
Solving Traveling Salesman Problem with Time Windows Using Hybrid Pointer Networks with Time Features

 , , ,
, , ,
Abstract
:1. Introduction
- 2-opt isn’t an exact algorithm so the generated data won’t be solved optimally.
- This method does not take advantage of GPU parallelization, therefore model training will be excruciatingly slow.
2. Problem Formulation
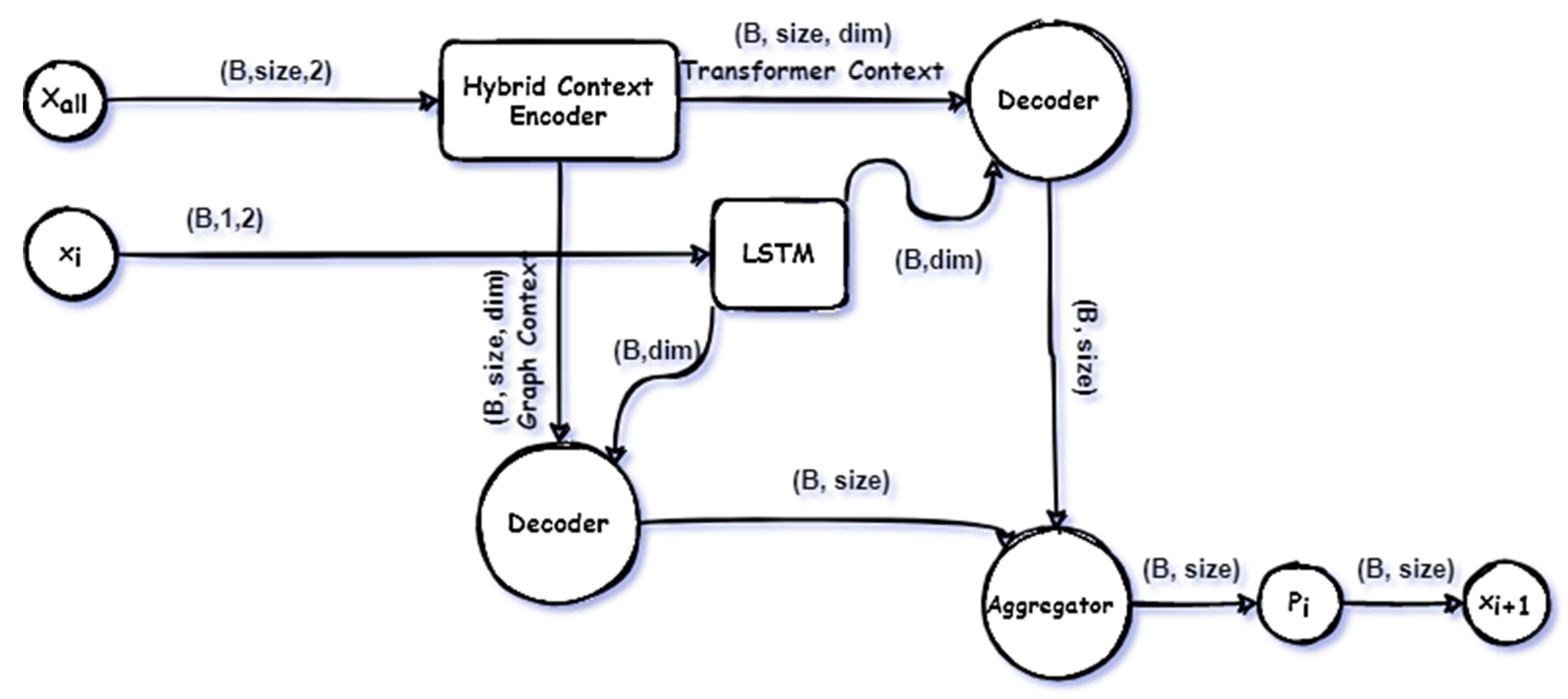
3. Model Architecture
3.1. Hybrid Encoder
- Hybrid context encoder, the function of the hybrid context encoder is to encode the Feature vector into two contextual vectors. Where , , and are the coordinates, entrance time and exit time for each point, respectively.
- Point encoder, which encodes the currently selected city using LSTM.
3.2. Multi-Decoder
4. Experimental Work
4.1. Simulated Dataset Generation
4.2. Reward Function
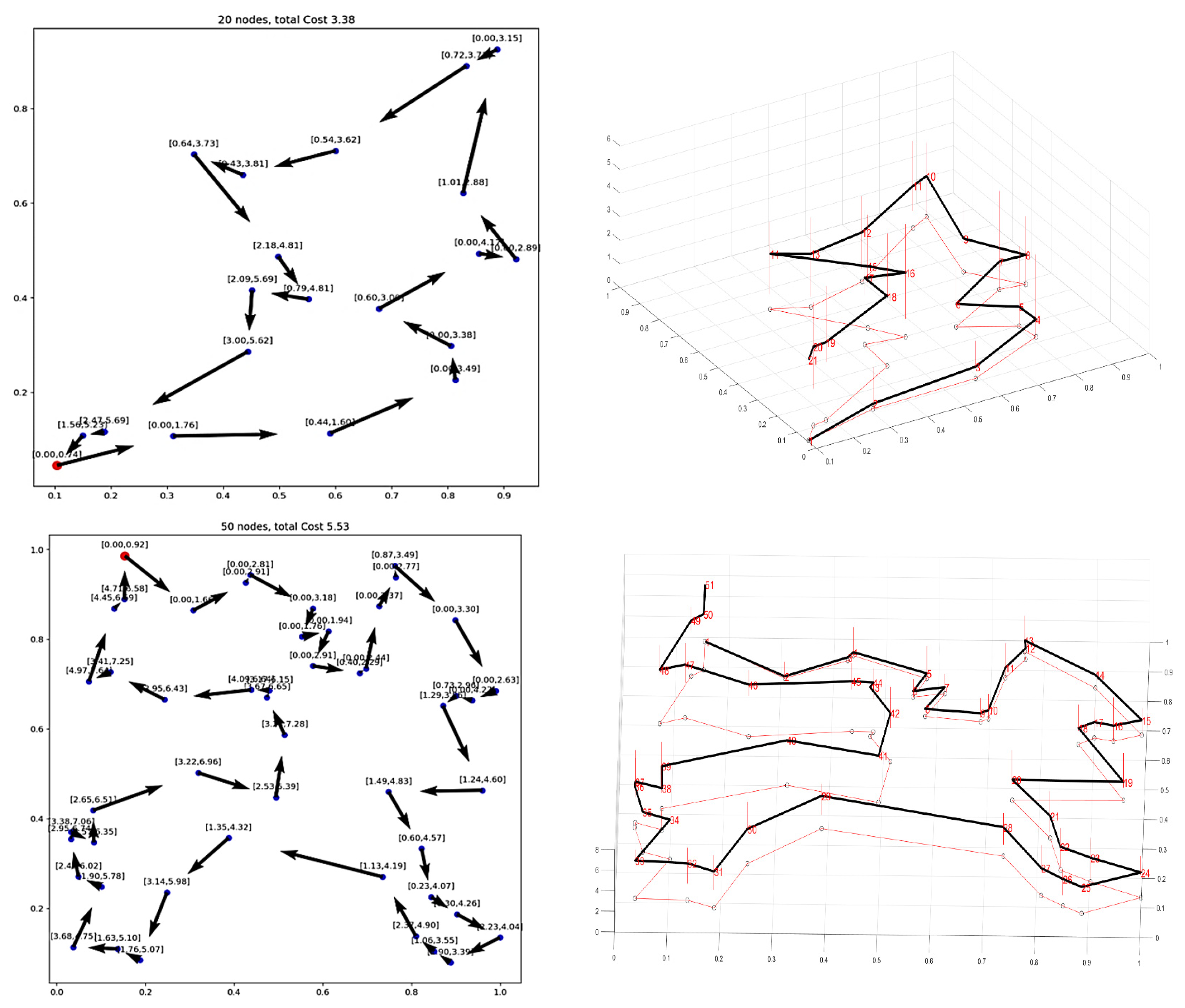
5. Results and Analysis
5.1. The Effect of Time Window
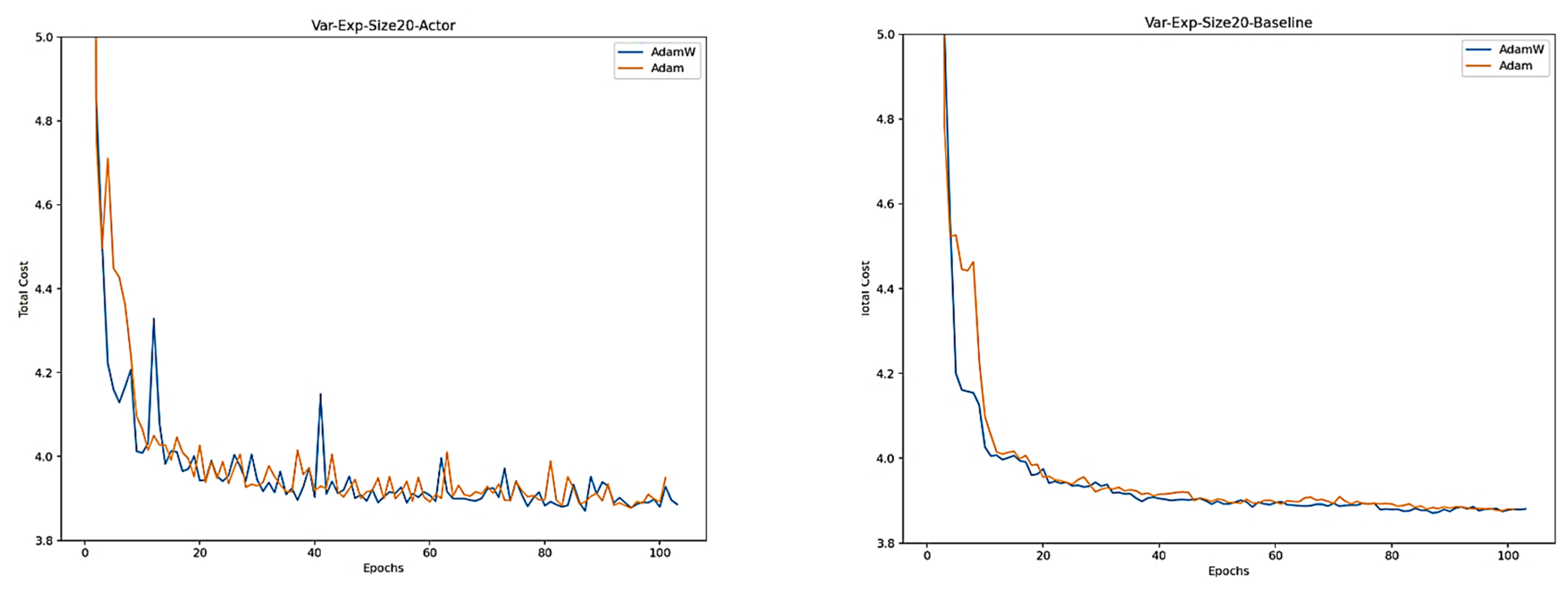
5.2. Variable Time Window
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stohy, A.; Abdelhakam, H.-T.; Ali, S.; Elhenawy, M.; Hassan, A.A.; Masoud, M.; Glaser, S.; Rakotonirainy, A. Hybrid Pointer Networks for Traveling Salesman Problems Optimization. arXiv 2021, arXiv:2110.03104. [Google Scholar]
- Carlton, W.B.; Barnes, J.W. Solving the Traveling-Salesman Problem with Time Windows Using Tabu Search. IIE Trans. 1996, 28, 617–629. [Google Scholar] [CrossRef]
- Gendreau, M.; Hertz, A.; Laporte, G.; Stan, M. A Generalized Insertion Heuristic for the Traveling Salesman Problem with Time Windows. Oper. Res. 1998, 46, 330–335. [Google Scholar] [CrossRef]
- Gendreau, M.; Hertz, A.; Laporte, G. New Insertion and Postoptimization Procedures for the Traveling Salesman Problem. Oper. Res. 1992, 40, 1086–1094. [Google Scholar] [CrossRef]
- Calvo, R.W. A New Heuristic for the Traveling Salesman Problem with Time Windows. Transp. Sci. 2000, 34, 113–124. [Google Scholar] [CrossRef]
- Ohlmann, J.W.; Thomas, B.W. A compressed-annealing heuristic for the traveling salesman problem with time windows. Informs J. Comput. 2007, 19, 80–90. [Google Scholar] [CrossRef] [Green Version]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Savelsbergh, M.W. Local search in routing problems with time windows. Ann. Oper. Res. 1985, 4, 285–305. [Google Scholar] [CrossRef] [Green Version]
- Christofides, N.; Mingozzi, A.; Toth, P. State-space relaxation procedures for the computation of bounds to routing problems. Networks 1981, 11, 145–164. [Google Scholar] [CrossRef]
- Baker, E.K. Technical Note—An Exact Algorithm for the Time-Constrained Traveling Salesman Problem. Oper. Res. 1983, 31, 938–945. [Google Scholar] [CrossRef] [Green Version]
- Dumas, Y.; Desrosiers, J.; Gelinas, E.; Solomon, M.M. An Optimal Algorithm for the Traveling Salesman Problem with Time Windows. Oper. Res. 1995, 43, 367–371. [Google Scholar] [CrossRef] [Green Version]
- Pesant, G.; Gendreau, M.; Potvin, J.-Y.; Rousseau, J.-M. An Exact Constraint Logic Programming Algorithm for the Traveling Salesman Problem with Time Windows. Transp. Sci. 1998, 32, 12–29. [Google Scholar] [CrossRef] [Green Version]
- Pesant, G.; Gendreau, M.; Potvin, J.-Y.; Rousseau, J.-M. On the flexibility of constraint programming models: From single to multiple time windows for the traveling salesman problem. Eur. J. Oper. Res. 1999, 117, 253–263. [Google Scholar] [CrossRef]
- Ma, Q.; Ge, S.; He, D.; Thaker, D.; Drori, I. Combinatorial optimization by graph pointer networks and hierarchical reinforcement learning. arXiv 2019, arXiv:1911.04936. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. arXiv 2015, arXiv:1506.03134. [Google Scholar]
- Stohy, A. Solving Traveling Salesman Problem with Time Windows Using Hybrid Pointer Networks with Time Features. 2021. Available online: https://www.researchgate.net/publication/355142062_Hybrid_Pointer_Networks_for_Traveling_Salesman_Problems_Optimization (accessed on 17 November 2021).
- Kool, W.; Van Hoof, H.; Welling, M. Attention, learn to solve routing problems! arXiv 2018, arXiv:1803.08475. [Google Scholar]
- Cheng, C.-B.; Mao, C.-P. A modified ant colony system for solving the travelling salesman problem with time windows. Math. Comput. Model. 2007, 46, 1225–1235. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set of Nodes that Needs Service | |
|---|---|
| Set of all nodes in the network | |
| Set of all nodes that the salesman can depart | |
| Set of all nodes that the salesman can visit | |
| The time at the witch the salesman service node | |
| The earliest time the salesman can service node | |
| The latest time the salesman can arrive at node |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Graph Embedding layer | 3 | Learning rate | 1 × 10−4 |
| Transformer Encoder | 6 | Batch size | 512 |
| Feed-forward dim | 512 | Training steps | 2500 |
| Optimizer | Adam | Tanh clipping | 10 |
| Epochs | 100 | Time Windows Expectation | 1 |
| #Algorithm 1 Data Simulation |
|---|
| 1: Input: pre-trained model for TSP, batch size B, problem size |
| 2: InputData = RandomInstance (B, size, 2) #Random generate TSP points Features |
| 3: X = pre_trainedModel(InputData) #Solve the points using pre-trained model, X is a tensor |
| 4: PrevCities = FirstCities #contains the pre-trained model’s solution |
| 5: for t = 1,…, size do: |
| 6: current cities = X[t] #Pick the current city |
| 7: cur_time ← EuclideanDistance(current_cities, PrevCities) #Caluclate the Euc Distance |
| 8: X[:,t,2] ← max(0,(cur_time − 2 ∗ RandomNumber)) #Entrance Time |
| 9: X[:,t,3] ← cur_time + 2 ∗ RandomNumber + 1 #Leaving Time |
| 10: end for |
| 11: Shuffle(X) |
| TWTSP20 | TWTSP50 | TWTSP100 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Obj | Time | Feasible% | Obj | Time | Feasible% | Obj | Time | Feasible% |
| OR-Tools (Savings) | 4.045 | 121 s | 72.06% | 6.251 | 1120 s | 70.21% | |||
| ACO | 4.655 | 204 s | 62.10% | 8.136 | 1493 s | 61.52% | |||
| GPN Greedy | 3.871 | 1 s | 99.7% | 5.95 | 3 s | 99.97% | 9.78 | 8 s | 32.8% |
| HPN Greedy | 3.867 | 1 s | 100% | 5.86 | 4 s | 100% | 8.32 | 12 s | 99.97% |
| NET1 (E(WT)) = ½ | NET2 (E(WT)) = 1 | NET3 (E(WT)) = 2 | NET4 (E(WT)) = 4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cost | Wait | Acc | Cost | Wait | Acc | Cost | Wait | Acc | Cost | Wait | Acc | |
| = ½ e~2 ∗ uniform (0,1) L~2 ∗ uniform (0,1) + ½ | 3.89 | 0.003 | 99.99% | 3.89 | 0.002 | 99.8 | 3.90 | 0.003 | 99.62% | 4.2 | 0.001 | 85.5% |
| = 1 e~2 ∗ uniform (0,1) L~2 ∗ uniform (0,1) +1 | 3.897 | 0.004 | 100% | 3.88 | 0.002 | 100% | 3.875 | 0.002 | 100% | 4.04 | 0.008 | 99.51% |
| = 2 e~2 ∗ uniform (0,1) L~2 ∗ uniform (0,1) + 2 | 4.14 | 0.009 | 100% | 3.93 | 0.005 | 100% | 3.858 | 0.001 | 100% | 3.91 | 0.003 | 100% |
| = 4 e~2 ∗ uniform (0,1) L~2 ∗ uniform (0,1) + 4 | 4.67 | 0.0113 | 100% | 4.39 | 0.013 | 100% | 3.985 | 0.009 | 100% | 3.836 | 0.0008 | 100% |
| Type of Data | NET1 AdamW | NET2 Adam | ||||
|---|---|---|---|---|---|---|
| Data-Variable-Exp | Cost | Acc | Wait | Cost | Acc | Wait |
| = ½ | 3.875 | 100% | 0.0037 | 3.877 | 100% | 0.003 |
| = 1 | 3.89 | 99.14% | 0.0022 | 3.90 | 98.76% | 0.0019 |
| = 2 | 3.885 | 99.89% | 0.002 | 3.887 | 99.97% | 0.0019 |
| = 4 | 3.88 | 99.98% | 0.003 | 3.876 | 100% | 0.003 |
| = 8 | 3.875 | 100% | 0.005 | 3.887 | 100% | 0.007 |
| = 16 | 4.086 | 100% | 0.008 | 3.99 | 100% | 0.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alharbi, M.G.; Stohy, A.; Elhenawy, M.; Masoud, M.; El-Wahed Khalifa, H.A. Solving Traveling Salesman Problem with Time Windows Using Hybrid Pointer Networks with Time Features. Sustainability 2021, 13, 12906. https://0-doi-org.brum.beds.ac.uk/10.3390/su132212906
Alharbi MG, Stohy A, Elhenawy M, Masoud M, El-Wahed Khalifa HA. Solving Traveling Salesman Problem with Time Windows Using Hybrid Pointer Networks with Time Features. Sustainability. 2021; 13(22):12906. https://0-doi-org.brum.beds.ac.uk/10.3390/su132212906
Chicago/Turabian StyleAlharbi, Majed G., Ahmed Stohy, Mohammed Elhenawy, Mahmoud Masoud, and Hamiden Abd El-Wahed Khalifa. 2021. "Solving Traveling Salesman Problem with Time Windows Using Hybrid Pointer Networks with Time Features" Sustainability 13, no. 22: 12906. https://0-doi-org.brum.beds.ac.uk/10.3390/su132212906