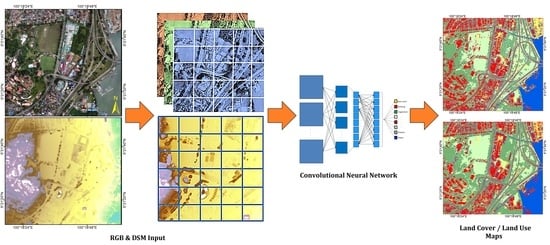
1. Introduction
In the past few years, unmanned aerial vehicles (UAVs) have been extensively used to collect image data over inaccessible/remote areas [
1,
2,
3]. Ease-of-use and affordability are two catalysing factors for the widespread use of UAVs in civilian and military applications [
1,
4]. Images captured using UAVs are used for geographical information system databases, datasets for automated decision-making, agricultural mapping, urban planning, land use and land cover detection and environmental monitoring and assessment [
1,
5,
6,
7]. Such images are commonly used in supervised machine learning-based classification tasks as training data [
8,
9,
10]. One reason for this is that these images have high resolution and a good range of spectral bands [
6]. This is an advantage since training and validating a supervised classifier for a remote sensing task demands reliable features. Due to the quality of UAV images nowadays, extracting reliable features to form a dataset becomes less of a problem. Example of such features are land cover characteristics (geometrical and spectral) from Light Detection and Ranging (LiDAR) and hyperspectral data [
11]. Moreover, to enhance land cover classification, the combination of multisource (active/passive sensors) or multimodal data (data with different characteristics) is recommended [
12,
13]. For example, Jahan et al. [
11] fused different LiDAR and hyperspectral datasets, and their derivatives, and proved that the overall accuracy of the fused datasets are higher than the single dataset. Another fusion of LiDAR and aerial colour images was performed to enhance building and vegetation detection [
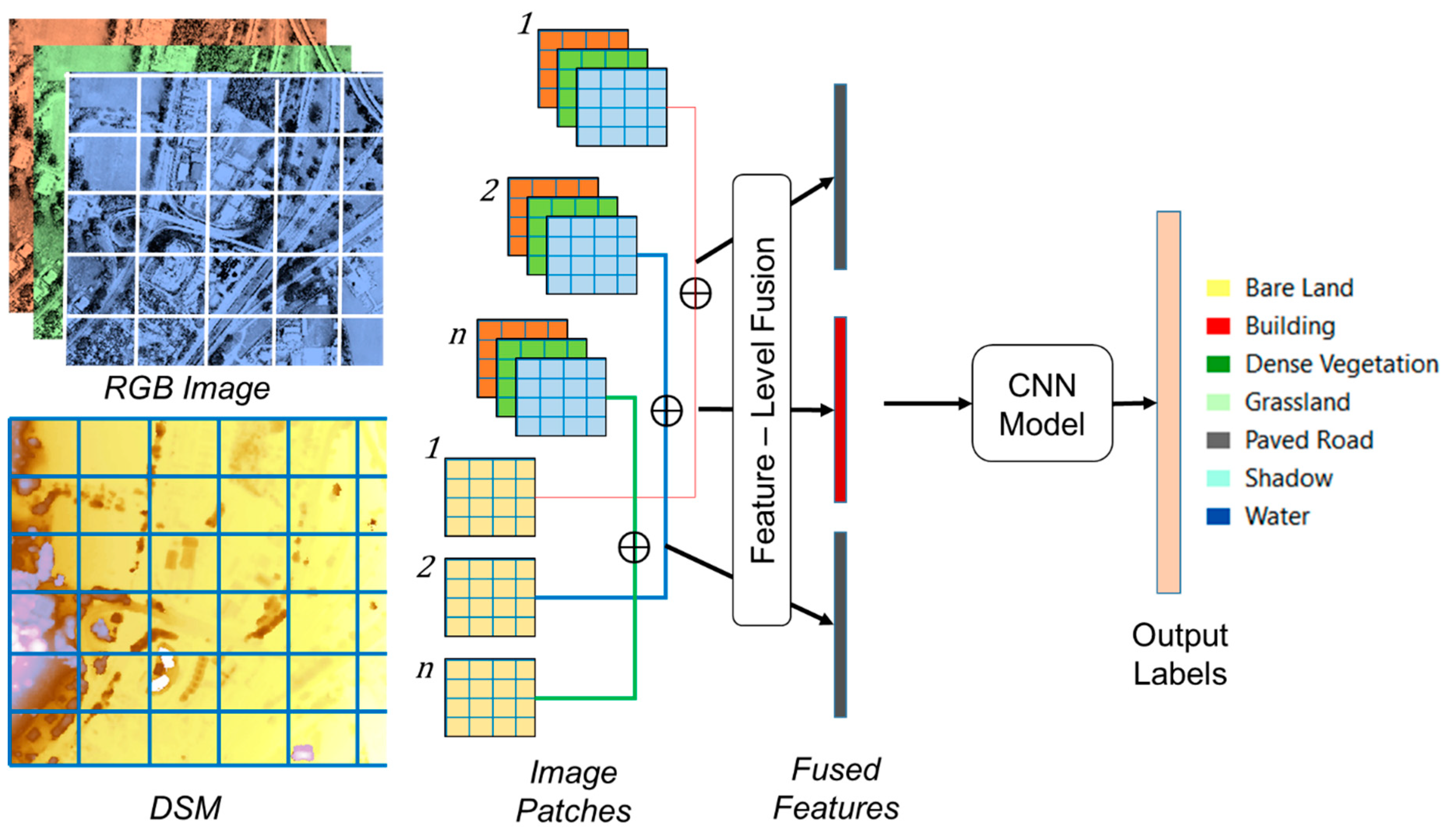
11]. These additional features can sometimes improve the classification accuracy for specific domains and use cases. For example, dataset fusion of RGB (Red, Green and Blue) images obtained from UAVs or other sources together with elevation information from digital surface models (DSM) provided a more holistic representation for the construction of accurate maps [
11]. Considering DSMs as additional features was shown to improve classification results for image segmentation [
14].
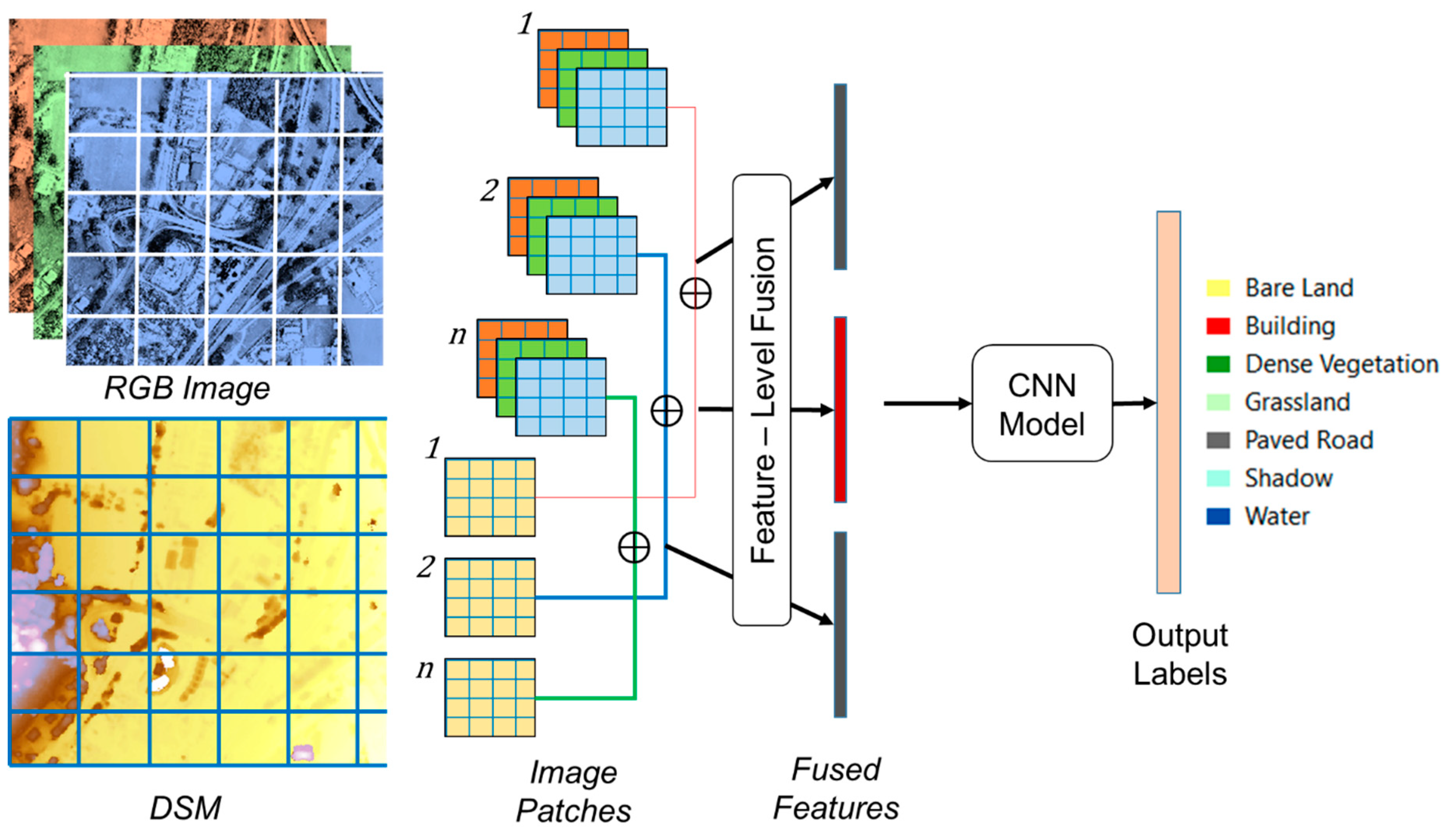
Based on the success of previous studies [
11,
15,
16,
17], this paper also examines feature fusion but for the specific task of land cover classification taking advantage of fused DSM–UAV images. Specifically, we investigated the effectiveness of using a single feature modality (RGB data only) versus the fusion of RGB and DSM data. The classification algorithm used to compare the two datasets is a convolutional neural network (CNN), which is a deep-learning technique that hierarchically learns representations from training data, regulates and shares the weight with respect to the training data, generalizes, optimizes, and reduces the parameters with the higher ability to discriminate and extract features, automatically [
18,
19]. The specific land cover classifications that we considered were: (i) bare land, (ii) buildings, (iii) dense vegetation/trees, (iv) grassland, (v) paved roads, (vi) shadows, and (vii) water bodies.
2. Related Studies
Several studies have been conducted using different approaches and models for tasks such as land use land cover and crops classification. These studies have primarily varied according to the technique used. Reference [
20] developed a hybrid model based on the integration of random forest and a texture analysis to classify urban-vegetated areas. Their model contained 200 decision trees trained on hand-crafted spectral–textural features. The highest accuracy reported was 90.6%. The work in [
21] used a multiple kernel-learning (MKL) model to classify UAV data in Kigali, Rwanda. Their model showed superior classification performance (90.6% accuracy) and outperformed the single standard single-kernel Support Vector Machine model by 5.2%. In another study [
22], a classification framework based on deep-learning and an object-based image analysis (OBIA) proposed to classify UAV data into five categories, namely, water, roads, green land, buildings, and bare land. The proposed framework first performed graph-based minimal spanning-tree segmentation, followed by spatial, spectral, and texture feature extraction from each object. The features were fed into a stacked autoencoder (SAE) for training and achieved an overall accuracy of 97%.
Recently, cameras mounted on UAVs have enabled the acquisition of higher quality images from remote locations, especially those of wet and cropland images. Machine learning has also played an important role, where algorithms such as Support Vector Machine (SVM), Logistic Regression and Artificial Neural Networks (ANN) have been used to perform automatic land classification [
23,
24]. Lie et al. [
25] used high-quality images with OBIA based on multi-view information. They classified wetlands in Florida, USA, into seven classes, namely, Cogon grass, improved pasture, Saw Palmetto shrubland, broadleaf emergent marsh, graminoid freshwater marsh, hardwood hammock–pine, forest, and shadows with an overall accuracy of 80.4%, a user accuracy of 89.7%, and a producer accuracy of 93.3%. Reference [
26] developed a model combining deep CNNs with OBIA to create land cover maps from high resolution UAV images with a very good overall accuracy of 82.08%.
The work in [
27] developed a model based on conditional random fields where they integrated multi-view and context information. Their work looked at different classifiers, namely, the Gaussian mixed model (GMM), random forests (RF), SVM and DCNN. Machine learning algorithms seem to provide very good classification accuracy, with GMM and DCNN outperforming the rest. Reference [
28] evaluated classifications after applying an advanced feature selection model to SVM and RF classifiers. A novel method was developed in [
6] where the fuzzy unordered rule algorithm and OBIA were integrated to extract land cover from UAV images. Their method first segments the images based on multi-resolution segmentation, then optimises them based on feature selection (integrating feature space optimisation into the plateau objective function) and finally classifies them using a decision tree and an SVM. Overall accuracy was reported to be 91.23%. Very-high resolution aerial images were classified using a CNN in [
29], which has been shown to be effective for the extraction of specific objects such as cars. In another study [
18], the capability of CNN to classify aerial photos (with 10 cm resolution) was examined and verified using medium-scale datasets.
To the best of our knowledge, CNNs have not yet been applied to fused DSM and UAV datasets for land cover classification. Because the resolution of the imagery directly affects the accuracy of the land cover classification, we applied a CNN algorithm to the fusion of a UAV image and DSM (both with 0.8 m/pixel resolution) for urban feature extraction to inspect the accuracy of the result. In general, UAV datasets have lower resolution and accuracy compared to aerial photos [
30]. Therefore, this study looks at improving the accuracy by exploiting CNNs for these datasets. The following sections explain and discuss the state of the art with respect to classifying UAV datasets with a focus on deep-learning-based methods.
4. Results
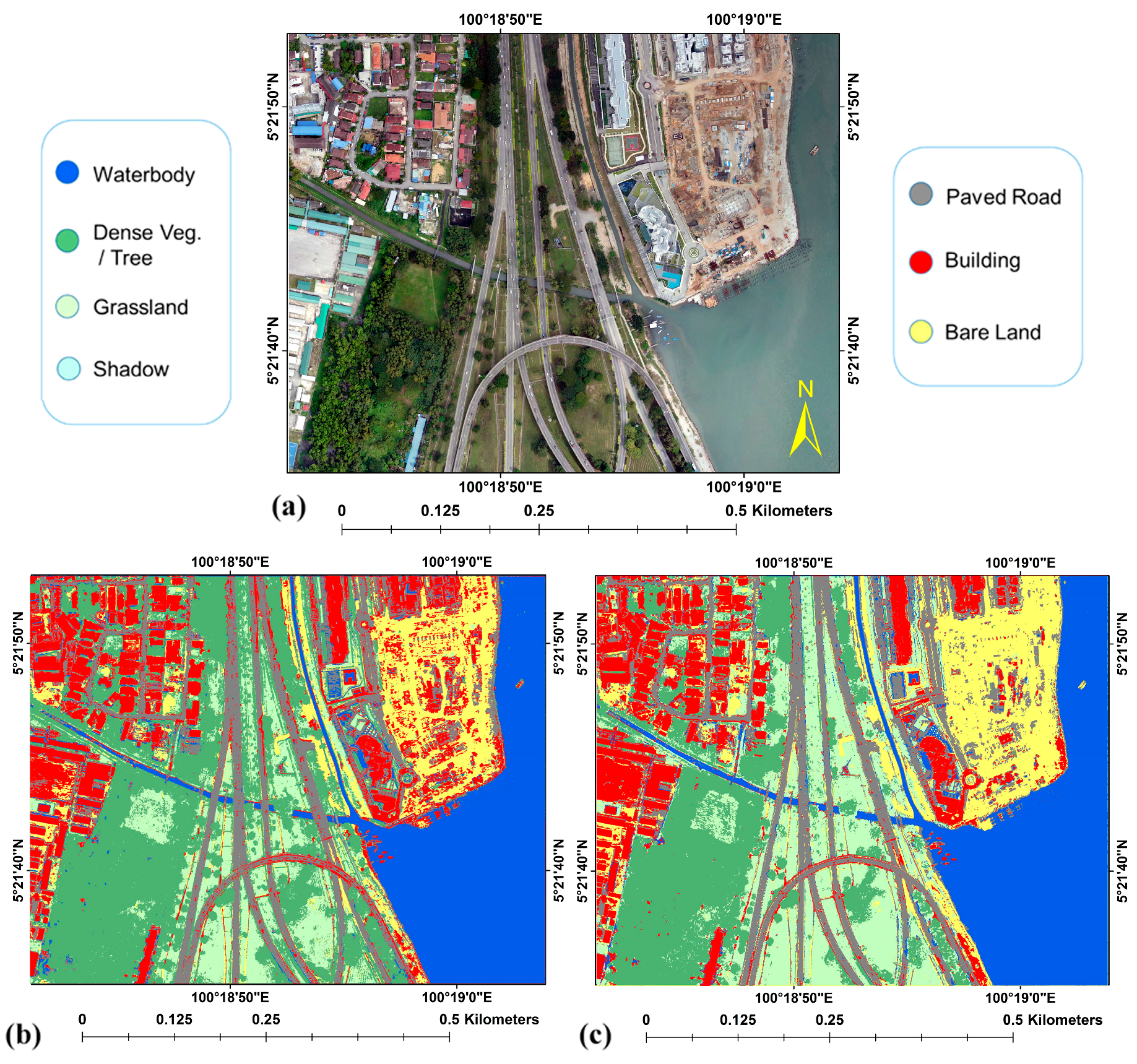
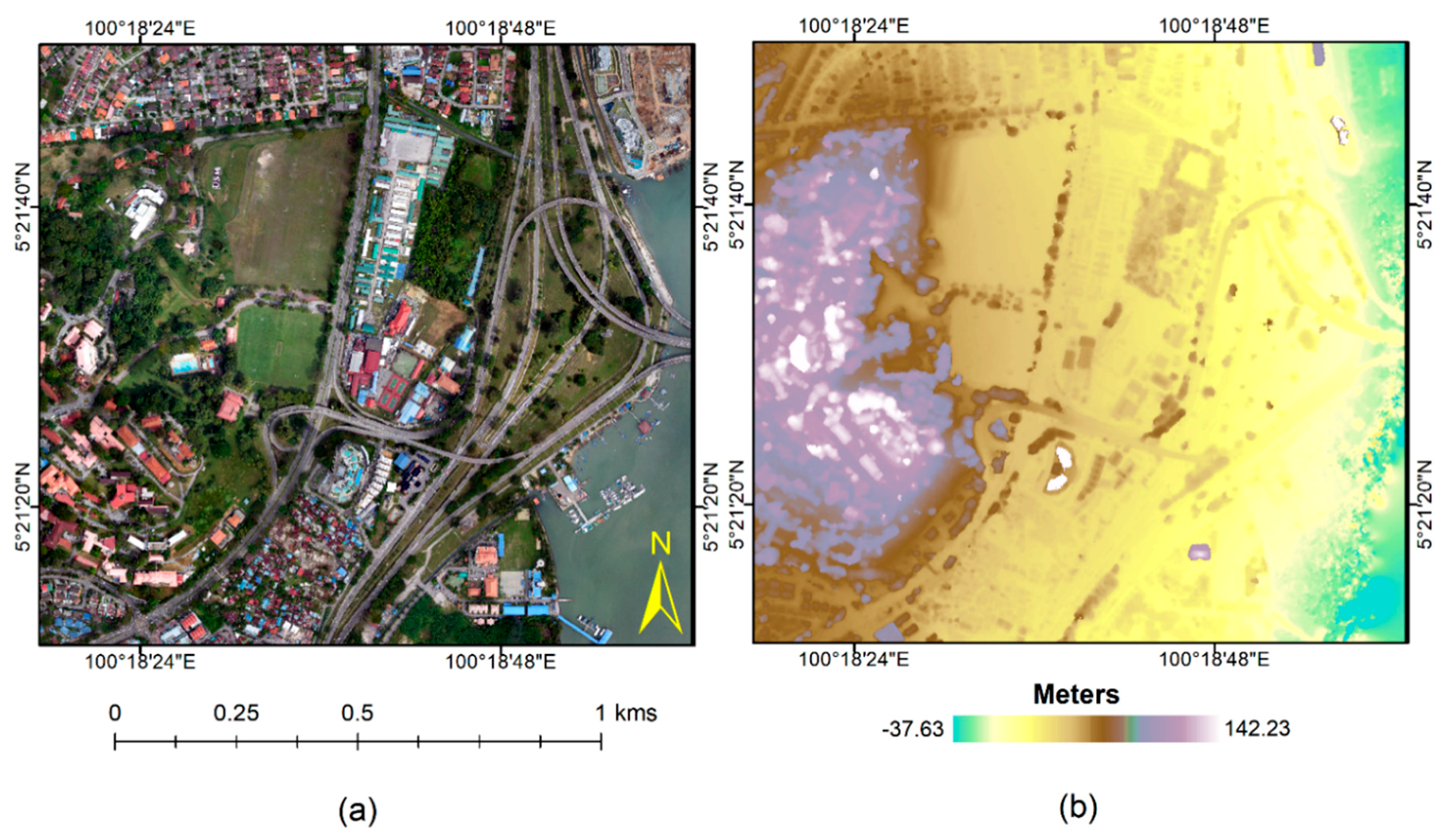
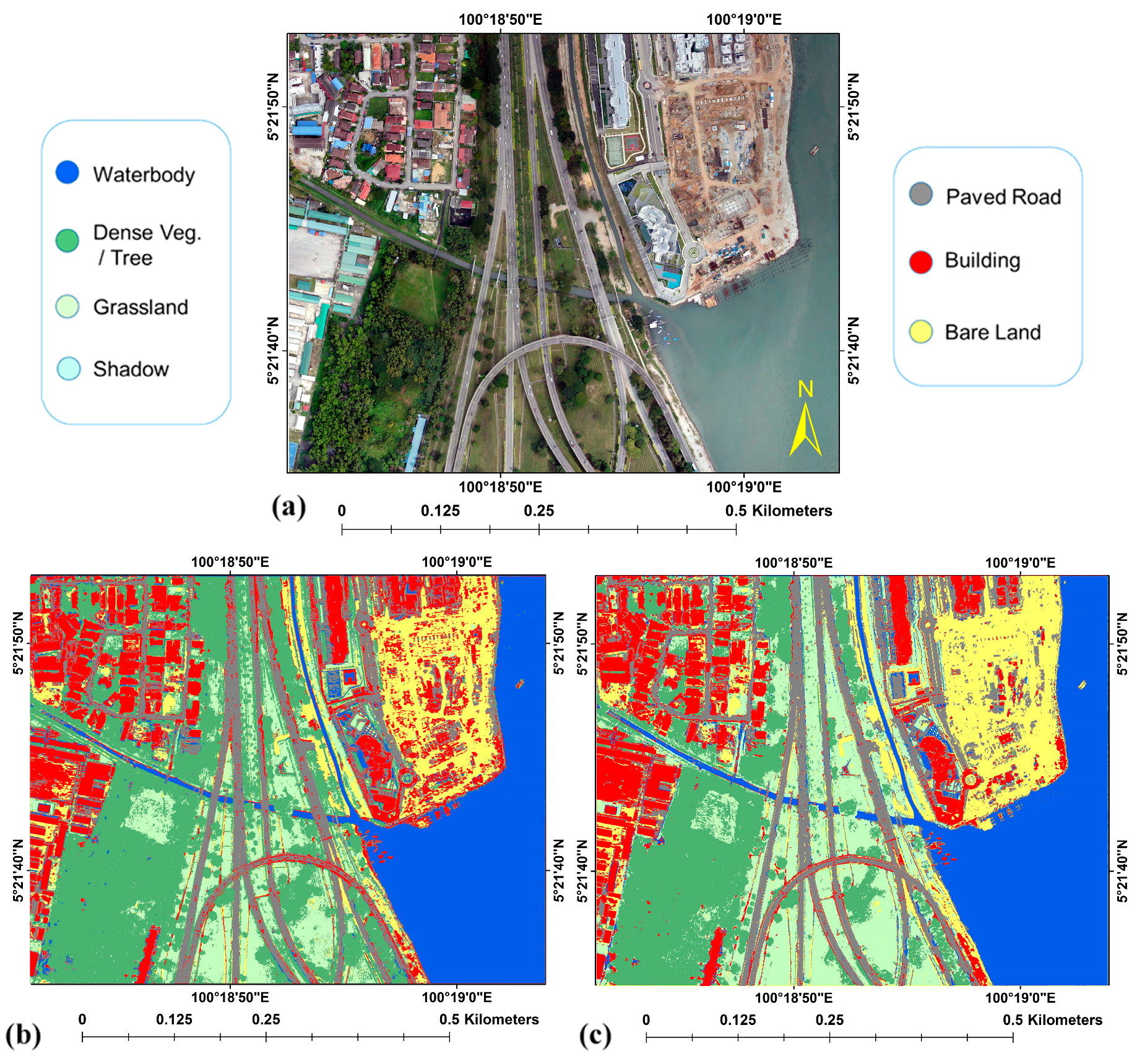
This section provides the experimental results of our study. The CNN was implemented in Python on an Intel Core-i7 (2.90 GHz) system with 32 GB RAM. The classification maps produced by CNN for both datasets are shown in
Figure 3. The GT (
Figure 3a) and the classified maps (
Figure 3b,c) provided promising land cover classifications throughout the study area.
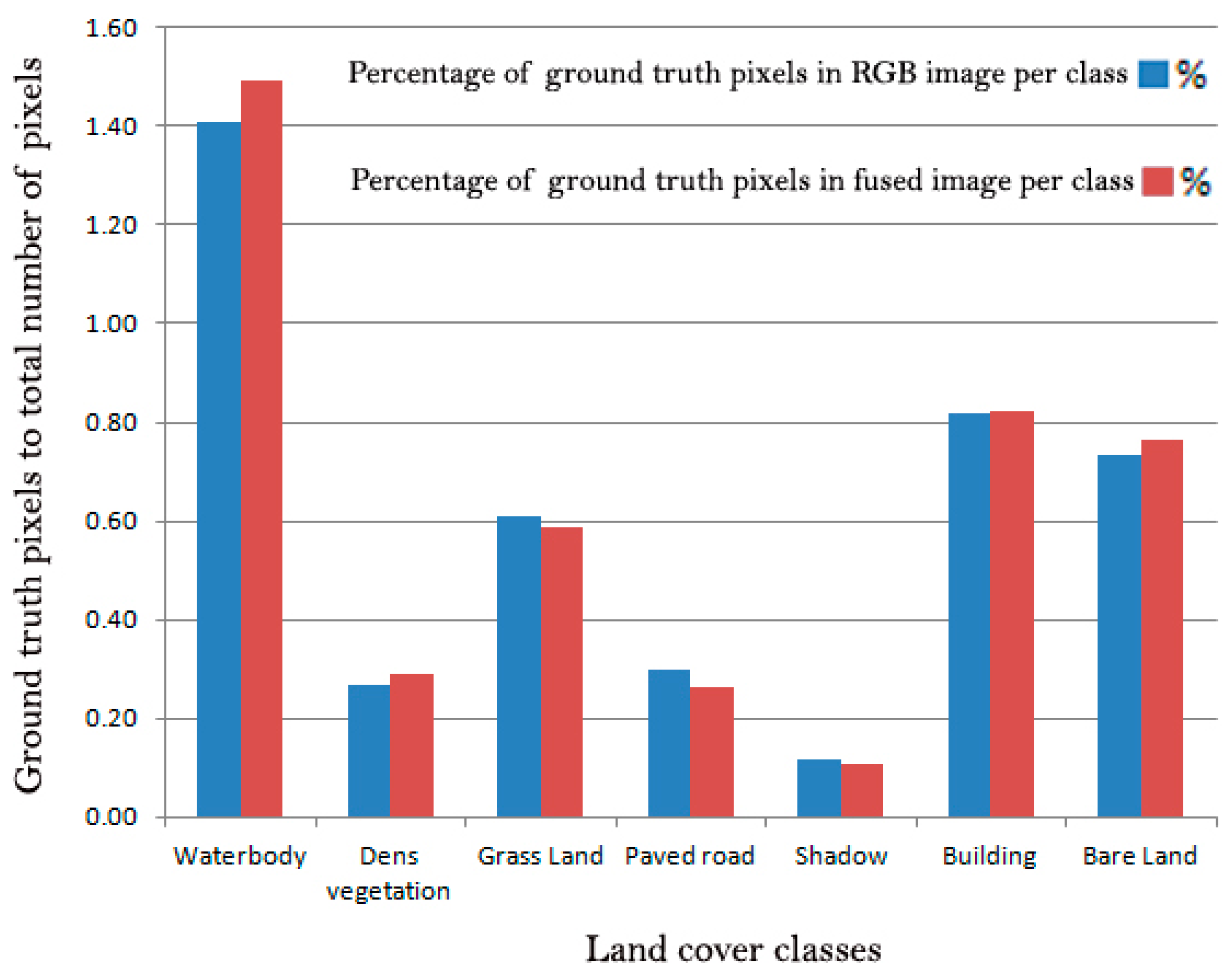
Figure 4 depicts the percentage of GT datasets pixels for each land cover class for both RGB and fused images. The GT samples in each class within the RGB image and the fused data were approximately balanced. Conversely, samplings between classes were not equally collected. For example, the number of GT pixels for the paved road classes in both datasets was approximately 0.3% while the percentages for the building class were close to 0.8%, which was nearly 2.6 times more sampling than for the paved road class. The percentage of GT pixels displayed variation from a minimum of 0.1% (in the shadow class) to a maximum of 1.5% (in the water body class). Therefore, the unbalanced distribution of GT samples between land cover classes resulted in obvious unfair distribution in training (50% of GT), validation (25% of GT), and testing (25% of GT) pixels, as well.
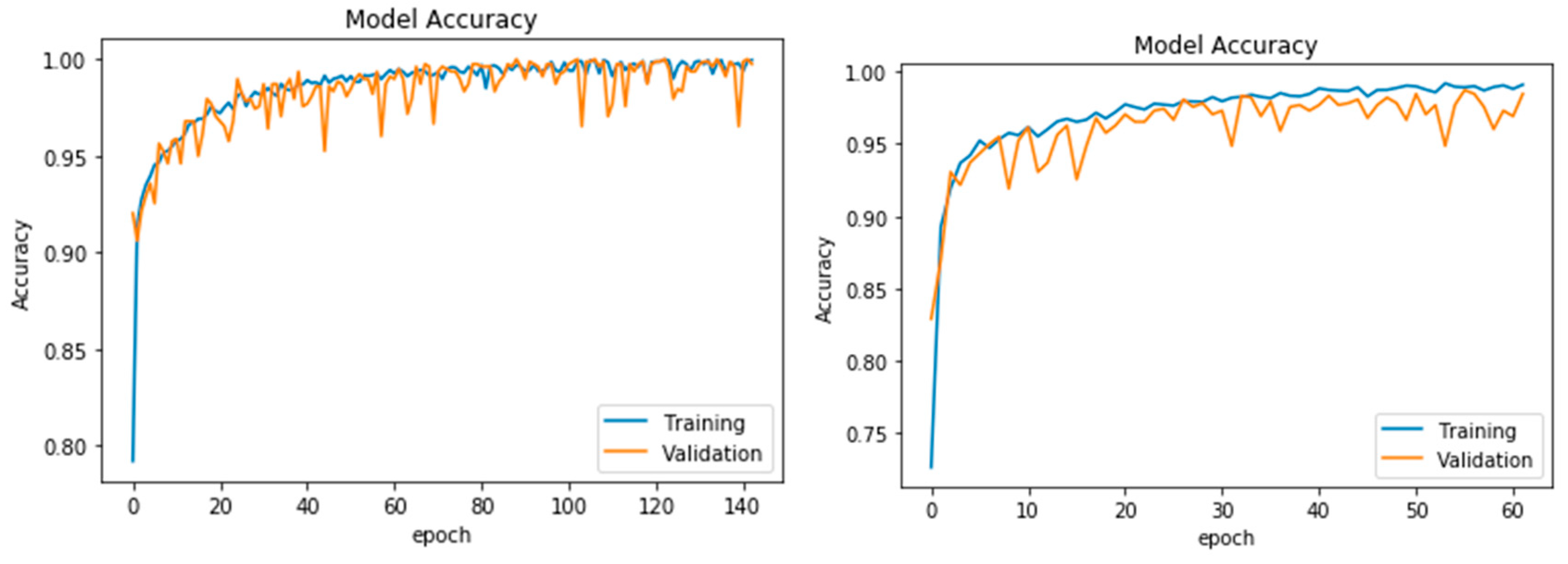
To evaluate the results, validation curves (accuracy and loss) of the two models are shown in
Figure 5 and
Figure 6.
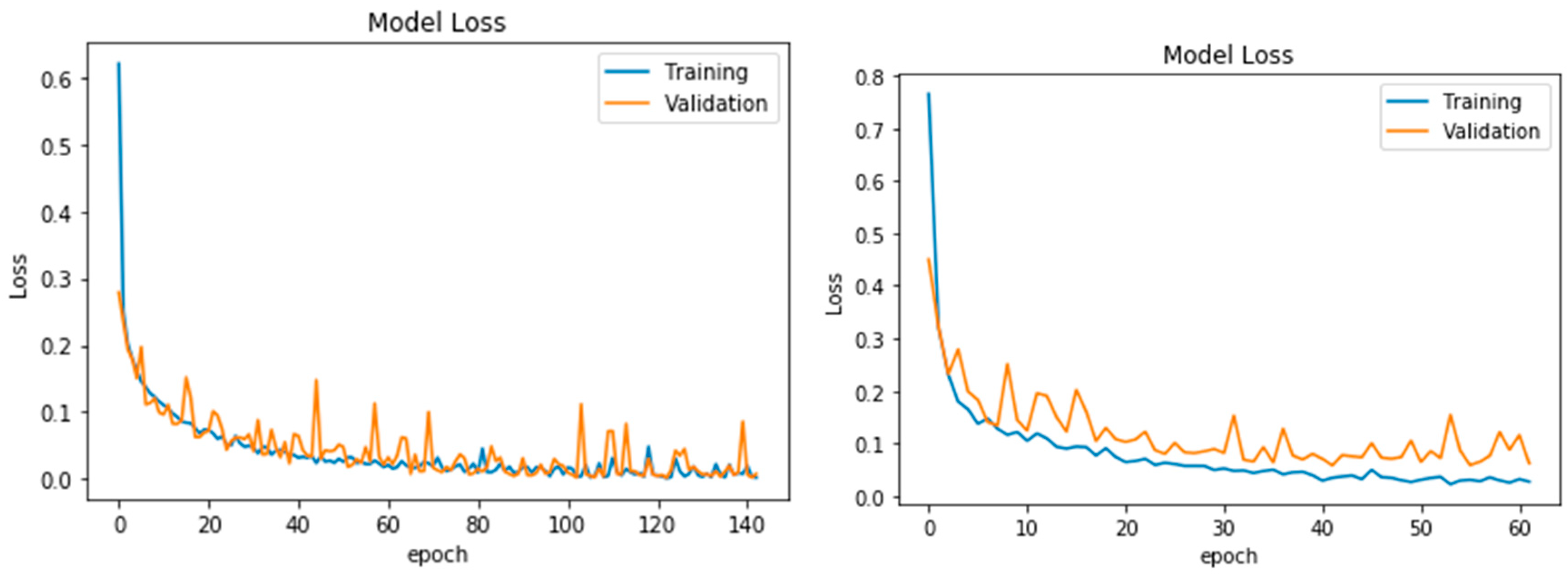
Figure 5 shows the accuracy curves (training and validation) for both datasets. Comparing the accuracies curves of the two methods, it is obvious that the two models were perfectly generalised, and that the validation accuracy curve is slightly higher than the training accuracy curve.
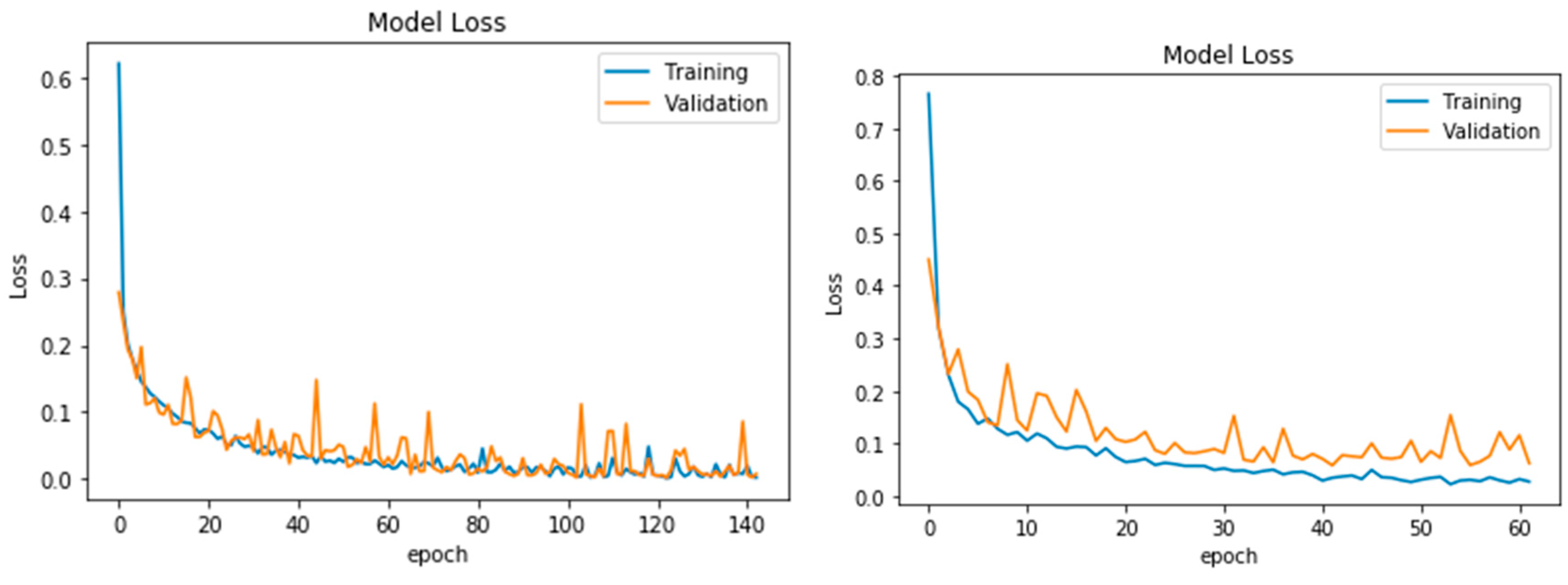
Figure 6 represents the loss curves for the two CNN dataset classifiers. The loss of information in each model continued to decrease with training iteration for both methods. This pattern was also followed by the validation dataset.
Other evaluation metrics are presented in
Table 2. The overall accuracy (
OA) appeared to increase from 0.965 to 0.991 when the DSM image was considered. A similar improvement in the average accuracy (
AA) was also recorded, from 0.933 to 0.989, when considering the DSM data. Similarly, the testing data (
Table 2) showed an improvement in the
OA from 0.968 to 0.980 and the
AA improved from 0.952 to 0.970. Conversely, the highest value of the Kappa index (
K) was measured (0.988) in the training data based on the implementation of the CNN with DSM. Undoubtedly, the model that did not include the DSM feature had a lower performance than the fused datasets using the testing and training datasets.
Table 3 shows the per-class accuracies (
PA) achieved by the proposed model based on the training data.
These results suggest that the CNN with DSM model was able to classify nearly all of the classes with relatively high accuracy. The maximum accuracy was 1.0 for the water body and dense vegetation classes, while the minimum accuracy belonged to the grassland class (0.956). Similarly, the maximum accuracy obtained by CNN without DSM was 1.0 for the water body class. Conversely, the minimum accuracy was obtained by the dense vegetation class at 0.769 for the CNN without DSM.
Table 4 shows that the additional DSM data improved the classification accuracy in the testing dataset compared to the RGB data alone. The highest
PA recorded based on CNN with DSM was 0.999 referring to the water body class, and the lowest
PA occurred in the bare land class with a value of 0.925. Conversely, the CNN without DSM (RGB only) had highest and lowest
PA values of 0.996 (paved roads) and 0.853 (grassland).
Table 5 shows the Precision, Recall and F1 score for each class. The highest F1 score recorded based on CNN with DSM was 1.00 belonging to waterbody class, and the lowest F1 score referred to shadow class with a value of 0.921. Conversely, the CNN without DSM (RGB only) had the highest and lowest F1 score values of 0.998 and 0.711 by water body and shadow classes, respectively.
To further assess the performance and functionality of the proposed method, its transferability to another UAV subset was evaluated. The visual interpretation showed that the area consisted of several land cover types, including bare land, dense vegetation, grassland, waterbody, building, shadow, and paved road. The UAV was taken from the same environment to the first dataset, hence, the same set of hyperparameters was used for CNN (Activations = ReLU and Softmax, optimizer = Adam, batch size = 32, patch size =
, number of epochs = 200, and dropout = 0.2 and 0.5).
Figure 7 shows the classified images obtained from the two datasets: (a) RGB only (b) fused RGB and DSM. The accuracy of the classification results is mentioned in
Table 6.
5. Discussion
The present study led to the generation of two land cover classification maps, as shown in
Figure 3. According to a visual inspection, the bare land and buildings were misclassified more in the north-eastern part of the map based on the RGB image (
Figure 3b) compared to the result based on the data fusion (
Figure 3c). The additional elevation data points resulted in the better overall bare land classification, as seen in
Figure 3c. A comparison between the classification results showed that more misclassifications were present when the DSM data were not considered in locations where there was confusion between grassland and dense vegetation areas. It is likely that the height data from the DSM allowed the network to correctly differentiate between grass and dense vegetation (trees).
Unexpectedly, despite including the DSM data, some paved roads were misclassified as buildings in the centre to south in
Figure 3c. Both datasets performed well for water body classification. From these results, we hypothesise that the CNNs performed misclassifications primarily due to dataset imbalances, which is a point mentioned by Marcos et al. [
14]. Lack of proper sampling could also be a contributing factor. Specifically, a majority of the sampled pixels was from water bodies (~1.5%); this class unsurprisingly had the best classification accuracy for both datasets. The smallest number of sampled GT pixels (
Figure 4) was for the shadow, paved roads, and dense vegetation classes (less than 0.3%). Therefore, the homogeneity of the selected GT dataset between the land cover classes and fully representative sampling may increase the quality of CNN classification operations. These results show that the proposed CNN with DSM is an effective image classification approach and highlight the improved model performance compared to the CNN without DSM classifiers.
In addition, the accuracy curves (
Figure 5) were used to qualitatively assess the results and indicated that there was no sign of overfitting in the processing and, therefore, using dropouts in the CNN process was a success. Likewise, the loss curves (
Figure 6) for each model behaved uniformly and the appearance of the curves showed that the learning progress and the optimising process in both datasets were relatively good, as there were no plateaus in the curves [
46], and the labelling improved during iteration [
42,
47]. This means that the optimisation process improved for several epochs and might suggest a comparably good performance of the model regularisation (dropout and batch normalisation) and optimisation algorithm (Adam optimiser), for both the CNN without DSM, and the CNN with DSM.
To confirm the success of setting the dropout, we carried on the whole experiments again, without setting dropout value in the process. The results of accuracy and loss curves (
Figure 8 and
Figure 9) showed that both model accuracy and model loss in validation dataset curves were associated with huge numerous fluctuations and plateaus. This behaviour in loss curves may suggest that model regularisation (without dropout) did not relatively improve within the iterations and it might affect the pixels labelling procedures. Validation curve showed variation from the actual label (i.e., training curve) and it fluctuated above the training curve, even though it finally decreased the loss of information, the curve was not as perfect as the previous experiment with dropout. Accuracy curves also showed unstable performance and they were lower than training curves especially in the RGB dataset, meaning that the model without dropout was not generalized as well as the model with setting dropout value. From those curves, it was concluded that removing the dropout had a more negative effect on the RGB dataset rather than the fused dataset.
According to the standard accuracy metrics (
Table 2), it is obvious that the CNN performed better after fusing the DSM with the RGB image. Moreover, the
PA value (
Table 3) showed a high accuracy enhancement of up to 23.1% for dense vegetation, and 10% and 4.1% improvements for the shadow and building classes, respectively. This finding indicates that adding the height of the features (e.g., trees and buildings) to RGB images can improve the classification accuracy, especially in dense vegetation areas. Even though the
PA value for paved roads showed a slight loss of accuracy (0.5%) for the CNN with DSM compared to the CNN without DSM and all the
PA values for the other classes improved with respect to the fusion. Overall, the experimental results for both datasets indicate that the model architecture was appropriate. The best obtained values for the
OA,
AA, and Kappa index for the CNN with DSM for the training dataset were 99.1%, 98.8% and 98.8%, respectively, using UAV datasets with resolutions of 0.8 m/pixel.
6. Conclusions
UAV data were used to produce an RGB orthomosaic photo and a DSM of the study area. For this study, a deep-learning classifier (CNN) was used to exploit the two different datasets to map the existing land cover classes into bare land, buildings, dense vegetation (trees), grassland, paved roads, shadows, and water bodies: 1) a CNN was used to classify the orthomosaic photo data and 2) a CNN was used to classify the fused orthomosaic photo and DSM data. Both datasets resulted in an acceptable OA, AA, K and PA for the testing and training datasets. However, the dataset associated with the height information (the fused orthomosaic photo and DSM) performed better in most of the discriminative classes. In particular, where the appearances of objects are mostly similar and when there is no height information, a model can mistakenly categorise bare land as a building or classify grassland as trees (dense vegetation). Comparing the accuracies of the results between the CNN with DSM and CNN without DSM, OA, AA and K showed improvements of 2.6%, 5.6% and 3.2%, respectively, for the training dataset and 1.2%, 1.8% and 1.5% for the testing dataset. The use of DSM successfully enhanced the PA obtained for both the testing and training datasets. Nevertheless, our observations of paved road and building misclassifications imply that the CNN with DSM was sensitive to the training dataset and hyperparameters. Therefore, to enhance the results, additional GTs are needed according to the height differences for a specific object and discriminative class, as well as homogenised and well-distributed GT samples. This study showed the capability of CNN to accurately classify UAV images that have a lower resolution to compare with very-high resolution aerial photos, and it confirmed that the fusion of datasets is promising. Future work will focus on the sensitivity of CNNs with other fusion methods to the training dataset, regularisation functions and optimisers.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}