1. Introduction
One of the major benefits of low resolution sensors, such as SPOT-VEGETATION, MODIS (MODerate Resolution Imaging Spectroradiometer), and Sentinel-3, with respect to agricultural applications, is their temporal resolution, therefore the possibility to obtain (regular) time series of vegetation indices, such as normalized difference vegetation index (NDVI), throughout the growing season of crops. The data can be further derived to generate information either for crop growth status or for crop type discrimination and mapping, thanks to their distinct evolutive behaviors of reflectance related to their growth patterns. However, the applications are restricted by the coarse resolution of these sensors, and hence, the mixture of crop types within a single pixel. To overcome this problem a variety of sub-pixel classification methods have been proposed in literature.
The sub-pixel classification approach is also termed “soft” classification, as unlike the “hard” classification methods where each pixel is unambiguously assigned to one single class, it tries to reveal possible mixtures and define for each pixel the area fractions covered by the different cover classes [
1]. Alternatively, instead of deriving area fractions of classes, similar softened classification output may be achieved by using posterior probabilities of class membership derived from maximum likelihood (MXL) classification [
2,
3]. Sub-pixel classification methods have been used in different contexts including crop area estimation [
4,
5], natural vegetation ecotone mapping [
3,
6], urban expansion [
7], and change detection studies [
8]. Different methods have been proposed for deriving sub-pixel class fractions including the linear mixture model (LMM) [
4], artificial neural network (ANN) [
9,
10,
11], regression tree [
5], fuzzy classification [
6,
12], and support vector machine (SVM) [
13].
Liu and Wu [
11] argued that the non-linear models, especially neural network-based models, outperformed the traditional linear unmixing models. Support for such a conclusion is given in Verbeiren et al. [
1] who compared ANN and LMM in an attempt to generate a sub-pixel map from SPOT-VEGETATION 1 km data across Belgium. The authors showed that the ANN approach outperformed LMM and that, for the major classes, the acreage estimates obtained via ANN, when aggregated to the level of the administrative regions, were in good agreement with the true values. Also, a multilayer perceptron (MLP) neural network regression algorithm has been shown to outperform the regression tree algorithm [
5]. Atkinson et al. [
9] also obtained better results with ANN than with the other tested methods but pointed out that its successful implementation depends on accurate co-registration and the availability of a training data set. Liu et al. [
14] compared a linear spectral unmixing model, a supervised fully-fuzzy classification method and a SVM to generate a fraction map and achieved the most accurate fraction result using SVM. Six machine learning methods were compared in a recent study [
15] based on multiple criteria, where the authors found that, in general, no method performs best for all evaluation criteria. However, when both time available for preprocessing and the magnitude of the training data set are unconstrained, support vector regression (SVR) and least-squares SVM for regression clearly outperform the other methods.
Regarding the satellite imagery widely used for agricultural monitoring, SPOT-VEGETATION (SPOT-VGT) sensors provided one of the longest time series of multispectral reflectance since 1998. The mission was succeeded in 2013 by PROBA-V (PRoject for On-Board Autonomy–Vegetation), a small satellite commissioned by the European Space Agency. The sensor on-board PROBA-V generates products at three different spatial resolutions: 1 km, 300 m and 100 m [
16,
17]. For agricultural applications, the 100 m product is of particular interest and has been shown useful for cropland and crop type mapping [
18,
19,
20]. These studies used the traditional, hard classification approach where each pixel is assigned to one class. However, even with the improved spatial resolution of 100 m, the presence of mixed pixels may be a problem in agro-systems dominated by small fields [
20]. It is thus meaningful to test the feasibility of the sub-pixel classification approach with the new PROBA-V 100 m data. Exhaustive testing and comparison of all possible sub-pixel classification methods is outside the scope of this study. Instead, we selected the ANN and the SVR methods as they have shown good results in previous studies for crop type area estimation, e.g., References [
1,
15].
Like all supervised approaches, the sub-pixel classification relies on ground truth data sampling. Ground sampling by field campaigns has to be designed following statistical principles, and therefore is onerous to be implemented. In a general circumstance, it provides data for a small number of spatially discontinuous polygons, which may not be sufficient for the training of a sub-pixel PROBA-V classification because pixels with different mixtures of classes must be included in the training samples. The area fractions for the training may be obtained, most conveniently, if we have high-resolution, wall-to-wall land-use datasets for one or more representative areas. These datasets may be obtained by classification of high-resolution satellite images for which purpose much smaller field datasets may be sufficient.
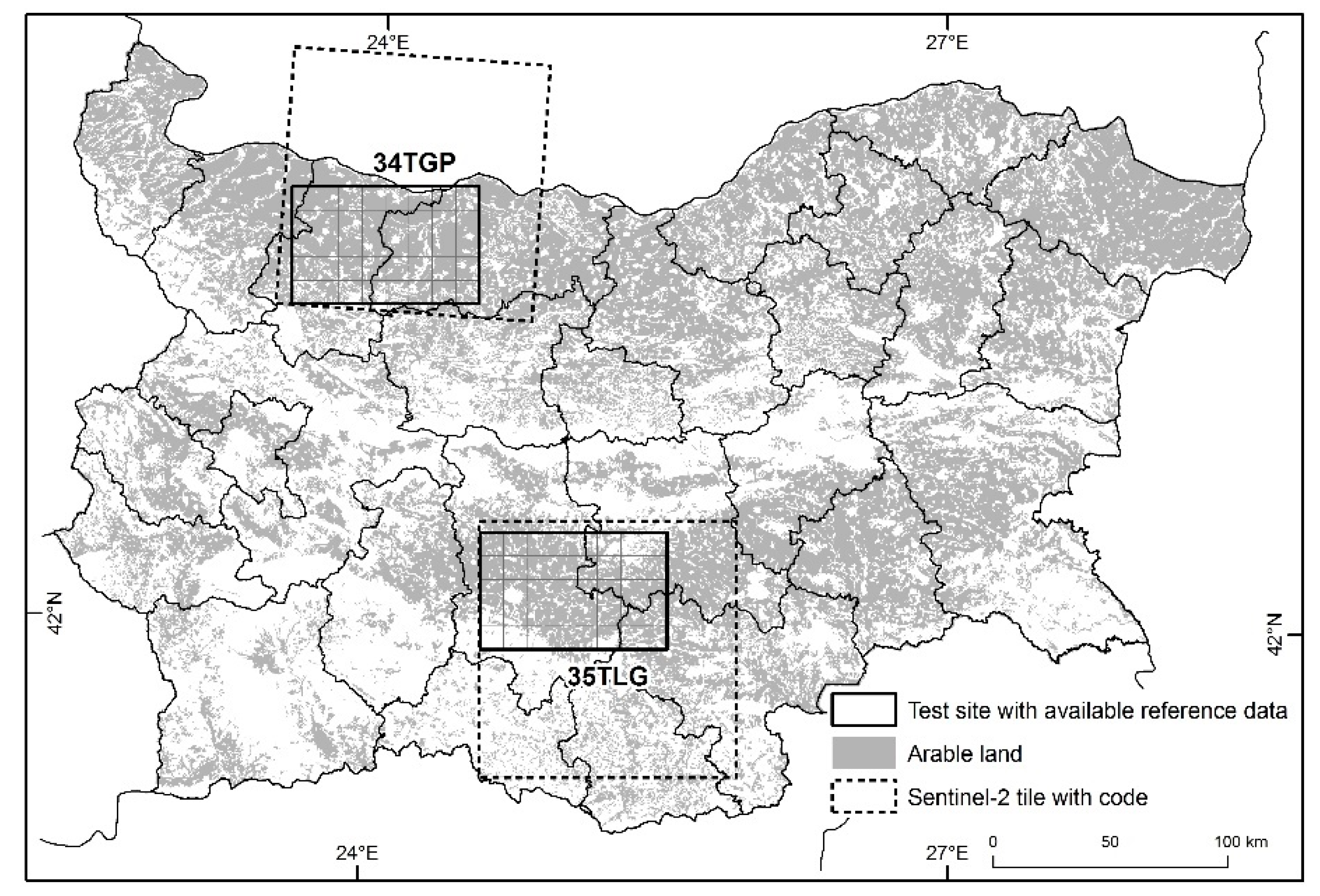
The general objective of this study was therefore to generate a sub-pixel crop (and land-use) map of Bulgaria using PROBA-V 100 m NDVI time series relying on a limited amount of ground reference data. To this aim, Sentinel-2 data was first used to produce a crop (and land-use) map at two test sites at 10 m spatial resolution. In a second stage, classification of the PROBA-V NDVI time series was performed using Sentinel-2 classifications results as training data. For Sentinel-2 classifications, two different input datasets, i.e., NDVI time series and multi-date cloud-free multi-spectral bands, as well as three different classifiers, i.e., maximum likelihood (MXL), SVM, and random forest (RF) were tested. The accuracy of the resulting Sentinel-2 maps was compared and the classification with the best results was used as reference dataset for training the PROBA-V classification.
3. Results
3.1. Sentinel-2 Crop/Land-Use Maps of the Two Test Sites
We compared the crop/land-use maps derived by two input Sentinel-2 datasets i.e., S10 NDVI time series and MSBS and the three classification methods.
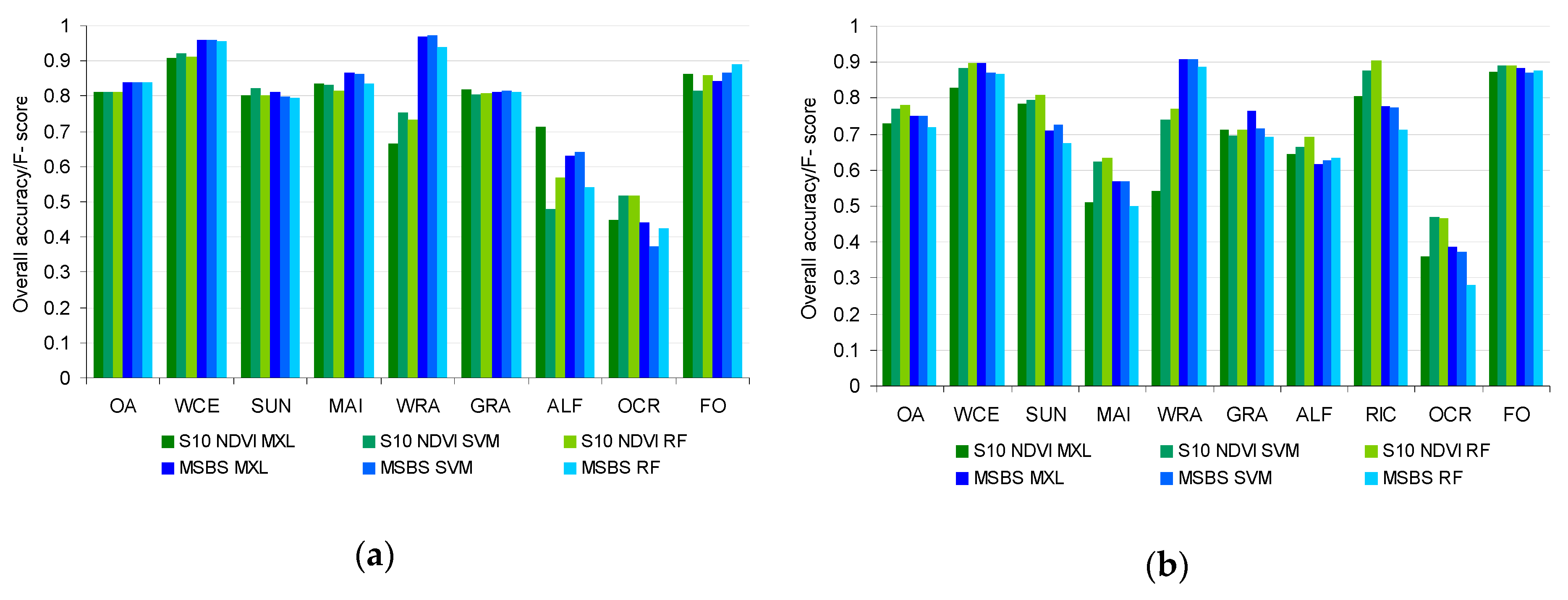
Figure 4 shows the overall map accuracy (OA) and the class
F-scores for all compared maps, calculated using Equations (6) and (5) respectively. The broad-leaved forest and coniferous forest classes were combined for the purpose of the accuracy assessment into a single class forest. This was necessary because very few reference points of coniferous forest class were available. However, it was important to retain both forest types in the adopted legend and therefore the maps as they have quite different phenology.
The OA of the Sentinel-2-derived crop/land-use maps varied between 72% and 84%. The best OA for Knezha test site, which was 84%, was achieved with the MSBS dataset and the results were very similar for all three classification methods. The S10 NDVI dataset produced slightly less accurate classification results (OA = 81%), and again, without major discrepancy between the classification methods. In the Belozem test site, none of the maps reached the 80% OA threshold. The most accurate map (OA = 78%) was produced by RF classification using the S10 NDVI dataset as input.
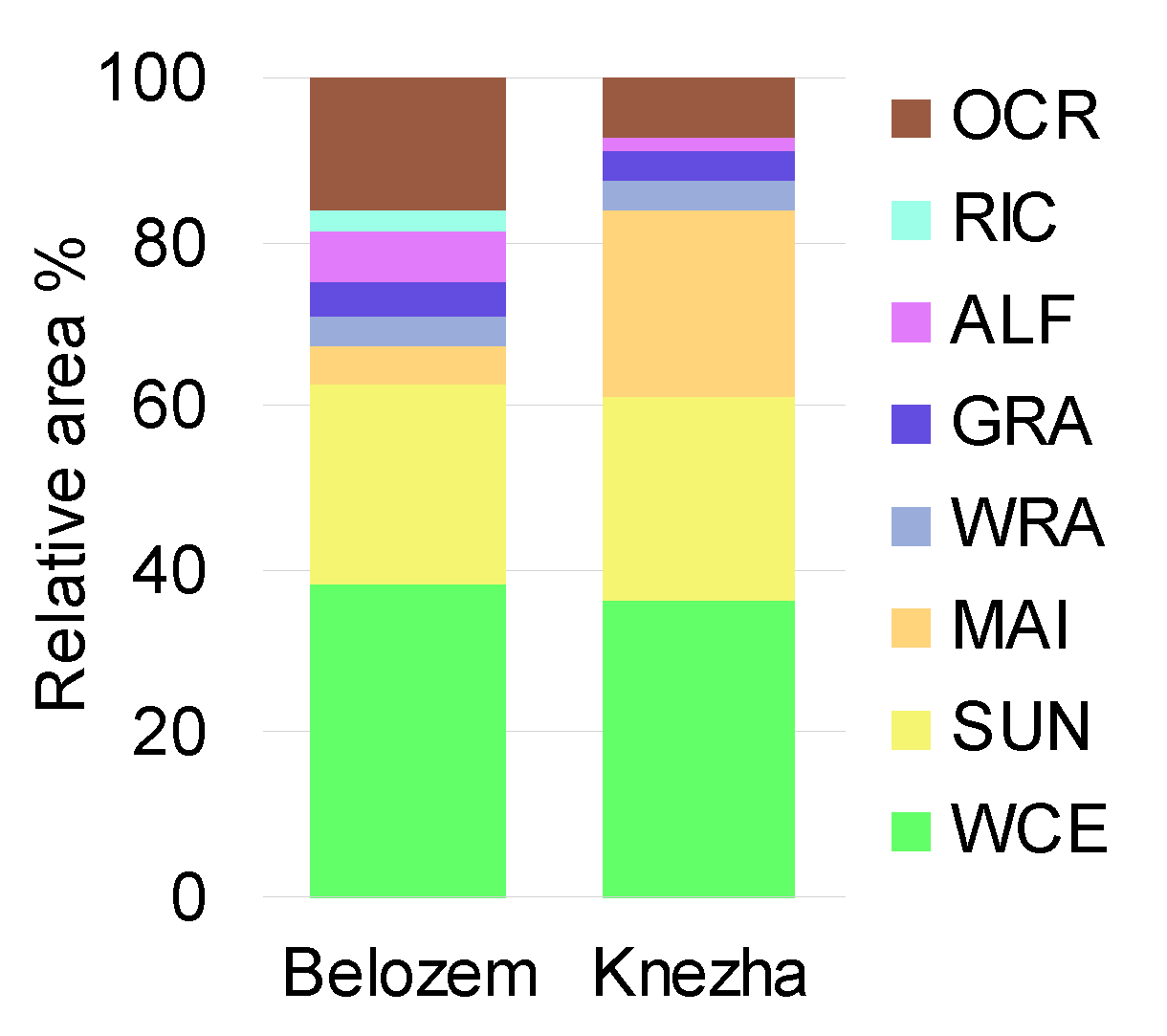
The F-scores differed significantly between classes. The highest F-scores, overall, were achieved for winter cereals and forest, for which the accuracy levels of about 85%–95% were stable among input dataset, classification method and test site. The F-score for the winter rapeseed was also high (about 90%–95%), but only with the MSBS dataset. The accuracy of rice was also dependent on the dataset but here S10 NDVI provided more accurate results than MSBS, with F-score up to 90%. The maximum achieved F-score for sunflower was 81%–82% for the two test sites. For that class, the input using S10 NDVI dataset generated consistent results for all classifiers and test sites. This was not the case with MSBS used as the input dataset, which performed well only in the Knezha test site. The accuracies of classification varied for other classes depending on the test site. In general, it was lower for the Belozem test site. For example, the F-score of maize was above 80% in Knezha for all maps, while it was 63% at maximum in the Belozem test site. Not so severe but still an important discrepancy was observed for grasslands where F-scores were about 10% lower in the Belozem test site for most combinations of input datasets and the used classifiers. Finally, the class with lower F-scores was other crops, not higher than 52%.
When class F-scores and OA were considered there is no clear indication which of the two input image datasets was better. For some classes this may be the MSBS while for others the S10 NDVI. The decision also seemed to vary with the test site and the classification method which further complicate the comparison. In short, none of the Sentinel-2 datasets is perfect for all classes. One clear advantage of the MSBS classifications in both test sites was the markedly higher F-score for winter rapeseed. The S10 NDVI dataset, from the other hand, provided better results for rice when SVM or RF were used. The same was true also for other crops, but as stated earlier the accuracy for this class was very low in all maps.
The relative performance of the three classification methods, MXL, SVM, and RF, with the test site and image dataset being constant, can be most easily assessed using the OA (
Figure 4). As stated before, the three methods performed equally well for the S10 NDVI dataset in the Knezha test site. There was no difference between methods for the MSBS dataset in the Knezha test site as well. For the S10 NDVI dataset in the Belozem test site RF produced the highest OA, followed by SVM and MXL. For the MSBS dataset in Belozem RF produced the lowest OA, while MXL and SVM topped the ranking with equal OAs (
Figure 4). In any case, the differences between the classifiers were negligible in magnitude. Another approach to evaluate the performance of classifiers is presented in
Table 4. The table contains the number of classes for which each of MXL, SVM, and RF was the best performing method according to the
F-score (
Figure 4). The data in the table shows for example that the RF classifier was top ranked in all nine classes (broad-leaved and coniferous forest being combined) in the Belozem test site map based on S10 NDVI. However, this classifier was worst for the other combinations of Sentinel-2 input image dataset and test site (
Table 4). The SVM and MXL classifiers were more stable in their performance in terms of the number of classes for which they provided the highest
F-score.
Finally, it is worth to single out, once again, that more accurate maps were produced in the Knezha test site regardless of the input dataset used or classifier. These results were consistent through all classes.
As a conclusion, we selected, for both test sites, the map derived by using the MSBS Sentinel-2 dataset and the SVM method as an optimal variant which was to be used as reference data for the sub-pixel PROBA-V classification. The MSBS-derived maps were preferred because of the higher accuracy for the winter rapeseed class. The SVM classifier was selected because it showed stable performance and, in general, allowed the use of a smaller training dataset than the MXL method.
3.2. Sub-Pixel Classification of NDVI Time Series from PROBA-V 100 m
Table 5 shows the validation results for the estimated AFIs at pixel level and at the level of the 80 artificial regions using the two methods. The overall R
2 amounted to 57.8% at pixel-level for the ANN, with higher scores for some of the dominant classes (73.7% for winter cereals, 64.9% for sunflower, 70.2% for broad-leaved forest and 61.7% for maize), but far worse performance for some other classes (e.g., 29.1% for alfalfa and 30.9% for winter rapeseed). The classes with higher R
2 also had a regression line with the slope close to one and intercept close to zero, which shows that the estimates were not biased.
Figure 5 and
Figure 6 show the AFIs for winter cereals and winter rapeseed, which are one of the most accurately and one of the least accurately estimated classes respectively. The ANN was generally successful in representing the spatial distribution of winter cereals as indicated by the similar spatial patterns depicted in the estimated and the true winter cereals AFIs (
Figure 5B,C). In contrast, the spatial distribution of winter rapeseed was poorly characterized by the estimated AFI (
Figure 6B,C). This was due to widespread overestimation of the true area fraction for this class.
The overall R
2 amounted to 64.9% at pixel-level for the SVR, with highest scores for broad-leaved forest (78.1%) and winter cereals (73.4%). Again, alfalfa and winter rapeseed were the classes which performed poorly. For most classes, the R
2 was higher for SVR. ANN resulted in higher R
2 only for winter cereals, but the difference was negligible. The most pronounced difference between the two methods was observed for rice, for which R
2 increased by 31% when SVR was used instead of ANN. The two methods also differed in the slope of the regression line for the rarest and poorly performing classes; it was closer to 1 with the SVR (for example see alfalfa in
Table 5).
The regional aggregation drastically improved the AFI estimation accuracies (
Table 5) for both methods.
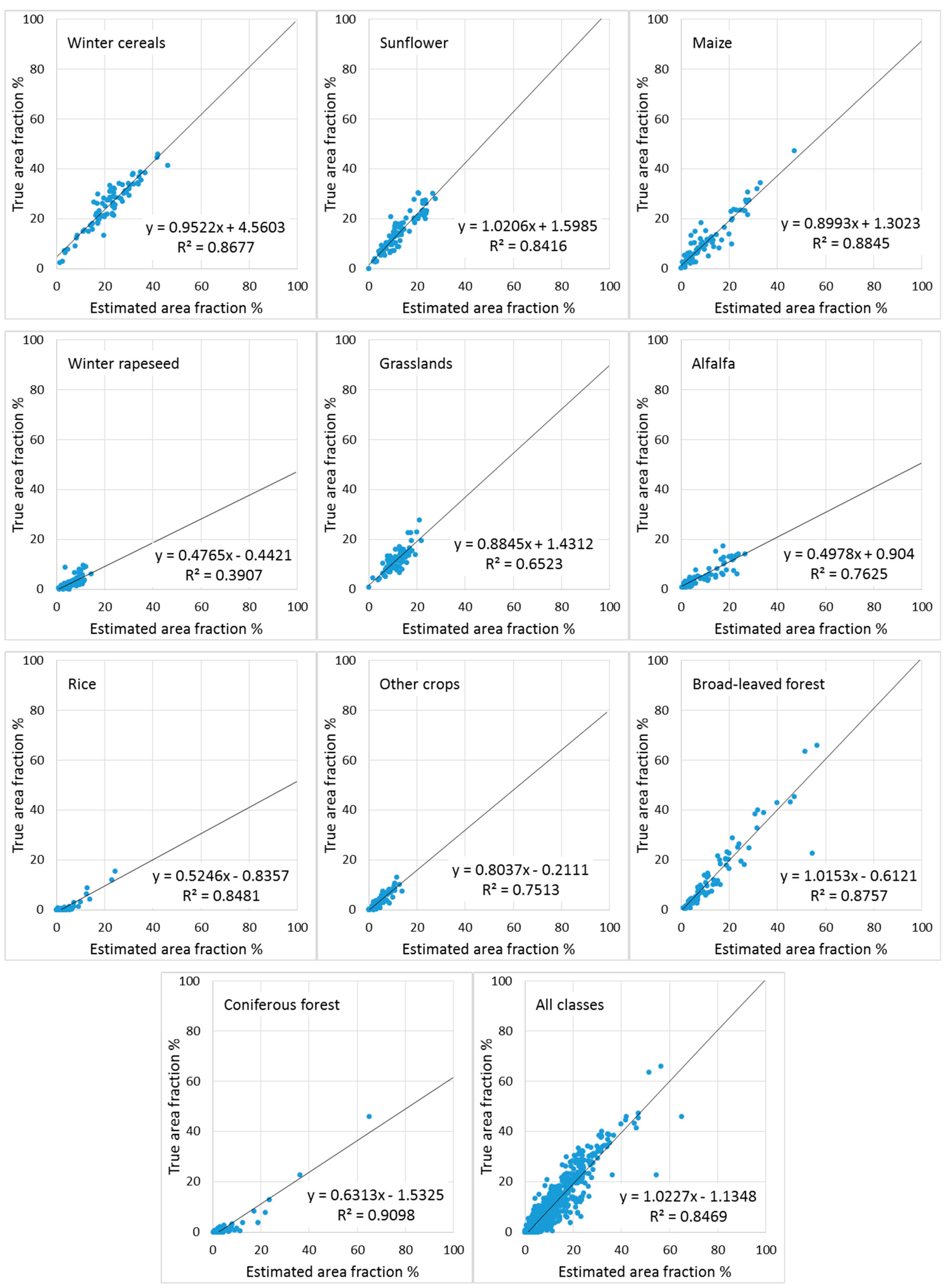
Figure 7 shows the scatterplots of estimated versus true area fractions for the ten classes and for the overall result (all classes merged together) at the region level obtained by ANN.
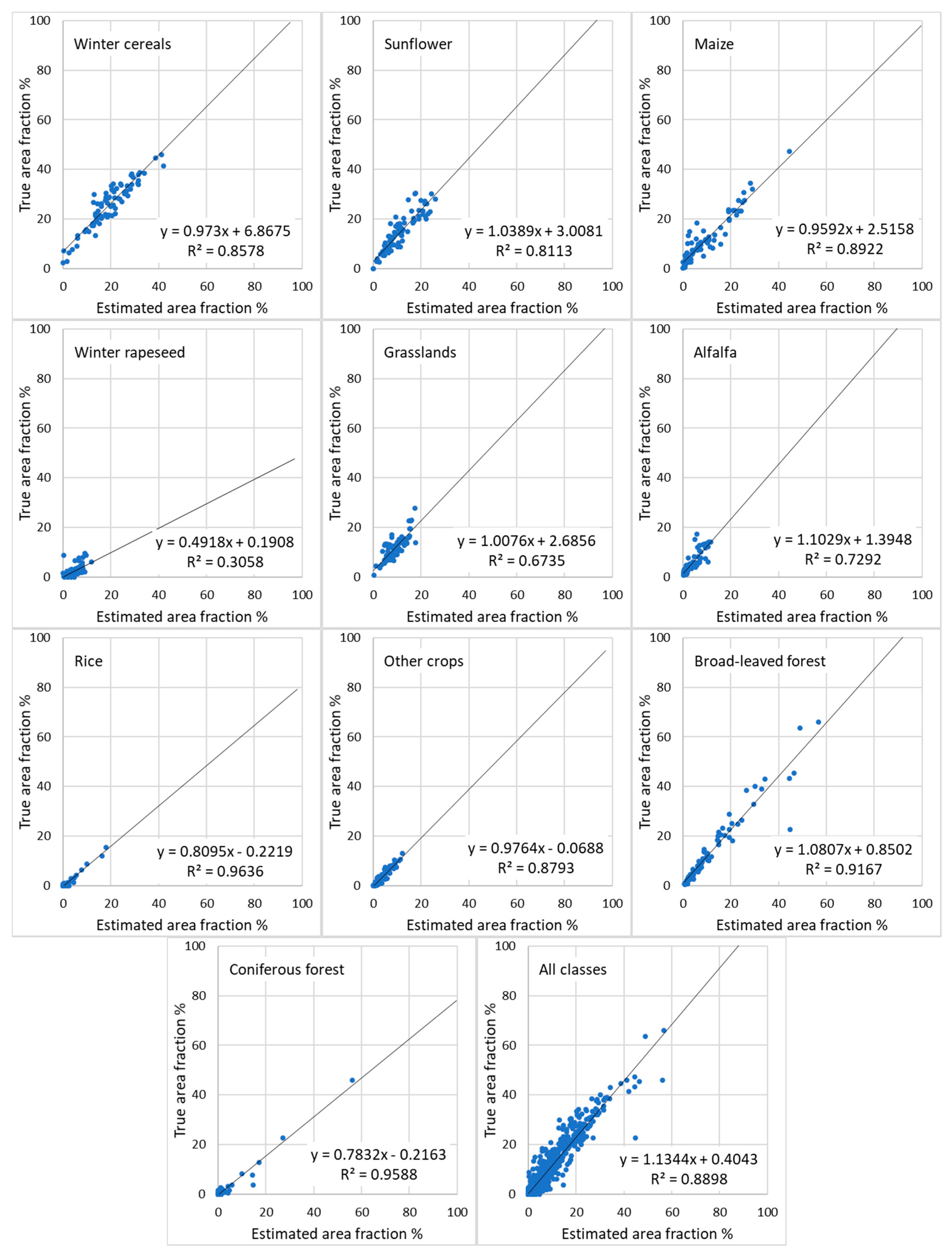
Figure 8 shows the corresponding data for the SVR method. When all classes are considered together, the R
2 was raised from 57.8% per pixel to 84.7% per region for the ANN method (
Table 5). The rise in the corresponding figures for the SVR method was from 64.9% to 89.0%. The improvement of R
2 was most important for the small classes: alfalfa, rice, other crops, and coniferous forest. With the ANN method the bias remained high in the estimates of alfalfa, coniferous forest, and rice, for which an overestimation of these true area fractions was observed (
Table 5,
Figure 7). With the SVR method the bias was much smaller for these same classes. Note, that severe overestimation was observed for winter rapeseed with both ANN and SVR, and this class did not show any practically important improvement in accuracy after regional aggregation.
4. Discussion
This study applied ANN and SVR methods for sub-pixel classification to produce crop (and land use) map of Bulgaria from PROBA-V 100 m NDVI time series. These methods were reported before using other low-resolution satellite images but have not been tested, to our knowledge, with PROBA-V 100 m data. Unlike previous studies (e.g., [
1]), which made use of existing crop type databases for training of the sub-pixel classification, here, the aim was to test the feasibility of an approach which is independent of such datasets. For this aim, crop/land-use maps of two test sites derived by classification of Sentinel-2 data were first produced. The classifications were trained with a limited number of ground truth observations collected during the dedicated field campaigns. The resulted high-resolution maps (10 m) provided the reference data needed for training and validation of the PROBA-V 100 m sub-pixel classification. In this study we considered the results of the Sentinel-2 data classifications as reference or ground truth even though they were not 100% accurate. This is justified in the cases where better ground truth data was not available or was too onerous to acquire.
Even though this study demonstrated an approach for crop mapping at national level, which was independent of existing crop type datasets, such as IACS, it did require the additional effort of collecting ground truth data in a small number of representative test sites. In addition, if spatial differences in crops phenology or cropping density were observed, the region should be stratified on an agro-meteorological principal or other agronomic parameters and should separate PROBA-V classifications made in each sub-region [
1].
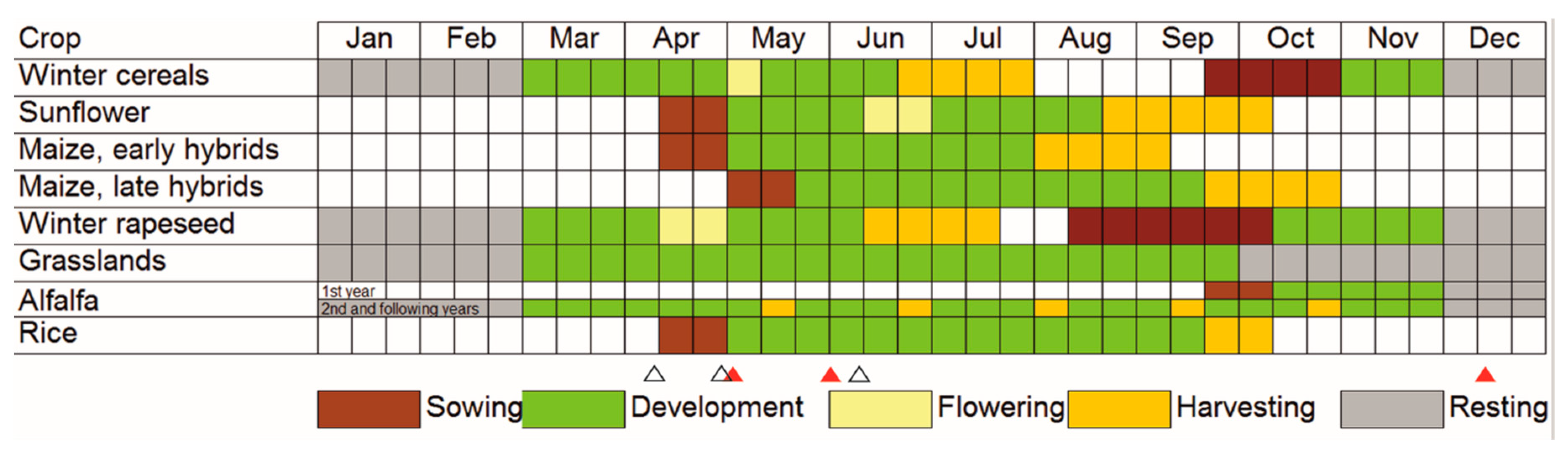
Two input datasets were compared for the production of reference, high-resolution crop maps from Sentinel-2 imagery. The approach using S10 NDVI time series as input data had the advantage of being operationally fully automated, and was generally less affected by the availability of cloud-free Sentinel-2 images. Disadvantage lay on the classification accuracy for the winter rapeseed class. The misclassification of winter rapeseed was not unexpected as the NDVI time profile of that crop was very similar to that of winter cereals. The approach using multidate stack of Sentinel-2 spectral bands (i.e., the MSBS approach) as input data had the advantage of enabling the extraction of more spectral information from a Sentinel-2 image including that of red edge bands. However, it highly relied on the availability of cloud-free images and their acquisition timing relative to important crop phenological events. The acquisition dates of the cloud-free Sentinel-2 images used for the multidate stack in this study seemed appropriate for most crops (at least in the Knezha test site) because they coincided with the periods when both winter and summer crops were observable in the field (
Figure 3). Moreover, the MSBS approach was successful in discriminating between winter cereals and winter rapeseed. For instance, April–May is the period of flowering of winter rapeseed and is the best time for discriminating it from winter cereals. The better performance of using MSBS dataset as input for discriminating winter rapeseed indicated that the spectral characteristics induced by the flowering were better captured by the combined nine Sentinel-2 bands. It can be concluded here that crop classification using Sentinel-2 data may deliver maps with higher accuracy when individual spectral bands of the images registered on the phenologically important dates are used as input. In the circumstances of unavailability, or for operational purposes, the approach using NDVI time series may be preferable.
None of the three hard classifiers tested for the Sentinel-2 classifications i.e., MXL, SVM, and RF, guarantied markedly and consistently a higher accuracy of classification. For example, RF was clearly the most successful method in classifying the S10 NDVI dataset in the Belozem test site, but was outperformed by the other methods when applied to the MSBS dataset or to the Knezha test site. To conclude, as with the input image dataset, no general recommendation could be given as for a best classifier in any circumstances. Moreover, such generalization of results was neither possible nor sought in this study. Instead, our results suggested that different classifiers should be tested for crop mapping using Sentinel-2 imagery, according to the region of interest and the dataset available for the input.
The lower accuracy of the crop/land-use maps of the Belozem test site may be related to the quality of the input satellite data and factors specific to this site. First, the accuracies for the classifications based on the MSBS datasets may differ due to the input images with different registration dates for the two test sites. In particular, the Knezha MSBS dataset contained three images in the most important period from April to June, while the Belozem MSBS dataset contained only two, the third being from the winter period (12 December). The S10 NDVI datasets for both test sites was composed of a regular series of 10-day composites covering the same period. The two NDVI time series, however, cannot be regarded as of precisely the same quality because the availability of cloud-free observations has some effect on the smoothing algorithm [
24]. The land-use or landscape specificity of each test site also contributed to the different accuracy. For example, the agricultural landscape in the Belozem test site was more complex due to the smaller average field size, greater diversity of cultivated crops, and larger relative area of the problematic other crops class.
Furthermore, the accuracy of the Sentinel-2-derived reference maps used for training of the PROBA-V classification is worth more discussion. For both test sites we selected the maps derived by SVM classification using the MSBS datasets. The OA of the maps was 75% and 84% for the Belozem and Knezha test site respectively. These accuracies may not seem high for a reference dataset especially when compared with ground-based crop datasets such as IACS available in many developed countries. However, maps derived from Sentinel-2 remain a feasible option as reference data where no other ground truth information is available, for example in data-poor countries. Compared with other studies the accuracy achieved here is reasonable. For example, Van Tricht et al. [
40] applied random forest classification algorithm on monthly NDVI time series from Sentinel-2 to map 12 crops and land cover types in Belgium. An overall accuracy of 78% was obtained using an input dataset encompassing the period March–August and 72% using another dataset covering the period March–June. Better results were achieved by incorporating radar data from Sentinel-1. Vuolo et al. [
27], also using random forest, classified multi-date Sentinel-2 datasets. They achieved overall accuracy of ~95% in mid-August based on stacks of five and eight cloud-free images in 2016 and 2017 growing seasons respectively. The accuracy was slightly lower (~85%) when images acquired till the end of June were used (four and six images in the two growing seasons respectively). In our study the number of used cloud-free images was lower, as such were not available, and this may explain the lower accuracy.
The MSBS dataset included 20 m Sentinel-2 bands upscaled to a higher spatial resolution of 10 m. The error introduced in the classifications by this upscaling was not thoroughly evaluated in this study. However, a preliminary test using the MXL classifier showed that the classification accuracies remain very similar when the datasets of 10 or 20 m resolution were used as input.
The area fraction estimates derived by applying the two sub-pixel classification methods on the PROBA-V time series were less reliable at pixel level, especially for small or less frequent classes. The SVM method slightly outperformed the ANN method. However, these results were better than those reported in the previous study by Verbeiren et al. [
1], which used ANN, notably for main dominant classes. For instance, the two highest R
2 values reported by these authors were 64% (for the forest class) and 58% (for the winter wheat class). In this study, the maximal R
2 values obtained at pixel level with the ANN method were 74% (for winter cereals) and 70% (for broad-leaved forest).
Nevertheless, our results confirmed once again that the accuracy of the estimated area fractions increased with the aggregation per region. For our artificial regions of size 100 km2, R2 was over 80% for most classes with R2 = 87% for the most important class (winter cereals) when the ANN method was applied. It can be expected that the accuracy may be further increased if estimates are aggregated at the municipality level, which most often, has areas larger than 100 km2. The crop area estimates are usually reported at the level 3 of the Nomenclature of Territorial Units for Statistics (NUTS 3) in the European Union, which is even larger.
In this study the area fraction estimates derived by the SVR method were more accurate than those derived by ANN at both pixel and region-level, as far as the R2 is considered. This remained true for most classes and for the general assessment of all classes combined.
The results of this work may be further considered in the context of future operational monitoring, for example on monthly basis, of the sub-pixel crop area fraction for whole country, based on 100 m imagery. Indeed, for classifying a large area using high resolution datasets, at high temporal frequency, would involve a large amount of ground truth data, and mosaicking dozen individual tile classification results. When only the crop area fractions at a certain administrative zone are needed, and its updates are frequently required, the sub-pixel classification as we described here would be the most convenient way.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}