Towards Real-Time Service from Remote Sensing: Compression of Earth Observatory Video Data via Long-Term Background Referencing



Abstract
:1. Introduction
- (1)
- We analyzed the characteristics of Earth observatory video data, and discovered the long-term background redundancy among the videos collected of the same location at different times, which provides a chance to further compress the EOVD.
- (2)
- We introduced the concept of a referencing library (the LBRL) as the fundamental infrastructure to facilitate the real-time collection of EOVD, which will further enhance online smart city applications.
- (3)
- We proposed an LBRL-based reference generation method and the coding framework for EOVD, which can significantly reduce the bitrate compared to the coding standard for a single video source, helping to alleviate the difference between data collection bitrate and the space to Earth transmission bandwidth.
2. Related Work
2.1. Video Compression of Satellite Videos
2.2. Video Compression of Surveillance Videos
2.3. Video Compression of Multisource Image/Video Data
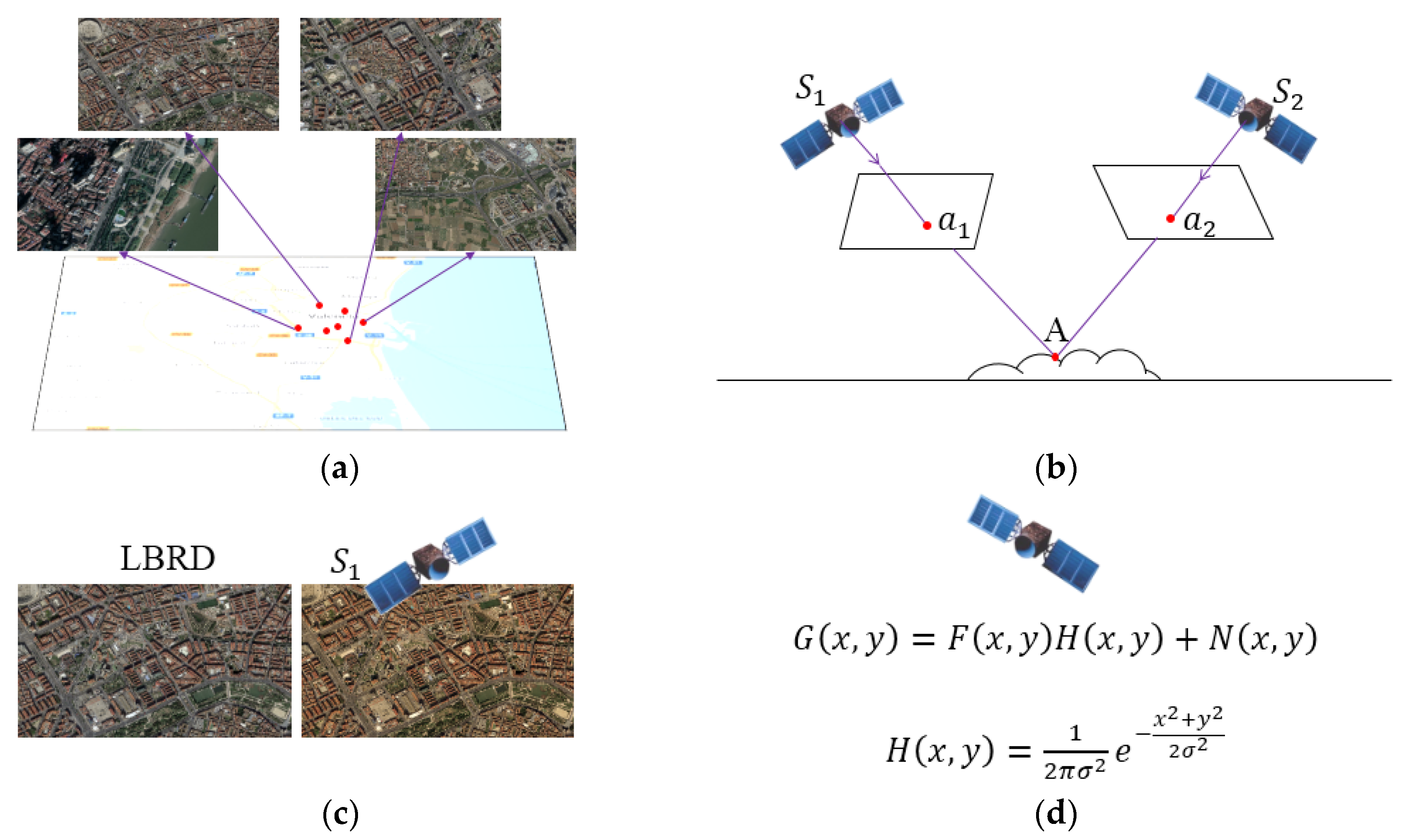
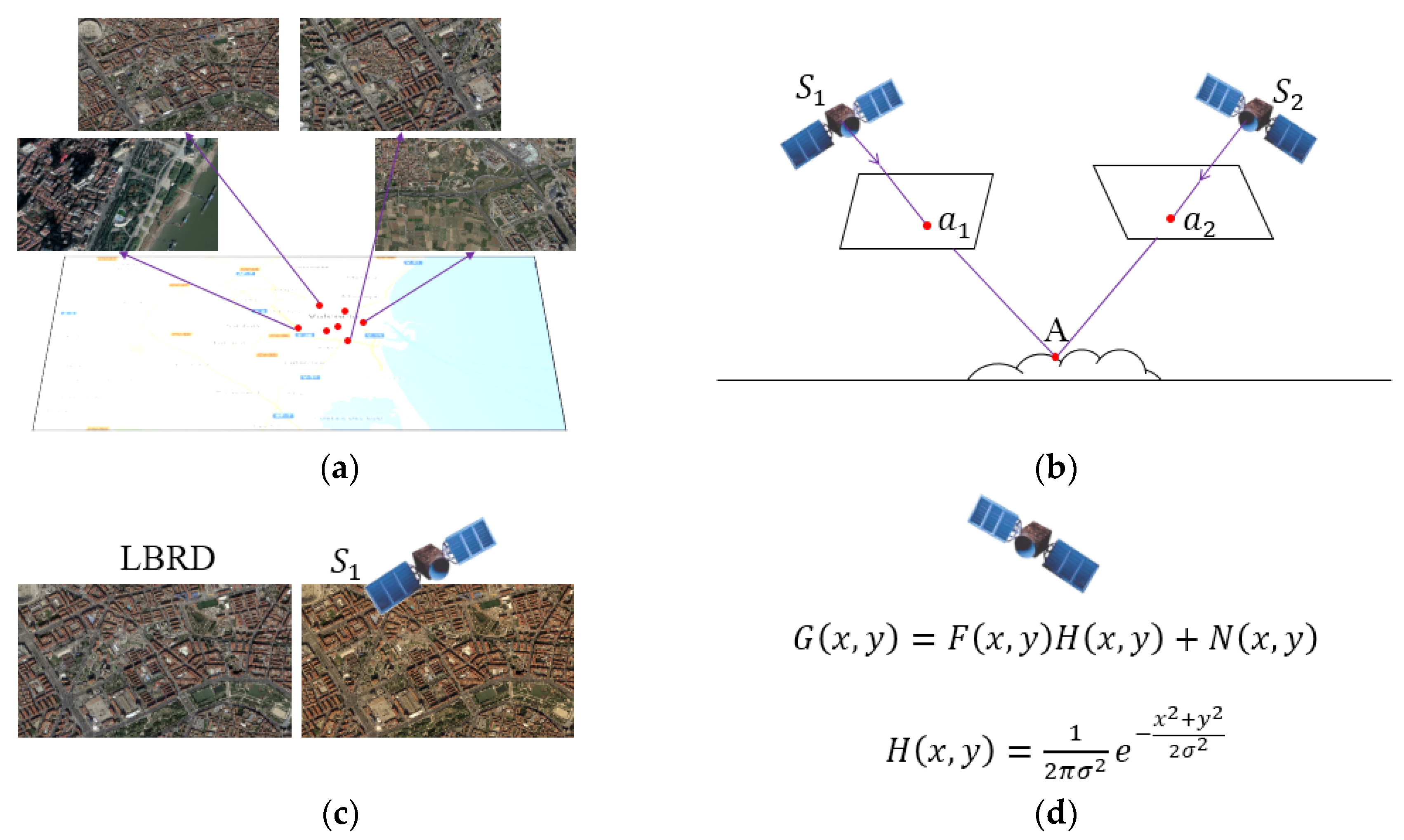
3. Long-Term Background Referencing Library
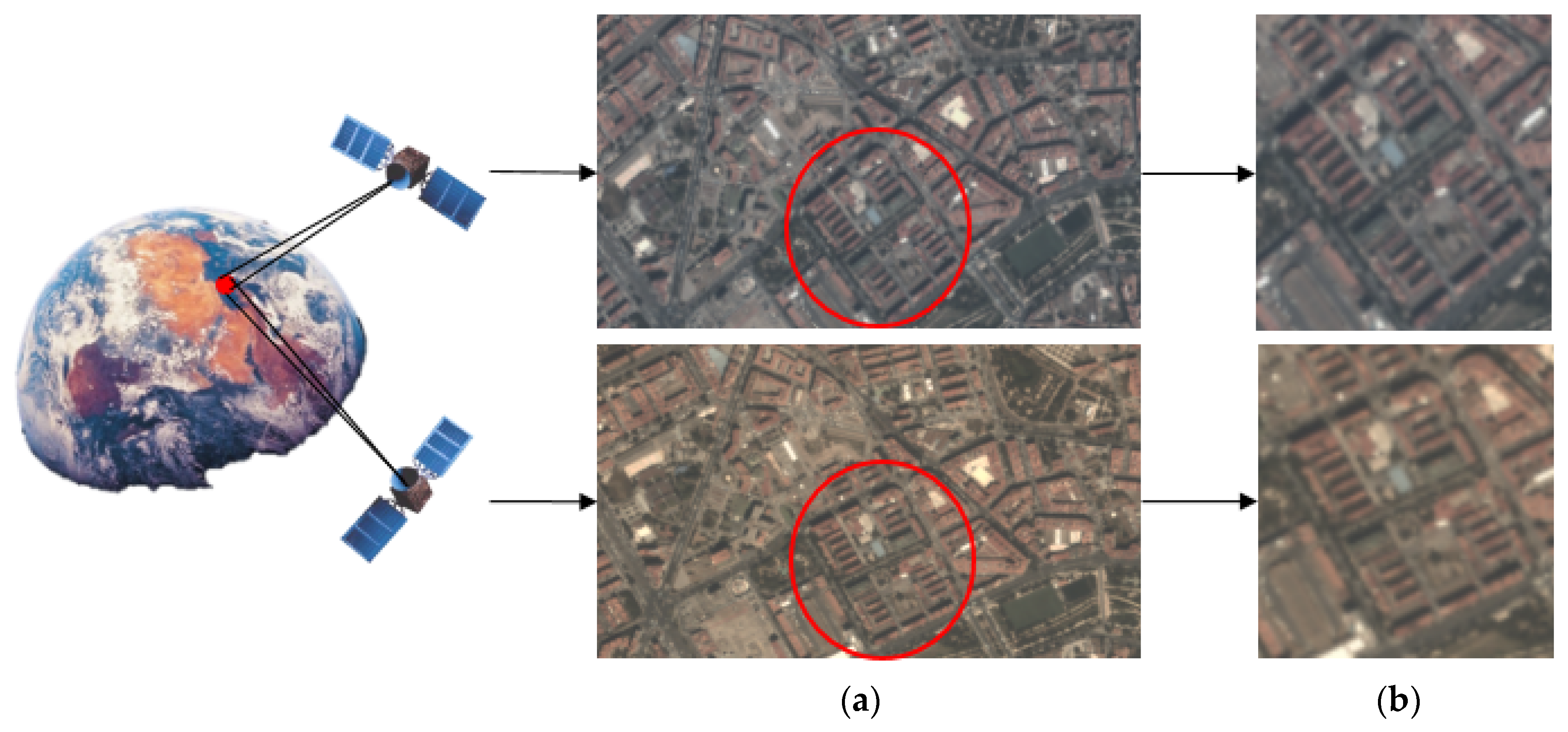
3.1. A New Redundancy Induced by Background Repetition
- (1)
- Projection difference: a location in a specific video clip can be represented by the projection of that area into the image plane, which is:where is the background in a picture and is the projection of area A into a video clip. Since the projection is decided by the position and angle of the camera, it changes for every frame.
- (2)
- Radiometric difference: the color of an image is affected by changes in the area’s environmental radiation. Radiation changes can be modeled because the factors causing them, such as illumination, are limited in the long term. Therefore, the image representation of an area can be expressed as follows:where is a radiation model that converts from the reference background to the current image, and is the image representation of the background after radiation change.
- (3)
- Quality difference: EOVD image quality is affected by many factors. Some are related to the sensor itself, such as the optical imaging system, electrical signal conversion, and motion of the platform. These factors remain stable for a certain video clip, leading to consistent quality degradation for that video clip. Therefore, the image representation of an area can be expressed as follows:where is the quality degradation of a certain satellite, and is the final image representation of the area.
3.2. Development of an LBRL
- (1)
- Be able to cover the entire area of smart city applications.
- (2)
- Be robust enough to handle changes in image representation due to various viewing angles.
- (3)
- Be compatible with changes in the visual appearance of the background caused by radiation changes and quality degradation.
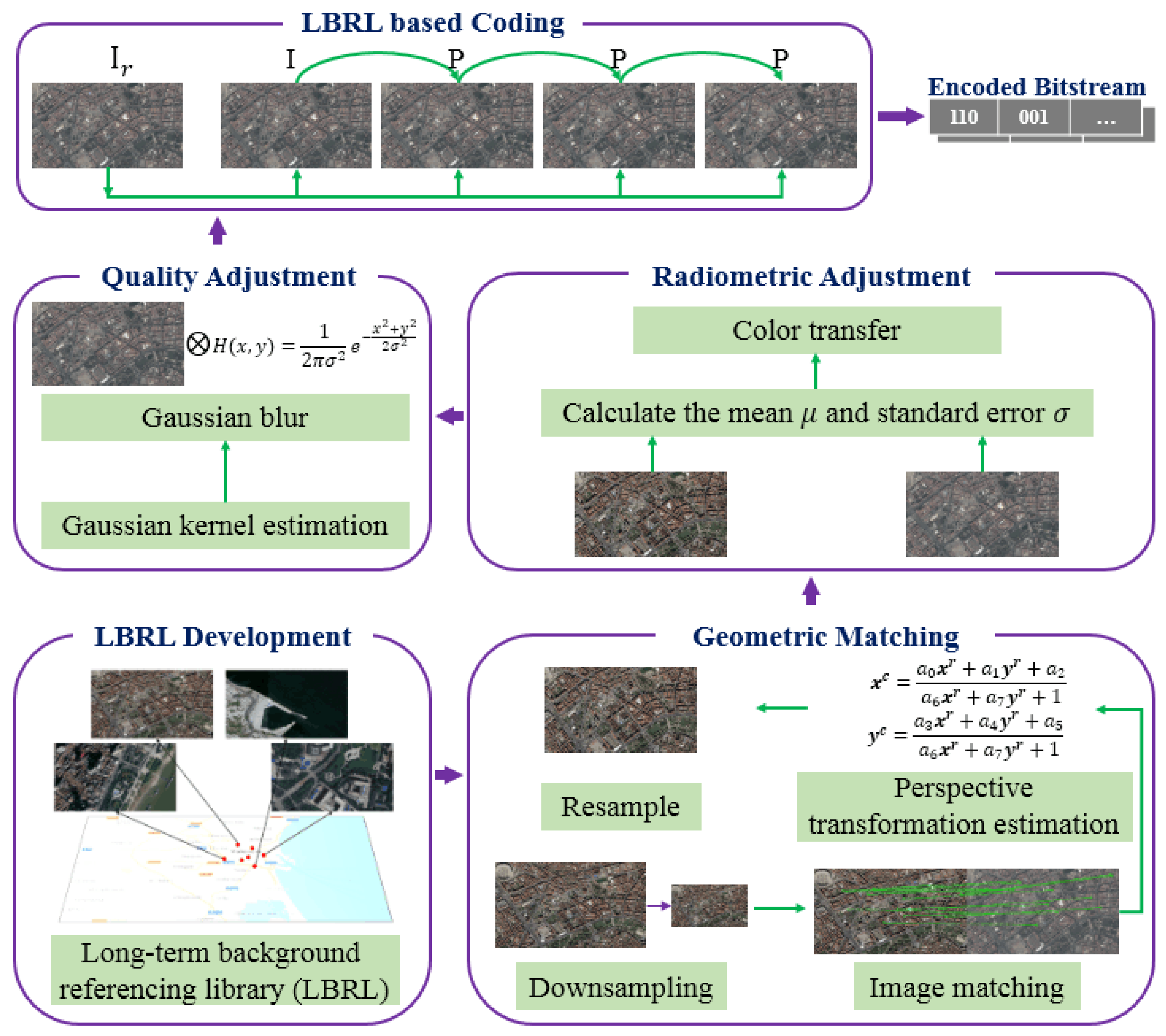
4. LBRL-Based Reference Generation and Coding Framework
4.1. Generating a Background Reference
4.1.1. Geometric Matching
4.1.2. Radiometric Adjustment
4.1.3. Quality Adjustment
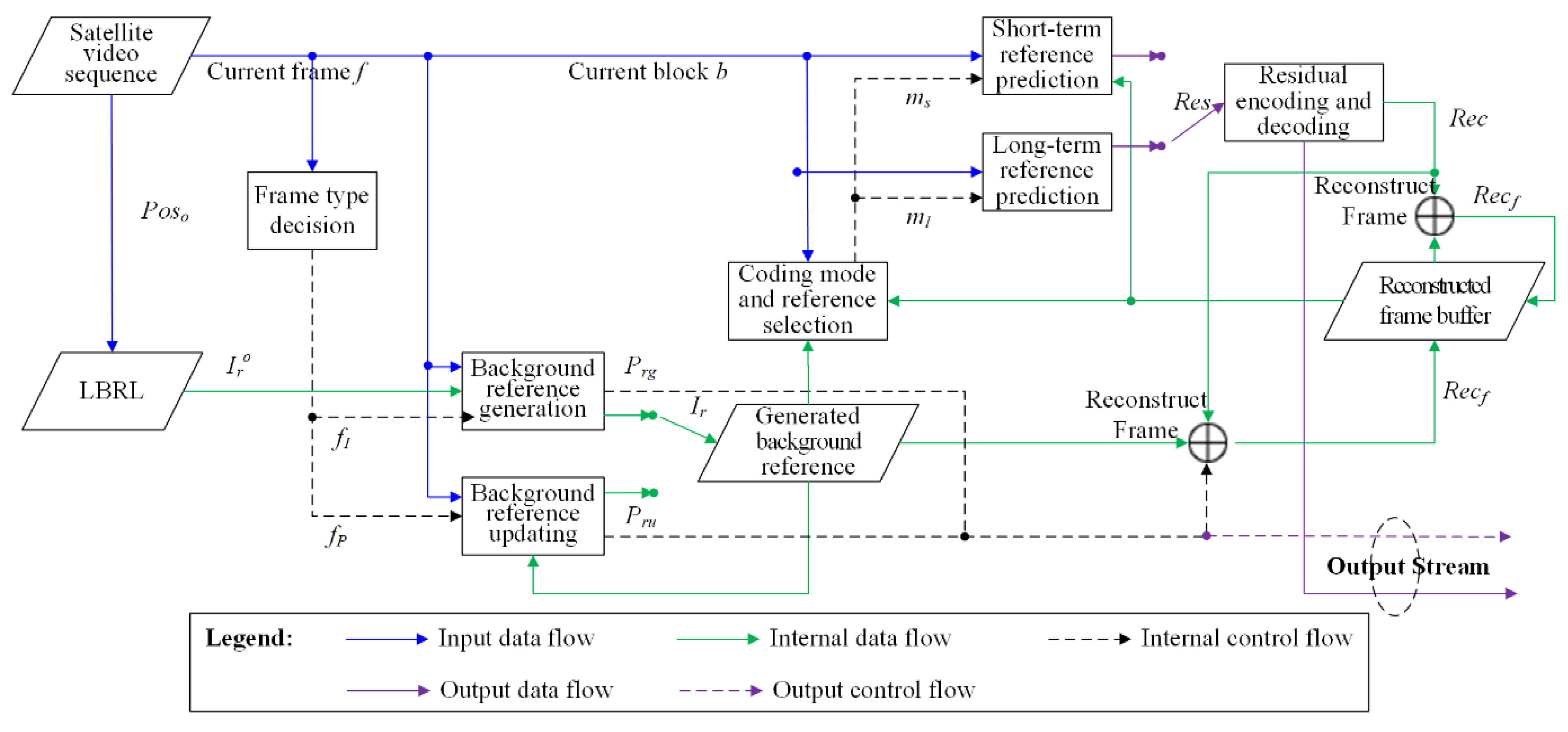
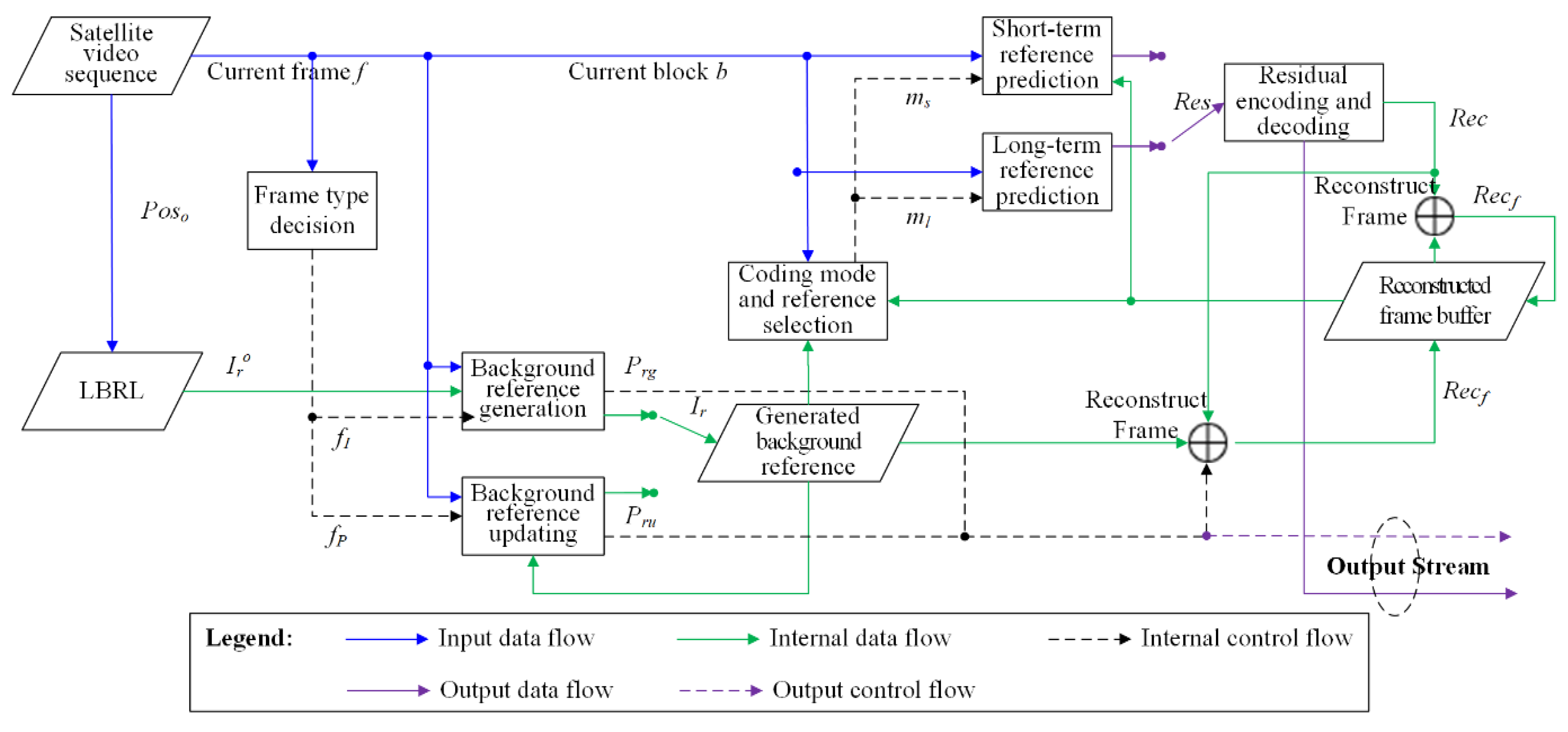
4.2. Encoding and Decoding Scheme
- Step 1.
- Generating the background reference. Initially, or for an I frame, , we used the proposed LBRL-based reference generation method described in Section 3.1 to initialize a background reference (denoted by in Figure 4) for the encoding of I frames. Since the generated background reference was not sent, we needed to send the control data together with the encoded frame to reconstruct the reference at the decoder. The control data for generating the background reference was denoted as , including the perspective transformation matrix in geometric matching, and in radiometric adjustment, and in quality adjustment. The generated background reference was stored in a temporal buffer in the encoder to update the reference for subsequent frames. At the same time that a newly generated was put into the reference buffer, previous data were removed from the buffer.
- Step 2.
- Updating the background reference. For P frames, , immediately after an I frame, the radiometric conditions and quality degradation did not vary markedly, only the projections changed slightly. Therefore, we only updated the perspective transformation from the background reference for the last frame. The output control data was denoted as , including a new PT matrix. The updated reference image was then added to the reference buffer.
- Step 3.
- Calculating candidate modes and performing predictions. A generated or updated background reference was added to the coding reference list. For any I frame, besides the traditional intra-picture prediction, a long-term prediction (denoted by ) taking as the additional reference could also be performed. Since inter-picture prediction is normally more efficient than intra-picture prediction, it is more efficient at reducing the bitrate. Then, for P frames, both short-term (denoted by ) and long-term predictions could be selected by referring to the adjacent frames or background reference, respectively. As proven by Reference [3], a high-quality background reference can help reduce the bitrate of blocks in P frames.
- Step 4.
- Encoding and reconstructing the current block. Rate-distortion was applied to select the best encoding mode. By performing the predictions, residuals (denoted as ) were computed and encoded by transform, scaling, quantization, and entropy coding. Frames were reconstructed (denoted as ) to provide short-term frame references by reconstructing each block by adding the block reference to the decoded block residuals. The reconstructed frames were stored in the reconstructed frame buffer to provide the reference list.
5. Experiments and Results
5.1. Experimental Setup
5.2. Experiments with UAV Video Clips
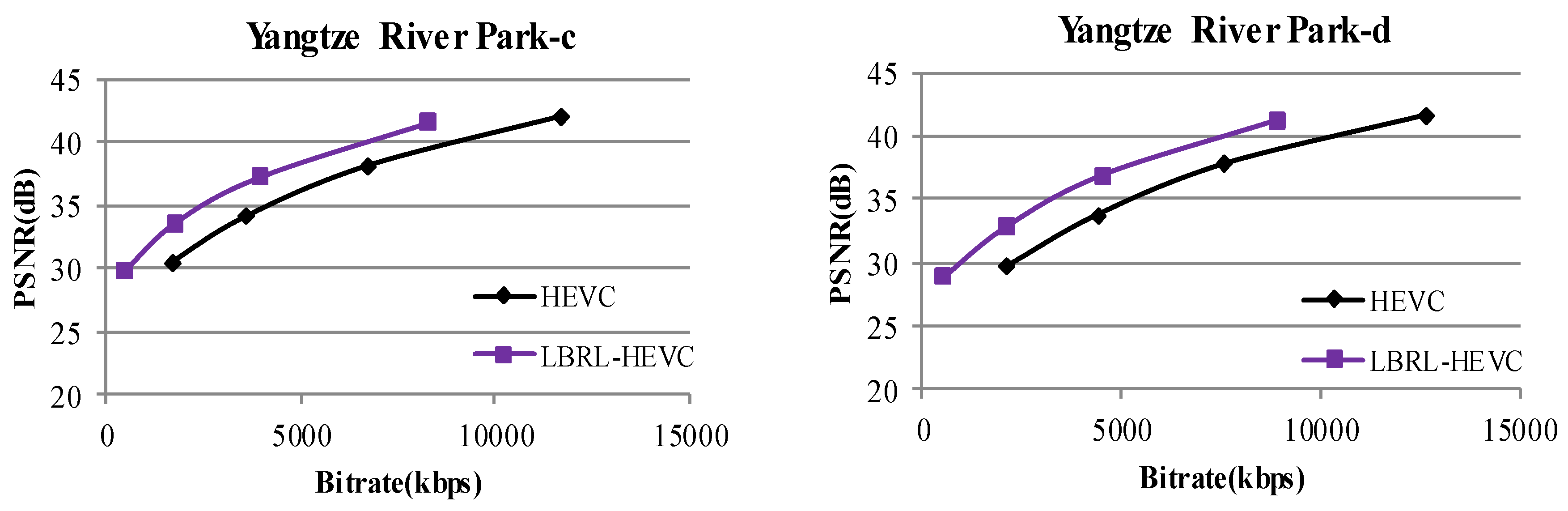
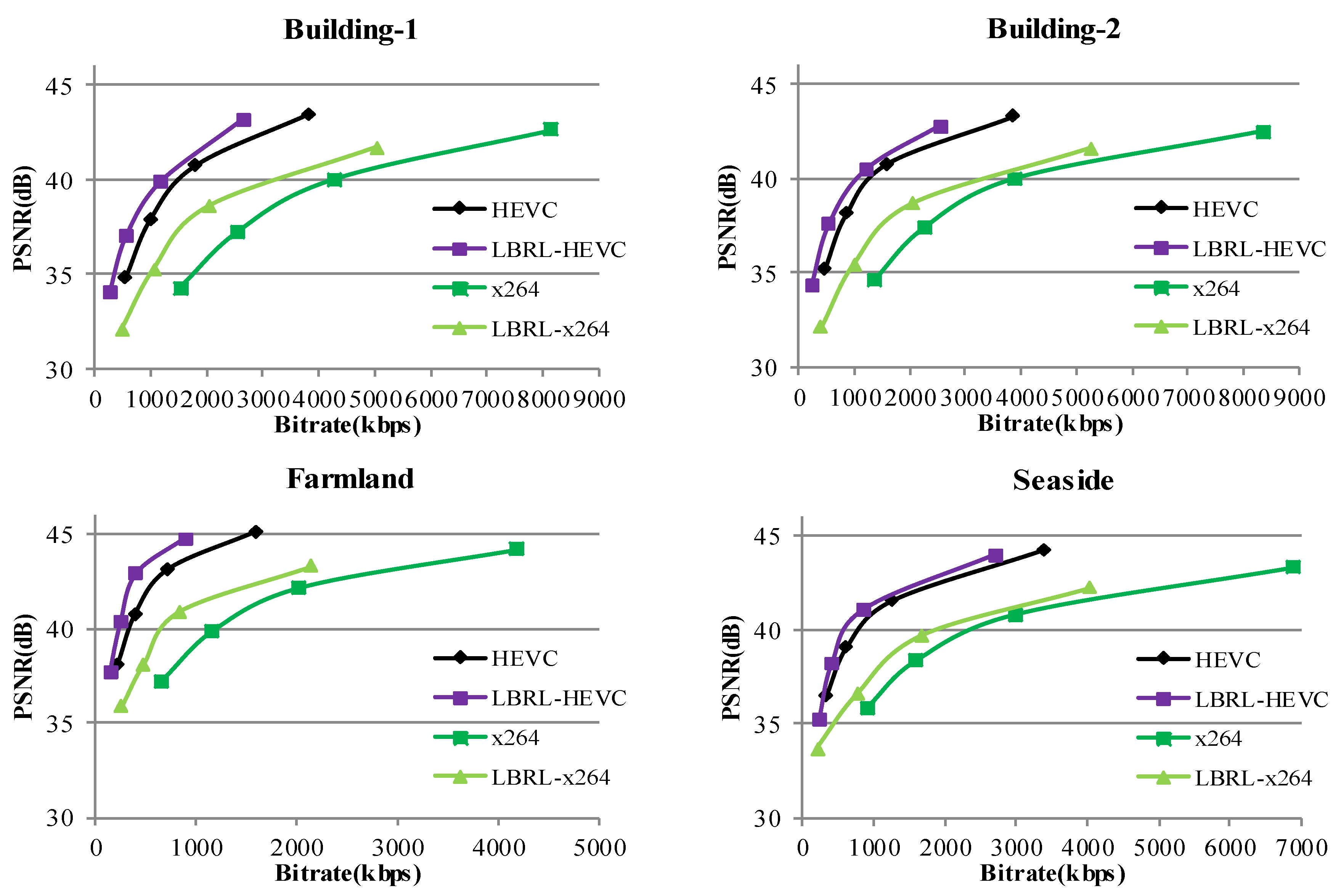
5.3. Experiments with Satellite Video Clips
5.3.1. Intermediate Results from Background Reference Generation
5.3.2. Results of LBRL-HEVC
5.3.3. Results of LBRL-x264
5.4. Computational Complexity Analysis
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Wang, L.; Lu, K.; Liu, P.; Ranjan, R.; Chen, L. IK-SVD: Dictionary Learning for Spatial Big Data via Incremental Atom Update. Comput. Sci. Eng. 2014, 16, 41–52. [Google Scholar] [CrossRef]
- Song, W.; Deng, Z.; Wang, L.; Du, B.; Liu, P.; Lu, K. G-IK-SVD: Parallel IK-SVD on GPUs for sparse representation of spatial big data. J. Supercomput. 2017, 73, 3433–3450. [Google Scholar] [CrossRef]
- Jing, X.Y.; Zhu, X.; Wu, F.; Hu, R.; You, X.; Wang, Y.; Feng, H.; Yang, J.Y. Super-resolution Person Re-identification with Semi-coupled Low-rank Discriminant Dictionary Learning. IEEE Trans. Image Process. 2017, 26, 1363–1378. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Jing, X.Y.; You, X.; Yue, D. Multi-view low-rank dictionary learning for image classification. Pattern Recognit. 2016, 50, 143–154. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the high efficiency video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, T.; Tian, Y.; Gao, W. Background-modeling-based adaptive prediction for surveillance video coding. IEEE Trans. Image Process. 2014, 23, 769–784. [Google Scholar] [CrossRef] [PubMed]
- Yue, H.; Sun, X.; Yang, J.; Wu, F. Cloud-based image coding for mobile devices—Toward thousands to one compression. IEEE Trans. Multimedia 2013, 15, 845–857. [Google Scholar]
- Shi, Z.; Sun, X.; Wu, F. Feature-based image set compression. In Proceedings of the IEEE International Conference on Multimedia and Expo, San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Wu, H.; Sun, X.; Yang, J.; Zeng, W.; Wu, F. Lossless compression of JPEG coded photo collections. IEEE Trans. Image Process. 2016, 25, 2684–2696. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Tian, T.; Ma, M.; Wu, J. Joint compression of near-duplicate Videos. IEEE Trans. Multimedia 2017, 19, 908–920. [Google Scholar] [CrossRef]
- Ma, C.; Liu, D.; Peng, X.; Wu, F. Surveillance video coding with vehicle library. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 270–274. [Google Scholar]
- Xiao, J.; Liao, L.; Hu, J.; Chen, Y.; Hu, R. Exploiting global redundancy in big surveillance video data for efficient coding. Clust. Comput. 2015, 18, 531–540. [Google Scholar] [CrossRef]
- Xiao, J.; Hu, R.; Liao, L.; Chen, Y.; Wang, Z.; Xiong, Z. Knowledge-based coding of objects for multi-source surveillance video data. IEEE Trans. Multimedia 2016, 18, 1691–1706. [Google Scholar] [CrossRef]
- Google Earth V 7.1.5.1557. (7 July 2015). Valencia, Spain. Available online: https://www.google.com/earth/download/gep/agree.html (accessed on 12 March 2018).
- Mielikainen, J.; Toivanen, P. Clustered DPCM for the lossless compression of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2003, 41, 2943–2946. [Google Scholar] [CrossRef]
- Magli, E.; Olmo, G.; Quacchio, E. Optimized onboard lossless and near-lossless compression of hyperspectral data using CALIC. IEEE Geosci. Remote Sens. Lett. 2004, 1, 21–25. [Google Scholar] [CrossRef]
- Toivanen, P.; Kubasova, O.; Mielikainen, J. Correlation-based band-ordering heuristic for lossless compression of hyperspectral sounder data. IEEE Geosci. Remote Sens. Lett. 2005, 2, 50–54. [Google Scholar] [CrossRef]
- Penna, B.; Tillo, T.; Magii, E.; Olino, G. Transform coding techniques for lossy hyperspectral data compression. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1408–1421. [Google Scholar] [CrossRef]
- Liu, G.; Zhao, F. Efficient compression algorithm for hyperspectral images based on correlation coefficients adaptive 3D zerotree coding. JET Image Process. 2007, 2, 72–82. [Google Scholar] [CrossRef]
- Cagnazzo, M.; Poggi, G.; Verdoliva, L. Region-based transform coding of multispectral images. IEEE Trans. Image Process. 2007, 16, 2916–2926. [Google Scholar] [CrossRef] [PubMed]
- Ngadiran, R.; Boussakta, S.; Bouridane, A.; Syarif, B. Hyperspectral image compression with modified 3D SPECK. In Proceedings of the International Symposium on Communication Systems Networks and Digital Signal Processing, Newcastle upon Tyne, UK, 21–23 July 2010; pp. 806–810. [Google Scholar]
- SkySat-C Generation Satellite Sensors. Available online: https://www.satimagingcorp.com/satellite-sensors/skysat-1/ (accessed on 12 March 2018).
- Chen, C.; Cai, J.; Lin, W.; Shi, G. Surveillance video coding via low-rank and sparse decomposition. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 713–716. [Google Scholar]
- Chen, C.; Cai, J.; Lin, W.; Shi, G. Incremental low-rank and sparse decomposition for compressing videos captured by fixed cameras. J. Vis. Commun. Image Represent. 2015, 26, 338–348. [Google Scholar] [CrossRef]
- Hou, J.; Chau, L.P.; Magnenat-Thalmann, N.; He, Y. Sparse low-rank matrix approximation for data compression. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1043–1054. [Google Scholar] [CrossRef]
- Guo, S.; Wang, Y.; Tian, Y.; Xing, P.; Gao, W. Quality-progressive coding for high bit-rate background frames on surveillance videos. In Proceedings of the IEEE International Symposium on Circuits and Systems, Lisbon, Portugal, 24–27 May 2015; pp. 2764–2767. [Google Scholar]
- Yin, L.; Hu, R.; Chen, S.; Xiao, J.; Hu, J. A block-based background model for surveillance video coding. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 7–9 April 2015; p. 476. [Google Scholar]
- Chen, F.; Li, H.; Li, L.; Liu, D.; Wu, F. Block-composed background reference for high efficiency video coding. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 2639–2651. [Google Scholar] [CrossRef]
- Chakraborty, S.; Paul, M.; Murshed, M.; Ali, M. Adaptive weighted non-parametric background model for efficient video coding. Neurocomputing 2017, 226, 35–45. [Google Scholar] [CrossRef]
- Song, X.; Peng, X.; Xu, J.; Wu, F. Cloud-based distributed image coding. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1926–1940. [Google Scholar] [CrossRef]
- Weinzaepfel, P.; Jégou, H.; Pérez, P. Reconstructing an image from its local descriptors. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 337–344. [Google Scholar]
- Au, O.; Li, S.; Zou, R.; Dai, W.; Sun, L. Digital photo album compression based on global motion compensation and intra/inter prediction. In Proceedings of the International Conference on Audio, Language and Image Processing, Shanghai, China, 16–18 July 2012; pp. 84–90. [Google Scholar]
- Zou, R.; Au, O.C.; Zhou, G.; Dai, W.; Hu, W.; Wan, P. Personal photo album compression and management. In Proceedings of the IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013; pp. 1428–1431. [Google Scholar]
- Lu, X.; Chen, Y.; Li, X. Hierarchical Recurrent Neural Hashing for Image Retrieval with Hierarchical Convolutional Features. IEEE Trans. Image Process. 2018, 27, 106–120. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Zhang, W.; Li, X. A Hybrid Sparsity and Distance-based Discrimination Detector for Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1704–1717. [Google Scholar] [CrossRef]
- Lu, X.; Wang, B.; Li, X.; Zheng, X. Exploring Models and Data for Remote Sensing Image Caption Generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Yuan, Y. Remote Sensing Scene Classification by Unsupervised Representation Learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef] [Green Version]
- Sedaghat, A.; Ebadi, H. Distinctive Order Based Self-Similarity descriptor for multi-sensor remote sensing image matching. ISPRS J. Photogramm. Remote Sens. 2015, 108, 62–71. [Google Scholar] [CrossRef]
- Reinhard, E.; Ashikhmin, M.; Gooch, B.; Shirley, P. Color Transfer between Image. IEEE Comput. Graph. Appl. 2002, 21, 34–41. [Google Scholar] [CrossRef]
- Ko, Y.; Yi, Y.; Ha, S. An efficient parallelization technique for x264 encoder on heterogeneous platforms consisting of CPUs and GPUs. J. Real-Time Image Process. 2014, 9, 5–18. [Google Scholar] [CrossRef]
- Bjontegaard, G. Calculation of Average PSNR Difference between RD-Curves; ITU-T SG16 Q.6 Doc.; Technical Report VCEG-M33; ITU-T: Austin, TX, USA, 2001. [Google Scholar]
- HEVC Test Model, HM Reference Software. Available online: https://hevc.hhi.fraunhofer.de/ (accessed on 28 July 2017).
- x264 Free Library/Codec, 64-bit, 8-bit Depth Version r2901. Available online: http://www.divx-digest.com/software/x264.html (accessed on 20 January 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Testing Platform | Codec | Detailed Settings | |
|---|---|---|---|
| First Implementation LBRL-HEVC vs. HEVC | Four-core Intel i5-4210m CPU @ 2.60 GHz | HM 16.8 [44] | Frame structure: Low Delay IPPP; GOP size = 8; QP = 22, 27, 32, 37; Max partition depth = 4; Fast search = Enable; Search range = 64; Intra period = 8; Rate control = −1; SA0 = 1; |
| Second Implementation LBRL-x264 vs. x264 | Nvidia Jetson TX2 contains four ARM Cortex A57 cores and one GPU with 256 CUDA cores | X264 [45]: version r2901 of 20 January 20 2018 | Profile = baseline; GOP size = 8; Slice mode = 0; QP = 22, 27, 32, 37; Preset = ultrafast; Keyint = 8; Search range = 32; Rate control = −1; |
| UAV | BD-PSNR | BD-Rate | UAV | BD-PSNR | BD-Rate |
|---|---|---|---|---|---|
| a | 5.34 | −62.77 | c | 3.51 | −49.65 |
| b | 4.21 | −53.32 | d | 4.21 | −50.97 |
| Average | 4.32 | −54.18 | |||
| Method | Satellite Jilin-1 | BD-PSNR | BD-Rate |
|---|---|---|---|
| Only-RA (Only Radiometric Adjustment) | Building-1 | 0.20 | −5.08 |
| Building-2 | 0.16 | −4.75 | |
| Farmland | 0.53 | −9.65 | |
| Seaside | 0.08 | −3.83 | |
| Average | 0.24 | −5.83 | |
| Only-QA (Only Quality Adjustment) | Building-1 | 0.26 | −6.38 |
| Building-2 | 0.26 | −6.76 | |
| Farmland | 0.61 | −13.86 | |
| Seaside | 0.22 | −6.68 | |
| Average | 0.34 | −8.42 | |
| LBRL-HEVC (Both RA and QA) | Building-1 | 1.19 | −26.21 |
| Building-2 | 0.95 | −23.80 | |
| Farmland | 1.76 | −33.04 | |
| Seaside | 0.65 | −16.68 | |
| Average | 1.14 | −24.93 |
| Satellite Video | BD-PSNR | BD-Rate | Satellite Video | BD-PSNR | BD-Rate |
|---|---|---|---|---|---|
| a | 2.13 | −36.30 | c | 2.20 | −40.47 |
| b | 1.42 | −29.88 | d | 1.05 | −24.43 |
| Average | 1.70 | −32.77 | |||
| Intel i5 CPU @ 2.60 GHz | Nvidia Jetson TX2 | |||
|---|---|---|---|---|
| LBRL-HEVC | HEVC | LBRL-x264 | x264 | |
| Building-1 | 0.0157 | 0.0167 | 15.91 | 93 |
| Building-2 | 0.0157 | 0.0167 | 16.25 | 99 |
| Farmland | 0.0175 | 0.0187 | 17.88 | 147 |
| Seaside | 0.0172 | 0.0184 | 17.04 | 125 |
| Average | 0.0165 | 0.0176 | 16.77 | 116 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, J.; Zhu, R.; Hu, R.; Wang, M.; Zhu, Y.; Chen, D.; Li, D. Towards Real-Time Service from Remote Sensing: Compression of Earth Observatory Video Data via Long-Term Background Referencing. Remote Sens. 2018, 10, 876. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10060876
Xiao J, Zhu R, Hu R, Wang M, Zhu Y, Chen D, Li D. Towards Real-Time Service from Remote Sensing: Compression of Earth Observatory Video Data via Long-Term Background Referencing. Remote Sensing. 2018; 10(6):876. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10060876
Chicago/Turabian StyleXiao, Jing, Rong Zhu, Ruimin Hu, Mi Wang, Ying Zhu, Dan Chen, and Deren Li. 2018. "Towards Real-Time Service from Remote Sensing: Compression of Earth Observatory Video Data via Long-Term Background Referencing" Remote Sensing 10, no. 6: 876. https://0-doi-org.brum.beds.ac.uk/10.3390/rs10060876