
Predicting China’s SME Credit Risk in Supply Chain Financing by Logistic Regression, Artificial Neural Network and Hybrid Models


Abstract
:1. Introduction
2. Methodology
2.1. Logistic Regression (LR) Model
2.2. Artificial Neural Network (ANN) Model
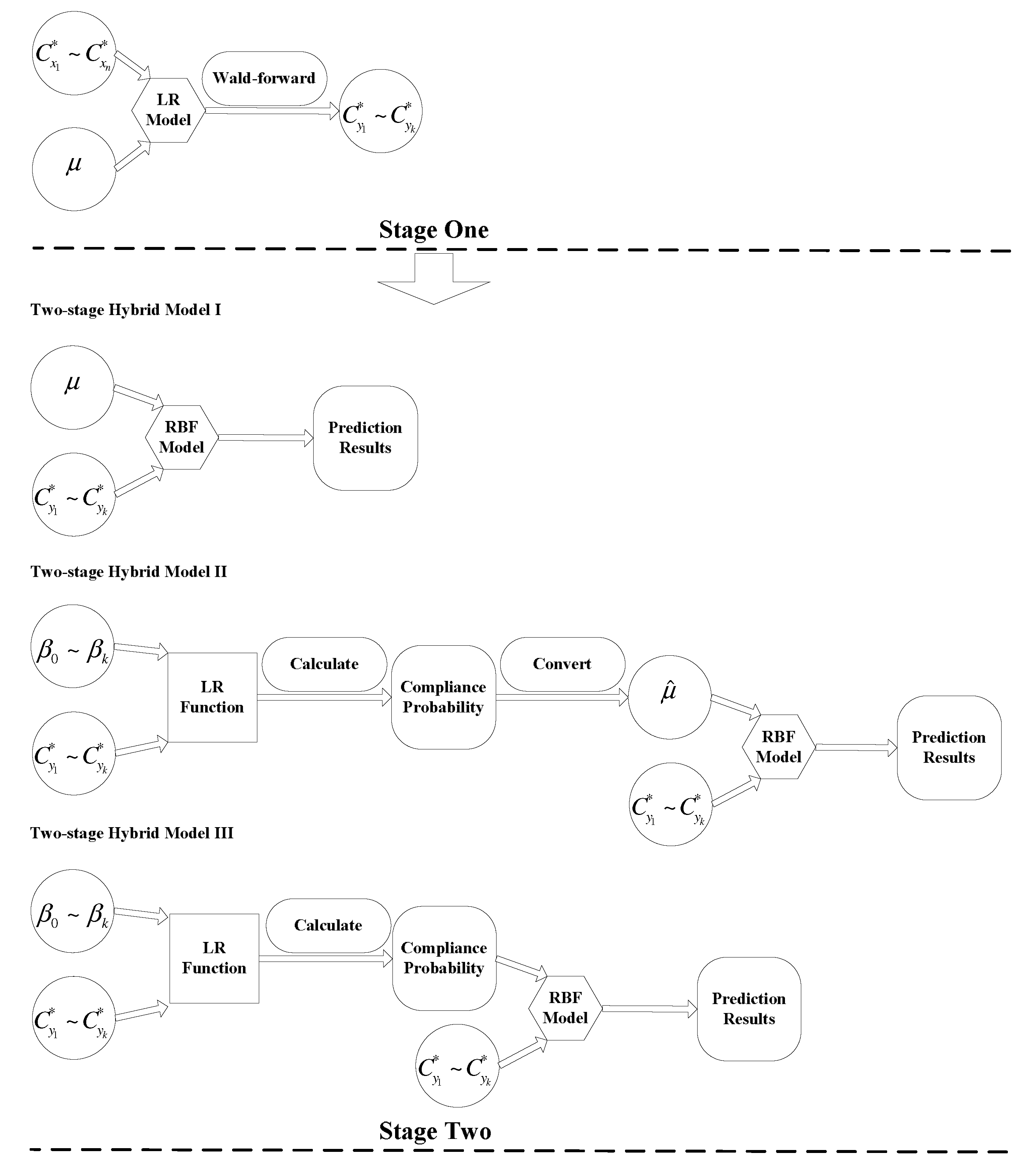
2.3. Two-Stage Hybrid Model
2.3.1. Two-Stage Hybrid Model of LR-ANN I
2.3.2. Two-Stage Model of LR-ANN II
2.3.3. Two-Stage Model of LR-ANN III
2.4. Methods of Improving the Prediction Accuracy Ratio
2.4.1. Data Normalization Method
2.4.2. Collinearity Diagnosis Method
2.4.3. Cross Validation Method
2.4.4. Optimal Cutoff Point Method
3. Description of Data and Sampling Procedure
3.1. Assumption of Applying Supply Chain Financing (SCF)
3.2. Variable Definitions
3.2.1. Dependent Variable
3.2.2. Independent Variables
3.3. Sampling Procedure
4. Experimental Results and Analysis
4.1. Experimental Results of Data Normalization
4.2. Experimental Results of Collinearity Diagnosis
4.3. Experimental Results of Cross Validation
4.4. Experimental Results of Logistic Regression (LR) Model
4.5. Experimental Results of the Artificial Neural Network (ANN) Model
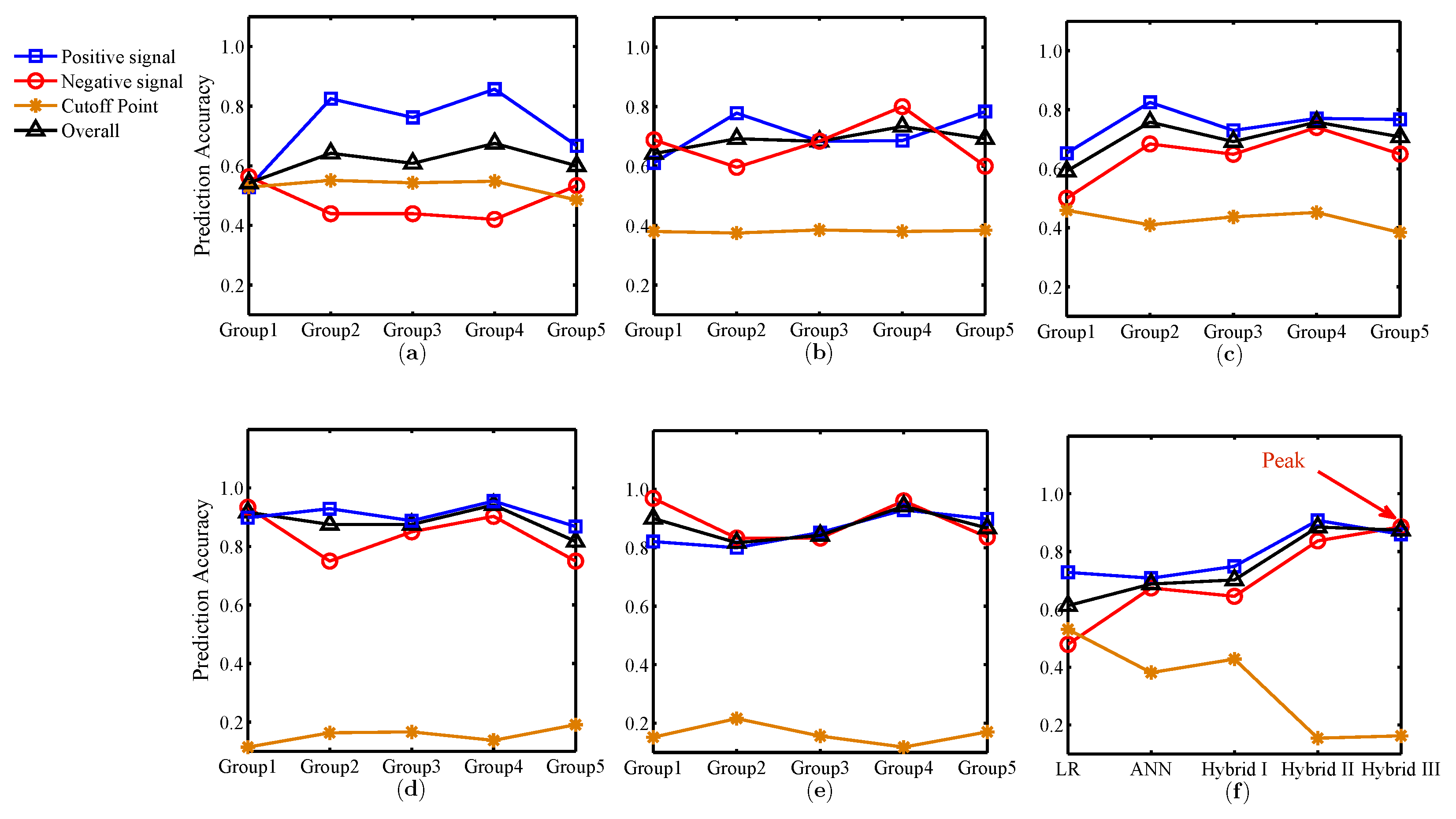
4.6. Experimental Results of Two-Stage Hybrid Model I
4.7. Experimental Results of Two-Stage Hybrid Model II
4.8. Experimental Results of Two-Stage Hybrid Model III
4.9. Comparing the SME Credit Risk Prediction Accuracies of the Five Models
- (1)
- If ROC = 0.5, it means no discrimination.
- (2)
- If 0.5 < ROC < 0.7, it means poor discrimination.
- (3)
- If 0.7 < ROC < 0.8, it means acceptable discrimination.
- (4)
- If 0.8 < ROC < 0.9, it means excellent discrimination.
- (5)
- If ROC ≥0.9, it means outstanding discrimination.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hofmann, E. Von der strategie bis zur finanziellen steuerung der performance in supply chains. In Interorganizational Operations Management; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2013; pp. 1–20. [Google Scholar]
- More, D.; Basu, P. Challenges of supply chain finance: A detailed study and a hierarchical model based on the experiences of an Indian firm. Bus. Process Manag. J. 2013, 19, 624–647. [Google Scholar] [CrossRef]
- Knox, A. Electronic payment: The missing link in supply chain efficiency. J. Financ. Transform. Mark. Imperfect. 2005, 14, 16–18. [Google Scholar]
- Fairchild, A. Intelligent matching: Integrating efficiencies in the financial supply chain. Supply Chain Manag. 2005, 10, 244–248. [Google Scholar] [CrossRef]
- Hofmann, E.; Belin, O. Value proposition of SCF. In Supply Chain Finance Solutions: Relevancel—Propositions— Market Value; Springer: Berlin, Germany; 2011; pp. 41–45. [Google Scholar]
- Gomm, M.L. Supply chain finance: Applying finance theory to supply chain management to enhance finance in supply chains. Int. J. Logist. Res. Appl. 2010, 13, 133–142. [Google Scholar] [CrossRef]
- Sopranzetti, B.J. Selling accounts receivable and the underinvestment problem. Q. Rev. Econ. Financ. 1999, 39, 291–301. [Google Scholar] [CrossRef]
- Seifert, R.W.; Seifert, D. Financing the chain. Int. Commer. Rev. 2011, 10, 32–44. [Google Scholar] [CrossRef]
- Wuttke, D.A.; Blome, C.; Henke, M. Focusing the financial flow of supply chains: An empirical investigation of financial supply chain management. Int. J. Prod. Econ. 2013, 145, 773–789. [Google Scholar] [CrossRef]
- Gouvêa, M.A.; Gonçalves, E.B. Credit risk analysis applying logistic regression, neural networks and genetic algorithms models. In Proccedings of the POMS 18th Annual Conference, Dallas, TX, USA, 4–7 May 2007; 2007; pp. 4–7. [Google Scholar]
- Lahsasna, A.; Ainon, R.N.; Teh, Y.W. Credit scoring models using soft computing methods: A survey. Int. Arab J. Inf. Technol. 2010, 7, 115–123. [Google Scholar]
- Wu, C.; Guo, Y.; Zhang, X.; Xia, H. Study of personal credit risk assessment based on support vector machine ensemble. Int. J. Innov. Comput. Inf. Control. 2010, 6, 2353–2360. [Google Scholar]
- Burgt, M.J.V.D. Calibrating low-default portfolios, using the cumulative accuracy profile. J. Risk Model Valid. 2007, 1, 1–17. [Google Scholar]
- Harrell, F.E.; Lee, K.L. A comparison of the discrimination of discriminant analysis and logistic regression under multivariate normality. In Biostatistics: Statistics in Biomedical, Public Health and Environmental Sciences; North-Holland: New York, NY, USA, 1985; pp. 333–343. [Google Scholar]
- Altman, E.I.; Sabato, G. Effects of the New Basel Capital Accord on bank capital requirements for SMEs. J. Financ. Serv. Res. 2005, 28, 15–42. [Google Scholar] [CrossRef]
- Altman, E.I.; Sabato, G. Modelling credit risk for SMEs: Evidence from the US market. Abacus J. Acc. Financ. Bus. Stud. 2007, 43, 332–357. [Google Scholar] [CrossRef]
- Behr, P.; Güttler, A. Credit risk assessment and relationship lending: An empirical analysis of German small and medium-sized enterprises. J. Small Bus. Manag. 2007, 45, 194–213. [Google Scholar] [CrossRef]
- Fantazzini, D.; Figini, S. Default forecasting for small-medium enterprises: Does heterogeneity matter. Int. J. Risk Assess. Manag. 2009, 11, 38–49. [Google Scholar] [CrossRef]
- Fidrmuc, J.; Heinz, C. Default rates in the loan market for SMEs: Evidence from Slovakia. Econ. Syst. 2009, 34, 133–147. [Google Scholar] [CrossRef]
- Pederzoli, C.; Torricelli, C. A parsimonious default prediction model for Italian SMEs. Banks Bank Syst. 2010, 5, 28–32. [Google Scholar]
- Pederzoli, C.; Thoma, G.C. Modelling credit risk for innovative firms: The role of innovation measures. J. Financ. Serv. Res. 2013, 44, 111–129. [Google Scholar] [CrossRef]
- Lee, T.S.; Chen, I.F. A two-stage hybrid credit scoring model using artificial neural networks and multivariate adaptive regression splines. Expert Syst. Appl. 2005, 28, 743–752. [Google Scholar] [CrossRef]
- Salchenberger, L.M.; Cinar, E.M.; Lash, N.A. Neural networks: A new tool for predicting thrift failures. Decis. Sci. 1992, 23, 899–916. [Google Scholar] [CrossRef]
- Sharda, R.; Wilson, R.L. Neural Network experiments in business-failure forecasting: Predictive performance measurement issues. Int. J. Comput. Intell. Organ. 1996, 1, 107–117. [Google Scholar]
- Zhang, G.; Hu, M.Y.; Patuwo, B. Artificial neural networks in bankruptcy prediction: General framework and cross-validation analysis. Eur. J. Oper. Res. 1999, 166, 16–32. [Google Scholar] [CrossRef]
- Lee, T.S.; Chiu, C.C.; Lu, C.J.; Chen, I.F. Credit scoring using the hybrid neural discriminant technique. Expert Syst. Appl. 2002, 23, 245–254. [Google Scholar] [CrossRef]
- Chung, H.M.; Gray, P. Special section: Data mining. J. Manag. Inf. Syst. 1999, 16, 11–16. [Google Scholar] [CrossRef]
- Craven, M.W.; Shavlik, J.W. Using neural networks for data mining. Future Gener. Comput. Syst. 1997, 13, 211–229. [Google Scholar] [CrossRef]
- Lin, S.L. A new two-stage hybrid approach of credit risk in banking industry. Expert Syst. Appl. 2009, 36, 8333–8341. [Google Scholar] [CrossRef]
- Falavigna, G. Models for Default Risk Analysis: Focus on Artificial Neural Networks, Model Comparisons, Hybrid Frameworks. Available online: http://www.ceris.cnr.it/ceris/workingpaper/2006/WP_10_06_FALAVIGNA.pdf (accessed on 28 April 2016).
- Deng, A.M.; Xiong, J.; Zhang, F. Order financing risk pre-warning model based on BP network. J. Intell. 2010, 29, 23–28. [Google Scholar]
- Bai, S.Z.; Li, S. Supply chain finance risk evaluation research based on BP neural network. Commer. Res. 2013, 6, 27–31. [Google Scholar]
- Xiong, X.; Ma, J.; Zhao, W. Credit risk analysis of supply chain finance. Nankai Bus. Rev. 2009, 12, 92–98. [Google Scholar]
- Bai, S.B. A research into the risk early-warning of enterprise supply chain financing based on ordered logistic model. Econ. Surv. 2010, 6, 66–71. [Google Scholar]
- Bei, Y.H.; Yang, L.; Wang, Y.H. Credit risk evaluation of car-making industry under supply chain financing mode. Logist. Technol. 2012, 31, 379–382. [Google Scholar]
- Jiang, J.; Jiang, X.; Song, X. Weighted composite quantile regression estimation of DTARCH models. Econ. J. 2014, 17, 1–23. [Google Scholar] [CrossRef]
- Jiang, X.; Song, X.; Xiong, Z. Efficient and robust estimation of GARCH models. J. Test. Eval. 2015. [Google Scholar] [CrossRef]
- Hosmer, J.D.W.; Lemeshow, S.; Sturdivant, R.X. Area under the receiver operating characteristic curve. In Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; pp. 184–197. [Google Scholar]
- Fidell, L.S.; Tabachnick, B.G. Fundmental equations for multiple regression. In Using Multivariate Statistics; Harper Collins: Boston, MA, USA, 2008; pp. 128–134. [Google Scholar]
- Li, J.; Burke, E.K.; Qu, R. Integrating neural networks and logistic regression to underpin hyper-heuristic search. Knowl. Based Syst. 2011, 24, 322–330. [Google Scholar] [CrossRef]
- Masters, T. Probabilistic neural networks I: Introduction. In Advanced Algorithms for Neural Networks: A C++ Sourcebook; John Wiley & Sons: New York, NY, USA, 1995; pp. 112–120. [Google Scholar]
- Gutierrez, P.A.; Segovia-Vargas, M.J.; Salcedo-Sanz, S.; Hervas-Martinez, C.; Sanchis, A.; Portilla-Figueras, J.A.; Fernandez-Navarro, F. Hybridizing logistic regression with product unit and RBF networks for accurate detection and prediction of banking crises. Omega 2010, 38, 333–344. [Google Scholar] [CrossRef]
- Broomhead, D.S.; Lowe, D. Radial basis functions, multi-variable functional interpolation and adaptive networks. DTIC Doc. 1988, 2, 321–355. [Google Scholar]
- Bekhet, H.A.; Eletter, S.F.K. Credit risk assessment model for Jordanian commercial banks: Neural scoring approach. Rev. Dev. Financ. 2014, 4, 20–28. [Google Scholar] [CrossRef]
- Way, Y. Collinearity diagnosis for a relative risk regression analysis an application to assessment of diet cancer relationship in epidemiological studies. Stat. Med. 1992, 11, 1273–1287. [Google Scholar]
- Goldstein, R. Book reviews: Conditioning diagnostics: Collinearity and weak data in regression. Technometrics 1993, 35, 85–86. [Google Scholar] [CrossRef]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. 1974, 36, 111–147. [Google Scholar]
- Efron, B.; Tibshirani, R.J. Crossvalidation and other estimates of prediction. In An Introduction to the Bootstrap; Chapman and Hall: New York, NY, USA, 1993; pp. 237–257. [Google Scholar]
- Zhu, Y.; Xie, C.; Wang, G.; Yan, X. Comparison of individual, ensemble and integrated ensemble machine learning methods to predict China’s SMEs credit risk in supply chain finance. Neural Comput. Appl. 2016. [Google Scholar] [CrossRef]
- Jiang, J. Multivariate Functional-coefficient regression models for multivariate nonlinear times series. Biometrika 2014, 101, 689–702. [Google Scholar] [CrossRef]
- Wong, F.S. Time series forecasting using backpropagation neural networks. Neurocomputing 1991, 2, 147–159. [Google Scholar] [CrossRef]
- Yap, B.W.; Ong, S.H.; Husain, N.H.M. Using data mining to improve assessment of credit worthiness via credit scoring models. Expert Syst. Appl. 2011, 38, 13274–13283. [Google Scholar] [CrossRef]
- Kürüm, E.; Yildirak, K.; Weber, G.W. A classification problem of credit risk rating investigated and solved by optimization of ROC curve. Cent. Eur. J. Oper. Res. 2012, 20, 529–557. [Google Scholar] [CrossRef]
- West, D. Neural network credit scoring models. Comput. Oper. Res. 2000, 27, 1131–1152. [Google Scholar] [CrossRef]
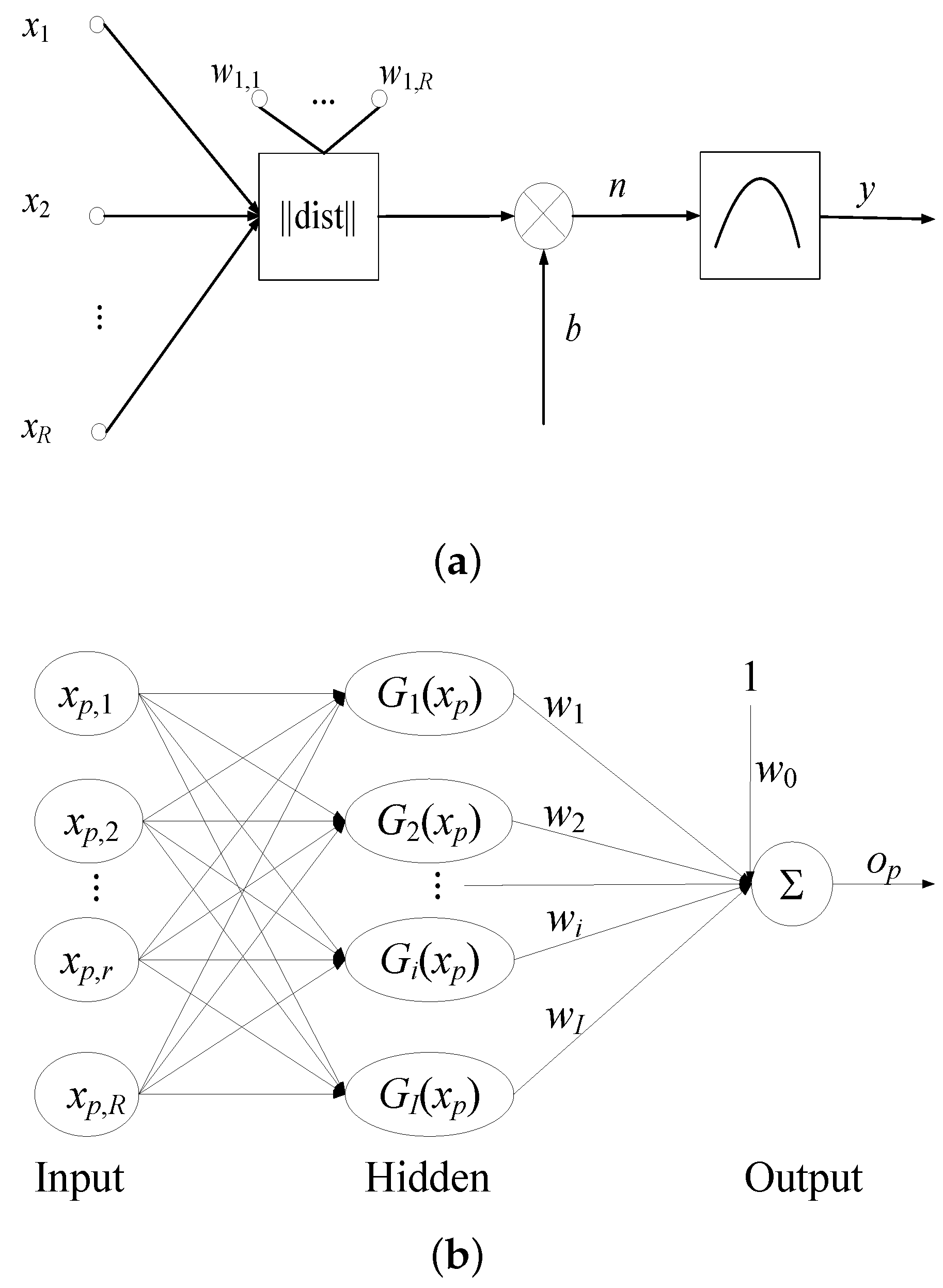



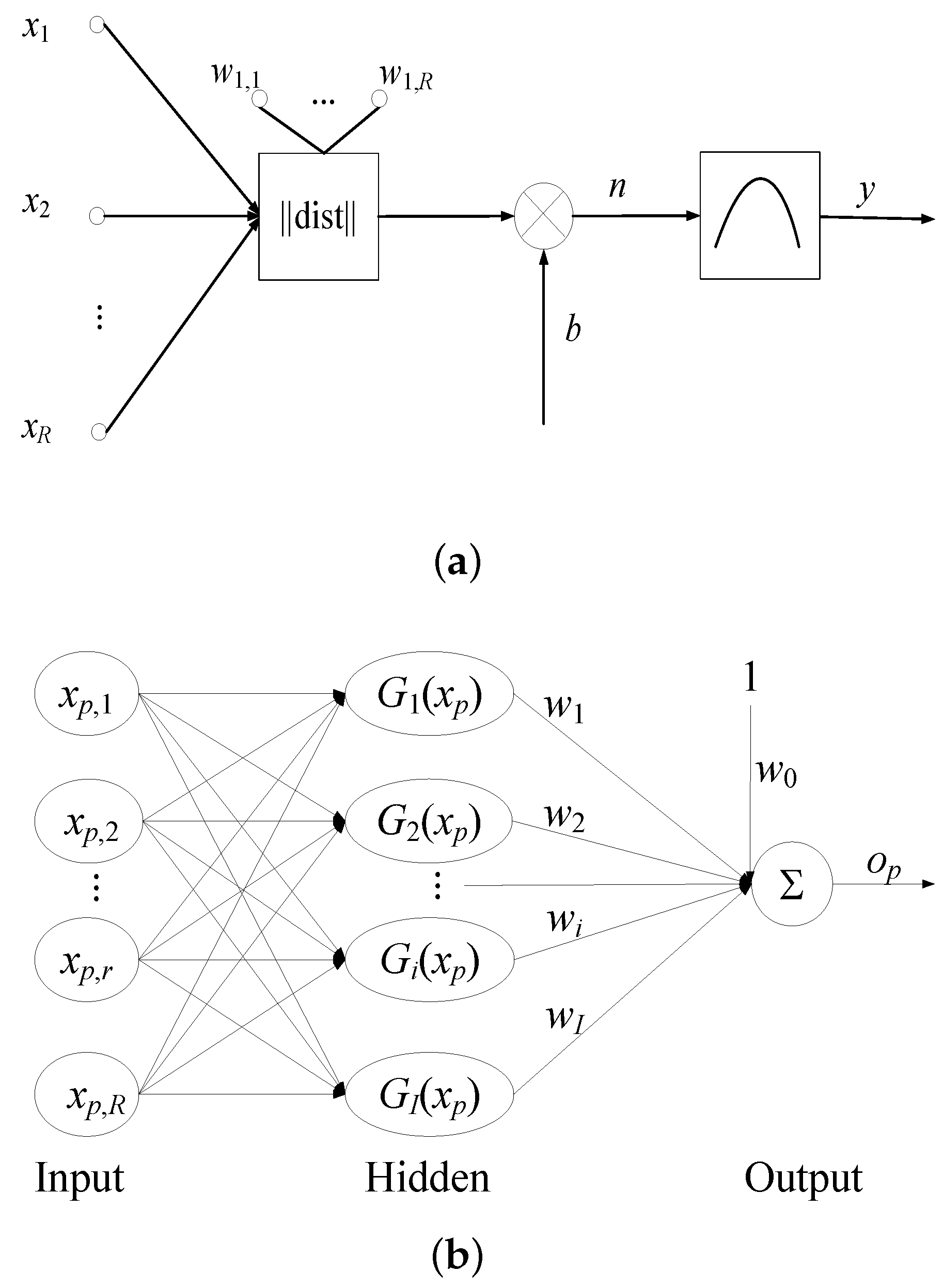{kind=link}
{kind=link}
{kind=link}
| Indexes | Variables | Categories |
|---|---|---|
| Current ratio of SME | Liquidity | |
| Quick ratio of SME | Liquidity | |
| Cash ratio of SME | Liquidity | |
| Working capital turnover of SME | Liquidity | |
| Return on equity of SME | Leverage | |
| Profit margin on sales of SME | Profitability | |
| Rate of Return on Total Assets of SME | Leverage | |
| Total Assets Growth Rate of SME | Activity | |
| Credit rating of CE | Non-financial | |
| Quick ratio of CE | Liquidity | |
| Turnover of total capital of CE | Liquidity | |
| Profit margin on sales of CE | Profitability | |
| Price rigidity, liquidation and vulnerable degree of trade goods | Non-financial | |
| Accounts receivable collection period of SME | Leverage | |
| Accounts receivable turnover ratio of SME | Leverage | |
| Industry trends of SME | Non-financial | |
| Transaction time and transaction frequency of SME | Non-financial | |
| Credit rating of SME | Non-financial |
| Independent Variables | Observations | Mean | Std. Deviation |
|---|---|---|---|
| 600 | 1.794 | 1.665 | |
| 600 | 1.351 | 1.539 | |
| 600 | 0.574 | 0.916 | |
| 600 | 14.566 | 71.026 | |
| 600 | 0.049 | 0.074 | |
| 600 | 0.051 | 0.080 | |
| 600 | 0.028 | 0.037 | |
| 600 | 0.221 | 0.258 | |
| 600 | 8.155 | 2.702 | |
| 600 | 0.990 | 0.204 | |
| 600 | 0.836 | 0.451 | |
| 600 | 0.0419 | 0.027 | |
| 600 | 6.300 | 2.278 | |
| 600 | 76.709 | 49.361 | |
| 600 | 6.751 | 9.670 | |
| 600 | 5.695 | 2.012 | |
| 600 | 6.300 | 2.278 | |
| 600 | 5.695 | 2.012 |
| Independent Variables | Original 18 Variables | Reserved 10 Variables | ||||
|---|---|---|---|---|---|---|
| T | VIF | CI | T | VIF | CI | |
| 0.008 | 126.175 | 1.195 | ||||
| 0.006 | 169.747 | 1.230 | ||||
| 0.084 | 11.975 | 1.584 | ||||
| 0.911 | 1.098 | 1.792 | 0.933 | 1.072 | 1.173 | |
| 0.121 | 8.236 | 1.909 | ||||
| 0.356 | 2.807 | 1.934 | 0.737 | 1.358 | 1.455 | |
| 0.108 | 9.236 | 2.088 | ||||
| 0.697 | 1.434 | 2.170 | 0.823 | 1.215 | 1.503 | |
| 0.392 | 2.552 | 2.644 | 0.518 | 1.932 | 1.549 | |
| 0.533 | 1.876 | 3.062 | 0.636 | 1.573 | 1.573 | |
| 0.692 | 1.446 | 3.591 | 0.714 | 1.400 | 1.701 | |
| 0.445 | 2.200 | 3.827 | 0.522 | 1.915 | 1.985 | |
| – | – | – | ||||
| 0.502 | 1.991 | 4.137 | 0.557 | 1.796 | 2.539 | |
| 0.437 | 2.289 | 6.995 | 0.458 | 2.184 | 2.767 | |
| – | – | – | ||||
| 0.477 | 2.094 | 7.874 | 0.534 | 1.874 | 3.211 | |
| 0.471 | 2.124 | 33.233 | ||||
| Model | Sum of Squares | df | Mean Square | F | Sig |
|---|---|---|---|---|---|
| Regression | 35.023 | 16 | 2.189 | 11.227 | 0.000 |
| Residual Total | 113.670 | 583 | 0.195 | ||
| 148.693 | 599 |
| Independent Variables | B. | Sig. | Situation |
|---|---|---|---|
| 0.169 | 0.681 | Excluded | |
| −0.414 | 0.000 | Reserved | |
| 0.239 | 0.017 | Excluded | |
| 0.866 | 0.000 | Reserved | |
| 0.281 | 0.015 | Excluded | |
| −0.176 | 0.085 | Excluded | |
| −0.354 | 0.003 | Reserved | |
| −0.753 | 0.000 | Reserved | |
| 0.123 | 0.762 | Excluded | |
| 1.405 | 0.236 | Excluded | |
| Constant | −0.282 | 0.003 | Reserved |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | ||
|---|---|---|---|---|---|---|
| Pearson chi-square | 8.808 | 8.810 | 10.830 | 11.199 | 3.068 | |
| Degree of freedom | 8.000 | 8.000 | 8.000 | 8.000 | 8.000 | |
| p-value | 0.160 | 0.359 | 0.212 | 0.191 | 0.930 | |
| Critical value | 15.507 | 15.507 | 15.507 | 15.507 | 15.507 |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Mean (SD) | |
|---|---|---|---|---|---|---|
| Optimal cutoff point | 0.528 | 0.551 | 0.543 | 0.548 | 0.485 | 0.531 (0.027) |
| Positive signal | 52.8% | 82.5% | 76.2% | 85.7% | 66.7% | 72.8% (0.133) |
| Negative signal | 56.3% | 43.9% | 43.9% | 42.0% | 53.3% | 47.9% (0.065) |
| Overall | 54.2% | 64.2% | 60.8% | 67.5% | 60.0% | 61.3% (0.050) |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Mean (SD) | |
|---|---|---|---|---|---|---|
| Optimal cutoff point | 0.380 | 0.375 | 0.385 | 0.380 | 0.384 | 0.381 (0.004) |
| Positive signal | 61.1% | 77.8% | 68.3% | 68.6% | 78.3% | 70.8% (0.073) |
| Negative signal | 68.8% | 59.6% | 68.4% | 80.0% | 60.0% | 67.4% (0.083) |
| Overall | 64.2% | 69.2% | 68.3% | 73.3% | 69.2% | 68.8% (0.032) |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Mean (SD) | |
|---|---|---|---|---|---|---|
| Optimal cutoff point | 0.459 | 0.410 | 0.437 | 0.452 | 0.384 | 0.428 (0.031) |
| Positive signal | 65.3% | 82.5% | 73.0% | 77.1% | 76.7% | 74.9% (0.064) |
| Negative signal | 50.0% | 68.4% | 64.9% | 74.0% | 65.0% | 64.5% (0.089) |
| Overall | 59.2% | 75.8% | 69.2% | 75.8% | 70.8% | 70.2% (0.068) |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Mean (SD) | |
|---|---|---|---|---|---|---|
| Optimal cutoff point | 0.114 | 0.163 | 0.166 | 0.137 | 0.191 | 0.154 (0.030) |
| Positive signal | 89.8% | 92.9% | 88.8% | 95.5% | 86.8% | 90.8% (0.035) |
| Negative signal | 93.4% | 75.0% | 85.0% | 90.3% | 75.0% | 83.7% (0.085) |
| Overall | 91.7% | 87.5% | 87.5% | 94.2% | 81.7% | 88.5% (0.048) |
| Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Mean (SD) | |
|---|---|---|---|---|---|---|
| Optimal cutoff point | 0.152 | 0.216 | 0.156 | 0.118 | 0.170 | 0.162 (0.036) |
| Positive signal | 82.1% | 80.0% | 85.2% | 92.9% | 89.8% | 86.0% (0.053) |
| Negative signal | 96.9% | 83.3% | 83.3% | 96.0% | 83.6% | 88.6% (0.072) |
| Overall | 90.0% | 81.7% | 84.2% | 94.2% | 86.7% | 87.4% (0.049) |
| Models | Group 1 | Group 2 | Group 3 | Group 4 | Group 5 | Mean (SD) | Discrimination Accuracy |
|---|---|---|---|---|---|---|---|
| LR | 0.608 | 0.611 | 0.623 | 0.628 | 0.653 | 0.625 (0.018) | No |
| ANN | 0.811 | 0.835 | 0.809 | 0.812 | 0.825 | 0.818 (0.011) | Excellent |
| Hybrid I | 0.751 | 0.796 | 0.764 | 0.764 | 0.819 | 0.779 (0.028) | Acceptable |
| Hybrid II | 0.974 | 0.958 | 0.959 | 0.967 | 0.952 | 0.962 (0.009) | Outstanding |
| Hybrid III | 0.959 | 0.940 | 0.963 | 0.968 | 0.959 | 0.958 (0.011) | Outstanding |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Xie, C.; Sun, B.; Wang, G.-J.; Yan, X.-G. Predicting China’s SME Credit Risk in Supply Chain Financing by Logistic Regression, Artificial Neural Network and Hybrid Models. Sustainability 2016, 8, 433. https://0-doi-org.brum.beds.ac.uk/10.3390/su8050433
Zhu Y, Xie C, Sun B, Wang G-J, Yan X-G. Predicting China’s SME Credit Risk in Supply Chain Financing by Logistic Regression, Artificial Neural Network and Hybrid Models. Sustainability. 2016; 8(5):433. https://0-doi-org.brum.beds.ac.uk/10.3390/su8050433
Chicago/Turabian StyleZhu, You, Chi Xie, Bo Sun, Gang-Jin Wang, and Xin-Guo Yan. 2016. "Predicting China’s SME Credit Risk in Supply Chain Financing by Logistic Regression, Artificial Neural Network and Hybrid Models" Sustainability 8, no. 5: 433. https://0-doi-org.brum.beds.ac.uk/10.3390/su8050433