1. Introduction
In the past few years, multiple new computational approaches to assess stock status in data-limited situations have been developed [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]. These new methods are invaluable to fishery managers around the world and agencies such as the Food and Agriculture Organization of the United Nations (FAO) that are tasked under the United Nation’s (UN) Sustainable Development Goals (Target 14) with tracking global progress on sustainable use of fisheries resources. The FAO (2020) already performs a systematic assessment with 445 stocks on a biannual basis which covers approximately 70% of the global landing records, yet many smaller stocks are still missing from these analyses due to data deficiencies (landing records on their own are insufficient for traditional stock assessment models that require also biological and fisheries effort data, and for many of the world’s stocks landing data themselves are unavailable). The fact remains that a large number of the world’s stocks lack formal assessments and because their status is ‘unknown’ they are generally omitted from calculating indicators of overfishing such as SDG14.4.1—a UN-agreed country-specific indicator of overfishing which counts the proportion of stocks that are biologically sustainable, but only among the stocks with a ‘known’ or quantitatively assessed stock status. Therefore, gaps in both data and methodology contribute to uncertainty over the real state of many of the world’s fisheries, and impede the measurement of progress towards achieving the UN’s sustainable development goals. Providing quantitative assessment of stock status requires some form of data on individual fisheries, and catch histories maintained by the FAO are in many cases the only data type available for fisheries large and small across the world [
8]. As such, a growing number of ‘catch-only’ models (COMs) have been developed in an effort to narrow the assessment gap between data-rich and data-poor fisheries. Given the increased dependence of global fishery assessments on COMs, it is imperative to assess the reliability of these tools as well as explore ways in which their performance might be improved. That is the central aim of this paper.
When data are limited, the structure of a given assessment model has relatively greater influence on assessment outcomes than the data. One consequence of this is that different methodologies applied to the same dataset can produce disconcertingly divergent conclusions, as model assumptions, rather than data, shape modeling results. This is exactly what we have seen when it comes to global assessments of the health of fish stocks, and this is what we would expect more generally in other model-based assessments, e.g., those that are used to measure SDGs, when data are insufficiently robust. Different teams of scientists relying on the same public databases of catch data using different methods (that make different assumptions and aggregate data in different ways) have variously concluded that around two-thirds of global stocks are overfished [
12] or that one-third are (FAO). FAO’s world assessment relies mostly on ‘traditional’ full statistical stock assessments, but also some data-limited assessments or expert elicitation methods [
13], and it is possible that the selection bias in favor of larger stocks with formal assessments is behind their relatively optimistic, e.g., compared to Worm’s, global outlook on the world’s fisheries. In addition, FAO’s methodology tends to aggregate stocks into larger units versus the Worm et al. approach and that can be a factor explaining the differences. There is evidence that smaller, often unassessed, stocks may be in poorer condition on average. Therefore, by aggregating data and by not being able to take these smaller unassessed stocks into account, the FAO’s and hence the UN’s global estimates of stock status may be positively biased [
14,
15]. Bringing more of the world’s stocks into assessment would reduce these biases, and enable more informed decision making and accountability, helping to achieve the UN’s sustainability goals.
Many of the stocks that are not yet assessed might be included in the global FAO assessments if the methodology of combining existing catch data and informative priors is sufficiently developed, validated and disseminated. In the current global toolbox, there are both model-based and model-free approaches that use primarily catch data to assess stock status. Model-free approaches include stock status plots, which might use catch time series to assign development stages to individual stocks based on catch levels in relation to the maximum/peak catch of the time series, e.g., [
16,
17,
18]. However, these methods have been criticized for their lack of theoretical underpinnings and the failure to utilize the knowledge of life history or dynamics [
19]. As a result, various catch-only model-based approaches (COMs) that incorporate formal assumptions about population dynamics were developed for data-limited stocks [
15,
20,
21]. In contrast to model-free approaches, COMs are designed to analyze catch time series in conjunction with existing prior knowledge about the stock’s resilience and exploitation history as well as general understanding about population dynamics. Among these methods are depletion-corrected average catch models [
22] and depletion-based stock reduction analysis [
20]. Carruthers et al. [
1] tested the performance of different catch-based MPs with different life history traits and found catch-only models often performed poorly as compared to simple indicator-based approaches in the context of fisheries management algorithms for decision making (on allowable catches or sustainable levels of fishing effort). Sun et al. [
2] also looked at different data-limited management procedures (MPs) to test whether they can achieve sustainable fishery targets similar to data-rich scenarios and found that length-based and SPR (Spawning Potential Ratio)-based approaches could perform well with data-poor indicators. These studies provide contrasting performance evaluations of catch-based and other types of data limited models in the context of fisheries management. While COMs are considered to be data limited, some of the stock parameters required for these methods to function reliably would be too difficult to obtain for the majority of global stocks. This paper attempts to clarify when should COMs be used and when information might be insufficient, and alternatives, perhaps qualitative methods, might be preferred.
2. Materials and Methods
The two models CMSY+ and SRA+ evolved from the early COMs Catch-MSY [
21] and CMSY [
23]. The core of SRA+ is a generalized Pella-Tomlinson [
24] production model, which is purposefully simplified to Schaefer model in the case of CMSY+ [
23]. While such simplified models abstract away many important details of fish biology and fleet behavior, they are the highest-resolution models that the data-limited cases will support. By contrast, traditional stock assessment methods are able to parameterize (for data-rich stocks) and model sophisticated biological and socioeconomic processes. The purpose of COMs is not to make substantial improvements in the fitting of surplus production models, but to provide flexible tools for improving estimates with additional sources of information. Growth rates can become unrealistically large when the population reaches low sizes under the Pella-Tomlinson model. CMSY+ and SRA+ deals with this problem by following the methods described in [
23,
25] to reduce the production rate of the population when it falls below a threshold of 25% of carrying capacity.
We allow for process error in the manner of the stochastic stock reduction analysis error suggested by [
26]. Process errors enable the population dynamics to deviate from the exact values given by the Pella-Tomlinson model, while still conforming to the assumptions of this model on average. Incorporation of process errors is useful for two reasons: (1) when the model is trying to fit an abundance index, process errors can reduce bias arising from lack of fit in a deterministic SRA whenever dynamics are poorly explained by catch history alone, and (2) with or without an abundance index (or other auxiliary information), the stochastic portion is necessary to get plausible uncertainty intervals in the final estimates [
27].
All estimates are Bayesian in nature and fall into two distinct categories: estimated with data and without. By ‘data’, we refer to measurements which are used to confront model estimates within a likelihood function. These might include (in addition to catch data) fishery-independent survey data, or a CPUE index. When there is no additional data, the model resorts to filtering priors through the model equations, along with any fixed parameters and catch data. Under this mode, the model is essentially a stock-reduction analysis model [
21,
26], which searches for combinations of prior probability distributions that do not crash the population, given the constraints of the population dynamics model and the catches. This process updates the prior distribution of population parameters by eliminating combinations of priors that are impossible for a given catch history and a specified functional form of the production model. To ensure that the algorithms were the only difference in the 2 COMs, all inputs were the same for both CMSY+ and SRA+.
2.1. Data
To find suitable data and knowledge-rich stocks, we sorted through the International Council for Exploration of the Seas (ICES) SAG (stock assessment graphs) database published at the beginning of 2020 that contained ICES stock assessments for 2019. Among these we selected 48 stocks that had data-rich age-structured assessments based on traditional analytical model frameworks (e.g., SAM, XSA, and Stock Synthesis [
28]). As biomass that provides maximum sustainable yield (B
MSY) is not always estimated by ICES, a proxy to B
MSY was consistently used, equal to 3* Blim, where Blim is a limit reference point based on the value of spawning stock biomass (SSB) below which the stock is considered to have reduced reproductive capacity. It is derived in post-processing from the breakpoint of a segmented regression fitted to the SSB-recruitment pairs estimated by the ICES stock assessment.
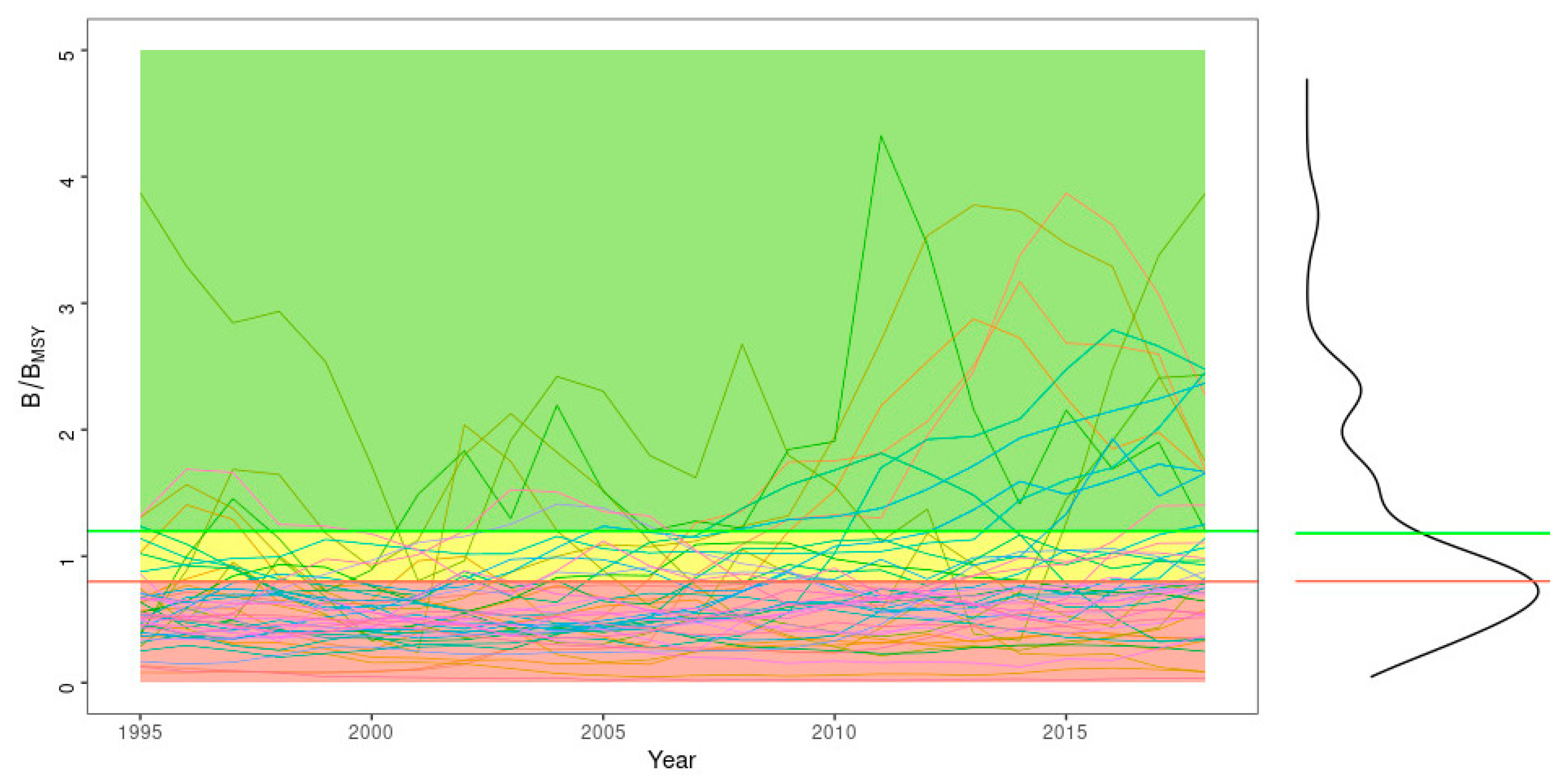
Figure 1 shows the stock trajectories relative to B
MSY. It can be seen that stocks tend to share a common trend, mainly due to the adoption of the maximum sustainable yield (MSY) approach by ICES after 2008.
According to the FAO classification, the majority of these 48 stocks were overfished (B/B
MSY is less than 0.8) for most of the time series, (
Figure 1). Among those 48 stocks, there were 3 families of fish: Clupeidae (herring, sardines and sprat), Gadidae (cod, haddock, hake and saithe), and Pleuronectidae (plaice and halibut). This highlights an issue that these are the families for which informative priors for life history parameters are readily available (e.g., through databases such as FishBase) while for other, less studied families of species/invertebrates this data may not exist. Note that in our scenarios the levels of uncertainty in the intrinsic rate of population increase (r) varied between CV of 10–30% depending on the knowledge of the life history parameters (r estimates were taken from FishBase database and adjusted in COMs based on the production function).
As most global fisheries that lack traditional assessments do not have a long time series of data (as can be glimpsed from RAM Legacy Stock Assessment Database or FAO Global Fisheries Database), to approximate data-poor fisheries we limited the analysis to the last 25 years of landings. Among the stocks selected, there is a wide variation in terms of levels of catch and some species exhibit large swings in relative abundance, temporarily overshooting B
MSY by up to fourfold (
Figure 1). For the purposes of evaluating COMs, we used the existing traditional assessment results that incorporate all available information into ICES data as the ‘true’ state of the stocks, acknowledging that the values produced by the ICES assessments are themselves model estimates containing their own uncertainty.
2.2. Scenarios
For each of the two COMs methods, SRA+ and CMSY+, we ran six scenarios that represented different kinds of informational inputs, where the default ‘naive’ settings represented a high level of uncertainty corresponding to large confidence bounds. The six scenarios are described in
Table 1. These scenarios were chosen from combinations of three sources of inputs: an index of abundance, a prior for the initial level of depletion and a prior for the depletion in the final year. Scenarios were identified by six distinct names (“Scenario Name” column in
Table 1): naive, naive2, cr2, exp, bsm1 and bsm2.
Four scenarios did not rely on any index of abundance and two scenarios (bsm1 and bsm2) used an index of abundance based on perfect knowledge (congruent with ICES assessments that represent ‘the truth’ in our evaluations). This represents an extremely idealized scenario where not only an index of abundance is available but it is unbiased and precise. Two different types of priors were considered for initial depletion level (Initial B/K), one representing a prior obtained through expert elicitations (EH, EC, EE, EI) and one based on a formal heuristic method (HH, HI). Again, in the case of expert priors, it was assumed that ‘the expert’ has good albeit somewhat uncertain knowledge. The expert priors were constructed as follows, in order to mimic good expert knowledge: if the stock is severely depleted (according to the ICES assessment), then ‘the expert’ is assumed to guess that the average biomass is 0.18 of unfished equilibrium (B0), with uncertainty in the expert prior always modeled by using a CV of at least 20%; if the ‘true’ state corresponds to intermediate depletion, then the guess is 0.38; if indeed it is fished at optimal levels, expert prior average is 0.58; and if the stock is underfished, the expert prior average is set to 0.87 of unfished biomass.
Heuristic priors and catch-rule priors were constructed based on various algorithms using available catch data and other external sources such as life history parameters from publicly available databases such as FishBase. One of the methods for an initial heuristic depletion prior is similar to the one identified by Rosenburg et. al. [
8]). For the final depletion prior, we used the following:
2.3. Heuristic Priors
If the final catch is greater than 50% of the maximum catch, then the final depletion is between 30% and 70%, 1–50% otherwise.
2.4. Catch-Rule Priors
If the final year catch is between 30% and 70% of the maximum catch, a prior centered around 40% of the catch is used instead of default mean; if the final year catch is greater than 70% of the peak, then the default prior’s mean is set to 70%; and if the final year catch is lower than 30% of the maximum, then the default prior is centered at 20%. All these priors have a CV of 0.2 and are based on the initial CMSY paper [
8,
21].
3. Results
First, we looked at how well these methods were able to capture the big picture, and describe the historic evolution of the fishery at an aggregate level (see
Figure 2 for SRA+ and
Figure 3 for CMSY+).
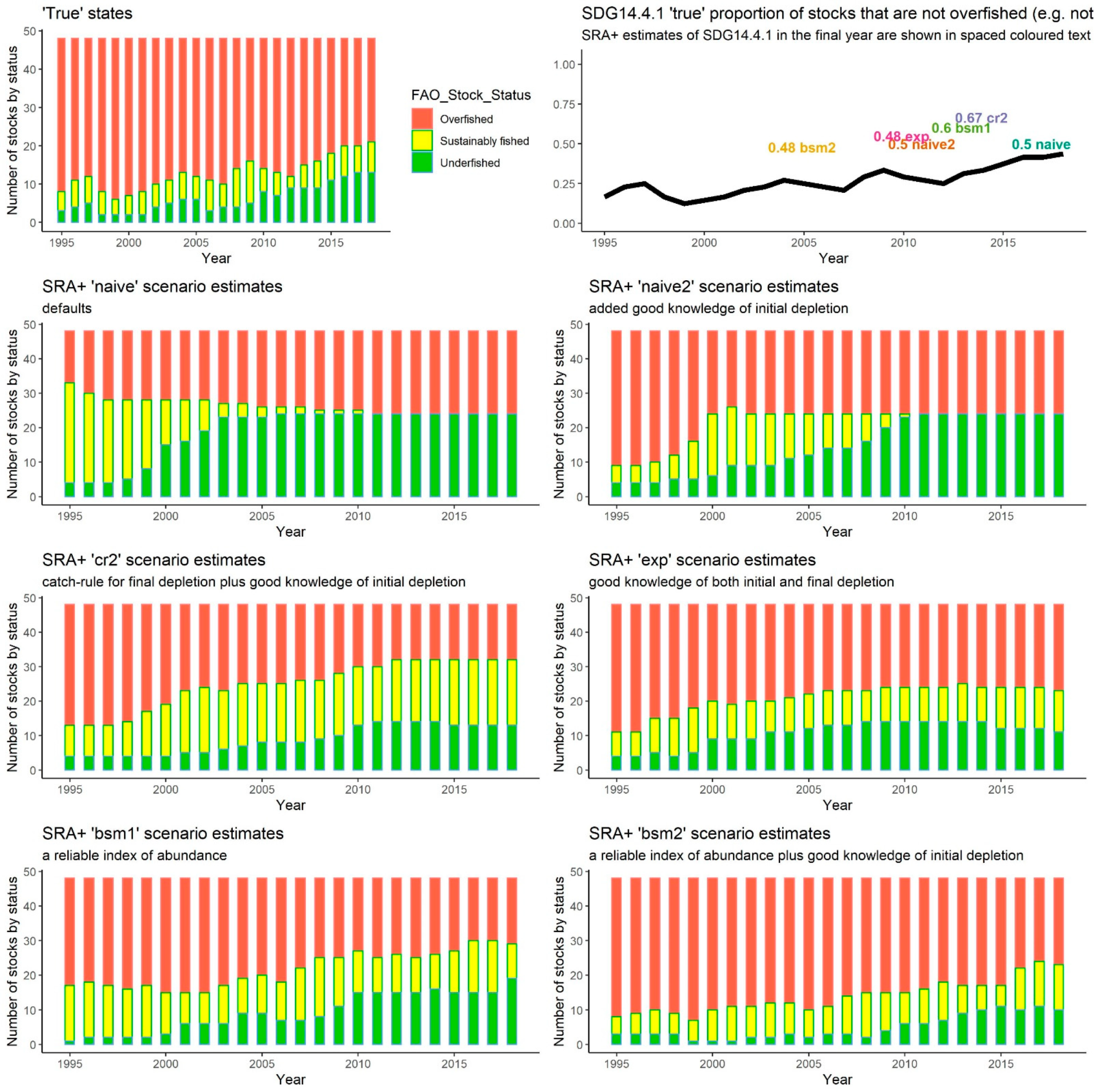
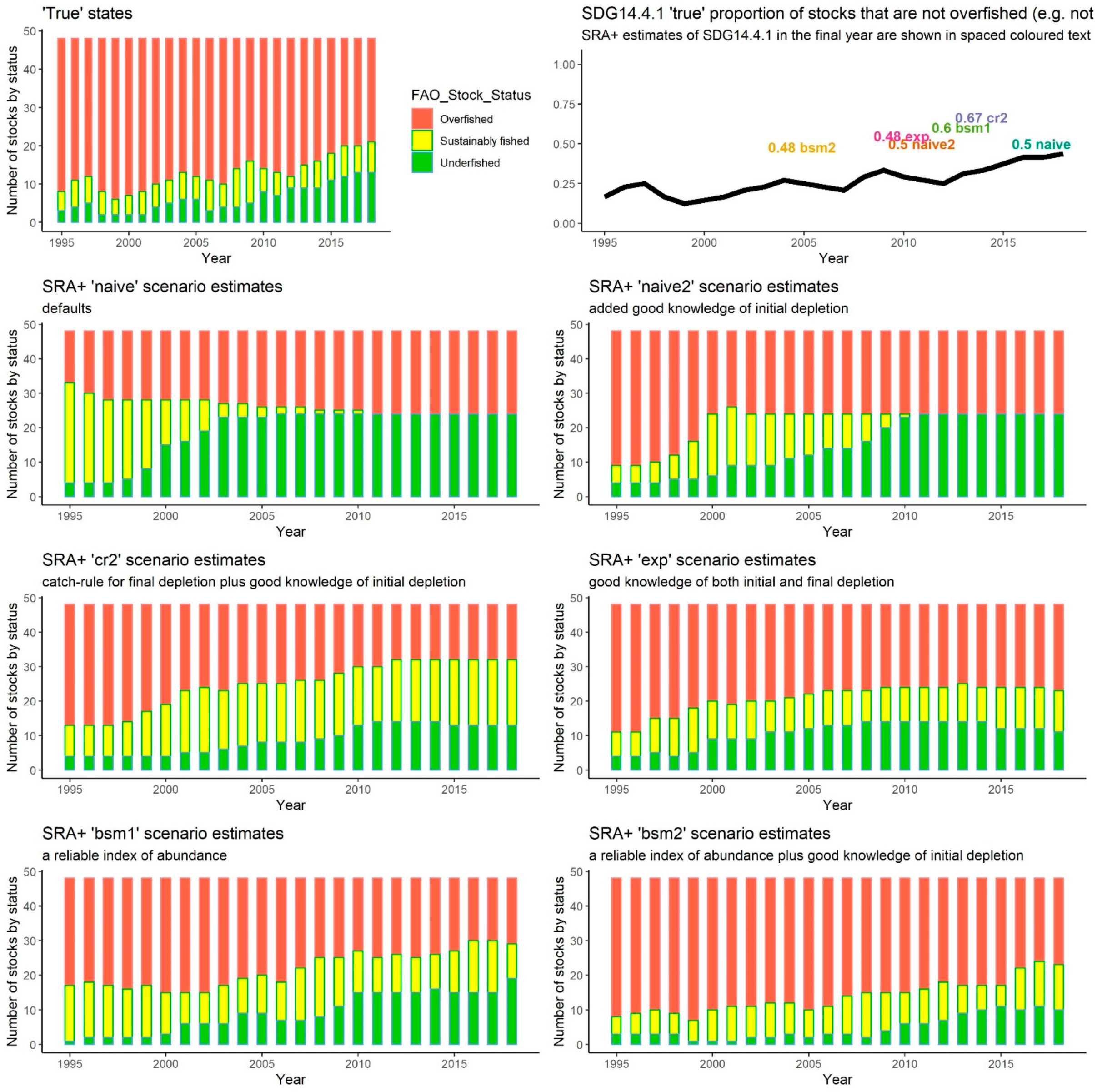
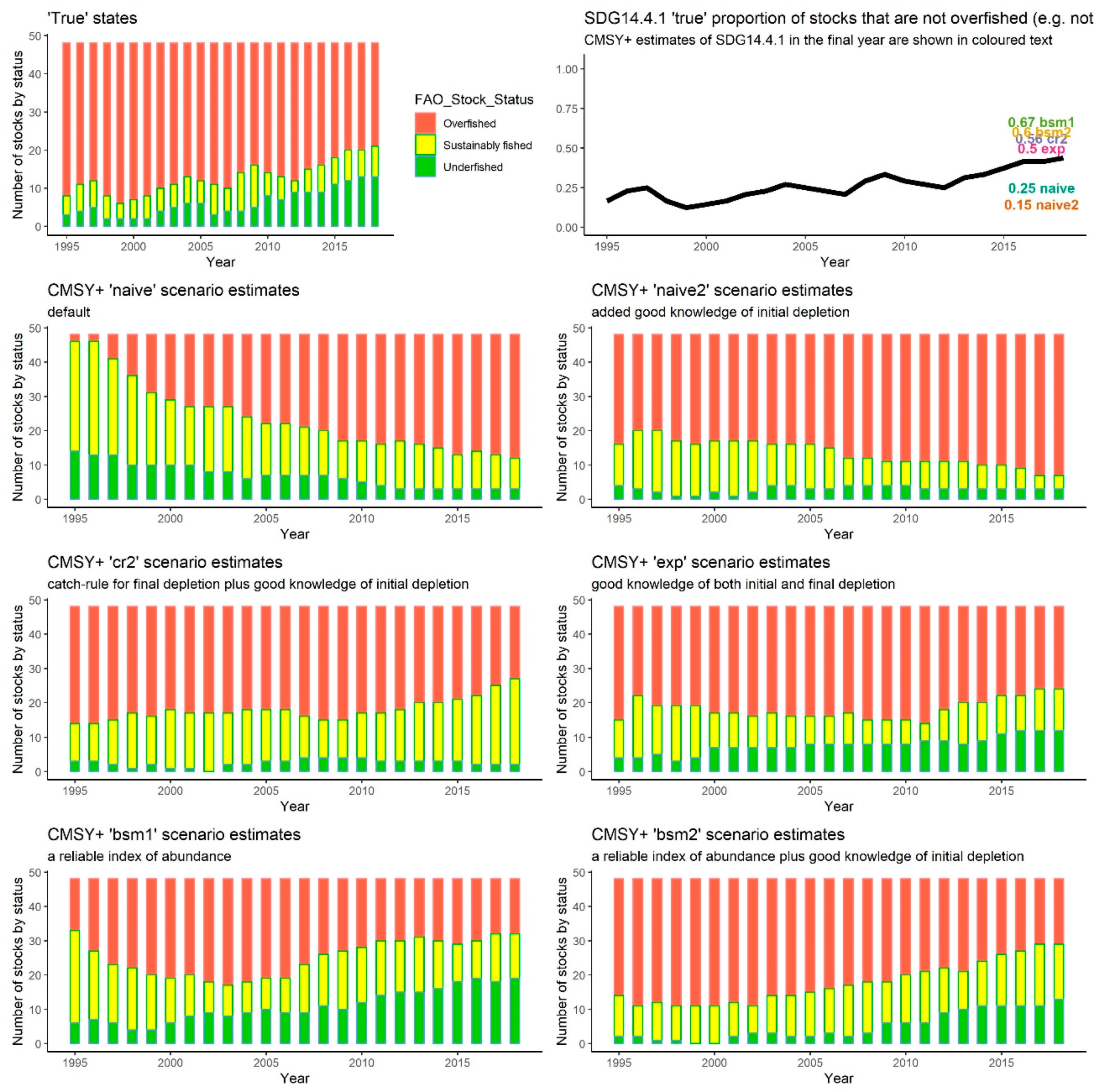
At a first glance, it does not seem that SRA+ can capture the dynamics particularly well. Only in the ‘bsm2’ and ‘exp’ scenarios, which correspond to having a very good guess about initial depletion and either a superb index of abundance (good expert knowledge of biomass dynamics over time) in the case of ‘bsm2’ or final depletion in the case of ‘exp’, can it be considered to do an adequate job, although that is a subjective judgement. In all scenarios, SRA+ overestimates the final value of SDG 14.4.1: the ‘exp’ and ‘bsm2’ estimates (~48%) come closest (
Figure 3), while the ‘cr2’ scenario is the most positively biased, predicting that the proportion of sustainably fished stocks in the final year is 67% while the true value is 44%.
Perhaps of less significance is that the models were only able to assess the initial depletion with a reasonable precision when given a very informative prior for that quantity. Without extra helpful knowledge of initial depletion, and especially with default heuristic as priors (‘naive’ scenario), the SRA+ model’s assessment of the initial proportion of overfished stocks was poor. The same conclusion holds for the CMSY+ model (
Figure 2); see ‘naive’ and ‘bsm1’ scenarios which lack informative priors on initial depletion.
Similarly, CMSY+ did not seem to document the evolution of the fishery to a satisfying degree, except in the case (‘bsm2’) when the model was given a very good hint of what was happening over time (a perfect index of abundance) and near-perfect information about what was going on at the beginning (a very informative initial depletion prior). Even in those fortunate circumstances, this method seems to be performing worse than the SRA+ model (given the same information) and, worryingly, it appears to arrive at overly optimistic conclusions. The ‘true’ SDG14.4.1 indicator tells us that 44% of stocks in the final year are not overfished, while SRA+ ‘bsm2’ estimates the percentage to be 48%, and CMSY+ ‘bsm2’ thinks that SDG14.4.1 is 60%. In terms of estimating the final proportion of stocks that are not overfished, the ‘exp’ scenario comes closest. For the CMSY+ its estimate of SDG14.4.1 in the final year is 50%, only somewhat overoptimistic compared to the true estimate of 44%.
Relative errors across trajectories indicate that it is possible for the methods to capture the trend in the aggregate even if individual stock trajectories are assessed with bias for most of the time series, since the bias is in both directions an average error across all stocks and might be small as biases cancel each other out (
Table 2).
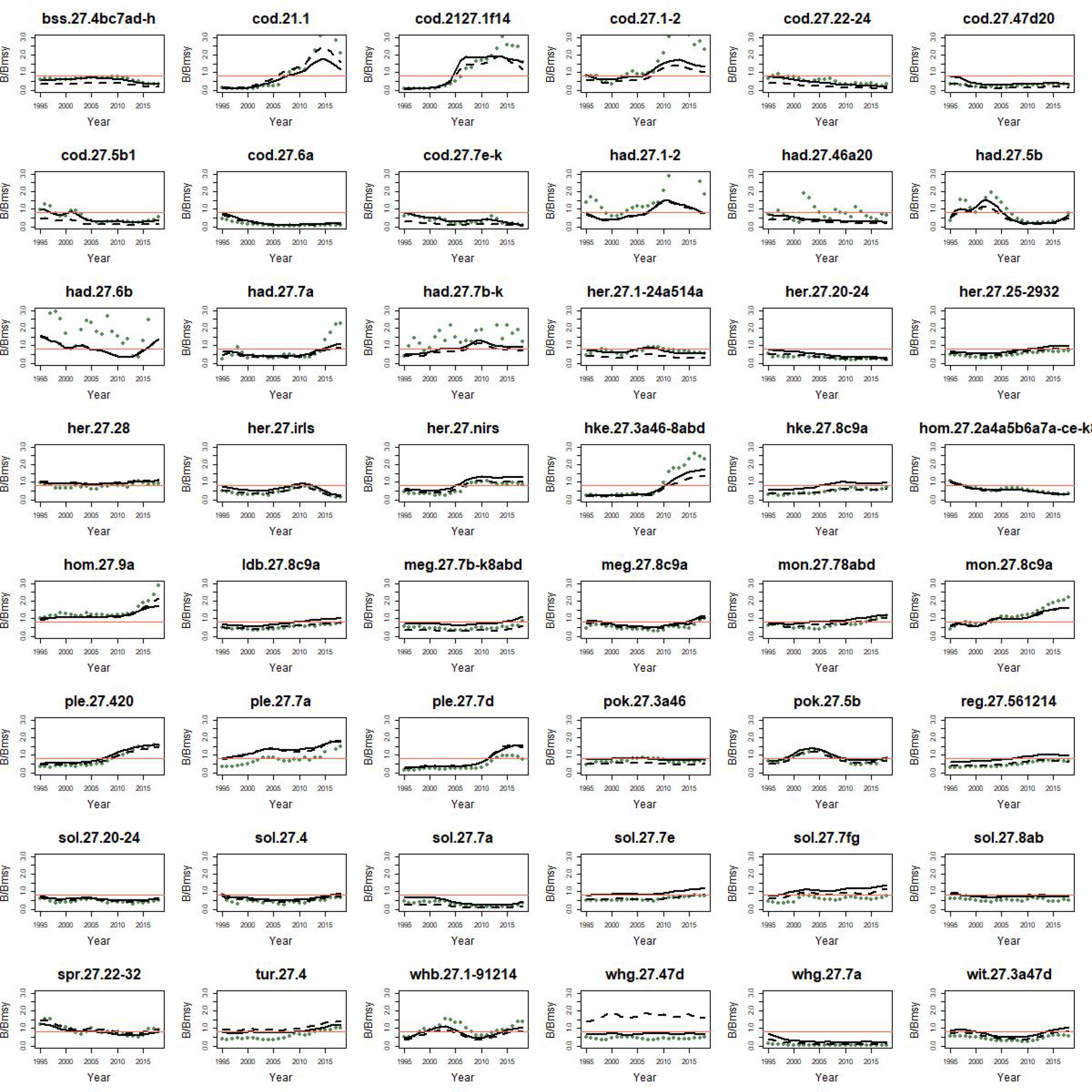
This emphasizes that while these methods appear to be good for classification on the aggregations of stocks, they probably should not be used for prescriptive assessment advice on a single species in the short term. In
Figure 4, we can compare how well these two best-performing scenarios, SRA+ ‘bsm2’ and CMSY ‘bsm2’, are able to estimate dynamics of individual stocks. It is clear from
Figure 4 that the methods are sometimes finding it difficult to track an individual species’ relative abundance over time even when given a very informative index of abundance and a spot-on guess at initial depletion (‘bsm2’). For many stocks, the ‘bsm2’ version allows both models to track relative abundance fairly consistently.
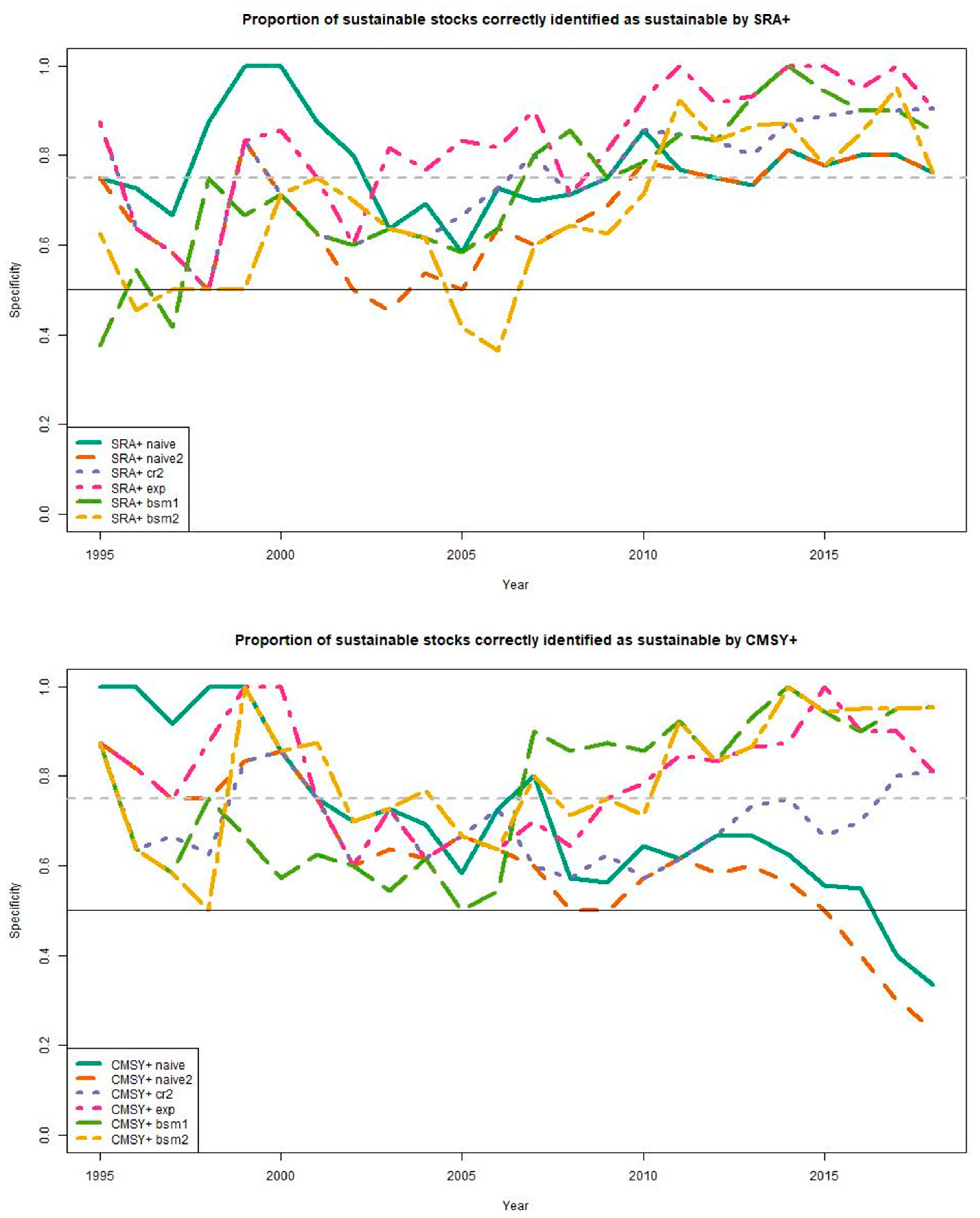
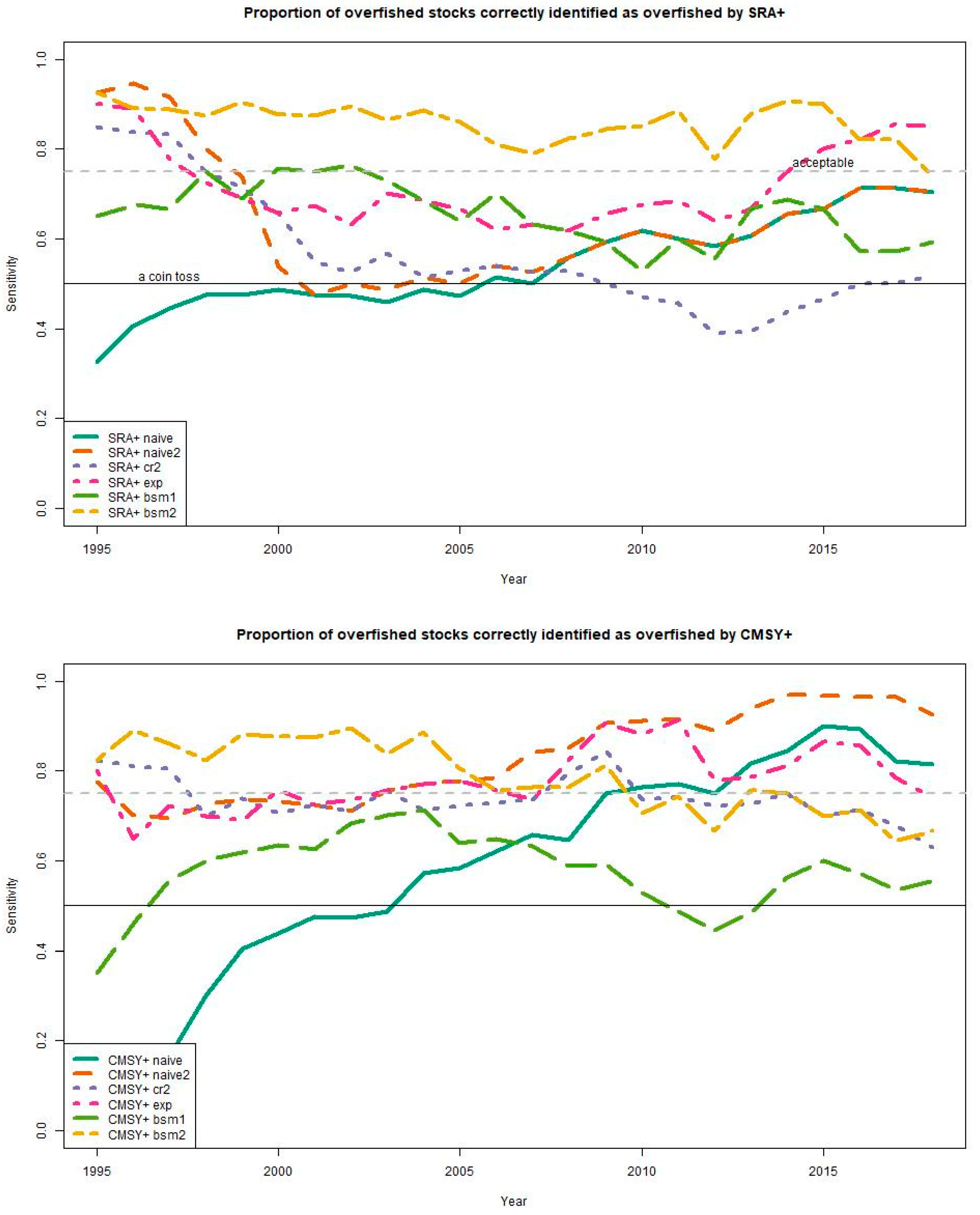
In
Figure 5 and
Figure 6 we consider the
sensitivity and
specificity of the two models under the same six scenarios. The
sensitivity of a test is the probability of correctly identifying an unwelcome condition, here overfishing, and
specificity is an ability to diagnose an absence of an ill condition correctly, so correctly identifying when there is no overfishing. Type II error, or the probability of labeling an overfished stock as ‘sustainable’ in FAO terminology, is 100% minus sensitivity, which is shown in
Figure 5. It is debatable what is the minimum sensitivity or specificity values that we would consider acceptable, but certainly the higher the better. We probably want at least a 75% chance of telling when a fishery is overfished and a similar probability for identifying correctly sustainable fisheries. This is equivalent to considering that an acceptable type II error should be less than 25% (100−75%), or, in other words, that fewer than 1 in 4 overfished stocks should be mislabeled as ‘sustainable’. By these criteria, only SRA+ (in the ‘bsm2’ and ‘exp’ scenarios) is acceptable in terms of both sensitivity and specificity as it is above 75% in the final year in two of the scenarios (
Figure 5 and
Figure 6). For the CMSY+ model, the scenarios that do okay on sensitivity (‘naive’ and ‘naive2’) do not perform well on specificity.
Of all of the scenarios explored here, only one potential method seems promising: SRA+ when it can be supplied with a good estimate of initial abundance and also provided with either a reliable index of abundance (‘bsm2’) or final depletion estimate (‘exp’). If the 75% threshold criterion is slightly relaxed then the ‘exp’ scenario in CMSY+ is also doing reasonably well (it dips slightly below the threshold in the final year but does well overall). However, it is not a scientist’s role to suggest acceptability criteria: the acceptability thresholds mentioned here are open to discussion and revisions; it is up to managers and stakeholders to make the final call. This leads us to cautious conclusions.
4. Discussion
While data-limited models (DLM) such as those seen in [
1,
2] focus on management procedures (MPs) that would ensure sustainable fisheries with simple data-poor control rules, the methods focused on here are estimating stock status in a synoptic sense.
We evaluated the ability of two COMs, SRA+ and CMSY+, to inform on the status of fisheries stocks, using varying levels of informative data. Our results corroborate those of [
8], pointing to problems with much of the heuristics-based methods used in COMs, and indicate that one should not run these models using the default settings. Knowledge of the shape of the production function and informative priors are essential for getting a good estimate of depletion in the final year when using COMs. Both implementations unsurprisingly performed well if one had a good prior knowledge of the fishery for a stock. In particular, good initial depletion estimates were needed. If the time series are short, which is the case for most assessment models (e.g., Stock Synthesis in [
29] or JABBA [
25]), initial depletion is difficult to estimate. Approaches currently under development [
29,
30,
31] indicate that using external sources of information, such as swept area ratio (SAR [
29]) or a fishery management index (FMI, [
32]) could provide information on current depletion. This would be especially valuable in cases where there is limited information on the history of the fishery. Catch data by themselves can be uninformative about changes in depletion; for example, catch could be relatively constant in a fishery where entry was unrestricted and the stock declining.
While these methods may be suitable for categorizing data-poor stocks in aggregate considering that the overall bias is relatively low when averaged for a number of stocks (
Table 2), there is no substitute for field programs and direct data relevant to assessments (survey data or length data). The better the information, the better we can truly understand the dynamics of these fisheries, and act to reduce the risk to both marine environments and society. In many parts of the world, however, this may not be possible without international assistance as such fisheries data collection programs are expensive to run, and government budgets are limited and stressed by other priorities [
32]. However, the long-term cost of depleting a resource may be much greater than the investment required to obtain better data and manage fisheries sustainably.
As shown in the analysis, these approaches have some potential in regional overviews even if the individual assignments are inaccurate. When combined with informative priors, COMs can provide broad advice for a region and globally. The algorithms used for classification need to be clearly documented, so one can replicate the methodology—reproducibility has been neglected in the global scale studies [
10]. In addition, the potential of developing priors from external sources make these approaches attractive as their performance can be improved as soon as more data is collected on the ground.
Finally, SDG 14.4.1, a UN sustainable development goal, states: “By 2020, effectively regulate harvesting and end overfishing, illegal, unreported and unregulated fishing and destructive fishing practices and implement science-based management plans, in order to restore fish stocks in the shortest time feasible, at least to levels that can produce maximum sustainable yield as determined by their biological characteristics”. COM models could be developed to report on SDG 14.4.1 on a country or regional level, providing a standardized method so we can track progress across the world in a universal manner. However, there are clearly problems when using COM models without the support of informative priors. The results of this paper support the concerns that were raised about catch-only methods in some of the previous evaluations [
8,
33]. In particular, it appears especially clear that the default settings for these models, even when informed by life history meta-analyses such as FishBase, should not be expected to provide reliable estimates of individual species dynamics. Under the default settings, these methods can provide a distorted picture of evolution of stocks over time on a regional level (FAO global assessments), and should not be relied upon in their default settings to provide meaningful estimates of the SDG14.4.1 indicator that the UN needs to track sustainable development goals related to overfishing. The SRA+ model seems to be positively biased, and is likely to say that a higher proportion of fish stocks are harvested sustainably than is really the case. Only when provided with informative priors does SRA+ mislabel fewer than 1 in 4 overfished stocks as ‘sustainable’. However, while the SRA+ model is likely to present a more optimistic outlook, the CMSY+ model’s estimates of SDG14.4.1 can be more pessimistic than reality (especially if close to default settings, when it mislabeled around 3 out of 4 sustainably fished stocks as ‘overfished’).
Performance of both models improves when extra knowledge is being supplied in terms of informative priors. Unsurprisingly, the most valuable thing in terms of improving overall model performance is informative priors of initial depletion combined with an excellent index of abundance. A natural recommendation follows that if alternative models are not applicable due to the lack of data, then investing in eliciting knowledge on the initial state of the stock and research that can be used to construct a plausible index of abundance would be worthwhile. Further, improving the knowledge basis on life history parameters for a wider range of fish stocks is paramount, if COMs are to find wider application, as this information is also used by the models. From this investigation, although it has various limitations, further broad conclusions can be drawn that are probably fairly robust. While, the SRA+ is marginally superior to the CMSY+ method if both sensitivity and specificity of the method are important, we recommend that both these methods continue to be developed and tested and alternative model options are explored. This study also raises concerns around using COMs when good information on initial depletion and index of abundance is not available, especially in the context of managing individual stocks. We found that COMs misidentify overfished stocks as ‘sustainable’ at a high rate. Therefore, our study lends weight to robust management practices approaches that are likely to protect marine ecosystems and the wellbeing of people dependent on them even in the absence of precise and timely information on the status of individual stocks.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}