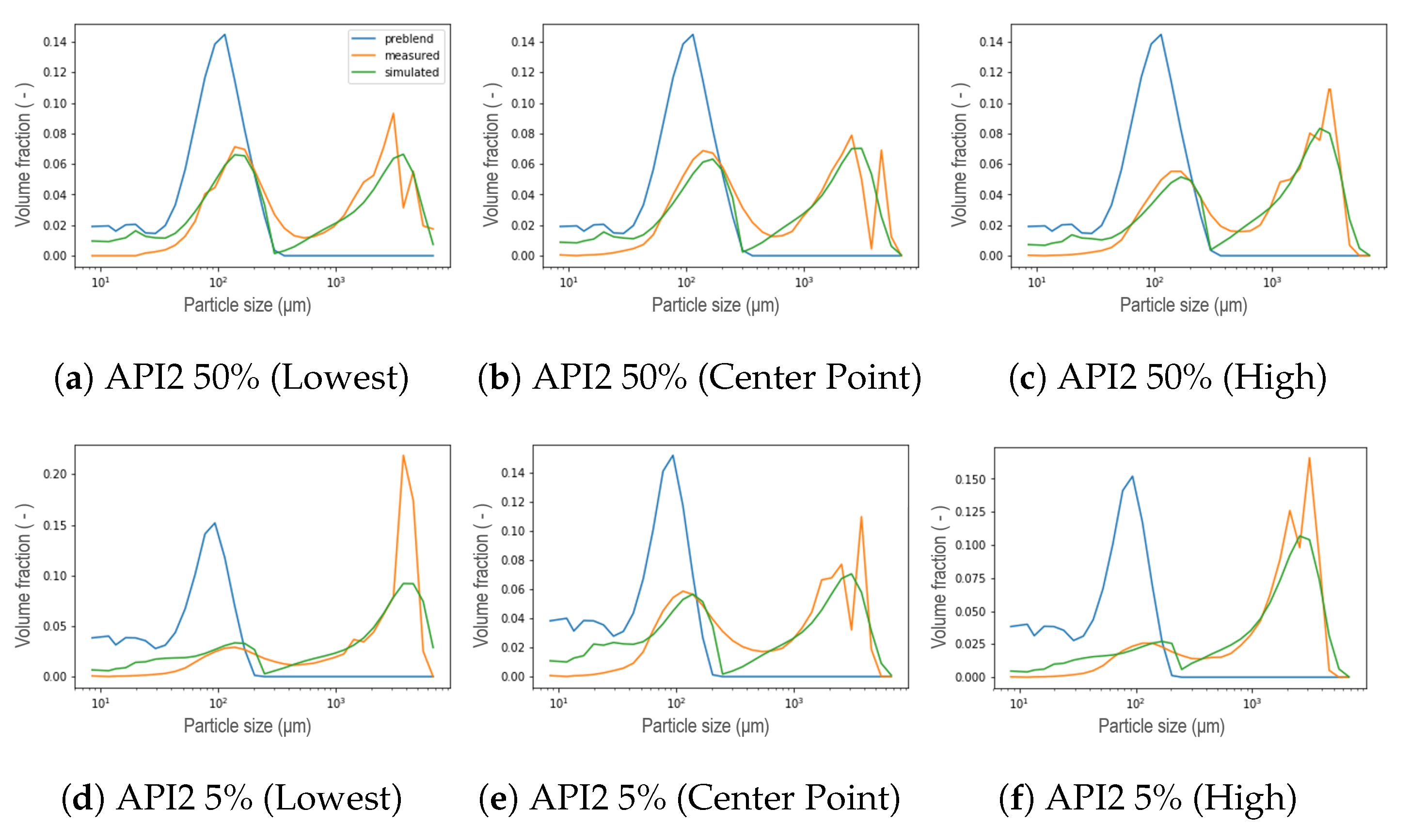
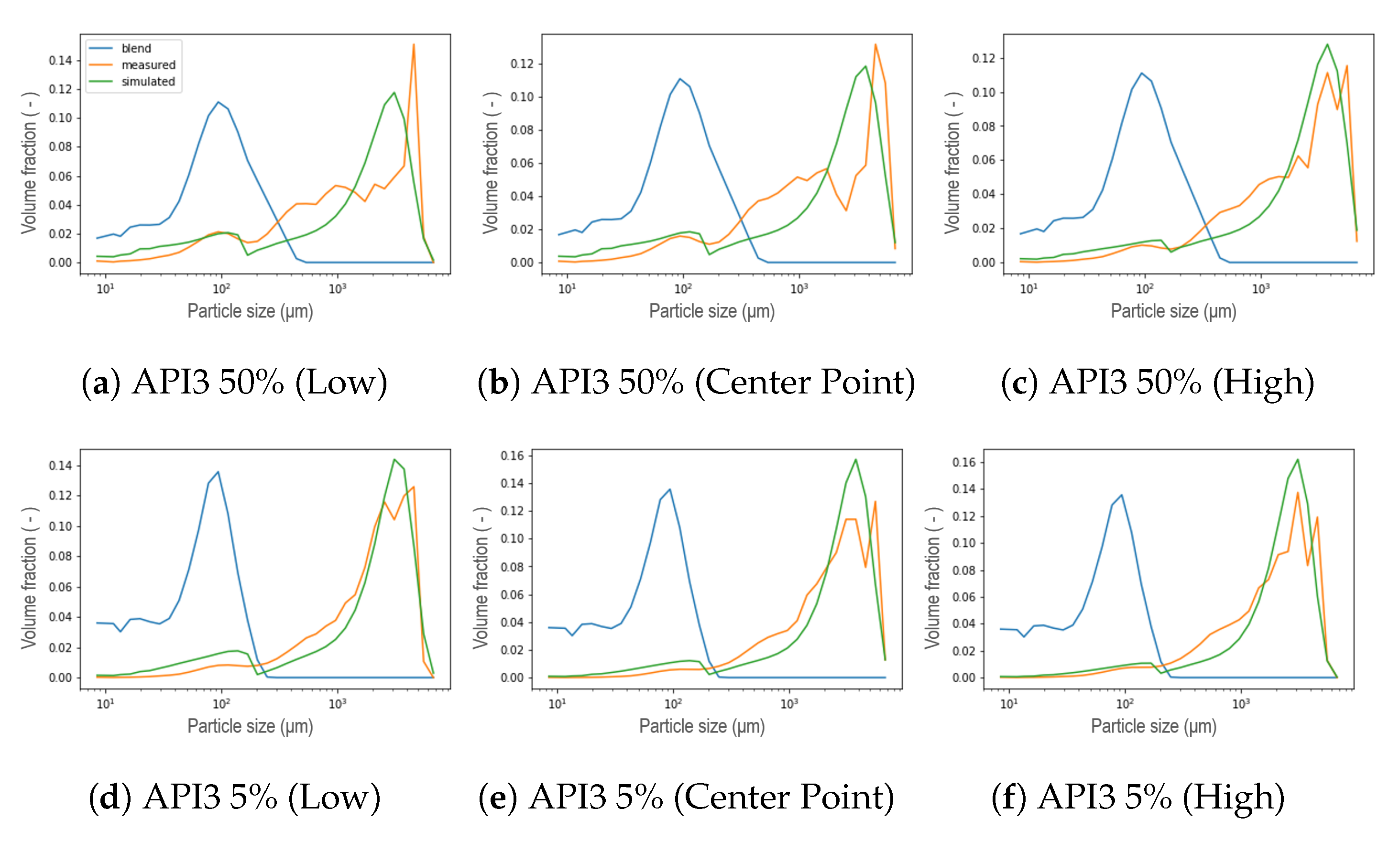
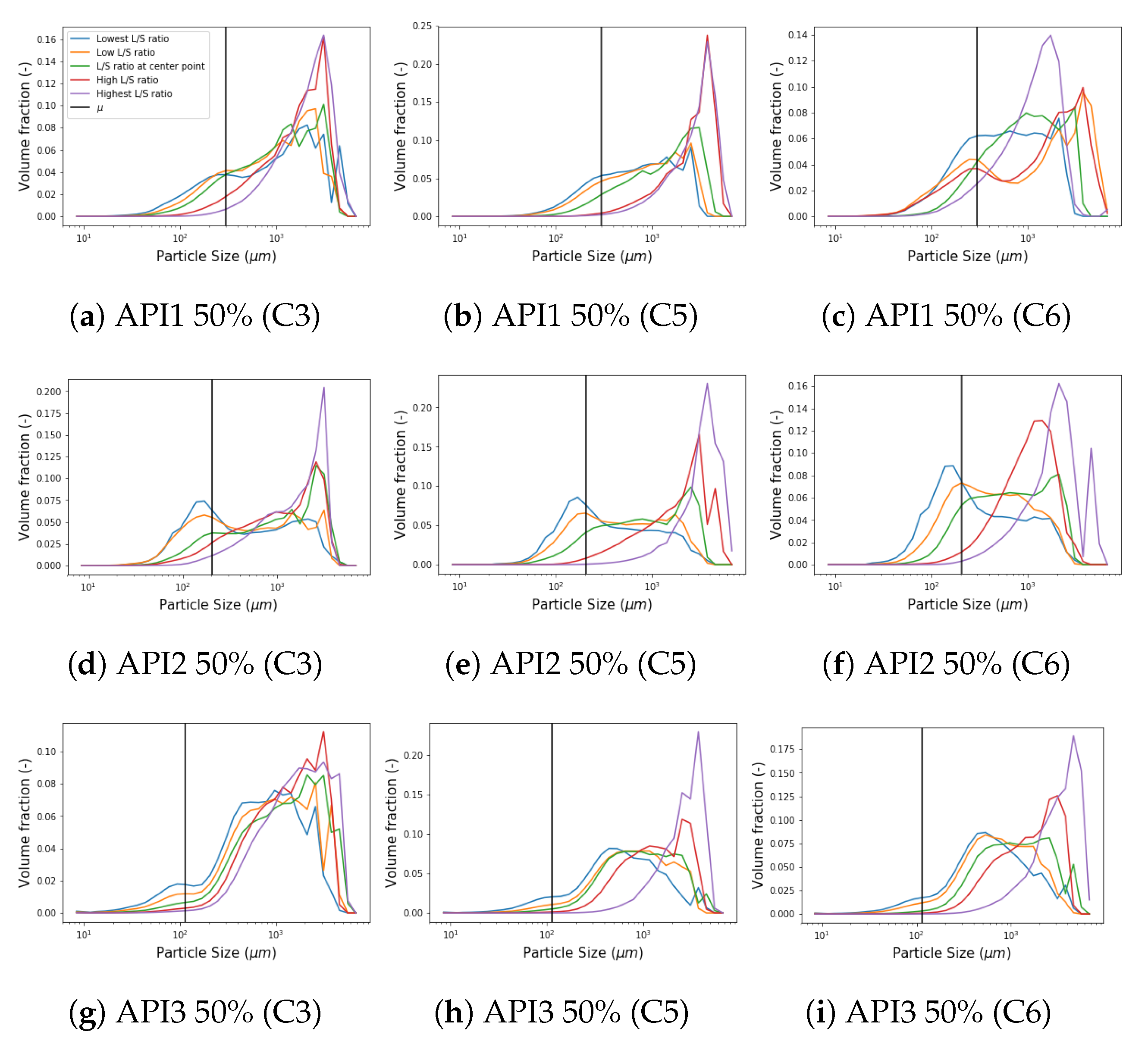
2.2. Design of Experiments
2.3. Particle Size Distribution Measurements
3. Population Balance Model
3.1. Base Model Description
3.2. Calibration Procedure
4. Identifiability
4.1. Introduction to Identifiability
A model is structurally identifiable if it is possible to determine the values of its parameters from observations of its outputs and knowledge of its dynamic Equations [29].
4.2. Identifiability Approach
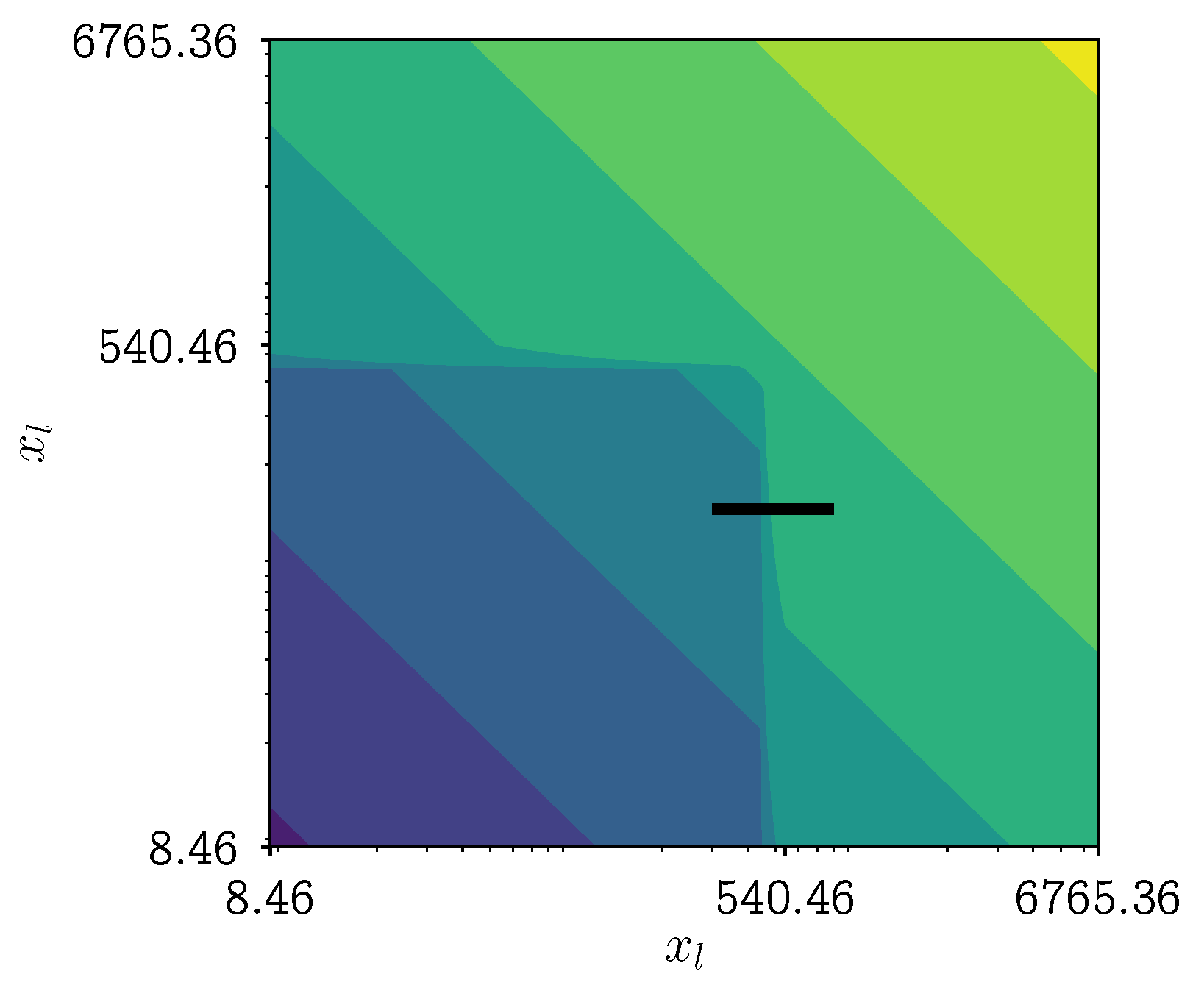
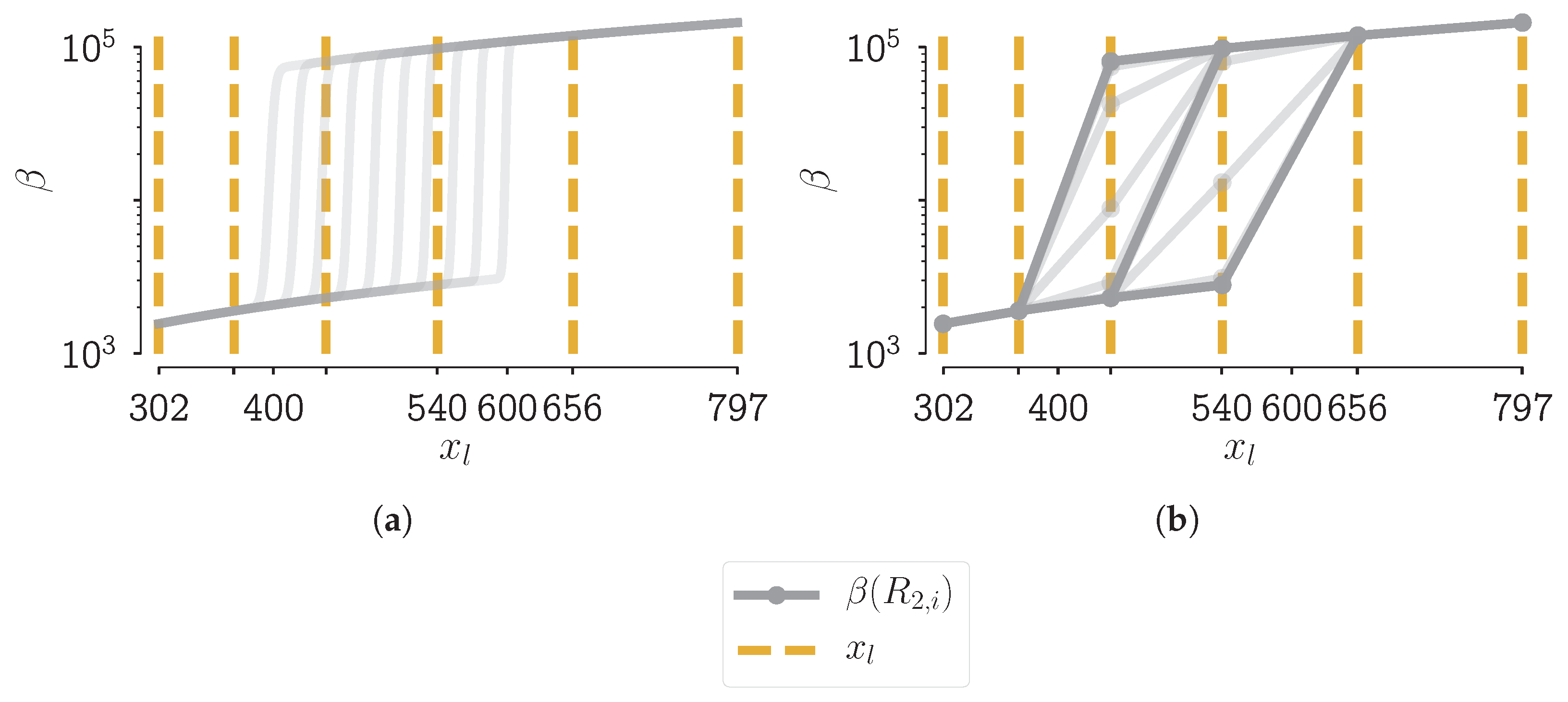
4.3. Potential Kernel Issues
4.3.1. The Origin of the Problem
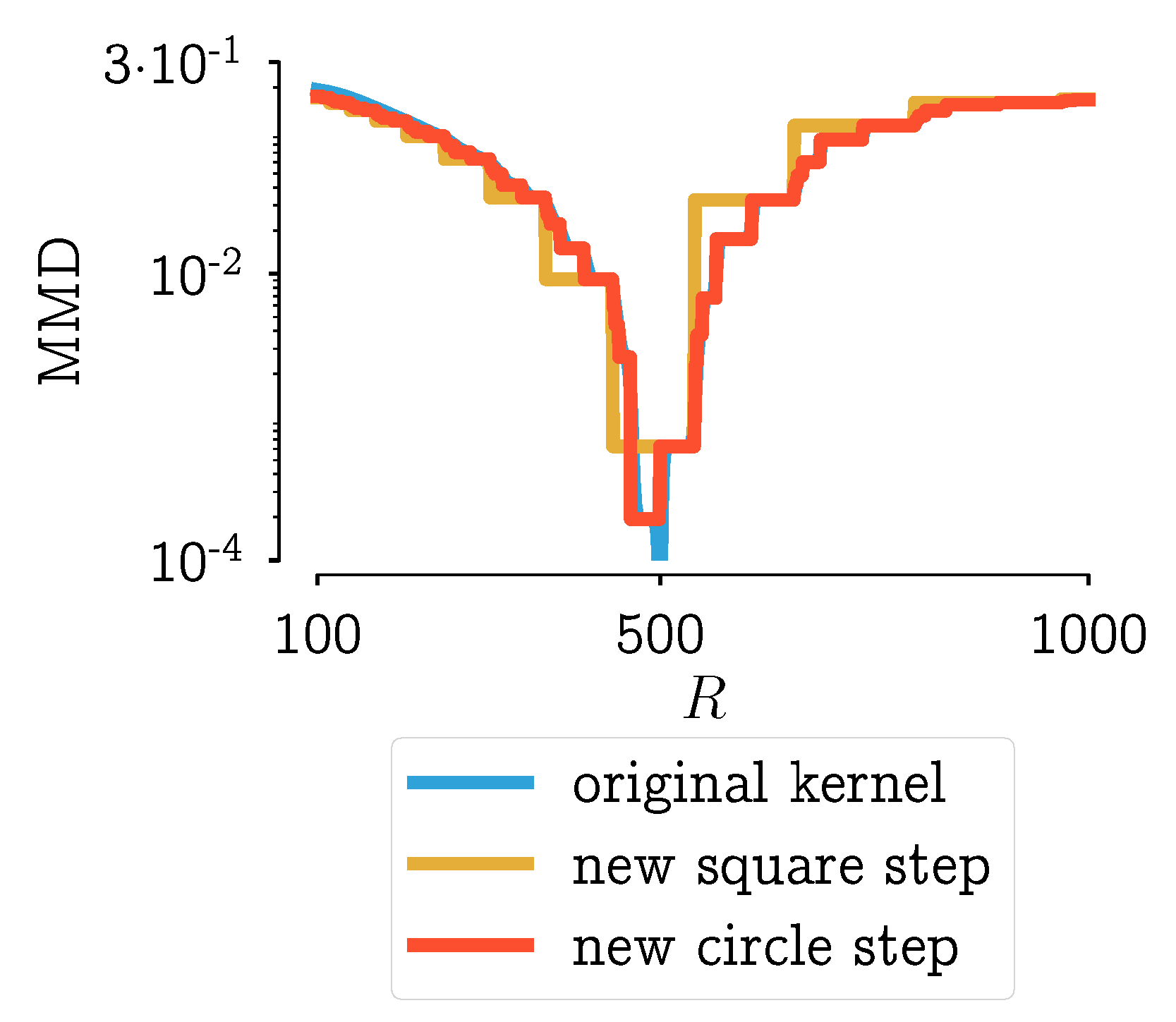
4.3.2. New Aggregation Kernels
4.3.3. Analysis of the New Aggregation Kernels
4.4. Incorporating Measurement Error into Parameter Estimations
- The original explanation of needing the smoothed step for numerical reasons does not hold, ergo it is not needed anymore.
- The new kernel has only two parameters (R and ), whereas the original kernel has six, which means a significant simplification for a parameter estimation problem.
- The new kernel has a single unique value below the measurement error threshold: this excludes ambiguity for choosing the right value.
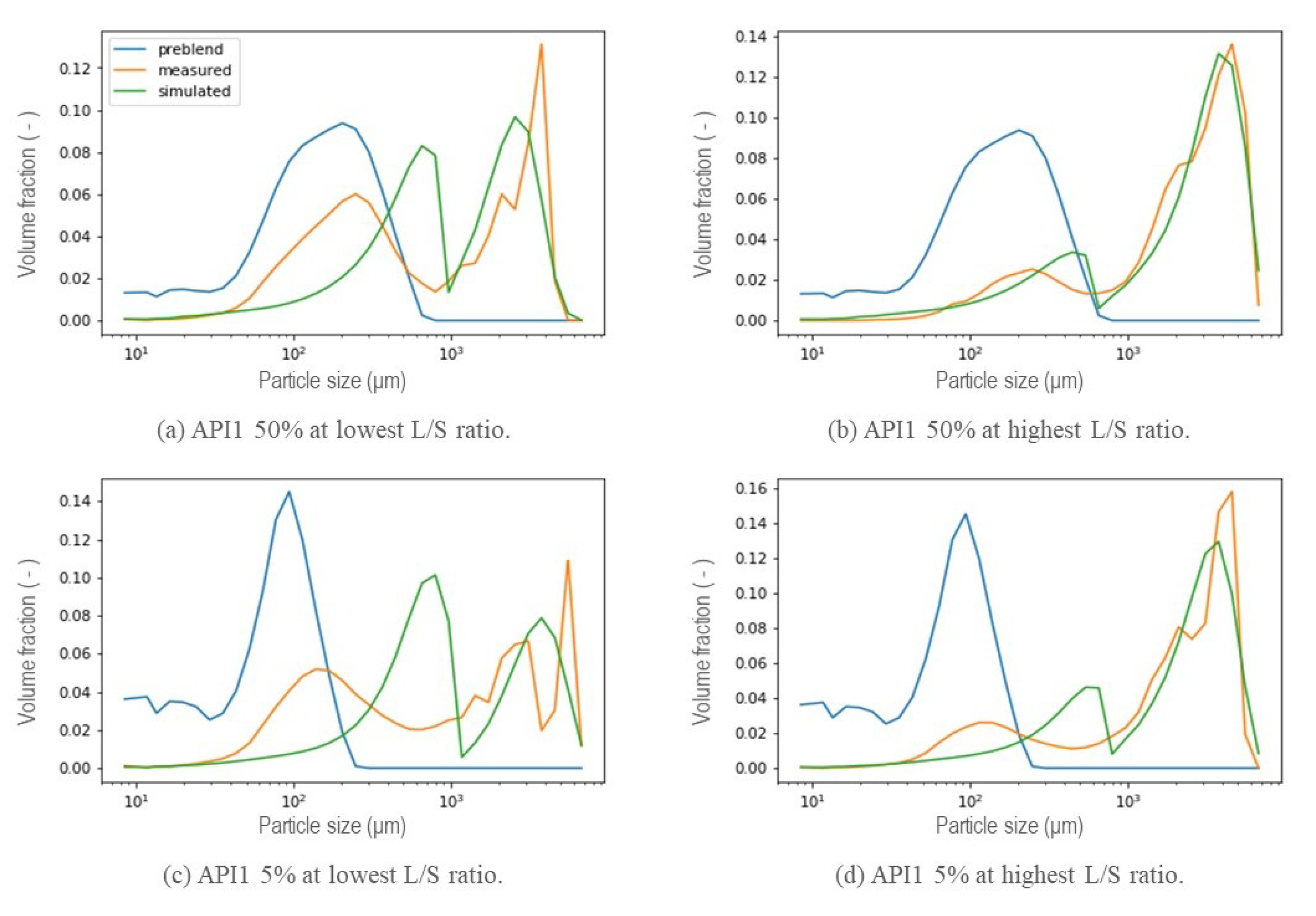
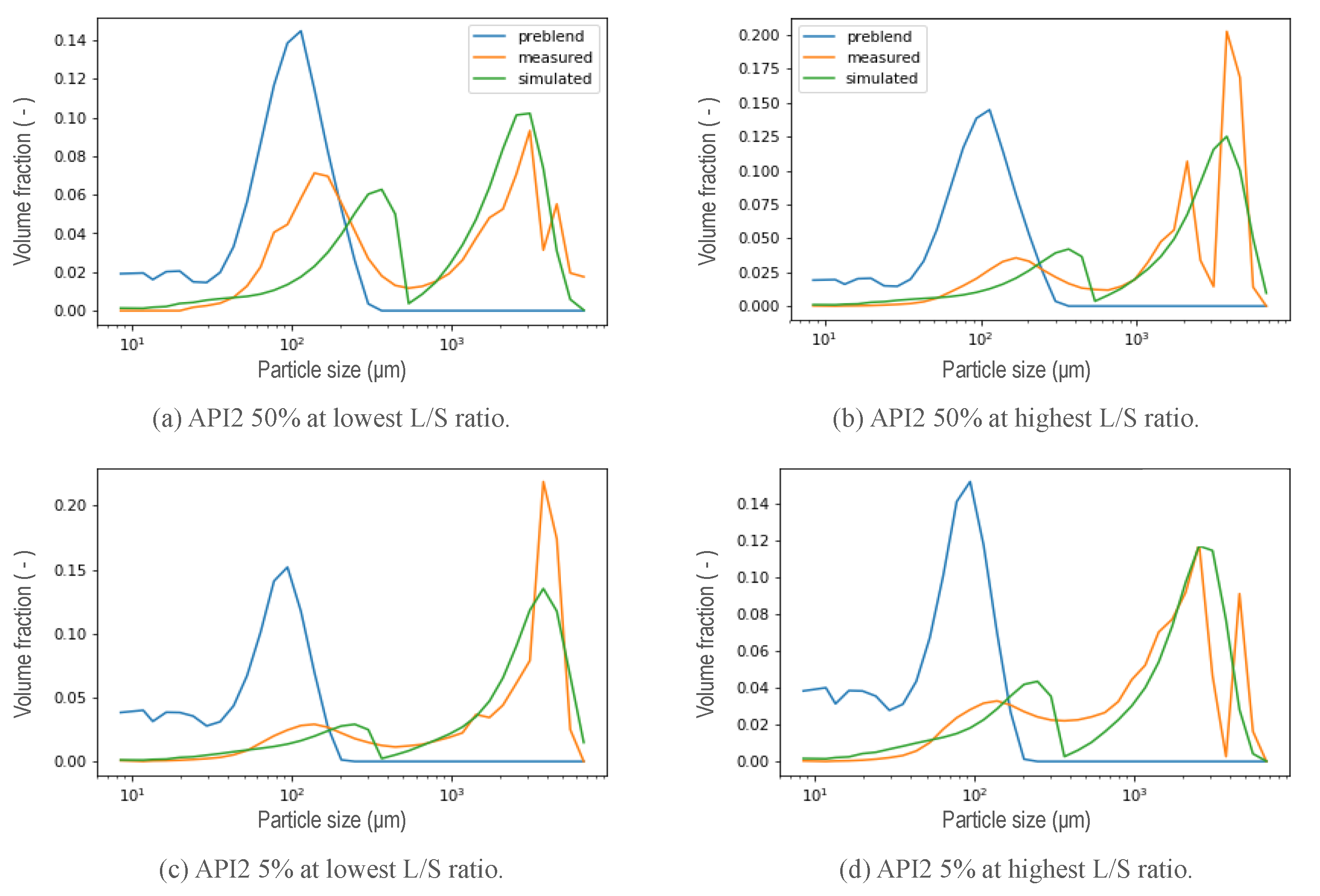
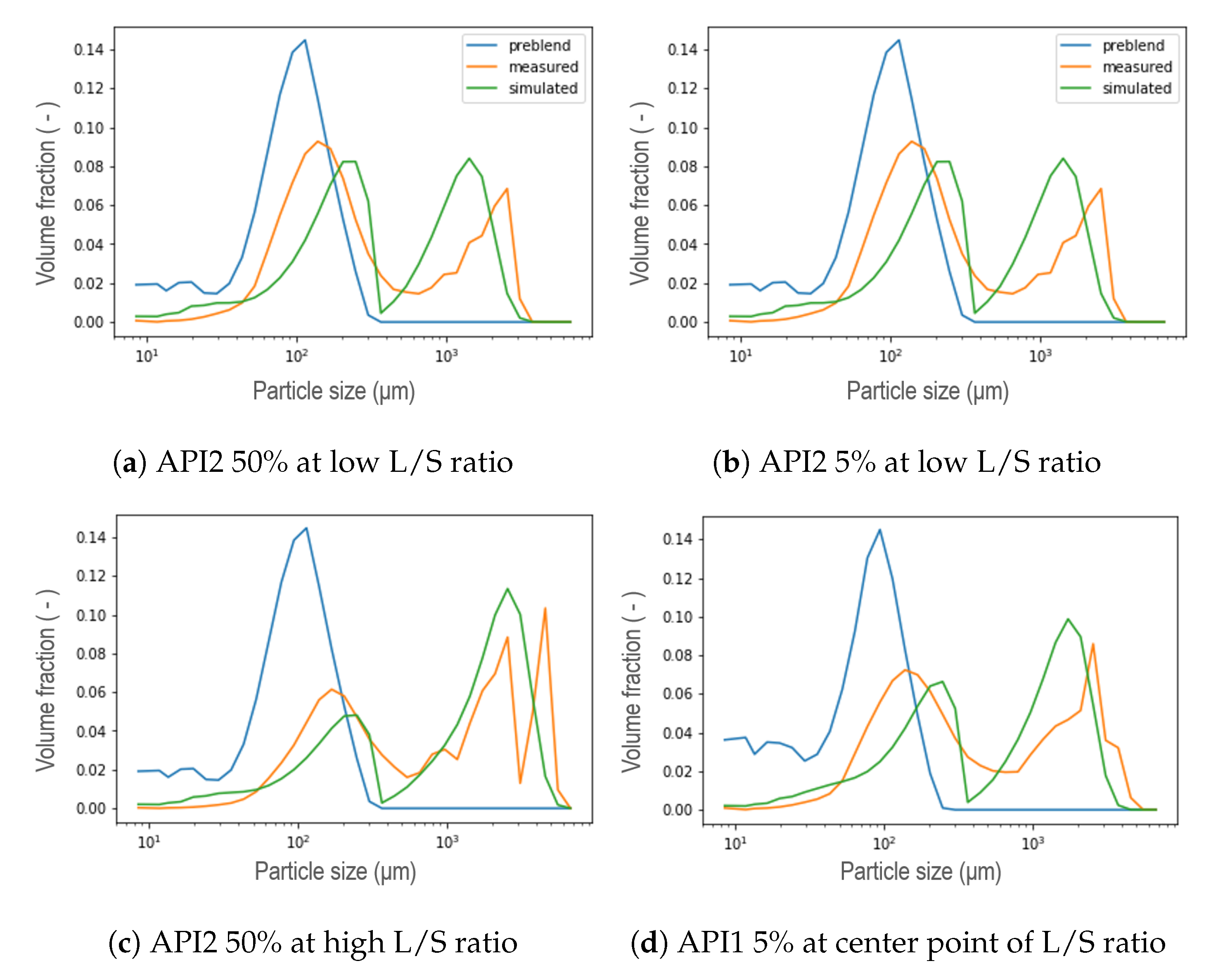
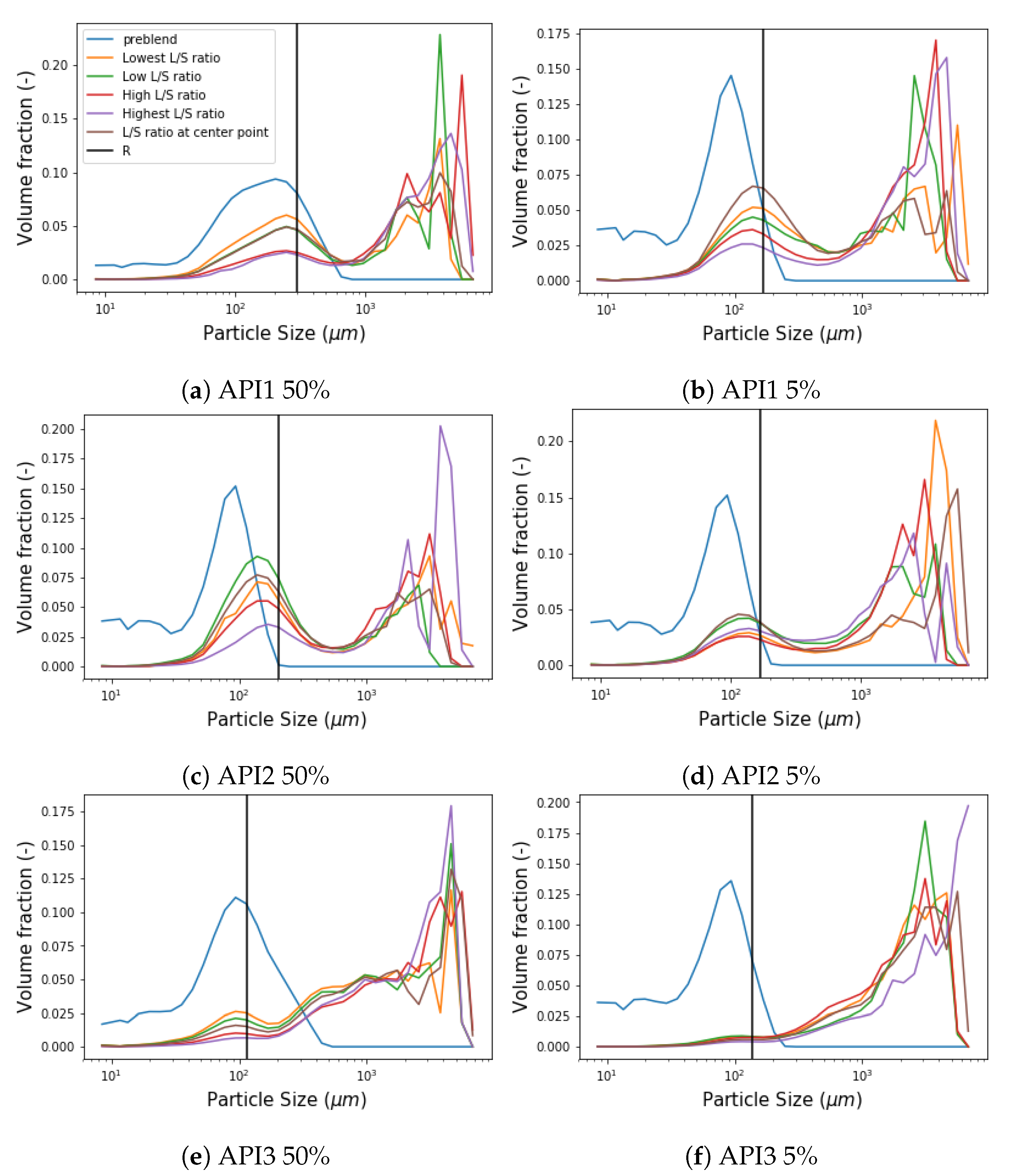
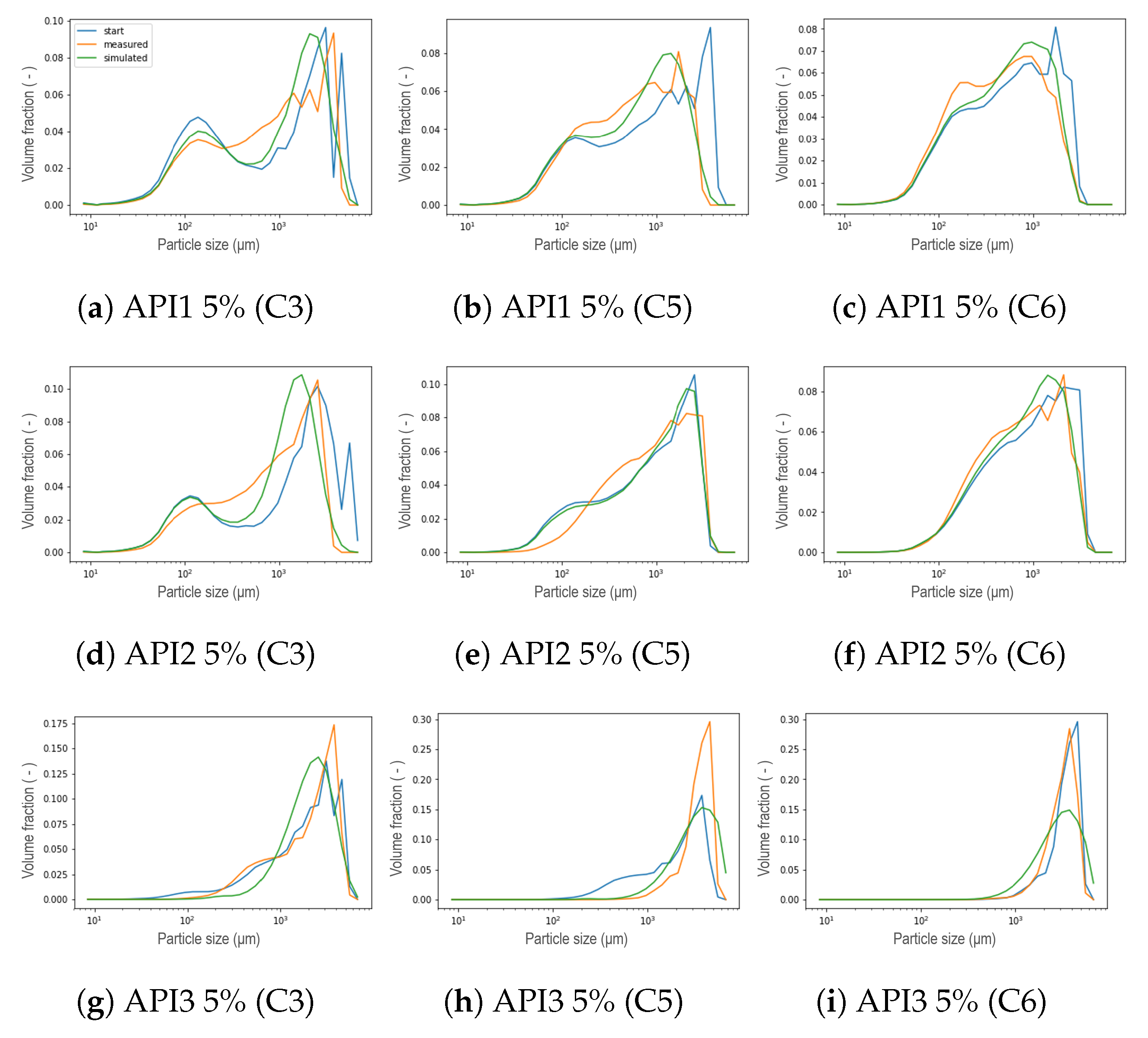
5. Results and Discussion
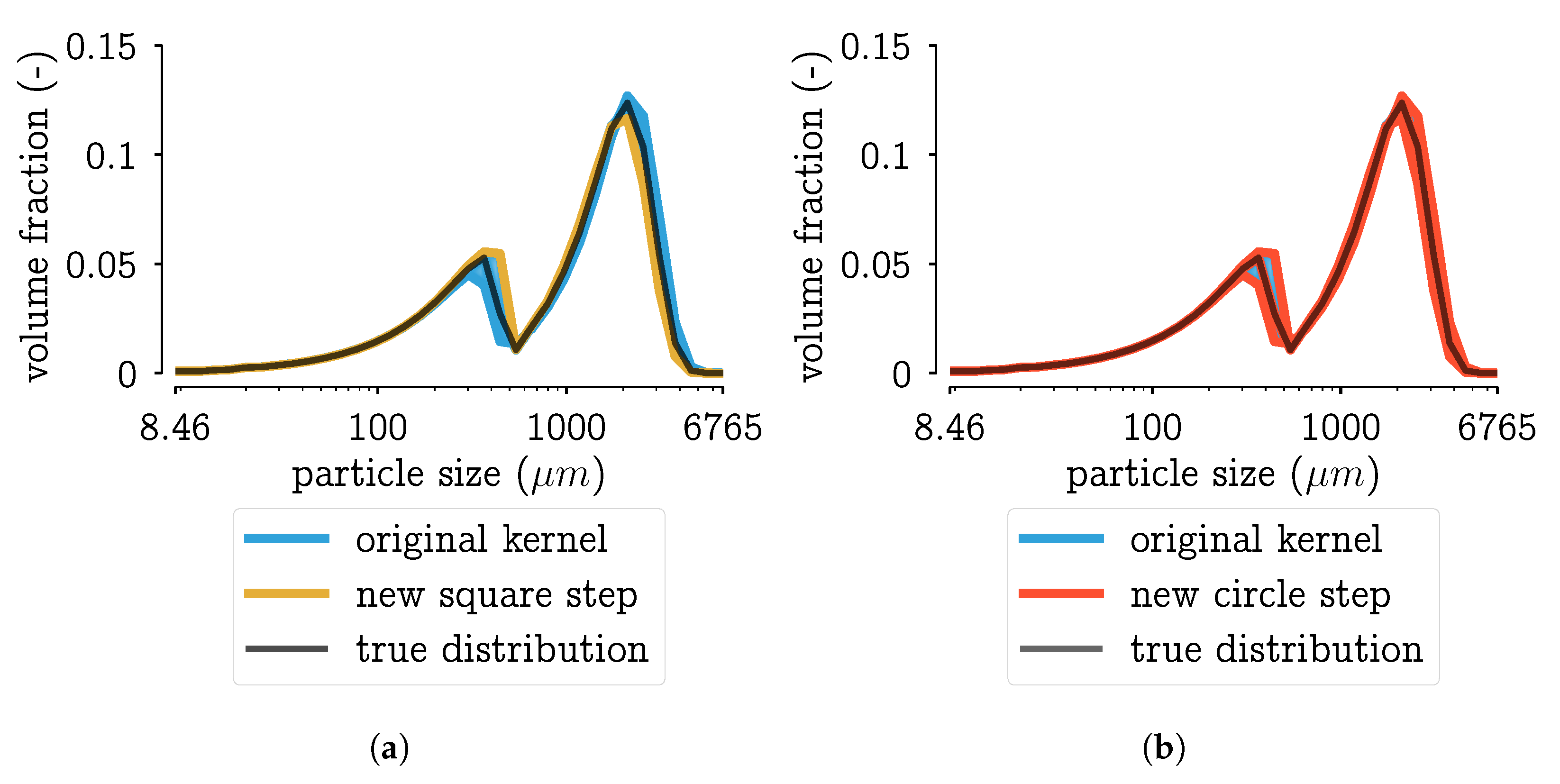
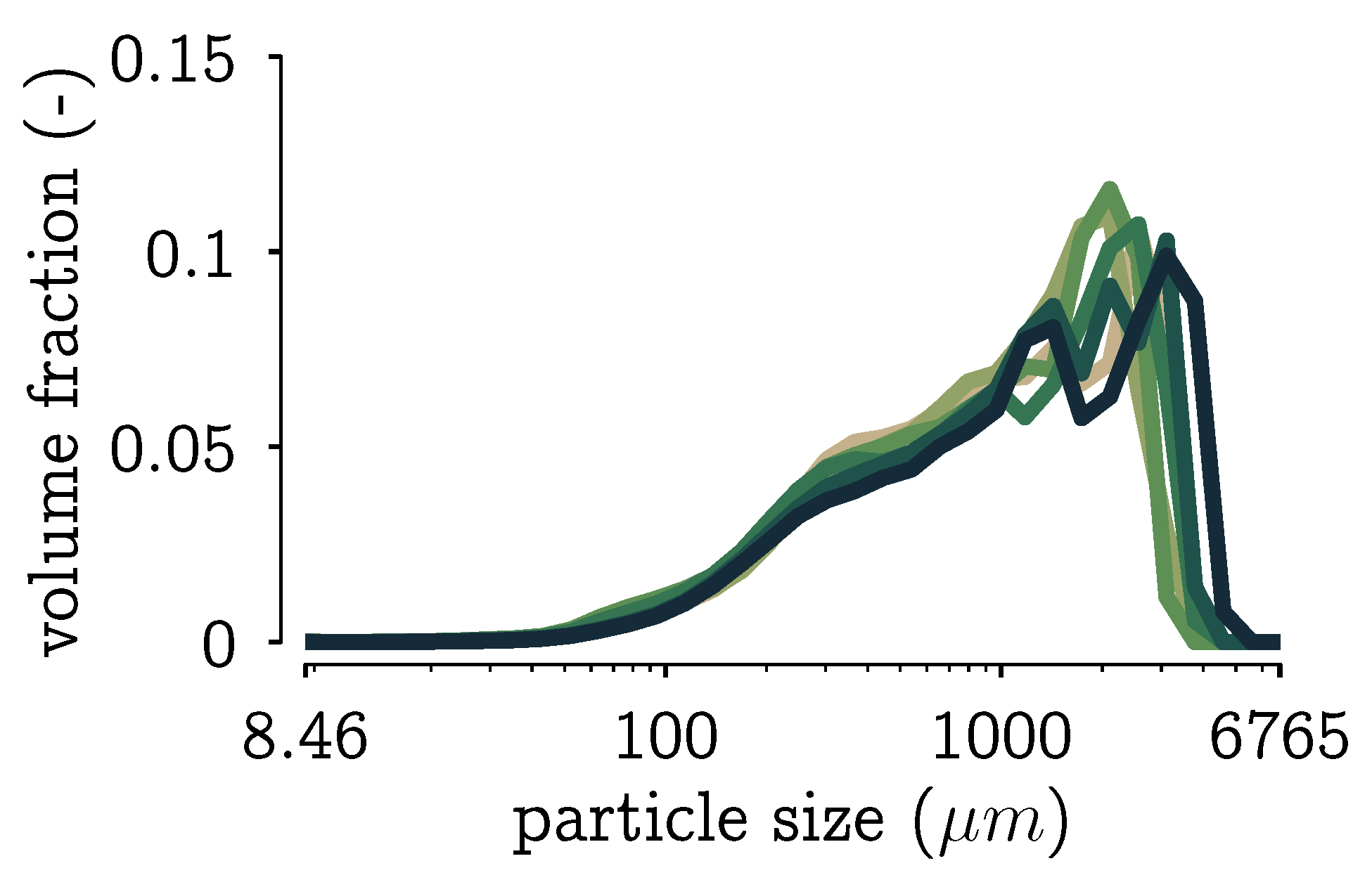
5.1. New Aggregation Kernel for the Wetting Zone
5.2. Reducing Unknown Model Parameters
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DoE | Design of Experiments |
| L/S | Liquid-to-Solid |
| MMD | Maximun Mean Discrepancy |
| PBM | Population Balance Modeling |
| PSD | Particle Size Distribution |
| TSWG | Twin-Screw wet granulation |
References
- Kumar, A.; Vercruysse, J.; Mortier, S.T.; Vervaet, C.; Remon, J.P.; Gernaey, K.V.; De Beer, T.; Nopens, I. Model-based analysis of a twin-screw wet granulation system for continuous solid dosage manufacturing. Comput. Chem. Eng. 2016, 89. [Google Scholar] [CrossRef]
- El Hagrasy, A.S.; Hennenkamp, J.R.; Burke, M.D.; Cartwright, J.J.; Litster, J.D. Twin screw wet granulation: Influence of formulation parameters on granule properties and growth behavior. Powder Technol. 2013, 238, 108–115. [Google Scholar] [CrossRef]
- Gorringe, L.J.; Kee, G.S.; Saleh, M.F.; Fa, N.H.; Elkes, R.G. Use of the channel fill level in defining a design space for twin screw wet granulation. Int. J. Pharm. 2017, 519, 165–177. [Google Scholar] [CrossRef]
- Pradhan, S.U.; Zhang, Y.; Li, J.; Litster, J.D.; Wassgren, C.R. Tailored granule properties using 3D printed screw geometries in twin screw granulation. Powder Technol. 2019, 341, 75–84. [Google Scholar] [CrossRef]
- Lute, S.V.; Dhenge, R.M.; Salman, A.D. Twin screw granulation: An investigation of the effect of barrel fill level. Pharmaceutics 2018, 10, 67. [Google Scholar] [CrossRef] [Green Version]
- Thapa, P.; Tripathi, J.; Jeong, S.H. Recent trends and future perspective of pharmaceutical wet granulation for better process understanding and product development. Powder Technol. 2019, 344, 864–882. [Google Scholar] [CrossRef]
- Vercruysse, J.; Burggraeve, A.; Fonteyne, M.; Cappuyns, P.; Delaet, U.; Van Assche, I.; De Beer, T.; Remon, J.P.; Vervaet, C. Impact of screw configuration on the particle size distribution of granules produced by twin screw granulation. Int. J. Pharm. 2015, 479, 171–180. [Google Scholar] [CrossRef] [PubMed]
- Lute, S.V.; Dhenge, R.M.; Hounslow, M.J.; Salman, A.D. Twin screw granulation: Understanding the mechanism of granule formation along the barrel length. Chem. Eng. Res. Des. 2016, 110, 43–53. [Google Scholar] [CrossRef]
- Verstraeten, M.; Van Hauwermeiren, D.; Lee, K.; Turnbull, N.; Wilsdon, D.; am Ende, M.; Doshi, P.; Vervaet, C.; Brouckaert, D.; Mortier, S.T.; et al. In-depth experimental analysis of pharmaceutical twin-screw wet granulation in view of detailed process understanding. Int. J. Pharm. 2017, 529, 678–693. [Google Scholar] [CrossRef] [PubMed]
- Portier, C.; Vigh, T.; Di Pretoro, G.; De Beer, T.; Vervaet, C.; Vanhoorne, V. Continuous twin screw granulation: Impact of binder addition method and surfactants on granulation of a high-dosed, poorly soluble API. Int. J. Pharm. 2020, 577, 119068. [Google Scholar] [CrossRef]
- Van Hauwermeiren, D.; Verstraeten, M.; Doshi, P.; Ende, M.T.; Turnbull, N.; Lee, K.; Beer, T.D.; Nopens, I. On the modelling of granule size distributions in twin-screw wet granulation: Calibration of a novel compartmental population balance model. Powder Technol. 2018, 341, 116–125. [Google Scholar] [CrossRef]
- Barrasso, D.; Ramachandran, R. Qualitative Assessment of a Multi-Scale, Compartmental PBM-DEM Model of a Continuous Twin-Screw Wet Granulation Process. J. Pharm. Innov. 2016, 11, 231–249. [Google Scholar] [CrossRef]
- Mcguire, A.D.; Mosbach, S.; Lee, K.F.; Reynolds, G.; Kraft, M.; Street, P.; Street, P. Twin-screw granulation Part 1: Model description New Museums Site. Chem. Eng. Sci. 2017, 188, 18–33. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.G.; Pradhan, S.U.; Wassgren, C.; Barrasso, D.; Slade, D.; Litster, J.D. A breakage kernel for use in population balance modelling of twin screw granulation. Powder Technol. 2020, 363, 525–540. [Google Scholar] [CrossRef]
- Ismail, H.Y.; Singh, M.; Albadarin, A.B.; Walker, G.M. Complete two dimensional population balance modelling of wet granulation in twin screw. Int. J. Pharm. 2020, 591, 120018. [Google Scholar] [CrossRef] [PubMed]
- Singh, M.; Kumar, A.; Shirazian, S.; Ranade, V.; Walker, G. Characterization of Simultaneous Evolution of Size and Composition Distributions Using Generalized Aggregation Population Balance Equation. Pharmaceutics 2020, 12, 1152. [Google Scholar] [CrossRef] [PubMed]
- Barrasso, D.; Walia, S.; Ramachandran, R. Multi-component population balance modeling of continuous granulation processes: A parametric study and comparison with experimental trends. Powder Technol. 2013, 241, 85–97. [Google Scholar] [CrossRef]
- Liu, H.; Galbraith, S.C.; Park, S.Y.; Cha, B.; Huang, Z.; Meyer, R.F.; Flamm, M.H.; O’Connor, T.; Lee, S.; Yoon, S. Assessment of spatial heterogeneity in continuous twin screw wet granulation process using three-compartmental population balance model. Pharm. Dev. Technol. 2019, 24, 105–117. [Google Scholar] [CrossRef]
- Shirazian, S.; Ismail, H.Y.; Singh, M.; Shaikh, R.; Croker, D.M.; Walker, G.M. Multi-dimensional population balance modelling of pharmaceutical formulations for continuous twin-screw wet granulation: Determination of liquid distribution. Int. J. Pharm. 2019, 566, 352–360. [Google Scholar] [CrossRef]
- Singh, M.; Kaur, G.; De Beer, T.; Nopens, I. Solution of bivariate aggregation population balance equation: A comparative study. React. Kinet. Mech. Catal. 2018, 123, 385–401. [Google Scholar] [CrossRef]
- Li, H.; Thompson, M.R.; O’Donnell, K.P. Examining drug hydrophobicity in continuous wet granulation within a twin screw extruder. Int. J. Pharm. 2015, 496. [Google Scholar] [CrossRef]
- Portier, C.; Pandelaere, K.; Delaet, U.; Vigh, T.; Di Pretoro, G.; De Beer, T.; Vervaet, C.; Vanhoorne, V. Continuous twin screw granulation: A complex interplay between formulation properties, process settings and screw design. Int. J. Pharm. 2020, 576, 11900. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Thompson, M.R.; O’Donnell, K.P. Understanding wet granulation in the kneading block of twin screw extruders. Chem. Eng. Sci. 2014, 113, 11–21. [Google Scholar] [CrossRef]
- Ramkrishna, D. Population Balances: Theory and Applications to Particulate Systems in Engineering; Academic Press: San Diego, CA, USA, 2000; Volume 1. [Google Scholar] [CrossRef]
- Parsopoulos, K.; Vrahatis, M. Recent approaches to global optimization problems through Particle Swarm Optimization. Nat. Comput. 2002, 1, 235–306. [Google Scholar] [CrossRef]
- Székely, G.J.; Rizzo, M.L. Energy statistics: A class of statistics based on distances. J. Stat. Plan. Inference 2013, 143, 1249–1272. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0-Fundamental Algorithms for Scientific Computing in Python. arXiv 2019, arXiv:1907.10121. [Google Scholar] [CrossRef] [Green Version]
- Van Hauwermeiren, D. On the Simulation of Particle Size Distributions in Continuous Pharmaceutical Wet Granulation. Ph.D. Thesis, Ghent University, Ghent, Belgium, 2020. [Google Scholar]
- Bellman, R.; Åström, K. On structural identifiability. Math. Biosci. 1970, 7, 329–339. [Google Scholar] [CrossRef]
- Chis, O.T.; Banga, J.R.; Balsa-Canto, E. Structural identifiability of systems biology models: A critical comparison of methods. PLoS ONE 2011, 6, e27755. [Google Scholar] [CrossRef] [Green Version]
- Mundozah, A.L.; Cartwright, J.J.; Tridon, C.C.; Hounslow, M.J.; Salman, A.D. Hydrophobic/hydrophilic powders: Practical implications of screw element type on the reduction of fines in twin screw granulation. Powder Technol. 2019, 341, 94–103. [Google Scholar] [CrossRef]
- Li, J.; Pradhan, S.U.; Wassgren, C.R. Granule transformation in a twin screw granulator: Effects of conveying, kneading, and distributive mixing elements. Powder Technol. 2019, 346, 363–372. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
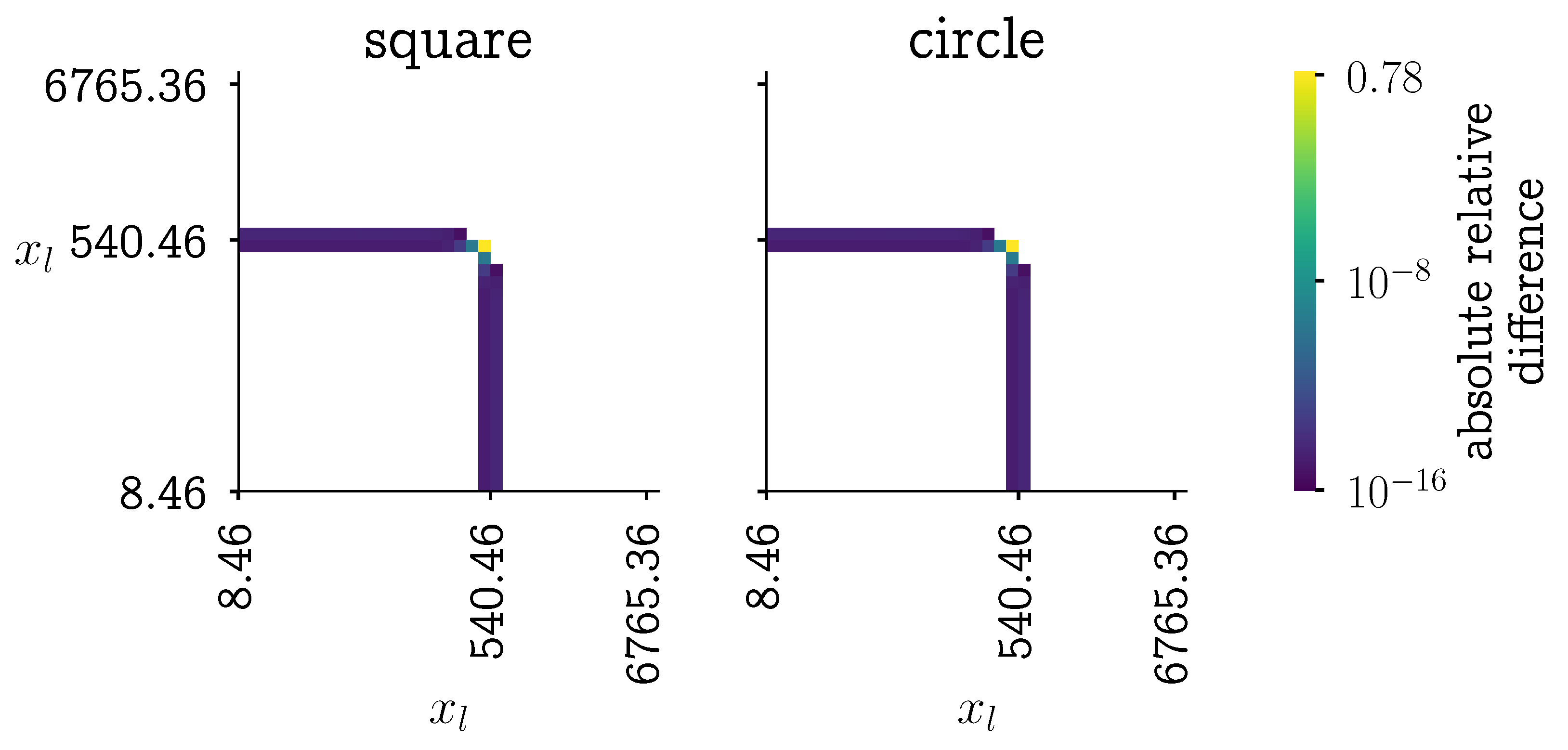{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| API | Number of Experiments | Screw Speed (rpm) | Throughput (kg/h) | L/S (%) |
|---|---|---|---|---|
| API1 (5%) | 11 | 675 | 15–25 | 8.9–20.2 |
| API1 (50%) | 11 | 675 | 15–25 | 13.6–23.7 |
| API2 (5%) | 17 | 450–675 | 15–25 | 8–18 |
| API2 (50%) | 17 | 450–675 | 15–25 | 5.2–16 |
| API3 (5%) | 17 | 750–900 | 15–25 | 15.2–18.5 |
| API3 (50%) | 17 | 450–675 | 15–25 | 5.2–13.4 |
| Formulation | |
|---|---|
| API1 (5%) | 168.35 |
| API1 (50%) | 301.64 |
| API2 (5%) | 168.35 |
| API2 (50%) | 204.47 |
| API3 (5%) | 138.61 |
| API3 (50%) | 114.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barrera Jiménez, A.A.; Van Hauwermeiren, D.; Peeters, M.; De Beer, T.; Nopens, I. Improvement of a 1D Population Balance Model for Twin-Screw Wet Granulation by Using Identifiability Analysis. Pharmaceutics 2021, 13, 692. https://0-doi-org.brum.beds.ac.uk/10.3390/pharmaceutics13050692
Barrera Jiménez AA, Van Hauwermeiren D, Peeters M, De Beer T, Nopens I. Improvement of a 1D Population Balance Model for Twin-Screw Wet Granulation by Using Identifiability Analysis. Pharmaceutics. 2021; 13(5):692. https://0-doi-org.brum.beds.ac.uk/10.3390/pharmaceutics13050692
Chicago/Turabian StyleBarrera Jiménez, Ana Alejandra, Daan Van Hauwermeiren, Michiel Peeters, Thomas De Beer, and Ingmar Nopens. 2021. "Improvement of a 1D Population Balance Model for Twin-Screw Wet Granulation by Using Identifiability Analysis" Pharmaceutics 13, no. 5: 692. https://0-doi-org.brum.beds.ac.uk/10.3390/pharmaceutics13050692