Dynamic Credit Risk Evaluation Method for E-Commerce Sellers Based on a Hybrid Artificial Intelligence Model

1
School of Information Technology and Management, University of International Business and Economics, Beijing 100029, China
2
Alibaba Business School, Hangzhou Normal University, Hangzhou 311121, China
*
Author to whom correspondence should be addressed.
Sustainability 2019, 11(19), 5521; https://0-doi-org.brum.beds.ac.uk/10.3390/su11195521
Submission received: 16 July 2019
/
Revised: 25 September 2019
/
Accepted: 1 October 2019
/
Published: 6 October 2019
(This article belongs to the Section Economic and Business Aspects of Sustainability)
Abstract
:Credit risk evaluation is important for e-commerce platforms, due to the uncertainty and transaction risk associated with buyers and sellers. Moreover, it is the key ingredient for the development of the e-commerce ecosystem and sustainability of the financial market. The main objective of this paper is to develop an effective and user-friendly system for seller credit risk evaluation. Three hybrid artificial intelligent models, including (1) decision tree—artificial neural network (ANN), (2) decision tree—logistic regression, and (3) decision tree—dynamic Bayesian network have been investigated. The models were trained using sellers credit cases from Taobao, which has 609 cases, and each case had 23 categorical and numerical attributes. The results suggest that the combination of decision tree—ANN provides the highest accuracy, which can promote healthy and fast transactions between buyers and sellers on the platforms. This model is regarded as a powerful tool that allows us to build an advanced credit risk evaluation system, and meet the requirements of the platform transaction mode to be dynamic and self-learning—which will ultimately contribute to the sustainable development of the e-commerce ecosystem. The empirical results can serve as a reference for e-commerce platforms promoting an optimum credit risk evaluation model to improve e-commerce transaction environment and for buyers and investors making decisions.
1. Introduction
Credit risk evaluation is the foundation in establishing trust between sellers and buyers in an e-commerce environment. It is an important part of e-commerce industrial chain, and the key ingredient for the sustainability of the financial market. In virtual e-commerce transactions, the information asymmetry between sellers and buyers results in increased uncertainty and transaction risk. While the e-commerce market is still rapidly developing, the problem of credit deficiency is becoming one of the most important bottlenecks for the sustainable development of e-commerce. Without effective credit risk evaluation the ‘lemon problem’ occurs in platform mediated network market. Credit deficiency undermines the orderliness, fairness and competitiveness of the financial market, which is extremely harmful to the healthy development of e-commerce.
The tensions between the U.S. and China have placed considerable pressure on China’s economy. Due to the recent development of IT infrastructure in China, many people who had a challenging time, because of economic downturn, can easily start their own small business using services offered by e-commerce platforms, such as Taobao. SMEs (small and medium-sized enterprises) on different e-commerce platforms play a pivotal role in increasing employment and spurring the economy. In 2018, Chinese e-commerce giant Alibaba created 40.82 million jobs, directly and indirectly, via its expansive retail ecosystem; and there are 10 million SMEs and start-ups on Taobao (Alibaba’s C2C e-commerce platform) alone. However, with the rapid development of e-commerce in China, there come all kinds of product quality problems. For example, although “the 2018 Double Eleven Shopping Festival” once again broke the record in sales, the major e-commerce websites, such as Taobao, Tmall.com, and JD.com, all suffered from a large number of complaints regarding the quality after the sales event. The inability of guarantee product quality and the proliferation of fake goods make consumers question the trustworthiness of the online shopping platforms and the demand for goods quality has become a bottleneck issue for the health and sustainability of e-commerce. Under such circumstances, a comprehensive credit risk evaluation system is highly necessary.
However, the current e-commerce platform’s seller credit is simply evaluated by summing up or averaging the consumer scores, which easily results in the phenomenon of manual intervention, such as click farming(a form of click fraud, where a large group of low-paid workers are hired to click on website elements to boost the status of the website or a product). Moreover, there is a time lag in consumer scores that do not dynamically respond to the changes in seller credit. We argue that the current credit risk evaluation method is oversimplified, neglect the key elements of the seller’s information that affect SMEs credibility. The factors, such as operating years, operating margin, etc., are not incorporated into current e-commerce platform credit risk evaluation. According to a survey of prevailing e-commerce platforms, the majority of platforms offer 0–5 scoring methods (such as Tmall, etc.) and use the weighted average consumer’s evaluation scores as the seller’s credit risk evaluation index. The method is simple and static, which hinders buyers from making correct decisions and improving the transaction environment of e-commerce platforms. Hence, a comprehensive and dynamic credit risk evaluation system is needed to accurately and dynamically evaluate the seller’s credit risks on an e-commerce platform.
Enabled by technological advances, such as the Internet, big data and artificial intelligence (AI), the models of preference prediction, intelligent recommendation, pattern recognition and other technologies have been gradually applied in many fields, providing consumers with optimized choices and more convenient and precise service. So far, many e-commerce platforms have applied big data technology to analyze and predict consumers’ purchasing behaviors and preferences and offer product recommendations based on analysis results, in the process transitioning from traditional transactions to intelligent development, and, to a certain extent, enhancing users’ purchasing enthusiasm and customer experience. However, the technology is much more user-oriented in e-commerce; that is, intelligent recommendation is based on users’ transaction data without systematic analysis of sellers. There is neither application of big data or AI technology to accurately and systematically evaluate the seller’s credit, nor two-way matching between sellers and customers. However, the quality of products recommended by AI is patchy and is unlikely to improve customer service.
Overall, an e-commerce platform does not apply AI algorithms and big data technology to dynamically and accurately evaluate the seller’s credit risks. The simple and static credit risk evaluation models have a bearing on consumers’ judgments to make correct decisions and sacrifice transaction experience. As millions of transactions take place on e-commerce platform everyday, these leave a trail of data, which is not only big, but also powerful. The data can be integrated into a platform to promote credibility and transparency for SMEs. However, the data from SMEs operations are scattered and hard to get, putting them in an unfavorable position in the competition. Moreover, the buyers lack resources, ability, willingness and economic incentives to build their own credit models, considering the relatively small transaction sizes. Recent studies have shown that the existing artificial intelligence (AI) technology, such as artificial neural network, decision tree, support vector machine, etc., in the problem of credit risk assessment, shows a better performance than the statistical model and optimization method. The e-commerce platform can build and operate the credit risk evaluation system that will make AI tools cost-effective and accessible for small business to adopt. Once the SMEs on the platform are proved to have a higher credit rating, they can have more development opportunities. With the credit sharing information, buyers, as well as business partners, can choose more professional and qualified SMEs. The use of dynamic and effective credit risk evaluation system may help small firms sustain their business. It is of great significance to create an optimum e-commerce transaction environment and achieve sustainable development within the e-commerce industry.
Our paper studies the process of credit risk evaluation and how advances in technology are changing this process. Specifically, we use data from Taobao to assess several approaches to evaluate seller credit and aim to explore an improved credit risk evaluation model to encourage honest transactions on the e-commerce platform. Our paper finds a dynamic and effective credit risk evaluation model which allows us to build an advanced and user-friendly system for credit risk evaluation. The contributions of this paper are summarized as follows: (1) We propose a hybrid AI model for credit risk evaluation of e-commerce sellers. The combination model would improve the credit risk prediction accuracy ratio, and meanwhile, overcome the shortcoming of a single AI model’s lack of interpretability. It can serve as a reference for e-commerce platform promoting optimum credit risk evaluation model to improve e-commerce transaction environment and for buyers and investors making decisions. (2) we demonstrate that the credit risk prediction performance of decision tree— artificial neural network (ANN) model is better than that of decision tree—logistic regression (LR), decision tree—dynamic Bayesian network (DBN) and single ANN, LR, DB models in evaluating the credit risk of sellers on Taobao platform.
The remainder of the paper is organized as follows. Section 2 gives a literature review, including the development of credit risk evaluation, credit risk evaluation index system, dynamic credit risk evaluation and AI models for credit risk evaluation. Section 3 builds a credit risk evaluation portfolio model for e-commerce sellers based on hybrid AI methods. The empirical analysis is evaluated in Section 4, and some concluding remarks are presented in Section 5.
2. Literature Review
2.1. The Development of Credit Risk Evaluation
The term ‘credit’ originated from the development of the bank credit business, with the concept of credit risk evaluation being introduced to reduce credit risk. In the middle of the nineteenth century, credit risk evaluation gradually became an independent research field. The research continued to flourish in the next decades, giving rise to novel and dynamic models.
After various financial crises, European and American scholars started to focus on credit risk analysis, and corporate financial indicators began to be included in the early credit risk evaluation method. For example, Beaver [1] used univariate analysis to provide a reference system to prevent bankruptcy risks through indicators, such as financial ratio, rate of return, return on assets and current ratio. Horrigan [2] introduced the logit model to prove that financial ratios can be used for long-term credit decisions. Altman [3] proposed multivariate discriminant analysis (MDA), which established a Z-score model based on liquidity, profitability, leverage ratio, solvency and operational ratio as discriminative indicators. Edmister [4] studied the financial indicators used to assess the default risk of small businesses. In this interpretation, after multivariate discriminant analysis, it is necessary to comprehensively take account of factors, such as operational capacity, profitability, industry environment, development trends, etc. Martin [5] used a few financial ratio variables to predict corporate bankruptcy and default rates and established the logit regression model.
In the late twentieth century, researchers have shown that financial institutions rely on soft information to evaluate the credibility of small enterprises [6,7,8]. This soft information is gathered through a contract with SMEs and observing the performance of borrowers. It also includes an assessment of future prospects based on past communication with suppliers, customers and neighboring business [7,9]. Dennis [10] examined cognitive constraints and behavioral biases that might affect the use of soft information, and explored three constraints and biases, including limited attention, task-specific human capital and common identity that would affect the lending decision. Berger and Udell [11] proposed a more detailed conceptual framework for the analysis of SME credit availability issues. This work suggested that the elements, including information environment, the legal, judicial and bankruptcy environments, the social environment, and the tax and regulatory environments would affect SME credit availability. Standard and Poor catagories suggest that credit risk evaluation should focus on assessing the dynamic solvency of enterprises, including the economic cycle, competitive position, industry and development situation, legal proceedings, policy environment and emergencies and other dynamic factors.
2.2. Credit Risk Evaluation Index System
In the field of structuring the credit risk evaluation index system, numerous studies have focused on application and improvement of the models of regression, stochastic probability and machine learning and testing the evaluation performance of these models based on small and micro-enterprise data. Beginning in the 1960s, Altman [3], Martin [5], and other scholars, have used the statistical analysis method for corporate credit risk evaluation. In the 1980s, systematic analysis methods were gradually applied, and a few scholars suggested the expert system, neutral network, vector machine and other methods to effectively explore credit rating issues. Messier and Hansen [12] introduced an expert system into credit risk evaluation and compared it with the discriminant model. These researchers concluded that an expert system based on inductive inference could better analyze users’ credit risks. Odom and Shard [13] built a neural network model to investigate the bankruptcy of banks. Their model initiated the application of neural networks in credit risk management. Later, Desai et al. [14] introduced the model neural network (MNN) to analyze credit risk. Huang [15] applied the support vector machine (SVM) to process the data of financial institutions in the United States and Taiwan with a test accuracy of 80%, which is an ideal credit risk evaluation result. Fantazzini et al. [16] suggested that the accuracy of sample prediction of random survival forests was higher, while the accuracy of out-of-sample prediction of the regression model was higher. Sohn and Jeon [17] proposed the Weilbull competition risk model and analyzed the influencing factors, while Ono et al. [18] used propensity score matching (PSM) to determine the index weights and evaluate the credit score. Meanwhile, hybrid methods have gradually applied to credit risk evaluation [19,20,21].
2.3. Dynamic Credit Risk Evaluation
Abdul-Rahman [22] introduced the concept of dynamic credit and built a simple credit risk evaluation model to describe the weighting and changing process of credit. The current methods of dynamic credit risk evaluation consist mainly of a dynamic credit risk evaluation index, discrete time model, continuous time model and other features. Tomasz R. et al. [23] proposed dynamic limit growth indices (DLGI) to measure the long-term performance of a financial portfolio under the premise of discrete time series. They suggested that a sufficient and necessary condition should be provided for a DLGI to be dynamic assessment index. The paper used dynamic risk measures to build examples of DLGI. Zhen et al. [24] developed the METrust model in P2P networks based on the dynamic recommendation, and introduced two trust parameters, including updating range and updating strength for updating the credibility of recommendation. Bin-Wen [25] divided the credit risk evaluation index into three dimensions, including time, space and intensity, and dynamically evaluated credit risks with dynamic index data of different time and space.
Credit risk evaluation in continuous time is mostly combined with AI. The model simulates the thinking process of the human brain, and the data are processed instantly and dynamically by an optimized algorithm. Lim and Sohn [26] presented a dynamic neural network-based behavioral scoring model to replace the current static model. This minimizes the loss of bad debt as it dynamically accommodates the changes in borrowers’ characteristics after the loans are made. Jiang et al. [27] simulated the cognitive processes of the human brain by optimizing the case-based reasoning model (CBR) and dynamically constructing a consumer evaluation system.
2.4. Artificial Intelligence Models for Credit Risk Evaluation
An AI algorithm simulates the decision-making process of the human brain with high accuracy and flexibility through data processing and complex computing. In view of the current complexity and diversity of credit risk measurement methods, AI algorithms have been widely used in the field of credit risk evaluation.
Logistic regression (LR) is a widely used algorithm because it is efficient and easy to understand with high prediction accuracy. The 1980s witnessed the first applications of logistic regression in the fields of credit scoring. Wiginton [28], Bensic and Zekic [29] propounded that among many methods, logistic regression would be the most accurate and effective method for establishing a credit scoring model. Koh et al. [30] proposed that LR could be applied instead of discriminant analysis. A few researchers have focused on analyzing the default probability of SMEs by the LR method and applying the logistic scoring model to predict default probability [31,32]. However, some researchers have shown that the credit risk prediction accuracy ratio of LR is lower than that of the neural network method [6,33].
An artificial neural network simulates the thinking process of the human brain by constructing a large number of nodes, connecting them by different connection modes and processing the input data to simulate the neuron conduction mechanism of the human brain. Rong-Zhou et al. [34] evaluated 120 credit applicants by neural network and classified the lenders based on the evaluation results. It is suggested that the accuracy of credit risk evaluation with a neural network is higher than traditional methods. Khashman [35] evaluated and validated 24 numerical attributes of an enterprise by using a German credit dataset. The results suggested that the credit risk evaluation neural network model performed best under LS4 learning scheme, and the method could be used to process credit applications efficiently and automatically. Xiao-Bin et al. [36] applied several neural network models to evaluate Chinese SME credit risk, and the probabilistic neural network achieved the best performance. Zhao-Quan et al. [37] proposed a hedge fund downside risk evaluation model based on multi-objective neural network. Madjid et al. [38] applied an artificial neural network and Bayesian network model to assess bank liquidity risks. The results demonstrated the efficiency, accuracy and flexibility of data mining methods in bank liquidity risk measurement.
A Bayesian network that has been developed to be time-specific is known as a dynamic Bayesian network. It carries forward the advantage of a Bayesian network to establish causality under uncertain conditions and links multiple such networks adjacent to each other, so that credit risk can be analyzed and measured according to the time characteristics of the data. Based on the powerful capability of dealing with uncertainties, a Bayesian network can be applied for decision-making and credit risk evaluation. A Bayesian network is applied to construct the causal relationship between credit indicators, so as to evaluate the subject’s credit risks based on series indicators. Banachewicz et al. [39] introduced the model of a Markov chain into the measurement of portfolio credit risk and extended it to the corporate risk measure, which is analyzed and verified with data of US enterprises. Murphy [40] compared the Markov model with the dynamic Bayesian model and argued that the Markov model lacks expressiveness in describing variables, while the dynamic Bayesian model could decompose variables into factors and describe the process in detail.
A decision tree is a tree diagram used in determining the optimum course of action. It illustrates the choices available to decision makers, including associated risks, costs, outcomes, or probabilities. The first generation of decision tree dates back to 1963, Morgan and Soquis [41] proposed Automatic Interaction Detection (AID), which is the first regression tree algorithm. In the 1970s, Dichtomiser3 (ID3) algorithm was proposed as the second-generation decision tree, and contributed to the research in the following years. These include the widely used C4.5 and C5.0 [42]. Quinlan [43] published the C4.5 algorithm in 1993. C4.5 is one of the most popular and widely used algorithms in data mining and machine learning nowadays. Sheng-Gang et al. [44] applied a decision tree to screen evaluation indicators. In the paper, a double evaluation model is built with the combination of a decision tree and neutral network, which improves the credit risk prediction accuracy ratio.
Our paper selects four AI models, consisting of the decision tree, artificial neural network, Bayesian network and logistic regression, after allowing for the characteristics of the seller credit risks of e-commerce platforms. The comparison of the models is displayed in Table 1.
Current research mostly focuses on the credit rating effect of a single AI model. However, in the case of quite a few different seller data types and complex credit risks on an e-commerce platforms, a single credit risk evaluation method might have a low credit risk prediction accuracy ratio. The predictive performance of a single model can be improved when combined with other models. In our study, we will build a hybrid AI model that combines decision tree and other models. A decision tree can decompose data regarding data characteristics, construct a relationship tree structure and remove data with lower influencing factors by pruning, which is usually used for the first stage of data processing. In this case, it is also applicable for combining with other algorithms, such as a decision tree—dynamic Bayesian network combination, etc. Moreover, as the behavior of an e-commerce transaction subject is complex, and characterization of credit status by a single financial or operational indicator is difficult, it is necessary to collect a variety of comprehensive indicators. However, too many indicators would interfere with any machine learning algorithms and lead to excessive learning, which would reduce the accuracy of the evaluation. Therefore, a hybrid model that combines decision tree and other models will be applicable to seller credit risk evaluation on e-commerce platforms.
Overall, this literature review suggests that a hybrid AI model can be applied to credit risk prediction of sellers on e-commerce platforms. However, there are few articles in the literature comparing and analyzing the evaluation effects of different credit risk evaluation models and hybrid models. Meanwhile, the current research of credit risk evaluation based on AI model mainly focuses on individuals, such as peer-to-peer (P2P), family loan borrowers, etc. [24,45]. Few studies apply the dynamic credit risk evaluation model for e-commerce sellers. Based on the intelligent analysis, automatic learning and accurate recommendation, credit risk evaluation of e-commerce sellers needs to have the function of identifying the dynamic credit risk indicators and automatically updating the credit risk evaluation status. A hybrid AI model can provide a new perspective for improving credit risk prediction accuracy ratio of e-commerce sellers, and is advantageous to learn based on current data with self-learning program. Furthermore, it improves interpretability and overcomes the shortcoming of current models’ lack of dynamics.
3. Modeling
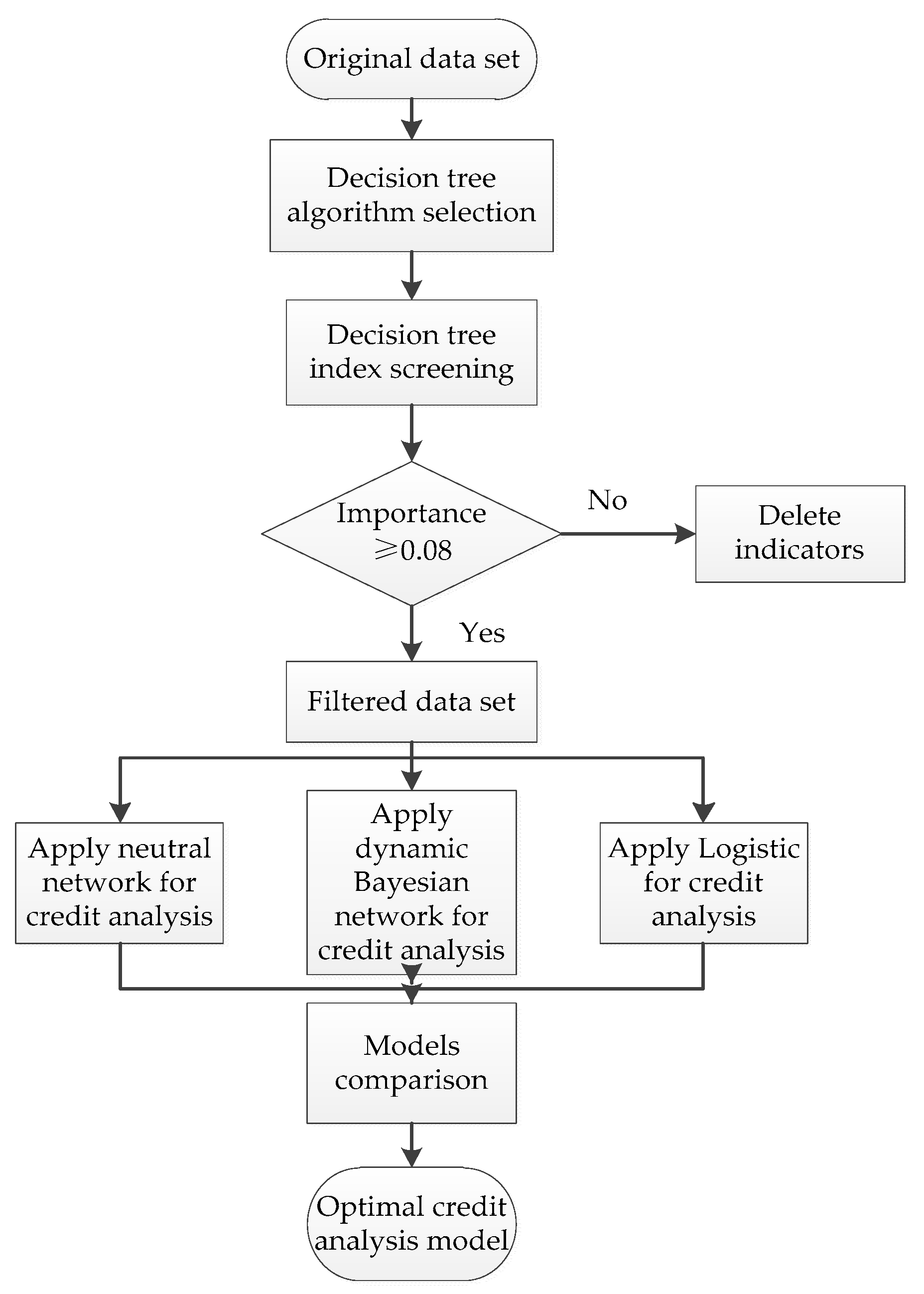
Our paper applies the tool of a decision tree to initially screen the indexes and evaluates the credit through the composition algorithms based on the characteristics of AI credit models and e-commerce platform sellers. Among them, frequently used decision tree algorithms include CHAID, CART, Quest and C5.0. By comparing several decision tree models, the model with the highest accuracy is selected to streamline the index system, followed by using simplified indexes for analysis. The data set selected by the decision tree is combined with an AI algorithm to form a combined model. Through comparison and screening of different models, the adopted combinatorial algorithms consist of the decision tree—ANN, decision tree—DBN and decision tree—LR. The specific process is shown in Figure 1.
Meanwhile, after allowing for the characteristics and requirements of intelligent transactions, the selection of the optimal credit risk evaluation model takes the following factors into consideration:
(1) Fitting degree
The fitting degree of the model is the most intuitive and effective index for evaluating the performance of the model, as well as being the most important factor regarding the choice of credit risk evaluation models. Based on the complexity of the machine learning model and the subject information appraisal, a more stereoscopic and diverse judgment method is presented, as follows:
① Total accuracy rate (TT + FF) / (TT + TF + FF + FT) × 100%
② Various error rate matrices
The class A error rate and the class B error rate are included, wherein the class A error is a misjudgment of good credit users as bad credit users, and the class B error is a misjudgment of bad credit users as good credit users:
Class A error rate = TF / (TT + TF + FF + FT)
Class B error rate = FT / (TT + TF + FF + FT)
③ Area under the curve (AUC) value
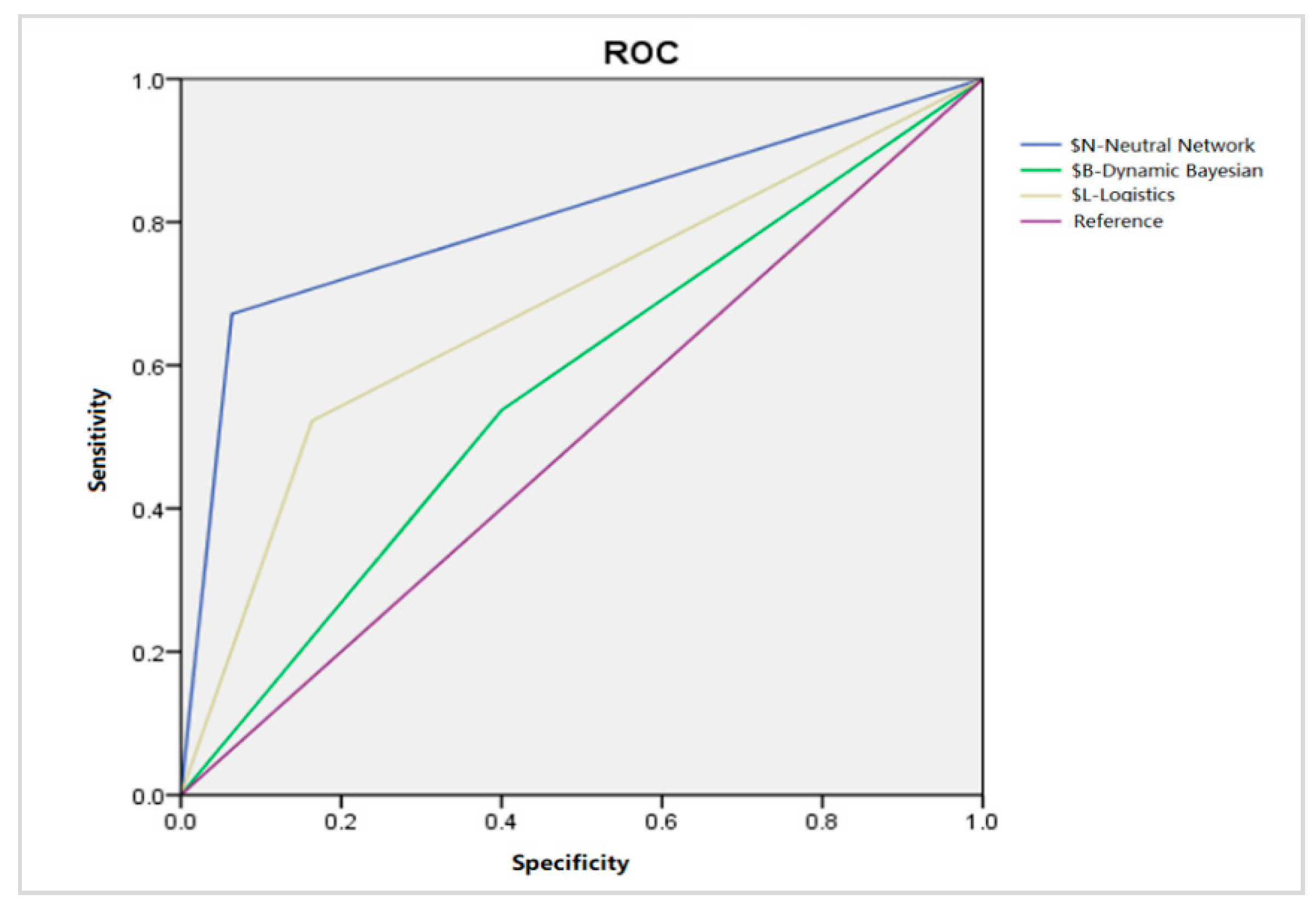
The receiver operating characteristic (ROC) curve is an important indicator to characterize the accuracy of the prediction model with the false positive rate (1-specificity) as abscissa and the true positive rate as ordinate (sensitivity). The closer the image is to the upper left, the higher the accuracy of the model. In order to more accurately characterize the ROC curve, the AUC value for the ROC curve is used to describe the accuracy of the model.
(2) Embodying the characteristics of platform transactions
Based on the characteristics of platform transactions, the selected credit risk evaluation model needs to meet the dynamic, intelligent and security requirements, that is, to be able to process data at different times, automatically identify the change of seller credit according to the change of data set, and carry out a certain judgement on the sellers’ credit level regarding the learning model.
(3) Explicable indicators
The indicators selected by the decision tree should have certain interpretability, which conforms to the logic of the e-commerce seller credit risk evaluation index system and plays a guiding role in the construction of the e-commerce seller credit risk evaluation system. Meanwhile, the excluded indicators have less influence on the seller’s credit risk evaluation. In principle, the indicators that closely correlated with seller credit, such as seller’s sales, review data and other indicators, should not be excluded.
(4) Rationality
The model needs to conform to the logic of credit risk evaluation process, so that the indicators that closely correlated with the seller’s credit will be selected, while the ones with less influential effect will be eliminated. Moreover, credit risks should be accurately judged through certain evaluation methods with intuitive and distinguishable results. Meanwhile, it is necessary to comply with the logic of the combined algorithms, while the accuracy is improved by combining the models, which shows that an AI algorithm could be improved and optimized through the combined model.
Based on the above evaluation criteria, we choose the model presenting the best performance after a few combination methods selected for comparative analysis. Meanwhile, it can be applied to the complex credit system of e-commerce platform sellers. Through the operation process of the model, the e-commerce platform and consumers will accurately identify the seller’s credit risks, and the indicators can provide a reference for the seller to improve service quality.
4. Empirical Analysis
4.1. Data Sets and Experimental Setup
Our paper uses the credit data of Taobao sellers. Taobao is the largest consumer-to-consumer (C2C) e-commerce platform in China. The credit dataset contains 609 firms, and the original data has a mix of 23 numerical and categorical attributes, including platform entry indicators, such as business license, regional information, consumer security deposit and Alipay personal certification, etc.; operation level indicators, such as the number of goods, main business share, buyer credit score, number of evaluators, operating years, etc.; commodity quality indicators, such as goods and description compatibility, after sales rate within 30 days, evaluation rate within 30 days and evaluation rate within half a year; and service level indicators, such as seller’s service attitude, logistics service quality, dispute rate within 30 days, etc. The categorical attributes are transformed into numerical ones, for example, business license and regional information integrity are coded as 0 or 1; while other numerical attributes, such as buyer credit score and number of evaluators retain the original data value. The last attribute classifies the sellers as good or bad credit. It consists of 259 sellers with good credit and 350 sellers with bad credit.
We will apply IBM SPSS Modeler 18.0 to conduct the experiment. The software automatic classifier model will be used to select the decision tree algorithm. We will include CHAID, C5.0, C&R and Quest to compare the results of the decision tree algorithms. All algorithms will be evaluated as measured by accuracy and gain ratio. Based on the accuracy ratio and gain ratio, an optimal decision tree method will be selected for the preliminary index screening.
Because our purpose is to find a model that would improve the credit risk prediction accuracy ratio, as well as easy to interpret and user friendly, we will build a hybrid model that combines the decision tree and other AI models. A variety of models will be selected in IBM SPSS Modeler for comparison and screening, such as support-vector machines (SVM), random forest algorithms, artificial neural networks, dynamic Bayesian networks, logistic regression, etc. Based on the accuracy ratio and gain ratio, three models will be selected. We will build three hybrid AI models combining decision tree and selected models.
In the process of the preliminary index screening, the indicators selected by the decision tree should have certain interpretability, which conforms to the logic of the e-commerce seller credit risk index system. In principle, the indicators that closely correlated with the seller’s credit will be selected, while the ones with less influential effect will be eliminated. After preliminary index screening from the decision tree, the reduced attributes will be selected to form a new dataset. The dataset is split into two subsets in our work, 70% training set and 30% testing set. Three hybrid AI models will be used to calculate the data set and each model will be performed five times. Also, the results of models will also be compared with those without index screening. Furthermore, we will use a cross-validation approach on each model to test for overfitting.
4.2. Experimental Results and Comparisons
The results of decision tree algorithms, including CHAID, C5.0, C&R and Quest, were obtained using IBM SPSS Modeler 18.0. The software automatic classifier model was used to compare the decision tree algorithms. The results are shown in Table 2:
Based on the accuracy and gain ratio, the C5.0 decision tree algorithm performed better than that of CHAID, C&R Tree and Quest. Meanwhile, C5.0 uses the information gain ratio as a measure index, which can avoid the interference of e-commerce sellers’ own data characteristics on machine learning results. It also has high accuracy and is regarded as a comparatively applicable index selection method for intelligent transactions. Furthermore, the results in our work have shown that the AUC value of C5.0 is highest among the four decision tree models. AUC is a numerical value, and the classifier corresponding to the larger AUC works better. Hence, C5.0 was selected for preliminary screening of indicators.
In order to build a hybrid model that combines the decision tree and AI model, we adopted a variety of models in IBM SPSS Modeler for comparison and screening, such as support-vector machines (SVM), random forest algorithms, etc. The results show that the three methods, including artificial neural networks, dynamic Bayesian networks and logistic regression, have high accuracy with the overall rate above 70%. The results are shown in Table 3.
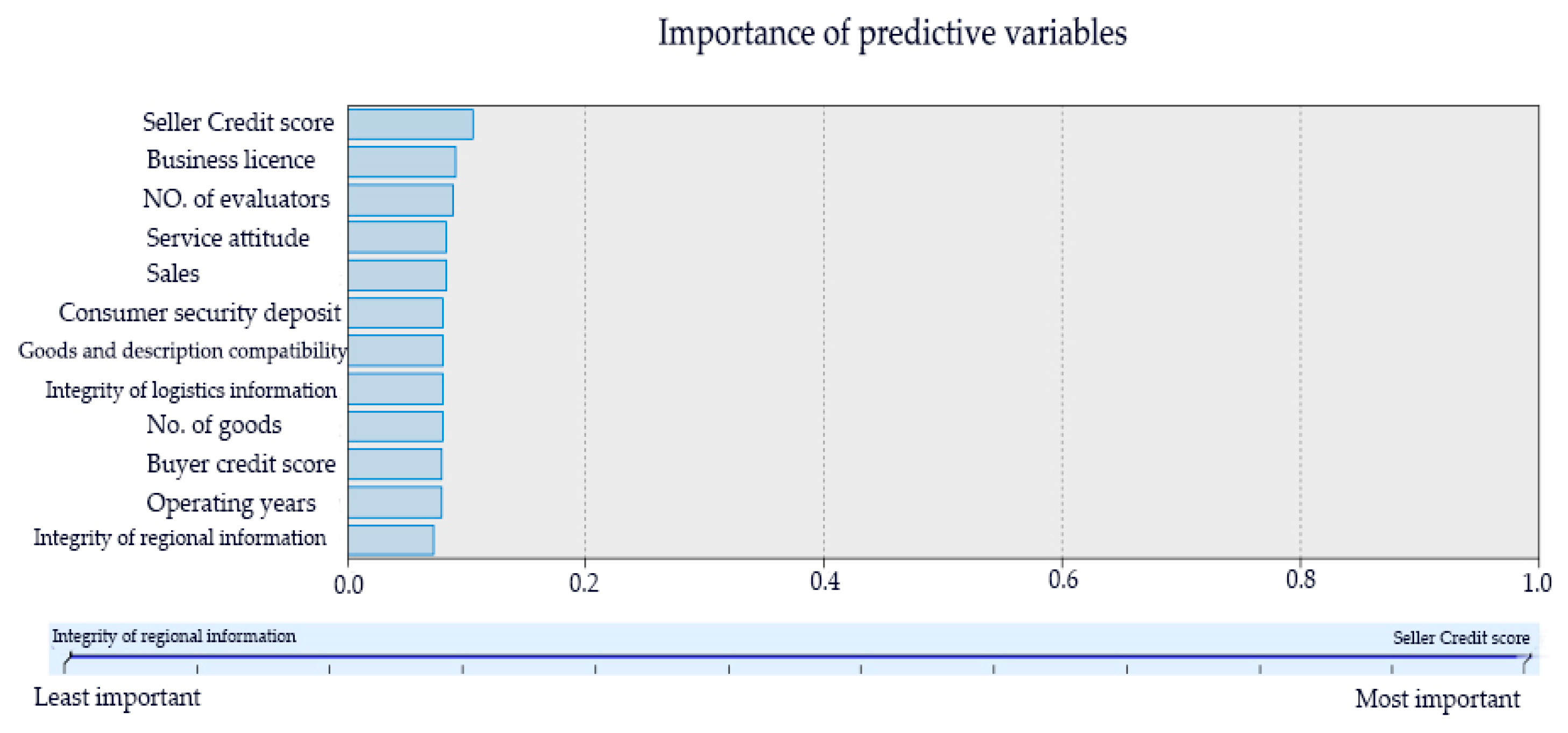
We applied the C5.0 decision tree for index screening. By adjusting boosting iteration times and selecting the optimal decision tree, a decision tree with 25 iterations was finally obtained with the accuracy rate of 97.09%. The iteration and accuracy are shown in Table 4 below. According to the characteristics of the decision tree, we selected the indicators that have an influence on the results and rejected the indicators with low impact on credit risk evaluation. We finally got 12 indicators, that is, seller credit score, business license, number of evaluators, service attitude, sales, consumer security deposit, operating years, goods and description compatibility, logistics service quality, regional information integrity, buyer credit score and number of goods. The selected 12 indicators are shown in Figure 2 below. The indicators selected by the decision tree include both financial information and soft information of the sellers on Taobao.
The data corresponding to the 12 indicators constitute a new dataset, and the learning scheme uses a ratio of (70:30). The first 70% of cases are selected as the training set, while the remaining 30% are not exposed to the model during training, as they will be used to test upon completion of training. We built three hybrid AI models, including decision tree—artificial neutral network (ANN), decision tree—logistic regression (LR), and decision tree—dynamic Bayesian network (DBN), and each model was performed five times. Moreover, the results were also compared with those without index screening. Among them, the result and comparison of the decision tree—Artificial Neural Network model are shown in Table 5.
The results and comparison of the decision tree—logistic regression model are shown in Table 6.
The results and comparison of the decision tree—dynamic Bayesian network regression model are shown in Table 7.
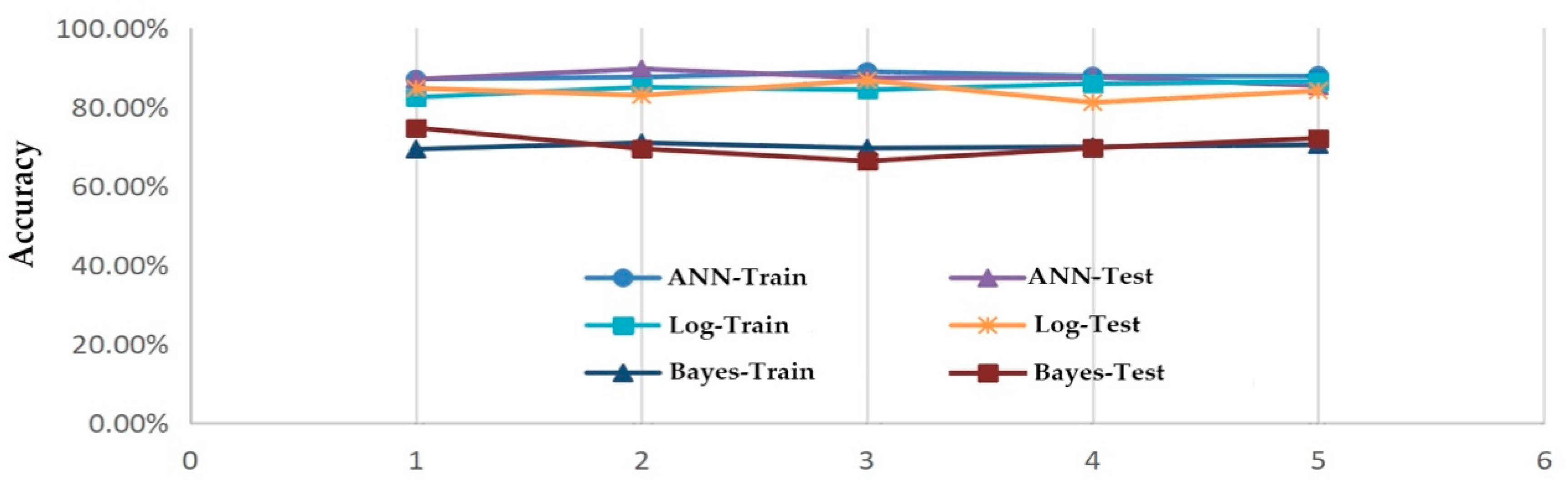
Figure 3 demonstrates the data in the table above.
It can be seen from the graphs that the prediction accuracy ratio of a decision tree—ANN is higher than the other two methods. At the same time, the running result data was plotted as the ROC curve, as shown below (Figure 4), and the AUC value was obtained. The AUC value of ANN, DBN and Logistics are shown in Table 8, and it is concluded that the AUC value of ANN is significantly higher than that of DBN and LR.
Furthermore, we used cross-validation approach on three models to ensure the findings are not due to overfitting. The sample size in our work is a bit small. As artificial intelligence systems are “trained” rather than programmed, various processes usually require a large amount of tag data to perform complex tasks accurately. However, getting large data sets would be difficult. In order to enhance the reliability of our study, instead of using a 70/30 split of the sample for training and testing, we used cross-validation approach on each model to test for overfitting.
We split the sample into 10 subsamples and ran the train/test process 10 times. For example, in the first iteration, the 10th subsample would be the testing fold, while the first nine are training folds; in the second iteration, the 9th subsample would be the testing fold, while the other nine (1st–8th, and 10th) are training folds;, etc. The average of the 10 results is used as the final result. The average prediction accuracy ratio of decision tree—ANN, decision tree—DBN and decision tree—LR are 0.85, 0.80 and 0.72, respectively. It is concluded that the decision tree—ANN presents the best performance with the highest prediction accuracy ratio among the three models. The results are consistent with previous results.
4.3. Discussion
From the experimental results of the three models, we find that the combination model of a decision tree—ANN has the highest accuracy in credit risk evaluation, followed by the decision tree—LR model. The accuracy of the decision tree—DBN is lowest. Also, it has to be noted that after the preliminary index screening from the decision tree, we finally got 12 indicators. The indicators selected by the decision tree are closely correlated with seller credit, and have certain interpretability which conforms to the logic of the e-commerce seller credit risk index system and plays a guiding role in the construction of the seller credit risk index system. Not only financial information, but also soft information was included in the selected indicators, as researchers have shown that financial institutions rely on soft information to evaluate the credibility of small enterprises [6,7,8]. Meanwhile, through the comparison of the accuracy before and after index screening, we conclude that applying a decision tree to select indicators can improve the accuracy of a neural network to a certain extent and significantly improve the accuracy of logistic regression. The reason for improving the accuracy is that through the preliminary index screening, weakly correlated indicators have been deleted for logistic regression and the neural network. Hence, unnecessary calculation redundancy is reduced, which boosts model learning and reduces the probability of excessive learning, thus, improving the accuracy of the model. Although the difference between ‘before’ and ‘after’ for the neural network might seem small, it has to be noted that small improvement in accuracy may be large enough to have commercial implication. However, the accuracy of dynamic Bayesian network is lowered after index screening. As the principle of a dynamic Bayesian network model is to construct the relationship network of indicators, the streamlining of indicators may breakdown the network architecture, which reduces the accuracy of the model.
Based on the comparison of total accuracy rate, error rate matrix and AUC value, it can be concluded that the combination model of a decision tree—ANN has higher credit risk prediction accuracy rate, lower error rate and higher AUC value. The model can automatically learn from the seller’s historical data and current data to form a mental model similar to the human brain, and achieve the results accurately. We conclude by saying that a decision tree—ANN model is an effective and powerful tool which allows us to build an advanced and user-friendly system for credit risk evaluation on the Taobao platform.
While the proposed decision tree—ANN model is a user-friendly model with high credit risk prediction accuracy ratio, it is not necessary for the optimal model to evaluate credit risks. In our work, the combination of two models has been investigated, while other more complex models have not been tried to compare the performance. However, more complex models make it difficult to explain how and why a decision is made (and more difficult in making decisions in real life). This is one of the reasons why some artificial intelligence tools are still not applied in real life where interpretation is important or really needed.
Furthermore, AI technology is regarded as a ‘black box’. Users sometimes need to know the “reasons” behind the technology, such as why algorithms can provide recommendations for business decision making (such as loans), and why certain factors (rather than others) are important in particular situations. There are also other issues concerning AI, such as legitimacy of big data behind AI, ‘over-fit’ (over-coupling of machine learning and learning data) problem in the process of artificial intelligent system, etc. Therefore, relying too much on AI technology is not appropriate. There is no denying that in the field of credit risk evaluation, artificial intelligence technology can improve the credit risk prediction accuracy ratio, and achieve high efficiency and intelligence. However, we should pay attention to the foundation of credit risk evaluation theory and the rationality and logic of credit risk evaluation instead of blindly pursuing efficiency and technological innovation.
5. Conclusions
In the mode of C2C or B2C e-commerce, because of the increased degree of information asymmetry and frequent occurrence of internet fraud, the credit problem has ever been the biggest obstacle in e-commerce development. Our paper studies the process of credit risk evaluation and how advances in technology are changing this process. Specifically, we use data from Taobao to assess several approaches to evaluate seller credit and aims to explore an improved credit risk evaluation model. A hybrid AI algorithm was applied to evaluate the seller credit risks of e-commerce platforms. We learn from the empirical result that a single learning model can be improved when combined with other models. Three hybrid models, including decision tree—ANN, decision tree—LR and decision tree—DBN, have been investigated, and comparison among their implementation results have been provided. It is concluded that the prediction performance of decision tree—ANN model is better than that of decision tree—LR, decision tree—DBN and single ANN, LR, DBN models in evaluating the credit risk of sellers on the Taobao platform. The decision tree—ANN model is regarded as an effective and powerful tool which allows us to build an advanced and user-friendly system for credit risk evaluation. The improvement of dynamic seller credit risk evaluation can promote healthy and fast transactions between buyers and sellers on the platforms, improve consumer satisfaction and create a healthy e-commerce environment.
This paper provides insights for practitioners. First of all, technology and consumption upgrade is creating demand for high quality goods and creditworthy sellers. The advanced credit risk evaluation model can dynamically and accurately assess the credibility of SMEs on the e-commerce platform. Once SMEs are proved to have a higher credit rating, they can have more capital and development opportunities. Secondly, the emergence of internet provides great convenience for information exchange and transmission, however, the virtual nature and openness of the Internet also make e-commerce lack of trust. Information asymmetry and lack of trust between sellers and buyers are factors that result in many problems like low quality goods and fake goods. Establishing a reliable credit risk evaluation system is necessary to reduce information asymmetry and increase trust between sellers and buyers. With the sharing information of the credit status of SMEs, the buyers, as well as business partners, can choose more professional and qualified SMEs. Lastly, credit risk evaluation is the key ingredient for the healthy development of the e-commerce ecosystem, and a necessary part of building e-commerce platform competitive advantages. The improved credit risk evaluation model can serve as a reference for policy makers to enhance the health and sustainability of the entire e-commerce ecosystem.
There are limitations to this paper, as follows. According to the evaluation results, it shows that there are many factors influencing the seller’s credit level, including the seller’s service level, operating level and financial status. Therefore, an e-commerce platform should take full account of the seller’s comprehensive indices when evaluating the seller’s credit risks. A comprehensive and dynamic evaluation of the seller’s credit risks, and a detailed assessment of the seller’s qualifications should be taken in order to reduce credit risk and create a good e-commerce transaction environment. However, as sellers of e-commerce platforms did not make financial information available to the public, the selected indicators may not be comprehensive and sufficient. Moreover, the credit dataset in our work contains 609 firms. As the sample is a bit small, we used cross-validation approach on three models to test for overfitting. However, human biases need to be controlled, or else cross validation will not be fruitful.
While the dynamic credit risk evaluation method proposed in this paper is applied to Taobao sellers, we can also apply a hybrid AI model to carryout empirical studies of other e-commerce platforms. Whether the conclusion in this paper is applicable to other platforms, need to be investigated for the future study. Furthermore, it would be interesting to apply the suggested approach to other interesting problems; e.g., dynamic evaluation of the performance of government or enterprises, and dynamic evaluation of regional economic development based on a hybrid AI model. The authors will follow up these issues in a future study.
Author Contributions
All authors discussed and agreed on the ideas and scientific contributions. Y.-Z.X., J.-L.Z. and L.-Y.W. contributed to the literature review, modelling, results, and analysis; Y.-Z.X. and Y.H. wrote the manuscript based on the idea; J.-L.Z., Y.H. and Y.-Z.X. contributed to the revision.
Funding
The authors would like to thank Zhejiang Federation of Humanities and Social Sciences Circles (ZJFHSSC) of China for financially supporting this research under Contract No.2018Z10.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Beaver, W.H. Financial Ratios as Predictors of Failure. J. Account. Res. 1966, 4, 71–111. [Google Scholar] [CrossRef]
- Horrigan, J.O. The Determination of Long-Term Credit Standing with Financial Ratios. J. Account. Res. 1966, 4, 44–62. [Google Scholar] [CrossRef]
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Edmister, R.O. An Empirical Test of Financial Ratio Analysis for Small Business Failure Prediction. J. Financ. Quant. Anal. 1972, 7, 1477–1493. [Google Scholar] [CrossRef]
- Martin, D. Early warning of bank failure: A logit regression approach. J. Bank. Financ. 1977, 1, 249–276. [Google Scholar] [CrossRef]
- Raghuram, G.R. Insiders and outsiders: the choice between informed and arm’s length debt. J. Financ. 1992, 47, 1367–1400. [Google Scholar]
- Mitchell, A.P.; Raghuram, G.R. The benefits of lending relationships: Evidence from small business data. J. Financ. 1994, 49, 3–37. [Google Scholar]
- Meyer, L.H. The Present and Future Roles of Banks in Small Business Finance. J. Bank. Financ. 1998, 22, 1109–1116. [Google Scholar] [CrossRef]
- Berger, A.N.; Udell, G.F. Relationship lending and lines of credit in small firm finance. J. Bus. 1995, 68, 351–382. [Google Scholar] [CrossRef]
- Dennis, C.; Maria, L.; Regina, W.M. Making Sense of Soft Information: Interpretation Bias and Loan Quality. J. Accont. Econ. 2019. [Google Scholar] [CrossRef]
- Allen N., B.; Gregory, F.U. A more complete conceptual framework for SME finance. J. Bank. Financ. 2006, 30, 2945–2966. [Google Scholar]
- Messier, W.F.; Hansen, J.V. Inducing Rules for Expert System Development: An Example Using Default and Bankruptcy Data. Manag. Sci. 1988, 34, 1403–1415. [Google Scholar] [CrossRef]
- Odom, M.D.; Sharda, R.A. Neural network for bankruptcy prediction. Proceedings of International Joint Conference on Neural Network, San Diego, CA, USA, 17–21 June 2000; pp. 163–168. [Google Scholar]
- Desai, V.S.; Crook, J.N.; Overstreet, G.A., Jr. A comparison of neural networks and linear scoring models in the credit union environment. Eur. J. Oper. Res. 1996, 95, 24–37. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.; Hsu, C.J.; Chen, W.H.; Wu, S. Credit rating analysis with support vector machines and neural networks: a market comparative study. Decis. Suppot. Syst. 2004, 37, 543–558. [Google Scholar] [CrossRef]
- Fantazzini, D.; Figini, S. Random Survival Forests Models for SME Credit Risk Measurement. Methodol. Comput. Appl. 2009, 11, 9–45. [Google Scholar] [CrossRef]
- Sohn, S.; Jeon, A.H. Competing Risk Model for Technology Credit Fund for Small and Medium-Sized Enterprises. J. Small. Bus. Manag. 2010, 48, 378–394. [Google Scholar] [CrossRef]
- Ono, A.; Hasumi, R.; Hirata, H. Differentiated Use of Small Business Credit Scoring by Relationship Lenders and Transactional Lenders: Evidence from Firm-Bank Matched Data in Japan. J. Bank. Financ. 2014, 42, 371–380. [Google Scholar] [CrossRef]
- Bart, B.; Rudy, S.; Christophe, M.; Jan, V. Using Neural Network Rule Extraction and Decision Tables for Credit-Risk Evaluation. Manag. Sci. 2003, 49, 312–329. [Google Scholar] [Green Version]
- You, Z.; Chi, X.; Bo, S.; Gang-Jin, W.; Xin-Guo, Y. Predicting China’s SME Credit Risk in Supply Chain Financing by Logistic Regression, Artificial Neural Network and Hybrid Models. Sustainability 2016, 8, 433. [Google Scholar]
- Chia-Chen, Y.; Shang-Ling, O.; Li-Chang, H. A Hybrid Multi-Criteria Decision-Making Model for Evaluating Companies’ Green Credit Rating. Sustainability 2019, 11, 1506. [Google Scholar]
- Abdul-Rahman, A.; Hails, S. Supporting trust in virtual communities. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2000; 2000; pp. 1–9. [Google Scholar]
- Bielecki, T.R.; Cialenco, I.; Pitera, M. Dynamic limit growth indices in discrete time. Stoch. Models 2013, 31, 494–523. [Google Scholar] [CrossRef]
- Yu, Z.; Zhu, J.; Shen, G.; Liu, G. Trust Management in peer-to-peer Networks. J. Softw. 2014, 9, 1062–1078. [Google Scholar] [CrossRef]
- Yan, B.W. Construction of Seller Credit Evaluation Model of E-commerce Platform from the Perspective of Dynamic Transaction Events. J. E. Bus. 2017, 12, 55–57. [Google Scholar]
- Lim, M.K.; Sohn, S.Y. Cluster-based dynamic scoring model. Expert. Syst. Appl. 2007, 32, 427–431. [Google Scholar] [CrossRef]
- Jiang, M.H.; Xu, P.; Ren, X.; Che, K. Development of Personal Credit Scoring Model and Analysis of Optimization Algorithms. J. H.I.T. 2015, 47, 40–45. [Google Scholar]
- Wiginton, J.C. A Note on the Comparison of Logit and Discriminant Models of Consumer Credit Behavior. J. Financ. Quant. Anal. 1980, 15, 757–771. [Google Scholar] [CrossRef]
- Mirta, B.; Natas, S.; Marijana, Z.S. Modelling Small-business Credit Scoring by Using Logistic Regression, Neural Networks and Decision Trees. Int. J. Intell. Syst. Account. Financ. Manag. 2005, 3, 133–150. [Google Scholar]
- Koh, H.C.; Tan, W.C.; Goh, C.P. A Two-step Method to Construct Credit Scoring Models with Data Mining Techniques. Int. J. Bus. Inform. 2004, 1, 96–118. [Google Scholar]
- Pederzoli, C.; Torricelli, C. A parsimonious default prediction model for Italian SMEs. Banks Bank Syst. 2010, 5, 28–32. [Google Scholar]
- Pederzoli, C.; Thoma, G.C. Modelling credit risk for innovative firms: The role of innovation measures. J. Financ. Serv. Res. 2013, 44, 111–129. [Google Scholar] [CrossRef]
- Lee, T.S.; Chen, I.F. A two-stage hybrid credit scoring model using artificial neural networks and multivariate adaptive regression splines. Expert Syst. Appl. 2005, 28, 743–752. [Google Scholar] [CrossRef]
- Li, R.; Pang, S.; Xu, J. Neural network credit-risk evaluation model based on back-propagation algorithm. In Proceedings of the International Conference on Machine Learning and Cybernetics, Beijing, China, 4–5 November 2002; pp. 1702–1706. [Google Scholar]
- Khashman, A. Neural networks for credit risk evaluation: Investigation of different neural models and learning schemes. Expert. Syst. Appl. 2010, 37, 6233–6239. [Google Scholar] [CrossRef]
- Xiao-Bing, H.; Xiao-Lian, L.; Yuan-Qian, R. Enterprise credit risk evaluation based on neural network algorithm. Cogn. Syst. Res. 2018, 52, 317–324. [Google Scholar]
- Zhao-Quan, C.; Guang-Cai, C.; Li-Ning, X.; Jing-Hui, Y.; Xu, T. Evaluating hedge fund downside risk using a multi-objective neural network. J. Vis. Commun. Image. R. 2019, 59, 433–438. [Google Scholar]
- Madjia, T.; Amir-Reza, A.; Debora, D.C.; Maryam, P. An artificial neural network and Bayesian network model for liquidity risk assessment in banking. Neurocomputing 2018, 275, 2525–2554. [Google Scholar]
- Banachewicz, K.; Lucas, A.; Van-Der-Vaart, A. Modelling Portfolio Defaults Using Hidden Markov Models with Covariates. Economet. J. 2008, 11, 155–171. [Google Scholar] [CrossRef]
- Murphy, K.P. Dynamic Bayesian Networks: Representation. Inference and Learning. Ph.D. thesis, University of California, Berkeley, CA, USA, 2002. [Google Scholar]
- Morgan, J.N.; Sonquist, J.A. Problems in the analysis of survey data, and a proposal. J. Am. Stat. Assoc. 1963, 58, 415–434. [Google Scholar] [CrossRef]
- Quinlan, J. Discovering Rules form Large Collections of Examples: A Case Study; Expert Systems in the Micro Electronic Age Edinburgh Press: Edingburgh, UK, 1979. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993. [Google Scholar]
- Yang, S.G.; Zhu, Q.; Cheng, C. Construction of Personal Credit Assessment Portfolio Model Based on Decision Tree-Neural Network. Fin. Forum. 2013, 18, 57–61. [Google Scholar]
- Hai-Feng, L.; Yue-Jin, Z.; Ning, Z. Evaluating the well-qualified borrowers from PaiPaiDai. Inform. Technol. Quant. Manag. 2017, 122, 775–779. [Google Scholar]
Figure 1.
Flow chart of credit risk evaluation hybrid model.

Figure 2.
C5.0 decision tree index screening result.

Figure 3.
Accuracy comparison of the three models.

Figure 4.
Receiver operating characteristic (ROC) figure.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison of credit risk evaluation models.
| Model | Decision Tree | Artificial Neural Network | Dynamic Bayesian | Logistic Regression |
|---|---|---|---|---|
| Theory | Classification and regression | Error back propagation algorithm | Total probability and inverse probability | Binary probability prediction |
| Application | Risk decision with uncertain probability | Recommendation system, image recognition and regression analysis | Uncertainty test, decision risk and reliability analysis | Separable discriminant analysis |
| Advantages | Easy to understand and interpret, insensitive to missing value and complex data, preprocessing of data is not required. | With self-learning function, it can learn based on current data and predict the future, the operation is fast, and the optimal solution is quickly obtained. | It can well describe and interpret the relationship between data, as well as variables. | High efficiency and accuracy, easy to interpret, no pre-processing required. |
| Disadvantages | It is difficult to predict continuous fields. The prediction accuracy would decrease with too many data types, so it could not well analyze characteristics of seller credit on e-commerce platforms. | Black-box operation results in poor interpretability. When data are insufficient, they cannot be manipulated. | Data smoothing is required, and the accuracy might be questionable. | It cannot solve the non-linear problem and has a high dependence on data. |
Table 2.
Accuracy of decision tree algorithms.
| Model | Maximum Profit | Maximum Profit Occurrence Ratio (%) | Gain Ratio (Top 30%) | AUC (Area Under Curve) | Overall Accuracy (%) |
|---|---|---|---|---|---|
| C5.0 | 1107 | 43 | 2.175 | 0.965 | 93.924 |
| CHAID | 940 | 46 | 2.158 | 0.947 | 88.342 |
| C&R Tree | 935 | 41 | 2.143 | 0.926 | 88.177 |
| Quest | 846.557 | 37 | 2.075 | 0.85 | 85.386 |
Table 3.
Accuracy of three AI models. AUC, area under the curve; ANN, artificial neural network; DBN, dynamic Bayesian networks.
Table 3.
Accuracy of three AI models. AUC, area under the curve; ANN, artificial neural network; DBN, dynamic Bayesian networks.
| Model | Maximum Profit | Maximum Profit Occurrence Ratio(%) | Gain Ratio (Top 30%) | AUC | Overall Accuracy (%) |
|---|---|---|---|---|---|
| ANN | 915 | 40 | 2.181 | 0.939 | 88.864 |
| Logistic | 725 | 39 | 2.014 | 0.892 | 79.803 |
| DBN | 455 | 37 | 1.757 | 0.806 | 71.921 |
Table 4.
Comparison of C5.0 decision tree parameter.
| Boosting Iteration Times | 15 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|
| A error rate | 4.348% | 7.692% | 4.412% | 8.333% | 6.41% | 1.389% |
| B error rate | 2.913% | 0 | 2.299% | 5.556% | 7.368% | 8.696% |
| Overall accuracy | 93.75% | 94.09% | 97.09% | 95.76% | 95.88% | 94.94% |
Table 5.
Artificial neutral network (ANN) operation result.
| 1 | 2 | 3 | 4 | 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Set | Test Set | Train Set | Test Set | Train Set | Test Set | Train Set | Test Set | Training Set | Test Set | ||
| After | A error rate | 15.41% | 15.39% | 16.17% | 13.79% | 15.44% | 9.04% | 15.27% | 13.97% | 17.17% | 14.68% |
| B error rate | 10.07% | 7.24% | 12.26% | 14.71% | 11.05% | 3.51% | 12.18% | 6.25% | 12% | 3.93% | |
| Overall accuracy | 87.05% | 87.01% | 87.56% | 89.62% | 88.95% | 87.36% | 87.82% | 87.57% | 88% | 85.33% | |
| Before | A error rate | 14.17% | 12.87% | 13.03% | 10.28% | 15.39% | 10.71% | 13.83% | 17.82% | 13.11% | 12.74% |
| B error rate | 16.28% | 19.44% | 14.12% | 22.97% | 13.51% | 18.84% | 15.47% | 19.34% | 15.32% | 15.17% | |
| Overall accuracy | 83.75% | 82.29% | 85.22% | 81.10% | 84.47% | 84.94% | 84.86% | 79.78% | 84.52% | 84.10% | |
Table 6.
Logistic regression (LR) operation result.
| 1 | 2 | 3 | 4 | 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train set | Test set | Train set | Test set | Train set | Testset | Train set | Test set | Train set | Test set | ||
| After | A error rate | 15.85% | 6.17% | 17.12% | 17.39% | 16.85% | 15% | 18.08% | 23.77% | 17.92% | 21.30% |
| B error rate | 11.95% | 13.59% | 12.90% | 22.58% | 14.47% | 14.93% | 11.88% | 16.67% | 13.02% | 14.52% | |
| Overall accuracy | 82.45% | 84.71% | 84.98% | 82.93% | 84.32% | 86.74% | 85.85% | 81.11% | 86.43% | 84.09% | |
| Before | A error rate | 26.77% | 25.93% | 29.51% | 21.95% | 26.23% | 20.29% | 28.04% | 29.87% | 27.57% | 20.29% |
| B error rate | 39.26% | 32.41% | 30.45% | 36.44% | 33.06% | 34.95% | 34.19% | 26.53% | 34.14% | 35.92% | |
| Overall accuracy | 68.25% | 68.68% | 70.18% | 70.22% | 69.17% | 74.57% | 67.54% | 70.29% | 71.26% | 70% | |
Table 7.
Dynamic Bayesian network (DBN) operation result.
| 1 | 2 | 3 | 4 | 5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Train Set | Test Set | Train Set | Test Set | Train Set | Test Set | Train Set | Test Set | Train Set | Test Set | ||
| After | A error rate | 34.29% | 32.03% | 29.28% | 29% | 31.56% | 25.36% | 29% | 25.85% | 31.35% | 24.44% |
| B error rate | 23.72% | 23.08% | 21.19% | 26.96% | 25.40% | 26.67% | 28.81% | 22.22% | 23.02% | 22.92% | |
| Overall accuracy | 69.32% | 74.71% | 70.94% | 69.44% | 69.56% | 66.30% | 69.89% | 69.61% | 70.44% | 72.11% | |
| Before | A error rate | 18.44% | 20.48% | 18.64% | 20.79% | 22.22% | 26.14% | 21.01% | 22.12% | 20.25% | 16.33% |
| B error rate | 39.07% | 26.14% | 29.35% | 23.36% | 27.75% | 16.38% | 28.27% | 22.22% | 27.98% | 29.55% | |
| Overall accuracy | 76.04% | 79.72% | 74.18% | 73.45% | 75.06% | 76.61% | 75.54% | 76.14% | 76.52% | 76% | |
Table 8.
AUC Comparison.
| Models | AUC | S.E. |
|---|---|---|
| ANN(N) | 0.804 | 0.038 |
| DBN(B) | 0.569 | 0.045 |
| Logistics (L) | 0.679 | 0.043 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Xu, Y.-Z.; Zhang, J.-L.; Hua, Y.; Wang, L.-Y. Dynamic Credit Risk Evaluation Method for E-Commerce Sellers Based on a Hybrid Artificial Intelligence Model. Sustainability 2019, 11, 5521. https://0-doi-org.brum.beds.ac.uk/10.3390/su11195521
AMA Style
Xu Y-Z, Zhang J-L, Hua Y, Wang L-Y. Dynamic Credit Risk Evaluation Method for E-Commerce Sellers Based on a Hybrid Artificial Intelligence Model. Sustainability. 2019; 11(19):5521. https://0-doi-org.brum.beds.ac.uk/10.3390/su11195521
Chicago/Turabian StyleXu, Yao-Zhi, Jian-Lin Zhang, Ying Hua, and Lin-Yue Wang. 2019. "Dynamic Credit Risk Evaluation Method for E-Commerce Sellers Based on a Hybrid Artificial Intelligence Model" Sustainability 11, no. 19: 5521. https://0-doi-org.brum.beds.ac.uk/10.3390/su11195521
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.