2.1. Real-time Big Data Processing in Manufacturing
As increasing the Internet of Things (IoT) and sensor devices, it is expected that the data generated from manufacturing process will grow exponentially, generating so called ‘big data’. One of the focuses of smart manufacturing is to create real-time monitoring system to support accurate and timely decision-making. Therefore, big data analytics is expected to contribute significantly to the advancement of smart manufacturing. Mani et al. (2017) explored the application of big data analytics in mitigating supply chain social risk and to demonstrate how such mitigation can help in achieving sustainability [
19]. The results show that companies can predict various social problems including workforce safety, fuel consumptions monitoring, workforce health, security, physical condition of vehicles, unethical behavior, theft, speeding and traffic violations through big data analytics, thereby demonstrating how information management actions can mitigate social risks. Malek et al. (2017) combined IoT with Big data technologies into single platform for continuous and real-time data monitoring and processing [
20]. The experiments utilized open hardware sensors, such as pulse and oximetry, carbon dioxide in air, humidity and temperature sensors. The purpose of study is to analyses how the lack of proper building’s ventilation can impair occupants’ performance and affect their health. The proposed system is able to monitor the sensor data in real-time, and found direct relationship between CO
2 and O
2 concentration inside building.
The development of information technology and sensor technology has enabled large-scale data collection when monitoring the manufacturing processes. Those data could be potentially useful when learning patterns and knowledge for the purpose of quality improvement in manufacturing processes. Therefore, the integration of big data and data mining technology in smart manufacturing is expected to help the management in decision making. He and Wang (2017) utilized statistical process monitoring for big data analytics tool in smart manufacturing [
21]. Proposed system is able to handle large volume of streaming data for real-time, statistical analysis and online monitoring. Siddique et al. (2017) proposed an efficient intrusion detection system which continuously monitors network traffic aiming to identify malicious actions [
22]. The proposed system is capable of handling large volume of network traffic in real-time environments. Based on contemporary dataset, the proposed model showed high performance and efficiency.
2.2. Open Source Technologies for Big Data Processing
Open Source Initiative defines Open Source Software (OSS) as; “software that can be freely used, changed, and shared (in modified or unmodified form) by anyone” [
23]. In contrast to traditional software development model, the OSS development model heavily relies on contributions of volunteers, rather than traditional employees. Many projects, such as the Linux operating systems, the Mozilla browser, Apache Kafka, Apache Strom, MongoDB, and the Apache web server have been successfully developed in OSS communities [
24]. In the manufacturing area, many researchers had used open source-based application to achieve the concept of integrated enterprise [
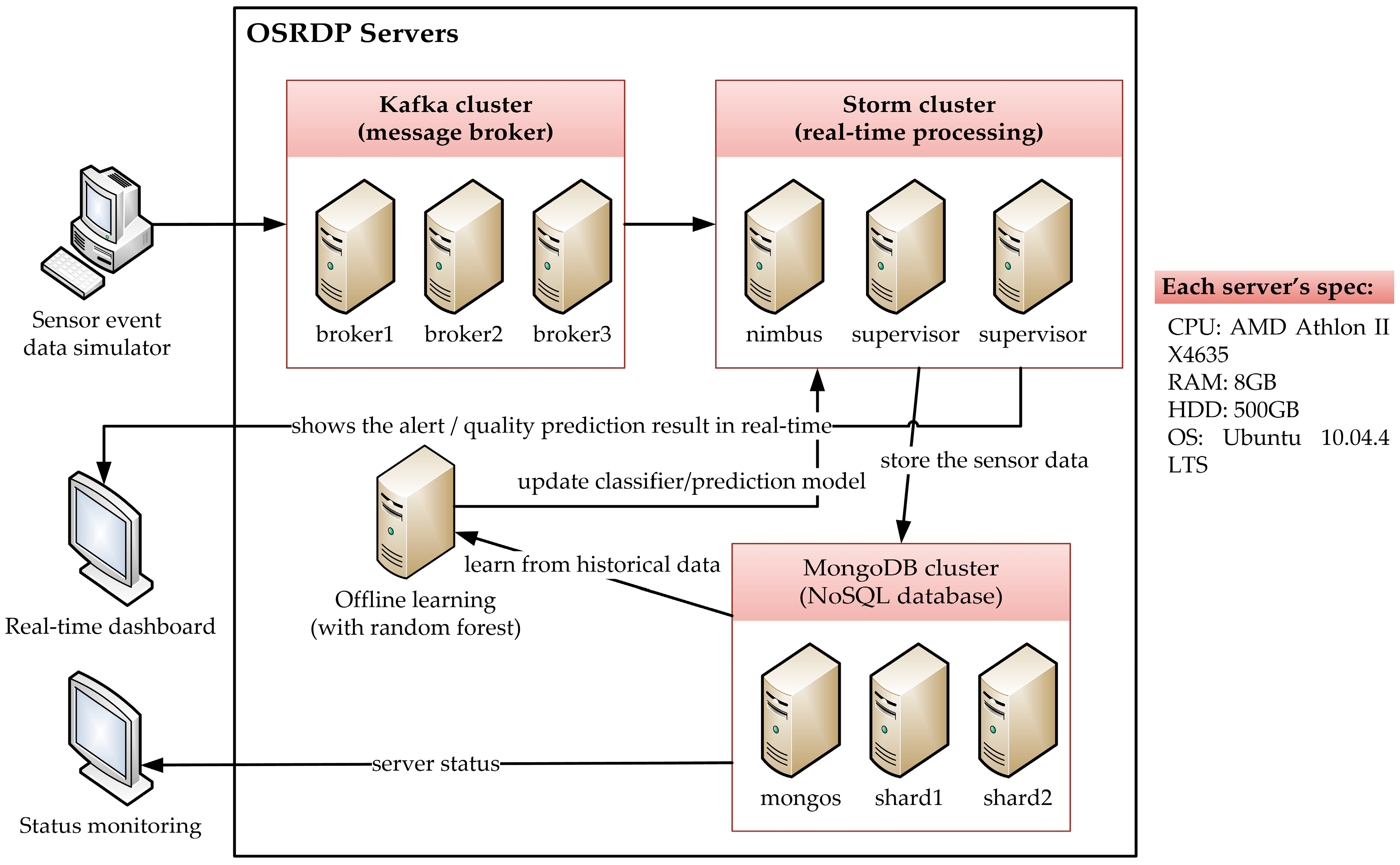
25]. In this study, three open source big data processing are used, they are Apache Kafka, Apache Storm and NoSQL MongoDB. The Apache Kafka is used for handling the incoming fast large volume of streaming data while Apache Storm is utilized for real-time distributed processing. In addition, MongoDB is used to store the large amount of unstructured sensor data.
Apache Kafka is a scalable publish-subscribe messaging system and used for building real-time data pipelines [
26]. It is built to be fault-tolerant, high-throughput, horizontally scalable, and allows geographically distributing data streams and processing. Apache Kafka consists of several components, they are
topics (the name of category or feed to which messages/logs are published),
producers (the processes that publish messages/logs into Apache Kafka),
consumers (the process that subscribes to topics and process the feed of published messages) and
broker (the name of the server which Apache Kafka process is operating on that server). Apache Kafka is well suited for situations wherein users must process real-time data, and analyze them. At LinkedIn, Apache Kafka supports dozens of subscribing systems, and delivers more than 55 billion messages to consumers daily [
27]. Kreps et al. (2011) introduced Kafka, a distributed messaging system that used for high volumes of log data. It also provides integrated distributed support and can scale out. The result showed that Kafka achieves much higher throughput than conventional messaging systems (such as ActiveMQ and RabbitMQ) [
28]. Fernandez-Rodriguez et al. (2017) proposed real-time vehicle data streaming models for a smart city [
29]. The proposed system gathers information from drivers in a big city, analyzing that information and sending real-time recommendations to improve driving efficiency and safety on roads. A simulation is used to evaluate the system performance and Apache Kafka is utilized for stream processing. The result showed that Apache Kafka achieve a higher scalability and faster responses as well as cost reduction compared to traditional system.
Apache Storm is an open-source distributed real-time computation system for processing large volumes of high-velocity data [
30]. Apache Storm includes multiple features such as horizontal scalability, fault tolerance, guaranteed data processing and the support of different programming languages. Scalability feature of Apache Storm includes possibility of rebalancing a cluster when new working nodes have been added. Guaranteed data processing ensures that if a worker node fails, Storm will automatically reassign tasks and replay all tuples to guarantee its processing. Apache Storm runs in-memory, therefore it is able to process large volumes of data at in-memory speed. Previous studies have utilized Apache Storm for real-time big data processing. Nivash et al. (2014) compared the performance of data processing models like Hadoop, Apache YARN, Mapreduce, Storm and Akka in the Big Data domain [
31]. The current study proposed two algorithms namely JATS and SD, which enhance the efficiency of the Storm data processing architecture. The proposed system is capable of handling huge amount of data in real-time. De Maio et al. (2017) proposed the temporal fuzzy concept analysis on a distributed real-time computation system based on Apache Storm [
32]. The proposed system is implemented by utilizing big data stream analysis in the smart city context and expected to support smart city decision-making processes. In addition, Yang et al. (2013) studied several technologies associated with real-time big data processing. The proposed system is built based on Storm, and the result showed that the big data real-time processing based on Storm can be widely used in various computing environment [
33].
The NoSQL MongoDB is used to store the large amount of unstructured sensor data. The term ‘NoSQL’ collectively refers to database technologies that do not abide by the strict data model of relational databases. MongoDB is a document-oriented NoSQL database that offers high performance and scalability. By sacrificing some properties of relational database model, NoSQL databases can achieve higher availability and scalability, essential requirements for big data processing. Unlike other NoSQL databases, its data structure is designed independently as a document unit so that schema definition is not needed. MongoDB uses a scale-out scheme, which is flexible against hardware expansion, and supports auto-sharding. Thus, the automatic distribution of data over several servers can be conveniently carried out [
34,
35,
36,
37]. There have been various researches on the performance of MongoDB. Nyati et al. (2013) compared the insertion/searching performance of MongoDB to MySQL in a single machine, showing that MongoDB outperformed MySQL [
38]. Kanade et al. (2014) conducted an experimental comparative study between embedding and referencing design patterns, showing that the embedding pattern performs better in terms of query response time [
39]. Liu et al. (2012) proposed an algorithm to solve irregular distribution of data among distributed storages, and demonstrated that the proposed approach can improve the throughput and read/write response time of the existing automatic data distribution [
40].
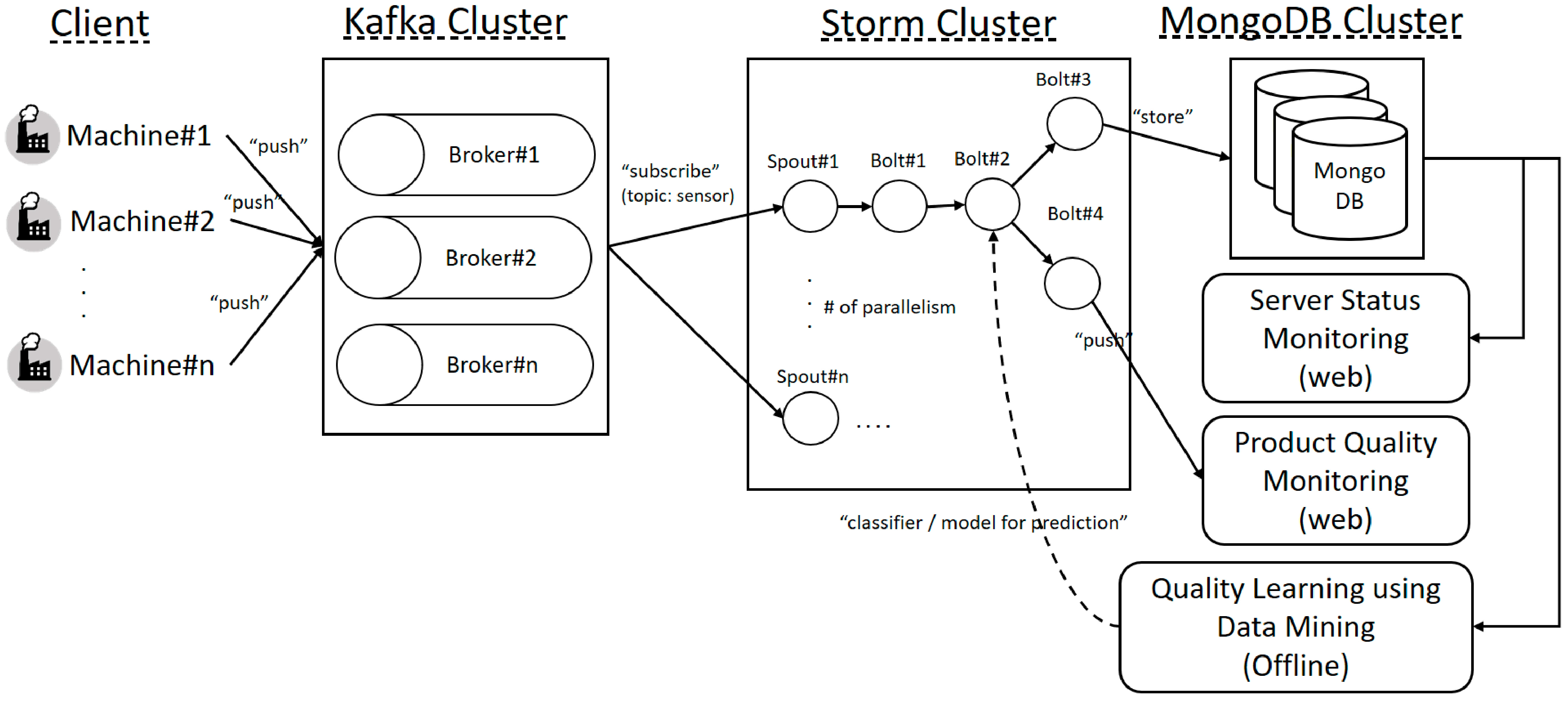
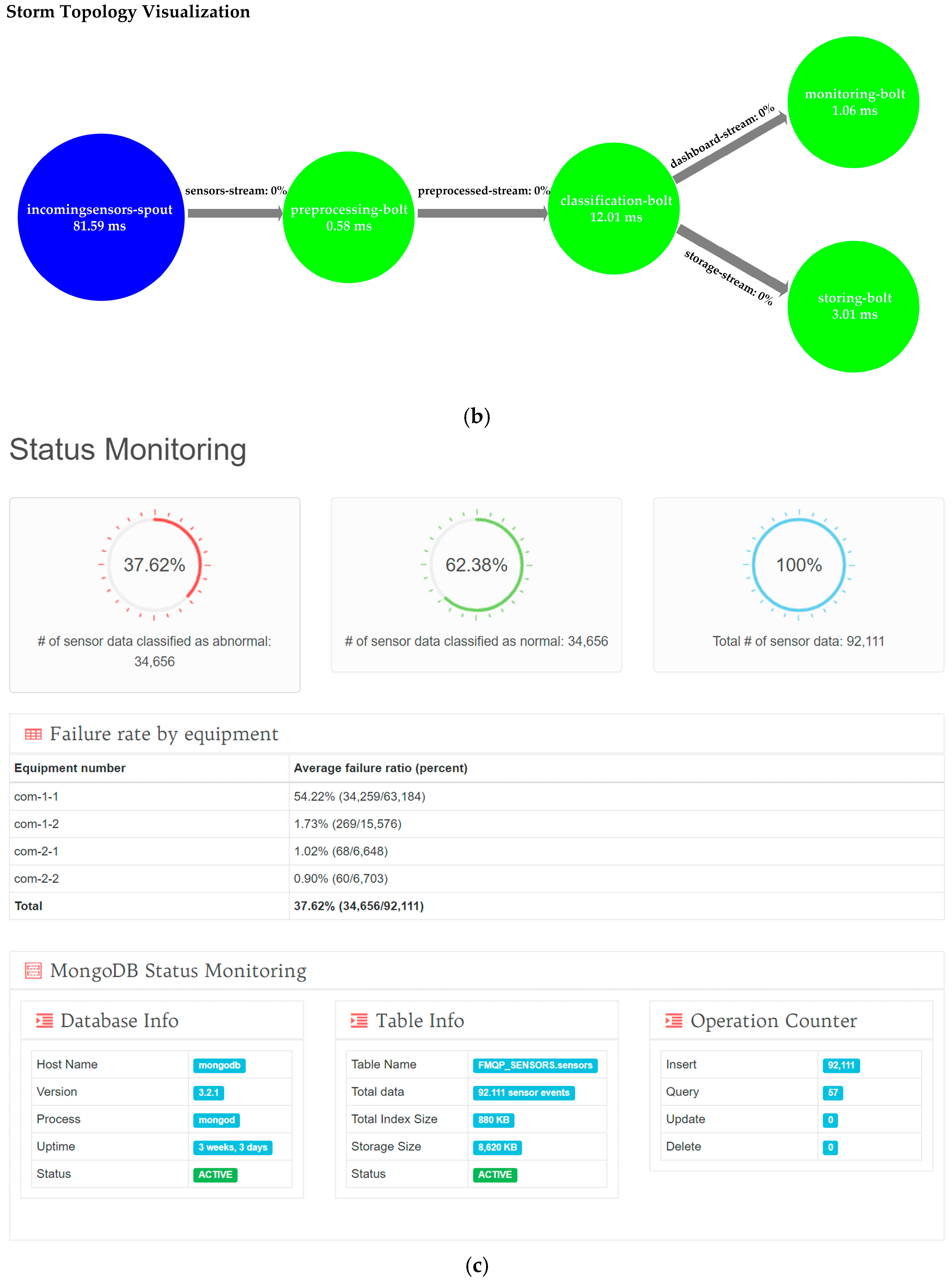
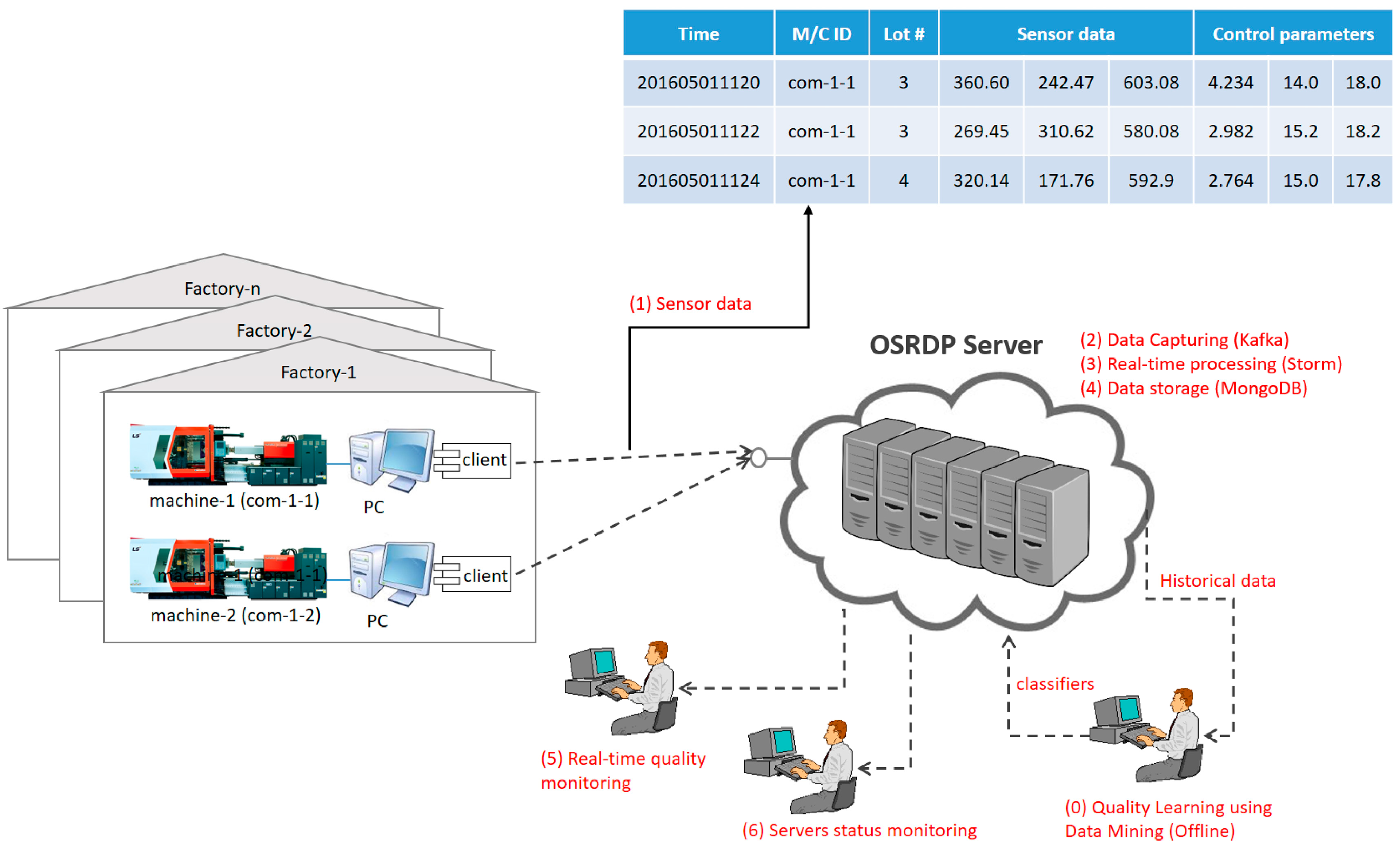
In our proposed OSRDP architecture framework, we created a topology that receives sensors data from Apache Kafka, executes, processes, analyzes, monitors and stores sensor data in real-time. Apache Storm is used to process streaming data continuously, while NoSQL MongoDB is used for saving data. For improving the quality prediction, the data mining technique is used as the last part to analyze the historical sensor data that previously stored in the NoSQL MongoDB.
2.3. Quality Improvement Based on Data Mining
Managing quality is crucial for the manufacturing enterprises to survive the competition in the global market. Industries today need to stay ahead in competition by servicing and satisfying customer’s needs. At the moment, the process to ensure the quality of the product in manufacturing is based on the visual inspection, and these operations increase the cost and the resources during the process [
15]. The application of data mining can help in identifying not only the defective products but can also simultaneously determine the significant factors that influence the success or failure of the process. Data mining is now used in many different areas in in manufacturing, especially in the areas of production processes, control, maintenance, customer relationship management (CRM), decision support systems (DSS), quality improvement, fault detection, and engineering design [
16]. Data can be analyzed to identify hidden patterns in the parameters that control manufacturing processes or to determine and improve the quality of products.
Quality of the products that satisfy customer demands is the key goal for a product manufacturing company. A product produced with variation in characteristics, than the anticipated are called as defect. Ferreiro et al. (2011) proposed the system to detect automatically the quality of material [
15]. The material for the tests was aluminum Al 7075-T6, commonly used in aeronautical structures. The current studied showed that probability technique Naive Bayes generated high accuracy around 95% to classify whether the burr from material is out of tolerance limits or not. Tseng et al. (2004) used rough set theory to resolve quality control problems in PCB manufacturing by identifying the features that produce solder ball defect and also determined the features that significantly affect the quality of the product [
41]. Chen et al. (2005) generated association rules for defect detection in semiconductor manufacturing. They determined the association between different machines and their combination with defects to determine the defective machine. In the mild steel coil manufacturing plants, large amount of data is generated with the help of many sensors deployed to measure different parameters which can be used for defect diagnosis of the coils produced [
42]. Patel and Jokhakar (2016) proposed defect cause analysis model to be applied in steel industry [
43]. The result showed that random forest can achieve accuracy of 95% compared to other algorithm. Tseng et al. (2005) used CNC machines based on rough set theory. The information of defined process is created as a rule-based [
44]. Syn et al. (2011) proposed model based on fuzzy theory that predict the surface quality of the products produced by the machine [
45]. Zeaiter et al. (2011) proposed real-time cavity pressure that estimate weight and dimensions of the product using force sensor data by using regression analysis model [
46].
For the case of injection molding process, the stability control of production is an important aspect. Improving product quality stability is main challenge for injection molding because the injection process is usually disturbed by several inevitable variations. Zhou et al. (2017) proposed a quality prediction model based on polymer melt properties to monitor product weight variation [
47]. The proposed control method results in a decrease in product weight variation from 0.16% to 0.02% in the case of varying mold temperature. In addition, the number of cycles to return stability decreases from 11 to 5 in with respect to variations in the melt temperature.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}