An Improved Neural Network for Regional Giant Panda Habitat Suitability Mapping: A Case Study in Ya’an Prefecture

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Approach and Methodology
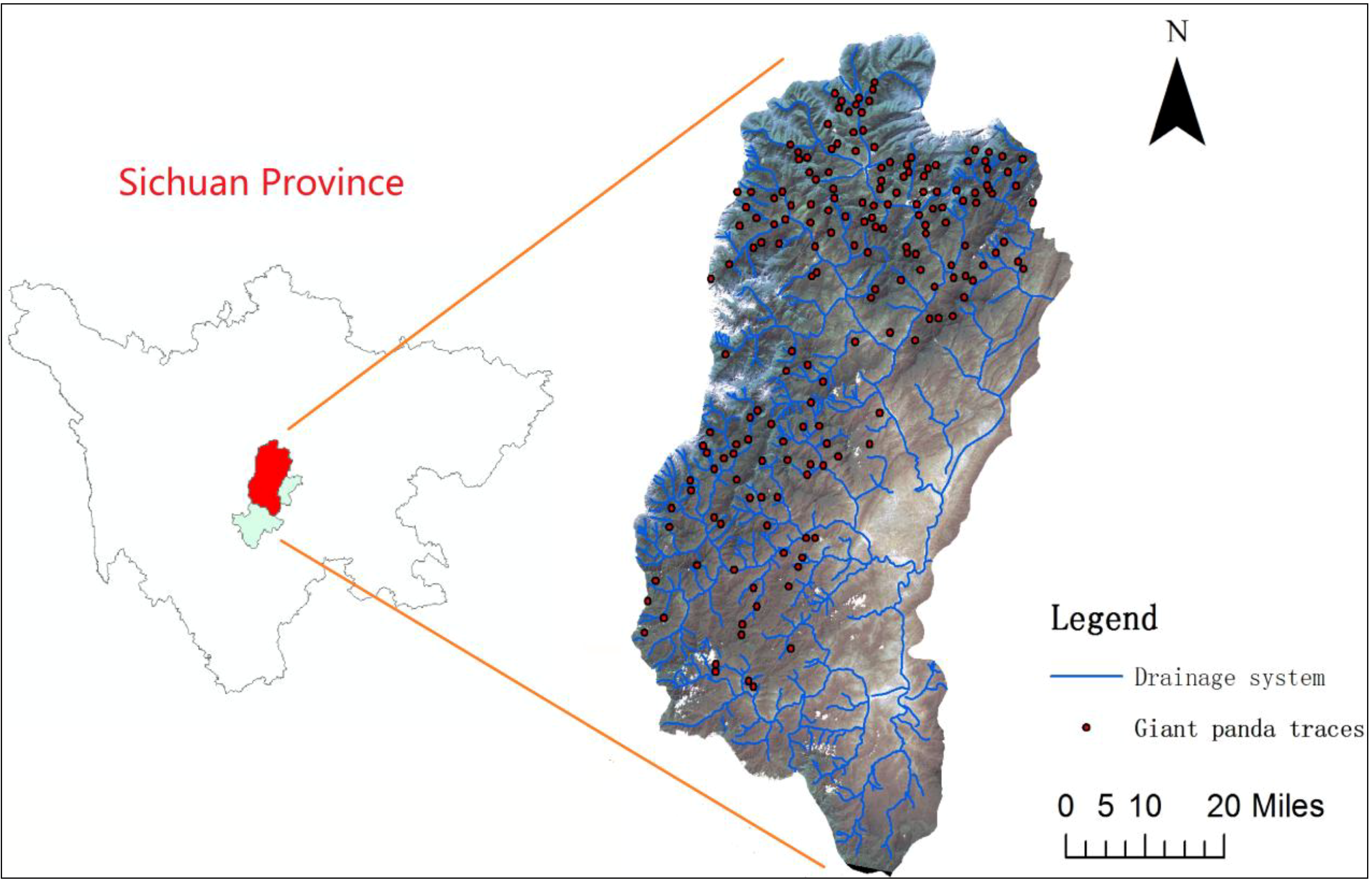
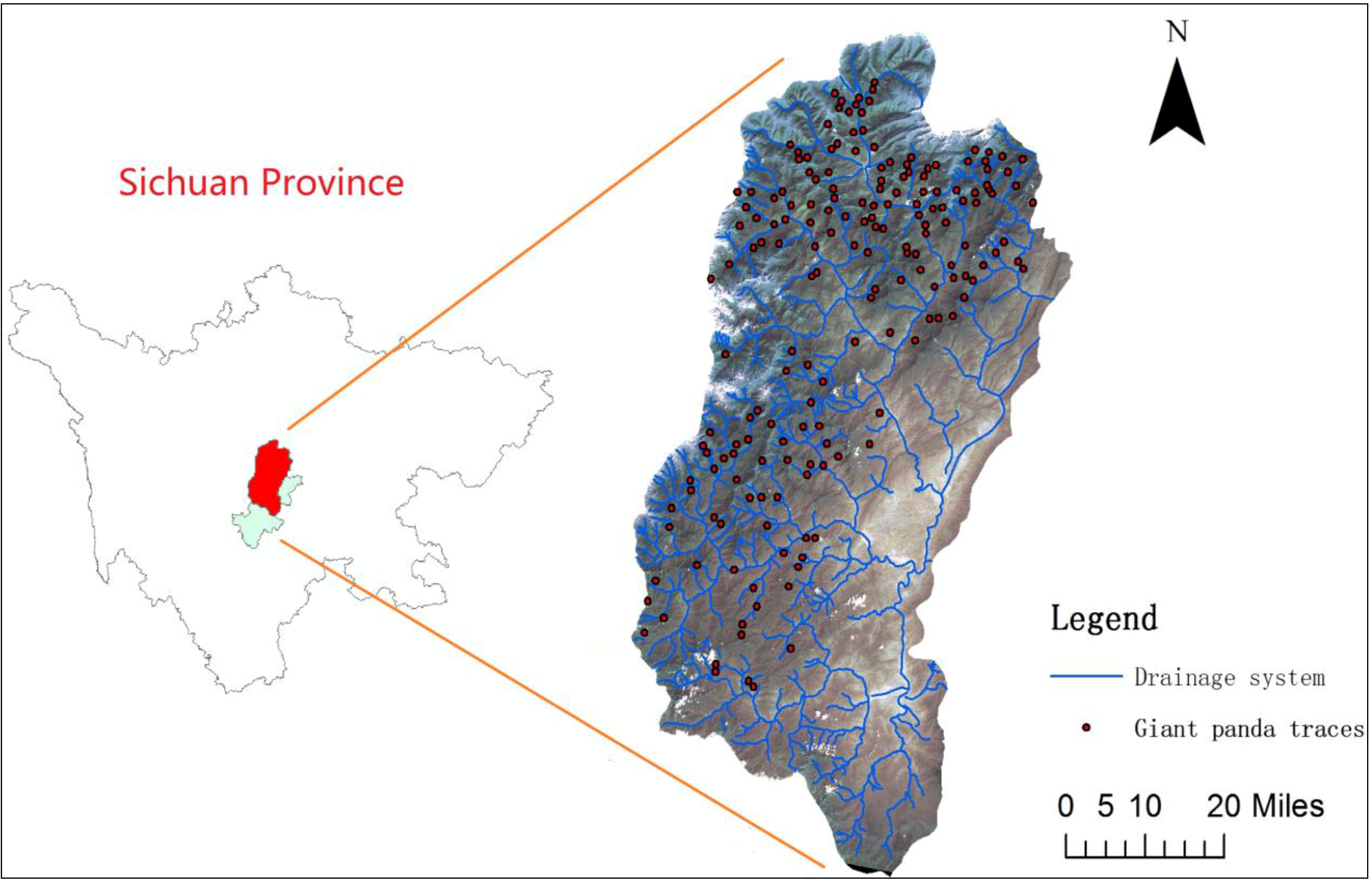
2.1. Study Area
2.2. Research Methods
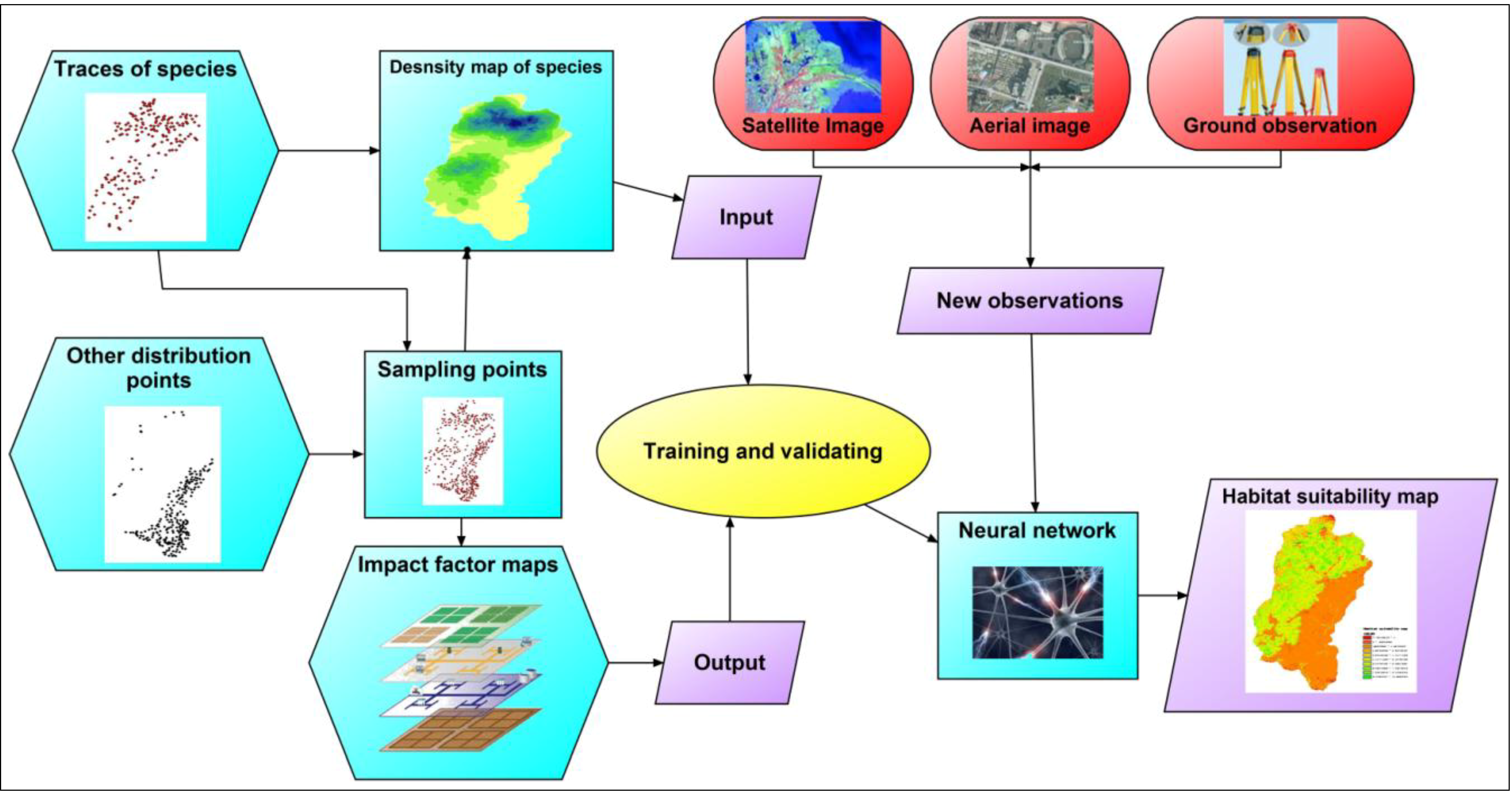
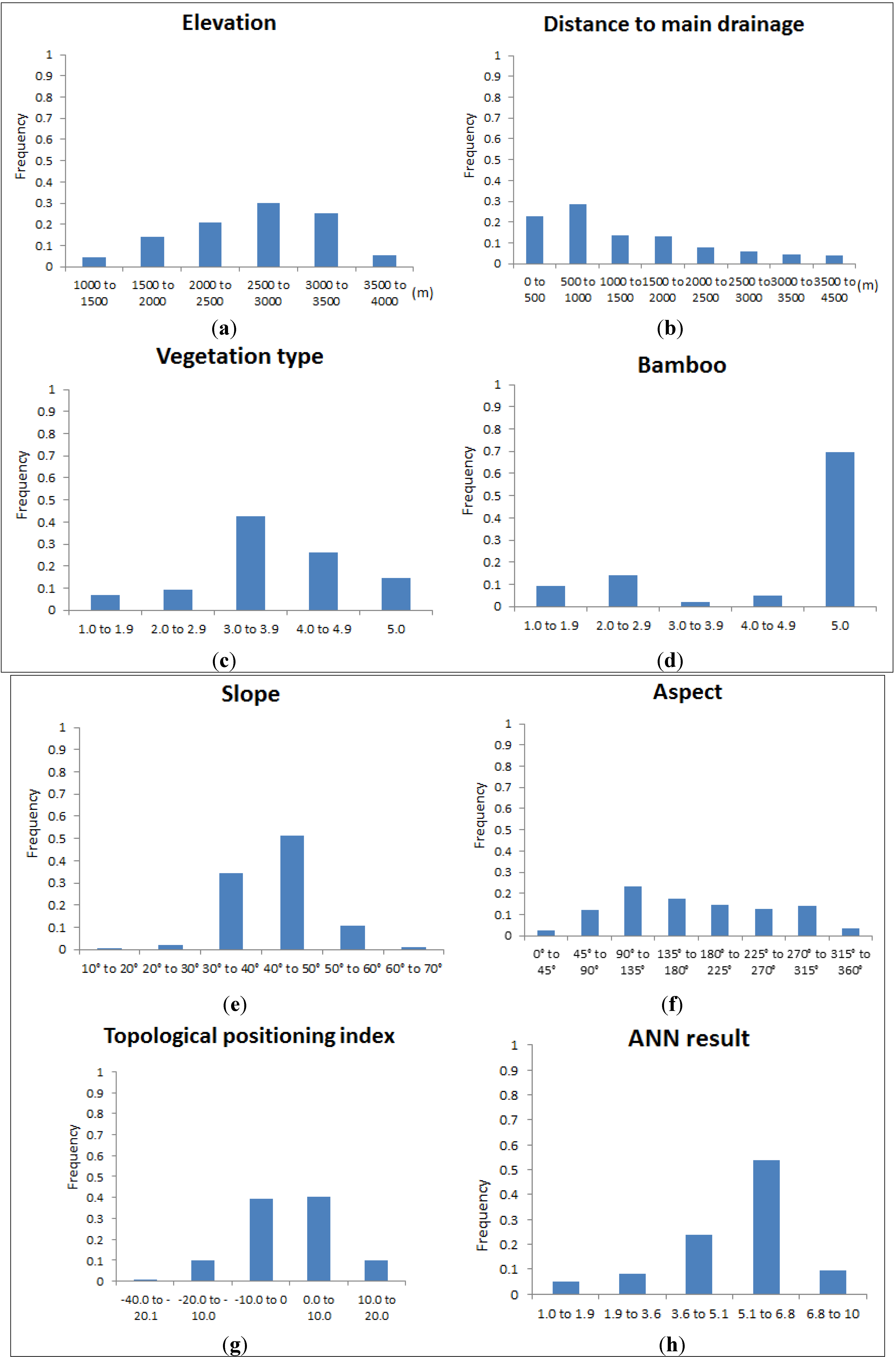
2.2.1. Feasibility of Using Apparent Density Map as a Measure of Habitat Quality
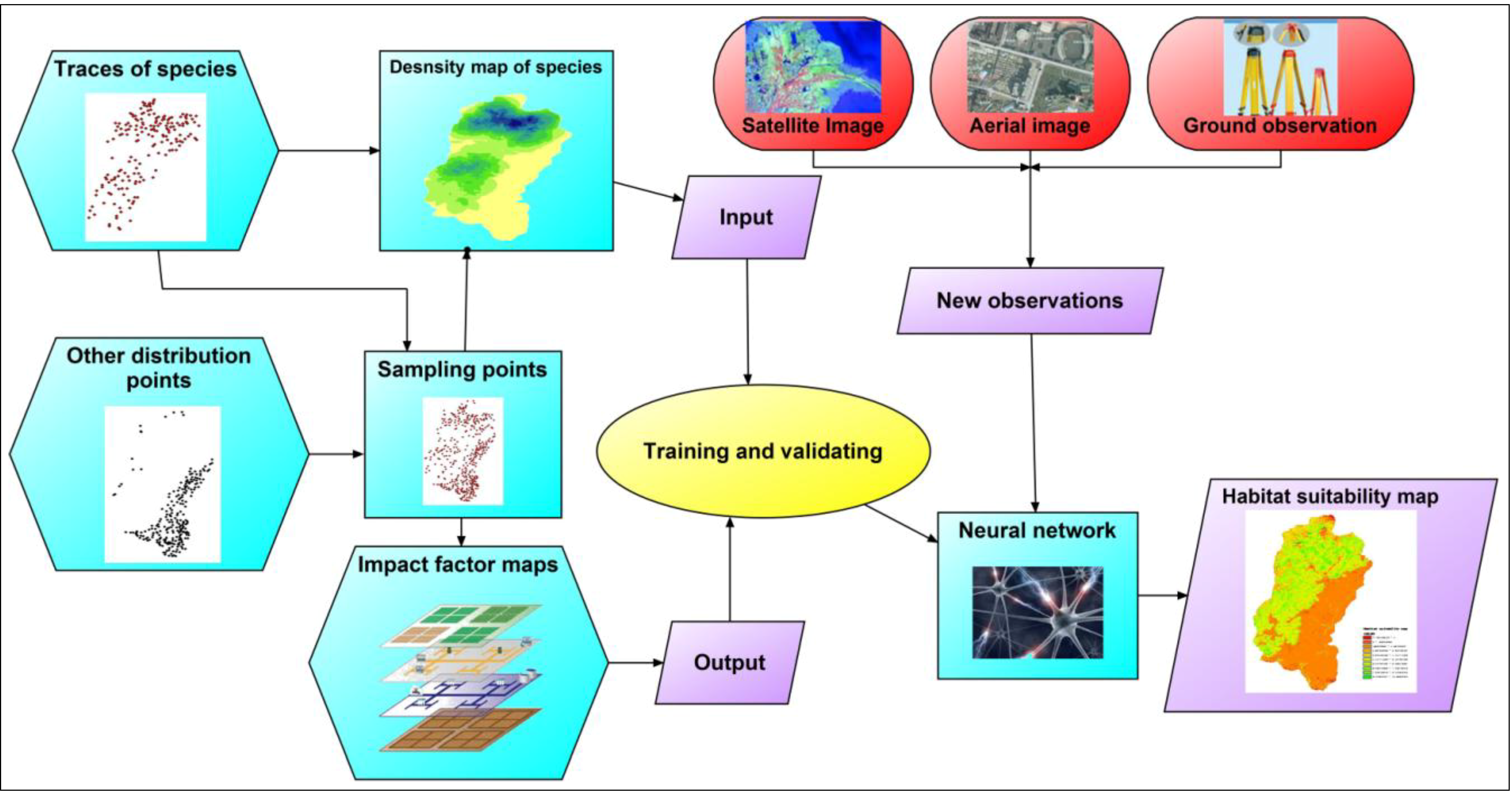
2.2.2. Neural Networks

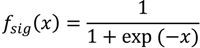
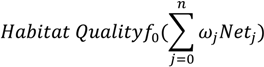

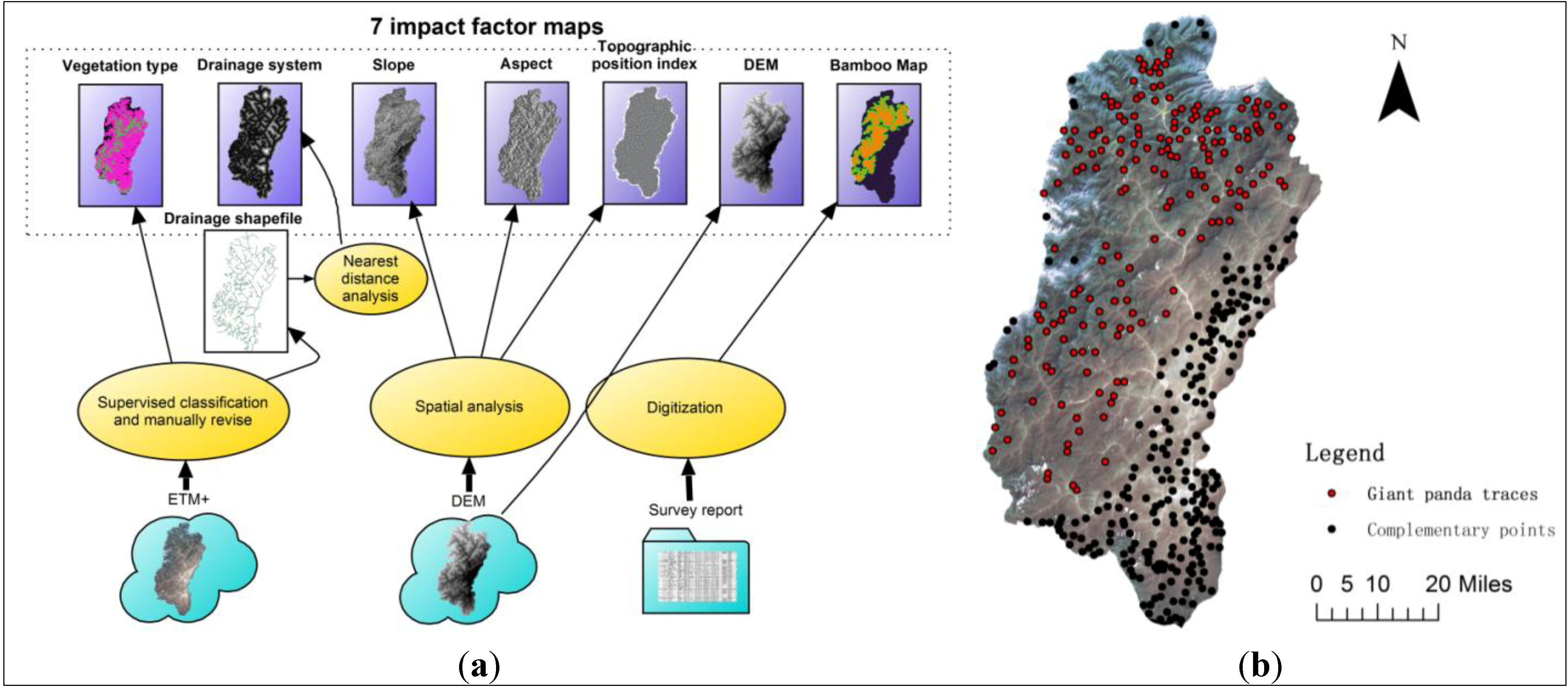
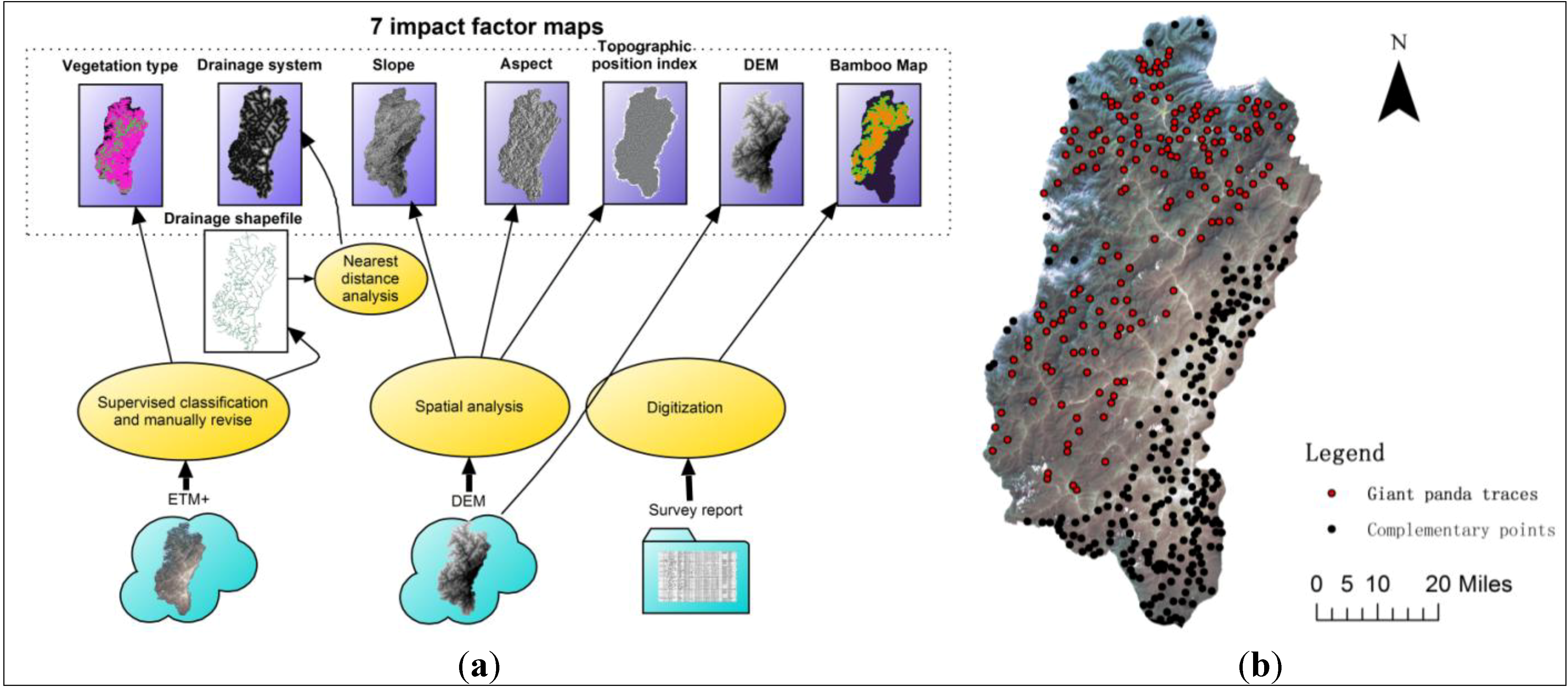
2.3. Pre-Processing of Date
3. Results and Discussion
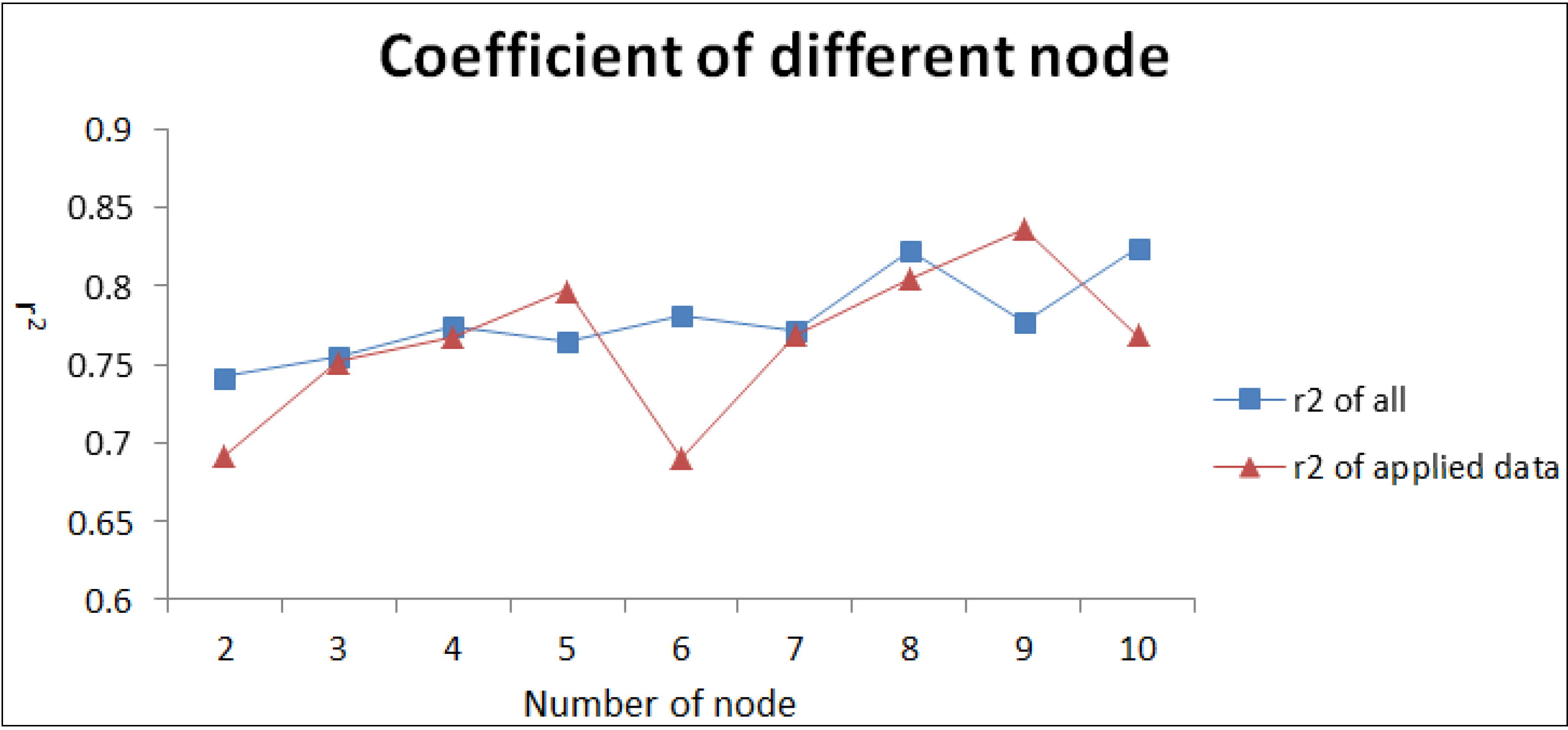
3.1. ANN Structure
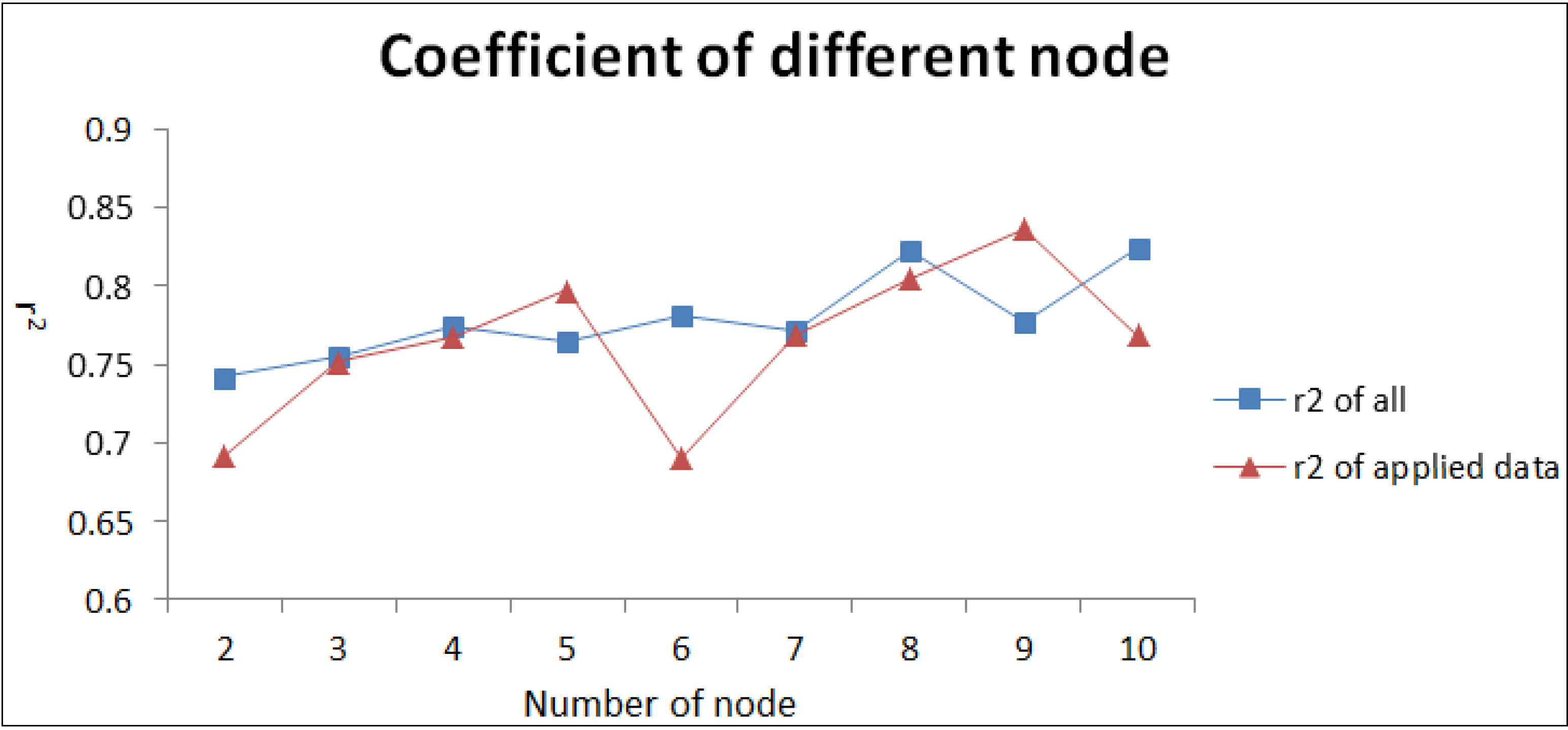
3.2. ANN Simulation Results
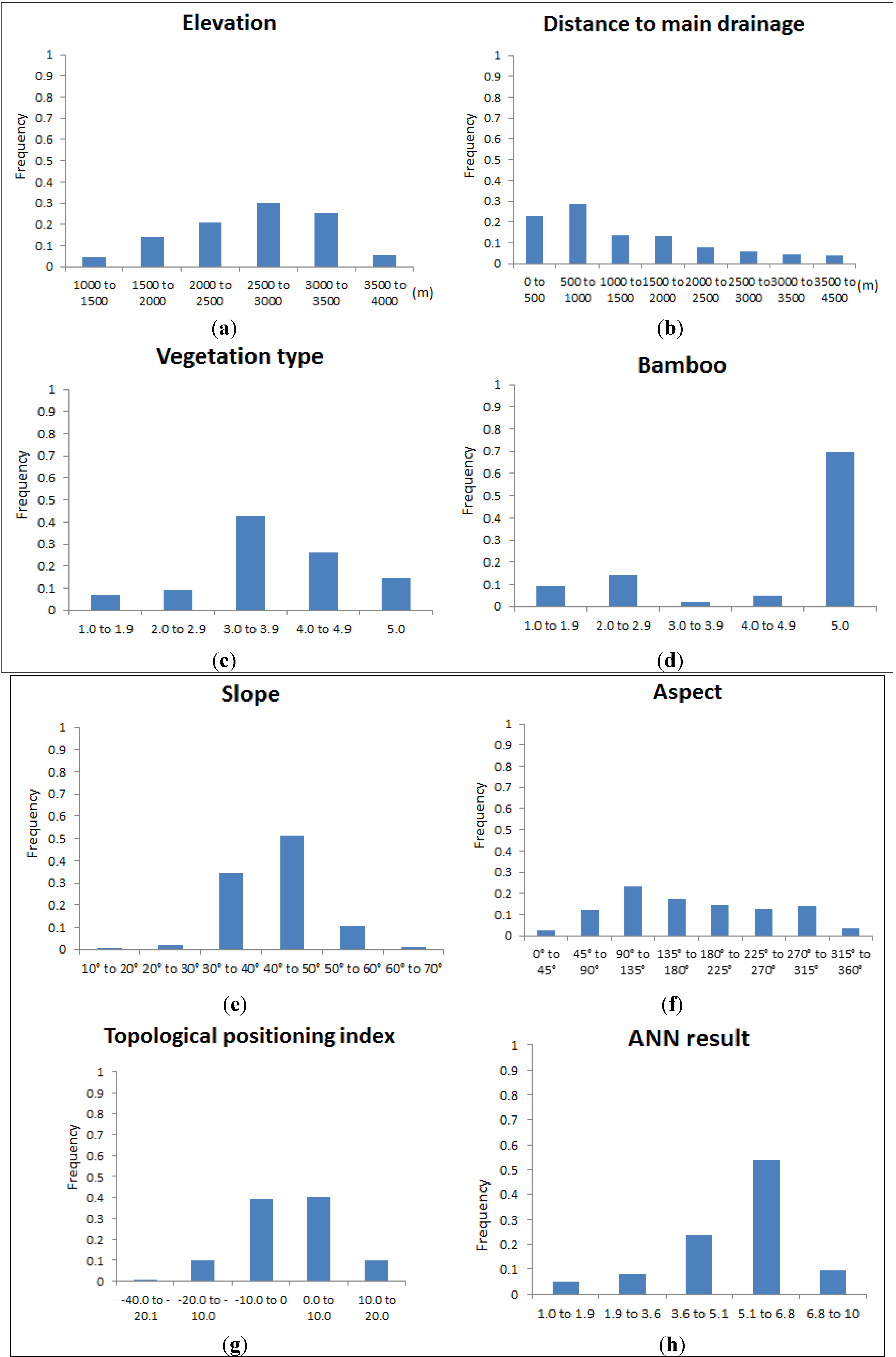

4. Conclusions
- (1)
- Compared with traditional HSI mapping method, this method avoids dependence on subjective views and interpretations of expert knowledge and uses ANN to extract information. However, expert knowledge and field experience would still be of great value to HSI mapping. Their knowledge should not be used in deciding weights for densities in different parts of the habitat or other such abstract purposes; it should be used for clearly defined purposes such as identifying high animal activity areas. For example, our first hypothesis assumes “discoveries of animal signs are events of equal detection probability in all regions”. In reality, grid-line transect method tries to meet that goal but there are still many errors introduced by differences in forest type, elevation or angle of the sun. Experts may add accuracies or weights to each sign and original density map may take them into consideration for providing more accurate training data to ANN. Besides, expert knowledge may be applied to deciding the resolution of the model by taking biological and ecological information into consideration.
- (2)
- One of the hypotheses assumes the equal detection probability of finding animal signs. In field work, few efforts have been made to test this hypothesis like building grids for sampling [44]. A more rigorous approach to dedicate equal searching time for signs in all areas may be welcome but may well be prohibitively expensive from the point of view of designing and conducting field work.
- (3)
- As our method provides a more objective way of assessing the habitat suitability of giant panda, future work may focus on incorporating near-real-time ground observation and remote sensing data to dynamically adjust the ANN model for better results. A dynamic data driven application system or data assimilation method [45] may be used to improve the performance of the ANN model.
Acknowledgments
Author Contributions
Supplementary Materials
Conflicts of Interest
References
- McCulloch, S.L. Inventory and Monitoring of Wildlife Habitat; US Department of the Interior, Bureau of Land Management: Washington, DC, USA, 1986. [Google Scholar]
- Larson, M.A.; Thompson, F.R., III; Millspaugh, J.J.; Dijak, W.D.; Shifley, S.R. Linking population viability, habitat suitability, and landscape simulation models for conservation planning. Ecol. Model. 2004, 180, 103–118. [Google Scholar] [CrossRef]
- Tirpak, J.M.; Jones-Farrand, D.T.; Thompson, F.R., III; Twedt, D.J.; Nelson, M.D.; Uihlein, W.B., III. Predicting bird habitat quality from a geospatial analysis of FIA data. In Proceedings of the Eighth Annual Forest Inventory and Analysis Symposium, Monterey, CA, USA, 16–19 October 2006.
- Zhang, J.; Hull, V.; Xu, W.; Liu, J.; Ouyang, Z.; Huang, J.; Wang, X.; Li, R. Impact of the 2008 Wenchuan earthquake on biodiversity and giant panda habitat in Wolong Nature Reserve, China. Ecol. Res. 2011, 26, 523–531. [Google Scholar] [CrossRef]
- Li, D.; Ren, B.; Hu, J.; Shen, Y.; He, X.; Krzton, A.; Li, M. Impact of snow storms on habitat and death of Yunnan snub-nosed monkeys in the baimaxueshan nature reserve, Yunnan, China. ISRN Zool. 2012, 2012. Article ID 813584. [Google Scholar]
- Lu, C.Y.; Gu, W.; Dai, A.H.; Wei, H.Y. Assessing habitat suitability based on geographic information system (GIS) and fuzzy: A case study of Schisandra sphenanthera Rehd. et Wils. in Qinling Mountains, China. Ecol. Model. 2012, 242, 105–115. [Google Scholar]
- Liu, X. Mapping and Modelling the Habitat of Giant Pandas in Foping Nature Reserve, China. Ph.D. Thesis, Tropical Nature Conservation and Vertebrate Ecology Group Wageningen University, Wageningen, The Netherlands, 12 December 2001. [Google Scholar]
- Liu, X.; Toxopeus, A.G.; Skidmore, A.K.; Shao, X.; Dang, G.; Wang, T.; Prins, H.H.T. Giant panda habitat selection in foping nature reserve, China. J. Wildl. Manag. 2005, 69, 1623–1632. [Google Scholar] [CrossRef]
- Liu, X.; Skidmore, A.K.; Bronsveld, M.C. Assessment of giant panda habitat based on integration of expert system and neural network. Ying Yong Sheng Tai Xue Bao 2006, 17, 438–443. [Google Scholar]
- Wang, X.; Xu, W.; Ouyang, Z. Integrating population size analysis into habitat suitability assessment: Implications for giant panda conservation in the Minshan Mountains, China. Ecol. Res. 2009, 24, 1101–1109. [Google Scholar] [CrossRef]
- Viña, A.; Bearer, S.; Zhang, H.; Ouyang, Z.; Liu, J. Evaluating MODIS data for mapping wildlife habitat distribution. Remote Sens. Environ. 2008, 112, 2160–2169. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, M.; Li, J. The impact of conservation projects on giant panda habitat. Acta Ecol. Sin. 2011, 31, 154–163. [Google Scholar]
- Viña, A.; Tuanmu, M.N.; Xu, W.; Lia, Y.; Ouyangb, Z.; DeFriesc, R.; Liua, J. Range-wide analysis of wildlife habitat: Implications for conservation. Biol. Conserv. 2010, 143, 1960–1969. [Google Scholar] [CrossRef]
- Vincenzi, S.; Caramori, G.; Rossi, R.; Leo, G.A.D. A GIS-based habitat suitability model for commercial yield estimation of Tapes philippinarum in a Mediterranean coastal lagoon (Sacca di Goro, Italy). Ecol. Model. 2006, 193, 90–104. [Google Scholar] [CrossRef]
- Ray, N.; Burgman, M.A. Subjective uncertainties in habitat suitability maps. Ecol. Model. 2006, 195, 172–186. [Google Scholar] [CrossRef]
- Beaudry, F.; Pidgeon, A.M.; Radeloff, V.C.; Howe, R.W.; Mladenoff, D.J.; Bartelt, G.A. Modeling regional-scale habitat of forest birds when land management guidelines are needed but information is limited. Biol. Conserv. 2010, 143, 1759–1769. [Google Scholar] [CrossRef]
- Mazur, M.L.C.; Kowalski, K.P.; Galbraith, D. Assessment of suitable habitat for Phragmites australis (common reed) in the Great Lakes coastal zone. Aquat. Invasions 2014, 9, 1–19. [Google Scholar]
- Douglas, S.J. Habitat Suitability Modelling in the New Forest National Park; Bournemouth University: Poole and Bournemouth, UK, 2009. [Google Scholar]
- Drake, J.M.; Randin, C.; Guisan, A. Modelling ecological niches with support vector machines. J. Appl. Ecol. 2006, 43, 424–432. [Google Scholar] [CrossRef]
- Douglas, S.J.; Newton, A.C. Evaluation of Bayesian networks for modelling habitat suitability and management of a protected area. J. Nat. Conserv. 2014, 22, 235–246. [Google Scholar] [CrossRef]
- Yegnanarayana, B. Artificial Neural Networks; PHI Learning Pvt. Ltd.: Delhi, India, 2009. [Google Scholar]
- State Forestry Administration. The Third National Survey Report on Giant Panda in China; Science Press: Beijing, China, 2006. [Google Scholar]
- NunesKehl, T.; Todt, V.; Veronez, M.R.; Cazella, S.C. Amazon rainforest deforestation daily detection tool using artificial neural networks and satellite images. Sustainability 2012, 4, 2566–2573. [Google Scholar] [CrossRef]
- Science Museum of China. Available online: http://www.kepu.net.cn/english/giantpanda/giantpanda_know/200409230031.html (accessed on 22 February 2014).
- Roseberry, J.L.; Woolf, A. Habitat-population density relationships for white-tailed deer in Illinois. Wildlife Soc. Bull. 1998, 26, 252–258. [Google Scholar]
- Bissonette, J.A.; Storch, I. (Eds.) Landscape Ecology and Resource Management: Linking Theory with Practice; Island Press: Washington, DC, USA, 2003.
- Lunetta, R.S.; Knight, J.F.; Ediriwickrema, J.; Lyon, J.G.; Worthy, L.D. Land-cover change detection using multi-temporal MODIS NDVI data. Remote Sens. Environ. 2006, 105, 142–154. [Google Scholar] [CrossRef]
- Shalaby, A.; Tateishi, R. Remote sensing and GIS for mapping and monitoring land cover and land-use changes in the Northwestern coastal zone of Egypt. Appl. Geogr. 2007, 27, 28–41. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Wang, X.; Xu, W.; Ouyang, Z.; Zhang, J. Impacts of Wenchuan Earthquake on giant panda habitat in Dujiangyan region. Acta Ecol. Sin. 2008, 28, 5856–5861. [Google Scholar]
- Zheng, W.; Xu, Y.; Liao, L.; Yang, X.; Gu, X.; Shang, T.; Ran, J. Effect of the Wenchuan earthquake on habitat use patterns of the giant panda in the Minshan Mountains, southwestern China. Biol. Conserv. 2012, 145, 241–245. [Google Scholar] [CrossRef]
- Wei, W.; Zhe, Z.; Yuan, J.; Liu, X.; Xu, C. Assessment of giant panda habitat after the Chengdu earthquake based on habitat suitability. Res. Environ. Sci. 2010, 23, 1128–1135. [Google Scholar]
- Deng, X.; Jiang, Q.; Ge, Q.; Yang, L. Impacts of the Wenchuan Earthquake on the giant panda nature reserves in China. J. Mt. Sci. 2010, 7, 197–206. [Google Scholar] [CrossRef]
- Vina, A.; Bearer, S.; Chen, X.; He, G.; Linderman, M.; An, L.; Zhang, H.; Ouyang, Z.; Liu, J. Temporal changes in giant panda habitat connectivity across boundaries of Wolong Nature Reserve, China. Ecol. Appl. 2007, 17, 1019–1030. [Google Scholar] [CrossRef]
- Li, J.; Li, T.; Jin, X.; Liu, X.; Tang, G. The quality evaluation of giant panda’s habitat based on analytic hierarchy process. J. Mt. Sci. 2005, 23, 694–701. [Google Scholar]
- Linderman, M.; Bearer, S.; An, L.; Tan, Y.; Ouyang, Z.; Liu, J. The effects of understory bamboo on broad-scale estimates of giant panda habitat. Biol. Conserv. 2005, 121, 383–390. [Google Scholar] [CrossRef]
- Jeff Jenness Topographic Position Index (TPI) v. 1.3a. Available online: http://www.jennessent.com/arcview/arcview_extensions.htm (accessed on 12 May 2014).
- Li, J.Q.; Shen, G.Z. The Habitat of Giant Pandas; Higher Education Press: Beijing, China, 2012. [Google Scholar]
- Beyer, H.L. Hawth’s Analysis Tools for ArcGIS. Available online: http://www.spatialecology.com/htools (accessed on 20 April 2014).
- Jenks, G.F. The data model concept in statistical mapping. Int. Yearb. Cartogr. 1967, 7, 186–190. [Google Scholar]
- Ouyang, Z.; Liu, J.; Xiao, H. An assessment of giant panda habitat in Wolong Nature Reserve. Acta Ecol. Sin. 2000, 21, 1869–1874. [Google Scholar]
- Hu, J; Wei, F.W. The biological Studies of the Giant Panda; Sichuan Public House of Science and Technology: Chengdu, China, 1990; pp. 24–28. [Google Scholar]
- Chen, L.; Liu, X.; Fu, B. Evaluation on giant panda habitat fragmentation in Wolong Nature Reserve. Acta Ecol. Sin. 1998, 19, 291–297. [Google Scholar]
- Chapman, C.A.; Fedigan, L.M. Dietary differences between neighboring Cebuscapucinus groups: Local traditions, food availability or responses to food profitability? Folia Primatol. 1990, 54, 177–186. [Google Scholar] [CrossRef]
- Song, J.W.; Xiang, B.; Wang, X.; Wu, L.; Chang, C. Application of dynamic data driven application system in environmental science. Environ. Rev. 2014. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Song, J.; Wang, X.; Liao, Y.; Zhen, J.; Ishwaran, N.; Guo, H.; Yang, R.; Liu, C.; Chang, C.; Zong, X. An Improved Neural Network for Regional Giant Panda Habitat Suitability Mapping: A Case Study in Ya’an Prefecture. Sustainability 2014, 6, 4059-4076. https://0-doi-org.brum.beds.ac.uk/10.3390/su6074059
Song J, Wang X, Liao Y, Zhen J, Ishwaran N, Guo H, Yang R, Liu C, Chang C, Zong X. An Improved Neural Network for Regional Giant Panda Habitat Suitability Mapping: A Case Study in Ya’an Prefecture. Sustainability. 2014; 6(7):4059-4076. https://0-doi-org.brum.beds.ac.uk/10.3390/su6074059
Chicago/Turabian StyleSong, Jingwei, Xinyuan Wang, Ying Liao, Jing Zhen, Natarajan Ishwaran, Huadong Guo, Ruixia Yang, Chuansheng Liu, Chun Chang, and Xin Zong. 2014. "An Improved Neural Network for Regional Giant Panda Habitat Suitability Mapping: A Case Study in Ya’an Prefecture" Sustainability 6, no. 7: 4059-4076. https://0-doi-org.brum.beds.ac.uk/10.3390/su6074059