
Real-Time DDoS Attack Detection System Using Big Data Approach

 ,
,  , ,
, ,
Abstract
:1. Introduction
- Intrusion detection (ID) is divided into two processes: monitoring the intrusions and analyzing a network’s events to seek any malicious packets or a source in the computer network or a computer system.
- Intrusion Detection System (IDS) detects an event as an intrusion when a noticeably different event occurs from a legitimate or authorized event [9].
- As far as we know, there is no study such as this, which has compared accuracies as well as execution time with machine learning and Apache Spark ML on Distributed Denial of Service (DDoS).
- We detected DoS attacks in an efficient manner with and without the use of big data machine learning approaches in Random Forest and Multi-Layer Perceptron models.
- In addition to the detection of DDoS attack, we have optimized the performance of the models by minimizing the execution time as compared with other existing approaches using the big data framework.
2. Related Work
3. Material and Methodology
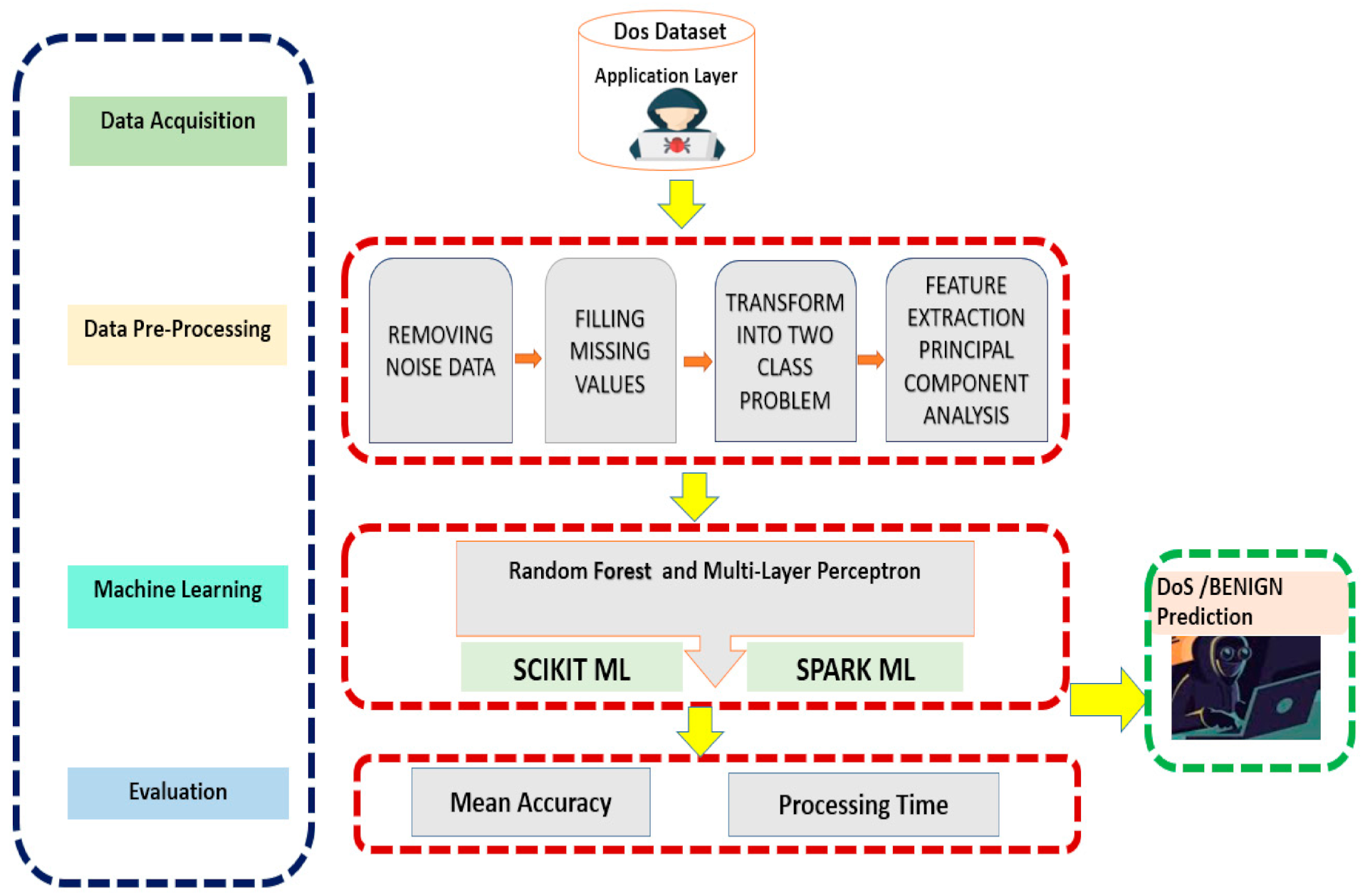
3.1. Dataset
3.2. Our Approach and Data Pre-Processing
3.3. Classification Machine Learning Models
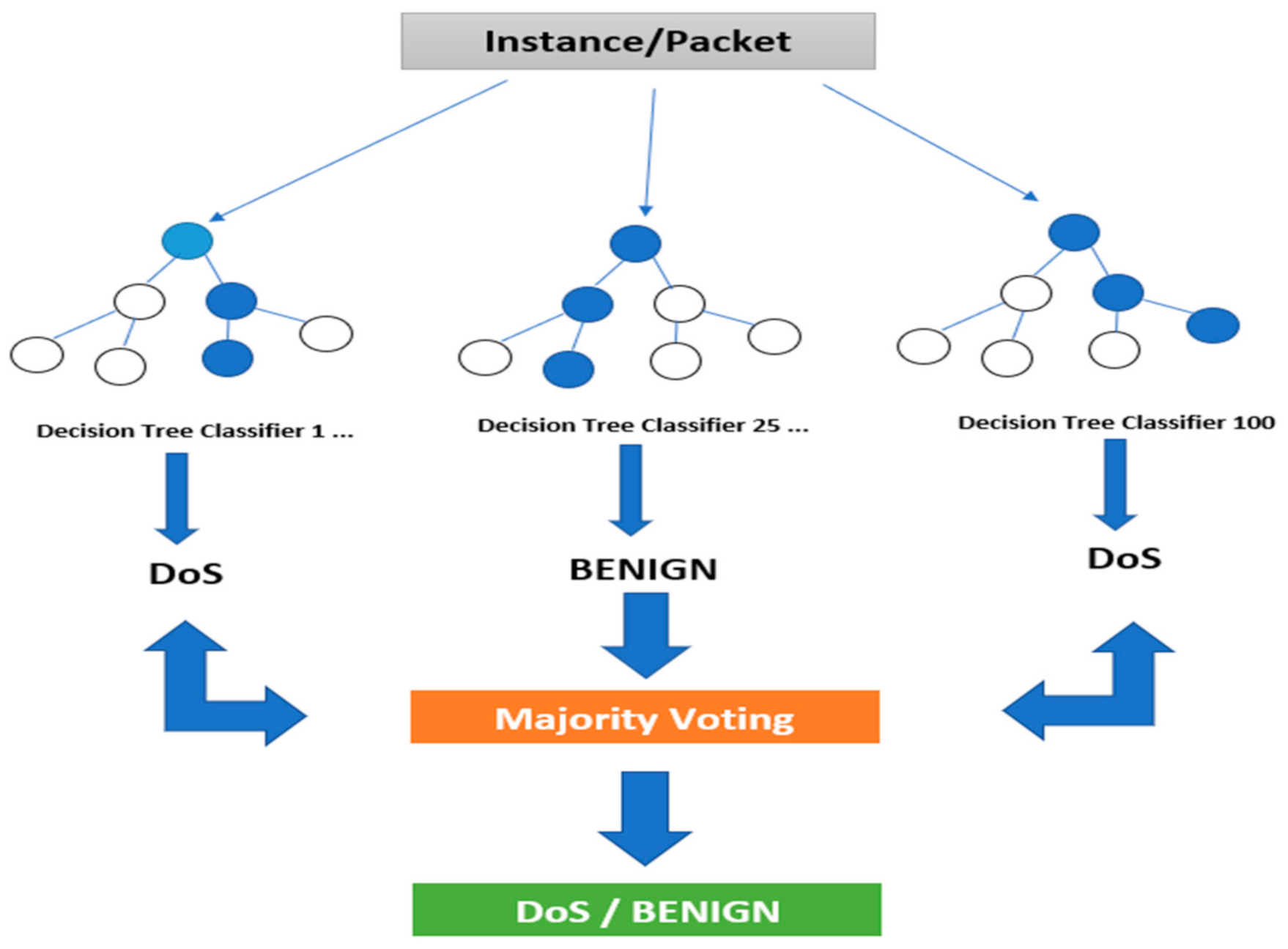
3.3.1. Random Forest
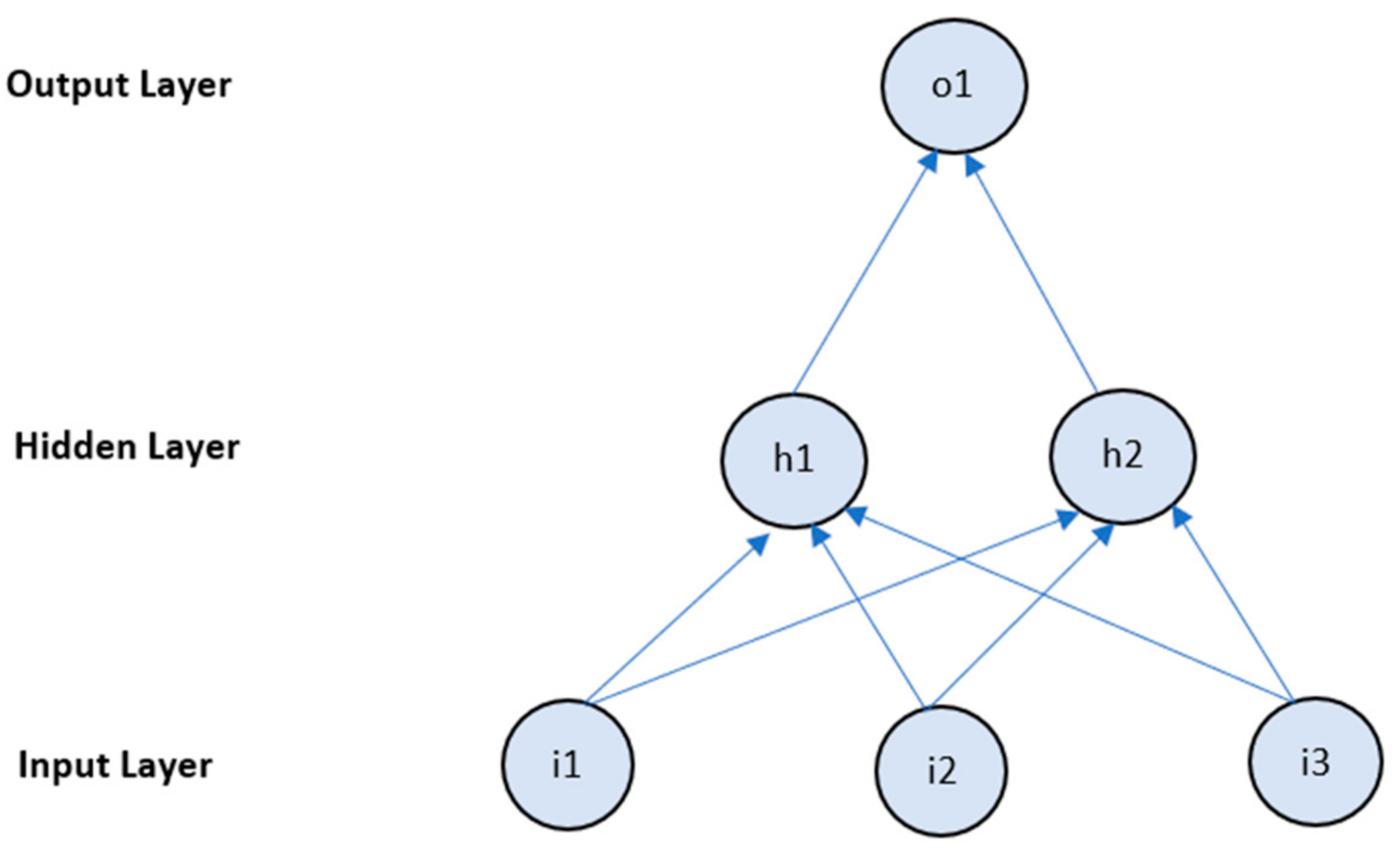
3.3.2. Multi-Layer Perceptron
4. Experiments and Results
4.1. Experiment Setup
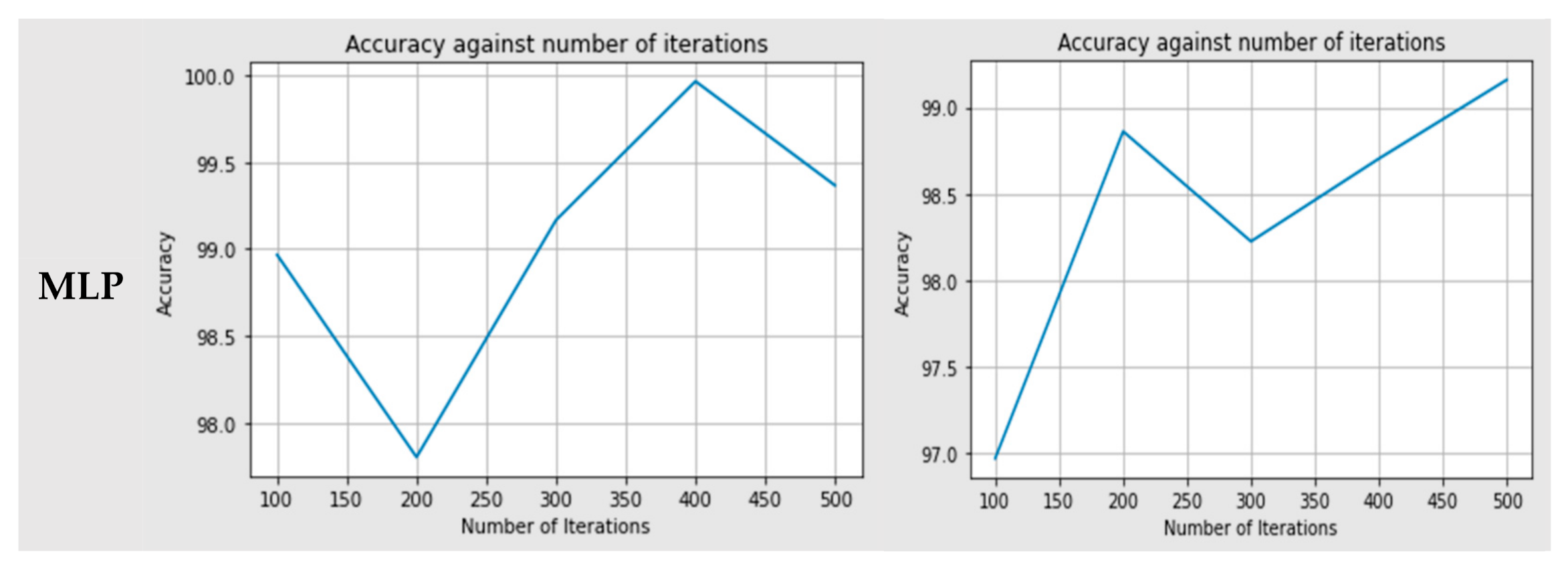
4.2. Experimental Parameters
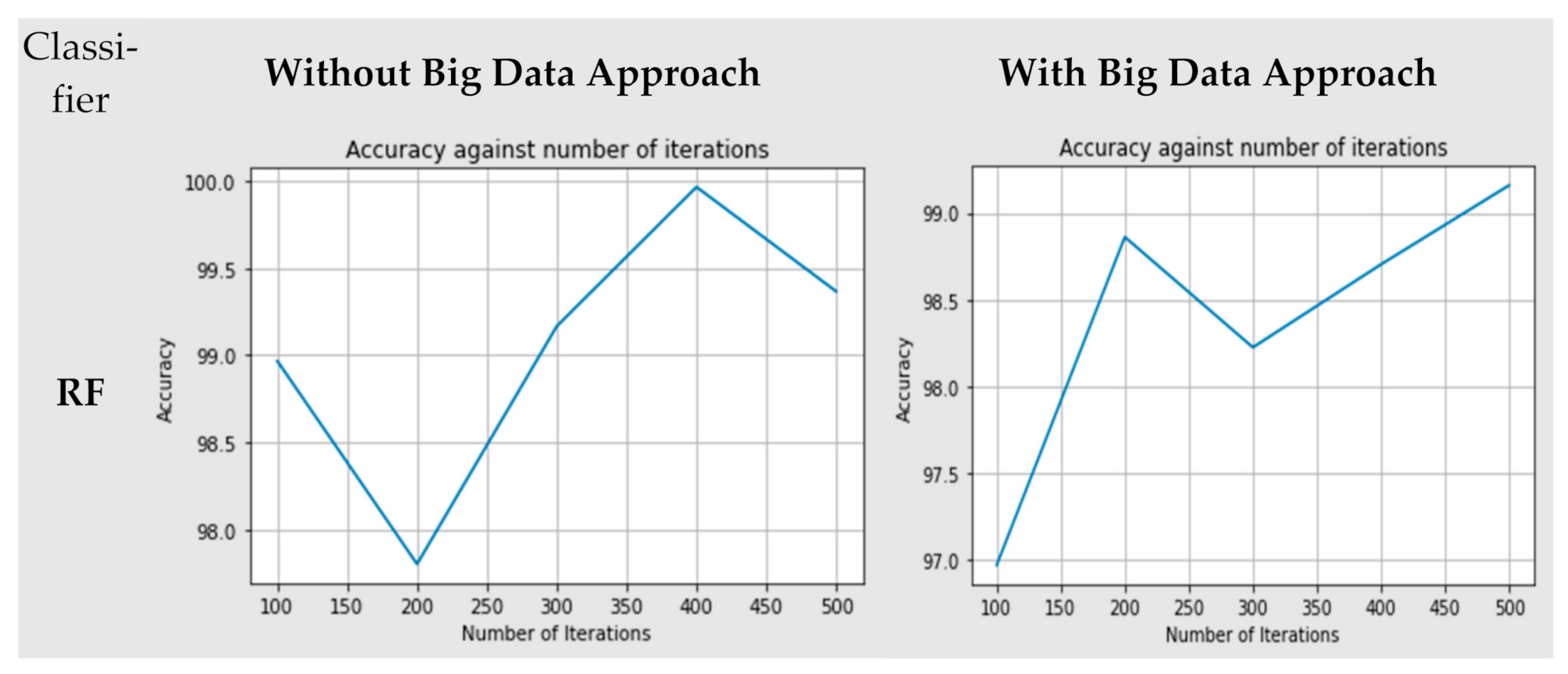
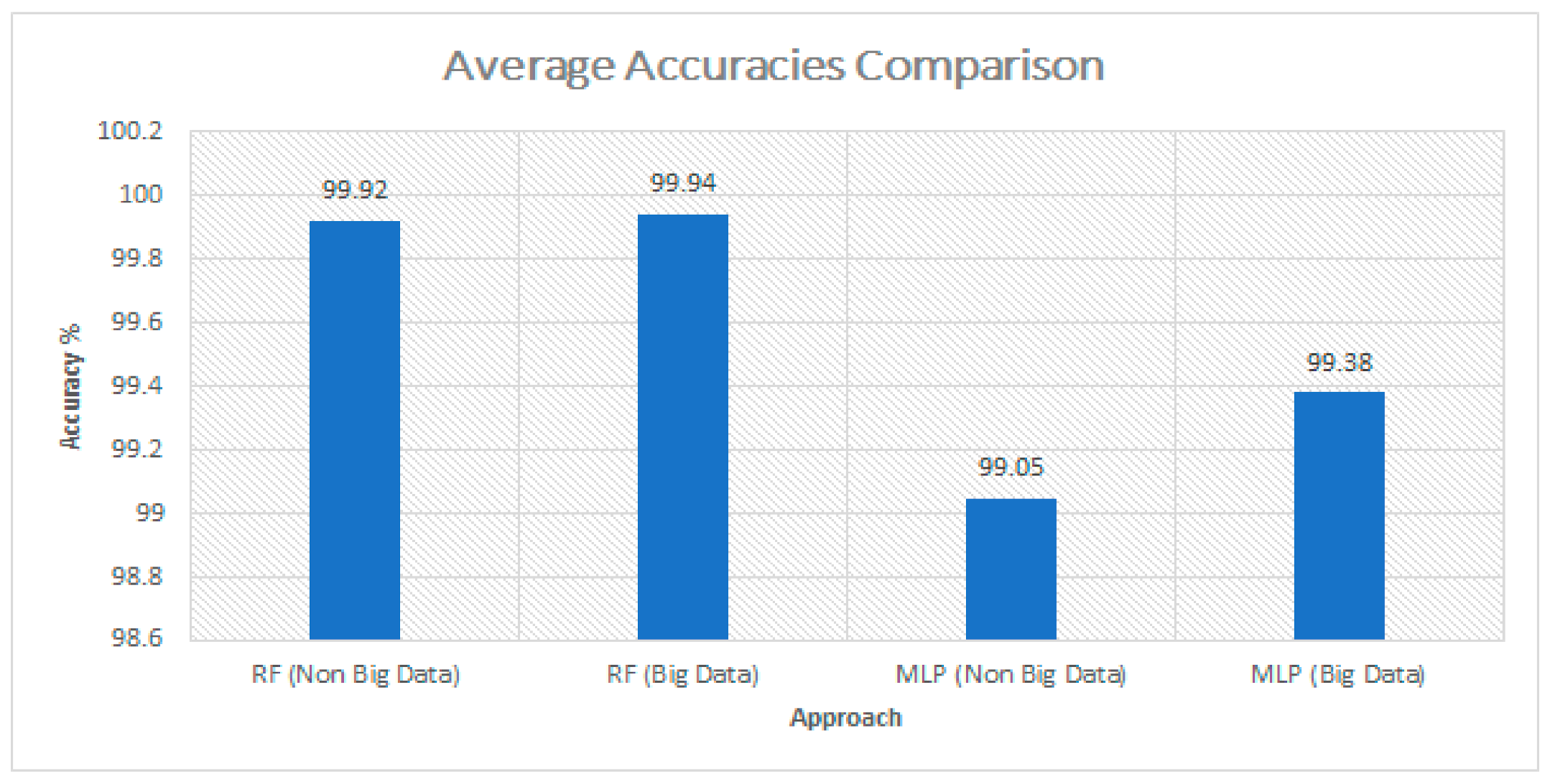
4.3. Evaluation Results
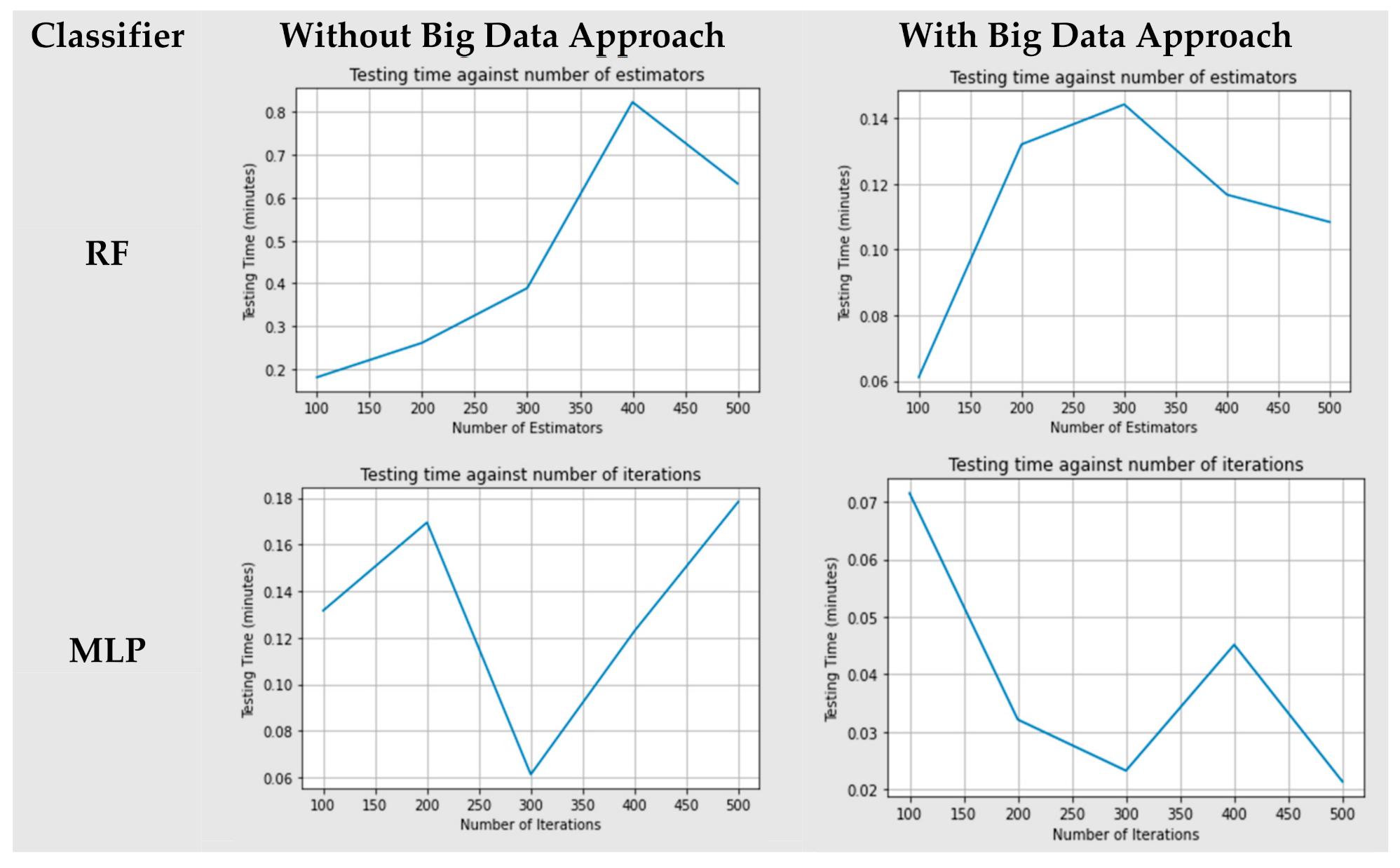
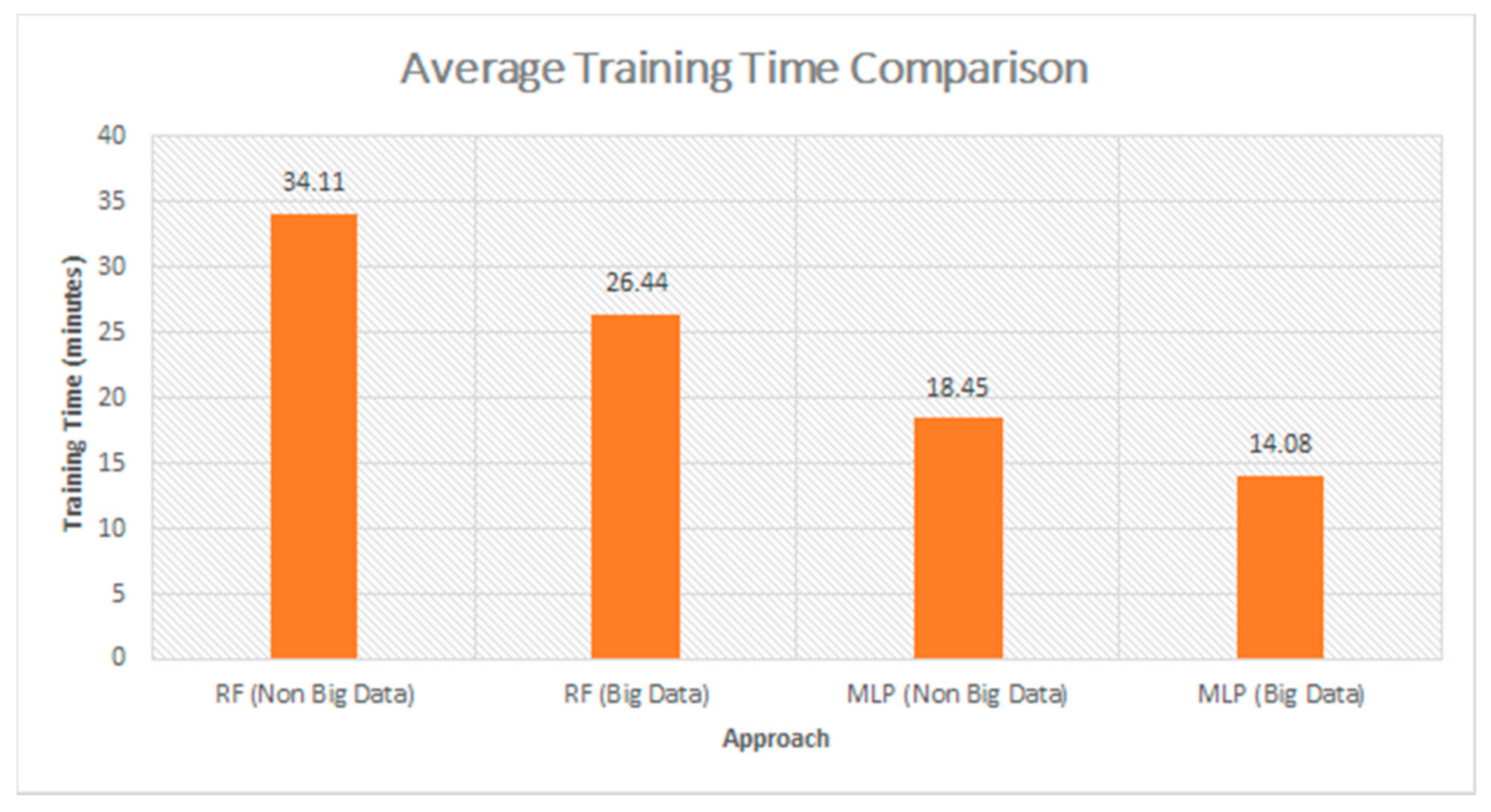
4.4. Execuation Time
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AODE | Average One-Dependence Estimator |
| CAIDM | Collaborative and Adaptive Intrusion Detection Model |
| CIA | Confidentiality, integrity and availability |
| CNN | Convolutional Neural Network |
| DBN | Deep Belief Network |
| DBN-EGWO-KELM | Deep Belief Network—Enhanced Grey Wolf Optimizer—Kernel-based Extreme Learning Machine |
| DDoS | Distributed Denial of Service |
| DoS | Denial of Service |
| DR | Diabetic retinopathy |
| DT | Decision Tree |
| E-CARGO | Environments classes, agents, roles, groups, and objects |
| EGWO | Enhanced Grey Wolf Optimizer |
| ELM | Extreme Learning Machine |
| FCM | Fuzzy C-Means |
| HG-GA | Hyper-graph based Genetic Algorithm |
| ID | Intrusion Detection |
| IDS | Intrusion Detection System |
| KELM | Kernel-based Extreme Learning Machine |
| KM | K-Means |
| KNN | K-Nearest Neighbors |
| LFCM | Literal Fuzzy c-Means |
| LMDRT | Logarithm Marginal Density Ratios Transformation |
| LR | Logistic Regression |
| LSTM | Long Short-Term Memory |
| ML | Machine learning |
| MLP | Multi-Layer Perceptron |
| MQTT | Message Queuing Telemetry Transport |
| NB | Naïve Bayes |
| NIST | National Institute of Standards and Technology |
| NSL | Network Security Laboratory |
| PCA | Parallel Principal Component Analysis |
| PSO and KNN | Particle Swarm Optimization and K-Nearest Neighbors |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| RNN-IDS | Recurrent Neural Network Intrusion Detection System |
| SDN | Software Defined Network |
| SGD | Stochastic Gradient Descent |
| SRSIO-FCM | The Scalable Random Sampling with Iterative Optimization Fuzzy c-Means algorithm |
| SVC | Support Vector Classifier |
| SVC-RF | Support Vector Classifier with Random Forest |
| SVM | Support Vector Machine |
References
- Munoz-Arcentales, A.; López-Pernas, S.; Pozo, A.; Alonso, Á.; Salvachúa, J.; Huecas, G. Data Usage and Access Control in Industrial Data Spaces: Implementation Using FIWARE. Sustainability 2020, 12, 3885. [Google Scholar] [CrossRef]
- Song, J.; Lee, Y.; Choi, J.-W.; Gil, J.-M.; Han, J.; Choi, S.-S. Practical In-Depth Analysis of IDS Alerts for Tracing and Identifying Potential Attackers on Darknet. Sustainability 2017, 9, 262. [Google Scholar] [CrossRef] [Green Version]
- Rehma, A.A.; Awan, M.J.; Butt, I. Comparison and Evaluation of Information Retrieval Models. VFAST Trans. Softw. Eng. 2018, 6, 7–14. [Google Scholar]
- Alam, T.M.; Awan, M.J. Domain analysis of information extraction techniques. Int. J. Multidiscip. Sci. Eng. 2018, 9, 1–9. [Google Scholar]
- Koo, J.; Kang, G.; Kim, Y.-G. Security and Privacy in Big Data Life Cycle: A Survey and Open Challenges. Sustainability 2020, 12, 10571. [Google Scholar] [CrossRef]
- Privalov, A.; Lukicheva, V.; Kotenko, I.; Saenko, I. Method of Early Detection of Cyber-Attacks on Telecommunication Networks Based on Traffic Analysis by Extreme Filtering. Energies 2019, 12, 4768. [Google Scholar] [CrossRef] [Green Version]
- Nishanth, N.; Mujeeb, A. Modeling and detection of flooding-based denial-of-service attack in wireless ad hoc network using Bayesian inference. IEEE Syst. J. 2020, 15, 17–26. [Google Scholar] [CrossRef]
- Scarfone, K.; Mell, P. Guide to intrusion detection and prevention systems (idps). NIST Spec. Publ. 2007, 800, 94. [Google Scholar]
- Mukherjee, B.; Heberlein, L.T.; Levitt, K.N. Network intrusion detection. IEEE Netw. 1994, 8, 26–41. [Google Scholar] [CrossRef]
- Gupta, M.; Jain, R.; Arora, S.; Gupta, A.; Awan, M.J.; Chaudhary, G.; Nobanee, H. AI-enabled COVID-9 Outbreak Analysis and Prediction: Indian States vs. Union Territories. Comput. Mater. Contin. 2021, 67, 933–950. [Google Scholar] [CrossRef]
- Anam, M.; Ponnusamy, V.; Hussain, M.; Nadeem, M.W.; Javed, M.; Guan Goh, H.; Qadeer, S. Osteoporosis Prediction for Trabecular Bone using Machine Learning: A Review. Comput. Mater. Contin. 2021, 67, 89–105. [Google Scholar] [CrossRef]
- Ali, Y.; Farooq, A.; Alam, T.M.; Farooq, M.S.; Awan, M.J.; Baig, T.I. Detection of Schistosomiasis Factors Using Association Rule Mining. IEEE Access 2019, 7, 186108–186114. [Google Scholar] [CrossRef]
- Javed, R.; Saba, T.; Humdullah, S.; Jamail, N.S.M.; Awan, M.J. An Efficient Pattern Recognition Based Method for Drug-Drug Interaction Diagnosis. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 221–226. [Google Scholar]
- Nagi, A.T.; Awan, M.J.; Javed, R.; Ayesha, N. A Comparison of Two-Stage Classifier Algorithm with Ensemble Techniques On Detection of Diabetic Retinopathy. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 212–215. [Google Scholar]
- Abdullah, A.; Awan, M.; Shehzad, M.; Ashraf, M. Fake News Classification Bimodal using Convolutional Neural Network and Long Short-Term Memory. Int. J. Emerg. Technol. Learn. 2020, 11, 209–212. [Google Scholar]
- Polat, H.; Polat, O.; Cetin, A. Detecting DDoS Attacks in Software-Defined Networks Through Feature Selection Methods and Machine Learning Models. Sustainability 2020, 12, 1035. [Google Scholar] [CrossRef] [Green Version]
- Ochôa, I.S.; Leithardt, V.R.Q.; Calbusch, L.; Santana, J.F.D.P.; Parreira, W.D.; Seman, L.O.; Zeferino, C.A. Performance and Security Evaluation on a Blockchain Architecture for License Plate Recognition Systems. Appl. Sci. 2021, 11, 1255. [Google Scholar] [CrossRef]
- Dos Anjos, J.C.S.; Gross, J.L.G.; Matteussi, K.J.; González, G.V.; Leithardt, V.R.Q.; Geyer, C.F.R. An Algorithm to Minimize Energy Consumption and Elapsed Time for IoT Workloads in a Hybrid Architecture. Sensors 2021, 21, 2914. [Google Scholar] [CrossRef]
- Ganguly, S.; Garofalakis, M.; Rastogi, R.; Sabnani, K. Streaming algorithms for robust, real-time detection of ddos attacks. In Proceedings of the 27th International Conference on Distributed Computing Systems (ICDCS’07), Toronto, ON, Canada, 25–27 June 2007; p. 4. [Google Scholar]
- Awan, M.J.; Rahim, M.S.M.; Nobanee, H.; Yasin, A.; Khalaf, O.I.; Ishfaq, U. A Big Data Approach to Black Friday Sales. Intell. Autom. Soft Comput. 2021, 27, 785–797. [Google Scholar] [CrossRef]
- Awan, M.J.; Rahim, M.S.M.; Nobanee, H.; Munawar, A.; Yasin, A.; Azlanmz, A.M.Z. Social Media and Stock Market Prediction: A Big Data Approach. Comput. Mater. Contin. 2021, 67, 2569–2583. [Google Scholar] [CrossRef]
- Ahmed, H.M.; Javed Awan, M.; Khan, N.S.; Yasin, A.; Shehzad, H.M.F. Sentiment Analysis of Online Food Reviews using Big Data Analytics. Elem. Educ. Online 2021, 20, 827–836. [Google Scholar]
- Awan, M.J.; Khan, R.A.; Nobanee, H.; Yasin, A.; Anwar, S.M.; Naseem, U.; Singh, V.P. A Recommendation Engine for Predicting Movie Ratings Using a Big Data Approach. Electronics 2021, 10, 1215. [Google Scholar] [CrossRef]
- Awan, M.J.; Gilani, S.A.H.; Ramzan, H.; Nobanee, H.; Yasin, A.; Zain, A.M.; Javed, R. Cricket Match Analytics Using the Big Data Approach. Electronics 2021, 10, 2350. [Google Scholar] [CrossRef]
- Khalil, A.; Awan, M.J.; Yasin, A.; Singh, V.P.; Shehzad, H.M.F. Flight Web Searches Analytics through Big Data. Int. J. Comput. Appl. Technol. 2021, in press. [Google Scholar]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef] [Green Version]
- Park, K.O. A study on sustainable usage intention of blockchain in the big data era: Logistics and supply chain management companies. Sustainability 2020, 12, 10670. [Google Scholar] [CrossRef]
- Awan, M.J.; Khan, M.A.; Ansari, Z.K.; Yasin, A.; Shehzad, H.M.F. Fake Profile Recognition using Big Data Analytics in Social Media Platforms. Int. J. Comput. Appl. Technol. 2021, in press. [Google Scholar]
- Kshetri, N.; Torres, D.C.R.; Besada, H.; Ochoa, M.A.M. Big Data as a Tool to Monitor and Deter Environmental Offenders in the Global South: A Multiple Case Study. Sustainability 2020, 12, 10436. [Google Scholar] [CrossRef]
- Awan, M.J.; Yasin, A.; Nobanee, H.; Ali, A.A.; Shahzad, Z.; Nabeel, M.; Zain, A.M.; Shahzad, H.M.F. Fake News Data Exploration and Analytics. Electronics 2021, 10, 2326. [Google Scholar] [CrossRef]
- Zhang, H.; Dai, S.; Li, Y.; Zhang, W. Real-time distributed-random-forest-based network intrusion detection system using Apache spark. In Proceedings of the 2018 IEEE 37th International Performance Computing and Communications Conference (IPCCC), Orlando, FL, USA, 17–19 November 2018; pp. 1–7. [Google Scholar]
- Wang, H.; Xiao, Y.; Long, Y. Research of intrusion detection algorithm based on parallel SVM on spark. In Proceedings of the 2017 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC), Macau, China, 21–23 July 2017; pp. 153–156. [Google Scholar]
- Zekri, M.; El Kafhali, S.; Aboutabit, N.; Saadi, Y. DDoS attack detection using machine learning techniques in cloud computing environments. In Proceedings of the 2017 3rd International Conference of Cloud Computing Technologies and Applications (CloudTech), Rabat, Morocco, 24–26 October 2017; pp. 1–7. [Google Scholar]
- Halimaa, A.; Sundarakantham, K. Machine learning based intrusion detection system. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 916–920. [Google Scholar]
- Raman, M.G.; Somu, N.; Kirthivasan, K.; Liscano, R.; Sriram, V.S.S. An efficient intrusion detection system based on hypergraph-Genetic algorithm for parameter optimization and feature selection in support vector machine. Knowl.-Based Syst. 2017, 134, 1–12. [Google Scholar] [CrossRef]
- Wang, H.; Gu, J.; Wang, S. An effective intrusion detection framework based on SVM with feature augmentation. Knowl.-Based Syst. 2017, 136, 130–139. [Google Scholar] [CrossRef]
- Teng, S.; Wu, N.; Zhu, H.; Teng, L.; Zhang, W. SVM-DT-based adaptive and collaborative intrusion detection. IEEE/CAA J. Autom. Sin. 2017, 5, 108–118. [Google Scholar] [CrossRef]
- Ahmad, I.; Basheri, M.; Iqbal, M.J.; Rahim, A. Performance comparison of support vector machine, random forest, and extreme learning machine for intrusion detection. IEEE Access 2018, 6, 33789–33795. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A deep learning approach for intrusion detection using recurrent neural networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Li, Z.; Yan, G. A Spark Platform-Based Intrusion Detection System by Combining MSMOTE and Improved Adaboost Algorithms. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 1046–1049. [Google Scholar]
- Aftab, M.O.; Awan, M.J.; Khalid, S.; Javed, R.; Shabir, H. Executing Spark BigDL for Leukemia Detection from Microscopic Images using Transfer Learning. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 216–220. [Google Scholar]
- Al-Qatf, M.; Lasheng, Y.; Al-Habib, M.; Al-Sabahi, K. Deep learning approach combining sparse autoencoder with SVM for network intrusion detection. IEEE Access 2018, 6, 52843–52856. [Google Scholar] [CrossRef]
- Kato, K.; Klyuev, V. Development of a network intrusion detection system using Apache Hadoop and Spark. In Proceedings of the 2017 IEEE Conference on Dependable and Secure Computing, Taipei, Taiwan, 7–10 August 2017; pp. 416–423. [Google Scholar]
- Marir, N.; Wang, H.; Feng, G.; Li, B.; Jia, M. Distributed abnormal behavior detection approach based on deep belief network and ensemble SVM using spark. IEEE Access 2018, 6, 59657–59671. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Thu, H.L.T.; Kim, H. Long short term memory recurrent neural network classifier for intrusion detection. In Proceedings of the 2016 International Conference on Platform Technology and Service (PlatCon), Jeju, Korea, 15–17 February 2016; pp. 1–5. [Google Scholar]
- Jha, P.; Tiwari, A.; Bharill, N.; Ratnaparkhe, M.; Nagendra, N.; Mounika, M. Fuzzy-Based Kernelized Clustering Algorithms for Handling Big Data Using Apache Spark. In Proceedings of 6th International Conference on Harmony Search, Soft Computing and Applications, ICHSA 2020, Advances in Intelligent Systems and Computing; Nigdeli, S.M., Kim, J.H., Bekdaş, G., Yadav, A., Eds.; Springer: Singapore, 2021; Volume 1275. [Google Scholar] [CrossRef]
- Saravanan, S. Performance evaluation of classification algorithms in the design of Apache Spark based intrusion detection system. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 443–447. [Google Scholar]
- Syed, N.F.; Baig, Z.; Ibrahim, A.; Valli, C. Denial of service attack detection through machine learning for the IoT. J. Inf. Telecommun. 2020, 4, 482–503. [Google Scholar] [CrossRef]
- Priya, S.S.; Sivaram, M.; Yuvaraj, D.; Jayanthiladevi, A. Machine learning based DDoS detection. In Proceedings of the 2020 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 12–14 March 2020; pp. 234–237. [Google Scholar]
- Ujjan, R.M.A.; Pervez, Z.; Dahal, K.; Khan, W.A.; Khattak, A.M.; Hayat, B. Entropy Based Features Distribution for Anti-DDoS Model in SDN. Sustainability 2021, 13, 1522. [Google Scholar] [CrossRef]
- Gadze, J.D.; Bamfo-Asante, A.A.; Agyemang, J.O.; Nunoo-Mensah, H.; Opare, K.A.-B. An Investigation into the Application of Deep Learning in the Detection and Mitigation of DDOS Attack on SDN Controllers. Technologies 2021, 9, 14. [Google Scholar] [CrossRef]
- Ahuja, N.; Singal, G.; Mukhopadhyay, D.; Kumar, N. Automated DDOS attack detection in software defined networking. J. Netw. Comput. Appl. 2021, 187, 103108. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, Y.; Liu, Y.; Li, D. Deep belief network integrating improved kernel-based extreme learning machine for network intrusion detection. IEEE Access 2021, 9, 16062–16091. [Google Scholar] [CrossRef]
- Dehkordi, A.B.; Soltanaghaei, M.; Boroujeni, F.Z. The DDoS attacks detection through machine learning and statistical methods in SDN. J. Supercomput. 2021, 77, 2383–2415. [Google Scholar] [CrossRef]
- Warda. Application-Layer DDoS Dataset. Available online: https://www.kaggle.com/wardac/applicationlayer-ddos-dataset (accessed on 7 November 2019).
- Wang, F.; Lu, W.; Zheng, J.; Li, S.; Zhang, X. Spatially explicit mapping of historical population density with random forest regression: A case study of Gansu Province, China, in 1820 and 2000. Sustainability 2020, 12, 1231. [Google Scholar] [CrossRef] [Green Version]
- Awan, M.J.; Raza, A.; Yasin, A.; Shehzad, H.M.F.; Butt, I. The Customized Convolutional Neural Network of Face Emotion Expression Classification. Ann. Rom. Soc. Cell Biol. 2021, 25, 5296–5304. [Google Scholar]
- Awan, M.J. Acceleration of Knee MRI Cancellous bone Classification on Google Colaboratory using Convolutional Neural Network. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 83–88. [Google Scholar] [CrossRef]
- Salloum, S.; Dautov, R.; Chen, X.; Peng, P.X.; Huang, J.Z. Big data analytics on Apache Spark. Int. J. Data Sci. Anal. 2016, 1, 145–164. [Google Scholar] [CrossRef] [Green Version]
- Mujahid, A.; Awan, M.J.; Yasin, A.; Mohammed, M.A.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K.H. Real-Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model. Appl. Sci. 2021, 11, 4164. [Google Scholar] [CrossRef]
- Mubashar, R.; Awan, M.J.; Ahsan, M.; Yasin, A.; Singh, V.P. Efficient Residential Load Forecasting using Deep Learning Approach. Int. J. Comput. Appl. Technol. 2021, in press. [Google Scholar]
- Awan, M.J.; Rahim, M.S.M.; Salim, N.; Mohammed, M.A.; Garcia-Zapirain, B.; Abdulkareem, K.H. Efficient Detection of Knee Anterior Cruciate Ligament from Magnetic Resonance Imaging Using Deep Learning Approach. Diagnostics 2021, 11, 105. [Google Scholar] [CrossRef] [PubMed]
- Awan, M.J.; Bilal, M.H.; Yasin, A.; Nobanee, H.; Khan, N.S.; Zain, A.M. Detection of COVID-19 in Chest X-ray Images: A Big Data Enabled Deep Learning Approach. Int. J. Environ. Res. Public Health 2021, 18, 10147. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Metrics | Random Forest Classifier | Multi-Layer Perceptron | ||
|---|---|---|---|---|
| Without Big Data | With Big Data | Without Big Data | With Big Data | |
| Accuracy | 99.97% | 99.95% | 99.96% | 99.95% |
| Precision | 99.97% | 99.94% | 99.96% | 99.94% |
| Sensitivity | 99.98% | 99.97% | 99.97% | 99.97% |
| F1 Score | 99.97% | 99.95% | 99.97% | 99.96% |
| Matthews Correlation Coefficient | 99.94% | 99.90% | 99.93% | 99.91% |
| False-positive Rate | 0.04% | 0.07% | 0.05% | 0.07% |
| False Discovery Rate | 0.03% | 0.06% | 0.04% | 0.06% |
| False-Negative Rate | 0.02% | 0.03% | 0.03% | 0.03% |
| Specificity | 99.96% | 99.93% | 99.95% | 99.93% |
| Negative Predictive Value | 99.97% | 99.96% | 99.97% | 99.97% |
| Studies and Year | Model | Accuracy% | Execution Time (s) | Big Data Framework |
|---|---|---|---|---|
| Saravanan [47], 2020 | Logistic Regression | 93.90 | 0.48 | - |
| Decision Tree | 96.80 | 1.02 | - | |
| SVM | 92.80 | 2.28 | - | |
| SVM with SGD | 91.10 | 2.06 | - | |
| Ujjan, Pervez, Dahal, Khan, Khattak and Hayat [50], 2021 | SAE | 94% | 25% CPU used | - |
| CNN | 93% | - | ||
| Zhang, Dai, Li and Zhang [31], 2018 | Random Forest | 97.4% | 1.10 | Spark, (IDS detection) |
| Wang, Xiao and Long [32], 2017 | PCA-SVM | 86.31 | - | Spark, (IDS detection) |
| Parallel SVM | 87.72 | - | ||
| SP-PCA-SVM | 90.24 | - | ||
| Zekri, El Kafhali, Aboutabit and Saadi [33], 2017 | Naive Bayes | 91.40 | 1.25 | - |
| Decision Tree | 98.80 | 0.58 | - | |
| K-Means | 95.90 | 1.12 | - | |
| Halimaa and Sundarakantham [34], 2019 | SVM | 93.95 | - | - |
| Naive Bayes | 56.54 | - | - | |
| Wang, Zeng, Liu and Li [53], 2021 | DBN-KELM | 93.50 | - | - |
| DBN-EGWO-KELM | 98.60 | - | - | |
| Gadze, Bamfo-Asante, Agyemang, Nunoo-Mensah and Opare [51], 2020 | Long Short-Term Memory | 89.63 | 12.83 | - |
| Convolutional Neural Network | 66.00 | - | - | |
| Ahuja, Singal, Mukhopadhyay and Kumar [52], 2021 | Support Vector Classifier with Random Forest | 98.80 | - | - |
| Syed, Baig, Ibrahim and Valli [48], 2020 | Decision Trees | 99.09 | - | - |
| Multi-Layer Perceptron | 99.00 | - | - | |
| Average One-Dependence Estimator | 95.93 | - | - | |
| Dehkordi, Soltanaghaei and Boroujeni [54], 2021 | Logistic algorithms | 99.62 | 1.19 | - |
| Bayes-Net algorithm | 99.87 | 1.17 | - | |
| Random Tree algorithm | 99.33 | 1.17 | - | |
| REPTree algorithm | 99.80 | 1.16 | - | |
| K-Nearest Neighbors | 99.88 | 1.15 | - | |
| Priya, Sivaram, Yuvaraj and Jayanthiladevi [49], 2020 | Naive Bayes | 98.50 | - | - |
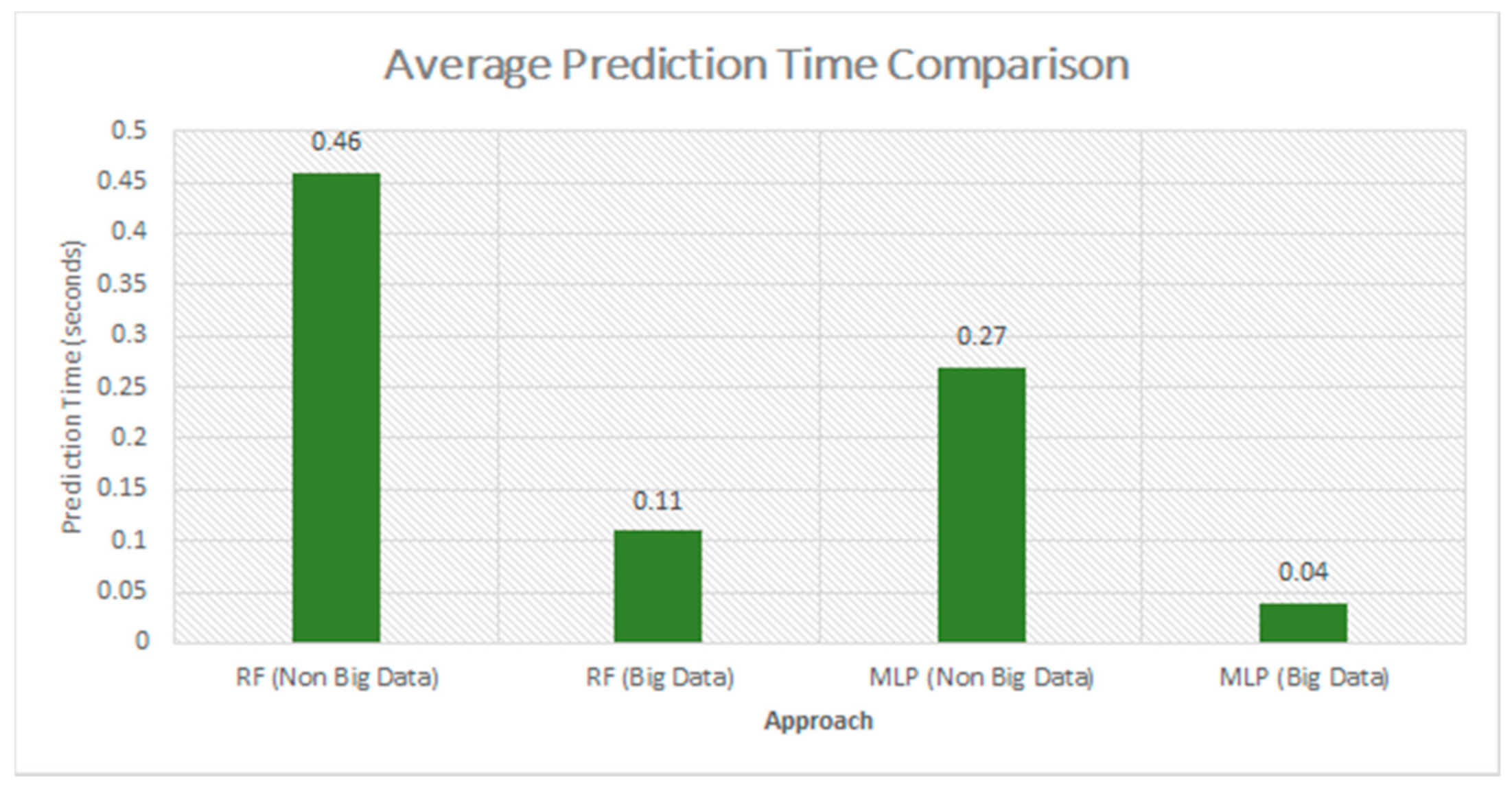
| Our Approach-I With and without big data | Random Forest | 99.92 | 0.46 | Without Big data |
| 99.94 | 0.11 | Spark ML | ||
| Our Approach-II With and without Big data | Multi-Layer Perceptron | 99.05 | 0.27 | Without Big data |
| 99.38 | 0.04 | Spark ML |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awan, M.J.; Farooq, U.; Babar, H.M.A.; Yasin, A.; Nobanee, H.; Hussain, M.; Hakeem, O.; Zain, A.M. Real-Time DDoS Attack Detection System Using Big Data Approach. Sustainability 2021, 13, 10743. https://0-doi-org.brum.beds.ac.uk/10.3390/su131910743
Awan MJ, Farooq U, Babar HMA, Yasin A, Nobanee H, Hussain M, Hakeem O, Zain AM. Real-Time DDoS Attack Detection System Using Big Data Approach. Sustainability. 2021; 13(19):10743. https://0-doi-org.brum.beds.ac.uk/10.3390/su131910743
Chicago/Turabian StyleAwan, Mazhar Javed, Umar Farooq, Hafiz Muhammad Aqeel Babar, Awais Yasin, Haitham Nobanee, Muzammil Hussain, Owais Hakeem, and Azlan Mohd Zain. 2021. "Real-Time DDoS Attack Detection System Using Big Data Approach" Sustainability 13, no. 19: 10743. https://0-doi-org.brum.beds.ac.uk/10.3390/su131910743