A Novel Intelligence Approach of a Sequential Minimal Optimization-Based Support Vector Machine for Landslide Susceptibility Mapping

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Data Acquisition
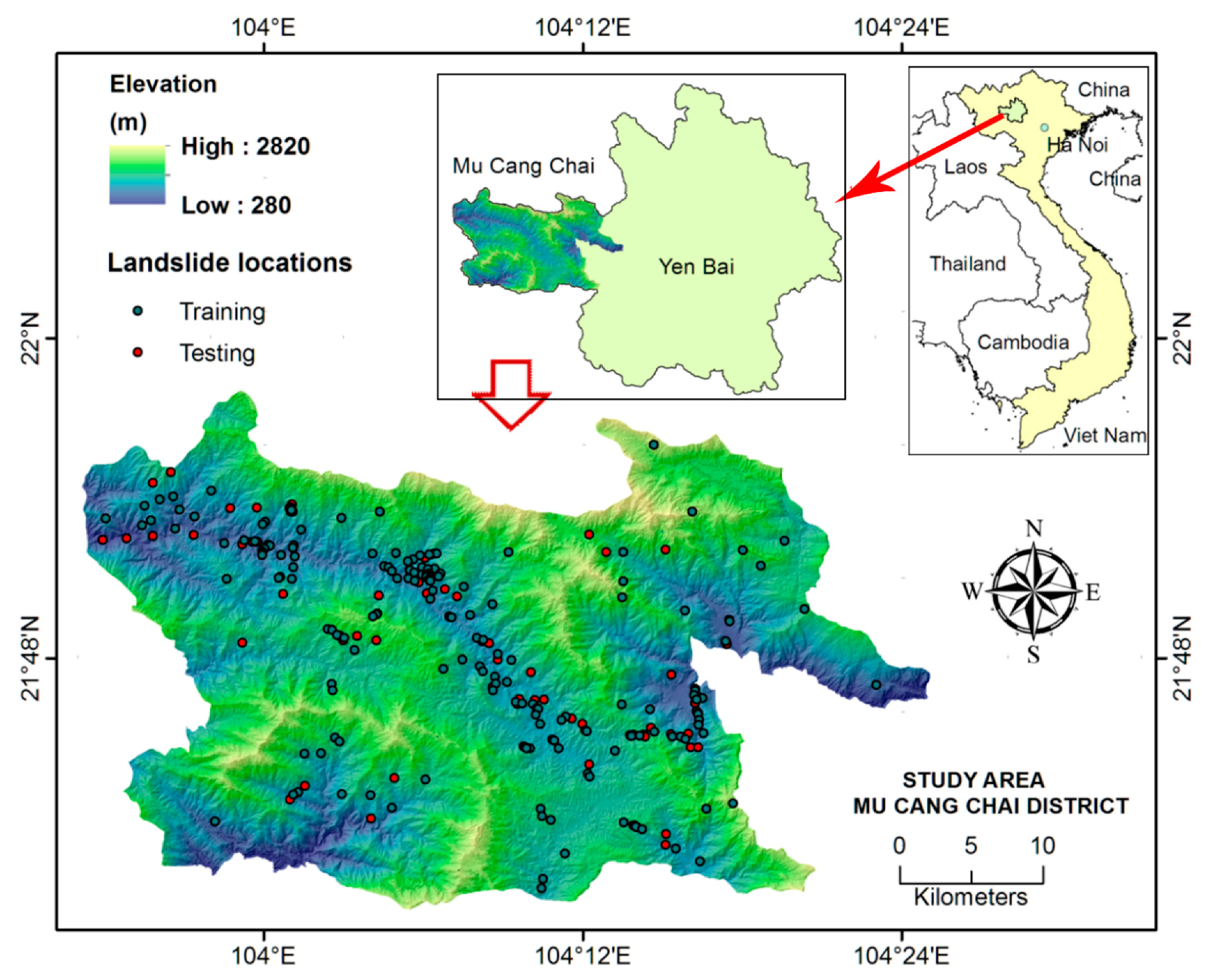
2.1. Description of the Study Area
2.2. Data Acquisition and Analysis
2.2.1. Landslide locations
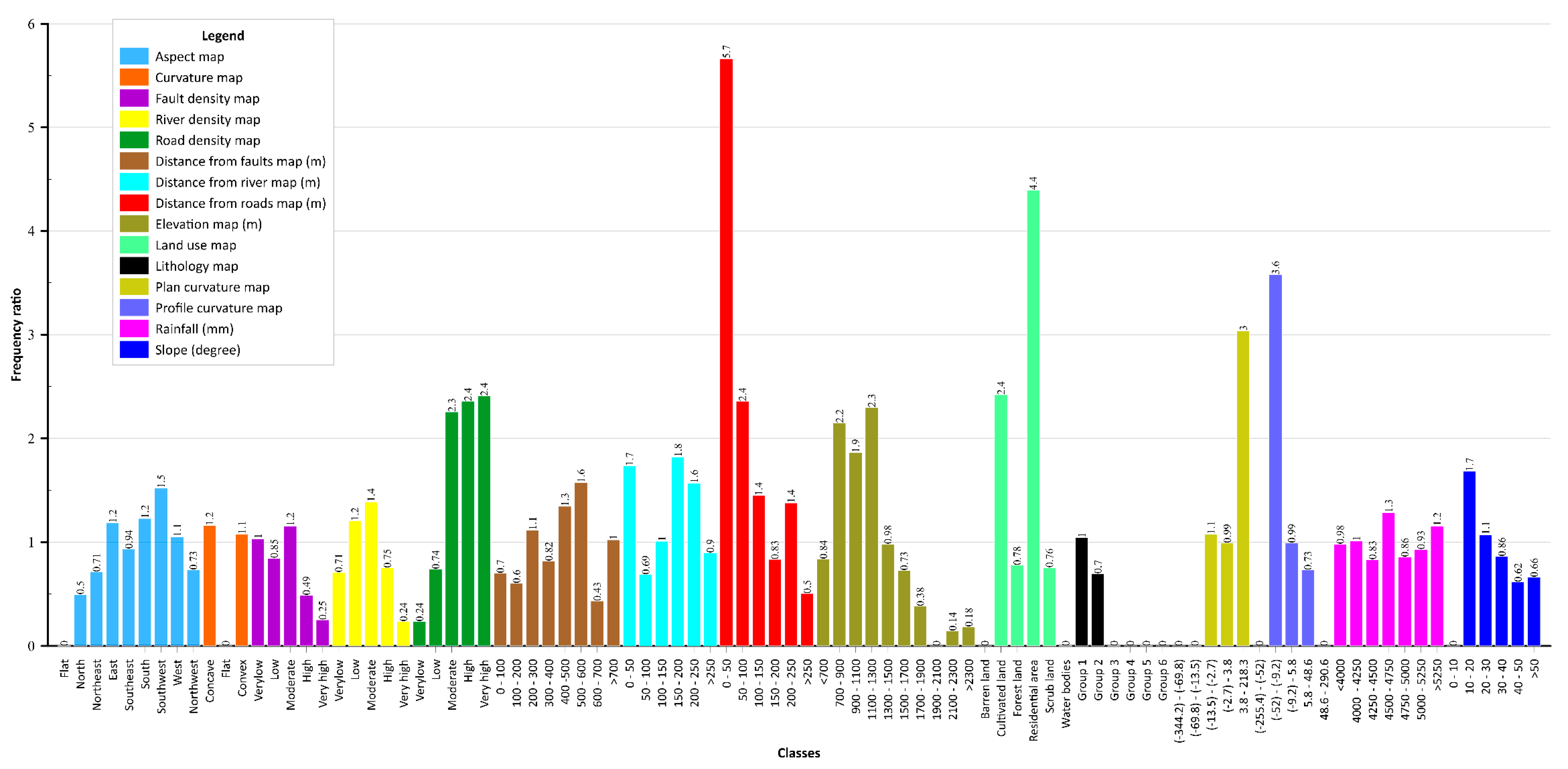
2.2.2. Landslide Influencing Factors
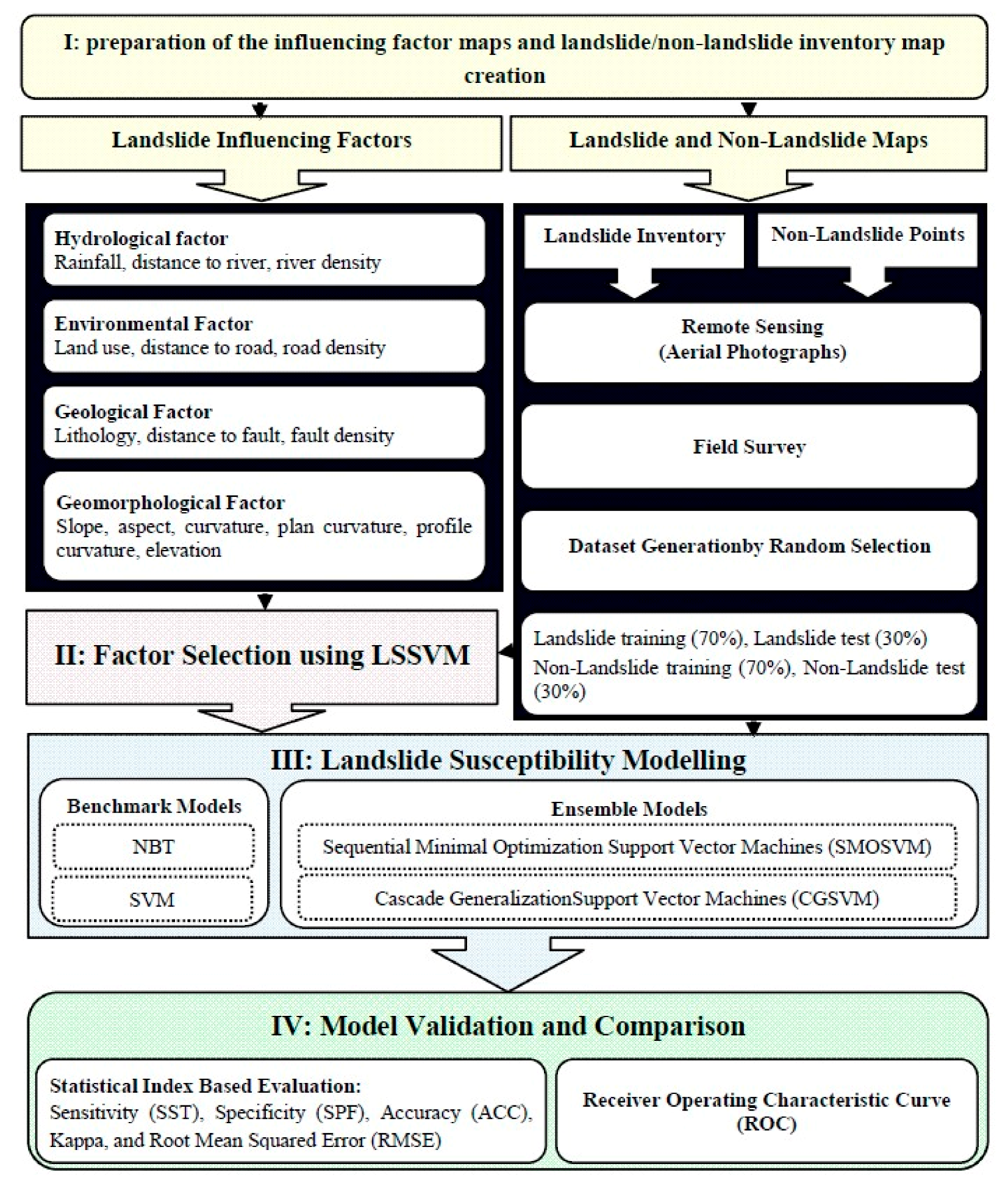
2.3. Dataset Generation
3. Methods Used
3.1. Support Vector Machines (SVM)
3.2. Sequential Minimal Optimization (SMO)
- (1)
- To identify and solve analytically the two Lagrange multipliers, at first, the constrained maximum value is obtained by the calculation of the constraints on the two Lagrange multipliers, and the constraint is utilized to restrict two Lagrange multipliers within a diagonal line [68]. Lagrange multipliers are then shifted to the point with the lowest value of the objective function [68].
- (2)
- To choose suitable Lagrange multipliers using heuristics for optimizing the quadratic programming problems [38], two heuristics are utilized to choose two suitable Lagrange multipliers [38]. One heuristic is employed to train all samples in the first multiplier and identify those that do not satisfy the Karush–Kuhn–Tucker (KKT) conditions [38]. A second heuristic is utilized to maximize approximately the size of the previous step in the second multiplier during the optimization process. Suitable Lagrange multipliers are selected based on selection of the sample having the largest error difference from the previous sample [68].
3.3. Cascade Generalization (CG)
3.4. Naïve Bayes Trees (NBT)
3.5. Evaluation and Comparison Methods
3.6. Linear Support Vector Machine (LSVM) Feature Selection
3.7. Methodological Flow Chart and Steps
4. Results and Analysis
4.1. Important Factors for Landslide Susceptibility Mapping
4.2. Model Construction
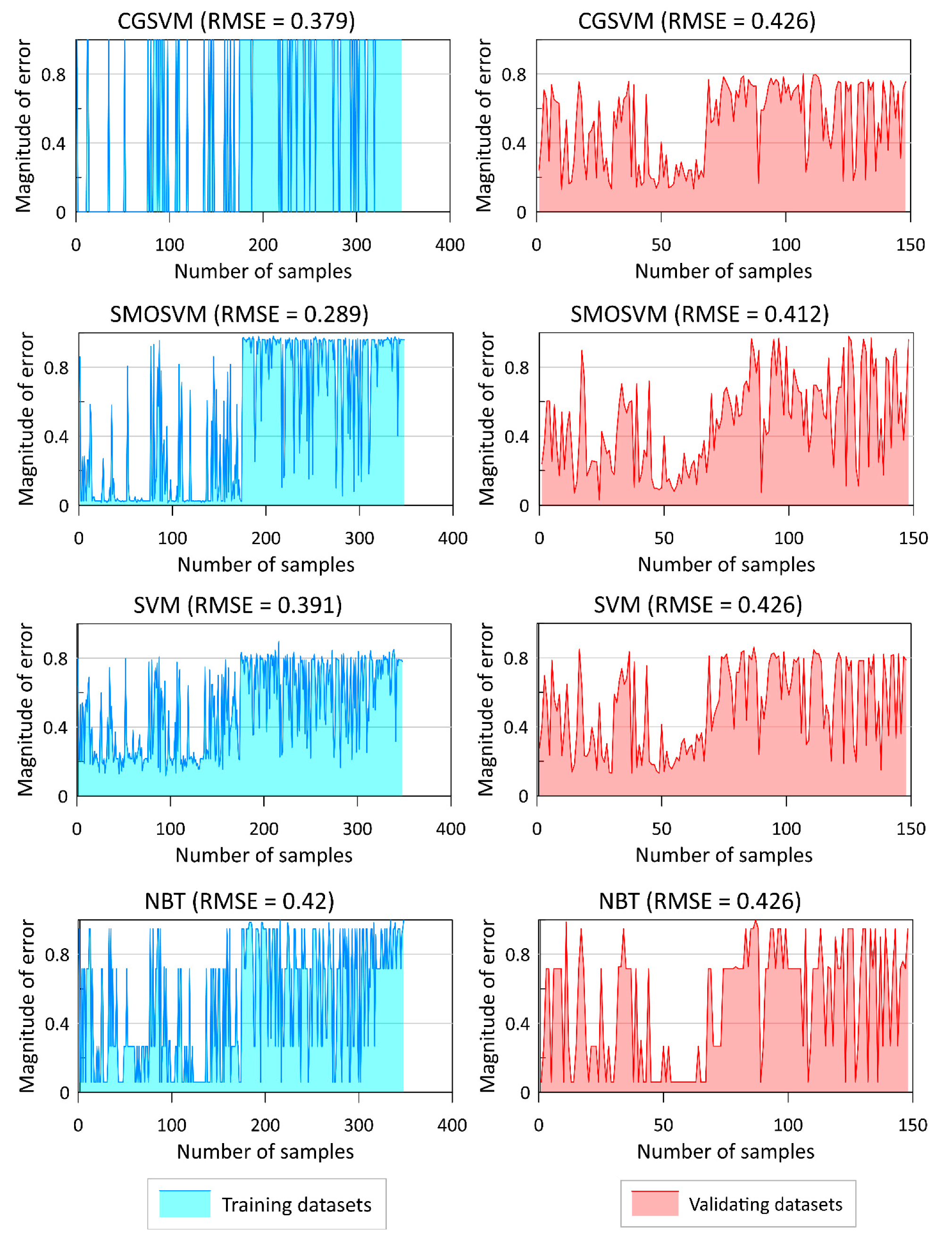
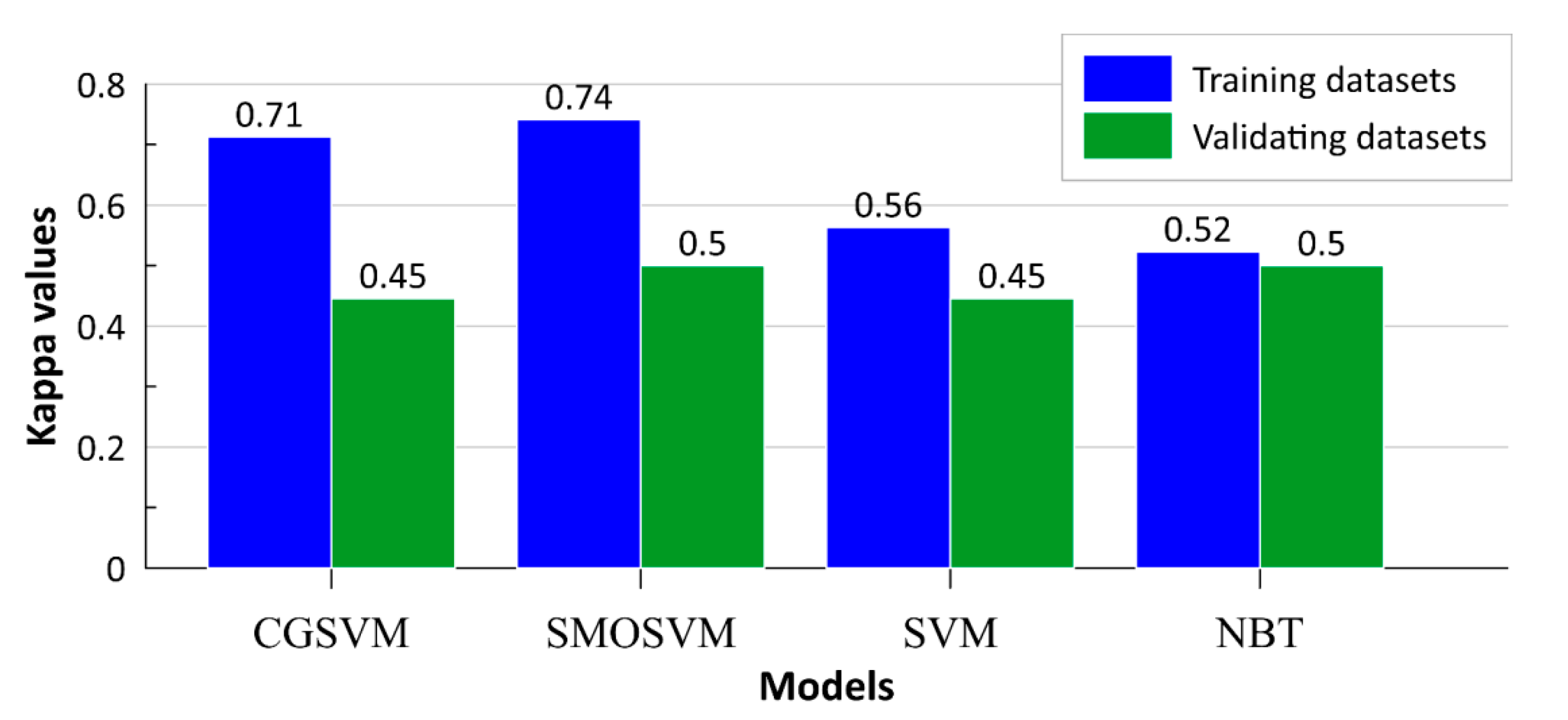
4.3. Model Validation and Comparison
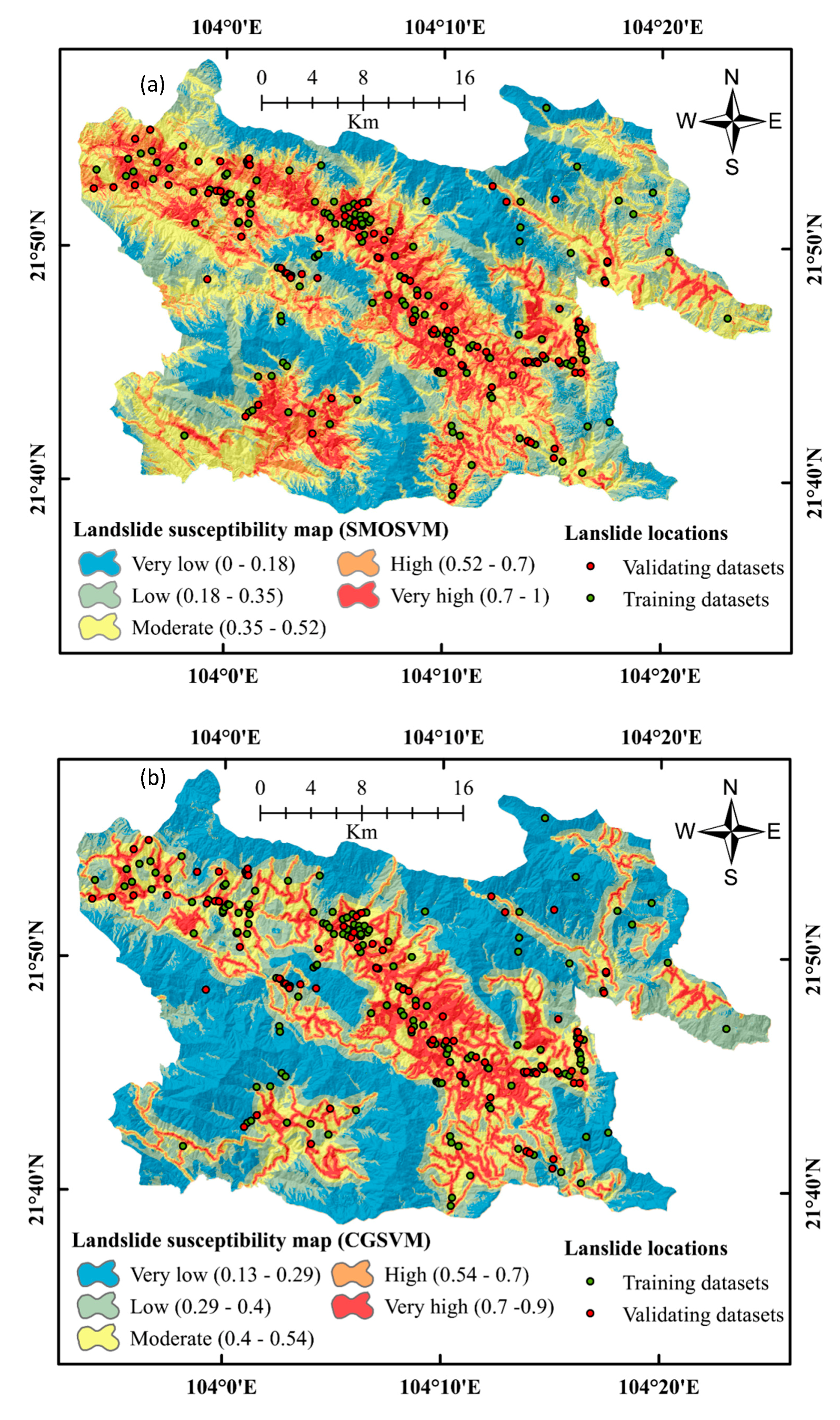
4.4. Development of Landslide Susceptibility Maps
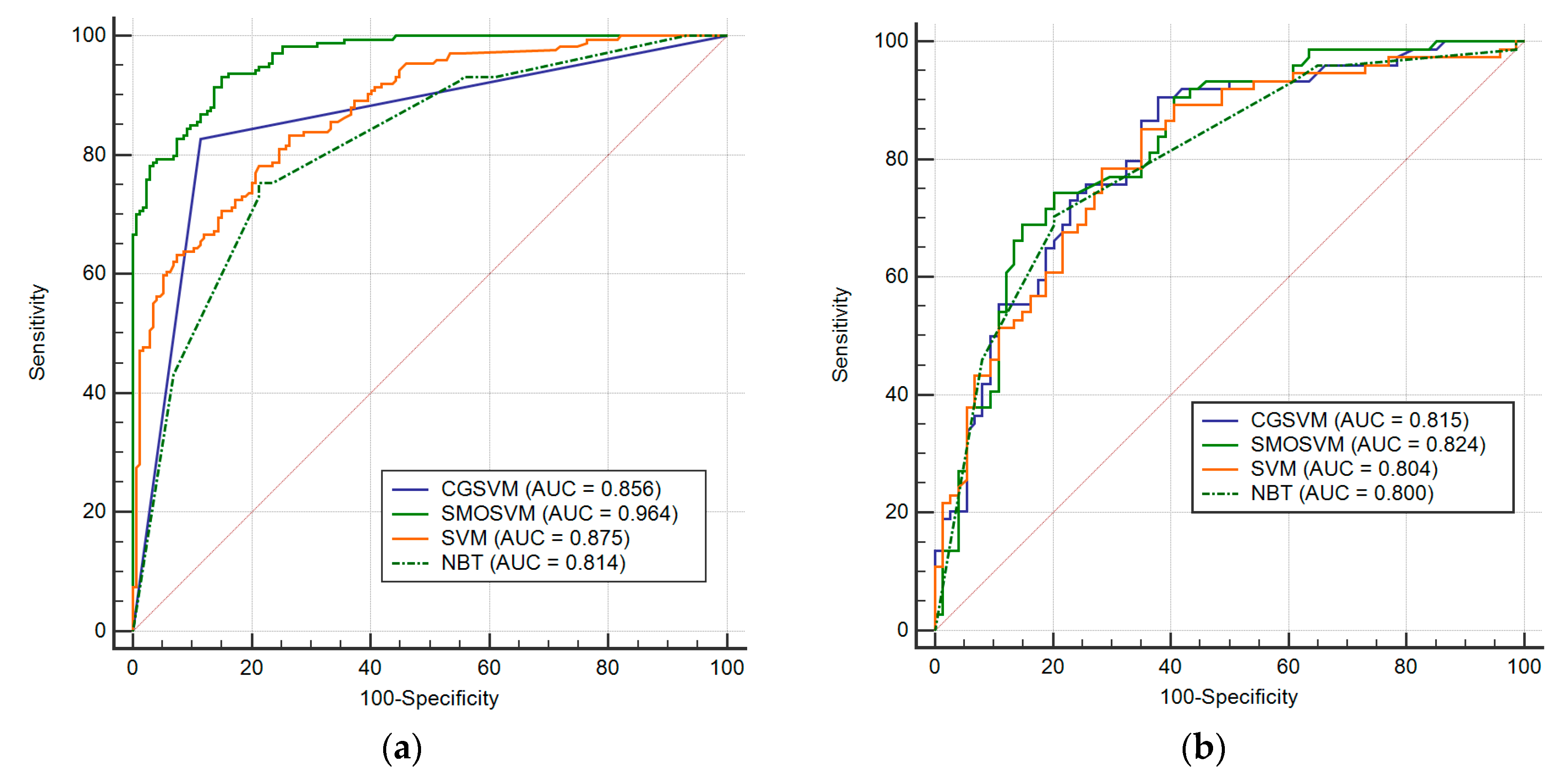
4.5. Evaluation of Landslide Susceptibility Maps
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial data for landslide susceptibility, hazard, and vulnerability assessment: An overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- Guzzetti, F. Landslide Hazard and Risk Assessment. Ph.D. Thesis, University of Bonn, Bonn, Germany, 2006. [Google Scholar]
- Varnes, D.J. Landslide Hazard. Zonation: A Review of Principles and Practice; UNESCO Press: Paris, France, 1984; p. 63. [Google Scholar]
- Shirzadi, A.; Solaimani, K.; Roshan, M.H.; Kavian, A.; Chapi, K.; Shahabi, H.; Keesstra, S.; Ahmad, B.B.; Bui, D.T. Uncertainties of prediction accuracy in shallow landslide modeling: Sample size and raster resolution. Catena 2019, 178, 172–188. [Google Scholar] [CrossRef]
- Yalcin, A. GIS-based landslide susceptibility mapping using analytical hierarchy process and bivariate statistics in Ardesen (Turkey): Comparisons of results and confirmations. Catena 2008, 72, 1–12. [Google Scholar] [CrossRef]
- Shirzadi, A.; Chapi, K.; Shahabi, H.; Solaimani, K.; Kavian, A.; Ahmad, B.B. Rock fall susceptibility assessment along a mountainous road: An evaluation of bivariate statistic, analytical hierarchy process and frequency ratio. Environ. Earth Sci. 2017, 76, 152. [Google Scholar] [CrossRef]
- Chen, W.; Chai, H.; Sun, X.; Wang, Q.; Ding, X.; Hong, H. A GIS-based comparative study of frequency ratio, statistical index and weights-of-evidence models in landslide susceptibility mapping. Arab. J. Geosci. 2016, 9, 204. [Google Scholar] [CrossRef]
- Chen, W.; Li, W.; Hou, E.; Zhao, Z.; Deng, N.; Bai, H.; Wang, D. Landslide susceptibility mapping based on GIS and information value model for the Chencang District of Baoji, China. Arab. J. Geosci. 2014, 7, 4499–4511. [Google Scholar] [CrossRef]
- Chen, Z.; Liang, S.; Ke, Y.; Yang, Z.; Zhao, H. Landslide susceptibility assessment using evidential belief function, certainty factor and frequency ratio model at Baxie River basin, NW China. Geocarto Int. 2019, 34, 348–367. [Google Scholar] [CrossRef]
- Hong, H.; Chen, W.; Xu, C.; Youssef, A.M.; Pradhan, B.; Tien Bui, D. Rainfall-induced landslide susceptibility assessment at the Chongren area (China) using frequency ratio, certainty factor, and index of entropy. Geocarto Int. 2017, 32, 139–154. [Google Scholar] [CrossRef]
- Ding, Q.; Chen, W.; Hong, H. Application of frequency ratio, weights of evidence and evidential belief function models in landslide susceptibility mapping. Geocarto Int. 2017, 32, 619–639. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Hong, H.; Akgun, A.; Tian, Y.; Liu, J.; Zhu, A.-X.; Li, S. Novel hybrid artificial intelligence approach of bivariate statistical-methods-based kernel logistic regression classifier for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 78, 4397–4419. [Google Scholar] [CrossRef]
- Zhu, A.-X.; Wang, R.; Qiao, J.; Qin, C.-Z.; Chen, Y.; Liu, J.; Du, F.; Lin, Y.; Zhu, T. An expert knowledge-based approach to landslide susceptibility mapping using GIS and fuzzy logic. Geomorphology 2014, 214, 128–138. [Google Scholar] [CrossRef]
- Pham, B.T.; Pradhan, B.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Shirzadi, A.; Shahabi, H.; Chapi, K.; Bui, D.T.; Pham, B.T.; Shahedi, K.; Ahmad, B.B. A comparative study between popular statistical and machine learning methods for simulating volume of landslides. Catena 2017, 157, 213–226. [Google Scholar] [CrossRef]
- Bui, D.T.; Nhat-Duc, H.; Hieu, N.; Xuan-Linh, T. Spatial prediction of shallow landslide using Bat algorithm optimized machine learning approach: A case study in Lang Son Province, Vietnam. Adv. Eng. Inform. 2019, 42, 100978. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Ahmad, B.; Panahi, M.; Hong, H. Landslide detection and susceptibility mapping by airsar data using support vector machine and index of entropy models in cameron highlands, malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef]
- Shirzadi, A.; Saro, L.; Joo, O.H.; Chapi, K. A GIS-based logistic regression model in rock-fall susceptibility mapping along a mountainous road: Salavat Abad case study, Kurdistan, Iran. Nat. Hazards 2012, 64, 1639–1656. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Pourghasemi, H.R.; Indra, P.; Dholakia, M. Landslide susceptibility assesssment in the Uttarakhand area (India) using GIS: A comparison study of prediction capability of naïve bayes, multilayer perceptron neural networks, and functional trees methods. Theor. Appl. Climatol. 2017, 128, 255–273. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Naghibi, S.A. A comparative study of landslide susceptibility maps produced using support vector machine with different kernel functions and entropy data mining models in China. Bull. Eng. Geol. Environ. 2018, 77, 647–664. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Pradhan, B.; Chen, W.; Khosravi, K.; Panahi, M.; Bin Ahmad, B.; Saro, L. Land subsidence susceptibility mapping in south korea using machine learning algorithms. Sensors 2018, 18, 2464. [Google Scholar] [CrossRef] [PubMed]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel GIS based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Li, T.; Guo, C.; Hong, H.; Li, W.; Pan, D.; Hui, J.; Ma, M. A novel ensemble approach of bivariate statistical-based logistic model tree classifier for landslide susceptibility assessment. Geocarto Int. 2018, 33, 1398–1420. [Google Scholar] [CrossRef]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Bin Ahmad, B.; Tien Bui, D. A novel hybrid approach of bayesian logistic regression and its ensembles for landslide susceptibility assessment. Geocarto Int. 2018, 1–31. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Hong, H.; Panahi, M.; Shirzadi, A.; Ma, T.; Liu, J.; Zhu, A.-X.; Chen, W.; Kougias, I.; Kazakis, N. Flood susceptibility assessment in Hengfeng area coupling adaptive neuro-fuzzy inference system with genetic algorithm and differential evolution. Sci. Total Environ. 2018, 621, 1124–1141. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W. New hybrids of anfis with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef]
- Ahmadlou, M.; Karimi, M.; Alizadeh, S.; Shirzadi, A.; Parvinnejhad, D.; Shahabi, H.; Panahi, M. Flood susceptibility assessment using integration of adaptive network-based fuzzy inference system (ANFIS) and biogeography-based optimization (BBO) BAT algorithms (BA). Geocarto Int. 2019, 34, 1252–1272. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hoang, N.-D.; Pham, B.; Bui, Q.-T.; Tran, C.-T.; Panahi, M.; Bin Ahamd, B. A novel integrated approach of relevance vector machine optimized by imperialist competitive algorithm for spatial modeling of shallow landslides. Remote Sens. 2018, 10, 1538. [Google Scholar] [CrossRef]
- Pham, B.T.; Shirzadi, A.; Bui, D.T.; Prakash, I.; Dholakia, M. A hybrid machine learning ensemble approach based on a radial basis function neural network and rotation forest for landslide susceptibility modeling: A case study in the Himalayan area, India. Int. J. Sediment. Res. 2018, 33, 157–170. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Sahin, E.K.; Colkesen, I. Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 2014, 11, 425–439. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Jirandeh, A.G.; Pradhan, B.; Xu, C.; Gokceoglu, C. Landslide susceptibility mapping using support vector machine and GIS at the Golestan Province, Iran. J. Earth Syst. Sci. 2013, 2, 349–369. [Google Scholar] [CrossRef] [Green Version]
- Yao, X.; Tham, L.G.; Dai, F.C. Landslide susceptibility mapping based on Support Vector Machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Lai, K.K.; Yu, L.; Zhou, L.; Wang, S. Credit Risk Evaluation with Least Square Support Vector Machine. In Proceedings of the International Conference on Rough Sets and Knowledge Technology; Springer: Berlin/Heidelberg, Germany, 2006; pp. 490–495. [Google Scholar]
- Platt, J. Fast training of support vector machines using sequential minimal optimization. In Advances in Kernel Methods Support Vector Learning; Schölkopf, B., Burges, C.J.C., Smola, A.J., Eds.; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Gama, J.; Brazdil, P. Cascade generalization. Mach. Learn. 2000, 41, 315–343. [Google Scholar] [CrossRef]
- Ercanoglu, M.; Gokceoglu, C. Assessment of landslide susceptibility for a landslide-prone area (north of Yenice, NW Turkey) by fuzzy approach. Environ. Geol. 2002, 41, 720–730. [Google Scholar]
- Bui, D.T.; Hoang, N.D.; Martínez-Álvarez, F.; Ngo, P.T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2019. [Google Scholar] [CrossRef]
- Bui, D.T.; Moayedi, H.; Kalantar, B.; Osouli, A.; Pradhan, B.; Nguyen, H.; Rashid, A.S.A. A Novel Swarm Intelligence—Harris Hawks Optimization for Spatial Assessment of Landslide Susceptibility. Sensors 2019, 19, 3590. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tien Bui, D.; Ho, T.-C.; Pradhan, B.; Pham, B.-T.; Nhu, V.-H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1–22. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H.; Ugawa, N. Landslide susceptibility mapping using GIS-based weighted linear combination, the case in Tsugawa area of Agano River, Niigata Prefecture, Japan. Landslides 2004, 1, 73–81. [Google Scholar] [CrossRef]
- Stocking, M. Relief analysis and soil erosion in Rhodesia using multi-variate techniques. Z. Geomorphol. NF 1972, 16, 432–443. [Google Scholar]
- Pham, B.T.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. Rotation forest fuzzy rule-based classifier ensemble for spatial prediction of landslides using GIS. Nat. Hazards 2016, 83, 1–31. [Google Scholar] [CrossRef]
- Brewer, C.A. Basic mapping principles for visualizing cancer data using geographic information systems (GIS). Am. J. Prev. Med. 2006, 30, S25–S36. [Google Scholar] [CrossRef] [PubMed]
- Pradhan, B. Use of GIS-based fuzzy logic relations and its cross application to produce landslide susceptibility maps in three test areas in Malaysia. Environ. Earth Sci. 2011, 63, 329–349. [Google Scholar] [CrossRef]
- Pradhan, B.; Abokharima, M.H.; Jebur, M.N.; Tehrany, M.S. Land subsidence susceptibility mapping at Kinta Valley (Malaysia) using the evidential belief function model in GIS. Nat. Hazards 2014, 73, 1019–1042. [Google Scholar] [CrossRef]
- Komac, M. A landslide susceptibility model using the analytical hierarchy process method and multivariate statistics in perialpine Slovenia. Geomorphology 2006, 74, 17–28. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Landslide susceptibility assessment and factor effect analysis: Backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ. Model. Softw. 2010, 25, 747–759. [Google Scholar] [CrossRef]
- Ercanoglu, M.; Gokceoglu, C.; Van Asch, T.W. Landslide susceptibility zoning north of Yenice (NW Turkey) by multivariate statistical techniques. Nat. Hazards 2004, 32, 1–23. [Google Scholar] [CrossRef]
- Ohlmacher, G.C.; Davis, J.C. Using multiple logistic regression and GIS technology to predict landslide hazard in northeast Kansas, USA. Eng. Geol. 2003, 69, 331–343. [Google Scholar] [CrossRef]
- Pham, B.T.; Tien Bui, D.; Indra, P.; Dholakia, M.B. Landslide susceptibility assessment at a part of Uttarakhand Himalaya, India using GIS—Based statistical approach of frequency ratio method. Int. J. Eng. Res. Technol. 2015, 4, 338–344. [Google Scholar]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility mapping at Hoa Binh province (Vietnam) using an adaptive neuro-fuzzy inference system and GIS. Comput. Geosci. 2012, 45, 199–211. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility assessment in the Hoa Binh province of Vietnam: A comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 2012, 171, 12–29. [Google Scholar] [CrossRef]
- Pham, B.T.; Nguyen, M.D.; Le, A.H. Shear resistance and stability study of embankments using different shear resistance parameters of soft soils from laboratory and field tests: A case study of Hai Phong city, Viet Nam. Int. J. Sci. Res. Dev. 2016, 3, 330–334. [Google Scholar]
- NCEP. Global Weather Data for SWAT. 2014. Available online: http://globalweather.tamu.edu/home (accessed on 15 March 2017).
- Ayalew, L.; Yamagishi, H. The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 2005, 65, 15–31. [Google Scholar] [CrossRef]
- Van, T.T.; Anh, D.T.; Hieu, H.H.; Giap, N.X.; Ke, T.D.; Nam, T.D.; Ngoc, D.; Ngoc, D.T.Y.; Thai, T.N.; Thang, D.V.; et al. Investigation and Assessment of the Current Status and Potential of Landslides in Some Sections of the Ho Chi Minh Road, National Road 1A and Proposed Remedial Measures to Prevent Landslides from Threat of Safety of People, Property, and Infrastructure; Vietnam Institute of Geosciences and Mineral Resources: Hanoi, Vietnam, 2006; p. 249. [Google Scholar]
- Tien Bui, D. Modeling of Rainfall-Induced Landslide Hazard for the Hoa Binh Province of Vietnam. Ph.D. Thesis, Norwegian University of Life Sciences, Aas, Norway, 2012. [Google Scholar]
- Nguyen, P.T.; Tuyen, T.T.; Shirzadi, A.; Pham, B.T.; Shahabi, H.; Omidvar, E.; Amini, A.; Entezami, H.; Prakash, I.; Phong, T.V. Development of a novel hybrid intelligence approach for landslide spatial prediction. Appl. Sci. 2019, 9, 2824. [Google Scholar] [CrossRef] [Green Version]
- Arora, M.; Das Gupta†, A.; Gupta, R. An artificial neural network approach for landslide hazard zonation in the Bhagirathi (Ganga) Valley, Himalayas. Int. J. Remote Sens. 2004, 25, 559–572. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NJ, USA, 1998; Volume 1. [Google Scholar]
- Gulyani, B.B.; Mangai, J.A.; Fathima, A. An Approach for Predicting River Water Quality Using Data Mining Technique. In Advances in Data Mining: Applications and Theoretical Aspects; Springer: Berlin/Heidelberg, Germany, 2015; pp. 233–243. [Google Scholar]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Bonansea, L. 3D Hand gesture recognition using a ZCam and an SVM-SMO classifier. Master’s Thesis, Iowa State University, Ames, IA, USA, 2009. [Google Scholar]
- Nugroho, K.A.; Setiawan, N.A.; Adji, T.B. Cascade Generalization for Breast Cancer Detection. In Proceedings of the 2013 International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 7–8 October 2013; pp. 57–61. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D. Cascade Generalization with Classification and Model Trees. In Proceedings of the 2008 Third International Conference on Convergence and Hybrid Information Technology, Busan, Korea, 11–13 November 2008; pp. 248–253. [Google Scholar]
- Zhao, H.; Ram, S. Entity matching across heterogeneous data sources: An approach based on constrained cascade generalization. Data Knowl. Eng. 2008, 66, 368–381. [Google Scholar] [CrossRef]
- Ludwig, O.; Nunes, U.; Ribeiro, B.; Premebida, C. Improving the Generalization Capacity of Cascade Classifiers. IEEE Trans. Cybern. 2013, 43, 2135–2146. [Google Scholar] [CrossRef] [PubMed]
- Barakat, N. Cascade generalization: Is SVMs’ inductive bias useful? In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1393–1399. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Wang, J.; Duan, Z.; Hong, H. GIS-based landslide susceptibility modelling: A comparative assessment of kernel logistic regression, Naïve-Bayes tree, and alternating decision tree models. Geomat. Nat. Hazards Risk 2017, 8, 950–973. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naïve Bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef] [PubMed]
- Pham, B.T.; Prakash, I. A novel hybrid model of Bagging-based Naïve Bayes Trees for landslide susceptibility assessment. Bull. Eng. Geol. Environ. 2017. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Hong, H.; Li, S.; Shahabi, H.; Wang, Y.; Wang, X.; Ahmad, B.B. Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles. J. Hydrol. 2019, 575, 864–873. [Google Scholar] [CrossRef]
- Bennett, N.D.; Croke, B.F.; Guariso, G.; Guillaume, J.H.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.; Norton, J.P.; Perrin, C. Characterising performance of environmental models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Bui, D.T. A comparative study of support vector machine and logistic model tree classifiers for shallow landslide susceptibility modeling. Environ. Earth Sci. 2019, 78, 560. [Google Scholar] [CrossRef]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Geertsema, M.; Omidvar, E.; Clague, J.J.; Thai Pham, B.; Dou, J.; Talebpour Asl, D.; Bin Ahmad, B. New Ensemble Models for Shallow Landslide Susceptibility Modeling in a Semi-Arid Watershed. Forests 2019, 10, 743. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Tsangaratos, P.; Ilia, I.; Duan, Z.; Chen, X. Groundwater spring potential mapping using population-based evolutionary algorithms and data mining methods. Sci. Total Environ. 2019, 684, 31–49. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Hong, H.; Panahi, M.; Shahabi, H.; Wang, Y.; Shirzadi, A.; Pirasteh, S.; Alesheikh, A.A.; Khosravi, K.; Panahi, S. Spatial Prediction of Landslide Susceptibility Using GIS-Based Data Mining Techniques of ANFIS with Whale Optimization Algorithm (WOA) and Grey Wolf Optimizer (GWO). Appl. Sci. 2019, 9, 3755. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Panahi, M.; Khosravi, K.; Pourghasemi, H.R.; Rezaie, F.; Parvinnezhad, D. Spatial prediction of groundwater potentiality using ANFIS ensembled with teaching-learning-based and biogeography-based optimization. J. Hydrol. 2019, 572, 435–448. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Dou, J.; Singh, S.K.; Trinh, P.T.; Tran, H.T.; Le, T.M.; Van Phong, T.; Khoi, D.K.; Shirzadi, A. A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int. 2019. [Google Scholar] [CrossRef]
- Chen, W.; Pradhan, B.; Li, S.; Shahabi, H.; Rizeei, H.M.; Hou, E.; Wang, S. Novel hybrid integration approach of bagging-based fisher’s linear discriminant function for groundwater potential analysis. Nat. Resour. Res. 2019, 28, 1239–1258. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.T.; Zhang, T.; Zhang, L.; Chai, H.; et al. Landslide Susceptibility Modeling Based on GIS and Novel Bagging-Based Kernel Logistic Regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef] [Green Version]
- Rahmati, O.; Falah, F.; Dayal, K.; Deo, R.C.; Mohammadi, F.; Biggs, T.; Moghaddam, D.D.; Naghibi, S.A.; Tien Bui, D. Machine learning approaches for spatial modeling of agricultural droughts in south-east region of Queensland Australia. Sci. Total Environ. 2019. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Tien Bui, D.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Krawiec, K.; Bhanu, B. Coevolution and linear genetic programming for visual learning. In Genetic and Evolutionary Computation—GECCO 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 332–343. [Google Scholar]
- Kibriya, A.M.; Frank, E.; Pfahringer, B.; Holmes, G. Multinomial naive bayes for text categorization revisited. In AI 2004: Advances in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2005; pp. 488–499. [Google Scholar]
- Kurokawa, M.; Yokoyama, H.; Sakurai, A. Averaged Naive Bayes Trees: A New Extension of AODE. In Advances in Machine Learning; Springer: Berlin/Heidelberg, Germany, 2009; pp. 191–205. [Google Scholar]
- Frye, C. About the Geometrical Interval Classification Method. 2007. Available online: http://blogs.esri.com/esri/arcgis (accessed on 15 April 2018).
- Tien Bui, D.; Shahabi, H.; Omidvar, E.; Shirzadi, A.; Geertsema, M.; Clague, J.J.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Chapi, K. Shallow landslide prediction using a novel hybrid functional machine learning algorithm. Remote Sens. 2019, 11, 931. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M. Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, Y. Comparison of decision tree methods for finding active objects. Adv. Space Res. 2008, 41, 1955–1959. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M. Evaluation of predictive ability of support vector machines and naive Bayes trees methods for spatial prediction of landslides in Uttarakhand state (India) using GIS. J. Geomat. 2016, 10, 71–79. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Factors | Average Merit (AM) | Standard Deviation (SD) |
|---|---|---|---|
| 1 | Road density | 14.7 | ±0.64 |
| 2 | Lithology | 13.7 | ±0.458 |
| 3 | Distance to roads | 12.9 | ±1.64 |
| 4 | Distance to faults | 11.1 | ±1.375 |
| 5 | Elevation | 10.9 | ±1.446 |
| 6 | Plan curvature | 9.1 | ±2.211 |
| 7 | Fault density | 8.3 | ±2.052 |
| 8 | Profile curvature | 7.7 | ±2.100 |
| 9 | Distance to rivers | 7.2 | ±3.450 |
| 10 | Slope | 6.6 | ±2.010 |
| 11 | Aspect | 5.8 | ±1.833 |
| 12 | Curvature | 3.4 | ±1.625 |
| 13 | Land use | 3.2 | ±1.778 |
| 14 | Rainfall | 3.1 | ±1.758 |
| 15 | River density | 2.3 | ±1.418 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, B.T.; Prakash, I.; Chen, W.; Ly, H.-B.; Ho, L.S.; Omidvar, E.; Tran, V.P.; Bui, D.T. A Novel Intelligence Approach of a Sequential Minimal Optimization-Based Support Vector Machine for Landslide Susceptibility Mapping. Sustainability 2019, 11, 6323. https://0-doi-org.brum.beds.ac.uk/10.3390/su11226323
Pham BT, Prakash I, Chen W, Ly H-B, Ho LS, Omidvar E, Tran VP, Bui DT. A Novel Intelligence Approach of a Sequential Minimal Optimization-Based Support Vector Machine for Landslide Susceptibility Mapping. Sustainability. 2019; 11(22):6323. https://0-doi-org.brum.beds.ac.uk/10.3390/su11226323
Chicago/Turabian StylePham, Binh Thai, Indra Prakash, Wei Chen, Hai-Bang Ly, Lanh Si Ho, Ebrahim Omidvar, Van Phong Tran, and Dieu Tien Bui. 2019. "A Novel Intelligence Approach of a Sequential Minimal Optimization-Based Support Vector Machine for Landslide Susceptibility Mapping" Sustainability 11, no. 22: 6323. https://0-doi-org.brum.beds.ac.uk/10.3390/su11226323